Data analysis write-ups
What should a data-analysis write-up look like.
Writing up the results of a data analysis is not a skill that anyone is born with. It requires practice and, at least in the beginning, a bit of guidance.

Organization
When writing your report, organization will set you free. A good outline is: 1) overview of the problem, 2) your data and modeling approach, 3) the results of your data analysis (plots, numbers, etc), and 4) your substantive conclusions.
1) Overview Describe the problem. What substantive question are you trying to address? This needn’t be long, but it should be clear.
2) Data and model What data did you use to address the question, and how did you do it? When describing your approach, be specific. For example:
- Don’t say, “I ran a regression” when you instead can say, “I fit a linear regression model to predict price that included a house’s size and neighborhood as predictors.”
- Justify important features of your modeling approach. For example: “Neighborhood was included as a categorical predictor in the model because Figure 2 indicated clear differences in price across the neighborhoods.”
Sometimes your Data and Model section will contain plots or tables, and sometimes it won’t. If you feel that a plot helps the reader understand the problem or data set itself—as opposed to your results—then go ahead and include it. A great example here is Tables 1 and 2 in the main paper on the PREDIMED study . These tables help the reader understand some important properties of the data and approach, but not the results of the study itself.
3) Results In your results section, include any figures and tables necessary to make your case. Label them (Figure 1, 2, etc), give them informative captions, and refer to them in the text by their numbered labels where you discuss them. Typical things to include here may include: pictures of the data; pictures and tables that show the fitted model; tables of model coefficients and summaries.
4) Conclusion What did you learn from the analysis? What is the answer, if any, to the question you set out to address?
General advice
Make the sections as short or long as they need to be. For example, a conclusions section is often pretty short, while a results section is usually a bit longer.
It’s OK to use the first person to avoid awkward or bizarre sentence constructions, but try to do so sparingly.
Do not include computer code unless explicitly called for. Note: model outputs do not count as computer code. Outputs should be used as evidence in your results section (ideally formatted in a nice way). By code, I mean the sequence of commands you used to process the data and produce the outputs.
When in doubt, use shorter words and sentences.
A very common way for reports to go wrong is when the writer simply narrates the thought process he or she followed: :First I did this, but it didn’t work. Then I did something else, and I found A, B, and C. I wasn’t really sure what to make of B, but C was interesting, so I followed up with D and E. Then having done this…” Do not do this. The desire for specificity is admirable, but the overall effect is one of amateurism. Follow the recommended outline above.
Here’s a good example of a write-up for an analysis of a few relatively simple problems. Because the problems are so straightforward, there’s not much of a need for an outline of the kind described above. Nonetheless, the spirit of these guidelines is clearly in evidence. Notice the clear exposition, the labeled figures and tables that are referred to in the text, and the careful integration of visual and numerical evidence into the overall argument. This is one worth emulating.
Find what you need to study
Academic Paper: Discussion and Analysis
5 min read • march 10, 2023
Dylan Black
Introduction
After presenting your data and results to readers, you have one final step before you can finally wrap up your paper and write a conclusion: analyzing your data! This is the big part of your paper that finally takes all the stuff you've been talking about - your method, the data you collected, the information presented in your literature review - and uses it to make a point!
The major question to be answered in your analysis section is simply "we have all this data, but what does it mean?" What questions does this data answer? How does it relate to your research question ? Can this data be explained by, and is it consistent with, other papers? If not, why? These are the types of questions you'll be discussing in this section.
Source: GIPHY
Writing a Discussion and Analysis
Explain what your data means.
The primary point of a discussion section is to explain to your readers, through both statistical means and thorough explanation, what your results mean for your project. In doing so, you want to be succinct, clear, and specific about how your data backs up the claims you are making. These claims should be directly tied back to the overall focus of your paper.
What is this overall focus, you may ask? Your research question ! This discussion along with your conclusion forms the final analysis of your research - what answers did we find? Was our research successful? How do the results we found tie into and relate to the current consensus by the research community? Were our results expected or unexpected? Why or why not? These are all questions you may consider in writing your discussion section.
You showing off all of the cool findings of your research! Source: GIPHY
Why Did Your Results Happen?
After presenting your results in your results section, you may also want to explain why your results actually occurred. This is integral to gaining a full understanding of your results and the conclusions you can draw from them. For example, if data you found contradicts certain data points found in other studies, one of the most important aspects of your discussion of said data is going to be theorizing as to why this disparity took place.
Note that making broad, sweeping claims based on your data is not enough! Everything, and I mean just about everything you say in your discussions section must be backed up either by your own findings that you showed in your results section or past research that has been performed in your field.
For many situations, finding these answers is not easy, and a lot of thinking must be done as to why your results actually occurred the way they did. For some fields, specifically STEM-related fields, a discussion might dive into the theoretical foundations of your research, explaining interactions between parts of your study that led to your results. For others, like social sciences and humanities, results may be open to more interpretation.
However, "open to more interpretation" does not mean you can make claims willy nilly and claim "author's interpretation". In fact, such interpretation may be harder than STEM explanations! You will have to synthesize existing analysis on your topic and incorporate that in your analysis.
Liam Neeson explains the major question of your analysis. Source: GIPHY
Discussion vs. Summary & Repetition
Quite possibly the biggest mistake made within a discussion section is simply restating your data in a different format. The role of the discussion section is to explain your data and what it means for your project. Many students, thinking they're making discussion and analysis, simply regurgitate their numbers back in full sentences with a surface-level explanation.
Phrases like "this shows" and others similar, while good building blocks and great planning tools, often lead to a relatively weak discussion that isn't very nuanced and doesn't lead to much new understanding.
Instead, your goal will be to, through this section and your conclusion, establish a new understanding and in the end, close your gap! To do this effectively, you not only will have to present the numbers and results of your study, but you'll also have to describe how such data forms a new idea that has not been found in prior research.
This, in essence, is the heart of research - finding something new that hasn't been studied before! I don't know if it's just us, but that's pretty darn cool and something that you as the researcher should be incredibly proud of yourself for accomplishing.
Rubric Points
Before we close out this guide, let's take a quick peek at our best friend: the AP Research Rubric for the Discussion and Conclusion sections.

Source: CollegeBoard
Scores of One and Two: Nothing New, Your Standard Essay
Responses that earn a score of one or two on this section of the AP Research Academic Paper typically don't find much new and by this point may not have a fully developed method nor well-thought-out results. For the most part, these are more similar to essays you may have written in a prior English class or AP Seminar than a true Research paper. Instead of finding new ideas, they summarize already existing information about a topic.

Score of Three: New Understanding, Not Enough Support
A score of three is the first row that establishes a new understanding! This is a great step forward from a one or a two. However, what differentiates a three from a four or a five is the explanation and support of such a new understanding. A paper that earns a three lacks in building a line of reasoning and does not present enough evidence, both from their results section and from already published research.
Scores of Four and Five: New Understanding With A Line of Reasoning
We've made it to the best of the best! With scores of four and five, successful papers describe a new understanding with an effective line of reasoning, sufficient evidence, and an all-around great presentation of how their results signify filling a gap and answering a research question .
As far as the discussions section goes, the difference between a four and a five is more on the side of complexity and nuance. Where a four hits all the marks and does it well, a five exceeds this and writes a truly exceptional analysis. Another area where these two sections differ is in the limitations described, which we discuss in the Conclusion section guide.

You did it!!!! You have, for the most part, finished the brunt of your research paper and are over the hump! All that's left to do is tackle the conclusion, which tends to be for most the easiest section to write because all you do is summarize how your research question was answered and make some final points about how your research impacts your field. Finally, as always...

Key Terms to Review ( 1 )
Research Question
Stay Connected
© 2024 Fiveable Inc. All rights reserved.
AP® and SAT® are trademarks registered by the College Board, which is not affiliated with, and does not endorse this website.

Research Paper Writing: 6. Results / Analysis
- 1. Getting Started
- 2. Abstract
- 3. Introduction
- 4. Literature Review
- 5. Methods / Materials
- 6. Results / Analysis
- 7. Discussion
- 8. Conclusion
- 9. Reference
Writing about the information
There are two sections of a research paper depending on what style is being written. The sections are usually straightforward commentary of exactly what the writer observed and found during the actual research. It is important to include only the important findings, and avoid too much information that can bury the exact meaning of the context.
The results section should aim to narrate the findings without trying to interpret or evaluate, and also provide a direction to the discussion section of the research paper. The results are reported and reveals the analysis. The analysis section is where the writer describes what was done with the data found. In order to write the analysis section it is important to know what the analysis consisted of, but does not mean data is needed. The analysis should already be performed to write the results section.
Written explanations
How should the analysis section be written?
- Should be a paragraph within the research paper
- Consider all the requirements (spacing, margins, and font)
- Should be the writer’s own explanation of the chosen problem
- Thorough evaluation of work
- Description of the weak and strong points
- Discussion of the effect and impact
- Includes criticism
How should the results section be written?
- Show the most relevant information in graphs, figures, and tables
- Include data that may be in the form of pictures, artifacts, notes, and interviews
- Clarify unclear points
- Present results with a short discussion explaining them at the end
- Include the negative results
- Provide stability, accuracy, and value
How the style is presented
Analysis section
- Includes a justification of the methods used
- Technical explanation
Results section
- Purely descriptive
- Easily explained for the targeted audience
- Data driven
Example of a Results Section
Publication Manual of the American Psychological Association Sixth Ed. 2010
- << Previous: 5. Methods / Materials
- Next: 7. Discussion >>
- Last Updated: Nov 7, 2023 7:37 AM
- URL: https://wiu.libguides.com/researchpaperwriting

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- BMJ Open Access
How to write statistical analysis section in medical research
Alok kumar dwivedi.
Department of Molecular and Translational Medicine, Division of Biostatistics and Epidemiology, Texas Tech University Health Sciences Center El Paso, El Paso, Texas, USA
Associated Data
jim-2022-002479supp001.pdf
Data sharing not applicable as no datasets generated and/or analyzed for this study.
Reporting of statistical analysis is essential in any clinical and translational research study. However, medical research studies sometimes report statistical analysis that is either inappropriate or insufficient to attest to the accuracy and validity of findings and conclusions. Published works involving inaccurate statistical analyses and insufficient reporting influence the conduct of future scientific studies, including meta-analyses and medical decisions. Although the biostatistical practice has been improved over the years due to the involvement of statistical reviewers and collaborators in research studies, there remain areas of improvement for transparent reporting of the statistical analysis section in a study. Evidence-based biostatistics practice throughout the research is useful for generating reliable data and translating meaningful data to meaningful interpretation and decisions in medical research. Most existing research reporting guidelines do not provide guidance for reporting methods in the statistical analysis section that helps in evaluating the quality of findings and data interpretation. In this report, we highlight the global and critical steps to be reported in the statistical analysis of grants and research articles. We provide clarity and the importance of understanding study objective types, data generation process, effect size use, evidence-based biostatistical methods use, and development of statistical models through several thematic frameworks. We also provide published examples of adherence or non-adherence to methodological standards related to each step in the statistical analysis and their implications. We believe the suggestions provided in this report can have far-reaching implications for education and strengthening the quality of statistical reporting and biostatistical practice in medical research.
Introduction
Biostatistics is the overall approach to how we realistically and feasibly execute a research idea to produce meaningful data and translate data to meaningful interpretation and decisions. In this era of evidence-based medicine and practice, basic biostatistical knowledge becomes essential for critically appraising research articles and implementing findings for better patient management, improving healthcare, and research planning. 1 However, it may not be sufficient for the proper execution and reporting of statistical analyses in studies. 2 3 Three things are required for statistical analyses, namely knowledge of the conceptual framework of variables, research design, and evidence-based applications of statistical analysis with statistical software. 4 5 The conceptual framework provides possible biological and clinical pathways between independent variables and outcomes with role specification of variables. The research design provides a protocol of study design and data generation process (DGP), whereas the evidence-based statistical analysis approach provides guidance for selecting and implementing approaches after evaluating data with the research design. 2 5 Ocaña-Riola 6 reported a substantial percentage of articles from high-impact medical journals contained errors in statistical analysis or data interpretation. These errors in statistical analyses and interpretation of results do not only impact the reliability of research findings but also influence the medical decision-making and planning and execution of other related studies. A survey of consulting biostatisticians in the USA reported that researchers frequently request biostatisticians for performing inappropriate statistical analyses and inappropriate reporting of data. 7 This implies that there is a need to enforce standardized reporting of the statistical analysis section in medical research which can also help rreviewers and investigators to improve the methodological standards of the study.
Biostatistical practice in medicine has been improving over the years due to continuous efforts in promoting awareness and involving expert services on biostatistics, epidemiology, and research design in clinical and translational research. 8–11 Despite these efforts, the quality of reporting of statistical analysis in research studies has often been suboptimal. 12 13 We noticed that none of the methods reporting documents were developed using evidence-based biostatistics (EBB) theory and practice. The EBB practice implies that the selection of statistical analysis methods for statistical analyses and the steps of results reporting and interpretation should be grounded based on the evidence generated in the scientific literature and according to the study objective type and design. 5 Previous works have not properly elucidated the importance of understanding EBB concepts and related reporting in the write-up of statistical analyses. As a result, reviewers sometimes ask to present data or execute analyses that do not match the study objective type. 14 We summarize the statistical analysis steps to be reported in the statistical analysis section based on review and thematic frameworks.
We identified articles describing statistical reporting problems in medicine using different search terms ( online supplemental table 1 ). Based on these studies, we prioritized commonly reported statistical errors in analytical strategies and developed essential components to be reported in the statistical analysis section of research grants and studies. We also clarified the purpose and the overall implication of reporting each step in statistical analyses through various examples.
Supplementary data
Although biostatistical inputs are critical for the entire research study ( online supplemental table 2 ), biostatistical consultations were mostly used for statistical analyses only 15 . Even though the conduct of statistical analysis mismatched with the study objective and DGP was identified as the major problem in articles submitted to high-impact medical journals. 16 In addition, multivariable analyses were often inappropriately conducted and reported in published studies. 17 18 In light of these statistical errors, we describe the reporting of the following components in the statistical analysis section of the study.
Step 1: specify study objective type and outcomes (overall approach)
The study objective type provides the role of important variables for a specified outcome in statistical analyses and the overall approach of the model building and model reporting steps in a study. In the statistical framework, the problems are classified into descriptive and inferential/analytical/confirmatory objectives. In the epidemiological framework, the analytical and prognostic problems are broadly classified into association, explanatory, and predictive objectives. 19 These study objectives ( figure 1 ) may be classified into six categories: (1) exploratory, (2) association, (3) causal, (4) intervention, (5) prediction and (6) clinical decision models in medical research. 20

Comparative assessments of developing and reporting of study objective types and models. Association measures include odds ratio, risk ratio, or hazard ratio. AUC, area under the curve; C, confounder; CI, confidence interval; E, exposure; HbA1C: hemoglobin A1c; M, mediator; MFT, model fit test; MST, model specification test; PI, predictive interval; R 2 , coefficient of determinant; X, independent variable; Y, outcome.
The exploratory objective type is a specific type of determinant study and is commonly known as risk factors or correlates study in medical research. In an exploratory study, all covariates are considered equally important for the outcome of interest in the study. The goal of the exploratory study is to present the results of a model which gives higher accuracy after satisfying all model-related assumptions. In the association study, the investigator identifies predefined exposures of interest for the outcome, and variables other than exposures are also important for the interpretation and considered as covariates. The goal of an association study is to present the adjusted association of exposure with outcome. 20 In the causal objective study, the investigator is interested in determining the impact of exposure(s) on outcome using the conceptual framework. In this study objective, all variables should have a predefined role (exposures, confounders, mediators, covariates, and predictors) in a conceptual framework. A study with a causal objective is known as an explanatory or a confirmatory study in medical research. The goal is to present the direct or indirect effects of exposure(s) on an outcome after assessing the model’s fitness in the conceptual framework. 19 21 The objective of an interventional study is to determine the effect of an intervention on outcomes and is often known as randomized or non-randomized clinical trials in medical research. In the intervention objective model, all variables other than the intervention are treated as nuisance variables for primary analyses. The goal is to present the direct effect of the intervention on the outcomes by eliminating biases. 22–24 In the predictive study, the goal is to determine an optimum set of variables that can predict the outcome, particularly in external settings. The clinical decision models are a special case of prognostic models in which high dimensional data at various levels are used for risk stratification, classification, and prediction. In this model, all variables are considered input features. The goal is to present a decision tool that has high accuracy in training, testing, and validation data sets. 20 25 Biostatisticians or applied researchers should properly discuss the intention of the study objective type before proceeding with statistical analyses. In addition, it would be a good idea to prepare a conceptual model framework regardless of study objective type to understand study concepts.
A study 26 showed a favorable effect of the beta-blocker intervention on survival outcome in patients with advanced human epidermal growth factor receptor (HER2)-negative breast cancer without adjusting for all the potential confounding effects (age or menopausal status and Eastern Cooperative Oncology Performance Status) in primary analyses or validation analyses or using a propensity score-adjusted analysis, which is an EBB preferred method for analyzing non-randomized studies. 27 Similarly, another study had the goal of developing a predictive model for prediction of Alzheimer’s disease progression. 28 However, this study did not internally or externally validate the performance of the model as per the requirement of a predictive objective study. In another study, 29 investigators were interested in determining an association between metabolic syndrome and hepatitis C virus. However, the authors did not clearly specify the outcome in the analysis and produced conflicting associations with different analyses. 30 Thus, the outcome should be clearly specified as per the study objective type.
Step 2: specify effect size measure according to study design (interpretation and practical value)
The study design provides information on the selection of study participants and the process of data collection conditioned on either exposure or outcome ( figure 2 ). The appropriate use of effect size measure, tabular presentation of results, and the level of evidence are mostly determined by the study design. 31 32 In cohort or clinical trial study designs, the participants are selected based on exposure status and are followed up for the development of the outcome. These study designs can provide multiple outcomes, produce incidence or incidence density, and are preferred to be analyzed with risk ratio (RR) or hazards models. In a case–control study, the selection of participants is conditioned on outcome status. This type of study can have only one outcome and is preferred to be analyzed with an odds ratio (OR) model. In a cross-sectional study design, there is no selection restriction on outcomes or exposures. All data are collected simultaneously and can be analyzed with a prevalence ratio model, which is mathematically equivalent to the RR model. 33 The reporting of effect size measure also depends on the study objective type. For example, predictive models typically require reporting of regression coefficients or weight of variables in the model instead of association measures, which are required in other objective types. There are agreements and disagreements between OR and RR measures. Due to the constancy and symmetricity properties of OR, some researchers prefer to use OR in studies with common events. Similarly, the collapsibility and interpretability properties of RR make it more appealing to use in studies with common events. 34 To avoid variable practice and interpretation issues with OR, it is recommended to use RR models in all studies except for case–control and nested case–control studies, where OR approximates RR and thus OR models should be used. Otherwise, investigators may report sufficient data to compute any ratio measure. Biostatisticians should educate investigators on the proper interpretation of ratio measures in the light of study design and their reporting. 34 35

Effect size according to study design.
Investigators sometimes either inappropriately label their study design 36 37 or report effect size measures not aligned with the study design, 38 39 leading to difficulty in results interpretation and evaluation of the level of evidence. The proper labeling of study design and the appropriate use of effect size measure have substantial implications for results interpretation, including the conduct of systematic review and meta-analysis. 40 A study 31 reviewed the frequency of reporting OR instead of RR in cohort studies and randomized clinical trials (RCTs) and found that one-third of the cohort studies used an OR model, whereas 5% of RCTs used an OR model. The majority of estimated ORs from these studies had a 20% or higher deviation from the corresponding RR.
Step 3: specify study hypothesis, reporting of p values, and interval estimates (interpretation and decision)
The clinical hypothesis provides information for evaluating formal claims specified in the study objectives, while the statistical hypothesis provides information about the population parameters/statistics being used to test the formal claims. The inference about the study hypothesis is typically measured by p value and confidence interval (CI). A smaller p value indicates that the data support against the null hypothesis. Since the p value is a conditional probability, it can never tell about the acceptance or rejection of the null hypothesis. Therefore, multiple alternative strategies of p values have been proposed to strengthen the credibility of conclusions. 41 42 Adaption of these alternative strategies is only needed in the explanatory objective studies. Although exact p values are recommended to be reported in research studies, p values do not provide any information about the effect size. Compared with p values, the CI provides a confidence range of the effect size that contains the true effect size if the study were repeated and can be used to determine whether the results are statistically significant or not. 43 Both p value and 95% CI provide complementary information and thus need to be specified in the statistical analysis section. 24 44
Researchers often test one or more comparisons or hypotheses. Accordingly, the side and the level of significance for considering results to be statistically significant may change. Furthermore, studies may include more than one primary outcome that requires an adjustment in the level of significance for multiplicity. All studies should provide the interval estimate of the effect size/regression coefficient in the primary analyses. Since the interpretation of data analysis depends on the study hypothesis, researchers are required to specify the level of significance along with the side (one-sided or two-sided) of the p value in the test for considering statistically significant results, adjustment of the level of significance due to multiple comparisons or multiplicity, and reporting of interval estimates of the effect size in the statistical analysis section. 45
A study 46 showed a significant effect of fluoxetine on relapse rates in obsessive-compulsive disorder based on a one-sided p value of 0.04. Clearly, there was no reason for using a one-sided p value as opposed to a two-sided p value. A review of the appropriate use of multiple test correction methods in multiarm clinical trials published in major medical journals in 2012 identified over 50% of the articles did not perform multiple-testing correction. 47 Similar to controlling a familywise error rate due to multiple comparisons, adjustment of the false discovery rate is also critical in studies involving multiple related outcomes. A review of RCTs for depression between 2007 and 2008 from six journals reported that only limited studies (5.8%) accounted for multiplicity in the analyses due to multiple outcomes. 48
Step 4: account for DGP in the statistical analysis (accuracy)
The study design also requires the specification of the selection of participants and outcome measurement processes in different design settings. We referred to this specific design feature as DGP. Understanding DGP helps in determining appropriate modeling of outcome distribution in statistical analyses and setting up model premises and units of analysis. 4 DGP ( figure 3 ) involves information on data generation and data measures, including the number of measurements after random selection, complex selection, consecutive selection, pragmatic selection, or systematic selection. Specifically, DGP depends on a sampling setting (participants are selected using survey sampling methods and one subject may represent multiple participants in the population), clustered setting (participants are clustered through a recruitment setting or hierarchical setting or multiple hospitals), pragmatic setting (participants are selected through mixed approaches), or systematic review setting (participants are selected from published studies). DGP also depends on the measurements of outcomes in an unpaired setting (measured on one occasion only in independent groups), paired setting (measured on more than one occasion or participants are matched on certain subject characteristics), or mixed setting (measured on more than one occasion but interested in comparing independent groups). It also involves information regarding outcomes or exposure generation processes using quantitative or categorical variables, quantitative values using labs or validated instruments, and self-reported or administered tests yielding a variety of data distributions, including individual distribution, mixed-type distribution, mixed distributions, and latent distributions. Due to different DGPs, study data may include messy or missing data, incomplete/partial measurements, time-varying measurements, surrogate measures, latent measures, imbalances, unknown confounders, instrument variables, correlated responses, various levels of clustering, qualitative data, or mixed data outcomes, competing events, individual and higher-level variables, etc. The performance of statistical analysis, appropriate estimation of standard errors of estimates and subsequently computation of p values, the generalizability of findings, and the graphical display of data rely on DGP. Accounting for DGP in the analyses requires proper communication between investigators and biostatisticians about each aspect of participant selection and data collection, including measurements, occasions of measurements, and instruments used in the research study.

Common features of the data generation process.
A study 49 compared the intake of fresh fruit and komatsuna juice with the intake of commercial vegetable juice on metabolic parameters in middle-aged men using an RCT. The study was criticized for many reasons, but primarily for incorrect statistical methods not aligned with the study DGP. 50 Similarly, another study 51 highlighted that 80% of published studies using the Korean National Health and Nutrition Examination Survey did not incorporate survey sampling structure in statistical analyses, producing biased estimates and inappropriate findings. Likewise, another study 52 highlighted the need for maintaining methodological standards while analyzing data from the National Inpatient Sample. A systematic review 53 identified that over 50% of studies did not specify whether a paired t-test or an unpaired t-test was performed in statistical analysis in the top 25% of physiology journals, indicating poor transparency in reporting of statistical analysis as per the data type. Another study 54 also highlighted the data displaying errors not aligned with DGP. As per DGP, delay in treatment initiation of patients with cancer defined from the onset of symptom to treatment initiation should be analyzed into three components: patient/primary delay, secondary delay, and tertiary delay. 55 Similarly, the number of cancerous nodes should be analyzed with count data models. 56 However, several studies did not analyze such data according to DGP. 57 58
Step 5: apply EBB methods specific to study design features and DGP (efficiency and robustness)
The continuous growth in the development of robust statistical methods for dealing with a specific problem produced various methods to analyze specific data types. Since multiple methods are available for handling a specific problem yet with varying performances, heterogeneous practices among applied researchers have been noticed. Variable practices could also be due to a lack of consensus on statistical methods in literature, unawareness, and the unavailability of standardized statistical guidelines. 2 5 59 However, it becomes sometimes difficult to differentiate whether a specific method was used due to its robustness, lack of awareness, lack of accessibility of statistical software to apply an alternative appropriate method, intention to produce expected results, or ignorance of model diagnostics. To avoid heterogeneous practices, the selection of statistical methodology and their reporting at each stage of data analysis should be conducted using methods according to EBB practice. 5 Since it is hard for applied researchers to optimally select statistical methodology at each step, we encourage investigators to involve biostatisticians at the very early stage in basic, clinical, population, translational, and database research. We also appeal to biostatisticians to develop guidelines, checklists, and educational tools to promote the concept of EBB. As an effort, we developed the statistical analysis and methods in biomedical research (SAMBR) guidelines for applied researchers to use EBB methods for data analysis. 5 The EBB practice is essential for applying recent cutting-edge robust methodologies to yield accurate and unbiased results. The efficiency of statistical methodologies depends on the assumptions and DGP. Therefore, investigators may attempt to specify the choice of specific models in the primary analysis as per the EBB.
Although details of evidence-based preferred methods are provided in the SAMBR checklists for each study design/objective, 5 we have presented a simplified version of evidence-based preferred methods for common statistical analysis ( online supplemental table 3 ). Several examples are available in the literature where inefficient methods not according to EBB practice have been used. 31 57 60
Step 6: report variable selection method in the multivariable analysis according to study objective type (unbiased)
Multivariable analysis can be used for association, prediction or classification or risk stratification, adjustment, propensity score development, and effect size estimation. 61 Some biological, clinical, behavioral, and environmental factors may directly associate or influence the relationship between exposure and outcome. Therefore, almost all health studies require multivariable analyses for accurate and unbiased interpretations of findings ( figure 1 ). Analysts should develop an adjusted model if the sample size permits. It is a misconception that the analysis of RCT does not require adjusted analysis. Analysis of RCT may require adjustment for prognostic variables. 23 The foremost step in model building is the entry of variables after finalizing the appropriate parametric or non-parametric regression model. In the exploratory model building process due to no preference of exposures, a backward automated approach after including any variables that are significant at 25% in the unadjusted analysis can be used for variable selection. 62 63 In the association model, a manual selection of covariates based on the relevance of the variables should be included in a fully adjusted model. 63 In a causal model, clinically guided methods should be used for variable selection and their adjustments. 20 In a non-randomized interventional model, efforts should be made to eliminate confounding effects through propensity score methods and the final propensity score-adjusted multivariable model may adjust any prognostic variables, while a randomized study simply should adjust any prognostic variables. 27 Maintaining the event per variable (EVR) is important to avoid overfitting in any type of modeling; therefore, screening of variables may be required in some association and explanatory studies, which may be accomplished using a backward stepwise method that needs to be clarified in the statistical analyses. 10 In a predictive study, a model with an optimum set of variables producing the highest accuracy should be used. The optimum set of variables may be screened with the random forest method or bootstrap or machine learning methods. 64 65 Different methods of variable selection and adjustments may lead to different results. The screening process of variables and their adjustments in the final multivariable model should be clearly mentioned in the statistical analysis section.
A study 66 evaluating the effect of hydroxychloroquine (HDQ) showed unfavorable events (intubation or death) in patients who received HDQ compared with those who did not (hazard ratio (HR): 2.37, 95% CI 1.84 to 3.02) in an unadjusted analysis. However, the propensity score-adjusted analyses as appropriate with the interventional objective model showed no significant association between HDQ use and unfavorable events (HR: 1.04, 95% CI 0.82 to 1.32), which was also confirmed in multivariable and other propensity score-adjusted analyses. This study clearly suggests that results interpretation should be based on a multivariable analysis only in observational studies if feasible. A recent study 10 noted that approximately 6% of multivariable analyses based on either logistic or Cox regression used an inappropriate selection method of variables in medical research. This practice was more commonly noted in studies that did not involve an expert biostatistician. Another review 61 of 316 articles from high-impact Chinese medical journals revealed that 30.7% of articles did not report the selection of variables in multivariable models. Indeed, this inappropriate practice could have been identified more commonly if classified according to the study objective type. 18 In RCTs, it is uncommon to report an adjusted analysis based on prognostic variables, even though an adjusted analysis may produce an efficient estimate compared with an unadjusted analysis. A study assessing the effect of preemptive intervention on development outcomes showed a significant effect of an intervention on reducing autism spectrum disorder symptoms. 67 However, this study was criticized by Ware 68 for not reporting non-significant results in unadjusted analyses. If possible, unadjusted estimates should also be reported in any study, particularly in RCTs. 23 68
Step 7: provide evidence for exploring effect modifiers (applicability)
Any variable that modifies the effect of exposure on the outcome is called an effect modifier or modifier or an interacting variable. Exploring the effect modifiers in multivariable analyses helps in (1) determining the applicability/generalizability of findings in the overall or specific subpopulation, (2) generating ideas for new hypotheses, (3) explaining uninterpretable findings between unadjusted and adjusted analyses, (4) guiding to present combined or separate models for each specific subpopulation, and (5) explaining heterogeneity in treatment effect. Often, investigators present adjusted stratified results according to the presence or absence of an effect modifier. If the exposure interacts with multiple variables statistically or conceptually in the model, then the stratified findings (subgroup) according to each effect modifier may be presented. Otherwise, stratified analysis substantially reduces the power of the study due to the lower sample size in each stratum and may produce significant results by inflating type I error. 69 Therefore, a multivariable analysis involving an interaction term as opposed to a stratified analysis may be presented in the presence of an effect modifier. 70 Sometimes, a quantitative variable may emerge as a potential effect modifier for exposure and an outcome relationship. In such a situation, the quantitative variable should not be categorized unless a clinically meaningful threshold is not available in the study. In fact, the practice of categorizing quantitative variables should be avoided in the analysis unless a clinically meaningful cut-off is available or a hypothesis requires for it. 71 In an exploratory objective type, any possible interaction may be obtained in a study; however, the interpretation should be guided based on clinical implications. Similarly, some objective models may have more than one exposure or intervention and the association of each exposure according to the level of other exposure should be presented through adjusted analyses as suggested in the presence of interaction effects. 70
A review of 428 articles from MEDLINE on the quality of reporting from statistical analyses of three (linear, logistic, and Cox) commonly used regression models reported that only 18.5% of the published articles provided interaction analyses, 17 even though interaction analyses can provide a lot of useful information.
Step 8: assessment of assumptions, specifically the distribution of outcome, linearity, multicollinearity, sparsity, and overfitting (reliability)
The assessment and reporting of model diagnostics are important in assessing the efficiency, validity, and usefulness of the model. Model diagnostics include satisfying model-specific assumptions and the assessment of sparsity, linearity, distribution of outcome, multicollinearity, and overfitting. 61 72 Model-specific assumptions such as normal residuals, heteroscedasticity and independence of errors in linear regression, proportionality in Cox regression, proportionality odds assumption in ordinal logistic regression, and distribution fit in other types of continuous and count models are required. In addition, sparsity should also be examined prior to selecting an appropriate model. Sparsity indicates many zero observations in the data set. 73 In the presence of sparsity, the effect size is difficult to interpret. Except for machine learning models, most of the parametric and semiparametric models require a linear relationship between independent variables and a functional form of an outcome. Linearity should be assessed using a multivariable polynomial in all model objectives. 62 Similarly, the appropriate choice of the distribution of outcome is required for model building in all study objective models. Multicollinearity assessment is also useful in all objective models. Assessment of EVR in multivariable analysis can be used to avoid the overfitting issue of a multivariable model. 18
Some review studies highlighted that 73.8%–92% of the articles published in MEDLINE had not assessed the model diagnostics of the multivariable regression models. 17 61 72 Contrary to the monotonically, linearly increasing relationship between systolic blood pressure (SBP) and mortality established using the Framingham’s study, 74 Port et al 75 reported a non-linear relationship between SBP and all-cause mortality or cardiovascular deaths by reanalysis of the Framingham’s study data set. This study identified a different threshold for treating hypertension, indicating the role of linearity assessment in multivariable models. Although a non-Gaussian distribution model may be required for modeling patient delay outcome data in cancer, 55 a study analyzed patient delay data using an ordinary linear regression model. 57 An investigation of the development of predictive models and their reporting in medical journals identified that 53% of the articles had fewer EVR than the recommended EVR, indicating over half of the published articles may have an overfitting model. 18 Another study 76 attempted to identify the anthropometric variables associated with non-insulin-dependent diabetes and found that none of the anthropometric variables were significant after adjusting for waist circumference, age, and sex, indicating the presence of collinearity. A study reported detailed sparse data problems in published studies and potential solutions. 73
Step 9: report type of primary and sensitivity analyses (consistency)
Numerous considerations and assumptions are made throughout the research processes that require assessment, evaluation, and validation. Some assumptions, executions, and errors made at the beginning of the study data collection may not be fixable 13 ; however, additional information collected during the study and data processing, including data distribution obtained at the end of the study, may facilitate additional considerations that need to be verified in the statistical analyses. Consistencies in the research findings via modifications in the outcome or exposure definition, study population, accounting for missing data, model-related assumptions, variables and their forms, and accounting for adherence to protocol in the models can be evaluated and reported in research studies using sensitivity analyses. 77 The purpose and type of supporting analyses need to be specified clearly in the statistical analyses to differentiate the main findings from the supporting findings. Sensitivity analyses are different from secondary or interim or subgroup analyses. 78 Data analyses for secondary outcomes are often referred to as secondary analyses, while data analyses of an ongoing study are called interim analyses and data analyses according to groups based on patient characteristics are known as subgroup analyses.
Almost all studies require some form of sensitivity analysis to validate the findings under different conditions. However, it is often underutilized in medical journals. Only 18%–20.3% of studies reported some forms of sensitivity analyses. 77 78 A review of nutritional trials from high-quality journals reflected that 17% of the conclusions were reported inappropriately using findings from sensitivity analyses not based on the primary/main analyses. 77
Step 10: provide methods for summarizing, displaying, and interpreting data (transparency and usability)
Data presentation includes data summary, data display, and data from statistical model analyses. The primary purpose of the data summary is to understand the distribution of outcome status and other characteristics in the total sample and by primary exposure status or outcome status. Column-wise data presentation should be preferred according to exposure status in all study designs, while row-wise data presentation for the outcome should be preferred in all study designs except for a case–control study. 24 32 Summary statistics should be used to provide maximum information on data distribution aligned with DGP and variable type. The purpose of results presentation primarily from regression analyses or statistical models is to convey results interpretation and implications of findings. The results should be presented according to the study objective type. Accordingly, the reporting of unadjusted and adjusted associations of each factor with the outcome may be preferred in the determinant objective model, while unadjusted and adjusted effects of primary exposure on the outcome may be preferred in the explanatory objective model. In prognostic models, the final predictive models may be presented in such a way that users can use models to predict an outcome. In the exploratory objective model, a final multivariable model should be reported with R 2 or area under the curve (AUC). In the association and interventional models, the assessment of internal validation is critically important through various sensitivity and validation analyses. A model with better fit indices (in terms of R 2 or AUC, Akaike information criterion, Bayesian information criterion, fit index, root mean square error) should be finalized and reported in the causal model objective study. In the predictive objective type, the model performance in terms of R 2 or AUC in training and validation data sets needs to be reported ( figure 1 ). 20 21 There are multiple purposes of data display, including data distribution using bar diagram or histogram or frequency polygons or box plots, comparisons using cluster bar diagram or scatter dot plot or stacked bar diagram or Kaplan-Meier plot, correlation or model assessment using scatter plot or scatter matrix, clustering or pattern using heatmap or line plots, the effect of predictors with fitted models using marginsplot, and comparative evaluation of effect sizes from regression models using forest plot. Although the key purpose of data display is to highlight critical issues or findings in the study, data display should essentially follow DGP and variable types and should be user-friendly. 54 79 Data interpretation heavily relies on the effect size measure along with study design and specified hypotheses. Sometimes, variables require standardization for descriptive comparison of effect sizes among exposures or interpreting small effect size, or centralization for interpreting intercept or avoiding collinearity due to interaction terms, or transformation for achieving model-related assumptions. 80 Appropriate methods of data reporting and interpretation aligned with study design, study hypothesis, and effect size measure should be specified in the statistical analysis section of research studies.
Published articles from reputed journals inappropriately summarized a categorized variable with mean and range, 81 summarized a highly skewed variable with mean and standard deviation, 57 and treated a categorized variable as a continuous variable in regression analyses. 82 Similarly, numerous examples from published studies reporting inappropriate graphical display or inappropriate interpretation of data not aligned with DGP or variable types are illustrated in a book published by Bland and Peacock. 83 84 A study used qualitative data on MRI but inappropriately presented with a Box-Whisker plot. 81 Another study reported unusually high OR for an association between high breast parenchymal enhancement and breast cancer in both premenopausal and postmenopausal women. 85 This reporting makes suspicious findings and may include sparse data bias. 86 A poor tabular presentation without proper scaling or standardization of a variable, missing CI for some variables, missing unit and sample size, and inconsistent reporting of decimal places could be easily noticed in table 4 of a published study. 29 Some published predictive models 87 do not report intercept or baseline survival estimates to use their predictive models in clinical use. Although a direct comparison of effect sizes obtained from the same model may be avoided if the units are different among variables, 35 a study had an objective to compare effect sizes across variables but the authors performed comparisons without standardization of variables or using statistical tests. 88
A sample for writing statistical analysis section in medical journals/research studies
Our primary study objective type was to develop a (select from figure 1 ) model to assess the relationship of risk factors (list critical variables or exposures) with outcomes (specify type from continuous/discrete/count/binary/polytomous/time-to-event). To address this objective, we conducted a (select from figure 2 or any other) study design to test the hypotheses of (equality or superiority or non-inferiority or equivalence or futility) or develop prediction. Accordingly, the other variables were adjusted or considered as (specify role of variables from confounders, covariates, or predictors or independent variables) as reflected in the conceptual framework. In the unadjusted or preliminary analyses as per the (select from figure 3 or any other design features) DGP, (specify EBB preferred tests from online supplemental table 3 or any other appropriate tests) were used for (specify variables and types) in unadjusted analyses. According to the EBB practice for the outcome (specify type) and DGP of (select from figure 3 or any other), we used (select from online supplemental table 1 or specify a multivariable approach) as the primary model in the multivariable analysis. We used (select from figure 1 ) variable selection method in the multivariable analysis and explored the interaction effects between (specify variables). The model diagnostics including (list all applicable, including model-related assumptions, linearity, or multicollinearity or overfitting or distribution of outcome or sparsity) were also assessed using (specify appropriate methods) respectively. In such exploration, we identified (specify diagnostic issues if any) and therefore the multivariable models were developed using (specify potential methods used to handle diagnostic issues). The other outcomes were analyzed with (list names of multivariable approaches with respective outcomes). All the models used the same procedure (or specify from figure 1 ) for variable selection, exploration of interaction effects, and model diagnostics using (specify statistical approaches) depending on the statistical models. As per the study design, hypothesis, and multivariable analysis, the results were summarized with effect size (select as appropriate or from figure 2 ) along with (specify 95% CI or other interval estimates) and considered statistically significant using (specify the side of p value or alternatives) at (specify the level of significance) due to (provide reasons for choosing a significance level). We presented unadjusted and/or adjusted estimates of primary outcome according to (list primary exposures or variables). Additional analyses were conducted for (specific reasons from step 9) using (specify methods) to validate findings obtained in the primary analyses. The data were summarized with (list summary measures and appropriate graphs from step 10), whereas the final multivariable model performance was summarized with (fit indices if applicable from step 10). We also used (list graphs) as appropriate with DGP (specify from figure 3 ) to present the critical findings or highlight (specify data issues) using (list graphs/methods) in the study. The exposures or variables were used in (specify the form of the variables) and therefore the effect or association of (list exposures or variables) on outcome should be interpreted in terms of changes in (specify interpretation unit) exposures/variables. List all other additional analyses if performed (with full details of all models in a supplementary file along with statistical codes if possible).
Concluding remarks
We highlighted 10 essential steps to be reported in the statistical analysis section of any analytical study ( figure 4 ). Adherence to minimum reporting of the steps specified in this report may enforce investigators to understand concepts and approach biostatisticians timely to apply these concepts in their study to improve the overall quality of methodological standards in grant proposals and research studies. The order of reporting information in statistical analyses specified in this report is not mandatory; however, clear reporting of analytical steps applicable to the specific study type should be mentioned somewhere in the manuscript. Since the entire approach of statistical analyses is dependent on the study objective type and EBB practice, proper execution and reporting of statistical models can be taught to the next generation of statisticians by the study objective type in statistical education courses. In fact, some disciplines ( figure 5 ) are strictly aligned with specific study objective types. Bioinformaticians are oriented in studying determinant and prognostic models toward precision medicine, while epidemiologists are oriented in studying association and causal models, particularly in population-based observational and pragmatic settings. Data scientists are heavily involved in prediction and classification models in personalized medicine. A common thing across disciplines is using biostatistical principles and computation tools to address any research question. Sometimes, one discipline expert does the part of others. 89 We strongly recommend using a team science approach that includes an epidemiologist, biostatistician, data scientist, and bioinformatician depending on the study objectives and needs. Clear reporting of data analyses as per the study objective type should be encouraged among all researchers to minimize heterogeneous practices and improve scientific quality and outcomes. In addition, we also encourage investigators to strictly follow transparent reporting and quality assessment guidelines according to the study design ( https://www.equator-network.org/ ) to improve the overall quality of the study, accordingly STROBE (Strengthening the Reporting of Observational Studies in Epidemiology) for observational studies, CONSORT (Consolidated Standards of Reporting Trials) for clinical trials, STARD (Standards for Reporting Diagnostic Accuracy Studies) for diagnostic studies, TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis OR Diagnosis) for prediction modeling, and ARRIVE (Animal Research: Reporting of In Vivo Experiments) for preclinical studies. The steps provided in this document for writing the statistical analysis section is essentially different from other guidance documents, including SAMBR. 5 SAMBR provides a guidance document for selecting evidence-based preferred methods of statistical analysis according to different study designs, while this report suggests the global reporting of essential information in the statistical analysis section according to study objective type. In this guidance report, our suggestion strictly pertains to the reporting of methods in the statistical analysis section and their implications on the interpretation of results. Our document does not provide guidance on the reporting of sample size or results or statistical analysis section for meta-analysis. The examples and reviews reported in this study may be used to emphasize the concepts and related implications in medical research.

Summary of reporting steps, purpose, and evaluation measures in the statistical analysis section.

Role of interrelated disciplines according to study objective type.
Acknowledgments
The author would like to thank the reviewers for their careful review and insightful suggestions.
Contributors: AKD developed the concept and design and wrote the manuscript.
Funding: The authors have not declared a specific grant for this research from any funding agency in the public, commercial or not-for-profit sectors.
Competing interests: AKD is a Journal of Investigative Medicine Editorial Board member. No other competing interests declared.
Provenance and peer review: Commissioned; externally peer reviewed.
Supplemental material: This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.
Data availability statement
Ethics statements, patient consent for publication.
Not required.
- Affiliate Program

- UNITED STATES
- 台灣 (TAIWAN)
- TÜRKIYE (TURKEY)
- Academic Editing Services
- - Research Paper
- - Journal Manuscript
- - Dissertation
- - College & University Assignments
- Admissions Editing Services
- - Application Essay
- - Personal Statement
- - Recommendation Letter
- - Cover Letter
- - CV/Resume
- Business Editing Services
- - Business Documents
- - Report & Brochure
- - Website & Blog
- Writer Editing Services
- - Script & Screenplay
- Our Editors
- Client Reviews
- Editing & Proofreading Prices
- Wordvice Points
- Partner Discount
- Plagiarism Checker
- APA Citation Generator
- MLA Citation Generator
- Chicago Citation Generator
- Vancouver Citation Generator
- - APA Style
- - MLA Style
- - Chicago Style
- - Vancouver Style
- Writing & Editing Guide
- Academic Resources
- Admissions Resources
How to Write the Results/Findings Section in Research
What is the research paper Results section and what does it do?
The Results section of a scientific research paper represents the core findings of a study derived from the methods applied to gather and analyze information. It presents these findings in a logical sequence without bias or interpretation from the author, setting up the reader for later interpretation and evaluation in the Discussion section. A major purpose of the Results section is to break down the data into sentences that show its significance to the research question(s).
The Results section appears third in the section sequence in most scientific papers. It follows the presentation of the Methods and Materials and is presented before the Discussion section —although the Results and Discussion are presented together in many journals. This section answers the basic question “What did you find in your research?”
What is included in the Results section?
The Results section should include the findings of your study and ONLY the findings of your study. The findings include:
- Data presented in tables, charts, graphs, and other figures (may be placed into the text or on separate pages at the end of the manuscript)
- A contextual analysis of this data explaining its meaning in sentence form
- All data that corresponds to the central research question(s)
- All secondary findings (secondary outcomes, subgroup analyses, etc.)
If the scope of the study is broad, or if you studied a variety of variables, or if the methodology used yields a wide range of different results, the author should present only those results that are most relevant to the research question stated in the Introduction section .
As a general rule, any information that does not present the direct findings or outcome of the study should be left out of this section. Unless the journal requests that authors combine the Results and Discussion sections, explanations and interpretations should be omitted from the Results.
How are the results organized?
The best way to organize your Results section is “logically.” One logical and clear method of organizing research results is to provide them alongside the research questions—within each research question, present the type of data that addresses that research question.
Let’s look at an example. Your research question is based on a survey among patients who were treated at a hospital and received postoperative care. Let’s say your first research question is:

“What do hospital patients over age 55 think about postoperative care?”
This can actually be represented as a heading within your Results section, though it might be presented as a statement rather than a question:
Attitudes towards postoperative care in patients over the age of 55
Now present the results that address this specific research question first. In this case, perhaps a table illustrating data from a survey. Likert items can be included in this example. Tables can also present standard deviations, probabilities, correlation matrices, etc.
Following this, present a content analysis, in words, of one end of the spectrum of the survey or data table. In our example case, start with the POSITIVE survey responses regarding postoperative care, using descriptive phrases. For example:
“Sixty-five percent of patients over 55 responded positively to the question “ Are you satisfied with your hospital’s postoperative care ?” (Fig. 2)
Include other results such as subcategory analyses. The amount of textual description used will depend on how much interpretation of tables and figures is necessary and how many examples the reader needs in order to understand the significance of your research findings.
Next, present a content analysis of another part of the spectrum of the same research question, perhaps the NEGATIVE or NEUTRAL responses to the survey. For instance:
“As Figure 1 shows, 15 out of 60 patients in Group A responded negatively to Question 2.”
After you have assessed the data in one figure and explained it sufficiently, move on to your next research question. For example:
“How does patient satisfaction correspond to in-hospital improvements made to postoperative care?”

This kind of data may be presented through a figure or set of figures (for instance, a paired T-test table).
Explain the data you present, here in a table, with a concise content analysis:
“The p-value for the comparison between the before and after groups of patients was .03% (Fig. 2), indicating that the greater the dissatisfaction among patients, the more frequent the improvements that were made to postoperative care.”
Let’s examine another example of a Results section from a study on plant tolerance to heavy metal stress . In the Introduction section, the aims of the study are presented as “determining the physiological and morphological responses of Allium cepa L. towards increased cadmium toxicity” and “evaluating its potential to accumulate the metal and its associated environmental consequences.” The Results section presents data showing how these aims are achieved in tables alongside a content analysis, beginning with an overview of the findings:
“Cadmium caused inhibition of root and leave elongation, with increasing effects at higher exposure doses (Fig. 1a-c).”
The figure containing this data is cited in parentheses. Note that this author has combined three graphs into one single figure. Separating the data into separate graphs focusing on specific aspects makes it easier for the reader to assess the findings, and consolidating this information into one figure saves space and makes it easy to locate the most relevant results.

Following this overall summary, the relevant data in the tables is broken down into greater detail in text form in the Results section.
- “Results on the bio-accumulation of cadmium were found to be the highest (17.5 mg kgG1) in the bulb, when the concentration of cadmium in the solution was 1×10G2 M and lowest (0.11 mg kgG1) in the leaves when the concentration was 1×10G3 M.”
Captioning and Referencing Tables and Figures
Tables and figures are central components of your Results section and you need to carefully think about the most effective way to use graphs and tables to present your findings . Therefore, it is crucial to know how to write strong figure captions and to refer to them within the text of the Results section.
The most important advice one can give here as well as throughout the paper is to check the requirements and standards of the journal to which you are submitting your work. Every journal has its own design and layout standards, which you can find in the author instructions on the target journal’s website. Perusing a journal’s published articles will also give you an idea of the proper number, size, and complexity of your figures.
Regardless of which format you use, the figures should be placed in the order they are referenced in the Results section and be as clear and easy to understand as possible. If there are multiple variables being considered (within one or more research questions), it can be a good idea to split these up into separate figures. Subsequently, these can be referenced and analyzed under separate headings and paragraphs in the text.
To create a caption, consider the research question being asked and change it into a phrase. For instance, if one question is “Which color did participants choose?”, the caption might be “Color choice by participant group.” Or in our last research paper example, where the question was “What is the concentration of cadmium in different parts of the onion after 14 days?” the caption reads:
“Fig. 1(a-c): Mean concentration of Cd determined in (a) bulbs, (b) leaves, and (c) roots of onions after a 14-day period.”
Steps for Composing the Results Section
Because each study is unique, there is no one-size-fits-all approach when it comes to designing a strategy for structuring and writing the section of a research paper where findings are presented. The content and layout of this section will be determined by the specific area of research, the design of the study and its particular methodologies, and the guidelines of the target journal and its editors. However, the following steps can be used to compose the results of most scientific research studies and are essential for researchers who are new to preparing a manuscript for publication or who need a reminder of how to construct the Results section.
Step 1 : Consult the guidelines or instructions that the target journal or publisher provides authors and read research papers it has published, especially those with similar topics, methods, or results to your study.
- The guidelines will generally outline specific requirements for the results or findings section, and the published articles will provide sound examples of successful approaches.
- Note length limitations on restrictions on content. For instance, while many journals require the Results and Discussion sections to be separate, others do not—qualitative research papers often include results and interpretations in the same section (“Results and Discussion”).
- Reading the aims and scope in the journal’s “ guide for authors ” section and understanding the interests of its readers will be invaluable in preparing to write the Results section.
Step 2 : Consider your research results in relation to the journal’s requirements and catalogue your results.
- Focus on experimental results and other findings that are especially relevant to your research questions and objectives and include them even if they are unexpected or do not support your ideas and hypotheses.
- Catalogue your findings—use subheadings to streamline and clarify your report. This will help you avoid excessive and peripheral details as you write and also help your reader understand and remember your findings. Create appendices that might interest specialists but prove too long or distracting for other readers.
- Decide how you will structure of your results. You might match the order of the research questions and hypotheses to your results, or you could arrange them according to the order presented in the Methods section. A chronological order or even a hierarchy of importance or meaningful grouping of main themes or categories might prove effective. Consider your audience, evidence, and most importantly, the objectives of your research when choosing a structure for presenting your findings.
Step 3 : Design figures and tables to present and illustrate your data.
- Tables and figures should be numbered according to the order in which they are mentioned in the main text of the paper.
- Information in figures should be relatively self-explanatory (with the aid of captions), and their design should include all definitions and other information necessary for readers to understand the findings without reading all of the text.
- Use tables and figures as a focal point to tell a clear and informative story about your research and avoid repeating information. But remember that while figures clarify and enhance the text, they cannot replace it.
Step 4 : Draft your Results section using the findings and figures you have organized.
- The goal is to communicate this complex information as clearly and precisely as possible; precise and compact phrases and sentences are most effective.
- In the opening paragraph of this section, restate your research questions or aims to focus the reader’s attention to what the results are trying to show. It is also a good idea to summarize key findings at the end of this section to create a logical transition to the interpretation and discussion that follows.
- Try to write in the past tense and the active voice to relay the findings since the research has already been done and the agent is usually clear. This will ensure that your explanations are also clear and logical.
- Make sure that any specialized terminology or abbreviation you have used here has been defined and clarified in the Introduction section .
Step 5 : Review your draft; edit and revise until it reports results exactly as you would like to have them reported to your readers.
- Double-check the accuracy and consistency of all the data, as well as all of the visual elements included.
- Read your draft aloud to catch language errors (grammar, spelling, and mechanics), awkward phrases, and missing transitions.
- Ensure that your results are presented in the best order to focus on objectives and prepare readers for interpretations, valuations, and recommendations in the Discussion section . Look back over the paper’s Introduction and background while anticipating the Discussion and Conclusion sections to ensure that the presentation of your results is consistent and effective.
- Consider seeking additional guidance on your paper. Find additional readers to look over your Results section and see if it can be improved in any way. Peers, professors, or qualified experts can provide valuable insights.
One excellent option is to use a professional English proofreading and editing service such as Wordvice, including our paper editing service . With hundreds of qualified editors from dozens of scientific fields, Wordvice has helped thousands of authors revise their manuscripts and get accepted into their target journals. Read more about the proofreading and editing process before proceeding with getting academic editing services and manuscript editing services for your manuscript.
As the representation of your study’s data output, the Results section presents the core information in your research paper. By writing with clarity and conciseness and by highlighting and explaining the crucial findings of their study, authors increase the impact and effectiveness of their research manuscripts.
For more articles and videos on writing your research manuscript, visit Wordvice’s Resources page.
Wordvice Resources
- How to Write a Research Paper Introduction
- Which Verb Tenses to Use in a Research Paper
- How to Write an Abstract for a Research Paper
- How to Write a Research Paper Title
- Useful Phrases for Academic Writing
- Common Transition Terms in Academic Papers
- Active and Passive Voice in Research Papers
- 100+ Verbs That Will Make Your Research Writing Amazing
- Tips for Paraphrasing in Research Papers
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

I Am Disconnected – Tuesday CX Thoughts
May 21, 2024

20 Best Customer Success Tools of 2024
May 20, 2024

AI-Based Services Buying Guide for Market Research (based on ESOMAR’s 20 Questions)

Data Information vs Insight: Essential differences
May 14, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Advanced essay writing guides for everyone
- Papers From Scratch
- Data Analysis Section
- Essay About Maturity
- MLA Formatting
- Informative Essay Writing
- 22 Great Examples
- Computer Science Papers
- Persuasive Essay Topics
- Argumentative Essay Topics
Helpful Tips on Composing a Research Paper Data Analysis Section
If you are given a research paper assignment, you should create a list of tasks to be done and try to stick to your working schedule. It is recommended that you complete your research and then start writing your work. One of the important steps is to prepare your data analysis section. However, that step is vital as it aims to explain how the data will be described in the results section. Use the following helpful tips to complete that section without a hitch.
17% OFF on your first order Type the code 17TUDENT
How to Compose a Data Analysis Section for Your Research Paper
Usually, a data analysis section is provided right after the methods and approaches used. There, you should explain how you organized your data, what statistical tests were applied, and how you evaluated the obtained results. Follow these simple tips to compose a strong piece of writing:
- Avoid analyzing your results in the data analysis section.
- Indicate whether your research is quantitative or qualitative.
- Provide your main research questions and the analysis methods that were applied to answer them.
- Report what software you used to gather and analyze your data.
- List the data sources, including electronic archives and online reports of different institutions.
- Explain how the data were summarized and what measures of variability you have used.
- Remember to mention the data transformations if any, including data normalizing.
- Make sure that you included the full name of statistical tests used.
- Describe graphical techniques used to analyze the raw data and the results.
Where to Find the Necessary Assistance If You Get Stuck
Research paper writing is hard, so if you get stuck, do not wait for enlightenment and start searching for some assistance. It is a good idea to consult a statistics expert if you have a large amount of data and have no idea on how to summarize it. Your academic advisor may suggest you where to find a statistician to ask your questions.
Another great help option is getting a sample of a data analysis section. At the school’s library, you can find sample research papers written by your fellow students, get a few works, and study how the students analyzed data. Pay special attention to the word choices and the structure of the writing.
If you decide to follow a section template, you should be careful and keep your professor’s instructions in mind. For example, you may be asked to place all the page-long data tables in the appendices or build graphs instead of providing tables.
2024 | tartanpr.com
- Privacy Policy
Home » Research Results Section – Writing Guide and Examples
Research Results Section – Writing Guide and Examples
Table of Contents

Research Results
Research results refer to the findings and conclusions derived from a systematic investigation or study conducted to answer a specific question or hypothesis. These results are typically presented in a written report or paper and can include various forms of data such as numerical data, qualitative data, statistics, charts, graphs, and visual aids.
Results Section in Research
The results section of the research paper presents the findings of the study. It is the part of the paper where the researcher reports the data collected during the study and analyzes it to draw conclusions.
In the results section, the researcher should describe the data that was collected, the statistical analysis performed, and the findings of the study. It is important to be objective and not interpret the data in this section. Instead, the researcher should report the data as accurately and objectively as possible.
Structure of Research Results Section
The structure of the research results section can vary depending on the type of research conducted, but in general, it should contain the following components:
- Introduction: The introduction should provide an overview of the study, its aims, and its research questions. It should also briefly explain the methodology used to conduct the study.
- Data presentation : This section presents the data collected during the study. It may include tables, graphs, or other visual aids to help readers better understand the data. The data presented should be organized in a logical and coherent way, with headings and subheadings used to help guide the reader.
- Data analysis: In this section, the data presented in the previous section are analyzed and interpreted. The statistical tests used to analyze the data should be clearly explained, and the results of the tests should be presented in a way that is easy to understand.
- Discussion of results : This section should provide an interpretation of the results of the study, including a discussion of any unexpected findings. The discussion should also address the study’s research questions and explain how the results contribute to the field of study.
- Limitations: This section should acknowledge any limitations of the study, such as sample size, data collection methods, or other factors that may have influenced the results.
- Conclusions: The conclusions should summarize the main findings of the study and provide a final interpretation of the results. The conclusions should also address the study’s research questions and explain how the results contribute to the field of study.
- Recommendations : This section may provide recommendations for future research based on the study’s findings. It may also suggest practical applications for the study’s results in real-world settings.
Outline of Research Results Section
The following is an outline of the key components typically included in the Results section:
I. Introduction
- A brief overview of the research objectives and hypotheses
- A statement of the research question
II. Descriptive statistics
- Summary statistics (e.g., mean, standard deviation) for each variable analyzed
- Frequencies and percentages for categorical variables
III. Inferential statistics
- Results of statistical analyses, including tests of hypotheses
- Tables or figures to display statistical results
IV. Effect sizes and confidence intervals
- Effect sizes (e.g., Cohen’s d, odds ratio) to quantify the strength of the relationship between variables
- Confidence intervals to estimate the range of plausible values for the effect size
V. Subgroup analyses
- Results of analyses that examined differences between subgroups (e.g., by gender, age, treatment group)
VI. Limitations and assumptions
- Discussion of any limitations of the study and potential sources of bias
- Assumptions made in the statistical analyses
VII. Conclusions
- A summary of the key findings and their implications
- A statement of whether the hypotheses were supported or not
- Suggestions for future research
Example of Research Results Section
An Example of a Research Results Section could be:
- This study sought to examine the relationship between sleep quality and academic performance in college students.
- Hypothesis : College students who report better sleep quality will have higher GPAs than those who report poor sleep quality.
- Methodology : Participants completed a survey about their sleep habits and academic performance.
II. Participants
- Participants were college students (N=200) from a mid-sized public university in the United States.
- The sample was evenly split by gender (50% female, 50% male) and predominantly white (85%).
- Participants were recruited through flyers and online advertisements.
III. Results
- Participants who reported better sleep quality had significantly higher GPAs (M=3.5, SD=0.5) than those who reported poor sleep quality (M=2.9, SD=0.6).
- See Table 1 for a summary of the results.
- Participants who reported consistent sleep schedules had higher GPAs than those with irregular sleep schedules.
IV. Discussion
- The results support the hypothesis that better sleep quality is associated with higher academic performance in college students.
- These findings have implications for college students, as prioritizing sleep could lead to better academic outcomes.
- Limitations of the study include self-reported data and the lack of control for other variables that could impact academic performance.
V. Conclusion
- College students who prioritize sleep may see a positive impact on their academic performance.
- These findings highlight the importance of sleep in academic success.
- Future research could explore interventions to improve sleep quality in college students.
Example of Research Results in Research Paper :
Our study aimed to compare the performance of three different machine learning algorithms (Random Forest, Support Vector Machine, and Neural Network) in predicting customer churn in a telecommunications company. We collected a dataset of 10,000 customer records, with 20 predictor variables and a binary churn outcome variable.
Our analysis revealed that all three algorithms performed well in predicting customer churn, with an overall accuracy of 85%. However, the Random Forest algorithm showed the highest accuracy (88%), followed by the Support Vector Machine (86%) and the Neural Network (84%).
Furthermore, we found that the most important predictor variables for customer churn were monthly charges, contract type, and tenure. Random Forest identified monthly charges as the most important variable, while Support Vector Machine and Neural Network identified contract type as the most important.
Overall, our results suggest that machine learning algorithms can be effective in predicting customer churn in a telecommunications company, and that Random Forest is the most accurate algorithm for this task.
Example 3 :
Title : The Impact of Social Media on Body Image and Self-Esteem
Abstract : This study aimed to investigate the relationship between social media use, body image, and self-esteem among young adults. A total of 200 participants were recruited from a university and completed self-report measures of social media use, body image satisfaction, and self-esteem.
Results: The results showed that social media use was significantly associated with body image dissatisfaction and lower self-esteem. Specifically, participants who reported spending more time on social media platforms had lower levels of body image satisfaction and self-esteem compared to those who reported less social media use. Moreover, the study found that comparing oneself to others on social media was a significant predictor of body image dissatisfaction and lower self-esteem.
Conclusion : These results suggest that social media use can have negative effects on body image satisfaction and self-esteem among young adults. It is important for individuals to be mindful of their social media use and to recognize the potential negative impact it can have on their mental health. Furthermore, interventions aimed at promoting positive body image and self-esteem should take into account the role of social media in shaping these attitudes and behaviors.
Importance of Research Results
Research results are important for several reasons, including:
- Advancing knowledge: Research results can contribute to the advancement of knowledge in a particular field, whether it be in science, technology, medicine, social sciences, or humanities.
- Developing theories: Research results can help to develop or modify existing theories and create new ones.
- Improving practices: Research results can inform and improve practices in various fields, such as education, healthcare, business, and public policy.
- Identifying problems and solutions: Research results can identify problems and provide solutions to complex issues in society, including issues related to health, environment, social justice, and economics.
- Validating claims : Research results can validate or refute claims made by individuals or groups in society, such as politicians, corporations, or activists.
- Providing evidence: Research results can provide evidence to support decision-making, policy-making, and resource allocation in various fields.
How to Write Results in A Research Paper
Here are some general guidelines on how to write results in a research paper:
- Organize the results section: Start by organizing the results section in a logical and coherent manner. Divide the section into subsections if necessary, based on the research questions or hypotheses.
- Present the findings: Present the findings in a clear and concise manner. Use tables, graphs, and figures to illustrate the data and make the presentation more engaging.
- Describe the data: Describe the data in detail, including the sample size, response rate, and any missing data. Provide relevant descriptive statistics such as means, standard deviations, and ranges.
- Interpret the findings: Interpret the findings in light of the research questions or hypotheses. Discuss the implications of the findings and the extent to which they support or contradict existing theories or previous research.
- Discuss the limitations : Discuss the limitations of the study, including any potential sources of bias or confounding factors that may have affected the results.
- Compare the results : Compare the results with those of previous studies or theoretical predictions. Discuss any similarities, differences, or inconsistencies.
- Avoid redundancy: Avoid repeating information that has already been presented in the introduction or methods sections. Instead, focus on presenting new and relevant information.
- Be objective: Be objective in presenting the results, avoiding any personal biases or interpretations.
When to Write Research Results
Here are situations When to Write Research Results”
- After conducting research on the chosen topic and obtaining relevant data, organize the findings in a structured format that accurately represents the information gathered.
- Once the data has been analyzed and interpreted, and conclusions have been drawn, begin the writing process.
- Before starting to write, ensure that the research results adhere to the guidelines and requirements of the intended audience, such as a scientific journal or academic conference.
- Begin by writing an abstract that briefly summarizes the research question, methodology, findings, and conclusions.
- Follow the abstract with an introduction that provides context for the research, explains its significance, and outlines the research question and objectives.
- The next section should be a literature review that provides an overview of existing research on the topic and highlights the gaps in knowledge that the current research seeks to address.
- The methodology section should provide a detailed explanation of the research design, including the sample size, data collection methods, and analytical techniques used.
- Present the research results in a clear and concise manner, using graphs, tables, and figures to illustrate the findings.
- Discuss the implications of the research results, including how they contribute to the existing body of knowledge on the topic and what further research is needed.
- Conclude the paper by summarizing the main findings, reiterating the significance of the research, and offering suggestions for future research.
Purpose of Research Results
The purposes of Research Results are as follows:
- Informing policy and practice: Research results can provide evidence-based information to inform policy decisions, such as in the fields of healthcare, education, and environmental regulation. They can also inform best practices in fields such as business, engineering, and social work.
- Addressing societal problems : Research results can be used to help address societal problems, such as reducing poverty, improving public health, and promoting social justice.
- Generating economic benefits : Research results can lead to the development of new products, services, and technologies that can create economic value and improve quality of life.
- Supporting academic and professional development : Research results can be used to support academic and professional development by providing opportunities for students, researchers, and practitioners to learn about new findings and methodologies in their field.
- Enhancing public understanding: Research results can help to educate the public about important issues and promote scientific literacy, leading to more informed decision-making and better public policy.
- Evaluating interventions: Research results can be used to evaluate the effectiveness of interventions, such as treatments, educational programs, and social policies. This can help to identify areas where improvements are needed and guide future interventions.
- Contributing to scientific progress: Research results can contribute to the advancement of science by providing new insights and discoveries that can lead to new theories, methods, and techniques.
- Informing decision-making : Research results can provide decision-makers with the information they need to make informed decisions. This can include decision-making at the individual, organizational, or governmental levels.
- Fostering collaboration : Research results can facilitate collaboration between researchers and practitioners, leading to new partnerships, interdisciplinary approaches, and innovative solutions to complex problems.
Advantages of Research Results
Some Advantages of Research Results are as follows:
- Improved decision-making: Research results can help inform decision-making in various fields, including medicine, business, and government. For example, research on the effectiveness of different treatments for a particular disease can help doctors make informed decisions about the best course of treatment for their patients.
- Innovation : Research results can lead to the development of new technologies, products, and services. For example, research on renewable energy sources can lead to the development of new and more efficient ways to harness renewable energy.
- Economic benefits: Research results can stimulate economic growth by providing new opportunities for businesses and entrepreneurs. For example, research on new materials or manufacturing techniques can lead to the development of new products and processes that can create new jobs and boost economic activity.
- Improved quality of life: Research results can contribute to improving the quality of life for individuals and society as a whole. For example, research on the causes of a particular disease can lead to the development of new treatments and cures, improving the health and well-being of millions of people.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples
data analysis Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords
Introduce a Survival Model with Spatial Skew Gaussian Random Effects and its Application in Covid-19 Data Analysis
Futuristic prediction of missing value imputation methods using extended ann.
Missing data is universal complexity for most part of the research fields which introduces the part of uncertainty into data analysis. We can take place due to many types of motives such as samples mishandling, unable to collect an observation, measurement errors, aberrant value deleted, or merely be short of study. The nourishment area is not an exemption to the difficulty of data missing. Most frequently, this difficulty is determined by manipulative means or medians from the existing datasets which need improvements. The paper proposed hybrid schemes of MICE and ANN known as extended ANN to search and analyze the missing values and perform imputations in the given dataset. The proposed mechanism is efficiently able to analyze the blank entries and fill them with proper examining their neighboring records in order to improve the accuracy of the dataset. In order to validate the proposed scheme, the extended ANN is further compared against various recent algorithms or mechanisms to analyze the efficiency as well as the accuracy of the results.
Applications of multivariate data analysis in shelf life studies of edible vegetal oils – A review of the few past years
Hypothesis formalization: empirical findings, software limitations, and design implications.
Data analysis requires translating higher level questions and hypotheses into computable statistical models. We present a mixed-methods study aimed at identifying the steps, considerations, and challenges involved in operationalizing hypotheses into statistical models, a process we refer to as hypothesis formalization . In a formative content analysis of 50 research papers, we find that researchers highlight decomposing a hypothesis into sub-hypotheses, selecting proxy variables, and formulating statistical models based on data collection design as key steps. In a lab study, we find that analysts fixated on implementation and shaped their analyses to fit familiar approaches, even if sub-optimal. In an analysis of software tools, we find that tools provide inconsistent, low-level abstractions that may limit the statistical models analysts use to formalize hypotheses. Based on these observations, we characterize hypothesis formalization as a dual-search process balancing conceptual and statistical considerations constrained by data and computation and discuss implications for future tools.
The Complexity and Expressive Power of Limit Datalog
Motivated by applications in declarative data analysis, in this article, we study Datalog Z —an extension of Datalog with stratified negation and arithmetic functions over integers. This language is known to be undecidable, so we present the fragment of limit Datalog Z programs, which is powerful enough to naturally capture many important data analysis tasks. In limit Datalog Z , all intensional predicates with a numeric argument are limit predicates that keep maximal or minimal bounds on numeric values. We show that reasoning in limit Datalog Z is decidable if a linearity condition restricting the use of multiplication is satisfied. In particular, limit-linear Datalog Z is complete for Δ 2 EXP and captures Δ 2 P over ordered datasets in the sense of descriptive complexity. We also provide a comprehensive study of several fragments of limit-linear Datalog Z . We show that semi-positive limit-linear programs (i.e., programs where negation is allowed only in front of extensional atoms) capture coNP over ordered datasets; furthermore, reasoning becomes coNEXP-complete in combined and coNP-complete in data complexity, where the lower bounds hold already for negation-free programs. In order to satisfy the requirements of data-intensive applications, we also propose an additional stability requirement, which causes the complexity of reasoning to drop to EXP in combined and to P in data complexity, thus obtaining the same bounds as for usual Datalog. Finally, we compare our formalisms with the languages underpinning existing Datalog-based approaches for data analysis and show that core fragments of these languages can be encoded as limit programs; this allows us to transfer decidability and complexity upper bounds from limit programs to other formalisms. Therefore, our article provides a unified logical framework for declarative data analysis which can be used as a basis for understanding the impact on expressive power and computational complexity of the key constructs available in existing languages.
An empirical study on Cross-Border E-commerce Talent Cultivation-—Based on Skill Gap Theory and big data analysis
To solve the dilemma between the increasing demand for cross-border e-commerce talents and incompatible students’ skill level, Industry-University-Research cooperation, as an essential pillar for inter-disciplinary talent cultivation model adopted by colleges and universities, brings out the synergy from relevant parties and builds the bridge between the knowledge and practice. Nevertheless, industry-university-research cooperation developed lately in the cross-border e-commerce field with several problems such as unstable collaboration relationships and vague training plans.
The Effects of Cross-border e-Commerce Platforms on Transnational Digital Entrepreneurship
This research examines the important concept of transnational digital entrepreneurship (TDE). The paper integrates the host and home country entrepreneurial ecosystems with the digital ecosystem to the framework of the transnational digital entrepreneurial ecosystem. The authors argue that cross-border e-commerce platforms provide critical foundations in the digital entrepreneurial ecosystem. Entrepreneurs who count on this ecosystem are defined as transnational digital entrepreneurs. Interview data were dissected for the purpose of case studies to make understanding from twelve Chinese immigrant entrepreneurs living in Australia and New Zealand. The results of the data analysis reveal that cross-border entrepreneurs are in actual fact relying on the significant framework of the transnational digital ecosystem. Cross-border e-commerce platforms not only play a bridging role between home and host country ecosystems but provide entrepreneurial capitals as digital ecosystem promised.
Subsampling and Jackknifing: A Practically Convenient Solution for Large Data Analysis With Limited Computational Resources
The effects of cross-border e-commerce platforms on transnational digital entrepreneurship, a trajectory evaluator by sub-tracks for detecting vot-based anomalous trajectory.
With the popularization of visual object tracking (VOT), more and more trajectory data are obtained and have begun to gain widespread attention in the fields of mobile robots, intelligent video surveillance, and the like. How to clean the anomalous trajectories hidden in the massive data has become one of the research hotspots. Anomalous trajectories should be detected and cleaned before the trajectory data can be effectively used. In this article, a Trajectory Evaluator by Sub-tracks (TES) for detecting VOT-based anomalous trajectory is proposed. Feature of Anomalousness is defined and described as the Eigenvector of classifier to filter Track Lets anomalous trajectory and IDentity Switch anomalous trajectory, which includes Feature of Anomalous Pose and Feature of Anomalous Sub-tracks (FAS). In the comparative experiments, TES achieves better results on different scenes than state-of-the-art methods. Moreover, FAS makes better performance than point flow, least square method fitting and Chebyshev Polynomial Fitting. It is verified that TES is more accurate and effective and is conducive to the sub-tracks trajectory data analysis.
Export Citation Format
Share document.
Enhancing Economic Resilience Through Multi-source Information Fusion in Financial Inclusion: A Big Data Analysis Approach
- Published: 23 May 2024
Cite this article

- Tzung-Feng Hu 1 &
- Fu-Sheng Tsai ORCID: orcid.org/0009-0001-6802-5533 2 , 3 , 4
In an era marked by economic volatility and complex global dynamics, assessing and enhancing economic resilience are of paramount importance. This research paper, submitted to the Journal of the Knowledge Economy , introduces a comprehensive approach to understanding and improving economic resilience through the lens of financial inclusion. As the global economy faces unprecedented challenges, financial inclusion, which extends financial services to the general public, becomes a vital indicator of economic stability and resilience. This study employs a cutting-edge big data analysis method that leverages multi-source information fusion. By integrating data from diverse sources, including user profiling, risk assessment, financial product design, and financial operation information, our approach provides a real-time assessment of economic resilience. Through the application of this method, economies can gain a deeper understanding of their economic situation and resilience, aiding policymakers in decision-making and fostering social stability. The paper delves into the impact of financial inclusion on economic resilience, emphasizing the role of digital inclusive finance in improving economic structure and stability. It also presents experimental results, demonstrating the superiority of the proposed method over existing spatio-temporal sequence processing techniques in predicting financial inclusion and assessing economic resilience. In conclusion, this research paper offers a valuable contribution to the fields of knowledge economy, innovation, and entrepreneurship, as it provides insights and tools to enhance economic resilience in the face of an ever-changing global landscape.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
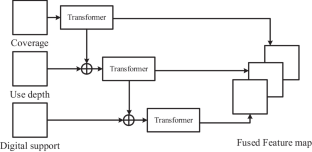
Data Availability
The data can be obtained according to the requirements.
Chen, F. (2022). Deep Neural Network Model Forecasting for Financial and Economic Market. Journal of Mathematics , 8146555.
Corrado, G., & Corrado, L. (2017). Inclusive finance for inclusive growth and development. Current Opinion in Environmental Sustainability , 24 , 19–23.
Article Google Scholar
Davies, S. (2011). Regional resilience in the 2008–2010 downturn: Comparative evidence from European countries. Cambridge Journal of Regions Economy and Society , 4 (3), 369–382.
Di, C. P. (2017). Testing and explaining economic resilience with an application to Italian regions. Papers in Regional Science , 96 (1), 93–114.
Du, X., Xiao, G., & Sui, Y. (2020). Fault triggers in the tensorflow framework: An experience report. 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE). IEEE, 1–12.
Guo, T., & Xiao, D. (2015). An International Comparative Study on Inclusive Finance-from the Perspective of Banking Services. Studies of International Finance , 2 , 55–64.
Google Scholar
Huston, S., & Warren, C. (2013). Knowledge city and urban economic resilience. Journal of Property Investment & Finance , 31 (1), 78–88.
James, S., & Martin, R. (2010). The economic resilience of regions: Towards an evolutionary approach. Cambridge Journal of Regions Economy & Society , 3 (1), 27–34.
Kovalev, V., Kalinovsky, A., & Kovalev, S. (2016). Deep learning with theano, torch, caffe, tensorflow, and deeplearning4j: Which one is the best in speed and accuracy?.
Liu, Z., & Wang, L. (2023). Analysis of Credit Risk Control for Small and Micro Enterprises in Chinese commercial banks: From the perspective of Big Data Credit Reporting. Financial Engineering and Risk Management , 6 (9), 1–15.
Martin, R., & Sunley, P. (2015). On the notion of regional economic resilience: Conceptualization and explanation. Journal of Economic Geography , 15 (1), 1–42.
Mazzia, V., Angarano, S., Salvetti, F., Angelini, F., & Chiaberge, M. (2022). Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognition: The Journal of the Pattern Recognition Society , 124.
Paruchuri, H. (2021). Conceptualization of machine learning in economic forecasting. Asian Business Review , 2 .
Peter-A-G, V. B., Brakman, S., & Marrewijk, C. V. (2017). Heterogeneous economic resilience and the Great recession’s world trade collapse. Papers in Regional Science , 96 (1), 3–13.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., & Clark, J. (2021). Learning transferable visual models from natural language supervision. International conference on machine learning. PMLR , 8748–8763.
Reggiani, A., Graaff, T. D., & Nijkamp, P. (2002). Resilience: An Evolutionary Approach to spatial Economic systems. Networks & Spatial Economics , 2 (2), 211–229.
Rose, A. (2004). Defining and measuring economic resilience to disasters. Disaster Prevention & Management , 13 (4), 307–314.
Samargandi, N., Fidrmuc, J., & Ghosh, S. (2014). Financial development and economic growth in an oil-rich economy: The case of Saudi Arabia. Economic Modelling , 43 , 267–278.
Sehgal, N., & Pandey, K. K. (2015). Artificial intelligence methods for oil price forecasting: A review and evaluation. Energy Systems , 6 (4).
Swanstrom, T. (2019). Coping with adversity: Regional economic resilience and public policy, by Harold Wolman, Howard Wial, Travis St. Clair, and Edward Hill. Journal of Urban Affairs , 41 (8), 1225–1227.
Wang, Y. (2023). Study on Impact of COVID-2019 on the Development of Financial technology on Internet Banking in China Based on Comparative Data. Proceedings of the 4th International Conference on Economic Management and Model Engineering .
Yu, C., Jia, N., Li, W., & Wu, R. (2022). Digital inclusive finance and rural consumption structure–evidence from Peking University digital inclusive financial index and China household finance survey. China Agricultural Economic Review , 14 (1), 165–183.
Zeng, A., Chen, M., Zhang, L., & Xu. (2023). Are transformers effective for time series forecasting? Proceedings of the AAAI conference on artificial intelligence, 37 (9), 11121–11128.
Zhmoginov, A., Sandler, M., & Vladymyrov, M. (2022). HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning, International Conference on Machine Learning. PMLR , 27075–27098.
Zhou, H., Zhang, S., Peng, J., Zhang, S., & Zhang, W. (2021). Informer: Beyond efficient transformer for long sequence time-series forecasting. Proceedings of the AAAI conference on artificial intelligence, 35 (12), 11106–11115.
Download references
Acknowledgements
Fu-Sheng Tsai acknowledges a visiting research project from the NCUWREP.
Author information
Authors and affiliations.
Department of Business Administration, Cheng Shiu University, Kaohsiung, Taiwan
Tzung-Feng Hu
North China University of Water Resources and Electric Power (NCUWREP), Zhengzhou, China
Fu-Sheng Tsai
Center for Environmental Toxin and Emerging-Contaminant Research, Kaohsiung, Taiwan
Super Micro Mass Research and Technology Center, Kaohsiung, Taiwan
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualization: Tzung-Feng Hu. Data collection and analysis: Fu-Sheng Tsai. Investigation: Tzung-Feng Hu. Writing: Tzung-Feng Hu, Fu-Sheng Tsai.
Corresponding author
Correspondence to Fu-Sheng Tsai .
Ethics declarations
Ethics approval.
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent
The authors declare that all the authors have informed consent.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Hu, TF., Tsai, FS. Enhancing Economic Resilience Through Multi-source Information Fusion in Financial Inclusion: A Big Data Analysis Approach. J Knowl Econ (2024). https://doi.org/10.1007/s13132-024-02085-7
Download citation
Received : 21 February 2024
Accepted : 13 May 2024
Published : 23 May 2024
DOI : https://doi.org/10.1007/s13132-024-02085-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Financial inclusion
- Economic resilience
- Multi-source information fusion
- Big data analysis
- Predictive models
- Global financial inclusion
Advertisement
- Find a journal
- Publish with us
- Track your research
Improving economic policy
Suggested keywords:
- decarbonisation
- climate change
- monetary policy
- / Publications
Research, innovation and data: a fifth freedom in the EU single market?
Research and innovation should be at the top of the EU economic policy agenda, but cannot over-rely on public investment
Share this page:

The European Union’s single market famously enables four freedoms: the movement of goods, services, capital and labour. Former Italian prime minister Enrico Letta, in his report on the single market issued and discussed by EU leaders in April, proposed a fifth freedom as a top priority, to encompass research, innovation, data and knowledge that have become indispensable drivers of innovation in modern economies (Letta, 2024) 1 The idea of a fifth freedom is not new. It was mentioned in 1989 by then European Commission president Jacques Delors (Delors, 1989), and by former science and research commissioner Janez Potocnik in 2007. See European Commission archived content, ‘Make “knowledge” a fifth Community freedom, says Potocnik at Green Paper launch’, https://cordis.europa.eu/article/id/27454-make-knowledge-a-fifth-commun… . .
Letta argues that the EU has under-utilised its pools of data, expertise and startups. This wealth of resources benefits global tech giants that are better positioned to capitalise on it and hampers the EU’s strategic autonomy and economic security. He claims that it is a necessary extension of the single market for the EU to become a creator of new technologies and foster the development of leading industrial ecosystems of global importance, with a strong European technological infrastructure in areas including data utilisation, artificial intelligence, quantum computing, biotech, bio-robotics and space.
The Letta report contains a number of constructive and innovative ideas. Most importantly, he does not just attempt to put the fifth freedom on par with other single market freedoms. Instead, he puts it squarely at the top of all single market freedoms: innovation as the necessary condition for the success of all other freedoms, indeed for the success of the EU as an economic project.
Should this be accepted and effectively implemented by the next European Commission, it could herald a major shift in the EU policy environment, which often prioritises precaution over innovation. It would also be a recognition that the empirical evidence of a slow-down in EU productivity growth, and thus in innovation, should be taken seriously (see for example Pinkus et al , 2024). EU productivity growth since the 2009 financial crisis has lagged about a third behind the US. That undermines the EU’s long-term economic welfare.
On the other hand, the fifth freedom sits somewhat uncomfortably in a report on the single market because it has little to do with geographical obstacles or borders. Insisting on the freedom to investigate, explore and create in a borderless single market feels like pushing at an open door. There are hardly any EU internal borders to the mobility of research projects, knowledge and researchers.
Helping data flow
Another positive message from the report is that digital data assumes a central role in Letta’s view of the knowledge economy. Data is a new production factor in modern economies. Eliminating barriers to data access is a powerful catalyst for innovation. Access to computing power and AI technologies are also a necessary ingredient. Letta acknowledges that considerable progress has already been made with several EU digital laws, including the Digital Markets Act, the Digital Services Act, the Data Act and the Data Governance Act. But these are considered insufficient to nurture the necessary level of innovation.
Letta supports the development of European data spaces in key sectors, in line with the European Commission’s (2020) data strategy. Opening access to data and creating data pooling spaces can leverage the value of digital data as a new production factor. Data portability is beneficial because data, once collected by one party for a particular purpose, can often be re-used by other parties for competing or complementary purposes. Data portability thus stimulates competition and innovation in data-driven services markets. Data pooling generates other types of benefits. The valuable insights that can be extracted from a large data pool often exceed the insights that can be extracted from fragmented and smaller datasets.
Letta refers to healthcare as an example of the implementation of the fifth freedom. He cites the European Health Data Space (EHDS) regulation that facilitates the portability of personal health data between medical service providers to stimulate competition between services, and will also create an EU-wide health data pool for research purposes to stimulate medical innovation 2 At time of writing, EHDS has been agreed but not fully ratified; see European Commission press release of 24 April 2024, ‘Commission welcomes European Parliament . EHDS would have been a good template for other data pooling initiatives. Unfortunately, other sectoral data pools may not be as generous to researchers and innovation. Preliminary ideas for a Common European Agricultural Data Space emphasise exclusive data rights for farms, at the expense of data pooling for innovation purposes 3 See the AgriDataSpace project, https://agridataspace-csa.eu/ . .
Typically, Letta’s report recommends removing barriers to cross-border data flows by means of interoperability and data regulations. But there are few restrictions on cross-border data flows inside the EU 4 Annex 5 in European Commission (2017) detected some restrictions, mostly on administrative and tax data, that represent only a tiny part of total data flows. . The real obstacles to access to data are located inside firms that collect and store data in their proprietary silos. They are reluctant to share data with users who generated the data or third parties selected by users, let alone in a common data pool accessible to many users.
The EU Data Act (Regulation (EU) 2023/2854) also makes data pooling difficult. It attributes exclusive data licensing and monopolistic data-pricing rights to device manufacturers, restricting data access for users to very narrowly defined datasets and limiting the use of this data for competitive purposes. That slows down data-driven innovation. The EU Data Governance Act (Regulation (EU) 2022/868) meanwhile does not drive innovation because it excludes precisely those platforms that produce data-driven innovation services, including data analytics, transformation and extraction of value-added from data pools. Over the last couple of years, EU data policies have moved back and forth between the debunked concept of private data ownership and the recognition that data sharing is beneficial for innovation and competition. If the European Commission is to take Letta seriously, is should move away decisively from exclusive data rights and start to see data as a collectively generated production factor that should be leveraged as an major driver of innovation in the digital economy.
Redistributing rents
The EU Digital Markets Act (DMA, Regulation (EU) 2022/1925) is a pioneering attempt to weaken the monopolistic market power of mostly US-based ‘gatekeeper’ platforms. If implemented correctly, it could redistribute some of these monopoly rents to EU consumers and small businesses. But will this redistribution evaporate in non-investable consumer surplus and fragmented financial resources? The EU will need financial instruments to channel these resources back into digital R&D and innovative start-up capital. Even after implementation of the DMA, Europe’s advanced digital technologies may still rely on US platforms to bring their services to consumers and businesses.
It is unlikely that EU publicly financed R&D can compete with these platforms, which are all privately financed for-profit companies. Letta recognises the need to mobilise more private investment as a complement to public-sector investment. One of his most interesting proposals is the creation of an “EU Stock Exchange for Deep Tech” companies that use cutting-edge science and technology, including AI, quantum and biotechnology. Start-ups are high-risk undertakings but offer high gains, if successful. In the EU, because of banking regulations, these types of risky asset are downgraded. The EU should facilitate the creation of a deep-tech stock exchange with specific rules adapted to this risk class.
Letta also argues in favour of creating a strong digital infrastructure layer through consolidation in the telecom sector, allowing many small national telecom providers to merge cross-border into a dozen or so large providers that can invest in advanced infrastructures, including 5G and 6G mobile networks. Among his more provocative and promising ideas, Letta suggests that the time may have come to re-evaluate rules on net neutrality, or non-discriminatory treatment of online traffic. Different treatment of different types of data flows allows optimisation of connectivity, which is important for robotics, the internet of things and AI. It would allow the introduction of innovative use cases that are currently non-compliant with net neutrality. In the US, the FTC abandoned net neutrality in 2018, without major upheaval in the sector.
Another important infrastructure component is cloud-computing capacity for the development of AI models, in which Letta endorses EU public investment. The EU is running far behind the US platforms, which invest massively in cloud computing. Letta suggests that the EU should prioritise shared networks of computational resources and supercomputers, such as the EU’s High-Performance Computing (HPC) initiative 5 See https://eurohpc-ju.europa.eu/index_en . . Unfortunately, HPC’s centralised and public sector governance model is more adapted to academic research than to the requirements of AI start-ups, which require flexible and scalable computing capacity and dedicated AI processors. The public sector will not be able to match the financial resources of the big platforms to invest in hyperscale computing capacity for AI models.
Unfortunately, some of Letta’s more concrete implementation proposals boil down to old European wines in barely new bottles. Letta proposes the creation of a European Knowledge Commons, a centralised digital platform to provide access to publicly funded research, datasets and educational resources, allowing citizens and businesses to tap into a wealth of knowledge for innovation. This Commons should be accompanied by facilitation of cross-border data flows, development of European data spaces, creation of data regulation sandboxes and promotion of researcher mobility within the European Research Area and efforts to retain talent in Europe. There is nothing new in these proposals. Access to EU research findings and data has already opened up considerably over the last decade. But Letta does not mention how sharing knowledge in a commons can be squared with incentives to invest in patentable and commercially exploitable research. Public-private partnerships in strategic areas focused on knowledge exchange and innovation uptake may be important at the research stage, but often become more problematic at the commercial stage, when the public sector may need to spin off successful projects to the private sector.
Almost inevitably, Europe’s old ideas about selecting industrial champions pop up again. Letta clearly favours a centralist, public-sector-driven approach to innovation, in order to be able to draw in substantial private investments. He emphasises public sector financing and commons-based approaches to knowledge accumulation and innovation. He claims that establishing European technological infrastructure involves granting authority to a collective industrial policy at European scale, moving beyond national confines. This is unfortunate. One would have expected the Letta report to acknowledge the enormous private-sector contribution to innovation and productivity growth.
AI and cybersecurity
Letta underscores the importance of the development and deployment of AI technologies, including ethical guidelines and regulatory compliance standards. He argues that even if the most powerful AI models have been developed outside the EU, it can still win the race to make the most of AI applications. He expresses belief in the EU’s position as a leading hub for AI innovation.
This optimistic view may be difficult to square with the realities of the EU AI Act that will impose considerable compliance costs on smaller EU AI developers and may complicate access to model training data 6 The Act has been approved but not published in its final form. See Council of the EU press release of 21 May 2024, ‘Artificial intelligence (AI) act: Council gives final green light to the first worldwide rules on AI’, https://www.consilium.europa.eu/en/press/press-releases/2024/05/21/arti… . . Combined with the lack of adequate computing capacity and finance in the EU, it is easy to understand why EU AI start-ups have opted for collaboration with US platforms. That collaboration gives them access to computing power and inputs data, and also to commercial outlets for their AI model applications, a prerequisite for generating revenue. It is difficult for a start-up to launch a new business model from scratch. Smaller models and applications on top of existing foundation models may have some commercial future but they are vulnerable to competition and high intermediation fees from Big Tech AI services.
Letta’s report rightly observes that the current fragmentation in cybersecurity standards hampers the development of robust security capabilities, by preventing network operators from leveraging centralised network architectures that could benefit from economies of scale. Fragmented national cybersecurity standards and reporting requirements undermine the efficiency of cybersecurity strategies at EU level. Much cybersecurity work is done by giants such as Google and Microsoft because they have a global overview of threats through their sprawling consumer- and business-facing networks. In the absence of EU players of this size, and further handicapped by fragmented national regulation, this remains a source of concern, especially at a time when cyberwarfare is increasingly important.
In sum, the main merit of Letta’s fifth freedom idea is that it puts research and innovation back at the top of the EU economic policy agenda, to counter the slow-down in EU productivity growth. Wrapping it up in a single market freedom anchors it very well in the EU’s institutional and policy foundations. Bringing in data and AI policies to leverage productivity growth chimes with current frontier technologies. Several of his policy proposals challenge the current status quo. However, his reliance on public sector-led industrial policies and investment ignores the fact that private sector R&D and investment now vastly exceed public-sector financing capacities. A Knowledge Commons overlooks the fact that private appropriation of innovation rents has become the main driver of R&D financing. Letta’s ideas will require considerable polishing and fine-tuning to make them fit in the realities of today’s innovation economics.
Delors, J. (1989) ‘Address given by Jacques Delors to the European Parliament (17 January 1989)’, available at https://www.cvce.eu/obj/address_given_by_jacques_delors_to_the_european_parliament_17_january_1989-en-b9c06b95-db97-4774-a700-e8aea5172233.html
European Commission (2017) ‘Impact assessment accompanying proposal for a Regulation on a framework for the free flow of non-personal data in the European Union’, SWD(2017) 304 final, available at https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=SWD:2017:304:FIN
European Commission (2020) ‘A European strategy for data’, COM(2020) 66 final, available at https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52020DC0066
Letta, E. (2024) Much More Than a Market , report to the European Council, available at https://www.consilium.europa.eu/media/ny3j24sm/much-more-than-a-market-report-by-enrico-letta.pdf
Pinkus, D., J. Pisani-Ferry, S. Tagliapietra, R. Veugelers, G. Zachmann and J. Zettelmeyer (2024) Coordination for competitiveness , study requested by the ECON committee, European Parliament, available at https://www.europarl.europa.eu/RegData/etudes/STUD/2024/747838/IPOL_STU(2024)747838_EN.pdf
About the authors
Bertin martens.
Bertin Martens is a Senior fellow at Bruegel. He has been working on digital economy issues, including e-commerce, geo-blocking, digital copyright and media, online platforms and data markets and regulation, as senior economist at the Joint Research Centre (Seville) of the European Commission, for more than a decade until April 2022. Prior to that, he was deputy chief economist for trade policy at the European Commission, and held various other assignments in the international economic policy domain. He is currently a non-resident research fellow at the Tilburg Law & Economics Centre (TILEC) at Tilburg University (Netherlands).
His current research interests focus on economic and regulatory issues in digital data markets and online platforms, the impact of digital technology on institutions in society and, more broadly, the long-term evolution of knowledge accumulation and transmission systems in human societies. Institutions are tools to organise information flows. When digital technologies change information costs and distribution channels, institutional and organisational borderlines will shift.
He holds a PhD in economics from the Free University of Brussels.
Disclosure of external interests
Declaration of interests 2023
Related content

Economic arguments in favour of reducing copyright protection for generative AI inputs and outputs
The licensing of training inputs slows down economic growth compared to what it could be with competitive and high-quality GenAI

Why should EU copyright protection be reduced to realise the innovation benefits of Generative AI?
The eu artificial intelligence act: premature or precocious regulation.

The European Union AI Act: premature or precocious regulation?
As it stands, it is unknown whether the Act will stimulate responsible AI use or smother innovation.
Financial Statement Analysis with Large Language Models

We investigate whether an LLM can successfully perform financial statement analysis in a way similar to a professional human analyst. We provide standardized and anonymous financial statements to GPT4 and instruct the model to analyze them to determine the direction of future earnings. Even without any narrative or industry-specific information, the LLM outperforms financial analysts in its ability to predict earnings changes. The LLM exhibits a relative advantage over human analysts in situations when the analysts tend to struggle. Furthermore, we find that the prediction accuracy of the LLM is on par with the performance of a narrowly trained state-of-the-art ML model. LLM prediction does not stem from its training memory. Instead, we find that the LLM generates useful narrative insights about a company’s future performance. Lastly, our trading strategies based on GPT’s predictions yield a higher Sharpe ratio and alphas than strategies based on other models. Taken together, our results suggest that LLMs may take a central role in decision-making.
More Research From These Scholars
Do conflict of interests disclosures work evidence from citations in medical journals, profitability context and the cross-section of stock returns, from transcripts to insights: uncovering corporate risks using generative ai.
IMAGES
VIDEO
COMMENTS
- Data - Methods - Analysis - Results This format is very familiar to those who have written psych research papers. It often works well for a data analysis paper as well, though one problem with it is that the Methods section often sounds like a bit of a stretch: In a psych research paper the Methods section describes what you did to ...
The methods section of an APA style paper is where you report in detail how you performed your study. Research papers in the social and natural sciences often follow APA style. ... Specify the data collection methods, the research design and data analysis strategy, including any steps taken to transform the data and statistical analyses. ...
For those interested in conducting qualitative research, previous articles in this Research Primer series have provided information on the design and analysis of such studies. 2, 3 Information in the current article is divided into 3 main sections: an overview of terms and concepts used in data analysis, a review of common methods used to ...
This article is a practical guide to conducting data analysis in general literature reviews. The general literature review is a synthesis and analysis of published research on a relevant clinical issue, and is a common format for academic theses at the bachelor's and master's levels in nursing, physiotherapy, occupational therapy, public health and other related fields.
Reporting Research Results in APA Style | Tips & Examples. Published on December 21, 2020 by Pritha Bhandari.Revised on January 17, 2024. The results section of a quantitative research paper is where you summarize your data and report the findings of any relevant statistical analyses.. The APA manual provides rigorous guidelines for what to report in quantitative research papers in the fields ...
Sometimes your Data and Model section will contain plots or tables, and sometimes it won't. If you feel that a plot helps the reader understand the problem or data set itself—as opposed to your results—then go ahead and include it. A great example here is Tables 1 and 2 in the main paper on the PREDIMED study. These tables help the reader ...
Data Analysis Summary The methods section of a research paper provides the information by which a study's validity is judged. Therefore, it requires a clear and precise description of how an experiment was done, and the rationale for why specific experimental procedures were chosen. The methods section should describe what was
The methods section of a research paper describes the research design, the sample selection, the data collection and analysis procedures, and the statistical methods used to analyze the data. ... Research papers are often used as teaching tools in universities and colleges to educate students about research methods, data analysis, and academic ...
The Results section should also describe other pertinent discoveries, trends, or insights revealed by analysis of the raw data. Typical structure of the Results section in an empirical research paper: Data Analysis. In some disciplines, the Results section begins with a description of how the researchers analyzed
Reporting qualitative research results. In qualitative research, your results might not all be directly related to specific hypotheses. In this case, you can structure your results section around key themes or topics that emerged from your analysis of the data. For each theme, start with general observations about what the data showed. You can ...
On the basis of Rocco (2010), Storberg-Walker's (2012) amended list on qualitative data analysis in research papers included the following: (a) the article should provide enough details so that reviewers could follow the same analytical steps; (b) the analysis process selected should be logically connected to the purpose of the study; and (c ...
With scores of four and five, successful papers describe a new understanding with an effective line of reasoning, sufficient evidence, and an all-around great presentation of how their results signify filling a gap and answering a research question. As far as the discussions section goes, the difference between a four and a five is more on the ...
The results section should aim to narrate the findings without trying to interpret or evaluate, and also provide a direction to the discussion section of the research paper. The results are reported and reveals the analysis. The analysis section is where the writer describes what was done with the data found.
Data analysis is a comprehensive method of inspecting, cleansing, transforming, and modeling data to discover useful information, draw conclusions, and support decision-making. It is a multifaceted process involving various techniques and methodologies to interpret data from various sources in different formats, both structured and unstructured.
Results. Although biostatistical inputs are critical for the entire research study (online supplemental table 2), biostatistical consultations were mostly used for statistical analyses only 15.Even though the conduct of statistical analysis mismatched with the study objective and DGP was identified as the major problem in articles submitted to high-impact medical journals. 16 In addition ...
Answers to. the questions and interpretations are presented in the discussion section. Data analysis is primarily linked with writing text part of the results. and discussion of results. This is a ...
Step 1: Consult the guidelines or instructions that the target journal or publisher provides authors and read research papers it has published, especially those with similar topics, methods, or results to your study. The guidelines will generally outline specific requirements for the results or findings section, and the published articles will ...
The results section of a research paper tells the reader what you found, while the discussion section tells the reader what your findings mean. The results section should present the facts in an academic and unbiased manner, avoiding any attempt at analyzing or interpreting the data. Think of the results section as setting the stage for the ...
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
Follow these simple tips to compose a strong piece of writing: Avoid analyzing your results in the data analysis section. Indicate whether your research is quantitative or qualitative. Provide your main research questions and the analysis methods that were applied to answer them. Report what software you used to gather and analyze your data.
The results section of the research paper presents the findings of the study. ... Data analysis: In this section, the data presented in the previous section are analyzed and interpreted. The statistical tests used to analyze the data should be clearly explained, and the results of the tests should be presented in a way that is easy to ...
A simple rule of thumb for sectioning the method section is to begin by explaining the methodological approach (what was done), describing the data collection methods (how it was done), providing the analysis method (how the data was analyzed), and explaining the rationale for choosing the methodological strategy.
The Given. Missing data is universal complexity for most part of the research fields which introduces the part of uncertainty into data analysis. We can take place due to many types of motives such as samples mishandling, unable to collect an observation, measurement errors, aberrant value deleted, or merely be short of study.
In order to explore and study whether financial inclusion of financial services is an important indicator of economic stability and resilience, this paper proposes a financial inclusion big data analysis model based on multi-source information fusion, which is mainly described from the perspectives of multi-source information fusion, financial inclusion big data analysis, and economic ...
Section 4 of this study will ultimately detail our data analysis and visualization results interpretation. The interpretation includes an essential reading of the data and an in-depth understanding of the research area. Such analysis and interpretation help to better reveal current and future remote sensing STF trends.
The European Union's single market famously enables four freedoms: the movement of goods, services, capital and labour. Former Italian prime minister Enrico Letta, in his report on the single market issued and discussed by EU leaders in April, proposed a fifth freedom as a top priority, to encompass research, innovation, data and knowledge ...
Financial Statement Analysis with Large Language Models. We investigate whether an LLM can successfully perform financial statement analysis in a way similar to a professional human analyst. We provide standardized and anonymous financial statements to GPT4 and instruct the model to analyze them to determine the direction of future earnings.
Establishing reliable and effective prediction models is a major research priority for air quality parameter monitoring and prediction and is utilized extensively in numerous fields. The sample dataset of air quality metrics often established has missing data and outliers because of certain uncontrollable causes. A broad learning system based on a semi-supervised mechanism is built to address ...
Access the portal of NASS, the official source of agricultural data and statistics in the US, and explore various reports and products.