Reconocimiento de voz

https://myactivity.google.com/myactivity?restrict=vaa&hl=en&utm_source=udc&utm_medium=r&utm_campaign=

Librerias para Speech Recognition
- google-cloud-speech
- pocketsphinx
- SpeechRecognition
- watson-developer-cloud
Instalacion de la Libreria SpeechRecognition
Se utilizara la Libreria SpeechRecognition que se puede instalar asi:
conda install -c conda-forge portaudio
conda install -c anaconda pyaudio
conda install -c conda-forge speechrecognition
Con esta libreria se pueden usar diferentes sistemas de reconocimiento de voz
- recognize_bing(): Microsoft Bing Speech
- recognize_google(): Google Web Speech API
- recognize_google_cloud(): Google Cloud Speech - requiere instalar de google-cloud-speech package
- recognize_houndify(): Houndify by SoundHound
- recognize_ibm(): IBM Speech to Text
- recognize_sphinx(): CMU Sphinx - requiere instalar PocketSphinx
- recognize_wit(): Wit.ai
Reconocer archivos de Audio
El sistema actualmente solo reconoce los siguientes formatos de audio sin perdidas:
- WAV: must be in PCM/LPCM format
El Efecto del ruido en el reconocimiento de voz
El siguiente audio tiene un ruido de un martillo neumatico mientras se graba la frase “the stale smell of old beer lingers”
Bueno, se obtuvo “the” al comienzo de la frase, ¡pero no se pudo obtener correctamente la frase! A veces no es posible eliminar el efecto del ruido: la señal es demasiado ruidosa para ser tratada con éxito. Ese es el caso con este archivo. Si este es un problema frecuente entonces es necesario recurrir a preprocesamiento de la señal de audio.
Configuracion del Idioma
El Listado de los lenguajes soportados se puede ver en esta lista
https://stackoverflow.com/questions/14257598/what-are-language-codes-in-chromes-implementation-of-the-html5-speech-recogniti
español de colombia = es-CO
Texto a voz
Se pueden usar varias librerias,existen las que neccesitan de internet (Ej: Google) y otras que funcionan offline
pytts3 (offline)
- https://pyttsx3.readthedocs.io/en/latest/
gTTS - Google Text to Speech (Online)
Referencias.
- https://pypi.org/project/gTTS/
- https://vimeo.com/188095475
Was this page helpful?
Last updated on Jul 7, 2021
Spanish Speech-to-Text with Python
Speech-to-Text, also known as Automatic Speech Recognition, is a technology that converts spoken audio into text. The technology has a wide range of applications, from video transcription to hands-free user interfaces.
While many cloud Speech-to-Text APIs are available on the market, most can only transcribe in English. Picovoice's Leopard Speech-to-Text engine , however, supports 8 different languages and achieves state-of-the-art performance, all while running locally on-device.
In this tutorial, we will walk through the process of using the Leopard Speech-to-Text Python SDK to transcribe Spanish audio in just a few lines of code.
Prerequisites
Sign up for a free Picovoice Console account. Once you've created an account, copy your AccessKey on the main dashboard.
Install Python (version 3.7 or higher) and ensure it is successfully installed:
Install the pvleopard Python SDK package:
Leopard Speech-to-Text Model File
To initialize Leopard Speech-to-Text, we will need a Leopard Speech-to-Text model file. The Leopard Speech-to-Text model files for all supported languages are publicly available on GitHub . For Spanish Speech-to-Text, download the leopard_params_es.pv model file.
Implementation
After completing the setup, the actual implementation of the Speech-to-Text system can be written in just a few lines of code.
Import the pvleopard package:
Set the paths for all the required files. Make sure to replace ${ACCESS_KEY} with your actual AccessKey from the Picovoice Console , ${MODEL_FILE} with the Spanish Leopard Speech-to-Text model file and ${AUDIO_FILE} with the audio file you want to transcribe:
Initialize Leopard Speech-to-Text and transcribe the audio file:
Leopard Speech-to-Text also provides start and end time-stamps, as well as confidence scores for each word:
Additional Languages
Leopard Speech-to-Text supports 8 different languages, all of which are equally straightforward to use. Simply download the corresponding model file from GitHub , initialize Leopard Speech-to-Text with the file, and begin transcribing.
Subscribe to our newsletter
More from Picovoice

Learn how to perform Speech Recognition in JavaScript, including Speech-to-Text, Voice Commands, Wake Word Detection, and Voice Activity Det...

Have you ever thought of getting a summary of a YouTube video by sending a WhatsApp message? Ezzeddin Abdullah built an application that tra...

The launch of Leopard Speech-to-Text and Cheetah Speech-to-Text for streaming brought cloud-level automatic speech recognition (ASR) to loca...

Transcribe speech-to-text in real-time using Picovoice Cheetah Streaming Speech-to-Text React.js SDK. The SDK runs on Linux, macOS, Windows,...

Transcribe speech to text using Picovoice Leopard speech-to-text React.js SDK. The SDK runs on Linux, macOS, Windows, Raspberry Pi, and NVID...

Learn how to create a custom speech-to-text model on the Picovoice Console using the Leopard & Cheetah Speech-to-Text Engines

Add speech-to-text to a Django project using Picovoice Leopard Speech-to-Text Python SDK. The SDK runs on Linux, macOS, Windows, Raspberry P...

Voice has been central to how humans interact with each other for centuries. Researchers have been trying to enable a similar interaction wi...

Ejemplos de reconocimiento de voz con Python
El reconocimiento de voz es el proceso de convertir palabras habladas en texto. Python es compatible con muchos motores de reconocimiento de voz y API, incluidos Google Speech Engine, Google Cloud Speech API, Reconocimiento de voz de Microsoft Bing e IBM Speech to Text.
En este tutorial usaremos Google Speech Recognition Engine con Python.
Leer : Cuantos lenguajes de programación existen
Instalación
Una biblioteca que ayuda se llama «Reconocimiento de voz». Debes instalarlo con pyenv, pipenv o virtualenv. También puede instalarlo en todo el sistema:
El módulo SpeechRecognition depende de pyaudio, puede instalarlos desde su administrador de paquetes. En Manjaro Linux, estos paquetes se llaman “python-pyaudio” y “python2-pyaudio”, pueden tener otro nombre en su sistema.
Demostración de reconocimiento de voz Puede probar el módulo de reconocimiento de voz, con el comando:
Los resultados se muestran en la terminal.
Reconocimiento de voz con Google El siguiente ejemplo utiliza el motor de reconocimiento de voz de Google, que he probado para el idioma inglés.
Para fines de prueba, utiliza la clave API predeterminada. Para usar otra clave API, use
Copie el código a continuación y guarde el archivo como speechtest.py. Ejecútelo con Python 3.
También te puede interesar estos artículos sobre Machine Learning :
¿ Te fue de valor esta entrada Ejemplos de reconocimiento de voz con Python? ⬇️ Si compartes esta entrada otras personas podrán aprender.⬇️
Reconocimiento de voz python
El reconocimiento de voz es una tecnología que permite a las computadoras convertir el habla humana en texto escrito. En Python, existen bibliotecas y herramientas disponibles que facilitan la implementación de esta funcionalidad. Una de ellas es SpeechRecognition , una biblioteca de código abierto que ofrece una interfaz sencilla para capturar y procesar el audio. Con esta biblioteca, los desarrolladores pueden crear aplicaciones que respondan a comandos de voz y realicen tareas específicas.
Para utilizar SpeechRecognition , es necesario tener instalado Python en el sistema. Una vez instalado, se puede instalar la biblioteca a través del gestor de paquetes pip. Después de la instalación, es posible utilizar las funciones de reconocimiento de voz con solo unas pocas líneas de código. Por ejemplo, se puede utilizar la función recognize_google() para convertir el habla en texto utilizando el servicio de reconocimiento de voz de Google. Esta función toma como entrada un archivo de audio o un flujo de audio en tiempo real y devuelve el texto reconocido.
Además de SpeechRecognition , Python ofrece otras bibliotecas que permiten el reconocimiento de voz. Una de ellas es pyttsx3 , que permite convertir texto en habla. Con esta biblioteca, los desarrolladores pueden crear aplicaciones que no solo reconocen el habla, sino que también generan respuestas de audio. Por ejemplo, se puede utilizar pyttsx3 para crear un asistente de voz que responda preguntas y realice tareas a través de la voz.
El reconocimiento de voz en Python ofrece muchas posibilidades en diferentes áreas, como la automatización de tareas, la asistencia virtual y la accesibilidad. Con la combinación de bibliotecas como SpeechRecognition y pyttsx3 , los desarrolladores pueden crear aplicaciones interactivas que respondan a comandos de voz y faciliten la interacción con las computadoras. Esta tecnología continúa avanzando y mejorando, lo que abre nuevas oportunidades para su implementación en diversos campos.
Inteligencia artificial reconocimiento de voz
La inteligencia artificial ha revolucionado muchos aspectos de nuestra vida cotidiana, y una de las áreas donde ha demostrado un gran avance es en el reconocimiento de voz . Esta tecnología permite a las máquinas interpretar y comprender el lenguaje hablado por los seres humanos, abriendo un sinfín de posibilidades en términos de interacción entre humanos y máquinas.
Un ejemplo concreto de reconocimiento de voz con Python es el asistente virtual Alexa , desarrollado por Amazon. Alexa utiliza algoritmos de inteligencia artificial para entender y responder a comandos de voz. Los usuarios pueden hacer preguntas, solicitar información o incluso controlar dispositivos domésticos simplemente hablando con Alexa.
Otro ejemplo de reconocimiento de voz es el asistente de voz de Google . Este asistente utiliza técnicas de procesamiento de lenguaje natural y aprendizaje automático para interpretar y responder a los comandos de voz de los usuarios. Además, Google ha desarrollado aplicaciones como Google Translate, que utiliza reconocimiento de voz para traducir el lenguaje hablado en tiempo real.
El reconocimiento de voz también ha sido aplicado en el campo de la medicina. Por ejemplo, algunos hospitales utilizan sistemas de reconocimiento de voz para transcribir automáticamente los informes médicos dictados por los doctores. Esto agiliza el proceso de documentación y reduce el margen de error humano al transcribir la información.
En resumen, el reconocimiento de voz es una de las aplicaciones más destacadas de la inteligencia artificial. A través de algoritmos y técnicas avanzadas, las máquinas pueden interpretar y comprender el lenguaje hablado, abriendo un mundo de posibilidades en términos de interacción entre humanos y máquinas. Ejemplos como Alexa de Amazon y el asistente de voz de Google demuestran el potencial de esta tecnología, que también ha encontrado aplicaciones en campos como la medicina.
Speech recognition python spanish
Python ofrece una poderosa biblioteca de reconocimiento de voz llamada SpeechRecognition , que permite a los programadores desarrollar aplicaciones que pueden recibir y procesar comandos de voz. Esta biblioteca es compatible con varios motores de reconocimiento de voz, incluido el reconocimiento de voz de Google, lo que facilita la integración de la tecnología de reconocimiento de voz en aplicaciones Python.
Uno de los casos de uso más comunes para el reconocimiento de voz en Python es la transcripción de archivos de audio en español. Con SpeechRecognition , los desarrolladores pueden escribir código para transcribir automáticamente archivos de audio en español, lo que ahorra tiempo y esfuerzo en comparación con la transcripción manual.
Para utilizar el reconocimiento de voz en español con Python, es necesario instalar el motor de reconocimiento de voz adecuado. Por ejemplo, para reconocimiento de voz en español utilizando el motor de Google, es necesario instalar el paquete google-api-python-client . Una vez instalado, se puede utilizar SpeechRecognition para reconocer y transcribir comandos de voz en español.
Además de la transcripción de archivos de audio en español, el reconocimiento de voz en Python también se puede utilizar para desarrollar aplicaciones de control por voz en español. Por ejemplo, se puede utilizar el reconocimiento de voz para controlar dispositivos domésticos inteligentes en español, como encender y apagar luces o ajustar la temperatura en una habitación.
En resumen, el reconocimiento de voz con Python es una herramienta poderosa que permite a los programadores desarrollar aplicaciones que pueden recibir y procesar comandos de voz en español. Con la biblioteca SpeechRecognition y los motores de reconocimiento de voz adecuados, es posible transcribir archivos de audio en español y desarrollar aplicaciones de control por voz en español.
Ia reconocimiento de voz
El reconocimiento de voz es una tecnología que permite a las máquinas interpretar y comprender el lenguaje humano hablado. Gracias a los avances en inteligencia artificial (IA), esta funcionalidad se ha vuelto cada vez más precisa y accesible. En el ámbito de la programación, Python se ha convertido en uno de los lenguajes más populares para desarrollar aplicaciones de reconocimiento de voz.
La IA ha revolucionado el campo del reconocimiento de voz al permitir que las máquinas aprendan y mejoren su capacidad para entender y procesar el lenguaje hablado. Los algoritmos de aprendizaje automático y las redes neuronales son utilizados para entrenar a los sistemas de reconocimiento de voz, lo que les permite adaptarse y mejorar con el tiempo. Esto ha llevado a una mayor precisión y fiabilidad en las aplicaciones de reconocimiento de voz.
Python es un lenguaje de programación que se ha vuelto muy popular en el campo de la IA y el procesamiento del lenguaje natural. Ofrece una amplia gama de bibliotecas y herramientas que facilitan el desarrollo de aplicaciones de reconocimiento de voz. Una de estas bibliotecas es SpeechRecognition , que proporciona una interfaz sencilla para interactuar con los motores de reconocimiento de voz más populares, como Google Speech Recognition o IBM Watson.
Con Python y la biblioteca SpeechRecognition, es posible desarrollar aplicaciones que conviertan el habla en texto de manera rápida y precisa. Esto tiene un gran potencial en diversos campos, como la transcripción automática de audios, la creación de asistentes virtuales o la accesibilidad para personas con discapacidades auditivas. La facilidad de uso y la comunidad activa de Python hacen que el desarrollo de aplicaciones de reconocimiento de voz sea accesible para programadores de todos los niveles de experiencia.
Python reconocimiento de voz
Python reconocimiento de voz es una tecnología que permite a las máquinas entender y procesar comandos hablados por los usuarios. Con la ayuda de bibliotecas como SpeechRecognition, es posible desarrollar aplicaciones que reconozcan voz en tiempo real y realicen acciones en consecuencia. Esta tecnología ha ganado popularidad en los últimos años debido a su facilidad de uso y su capacidad para mejorar la experiencia del usuario en diferentes aplicaciones.
Un ejemplo de reconocimiento de voz con Python es el control de voz de asistentes virtuales como Siri y Alexa. Estos asistentes utilizan algoritmos de procesamiento de voz implementados en Python para entender y responder a los comandos de voz de los usuarios. Además, también se utiliza en aplicaciones de transcripción de voz, donde se convierte el habla en texto escrito. Esto es especialmente útil en situaciones donde se requiere una transcripción precisa y rápida, como en reuniones o conferencias.
Otro ejemplo de reconocimiento de voz con Python es el control de dispositivos domésticos inteligentes. Con el uso de bibliotecas como PyAudio, es posible desarrollar aplicaciones que permitan a los usuarios controlar luces, electrodomésticos y otros dispositivos mediante comandos de voz. Esto brinda una forma conveniente y manos libres de interactuar con los dispositivos y aumenta la accesibilidad para personas con discapacidades.
Además, el reconocimiento de voz con Python se utiliza en aplicaciones de traducción de voz en tiempo real. Estas aplicaciones utilizan algoritmos de reconocimiento de voz para convertir el habla en un idioma y luego traducirlo a otro idioma. Esto es especialmente útil en situaciones donde se requiere una comunicación efectiva entre personas que hablan diferentes idiomas.
En resumen, el reconocimiento de voz con Python es una tecnología poderosa que ha encontrado aplicaciones en diversas áreas, desde asistentes virtuales hasta control de dispositivos domésticos y traducción de voz en tiempo real. Su facilidad de uso y versatilidad lo convierten en una herramienta valiosa para mejorar la experiencia del usuario y hacer que las aplicaciones sean más accesibles y eficientes.
Api de reconocimiento de voz
La API de reconocimiento de voz es una herramienta que permite a los desarrolladores agregar funcionalidades de reconocimiento de voz a sus aplicaciones. Esta API utiliza algoritmos avanzados de procesamiento de señales de audio para convertir el habla en texto.
Una de las principales ventajas de utilizar una API de reconocimiento de voz es su facilidad de uso. Los desarrolladores no necesitan tener conocimientos profundos sobre procesamiento de señales de audio o algoritmos de reconocimiento de voz. Simplemente necesitan utilizar el conjunto de instrucciones proporcionado por la API para implementar la funcionalidad en su aplicación.
Otra ventaja importante de utilizar una API de reconocimiento de voz es su precisión. Los algoritmos utilizados en estas API han sido entrenados con grandes cantidades de datos y han demostrado tener una alta tasa de precisión en el reconocimiento de voz. Esto significa que las aplicaciones que utilizan esta API pueden convertir el habla en texto de manera muy precisa.
Además de su precisión, otra ventaja de utilizar una API de reconocimiento de voz es su velocidad. Estas API están diseñadas para procesar grandes cantidades de datos de audio en tiempo real, lo que permite que las aplicaciones de reconocimiento de voz funcionen de manera rápida y eficiente.
En resumen, la API de reconocimiento de voz es una herramienta muy útil para los desarrolladores que desean agregar funcionalidades de reconocimiento de voz a sus aplicaciones. Es fácil de usar, precisa y rápida, lo que la convierte en una opción ideal para implementar el reconocimiento de voz en aplicaciones de todo tipo.
Speechrecognition python spanish
El reconocimiento de voz es una tecnología fascinante que ha avanzado significativamente en los últimos años. Con Python, uno de los lenguajes de programación más populares y versátiles, es posible desarrollar aplicaciones de reconocimiento de voz en español de manera sencilla y efectiva.
Python ofrece una amplia gama de bibliotecas y herramientas para trabajar con reconocimiento de voz. Una de las más destacadas es SpeechRecognition , una biblioteca que permite convertir el habla en texto utilizando diferentes motores de reconocimiento de voz.
Con SpeechRecognition, es posible realizar tareas como transcribir grabaciones de voz, controlar aplicaciones mediante comandos de voz o incluso crear asistentes virtuales. La biblioteca es compatible con varios motores de reconocimiento de voz en español, lo que la convierte en una opción ideal para desarrollar aplicaciones en este idioma.
Para utilizar SpeechRecognition en Python, es necesario instalar la biblioteca mediante el comando pip install SpeechRecognition . Una vez instalada, se pueden utilizar las funciones y métodos proporcionados para capturar y procesar la entrada de audio.
Un ejemplo sencillo de reconocimiento de voz con Python sería el siguiente:
import speech_recognition as sr r = sr.Recognizer()
with sr.Microphone() as source: print(«Di algo…») audio = r.listen(source)
try: texto = r.recognize_google(audio, language=’es-ES’) print(«Has dicho: » + texto) except sr.UnknownValueError: print(«No se pudo entender el audio») except sr.RequestError as e: print(«Error al solicitar los resultados: {0}».format(e))
En este ejemplo, utilizamos el micrófono como fuente de audio y capturamos la entrada del usuario. Luego, utilizamos el motor de reconocimiento de voz de Google para convertir el habla en texto en español. Si se produce un error durante el proceso de reconocimiento, se muestra un mensaje de error adecuado.
En resumen, Python ofrece una gran cantidad de herramientas y bibliotecas para trabajar con reconocimiento de voz en español. Con SpeechRecognition, es posible desarrollar aplicaciones de reconocimiento de voz de manera sencilla y efectiva, abriendo un mundo de posibilidades para la interacción con dispositivos y aplicaciones mediante comandos de voz.
Reconocimiento de voz en python
El reconocimiento de voz en Python es una tecnología que permite a los ordenadores interpretar y comprender el lenguaje hablado. Python, un lenguaje de programación versátil y fácil de aprender, ofrece varias bibliotecas y herramientas que facilitan el desarrollo de aplicaciones de reconocimiento de voz. Una de las bibliotecas más populares para este propósito es SpeechRecognition , que proporciona una interfaz sencilla para trabajar con servicios de reconocimiento de voz como Google Speech API o IBM Watson.
Para comenzar a utilizar el reconocimiento de voz en Python, es necesario instalar la biblioteca SpeechRecognition. Esto se puede hacer fácilmente a través del gestor de paquetes de Python, utilizando el comando pip install SpeechRecognition . Una vez instalada, se pueden utilizar las funciones y métodos de la biblioteca para grabar y transcribir el audio. Por ejemplo, mediante el uso de la función recognize_google() , se puede enviar el audio grabado a la API de reconocimiento de voz de Google y obtener la transcripción en forma de texto.
Otra biblioteca útil para el reconocimiento de voz en Python es pyttsx3 , que permite convertir texto en voz. Esto es especialmente útil cuando se desea que el ordenador «hable». Con pyttsx3, se pueden generar voces sintéticas a partir de cadenas de texto y reproducirlas a través de los altavoces del sistema. También es posible ajustar la velocidad de reproducción, el tono y el volumen de la voz generada.
Además de las bibliotecas mencionadas, existen otras opciones para el reconocimiento de voz en Python, como DeepSpeech , una biblioteca de código abierto desarrollada por Mozilla que utiliza algoritmos de aprendizaje profundo para mejorar la precisión del reconocimiento de voz. También se puede utilizar CMUSphinx , una herramienta de reconocimiento de voz basada en modelos ocultos de Markov.
Python speech recognition spanish
Python speech recognition spanish es una biblioteca de Python que permite reconocer y transcribir voz en español utilizando el reconocimiento de voz automático. Es una herramienta poderosa que facilita la interacción con los usuarios a través del habla y abre muchas posibilidades en el desarrollo de aplicaciones.
Python speech recognition spanish utiliza el motor de reconocimiento de voz Sphinx, que es una tecnología de código abierto desarrollada por Carnegie Mellon University. Este motor es altamente preciso y puede reconocer palabras y frases en español con gran precisión, lo que lo convierte en una opción ideal para proyectos que requieren reconocimiento de voz en este idioma.
Con Python speech recognition spanish, los desarrolladores pueden crear aplicaciones que permiten a los usuarios dictar texto en español en lugar de escribirlo. Esto puede ser especialmente útil para personas con discapacidades físicas o para aquellos que prefieren hablar en lugar de escribir. Además, esta biblioteca también permite realizar comandos de voz, lo que permite controlar aplicaciones y dispositivos utilizando la voz.
Python speech recognition spanish es fácil de instalar y utilizar. Los desarrolladores solo necesitan importar la biblioteca y utilizar las funciones proporcionadas para grabar y transcribir voz en español. Además, la biblioteca también ofrece opciones para ajustar la configuración de reconocimiento, como el idioma y la sensibilidad, lo que permite adaptarla a las necesidades específicas de cada proyecto.
En resumen, Python speech recognition spanish es una herramienta poderosa para reconocer y transcribir voz en español en aplicaciones de Python. Con su precisión y facilidad de uso, esta biblioteca abre muchas posibilidades en el desarrollo de aplicaciones interactivas y accesibles que utilizan el reconocimiento de voz en español.
Reconocimiento de voz java
Reconocedor de voz, foto voz ejemplos, reconocimiento de voz en ingles.
Aquí tienes un ejemplo de tabla que se centra en el reconocimiento de voz en inglés:
Ten en cuenta que esta tabla se centra en ejemplos generales de librerías y servicios de reconocimiento de voz en inglés. Puedes encontrar más información sobre cada uno de ellos en sus respectivas documentaciones.
Recognize_google python
import speech_recognition as srr = sr.Recognizer()with sr.AudioFile(«audio.wav») as source:audio = r.record(source)text = r.recognize_google(audio, language=»es-ES»)print(text)
Reconocimiento de voz javascript
Reconocimiento del habla, reconocimiento ejemplos.

Apasionado del desarrollo de software. Me encanta trabajar en el backend, es por eso que decidí abrir este blog de python , para poder compartir con otros mi conocimiento. Espero poder aportar en tu carrera como desarrollador python.
5 comentarios en «Ejemplos de reconocimiento de voz con Python»
¿Es realmente efectivo el reconocimiento de voz en Python para el español? Opiniones variadas.
¡Creo que Python es genial para reconocimiento de voz! ¿Qué opinan ustedes? 🐍🗣️
¡Totalmente de acuerdo contigo! Python es definitivamente una excelente opción para el reconocimiento de voz. Su facilidad de uso y amplia variedad de librerías hacen que sea una herramienta poderosa en este campo. Sin duda, ¡un acierto utilizar Python para estas aplicaciones! 🐍🗣️
¿Es realmente efectivo el reconocimiento de voz en Python para el español? Opiniones.
Sí, el reconocimiento de voz en Python para español es bastante efectivo si se utiliza correctamente. Personalmente lo he probado y ha funcionado muy bien. ¿Has tenido alguna mala experiencia al respecto? ¡Me interesaría saber más detalles!
Los comentarios están cerrados.
Valoramos mucho tu opinión, ¿Te ha gustado el contenido que estas viendo?
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Speech recognition module for Python, supporting several engines and APIs, online and offline.
Licenses found
Uberi/speech_recognition, folders and files, repository files navigation, speechrecognition.
Library for performing speech recognition, with support for several engines and APIs, online and offline.
UPDATE 2022-02-09 : Hey everyone! This project started as a tech demo, but these days it needs more time than I have to keep up with all the PRs and issues. Therefore, I'd like to put out an open invite for collaborators - just reach out at [email protected] if you're interested!
Speech recognition engine/API support:
- CMU Sphinx (works offline)
- Google Speech Recognition
- Google Cloud Speech API
- Microsoft Azure Speech
- Microsoft Bing Voice Recognition (Deprecated)
- Houndify API
- IBM Speech to Text
- Snowboy Hotword Detection (works offline)
- Vosk API (works offline)
- OpenAI whisper (works offline)
- Whisper API
Quickstart: pip install SpeechRecognition . See the "Installing" section for more details.
To quickly try it out, run python -m speech_recognition after installing.
Project links:
- Source code
- Issue tracker
Library Reference
The library reference documents every publicly accessible object in the library. This document is also included under reference/library-reference.rst .
See Notes on using PocketSphinx for information about installing languages, compiling PocketSphinx, and building language packs from online resources. This document is also included under reference/pocketsphinx.rst .
You have to install Vosk models for using Vosk. Here are models avaiable. You have to place them in models folder of your project, like "your-project-folder/models/your-vosk-model"
See the examples/ directory in the repository root for usage examples:
- Recognize speech input from the microphone
- Transcribe an audio file
- Save audio data to an audio file
- Show extended recognition results
- Calibrate the recognizer energy threshold for ambient noise levels (see recognizer_instance.energy_threshold for details)
- Listening to a microphone in the background
- Various other useful recognizer features
First, make sure you have all the requirements listed in the "Requirements" section.
The easiest way to install this is using pip install SpeechRecognition .
Otherwise, download the source distribution from PyPI , and extract the archive.
In the folder, run python setup.py install .
Requirements
To use all of the functionality of the library, you should have:
- Python 3.8+ (required)
- PyAudio 0.2.11+ (required only if you need to use microphone input, Microphone )
- PocketSphinx (required only if you need to use the Sphinx recognizer, recognizer_instance.recognize_sphinx )
- Google API Client Library for Python (required only if you need to use the Google Cloud Speech API, recognizer_instance.recognize_google_cloud )
- FLAC encoder (required only if the system is not x86-based Windows/Linux/OS X)
- Vosk (required only if you need to use Vosk API speech recognition recognizer_instance.recognize_vosk )
- Whisper (required only if you need to use Whisper recognizer_instance.recognize_whisper )
- openai (required only if you need to use Whisper API speech recognition recognizer_instance.recognize_whisper_api )
The following requirements are optional, but can improve or extend functionality in some situations:
- If using CMU Sphinx, you may want to install additional language packs to support languages like International French or Mandarin Chinese.
The following sections go over the details of each requirement.
The first software requirement is Python 3.8+ . This is required to use the library.
PyAudio (for microphone users)
PyAudio is required if and only if you want to use microphone input ( Microphone ). PyAudio version 0.2.11+ is required, as earlier versions have known memory management bugs when recording from microphones in certain situations.
If not installed, everything in the library will still work, except attempting to instantiate a Microphone object will raise an AttributeError .
The installation instructions on the PyAudio website are quite good - for convenience, they are summarized below:
- On Windows, install PyAudio using Pip : execute pip install pyaudio in a terminal.
- If the version in the repositories is too old, install the latest release using Pip: execute sudo apt-get install portaudio19-dev python-all-dev python3-all-dev && sudo pip install pyaudio (replace pip with pip3 if using Python 3).
- On OS X, install PortAudio using Homebrew : brew install portaudio . Then, install PyAudio using Pip : pip install pyaudio .
- On other POSIX-based systems, install the portaudio19-dev and python-all-dev (or python3-all-dev if using Python 3) packages (or their closest equivalents) using a package manager of your choice, and then install PyAudio using Pip : pip install pyaudio (replace pip with pip3 if using Python 3).
PyAudio wheel packages for common 64-bit Python versions on Windows and Linux are included for convenience, under the third-party/ directory in the repository root. To install, simply run pip install wheel followed by pip install ./third-party/WHEEL_FILENAME (replace pip with pip3 if using Python 3) in the repository root directory .
PocketSphinx-Python (for Sphinx users)
PocketSphinx-Python is required if and only if you want to use the Sphinx recognizer ( recognizer_instance.recognize_sphinx ).
PocketSphinx-Python wheel packages for 64-bit Python 3.4, and 3.5 on Windows are included for convenience, under the third-party/ directory . To install, simply run pip install wheel followed by pip install ./third-party/WHEEL_FILENAME (replace pip with pip3 if using Python 3) in the SpeechRecognition folder.
On Linux and other POSIX systems (such as OS X), follow the instructions under "Building PocketSphinx-Python from source" in Notes on using PocketSphinx for installation instructions.
Note that the versions available in most package repositories are outdated and will not work with the bundled language data. Using the bundled wheel packages or building from source is recommended.
Vosk (for Vosk users)
Vosk API is required if and only if you want to use Vosk recognizer ( recognizer_instance.recognize_vosk ).
You can install it with python3 -m pip install vosk .
You also have to install Vosk Models:
Here are models avaiable for download. You have to place them in models folder of your project, like "your-project-folder/models/your-vosk-model"
Google Cloud Speech Library for Python (for Google Cloud Speech API users)
Google Cloud Speech library for Python is required if and only if you want to use the Google Cloud Speech API ( recognizer_instance.recognize_google_cloud ).
If not installed, everything in the library will still work, except calling recognizer_instance.recognize_google_cloud will raise an RequestError .
According to the official installation instructions , the recommended way to install this is using Pip : execute pip install google-cloud-speech (replace pip with pip3 if using Python 3).
FLAC (for some systems)
A FLAC encoder is required to encode the audio data to send to the API. If using Windows (x86 or x86-64), OS X (Intel Macs only, OS X 10.6 or higher), or Linux (x86 or x86-64), this is already bundled with this library - you do not need to install anything .
Otherwise, ensure that you have the flac command line tool, which is often available through the system package manager. For example, this would usually be sudo apt-get install flac on Debian-derivatives, or brew install flac on OS X with Homebrew.
Whisper (for Whisper users)
Whisper is required if and only if you want to use whisper ( recognizer_instance.recognize_whisper ).
You can install it with python3 -m pip install SpeechRecognition[whisper-local] .
Whisper API (for Whisper API users)
The library openai is required if and only if you want to use Whisper API ( recognizer_instance.recognize_whisper_api ).
If not installed, everything in the library will still work, except calling recognizer_instance.recognize_whisper_api will raise an RequestError .
You can install it with python3 -m pip install SpeechRecognition[whisper-api] .
Troubleshooting
The recognizer tries to recognize speech even when i'm not speaking, or after i'm done speaking..
Try increasing the recognizer_instance.energy_threshold property. This is basically how sensitive the recognizer is to when recognition should start. Higher values mean that it will be less sensitive, which is useful if you are in a loud room.
This value depends entirely on your microphone or audio data. There is no one-size-fits-all value, but good values typically range from 50 to 4000.
Also, check on your microphone volume settings. If it is too sensitive, the microphone may be picking up a lot of ambient noise. If it is too insensitive, the microphone may be rejecting speech as just noise.
The recognizer can't recognize speech right after it starts listening for the first time.
The recognizer_instance.energy_threshold property is probably set to a value that is too high to start off with, and then being adjusted lower automatically by dynamic energy threshold adjustment. Before it is at a good level, the energy threshold is so high that speech is just considered ambient noise.
The solution is to decrease this threshold, or call recognizer_instance.adjust_for_ambient_noise beforehand, which will set the threshold to a good value automatically.
The recognizer doesn't understand my particular language/dialect.
Try setting the recognition language to your language/dialect. To do this, see the documentation for recognizer_instance.recognize_sphinx , recognizer_instance.recognize_google , recognizer_instance.recognize_wit , recognizer_instance.recognize_bing , recognizer_instance.recognize_api , recognizer_instance.recognize_houndify , and recognizer_instance.recognize_ibm .
For example, if your language/dialect is British English, it is better to use "en-GB" as the language rather than "en-US" .
The recognizer hangs on recognizer_instance.listen ; specifically, when it's calling Microphone.MicrophoneStream.read .
This usually happens when you're using a Raspberry Pi board, which doesn't have audio input capabilities by itself. This causes the default microphone used by PyAudio to simply block when we try to read it. If you happen to be using a Raspberry Pi, you'll need a USB sound card (or USB microphone).
Once you do this, change all instances of Microphone() to Microphone(device_index=MICROPHONE_INDEX) , where MICROPHONE_INDEX is the hardware-specific index of the microphone.
To figure out what the value of MICROPHONE_INDEX should be, run the following code:
This will print out something like the following:
Now, to use the Snowball microphone, you would change Microphone() to Microphone(device_index=3) .
Calling Microphone() gives the error IOError: No Default Input Device Available .
As the error says, the program doesn't know which microphone to use.
To proceed, either use Microphone(device_index=MICROPHONE_INDEX, ...) instead of Microphone(...) , or set a default microphone in your OS. You can obtain possible values of MICROPHONE_INDEX using the code in the troubleshooting entry right above this one.
The program doesn't run when compiled with PyInstaller .
As of PyInstaller version 3.0, SpeechRecognition is supported out of the box. If you're getting weird issues when compiling your program using PyInstaller, simply update PyInstaller.
You can easily do this by running pip install --upgrade pyinstaller .
On Ubuntu/Debian, I get annoying output in the terminal saying things like "bt_audio_service_open: [...] Connection refused" and various others.
The "bt_audio_service_open" error means that you have a Bluetooth audio device, but as a physical device is not currently connected, we can't actually use it - if you're not using a Bluetooth microphone, then this can be safely ignored. If you are, and audio isn't working, then double check to make sure your microphone is actually connected. There does not seem to be a simple way to disable these messages.
For errors of the form "ALSA lib [...] Unknown PCM", see this StackOverflow answer . Basically, to get rid of an error of the form "Unknown PCM cards.pcm.rear", simply comment out pcm.rear cards.pcm.rear in /usr/share/alsa/alsa.conf , ~/.asoundrc , and /etc/asound.conf .
For "jack server is not running or cannot be started" or "connect(2) call to /dev/shm/jack-1000/default/jack_0 failed (err=No such file or directory)" or "attempt to connect to server failed", these are caused by ALSA trying to connect to JACK, and can be safely ignored. I'm not aware of any simple way to turn those messages off at this time, besides entirely disabling printing while starting the microphone .
On OS X, I get a ChildProcessError saying that it couldn't find the system FLAC converter, even though it's installed.
Installing FLAC for OS X directly from the source code will not work, since it doesn't correctly add the executables to the search path.
Installing FLAC using Homebrew ensures that the search path is correctly updated. First, ensure you have Homebrew, then run brew install flac to install the necessary files.
To hack on this library, first make sure you have all the requirements listed in the "Requirements" section.
- Most of the library code lives in speech_recognition/__init__.py .
- Examples live under the examples/ directory , and the demo script lives in speech_recognition/__main__.py .
- The FLAC encoder binaries are in the speech_recognition/ directory .
- Documentation can be found in the reference/ directory .
- Third-party libraries, utilities, and reference material are in the third-party/ directory .
To install/reinstall the library locally, run python -m pip install -e .[dev] in the project root directory .
Before a release, the version number is bumped in README.rst and speech_recognition/__init__.py . Version tags are then created using git config gpg.program gpg2 && git config user.signingkey DB45F6C431DE7C2DCD99FF7904882258A4063489 && git tag -s VERSION_GOES_HERE -m "Version VERSION_GOES_HERE" .
Releases are done by running make-release.sh VERSION_GOES_HERE to build the Python source packages, sign them, and upload them to PyPI.
To run all the tests:
To run static analysis:
To ensure RST is well-formed:
Testing is also done automatically by GitHub Actions, upon every push.
FLAC Executables
The included flac-win32 executable is the official FLAC 1.3.2 32-bit Windows binary .
The included flac-linux-x86 and flac-linux-x86_64 executables are built from the FLAC 1.3.2 source code with Manylinux to ensure that it's compatible with a wide variety of distributions.
The built FLAC executables should be bit-for-bit reproducible. To rebuild them, run the following inside the project directory on a Debian-like system:
The included flac-mac executable is extracted from xACT 2.39 , which is a frontend for FLAC 1.3.2 that conveniently includes binaries for all of its encoders. Specifically, it is a copy of xACT 2.39/xACT.app/Contents/Resources/flac in xACT2.39.zip .
Please report bugs and suggestions at the issue tracker !
How to cite this library (APA style):
Zhang, A. (2017). Speech Recognition (Version 3.8) [Software]. Available from https://github.com/Uberi/speech_recognition#readme .
How to cite this library (Chicago style):
Zhang, Anthony. 2017. Speech Recognition (version 3.8).
Also check out the Python Baidu Yuyin API , which is based on an older version of this project, and adds support for Baidu Yuyin . Note that Baidu Yuyin is only available inside China.
Copyright 2014-2017 Anthony Zhang (Uberi) . The source code for this library is available online at GitHub .
SpeechRecognition is made available under the 3-clause BSD license. See LICENSE.txt in the project's root directory for more information.
For convenience, all the official distributions of SpeechRecognition already include a copy of the necessary copyright notices and licenses. In your project, you can simply say that licensing information for SpeechRecognition can be found within the SpeechRecognition README, and make sure SpeechRecognition is visible to users if they wish to see it .
SpeechRecognition distributes source code, binaries, and language files from CMU Sphinx . These files are BSD-licensed and redistributable as long as copyright notices are correctly retained. See speech_recognition/pocketsphinx-data/*/LICENSE*.txt and third-party/LICENSE-Sphinx.txt for license details for individual parts.
SpeechRecognition distributes source code and binaries from PyAudio . These files are MIT-licensed and redistributable as long as copyright notices are correctly retained. See third-party/LICENSE-PyAudio.txt for license details.
SpeechRecognition distributes binaries from FLAC - speech_recognition/flac-win32.exe , speech_recognition/flac-linux-x86 , and speech_recognition/flac-mac . These files are GPLv2-licensed and redistributable, as long as the terms of the GPL are satisfied. The FLAC binaries are an aggregate of separate programs , so these GPL restrictions do not apply to the library or your programs that use the library, only to FLAC itself. See LICENSE-FLAC.txt for license details.
Releases 29
Contributors 46.
- Python 99.6%
openai-whisper 20231117
pip install openai-whisper Copy PIP instructions
Released: Nov 17, 2023
Robust Speech Recognition via Large-Scale Weak Supervision
Verified details
Maintainers.

Unverified details
Project links, github statistics.
- Open issues:
View statistics for this project via Libraries.io , or by using our public dataset on Google BigQuery
License: MIT
Author: OpenAI
Requires: Python >=3.8
Project description
[Blog] [Paper] [Model card] [Colab example]
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.

A Transformer sequence-to-sequence model is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. These tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing a single model to replace many stages of a traditional speech-processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.
We used Python 3.9.9 and PyTorch 1.10.1 to train and test our models, but the codebase is expected to be compatible with Python 3.8-3.11 and recent PyTorch versions. The codebase also depends on a few Python packages, most notably OpenAI's tiktoken for their fast tokenizer implementation. You can download and install (or update to) the latest release of Whisper with the following command:
Alternatively, the following command will pull and install the latest commit from this repository, along with its Python dependencies:
To update the package to the latest version of this repository, please run:
It also requires the command-line tool ffmpeg to be installed on your system, which is available from most package managers:
You may need rust installed as well, in case tiktoken does not provide a pre-built wheel for your platform. If you see installation errors during the pip install command above, please follow the Getting started page to install Rust development environment. Additionally, you may need to configure the PATH environment variable, e.g. export PATH="$HOME/.cargo/bin:$PATH" . If the installation fails with No module named 'setuptools_rust' , you need to install setuptools_rust , e.g. by running:
Available models and languages
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and inference speed relative to the large model; actual speed may vary depending on many factors including the available hardware.
The .en models for English-only applications tend to perform better, especially for the tiny.en and base.en models. We observed that the difference becomes less significant for the small.en and medium.en models.
Whisper's performance varies widely depending on the language. The figure below shows a performance breakdown of large-v3 and large-v2 models by language, using WERs (word error rates) or CER (character error rates, shown in Italic ) evaluated on the Common Voice 15 and Fleurs datasets. Additional WER/CER metrics corresponding to the other models and datasets can be found in Appendix D.1, D.2, and D.4 of the paper , as well as the BLEU (Bilingual Evaluation Understudy) scores for translation in Appendix D.3.

Command-line usage
The following command will transcribe speech in audio files, using the medium model:
The default setting (which selects the small model) works well for transcribing English. To transcribe an audio file containing non-English speech, you can specify the language using the --language option:
Adding --task translate will translate the speech into English:
Run the following to view all available options:
See tokenizer.py for the list of all available languages.
Python usage
Transcription can also be performed within Python:
Internally, the transcribe() method reads the entire file and processes the audio with a sliding 30-second window, performing autoregressive sequence-to-sequence predictions on each window.
Below is an example usage of whisper.detect_language() and whisper.decode() which provide lower-level access to the model.
More examples
Please use the 🙌 Show and tell category in Discussions for sharing more example usages of Whisper and third-party extensions such as web demos, integrations with other tools, ports for different platforms, etc.
Whisper's code and model weights are released under the MIT License. See LICENSE for further details.
Project details
Release history release notifications | rss feed.
Nov 17, 2023
Nov 6, 2023
Sep 19, 2023
Mar 15, 2023
Mar 8, 2023
Mar 7, 2023
Jan 24, 2023
Jan 18, 2023
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages .
Source Distribution
Uploaded Nov 17, 2023 Source
Hashes for openai-whisper-20231117.tar.gz
- português (Brasil)
Supported by

Reconocimiento de voz en Python usando Google Speech API
El reconocimiento de voz es una característica importante en varias aplicaciones utilizadas, como la domótica, la inteligencia artificial, etc. Este artículo tiene como objetivo proporcionar una introducción sobre cómo utilizar la biblioteca SpeechRecognition de Python. Esto es útil ya que puede usarse en microcontroladores como Raspberri Pis con la ayuda de un micrófono externo.
Instalaciones requeridas
Se debe instalar lo siguiente:
- Módulo de reconocimiento de voz de Python: sudo pip install SpeechRecognition
Si las versiones en los repositorios son demasiado antiguas, instale pyaudio usando el siguiente comando
Use pip3 en lugar de pip para python3. Los usuarios de Windows pueden instalar pyaudio ejecutando el siguiente comando en una terminal
Entrada de voz usando un micrófono y traducción de voz a texto
Tome nota de esto, ya que se utilizará en el programa.
- Establecer tamaño de fragmento: esto básicamente implicó especificar cuántos bytes de datos queremos leer a la vez. Por lo general, este valor se especifica en potencias de 2, como 1024 o 2048
- Establecer frecuencia de muestreo: la frecuencia de muestreo define con qué frecuencia se registran los valores para su procesamiento
- Establezca la ID del dispositivo en el micrófono seleccionado : en este paso, especificamos la ID del dispositivo del micrófono que deseamos usar para evitar ambigüedades en caso de que haya varios micrófonos. Esto también ayuda a la depuración, en el sentido de que, mientras ejecutamos el programa, sabremos si se está reconociendo el micrófono especificado. Durante el programa, especificamos un parámetro device_id. El programa dirá que no se pudo encontrar device_id si no se reconoce el micrófono.
- Permitir ajuste por ruido ambiental: dado que el ruido ambiental varía, debemos permitir que el programa ajuste el umbral de energía de grabación por un segundo o más para que se ajuste de acuerdo con el nivel de ruido externo.
- Traducción de voz a texto: Esto se hace con la ayuda de Google Speech Recognition. Esto requiere una conexión a Internet activa para funcionar. Sin embargo, hay ciertos sistemas de Reconocimiento fuera de línea como PocketSphinx, pero tienen un proceso de instalación muy riguroso que requiere varias dependencias. El reconocimiento de voz de Google es uno de los más fáciles de usar.
Los pasos anteriores se han implementado a continuación:
Transcribir un archivo de audio a texto
Si tenemos un archivo de audio que queremos traducir a texto, simplemente debemos reemplazar la fuente con el archivo de audio en lugar de un micrófono. Coloque el archivo de audio y el programa en la misma carpeta para mayor comodidad. Esto funciona para archivos WAV, AIFF o FLAC. A continuación se muestra una implementación.
Solución de problemas
Los siguientes problemas se encuentran comúnmente
Escriba un mezclador . La salida se verá algo así
- Sin conexión a Internet: la conversión de voz a texto requiere una conexión a Internet activa.
Este artículo es una contribución de Deepak Srivatsav . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a [email protected]. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here . Licence: CCBY-SA
Deja una respuesta Cancelar la respuesta
Tu dirección de correo electrónico no será publicada. Los campos obligatorios están marcados con *
Comentario *
Correo electrónico *
Guarda mi nombre, correo electrónico y web en este navegador para la próxima vez que comente.
jonatasgrosman / wav2vec2-large-xlsr-53-spanish like 26
Fine-tuned xlsr-53 large model for speech recognition in spanish.
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Spanish using the train and validation splits of Common Voice 6.1 . When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the OVHcloud :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
The model can be used directly (without a language model) as follows...
Using the HuggingSound library:
Writing your own inference script:
- To evaluate on mozilla-foundation/common_voice_6_0 with split test
- To evaluate on speech-recognition-community-v2/dev_data
If you want to cite this model you can use this:
Datasets used to train jonatasgrosman/wav2vec2-large-xlsr-53-spanish
Spaces using jonatasgrosman/wav2vec2-large-xlsr-53-spanish 14, evaluation results.
- Test WER on Common Voice es self-reported 8.820
- Test CER on Common Voice es self-reported 2.580
- Test WER (+LM) on Common Voice es self-reported 6.270
- Test CER (+LM) on Common Voice es self-reported 2.060
- Dev WER on Robust Speech Event - Dev Data self-reported 30.190
- Dev CER on Robust Speech Event - Dev Data self-reported 13.560
- Dev WER (+LM) on Robust Speech Event - Dev Data self-reported 24.710
- Dev CER (+LM) on Robust Speech Event - Dev Data self-reported 12.610
- Python for Machine Learning
- Machine Learning with R
- Machine Learning Algorithms
- Math for Machine Learning
- Machine Learning Interview Questions
- ML Projects
- Deep Learning
- Computer vision
- Data Science
- Artificial Intelligence
Speech Recognition Module Python
- Python | Speech recognition on large audio files
- Speech Recognition in Python using CMU Sphinx
- Python | Face recognition using GUI
- Python Text To Speech | pyttsx module
- What is Speech Recognition?
- How to Set Up Speech Recognition on Windows?
- Python word2number Module
- Automatic Speech Recognition using Whisper
- Speech Recognition in Hindi using Python
- Speech Recognition in Python using Google Speech API
- Python text2digits Module
- Python - Get Today's Current Day using Speech Recognition
- Python winsound module
- Automatic Speech Recognition using CTC
- TextaCy module in Python
- Python subprocess module
- Google Chrome Dino Bot using Image Recognition | Python
- Restart your Computer with Speech Recognition
- Python Modules
Speech recognition, a field at the intersection of linguistics, computer science, and electrical engineering, aims at designing systems capable of recognizing and translating spoken language into text. Python, known for its simplicity and robust libraries, offers several modules to tackle speech recognition tasks effectively. In this article, we’ll explore the essence of speech recognition in Python, including an overview of its key libraries, how they can be implemented, and their practical applications.
Key Python Libraries for Speech Recognition
- SpeechRecognition : One of the most popular Python libraries for recognizing speech. It provides support for several engines and APIs, such as Google Web Speech API, Microsoft Bing Voice Recognition, and IBM Speech to Text. It’s known for its ease of use and flexibility, making it a great starting point for beginners and experienced developers alike.
- PyAudio : Essential for audio input and output in Python, PyAudio provides Python bindings for PortAudio, the cross-platform audio I/O library. It’s often used alongside SpeechRecognition to capture microphone input for real-time speech recognition.
- DeepSpeech : Developed by Mozilla, DeepSpeech is an open-source deep learning-based voice recognition system that uses models trained on the Baidu’s Deep Speech research project. It’s suitable for developers looking to implement more sophisticated speech recognition features with the power of deep learning.
Implementing Speech Recognition with Python
A basic implementation using the SpeechRecognition library involves several steps:
- Audio Capture : Capturing audio from the microphone using PyAudio.
- Audio Processing : Converting the audio signal into data that the SpeechRecognition library can work with.
- Recognition : Calling the recognize_google() method (or another available recognition method) on the SpeechRecognition library to convert the audio data into text.
Here’s a simple example:
Practical Applications
Speech recognition has a wide range of applications:
- Voice-activated Assistants: Creating personal assistants like Siri or Alexa.
- Accessibility Tools: Helping individuals with disabilities interact with technology.
- Home Automation: Enabling voice control over smart home devices.
- Transcription Services: Automatically transcribing meetings, lectures, and interviews.
Challenges and Considerations
While implementing speech recognition, developers might face challenges such as background noise interference, accents, and dialects. It’s crucial to consider these factors and test the application under various conditions. Furthermore, privacy and ethical considerations must be addressed, especially when handling sensitive audio data.
Speech recognition in Python offers a powerful way to build applications that can interact with users in natural language. With the help of libraries like SpeechRecognition, PyAudio, and DeepSpeech, developers can create a range of applications from simple voice commands to complex conversational interfaces. Despite the challenges, the potential for innovative applications is vast, making speech recognition an exciting area of development in Python.
FAQ on Speech Recognition Module in Python
What is the speech recognition module in python.
The Speech Recognition module, often referred to as SpeechRecognition, is a library that allows Python developers to convert spoken language into text by utilizing various speech recognition engines and APIs. It supports multiple services like Google Web Speech API, Microsoft Bing Voice Recognition, IBM Speech to Text, and others.
How can I install the Speech Recognition module?
You can install the Speech Recognition module by running the following command in your terminal or command prompt: pip install SpeechRecognition For capturing audio from the microphone, you might also need to install PyAudio. On most systems, this can be done via pip: pip install PyAudio
Do I need an internet connection to use the Speech Recognition module?
Yes, for most of the supported APIs like Google Web Speech, Microsoft Bing Voice Recognition, and IBM Speech to Text, an active internet connection is required. However, if you use the CMU Sphinx engine, you do not need an internet connection as it operates offline.
Please Login to comment...
Similar reads.
- AI-ML-DS With Python
- Python Framework
- Python-Library
- Machine Learning
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
The Developer's Guide to Speech Recognition in Python
Jose Nicholas Francisco

Introduction
“Hey, Alexa, is speech recognition really important?”
The short answer? Yes.
If you’ve been paying attention to hardware and software trends, you’ll notice speech recognition, audio analysis, and speech creation have become top of mind for modern developers. As we move towards a world full of VR and ambient computing, learning how to use these APIs is going to be an important part of new architectures. In this article, we’ll talk most about speech recognition APIs, but you will want to use a number of tools to first edit, filter, and improve audio.
But first, let's go over some of the basics.
What is Speech Recognition?
Speech recognition (a.k.a. speech-to-text) converts audio data into data formats that data scientists use to get actionable insights for business, industry, and academia. It is a method to change unstructured data (data not organized in a pre-defined manner) into structured data (organized, machine-readable, and searchable). Other names of speech recognition are speech-to-text (STT), computer speech recognition, or automatic speech recognition (ASR).
Some have also called it voice recognition but that term is defined differently. Voice recognition is defined as identifying a specific person from their voice patterns. Voice recognition is a feature of speech recognition. You can use speech recognition solutions in combination with artificial intelligence to identify a specific speaker and tie that voice pattern to a name.
Why is Speech Recognition Important?
When you look at all the data being generated in the world, only 10% of that data is structured data. That means 90% of the world’s data is unstructured; unsearchable and unorganized, not yet being used for business insights. In addition, unstructured data is forecasted to increase by 60% per year. When you think about it, many organizations are making important decisions on only 10% of the data.
Most of this unstructured data is voice or video data that needs to be changed into machine-readable data to be used for decision-making. This is where ASR comes in and why it is so important.
The History of Speech Recognition
The history of speech recognition can be traced to technologies first developed in the 1950 and 1960s, when researchers made hard-wired (vacuum tubes, resistors, transistors and solder) systems that could recognize individual words, not sentences or phrases. That technology, as you might imagine, is essentially obsolete. The first known ASR was developed by Bell Labs and used a program called Audrey, which could transcribe simple numbers. The next breakthrough did not occur until mid-1970 when researchers started using Hidden Markov Models (HMM). HMM uses probability functions to determine the correct words to transcribe.

Tife Sanusi
May 21, 2024

Samuel Adebayo
May 20, 2024

May 15, 2024

May 16, 2024
Unlock language AI at scale with an API call.
Get conversational intelligence with transcription and understanding on the world's best speech AI platform.
- Español – América Latina
- Português – Brasil
- Cloud Speech-to-Text
- Documentation
Speech-to-Text supported languages
This page lists all languages supported by Cloud Speech-to-Text. Language is specified within a recognition request's languageCode parameter. For more information about sending a recognition request and specifying the language of the transcription, see the how-to guides about performing speech recognition. For more information about the class tokens available for each language, see the class tokens page .
Try it for yourself
If you're new to Google Cloud, create an account to evaluate how Speech-to-Text performs in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
The table below lists the models available for each language. Cloud Speech-to-Text offers multiple recognition models , each tuned to different audio types. The default and command_and_search recognition models support all available languages. The command_and_search model is optimized for short audio clips, such as voice commands or voice searches. The default model can be used to transcribe any audio type.
Some languages are supported by additional models, optimized for additional audio types: enhanced phone_call , and enhanced video . These models can recognize speech captured from these audio sources more accurately than the default model. See the enhanced models page for more information. If any of these additional models are available for your language, they will be listed with the default and command_and_search models for your language. If only the default and command_and_search models are listed with your language, no additional models are currently available.
Use only the language codes shown in the following table. The following language codes are officially maintained and monitored externally by Google. Using other language codes can result in breaking changes.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2024-05-13 UTC.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 20 May 2024
A bilingual speech neuroprosthesis driven by cortical articulatory representations shared between languages
- Alexander B. Silva ORCID: orcid.org/0000-0003-0838-4136 1 , 2 , 3 ,
- Jessie R. Liu ORCID: orcid.org/0000-0001-9316-7624 1 , 2 , 3 ,
- Sean L. Metzger 1 , 2 , 3 ,
- Ilina Bhaya-Grossman 1 , 2 , 3 ,
- Maximilian E. Dougherty ORCID: orcid.org/0000-0002-0698-5678 1 ,
- Margaret P. Seaton 1 ,
- Kaylo T. Littlejohn 1 , 2 , 4 ,
- Adelyn Tu-Chan 5 ,
- Karunesh Ganguly ORCID: orcid.org/0000-0002-2570-9943 2 , 5 ,
- David A. Moses 1 , 2 &
- Edward F. Chang ORCID: orcid.org/0000-0003-2480-4700 1 , 2 , 3
Nature Biomedical Engineering ( 2024 ) Cite this article
14 Altmetric
Metrics details
- Amyotrophic lateral sclerosis
- Biomedical engineering
- Brain–machine interface
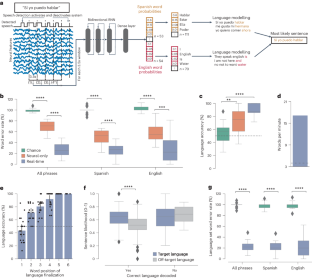
Advancements in decoding speech from brain activity have focused on decoding a single language. Hence, the extent to which bilingual speech production relies on unique or shared cortical activity across languages has remained unclear. Here, we leveraged electrocorticography, along with deep-learning and statistical natural-language models of English and Spanish, to record and decode activity from speech-motor cortex of a Spanish–English bilingual with vocal-tract and limb paralysis into sentences in either language. This was achieved without requiring the participant to manually specify the target language. Decoding models relied on shared vocal-tract articulatory representations across languages, which allowed us to build a syllable classifier that generalized across a shared set of English and Spanish syllables. Transfer learning expedited training of the bilingual decoder by enabling neural data recorded in one language to improve decoding in the other language. Overall, our findings suggest shared cortical articulatory representations that persist after paralysis and enable the decoding of multiple languages without the need to train separate language-specific decoders.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
92,52 € per year
only 7,71 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Similar content being viewed by others

The speech neuroprosthesis

A high-performance speech neuroprosthesis

Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis
Data availability.
The data needed to recreate the main figures are provided as Source Data , and are also available in GitHub at https://github.com/asilvaalex4/bilingual_speech_bci . The raw patient data are accessible to researchers from other institutions, but public sharing is restricted pursuant to our clinical trial protocol. Full access to the data will be granted on reasonable request to E.F.C. at [email protected], and a response can be expected in under 3 weeks. Shared data must be kept confidential and not provided to others unless approval is obtained. Shared data will not contain any information that may identify the participant, to protect their anonymity. Source data are provided with this paper.
Code availability
The code required to replicate the main findings of the study is available via GitHub at https://github.com/asilvaalex4/bilingual_speech_bci .
Nip, I. & Roth, C. R. in Encyclopedia of Clinical Neuropsychology (eds Kreutzer, J. et al.) 1-1 (Springer, 2017).
Chartier, J., Anumanchipalli, G. K., Johnson, K. & Chang, E. F. Encoding of articulatory kinematic trajectories in human speech sensorimotor cortex. Neuron 98 , 1042–1054.e4 (2018).
Article CAS PubMed PubMed Central Google Scholar
Herff, C. et al. Generating natural, intelligible speech from brain activity in motor, premotor, and inferior frontal cortices. Front. Neurosci. 13 , 1267 (2019).
Article PubMed PubMed Central Google Scholar
Moses, D. A., Leonard, M. K., Makin, J. G. & Chang, E. F. Real-time decoding of question-and-answer speech dialogue using human cortical activity. Nat. Commun. 10 , 3096 (2019).
Soroush, P. Z. et al. The nested hierarchy of overt, mouthed, and imagined speech activity evident in intracranial recordings. NeuroImage 269 , 119913 (2023).
Article PubMed Google Scholar
Thomas, T. M. et al. Decoding articulatory and phonetic components of naturalistic continuous speech from the distributed language network. J. Neural Eng. 20 , 046030 (2023).
Article Google Scholar
Stavisky, S. D. et al. Neural ensemble dynamics in dorsal motor cortex during speech in people with paralysis. eLife 8 , e46015 (2019).
Willett, F. R. et al. A high-performance speech neuroprosthesis. Nature 620 , 1031–1036 (2023).
Wandelt, S. K. et al. Decoding grasp and speech signals from the cortical grasp circuit in a tetraplegic human. Neuron 110 , 1777–1787.e3 (2022).
Angrick, M. et al. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 16 , 036019 (2019).
Berezutskaya, J. et al. Direct speech reconstruction from sensorimotor brain activity with optimized deep learning models. J. Neural Eng. 20 , 056010 (2023).
Dash, D., Ferrari, P. & Wang, J. Decoding imagined and spoken phrases from non-invasive neural (MEG) signals. Front. Neurosci. 14 , 290 (2020).
Moses, D. A. et al. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. N. Engl. J. Med. 385 , 217–227 (2021).
Mugler, E. M. et al. Direct classification of all American English phonemes using signals from functional speech motor cortex. J. Neural Eng. 11 , 035015 (2014).
Metzger, S. L. et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature 620 , 1037–1046 (2023).
Choe, J. et al. Language-specific effects on automatic speech recognition errors for world Englishes. In Proc. 29th International Conference on Computational Linguistics 7177–7186 (International Committee on Computational Linguistics, 2022).
DiChristofano, A., Shuster, H., Chandra, S. & Patwari, N. Global performance disparities between English-language accents in automatic speech recognition. Preprint at http://arxiv.org/abs/2208.01157 (2023).
Baker, C. & Jones, S. Encyclopedia of Bilingualism and Bilingual Education (Multilingual Matters, 1998).
Athanasopoulos, P. et al. Two languages, two minds: flexible cognitive processing driven by language of operation. Psychol. Sci. 26 , 518–526 (2015).
Chen, S. X. & Bond, M. H. Two languages, two personalities? Examining language effects on the expression of personality in a bilingual context. Pers. Soc. Psychol. Bull. 36 , 1514–1528 (2010).
Costa, A. & Sebastián-Gallés, N. How does the bilingual experience sculpt the brain? Nat. Rev. Neurosci. 15 , 336–345 (2014).
Naranowicz, M., Jankowiak, K. & Behnke, M. Native and non-native language contexts differently modulate mood-driven electrodermal activity. Sci. Rep. 12 , 22361 (2022).
Li, Q. et al. Monolingual and bilingual language networks in healthy subjects using functional MRI and graph theory. Sci. Rep. 11 , 10568 (2021).
Pierce, L. J., Chen, J.-K., Delcenserie, A., Genesee, F. & Klein, D. Past experience shapes ongoing neural patterns for language. Nat. Commun. 6 , 10073 (2015).
Article CAS PubMed Google Scholar
Dehaene, S. Fitting two languages into one brain. Brain 122 , 2207–2208 (1999).
Kim, K. H. S., Relkin, N. R., Lee, K.-M. & Hirsch, J. Distinct cortical areas associated with native and second languages. Nature 388 , 171–174 (1997).
Tham, W. W. P. et al. Phonological processing in Chinese–English bilingual biscriptals: an fMRI study. NeuroImage 28 , 579–587 (2005).
Xu, M., Baldauf, D., Chang, C. Q., Desimone, R. & Tan, L. H. Distinct distributed patterns of neural activity are associated with two languages in the bilingual brain. Sci. Adv. 3 , e1603309 (2017).
Berken, J. A. et al. Neural activation in speech production and reading aloud in native and non-native languages. NeuroImage 112 , 208–217 (2015).
Del Maschio, N. & Abutalebi, J. The Handbook of the Neuroscience of Multilingualism (Wiley-Blackwell, 2019).
DeLuca, V., Rothman, J., Bialystok, E. & Pliatsikas, C. Redefining bilingualism as a spectrum of experiences that differentially affects brain structure and function. Proc. Natl Acad. Sci. USA 116 , 7565–7574 (2019).
Liu, H., Hu, Z., Guo, T. & Peng, D. Speaking words in two languages with one brain: neural overlap and dissociation. Brain Res. 1316 , 75–82 (2010).
Shimada, K. et al. Fluency-dependent cortical activation associated with speech production and comprehension in second language learners. Neuroscience 300 , 474–492 (2015).
Treutler, M. & Sörös, P. Functional MRI of native and non-native speech sound production in sequential German–English Bilinguals. Front. Hum. Neurosci. 15 , 683277 (2021).
Cao, F., Tao, R., Liu, L., Perfetti, C. A. & Booth, J. R. High proficiency in a second language is characterized by greater involvement of the first language network: evidence from Chinese learners of English. J. Cogn. Neurosci. 25 , 1649–1663 (2013).
Geng, S. et al. Intersecting distributed networks support convergent linguistic functioning across different languages in bilinguals. Commun. Biol. 6 , 99 (2023).
Malik-Moraleda, S. et al. An investigation across 45 languages and 12 language families reveals a universal language network. Nat. Neurosci. 25 , 1014–1019 (2022).
Perani, D. & Abutalebi, J. The neural basis of first and second language processing. Curr. Opin. Neurobiol. 15 , 202–206 (2005).
Alario, F.-X., Goslin, J., Michel, V. & Laganaro, M. The functional origin of the foreign accent: evidence from the syllable-frequency effect in bilingual speakers. Psychol. Sci. 21 , 15–20 (2010).
Simmonds, A., Wise, R. & Leech, R. Two tongues, one brain: imaging bilingual speech production. Front. Psychol. 2 , 166 (2011).
Hannun, A. Y., Maas, A. L., Jurafsky, D. & Ng, A. Y. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. Preprint at https://arxiv.org/abs/1408.2873 (2014).
Metzger, S. L. et al. Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis. Nat. Commun. 13 , 6510 (2022).
Willett, F. R., Avansino, D. T., Hochberg, L. R., Henderson, J. M. & Shenoy, K. V. High-performance brain-to-text communication via handwriting. Nature 593 , 249–254 (2021).
Radford, A. et al. Language models are unsupervised multitask learners. Preprint at Semantic Scholar https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe (2018).
Blakely, T., Miller, K. J., Zanos, S. P., Rao, R. P. N. & Ojemann, J. G. Robust, long-term control of an electrocorticographic brain–computer interface with fixed parameters. Neurosurg. Focus 27 , E13 (2009).
Pels, E. G. M. et al. Stability of a chronic implanted brain–computer interface in late-stage amyotrophic lateral sclerosis. Clin. Neurophysiol. 130 , 1798–1803 (2019).
Silversmith, D. B. et al. Plug-and-play control of a brain–computer interface through neural map stabilization. Nat. Biotechnol. 39 , 326–335 (2021).
Volkova, K., Lebedev, M. A., Kaplan, A. & Ossadtchi, A. Decoding movement from electrocorticographic activity: a review. Front. Neuroinform. 13 , 74 (2019).
Luo, S. et al. Stable decoding from a speech BCI enables control for an individual with ALS without recalibration for 3 months. Adv. Sci. 10 , 2304853 (2023).
Bouchard, K. E., Mesgarani, N., Johnson, K. & Chang, E. F. Functional organization of human sensorimotor cortex for speech articulation. Nature 495 , 327–332 (2013).
Carey, D., Krishnan, S., Callaghan, M. F., Sereno, M. I. & Dick, F. Functional and quantitative MRI mapping of somatomotor representations of human supralaryngeal vocal tract. Cereb. Cortex 27 , 265–278 (2017).
PubMed PubMed Central Google Scholar
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space. Preprint at https://arxiv.org/abs/1301.3781v3 (2013).
Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proc. IEEE Pacific Rim Conference on Communications, Computers and Signal Processing 125–128 (IEEE, 1993).
Mitra, V. et al. Joint modeling of articulatory and acoustic spaces for continuous speech recognition tasks. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 5205 (IEEE, 2017).
Caruana, R. Multitask learning. Mach. Learn. 28 , 41–75 (1997).
Tan, C. et al. A survey on deep transfer learning. In Artificial Neural Networks and Machine Learning – ICANN 2018 (eds Kůrková, V. et al.) 270–279 (Springer, 2018).
Makin, J. G., Moses, D. A. & Chang, E. F. Machine translation of cortical activity to text with an encoder–decoder framework. Nat. Neurosci. 23 , 575–582 (2020).
Peterson, S. M., Steine-Hanson, Z., Davis, N., Rao, R. P. N. & Brunton, B. W. Generalized neural decoders for transfer learning across participants and recording modalities. J. Neural Eng. 18 , 026014 (2021).
Watanabe, S., Delcroix, M., Metze, F. & Hershey, J. R. New Era for Robust Speech Recognition: Exploiting Deep Learning (Springer, 2017).
Gao, H. et al. Domain generalization for language-independent automatic speech recognition. Front. Artif. Intell. 5 , 806274 (2022).
Radford, A. et al. Robust speech recognition via large-scale weak supervision. Preprint at http://arxiv.org/abs/2212.04356 (2022).
Zhang, Y. et al. Google USM: scaling automatic speech recognition beyond 100 languages. Preprint at http://arxiv.org/abs/2303.01037 (2023).
Hartshorne, J. K., Tenenbaum, J. B. & Pinker, S. A critical period for second language acquisition: evidence from 2/3 million English speakers. Cognition 177 , 263–277 (2018).
Huggins, J. E., Wren, P. A. & Gruis, K. L. What would brain–computer interface users want? Opinions and priorities of potential users with amyotrophic lateral sclerosis. Amyotroph. Lateral Scler. 12 , 318–324 (2011).
Peters, B. et al. Brain–computer interface users speak up: the Virtual Users’ Forum at the 2013 International Brain-Computer Interface Meeting. Arch. Phys. Med. Rehabil. 96 , S33–S37 (2015).
Herff, C. et al. Brain-to-text: decoding spoken phrases from phone representations in the brain. Front. Neurosci. 9 , 217 (2015).
Tang, J., LeBel, A., Jain, S. & Huth, A. G. Semantic reconstruction of continuous language from non-invasive brain recordings. Nat. Neurosci. 26 , 858–866 (2023).
Correia, J. et al. Brain-based translation: fMRI decoding of spoken words in bilinguals reveals language-independent semantic representations in anterior temporal lobe. J. Neurosci. 34 , 332–338 (2014).
Lucas, T. H., McKhann, G. M. & Ojemann, G. A. Functional separation of languages in the bilingual brain: a comparison of electrical stimulation language mapping in 25 bilingual patients and 117 monolingual control patients. J. Neurosurg. 101 , 449–457 (2004).
Giussani, C., Roux, F.-E., Lubrano, V., Gaini, S. M. & Bello, L. Review of language organisation in bilingual patients: what can we learn from direct brain mapping? Acta Neurochir. 149 , 1109–1116 (2007).
Best, C. T. The diversity of tone languages and the roles of pitch variation in non-tone languages: considerations for tone perception research. Front. Psychol. 10 , 364 (2019).
Li, Y., Tang, C., Lu, J., Wu, J. & Chang, E. F. Human cortical encoding of pitch in tonal and non-tonal languages. Nat. Commun. 12 , 1161 (2021).
Lee, G. & Li, H. Modeling code-switch languages using bilingual parallel corpus. In Proc. 58th Annual Meeting of the Association for Computational Linguistics 860–870 (Association for Computational Linguistics, 2020).
Rossi, E., Dussias, P. E., Diaz, M., van Hell, J. G. & Newman, S. Neural signatures of inhibitory control in intra-sentential code-switching: evidence from fMRI. J. Neurolinguist. 57 , 100938 (2021).
Zheng, X., Roelofs, A., Erkan, H. & Lemhöfer, K. Dynamics of inhibitory control during bilingual speech production: an electrophysiological study. Neuropsychologia 140 , 107387 (2020).
Moses, D. A., Leonard, M. K. & Chang, E. F. Real-time classification of auditory sentences using evoked cortical activity in humans. J. Neural Eng. 15 , 036005 (2018).
Ludwig, K. A. et al. Using a common average reference to improve cortical neuron recordings from microelectrode arrays. J. Neurophysiol. 101 , 1679–1689 (2009).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. Preprint at https://arxiv.org/abs/1412.6980 (2017).
Cho, K. et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. Preprint at https://arxiv.org/abs/1406.1078 (2014).
Fort, S., Hu, H. & Lakshminarayanan, B. Deep ensembles: a loss landscape perspective. Preprint at https://arxiv.org/abs/1912.02757 (2020).
Simonyan, K., Vedaldi, A. & Zisserman, A. Deep inside convolutional networks: visualising image classification models and saliency maps. Preprint at https://arxiv.org/abs/1312.6034 (2014).
Lux, F., Koch, J., Schweitzer, A. & Vu, N. T. The IMS Toucan system for the Blizzard Challenge 2021. Preprint at https://arxiv.org/pdf/2310.17499 (2021).
Download references
Acknowledgements
We thank our participant ‘Pancho’ for his tireless perseverance, commitment and dedication to the work described in this paper, and his family and caregivers for their incredible support. We also thank members of the Chang lab for feedback on the project; V. Her for administrative support; B. Spidel for imaging reconstruction; T. Dubnicoff for video editing; J. Davidson for help in designing initial bilingual stimuli; C. Kurtz-Miott, V. Anderson and S. Brosler for help with data collection with our participant; and the members of Karunesh Ganguly’s lab for help with the clinical trial. The National Institutes of Health (grant NIH U01 DC018671-01A1) and the William K. Bowes, Jr. Foundation supported authors S.L.M., J.R.L., D.A.M., M.E.D., M.P.S., K.T.L. and E.F.C. A.B.S. was supported by the National Institute of General Medical Sciences (NIGMS) Medical Scientist Training Program (Grant #T32GM007618) and by the National Institute On Deafness And Other Communication Disorders of the National Institutes of Health (award number F30DC021872). K.T.L. was supported by the National Science Foundation GRFP. A.T.-C. and K.G. did not have relevant funding for this work.
Author information
Authors and affiliations.
Department of Neurological Surgery, University of California, San Francisco, San Francisco, CA, USA
Alexander B. Silva, Jessie R. Liu, Sean L. Metzger, Ilina Bhaya-Grossman, Maximilian E. Dougherty, Margaret P. Seaton, Kaylo T. Littlejohn, David A. Moses & Edward F. Chang
Weill Institute for Neuroscience, University of California, San Francisco, San Francisco, CA, USA
Alexander B. Silva, Jessie R. Liu, Sean L. Metzger, Ilina Bhaya-Grossman, Kaylo T. Littlejohn, Karunesh Ganguly, David A. Moses & Edward F. Chang
University of California, Berkeley - University of California, San Francisco Graduate Program in Bioengineering, Berkeley, CA, USA
Alexander B. Silva, Jessie R. Liu, Sean L. Metzger, Ilina Bhaya-Grossman & Edward F. Chang
Department of Electrical Engineering and Computer Sciences, University of California, Berkeley, Berkeley, CA, USA
Kaylo T. Littlejohn
Department of Neurology, University of California, San Francisco, San Francisco, CA, USA
Adelyn Tu-Chan & Karunesh Ganguly
You can also search for this author in PubMed Google Scholar
Contributions
A.B.S. developed deep-learning classification and language models. J.R.L. developed speech detection models. D.A.M. implemented software for online decoding and data collection. A.B.S. generated figures and performed statistical analyses. A.B.S., along with J.R.L., wrote the manuscript with input from I.B.-G., S.L.M., K.T.L., D.A.M. and E.F.C. A.B.S. and D.A.M., along with J.R.L., S.L.M., I.B.-G. and M.E.D., designed the experiments, utterance sets and analyses. A.B.S., M.E.D. and M.P.S. led data collection with help from J.R.L., S.L.M., K.T.L. and D.A.M. M.P.S., A.T.-C., K.G. and E.F.C. performed regulatory and clinical supervision. E.F.C. conceived and supervised the study.
Corresponding author
Correspondence to Edward F. Chang .
Ethics declarations
Competing interests.
S.L.M., D.A.M., J.R.L. and E.F.C. are inventors on a pending provisional UCSF patent application relevant to the neural-decoding approaches used in this work (Application number: WO2022251472A1, 2022, WIPO PCT - International patent system). G.K.A. and E.F.C. are inventors on patent application PCT/US2020/028926; D.A.M. and E.F.C. are inventors on patent application PCT/US2020/043706; and E.F.C. is an inventor on patent US9905239B2. These patents are broadly relevant to the neural-decoding approaches used in this work. The remaining authors declare no competing interests.
Peer review
Peer review information.
Nature Biomedical Engineering thanks Vikash Gilja, Jonas Obleser and Karim Oweiss for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended data fig. 1 timing and information flow through the bilingual-sentence decoding system..
Shown is a more detailed schematic overview of the bilingual-sentence decoding system to complement Fig. 1a . Three levels of information are depicted: the neural features, the decoding system, and the output to the participant monitor. To start, the participant makes a speech attempt. This is detected by the system and cues activation of an ongoing decoding process. Following activation, a series of 3.5 s windows are cued to the participant. At the end of each window, after the full 3.5 s have passed, the neural features from that window are passed to the decoding process illustrated in Fig. 1a . Following a latency to conduct the decoding, the most likely beam from the process in Fig. 1a is displayed on the participant monitor. This process continues to occur for sequential 3.5 s windows until a window with no detected speech occurs. After such a window, the decoding is finalized and terminated. The system then listens for another speech attempt to activate and repeat the process.
Extended Data Fig. 2 Graphical depiction of bilingual-word classification.
Shown is a schematic of the bilingual-word classification process. Neural features (256 total; 128 HGA and 128 LFS time series over 3.5 s) are classified as a word in the bilingual vocabulary. Neural features are first processed by a temporal convolution. Next, the features are passed through three bidirectional GRU layers. The latent state from these layers is then read out by a dense, linear layer that emits probabilities over the 104 words in the bilingual vocabulary. This process is performed by 10 distinct models, each with a different weight initialization and trained on different folds of the data. The probabilities generated across these 10 models are averaged to create one probability vector across the bilingual vocabulary. This vector is finally split by language and the probability for a given word is broadcast to all conjugated forms of the word before being combined with the language model, as shown in Fig. 1a .
Extended Data Fig. 3 Neural-only chance sentence-decoding performance.
Shown are neural-only specific chance sentence-decoding distributions, alongside the neural-only decoding performance shown in Fig. 1 . Here, we specifically computed a chance distribution with respect to neural-only decoding. We did this by shuffling the neural features and passing them through the classifier. The chance error rate was then computed the same way as for neural-only performance (**** P < 0.0001; two-sided Mann-Whitney U-test with 3-way Holm-Bonferroni correction for multiple comparisons). Distributions are over 21 online phrase-decoding blocks. Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Source data
Extended data fig. 4 performance of attempted speech model on silent reading and listening..
For a subset of 10 bilingual words, we collected neural features during attempted speech, passive listening, and silent reading (roughly 250 trials in each paradigm). A model was trained on attempted speech data, using the same procedure throughout the manuscript, and evaluated on neural features from held-out attempted speech, passive listening, and silent reading trials. Performance was not significantly different from chance when evaluating the attempted speech model on listening or silent reading, in contrast to evaluation on attempted speech. This provides evidence that attempted speech neural features are specific to motor production of speech and not reflecting a process that strongly underlies listening or silent reading. Results are from 10-fold cross validation within each paradigm. Dashed line indicates chance performance (10%). Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 5 Classification accuracy over the full 104 bilingual-words.
a , Shown is unmasked classification accuracy over the full 104 bilingual-words. The classifier retained stable performance without retraining (weights frozen at black dotted line) as in Fig. 2b . b , Classification performance before and after a 30-day break in recording without retraining (P = 0.31, two- sided Mann-Whitney U-test). Distributions are over 5 days. c , 10-fold cross validation (CV) accuracy over the unmasked 104 bilingual-words using all collected data. Median CV accuracy 47.24% (99% CI: [45.83,48.23] %). Distributions are over 10 non-overlapping folds. Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 6 Acoustic similarity of words within the English and Spanish bilingual words.
For each word in the English vocabulary we calculated the mean pairwise mel-cepstral distortion (MCD) to all other English words. We repeated the same procedure for Spanish. Distributions are over 51 English and 50 Spanish words (shared words were excluded). English words have a significantly lower mean pairwise MCD (**** P < 0.0001, two-sided Mann-Whitney U-test). This indicates that English words, on average, are more acoustically confusable with other English words than Spanish words are with other Spanish words. Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 7 Effects of re-training models daily during frozen-decoder evaluation.
Shown is a comparison between performance with and without re-calibration. (a) Shown is the performance without re-calibration for reference taken from (Fig. 2b ). (b) Shown is the performance with re-training the classifier with sequential addition of each day’s data. (c) Shown are distributions of accuracy with and without re-training, demonstrating that small improvements may be found with re-training the decoders with each day’s data. Distributions are over 9 days in each boxplot (starting after the first-day when retraining is possible). Chance is 1.85% for English, 1.89% for Spanish, and 1.87% for all words (masked). Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 8 Distinct contributions of HGA and LFS to classifier performance.
Shown are plots of electrode contributions for HGA against LFS, separately for English (left) and Spanish (right) trained models (as in Fig. 2d,e ). The dotted lines indicate the 90th percentile of HGA and LFS contributions. The majority of electrodes only fall above the 90th percentile for one of HGA or LFS.
Extended Data Fig. 9 Full confusion matrix over all bilingual-words.
Full confusion matrix over the 104 bilingual-words. The sum of each row was normalized to 1, making confusion a proportion from (0-1). Predictions were generated using 10-fold cross validation over the full 104 bilingual-words with no masking (as in Extended Data Fig. 5 ).
Extended Data Fig. 10 Acoustic coverage of large-bilingual-phrase set.
We quantified the distribution of phonemes and phoneme place of articulation features to ensure the large-bilingual-phrase set covered a broad space in each language. We designed the large-bilingual-phrase set to sample a broad range of English (a) and Spanish (b) phonemes. We ensured that the relative proportion of phoneme place of articulation features was similar between English (c) and Spanish (d).
Supplementary information
Main supplementary information.
Supplementary Notes, Methods, Figures, Tables, References and Video captions.
Reporting Summary
Peer review file, supplementary video 1.
A demonstration of online word-by-word bilingual sentence decoding from the brain of a participant with paralysis.
Supplementary Video 2
A demonstration of online word-by-word bilingual sentence decoding from the brain of a participant with paralysis, using three new sentences.
Supplementary Video 3
The participant using the bilingual speech neuroprosthesis has a conversation with a researcher.
Supplementary Data 1
Source data for Supplementary Fig. 1.
Supplementary Data 2
Source data for Supplementary Fig. 2.
Supplementary Data 3
Source data for Supplementary Fig. 3.
Supplementary Data 4
Source data for Supplementary Fig. 4.
Source Data Fig. 1
Source data.
Source Data Fig. 2
Source data fig. 3, source data fig. 4, source data extended data fig. 3, source data extended data fig. 4, source data extended data fig. 5, source data extended data fig. 6, source data extended data fig. 7, source data extended data fig. 8, source data extended data fig. 9, source data extended data fig. 10, rights and permissions.
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Cite this article.
Silva, A.B., Liu, J.R., Metzger, S.L. et al. A bilingual speech neuroprosthesis driven by cortical articulatory representations shared between languages. Nat. Biomed. Eng (2024). https://doi.org/10.1038/s41551-024-01207-5
Download citation
Received : 15 June 2023
Accepted : 01 April 2024
Published : 20 May 2024
DOI : https://doi.org/10.1038/s41551-024-01207-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

IMAGES
VIDEO
COMMENTS
1. So, You'll need to send the language code in config in your request. client = speech.SpeechClient() audio = types.RecognitionAudio(uri=url) config = types.RecognitionConfig(. encoding=enums.RecognitionConfig.AudioEncoding.FLAC, language_code='es-US' // Language code Español (Estados Unidos) ) response = client.long_running_recognize(config ...
To quickly try it out, run python -m speech_recognition after installing. Project links: PyPI; Source code; Issue tracker; ... Speech Recognition (version 3.8). Also check out the Python Baidu Yuyin API, which is based on an older version of this project, and adds support for Baidu Yuyin. Note that Baidu Yuyin is only available inside China.
Reconocer archivos de Audio. El sistema actualmente solo reconoce los siguientes formatos de audio sin perdidas: WAV: must be in PCM/LPCM format. AIFF. AIFF-C. FLAC. # se utiliza el metodo record para cargar el archivo de audio harvard = sr.AudioFile('speech_harvard.wav') # cargar el archivo de audio with harvard as source: audio1 = r.record ...
Spanish Speech-to-Text with Python. Speech-to-Text, also known as Automatic Speech Recognition, is a technology that converts spoken audio into text. The technology has a wide range of applications, from video transcription to hands-free user interfaces. While many cloud Speech-to-Text APIs are available on the market, most can only transcribe ...
Spanish Automatic Speech Recognition pytorch Python · Spanish Single Speaker Speech Dataset, 120h Spanish Speech, [Private Datasource] +3. Spanish Automatic Speech Recognition pytorch. Notebook. Input. Output. Logs. Comments (2) Run. 25854.3s - GPU P100. history Version 3 of 14. GPU.
SpeechBrain is an open-source PyTorch toolkit that accelerates Conversational AI development, i.e., the technology behind speech assistants, chatbots, and large language models. It is crafted for fast and easy creation of advanced technologies for Speech and Text Processing. 🌐 Vision
This is a Python module for Vosk. Vosk is an offline open source speech recognition toolkit. It enables speech recognition for 20+ languages and dialects - English ...
The accessibility improvements alone are worth considering. Speech recognition allows the elderly and the physically and visually impaired to interact with state-of-the-art products and services quickly and naturally—no GUI needed! Best of all, including speech recognition in a Python project is really simple. In this guide, you'll find out ...
¿Necesitas analizar un audio? Aquí te mostramos qué fácil es trabajar con esos archivos utilizando el módulo de Python: SpeechRecognition ¡Es de lo más senci...
Spanish Wav2Vec2 model pre-trained using the Spanish portion of the Common Voice dataset. Part of the Flax x Hugging Face community event. Team: @mariagrandury , @mrm8488 , @edugp and @pcuenq .
Using the speech_recognition library, ... English text is translated to Spanish, and vice versa. ... Offline Speech to Text in Python. Writing, coding, blogging, office work, documentation ...
Python speech recognition spanish es fácil de instalar y utilizar. Los desarrolladores solo necesitan importar la biblioteca y utilizar las funciones proporcionadas para grabar y transcribir voz en español. Además, la biblioteca también ofrece opciones para ajustar la configuración de reconocimiento, como el idioma y la sensibilidad, lo ...
To use all of the functionality of the library, you should have: Python 3.8+ (required); PyAudio 0.2.11+ (required only if you need to use microphone input, Microphone); PocketSphinx (required only if you need to use the Sphinx recognizer, recognizer_instance.recognize_sphinx); Google API Client Library for Python (required only if you need to use the Google Cloud Speech API, recognizer ...
In this course, you'll learn: How speech recognition works. What speech recognition packages are available on PyPI. How to install and use the SpeechRecognition package —a full-featured and straightforward Python speech recognition library. What's Included: 11 Lessons. Video Subtitles and Full Transcripts. 2 Downloadable Resources.
This paper provides an overview of the development of a Speech Recognition Model in Spanish for ... Cleaning the data also means treating the text transcription of the audio tracks with a Python ...
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification. ... We used Python 3.9.9 and PyTorch 1.10.1 to train and test our models, ...
Módulo de reconocimiento de voz de Python: sudo pip install SpeechRecognition. PyAudio: use el siguiente comando para usuarios de Linux. sudo apt-get install python-pyaudio python3-pyaudio. Si las versiones en los repositorios son demasiado antiguas, instale pyaudio usando el siguiente comando. sudo apt-get install portaudio19-dev python-all ...
Fine-tuned XLSR-53 large model for speech recognition in Spanish. Fine-tuned facebook/wav2vec2-large-xlsr-53 on Spanish using the train and validation splits of Common Voice 6.1 . When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned thanks to the GPU credits generously given by the OVHcloud ...
The Speech Recognition module, often referred to as SpeechRecognition, is a library that allows Python developers to convert spoken language into text by utilizing various speech recognition engines and APIs. It supports multiple services like Google Web Speech API, Microsoft Bing Voice Recognition, IBM Speech to Text, and others.
Deepgram provides a Python package for its speech recognition APIs that use powerful deep learning models to recognize speech. It is designed to be easy to use and integrate into existing applications. ... Spanish, French, German, and Chinese. It can also be used to recognize speech in noisy environments. Deepgram's deep learning models have ...
The table below lists the models available for each language. Cloud Speech-to-Text offers multiple recognition models, each tuned to different audio types.The default and command_and_search recognition models support all available languages. The command_and_search model is optimized for short audio clips, such as voice commands or voice searches. The default model can be used to transcribe any ...
During attempted speech, we decoded neural activity from the speech-motor cortex, recorded with a 128-channel ECoG array, word-by-word into English and Spanish phrases, using a vocabulary of 178 ...