- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research

Quantitative Data Collection: Best 5 methods

In contrast to qualitative data , quantitative data collection is everything about figures and numbers. Researchers often rely on quantitative data when they intend to quantify attributes, attitudes, behaviors, and other defined variables with a motive to either back or oppose the hypothesis of a specific phenomenon by contextualizing the data obtained via surveying or interviewing the study sample.
Content Index
What is Quantitative Data Collection?
Importance of quantitative data collection, probability sampling, surveys/questionnaires, observations, document review in quantitative data collection.
Quantitative data collection refers to the collection of numerical data that can be analyzed using statistical methods. This type of data collection is often used in surveys, experiments, and other research methods. It measure variables and establish relationships between variables. The data collected through quantitative methods is typically in the form of numbers, such as response frequencies, means, and standard deviations, and can be analyzed using statistical software.
LEARN ABOUT: Research Process Steps
As a researcher, you do have the option to opt either for data collection online or use traditional data collection methods via appropriate research. Quantitative data collection is important for several reasons:
- Objectivity: Quantitative data collection provides objective and verifiable information, as the data is collected in a systematic and standardized manner.
- Generalizability: The results from quantitative data collection can be generalized to a larger population, making it an effective way to study large groups of people.
- Precision: Numerical data allows for precise measurement and unit of analysis , providing more accurate results than other data collection forms.
- Hypothesis testing: Quantitative data collection allows for testing hypotheses and theories, leading to a better understanding of the relationships between variables.
- Comparison: Quantitative data collection allows for data comparison and analysis. It can be useful in making decisions and identifying trends or patterns.
- Replicability: The numerical nature of quantitative data makes it easier to replicate research results. It is essential for building knowledge in a particular field.
Quantitative data collection provides valuable information for understanding complex phenomena and making informed decisions based on empirical evidence.
LEARN ABOUT: Best Data Collection Tools
Methods used for Quantitative Data Collection
A data that can be counted or expressed in numerical’s constitute the quantitative data. It is commonly used to study the events or levels of concurrence. And is collected through a Structured Question & structured questionnaire asking questions starting with “how much” or “how many.” As the quantitative data is numerical, it represents both definitive and objective data. Furthermore, quantitative information is much sorted for statistical analysis and mathematical analysis, making it possible to illustrate it in the form of charts and graphs.
Discrete and continuous are the two major categories of quantitative data where discreet data have finite numbers and the constant data values falling on a continuum possessing the possibility to have fractions or decimals. If research is conducted to find out the number of vehicles owned by the American household, then we get a whole number, which is an excellent example of discrete data. When research is limited to the study of physical measurements of the population like height, weight, age, or distance, then the result is an excellent example of continuous data.
Any traditional or online data collection method that helps in gathering numerical data is a proven method of collecting quantitative data.
LEARN ABOUT: Survey Sampling

There are four significant types of probability sampling:
- Simple random sampling : More often, the targeted demographic is chosen for inclusion in the sample.
- Cluster sampling : Cluster sampling is a technique in which a population is divided into smaller groups or clusters, and a random sample of these clusters is selected. This method is used when it is impractical or expensive to obtain a random sample from the entire population .
- Systematic sampling : Any of the targeted demographic would be included in the sample, but only the first unit for inclusion in the sample is selected randomly, rest are selected in the ordered fashion as if one out of every ten people on the list .
- Stratified sampling : It allows selecting each unit from a particular group of the targeted audience while creating a sample. It is useful when the researchers are selective about including a specific set of people in the sample, i.e., only males or females, managers or executives, people working within a particular industry.
Interviewing people is a standard method used for data collection . However, the interviews conducted to collect quantitative data are more structured, wherein the researchers ask only a standard set of online questionnaires and nothing more than that.
There are three major types of interviews conducted for data collection
- Telephone interviews: For years, telephone interviews ruled the charts of data collection methods. Nowadays, there is a significant rise in conducting video interviews using the internet, Skype, or similar online video calling platforms.
- Face-to-face interviews: It is a proven technique to collect data directly from the participants. It helps in acquiring quality data as it provides a scope to ask detailed questions and probing further to collect rich and informative data. Literacy requirements of the participant are irrelevant as F2F surveys offer ample opportunities to collect non-verbal data through observation or to explore complex and unknown issues. Although it can be an expensive and time-consuming method, the response rates for F2F interviews are often higher.
- Computer-Assisted Personal Interviewing (CAPI): It is nothing but a similar setup of the face-to-face interview where the interviewer carries a desktop or laptop along with him at the time of interview to upload the data obtained from the interview directly into the database. CAPI saves a lot of time in updating and processing the data and also makes the entire process paperless as the interviewer does not carry a bunch of papers and questionnaires.

There are two significant types of survey questionnaires used to collect online data for quantitative market research.
- Web-based questionnaire : This is one of the ruling and most trusted methods for internet-based research or online research. In a web-based questionnaire, the receive an email containing the survey link, clicking on which takes the respondent to a secure online survey tool from where he/she can take the survey or fill in the survey questionnaire. Being a cost-efficient, quicker, and having a wider reach, web-based surveys are more preferred by the researchers. The primary benefit of a web-based questionnaire is flexibility. Respondents are free to take the survey in their free time using either a desktop, laptop, tablet, or mobile.
- Mail Questionnaire : In a mail questionnaire, the survey is mailed out to a host of the sample population, enabling the researcher to connect with a wide range of audiences. The mail questionnaire typically consists of a packet containing a cover sheet that introduces the audience about the type of research and reason why it is being conducted along with a prepaid return to collect data online. Although the mail questionnaire has a higher churn rate compared to other quantitative data collection methods, adding certain perks such as reminders and incentives to complete the survey help in drastically improving the churn rate. One of the major benefits of the mail questionnaire is all the responses are anonymous, and respondents are allowed to take as much time as they want to complete the survey and be completely honest about the answer without the fear of prejudice.
LEARN ABOUT: Steps in Qualitative Research
As the name suggests, it is a pretty simple and straightforward method of collecting quantitative data. In this method, researchers collect quantitative data through systematic observations by using techniques like counting the number of people present at the specific event at a particular time and a particular venue or number of people attending the event in a designated place. More often, for quantitative data collection, the researchers have a naturalistic observation approach. It needs keen observation skills and senses for getting the numerical data about the “what” and not about “why” and ”how.”
Naturalistic observation is used to collect both types of data; qualitative and quantitative. However, structured observation is more used to collect quantitative rather than qualitative data collection .
- Structured observation: In this type of observation method, the researcher has to make careful observations of one or more specific behaviors in a more comprehensive or structured setting compared to naturalistic or participant observation . In a structured observation, the researchers, rather than observing everything, focus only on very specific behaviors of interest. It allows them to quantify the behaviors they are observing. When the qualitative observations require a judgment on the part of the observers – it is often described as coding, which requires a clearly defining a set of target behaviors.
Document review is a process used to collect data after reviewing the existing documents. It is an efficient and effective way of gathering data as documents are manageable. Those are the practical resource to get qualified data from the past. Apart from strengthening and supporting the research by providing supplementary research data document review has emerged as one of the beneficial methods to gather quantitative research data.
Three primary document types are being analyzed for collecting supporting quantitative research data.
- Public Records: Under this document review, official, ongoing records of an organization are analyzed for further research. For example, annual reports policy manuals, student activities, game activities in the university, etc.
- Personal Documents: In contrast to public documents, this type of document review deals with individual personal accounts of individuals’ actions, behavior, health, physique, etc. For example, the height and weight of the students, distance students are traveling to attend the school, etc.
- Physical Evidence: Physical evidence or physical documents deal with previous achievements of an individual or of an organization in terms of monetary and scalable growth.
LEARN ABOUT: 12 Best Tools for Researchers
Quantitative data is not about convergent reasoning, but it is about divergent thinking. It deals with the numerical, logic, and an objective stance, by focusing on numeric and unchanging data. More often, data collection methods are used to collect quantitative research data, and the results are dependent on the larger sample sizes that are commonly representing the population researcher intend to study.
Although there are many other methods to collect quantitative data. Those mentioned above probability sampling, interviews, questionnaire observation, and document review are the most common and widely used methods for data collection.
With QuestionPro, you can precise results, and data analysis . QuestionPro provides the opportunity to collect data from a large number of participants. It increases the representativeness of the sample and providing more accurate results.
FREE TRIAL LEARN MORE
MORE LIKE THIS

Top 20 Employee Engagement Software Solutions
May 3, 2024

15 Best Customer Experience Software of 2024
May 2, 2024

Journey Orchestration Platforms: Top 11 Platforms in 2024

Top 12 Employee Pulse Survey Tools Unlocking Insights in 2024
May 1, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
- A/B Monadic Test
- A/B Pre-Roll Test
- Key Driver Analysis
- Multiple Implicit
- Penalty Reward
- Price Sensitivity
- Segmentation
- Single Implicit
- Category Exploration
- Competitive Landscape
- Consumer Segmentation
- Innovation & Renovation
- Product Portfolio
- Marketing Creatives
- Advertising
- Shelf Optimization
- Performance Monitoring
- Better Brand Health Tracking
- Ad Tracking
- Trend Tracking
- Satisfaction Tracking
- AI Insights
- Case Studies
quantilope is the Consumer Intelligence Platform for all end-to-end research needs
5 Methods of Data Collection for Quantitative Research

In this blog, read up on five different data collection techniques for quantitative research studies.
Quantitative research forms the basis for many business decisions. But what is quantitative data collection, why is it important, and which data collection methods are used in quantitative research?
Table of Contents:
- What is quantitative data collection?
- The importance of quantitative data collection
- Methods used for quantitative data collection
- Example of a survey showing quantitative data
- Strengths and weaknesses of quantitative data
What is quantitative data collection?
Quantitative data collection is the gathering of numeric data that puts consumer insights into a quantifiable context. It typically involves a large number of respondents - large enough to extract statistically reliable findings that can be extrapolated to a larger population.
The actual data collection process for quantitative findings is typically done using a quantitative online questionnaire that asks respondents yes/no questions, ranking scales, rating matrices, and other quantitative question types. With these results, researchers can generate data charts to summarize the quantitative findings and generate easily digestible key takeaways.
Back to Table of Contents
The importance of quantitative data collection
Quantitative data collection can confirm or deny a brand's hypothesis, guide product development, tailor marketing materials, and much more. It provides brands with reliable information to make decisions off of (i.e. 86% like lemon-lime flavor or just 12% are interested in a cinnamon-scented hand soap).
Compared to qualitative data collection, quantitative data allows for comparison between insights given higher base sizes which leads to the ability to have statistical significance. Brands can cut and analyze their dataset in a variety of ways, looking at their findings among different demographic groups, behavioral groups, and other ways of interest. It's also generally easier and quicker to collect quantitative data than it is to gather qualitative feedback, making it an important data collection tool for brands that need quick, reliable, concrete insights.
In order to make justified business decisions from quantitative data, brands need to recruit a high-quality sample that's reflective of their true target market (one that's comprised of all ages/genders rather than an isolated group). For example, a study into usage and attitudes around orange juice might include consumers who buy and/or drink orange juice at a certain frequency or who buy a variety of orange juice brands from different outlets.
Methods used for quantitative data collection
So knowing what quantitative data collection is and why it's important , how does one go about researching a large, high-quality, representative sample ?
Below are five examples of how to conduct your study through various data collection methods :
Online quantitative surveys
Online surveys are a common and effective way of collecting data from a large number of people. They tend to be made up of closed-ended questions so that responses across the sample are comparable; however, a small number of open-ended questions can be included as well (i.e. questions that require a written response rather than a selection of answers in a close-ended list). Open-ended questions are helpful to gather actual language used by respondents on a certain issue or to collect feedback on a view that might not be shown in a set list of responses).
Online surveys are quick and easy to send out, typically done so through survey panels. They can also appear in pop-ups on websites or via a link embedded in social media. From the participant’s point of view, online surveys are convenient to complete and submit, using whichever device they prefer (mobile phone, tablet, or computer). Anonymity is also viewed as a positive: online survey software ensures respondents’ identities are kept completely confidential.
To gather respondents for online surveys, researchers have several options. Probability sampling is one route, where respondents are selected using a random selection method. As such, everyone within the population has an equal chance of getting selected to participate.
There are four common types of probability sampling .
- Simple random sampling is the most straightforward approach, which involves randomly selecting individuals from the population without any specific criteria or grouping.
- Stratified random sampling divides the population into subgroups (strata) and selects a random sample from each stratum. This is useful when a population includes subgroups that you want to be sure you cover in your research.
- Cluster sampling divides the population into clusters and then randomly selects some of the clusters to sample in their entirety. This is useful when a population is geographically dispersed and it would be impossible to include everyone.
- Systematic sampling begins with a random starting point and then selects every nth member of the population after that point (i.e. every 15th respondent).
Learn how to leverage AI to help generate your online quantitative survey inputs:

While online surveys are by far the most common way to collect quantitative data in today’s modern age, there are still some harder-to-reach respondents where other mediums can be beneficial; for example, those who aren’t tech-savvy or who don’t have a stable internet connection. For these audiences, offline surveys may be needed.
Offline quantitative surveys
Offline surveys (though much rarer to come across these days) are a way of gathering respondent feedback without digital means. This could be something like postal questionnaires that are sent out to a sample population and asked to return the questionnaire by mail (like the Census) or telephone surveys where questions are asked of respondents over the phone.
Offline surveys certainly take longer to collect data than online surveys and they can become expensive if the population is difficult to reach (requiring a higher incentive). As with online surveys, anonymity is protected, assuming the mail is not intercepted or lost.
Despite the major difference in data collection to an online survey approach, offline survey data is still reported on in an aggregated, numeric fashion.
In-person interviews are another popular way of researching or polling a population. They can be thought of as a survey but in a verbal, in-person, or virtual face-to-face format. The online format of interviews is becoming more popular nowadays, as it is cheaper and logistically easier to organize than in-person face-to-face interviews, yet still allows the interviewer to see and hear from the respondent in their own words.
Though many interviews are collected for qualitative research, interviews can also be leveraged quantitatively; like a phone survey, an interviewer runs through a survey with the respondent, asking mainly closed-ended questions (yes/no, multiple choice questions, or questions with rating scales that ask how strongly the respondent agrees with statements). The advantage of structured interviews is that the interviewer can pace the survey, making sure the respondent gives enough consideration to each question. It also adds a human touch, which can be more engaging for some respondents. On the other hand, for more sensitive issues, respondents may feel more inclined to complete a survey online for a greater sense of anonymity - so it all depends on your research questions, the survey topic, and the audience you're researching.
Observations
Observation studies in quantitative research are similar in nature to a qualitative ethnographic study (in which a researcher also observes consumers in their natural habitats), yet observation studies for quant research remain focused on the numbers - how many people do an action, how much of a product consumer pick up, etc.
For quantitative observations, researchers will record the number and types of people who do a certain action - such as choosing a specific product from a grocery shelf, speaking to a company representative at an event, or how many people pass through a certain area within a given timeframe. Observation studies are generally structured, with the observer asked to note behavior using set parameters. Structured observation means that the observer has to hone in on very specific behaviors, which can be quite nuanced. This requires the observer to use his/her own judgment about what type of behavior is being exhibited (e.g. reading labels on products before selecting them; considering different items before making the final choice; making a selection based on price).
Document reviews and secondary data sources
A fifth method of data collection for quantitative research is known as secondary research : reviewing existing research to see how it can contribute to understanding a new issue in question. This is in contrast to the primary research methods above, which is research that is specially commissioned and carried out for a research project.
There are numerous secondary data sources that researchers can analyze such as public records, government research, company databases, existing reports, paid-for research publications, magazines, journals, case studies, websites, books, and more.
Aside from using secondary research alone, secondary research documents can also be used in anticipation of primary research, to understand which knowledge gaps need to be filled and to nail down the issues that might be important to explore further in a primary research study. Back to Table of Contents
Example of a survey showing quantitative data
The below study shows what quantitative data might look like in a final study dashboard, taken from quantilope's Sneaker category insights study .
The study includes a variety of usage and attitude metrics around sneaker wear, sneaker purchases, seasonality of sneakers, and more. Check out some of the data charts below showing these quantitative data findings - the first of which even cuts the quantitative data findings by demographics.

Beyond these basic usage and attitude (or, descriptive) data metrics, quantitative data also includes advanced methods - such as implicit association testing. See what these quantitative data charts look like from the same sneaker study below:

These are just a few examples of how a researcher or insights team might show their quantitative data findings. However, there are many ways to visualize quantitative data in an insights study, from bar charts, column charts, pie charts, donut charts, spider charts, and more, depending on what best suits the story your data is telling. Back to Table of Contents
Strengths and weaknesses of quantitative data collection
quantitative data is a great way to capture informative insights about your brand, product, category, or competitors. It's relatively quick, depending on your sample audience, and more affordable than other data collection methods such as qualitative focus groups. With quantitative panels, it's easy to access nearly any audience you might need - from something as general as the US population to something as specific as cannabis users . There are many ways to visualize quantitative findings, making it a customizable form of insights - whether you want to show the data in a bar chart, pie chart, etc.
For those looking for quick, affordable, actionable insights, quantitative studies are the way to go.
quantitative data collection, despite the many benefits outlined above, might also not be the right fit for your exact needs. For example, you often don't get as detailed and in-depth answers quantitatively as you would with an in-person interview, focus group, or ethnographic observation (all forms of qualitative research). When running a quantitative survey, it’s best practice to review your data for quality measures to ensure all respondents are ones you want to keep in your data set. Fortunately, there are a lot of precautions research providers can take to navigate these obstacles - such as automated data cleaners and data flags. Of course, the first step to ensuring high-quality results is to use a trusted panel provider. Back to Table of Contents
Quantitative research typically needs to undergo statistical analysis for it to be useful and actionable to any business. It is therefore crucial that the method of data collection, sample size, and sample criteria are considered in light of the research questions asked.
quantilope’s online platform is ideal for quantitative research studies. The online format means a large sample can be reached easily and quickly through connected respondent panels that effectively reach the desired target audience. Response rates are high, as respondents can take their survey from anywhere, using any device with internet access.
Surveys are easy to build with quantilope’s online survey builder. Simply choose questions to include from pre-designed survey templates or build your own questions using the platform’s drag & drop functionality (of which both options are fully customizable). Once the survey is live, findings update in real-time so that brands can get an idea of consumer attitudes long before the survey is complete. In addition to basic usage and attitude questions, quantilope’s suite of advanced research methodologies provides an AI-driven approach to many types of research questions. These range from exploring the features of products that drive purchase through a Key Driver Analysis , compiling the ideal portfolio of products using a TURF , or identifying the optimal price point for a product or service using a Price Sensitivity Meter (PSM) .
Depending on the type of data sought it might be worth considering a mixed-method approach, including both qual and quant in a single research study. Alongside quantitative online surveys, quantilope’s video research solution - inColor , offers qualitative research in the form of videoed responses to survey questions. inColor’s qualitative data analysis includes an AI-drive read on respondent sentiment, keyword trends, and facial expressions.
To find out more about how quantilope can help with any aspect of your research design and to start conducting high-quality, quantitative research, get in touch below:
Get in touch to learn more about quantitative research studies!
Related posts, non-probability sampling: when and how to use it effectively, survey results: how to analyze data and report on findings, how florida's natural leveraged better brand health tracking, quirk's virtual event: fab-brew-lous collaboration: product innovations from the melitta group.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
3.3 Methods of Quantitative Data Collection
Data collection is the process of gathering information for research purposes. Data collection methods in quantitative research refer to the techniques or tools used to collect data from participants or units in a study. Data are the most important asset for any researcher because they provide the researcher with the knowledge necessary to confirm or refute their research hypothesis. 2 The choice of data collection method will depend on the research question, the study design, the type of data to be collected, and the available resources. There are two main types of data which are primary data and secondary data. 34 These data types and their examples are discussed below.
Data Sources
Secondary data
Secondary data is data that is already in existence and was collected for other purposes and not for the sole purpose of a researcher’s project. 34 These pre-existing data include data from surveys, administrative records, medical records, or other sources (databases, internet). Examples of these data sources include census data, vital registration (birth and death), registries of notifiable diseases, hospital data and health-related data such as the national health survey data and national drug strategy household survey. 2 While secondary data are population-based, quicker to access, and cheaper to collect than primary data, there are some drawbacks to this data source. Potential disadvantages include accuracy of the data, completeness, and appropriateness of the data, given that the data was collected for an alternative purpose. 2
Primary data
Primary data is collected directly from the study participants and used expressly for research purposes. 34 The data collected is specifically targeted at the research question, hypothesis and aims. Examples of primary data include observations and surveys (questionnaires). 34
- Observations: In quantitative research, observations entail systematically watching and recording the events or behaviours of interest. Observations can be used to collect information on variables that may be difficult to quantify through self-reported methods. Observations, for example, can be used to obtain clinical measurements involving the use of standardised instruments or tools to measure physical, cognitive, or other variables of interest. Other examples include experimental or laboratory studies that necessitate the collection of physiological data such as blood pressure, heart rate, urine, e.t.c. 2
- Surveys: While observations are useful data collection methods, surveys are more commonly used data collection methods in healthcare research. 2, 34 Surveys or questionnaires are designed to seek specific information such as knowledge, beliefs, attitudes and behaviour from respondents. 2, 34 Surveys can be employed as a single research tool (as in a cross-sectional survey) or as part of clinical trials or epidemiological studies. 2, 34 They can be administered face-to-face, via telephone, paper-based, computer-based or a combination of the different methods. 2 Figure 3.7 outlines some advantages and disadvantages of questionnaires/surveys.
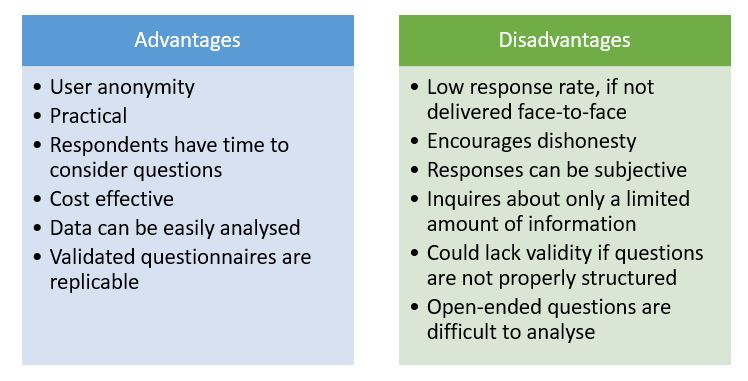
Designing a survey/questionnaire
A questionnaire is a research tool that consists of questions that are designed to collect information and generate statistical data from a specified group of people (target population). There are two main considerations in relation to design principles, and these are (1) content and (2) layout and sequence. 36 In terms of content, it is important to review the literature for related validated survey tools, as this saves time and allows for the comparison of results. Additionally, researchers need to minimise complexity by using simple direct language, including only relevant and accurate questions, with no jargon. 36 Concerning layout and sequence, there should be a logical flow of questions from general and easier to more sensitive ones, and the questionnaire should be as short as possible and NOT overcrowded. 36 The following steps can be used to develop a survey/ questionnaire.
Question Formats
Open and closed-ended questions are the two main types of question formats. 2 Open-ended questions allow respondents to express their thoughts without being constrained by the available options. 2, 38 Open-ended questions are chosen if the options are many and the range of answers is unknown. 38
On the other hand, closed-ended questions provide respondents with alternatives and require that they select one or more options from a list. 38 The question type is favoured if the choices are few and the range of responses is well-known. 38 However, other question formats may be used when assessing things on a continuum, like attitudes and behaviour. These variables can be considered using rating scales like visual analogue scales, adjectival scales and Likert scales. 2 Figure 3.8 presents a visual representation of some question types, including open-ended, closed-ended, likert rating scales, symbols, and visual Analogue Scales.
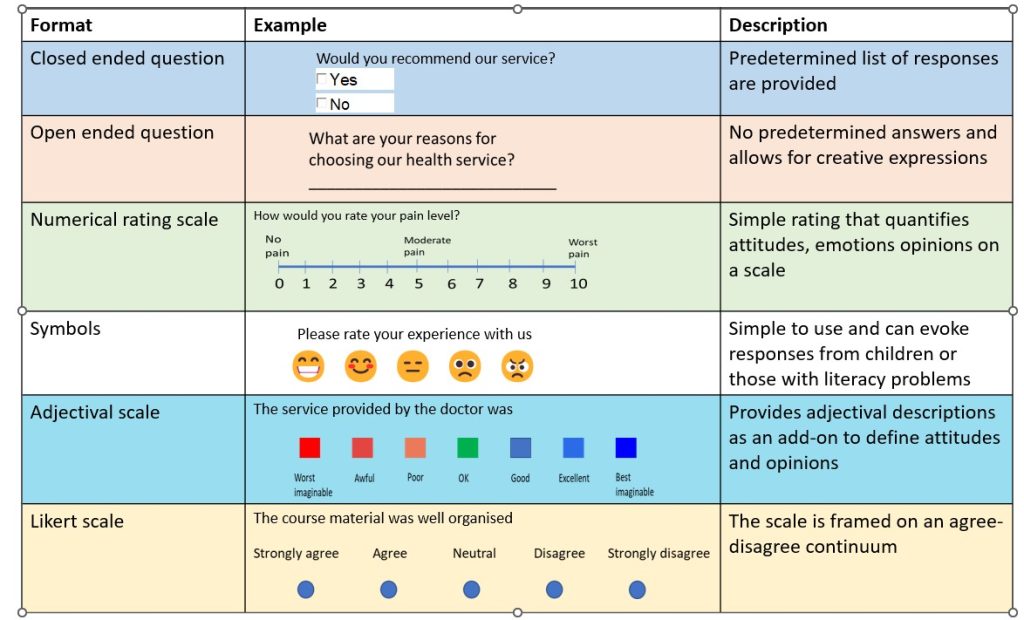
It is important to carefully craft survey questions to ensure that they are clear, unbiased and accurately capture the information researchers seek to gather. Clearly written questions with consistency in wording increase the likelihood of obtaining accurate and reliable data. Poorly crafted questions, on the other hand, may sway respondents to answer in a particular way which can undermine the validity of the survey. The following are some general guidelines for question wording. 39
Be concise and clear: Ask succinct and precise questions, and do not use ambiguous and vague words. For example, do not ask a patient, “ how was your clinic experience ? What do you mean by clinic experience? Are you referring to their interactions with the nurses, doctors or physiotherapists?
Instead, consider using a better-phrased question such as “ please rate your experience with the doctor during your visit today ”.
Avoid double-barrelled questions. Some questions may have dual questions, for example: Do you think you should eat less and exercise more?
Instead, ask:
- Do you think you should eat less?
- Do you think you should exercise more?
Steer clear of questions that involve negatives: Negatively worded questions can be confusing. For example, I find it difficult to fall asleep unless I take sleeping pills .
A better phrase is, “sleeping pills make it easy for me to fall asleep.”
Ask for specific answers. It is better to ask for more precise information. For example, “what is your age in years?________ Is preferable to -Which age category do you belong to?
☐ <18 years
☐ 18 – 25 years
☐ 25 – 35 years
☐ > 35 years
The options above will give more room for errors because the options are not mutually exclusive (there are overlaps) and not exhaustive (there are older age groups above 35 years).
Avoid leading questions. Leading questions reduces objectivity and make respondents answer in a particular way. Questions related to values and beliefs should be neutrally phrased. For example, the question below is worded in a leading way – Conducting research is challenging. Does research training help to prepare you for your research project?
An appropriate alternative: Research training prepares me for my research project.
Strongly agree Agree Disagree Strongly disagree
An Introduction to Research Methods for Undergraduate Health Profession Students Copyright © 2023 by Faith Alele and Bunmi Malau-Aduli is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Quantitative Methods
- Living reference work entry
- First Online: 11 June 2021
- Cite this living reference work entry

- Juwel Rana 2 , 3 , 4 ,
- Patricia Luna Gutierrez 5 &
- John C. Oldroyd 6
369 Accesses
1 Citations
Quantitative analysis ; Quantitative research methods ; Study design
Quantitative method is the collection and analysis of numerical data to answer scientific research questions. Quantitative method is used to summarize, average, find patterns, make predictions, and test causal associations as well as generalizing results to wider populations. It allows us to quantify effect sizes, determine the strength of associations, rank priorities, and weigh the strength of evidence of effectiveness.
Introduction
This entry aims to introduce the most common ways to use numbers and statistics to describe variables, establish relationships among variables, and build numerical understanding of a topic. In general, the quantitative research process uses a deductive approach (Neuman 2014 ; Leavy 2017 ), extrapolating from a particular case to the general situation (Babones 2016 ).
In practical ways, quantitative methods are an approach to studying a research topic. In research, the...
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Institutional subscriptions
Babones S (2016) Interpretive quantitative methods for the social sciences. Sociology. https://doi.org/10.1177/0038038515583637
Balnaves M, Caputi P (2001) Introduction to quantitative research methods: an investigative approach. Sage, London
Book Google Scholar
Brenner PS (2020) Understanding survey methodology: sociological theory and applications. Springer, Boston
Google Scholar
Creswell JW (2014) Research design: qualitative, quantitative, and mixed methods approaches. Sage, London
Leavy P (2017) Research design. The Gilford Press, New York
Mertens W, Pugliese A, Recker J (2018) Quantitative data analysis, research methods: information, systems, and contexts: second edition. https://doi.org/10.1016/B978-0-08-102220-7.00018-2
Neuman LW (2014) Social research methods: qualitative and quantitative approaches. Pearson Education Limited, Edinburgh
Treiman DJ (2009) Quantitative data analysis: doing social research to test ideas. Jossey-Bass, San Francisco
Download references
Author information
Authors and affiliations.
Department of Public Health, School of Health and Life Sciences, North South University, Dhaka, Bangladesh
Department of Biostatistics and Epidemiology, School of Health and Health Sciences, University of Massachusetts Amherst, MA, USA
Department of Research and Innovation, South Asia Institute for Social Transformation (SAIST), Dhaka, Bangladesh
Independent Researcher, Masatepe, Nicaragua
Patricia Luna Gutierrez
School of Behavioral and Health Sciences, Australian Catholic University, Fitzroy, VIC, Australia
John C. Oldroyd
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Juwel Rana .
Editor information
Editors and affiliations.
Florida Atlantic University, Boca Raton, FL, USA
Ali Farazmand
Rights and permissions
Reprints and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this entry
Cite this entry.
Rana, J., Gutierrez, P.L., Oldroyd, J.C. (2021). Quantitative Methods. In: Farazmand, A. (eds) Global Encyclopedia of Public Administration, Public Policy, and Governance. Springer, Cham. https://doi.org/10.1007/978-3-319-31816-5_460-1
Download citation
DOI : https://doi.org/10.1007/978-3-319-31816-5_460-1
Received : 31 January 2021
Accepted : 14 February 2021
Published : 11 June 2021
Publisher Name : Springer, Cham
Print ISBN : 978-3-319-31816-5
Online ISBN : 978-3-319-31816-5
eBook Packages : Springer Reference Economics and Finance Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
- Publish with us
Policies and ethics
- Find a journal
- Track your research

Quantitative Data Collection Methods
Quantitative research methods describe and measure the level of occurrences on the basis of numbers and calculations. Moreover, the questions of “how many?” and “how often?” are often asked in quantitative studies. Accordingly, quantitative data collection methods are based on numbers and mathematical calculations.
Quantitative research can be described as ‘entailing the collection of numerical data and exhibiting the view of relationship between theory and research as deductive, a predilection for natural science approach, and as having an objectivist conception of social reality’ [1] . In other words, quantitative studies mainly examine relationships between numerically measured variables with the application of statistical techniques.
Quantitative data collection methods are based on random sampling and structured data collection instruments. Findings of quantitative studies are usually easy to present, summarize, compare and generalize.
Qualitative studies , on the contrary, are usually based on non-random sampling methods and use non-quantifiable data such as words, feelings, emotions ect. Table below illustrates the main differences between qualitative and quantitative data collection and research methods:
Main differences between quantitative and qualitative methods
The most popular quantitative data collection methods include the following:
- Face-to-face interviews;
- Telephone interviews;
- Computer-Assisted Personal Interviewing (CAPI).
- Internet-based questionnaire;
- Mail questionnaire;
- Face-to-face survey.
- Observations . The type of observation that can be used to collect quantitative data is systematic, where the researcher counts the number of occurrences of phenomenon.
My e-book, The Ultimate Guide to Writing a Dissertation in Business Studies: a step by step approach contains a detailed, yet simple explanation of quantitative methods. The e-book explains all stages of the research process starting from the selection of the research area to writing personal reflection. Important elements of dissertations such as research philosophy, research approach, research design, methods of data collection and data analysis are explained in simple words. John Dudovskiy

[1] Bryman, A. & Bell, E. (2015) “Business Research Methods” 4 th edition, p.160
Popular searches
- How to Get Participants For Your Study
- How to Do Segmentation?
- Conjoint Preference Share Simulator
- MaxDiff Analysis
- Likert Scales
- Reliability & Validity
Request consultation
Do you need support in running a pricing or product study? We can help you with agile consumer research and conjoint analysis.
Looking for an online survey platform?
Conjointly offers a great survey tool with multiple question types, randomisation blocks, and multilingual support. The Basic tier is always free.
Catherine Chipeta
Fully-functional online survey tool with various question types, logic, randomisation, and reporting for unlimited number of surveys.
Monthly newsletter
Get the latest updates about market research, automated tools, product testing and pricing techniques.
We explore quantitative data collection methods’ best use, and the pros and cons of each to help you decide which method to use for your next quantitative study.
Survey Tool
There are many ways to categorise research methods, with most falling into the fields of either qualitative or quantitative.
Qualitative research uses non-measurable sources of data and relies mostly on observation techniques to gain insights. It is mostly used to answer questions beginning with “why?” and how?”. Examples of qualitative data collection methods include focus groups, observation, written records, and individual interviews.
Quantitative research presents data in a numerical format, enabling researchers to evaluate and understand this data through statistical analysis . It answers questions such as “who?”, “when?” “what?”, and “where?”. Common examples include interviews , surveys , and case studies/document review. Generally, quantitative data tells us what respondents’ choices are and qualitative tells us why they made those choices.
Once you have determined which type of research you wish to undertake, it is time to select a data collection method. Whilst quantitative and qualitative collection methods often overlap, this article focuses on quantitative data collection methods.
The Nature of Quantitative Observation
As quantitative observation uses numerical measurement , its results are more accurate than qualitative observation methods, which cannot be measured.
To ensure accuracy and consistency, an appropriate sample size needs to be determined for quantitative research. A sample should include enough respondents to make general observations that are most reflective of the whole population.
The more credible the sample size, the more meaningful the insights that the market researcher can draw during the analysis process.
Quantitative surveys are a data collection tool used to gather close-ended responses from individuals and groups. Question types primarily include categorical (e.g. “yes/no”) and interval/ratio questions (e.g. rating-scale, Likert-scale ). They are used to gather information such based upon the behaviours, characteristics, or opinions , and demographic information such as gender, income, occupation.
Surveys are traditionally completed on pen-and-paper but these days are commonly found online , which is a more convenient method.
When to use
Surveys are an ideal choice when you want simple, Quick Feedback which easily translates into statistics for analysis. For example, “60% of respondents think price is the most important factor when making buying decisions”.
- Speedy collection: User-friendly, optimal length surveys are quick to complete and online responses are available instantly.
- Wide reach: Online survey invites can be sent out to hundreds of potential respondents at a time.
- Targeted respondents: Using online panels allows you to target the right respondents for your study based on demographics and other profiling information.
Disadvantages
- Less detail: Surveys often collect less detailed responses than other forms of collection due to the limited options available for respondents to choose.
- Design reliant: If survey design is not effective, the quality of responses will be diminished.
- Potential bias: If respondents feel compelled to answer a question in a particular way due to social or other reasons, this lowers the accuracy of results.
Quantitative interviews are like surveys in that they use a question-and-answer format. The major difference between the two methods is the recording process.
In interviews, respondents are read each question and answer option to them by an interviewer who records responses, whereas in surveys, the respondent reads each question and answers themselves, recording their own response.
For quantitative interviews to be effective, each question and answer must be asked the same way to each respondent, with little to no input from the interviewer.
Quantitative interviews work well when the market researcher is conducting fieldwork to scope potential respondents. For example, approaching buyers of a certain product at a supermarket.
- Higher responsiveness: Potential respondents are more likely to say ‘yes’ to a market researcher in-person than in other ways, e.g. a phone call.
- Clearer understanding: Interviews allow respondents to seek classification from the interviewer if they are confused by a question.
- Less downtime: The market researcher can collect data as soon as the interview is conducted, rather than wait to hear back from the respondent first.
- Interviewer effect: Having an interviewer present questions to the respondent poses the risk of influencing the way in which the respondent answers.
- Time consuming: Interviews usually take longer to complete than other methods, such as surveys.
- Less control: Interviews present more variables, such as tone and pace, which could affect data quality.
Secondary Data Collection Methods
Published case studies and online sources are forms of secondary data, that is, data which has already been prepared and compiled for analysis.
Case studies are descriptive or explanatory publications which detail specific individuals, groups, or events. Whilst case studies are conducted using qualitative methods such as direct observation and unstructured interviewing, researchers can gather statistical data published in these sources to gain quantitative insights.
Other forms of secondary data include journals, books, magazines, and government publications.
Secondary data collection methods are most appropriately used when the market researcher is exploring a topic which already has extensive information and data available and is looking for supplementary insights for guidance.
For example, a study on caffeine consumption habits could draw statistics from existing medical case studies.
- Easier collection: As secondary data is readily available, it is relatively easy to collect for further analysis.
- More credibility: If collected from reputable sources, secondary data can be trusted as accurate and of quality.
- Less expensive: Collecting secondary data often costs a lot less than if the same data were collected primarily.
- Differing context: Secondary data collected will not necessarily align with the market researcher’s research questions or objectives.
- Limited availability: The amount and detail of secondary data available for a particular research topic is varied and not dependable.
- Less control: As secondary data is originally collected externally, there is no control over the quality of available data on a topic.
Quantitative research produces the most accurate and meaningful insights for analysis.
Surveys are a common form of quantitative data collection and can be created and completed online, making them a convenient and accessible choice. However, they must be well-designed and executed to ensure accurate results.
Interviews are an ideal choice for in-person data collection and can improve respondents’ understanding of questions. Time and potential interview bias are drawbacks to this method.
Collecting secondary data is a relatively quick and inexpensive way of gathering supplementary insights for research but there is limited control over context, availability, and quality of the data.
Find the right respondents for your survey
We use quality panel providers to source respondents that suit your specific research needs.
Read these articles next:
How to use the clustering demo.
Easily segment your audience using preference data and other survey answers with the Clustering Demo.
How to perform smart sampling and data checking?
With 5,000+ projects performed on the platform, Conjointly market research experts have compiled common concerns regarding sampling and data checking and provide their suggestions.
How to improve your research with time series analysis
Time series analysis is a powerful tool for analysing data collected throughout an extended period. Here is how you can use it to understand changes in consumer and market trends, and make data-driven decisions.
Which one are you?
I am new to conjointly, i am already using conjointly, cookie consent.
Conjointly uses essential cookies to make our site work. We also use additional cookies in order to understand the usage of the site, gather audience analytics, and for remarketing purposes.
For more information on Conjointly's use of cookies, please read our Cookie Policy .
Do you want to be updated on new features from Conjointly?
We send an occasional email to keep our users informed about new developments on Conjointly : new types of analysis and features for quality insight.
Subscribe to updates from Conjointly
You can always unsubscribe later. Your email will not be shared with other companies.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Data Collection Methods | Step-by-Step Guide & Examples
Data Collection Methods | Step-by-Step Guide & Examples
Published on 4 May 2022 by Pritha Bhandari .
Data collection is a systematic process of gathering observations or measurements. Whether you are performing research for business, governmental, or academic purposes, data collection allows you to gain first-hand knowledge and original insights into your research problem .
While methods and aims may differ between fields, the overall process of data collection remains largely the same. Before you begin collecting data, you need to consider:
- The aim of the research
- The type of data that you will collect
- The methods and procedures you will use to collect, store, and process the data
To collect high-quality data that is relevant to your purposes, follow these four steps.
Table of contents
Step 1: define the aim of your research, step 2: choose your data collection method, step 3: plan your data collection procedures, step 4: collect the data, frequently asked questions about data collection.
Before you start the process of data collection, you need to identify exactly what you want to achieve. You can start by writing a problem statement : what is the practical or scientific issue that you want to address, and why does it matter?
Next, formulate one or more research questions that precisely define what you want to find out. Depending on your research questions, you might need to collect quantitative or qualitative data :
- Quantitative data is expressed in numbers and graphs and is analysed through statistical methods .
- Qualitative data is expressed in words and analysed through interpretations and categorisations.
If your aim is to test a hypothesis , measure something precisely, or gain large-scale statistical insights, collect quantitative data. If your aim is to explore ideas, understand experiences, or gain detailed insights into a specific context, collect qualitative data.
If you have several aims, you can use a mixed methods approach that collects both types of data.
- Your first aim is to assess whether there are significant differences in perceptions of managers across different departments and office locations.
- Your second aim is to gather meaningful feedback from employees to explore new ideas for how managers can improve.
Prevent plagiarism, run a free check.
Based on the data you want to collect, decide which method is best suited for your research.
- Experimental research is primarily a quantitative method.
- Interviews , focus groups , and ethnographies are qualitative methods.
- Surveys , observations, archival research, and secondary data collection can be quantitative or qualitative methods.
Carefully consider what method you will use to gather data that helps you directly answer your research questions.
When you know which method(s) you are using, you need to plan exactly how you will implement them. What procedures will you follow to make accurate observations or measurements of the variables you are interested in?
For instance, if you’re conducting surveys or interviews, decide what form the questions will take; if you’re conducting an experiment, make decisions about your experimental design .
Operationalisation
Sometimes your variables can be measured directly: for example, you can collect data on the average age of employees simply by asking for dates of birth. However, often you’ll be interested in collecting data on more abstract concepts or variables that can’t be directly observed.
Operationalisation means turning abstract conceptual ideas into measurable observations. When planning how you will collect data, you need to translate the conceptual definition of what you want to study into the operational definition of what you will actually measure.
- You ask managers to rate their own leadership skills on 5-point scales assessing the ability to delegate, decisiveness, and dependability.
- You ask their direct employees to provide anonymous feedback on the managers regarding the same topics.
You may need to develop a sampling plan to obtain data systematically. This involves defining a population , the group you want to draw conclusions about, and a sample, the group you will actually collect data from.
Your sampling method will determine how you recruit participants or obtain measurements for your study. To decide on a sampling method you will need to consider factors like the required sample size, accessibility of the sample, and time frame of the data collection.
Standardising procedures
If multiple researchers are involved, write a detailed manual to standardise data collection procedures in your study.
This means laying out specific step-by-step instructions so that everyone in your research team collects data in a consistent way – for example, by conducting experiments under the same conditions and using objective criteria to record and categorise observations.
This helps ensure the reliability of your data, and you can also use it to replicate the study in the future.
Creating a data management plan
Before beginning data collection, you should also decide how you will organise and store your data.
- If you are collecting data from people, you will likely need to anonymise and safeguard the data to prevent leaks of sensitive information (e.g. names or identity numbers).
- If you are collecting data via interviews or pencil-and-paper formats, you will need to perform transcriptions or data entry in systematic ways to minimise distortion.
- You can prevent loss of data by having an organisation system that is routinely backed up.
Finally, you can implement your chosen methods to measure or observe the variables you are interested in.
The closed-ended questions ask participants to rate their manager’s leadership skills on scales from 1 to 5. The data produced is numerical and can be statistically analysed for averages and patterns.
To ensure that high-quality data is recorded in a systematic way, here are some best practices:
- Record all relevant information as and when you obtain data. For example, note down whether or how lab equipment is recalibrated during an experimental study.
- Double-check manual data entry for errors.
- If you collect quantitative data, you can assess the reliability and validity to get an indication of your data quality.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organisations.
When conducting research, collecting original data has significant advantages:
- You can tailor data collection to your specific research aims (e.g., understanding the needs of your consumers or user testing your website).
- You can control and standardise the process for high reliability and validity (e.g., choosing appropriate measurements and sampling methods ).
However, there are also some drawbacks: data collection can be time-consuming, labour-intensive, and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to test a hypothesis by systematically collecting and analysing data, while qualitative methods allow you to explore ideas and experiences in depth.
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research , you also have to consider the internal and external validity of your experiment.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
Operationalisation means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioural avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalise the variables that you want to measure.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, May 04). Data Collection Methods | Step-by-Step Guide & Examples. Scribbr. Retrieved 6 May 2024, from https://www.scribbr.co.uk/research-methods/data-collection-guide/
Is this article helpful?

Pritha Bhandari
Other students also liked, qualitative vs quantitative research | examples & methods, triangulation in research | guide, types, examples, what is a conceptual framework | tips & examples.
Part I: Sampling, Data Collection, & Analysis in Quantitative Research
In this module, we will focus on how quantitative research collects and analyzes data, as well as methods for obtaining sample population.
- Levels of Measurement
- Reliability and Validity
- Population and Samples
- Common Data Collection Methods
- Data Analysis
- Statistical Significance versus Clinical Significance
Objectives:
- Describe levels of measurement
- Describe reliability and validity as applied to critical appraisal of research
- Differentiate methods of obtaining samples for population generalizability
- Describe common data collection methods in quantitative research
- Describe various data analysis methods in quantitative research
- Differentiate statistical significance versus clinical significance
Levels of measurement
Once researchers have collected their data (we will talk about data collection later in this module), they need methods to organize the data before they even start to think about statistical analyses. Statistical operations depend on a variable’s level of measurement. Think about this similarly to shuffling all of your bills in some type of organization before you pay them. With levels of measurement, we are precisely recording variables in a method to help organize them.
There are four levels of measurement:
Nominal: The data can only be categorized
Ordinal: The data can be categorized and ranked
Interval: The data can be categorized, ranked, and evenly spaced
Ratio: The data can be categorized, ranked, even spaced, and has a natural zero
Going from lowest to highest, the 4 levels of measurement are cumulative. This means that they each take on the properties of lower levels and add new properties.

- A variable is nominal if the values could be interchanged (e.g. 1 = male, 2 = female OR 1 = female, 2 = male).
- A variable is ordinal if there is a quantitative ordering of values AND if there are a small number of values (e.g. excellent, good, fair, poor).
- A variable is usually considered interval if it is measured with a composite scale or test.
- A variable is ratio level if it makes sense to say that one value is twice as much as another (e.g. 100 mg is twice as much as 50 mg) (Polit & Beck, 2021).
Reliability and Validity as Applied to Critical Appraisal of Research
Reliability measures the ability of a measure to consistently measure the same way. Validity measures what it is supposed to measure. Do we have the need for both in research? Yes! If a variable is measured inaccurately, the data is useless. Let’s talk about why.
For example, let’s set out to measure blood glucose for our study. The validity is how well the measure can determine the blood glucose. If we used a blood pressure cuff to measure blood glucose, this would not be a valid measure. If we used a blood glucose meter, it would be a more valid measure. It does not stop there, however. What about the meter itself? Has it been calibrated? Are the correct sticks for the meter available? Are they expired? Does the meter have fresh batteries? Are the patient’s hands clean?
Reliability wants to know: Is the blood glucose meter measuring the same way, every time?
Validity is asking, “Does the meter measure what it is supposed to measure?” Construct validity: Does the test measure the concept that it’s intended to measure? Content validity: Is the test fully representative of what it aims to measure? Face validity: Does the content of the test appear to be suitable to its aims?
Leibold, 2020
Obtaining Samples for Population Generalizability
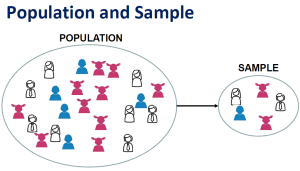
In quantitative research, a population is the entire group that the researcher wants to draw conclusions about.
A sample is the specific group that the researcher will actually collect data from. A sample is always a much smaller group of people than the total size of the population. For example, if we wanted to investigate heart failure, there would be no possible way to measure every single human with heart failure. Therefore, researchers will attempt to select a sample of that large population which would most likely reflect (AKA: be a representative sample) the larger population of those with heart failure. Remember, in quantitative research, the results should be generalizable to the population studied.
A researcher will specify population characteristics through eligibility criteria. This means that they consider which characteristics to include ( inclusion criteria ) and which characteristics to exclude ( exclusion criteria ).
For example, if we were studying chemotherapy in breast cancer subjects, we might specify:
- Inclusion Criteria: Postmenopausal women between the ages of 45 and 75 who have been diagnosed with Stage II breast cancer.
- Exclusion Criteria: Abnormal renal function tests since we are studying a combination of drugs that may be nephrotoxic. Renal function tests are to be performed to evaluate renal function and the threshold values that would disqualify the prospective subject is serum creatinine above 1.9 mg/dl.
Sampling Designs:
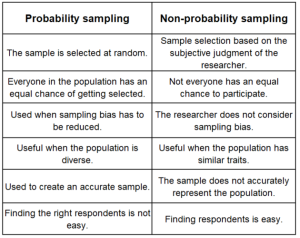
There are two broad classes of sampling in quantitative research: Probability and nonprobability sampling.
Probability sampling : As the name implies, probability sampling means that each eligible individual has a random chance (same probability) of being selected to participate in the study.
There are three types of probability sampling:
Simple random sampling : Every eligible participant is randomly selected (e.g. drawing from a hat).
Stratified random sampling : Eligible population is first divided into two or more strata (categories) from which randomization occurs (e.g. pollution levels selected from restaurants, bars with ordinances of state laws, and bars with no ordinances).
Systematic sampling : Involves the selection of every __ th eligible participant from a list (e.g. every 9 th person).
Nonprobability sampling : In nonprobability sampling, eligible participants are selected using a subjective (non-random) method.
There are four types of nonprobability sampling:
Convenience sampling : Participants are selected for inclusion in the sample because they are the easiest for the researcher to access. This can be due to geographical proximity, availability at a given time, or willingness to participate in the research.
Quota sampling : Participants are from a very tailored sample that’s in proportion to some characteristic or trait of a population. For example, the researcher could divide a population by the state they live in, income or education level, or sex. The population is divided into groups (also called strata) and samples are taken from each group to meet a quota.
Consecutive sampling : A sampling technique in which every subject meeting the criteria of inclusion is selected until the required sample size is achieved. Consecutive sampling is defined as a nonprobability technique where samples are picked at the ease of a researcher more like convenience sampling, only with a slight variation. Here, the researcher selects a sample or group of people, conducts research over a period, collects results, and then moves on to another sample.
Purposive sampling : A group of non-probability sampling techniques in which units are selected because they have characteristics that the researcher needs in their sample. In other words, units are selected “on purpose” in purposive sampling.
Common Data Collection Methods in Quantitative Research
There are various methods that researchers use to collect data for their studies. For nurse researchers, existing records are an important data source. Researchers need to decide if they will collect new data or use existing data. There is also a wealth of clinical data that can be used for non-research purposed to help answer clinical questions.
Let’s look at some general data collection methods and data sources in quantitative research.
Existing data could include medical records, school records, corporate diaries, letters, meeting minutes, and photographs. These are easy to obtain do not require participation from those being studied.
Collecting new data:
Let’s go over a few methods in which researcher can collect new data. These usually requires participation from those being studied.
Self-reports can be obtained via interviews or questionnaires . Closed-ended questions can be asked (“Within the past 6 months, were you ever a member of a fitness gym?” Yes/No) or open-ended questions such as “Why did you decide to join a fitness gym?” Important to remember (this sometimes throws students off) is that conducting interviews and questionnaires does not mean it is qualitative in nature! Do not let that throw you off in assessing whether a published article is quantitative or qualitative. The nature of the questions, however, may help to determine the type of research (quantitative or qualitative), as qualitative questions deal with ascertaining a very organic collection of people’s experiences in open-ended questions.
Advantages of questionnaires (compared to interviews):
- Questionnaires are less costly and are advantageous for geographically dispersed samples.
- Questionnaires offer the possibility of anonymity, which may be crucial in obtaining information about certain opinions or traits.
Advances of interviews (compared to questionnaires):
- Higher response rates
- Some people cannot fill out a questionnaire.
- Opportunities to clarify questions or to determine comprehension
- Opportunity to collect supplementary data through observation
Psychosocial scales are often utilized within questionnaires or interviews. These can help to obtain attitudes, perceptions, and psychological traits.
Likert Scales :
- Consist of several declarative statements ( items ) expressing viewpoints
- Responses are on an agree/disagree continuum (usually five or seven response options).
- Responses to items are summed to compute a total scale score.
Visual Analog Scale:
- Used to measure subjective experiences (e.g., pain, nausea)
- Measurements are on a straight line measuring 100 mm.
- End points labeled as extreme limits of sensation

Observational Methods include the observation method of data collection involves seeing people in a certain setting or place at a specific time and day. Essentially, researchers study the behavior of the individuals or surroundings in which they are analyzing. This can be controlled, spontaneous, or participant-based research .
When a researcher utilizes a defined procedure for observing individuals or the environment, this is known as structured observation. When individuals are observed in their natural environment, this is known as naturalistic observation. In participant observation, the researcher immerses himself or herself in the environment and becomes a member of the group being observed.
Biophysiologic Measures are defined as ‘those physiological and physical variables that require specialized technical instruments and equipment for their measurement’. Biophysiological measures are the most common instruments for collecting data in medical science studies. To collect valid and reliable data, it is critical to apply these measures appropriately.
- In vivo refers to when research or work is done with or within an entire, living organism. Examples can include studies in animal models or human clinical trials.
- In vitro is used to describe work that’s performed outside of a living organism. This usually involves isolated tissues, organs, or cells.

Let’s watch a video about Sampling and Data Collection that I made a couple of years ago.

Quantitative Data Collection
Quantitative methods to collect data involve measures and numerical information that can be further tested and analyzed with statistical methods. The most common forms of quantitative data collection methods are:
- Experiments
- Observation with instruments
- Spatial data
- Surveys with numerical scaled questions
Below are some resources from the UNT Libraries that provide guidance on quantitative data collection methods and sampling techniques commonly used in social science research.

Qualitative Data Collection
Qualitative data collection focuses on collecting information based on experience, thoughts, and feelings from your subjects or representations from artifacts in your discipline. The most common ways to collect qualitative data are:
- Examining artifacts (e.g. text, documents, images, video, audio, objects)
- Holding focus Group
- Conducting interviews
- Observing phenomena
- Conducting surveys with open-ended questions
Below are some resources from the UNT Libraries that provide guidance on qualitative data collection methods and sampling techniques commonly used in social science research.

- << Previous: Research Design
- Next: Data Analysis and Reporting >>
- Last Updated: Jan 26, 2024 9:43 AM
- URL: https://guides.library.unt.edu/rmss
Additional Links
UNT: Apply now UNT: Schedule a tour UNT: Get more info about the University of North Texas
UNT: Disclaimer | UNT: AA/EOE/ADA | UNT: Privacy | UNT: Electronic Accessibility | UNT: Required Links | UNT: UNT Home

An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
National Research Council; Division of Behavioral and Social Sciences and Education; Commission on Behavioral and Social Sciences and Education; Committee on Basic Research in the Behavioral and Social Sciences; Gerstein DR, Luce RD, Smelser NJ, et al., editors. The Behavioral and Social Sciences: Achievements and Opportunities. Washington (DC): National Academies Press (US); 1988.

The Behavioral and Social Sciences: Achievements and Opportunities.
- Hardcopy Version at National Academies Press
5 Methods of Data Collection, Representation, and Analysis
This chapter concerns research on collecting, representing, and analyzing the data that underlie behavioral and social sciences knowledge. Such research, methodological in character, includes ethnographic and historical approaches, scaling, axiomatic measurement, and statistics, with its important relatives, econometrics and psychometrics. The field can be described as including the self-conscious study of how scientists draw inferences and reach conclusions from observations. Since statistics is the largest and most prominent of methodological approaches and is used by researchers in virtually every discipline, statistical work draws the lion’s share of this chapter’s attention.
Problems of interpreting data arise whenever inherent variation or measurement fluctuations create challenges to understand data or to judge whether observed relationships are significant, durable, or general. Some examples: Is a sharp monthly (or yearly) increase in the rate of juvenile delinquency (or unemployment) in a particular area a matter for alarm, an ordinary periodic or random fluctuation, or the result of a change or quirk in reporting method? Do the temporal patterns seen in such repeated observations reflect a direct causal mechanism, a complex of indirect ones, or just imperfections in the data? Is a decrease in auto injuries an effect of a new seat-belt law? Are the disagreements among people describing some aspect of a subculture too great to draw valid inferences about that aspect of the culture?
Such issues of inference are often closely connected to substantive theory and specific data, and to some extent it is difficult and perhaps misleading to treat methods of data collection, representation, and analysis separately. This report does so, as do all sciences to some extent, because the methods developed often are far more general than the specific problems that originally gave rise to them. There is much transfer of new ideas from one substantive field to another—and to and from fields outside the behavioral and social sciences. Some of the classical methods of statistics arose in studies of astronomical observations, biological variability, and human diversity. The major growth of the classical methods occurred in the twentieth century, greatly stimulated by problems in agriculture and genetics. Some methods for uncovering geometric structures in data, such as multidimensional scaling and factor analysis, originated in research on psychological problems, but have been applied in many other sciences. Some time-series methods were developed originally to deal with economic data, but they are equally applicable to many other kinds of data.
- In economics: large-scale models of the U.S. economy; effects of taxation, money supply, and other government fiscal and monetary policies; theories of duopoly, oligopoly, and rational expectations; economic effects of slavery.
- In psychology: test calibration; the formation of subjective probabilities, their revision in the light of new information, and their use in decision making; psychiatric epidemiology and mental health program evaluation.
- In sociology and other fields: victimization and crime rates; effects of incarceration and sentencing policies; deployment of police and fire-fighting forces; discrimination, antitrust, and regulatory court cases; social networks; population growth and forecasting; and voting behavior.
Even such an abridged listing makes clear that improvements in methodology are valuable across the spectrum of empirical research in the behavioral and social sciences as well as in application to policy questions. Clearly, methodological research serves many different purposes, and there is a need to develop different approaches to serve those different purposes, including exploratory data analysis, scientific inference about hypotheses and population parameters, individual decision making, forecasting what will happen in the event or absence of intervention, and assessing causality from both randomized experiments and observational data.
This discussion of methodological research is divided into three areas: design, representation, and analysis. The efficient design of investigations must take place before data are collected because it involves how much, what kind of, and how data are to be collected. What type of study is feasible: experimental, sample survey, field observation, or other? What variables should be measured, controlled, and randomized? How extensive a subject pool or observational period is appropriate? How can study resources be allocated most effectively among various sites, instruments, and subsamples?
The construction of useful representations of the data involves deciding what kind of formal structure best expresses the underlying qualitative and quantitative concepts that are being used in a given study. For example, cost of living is a simple concept to quantify if it applies to a single individual with unchanging tastes in stable markets (that is, markets offering the same array of goods from year to year at varying prices), but as a national aggregate for millions of households and constantly changing consumer product markets, the cost of living is not easy to specify clearly or measure reliably. Statisticians, economists, sociologists, and other experts have long struggled to make the cost of living a precise yet practicable concept that is also efficient to measure, and they must continually modify it to reflect changing circumstances.
Data analysis covers the final step of characterizing and interpreting research findings: Can estimates of the relations between variables be made? Can some conclusion be drawn about correlation, cause and effect, or trends over time? How uncertain are the estimates and conclusions and can that uncertainty be reduced by analyzing the data in a different way? Can computers be used to display complex results graphically for quicker or better understanding or to suggest different ways of proceeding?
Advances in analysis, data representation, and research design feed into and reinforce one another in the course of actual scientific work. The intersections between methodological improvements and empirical advances are an important aspect of the multidisciplinary thrust of progress in the behavioral and social sciences.
- Designs for Data Collection
Four broad kinds of research designs are used in the behavioral and social sciences: experimental, survey, comparative, and ethnographic.
Experimental designs, in either the laboratory or field settings, systematically manipulate a few variables while others that may affect the outcome are held constant, randomized, or otherwise controlled. The purpose of randomized experiments is to ensure that only one or a few variables can systematically affect the results, so that causes can be attributed. Survey designs include the collection and analysis of data from censuses, sample surveys, and longitudinal studies and the examination of various relationships among the observed phenomena. Randomization plays a different role here than in experimental designs: it is used to select members of a sample so that the sample is as representative of the whole population as possible. Comparative designs involve the retrieval of evidence that is recorded in the flow of current or past events in different times or places and the interpretation and analysis of this evidence. Ethnographic designs, also known as participant-observation designs, involve a researcher in intensive and direct contact with a group, community, or population being studied, through participation, observation, and extended interviewing.
Experimental Designs
Laboratory experiments.
Laboratory experiments underlie most of the work reported in Chapter 1 , significant parts of Chapter 2 , and some of the newest lines of research in Chapter 3 . Laboratory experiments extend and adapt classical methods of design first developed, for the most part, in the physical and life sciences and agricultural research. Their main feature is the systematic and independent manipulation of a few variables and the strict control or randomization of all other variables that might affect the phenomenon under study. For example, some studies of animal motivation involve the systematic manipulation of amounts of food and feeding schedules while other factors that may also affect motivation, such as body weight, deprivation, and so on, are held constant. New designs are currently coming into play largely because of new analytic and computational methods (discussed below, in “Advances in Statistical Inference and Analysis”).
Two examples of empirically important issues that demonstrate the need for broadening classical experimental approaches are open-ended responses and lack of independence of successive experimental trials. The first concerns the design of research protocols that do not require the strict segregation of the events of an experiment into well-defined trials, but permit a subject to respond at will. These methods are needed when what is of interest is how the respondent chooses to allocate behavior in real time and across continuously available alternatives. Such empirical methods have long been used, but they can generate very subtle and difficult problems in experimental design and subsequent analysis. As theories of allocative behavior of all sorts become more sophisticated and precise, the experimental requirements become more demanding, so the need to better understand and solve this range of design issues is an outstanding challenge to methodological ingenuity.
The second issue arises in repeated-trial designs when the behavior on successive trials, even if it does not exhibit a secular trend (such as a learning curve), is markedly influenced by what has happened in the preceding trial or trials. The more naturalistic the experiment and the more sensitive the meas urements taken, the more likely it is that such effects will occur. But such sequential dependencies in observations cause a number of important conceptual and technical problems in summarizing the data and in testing analytical models, which are not yet completely understood. In the absence of clear solutions, such effects are sometimes ignored by investigators, simplifying the data analysis but leaving residues of skepticism about the reliability and significance of the experimental results. With continuing development of sensitive measures in repeated-trial designs, there is a growing need for more advanced concepts and methods for dealing with experimental results that may be influenced by sequential dependencies.
Randomized Field Experiments
The state of the art in randomized field experiments, in which different policies or procedures are tested in controlled trials under real conditions, has advanced dramatically over the past two decades. Problems that were once considered major methodological obstacles—such as implementing randomized field assignment to treatment and control groups and protecting the randomization procedure from corruption—have been largely overcome. While state-of-the-art standards are not achieved in every field experiment, the commitment to reaching them is rising steadily, not only among researchers but also among customer agencies and sponsors.
The health insurance experiment described in Chapter 2 is an example of a major randomized field experiment that has had and will continue to have important policy reverberations in the design of health care financing. Field experiments with the negative income tax (guaranteed minimum income) conducted in the 1970s were significant in policy debates, even before their completion, and provided the most solid evidence available on how tax-based income support programs and marginal tax rates can affect the work incentives and family structures of the poor. Important field experiments have also been carried out on alternative strategies for the prevention of delinquency and other criminal behavior, reform of court procedures, rehabilitative programs in mental health, family planning, and special educational programs, among other areas.
In planning field experiments, much hinges on the definition and design of the experimental cells, the particular combinations needed of treatment and control conditions for each set of demographic or other client sample characteristics, including specification of the minimum number of cases needed in each cell to test for the presence of effects. Considerations of statistical power, client availability, and the theoretical structure of the inquiry enter into such specifications. Current important methodological thresholds are to find better ways of predicting recruitment and attrition patterns in the sample, of designing experiments that will be statistically robust in the face of problematic sample recruitment or excessive attrition, and of ensuring appropriate acquisition and analysis of data on the attrition component of the sample.
Also of major significance are improvements in integrating detailed process and outcome measurements in field experiments. To conduct research on program effects under field conditions requires continual monitoring to determine exactly what is being done—the process—how it corresponds to what was projected at the outset. Relatively unintrusive, inexpensive, and effective implementation measures are of great interest. There is, in parallel, a growing emphasis on designing experiments to evaluate distinct program components in contrast to summary measures of net program effects.
Finally, there is an important opportunity now for further theoretical work to model organizational processes in social settings and to design and select outcome variables that, in the relatively short time of most field experiments, can predict longer-term effects: For example, in job-training programs, what are the effects on the community (role models, morale, referral networks) or on individual skills, motives, or knowledge levels that are likely to translate into sustained changes in career paths and income levels?
Survey Designs
Many people have opinions about how societal mores, economic conditions, and social programs shape lives and encourage or discourage various kinds of behavior. People generalize from their own cases, and from the groups to which they belong, about such matters as how much it costs to raise a child, the extent to which unemployment contributes to divorce, and so on. In fact, however, effects vary so much from one group to another that homespun generalizations are of little use. Fortunately, behavioral and social scientists have been able to bridge the gaps between personal perspectives and collective realities by means of survey research. In particular, governmental information systems include volumes of extremely valuable survey data, and the facility of modern computers to store, disseminate, and analyze such data has significantly improved empirical tests and led to new understandings of social processes.
Within this category of research designs, two major types are distinguished: repeated cross-sectional surveys and longitudinal panel surveys. In addition, and cross-cutting these types, there is a major effort under way to improve and refine the quality of survey data by investigating features of human memory and of question formation that affect survey response.
Repeated cross-sectional designs can either attempt to measure an entire population—as does the oldest U.S. example, the national decennial census—or they can rest on samples drawn from a population. The general principle is to take independent samples at two or more times, measuring the variables of interest, such as income levels, housing plans, or opinions about public affairs, in the same way. The General Social Survey, collected by the National Opinion Research Center with National Science Foundation support, is a repeated cross sectional data base that was begun in 1972. One methodological question of particular salience in such data is how to adjust for nonresponses and “don’t know” responses. Another is how to deal with self-selection bias. For example, to compare the earnings of women and men in the labor force, it would be mistaken to first assume that the two samples of labor-force participants are randomly selected from the larger populations of men and women; instead, one has to consider and incorporate in the analysis the factors that determine who is in the labor force.
In longitudinal panels, a sample is drawn at one point in time and the relevant variables are measured at this and subsequent times for the same people. In more complex versions, some fraction of each panel may be replaced or added to periodically, such as expanding the sample to include households formed by the children of the original sample. An example of panel data developed in this way is the Panel Study of Income Dynamics (PSID), conducted by the University of Michigan since 1968 (discussed in Chapter 3 ).
Comparing the fertility or income of different people in different circumstances at the same time to find correlations always leaves a large proportion of the variability unexplained, but common sense suggests that much of the unexplained variability is actually explicable. There are systematic reasons for individual outcomes in each person’s past achievements, in parental models, upbringing, and earlier sequences of experiences. Unfortunately, asking people about the past is not particularly helpful: people remake their views of the past to rationalize the present and so retrospective data are often of uncertain validity. In contrast, generation-long longitudinal data allow readings on the sequence of past circumstances uncolored by later outcomes. Such data are uniquely useful for studying the causes and consequences of naturally occurring decisions and transitions. Thus, as longitudinal studies continue, quantitative analysis is becoming feasible about such questions as: How are the decisions of individuals affected by parental experience? Which aspects of early decisions constrain later opportunities? And how does detailed background experience leave its imprint? Studies like the two-decade-long PSID are bringing within grasp a complete generational cycle of detailed data on fertility, work life, household structure, and income.
Advances in Longitudinal Designs
Large-scale longitudinal data collection projects are uniquely valuable as vehicles for testing and improving survey research methodology. In ways that lie beyond the scope of a cross-sectional survey, longitudinal studies can sometimes be designed—without significant detriment to their substantive interests—to facilitate the evaluation and upgrading of data quality; the analysis of relative costs and effectiveness of alternative techniques of inquiry; and the standardization or coordination of solutions to problems of method, concept, and measurement across different research domains.
Some areas of methodological improvement include discoveries about the impact of interview mode on response (mail, telephone, face-to-face); the effects of nonresponse on the representativeness of a sample (due to respondents’ refusal or interviewers’ failure to contact); the effects on behavior of continued participation over time in a sample survey; the value of alternative methods of adjusting for nonresponse and incomplete observations (such as imputation of missing data, variable case weighting); the impact on response of specifying different recall periods, varying the intervals between interviews, or changing the length of interviews; and the comparison and calibration of results obtained by longitudinal surveys, randomized field experiments, laboratory studies, onetime surveys, and administrative records.
It should be especially noted that incorporating improvements in methodology and data quality has been and will no doubt continue to be crucial to the growing success of longitudinal studies. Panel designs are intrinsically more vulnerable than other designs to statistical biases due to cumulative item non-response, sample attrition, time-in-sample effects, and error margins in repeated measures, all of which may produce exaggerated estimates of change. Over time, a panel that was initially representative may become much less representative of a population, not only because of attrition in the sample, but also because of changes in immigration patterns, age structure, and the like. Longitudinal studies are also subject to changes in scientific and societal contexts that may create uncontrolled drifts over time in the meaning of nominally stable questions or concepts as well as in the underlying behavior. Also, a natural tendency to expand over time the range of topics and thus the interview lengths, which increases the burdens on respondents, may lead to deterioration of data quality or relevance. Careful methodological research to understand and overcome these problems has been done, and continued work as a component of new longitudinal studies is certain to advance the overall state of the art.
Longitudinal studies are sometimes pressed for evidence they are not designed to produce: for example, in important public policy questions concerning the impact of government programs in such areas as health promotion, disease prevention, or criminal justice. By using research designs that combine field experiments (with randomized assignment to program and control conditions) and longitudinal surveys, one can capitalize on the strongest merits of each: the experimental component provides stronger evidence for casual statements that are critical for evaluating programs and for illuminating some fundamental theories; the longitudinal component helps in the estimation of long-term program effects and their attenuation. Coupling experiments to ongoing longitudinal studies is not often feasible, given the multiple constraints of not disrupting the survey, developing all the complicated arrangements that go into a large-scale field experiment, and having the populations of interest overlap in useful ways. Yet opportunities to join field experiments to surveys are of great importance. Coupled studies can produce vital knowledge about the empirical conditions under which the results of longitudinal surveys turn out to be similar to—or divergent from—those produced by randomized field experiments. A pattern of divergence and similarity has begun to emerge in coupled studies; additional cases are needed to understand why some naturally occurring social processes and longitudinal design features seem to approximate formal random allocation and others do not. The methodological implications of such new knowledge go well beyond program evaluation and survey research. These findings bear directly on the confidence scientists—and others—can have in conclusions from observational studies of complex behavioral and social processes, particularly ones that cannot be controlled or simulated within the confines of a laboratory environment.
Memory and the Framing of Questions
A very important opportunity to improve survey methods lies in the reduction of nonsampling error due to questionnaire context, phrasing of questions, and, generally, the semantic and social-psychological aspects of surveys. Survey data are particularly affected by the fallibility of human memory and the sensitivity of respondents to the framework in which a question is asked. This sensitivity is especially strong for certain types of attitudinal and opinion questions. Efforts are now being made to bring survey specialists into closer contact with researchers working on memory function, knowledge representation, and language in order to uncover and reduce this kind of error.
Memory for events is often inaccurate, biased toward what respondents believe to be true—or should be true—about the world. In many cases in which data are based on recollection, improvements can be achieved by shifting to techniques of structured interviewing and calibrated forms of memory elicitation, such as specifying recent, brief time periods (for example, in the last seven days) within which respondents recall certain types of events with acceptable accuracy.
- “Taking things altogether, how would you describe your marriage? Would you say that your marriage is very happy, pretty happy, or not too happy?”
- “Taken altogether how would you say things are these days—would you say you are very happy, pretty happy, or not too happy?”
Presenting this sequence in both directions on different forms showed that the order affected answers to the general happiness question but did not change the marital happiness question: responses to the specific issue swayed subsequent responses to the general one, but not vice versa. The explanations for and implications of such order effects on the many kinds of questions and sequences that can be used are not simple matters. Further experimentation on the design of survey instruments promises not only to improve the accuracy and reliability of survey research, but also to advance understanding of how people think about and evaluate their behavior from day to day.
Comparative Designs
Both experiments and surveys involve interventions or questions by the scientist, who then records and analyzes the responses. In contrast, many bodies of social and behavioral data of considerable value are originally derived from records or collections that have accumulated for various nonscientific reasons, quite often administrative in nature, in firms, churches, military organizations, and governments at all levels. Data of this kind can sometimes be subjected to careful scrutiny, summary, and inquiry by historians and social scientists, and statistical methods have increasingly been used to develop and evaluate inferences drawn from such data. Some of the main comparative approaches are cross-national aggregate comparisons, selective comparison of a limited number of cases, and historical case studies.
Among the more striking problems facing the scientist using such data are the vast differences in what has been recorded by different agencies whose behavior is being compared (this is especially true for parallel agencies in different nations), the highly unrepresentative or idiosyncratic sampling that can occur in the collection of such data, and the selective preservation and destruction of records. Means to overcome these problems form a substantial methodological research agenda in comparative research. An example of the method of cross-national aggregative comparisons is found in investigations by political scientists and sociologists of the factors that underlie differences in the vitality of institutions of political democracy in different societies. Some investigators have stressed the existence of a large middle class, others the level of education of a population, and still others the development of systems of mass communication. In cross-national aggregate comparisons, a large number of nations are arrayed according to some measures of political democracy and then attempts are made to ascertain the strength of correlations between these and the other variables. In this line of analysis it is possible to use a variety of statistical cluster and regression techniques to isolate and assess the possible impact of certain variables on the institutions under study. While this kind of research is cross-sectional in character, statements about historical processes are often invoked to explain the correlations.
More limited selective comparisons, applied by many of the classic theorists, involve asking similar kinds of questions but over a smaller range of societies. Why did democracy develop in such different ways in America, France, and England? Why did northeastern Europe develop rational bourgeois capitalism, in contrast to the Mediterranean and Asian nations? Modern scholars have turned their attention to explaining, for example, differences among types of fascism between the two World Wars, and similarities and differences among modern state welfare systems, using these comparisons to unravel the salient causes. The questions asked in these instances are inevitably historical ones.
Historical case studies involve only one nation or region, and so they may not be geographically comparative. However, insofar as they involve tracing the transformation of a society’s major institutions and the role of its main shaping events, they involve a comparison of different periods of a nation’s or a region’s history. The goal of such comparisons is to give a systematic account of the relevant differences. Sometimes, particularly with respect to the ancient societies, the historical record is very sparse, and the methods of history and archaeology mesh in the reconstruction of complex social arrangements and patterns of change on the basis of few fragments.
Like all research designs, comparative ones have distinctive vulnerabilities and advantages: One of the main advantages of using comparative designs is that they greatly expand the range of data, as well as the amount of variation in those data, for study. Consequently, they allow for more encompassing explanations and theories that can relate highly divergent outcomes to one another in the same framework. They also contribute to reducing any cultural biases or tendencies toward parochialism among scientists studying common human phenomena.
One main vulnerability in such designs arises from the problem of achieving comparability. Because comparative study involves studying societies and other units that are dissimilar from one another, the phenomena under study usually occur in very different contexts—so different that in some cases what is called an event in one society cannot really be regarded as the same type of event in another. For example, a vote in a Western democracy is different from a vote in an Eastern bloc country, and a voluntary vote in the United States means something different from a compulsory vote in Australia. These circumstances make for interpretive difficulties in comparing aggregate rates of voter turnout in different countries.
The problem of achieving comparability appears in historical analysis as well. For example, changes in laws and enforcement and recording procedures over time change the definition of what is and what is not a crime, and for that reason it is difficult to compare the crime rates over time. Comparative researchers struggle with this problem continually, working to fashion equivalent measures; some have suggested the use of different measures (voting, letters to the editor, street demonstration) in different societies for common variables (political participation), to try to take contextual factors into account and to achieve truer comparability.
A second vulnerability is controlling variation. Traditional experiments make conscious and elaborate efforts to control the variation of some factors and thereby assess the causal significance of others. In surveys as well as experiments, statistical methods are used to control sources of variation and assess suspected causal significance. In comparative and historical designs, this kind of control is often difficult to attain because the sources of variation are many and the number of cases few. Scientists have made efforts to approximate such control in these cases of “many variables, small N.” One is the method of paired comparisons. If an investigator isolates 15 American cities in which racial violence has been recurrent in the past 30 years, for example, it is helpful to match them with 15 cities of similar population size, geographical region, and size of minorities—such characteristics are controls—and then search for systematic differences between the two sets of cities. Another method is to select, for comparative purposes, a sample of societies that resemble one another in certain critical ways, such as size, common language, and common level of development, thus attempting to hold these factors roughly constant, and then seeking explanations among other factors in which the sampled societies differ from one another.
Ethnographic Designs
Traditionally identified with anthropology, ethnographic research designs are playing increasingly significant roles in most of the behavioral and social sciences. The core of this methodology is participant-observation, in which a researcher spends an extended period of time with the group under study, ideally mastering the local language, dialect, or special vocabulary, and participating in as many activities of the group as possible. This kind of participant-observation is normally coupled with extensive open-ended interviewing, in which people are asked to explain in depth the rules, norms, practices, and beliefs through which (from their point of view) they conduct their lives. A principal aim of ethnographic study is to discover the premises on which those rules, norms, practices, and beliefs are built.
The use of ethnographic designs by anthropologists has contributed significantly to the building of knowledge about social and cultural variation. And while these designs continue to center on certain long-standing features—extensive face-to-face experience in the community, linguistic competence, participation, and open-ended interviewing—there are newer trends in ethnographic work. One major trend concerns its scale. Ethnographic methods were originally developed largely for studying small-scale groupings known variously as village, folk, primitive, preliterate, or simple societies. Over the decades, these methods have increasingly been applied to the study of small groups and networks within modern (urban, industrial, complex) society, including the contemporary United States. The typical subjects of ethnographic study in modern society are small groups or relatively small social networks, such as outpatient clinics, medical schools, religious cults and churches, ethnically distinctive urban neighborhoods, corporate offices and factories, and government bureaus and legislatures.
As anthropologists moved into the study of modern societies, researchers in other disciplines—particularly sociology, psychology, and political science—began using ethnographic methods to enrich and focus their own insights and findings. At the same time, studies of large-scale structures and processes have been aided by the use of ethnographic methods, since most large-scale changes work their way into the fabric of community, neighborhood, and family, affecting the daily lives of people. Ethnographers have studied, for example, the impact of new industry and new forms of labor in “backward” regions; the impact of state-level birth control policies on ethnic groups; and the impact on residents in a region of building a dam or establishing a nuclear waste dump. Ethnographic methods have also been used to study a number of social processes that lend themselves to its particular techniques of observation and interview—processes such as the formation of class and racial identities, bureaucratic behavior, legislative coalitions and outcomes, and the formation and shifting of consumer tastes.
Advances in structured interviewing (see above) have proven especially powerful in the study of culture. Techniques for understanding kinship systems, concepts of disease, color terminologies, ethnobotany, and ethnozoology have been radically transformed and strengthened by coupling new interviewing methods with modem measurement and scaling techniques (see below). These techniques have made possible more precise comparisons among cultures and identification of the most competent and expert persons within a culture. The next step is to extend these methods to study the ways in which networks of propositions (such as boys like sports, girls like babies) are organized to form belief systems. Much evidence suggests that people typically represent the world around them by means of relatively complex cognitive models that involve interlocking propositions. The techniques of scaling have been used to develop models of how people categorize objects, and they have great potential for further development, to analyze data pertaining to cultural propositions.
Ideological Systems
Perhaps the most fruitful area for the application of ethnographic methods in recent years has been the systematic study of ideologies in modern society. Earlier studies of ideology were in small-scale societies that were rather homogeneous. In these studies researchers could report on a single culture, a uniform system of beliefs and values for the society as a whole. Modern societies are much more diverse both in origins and number of subcultures, related to different regions, communities, occupations, or ethnic groups. Yet these subcultures and ideologies share certain underlying assumptions or at least must find some accommodation with the dominant value and belief systems in the society.
The challenge is to incorporate this greater complexity of structure and process into systematic descriptions and interpretations. One line of work carried out by researchers has tried to track the ways in which ideologies are created, transmitted, and shared among large populations that have traditionally lacked the social mobility and communications technologies of the West. This work has concentrated on large-scale civilizations such as China, India, and Central America. Gradually, the focus has generalized into a concern with the relationship between the great traditions—the central lines of cosmopolitan Confucian, Hindu, or Mayan culture, including aesthetic standards, irrigation technologies, medical systems, cosmologies and calendars, legal codes, poetic genres, and religious doctrines and rites—and the little traditions, those identified with rural, peasant communities. How are the ideological doctrines and cultural values of the urban elites, the great traditions, transmitted to local communities? How are the little traditions, the ideas from the more isolated, less literate, and politically weaker groups in society, transmitted to the elites?
India and southern Asia have been fruitful areas for ethnographic research on these questions. The great Hindu tradition was present in virtually all local contexts through the presence of high-caste individuals in every community. It operated as a pervasive standard of value for all members of society, even in the face of strong little traditions. The situation is surprisingly akin to that of modern, industrialized societies. The central research questions are the degree and the nature of penetration of dominant ideology, even in groups that appear marginal and subordinate and have no strong interest in sharing the dominant value system. In this connection the lowest and poorest occupational caste—the untouchables—serves as an ultimate test of the power of ideology and cultural beliefs to unify complex hierarchical social systems.
Historical Reconstruction
Another current trend in ethnographic methods is its convergence with archival methods. One joining point is the application of descriptive and interpretative procedures used by ethnographers to reconstruct the cultures that created historical documents, diaries, and other records, to interview history, so to speak. For example, a revealing study showed how the Inquisition in the Italian countryside between the 1570s and 1640s gradually worked subtle changes in an ancient fertility cult in peasant communities; the peasant beliefs and rituals assimilated many elements of witchcraft after learning them from their persecutors. A good deal of social history—particularly that of the family—has drawn on discoveries made in the ethnographic study of primitive societies. As described in Chapter 4 , this particular line of inquiry rests on a marriage of ethnographic, archival, and demographic approaches.
Other lines of ethnographic work have focused on the historical dimensions of nonliterate societies. A strikingly successful example in this kind of effort is a study of head-hunting. By combining an interpretation of local oral tradition with the fragmentary observations that were made by outside observers (such as missionaries, traders, colonial officials), historical fluctuations in the rate and significance of head-hunting were shown to be partly in response to such international forces as the great depression and World War II. Researchers are also investigating the ways in which various groups in contemporary societies invent versions of traditions that may or may not reflect the actual history of the group. This process has been observed among elites seeking political and cultural legitimation and among hard-pressed minorities (for example, the Basque in Spain, the Welsh in Great Britain) seeking roots and political mobilization in a larger society.
Ethnography is a powerful method to record, describe, and interpret the system of meanings held by groups and to discover how those meanings affect the lives of group members. It is a method well adapted to the study of situations in which people interact with one another and the researcher can interact with them as well, so that information about meanings can be evoked and observed. Ethnography is especially suited to exploration and elucidation of unsuspected connections; ideally, it is used in combination with other methods—experimental, survey, or comparative—to establish with precision the relative strengths and weaknesses of such connections. By the same token, experimental, survey, and comparative methods frequently yield connections, the meaning of which is unknown; ethnographic methods are a valuable way to determine them.
- Models for Representing Phenomena
The objective of any science is to uncover the structure and dynamics of the phenomena that are its subject, as they are exhibited in the data. Scientists continuously try to describe possible structures and ask whether the data can, with allowance for errors of measurement, be described adequately in terms of them. Over a long time, various families of structures have recurred throughout many fields of science; these structures have become objects of study in their own right, principally by statisticians, other methodological specialists, applied mathematicians, and philosophers of logic and science. Methods have evolved to evaluate the adequacy of particular structures to account for particular types of data. In the interest of clarity we discuss these structures in this section and the analytical methods used for estimation and evaluation of them in the next section, although in practice they are closely intertwined.
A good deal of mathematical and statistical modeling attempts to describe the relations, both structural and dynamic, that hold among variables that are presumed to be representable by numbers. Such models are applicable in the behavioral and social sciences only to the extent that appropriate numerical measurement can be devised for the relevant variables. In many studies the phenomena in question and the raw data obtained are not intrinsically numerical, but qualitative, such as ethnic group identifications. The identifying numbers used to code such questionnaire categories for computers are no more than labels, which could just as well be letters or colors. One key question is whether there is some natural way to move from the qualitative aspects of such data to a structural representation that involves one of the well-understood numerical or geometric models or whether such an attempt would be inherently inappropriate for the data in question. The decision as to whether or not particular empirical data can be represented in particular numerical or more complex structures is seldom simple, and strong intuitive biases or a priori assumptions about what can and cannot be done may be misleading.
Recent decades have seen rapid and extensive development and application of analytical methods attuned to the nature and complexity of social science data. Examples of nonnumerical modeling are increasing. Moreover, the widespread availability of powerful computers is probably leading to a qualitative revolution, it is affecting not only the ability to compute numerical solutions to numerical models, but also to work out the consequences of all sorts of structures that do not involve numbers at all. The following discussion gives some indication of the richness of past progress and of future prospects although it is by necessity far from exhaustive.
In describing some of the areas of new and continuing research, we have organized this section on the basis of whether the representations are fundamentally probabilistic or not. A further useful distinction is between representations of data that are highly discrete or categorical in nature (such as whether a person is male or female) and those that are continuous in nature (such as a person’s height). Of course, there are intermediate cases involving both types of variables, such as color stimuli that are characterized by discrete hues (red, green) and a continuous luminance measure. Probabilistic models lead very naturally to questions of estimation and statistical evaluation of the correspondence between data and model. Those that are not probabilistic involve additional problems of dealing with and representing sources of variability that are not explicitly modeled. At the present time, scientists understand some aspects of structure, such as geometries, and some aspects of randomness, as embodied in probability models, but do not yet adequately understand how to put the two together in a single unified model. Table 5-1 outlines the way we have organized this discussion and shows where the examples in this section lie.
A Classification of Structural Models.
Probability Models
Some behavioral and social sciences variables appear to be more or less continuous, for example, utility of goods, loudness of sounds, or risk associated with uncertain alternatives. Many other variables, however, are inherently categorical, often with only two or a few values possible: for example, whether a person is in or out of school, employed or not employed, identifies with a major political party or political ideology. And some variables, such as moral attitudes, are typically measured in research with survey questions that allow only categorical responses. Much of the early probability theory was formulated only for continuous variables; its use with categorical variables was not really justified, and in some cases it may have been misleading. Recently, very significant advances have been made in how to deal explicitly with categorical variables. This section first describes several contemporary approaches to models involving categorical variables, followed by ones involving continuous representations.
Log-Linear Models for Categorical Variables
Many recent models for analyzing categorical data of the kind usually displayed as counts (cell frequencies) in multidimensional contingency tables are subsumed under the general heading of log-linear models, that is, linear models in the natural logarithms of the expected counts in each cell in the table. These recently developed forms of statistical analysis allow one to partition variability due to various sources in the distribution of categorical attributes, and to isolate the effects of particular variables or combinations of them.
Present log-linear models were first developed and used by statisticians and sociologists and then found extensive application in other social and behavioral sciences disciplines. When applied, for instance, to the analysis of social mobility, such models separate factors of occupational supply and demand from other factors that impede or propel movement up and down the social hierarchy. With such models, for example, researchers discovered the surprising fact that occupational mobility patterns are strikingly similar in many nations of the world (even among disparate nations like the United States and most of the Eastern European socialist countries), and from one time period to another, once allowance is made for differences in the distributions of occupations. The log-linear and related kinds of models have also made it possible to identify and analyze systematic differences in mobility among nations and across time. As another example of applications, psychologists and others have used log-linear models to analyze attitudes and their determinants and to link attitudes to behavior. These methods have also diffused to and been used extensively in the medical and biological sciences.
Regression Models for Categorical Variables
Models that permit one variable to be explained or predicted by means of others, called regression models, are the workhorses of much applied statistics; this is especially true when the dependent (explained) variable is continuous. For a two-valued dependent variable, such as alive or dead, models and approximate theory and computational methods for one explanatory variable were developed in biometry about 50 years ago. Computer programs able to handle many explanatory variables, continuous or categorical, are readily available today. Even now, however, the accuracy of the approximate theory on given data is an open question.
Using classical utility theory, economists have developed discrete choice models that turn out to be somewhat related to the log-linear and categorical regression models. Models for limited dependent variables, especially those that cannot take on values above or below a certain level (such as weeks unemployed, number of children, and years of schooling) have been used profitably in economics and in some other areas. For example, censored normal variables (called tobits in economics), in which observed values outside certain limits are simply counted, have been used in studying decisions to go on in school. It will require further research and development to incorporate information about limited ranges of variables fully into the main multivariate methodologies. In addition, with respect to the assumptions about distribution and functional form conventionally made in discrete response models, some new methods are now being developed that show promise of yielding reliable inferences without making unrealistic assumptions; further research in this area promises significant progress.
One problem arises from the fact that many of the categorical variables collected by the major data bases are ordered. For example, attitude surveys frequently use a 3-, 5-, or 7-point scale (from high to low) without specifying numerical intervals between levels. Social class and educational levels are often described by ordered categories. Ignoring order information, which many traditional statistical methods do, may be inefficient or inappropriate, but replacing the categories by successive integers or other arbitrary scores may distort the results. (For additional approaches to this question, see sections below on ordered structures.) Regression-like analysis of ordinal categorical variables is quite well developed, but their multivariate analysis needs further research. New log-bilinear models have been proposed, but to date they deal specifically with only two or three categorical variables. Additional research extending the new models, improving computational algorithms, and integrating the models with work on scaling promise to lead to valuable new knowledge.
Models for Event Histories
Event-history studies yield the sequence of events that respondents to a survey sample experience over a period of time; for example, the timing of marriage, childbearing, or labor force participation. Event-history data can be used to study educational progress, demographic processes (migration, fertility, and mortality), mergers of firms, labor market behavior, and even riots, strikes, and revolutions. As interest in such data has grown, many researchers have turned to models that pertain to changes in probabilities over time to describe when and how individuals move among a set of qualitative states.
Much of the progress in models for event-history data builds on recent developments in statistics and biostatistics for life-time, failure-time, and hazard models. Such models permit the analysis of qualitative transitions in a population whose members are undergoing partially random organic deterioration, mechanical wear, or other risks over time. With the increased complexity of event-history data that are now being collected, and the extension of event-history data bases over very long periods of time, new problems arise that cannot be effectively handled by older types of analysis. Among the problems are repeated transitions, such as between unemployment and employment or marriage and divorce; more than one time variable (such as biological age, calendar time, duration in a stage, and time exposed to some specified condition); latent variables (variables that are explicitly modeled even though not observed); gaps in the data; sample attrition that is not randomly distributed over the categories; and respondent difficulties in recalling the exact timing of events.
Models for Multiple-Item Measurement
For a variety of reasons, researchers typically use multiple measures (or multiple indicators) to represent theoretical concepts. Sociologists, for example, often rely on two or more variables (such as occupation and education) to measure an individual’s socioeconomic position; educational psychologists ordinarily measure a student’s ability with multiple test items. Despite the fact that the basic observations are categorical, in a number of applications this is interpreted as a partitioning of something continuous. For example, in test theory one thinks of the measures of both item difficulty and respondent ability as continuous variables, possibly multidimensional in character.
Classical test theory and newer item-response theories in psychometrics deal with the extraction of information from multiple measures. Testing, which is a major source of data in education and other areas, results in millions of test items stored in archives each year for purposes ranging from college admissions to job-training programs for industry. One goal of research on such test data is to be able to make comparisons among persons or groups even when different test items are used. Although the information collected from each respondent is intentionally incomplete in order to keep the tests short and simple, item-response techniques permit researchers to reconstitute the fragments into an accurate picture of overall group proficiencies. These new methods provide a better theoretical handle on individual differences, and they are expected to be extremely important in developing and using tests. For example, they have been used in attempts to equate different forms of a test given in successive waves during a year, a procedure made necessary in large-scale testing programs by legislation requiring disclosure of test-scoring keys at the time results are given.
An example of the use of item-response theory in a significant research effort is the National Assessment of Educational Progress (NAEP). The goal of this project is to provide accurate, nationally representative information on the average (rather than individual) proficiency of American children in a wide variety of academic subjects as they progress through elementary and secondary school. This approach is an improvement over the use of trend data on university entrance exams, because NAEP estimates of academic achievements (by broad characteristics such as age, grade, region, ethnic background, and so on) are not distorted by the self-selected character of those students who seek admission to college, graduate, and professional programs.
Item-response theory also forms the basis of many new psychometric instruments, known as computerized adaptive testing, currently being implemented by the U.S. military services and under additional development in many testing organizations. In adaptive tests, a computer program selects items for each examinee based upon the examinee’s success with previous items. Generally, each person gets a slightly different set of items and the equivalence of scale scores is established by using item-response theory. Adaptive testing can greatly reduce the number of items needed to achieve a given level of measurement accuracy.
Nonlinear, Nonadditive Models
Virtually all statistical models now in use impose a linearity or additivity assumption of some kind, sometimes after a nonlinear transformation of variables. Imposing these forms on relationships that do not, in fact, possess them may well result in false descriptions and spurious effects. Unwary users, especially of computer software packages, can easily be misled. But more realistic nonlinear and nonadditive multivariate models are becoming available. Extensive use with empirical data is likely to force many changes and enhancements in such models and stimulate quite different approaches to nonlinear multivariate analysis in the next decade.
Geometric and Algebraic Models
Geometric and algebraic models attempt to describe underlying structural relations among variables. In some cases they are part of a probabilistic approach, such as the algebraic models underlying regression or the geometric representations of correlations between items in a technique called factor analysis. In other cases, geometric and algebraic models are developed without explicitly modeling the element of randomness or uncertainty that is always present in the data. Although this latter approach to behavioral and social sciences problems has been less researched than the probabilistic one, there are some advantages in developing the structural aspects independent of the statistical ones. We begin the discussion with some inherently geometric representations and then turn to numerical representations for ordered data.
Although geometry is a huge mathematical topic, little of it seems directly applicable to the kinds of data encountered in the behavioral and social sciences. A major reason is that the primitive concepts normally used in geometry—points, lines, coincidence—do not correspond naturally to the kinds of qualitative observations usually obtained in behavioral and social sciences contexts. Nevertheless, since geometric representations are used to reduce bodies of data, there is a real need to develop a deeper understanding of when such representations of social or psychological data make sense. Moreover, there is a practical need to understand why geometric computer algorithms, such as those of multidimensional scaling, work as well as they apparently do. A better understanding of the algorithms will increase the efficiency and appropriateness of their use, which becomes increasingly important with the widespread availability of scaling programs for microcomputers.
Over the past 50 years several kinds of well-understood scaling techniques have been developed and widely used to assist in the search for appropriate geometric representations of empirical data. The whole field of scaling is now entering a critical juncture in terms of unifying and synthesizing what earlier appeared to be disparate contributions. Within the past few years it has become apparent that several major methods of analysis, including some that are based on probabilistic assumptions, can be unified under the rubric of a single generalized mathematical structure. For example, it has recently been demonstrated that such diverse approaches as nonmetric multidimensional scaling, principal-components analysis, factor analysis, correspondence analysis, and log-linear analysis have more in common in terms of underlying mathematical structure than had earlier been realized.
Nonmetric multidimensional scaling is a method that begins with data about the ordering established by subjective similarity (or nearness) between pairs of stimuli. The idea is to embed the stimuli into a metric space (that is, a geometry with a measure of distance between points) in such a way that distances between points corresponding to stimuli exhibit the same ordering as do the data. This method has been successfully applied to phenomena that, on other grounds, are known to be describable in terms of a specific geometric structure; such applications were used to validate the procedures. Such validation was done, for example, with respect to the perception of colors, which are known to be describable in terms of a particular three-dimensional structure known as the Euclidean color coordinates. Similar applications have been made with Morse code symbols and spoken phonemes. The technique is now used in some biological and engineering applications, as well as in some of the social sciences, as a method of data exploration and simplification.
One question of interest is how to develop an axiomatic basis for various geometries using as a primitive concept an observable such as the subject’s ordering of the relative similarity of one pair of stimuli to another, which is the typical starting point of such scaling. The general task is to discover properties of the qualitative data sufficient to ensure that a mapping into the geometric structure exists and, ideally, to discover an algorithm for finding it. Some work of this general type has been carried out: for example, there is an elegant set of axioms based on laws of color matching that yields the three-dimensional vectorial representation of color space. But the more general problem of understanding the conditions under which the multidimensional scaling algorithms are suitable remains unsolved. In addition, work is needed on understanding more general, non-Euclidean spatial models.
Ordered Factorial Systems
One type of structure common throughout the sciences arises when an ordered dependent variable is affected by two or more ordered independent variables. This is the situation to which regression and analysis-of-variance models are often applied; it is also the structure underlying the familiar physical identities, in which physical units are expressed as products of the powers of other units (for example, energy has the unit of mass times the square of the unit of distance divided by the square of the unit of time).
There are many examples of these types of structures in the behavioral and social sciences. One example is the ordering of preference of commodity bundles—collections of various amounts of commodities—which may be revealed directly by expressions of preference or indirectly by choices among alternative sets of bundles. A related example is preferences among alternative courses of action that involve various outcomes with differing degrees of uncertainty; this is one of the more thoroughly investigated problems because of its potential importance in decision making. A psychological example is the trade-off between delay and amount of reward, yielding those combinations that are equally reinforcing. In a common, applied kind of problem, a subject is given descriptions of people in terms of several factors, for example, intelligence, creativity, diligence, and honesty, and is asked to rate them according to a criterion such as suitability for a particular job.
In all these cases and a myriad of others like them the question is whether the regularities of the data permit a numerical representation. Initially, three types of representations were studied quite fully: the dependent variable as a sum, a product, or a weighted average of the measures associated with the independent variables. The first two representations underlie some psychological and economic investigations, as well as a considerable portion of physical measurement and modeling in classical statistics. The third representation, averaging, has proved most useful in understanding preferences among uncertain outcomes and the amalgamation of verbally described traits, as well as some physical variables.
For each of these three cases—adding, multiplying, and averaging—researchers know what properties or axioms of order the data must satisfy for such a numerical representation to be appropriate. On the assumption that one or another of these representations exists, and using numerical ratings by subjects instead of ordering, a scaling technique called functional measurement (referring to the function that describes how the dependent variable relates to the independent ones) has been developed and applied in a number of domains. What remains problematic is how to encompass at the ordinal level the fact that some random error intrudes into nearly all observations and then to show how that randomness is represented at the numerical level; this continues to be an unresolved and challenging research issue.
During the past few years considerable progress has been made in understanding certain representations inherently different from those just discussed. The work has involved three related thrusts. The first is a scheme of classifying structures according to how uniquely their representation is constrained. The three classical numerical representations are known as ordinal, interval, and ratio scale types. For systems with continuous numerical representations and of scale type at least as rich as the ratio one, it has been shown that only one additional type can exist. A second thrust is to accept structural assumptions, like factorial ones, and to derive for each scale the possible functional relations among the independent variables. And the third thrust is to develop axioms for the properties of an order relation that leads to the possible representations. Much is now known about the possible nonadditive representations of both the multifactor case and the one where stimuli can be combined, such as combining sound intensities.
Closely related to this classification of structures is the question: What statements, formulated in terms of the measures arising in such representations, can be viewed as meaningful in the sense of corresponding to something empirical? Statements here refer to any scientific assertions, including statistical ones, formulated in terms of the measures of the variables and logical and mathematical connectives. These are statements for which asserting truth or falsity makes sense. In particular, statements that remain invariant under certain symmetries of structure have played an important role in classical geometry, dimensional analysis in physics, and in relating measurement and statistical models applied to the same phenomenon. In addition, these ideas have been used to construct models in more formally developed areas of the behavioral and social sciences, such as psychophysics. Current research has emphasized the communality of these historically independent developments and is attempting both to uncover systematic, philosophically sound arguments as to why invariance under symmetries is as important as it appears to be and to understand what to do when structures lack symmetry, as, for example, when variables have an inherent upper bound.
Many subjects do not seem to be correctly represented in terms of distances in continuous geometric space. Rather, in some cases, such as the relations among meanings of words—which is of great interest in the study of memory representations—a description in terms of tree-like, hierarchial structures appears to be more illuminating. This kind of description appears appropriate both because of the categorical nature of the judgments and the hierarchial, rather than trade-off, nature of the structure. Individual items are represented as the terminal nodes of the tree, and groupings by different degrees of similarity are shown as intermediate nodes, with the more general groupings occurring nearer the root of the tree. Clustering techniques, requiring considerable computational power, have been and are being developed. Some successful applications exist, but much more refinement is anticipated.
Network Models
Several other lines of advanced modeling have progressed in recent years, opening new possibilities for empirical specification and testing of a variety of theories. In social network data, relationships among units, rather than the units themselves, are the primary objects of study: friendships among persons, trade ties among nations, cocitation clusters among research scientists, interlocking among corporate boards of directors. Special models for social network data have been developed in the past decade, and they give, among other things, precise new measures of the strengths of relational ties among units. A major challenge in social network data at present is to handle the statistical dependence that arises when the units sampled are related in complex ways.
- Statistical Inference and Analysis
As was noted earlier, questions of design, representation, and analysis are intimately intertwined. Some issues of inference and analysis have been discussed above as related to specific data collection and modeling approaches. This section discusses some more general issues of statistical inference and advances in several current approaches to them.
Causal Inference
Behavioral and social scientists use statistical methods primarily to infer the effects of treatments, interventions, or policy factors. Previous chapters included many instances of causal knowledge gained this way. As noted above, the large experimental study of alternative health care financing discussed in Chapter 2 relied heavily on statistical principles and techniques, including randomization, in the design of the experiment and the analysis of the resulting data. Sophisticated designs were necessary in order to answer a variety of questions in a single large study without confusing the effects of one program difference (such as prepayment or fee for service) with the effects of another (such as different levels of deductible costs), or with effects of unobserved variables (such as genetic differences). Statistical techniques were also used to ascertain which results applied across the whole enrolled population and which were confined to certain subgroups (such as individuals with high blood pressure) and to translate utilization rates across different programs and types of patients into comparable overall dollar costs and health outcomes for alternative financing options.
A classical experiment, with systematic but randomly assigned variation of the variables of interest (or some reasonable approach to this), is usually considered the most rigorous basis from which to draw such inferences. But random samples or randomized experimental manipulations are not always feasible or ethically acceptable. Then, causal inferences must be drawn from observational studies, which, however well designed, are less able to ensure that the observed (or inferred) relationships among variables provide clear evidence on the underlying mechanisms of cause and effect.
Certain recurrent challenges have been identified in studying causal inference. One challenge arises from the selection of background variables to be measured, such as the sex, nativity, or parental religion of individuals in a comparative study of how education affects occupational success. The adequacy of classical methods of matching groups in background variables and adjusting for covariates needs further investigation. Statistical adjustment of biases linked to measured background variables is possible, but it can become complicated. Current work in adjustment for selectivity bias is aimed at weakening implausible assumptions, such as normality, when carrying out these adjustments. Even after adjustment has been made for the measured background variables, other, unmeasured variables are almost always still affecting the results (such as family transfers of wealth or reading habits). Analyses of how the conclusions might change if such unmeasured variables could be taken into account is essential in attempting to make causal inferences from an observational study, and systematic work on useful statistical models for such sensitivity analyses is just beginning.
The third important issue arises from the necessity for distinguishing among competing hypotheses when the explanatory variables are measured with different degrees of precision. Both the estimated size and significance of an effect are diminished when it has large measurement error, and the coefficients of other correlated variables are affected even when the other variables are measured perfectly. Similar results arise from conceptual errors, when one measures only proxies for a theoretical construct (such as years of education to represent amount of learning). In some cases, there are procedures for simultaneously or iteratively estimating both the precision of complex measures and their effect on a particular criterion.
Although complex models are often necessary to infer causes, once their output is available, it should be translated into understandable displays for evaluation. Results that depend on the accuracy of a multivariate model and the associated software need to be subjected to appropriate checks, including the evaluation of graphical displays, group comparisons, and other analyses.
New Statistical Techniques
Internal resampling.
One of the great contributions of twentieth-century statistics was to demonstrate how a properly drawn sample of sufficient size, even if it is only a tiny fraction of the population of interest, can yield very good estimates of most population characteristics. When enough is known at the outset about the characteristic in question—for example, that its distribution is roughly normal—inference from the sample data to the population as a whole is straightforward, and one can easily compute measures of the certainty of inference, a common example being the 95 percent confidence interval around an estimate. But population shapes are sometimes unknown or uncertain, and so inference procedures cannot be so simple. Furthermore, more often than not, it is difficult to assess even the degree of uncertainty associated with complex data and with the statistics needed to unravel complex social and behavioral phenomena.
Internal resampling methods attempt to assess this uncertainty by generating a number of simulated data sets similar to the one actually observed. The definition of similar is crucial, and many methods that exploit different types of similarity have been devised. These methods provide researchers the freedom to choose scientifically appropriate procedures and to replace procedures that are valid under assumed distributional shapes with ones that are not so restricted. Flexible and imaginative computer simulation is the key to these methods. For a simple random sample, the “bootstrap” method repeatedly resamples the obtained data (with replacement) to generate a distribution of possible data sets. The distribution of any estimator can thereby be simulated and measures of the certainty of inference be derived. The “jackknife” method repeatedly omits a fraction of the data and in this way generates a distribution of possible data sets that can also be used to estimate variability. These methods can also be used to remove or reduce bias. For example, the ratio-estimator, a statistic that is commonly used in analyzing sample surveys and censuses, is known to be biased, and the jackknife method can usually remedy this defect. The methods have been extended to other situations and types of analysis, such as multiple regression.
There are indications that under relatively general conditions, these methods, and others related to them, allow more accurate estimates of the uncertainty of inferences than do the traditional ones that are based on assumed (usually, normal) distributions when that distributional assumption is unwarranted. For complex samples, such internal resampling or subsampling facilitates estimating the sampling variances of complex statistics.
An older and simpler, but equally important, idea is to use one independent subsample in searching the data to develop a model and at least one separate subsample for estimating and testing a selected model. Otherwise, it is next to impossible to make allowances for the excessively close fitting of the model that occurs as a result of the creative search for the exact characteristics of the sample data—characteristics that are to some degree random and will not predict well to other samples.
Robust Techniques
Many technical assumptions underlie the analysis of data. Some, like the assumption that each item in a sample is drawn independently of other items, can be weakened when the data are sufficiently structured to admit simple alternative models, such as serial correlation. Usually, these models require that a few parameters be estimated. Assumptions about shapes of distributions, normality being the most common, have proved to be particularly important, and considerable progress has been made in dealing with the consequences of different assumptions.
More recently, robust techniques have been designed that permit sharp, valid discriminations among possible values of parameters of central tendency for a wide variety of alternative distributions by reducing the weight given to occasional extreme deviations. It turns out that by giving up, say, 10 percent of the discrimination that could be provided under the rather unrealistic assumption of normality, one can greatly improve performance in more realistic situations, especially when unusually large deviations are relatively common.
These valuable modifications of classical statistical techniques have been extended to multiple regression, in which procedures of iterative reweighting can now offer relatively good performance for a variety of underlying distributional shapes. They should be extended to more general schemes of analysis.
In some contexts—notably the most classical uses of analysis of variance—the use of adequate robust techniques should help to bring conventional statistical practice closer to the best standards that experts can now achieve.
Many Interrelated Parameters
In trying to give a more accurate representation of the real world than is possible with simple models, researchers sometimes use models with many parameters, all of which must be estimated from the data. Classical principles of estimation, such as straightforward maximum-likelihood, do not yield reliable estimates unless either the number of observations is much larger than the number of parameters to be estimated or special designs are used in conjunction with strong assumptions. Bayesian methods do not draw a distinction between fixed and random parameters, and so may be especially appropriate for such problems.
A variety of statistical methods have recently been developed that can be interpreted as treating many of the parameters as or similar to random quantities, even if they are regarded as representing fixed quantities to be estimated. Theory and practice demonstrate that such methods can improve the simpler fixed-parameter methods from which they evolved, especially when the number of observations is not large relative to the number of parameters. Successful applications include college and graduate school admissions, where quality of previous school is treated as a random parameter when the data are insufficient to separately estimate it well. Efforts to create appropriate models using this general approach for small-area estimation and undercount adjustment in the census are important potential applications.
Missing Data
In data analysis, serious problems can arise when certain kinds of (quantitative or qualitative) information is partially or wholly missing. Various approaches to dealing with these problems have been or are being developed. One of the methods developed recently for dealing with certain aspects of missing data is called multiple imputation: each missing value in a data set is replaced by several values representing a range of possibilities, with statistical dependence among missing values reflected by linkage among their replacements. It is currently being used to handle a major problem of incompatibility between the 1980 and previous Bureau of Census public-use tapes with respect to occupation codes. The extension of these techniques to address such problems as nonresponse to income questions in the Current Population Survey has been examined in exploratory applications with great promise.
Computer Packages and Expert Systems
The development of high-speed computing and data handling has fundamentally changed statistical analysis. Methodologies for all kinds of situations are rapidly being developed and made available for use in computer packages that may be incorporated into interactive expert systems. This computing capability offers the hope that much data analyses will be more carefully and more effectively done than previously and that better strategies for data analysis will move from the practice of expert statisticians, some of whom may not have tried to articulate their own strategies, to both wide discussion and general use.
But powerful tools can be hazardous, as witnessed by occasional dire misuses of existing statistical packages. Until recently the only strategies available were to train more expert methodologists or to train substantive scientists in more methodology, but without the updating of their training it tends to become outmoded. Now there is the opportunity to capture in expert systems the current best methodological advice and practice. If that opportunity is exploited, standard methodological training of social scientists will shift to emphasizing strategies in using good expert systems—including understanding the nature and importance of the comments it provides—rather than in how to patch together something on one’s own. With expert systems, almost all behavioral and social scientists should become able to conduct any of the more common styles of data analysis more effectively and with more confidence than all but the most expert do today. However, the difficulties in developing expert systems that work as hoped for should not be underestimated. Human experts cannot readily explicate all of the complex cognitive network that constitutes an important part of their knowledge. As a result, the first attempts at expert systems were not especially successful (as discussed in Chapter 1 ). Additional work is expected to overcome these limitations, but it is not clear how long it will take.
Exploratory Analysis and Graphic Presentation
The formal focus of much statistics research in the middle half of the twentieth century was on procedures to confirm or reject precise, a priori hypotheses developed in advance of collecting data—that is, procedures to determine statistical significance. There was relatively little systematic work on realistically rich strategies for the applied researcher to use when attacking real-world problems with their multiplicity of objectives and sources of evidence. More recently, a species of quantitative detective work, called exploratory data analysis, has received increasing attention. In this approach, the researcher seeks out possible quantitative relations that may be present in the data. The techniques are flexible and include an important component of graphic representations. While current techniques have evolved for single responses in situations of modest complexity, extensions to multiple responses and to single responses in more complex situations are now possible.
Graphic and tabular presentation is a research domain in active renaissance, stemming in part from suggestions for new kinds of graphics made possible by computer capabilities, for example, hanging histograms and easily assimilated representations of numerical vectors. Research on data presentation has been carried out by statisticians, psychologists, cartographers, and other specialists, and attempts are now being made to incorporate findings and concepts from linguistics, industrial and publishing design, aesthetics, and classification studies in library science. Another influence has been the rapidly increasing availability of powerful computational hardware and software, now available even on desktop computers. These ideas and capabilities are leading to an increasing number of behavioral experiments with substantial statistical input. Nonetheless, criteria of good graphic and tabular practice are still too much matters of tradition and dogma, without adequate empirical evidence or theoretical coherence. To broaden the respective research outlooks and vigorously develop such evidence and coherence, extended collaborations between statistical and mathematical specialists and other scientists are needed, a major objective being to understand better the visual and cognitive processes (see Chapter 1 ) relevant to effective use of graphic or tabular approaches.
Combining Evidence
Combining evidence from separate sources is a recurrent scientific task, and formal statistical methods for doing so go back 30 years or more. These methods include the theory and practice of combining tests of individual hypotheses, sequential design and analysis of experiments, comparisons of laboratories, and Bayesian and likelihood paradigms.
There is now growing interest in more ambitious analytical syntheses, which are often called meta-analyses. One stimulus has been the appearance of syntheses explicitly combining all existing investigations in particular fields, such as prison parole policy, classroom size in primary schools, cooperative studies of therapeutic treatments for coronary heart disease, early childhood education interventions, and weather modification experiments. In such fields, a serious approach to even the simplest question—how to put together separate estimates of effect size from separate investigations—leads quickly to difficult and interesting issues. One issue involves the lack of independence among the available studies, due, for example, to the effect of influential teachers on the research projects of their students. Another issue is selection bias, because only some of the studies carried out, usually those with “significant” findings, are available and because the literature search may not find out all relevant studies that are available. In addition, experts agree, although informally, that the quality of studies from different laboratories and facilities differ appreciably and that such information probably should be taken into account. Inevitably, the studies to be included used different designs and concepts and controlled or measured different variables, making it difficult to know how to combine them.
Rich, informal syntheses, allowing for individual appraisal, may be better than catch-all formal modeling, but the literature on formal meta-analytic models is growing and may be an important area of discovery in the next decade, relevant both to statistical analysis per se and to improved syntheses in the behavioral and social and other sciences.
- Opportunities and Needs
This chapter has cited a number of methodological topics associated with behavioral and social sciences research that appear to be particularly active and promising at the present time. As throughout the report, they constitute illustrative examples of what the committee believes to be important areas of research in the coming decade. In this section we describe recommendations for an additional $16 million annually to facilitate both the development of methodologically oriented research and, equally important, its communication throughout the research community.
Methodological studies, including early computer implementations, have for the most part been carried out by individual investigators with small teams of colleagues or students. Occasionally, such research has been associated with quite large substantive projects, and some of the current developments of computer packages, graphics, and expert systems clearly require large, organized efforts, which often lie at the boundary between grant-supported work and commercial development. As such research is often a key to understanding complex bodies of behavioral and social sciences data, it is vital to the health of these sciences that research support continue on methods relevant to problems of modeling, statistical analysis, representation, and related aspects of behavioral and social sciences data. Researchers and funding agencies should also be especially sympathetic to the inclusion of such basic methodological work in large experimental and longitudinal studies. Additional funding for work in this area, both in terms of individual research grants on methodological issues and in terms of augmentation of large projects to include additional methodological aspects, should be provided largely in the form of investigator-initiated project grants.
Ethnographic and comparative studies also typically rely on project grants to individuals and small groups of investigators. While this type of support should continue, provision should also be made to facilitate the execution of studies using these methods by research teams and to provide appropriate methodological training through the mechanisms outlined below.
Overall, we recommend an increase of $4 million in the level of investigator-initiated grant support for methodological work. An additional $1 million should be devoted to a program of centers for methodological research.
Many of the new methods and models described in the chapter, if and when adopted to any large extent, will demand substantially greater amounts of research devoted to appropriate analysis and computer implementation. New user interfaces and numerical algorithms will need to be designed and new computer programs written. And even when generally available methods (such as maximum-likelihood) are applicable, model application still requires skillful development in particular contexts. Many of the familiar general methods that are applied in the statistical analysis of data are known to provide good approximations when sample sizes are sufficiently large, but their accuracy varies with the specific model and data used. To estimate the accuracy requires extensive numerical exploration. Investigating the sensitivity of results to the assumptions of the models is important and requires still more creative, thoughtful research. It takes substantial efforts of these kinds to bring any new model on line, and the need becomes increasingly important and difficult as statistical models move toward greater realism, usefulness, complexity, and availability in computer form. More complexity in turn will increase the demand for computational power. Although most of this demand can be satisfied by increasingly powerful desktop computers, some access to mainframe and even supercomputers will be needed in selected cases. We recommend an additional $4 million annually to cover the growth in computational demands for model development and testing.
Interaction and cooperation between the developers and the users of statistical and mathematical methods need continual stimulation—both ways. Efforts should be made to teach new methods to a wider variety of potential users than is now the case. Several ways appear effective for methodologists to communicate to empirical scientists: running summer training programs for graduate students, faculty, and other researchers; encouraging graduate students, perhaps through degree requirements, to make greater use of the statistical, mathematical, and methodological resources at their own or affiliated universities; associating statistical and mathematical research specialists with large-scale data collection projects; and developing statistical packages that incorporate expert systems in applying the methods.
Methodologists, in turn, need to become more familiar with the problems actually faced by empirical scientists in the laboratory and especially in the field. Several ways appear useful for communication in this direction: encouraging graduate students in methodological specialties, perhaps through degree requirements, to work directly on empirical research; creating postdoctoral fellowships aimed at integrating such specialists into ongoing data collection projects; and providing for large data collection projects to engage relevant methodological specialists. In addition, research on and development of statistical packages and expert systems should be encouraged to involve the multidisciplinary collaboration of experts with experience in statistical, computer, and cognitive sciences.
A final point has to do with the promise held out by bringing different research methods to bear on the same problems. As our discussions of research methods in this and other chapters have emphasized, different methods have different powers and limitations, and each is designed especially to elucidate one or more particular facets of a subject. An important type of interdisciplinary work is the collaboration of specialists in different research methodologies on a substantive issue, examples of which have been noted throughout this report. If more such research were conducted cooperatively, the power of each method pursued separately would be increased. To encourage such multidisciplinary work, we recommend increased support for fellowships, research workshops, and training institutes.
Funding for fellowships, both pre-and postdoctoral, should be aimed at giving methodologists experience with substantive problems and at upgrading the methodological capabilities of substantive scientists. Such targeted fellowship support should be increased by $4 million annually, of which $3 million should be for predoctoral fellowships emphasizing the enrichment of methodological concentrations. The new support needed for research workshops is estimated to be $1 million annually. And new support needed for various kinds of advanced training institutes aimed at rapidly diffusing new methodological findings among substantive scientists is estimated to be $2 million annually.
- Cite this Page National Research Council; Division of Behavioral and Social Sciences and Education; Commission on Behavioral and Social Sciences and Education; Committee on Basic Research in the Behavioral and Social Sciences; Gerstein DR, Luce RD, Smelser NJ, et al., editors. The Behavioral and Social Sciences: Achievements and Opportunities. Washington (DC): National Academies Press (US); 1988. 5, Methods of Data Collection, Representation, and Analysis.
- PDF version of this title (16M)
In this Page
Other titles in this collection.
- The National Academies Collection: Reports funded by National Institutes of Health
Recent Activity
- Methods of Data Collection, Representation, and Analysis - The Behavioral and So... Methods of Data Collection, Representation, and Analysis - The Behavioral and Social Sciences: Achievements and Opportunities
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
- Data Science
Caltech Bootcamp / Blog / /
Data Collection Methods: A Comprehensive View
- Written by John Terra
- Updated on February 21, 2024

Companies that want to be competitive in today’s digital economy enjoy the benefit of countless reams of data available for market research. In fact, thanks to the advent of big data, there’s a veritable tidal wave of information ready to be put to good use, helping businesses make intelligent decisions and thrive.
But before that data can be used, it must be processed. But before it can be processed, it must be collected, and that’s what we’re here for. This article explores the subject of data collection. We will learn about the types of data collection methods and why they are essential.
We will detail primary and secondary data collection methods and discuss data collection procedures. We’ll also share how you can learn practical skills through online data science training.
But first, let’s get the definition out of the way. What is data collection?
What is Data Collection?
Data collection is the act of collecting, measuring and analyzing different kinds of information using a set of validated standard procedures and techniques. The primary objective of data collection procedures is to gather reliable, information-rich data and analyze it to make critical business decisions. Once the desired data is collected, it undergoes a process of data cleaning and processing to make the information actionable and valuable for businesses.
Your choice of data collection method (or alternately called a data gathering procedure) depends on the research questions you’re working on, the type of data required, and the available time and resources and time. You can categorize data-gathering procedures into two main methods:
- Primary data collection . Primary data is collected via first-hand experiences and does not reference or use the past. The data obtained by primary data collection methods is exceptionally accurate and geared to the research’s motive. They are divided into two categories: quantitative and qualitative. We’ll explore the specifics later.
- Secondary data collection. Secondary data is the information that’s been used in the past. The researcher can obtain data from internal and external sources, including organizational data.
Let’s take a closer look at specific examples of both data collection methods.
The Specific Types of Data Collection Methods
As mentioned, primary data collection methods are split into quantitative and qualitative. We will examine each method’s data collection tools separately. Then, we will discuss secondary data collection methods.
Quantitative Methods
Quantitative techniques for demand forecasting and market research typically use statistical tools. When using these techniques, historical data is used to forecast demand. These primary data-gathering procedures are most often used to make long-term forecasts. Statistical analysis methods are highly reliable because they carry minimal subjectivity.
- Barometric Method. Also called the leading indicators approach, data analysts and researchers employ this method to speculate on future trends based on current developments. When past events are used to predict future events, they are considered leading indicators.
- Smoothing Techniques. Smoothing techniques can be used in cases where the time series lacks significant trends. These techniques eliminate random variation from historical demand and help identify demand levels and patterns to estimate future demand. The most popular methods used in these techniques are the simple moving average and the weighted moving average methods.
- Time Series Analysis. The term “time series” refers to the sequential order of values in a variable, also known as a trend, at equal time intervals. Using patterns, organizations can predict customer demand for their products and services during the projected time.
Qualitative Methods
Qualitative data collection methods are instrumental when no historical information is available, or numbers and mathematical calculations aren’t required. Qualitative research is closely linked to words, emotions, sounds, feelings, colors, and other non-quantifiable elements. These techniques rely on experience, conjecture, intuition, judgment, emotion, etc. Quantitative methods do not provide motives behind the participants’ responses. Additionally, they often don’t reach underrepresented populations and usually involve long data collection periods. Therefore, you get the best results using quantitative and qualitative methods together.
- Questionnaires . Questionnaires are a printed set of either open-ended or closed-ended questions. Respondents must answer based on their experience and knowledge of the issue. A questionnaire is a part of a survey, while the questionnaire’s end goal doesn’t necessarily have to be a survey.
- Surveys. Surveys collect data from target audiences, gathering insights into their opinions, preferences, choices, and feedback on the organization’s goods and services. Most survey software has a wide range of question types, or you can also use a ready-made survey template that saves time and effort. Surveys can be distributed via different channels such as e-mail, offline apps, websites, social media, QR codes, etc.
Once researchers collect the data, survey software generates reports and runs analytics algorithms to uncover hidden insights. Survey dashboards give you statistics relating to completion rates, response rates, filters based on demographics, export and sharing options, etc. Practical business intelligence depends on the synergy between analytics and reporting. Analytics uncovers valuable insights while reporting communicates these findings to the stakeholders.
- Polls. Polls consist of one or more multiple-choice questions. Marketers can turn to polls when they want to take a quick snapshot of the audience’s sentiments. Since polls tend to be short, getting people to respond is more manageable. Like surveys, online polls can be embedded into various media and platforms. Once the respondents answer the question(s), they can be shown how they stand concerning other people’s responses.
- Delphi Technique. The name is a callback to the Oracle of Delphi, a priestess at Apollo’s temple in ancient Greece, renowned for her prophecies. In this method, marketing experts are given the forecast estimates and assumptions made by other industry experts. The first batch of experts may then use the information provided by the other experts to revise and reconsider their estimates and assumptions. The total expert consensus on the demand forecasts creates the final demand forecast.
- Interviews. In this method, interviewers talk to the respondents either face-to-face or by telephone. In the first case, the interviewer asks the interviewee a series of questions in person and notes the responses. The interviewer can opt for a telephone interview if the parties cannot meet in person. This data collection form is practical for use with only a few respondents; repeating the same process with a considerably larger group takes longer.
- Focus Groups. Focus groups are one of the primary examples of qualitative data in education. In focus groups, small groups of people, usually around 8-10 members, discuss the research problem’s common aspects. Each person provides their insights on the issue, and a moderator regulates the discussion. When the discussion ends, the group reaches a consensus.
Secondary Data Collection Methods
Secondary data is the information that’s been used in past situations. Secondary data collection methods can include quantitative and qualitative techniques. In addition, secondary data is easily available, so it’s less time-consuming and expensive than using primary data. However, the authenticity of data gathered with secondary data collection tools cannot be verified.
Internal secondary data sources:
- CRM Software
- Executive summaries
- Financial Statements
- Mission and vision statements
- Organization’s health and safety records
- Sales Reports
External secondary data sources:
- Business journals
- Government reports
- Press releases
The Importance of Data Collection Methods
Data collection methods play a critical part in the research process as they determine the accuracy and quality and accuracy of the collected data. Here’s a sample of some reasons why data collection procedures are so important:
- They determine the quality and accuracy of collected data
- They ensure the data and the research findings are valid, relevant and reliable
- They help reduce bias and increase the sample’s representation
- They are crucial for making informed decisions and arriving at accurate conclusions
- They provide accurate data, which facilitates the achievement of research objectives
So, What’s the Difference Between Data Collecting and Data Processing?
Data collection is the first step in the data processing process. Data collection involves gathering information (raw data) from various sources such as interviews, surveys, questionnaires, etc. Data processing describes the steps taken to organize, manipulate and transform the collected data into a useful and meaningful resource. This process may include tasks such as cleaning and validating data, analyzing and summarizing data, and creating visualizations or reports.
So, data collection is just one step in the overall data processing chain of events.
Do You Want to Become a Data Scientist?
If this discussion about data collection and the professionals who conduct it has sparked your enthusiasm for a new career, why not check out this online data science program ?
The Glassdoor.com jobs website shows that data scientists in the United States typically make an average yearly salary of $129,127 plus additional bonuses and cash incentives. So, if you’re interested in a new career or are already in the field but want to upskill or refresh your current skill set, sign up for this bootcamp and prepare to tackle the challenges of today’s big data.
Data Science Bootcamp
- Learning Format:
Online Bootcamp
Leave a comment cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Recommended Articles

Why Use Python for Data Science?
This article explains why you should use Python for data science tasks, including how it’s done and the benefits.

A Beginner’s Guide to the Data Science Process
Data scientists are in high demand today. If you’re considering pursuing a career in this rewarding field, read on to better understand the data science process, tools, roles, and more.

What Is Data Mining? A Beginner’s Guide
This article explores data mining, including the steps involved in the data mining process, data mining tools and applications, and the associated challenges.

What Is Data Processing? Definition, Examples, Trends
This article addresses the question, “What is data processing?” It covers the data processing cycle, types and methods of data processing, and examples.

Navigating Data Scientist Roles and Responsibilities in Today’s Market
Data scientists are in high demand. If the job sounds interesting, read on to learn more about a data scientist’s roles and responsibilities.

Differences Between Data Scientist and Data Analyst: Complete Explanation
The ever-changing world of information technology (IT) has brought us new innovations and ways of doing things and a host of new terms, phrases, and
Learning Format
Program Benefits
- 12+ tools covered, 25+ hands-on projects
- Masterclasses by distinguished Caltech CTME instructors
- Caltech CTME Circle Membership
- Industry-specific training from global experts
- Call us on : 1800-212-7688
Chapter 10. Introduction to Data Collection Techniques
Introduction.
Now that we have discussed various aspects of qualitative research, we can begin to collect data. This chapter serves as a bridge between the first half and second half of this textbook (and perhaps your course) by introducing techniques of data collection. You’ve already been introduced to some of this because qualitative research is often characterized by the form of data collection; for example, an ethnographic study is one that employs primarily observational data collection for the purpose of documenting and presenting a particular culture or ethnos. Thus, some of this chapter will operate as a review of material already covered, but we will be approaching it from the data-collection side rather than the tradition-of-inquiry side we explored in chapters 2 and 4.
Revisiting Approaches
There are four primary techniques of data collection used in qualitative research: interviews, focus groups, observations, and document review. [1] There are other available techniques, such as visual analysis (e.g., photo elicitation) and biography (e.g., autoethnography) that are sometimes used independently or supplementarily to one of the main forms. Not to confuse you unduly, but these various data collection techniques are employed differently by different qualitative research traditions so that sometimes the technique and the tradition become inextricably entwined. This is largely the case with observations and ethnography. The ethnographic tradition is fundamentally based on observational techniques. At the same time, traditions other than ethnography also employ observational techniques, so it is worthwhile thinking of “tradition” and “technique” separately (see figure 10.1).
Figure 10.1. Data Collection Techniques
Each of these data collection techniques will be the subject of its own chapter in the second half of this textbook. This chapter serves as an orienting overview and as the bridge between the conceptual/design portion of qualitative research and the actual practice of conducting qualitative research.
Overview of the Four Primary Approaches
Interviews are at the heart of qualitative research. Returning to epistemological foundations, it is during the interview that the researcher truly opens herself to hearing what others have to say, encouraging her interview subjects to reflect deeply on the meanings and values they hold. Interviews are used in almost every qualitative tradition but are particularly salient in phenomenological studies, studies seeking to understand the meaning of people’s lived experiences.
Focus groups can be seen as a type of interview, one in which a group of persons (ideally between five and twelve) is asked a series of questions focused on a particular topic or subject. They are sometimes used as the primary form of data collection, especially outside academic research. For example, businesses often employ focus groups to determine if a particular product is likely to sell. Among qualitative researchers, it is often used in conjunction with any other primary data collection technique as a form of “triangulation,” or a way of increasing the reliability of the study by getting at the object of study from multiple directions. [2] Some traditions, such as feminist approaches, also see the focus group as an important “consciousness-raising” tool.
If interviews are at the heart of qualitative research, observations are its lifeblood. Researchers who are more interested in the practices and behaviors of people than what they think or who are trying to understand the parameters of an organizational culture rely on observations as their primary form of data collection. The notes they make “in the field” (either during observations or afterward) form the “data” that will be analyzed. Ethnographers, those seeking to describe a particular ethnos, or culture, believe that observations are more reliable guides to that culture than what people have to say about it. Observations are thus the primary form of data collection for ethnographers, albeit often supplemented with in-depth interviews.
Some would say that these three—interviews, focus groups, and observations—are really the foundational techniques of data collection. They are far and away the three techniques most frequently used separately, in conjunction with one another, and even sometimes in mixed methods qualitative/quantitative studies. Document review, either as a form of content analysis or separately, however, is an important addition to the qualitative researcher’s toolkit and should not be overlooked (figure 10.1). Although it is rare for a qualitative researcher to make document review their primary or sole form of data collection, including documents in the research design can help expand the reach and the reliability of a study. Document review can take many forms, from historical and archival research, in which the researcher pieces together a narrative of the past by finding and analyzing a variety of “documents” and records (including photographs and physical artifacts), to analyses of contemporary media content, as in the case of compiling and coding blog posts or other online commentaries, and content analysis that identifies and describes communicative aspects of media or documents.
In addition to these four major techniques, there are a host of emerging and incidental data collection techniques, from photo elicitation or photo voice, in which respondents are asked to comment upon a photograph or image (particularly useful as a supplement to interviews when the respondents are hesitant or unable to answer direct questions), to autoethnographies, in which the researcher uses his own position and life to increase our understanding about a phenomenon and its historical and social context.
Taken together, these techniques provide a wide range of practices and tools with which to discover the world. They are particularly suited to addressing the questions that qualitative researchers ask—questions about how things happen and why people act the way they do, given particular social contexts and shared meanings about the world (chapter 4).
Triangulation and Mixed Methods
Because the researcher plays such a large and nonneutral role in qualitative research, one that requires constant reflectivity and awareness (chapter 6), there is a constant need to reassure her audience that the results she finds are reliable. Quantitative researchers can point to any number of measures of statistical significance to reassure their audiences, but qualitative researchers do not have math to hide behind. And she will also want to reassure herself that what she is hearing in her interviews or observing in the field is a true reflection of what is going on (or as “true” as possible, given the problem that the world is as large and varied as the elephant; see chapter 3). For those reasons, it is common for researchers to employ more than one data collection technique or to include multiple and comparative populations, settings, and samples in the research design (chapter 2). A single set of interviews or initial comparison of focus groups might be conceived as a “pilot study” from which to launch the actual study. Undergraduate students working on a research project might be advised to think about their projects in this way as well. You are simply not going to have enough time or resources as an undergraduate to construct and complete a successful qualitative research project, but you may be able to tackle a pilot study. Graduate students also need to think about the amount of time and resources they have for completing a full study. Masters-level students, or students who have one year or less in which to complete a program, should probably consider their study as an initial exploratory pilot. PhD candidates might have the time and resources to devote to the type of triangulated, multifaceted research design called for by the research question.
We call the use of multiple qualitative methods of data collection and the inclusion of multiple and comparative populations and settings “triangulation.” Using different data collection methods allows us to check the consistency of our findings. For example, a study of the vaccine hesitant might include a set of interviews with vaccine-hesitant people and a focus group of the same and a content analysis of online comments about a vaccine mandate. By employing all three methods, we can be more confident of our interpretations from the interviews alone (especially if we are hearing the same thing throughout; if we are not, then this is a good sign that we need to push a little further to find out what is really going on). [3] Methodological triangulation is an important tool for increasing the reliability of our findings and the overall success of our research.
Methodological triangulation should not be confused with mixed methods techniques, which refer instead to the combining of qualitative and quantitative research methods. Mixed methods studies can increase reliability, but that is not their primary purpose. Mixed methods address multiple research questions, both the “how many” and “why” kind, or the causal and explanatory kind. Mixed methods will be discussed in more detail in chapter 15.
Let us return to the three examples of qualitative research described in chapter 1: Cory Abramson’s study of aging ( The End Game) , Jennifer Pierce’s study of lawyers and discrimination ( Racing for Innocence ), and my own study of liberal arts college students ( Amplified Advantage ). Each of these studies uses triangulation.
Abramson’s book is primarily based on three years of observations in four distinct neighborhoods. He chose the neighborhoods in such a way to maximize his ability to make comparisons: two were primarily middle class and two were primarily poor; further, within each set, one was predominantly White, while the other was either racially diverse or primarily African American. In each neighborhood, he was present in senior centers, doctors’ offices, public transportation, and other public spots where the elderly congregated. [4] The observations are the core of the book, and they are richly written and described in very moving passages. But it wasn’t enough for him to watch the seniors. He also engaged with them in casual conversation. That, too, is part of fieldwork. He sometimes even helped them make it to the doctor’s office or get around town. Going beyond these interactions, he also interviewed sixty seniors, an equal amount from each of the four neighborhoods. It was in the interviews that he could ask more detailed questions about their lives, what they thought about aging, what it meant to them to be considered old, and what their hopes and frustrations were. He could see that those living in the poor neighborhoods had a more difficult time accessing care and resources than those living in the more affluent neighborhoods, but he couldn’t know how the seniors understood these difficulties without interviewing them. Both forms of data collection supported each other and helped make the study richer and more insightful. Interviews alone would have failed to demonstrate the very real differences he observed (and that some seniors would not even have known about). This is the value of methodological triangulation.
Pierce’s book relies on two separate forms of data collection—interviews with lawyers at a firm that has experienced a history of racial discrimination and content analyses of news stories and popular films that screened during the same years of the alleged racial discrimination. I’ve used this book when teaching methods and have often found students struggle with understanding why these two forms of data collection were used. I think this is because we don’t teach students to appreciate or recognize “popular films” as a legitimate form of data. But what Pierce does is interesting and insightful in the best tradition of qualitative research. Here is a description of the content analyses from a review of her book:
In the chapter on the news media, Professor Pierce uses content analysis to argue that the media not only helped shape the meaning of affirmative action, but also helped create white males as a class of victims. The overall narrative that emerged from these media accounts was one of white male innocence and victimization. She also maintains that this narrative was used to support “neoconservative and neoliberal political agendas” (p. 21). The focus of these articles tended to be that affirmative action hurt white working-class and middle-class men particularly during the recession in the 1980s (despite statistical evidence that people of color were hurt far more than white males by the recession). In these stories fairness and innocence were seen in purely individual terms. Although there were stories that supported affirmative action and developed a broader understanding of fairness, the total number of stories slanted against affirmative action from 1990 to 1999. During that time period negative stories always outnumbered those supporting the policy, usually by a ratio of 3:1 or 3:2. Headlines, the presentation of polling data, and an emphasis in stories on racial division, Pierce argues, reinforced the story of white male victimization. Interestingly, the news media did very few stories on gender and affirmative action. The chapter on the film industry from 1989 to 1999 reinforces Pierce’s argument and adds another layer to her interpretation of affirmative action during this time period. She sampled almost 60 Hollywood films with receipts ranging from four million to 184 million dollars. In this chapter she argues that the dominant theme of these films was racial progress and the redemption of white Americans from past racism. These movies usually portrayed white, elite, and male experiences. People of color were background figures who supported the protagonist and “anointed” him as a savior (p. 45). Over the course of the film the protagonists move from “innocence to consciousness” concerning racism. The antagonists in these films most often were racist working-class white men. A Time to Kill , Mississippi Burning , Amistad , Ghosts of Mississippi , The Long Walk Home , To Kill a Mockingbird , and Dances with Wolves receive particular analysis in this chapter, and her examination of them leads Pierce to conclude that they infused a myth of racial progress into America’s cultural memory. White experiences of race are the focus and contemporary forms of racism are underplayed or omitted. Further, these films stereotype both working-class and elite white males, and underscore the neoliberal emphasis on individualism. ( Hrezo 2012 )
With that context in place, Pierce then turned to interviews with attorneys. She finds that White male attorneys often misremembered facts about the period in which the law firm was accused of racial discrimination and that they often portrayed their firms as having made substantial racial progress. This was in contrast to many of the lawyers of color and female lawyers who remembered the history differently and who saw continuing examples of racial (and gender) discrimination at the law firm. In most of the interviews, people talked about individuals, not structure (and these are attorneys, who really should know better!). By including both content analyses and interviews in her study, Pierce is better able to situate the attorney narratives and explain the larger context for the shared meanings of individual innocence and racial progress. Had this been a study only of films during this period, we would not know how actual people who lived during this period understood the decisions they made; had we had only the interviews, we would have missed the historical context and seen a lot of these interviewees as, well, not very nice people at all. Together, we have a study that is original, inventive, and insightful.
My own study of how class background affects the experiences and outcomes of students at small liberal arts colleges relies on mixed methods and triangulation. At the core of the book is an original survey of college students across the US. From analyses of this survey, I can present findings on “how many” questions and descriptive statistics comparing students of different social class backgrounds. For example, I know and can demonstrate that working-class college students are less likely to go to graduate school after college than upper-class college students are. I can even give you some estimates of the class gap. But what I can’t tell you from the survey is exactly why this is so or how it came to be so . For that, I employ interviews, focus groups, document reviews, and observations. Basically, I threw the kitchen sink at the “problem” of class reproduction and higher education (i.e., Does college reduce class inequalities or make them worse?). A review of historical documents provides a picture of the place of the small liberal arts college in the broader social and historical context. Who had access to these colleges and for what purpose have always been in contest, with some groups attempting to exclude others from opportunities for advancement. What it means to choose a small liberal arts college in the early twenty-first century is thus different for those whose parents are college professors, for those whose parents have a great deal of money, and for those who are the first in their family to attend college. I was able to get at these different understandings through interviews and focus groups and to further delineate the culture of these colleges by careful observation (and my own participation in them, as both former student and current professor). Putting together individual meanings, student dispositions, organizational culture, and historical context allowed me to present a story of how exactly colleges can both help advance first-generation, low-income, working-class college students and simultaneously amplify the preexisting advantages of their peers. Mixed methods addressed multiple research questions, while triangulation allowed for this deeper, more complex story to emerge.
In the next few chapters, we will explore each of the primary data collection techniques in much more detail. As we do so, think about how these techniques may be productively joined for more reliable and deeper studies of the social world.
Advanced Reading: Triangulation
Denzin ( 1978 ) identified four basic types of triangulation: data, investigator, theory, and methodological. Properly speaking, if we use the Denzin typology, the use of multiple methods of data collection and analysis to strengthen one’s study is really a form of methodological triangulation. It may be helpful to understand how this differs from the other types.
Data triangulation occurs when the researcher uses a variety of sources in a single study. Perhaps they are interviewing multiple samples of college students. Obviously, this overlaps with sample selection (see chapter 5). It is helpful for the researcher to understand that these multiple data sources add strength and reliability to the study. After all, it is not just “these students here” but also “those students over there” that are experiencing this phenomenon in a particular way.
Investigator triangulation occurs when different researchers or evaluators are part of the research team. Intercoding reliability is a form of investigator triangulation (or at least a way of leveraging the power of multiple researchers to raise the reliability of the study).
Theory triangulation is the use of multiple perspectives to interpret a single set of data, as in the case of competing theoretical paradigms (e.g., a human capital approach vs. a Bourdieusian multiple capital approach).
Methodological triangulation , as explained in this chapter, is the use of multiple methods to study a single phenomenon, issue, or problem.
Further Readings
Carter, Nancy, Denise Bryant-Lukosius, Alba DiCenso, Jennifer Blythe, Alan J. Neville. 2014. “The Use of Triangulation in Qualitative Research.” Oncology Nursing Forum 41(5):545–547. Discusses the four types of triangulation identified by Denzin with an example of the use of focus groups and in-depth individuals.
Mathison, Sandra. 1988. “Why Triangulate?” Educational Researcher 17(2):13–17. Presents three particular ways of assessing validity through the use of triangulated data collection: convergence, inconsistency, and contradiction.
Tracy, Sarah J. 2010. “Qualitative Quality: Eight ‘Big-Tent’ Criteria for Excellent Qualitative Research.” Qualitative Inquiry 16(10):837–851. Focuses on triangulation as a criterion for conducting valid qualitative research.
- Marshall and Rossman ( 2016 ) state this slightly differently. They list four primary methods for gathering information: (1) participating in the setting, (2) observing directly, (3) interviewing in depth, and (4) analyzing documents and material culture (141). An astute reader will note that I have collapsed participation into observation and that I have distinguished focus groups from interviews. I suspect that this distinction marks me as more of an interview-based researcher, while Marshall and Rossman prioritize ethnographic approaches. The main point of this footnote is to show you, the reader, that there is no single agreed-upon number of approaches to collecting qualitative data. ↵
- See “ Advanced Reading: Triangulation ” at end of this chapter. ↵
- We can also think about triangulating the sources, as when we include comparison groups in our sample (e.g., if we include those receiving vaccines, we might find out a bit more about where the real differences lie between them and the vaccine hesitant); triangulating the analysts (building a research team so that your interpretations can be checked against those of others on the team); and even triangulating the theoretical perspective (as when we “try on,” say, different conceptualizations of social capital in our analyses). ↵
Introduction to Qualitative Research Methods Copyright © 2023 by Allison Hurst is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
Research Paper Guide
Quantitative Research
Understanding Quantitative Research - Types & Data Collection Techniques
13 min read

People also read
Research Paper Writing - A Step by Step Guide
Research Paper Examples - Free Sample Papers for Different Formats!
Guide to Creating Effective Research Paper Outline
Interesting Research Paper Topics for 2024
Research Proposal Writing - A Step-by-Step Guide
How to Start a Research Paper - 7 Easy Steps
How to Write an Abstract for a Research Paper - A Step by Step Guide
Writing a Literature Review For a Research Paper - A Comprehensive Guide
Qualitative Research - Methods, Types, and Examples
8 Types of Qualitative Research - Overview & Examples
Qualitative vs Quantitative Research - Learning the Basics
200+ Engaging Psychology Research Paper Topics for Students in 2024
Learn How to Write a Hypothesis in a Research Paper: Examples and Tips!
20+ Types of Research With Examples - A Detailed Guide
230+ Sociology Research Topics & Ideas for Students
How to Cite a Research Paper - A Complete Guide
Excellent History Research Paper Topics- 300+ Ideas
A Guide on Writing the Method Section of a Research Paper - Examples & Tips
How To Write an Introduction Paragraph For a Research Paper: Learn with Examples
Crafting a Winning Research Paper Title: A Complete Guide
Writing a Research Paper Conclusion - Step-by-Step Guide
Writing a Thesis For a Research Paper - A Comprehensive Guide
How To Write A Discussion For A Research Paper | Examples & Tips
How To Write The Results Section of A Research Paper | Steps & Examples
Writing a Problem Statement for a Research Paper - A Comprehensive Guide
Finding Sources For a Research Paper: A Complete Guide
A Guide on How to Edit a Research Paper
200+ Ethical Research Paper Topics to Begin With (2024)
300+ Controversial Research Paper Topics & Ideas - 2024 Edition
150+ Argumentative Research Paper Topics For You - 2024
How to Write a Research Methodology for a Research Paper
Ever had a tough time with quantitative research? You're not alone!
Quantitative research is the process of collecting and analyzing numerical data to understand and study various phenomena using statistical methods. Many find this tedious process tricky.
But don't worry!
Our complete guide is here to guide you through the important steps and tricks to handle this challenge with confidence. We've even added some examples to make it easier.
So, let's dive in and learn together!
- 1. Quantitative Research Definition - What is Quantitative Research?
- 2. Data Collection in Quantitative Research
- 3. Data Analysis in Quantitative Research
- 4. Types of Quantitative Research Methods for Students and Researchers
- 5. Types of Data Collection Methodologies in Quantitative Research
- 6. Quantitative vs. Qualitative Research
- 7. Advantages and Strengths of Quantitative Research
- 8. Disadvantages and Weaknesses of Quantitative Research
Quantitative Research Definition - What is Quantitative Research?
Quantitative research involves gathering and studying numerical data. Its applications include identifying trends, making forecasts, testing cause-and-effect links, and drawing broader conclusions applicable to larger groups.
In this method, researchers employ tools such as surveys, experiments, and observations to gather data. Whereas in qualitative research, you deal with non-numeric data, such as text, video, or audio.
Quantitative research is extensively applied in natural and social sciences, including biology, chemistry, psychology, economics, sociology, and marketing, among others.
Characteristics of Quantitative Research
Here are some distinct quantitative research characteristics:
- Large Sample Sizes: Quantitative studies often involve larger sample sizes, allowing for more robust statistical analyses and generalizability of findings.
- Statistical Analysis: Statistical techniques and tools are extensively used to analyze data, unveiling patterns, relationships, and significance.
- Objective and Replicable: Quantitative research aims for objectivity and replicability. Other researchers should be able to conduct the same study and obtain similar results.
- Closed-Ended Questions: Surveys and questionnaires typically use closed-ended questions with predefined response options, making data analysis more straightforward.
- Quantifiable Variables: Researchers identify and measure variables that can be quantified, such as age, income, or test scores, for precise analysis.
- Hypothesis Testing: It often involves testing hypotheses and making inferences about populations based on sample data.
- Cross-Sectional or Longitudinal: Studies can be cross-sectional (data collected at a single point in time) or longitudinal (data collected over an extended period).
- Generalizability: Quantitative research seeks to generalize findings from a sample to a larger population, provided the sample is representative.
These characteristics make quantitative research different from qualitative research.
Data Collection in Quantitative Research
Data collection is the systematic process of gathering information for research purposes. It is a critical starting point, ensuring that the information gathered is relevant, accurate, and comprehensive.
- Structured Instruments - Quantitative research typically employs structured instruments like surveys and questionnaires. These tools ensure consistency in data gathering by posing the same set of questions to each participant.
- Sampling Methods - Researchers use various sampling techniques, such as random sampling, stratified sampling, or convenience sampling, to select a representative group from the target population.
- Objective Observation - Data collection often involves objective observations of phenomena. This may include recording numerical data, such as counting occurrences or measuring attributes.
- Experimental Control - In experimental research, control over variables is essential. Researchers manipulate one or more variables to observe their impact on the outcome, maintaining control over external factors.
Data Analysis in Quantitative Research
Data analysis is the second important aspect of quantitative research. After collecting the data, the data is analyzed with statistical methods. When analyzing, it is important that the results are relevant and related to the objective and aim of the research.
Below are some common statistical analysis methods that are used to analyze the collected data.
- SWOT Analysis - It stands for Strengths, Weaknesses, Opportunities, and Threats. Businesses use this kind of analysis to evaluate their performance and develop appropriate strategies.
- Conjoint Analysis - This kind of analysis helps businesses to identify how customers make difficult purchasing decisions. The businesses involved in direct sales and purchases know this and use the analysis to make the decisions.
- Cross-tabulation - A preliminary statistical analysis helps understand patterns, trends, and relationships between the various factors of the research.
- TURF Analysis - It stands for Totally Unduplicated Reach and Frequency Analysis. It is conducted to collect and analyze the data and responses of a chosen or favored target group.
Afterward, other methods like inferential statistics could be used to gather the results.
Types of Quantitative Research Methods for Students and Researchers
‘What are the four types of quantitative research?’
Quantitative research has four distinct types, and all four of them are regarded as primary research methods. Primary quantitative research is more common and useful than secondary research methods.
It is mainly because, in them, the researcher collects the data directly. He does not depend on previous research and collects the data from scratch.
Below are the four types of quantitative research methods.
Survey Research
This type of research is conducted through means of online surveys, online polls, and questionnaires. A group of people is chosen for the survey, and the method is used by big and small organizations and companies. They use it to understand their customers better.
Ideally, the survey is done through face-to-face meetings and interviews. Now, it is conducted through various online methodologies. Below are the common types of surveys.
- Cross-Sectional Survey - This research is conducted on a selected group of people at a certain point in time. The researcher evaluates several things. The selected group of people has similarities in all aspects except the ones chosen by the researcher. This kind of research is used for industries like retail, small-scale businesses, and healthcare industries.
- Longitudinal Survey - This research is based on observing a specific group of people for a set duration. The duration could be days, months, or even years. The researcher observes the change in behavior of the selected group of people.
This kind of research is used in the fields of applied sciences, medicine, and marketing.
Correlational Research
Correlational research is conducted to identify the relationship between two entities. These entities must be closely related and have a significant impact on each other.
This research is conducted to identify, evaluate, and understand the correlation between the variables and how they depend on each other.
The researchers use mathematical and statistical methods to understand this correlation. Some factors that they consider include relationships, trends, and patterns between these variables.
Sometimes, the researchers make changes in one of the variables to notice the effect on the other one.
Causal-comparative Research
This research is also known as quasi-experimental research. It is based on the cause and effect relationship between the two variables. Here, one of the variables is dependent on the other one, but the other one is independent. The researcher does not change the independent variable.
The research is not limited to statistical analysis only but includes other groups and variables also. The research could be conducted on the variables, no matter the kind of relationship they have. The statistical analysis method is used to acquire the results.
Experimental Research
This kind of research is based on proving or contradicting a theory or statement. It is also known as true experimentation and is usually focused on single or multiple theories.
The respective theory is not proven yet, and the research method is commonly used in natural sciences.
There could be some theories involved in this research. Due to this, it is more common in social sciences.
Types of Data Collection Methodologies in Quantitative Research
After determining the kind of research, finding the right data collection method is the most important step. Data could be collected through both the sampling and surveys and polls method.
Sampling Data Collection Method
In quantitative research, two types of sampling methods are used: probability and non-probability sampling.
1. Probability Sampling
The data is collected by sifting some individuals from the general population and creating samples. The individuals, data samples are chosen randomly and without any particular selection criteria.
Probability sampling is further divided into the following kinds.
- Simple Random Sampling - This kind of data selection is the simplest one, and the participants are chosen randomly. This kind of sampling is conducted on a large population.
- Stratified Random Sampling - In this sampling, the population is divided into several groups and strata. The participants for the research are chosen randomly from those groups.
- Cluster Sampling - In cluster sampling, the population is divided into several clusters based on geography and demography.
- Systematic Sampling - In this, the samples from the population are chosen at regular intervals. These intervals are predefined, and usually, they are calculated based on the population or size of the target sample.
2. Non-Probability Sampling
In this kind of data collection, the researcher uses his knowledge and experience to choose the samples. The researcher is involved and has a set of criteria. Due to this, not all individuals have the chance to be selected for the research.
Below are the main types of non-probability sampling frameworks.
- Convenience Sampling - These kinds of samples are probably the easiest to obtain. They are chosen only because they are the easiest ones to obtain. They are usually closer to the researcher, and these samples are easy to work with because there are no rigid parameters.
- Consecutive Sampling - This is similar to convenience sampling, but the researcher could choose a specific group of people for his research. The researcher could repeat the process with other groups of samples.
- Quota Sampling - The researchers select some specific elements based on the researcher’s target personalities and traits. Based on this, different individuals in the groups have equal chances of getting selected.
- Snowball Sampling - This kind of sampling is done on a target audience or a chosen group that is difficult to contact. In this, the chosen group is difficult to put together.
- Judgemental Sampling - This kind of sample is built based on the researcher’s skills, experience, and preferences.
Survey and Polls Data Collection Method
After the sample or group is chosen, the researcher could use polls or surveys to collect the required research data.
In this kind of research, the data is collected from a selected group of people. The data is used to identify new trends and collect information about different things and topics. Through the survey, the researcher could reach a wider population.
Based on the time allocated for the research, it could be used to collect more information and data.
When creating questions and options for the survey, the researchers use four measurement scales or criteria. These four parameters include nominal, interval, ordinal, and ratio measurement scales. Without them, no multiple-choice questions could be created.
The questions used for the survey must be close-ended. These could be a mix of different kinds of questions, and the responses could be analyzed through different rating scales.
After creating the survey, the next thing is to distribute it. Below are some of the commonly used survey distribution methods.
- Email - The most common method of distributing the survey is email management software to dispense the survey to your selected participants.
- Buying the Respondents - This is also a quite famous and widely used survey distribution method. Select the respondent and have him respond to the survey. Since the respondents would be knowledgeable, they will help in maximizing the results.
- Embedding the Survey on a Website - This is a great way of getting more responses and targeted results. Embedding the survey on a website works because the researcher is at the right place and close to the brand.
- Social Distribution - Distributing the survey through a social media platform helps collect more responses from the right audience.
- QR Code - The survey is stored in the QR code, and it is printed in magazines or on business cards.
- SMS Survey - It is the most convenient way of collecting more responses and data.
Like surveys, polls are also used to collect the data. It also has close-ended quantitative research questions, and election and exit polls are commonly used in this survey.
Quantitative vs. Qualitative Research
Quantitative and qualitative research are major kinds of research. They are mainly used in the subjects that follow detailed research patterns. How does it differ from quantitative research?
Below is a detailed comparison of the two kinds of research.
Want to know more about the differences between these types of research? Check out this extensive read on qualitative vs. quantitative research to get more insights!
Advantages and Strengths of Quantitative Research
Quantitative research offers several advantages to researchers. Some of the main reasons why researchers use this kind of research are discussed below:
- The Data Can Be Replicated - The research and study could be replicated. The data collection methods and definitions of the concepts are clear and easy to understand.
- The Results Can Be Compared Easily - The same study could be conducted in different cultural settings and sample groups. The results could also be compared statistically.
- Usage of Large Samples - Data and information from large samples could be processed and analyzed using different research procedures.
- Hypothesis Could be Tested - The researcher could use formal hypothesis testing. He could report the data collection, research variables, research predictions, and testing techniques before forecasting and establishing any conclusion.
- The Data Collection is Quick - The data could be collected easily and from a wider population. The usage of statistical methods and conducting and analyzing results is also easy and to the point.
- The Data Analysis is Inclusive - Quantitative data and research offer a wider population for sampling. They could be analyzed through research and analysis procedures.
Due to all of these advantages, researchers prefer using this kind of research method. It is easy to sample, collect, and analyze data and repeat the procedure easily.
Disadvantages and Weaknesses of Quantitative Research
Despite the benefits for the researchers, quantitative research design has some limitations. It may not be suitable for more complex and detailed kinds of topics.
Below are some common quantitative research limitations.
- Superficial - since the research includes limited and precise research samples. In quantitative research, the research is presented in numbers. They could be explained in detail through qualitative data and research.
- Limited Focus - the focus is narrow and limited, and the researcher would have to ignore other relevant and important variables.
- Biased Structure - structural biases could exist and affect sampling methods, data collection, and measurement results.
- Lack of Proper Conditions - sometimes, quantitative research may not include other important factors to collect the data.
Due to these reasons, quantitative research is not an ideal choice for detailed kinds of research. For them, qualitative research works better.
To help you further, we have added some useful examples of quantitative research here.
Quantitative Research Examples
Below are some helpful quantitative research examples to help you understand it better.
Sample Quantitative Research
Quantitative Research Example for Students
Now that you've got the hang of how to do quantitative research and why it's valuable, you're all set to begin your research journey.
The qualitative research method shows the idea and perception of your targeted audience. However, not every student is able to choose the right approach while writing a research paper. It requires a thorough understanding of both qualitative research and quantitative research methods.
This is where the professional help from MyPerfectWords.com comes in. We offer custom essay help with your academic assignments at affordable rates.
Contact our customer support and place " write my research paper " order today!

Write Essay Within 60 Seconds!

Nova Allison is a Digital Content Strategist with over eight years of experience. Nova has also worked as a technical and scientific writer. She is majorly involved in developing and reviewing online content plans that engage and resonate with audiences. Nova has a passion for writing that engages and informs her readers.

Paper Due? Why Suffer? That’s our Job!
Keep reading

An Overview of Data Collection in Health Preference Research.
This paper focuses on survey administration and data collection methods employed for stated-preference studies in health applications. First, it describes different types of survey administration methods, encompassing web-based surveys, face-to-face (in-person) surveys, and mail surveys. Second, the concept of sampling frames is introduced, clarifying distinctions between the target population and survey frame population. The discussion then extends to different types of sampling methods, such as probability and non-probability sampling, along with an evaluation of potential issues associated with different sampling methods within the context of health preference research. Third, the paper provides information about different recruitment methods, including web-surveys, leveraging patient groups, and in-clinic recruitment. Fourth, a crucial aspect addressed is the calculation of response rate, with insights into determining an adequate response rate and strategies to improve response rates in stated-preference surveys. Lastly, the paper concludes by discussing data management plans and suggesting insights for future research in this field. In summary, this paper examines the nuanced aspects of survey administration and data collection methods in stated-preference studies, offering valuable guidance for researchers and practitioners in the health domain.
Duke Scholars

Altmetric Attention Stats
Dimensions citation stats, published in, publication date, related subject headings.
- 42 Health sciences
- 32 Biomedical and clinical sciences
- 11 Medical and Health Sciences
An Overview of Data Collection in Health Preference Research
Affiliations.
- 1 Department of Population Health Sciences, Duke Clinical Research Institute, Duke University, Durham, NC, USA. [email protected].
- 2 Evidera Inc, London, England, UK.
- 3 Bayer Healthcare, Whippany, NJ, USA.
- 4 Curtin School of Population Health, Curtin University, Perth, Australia.
- PMID: 38662323
- DOI: 10.1007/s40271-024-00695-6
This paper focuses on survey administration and data collection methods employed for stated-preference studies in health applications. First, it describes different types of survey administration methods, encompassing web-based surveys, face-to-face (in-person) surveys, and mail surveys. Second, the concept of sampling frames is introduced, clarifying distinctions between the target population and survey frame population. The discussion then extends to different types of sampling methods, such as probability and non-probability sampling, along with an evaluation of potential issues associated with different sampling methods within the context of health preference research. Third, the paper provides information about different recruitment methods, including web-surveys, leveraging patient groups, and in-clinic recruitment. Fourth, a crucial aspect addressed is the calculation of response rate, with insights into determining an adequate response rate and strategies to improve response rates in stated-preference surveys. Lastly, the paper concludes by discussing data management plans and suggesting insights for future research in this field. In summary, this paper examines the nuanced aspects of survey administration and data collection methods in stated-preference studies, offering valuable guidance for researchers and practitioners in the health domain.
© 2024. The Author(s), under exclusive licence to Springer Nature Switzerland AG.
IMAGES
VIDEO
COMMENTS
Step 2: Choose your data collection method. Based on the data you want to collect, decide which method is best suited for your research. Experimental research is primarily a quantitative method. Interviews, focus groups, and ethnographies are qualitative methods. Surveys, observations, archival research and secondary data collection can be ...
The first is intermethod mixing, which means two or moreof the different methods of data collection are used in a research study. This is seen in the two examples in the previous paragraph. In the first example, standardized test data and qualitative interview data were mixed/combined in the study.
The data collected through quantitative methods is typically in the form of numbers, such as response frequencies, means, and standard deviations, and can be analyzed using statistical software. LEARN ABOUT: Research Process Steps. Importance of Quantitative Data Collection. As a researcher, you do have the option to opt either for data ...
A fifth method of data collection for quantitative research is known as secondary research: reviewing existing research to see how it can contribute to understanding a new issue in question. This is in contrast to the primary research methods above, which is research that is specially commissioned and carried out for a research project.
Data collection methods in quantitative research refer to the techniques or tools used to collect data from participants or units in a study. Data are the most important asset for any researcher because they provide the researcher with the knowledge necessary to confirm or refute their research hypothesis. 2 The choice
We offer best-practice recommendations for journal reviewers, editors, and authors regarding data collection and preparation. Our recommendations are applicable to research adopting different epistemological and ontological perspectives—including both quantitative and qualitative approaches—as well as research addressing micro (i.e., individuals, teams) and macro (i.e., organizations ...
Quantitative method is the collection and analysis of numerical data to answer scientific research questions. Quantitative method is used to summarize, average, find patterns, make predictions, and test causal associations as well as generalizing results to wider populations. It allows us to quantify effect sizes, determine the strength of ...
Accordingly, quantitative data collection methods are based on numbers and mathematical calculations. Quantitative research can be described as 'entailing the collection of numerical data and exhibiting the view of relationship between theory and research as deductive, a predilection for natural science approach, and as having an objectivist ...
Quantitative surveys are a data collection tool used to gather close-ended responses from individuals and groups. Question types primarily include categorical (e.g. "yes/no") and interval/ratio questions (e.g. rating-scale, Likert-scale ). They are used to gather information such based upon the behaviours, characteristics, or opinions, and ...
Summary. For many people, collecting quantitative data is the core of social research. Types of quantitative techniques are the things that first come to mind when people think of social research - techniques such as self-completion questionnaires and interview surveys. They are all founded on the principle that you can generate information ...
Hypothesis-testing (Quantitative hypothesis-testing research) - Quantitative research uses deductive reasoning. - This involves the formation of a hypothesis, collection of data in the investigation of the problem, analysis and use of the data from the investigation, and drawing of conclusions to validate or nullify the hypotheses.
Of all the quantitative data collection methods, surveys and questionnaires are among the easiest and most effective. Many graduate students conducting doctoral research use this method because surveys and questionnaires are applicable to both quantitative and qualitative research. You should consider a few questions when planning a survey or ...
In quantitative research process, data collection is a very important step. Quality data collection methods improve the accuracy or validity of study outcomes or findings. Nurse researchers have emphasized on the use of valid and reliable instruments to measure a variety of phenomena of interest in nursing.
Step 2: Choose your data collection method. Based on the data you want to collect, decide which method is best suited for your research. Experimental research is primarily a quantitative method. Interviews, focus groups, and ethnographies are qualitative methods. Surveys, observations, archival research, and secondary data collection can be ...
Obtaining Samples for Population Generalizability. In quantitative research, a population is the entire group that the researcher wants to draw conclusions about.. A sample is the specific group that the researcher will actually collect data from. A sample is always a much smaller group of people than the total size of the population.
The most common forms of quantitative data collection methods are: Experiments; Observation with instruments; Spatial data; Surveys with numerical scaled questions; Below are some resources from the UNT Libraries that provide guidance on quantitative data collection methods and sampling techniques commonly used in social science research.
3. Data Collection in Quantitative Research: Data collection in quantitative research involves gathering numerical data to analyze and test hypotheses. Here are some common methods and techniques used in quantitative data collection: 1. Surveys: Surveys involve collecting data through questionnaires or structured interviews. They can be ...
This chapter concerns research on collecting, representing, and analyzing the data that underlie behavioral and social sciences knowledge. Such research, methodological in character, includes ethnographic and historical approaches, scaling, axiomatic measurement, and statistics, with its important relatives, econometrics and psychometrics. The field can be described as including the self ...
The data obtained by primary data collection methods is exceptionally accurate and geared to the research's motive. They are divided into two categories: quantitative and qualitative. We'll explore the specifics later. Secondary data collection. Secondary data is the information that's been used in the past.
Data Collection, Research Methodology, Data Collection Methods, Academic Research Paper, Data Collection Techniques. I. INTRODUCTION Different methods for gathering information regarding specific variables of the study aiming to employ them in the data analysis phase to achieve the results of the study, gain the answer of the research
Figure 10.1. Data Collection Techniques. Each of these data collection techniques will be the subject of its own chapter in the second half of this textbook. This chapter serves as an orienting overview and as the bridge between the conceptual/design portion of qualitative research and the actual practice of conducting qualitative research.
After determining the kind of research, finding the right data collection method is the most important step. Data could be collected through both the sampling and surveys and polls method. Sampling Data Collection Method. In quantitative research, two types of sampling methods are used: probability and non-probability sampling. 1. Probability ...
This paper focuses on survey administration and data collection methods employed for stated-preference studies in health applications. First, it describes different types of survey administration methods, encompassing web-based surveys, face-to-face (in-person) surveys, and mail surveys. Second, the concept of sampling frames is introduced ...
Abstract. This paper focuses on survey administration and data collection methods employed for stated-preference studies in health applications. First, it describes different types of survey administration methods, encompassing web-based surveys, face-to-face (in-person) surveys, and mail surveys. Second, the concept of sampling frames is ...