- How it works


Useful Links
How much will your dissertation cost?
Have an expert academic write your dissertation paper!
Dissertation Services

Get unlimited topic ideas and a dissertation plan for just £45.00
Order topics and plan

Get 1 free topic in your area of study with aim and justification
Yes I want the free topic

Artificial Intelligence Topics for Dissertations
Published by Carmen Troy at January 6th, 2023 , Revised On August 16, 2023
Introduction
Artificial intelligence (AI) is the process of building machines, robots, and software that are intelligent enough to act like humans. With artificial intelligence, the world will move into a future where machines will be as knowledgeable as humans, and they will be able to work and act as humans.
When completely developed, AI-powered machines will replace a lot of humans in a lot of fields. But would that take away power from the humans? Would it cause humans to suffer as these machines will be intelligent enough to carry out daily tasks and perform routine work? Will AI wreak havoc in the coming days? Well, these are questions that can only be answered after thorough research.
To understand how powerful AI machines will be in the future and what sort of a world we will witness, here are the best AI topics you can choose for your dissertation.
You may also want to start your dissertation by requesting a brief research proposal from our writers on any of these topics, which includes an introduction to the topic, research question , aim and objectives , literature review along with the proposed methodology of research to be conducted. Let us know if you need any help in getting started.
Check our dissertation examples to get an idea of how to structure your dissertation .
Review the full list of dissertation topics for 2022 here.
You may also be interested in technology dissertation topics , computer engineering dissertation topics , networking dissertation topics , and data security dissertation topics .
2022 Artificial Intelligence Topics for Dissertations
Topic 1: artificial intelligence (ai) and supply chain management- an assessment of the present and future role played by ai in supply chain process: a case of ibm corporation in the us.
Research Aim: This research aims to find the present, and future role AI plays in supply chain management. It will analyze how AI affects various components of the supply chain process, such as procurement, distribution, etc. It will use the case study of IBM Corporation, which uses AI in the US to make the supply chain process more efficient and reduce losses. Moreover, through various technological and business frameworks, it will recommend changes in the current AI-based supply chain models to improve their efficiency.
Topic 2: Artificial Intelligence (AI) and Blockchain Technology a Transition Towards Decentralized and Automated Finance- A Study to Find the Role of AI and Blockchains in Making Various Segments of Financial Sector Automated and Decentralized
Research Aim: This study will analyze the role of AI and blockchains in making various segments of financial markets (banking, insurance, investment, stock market, etc.) automated and decentralized. It will find how AI and blockchains can eliminate the part of intimidators and commission charging players such as large banks and corporations to make the economy and financial system more efficient and cheaper. Therefore, it will study applications of various AI and blockchain models to show how they can affect economic governance.
Topic 3: AI and Healthcare- A Comparative Analysis of the Machine Learning (ML) and Deep Learning Models for Cancer Diagnosis
Research Aim: This study aims to identify the role of AI in modern healthcare. It will analyze the efficacy of the contemporary ML and DL models for cancer diagnosis. It will find how these models diagnose cancer, which technology ML or DL does it better, and how much better efficient. Moreover, it will also discuss criticism of these models and ways to improve them for better results.
Topic 4: Are AI and Big Data Analytics New Tools for Digital Innovation? An Assessment of Available Blockchain and Data Analytics Tools for Startups Development
Research Aim: This study aims to assess the role of present AI and data analytics tools for startups development. It will identify how modern startups use these technologies in their development stages to innovate and increase their effectiveness. Moreover, it will analyze its macroeconomic effects by examining its role in speeding up the startup culture, creating more employment, and rising incomes.
Topic 5: The Role of AI and Robotics in Economic Growth and Development- A Case of Emerging Economies
Research Aim: This study aims to find the impact of AI and Robotics on economic growth and development in emerging economies. It will identify how AI and Robotics speed up production and other business-related processes in emerging economies, create more employment, and raise aggregate income levels. Moreover, it will see how it leads to innovation and increasing attention towards learning modern skills such as web development, data analytics, data science, etc. Lastly, it will use two or three emerging countries as a case study to show the analysis.
Artificial Intelligence Topics
Topic 1: machine learning and artificial intelligence in the next generation wearable devices.
Research Aim: This study will aim to understand the role of machine learning and big data in the future of wearables. The research will focus on how an individual’s health and wellbeing can be improved with devices that are powered by AI. The study will first focus on the concept of ML and its implications in various fields. Then, it will be narrowed down to the role of machine learning in the future of wearable devices and how it can help individuals improve their daily routine and lifestyle and move towards a better and healthier life. The research will then conclude how ML will play its role in the future of wearables and help people improve their well-being.
Topic 2: Automation, machine learning and artificial intelligence in the field of medicine
Research Aim: Machine learning and artificial intelligence play a huge role in the field of medicine. From diagnosis to treatment, artificial intelligence is playing a crucial role in the healthcare industry today. This study will highlight how machine learning and automation can help doctors provide the right treatment to patients at the right time. With AI-powered machines, advanced diagnostic tests are being introduced to track diseases much before their occurrence. Moreover, AI is also helping in developing drugs at a faster pace and personalised treatment. All these aspects will be discussed in this study with relevant case studies.
Topic 3: Robotics and artificial intelligence – Assessing the Impact on business and economics
Research Aim: Businesses are changing the way they work due to technological advancements. Robotics and artificial intelligence have paved the way for new technologies and new methods of working. Many people argue that the introduction of robotics and AI will adversely impact humans as most of them might be replaced by AI-powered machines. While this cannot be denied, this artificial intelligence research topic will aim to understand how much the business will be impacted by these new technologies and assess the future of robotics and artificial intelligence in different businesses.
Topic 4: Artificial intelligence governance: Ethical, legal and social challenges
Research Aim: With artificial intelligence taking over the world, many people have reservations over the technology tracking people and their activities 24/7. They have called for strict governance for these intelligent systems and demanded that this technology be fair and transparent. This research will address these issues and present the ethical, legal, and social challenges governing AI-powered systems. The study will be qualitative in nature and will talk about the various ways through which artificial intelligence systems can be governed. It will also address the challenges that will hinder fair and transparent governance.
Topic 5: Will quantum computing improve artificial intelligence? An analysis
Research Aim: Quantum computing (QC) is set to revolutionize the field of artificial intelligence. According to experts, quantum computing combined with artificial intelligence will change medicine, business, and the economy. This research will first introduce the concept of quantum computing and will explain how powerful it is. The study will then talk about how quantum computing will change and help increase the efficiency of artificially intelligent systems. Examples of algorithms that quantum computing utilises will also be presented to help explain how this field of computer science will help improve artificial intelligence.
Topic 6: The role of deep learning in building intelligent systems
Research Aim: Deep learning, an essential branch of artificial intelligence, utilizes neural networks to assess the various factors similar to a human neural system. This research will introduce the concept of deep learning and discuss how it works in artificial intelligence. Deep learning algorithms will also be explored in this study to have a deeper understanding of this artificial intelligence topic. Using case examples and evidence, the research will explore how deep learning assists in creating machines that are intelligent and how they can process information like a human being. The various applications of deep learning will also be discussed in this study.
Topic 7: Evaluating the role of natural language processing in artificial intelligence
Research Aim: Natural language processing (NLP) is an essential element of artificial intelligence. It provides systems and machines with the ability to read, understand and interpret the human language. With the help of natural language processing, systems can even measure sentiments and predict which parts of human language are important. This research will aim to evaluate the role of this language in the field of artificial intelligence. It will further assist in understanding how natural language processing helps build intelligent systems that various organizations can use. Furthermore, the various applications of NLP will also be discussed.
Topic 8: Application of computer vision in building intelligent systems
Research Aim: Computer vision in the field of artificial intelligence makes systems so smart that they can analyze and understand images and pictures. These machines then derive some intelligence from the image that has been fed to the system. This research will first aim to understand computer vision and its role in artificial intelligence. A framework will be presented that will explain the working of computer vision in artificial intelligence. This study will present the applications of computer vision to clarify further how artificial intelligence uses computer vision to build smart systems.
Topic 9: Analysing the use of the IoT in artificial intelligence
Research Aim: The Internet of things and artificial intelligence are two separate, powerful tools. IoT can connect devices wirelessly, which can perform a set of actions without human intervention. When this powerful tool is combined with artificial intelligence, systems become extremely powerful to simulate human behaviour and make decisions without human interference. This artificial intelligence topic will aim to analyze the use of the internet of things in artificial intelligence. Machines that use IoT and AI will be analyzed, and the study will present how human behaviour is simulated so accurately.
Topic 10: Recommender systems – exploring its power in e-commerce
Research Aim: Recommender systems use algorithms to offer relevant suggestions to users. Be it a product, a service, a search result, or a movie/TV show/series. Users receive tons of recommendations after searching for a particular product or browsing their favourite TV shows list. With the help of AI, recommender systems can offer relevant and accurate suggestions to users. The main aim of this research will be to explore the use of recommender systems in e-commerce. Industry giants use this tool to help customers find the product or service they are looking for and make the right decision. This research will discuss where recommender systems are used, how they are implemented, and their results for e-commerce businesses.
Free Dissertation Topic
Phone Number
Academic Level Select Academic Level Undergraduate Graduate PHD
Academic Subject
Area of Research
Frequently Asked Questions
How to find artificial intelligence dissertation topics.
To find artificial intelligence dissertation topics:
- Study recent AI advancements.
- Explore ethical concerns.
- Investigate AI in specific industries.
- Analyze AI’s societal impact.
- Consider human-AI interaction.
- Select a topic aligning with your expertise and passion.
You May Also Like
Go through some of the dissertation topics related to entrepreneurship given below, with their research aim, and get an idea to begin your dissertation.
Need interesting and manageable literature dissertation topics or thesis? Here are the trending literature dissertation titles so you can choose the most suitable one.
Need interesting and manageable Economics dissertation topics? Here are the trending Economics dissertation titles so you can choose the most suitable one.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works

- LibGuides
- A-Z List
- Help
Artificial Intelligence
- Background Information
- Getting started
- Browse Journals
- Dissertations & Theses
- Datasets and Repositories
- Research Data Management 101
- Scientific Writing
- Find Videos
- Related Topics
- Quick Links
- Ask Us/Contact Us
FIU dissertations

Non-FIU dissertations
Many universities provide full-text access to their dissertations via a digital repository. If you know the title of a particular dissertation or thesis, try doing a Google search.
Aims to be the best possible resource for finding open access graduate theses and dissertations published around the world with metadata from over 800 colleges, universities, and research institutions. Currently, indexes over 1 million theses and dissertations.
This is a discovery service for open access research theses awarded by European universities.
A union catalog of Canadian theses and dissertations, in both electronic and analog formats, is available through the search interface on this portal.
There are currently more than 90 countries and over 1200 institutions represented. CRL has catalog records for over 800,000 foreign doctoral dissertations.
An international collaborative resource, the NDLTD Union Catalog contains more than one million records of electronic theses and dissertations. Use BASE, the VTLS Visualizer or any of the geographically specific search engines noted lower on their webpage.
Indexes doctoral dissertations and masters' theses in all areas of academic research includes international coverage.
ProQuest Dissertations & Theses global
Related Sites

- << Previous: Browse Journals
- Next: Datasets and Repositories >>
- Last Updated: Apr 4, 2024 8:33 AM
- URL: https://library.fiu.edu/artificial-intelligence
Information
Fiu libraries floorplans, green library, modesto a. maidique campus, hubert library, biscayne bay campus.

Directions: Green Library, MMC
Directions: Hubert Library, BBC

- Onsite training
3,000,000+ delegates
15,000+ clients
1,000+ locations
- KnowledgePass
- Log a ticket
01344203999 Available 24/7
12 Best Artificial Intelligence Topics for Research in 2024
Explore the "12 Best Artificial Intelligence Topics for Research in 2024." Dive into the top AI research areas, including Natural Language Processing, Computer Vision, Reinforcement Learning, Explainable AI (XAI), AI in Healthcare, Autonomous Vehicles, and AI Ethics and Bias. Stay ahead of the curve and make informed choices for your AI research endeavours.

Exclusive 40% OFF
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Share this Resource
- AI Tools in Performance Marketing Training
- Deep Learning Course
- Natural Language Processing (NLP) Fundamentals with Python
- Machine Learning Course
- Duet AI for Workspace Training

Table of Contents
1) Top Artificial Intelligence Topics for Research
a) Natural Language Processing
b) Computer vision
c) Reinforcement Learning
d) Explainable AI (XAI)
e) Generative Adversarial Networks (GANs)
f) Robotics and AI
g) AI in healthcare
h) AI for social good
i) Autonomous vehicles
j) AI ethics and bias
2) Conclusion
Top Artificial Intelligence Topics for Research
This section of the blog will expand on some of the best Artificial Intelligence Topics for research.

Natural Language Processing
Natural Language Processing (NLP) is centred around empowering machines to comprehend, interpret, and even generate human language. Within this domain, three distinctive research avenues beckon:
1) Sentiment analysis: This entails the study of methodologies to decipher and discern emotions encapsulated within textual content. Understanding sentiments is pivotal in applications ranging from brand perception analysis to social media insights.
2) Language generation: Generating coherent and contextually apt text is an ongoing pursuit. Investigating mechanisms that allow machines to produce human-like narratives and responses holds immense potential across sectors.
3) Question answering systems: Constructing systems that can grasp the nuances of natural language questions and provide accurate, coherent responses is a cornerstone of NLP research. This facet has implications for knowledge dissemination, customer support, and more.
Computer Vision
Computer Vision, a discipline that bestows machines with the ability to interpret visual data, is replete with intriguing avenues for research:
1) Object detection and tracking: The development of algorithms capable of identifying and tracking objects within images and videos finds relevance in surveillance, automotive safety, and beyond.
2) Image captioning: Bridging the gap between visual and textual comprehension, this research area focuses on generating descriptive captions for images, catering to visually impaired individuals and enhancing multimedia indexing.
3) Facial recognition: Advancements in facial recognition technology hold implications for security, personalisation, and accessibility, necessitating ongoing research into accuracy and ethical considerations.
Reinforcement Learning
Reinforcement Learning revolves around training agents to make sequential decisions in order to maximise rewards. Within this realm, three prominent Artificial Intelligence Topics emerge:
1) Autonomous agents: Crafting AI agents that exhibit decision-making prowess in dynamic environments paves the way for applications like autonomous robotics and adaptive systems.
2) Deep Q-Networks (DQN): Deep Q-Networks, a class of reinforcement learning algorithms, remain under active research for refining value-based decision-making in complex scenarios.
3) Policy gradient methods: These methods, aiming to optimise policies directly, play a crucial role in fine-tuning decision-making processes across domains like gaming, finance, and robotics.

Explainable AI (XAI)
The pursuit of Explainable AI seeks to demystify the decision-making processes of AI systems. This area comprises Artificial Intelligence Topics such as:
1) Model interpretability: Unravelling the inner workings of complex models to elucidate the factors influencing their outputs, thus fostering transparency and accountability.
2) Visualising neural networks: Transforming abstract neural network structures into visual representations aids in comprehending their functionality and behaviour.
3) Rule-based systems: Augmenting AI decision-making with interpretable, rule-based systems holds promise in domains requiring logical explanations for actions taken.
Generative Adversarial Networks (GANs)
The captivating world of Generative Adversarial Networks (GANs) unfolds through the interplay of generator and discriminator networks, birthing remarkable research avenues:
1) Image generation: Crafting realistic images from random noise showcases the creative potential of GANs, with applications spanning art, design, and data augmentation.
2) Style transfer: Enabling the transfer of artistic styles between images, merging creativity and technology to yield visually captivating results.
3) Anomaly detection: GANs find utility in identifying anomalies within datasets, bolstering fraud detection, quality control, and anomaly-sensitive industries.
Robotics and AI
The synergy between Robotics and AI is a fertile ground for exploration, with Artificial Intelligence Topics such as:
1) Human-robot collaboration: Research in this arena strives to establish harmonious collaboration between humans and robots, augmenting industry productivity and efficiency.
2) Robot learning: By enabling robots to learn and adapt from their experiences, Researchers foster robots' autonomy and the ability to handle diverse tasks.
3) Ethical considerations: Delving into the ethical implications surrounding AI-powered robots helps establish responsible guidelines for their deployment.
AI in healthcare
AI presents a transformative potential within healthcare, spurring research into:
1) Medical diagnosis: AI aids in accurately diagnosing medical conditions, revolutionising early detection and patient care.
2) Drug discovery: Leveraging AI for drug discovery expedites the identification of potential candidates, accelerating the development of new treatments.
3) Personalised treatment: Tailoring medical interventions to individual patient profiles enhances treatment outcomes and patient well-being.
AI for social good
Harnessing the prowess of AI for Social Good entails addressing pressing global challenges:
1) Environmental monitoring: AI-powered solutions facilitate real-time monitoring of ecological changes, supporting conservation and sustainable practices.
2) Disaster response: Research in this area bolsters disaster response efforts by employing AI to analyse data and optimise resource allocation.
3) Poverty alleviation: Researchers contribute to humanitarian efforts and socioeconomic equality by devising AI solutions to tackle poverty.
Unlock the potential of Artificial Intelligence for effective Project Management with our Artificial Intelligence (AI) for Project Managers Course . Sign up now!
Autonomous vehicles
Autonomous Vehicles represent a realm brimming with potential and complexities, necessitating research in Artificial Intelligence Topics such as:
1) Sensor fusion: Integrating data from diverse sensors enhances perception accuracy, which is essential for safe autonomous navigation.
2) Path planning: Developing advanced algorithms for path planning ensures optimal routes while adhering to safety protocols.
3) Safety and ethics: Ethical considerations, such as programming vehicles to make difficult decisions in potential accident scenarios, require meticulous research and deliberation.
AI ethics and bias
Ethical underpinnings in AI drive research efforts in these directions:
1) Fairness in AI: Ensuring AI systems remain impartial and unbiased across diverse demographic groups.
2) Bias detection and mitigation: Identifying and rectifying biases present within AI models guarantees equitable outcomes.
3) Ethical decision-making: Developing frameworks that imbue AI with ethical decision-making capabilities aligns technology with societal values.
Future of AI
The vanguard of AI beckons Researchers to explore these horizons:
1) Artificial General Intelligence (AGI): Speculating on the potential emergence of AI systems capable of emulating human-like intelligence opens dialogues on the implications and challenges.
2) AI and creativity: Probing the interface between AI and creative domains, such as art and music, unveils the coalescence of human ingenuity and technological prowess.
3) Ethical and regulatory challenges: Researching the ethical dilemmas and regulatory frameworks underpinning AI's evolution fortifies responsible innovation.
AI and education
The intersection of AI and Education opens doors to innovative learning paradigms:
1) Personalised learning: Developing AI systems that adapt educational content to individual learning styles and paces.
2) Intelligent tutoring systems: Creating AI-driven tutoring systems that provide targeted support to students.
3) Educational data mining: Applying AI to analyse educational data for insights into learning patterns and trends.
Unleash the full potential of AI with our comprehensive Introduction to Artificial Intelligence Training . Join now!
Conclusion
The domain of AI is ever-expanding, rich with intriguing topics about Artificial Intelligence that beckon Researchers to explore, question, and innovate. Through the pursuit of these twelve diverse Artificial Intelligence Topics, we pave the way for not only technological advancement but also a deeper understanding of the societal impact of AI. By delving into these realms, Researchers stand poised to shape the trajectory of AI, ensuring it remains a force for progress, empowerment, and positive transformation in our world.
Unlock your full potential with our extensive Personal Development Training Courses. Join today!
Frequently Asked Questions
Upcoming data, analytics & ai resources batches & dates.
Fri 2nd Aug 2024
Fri 15th Nov 2024
Get A Quote
WHO WILL BE FUNDING THE COURSE?
My employer
By submitting your details you agree to be contacted in order to respond to your enquiry
- Business Analysis
- Lean Six Sigma Certification
Share this course
Our biggest spring sale.

We cannot process your enquiry without contacting you, please tick to confirm your consent to us for contacting you about your enquiry.
By submitting your details you agree to be contacted in order to respond to your enquiry.
We may not have the course you’re looking for. If you enquire or give us a call on 01344203999 and speak to our training experts, we may still be able to help with your training requirements.
Or select from our popular topics
- ITIL® Certification
- Scrum Certification
- Change Management Certification
- Business Analysis Courses
- Microsoft Azure Certification
- Microsoft Excel Courses
- Microsoft Project
- Explore more courses
Press esc to close
Fill out your contact details below and our training experts will be in touch.
Fill out your contact details below
Thank you for your enquiry!
One of our training experts will be in touch shortly to go over your training requirements.
Back to Course Information
Fill out your contact details below so we can get in touch with you regarding your training requirements.
* WHO WILL BE FUNDING THE COURSE?
Preferred Contact Method
No preference
Back to course information
Fill out your training details below
Fill out your training details below so we have a better idea of what your training requirements are.
HOW MANY DELEGATES NEED TRAINING?
HOW DO YOU WANT THE COURSE DELIVERED?
Online Instructor-led
Online Self-paced
WHEN WOULD YOU LIKE TO TAKE THIS COURSE?
Next 2 - 4 months
WHAT IS YOUR REASON FOR ENQUIRING?
Looking for some information
Looking for a discount
I want to book but have questions
One of our training experts will be in touch shortly to go overy your training requirements.
Your privacy & cookies!
Like many websites we use cookies. We care about your data and experience, so to give you the best possible experience using our site, we store a very limited amount of your data. Continuing to use this site or clicking “Accept & close” means that you agree to our use of cookies. Learn more about our privacy policy and cookie policy cookie policy .
We use cookies that are essential for our site to work. Please visit our cookie policy for more information. To accept all cookies click 'Accept & close'.
Dissertations in Artificial Intelligence
Issn online, aims and scope.
- Book Series Editors
Artificial Intelligence (AI) is one of the fastest growing research areas in computer science with a strong impact on various fields of science, industry, and society. This series publishes excellent doctoral dissertations in all sub-fields of AI, ranging from foundational work on AI methods and theories to application-oriented theses.
Book series editors
Editor-in-Chief Professor Dr. Ralph Bergmann Department of Business Information Systems II University of Trier, Germany
Books from this Series
Flexible workflows, publication date, from narratology to computational story composition and back, semantics of belief change operators for intelligent agents: iteration, postulates, and realizability, shallow discourse parsing for german, knowledge representation and inductive reasoning using conditional logic and sets of ranking functions, ontologie-basierte informationsextraktion zum aufbau einer wissensbasis für dokumentgetriebene workflows, related publications, international symposium on world ecological design, electronic engineering and informatics, artificial intelligence and human-computer interaction.
Machine Learning - CMU

PhD Dissertations
[all are .pdf files].
Learning Models that Match Jacob Tyo, 2024
Improving Human Integration across the Machine Learning Pipeline Charvi Rastogi, 2024
Reliable and Practical Machine Learning for Dynamic Healthcare Settings Helen Zhou, 2023
Automatic customization of large-scale spiking network models to neuronal population activity (unavailable) Shenghao Wu, 2023
Estimation of BVk functions from scattered data (unavailable) Addison J. Hu, 2023
Rethinking object categorization in computer vision (unavailable) Jayanth Koushik, 2023
Advances in Statistical Gene Networks Jinjin Tian, 2023 Post-hoc calibration without distributional assumptions Chirag Gupta, 2023
The Role of Noise, Proxies, and Dynamics in Algorithmic Fairness Nil-Jana Akpinar, 2023
Collaborative learning by leveraging siloed data Sebastian Caldas, 2023
Modeling Epidemiological Time Series Aaron Rumack, 2023
Human-Centered Machine Learning: A Statistical and Algorithmic Perspective Leqi Liu, 2023
Uncertainty Quantification under Distribution Shifts Aleksandr Podkopaev, 2023
Probabilistic Reinforcement Learning: Using Data to Define Desired Outcomes, and Inferring How to Get There Benjamin Eysenbach, 2023
Comparing Forecasters and Abstaining Classifiers Yo Joong Choe, 2023
Using Task Driven Methods to Uncover Representations of Human Vision and Semantics Aria Yuan Wang, 2023
Data-driven Decisions - An Anomaly Detection Perspective Shubhranshu Shekhar, 2023
Applied Mathematics of the Future Kin G. Olivares, 2023
METHODS AND APPLICATIONS OF EXPLAINABLE MACHINE LEARNING Joon Sik Kim, 2023
NEURAL REASONING FOR QUESTION ANSWERING Haitian Sun, 2023
Principled Machine Learning for Societally Consequential Decision Making Amanda Coston, 2023
Long term brain dynamics extend cognitive neuroscience to timescales relevant for health and physiology Maxwell B. Wang, 2023
Long term brain dynamics extend cognitive neuroscience to timescales relevant for health and physiology Darby M. Losey, 2023
Calibrated Conditional Density Models and Predictive Inference via Local Diagnostics David Zhao, 2023
Towards an Application-based Pipeline for Explainability Gregory Plumb, 2022
Objective Criteria for Explainable Machine Learning Chih-Kuan Yeh, 2022
Making Scientific Peer Review Scientific Ivan Stelmakh, 2022
Facets of regularization in high-dimensional learning: Cross-validation, risk monotonization, and model complexity Pratik Patil, 2022
Active Robot Perception using Programmable Light Curtains Siddharth Ancha, 2022
Strategies for Black-Box and Multi-Objective Optimization Biswajit Paria, 2022
Unifying State and Policy-Level Explanations for Reinforcement Learning Nicholay Topin, 2022
Sensor Fusion Frameworks for Nowcasting Maria Jahja, 2022
Equilibrium Approaches to Modern Deep Learning Shaojie Bai, 2022
Towards General Natural Language Understanding with Probabilistic Worldbuilding Abulhair Saparov, 2022
Applications of Point Process Modeling to Spiking Neurons (Unavailable) Yu Chen, 2021
Neural variability: structure, sources, control, and data augmentation Akash Umakantha, 2021
Structure and time course of neural population activity during learning Jay Hennig, 2021
Cross-view Learning with Limited Supervision Yao-Hung Hubert Tsai, 2021
Meta Reinforcement Learning through Memory Emilio Parisotto, 2021
Learning Embodied Agents with Scalably-Supervised Reinforcement Learning Lisa Lee, 2021
Learning to Predict and Make Decisions under Distribution Shift Yifan Wu, 2021
Statistical Game Theory Arun Sai Suggala, 2021
Towards Knowledge-capable AI: Agents that See, Speak, Act and Know Kenneth Marino, 2021
Learning and Reasoning with Fast Semidefinite Programming and Mixing Methods Po-Wei Wang, 2021
Bridging Language in Machines with Language in the Brain Mariya Toneva, 2021
Curriculum Learning Otilia Stretcu, 2021
Principles of Learning in Multitask Settings: A Probabilistic Perspective Maruan Al-Shedivat, 2021
Towards Robust and Resilient Machine Learning Adarsh Prasad, 2021
Towards Training AI Agents with All Types of Experiences: A Unified ML Formalism Zhiting Hu, 2021
Building Intelligent Autonomous Navigation Agents Devendra Chaplot, 2021
Learning to See by Moving: Self-supervising 3D Scene Representations for Perception, Control, and Visual Reasoning Hsiao-Yu Fish Tung, 2021
Statistical Astrophysics: From Extrasolar Planets to the Large-scale Structure of the Universe Collin Politsch, 2020
Causal Inference with Complex Data Structures and Non-Standard Effects Kwhangho Kim, 2020
Networks, Point Processes, and Networks of Point Processes Neil Spencer, 2020
Dissecting neural variability using population recordings, network models, and neurofeedback (Unavailable) Ryan Williamson, 2020
Predicting Health and Safety: Essays in Machine Learning for Decision Support in the Public Sector Dylan Fitzpatrick, 2020
Towards a Unified Framework for Learning and Reasoning Han Zhao, 2020
Learning DAGs with Continuous Optimization Xun Zheng, 2020
Machine Learning and Multiagent Preferences Ritesh Noothigattu, 2020
Learning and Decision Making from Diverse Forms of Information Yichong Xu, 2020
Towards Data-Efficient Machine Learning Qizhe Xie, 2020
Change modeling for understanding our world and the counterfactual one(s) William Herlands, 2020
Machine Learning in High-Stakes Settings: Risks and Opportunities Maria De-Arteaga, 2020
Data Decomposition for Constrained Visual Learning Calvin Murdock, 2020
Structured Sparse Regression Methods for Learning from High-Dimensional Genomic Data Micol Marchetti-Bowick, 2020
Towards Efficient Automated Machine Learning Liam Li, 2020
LEARNING COLLECTIONS OF FUNCTIONS Emmanouil Antonios Platanios, 2020
Provable, structured, and efficient methods for robustness of deep networks to adversarial examples Eric Wong , 2020
Reconstructing and Mining Signals: Algorithms and Applications Hyun Ah Song, 2020
Probabilistic Single Cell Lineage Tracing Chieh Lin, 2020
Graphical network modeling of phase coupling in brain activity (unavailable) Josue Orellana, 2019
Strategic Exploration in Reinforcement Learning - New Algorithms and Learning Guarantees Christoph Dann, 2019 Learning Generative Models using Transformations Chun-Liang Li, 2019
Estimating Probability Distributions and their Properties Shashank Singh, 2019
Post-Inference Methods for Scalable Probabilistic Modeling and Sequential Decision Making Willie Neiswanger, 2019
Accelerating Text-as-Data Research in Computational Social Science Dallas Card, 2019
Multi-view Relationships for Analytics and Inference Eric Lei, 2019
Information flow in networks based on nonstationary multivariate neural recordings Natalie Klein, 2019
Competitive Analysis for Machine Learning & Data Science Michael Spece, 2019
The When, Where and Why of Human Memory Retrieval Qiong Zhang, 2019
Towards Effective and Efficient Learning at Scale Adams Wei Yu, 2019
Towards Literate Artificial Intelligence Mrinmaya Sachan, 2019
Learning Gene Networks Underlying Clinical Phenotypes Under SNP Perturbations From Genome-Wide Data Calvin McCarter, 2019
Unified Models for Dynamical Systems Carlton Downey, 2019
Anytime Prediction and Learning for the Balance between Computation and Accuracy Hanzhang Hu, 2019
Statistical and Computational Properties of Some "User-Friendly" Methods for High-Dimensional Estimation Alnur Ali, 2019
Nonparametric Methods with Total Variation Type Regularization Veeranjaneyulu Sadhanala, 2019
New Advances in Sparse Learning, Deep Networks, and Adversarial Learning: Theory and Applications Hongyang Zhang, 2019
Gradient Descent for Non-convex Problems in Modern Machine Learning Simon Shaolei Du, 2019
Selective Data Acquisition in Learning and Decision Making Problems Yining Wang, 2019
Anomaly Detection in Graphs and Time Series: Algorithms and Applications Bryan Hooi, 2019
Neural dynamics and interactions in the human ventral visual pathway Yuanning Li, 2018
Tuning Hyperparameters without Grad Students: Scaling up Bandit Optimisation Kirthevasan Kandasamy, 2018
Teaching Machines to Classify from Natural Language Interactions Shashank Srivastava, 2018
Statistical Inference for Geometric Data Jisu Kim, 2018
Representation Learning @ Scale Manzil Zaheer, 2018
Diversity-promoting and Large-scale Machine Learning for Healthcare Pengtao Xie, 2018
Distribution and Histogram (DIsH) Learning Junier Oliva, 2018
Stress Detection for Keystroke Dynamics Shing-Hon Lau, 2018
Sublinear-Time Learning and Inference for High-Dimensional Models Enxu Yan, 2018
Neural population activity in the visual cortex: Statistical methods and application Benjamin Cowley, 2018
Efficient Methods for Prediction and Control in Partially Observable Environments Ahmed Hefny, 2018
Learning with Staleness Wei Dai, 2018
Statistical Approach for Functionally Validating Transcription Factor Bindings Using Population SNP and Gene Expression Data Jing Xiang, 2017
New Paradigms and Optimality Guarantees in Statistical Learning and Estimation Yu-Xiang Wang, 2017
Dynamic Question Ordering: Obtaining Useful Information While Reducing User Burden Kirstin Early, 2017
New Optimization Methods for Modern Machine Learning Sashank J. Reddi, 2017
Active Search with Complex Actions and Rewards Yifei Ma, 2017
Why Machine Learning Works George D. Montañez , 2017
Source-Space Analyses in MEG/EEG and Applications to Explore Spatio-temporal Neural Dynamics in Human Vision Ying Yang , 2017
Computational Tools for Identification and Analysis of Neuronal Population Activity Pengcheng Zhou, 2016
Expressive Collaborative Music Performance via Machine Learning Gus (Guangyu) Xia, 2016
Supervision Beyond Manual Annotations for Learning Visual Representations Carl Doersch, 2016
Exploring Weakly Labeled Data Across the Noise-Bias Spectrum Robert W. H. Fisher, 2016
Optimizing Optimization: Scalable Convex Programming with Proximal Operators Matt Wytock, 2016
Combining Neural Population Recordings: Theory and Application William Bishop, 2015
Discovering Compact and Informative Structures through Data Partitioning Madalina Fiterau-Brostean, 2015
Machine Learning in Space and Time Seth R. Flaxman, 2015
The Time and Location of Natural Reading Processes in the Brain Leila Wehbe, 2015
Shape-Constrained Estimation in High Dimensions Min Xu, 2015
Spectral Probabilistic Modeling and Applications to Natural Language Processing Ankur Parikh, 2015 Computational and Statistical Advances in Testing and Learning Aaditya Kumar Ramdas, 2015
Corpora and Cognition: The Semantic Composition of Adjectives and Nouns in the Human Brain Alona Fyshe, 2015
Learning Statistical Features of Scene Images Wooyoung Lee, 2014
Towards Scalable Analysis of Images and Videos Bin Zhao, 2014
Statistical Text Analysis for Social Science Brendan T. O'Connor, 2014
Modeling Large Social Networks in Context Qirong Ho, 2014
Semi-Cooperative Learning in Smart Grid Agents Prashant P. Reddy, 2013
On Learning from Collective Data Liang Xiong, 2013
Exploiting Non-sequence Data in Dynamic Model Learning Tzu-Kuo Huang, 2013
Mathematical Theories of Interaction with Oracles Liu Yang, 2013
Short-Sighted Probabilistic Planning Felipe W. Trevizan, 2013
Statistical Models and Algorithms for Studying Hand and Finger Kinematics and their Neural Mechanisms Lucia Castellanos, 2013
Approximation Algorithms and New Models for Clustering and Learning Pranjal Awasthi, 2013
Uncovering Structure in High-Dimensions: Networks and Multi-task Learning Problems Mladen Kolar, 2013
Learning with Sparsity: Structures, Optimization and Applications Xi Chen, 2013
GraphLab: A Distributed Abstraction for Large Scale Machine Learning Yucheng Low, 2013
Graph Structured Normal Means Inference James Sharpnack, 2013 (Joint Statistics & ML PhD)
Probabilistic Models for Collecting, Analyzing, and Modeling Expression Data Hai-Son Phuoc Le, 2013
Learning Large-Scale Conditional Random Fields Joseph K. Bradley, 2013
New Statistical Applications for Differential Privacy Rob Hall, 2013 (Joint Statistics & ML PhD)
Parallel and Distributed Systems for Probabilistic Reasoning Joseph Gonzalez, 2012
Spectral Approaches to Learning Predictive Representations Byron Boots, 2012
Attribute Learning using Joint Human and Machine Computation Edith L. M. Law, 2012
Statistical Methods for Studying Genetic Variation in Populations Suyash Shringarpure, 2012
Data Mining Meets HCI: Making Sense of Large Graphs Duen Horng (Polo) Chau, 2012
Learning with Limited Supervision by Input and Output Coding Yi Zhang, 2012
Target Sequence Clustering Benjamin Shih, 2011
Nonparametric Learning in High Dimensions Han Liu, 2010 (Joint Statistics & ML PhD)
Structural Analysis of Large Networks: Observations and Applications Mary McGlohon, 2010
Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy Brian D. Ziebart, 2010
Tractable Algorithms for Proximity Search on Large Graphs Purnamrita Sarkar, 2010
Rare Category Analysis Jingrui He, 2010
Coupled Semi-Supervised Learning Andrew Carlson, 2010
Fast Algorithms for Querying and Mining Large Graphs Hanghang Tong, 2009
Efficient Matrix Models for Relational Learning Ajit Paul Singh, 2009
Exploiting Domain and Task Regularities for Robust Named Entity Recognition Andrew O. Arnold, 2009
Theoretical Foundations of Active Learning Steve Hanneke, 2009
Generalized Learning Factors Analysis: Improving Cognitive Models with Machine Learning Hao Cen, 2009
Detecting Patterns of Anomalies Kaustav Das, 2009
Dynamics of Large Networks Jurij Leskovec, 2008
Computational Methods for Analyzing and Modeling Gene Regulation Dynamics Jason Ernst, 2008
Stacked Graphical Learning Zhenzhen Kou, 2007
Actively Learning Specific Function Properties with Applications to Statistical Inference Brent Bryan, 2007
Approximate Inference, Structure Learning and Feature Estimation in Markov Random Fields Pradeep Ravikumar, 2007
Scalable Graphical Models for Social Networks Anna Goldenberg, 2007
Measure Concentration of Strongly Mixing Processes with Applications Leonid Kontorovich, 2007
Tools for Graph Mining Deepayan Chakrabarti, 2005
Automatic Discovery of Latent Variable Models Ricardo Silva, 2005

MIT Libraries home DSpace@MIT
- DSpace@MIT Home
- MIT Libraries
- Graduate Theses
Artificial Intelligence and Machine Learning Capabilities and Application Programming Interfaces at Amazon, Google, and Microsoft

Terms of use
Date issued, collections.

Completed Theses
State space search solves navigation tasks and many other real world problems. Heuristic search, especially greedy best-first search, is one of the most successful algorithms for state space search. We improve the state of the art in heuristic search in three directions.
In Part I, we present methods to train neural networks as powerful heuristics for a given state space. We present a universal approach to generate training data using random walks from a (partial) state. We demonstrate that our heuristics trained for a specific task are often better than heuristics trained for a whole domain. We show that the performance of all trained heuristics is highly complementary. There is no clear pattern, which trained heuristic to prefer for a specific task. In general, model-based planners still outperform planners with trained heuristics. But our approaches exceed the model-based algorithms in the Storage domain. To our knowledge, only once before in the Spanner domain, a learning-based planner exceeded the state-of-the-art model-based planners.
A priori, it is unknown whether a heuristic, or in the more general case a planner, performs well on a task. Hence, we trained online portfolios to select the best planner for a task. Today, all online portfolios are based on handcrafted features. In Part II, we present new online portfolios based on neural networks, which receive the complete task as input, and not just a few handcrafted features. Additionally, our portfolios can reconsider their choices. Both extensions greatly improve the state-of-the-art of online portfolios. Finally, we show that explainable machine learning techniques, as the alternative to neural networks, are also good online portfolios. Additionally, we present methods to improve our trust in their predictions.
Even if we select the best search algorithm, we cannot solve some tasks in reasonable time. We can speed up the search if we know how it behaves in the future. In Part III, we inspect the behavior of greedy best-first search with a fixed heuristic on simple tasks of a domain to learn its behavior for any task of the same domain. Once greedy best-first search expanded a progress state, it expands only states with lower heuristic values. We learn to identify progress states and present two methods to exploit this knowledge. Building upon this, we extract the bench transition system of a task and generalize it in such a way that we can apply it to any task of the same domain. We can use this generalized bench transition system to split a task into a sequence of simpler searches.
In all three research directions, we contribute new approaches and insights to the state of the art, and we indicate interesting topics for future work.
Greedy best-first search (GBFS) is a sibling of A* in the family of best-first state-space search algorithms. While A* is guaranteed to find optimal solutions of search problems, GBFS does not provide any guarantees but typically finds satisficing solutions more quickly than A*. A classical result of optimal best-first search shows that A* with admissible and consistent heuristic expands every state whose f-value is below the optimal solution cost and no state whose f-value is above the optimal solution cost. Theoretical results of this kind are useful for the analysis of heuristics in different search domains and for the improvement of algorithms. For satisficing algorithms a similarly clear understanding is currently lacking. We examine the search behavior of GBFS in order to make progress towards such an understanding.
We introduce the concept of high-water mark benches, which separate the search space into areas that are searched by GBFS in sequence. High-water mark benches allow us to exactly determine the set of states that GBFS expands under at least one tie-breaking strategy. We show that benches contain craters. Once GBFS enters a crater, it has to expand every state in the crater before being able to escape.
Benches and craters allow us to characterize the best-case and worst-case behavior of GBFS in given search instances. We show that computing the best-case or worst-case behavior of GBFS is NP-complete in general but can be computed in polynomial time for undirected state spaces.
We present algorithms for extracting the set of states that GBFS potentially expands and for computing the best-case and worst-case behavior. We use the algorithms to analyze GBFS on benchmark tasks from planning competitions under a state-of-the-art heuristic. Experimental results reveal interesting characteristics of the heuristic on the given tasks and demonstrate the importance of tie-breaking in GBFS.
Classical planning tackles the problem of finding a sequence of actions that leads from an initial state to a goal. Over the last decades, planning systems have become significantly better at answering the question whether such a sequence exists by applying a variety of techniques which have become more and more complex. As a result, it has become nearly impossible to formally analyze whether a planning system is actually correct in its answers, and we need to rely on experimental evidence.
One way to increase trust is the concept of certifying algorithms, which provide a witness which justifies their answer and can be verified independently. When a planning system finds a solution to a problem, the solution itself is a witness, and we can verify it by simply applying it. But what if the planning system claims the task is unsolvable? So far there was no principled way of verifying this claim.
This thesis contributes two approaches to create witnesses for unsolvable planning tasks. Inductive certificates are based on the idea of invariants. They argue that the initial state is part of a set of states that we cannot leave and that contains no goal state. In our second approach, we define a proof system that proves in an incremental fashion that certain states cannot be part of a solution until it has proven that either the initial state or all goal states are such states.
Both approaches are complete in the sense that a witness exists for every unsolvable planning task, and can be verified efficiently (in respect to the size of the witness) by an independent verifier if certain criteria are met. To show their applicability to state-of-the-art planning techniques, we provide an extensive overview how these approaches can cover several search algorithms, heuristics and other techniques. Finally, we show with an experimental study that generating and verifying these explanations is not only theoretically possible but also practically feasible, thus making a first step towards fully certifying planning systems.
Heuristic search with an admissible heuristic is one of the most prominent approaches to solving classical planning tasks optimally. In the first part of this thesis, we introduce a new family of admissible heuristics for classical planning, based on Cartesian abstractions, which we derive by counterexample-guided abstraction refinement. Since one abstraction usually is not informative enough for challenging planning tasks, we present several ways of creating diverse abstractions. To combine them admissibly, we introduce a new cost partitioning algorithm, which we call saturated cost partitioning. It considers the heuristics sequentially and uses the minimum amount of costs that preserves all heuristic estimates for the current heuristic before passing the remaining costs to subsequent heuristics until all heuristics have been served this way.
In the second part, we show that saturated cost partitioning is strongly influenced by the order in which it considers the heuristics. To find good orders, we present a greedy algorithm for creating an initial order and a hill-climbing search for optimizing a given order. Both algorithms make the resulting heuristics significantly more accurate. However, we obtain the strongest heuristics by maximizing over saturated cost partitioning heuristics computed for multiple orders, especially if we actively search for diverse orders.
The third part provides a theoretical and experimental comparison of saturated cost partitioning and other cost partitioning algorithms. Theoretically, we show that saturated cost partitioning dominates greedy zero-one cost partitioning. The difference between the two algorithms is that saturated cost partitioning opportunistically reuses unconsumed costs for subsequent heuristics. By applying this idea to uniform cost partitioning we obtain an opportunistic variant that dominates the original. We also prove that the maximum over suitable greedy zero-one cost partitioning heuristics dominates the canonical heuristic and show several non-dominance results for cost partitioning algorithms. The experimental analysis shows that saturated cost partitioning is the cost partitioning algorithm of choice in all evaluated settings and it even outperforms the previous state of the art in optimal classical planning.
Classical planning is the problem of finding a sequence of deterministic actions in a state space that lead from an initial state to a state satisfying some goal condition. The dominant approach to optimally solve planning tasks is heuristic search, in particular A* search combined with an admissible heuristic. While there exist many different admissible heuristics, we focus on abstraction heuristics in this thesis, and in particular, on the well-established merge-and-shrink heuristics.
Our main theoretical contribution is to provide a comprehensive description of the merge-and-shrink framework in terms of transformations of transition systems. Unlike previous accounts, our description is fully compositional, i.e. can be understood by understanding each transformation in isolation. In particular, in addition to the name-giving merge and shrink transformations, we also describe pruning and label reduction as such transformations. The latter is based on generalized label reduction, a new theory that removes all of the restrictions of the previous definition of label reduction. We study the four types of transformations in terms of desirable formal properties and explain how these properties transfer to heuristics being admissible and consistent or even perfect. We also describe an optimized implementation of the merge-and-shrink framework that substantially improves the efficiency compared to previous implementations.
Furthermore, we investigate the expressive power of merge-and-shrink abstractions by analyzing factored mappings, the data structure they use for representing functions. In particular, we show that there exist certain families of functions that can be compactly represented by so-called non-linear factored mappings but not by linear ones.
On the practical side, we contribute several non-linear merge strategies to the merge-and-shrink toolbox. In particular, we adapt a merge strategy from model checking to planning, provide a framework to enhance existing merge strategies based on symmetries, devise a simple score-based merge strategy that minimizes the maximum size of transition systems of the merge-and-shrink computation, and describe another framework to enhance merge strategies based on an analysis of causal dependencies of the planning task.
In a large experimental study, we show the evolution of the performance of merge-and-shrink heuristics on planning benchmarks. Starting with the state of the art before the contributions of this thesis, we subsequently evaluate all of our techniques and show that state-of-the-art non-linear merge-and-shrink heuristics improve significantly over the previous state of the art.
Admissible heuristics are the main ingredient when solving classical planning tasks optimally with heuristic search. Higher admissible heuristic values are more accurate, so combining them in a way that dominates their maximum and remains admissible is an important problem.
The thesis makes three contributions in this area. Extensions to cost partitioning (a well-known heuristic combination framework) allow to produce higher estimates from the same set of heuristics. The new heuristic family called operator-counting heuristics unifies many existing heuristics and offers a new way to combine them. Another new family of heuristics called potential heuristics allows to cast the problem of finding a good heuristic as an optimization problem.
Both operator-counting and potential heuristics are closely related to cost partitioning. They offer a new look on cost partitioned heuristics and already sparked research beyond their use as classical planning heuristics.
Master's theses
Optimal planning is an ongoing topic of research, and requires efficient heuristic search algorithms. One way of calculating such heuristics is through the use of Linear Programs (LPs) and solvers thereof. This thesis investigates the efficiency of LP-based heuristic search strategies of different heuristics, focusing on how different LP solving strategies and solver settings impact the performance of calculating these heuristics. Using the Fast Downward planning system and a comprehensive benchmark set of planning tasks, we conducted a series of experiments to determine the effectiveness of the primal and dual simplex methods and the primal-dual logarithmic barrier method. Our results show that the choice of the LP solver and the application of specific solver settings influence the efficiency of calculating the required heuristics, and showed that the default setting of CPLEX is not optimal in some cases and can be enhanced by specifying an LP-solver or using other non-default solver settings. This thesis lays the groundwork for future research of using different LP solving algorithms and solver settings in the context of LP-based heuristic search in optimal planning.
Classical planning tasks are typically formulated in PDDL. Some of them can be described more concisely using derived variables. Contrary to basic variables, their values cannot be changed by operators and are instead determined by axioms which specify conditions under which they take a certain value. Planning systems often support axioms in their search component, but their heuristics’ support is limited or nonexistent. This leads to decreased search performance with tasks that use axioms. We compile axioms away using our implementation of a known algorithm in the Fast Downward planner. Our results show that the compilation has a negative impact on search performance with its only benefit being the ability to use heuristics that have no axiom support. As a compromise between performance and expressivity, we identify axioms of a simple form and devise a compilation for them. We compile away all axioms in several of the tested domains without a decline in search performance.
The International Planning Competitions (IPCs) serve as a testing suite for planning sys- tems. These domains are well-motivated as they are derived from, or possess characteristics analogous to real-life applications. In this thesis, we study the computational complexity of the plan existence and bounded plan existence decision problems of the following grid- based IPC domains: VisitAll, TERMES, Tidybot, Floortile, and Nurikabe. In all of these domains, there are one or more agents moving through a rectangular grid (potentially with obstacles) performing actions along the way. In many cases, we engineer instances that can be solved only if the movement of the agent or agents follows a Hamiltonian path or cycle in a grid graph. This gives rise to many NP-hardness reductions from Hamiltonian path/cycle problems on grid graphs. In the case of VisitAll and Floortile, we give necessary and suffi- cient conditions for deciding the plan existence problem in polynomial time. We also show that Tidybot has the game Push -1F as a special case, and its plan existence problem is thus PSPACE-complete. The hardness proofs in this thesis highlight hard instances of these domains. Moreover, by assigning a complexity class to each domain, researchers and practitioners can better assess the strengths and limitations of new and existing algorithms in these domains.
Planning tasks can be used to describe many real world problems of interest. Solving those tasks optimally is thus an avenue of great interest. One established and successful approach for optimal planning is the merge-and-shrink framework, which decomposes the task into a factored transition system. The factors initially represent the behaviour of one state variable and are repeatedly combined and abstracted. The solutions of these abstract states is then used as a heuristic to guide search in the original planning task. Existing merge-and-shrink transformations keep the factored transition system orthogonal, meaning that the variables of the planning task are represented in no more than one factor at any point. In this thesis we introduce the clone transformation, which duplicates a factor of the factored transition system, making it non-orthogonal. We test two classes of clone strategies, which we introduce and implement in the Fast Downward planning system and conclude that, while theoretically promising, our clone strategies are practically inefficient as their performance was worse than state-of-the-art methods for merge-and-shrink.
This thesis aims to present a novel approach for improving the performance of classical planning algorithms by integrating cost partitioning with merge-and-shrink techniques. Cost partitioning is a well-known technique for admissibly adding multiple heuristic values. Merge-and-shrink, on the other hand, is a technique to generate well-informed abstractions. The "merge” part of the technique is based on creating an abstract representation of the original problem by replacing two transition systems with their synchronised product. In contrast, the ”shrink” part refers to reducing the size of the factor. By combining these two approaches, we aim to leverage the strengths of both methods to achieve better scalability and efficiency in solving classical planning problems. Considering a range of benchmark domains and the Fast Downward planning system, the experimental results show that the proposed method achieves the goal of fusing merge and shrink with cost partitioning towards better outcomes in classical planning.
Planning is the process of finding a path in a planning task from the initial state to a goal state. Multiple algorithms have been implemented to solve such planning tasks, one of them being the Property-Directed Reachability algorithm. Property-Directed Reachability utilizes a series of propositional formulas called layers to represent a super-set of states with a goal distance of at most the layer index. The algorithm iteratively improves the layers such that they represent a minimum number of states. This happens by strengthening the layer formulas and therefore excluding states with a goal distance higher than the layer index. The goal of this thesis is to implement a pre-processing step to seed the layers with a formula that already excludes as many states as possible, to potentially improve the run-time performance. We use the pattern database heuristic and its associated pattern generators to make use of the planning task structure for the seeding algorithm. We found that seeding does not consistently improve the performance of the Property-Directed Reachability algorithm. Although we observed a significant reduction in planning time for some tasks, it significantly increased for others.
Certifying algorithms is a concept developed to increase trust by demanding affirmation of the computed result in form of a certificate. By inspecting the certificate, it is possible to determine correctness of the produced output. Modern planning systems have been certifying for long time in the case of solvable instances, where a generated plan acts as a certificate.
Only recently there have been the first steps towards certifying unsolvability judgments in the form of inductive certificates which represent certain sets of states. Inductive certificates are expressed with the help of propositional formulas in a specific formalism.
In this thesis, we investigate the use of propositional formulas in conjunctive normal form (CNF) as a formalism for inductive certificates. At first, we look into an approach that allows us to construct formulas representing inductive certificates in CNF. To show general applicability of this approach, we extend this to the family of delete relaxation heuristics. Furthermore, we present how a planning system is able to generate an inductive validation formula, a single formula that can be used to validate if the set found by the planner is indeed an inductive certificate. At last, we show with an experimental evaluation that the CNF formalism can be feasible in practice for the generation and validation of inductive validation formulas.
In generalized planning the aim is to solve whole classes of planning tasks instead of single tasks one at a time. Generalized representations provide information or knowledge about such classes to help solving them. This work compares the expressiveness of three generalized representations, generalized potential heuristics, policy sketches and action schema networks, in terms of compilability. We use a notion of equivalence that requires two generalized representations to decompose the tasks of a class into the same subtasks. We present compilations between pairs of equivalent generalized representations and proofs where a compilation is impossible.
A Digital Microfluidic Biochip (DMFB) is a digitally controllable lab-on-a-chip. Droplets of fluids are moved, merged and mixed on a grid. Routing these droplets efficiently has been tackled by various different approaches. We try to use temporal planning to do droplet routing, inspired by the use of it in quantum circuit compilation. We test a model for droplet routing in both classical and temporal planning and compare both versions. We show that our classical planning model is an efficient method to find droplet routes on DMFBs. Then we extend our model and include spawning, disposing, merging, splitting and mixing of droplets. The results of these extensions show that we are able to find plans for simple experiments. When scaling the problem size to real life experiments our model fails to find plans.
Cost partitioning is a technique used to calculate heuristics in classical optimal planning. It involves solving a linear program. This linear program can be decomposed into a master and pricing problems. In this thesis we combine Fourier-Motzkin elimination and the double description method in different ways to precompute the generating rays of the pricing problems. We further empirically evaluate these approaches and propose a new method that replaces the Fourier-Motzkin elimination. Our new method improves the performance of our approaches with respect to runtime and peak memory usage.
The increasing number of data nowadays has contributed to new scheduling approaches. Aviation is one of the domains concerned the most, as the aircraft engine implies millions of maintenance events operated by staff worldwide. In this thesis we present a constraint programming-based algorithm to solve the aircraft maintenance scheduling problem. We want to find the best time to do the maintenance by determining which employee will perform the work and when. Here we report how the scheduling process in aviation can be automatized.
To solve stochastic state-space tasks, the research field of artificial intelligence is mainly used. PROST2014 is state of the art when determining good actions in an MDP environment. In this thesis, we aimed to provide a heuristic by using neural networks to outperform the dominating planning system PROST2014. For this purpose, we introduced two variants of neural networks that allow to estimate the respective Q-value for a pair of state and action. Since we envisaged the learning method of supervised learning, in addition to the architecture as well as the components of the neural networks, the generation of training data was also one of the main tasks. To determine the most suitable network parameters, we performed a sequential parameter search, from which we expected a local optimum of the model settings. In the end, the PROST2014 planning system could not be surpassed in the total rating evaluation. Nevertheless, in individual domains, we could establish increased final scores on the side of the neural networks. The result shows the potential of this approach and points to eventual adaptations in future work pursuing this procedure furthermore.
In classical planning, there are tasks that are hard and tasks that are easy. We can measure the complexity of a task with the correlation complexity, the improvability width, and the novelty width. In this work, we compare these measures.
We investigate what causes a correlation complexity of at least 2. To do so we translate the state space into a vector space which allows us to make use of linear algebra and convex cones.
Additionally, we introduce the Basel measure, a new measure that is based on potential heuristics and therefore similar to the correlation complexity but also comparable to the novelty width. We show that the Basel measure is a lower bound for the correlation complexity and that the novelty width +1 is an upper bound for the Basel measure.
Furthermore, we compute the Basel measure for some tasks of the International Planning Competitions and show that the translation of a task can increase the Basel measure by removing seemingly irrelevant state variables.
Unsolvability is an important result in classical planning and has seen increased interest in recent years. This thesis explores unsolvability detection by automatically generating parity arguments, a well-known way of proving unsolvability. The argument requires an invariant measure, whose parity remains constant across all reachable states, while all goal states are of the opposite parity. We express parity arguments using potential functions in the field F 2 . We develop a set of constraints that describes potential functions with the necessary separating property, and show that the constraints can be represented efficiently for up to two-dimensional features. Enhanced with mutex information, an algorithm is formed that tests whether a parity function exists for a given planning task. The existence of such a function proves the task unsolvable. To determine its practical use, we empirically evaluate our approach on a benchmark of unsolvable problems and compare its performance to a state of the art unsolvability planner. We lastly analyze the arguments found by our algorithm to confirm their validity, and understand their expressive power.
We implemented the invariant synthesis algorithm proposed by Rintanen and experimentally compared it against Helmert’s mutex group synthesis algorithm as implemented in Fast Downward.
The context for the comparison is the translation of propositional STRIPS tasks to FDR tasks, which requires the identification of mutex groups.
Because of its dominating lead in translation speed, combined with few and marginal advantages in performance during search, Helmert’s algorithm is clearly better for most uses. Meanwhile Rintanen’s algorithm is capable of finding invariants other than mutexes, which Helmert’s algorithm per design cannot do.
The International Planning Competition (IPC) is a competition of state-of-the-art planning systems. The evaluation of these planning systems is done by measuring them with different problems. It focuses on the challenges of AI planning by analyzing classical, probabilistic and temporal planning and by presenting new problems for future research. Some of the probabilistic domains introduced in IPC 2018 are Academic Advising, Chromatic Dice, Cooperative Recon, Manufacturer, Push Your Luck, Red-finned Blue-eyes, etc.
This thesis aims to solve (near)-optimally two probabilistic IPC 2018 domains, Academic Advising and Chromatic Dice. We use different techniques to solve these two domains. In Academic Advising, we use a relevance analysis to remove irrelevant actions and state variables from the planning task. We then convert the problem from probabilistic to classical planning, which helped us solve it efficiently. In Chromatic Dice, we implement backtracking search to solve the smaller instances optimally. More complex instances are partitioned into several smaller planning tasks, and a near-optimal policy is derived as a combination of the optimal solutions to the small instances.
The motivation for finding (near)-optimal policies is related to the IPC score, which measures the quality of the planners. By providing the optimal upper bound of the domains, we contribute to the stabilization of the IPC score evaluation metric for these domains.
Most well-known and traditional online planners for probabilistic planning are in some way based on Monte-Carlo Tree Search. SOGBOFA, symbolic online gradient-based optimization for factored action MDPs, offers a new perspective on this: it constructs a function graph encoding the expected reward for a given input state using independence assumptions for states and actions. On this function, they use gradient ascent to perform a symbolic search optimizing the actions for the current state. This unique approach to probabilistic planning has shown very strong results and even more potential. In this thesis, we attempt to integrate the new ideas SOGBOFA presents into the traditionally successful Trial-based Heuristic Tree Search framework. Specifically, we design and evaluate two heuristics based on the aforementioned graph and its Q value estimations, but also the search using gradient ascent. We implement and evaluate these heuristics in the Prost planner, along with a version of the current standalone planner.
In this thesis, we consider cyclical dependencies between landmarks for cost-optimal planning. Landmarks denote properties that must hold at least once in all plans. However, if the orderings between them induce cyclical dependencies, one of the landmarks in each cycle must be achieved an additional time. We propose the generalized cycle-covering heuristic which considers this in addition to the cost for achieving all landmarks once.
Our research is motivated by recent applications of cycle-covering in the Freecell and logistics domain where it yields near-optimal results. We carry it over to domain-independent planning using a linear programming approach. The relaxed version of a minimum hitting set problem for the landmarks is enhanced by constraints concerned with cyclical dependencies between them. In theory, this approach surpasses a heuristic that only considers landmarks.
We apply the cycle-covering heuristic in practice where its theoretical dominance is confirmed; Many planning tasks contain cyclical dependencies and considering them affects the heuristic estimates favorably. However, the number of tasks solved using the improved heuristic is virtually unaffected. We still believe that considering this feature of landmarks offers great potential for future work.
Potential heuristics are a class of heuristics used in classical planning to guide a search algorithm towards a goal state. Most of the existing research on potential heuristics is focused on finding heuristics that are admissible, such that they can be used by an algorithm such as A* to arrive at an optimal solution. In this thesis, we focus on the computation of potential heuristics for satisficing planning, where plan optimality is not required and the objective is to find any solution. Specifically, our focus is on the computation of potential heuristics that are descending and dead-end avoiding (DDA), since these prop- erties guarantee favorable search behavior when used with greedy search algorithms such as hillclimbing. We formally prove that the computation of DDA heuristics is a PSPACE-complete problem and propose several approximation algorithms. Our evaluation shows that the resulting heuristics are competitive with established approaches such as Pattern Databases in terms of heuristic quality but suffer from several performance bottlenecks.
Most automated planners use heuristic search to solve the tasks. Usually, the planners get as input a lifted representation of the task in PDDL, a compact formalism describing the task using a fragment of first-order logic. The planners then transform this task description into a grounded representation where the task is described in propositional logic. This new grounded format can be exponentially larger than the lifted one, but many planners use this grounded representation because it is easier to implement and reason about.
However, sometimes this transformation between lifted and grounded representations is not tractable. When this is the case, there is not much that planners based on heuristic search can do. Since this transformation is a required preprocess, when this fails, the whole planner fails.
To solve the grounding problem, we introduce new methods to deal with tasks that cannot be grounded. Our work aims to find good ways to perform heuristic search while using a lifted representation of planning problems. We use the point-of-view of planning as a database progression problem and borrow solutions from the areas of relational algebra and database theory.
Our theoretical and empirical results are motivating: several instances that were never solved by any planner in the literature are now solved by our new lifted planner. For example, our planner can solve the challenging Organic Synthesis domain using a breadth-first search, while state-of-the-art planners cannot solve more than 60% of the instances. Furthermore, our results offer a new perspective and a deep theoretical study of lifted representations for planning tasks.
The generation of independently verifiable proofs for the unsolvability of planning tasks using different heuristics, including linear Merge-and-Shrink heuristics, is possible by usage of a proof system framework. Proof generation in the case of non-linear Merge-and-Shrink heuristic, however, is currently not supported. This is due to the lack of a suitable state set representation formalism that allows to compactly represent states mapped to a certain value in the belonging Merge-and-Shrink representation (MSR). In this thesis, we overcome this shortcoming using Sentential Decision Diagrams (SDDs) as set representations. We describe an algorithm that constructs the desired SDD from the MSR, and show that efficient proof verification is possible with SDDs as representation formalism. Aditionally, we use a proof of concept implementation to analyze the overhead occurred by the proof generation functionality and the runtime of the proof verification.
The operator-counting framework is a framework in classical planning for heuristics that are based on linear programming. The operator-counting framework covers several kinds of state-of-the-art linear programming heuristics, among them the post-hoc optimization heuristic. In this thesis we will use post-hoc optimization constraints and evaluate them under altered cost functions instead of the original cost function of the planning task. We show that such cost-altered post-hoc optimization constraints are also covered by the operator-counting framework and that it is possible to achieve improved heuristic estimates with them, compared with post-hoc optimization constraints under the original cost function. In our experiments we have not been able to achieve improved problem coverage, as we were not able to find a method for generating favorable cost functions that work well in all domains.
Heuristic forward search is the state-of-the-art approach to solve classical planning problems. On the other hand, bidirectional heuristic search has a lot of potential but was never able to deliver on those expectations in practice. Only recently the near-optimal bidirectional search algorithm (NBS) was introduces by Chen et al. and as the name suggests, NBS expands nearly the optimal number of states to solve any search problem. This is a novel achievement and makes the NBS algorithm a very promising and efficient algorithm in search. With this premise in mind, we raise the question of how applicable NBS is to planning. In this thesis, we inquire this very question by implementing NBS in the state- of-the-art planner Fast-Downward and analyse its performance on the benchmark of the latest international planning competition. We additionally implement fractional meet-in- the-middle and computeWVC to analyse NBS’ performance more thoroughly in regards to the structure of the problem task.
The conducted experiments show that NBS can successfully be applied to planning as it was able to consistently outperform A*. Especially good results were achieved on the domains: blocks, driverlog, floortile-opt11-strips, get-opt14-strips, logistics00, and termes- opt18-strips. Analysing these results, we deduce that the efficiency of forward and backward search depends heavily upon the underlying implicit structure of the transition system which is induced by the problem task. This suggests that bidirectional search is inherently more suited for certain problems. Furthermore, we find that this aptitude for a certain search direction correlates with the domain, thereby providing a powerful analytic tool to a priori derive the effectiveness of certain search approaches.
In conclusion, even without intricate improvements the NBS algorithm is able to compete with A*. It therefore has further potential for future research. Additionally, the underlying transition system of a problem instance is shown to be an important factor which influences the efficiency of certain search approaches. This knowledge could be valuable for devising portfolio planners.
Multiple Sequence Alignment (MSA) is the problem of aligning multiple biological sequences in the evoluationary most plausible way. It can be viewed as a shortest path problem through an n-dimensional lattice. Because of its large branching factor of 2^n − 1, it has found broad attention in the artificial intelligence community. Finding a globally optimal solution for more than a few sequences requires sophisticated heuristics and bounding techniques in order to solve the problem in acceptable time and within memory limitations. In this thesis, we show how existing heuristics fall into the category of combining certain pattern databases. We combine arbitrary pattern collections that can be used as heuristic estimates and apply cost partitioning techniques from classical planning for MSA. We implement two of those heuristics for MSA and compare their estimates to the existing heuristics.
Increasing Cost Tree Search is a promising approach to multi-agent pathfinding problems, but like all approaches it has to deal with a huge number of possible joint paths, growing exponentially with the number of agents. We explore the possibility of reducing this by introducing a value abstraction to the Multi-valued Decision Diagrams used to represent sets of joint paths. To that end we introduce a heat map to heuristically judge how collisionprone agent positions are and present how to use and possible refine abstract positions in order to still find valid paths.
Estimating cheapest plan costs with the help of network flows is an established technique. Plans and network flows are already very similar, however network flows can differ from plans in the presence of cycles. If a transition system contains cycles, flows might be composed of multiple disconnected parts. This discrepancy can make the cheapest plan estimation worse. One idea to get rid of the cycles works by introducing time steps. For every time step the states of a transition system are copied. Transitions will be changed, so that they connect states only with states of the next time step, which ensures that there are no cycles. It turned out, that by applying this idea to multiple transitions systems, network flows of the individual transition systems can be synchronized via the time steps to get a new kind of heuristic, that will also be discussed in this thesis.
Probabilistic planning is a research field that has become popular in the early 1990s. It aims at finding an optimal policy which maximizes the outcome of applying actions to states in an environment that feature unpredictable events. Such environments can consist of a large number of states and actions which make finding an optimal policy intractable using classical methods. Using a heuristic function for a guided search allows for tackling such problems. Designing a domain-independent heuristic function requires complex algorithms which may be expensive when it comes to time and memory consumption.
In this thesis, we are applying the supervised learning techniques for learning two domain-independent heuristic functions. We use three types of gradient descent methods: stochastic, batch and mini-batch gradient descent and their improved versions using momen- tum, learning decay rate and early stopping. Furthermore, we apply the concept of feature combination in order to better learn the heuristic functions. The learned functions are pro- vided to Prost, a domain-independent probabilistic planner, and benchmarked against the winning algorithms of the International Probabilistic Planning Competition held in 2014. The experiments show that learning an offline heuristic improves the overall score of the search for some of the domains used in aforementioned competition.
The merge-and-shrink heuristic is a state-of-the-art admissible heuristic that is often used for optimal planning. Recent studies showed that the merge strategy is an important factor for the performance of the merge-and-shrink algorithm. There are many different merge strategies and improvements for merge strategies described in the literature. One out of these merge strategies is MIASM by Fan et al. MIASM tries to merge transition systems that produce unnecessary states in their product which can be pruned. Another merge strategy is the symmetry-based merge-and-shrink framework by Sievers et al. This strategy tries to merge transition systems that cause factored symmetries in their product. This strategy can be combined with other merge strategies and it often improves the performance for many merge strategy. However, the current combination of MIASM with factored symmetries performs worse than MIASM. We implement a different combination of MIASM that uses factored symmetries during the subset search of MIASM. Our experimental evaluation shows that our new combination of MIASM with factored symmetries solves more tasks than the existing MIASM and the previously implemented combination of MIASM with factored symmetries. We also evaluate different combinations of existing merge strategies and find combinations that perform better than their basic version that were not evaluated before.
Tree Cache is a pathfinding algorithm that selects one vertex as a root and constructs a tree with cheapest paths to all other vertices. A path is found by traversing up the tree from both the start and goal vertices to the root and concatenating the two parts. This is fast, but as all paths constructed this way pass through the root vertex they can be highly suboptimal.
To improve this algorithm, we consider two simple approaches. The first is to construct multiple trees, and save the distance to each root in each vertex. To find a path, the algorithm first selects the root with the lowest total distance. The second approach is to remove redundant vertices, i.e. vertices that are between the root and the lowest common ancestor (LCA) of the start and goal vertices. The performance and space requirements of the resulting algorithm are then compared to the conceptually similar hub labels and differential heuristics.
Greedy Best-First Search (GBFS) is a prominent search algorithm to find solutions for planning tasks. GBFS chooses nodes for further expansion based on a distance-to-goal estimator, the heuristic. This makes GBFS highly dependent on the quality of the heuristic. Heuristics often face the problem of producing Uninformed Heuristic Regions (UHRs). GBFS additionally suffers the possibility of simultaneously expanding nodes in multiple UHRs. In this thesis we change the heuristic approach in UHRs. The heuristic was unable to guide the search and so we try to expand novel states to escape the UHRs. The novelty measures how “new” a state is in the search. The result is a combination of heuristic and novelty guided search, which is indeed able to escape UHRs quicker and solve more problems in reasonable time.
In classical AI planning, the state explosion problem is a reoccurring subject: although the problem descriptions are compact, often a huge number of states needs to be considered. One way to tackle this problem is to use static pruning methods which reduce the number of variables and operators in the problem description before planning.
In this work, we discuss the properties and limitations of three existing static pruning techniques with a focus on satisficing planning. We analyse these pruning techniques and their combinations, and identify synergy effects between them and the domains and problem structures in which they occur. We implement the three methods into an existing propositional planner, and evaluate the performance of different configurations and combinations in a set of experiments on IPC benchmarks. We observe that static pruning techniques can increase the number of solved problems, and that the synergy effects of the combinations also occur on IPC benchmarks, although they do not lead to a major performance increase.
The goal of classical domain-independent planning is to find a sequence of actions which lead from a given initial state to a goal state that satisfies some goal criteria. Most planning systems use heuristic search algorithms to find such a sequence of actions. A critical part of heuristic search is the heuristic function. In order to find a sequence of actions from an initial state to a goal state efficiently this heuristic function has to guide the search towards the goal. It is difficult to create such an efficient heuristic function. Arfaee et al. show that it is possible to improve a given heuristic function by applying machine learning techniques on a single domain in the context of heuristic search. To achieve this improvement of the heuristic function, they propose a bootstrap learning approach which subsequently improves the heuristic function.
In this thesis we will introduce a technique to learn heuristic functions that can be used in classical domain-independent planning based on the bootstrap-learning approach introduced by Arfaee et al. In order to evaluate the performance of the learned heuristic functions, we have implemented a learning algorithm for the Fast Downward planning system. The experiments have shown that a learned heuristic function generally decreases the number of explored states compared to blind-search . The total time to solve a single problem increases because the heuristic function has to be learned before it can be applied.
Essential for the estimation of the performance of an algorithm in satisficing planning is its ability to solve benchmark problems. Those results can not be compared directly as they originate from different implementations and different machines. We implemented some of the most promising algorithms for greedy best-first search, published in the last years, and evaluated them on the same set of benchmarks. All algorithms are either based on randomised search, localised search or a combination of both. Our evaluation proves the potential of those algorithms.
Heuristic search with admissible heuristics is the leading approach to cost-optimal, domain-independent planning. Pattern database heuristics - a type of abstraction heuristics - are state-of-the-art admissible heuristics. Two recent pattern database heuristics are the iPDB heuristic by Haslum et al. and the PhO heuristic by Pommerening et al.
The iPDB procedure performs a hill climbing search in the space of pattern collections and evaluates selected patterns using the canonical heuristic. We apply different techniques to the iPDB procedure, improving its hill climbing algorithm as well as the quality of the resulting heuristic. The second recent heuristic - the PhO heuristic - obtains strong heuristic values through linear programming. We present different techniques to influence and improve on the PhO heuristic.
We evaluate the modified iPDB and PhO heuristics on the IPC benchmark suite and show that these abstraction heuristics can compete with other state-of-the-art heuristics in cost-optimal, domain-independent planning.
Greedy best-first search (GBFS) is a prominent search algorithm for satisficing planning - finding good enough solutions to a planning task in reasonable time. GBFS selects the next node to consider based on the most promising node estimated by a heuristic function. However, this behaviour makes GBFS heavily depend on the quality of the heuristic estimator. Inaccurate heuristics can lead GBFS into regions far away from a goal. Additionally, if the heuristic ranks several nodes the same, GBFS has no information on which node it shall follow. Diverse best-first search (DBFS) is a new algorithm by Imai and Kishimoto [2011] which has a local search component to emphasis exploitation. To enable exploration, DBFS deploys probabilities to select the next node.
In two problem domains, we analyse GBFS' search behaviour and present theoretical results. We evaluate these results empirically and compare DBFS and GBFS on constructed as well as on provided problem instances.
State-of-the-art planning systems use a variety of control knowledge in order to enhance the performance of heuristic search. Unfortunately most forms of control knowledge use a specific formalism which makes them hard to combine. There have been several approaches which describe control knowledge in Linear Temporal Logic (LTL). We build upon this work and propose a general framework for encoding control knowledge in LTL formulas. The framework includes a criterion that any LTL formula used in it must fulfill in order to preserve optimal plans when used for pruning the search space; this way the validity of new LTL formulas describing control knowledge can be checked. The framework is implemented on top of the Fast Downward planning system and is tested with a pruning technique called Unnecessary Action Application, which detects if a previously applied action achieved no useful progress.
Landmarks are known to be useable for powerful heuristics for informed search. In this thesis, we explain and evaluate a novel algorithm to find ordered landmarks of delete free tasks by intersecting solutions in the relaxation. The proposed algorithm efficiently finds landmarks and natural orders of delete free tasks, such as delete relaxations or Pi-m compilations.
Planning as heuristic search is the prevalent technique to solve planning problems of any kind of domains. Heuristics estimate distances to goal states in order to guide a search through large state spaces. However, this guidance is sometimes moderate, since still a lot of states lie on plateaus of equally prioritized states in the search space topology. Additional techniques that ignore or prefer some actions for solving a problem are successful to support the search in such situations. Nevertheless, some action pruning techniques lead to incomplete searches.
We propose an under-approximation refinement framework for adding actions to under-approximations of planning tasks during a search in order to find a plan. For this framework, we develop a refinement strategy. Starting a search on an initial under-approximation of a planning task, the strategy adds actions determined at states close to a goal, whenever the search does not progress towards a goal, until a plan is found. Key elements of this strategy consider helpful actions and relaxed plans for refinements. We have implemented the under-approximation refinement framework into the greedy best first search algorithm. Our results show considerable speedups for many classical planning problems. Moreover, we are able to plan with fewer actions than standard greedy best first search.
The main approach for classical planning is heuristic search. Many cost heuristics are based on the delete relaxation. The optimal heuristic of a delete free planning problem is called h + . This thesis explores two new ways to compute h + . Both approaches use factored planning, which decomposes the original planning problem to work on each subproblem separately. The algorithm reuses the subsolutions and combines them to a global solution.
The two algorithms are used to compute a cost heuristic for an A* search. As both approaches compute the optimal heuristic for delete free planning tasks, the algorithms can also be used to find a solution for relaxed planning tasks.
Multi-Agent-Path-Finding (MAPF) is a common problem in robotics and memory management. Pebbles in Motion is an implementation of a problem solver for MAPF in polynomial time, based on a work by Daniel Kornhauser from 1984. Recently a lot of research papers have been published on MAPF in the research community of Artificial Intelligence, but the work by Kornhauser seems hardly to be taken into account. We assumed that this might be related to the fact that said paper was more mathematically and hardly describing algorithms intuitively. This work aims at filling this gap, by providing an easy understandable approach of implementation steps for programmers and a new detailed description for researchers in Computer Science.
Bachelor's theses
Fast Downward is a classical planner using heuristical search. The planner uses many advanced planning techniques that are not easy to teach, since they usually rely on complex data structures. To introduce planning techniques to the user an interactive application is created. This application uses an illustrative example to showcase planning techniques: Blocksworld
Blocksworld is an easy understandable planning problem which allows a simple representation of a state space. It is implemented in the Unreal Engine and provides an interface to the Fast Downward planner. Users can explore a state space themselves or have Fast Downward generate plans for them. The concept of heuristics as well as the state space are explained and made accessible to the user. The user experiences how the planner explores a state space and which techniques the planner uses.
This thesis is about implementing Jussi Rintanen’s algorithm for schematic invariants. The algo- rithm is implemented in the planning tool Fast Downward and refers to Rintanen’s paper Schematic Invariants by Reduction to Ground Invariants. The thesis describes all necessary definitions to under- stand the algorithm and draws a comparison between the original task and a reduced task in terms of runtime and number of grounded actions.
Planning is a field of Artificial Intelligence. Planners are used to find a sequence of actions, to get from the initial state to a goal state. Many planning algorithms use heuristics, which allow the planner to focus on more promising paths. Pattern database heuristics allow us to construct such a heuristic, by solving a simplified version of the problem, and saving the associated costs in a pattern database. These pattern databases can be computed and stored by using symbolic data structures.
In this paper we will look at how pattern databases using symbolic data structures using binary decision diagrams and algebraic decision diagrams can be implemented. We will extend fast down- ward (Helmert [2006]) with it, and compare the performance of this implementation with the already implemented explicit pattern database.
In the field of automated planning and scheduling, a planning task is essentially a state space which can be defined rigorously using one of several different formalisms (e.g. STRIPS, SAS+, PDDL etc.). A planning algorithm tries to determine a sequence of actions that lead to a goal state for a given planning task. In recent years, attempts have been made to group certain planners together into so called planner portfolios, to try and leverage their effectiveness on different specific problem classes. In our project, we create an online planner which in contrast to its offline counterparts, makes use of task specific information when allocating a planner to a task. One idea that has recently gained interest, is to apply machine learning methods to planner portfolios.
In previous work such as Delfi (Katz et al., 2018; Sievers et al., 2019a) supervised learning techniques were used, which made it necessary to train multiple networks to be able to attempt multiple, potentially different, planners for a given task. The reason for this being that, if we used the same network, the output would always be the same, as the input to the network would remain unchanged. In this project we make use of techniques from rein- forcement learning such as DQNs (Mnih et al., 2013). Using RL approaches such as DQNs, allows us to extend the input to the network to include information on things, such as which planners were previously attempted and for how long. As a result multiple attempts can be made after only having trained a single network.
Unfortunately the results show that current reinforcement learning agents are, amongst other reasons, too sample inefficient to be able to deliver viable results given the size of the currently available data sets.
Planning tasks are important and difficult problems in computer science. A widely used approach is the use of delete relaxation heuristics to which the additive and FF heuristic belong. Those two heuristics use a graph in their calculation, which only has to be constructed once for a planning task but then can be used repeatedly. To solve such a problem efficiently it is important that the calculation of the heuristics are fast. In this thesis the idea to achieve a faster calculation is to combine redundant parts of the graph when building it to reduce the number of edges and therefore speed up the calculation. Here the reduction of the redundancies is done for each action within a planning task individually, but further ideas to simplify over all actions are also discussed.
Monte Carlo search methods are widely known, mostly for their success in game domains, although they are also applied to many non-game domains. In previous work done by Schulte and Keller, it was established that best-first searches could adapt to the action selection functionality which make Monte Carlo methods so formidable. In practice however, the trial-based best first search, without exploration, was shown to be slightly slower than its explicit open list counterpart. In this thesis we examine the non-trial and trial-based searches and how they can address the exploitation exploration dilemma. Lastly, we will see how trial-based BFS can rectify a slower search by allowing occasional random action selection, by comparing it to regular open list searches in a line of experiments.
Sudoku has become one of the world’s most popular logic puzzles, arousing interest in the general public and the science community. Although the rules of Sudoku may seem simple, they allow for nearly countless puzzle instances, some of which are very hard to solve. SAT-solvers have proven to be a suitable option to solve Sudokus automatically. However, they demand the puzzles to be encoded as logical formulae in Conjunctive Normal Form. In earlier work, such encodings have been successfully demonstrated for original Sudoku Puzzles. In this thesis, we present encodings for rather unconventional Sudoku Variants, developed by the puzzle community to create even more challenging solving experiences. Furthermore, we demonstrate how Pseudo-Boolean Constraints can be utilized to encode Sudoku Variants that follow rules involving sums. To implement an encoding of Pseudo-Boolean Constraints, we use Binary Decision Diagrams and Adder Networks and study how they compare to each other.
In optimal classical planning, informed search algorithms like A* need admissible heuristics to find optimal solutions. Counterexample-guided abstraction refinement (CEGAR) is a method used to generate abstractions that yield suitable abstraction heuristics iteratively. In this thesis, we propose a class of CEGAR algorithms for the generation of domain abstractions, which are a class of abstractions that rank in between projections and Cartesian abstractions regarding the grade of refinement they allow. As no known algorithm constructs domain abstractions, we show that our algorithm is competitive with CEGAR algorithms that generate one projection or Cartesian abstraction.
This thesis will look at Single-Player Chess as a planning domain using two approaches: one where we look at how we can encode the Single-Player Chess problem as a domain-independent (general-purpose AI) approach and one where we encode the problem as a domain-specific solver. Lastly, we will compare the two approaches by doing some experiments and comparing the results of the two approaches. Both the domain-independent implementation and the domain-specific implementation differ from traditional chess engines because the task of the agent is not to find the best move for a given position and colour, but the agent’s task is to check if a given chess problem has a solution or not. If the agent can find a solution, the given chess puzzle is valid. The results of both approaches were measured in experiments, and we found out that the domain-independent implementation is too slow and that the domain-specific implementation, on the other hand, can solve the given puzzles reliably, but it has a memory bottleneck rooted in the search method that was used.
Carcassonne is a tile-based board game with a large state space and a high branching factor and therefore poses a challenge to artificial intelligence. In the past, Monte Carlo Tree Search (MCTS), a search algorithm for sequential decision-making processes, has been shown to find good solutions in large state spaces. MCTS works by iteratively building a game tree according to a tree policy. The profitability of paths within that tree is evaluated using a default policy, which influences in what directions the game tree is expanded. The functionality of these two policies, as well as other factors, can be implemented in many different ways. In consequence, many different variants of MCTS exist. In this thesis, we applied MCTS to the domain of two-player Carcassonne and evaluated different variants in regard to their performance and runtime. We found significant differences in performance for various variable aspects of MCTS and could thereby evaluate a configuration which performs best on the domain of Carcassonne. This variant consistently outperformed an average human player with a feasible runtime.
In general, it is important to verify software as it is prone to error. This also holds for solving tasks in classical planning. So far, plans in general as well as the fact that there is no plan for a given planning task can be proven and independently verified. However, no such proof for the optimality of a solution of a task exists. Our aim is to introduce two methods with which optimality can be proven and independently verified. We first reduce unit cost tasks to unsolvable tasks, which enables us to make use of the already existing certificates for unsolvability. In a second approach, we propose a proof system for optimality, which enables us to infer that the determined cost of a task is optimal. This permits the direct generation of optimality certificates.
Pattern databases are one of the most powerful heuristics in classical planning. They evaluate the perfect cost for a simplified sub-problem. The post-hoc optimization heuristic is a technique on how to optimally combine a set of pattern databases. In this thesis, we will adapt the post-hoc optimization heuristic for the sliding tile puzzle. The sliding tile puzzle serves as a benchmark to compare the post-hoc optimization heuristic to already established methods, which also deal with the combining of pattern databases. We will then show how the post-hoc optimization heuristic is an improvement over the already established methods.
In this thesis, we generate landmarks for a logistics-specific task. Landmarks are actions that need to occur at least once in every plan. A landmark graph denotes a structure with landmarks and their edges called orderings. If there are cycles in a landmark graph, one of those landmarks needs to be achieved at least twice for every cycle. The generation of the logistics-specific landmarks and their orderings calculate the cyclic landmark heuristic. The task is to pick up on related work, the evaluation of the cyclic landmark heuristic. We compare the generation of landmark graphs from a domain-independent landmark generator to a domain-specific landmark generator, the latter being the focus. We aim to bridge the gap between domain-specific and domain-independent landmark generators. In this thesis, we compare one domain-specific approach for the logistics domain with results from a domain- independent landmark generator. We devise a unit to pre-process data for other domain- specific tasks as well. We will show that specificity is better suited than independence.
Lineare Programmierung ist eine mathematische Modellierungstechnik, bei der eine lineare Funktion, unter der Berücksichtigung verschiedenen Beschränkungen, maximiert oder minimiert werden soll. Diese Technik ist besonders nützlich, falls Entscheidungen für Optimierungsprobleme getroffen werden sollen. Ziel dieser Arbeit war es ein Tool für das Spiel Factory Town zu entwickeln, mithilfe man Optimierungsanfragen bearbeiten kann. Dabei ist es möglich wahlweise zwischen diversen Fragestellungen zu wählen und anhand von LP-\ IP-Solvern diese zu beantworten. Zudem wurden die mathematischen Formulierungen, sowie die Unterschiede beider Methoden angegangen. Schlussendlich unterstrichen die generierten Resultate, dass LP Lösungen mindestens genauso gut oder sogar besser seien als die Lösungen eines IP.
Symbolic search is an important approach to classical planning. Symbolic search uses search algorithms that process sets of states at a time. For this we need states to be represented by a compact data structure called knowledge compilations. Merge-and-shrink representations come a different field of planning, where they have been used to derive heuristic functions for state-space search. More generally they represent functions that map variable assignments to a set of values, as such we can regard them as a data structure we will call Factored Mappings. In this thesis, we will investigate Factored Mappings (FMs) as a knowledge compilation language with the hope of using them for symbolic search. We will analyse the necessary transformations and queries for FMs, by defining the needed operations and a canonical representation of FMs, and showing that they run in polynomial time. We will then show that it is possible to use Factored Mappings as a knowledge compilation for symbolic search by defining a symbolic search algorithm for a finite-domain plannings task that works with FMs.
Version control systems use a graph data structure to track revisions of files. Those graphs are mutated with various commands by the respective version control system. The goal of this thesis is to formally define a model of a subset of Git commands which mutate the revision graph, and to model those mutations as a planning task in the Planning Domain Definition Language. Multiple ways to model those graphs will be explored and those models will be compared by testing them using a set of planners.
Pattern Databases are admissible abstraction heuristics for classical planning. In this thesis we are introducing the Boosting processes, which consists of enlarging the pattern of a Pattern Database P, calculating a more informed Pattern Database P' and then min-compress P' to the size of P resulting in a compressed and still admissible Pattern Database P''. We design and implement two boosting algorithms, Hillclimbing and Randomwalk.
We combine pattern database heuristics using five different cost partitioning methods. The experiments compare computing cost partitionings over regular and boosted pattern databases. The experiments, performed on IPC (optimal track) tasks, show promising results which increased the coverage (number of solved tasks) by 9 for canonical cost partitioning using our Randomwalk boosting variant.
One dimensional potential heuristics assign a numerical value, the potential, to each fact of a classical planning problem. The heuristic value of a state is the sum over the poten- tials belonging to the facts contained in the state. Fišer et al. (2020) recently proposed to strengthen potential heuristics utilizing mutexes and disambiguations. In this thesis, we embed the same enhancements in the planning system Fast Downward. The experi- mental evaluation shows that the strengthened potential heuristics are a refinement, but too computationally expensive to solve more problems than the non-strengthened potential heuristics.
The potentials are obtained with a Linear Program. Fišer et al. (2020) introduced an additional constraint on the initial state and we propose additional constraints on random states. The additional constraints improve the amount of solved problems by up to 5%.
This thesis discusses the PINCH heuristic, a specific implementation of the additive heuristic. PINCH intends to combine the strengths of existing implementations of the additive heuristic. The goal of this thesis is to really dig into the PINCH heuristic. I want to provide the most accessible resource for understanding PINCH and I want to analyze the performance of PINCH by comparing it to the algorithm on which it is based, Generalized Dijkstra.
Suboptimal search algorithms can offer attractive benefits compared to optimal search, namely increased coverage of larger search problems and quicker search times. Improving on such algorithms, such as reducing costs further towards optimal solutions and reducing the number of node expansions, is therefore a compelling area for further research. This paper explores the utility and scalability of recently developed priority functions, XDP, XUP, and PWXDP, and the Improved Optimistic Search algorithm, compared to Weighted A*, in the Fast Downward planner. Analyses focus on the cost, total time, coverage, and node expansion parameters, with experimental evidence suggesting preferable performance if strict optimality is not desired. The implementation of priorityb functions in eager best-first search showed marked improvements compared to A* search on coverage, total time, and number of expansions, without significant cost penalties. Following previous suboptimal search research, experimental evidence even seems to indicate that these cost penalties do not reach the designated bound, even in larger search spaces.
In the Automated Planning field, algorithms and systems are developed for exploring state spaces and ultimately finding an action sequence leading from a task’s initial state to its goal. Such planning systems may sometimes show unexpected behavior, caused by a planning task or a bug in the planner itself. Generally speaking, finding the source of a bug tends to be easier when the cause can be isolated or simplified. In this thesis, we tackle this problem by making PDDL and SAS+ tasks smaller while ensuring they still invoke a certain characteristic when executed with a planner. We implement a system that successively removes elements, such as objects, from a task and checks whether the transformed task still fails on the planner. Elements are removed in a syntactically consistent way, however, no semantic integrity is enforced. Our system’s design is centered around the Fast Downward Planning System, as we re-use some of its translator modules and all test runs are performed with Fast Downward. At the core of our system, first-choice hill-climbing is used for optimization. Our “minimizer” takes (1) a failing planner execution command, (2) a description of the failing characteristic and (3) the type of element to be deleted as arguments. We evaluate our system’s functionality on the basis of three use-cases. In our most successful test runs, (1) a SAS+ task with initially 1536 operators and 184 variables is reduced to 2 operators and 2 variables and (2)a PDDL task with initially 46 actions, 62 objects and 29 predicate symbols is reduced to 2 actions, 6 objects and 4 predicates.
Fast Downward is a classical planning system based on heuristic search. Its successor generator is an efficient and intelligent tool to process state spaces and generate their successor states. In this thesis we implement different successor generators in the Fast Downward planning system and compare them against each other. Apart from the given fast downward successor generator we implement four other successor generators: a naive successor generator, one based on the marking of delete relaxed heuristics, one based on the PSVN planning system and one based on watched literals as used in modern SAT solvers. These successor generators are tested in a variety of different planning benchmarks to see how well they compete against each other. We verified that there is a trade-off between precomputation and faster successor generation and showed that all of the implemented successor generators have a use case and it is advisable to switch to a successor generator that fits the style of the planning task.
Verifying whether a planning algorithm came to the correct result for a given planning task is easy if a plan is emitted which solves the problem. But if a task is unsolvable most planners just state this fact without any explanation or even proof. In this thesis we present extended versions of the symbolic search algorithms SymPA and symbolic bidirectional uniform-cost search which, if a given planning task is unsolvable, provide certificates which prove unsolvability. We also discuss a concrete implementation of this version of SymPA.
Classical planning is an attractive approach to solving problems because of its generality and its relative ease of use. Domain-specific algorithms are appealing because of their performance, but require a lot of resources to be implemented. In this thesis we evaluate concepts languages as a possible input language for expert domain knowledge into a planning system. We also explore mixed integer programming as a way to use this knowledge to improve search efficiency and to help the user find and refine useful domain knowledge.
Classical Planning is a branch of artificial intelligence that studies single agent, static, deterministic, fully observable, discrete search problems. A common challenge in this field is the explosion of states to be considered when searching for the goal. One technique that has been developed to mitigate this is Strong Stubborn Set based pruning, where on each state expansion, the considered successors are restricted to Strong Stubborn Sets, which exploit the properties of independent operators to cut down the tree or graph search. We adopt the definitions of the theory of Strong Stubborn Sets from the SAS+ setting to transition systems and validate a central theorem about the correctness of Strong Stubborn Set based pruning for transition systems in the interactive theorem prover Isabelle/HOL.
Ein wichtiges Feld in der Wissenschaft der künstliche Intelligenz sind Planungsprobleme. Man hat das Ziel, eine künstliche intelligente Maschine zu bauen, die mit so vielen ver- schiedenen Probleme umgehen und zuverlässig lösen kann, indem sie ein optimaler Plan herstellt.
Der Trial-based Heuristic Tree Search(THTS) ist ein mächtiges Werkzeug um Multi-Armed- Bandit-ähnliche Probleme, Marcow Decsision Processe mit verändernden Rewards, zu lösen. Beim momentanen THTS können explorierte gefundene gute Rewards auf Grund von der grossen Anzahl der Rewards nicht beachtet werden. Ebenso können beim explorieren schlech- te Rewards, gute Knoten im Suchbaum, verschlechtern. Diese Arbeit führt eine Methodik ein, die von der stückweise stationären MABs Problematik stammt, um den THTS weiter zu optimieren.
Abstractions are a simple yet powerful method of creating a heuristic to solve classical planning problems optimally. In this thesis we make use of Cartesian abstractions generated with Counterexample-Guided Abstraction Refinement (CEGAR). This method refines abstractions incrementally by finding flaws and then resolving them until the abstraction is sufficiently evolved. The goal of this thesis is to implement and evaluate algorithms which select solutions of such flaws, in a way which results in the best abstraction (that is, the abstraction which causes the problem to then be solved most efficiently by the planner). We measure the performance of a refinement strategy by running the Fast Downward planner on a problem and measuring how long it takes to generate the abstraction, as well as how many expansions the planner requires to find a goal using the abstraction as a heuristic. We use a suite of various benchmark problems for evaluation, and we perform this experiment for a single abstraction and on abstractions for multiple subtasks. Finally, we attempt to predict which refinement strategy should be used based on parameters of the task, potentially allowing the planner to automatically select the best strategy at runtime.
Heuristic search is a powerful paradigm in classical planning. The information generated by heuristic functions to guide the search towards a goal is a key component of many modern search algorithms. The paper “Using Backwards Generated Goals for Heuristic Planning” by Alcázar et al. proposes a way to make additional use of this information. They take the last actions of a relaxed plan as a basis to generate intermediate goals with a known path to the original goal. A plan is found when the forward search reaches an intermediate goal.
The premise of this thesis is to modify their approach by focusing on a single sequence of intermediate goals. The aim is to improve efficiency while preserving the benefits of backwards goal expansion. We propose different variations of our approach by introducing multiple ways to make decisions concerning the construction of intermediate goals. We evaluate these variations by comparing their performance and illustrate the challenges posed by this approach.
Counterexample-guided abstraction refinement (CEGAR) is a way to incrementally compute abstractions of transition systems. It starts with a coarse abstraction and then iteratively finds an abstract plan, checks where the plan fails in the concrete transition system and refines the abstraction such that the same failure cannot happen in subsequent iterations. As the abstraction grows in size, finding a solution for the abstract system becomes more and more costly. Because the abstraction grows incrementally, however, it is possible to maintain heuristic information about the abstract state space, allowing the use of informed search algorithms like A*. As the quality of the heuristic is crucial to the performance of informed search, the method for maintaining the heuristic has a significant impact on the performance of the abstraction refinement as a whole. In this thesis, we investigate different methods for maintaining the value of the perfect heuristic h* at all times and evaluate their performance.
Pattern Databases are a powerful class of abstraction heuristics which provide admissible path cost estimates by computing exact solution costs for all states of a smaller task. Said task is obtained by abstracting away variables of the original problem. Abstractions with few variables offer weak estimates, while introduction of additional variables is guaranteed to at least double the amount of memory needed for the pattern database. In this thesis, we present a class of algorithms based on counterexample-guided abstraction refinement (CEGAR), which exploit additivity relations of patterns to produce pattern collections from which we can derive heuristics that are both informative and computationally tractable. We show that our algorithms are competitive with already existing pattern generators by comparing their performance on a variety of planning tasks.
We consider the problem of Rubik’s Cube to evaluate modern abstraction heuristics. In order to find feasible abstractions of the enormous state space spanned by Rubik’s Cube, we apply projection in the form of pattern databases, Cartesian abstraction by doing counterexample guided abstraction refinement as well as merge-and-shrink strategies. While previous publications on Cartesian abstractions have not covered applicability for planning tasks with conditional effects, we introduce factorized effect tasks and show that Cartesian abstraction can be applied to them. In order to evaluate the performance of the chosen heuristics, we run experiments on different problem instances of Rubik’s Cube. We compare them by the initial h-value found for all problems and analyze the number of expanded states up to the last f-layer. These criteria provide insights about the informativeness of the considered heuristics. Cartesian Abstraction yields perfect heuristic values for problem instances close to the goal, however it is outperformed by pattern databases for more complex instances. Even though merge-and-shrink is the most general abstraction among the considered, it does not show better performance than the others.
Probabilistic planning expands on classical planning by tying probabilities to the effects of actions. Due to the exponential size of the states, probabilistic planners have to come up with a strong policy in a very limited time. One approach to optimising the policy that can be found in the available time is called metareasoning, a technique aiming to allocate more deliberation time to steps where more time to plan results in an improvement of the policy and less deliberation time to steps where an improvement of the policy with more time to plan is unlikely.
This thesis aims to adapt a recent proposal of a formal metareasoning procedure from Lin. et al. for the search algorithm BRTDP to work with the UCT algorithm in the Prost planner and compare its viability to the current standard and a number of less informed time management methods in order to find a potential improvement to the current uniform deliberation time distribution.
A planner tries to produce a policy that leads to a desired goal given the available range of actions and an initial state. A traditional approach for an algorithm is to use abstraction. In this thesis we implement the algorithm described in the ASAP-UCT paper: Abstraction of State-Action Pairs in UCT by Ankit Anand, Aditya Grover, Mausam and Parag Singla.
The algorithm combines state and state-action abstraction with a UCT-algorithm. We come to the conclusion that the algorithm needs to be improved because the abstraction of action-state often cannot detect a similarity that a reasonable action abstraction could find.
The notion of adding a form of exploration to guide a search has been proven to be an effective method of combating heuristical plateaus and improving the performance of greedy best-first search. The goal of this thesis is to take the same approach and introduce exploration in a bounded suboptimal search problem. Explicit estimation search (EES), established by Thayer and Ruml, consults potentially inadmissible information to determine the search order. Admissible heuristics are then used to guarantee the cost bound. In this work we replace the distance-to-go estimator used in EES with an approach based on the concept of novelty.
Classical domain-independent planning is about finding a sequence of actions which lead from an initial state to a goal state. A popular approach for solving planning problems efficiently is to utilize heuristic functions. A possible heuristic function is the perfect heuristic of a delete relaxed planning problem denoted as h+. Delete relaxation simplifies the planning problem thus making it easier to find a perfect heuristic. However computing h+ is still NP-hard problem.
In this thesis we discuss a promising looking approach to compute h+ in practice. Inspired by the paper from Gnad, Hoffmann and Domshlak about star-shaped planning problems, we implemented the Flow-Cut algorithm. The basic idea behind flow-cut to divide a problem that is unsolvable in practice, into smaller sub problems that can be solved. We further tested the flow-cut algorithm on the domains provided by the International Planning Competition benchmarks, resulting in the following conclusion: Using a divide and conquer approach can successfully be used to solve classical planning problems, however it is not trivial to design such an algorithm to be more efficient than state-of-the-art search algorithm.
This thesis deals with the algorithm presented in the paper "Landmark-based Meta Best-First Search Algorithm: First Parallelization Attempt and Evaluation" by Simon Vernhes, Guillaume Infantes and Vincent Vidal. Their idea was to reconsider the approach to landmarks as a tool in automated planning, but in a markedly different way than previous work had done. Their result is a meta-search algorithm which explores landmark orderings to find a series of subproblems that reliably lead to an effective solution. Any complete planner may be used to solve the subproblems. While the referenced paper also deals with an attempt to effectively parallelize the Landmark-based Meta Best-First Search Algorithm, this thesis is concerned mainly with the sequential implementation and evaluation of the algorithm in the Fast Downward planning system.
Heuristics play an important role in classical planning. Using heuristics during state space search often reduces the time required to find a solution, but constructing heuristics and using them to calculate heuristic values takes time, reducing this benefit. Constructing heuristics and calculating heuristic values as quickly as possible is very important to the effectiveness of a heuristic. In this thesis we introduce methods to bound the construction of merge-and-shrink to reduce its construction time and increase its accuracy for small problems and to bound the heuris- tic calculation of landmark cut to reduce heuristic value calculation time. To evaluate the performance of these depth-bound heuristics we have implemented them in the Fast Down- ward planning system together with three iterative-deepening heuristic search algorithms: iterative-deepening A* search, a new breadth-first iterative-deepening version of A* search and iterative-deepening breadth-first heuristic search.
Greedy best-first search has proven to be a very efficient approach to satisficing planning but can potentially lose some of its effectiveness due to the used heuristic function misleading it to a local minimum or plateau. This is where exploration with additional open lists comes in, to assist greedy best-first search with solving satisficing planning tasks more effectively. Building on the idea of exploration by clustering similar states together as described by Xie et al. [2014], where states are clustered according to heuristic values, we propose in this paper to instead cluster states based on the Hamming distance of the binary representation of states [Hamming, 1950]. The resulting open list maintains k buckets and inserts each given state into the bucket with the smallest average hamming distance between the already clustered states and the new state. Additionally, our open list is capable of reclustering all states periodically with the use of the k-means algorithm. We were able to achieve promising results concerning the amount of expansions necessary to reach a goal state, despite not achieving a higher coverage than fully random exploration due to slow performance. This was caused by the amount of calculations required to identify the most fitting cluster when inserting a new state.
Monte Carlo Tree Search Algorithms are an efficient method of solving probabilistic planning tasks that are modeled by Markov Decision Problems. MCTS uses two policies, a tree policy for iterating through the known part of the decission tree and a default policy to simulate the actions and their reward after leaving the tree. MCTS algorithms have been applied with great success to computer Go. To make the two policies fast many enhancements based on online knowledge have been developed. The goal of All Moves as First enhancements is to improve the quality of a reward estimate in the tree policy. In the context of this thesis the, in the field of computer Go very efficient, α-AMAF, Cutoff-AMAF as well as Rapid Action Value Estimation enhancements are implemented in the probabilistic planner PROST. To obtain a better default policy, Move Average Sampling is implemented into PROST and benchmarked against it’s current default policies.
In classical planning the objective is to find a sequence of applicable actions that lead from the initial state to a goal state. In many cases the given problem can be of enormous size. To deal with these cases, a prominent method is to use heuristic search, which uses a heuristic function to evaluate states and can focus on the most promising ones. In addition to applying heuristics, the search algorithm can apply additional pruning techniques that exclude applicable actions in a state because applying them at a later point in the path would result in a path consisting of the same actions but in a different order. The question remains as to how these actions can be selected without generating too much additional work to still be useful for the overall search. In this thesis we implement and evaluate the partition-based path pruning method, proposed by Nissim et al. [1], which tries to decompose the set of all actions into partitions. Based on this decomposition, actions can be pruned with very little additional information. The partition-based pruning method guarantees with some alterations to the A* search algorithm to preserve it’s optimality. The evaluation confirms that in several standard planning domains, the pruning method can reduce the size of the explored state space.
Validating real-time systems is an important and complex task which becomes exponentially harder with increasing sizes of systems. Therefore finding an automated approach to check real-time systems for possible errors is crucial. The behaviour of such real-time systems can be modelled with timed automata. This thesis adapts and implements the under-approximation refinement algorithm developed for search based planners proposed by Heusner et al. to find error states in timed automata via the directed model checking approach. The evaluation compares the algorithm to already existing search methods and shows that a basic under-approximation refinement algorithm yields a competitive search method for directed model checking which is both fast and memory efficient. Additionally we illustrate that with the introduction of some minor alterations the proposed under- approximation refinement algorithm can be further improved.
In dieser Arbeit wird versucht eine Heuristik zu lernen. Damit eine Heuristik erlernbar ist, muss sie über Parameter verfügen, die die Heuristik bestimmen. Eine solche Möglichkeit bieten Potential-Heuristiken und ihre Parameter werden Potentiale genannt. Pattern-Databases können mit vergleichsweise wenig Aufwand Eigenschaften eines Zustandsraumes erkennen und können somit eingesetzt werden als Grundlage um Potentiale zu lernen. Diese Arbeit untersucht zwei verschiedene Ansätze zum Erlernen der Potentiale aufgrund der Information aus Pattern-Databases. In Experimenten werden die beiden Ansätze genauer untersucht und schliesslich mit der FF-Heuristik verglichen.
We consider real-time strategy (RTS) games which have temporal and numerical aspects and pose challenges which have to be solved within limited search time. These games are interesting for AI research because they are more complex than board games. Current AI agents cannot consistently defeat average human players, while even the best players make mistakes we think an AI could avoid. In this thesis, we will focus on StarCraft Brood War. We will introduce a formal definition of the model Churchill and Buro proposed for StarCraft. This allows us to focus on Build Order optimization only. We have implemented a base version of the algorithm Churchill and Buro used for their agent. Using the implementation we are able to find solutions for Build Order Problems in StarCraft Brood War.
Auf dem Gebiet der Handlungsplanung stellt die symbolische Suche eine der erfolgversprechendsten angewandten Techniken dar. Um eine symbolische Suche auf endlichen Zustandsräumen zu implementieren bedarf es einer geeigneten Datenstruktur für logische Formeln. Diese Arbeit erprobt die Nutzung von Sentential Decision Diagrams (SDDs) anstelle der gängigen Binary Decision Diagrams (BDDs) zu diesem Zweck. SDDs sind eine Generalisierung von BDDs. Es wird empirisch getestet wie eine Implementierung der symbolischen Suche mit SDDs im FastDownward-Planer sich mit verschiedenen vtrees unterscheidet. Insbesondere wird die Performance von balancierten vtrees, mit welchen die Stärken von SDDs oft gut zur Geltung kommen, mit rechtsseitig linearen vtrees verglichen, bei welchen sich SDDs wie BDDs verhalten.
Die Frage ob es gültige Sudokus - d.h. Sudokus mit nur einer Lösung - gibt, die nur 16 Vorgaben haben, konnte im Dezember 2011 mithilfe einer erschöpfenden Brute-Force-Methode von McGuire et al. verneint werden. Die Schwierigkeit dieser Aufgabe liegt in dem ausufernden Suchraum des Problems und der dadurch entstehenden Erforderlichkeit einer effizienten Beweisidee sowie schnellerer Algorithmen. In dieser Arbeit wird die Beweismethode von McGuire et al. bestätigt werden und für 2 2 × 2 2 und 3 2 × 3 2 Sudokus in C++ implementiert.
Das Finden eines kürzesten Pfades zwischen zwei Punkten ist ein fundamentales Problem in der Graphentheorie. In der Praxis ist es oft wichtig, den Ressourcenverbrauch für das Ermitteln eines solchen Pfades minimal zu halten, was mithilfe einer komprimierten Pfaddatenbank erreicht werden kann. Im Rahmen dieser Arbeit bestimmen wir drei Verfahren, mit denen eine Pfaddatenbank möglichst platzsparend aufgestellt werden kann, und evaluieren die Effektivität dieser Verfahren anhand von Probleminstanzen verschiedener Grösse und Komplexität.
In planning what we want to do is to get from an initial state into a goal state. A state can be described by a finite number of boolean valued variables. If we want to transition from one state to the other we have to apply an action and this, at least in probabilistic planning, leads to a probability distribution over a set of possible successor states. From each transition the agent gains a reward dependent on the current state and his action. In this setting the growth of the number of possible states is exponential with the number of variables. We assume that the value of these variables is determined for each variable independently in a probabilistic fashion. So these variables influence the number of possible successor states in the same way as they did the state space. In consequence it is almost impossible to obtain an optimal amount of reward approaching this problem with a brute force technique. One way to get past this problem is to abstract the problem and then solve a simplified version of the aforementioned. That’s in general the idea proposed by Boutilier and Dearden [1]. They have introduced a method to create an abstraction which depends on the reward formula and the dependencies contained in the problem. With this idea as a basis we’ll create a heuristic for a trial-based heuristic tree search (THTS) algorithm [5] and a standalone planner using the framework PROST (Keller and Eyerich, 2012). These will then be tested on all the domains of the International Probabilistic Planning Competition (IPPC).
In einer Planungsaufgabe geht es darum einen gegebenen Wertezustand durch sequentielles Anwenden von Aktionen in einen Wertezustand zu überführen, welcher geforderte Zieleigenschaften erfüllt. Beim Lösen von Planungsaufgaben zählt Effizienz. Um Zeit und Speicher zu sparen verwenden viele Planer heuristische Suche. Dabei wird mittels einer Heuristik abgeschätzt, welche Aktion als nächstes angewendet werden soll um möglichst schnell in einen gewünschten Zustand zu gelangen.
In dieser Arbeit geht es darum, die von Haslum vorgeschlagene P m -Kompilierung für Planungsaufgaben zu implementieren und die h max -Heuristik auf dem kompilierten Problem gegen die h m -Heuristik auf dem originalen Problem zu testen. Die Implementation geschieht als Ergänzung zum Fast-Downward-Planungssystem. Die Resultate der Tests zeigen, dass mittels der Kompilierung die Zahl der gelösten Probleme erhöht werden kann. Das Lösen eines kompilierten Problems mit der h max -Heuristik geschieht im allgemeinen mit selbiger Informationstiefe schneller als das Lösen des originalen Problems mit der h m -Heuristik. Diesen Zeitgewinn erkauft man sich mit einem höheren Speicherbedarf.
The objective of classical planning is to find a sequence of actions which begins in a given initial state and ends in a state that satisfies a given goal condition. A popular approach to solve classical planning problems is based on heuristic forward search algorithms. In contrast, regression search algorithms apply actions “backwards” in order to find a plan from a goal state to the initial state. Currently, regression search algorithms are somewhat unpopular, as the generation of partial states in a basic regression search often leads to a significant growth of the explored search space. To tackle this problem, state subsumption is a pruning technique that additionally discards newly generated partial states for which a more general partial state has already been explored.
In this thesis, we discuss and evaluate techniques of regression and state subsumption. In order to evaluate their performance, we have implemented a regression search algorithm for the planning system Fast Downward, supporting both a simple subsumption technique as well as a refined subsumption technique using a trie data structure. The experiments have shown that a basic regression search algorithm generally increases the number of explored states compared to uniform-cost forward search. Regression with pruning based on state subsumption with a trie data structure significantly reduces the number of explored states compared to basic regression.
This thesis discusses the Traveling Tournament Problem and how it can be solved with heuristic search. The Traveling Tournament problem is a sports scheduling problem where one tries to find a schedule for a league that meets certain constraints while minimizing the overall distance traveled by the teams in this league. It is hard to solve for leagues with many teams involved since its complexity grows exponentially in the number of teams. The largest instances solved up to date, are instances with leagues of up to 10 teams.
Previous related work has shown that it is a reasonable approach to solve the Traveling Tournament Problem with an IDA*-based tree search. In this thesis I implemented such a search and extended it with several enhancements to examine whether they improve performance of the search. The heuristic that I used in my implementation is the Independent Lower Bound heuristic. It tries to find lower bounds to the traveling costs of each team in the considered league. With my implementation I was able to solve problem instances with up to 8 teams. The results of my evaluation have mostly been consistent with the expected impact of the implemented enhancements on the overall performance.
One huge topic in Artificial Intelligence is the classical planning. It is the process of finding a plan, therefore a sequence of actions that leads from an initial state to a goal state for a specified problem. In problems with a huge amount of states it is very difficult and time consuming to find a plan. There are different pruning methods that attempt to lower the amount of time needed to find a plan by trying to reduce the number of states to explore. In this work we take a closer look at two of these pruning methods. Both of these methods rely on the last action that led to the current state. The first one is the so called tunnel pruning that is a generalisation of the tunnel macros that are used to solve Sokoban problems. The idea is to find actions that allow a tunnel and then prune all actions that are not in the tunnel of this action. The second method is the partition-based path pruning. In this method all actions are distributed into different partitions. These partitions then can be used to prune actions that do not belong to the current partition.
The evaluation of these two pruning methods show, that they can reduce the number of explored states for some problem domains, however the difference between pruned search and normal search gets smaller when we use heuristic functions. It also shows that the two pruning rules effect different problem domains.
Ziel klassischer Handlungsplanung ist es auf eine möglichst effiziente Weise gegebene Planungsprobleme zu lösen. Die Lösung bzw. der Plan eines Planungsproblems ist eine Sequenz von Operatoren mit denen man von einem Anfangszustand in einen Zielzustand gelangt. Um einen Zielzustand gezielter zu finden, verwenden einige Suchalgorithmen eine zusätzliche Information über den Zustandsraum - die Heuristik. Sie schätzt, ausgehend von einem Zustand den Abstand zum Zielzustand. Demnach wäre es ideal, wenn jeder neue besuchte Zustand einen kleineren heuristischen Wert aufweisen würde als der bisher besuchte Zustand. Es gibt allerdings Suchszenarien bei denen die Heuristik nicht weiterhilft um einem Ziel näher zu kommen. Dies ist insbesondere dann der Fall, wenn sich der heuristische Wert von benachbarten Zuständen nicht ändert. Für die gierige Bestensuche würde das bedeuten, dass die Suche auf Plateaus und somit blind verläuft, weil sich dieser Suchalgorithmus ausschliesslich auf die Heuristik stützt. Algorithmen, die die Heuristik als Wegweiser verwenden, gehören zur Klasse der heuristischen Suchalgorithmen.
In dieser Arbeit geht es darum, in Fällen wie den Plateaus trotzdem eine Orientierung im Zustandsraum zu haben, indem Zustände neben der Heuristik einer weiteren Priorisierung unterliegen. Die hier vorgestellte Methode nutzt Abhängigkeiten zwischen Operatoren aus und erweitert die gierige Bestensuche. Wie stark Operatoren voneinander abhängen, betrachten wir anhand eines Abstandsmasses, welches vor der eigentlichen Suche berechnet wird. Die grundlegende Idee ist, Zustände zu bevorzugen, deren Operatoren im Vorfeld voneinander profitierten. Die Heuristik fungiert hierbei erst im Nachhinein als Tie-Breaker, sodass wir einem vielversprechenden Pfad zunächst folgen können, ohne dass uns die Heuristik an einer anderen, weniger vielversprechenden Stelle suchen lässt.
Die Ergebnisse zeigen, dass unser Ansatz in der reinen Suchzeit je nach Heuristik performanter sein kann, als wenn man sich ausschliesslich auf die Heuristik stützt. Bei sehr informationsreichen Heuristiken kann es jedoch passieren, dass die Suche durch unseren Ansatz eher gestört wird. Zudem werden viele Probleme nicht gelöst, weil die Berechnung der Abstände zu zeitaufwändig ist.
In classical planning, heuristic search is a popular approach to solving problems very efficiently. The objective of planning is to find a sequence of actions that can be applied to a given problem and that leads to a goal state. For this purpose, there are many heuristics. They are often a big help if a problem has a solution, but what happens if a problem does not have one? Which heuristics can help proving unsolvability without exploring the whole state space? How efficient are they? Admissible heuristics can be used for this purpose because they never overestimate the distance to a goal state and are therefore able to safely cut off parts of the search space. This makes it potentially easier to prove unsolvability
In this project we developed a problem generator to automatically create unsolvable problem instances and used those generated instances to see how different admissible heuristics perform on them. We used the Japanese puzzle game Sokoban as the first problem because it has a high complexity but is still easy to understand and to imagine for humans. As second problem, we used a logistical problem called NoMystery because unlike Sokoban it is a resource constrained problem and therefore a good supplement to our experiments. Furthermore, unsolvability occurs rather 'naturally' in these two domains and does not seem forced.
Sokoban is a computer game where each level consists of a two-dimensional grid of fields. There are walls as obstacles, moveable boxes and goal fields. The player controls the warehouse worker (Sokoban in Japanese) to push the boxes to the goal fields. The problem is very complex and that is why Sokoban has become a domain in planning.
Phase transitions mark a sudden change in solvability when traversing through the problem space. They occur in the region of hard instances and have been found for many domains. In this thesis we investigate phase transitions in the Sokoban puzzle. For our investigation we generate and evaluate random instances. We declare the defining parameters for Sokoban and measure their influence on the solvability. We show that phase transitions in the solvability of Sokoban can be found and their occurrence is measured. We attempt to unify the parameters of Sokoban to get a prediction on the solvability and hardness of specific instances.
In planning, we address the problem of automatically finding a sequence of actions that leads from a given initial state to a state that satisfies some goal condition. In satisficing planning, our objective is to find plans with preferably low, but not necessarily the lowest possible costs while keeping in mind our limited resources like time or memory. A prominent approach for satisficing planning is based on heuristic search with inadmissible heuristics. However, depending on the applied heuristic, plans found with heuristic search might be of low quality, and hence, improving the quality of such plans is often desirable. In this thesis, we adapt and apply iterative tunneling search with A* (ITSA*) to planning. ITSA* is an algorithm for plan improvement which has been originally proposed by Furcy et al. for search problems. ITSA* intends to search the local space of a given solution path in order to find "short cuts" which allow us to improve our solution. In this thesis, we provide an implementation and systematic evaluation of this algorithm on the standard IPC benchmarks. Our results show that ITSA* also successfully works in the planning area.
In action planning, greedy best-first search (GBFS) is one of the standard techniques if suboptimal plans are accepted. GBFS uses a heuristic function to guide the search towards a goal state. To achieve generality, in domain-independant planning the heuristic function is generated automatically. A well-known problem of GBFS are search plateaus, i.e., regions in the search space where all states have equal heuristic values. In such regions, heuristic search can degenerate to uninformed search. Hence, techniques to escape from such plateaus are desired to improve the efficiency of the search. A recent approach to avoid plateaus is based on diverse best-first search (DBFS) proposed by Imai and Kishimoto. However, this approach relies on several parameters. This thesis presents an implementation of DBFS into the Fast Downward planner. Furthermore, this thesis presents a systematic evaluation of DBFS for several parameter settings, leading to a better understanding of the impact of the parameter choices to the search performance.
Risk is a popular board game where players conquer each other's countries. In this project, I created an AI that plays Risk and is capable of learning. For each decision it makes, it performs a simple search one step ahead, looking at the outcomes of all possible moves it could make, and picks the most beneficial. It judges the desirability of outcomes by a series of parameters, which are modified after each game using the TD(λ)-Algorithm, allowing the AI to learn.
The Canadian Traveler's Problem ( ctp ) is a path finding problem where due to unfavorable weather, some of the roads are impassable. At the beginning, the agent does not know which roads are traversable and which are not. Instead, it can observe the status of roads adjacent to its current location. We consider the stochastic variant of the problem, where the blocking status of a connection is randomly defined with known probabilities. The goal is to find a policy which minimizes the expected travel costs of the agent.
We discuss several properties of the stochastic ctp and present an efficient way to calculate state probabilities. With the aid of these theoretical results, we introduce an uninformed algorithm to find optimal policies.
Finding optimal solutions for general search problems is a challenging task. A powerful approach for solving such problems is based on heuristic search with pattern database heuristics. In this thesis, we present a domain specific solver for the TopSpin Puzzle problem. This solver is based on the above-mentioned pattern database approach. We investigate several pattern databases, and evaluate them on problem instances of different size.
Merge-and-shrink abstractions are a popular approach to generate abstraction heuristics for planning. The computation of merge-and-shrink abstractions relies on a merging and a shrinking strategy. A recently investigated shrinking strategy is based on using bisimulations. Bisimulations are guaranteed to produce perfect heuristics. In this thesis, we investigate an efficient algorithm proposed by Dovier et al. for computing coarsest bisimulations. The algorithm, however, cannot directly be applied to planning and needs some adjustments. We show how this algorithm can be reduced to work with planning problems. In particular, we show how an edge labelled state space can be translated to a state labelled one and what other changes are necessary for the algorithm to be usable for planning problems. This includes a custom data structure to fulfil all requirements to meet the worst case complexity. Furthermore, the implementation will be evaluated on planning problems from the International Planning Competitions. We will see that the resulting algorithm can often not compete with the currently implemented algorithm in Fast Downward. We discuss the reasons why this is the case and propose possible solutions to resolve this issue.
In order to understand an algorithm, it is always helpful to have a visualization that shows step for step what the algorithm is doing. Under this presumption this Bachelor project will explain and visualize two AI techniques, Constraint Satisfaction Processing and SAT Backbones, using the game Gnomine as an example.
CSP techniques build up a network of constraints and infer information by propagating through a single or several constraints at a time, reducing the domain of the variables in the constraint(s). SAT Backbone Computations find literals in a propositional formula, which are true in every model of the given formula.
By showing how to apply these algorithms on the problem of solving a Gnomine game I hope to give a better insight on the nature of how the chosen algorithms work.
Planning as heuristic search is a powerful approach to solve domain-independent planning problems. An important class of heuristics is based on abstractions of the original planning task. However, abstraction heuristics usually come with loss in precision. The contribution of this thesis is the investigation of constrained abstraction heuristics in general, and the application of this concept to pattern database and merge and shrink abstractions in particular. The idea is to use a subclass of mutexes which represent sets of variable-value-pairs so that only one of these pairs can be true at any given time, to regain some of the precision which is lost in the abstraction without increasing its size. By removing states and operators in the abstraction which conflict with such a mutex, the abstraction is refined and hence, the corresponding abstraction heuristic can get more informed. We have implemented the refinements of these heuristics in the Fast Downward planner and evaluated the different approaches using standard IPC benchmarks. The results show that the concept of constrained abstraction heuristics can improve planning as heuristic search in terms of time and coverage.
A permutation problem considers the task where an initial order of objects (ie, an initial mapping of objects to locations) must be reordered into a given goal order by using permutation operators. Permutation operators are 1:1 mappings of the objects from their locations to (possibly other) locations. An example for permutation problems are the wellknown Rubik's Cube and TopSpin Puzzle. Permutation problems have been a research area for a while, and several methods for solving such problems have been proposed in the last two centuries. Most of these methods focused on finding optimal solutions, causing an exponential runtime in the worst case.
In this work, we consider an algorithm for solving permutation problems that has been originally proposed by M. Furst, J. Hopcroft and E. Luks in 1980. This algorithm has been introduced on a theoretical level within a proof for "Testing Membership and Determining the Order of a Group", but has not been implemented and evaluated on practical problems so far. In contrast to the other abovementioned solving algorithms, it only finds suboptimal solutions, but is guaranteed to run in polynomial time. The basic idea is to iteratively reach subgoals, and then to let them fix when we go further to reach the next goals. We have implemented this algorithm and evaluated it on different models, as the Pancake Problem and the TopSpin Puzzle .
Pattern databases (Culberson & Schaeffer, 1998) or PDBs, have been proven very effective in creating admissible Heuristics for single-agent search, such as the A*-algorithm. Haslum et. al proposed, a hill-climbing algorithm can be used to construct the PDBs, using the canonical heuristic. A different approach would be to change action-costs in the pattern-related abstractions, in order to obtain the admissible heuristic. This the so called Cost-Partitioning.
The aim of this project was to implement a cost-partitioning inside the hill-climbing algorithm by Haslum, and compare the results with the standard way which uses the canonical heuristic.
UCT ("upper confidence bounds applied to trees") is a state-of-the-art algorithm for acting under uncertainty, e.g. in probabilistic environments. In the last years it has been very successfully applied in numerous contexts, including two-player board games like Go and Mancala and stochastic single-agent optimization problems such as path planning under uncertainty and probabilistic action planning.
In this project the UCT algorithm was implemented, adapted and evaluated for the classical arcade game "Ms Pac-Man". The thesis introduces Ms Pac-Man and the UCT algorithm, discusses some critical design decisions for developing a strong UCT-based algorithm for playing Ms Pac-Man, and experimentally evaluates the implementation.
- Bibliography
- More Referencing guides Blog Automated transliteration Relevant bibliographies by topics
- Automated transliteration
- Relevant bibliographies by topics
- Referencing guides
8 Best Topics for Research and Thesis in Artificial Intelligence
- Top 5 Artificial Intelligence(AI) Predictions in 2020
- Top 7 Artificial Intelligence Frameworks to Learn in 2022
- What Are The Ethical Problems in Artificial Intelligence?
- Top 7 Artificial Intelligence and Machine Learning Trends For 2022
- The State of Artificial Intelligence in India and How Far is Too Far?
- 5 Dangers of Artificial Intelligence in the Future
- Top Challenges for Artificial Intelligence in 2020
- Difference Between Machine Learning and Artificial Intelligence
- What is Artificial Intelligence as a Service (AIaaS) in the Tech Industry?
- 10 Best Artificial Intelligence Project Ideas To Kick-Start Your Career
- Artificial Intelligence (AI) Researcher Jobs in China
- Applied Artificial Intelligence in Estonia : A global springboard for startups
- Types of Reasoning in Artificial Intelligence
- Mapping Techniques in Artificial Intelligence and Robotics
- Top 15 Artificial Intelligence(AI) Tools List
- Artificial Intelligence in Robotics
- Top Data Science with Artificial Intelligence Colleges in India
- Difference Between Data Science and Artificial Intelligence
- Difference Between Artificial Intelligence and Human Intelligence
Imagine a future in which intelligence is not restricted to humans!!! A future where machines can think as well as humans and work with them to create an even more exciting universe. While this future is still far away, Artificial Intelligence has still made a lot of advancement in these times. There is a lot of research being conducted in almost all fields of AI like Quantum Computing, Healthcare, Autonomous Vehicles, Internet of Things , Robotics , etc. So much so that there is an increase of 90% in the number of annually published research papers on Artificial Intelligence since 1996. Keeping this in mind, if you want to research and write a thesis based on Artificial Intelligence, there are many sub-topics that you can focus on. Some of these topics along with a brief introduction are provided in this article. We have also mentioned some published research papers related to each of these topics so that you can better understand the research process.

So without further ado, let’s see the different Topics for Research and Thesis in Artificial Intelligence!
1. Machine Learning
Machine Learning involves the use of Artificial Intelligence to enable machines to learn a task from experience without programming them specifically about that task. (In short, Machines learn automatically without human hand holding!!!) This process starts with feeding them good quality data and then training the machines by building various machine learning models using the data and different algorithms. The choice of algorithms depends on what type of data do we have and what kind of task we are trying to automate. However, generally speaking, Machine Learning Algorithms are divided into 3 types i.e. Supervised Machine Learning Algorithms, Unsupervised Machine Learning Algorithms , and Reinforcement Machine Learning Algorithms.
2. Deep Learning
Deep Learning is a subset of Machine Learning that learns by imitating the inner working of the human brain in order to process data and implement decisions based on that data. Basically, Deep Learning uses artificial neural networks to implement machine learning. These neural networks are connected in a web-like structure like the networks in the human brain (Basically a simplified version of our brain!). This web-like structure of artificial neural networks means that they are able to process data in a nonlinear approach which is a significant advantage over traditional algorithms that can only process data in a linear approach. An example of a deep neural network is RankBrain which is one of the factors in the Google Search algorithm.
3. Reinforcement Learning
Reinforcement Learning is a part of Artificial Intelligence in which the machine learns something in a way that is similar to how humans learn. As an example, assume that the machine is a student. Here the hypothetical student learns from its own mistakes over time (like we had to!!). So the Reinforcement Machine Learning Algorithms learn optimal actions through trial and error. This means that the algorithm decides the next action by learning behaviors that are based on its current state and that will maximize the reward in the future. And like humans, this works for machines as well! For example, Google’s AlphaGo computer program was able to beat the world champion in the game of Go (that’s a human!) in 2017 using Reinforcement Learning.
4. Robotics
Robotics is a field that deals with creating humanoid machines that can behave like humans and perform some actions like human beings. Now, robots can act like humans in certain situations but can they think like humans as well? This is where artificial intelligence comes in! AI allows robots to act intelligently in certain situations. These robots may be able to solve problems in a limited sphere or even learn in controlled environments. An example of this is Kismet , which is a social interaction robot developed at M.I.T’s Artificial Intelligence Lab. It recognizes the human body language and also our voice and interacts with humans accordingly. Another example is Robonaut , which was developed by NASA to work alongside the astronauts in space.
5. Natural Language Processing
It’s obvious that humans can converse with each other using speech but now machines can too! This is known as Natural Language Processing where machines analyze and understand language and speech as it is spoken (Now if you talk to a machine it may just talk back!). There are many subparts of NLP that deal with language such as speech recognition, natural language generation, natural language translation , etc. NLP is currently extremely popular for customer support applications, particularly the chatbot . These chatbots use ML and NLP to interact with the users in textual form and solve their queries. So you get the human touch in your customer support interactions without ever directly interacting with a human.
Some Research Papers published in the field of Natural Language Processing are provided here. You can study them to get more ideas about research and thesis on this topic.
6. Computer Vision
The internet is full of images! This is the selfie age, where taking an image and sharing it has never been easier. In fact, millions of images are uploaded and viewed every day on the internet. To make the most use of this huge amount of images online, it’s important that computers can see and understand images. And while humans can do this easily without a thought, it’s not so easy for computers! This is where Computer Vision comes in. Computer Vision uses Artificial Intelligence to extract information from images. This information can be object detection in the image, identification of image content to group various images together, etc. An application of computer vision is navigation for autonomous vehicles by analyzing images of surroundings such as AutoNav used in the Spirit and Opportunity rovers which landed on Mars.
7. Recommender Systems
When you are using Netflix, do you get a recommendation of movies and series based on your past choices or genres you like? This is done by Recommender Systems that provide you some guidance on what to choose next among the vast choices available online. A Recommender System can be based on Content-based Recommendation or even Collaborative Filtering. Content-Based Recommendation is done by analyzing the content of all the items. For example, you can be recommended books you might like based on Natural Language Processing done on the books. On the other hand, Collaborative Filtering is done by analyzing your past reading behavior and then recommending books based on that.
8. Internet of Things
Artificial Intelligence deals with the creation of systems that can learn to emulate human tasks using their prior experience and without any manual intervention. Internet of Things , on the other hand, is a network of various devices that are connected over the internet and they can collect and exchange data with each other. Now, all these IoT devices generate a lot of data that needs to be collected and mined for actionable results. This is where Artificial Intelligence comes into the picture. Internet of Things is used to collect and handle the huge amount of data that is required by the Artificial Intelligence algorithms. In turn, these algorithms convert the data into useful actionable results that can be implemented by the IoT devices.
Please Login to comment...
Similar reads.

- AI-ML-DS Blogs
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Impact.AI: Democratizing AI through K-12 Artificial Intelligence Education
Creative Commons
Attribution 4.0 International
Randi Williams
Feb. 1, 2024
- Randi Williams Former Research Assistant
- Cynthia Breazeal Professor of Media Arts and Sciences; MIT Dean for Digital Learning
- Impact.AI: K-12 AI Literacy
Share this publication
Williams, R. (2024) Impact.AI: Democratizing AI through K-12 artificial intelligence education. [Doctoral dissertation, Massachusetts Institute of Technology].
Today's youth are growing up in a world where artificial intelligence (AI) technologies shape how we live, work, play, socialize, and navigate our world. This rapid technological change is already significantly shifting individuals' lives and the opportunities they can obtain. Thus, researchers, educators, and government leaders must consider how to prepare a diverse citizenry to thrive in the emerging age of AI, for example, through outreach initiatives like grade school AI curricula. My thesis delves into K-12 AI literacy, particularly how AI curricula might empower students to see themselves as technosocial change agents, capable of using technology to work toward positive, equitable social change.

Williams, Randi. Impact.AI: democratizing AI through K-12 artificial intelligence education. Dissertation Proposal. Massachusetts Institute of Technology, 2023.
Dr. R.O. Bott Will See You Now: Exploring AI for Wellbeing with Middle School Students
Williams, R.; and Breazeal, C. 2023. Dr. R.O. Bott Will See You Now: Exploring AI for Wellbeing with Middle School Students. In Proceedings of the 13th Symposium on Education Advances in Artificial Intelligence (EAAI ’24). AAAI, Menlo Park, CA, USA.
AI literacy, explained
Cynthia Breazeal, head of the Personal Robots research group, talks to Education Week about early opportunities for AI literacy.
Career Girls Role Models: Randi Williams
Randi Williams talks about her work. Her advice to girls is never to be afraid to make yourself heard; your ideas are essential.
- Why Choose Us
- Vision and Mission
- Hire Writers
- How it Works
Best Artificial Intelligence Dissertation Topics for Your Paper

Table of Contents
What Is Artificial Intelligence? Understand in Brief!
Know about the basic ai dissertation structure, 6 tips for choosing dissertation topics on ai, 61 artificial intelligence topics for dissertations, struggling with dissertation topics ask our experts.
Are you struggling to decide on a topic for your paper? Worry not! This blog will provide with all you need to choose the best topic for your dissertation. Besides, it will also tell you about what it is and the tips to remember while deciding. After reading this, you will easily decide on the perfect artificial intelligence dissertation topics for the document. So, you will read more about it ahead.
Artificial intelligence, or AI, is the ability of a machine to perform tasks related to cognitive functions, or, as we call it, the human work-frame. It can do everything you imagined, being human functions and never others. It includes activities like reasoning, learning, exercising, thinking, interaction, and creativity. Likewise, it's much more than we already got a glimpse of, with the wide range of development in AI. Artificial intelligence can do functions that humans might take several infinite years to do in the blink of an eye, like solving complex calculations. It has made AI dissertation topics, a curious choice for students to learn about.
Today, AI is used in almost all places and has become a part of your life, whether you realize it yet or not. It is helping us navigate the world of easier functioning with tasks such as logistics, predictive maintenance, customer service, and much more.
So, this blog will help you to know about it, along with helping you choose some of the best artificial intelligence dissertation topics that will guide you to learn more about it in depth.
Order on Whatsapp
With the rapid increase in AI use, it is becoming a topic of interest to learners, with its applications in almost all sectors. But, before deciding your research topics on AI, it's essential to understand its basic structure first. It's necessary so you don't get confused with what's to be done in your document. It mainly depends on the type of paper, but scientifically, there are a few things common in them all. There are some of them below for your proper understanding.
Knowing these will help you in deciding the artificial intelligence dissertation topics for your paper.
The Introduction:
Here, you have to mention the context of your studies. Talk about your problem statement and the motivation behind whatever you choose. Give a brief description of the AI and scope you are looking to achieve, along with its significance. Tell your audience about the artificial intelligence dissertation ideas for the overall study overview.
Background Chapters:
In these chapters, you might want to include everything that proceeds in your paper. Along with all the experiments, methods, discussions, results, and organization, we include them all in different sections and chapters here. Also, you will clarify the paper type you decide among all the different types of dissertation documents.
The Conclusion:
While ending your dissertation, remember to interlink it all before wrapping up. Connect everything, including all the discussions and results, with each other before you end. Ensure to talk about the artificial intelligence dissertation topics that you select. Furthermore, elaborate on the future call to action for the document and how it can have an impact. Avoid adding new information here, but focus and highlight whatever you have already written.
So, you have read about the basic structure of writing a dissertation paper. Now, let us read about how to choose the best AI dissertation topics for it.
Struggling to Find Best Dissertation Topic?
Get a Unique Title & Dissertation Proposal Outline for FREE!
Many tips around might confuse and divert your attention. So, here we have combined the basic and most essential tips in one place to help you find good research topics on AI. So, moving further you will read about them in detail.
Select a Field You Are Interested In:
A dissertation document may take a long time to finish, so select a topic that interests you. It is very significant to choose dissertation topics in artificial intelligence that make you curious as well as help you in your career. Picking such a subject or field for your research will enable a great understanding of it. Furthermore, it will give you the additional strength to move ahead on your chosen path as you like. It will help you maintain the same passion throughout your journey.
Ensure It's Unique and Not Generic:
Your artificial intelligence research topics should be quite different in themselves. Picking a unique topic will give you the freedom to take the desired approach to the topic and find your results. For this, you can either select a completely off-beat topic that requires dedicated research within its scope. Moreover, take your perspective on something already done before. It will help make an impression on your mentor and audience with something they haven't read yet.
Do Not Decide Something Vague or Narrow:
A dissertation project is academic writing which has everything contributing towards something. Therefore, deciding on a fuzzy idea might not give the desired results. To avoid this from happening, you should select a topic that is precise and follows a proper dissertation structure . It will help you explore the topic and draw concise results from the given word count. Keep it broad for the proper research scope.
For this, you can even seek dissertation help online to make your document worth it all.
Plan the Type of Research and Relevance:
There are various types of research, so it is necessary to plan what type of research you wish to do and its relevance. For this, you can even find many examples of dissertations online or in your university library. However, it should contribute to your field and advance the reader's knowledge about the problems and solutions. To do this in a good way, feel free to decide on something that is currently working or is commonly faced. Analyse and collect the data, and then define these details about your paper.
To Proper Research Before Choosing:
Doing good research before choosing artificial intelligence dissertation topics for you is probably the best thing you can do. It will help you know if there's enough scope to proceed with the idea in your head. Keep narrowing down to the potential topic that looks good to you and getting more specific slowly. Furthermore, try to find a proper niche that you wish to cover in your document. For this, you can try the artificial intelligence assignment help to get support in deciding the steps to move ahead.
Stay Objective and Seek Required Help:
Being objective while working on your paper is necessary because it will help you stay balanced and do justice to it. Sometimes, when you are in the flow, it's easier to lose track and leave blind spots. To avoid that, imagine yourself as an outsider and look at the work from a new perspective.
Seek help from your mentor because they are there to help and have years of experience to see things you may miss. So, seek their guidance and recommendations to find the best artificial intelligence dissertation topics for your document.
Remember that it's not bad to seek help whenever you need it. Be flexible and strengthen your mind for all the changes you face on your journey. It will ensure that you have an open mind while choosing your Dissertation Topics on AI and make them useful. So, these are all the basic tips to help you do just that.
Need Personalised Assistance from Our Experts?
Share Your Requirements via Whatsapp!
Here, you will learn about some of the most trendy artificial intelligence topics for dissertations that are used in the areas with their in-depth fields of research. But, remember that with the new developments daily, these might need more new things added from time to time. So, let's go through some of them below.
Top Artificial Intelligence Dissertation Topics
- Is AI creating a threat to employment?
- Possible future with AI
- Impact of AI on upcoming generations
- Will robotics take over the world?
- AI in cybersecurity
- AI in machine learning
- Use of AI in emergencies
- Cost efficient AI
- Changes in human behavior after using AI
- Social interaction vs. AI interaction
Master Artificial Intelligence Dissertation Topics
- Limitation of artificial intelligence
- Use of artificial intelligence in education
- Online security and threats using AI
- Businesses using artificial intelligence
- Automated banking with AI
- Data management from artificial intelligence
- Stopping online attacks using AI
- Best trends in artificial intelligence
- Use of AI at unimaginable places
- AI in machine learning
Trendy Dissertation Topics on Artificial Intelligence
- Educating artificial intelligence
- Beginning of AI and its development
- Major ethical issues caused by the use of AI
- AI breaching data privacy
- Development in computing after AI
- AI quantum and edge computing
- Space exploration with AI
- Collaboration of robotics and event management
- How can AI save lives?
- Achieving the impossible with AI
Need Help with Dissertation?
Get a 100% Original Dissertation Written by EXPERTS
Unique AI Research Paper Topics
- Robotic and automated driving
- Educational artificial intelligence
- National security threats with the wide use of AI
- Disappointing AI experiments
- AI robotics in the Mars rover
- Lack of intellectual and emotional knowledge in AI
- Internet of Things (IoT) and artificial intelligence (AI)
- Technologies with AI & ml (machine learning)
- Brainstimulation with artificial intelligence
- Big data analysis using artificial intelligence
In-Depth Artificial Intelligence Research Topics
- AI perspective in cybernetics
- Social intelligence vs. Emotional intelligence in AI
- The threat caused by the narrow use of artificial intelligence
- Data science and artificial intelligence
- Major challenges in using artificial intelligence
- How does AI learn behavioral patterns?
- Virtualization in computer frameworks using AI
- Future of AI in Cybersecurity
- Data mining by artificial intelligence
- AI in online payment frauds
Important Artificial Intelligence Dissertation Topics
- Ethical hacking using artificial intelligence
- AI law enforcement
- Types of artificial intelligence
- Common issues in AI
- Artificial intelligence and schooling
- Hybrid techniques of AI
- AI chatbots (Siri, Alexa)
- Use of AI in logistics
- Making of artificial intelligence
- Clash of creative domains with AI
- Using AI to solve complex problems
Here, you read about the 61 best artificial intelligence dissertation topics that will help you brainstorm the ideas for your paper.
First, deciding on some good artificial intelligence dissertation topics and then working on lengthy documents can sometimes be tough. Especially when you have to take care of everything, even an error can bring you many steps backward. Thus, you can hire our experts or seek support from the Assignment Desk, which provides very cheap dissertation writing services .
The professionals here have years of experience in writing documents with the subject expertise you might need. Furthermore, various offers and tools on the Assignment Desk will help you find the perfect artificial intelligence dissertation topics for your paper. So, contact us today!
Let Us Help With Dissertation
Share Your Requirements Now for Customized Solutions.
Delivered on-time or your money back
Our Services
- Assignment Writing Service
- Essay Writing Help
- Dissertation Writing Service
- Coursework Writing Service
- Proofreading & Editing Service
- Online Exam Help
- Term paper writing service
- Ghost Writing Service
- Case Study Writing Service
- Research Paper Writing Service
- Personal Statement Writing Service
- Resume Writing Service
- Report Writing Service
To Make Your Work Original
Check your work against paraphrasing & get a free Plagiarism report!
Check your work against plagiarism & get a free Plagiarism report!
Quick and Simple Tool to Generate Dissertation Outline Instantly
Get citations & references in your document in the desired style!
Make your content free of errors in just a few clicks for free!
Generate plagiarism-free essays as per your topic’s requirement!
Generate a Compelling Thesis Statement and Impress Your Professor
FREE Features
- Topic Creation USD 3.87 FREE
- Outline USD 9.33 FREE
- Unlimited Revisions USD 20.67 FREE
- Editing/Proofreading USD 28 FREE
- Formatting USD 8 FREE
- Bibliography USD 7.33 FREE
Get all these features for
USD 80.67 FREE
RELATED BLOGS

50+ In- Depth Geography Dissertation Ideas & Topics [2024]

A Comprehensive List of 35+ Trending Brexit Dissertation Topics

Interesting 40+ Early Childhood Studies Dissertation Ideas

Top 50 Unique Topics for Writing Palliative Care Dissertation

45+ Best Supply Chain Management Dissertation Topics 2024

How to Write a Compelling Dissertation Outline?
Professional assignment writers.
Choose a writer for your task among hundreds of professionals

Please rotate your device
We don't support landscape mode yet. Please go back to portrait mode for the best experience
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it. Know more
Calculate the Price
Professional Academic Help at Pocket-Friendly Prices!
Estimated Price
Limited Time Offer
Exclusive Library Membership + FREE Wallet Balance
1 Month Access !
5000 Student Samples
10,000 Answers by Experts
Get $300 Now
- How It Works
- PhD thesis writing
- Master thesis writing
- Bachelor thesis writing
- Dissertation writing service
- Dissertation abstract writing
- Thesis proposal writing
- Thesis editing service
- Thesis proofreading service
- Thesis formatting service
- Coursework writing service
- Research paper writing service
- Architecture thesis writing
- Computer science thesis writing
- Engineering thesis writing
- History thesis writing
- MBA thesis writing
- Nursing dissertation writing
- Psychology dissertation writing
- Sociology thesis writing
- Statistics dissertation writing
- Buy dissertation online
- Write my dissertation
- Cheap thesis
- Cheap dissertation
- Custom dissertation
- Dissertation help
- Pay for thesis
- Pay for dissertation
- Senior thesis
- Write my thesis
163 Unique Artificial Intelligence Topics For Your Dissertation

The artificial intelligence industry is an industry of the future, but it’s also a course many students find difficult to write about. According to some students, the main reason is that there are many research topics on artificial intelligence. Several topics are already covered, and they claim not to know what to write about.
However, one of the interesting things about writing a dissertation or thesis is that you don’t need to be the number one author of an idea. It would be best if you write about the idea from a unique perspective instead. Writing from a unique perspective also means coupling your ideas with original research, giving your long essay quality and value to your professors and other students who may want to cover the same topic in the future.
This blog post will cover basic advanced AI topics and interesting ones for your next research paper or debate. This will help prepare you for your next long essay or presentation.
What is Artificial Intelligence?
Artificial Intelligence (AI) is the concept that enables humans to perform their tasks more smartly and faster through automated systems. AI is human intelligence packed in machines.
AI facilitates several computer systems such as voice recognition, machine vision, natural language processing, robotics engineering, and many others. All these systems revolutionize how work is done in today’s world.
Now that you know what artificial intelligence is, here are some advanced AI topics for your college research.
Writing Tips to Create a Good Thesis or Dissertation
Every student wants to create the best thesis and dissertation in their class. The first step to creating or researching the perfect dissertation is to write a great thesis. What are the things to be on the lookout for?
- Create a Strong Thesis Statement You need this to have a concise approach to your research. Your thesis statement should, therefore, be specific, precise, factual, debatable, and logical enough to be an assertive point. Afterwards, the only way to create a competitive dissertation is to draw from existing research in journals and other sources.
- Strong Arguments You can create a good dissertation if you have strong arguments. Your arguments must be backed by reputed sources such as academics, government, reputed media organizations, or statistic-oriented websites. All these make your arguments recognizable and accepted.
- Well Organized and Logically Structured Your dissertation has different subsections, including an abstract, thesis statement, background to the study, chapters (where your body is), and concluding arguments. If you’ve embarked on quantitative data analysis, you must report the data you got and what it means for your discourse. You can even add recommendations for future research. The information you want to convey must be well structured to improve its reception by your university professors.
- Concise and Free of Errors Your essay must also be straightforward. Your ideas must not be complex to understand, and you must always explain ambiguous industry terms. Revising your draft to check for grammatical errors several times is also important. Editing can be difficult, but it’s integral to determining whether your professors will love your dissertation or otherwise.
Artificial Intelligence Research Topics
Artificial intelligence is here to stay in several industries and sectors worldwide. It is the technology of the present and the future, and here are some AI topics to write about:
- How will artificial intelligence contribute to the flight to Mars?
- Machine learning and the challenges it poses to scientists
- How can retail stores maximize machine learning?
- Expatiate on what is meant by deep learning
- General AI and Narrow AI: what does it mean?
- AI changes the world: a case study of the gambling industry
- AI improved business: a case study of SaaS industries
- AI in homes: how smart homes change how humans live
- The critical challenges scientists have not yet solved with AI
- How students can contribute to both research and development of AI systems
- Is automation the way forward for the interconnected world: an overview of the ethical issues in AI
- How does cybernetics connect with AI?
- How do artificial intelligence systems manifest in healthcare?
- A case for artificial intelligence in how it facilitates the use of data in the criminal department
- What are the innovations in the vision system applications
- The inductive logic program: meaning and origin
- Brain simulation and AI: right or wrong
- How to maximize AI in Big data
- How AI can increase cybersecurity threat
- AI in companies: a case study of Telegram
Hot Topics in Artificial Intelligence
If you’d love to be one of the few who will cover hot topics in AI, researching some sub-sectors could be a way to go. There are several subsections of AI, some of which are hot AI topics causing several arguments among scholars and moralists today. Some of these are:
- How natural language is generated and how AI maximizes it
- Speech recognition: a case study of Alexa and how it works
- How AI makes its decisions
- What are known as virtual agents?
- Key deep learning platforms for governments
- Text analytics and the future of text-to-speech systems
- How marketing automation works
- Do robots operate based on rules?
- AI and emotion recognition
- AI and the future of biometrics
- AI in content creation
- AI and how data is used to create social media addiction
- What can be considered core problems with AI?
- What do five pieces of literature say about AI taking over the world?
- How does AI help with predictive sales?
- Motion planning and how AI is used in video editing
- Distinguish between data science vs. artificial intelligence
- Account for five failed AI experiments in the past decade
- The world from the machine’s view
- Project management systems from the machine’s view
Artificial Intelligence Topics for Presentation
Students are sometimes fond of presentations to show knowledge or win debates. If you’re in a debate club and would love to add a presentation to your AI topics, here are topics in artificial intelligence for you.
You can even expand these for your artificial intelligence research paper topics:
- How AI has penetrated all industries
- The future of cloud technologies
- The future of AI in military equipment
- The evolution of AI in a security application
- Industrial robots: an account of Tesla’s factory
- Industrial robots: an account of Amazon’s factories
- An overview of deep generative models and what they mean
- What are the space travel ideas fueling the innovation of AI?
- What is amortized inference?
- Examine the Monte Carlo methods in AI
- How technology has improved maps
- Comment on how AI is used to find fresh craters on the moon
- Comment on two previous papers from your professor about AI
AI Research Topics
If you’d like to take a general perspective on AI, here are some topics in AI to discuss amongst your friends or for your next essay:
- Are robots a threat to human jobs?
- How automation has changed the world since 2020
- Would you say Tesla produces robot cars?
- What are the basic violations of artificial intelligence?
- Account for the evolution of AI models
- Weapon systems and the future of weaponry
- Account for the interaction between machines and humans
- Basic principles of AI risk management
- How AI protects people against spam
- Can AI predict election results?
- What are the limits of AI?
- Detailed reports on image recognition algorithms in two companies of your choice
- How is AI used in customer service?
- Telehealth and its significance
- Can AI help predict the future?
- How to measure water quality and cleanness through AI
- Analyze the technology used for the Breathometer products
- Key trends in AI and robotics research and development
- How AI helps with fraud detection in a bank of your choice
- How AI helps the academic industry.
Argument Debate Topics in AI
You’d expect controversial topics in AI, and here are some of them. These are topics for friendly debates in class or topics to start a conversation with industry leaders:
- Will humans end all work when AI replaces them?
- Who is liable for AI’s misdoing?
- AI is smarter than humans: can it be controlled?
- Machines will affect human interactions: discuss
- AI bias exists and is here to stay
- Artificial Intelligence cannot be humanized even if it understands emotions
- New wealth and AI: how will it be distributed?
- Can humans prevent AI bias?
- Can AI be protected from hackers?
- What will happen with the unintended consequences of using AI?
Computer Science AI Topics
Every computer science student also needs AI topics for research papers, presentations or scientific thesis . Whatever it is, here are some helpful ideas:
- AI and machine learning: how does it help healthcare systems?
- What does hierarchical deep learning neural network mean
- AI in architecture and engineering: explain
- Can robots safely perform surgery?
- Can robots help with teaching?
- Recent trends in machine learning
- Recent trends in big data that will affect the future of the internet of things
- How does AI contribute to the excavation management Industry?
- Can AI help spot drug distribution?
- AI and imaging system: Trends since 1990
- Explain five pieces of literature on how AI can be contained
- Discuss how AI reduced the escalation of COVID-19
- How can natural language processing help interpret sign languages?
- Review a recent book about AI and cybersecurity
- Discuss the key discoveries from a recent popular seminar on AI and cybercrime
- What does Stephen Hawking think about AI?
- How did AI make Tesla a possibility?
- How recommender systems work in the retail industry
- What is the artificial Internet of Things (A-IoT)?
- Explain the intricacies of enhanced AI in the pharmaceutical industry
AI Ethics Topics
There are always argumentative debate topics on AI, especially on the ethical and moral components. Here are a few ethical topics in artificial intelligence to discuss:
- Is AI the end of all jobs?
- Is artificial intelligence in concert with patent law?
- Do humans understand machines?
- What happens when robots gain self-control?
- Can machines make catastrophic mistakes?
- What happens when AI reads minds and executes actions even if they’re violent?
- What can be done about racist robots?
- Comments on how science can mediate human-machine interactions
- What does Google CEO mean when he said AI would be the world’s saviour?
- What are robots’ rights?
- How does power balance shift with a rise in AI development?
- How can human privacy be assured when robots are used as police?
- What is morality for AI?
- Can AI affect the environment?
- Discuss ways to keep robots safe from enemies.
AI Essay Topics Technology
Technology is already intertwined with AI, but you may need hot AI topics that focus on the tech side of the innovation. Here are 20 custom topics for you:
- How can we understand autonomous driving?
- Pros and cons of artificial intelligence to the world?
- How does modern science interact with AI?
- Account for the scandalous innovations in AI in the 21st century
- Account for the most destructive robots ever built
- Review a documentary on AI
- Review three books or journals that express AI as a threat to humans and draw conclusions based on your thoughts
- What do non-experts think about AI?
- Discuss the most ingenious robots developed in the past decade
- Can the robotic population replace human significance?
- Is it possible to be ruled by robots?
- What would world domination look like: from the machine perspective
- He who controls AI controls the world: discuss
- Key areas in AI engineering that man must control
- How Apple is using AI for its products
- Would you say AI is a positive or negative invention?
- AI and video gaming: how it changed the arcade Industry
- Would you say eSports is toxic?
- How AI helps in the hospitality industry
- AI and its use in sustainable energy.
Interesting Topics in AI
There are interesting ways to look at the subject of AI in today’s world. Here are some good research topics for AI to answer some questions:
- AI can be toxic: Should a high school student pursue a career in artificial intelligence?
- Prediction vs. judgment: experimenting with AI
- What makes AI know what’s right or wrong?
- Human judgment in AI: explain
- Effects of AI on businesses
- Will AI play critical roles in human future affairs?
- Tech devices and AI
- Search application and AI: account for how AI maximizes programming languages
- The history of artificial intelligence
- How AI impacts market design
- Data management and AI: discuss
- How can AI influence the future of computing
- How AI has changed the video viewing industry
- How can AI contribute to the global economy?
- How smart would you say artificial intelligence is?
Graduate AI NLP Research Topics
NLP (Natural Language Processing) is the aspect of artificial intelligence or computer science that deals with the ability of machines to understand spoken words and simplify them as humans can. It’s as simple as saying NLP is how computers understand human language.
If you’d like to focus your research topics on artificial intelligence on NLP, here are some topics for you:
- How did natural language processing help with Twitter Space discussions?
- How language is essential for regulatory and legal texts
- NLP in the eCommerce industry: top trends
- How NLP is used in language modelling and occlusion
- How does AI manoeuvre semantic analysis in natural language processing?
- History and top trends in NLP conference video call apps
- Text mining techniques and the role of NLP
- How physicians detected stroke since 2020 through NLP of radiology results
- How does big data contribute to understanding medical acronyms in the NLP section of AI?
- What does applied natural language processing mean in the mental health world?
Get Thesis Help Today
These 163 custom artificial intelligence topics are carefully selected and written by dissertation writers to help you prepare a quality dissertation. However, there are instances where you may be unable to come up with a quality dissertation by yourself.
In that case, you can reach out to us to help you create compelling content that will guarantee good grades. We have many expert writers that can attend to you if you need a thesis writing service to help create an impeccable essay. Our writers are top-class professionals with years of academic experience and are willing to create quality copy for your dissertation at friendly rates.
Researching and editing complex essays for university or college students is hard, but these online writers make it easy by relieving you of the burden. All you need to do is fill in a form and share your needs.

Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Comment * Error message
Name * Error message
Email * Error message
Save my name, email, and website in this browser for the next time I comment.
As Putin continues killing civilians, bombing kindergartens, and threatening WWIII, Ukraine fights for the world's peaceful future.
Ukraine Live Updates
Teaching and learning artificial intelligence: Insights from the literature
- Published: 02 May 2024
Cite this article

- Bahar Memarian ORCID: orcid.org/0000-0003-0671-3127 1 &
- Tenzin Doleck 1
153 Accesses
Explore all metrics
Artificial Intelligence (AI) has been around for nearly a century, yet in recent years the rapid advancement and public access to AI applications and algorithms have led to increased attention to the role of AI in higher education. An equally important but overlooked topic is the study of AI teaching and learning in higher education. We wish to examine the overview of the study, pedagogical outcomes, challenges, and limitations through a systematic review process amidst the COVID-19 pandemic and public access to ChatGPT. Twelve articles from 2020 to 2023 focused on AI pedagogy are explored in this systematic literature review. We find in-depth analysis and comparison of work post-COVID and AI teaching and learning era is needed to have a more focused lens on the current state of AI pedagogy. Findings reveal that the use of self-reported surveys in a pre-and post-design form is most prevalent in the reviewed studies. A diverse set of constructs are used to conceptualize AI literacy and their associated metrics and scales of measure are defined based on the work of specific authors rather than a universally accepted framework. There remains work and consensus on what learning objectives, levels of thinking skills, and associated activities lead to the advanced development of AI literacy. An overview of the studies, pedagogical outcomes, and challenges are provided. Further implications of the studies are also shared. The contribution of this work is to open discussions on the overlooked topic of AI teaching and learning in higher education.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
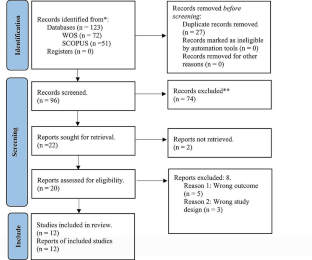
Similar content being viewed by others

Artificial intelligence in education: Addressing ethical challenges in K-12 settings

Artificial Intelligence (AI) Student Assistants in the Classroom: Designing Chatbots to Support Student Success

Systematic review of research on artificial intelligence applications in higher education – where are the educators?
Data availability.
Data sharing does not apply to this article as no datasets were generated or analyzed during the current study.
Ali, M., & Abdel-Haq, M. K. (2021). Bibliographical analysis of artificial intelligence learning in Higher Education: is the role of the human educator and educated a thing of the past? Fostering Communication and Learning With Underutilized Technologies in Higher Education , 36–52.
Anderson, J., Rainie, L., & Luchsinger, A. (2018). Artificial intelligence and the future of humans. Pew Research Center , 10 (12).
Bates, T., Cobo, C., Mariño, O., & Wheeler, S. (2020). No can artificial intelligence transform higher education? International Journal of Educational Technology in Higher Education , 17 (1), 1–12.
Article Google Scholar
Biggs, J., & Tang, C. (2011). Train-the-trainers: Implementing outcomes-based teaching and learning in Malaysian higher education. Malaysian Journal of Learning and Instruction , 8 , 1–19.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research , 3 , 993–1022.
Google Scholar
Chang, Y. S., Wang, Y. Y., & Ku, Y. T. (2023). Influence of online STEAM hands-on learning on AI learning, creativity, and creative emotions. Interact Learn Environ PG . https://doi.org/10.1080/10494820.2023.2205898 .
Chen, X., Xie, H., Zou, D., & Hwang, G. J. (2020). Application and theory gaps during the rise of artificial intelligence in education. Computers and Education: Artificial Intelligence , 1 , 100002.
Clark, D. (2023). PedAIgogy – New Era of Knowledge and Learning Where AI changes Everything .
Covidence (2023). Covidence systematic review software . www.covidence.org.
Crompton, H., & Burke, D. (2023). Artificial intelligence in higher education: The state of the field. International Journal of Educational Technology in Higher Education , 20 (1), 1–22.
Cumming, G., & McDougall, A. (2000). Mainstreaming AIED into education. International Journal of Artificial Intelligence in Education , 11 (2), 197–207.
Dignum, V. (2020). AI is multidisciplinary. AI Matters , 5 (4), 18–21.
Fuller, C. M., Simmering, M. J., Atinc, G., Atinc, Y., & Babin, B. J. (2016). Common methods variance detection in business research. Journal of Business Research , 69 (8), 3192–3198. https://doi.org/10.1016/j.jbusres.2015.12.008 .
Gao, Z., Wanyama, T., & Singh, I. (2020). Project and practice centered learning: A systematic methodology and strategy to cultivate future full stack artificial intelligence engineers. Int. J. Eng. Educ , 36 (6 PG-1760–1772), 1760–1772. https://www.scopus.com/inward/record.uri?eid=2s2.085096038454&partnerID=40&md5=b4778257adf34da504fdf1f97ebb7fe9NS .
Halic, O., Lee, D., Paulus, T., & Spence, M. (2010). To blog or not to blog: Student perceptions of blog effectiveness for learning in a college-level course. The Internet and Higher Education , 13 (4), 206–213.
Herrington, J., & Oliver, R. (2000). An instructional design framework for authentic learning environments. Educational Technology Research and Development , 48 (3), 23–48.
Hsu, T. C., & Chen, M. S. (2022). The engagement of students when learning to use a personal audio classifier to control robot cars in a computational thinking board game. Res Pract Technol Enhanc Learn , 17 (1 PG-). https://doi.org/10.1186/s41039-022-00202-1 .
Hwang, G. J., Xie, H., Wah, B. W., & Gašević, D. (2020). Vision, challenges, roles and research issues of Artificial Intelligence in Education. Computers and Education: Artificial Intelligence , 1 , 100001.
Jaramillo, F., Locander, W. B., Spector, P. E., & Harris, E. G. (2007). Getting the job done: The moderating role of initiative on the relationship between intrinsic motivation and adaptive selling. Journal of Personal Selling and Sales Management , 27 (1), 59–74.
Javed, R. T., Nasir, O., Borit, M., Vanhée, L., Zea, E., Gupta, S., Vinuesa, R., & Qadir, J. (2022). Get out of the BAG! Silos in AI Ethics Education: Unsupervised topic modeling analysis of global AI Curricula. Journal of Artificial Intelligence Research , 73 , 933–965. https://doi.org/10.1613/jair.1.13550 .
Jiang, L. (2021). Virtual reality Action interactive teaching Artificial Intelligence Education System. Complexity , 2021 (PG-). https://doi.org/10.1155/2021/5553211 .
Jobin, A., Ienca, M., & Vayena, E. (2019). The global landscape of AI ethics guidelines. Nature Machine Intelligence , 1 (9), 389–399.
Keller, J. M. (1987). Development and use of the ARCS model of instructional design. Journal of Instructional Development , 10 (3), 2–10.
Article MathSciNet Google Scholar
Kim, S., Jang, Y., Choi, S., Kim, W., Jung, H., Kim, S., & Kim, H. (2021). Analyzing teacher competency with TPACK for K-12 AI education. KI-Künstliche Intelligenz , 35 (2), 139–151.
Koh, J. H., Chai, L., Wong, C. S., & Hong, B., H.-Y (2015). Design thinking for education: Conceptions and applications in teaching and learning . Springer.
Kong, S. C., Cheung, W. M. Y., & Zhang, G. (2023). Evaluating an Artificial Intelligence Literacy Programme for developing University students’ conceptual understanding, literacy, empowerment and ethical awareness. Educational Technology and Society , 26 (1), 16–30. https://doi.org/10.30191/ETS.202301_26(1).0002 .
Korkmaz, Ö., & Xuemei, B. A. I. (2019). Adapting computational thinking scale (CTS) for Chinese high school students and their thinking scale skills level. Participatory Educational Research , 6 (1), 10–26.
Krathwohl, D. R. (2002). A revision of Bloom’s taxonomy: An overview. Theory into Practice , 41 (4), 212–218. https://doi.org/10.1207/s15430421tip4104_2 .
Lin, C. H., Wu, L. Y., Wang, W. C., Wu, P. L., & Cheng, S. Y. (2020). Development and validation of an instrument for AI-Literacy. 3rd Eurasian Conference on Educational Innovation (ECEI 2020) .
Lin, X. F., Chen, L., Chan, K. K., Peng, S. Q., Chen, X. F., Xie, S. Q., Liu, J. C., & Hu, Q. T. (2022). Teachers’ perceptions of teaching sustainable Artificial Intelligence: A Design Frame Perspective. SUSTAINABILITY , 14 (13 PG-). https://doi.org/10.3390/su14137811 .
Martín-Núñez, J. L., Ar, A. Y., Fernández, R. P., Abbas, A., & Radovanović, D. (2023). Does intrinsic motivation mediate perceived artificial intelligence (AI) learning and computational thinking of students during the COVID-19 pandemic? Computers & Education , 4(PG-) . https://doi.org/10.1016/j.caeai.2023.100128 .
Meek, T., Barham, H., Beltaif, N., Kaadoor, A., & Akhter, T. (2016). Managing the ethical and risk implications of rapid advances in artificial intelligence: A literature review. 2016 Portland International Conference on Management of Engineering and Technology (PICMET) , 682–693.
Miriyev, A., & Kovač, M. (2020). Skills for physical artificial intelligence. Nature Machine Intelligence , 2 (11), 658–660.
Ng, D. T. K., Lee, M., Tan, R. J. Y., Hu, X., Downie, J. S., & Chu, S. K. W. (2022). A review of AI teaching and learning from 2000 to 2020. EDUCATION AND INFORMATION TECHNOLOGIES . https://doi.org/10.1007/s10639-022-11491-w .
Pinkwart, N. (2016). Another 25 years of AIED? Challenges and opportunities for intelligent educational technologies of the future. International Journal of Artificial Intelligence in Education , 26 , 771–783.
Popenici, S. A., & Kerr, S. (2017). Exploring the impact of artificial intelligence on teaching and learning in higher education. Research and Practice in Technology Enhanced Learning , 12 (1), 1–13.
Rizvi, S., Waite, J., & Sentance, S. (2023). Artificial Intelligence teaching and learning in K-12 from 2019 to 2022: A systematic literature review. Computers and Education: Artificial Intelligence , 100145.
Shih, P. K., Lin, C. H., Wu, L. Y., & Yu, C. C. (2021). Learning ethics in AI—teaching non-engineering undergraduates through situated learning. Sustainability , 13 (7), 3718.
Southworth, J., Migliaccio, K., Glover, J., Glover, J. N., Reed, D., McCarty, C., Brendemuhl, J., & Thomas, A. (2023). Developing a model for AI across the curriculum: Transforming the higher education landscape via innovation in AI literacy. Computers & Education , 4 , PG–. https://doi.org/10.1016/j.caeai.2023.100127 .
Su, J., Guo, K., Chen, X., & Chu, S. K. W. (2023). Teaching artificial intelligence in K–12 classrooms: A scoping review. Interactive Learning Environments , 1–20.
Tedre, M., Toivonen, T., Kahila, J., Vartiainen, H., Valtonen, T., Jormanainen, I., & Pears, A. (2021). Teaching machine learning in K–12 classroom: Pedagogical and technological trajectories for artificial intelligence education. Ieee Access : Practical Innovations, Open Solutions , 9 , 110558–110572.
UNESCO (2023). 10 Innovative Learning Strategies For Modern Pedagogy . TeachThought Staff. https://policytoolbox.iiep.unesco.org/library/BHABKKH6 .
Wong, M. K., Wu, J., Ong, Z. Y., Goh, J. L., Cheong, C. W. S., Tay, K. T., Tan, L. H. S., & Krishna, L. K. R (2019). Teaching ethics in medical schools: A systematic review from 2000 to 2018. Journal of Medical Education , 18 , 226–250.
Xu, B. (2021). Artificial Intelligence Teaching System and Data Processing Method based on Big Data. Complexity , 2021(PG-) . https://doi.org/10.1155/2021/9919401 .
Yağcı, M. (2019). A valid and reliable tool for examining computational thinking skills. Education and Information Technologies , 24 (1), 929–951.
Yi, Y. (2021). Establishing the concept of AI literacy. European Journal of Bioethics , 12 (2), 353–368.
Yue, M., Jong, M. S. Y., & Dai, Y. (2022). Pedagogical design of K-12 artificial intelligence education: A systematic review. Sustainability , 14 (23), 15620.
Zawacki-Richter, O., Marín, V. I., Bond, M., & Gouverneur, F. (2019). Systematic review of research on artificial intelligence applications in higher education–where are the educators? International Journal of Educational Technology in Higher Education , 16 (1), 1–27.
Zeide, E. (2019). Artificial intelligence in higher education: Applications, promise and perils, and ethical questions. Educause Review , 54 (3).
Zhang, K., & Aslan, A. B. (2021). AI technologies for education: Recent research & future directions. Computers and Education: Artificial Intelligence , 2 , 100025.
Download references
Acknowledgements
Not applicable.
Author information
Authors and affiliations.
Faculty of Education, Simon Fraser University, Vancouver, BC, Canada
Bahar Memarian & Tenzin Doleck
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Bahar Memarian .
Ethics declarations
Conflict of interest, additional information, publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Memarian, B., Doleck, T. Teaching and learning artificial intelligence: Insights from the literature. Educ Inf Technol (2024). https://doi.org/10.1007/s10639-024-12679-y
Download citation
Received : 03 August 2023
Accepted : 10 April 2024
Published : 02 May 2024
DOI : https://doi.org/10.1007/s10639-024-12679-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Higher education
- Artificial intelligence (AI)
- Find a journal
- Publish with us
- Track your research
The Main Topics for Coursework or a Thesis Statement in Artificial Intelligence
Artificial Intelligence (AI) is changing the world, from machine learning and the Internet of Things to Robotics and Natural Language processing.
Research is needed to understand more about AI and how it will affect the future.
AI-powered machines are likely to replace humans in many fields and the consequences of this are still largely unknown.
There are many topics of vital importance to choose from if you’re a student trying to decide on a topic involving AI for your thesis.

Image source: Freepik.com
Machine learning (ML) as a Thesis Topic
Artificial intelligence enables machines to automatically learn a task from experience and improve performance without any human intervention.
Machines need high-quality data to start with. They are trained by building machine learning models using the data and different algorithms.
The algorithms depend on the type of data and the tasks that need automation.
A topic for your research could involve discussing wearable devices. They are powered by machine learning and are becoming increasingly popular.
You could discuss their relevance in fields like health and insurance as well as how they can help individuals to improve their daily routines and move towards a more healthy lifestyle.
Deep learning (DL) as a Thesis Topic
Deep Learning is a subset of ML where learning imitates the inner workings of the human brain. It uses artificial neural networks to process data and make decisions.
The web-like networks take a non-linear approach to processing data which is superior to traditional algorithms that take a linear approach.
Google’s RankBrain is an example of an artificial neural network.
Deep learning is driving many AI applications such as object recognition, playing computer games, controlling self-driving cars and language translation.
A research topic could involve discussing deep learning and its various applications.
Reinforcement learning (RL) as a Thesis Topic
Reinforcement learning is the closest form of learning to the way human beings learn. For instance, students learn from their mistakes and a process of trial-and-error.
There are many different ways to use AI in education to help students, such as using AI-powered tutors, customized learning and smart content.
RL works on a similar principle to learning from a process of trial-and-error. Google’s AlphaGo program beat the world champion of Go in 2017 by using RL.
Students who don’t yet have the skills to handle complex assignments can make use of various tools, writing apps and professional writers.
To find help with your student papers when you’re conducting research for a university, EduBirdie has free plagiarism checker and citations tools but professional writers who can take the pressure off you.
At U.K. EduBirdie , a professional thesis writer will finish your paper for you. It also offers editing and proofreading services at very reasonable prices.

Image source: Freepik.com
Natural language processing (NLP) as a Thesis Topic
This area of AI relates to how machines can learn to recognize and analyze human speech. Speech recognition, natural language translation and natural language generation are some of the areas of NLP.
With the help of NLP, systems can even read sentiment and predict which parts of the language are important. Revolutionary tools like IBM Watson, Google Translate, Speech Recognition and sentiment analysis show the importance of NLP in the daily lives of individuals.
NLP helps build intelligent systems, such as customer support applications like chatbots and AI in education is also a great example.
Chatbots use NLP and machine learning to interact with customers and solve their queries. Your research topic could relate to chatbots and their interaction with humans.
Computer vision (CV) as a Thesis Topic
Millions of images are uploaded daily on the internet. Computers are very good at certain tasks but they can struggle with simple tasks like being able to recognize and identify objects.
Computer vision is a field of AI that makes systems so smart that they can analyze and understand images. CV systems can even outperform humans now in some tasks like classifying visual objects.
One of the applications of computer vision is in autonomous vehicles that need to analyze images of surroundings in order to navigate.
A study topic could involve discussing computer vision and how using it allows smart systems to be built. Applications of computer vision could then be presented.
Recommender systems (RS) as a Thesis Topic
Recommender systems use algorithms to offer relevant suggestions to users. These may be suggestions on a TV show, a product, a service or even who to date.
You will receive many recommendations after you search for a particular product or browse a list of favorite movies. RS can base suggestions on your past behavior and past preferences, trends and the preferences of your peers.
A very relevant topic would be to explore the use of recommender systems in the field of e-commerce. Industry giants like Amazon are currently using recommender systems to help customers find the right products or services.
You could discuss their implementation and the type of results they bring to ecommerce businesses.
Robotics as a Thesis Topic
Robots can behave and perform the same actions as human beings, thanks to AI. They can act intelligently and even solve problems and learn in controlled environments.
For example, Kismet is a social interaction robot developed by MIT’s AI lab that can recognize human language and interact with humans.
Robots and AI are changing the way businesses work. Some people argue that this will have an adverse effect on humans as they are replaced by AI-powered machines.
A research topic could aim to understand to what extent businesses will be impacted by AI-powered machines and assess their future in different businesses.
There is an increase in the number of research papers being published in different areas of AI. If you’re a student wanting to come up with a topic involving artificial intelligence for your thesis, there are many vitally important sub-topics to choose from.
Each of these sub-topics provides plenty of opportunities for meaningful research into AI and new ideas on its application in the future as machines keep growing in intelligence.
About The Author

Paul Calderon
Paul Calderon is data security specialist working with a tech startup based in Silicon Valley. After work hours, he helps students studying for their computer science degrees or programming courses with essays, dissertations and term papers. When he isn’t doing any work, he likes playing tennis, cycling, and creating vlogs on local travel.
Leave a Reply Cancel Reply
This site uses Akismet to reduce spam. Learn how your comment data is processed .
.png "dissertation on artificial intelligence")
- Log in Try For Free
Write a Dissertation with AI
.png "dissertation on artificial intelligence")
Molin can help you with your dissertation in many ways from picking the topic, creating the outline, and writing entire sections.
How can I write a dissertation with AI?
Follow this step-by-step guide on how you can make your student life easier and use artificial intelligence to generate entire essays for your homework.
- Visit https://molin.ai
- From the Students category, pick the Dissertation Ideas template
- Enter your field of study (you can add your interests too for better results)
- Copy the chosen topic from the list of ideas (if you don't like any of them, simply generate again)
- Paste the topic into the Essay Outline template and generate. This will give you the entire outline of your dissertation.
- Finally, start copying the outline elements into the Entire Essay template one by one and create your essay from these pieces.
- That's it! You now have a plagiarism-free dissertation.
This is how you can get your AI dissertation in a few minutes with references in multiple languages.
Watch this video guide for more information:
@molin_ai Hogyan írj szakdolgozatot Molinnal? #foryou #fyp #nekedbe #magyartiktok #szakdolgozat #mesterségesintelligencia #egyetem #lifehack #essay ♬ Monkeys Spinning Monkeys - Kevin MacLeod & Kevin The Monkey

Sell more with AI today. For Free.
Sign up for Molin's free trial to access all of the AI tools and services you need to upscale your online store.
Related articles
.png "dissertation on artificial intelligence")
Molin is now available on UNAS!

Elevate Your Webshop Support Game with Molin's AI Chatbot
.png "dissertation on artificial intelligence")
Our Shopify plugin is launching today!

Automate your entire ecommerce business with Molin.
.png "dissertation on artificial intelligence")
IMAGES
VIDEO
COMMENTS
Part of the Artificial Intelligence and Robotics Commons This Dissertation is brought to you for free and open access by the Walden Dissertations and Doctoral Studies Collection at ScholarWorks. It has been accepted for inclusion in Walden Dissertations and Doctoral Studies by an authorized administrator of ScholarWorks.
Artificial intelligence (AI) is the process of building machines, robots, and software that are intelligent enough to act like humans. With artificial intelligence, the world will move into a future where machines will be as knowledgeable as humans, and they will be able to work and act as humans. When completely developed, AI-powered machines ...
Many universities provide full-text access to their dissertations via a digital repository. If you know the title of a particular dissertation or thesis, try doing a Google search. OATD (Open Access Theses and Dissertations) Aims to be the best possible resource for finding open access graduate theses and dissertations published around the world with metadata from over 800 colleges ...
PhD thesis. University of Cambridge, 2016. [54] M. O. Riedl. ... Artificial intelligence is the study and design of an intelligent agent that can mimic human behavior and cognitive functions, in ...
In this blog, we embark on a journey to delve into 12 Artificial Intelligence Topics that stand as promising avenues for thorough research and exploration. Table of Contents. 1) Top Artificial Intelligence Topics for Research. a) Natural Language Processing. b) Computer vision. c) Reinforcement Learning. d) Explainable AI (XAI)
Artificial intelligence (AI) is a branch of computer science that involves the use of machines to simulate human intelligence, such as learning and problem-solving. AI encompasses machine learning and natural language processing. Machine learning is a branch of AI that involves the use of machines to learn from new data to improve its
Aims and Scope. Artificial Intelligence (AI) is one of the fastest growing research areas in computer science with a strong impact on various fields of science, industry, and society. This series publishes excellent doctoral dissertations in all sub-fields of AI, ranging from foundational work on AI methods and theories to application-oriented ...
Towards Literate Artificial Intelligence Mrinmaya Sachan, 2019. Accelerating Text-as-Data Research in Computational Social Science Dallas Card, 2019. Learning Gene Networks Underlying Clinical Phenotypes Under SNP Perturbations From Genome-Wide Data Calvin McCarter, 2019. Unified Models for Dynamical Systems Carlton Downey, 2019
Artificial Intelligence (AI) is changing the world around us . As a term it is difficult to define even for experts because of its interdisciplinary nature and evolving capabilities. ... Doctoral dissertation, UCL University College London, London, (2020) Mohamed, H., Lamia, M.: Implementing flipped classroom that used an intelligent tutoring ...
With the continuous development of artificial intelligence (AI) and machine learning (ML), cloudbased AI and ML have been hot in recent years. ... This thesis starts with the overall development of AI and ML and introduces the history and status of cloud-based AI and ML development in technology companies. Then, by introducing official websites ...
This thesis contributes two approaches to create witnesses for unsolvable planning tasks. Inductive certificates are based on the idea of invariants. ... Classical Planning is a branch of artificial intelligence that studies single agent, static, deterministic, fully observable, discrete search problems. A common challenge in this field is the ...
Consult the top 50 dissertations / theses for your research on the topic 'Artificial intelligence.'. Next to every source in the list of references, there is an 'Add to bibliography' button. Press on it, and we will generate automatically the bibliographic reference to the chosen work in the citation style you need: APA, MLA, Harvard, Chicago ...
So without further ado, let's see the different Topics for Research and Thesis in Artificial Intelligence!. 1. Machine Learning. Machine Learning involves the use of Artificial Intelligence to enable machines to learn a task from experience without programming them specifically about that task. (In short, Machines learn automatically without human hand holding!!!)
Abstract. Today's youth are growing up in a world where artificial intelligence (AI) technologies shape how we live, work, play, socialize, and navigate our world. This rapid technological change is already significantly shifting individuals' lives and the opportunities they can obtain. Thus, researchers, educators, and government leaders must ...
Hybrid techniques of AI. AI chatbots (Siri, Alexa) Use of AI in logistics. Making of artificial intelligence. Clash of creative domains with AI. Using AI to solve complex problems. Here, you read about the 61 best artificial intelligence dissertation topics that will help you brainstorm the ideas for your paper.
The main aim of this thesis is to determine whether AI systems may be held liable for tort and contractual damages caused by their actions or even omissions. In the absence of direct legal regulation of AI, the thesis begins by recounting the history and definition of AI and examines current technological AI applications.
PhD dissertation: Artificial intelligence methods to support people management in organisations ... documentary and observational data for insights on the proliferation of artificial intelligence ...
Artificial Intelligence (AI) is the ability of a machine or computer system to adapt and improvise in new situations, usually demonstrating the ability to solve new problems. The term is also applied to machines that can perform tasks usually requiring human intelligence and thought. View All Dissertation Examples.
Artificial Intelligence (AI) is the concept that enables humans to perform their tasks more smartly and faster through automated systems. AI is human intelligence packed in machines. ... Get Thesis Help Today. These 163 custom artificial intelligence topics are carefully selected and written by dissertation writers to help you prepare a quality ...
Artificial Intelligence (AI) has been around for nearly a century, yet in recent years the rapid advancement and public access to AI applications and algorithms have led to increased attention to the role of AI in higher education. An equally important but overlooked topic is the study of AI teaching and learning in higher education. We wish to examine the overview of the study, pedagogical ...
Deep learning (DL) as a Thesis Topic. Deep Learning is a subset of ML where learning imitates the inner workings of the human brain. It uses artificial neural networks to process data and make decisions. The web-like networks take a non-linear approach to processing data which is superior to traditional algorithms that take a linear approach.
Molin can help you with your dissertation in many ways from picking the topic, creating the outline, and writing entire sections. How can I write a dissertation with AI? Follow this step-by-step guide on how you can make your student life easier and use artificial intelligence to generate entire essays for your homework. Steps:
May 10, 2024. Source: Cell Press. Summary: Many artificial intelligence (AI) systems have already learned how to deceive humans, even systems that have been trained to be helpful and honest ...
Artificial Intelligence, MBA The Open University has been accused of using a computer algorithm to mark ... In dozens of instances where dissertations were marked last year, the third marker had ...