deep learning Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords

Synergic Deep Learning for Smart Health Diagnosis of COVID-19 for Connected Living and Smart Cities
COVID-19 pandemic has led to a significant loss of global deaths, economical status, and so on. To prevent and control COVID-19, a range of smart, complex, spatially heterogeneous, control solutions, and strategies have been conducted. Earlier classification of 2019 novel coronavirus disease (COVID-19) is needed to cure and control the disease. It results in a requirement of secondary diagnosis models, since no precise automated toolkits exist. The latest finding attained using radiological imaging techniques highlighted that the images hold noticeable details regarding the COVID-19 virus. The application of recent artificial intelligence (AI) and deep learning (DL) approaches integrated to radiological images finds useful to accurately detect the disease. This article introduces a new synergic deep learning (SDL)-based smart health diagnosis of COVID-19 using Chest X-Ray Images. The SDL makes use of dual deep convolutional neural networks (DCNNs) and involves a mutual learning process from one another. Particularly, the representation of images learned by both DCNNs is provided as the input of a synergic network, which has a fully connected structure and predicts whether the pair of input images come under the identical class. Besides, the proposed SDL model involves a fuzzy bilateral filtering (FBF) model to pre-process the input image. The integration of FBL and SDL resulted in the effective classification of COVID-19. To investigate the classifier outcome of the SDL model, a detailed set of simulations takes place and ensures the effective performance of the FBF-SDL model over the compared methods.
A deep learning approach for remote heart rate estimation
Weakly supervised spatial deep learning for earth image segmentation based on imperfect polyline labels.
In recent years, deep learning has achieved tremendous success in image segmentation for computer vision applications. The performance of these models heavily relies on the availability of large-scale high-quality training labels (e.g., PASCAL VOC 2012). Unfortunately, such large-scale high-quality training data are often unavailable in many real-world spatial or spatiotemporal problems in earth science and remote sensing (e.g., mapping the nationwide river streams for water resource management). Although extensive efforts have been made to reduce the reliance on labeled data (e.g., semi-supervised or unsupervised learning, few-shot learning), the complex nature of geographic data such as spatial heterogeneity still requires sufficient training labels when transferring a pre-trained model from one region to another. On the other hand, it is often much easier to collect lower-quality training labels with imperfect alignment with earth imagery pixels (e.g., through interpreting coarse imagery by non-expert volunteers). However, directly training a deep neural network on imperfect labels with geometric annotation errors could significantly impact model performance. Existing research that overcomes imperfect training labels either focuses on errors in label class semantics or characterizes label location errors at the pixel level. These methods do not fully incorporate the geometric properties of label location errors in the vector representation. To fill the gap, this article proposes a weakly supervised learning framework to simultaneously update deep learning model parameters and infer hidden true vector label locations. Specifically, we model label location errors in the vector representation to partially reserve geometric properties (e.g., spatial contiguity within line segments). Evaluations on real-world datasets in the National Hydrography Dataset (NHD) refinement application illustrate that the proposed framework outperforms baseline methods in classification accuracy.
Prediction of Failure Categories in Plastic Extrusion Process with Deep Learning
Hyperparameters tuning of faster r-cnn deep learning transfer for persistent object detection in radar images, a comparative study of automated legal text classification using random forests and deep learning, a semi-supervised deep learning approach for vessel trajectory classification based on ais data, an improved approach towards more robust deep learning models for chemical kinetics, power system transient security assessment based on deep learning considering partial observability, a multi-attention collaborative deep learning approach for blood pressure prediction.
We develop a deep learning model based on Long Short-term Memory (LSTM) to predict blood pressure based on a unique data set collected from physical examination centers capturing comprehensive multi-year physical examination and lab results. In the Multi-attention Collaborative Deep Learning model (MAC-LSTM) we developed for this type of data, we incorporate three types of attention to generate more explainable and accurate results. In addition, we leverage information from similar users to enhance the predictive power of the model due to the challenges with short examination history. Our model significantly reduces predictive errors compared to several state-of-the-art baseline models. Experimental results not only demonstrate our model’s superiority but also provide us with new insights about factors influencing blood pressure. Our data is collected in a natural setting instead of a setting designed specifically to study blood pressure, and the physical examination items used to predict blood pressure are common items included in regular physical examinations for all the users. Therefore, our blood pressure prediction results can be easily used in an alert system for patients and doctors to plan prevention or intervention. The same approach can be used to predict other health-related indexes such as BMI.
Export Citation Format
Share document.
Google Research, 2022 & beyond: Algorithms for efficient deep learning
February 7, 2023
Posted by Sanjiv Kumar, VP and Google Fellow, Google Research

The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning.
As these models increasingly find themselves deployed in production and business applications, the efficiency and costs of these models has gone from a minor consideration to a primary constraint. In response, Google has continued to invest heavily in ML efficiency, taking on the biggest challenges in (a) efficient architectures, (b) training efficiency, (c) data efficiency, and (d) inference efficiency. Beyond efficiency, there are a number of other challenges around factuality, security, privacy and freshness in these models. Below, we highlight an array of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
Efficient architectures
A fundamental question is “Are there better ways of parameterizing a model to allow for greater efficiency?” In 2022, we focused on new techniques for infusing external knowledge by augmenting models via retrieved context; mixture of experts; and making transformers (which lie at the heart of most large ML models) more efficient.
Context-augmented models
In the quest for higher quality and efficiency, neural models can be augmented with external context from large databases or trainable memory. By leveraging retrieved context, a neural network may not have to memorize the huge amount of world knowledge within its internal parameters, leading to better parameter efficiency, interpretability and factuality.
In “ Decoupled Context Processing for Context Augmented Language Modeling ”, we explored a simple architecture for incorporating external context into language models based on a decoupled encoder-decoder architecture. This led to significant computational savings while giving competitive results on auto-regressive language modeling and open domain question answering tasks. However, pre-trained large language models (LLMs) consume a significant amount of information through self-supervision on big training sets. But, it is unclear precisely how the “world knowledge” of such models interacts with the presented context. With knowledge aware fine-tuning (KAFT), we strengthen both controllability and robustness of LLMs by incorporating counterfactual and irrelevant contexts into standard supervised datasets.
One of the questions in the quest for a modular deep network is how a database of concepts with corresponding computational modules could be designed. We proposed a theoretical architecture that would “remember events” in the form of sketches stored in an external LSH table with pointers to modules that process such sketches.
Another challenge in context-augmented models is fast retrieval on accelerators of information from a large database. We have developed a TPU-based similarity search algorithm that aligns with the performance model of TPUs and gives analytical guarantees on expected recall , achieving peak performance. Search algorithms typically involve a large number of hyperparameters and design choices that make it hard to tune them on new tasks. We have proposed a new constrained optimization algorithm for automating hyperparameter tuning. Fixing the desired cost or recall as input, the proposed algorithm generates tunings that empirically are very close to the speed-recall Pareto frontier and give leading performance on standard benchmarks.
Mixture-of-experts models
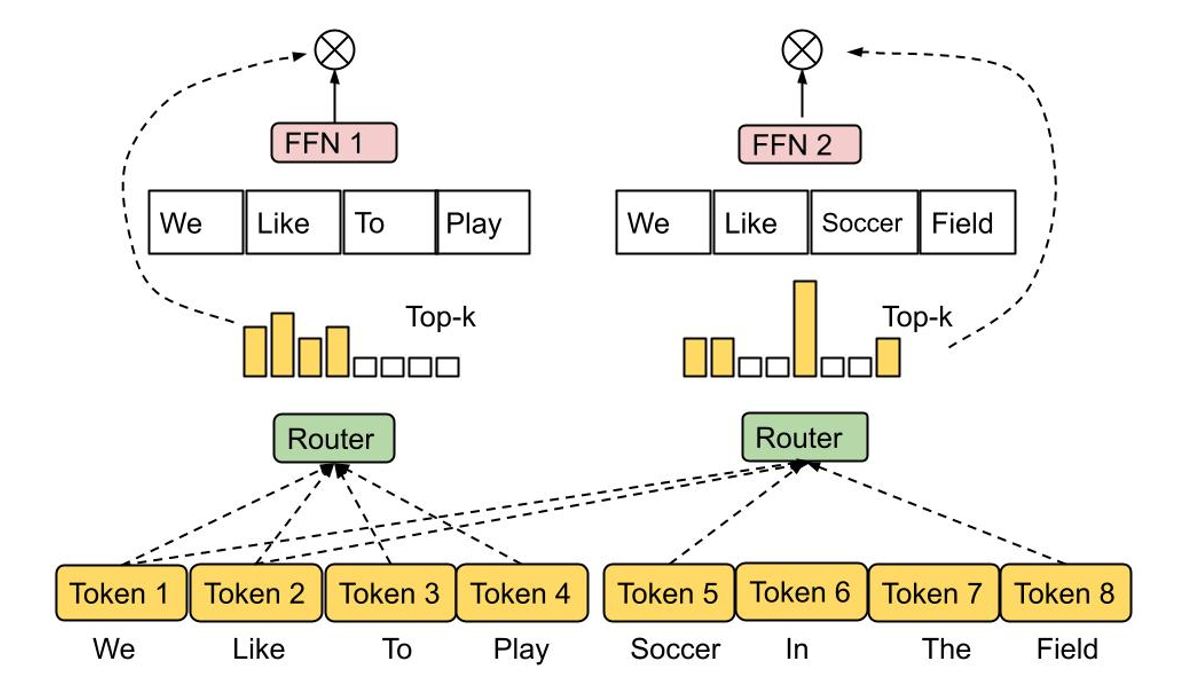
Mixture-of-experts (MoE) models have proven to be an effective means of increasing neural network model capacity without overly increasing their computational cost. The basic idea of MoEs is to construct a network from a number of expert sub-networks, where each input is processed by a suitable subset of experts. Thus, compared to a standard neural network, MoEs invoke only a small portion of the overall model, resulting in high efficiency as shown in language model applications such as GLaM .
The decision of which experts should be active for a given input is determined by a routing function , the design of which is challenging, since one would like to prevent both under- and over-utilization of each expert. In a recent work, we proposed Expert Choice Routing , a new routing mechanism that, instead of assigning each input token to the top- k experts, assigns each expert to the top- k tokens. This automatically ensures load-balancing of experts while also naturally allowing for an input token to be handled by multiple experts.
Efficient transformers
Transformers are popular sequence-to-sequence models that have shown remarkable success in a range of challenging problems from vision to natural language understanding. A central component of such models is the attention layer, which identifies the similarity between “queries” and “keys”, and uses these to construct a suitable weighted combination of “values”. While effective, attention mechanisms have poor (i.e., quadratic) scaling with sequence length.
As the scale of transformers continues to grow, it is interesting to study if there are any naturally occurring structures or patterns in the learned models that may help us decipher how they work. Towards that, we studied the learned embeddings in intermediate MLP layers, revealing that they are very sparse — e.g, T5-Large models have <1% nonzero entries. Sparsity further suggests that we can potentially reduce FLOPs without affecting model performance.
We recently proposed Treeformer , an alternative to standard attention computation that relies on decision trees. Intuitively, this quickly identifies a small subset of keys that are relevant for a query and only performs the attention operation on this set. Empirically, the Treeformer can lead to a 30x reduction in FLOPs for the attention layer. We also introduced Sequential Attention , a differentiable feature selection method that combines attention with a greedy algorithm . This technique has strong provable guarantees for linear models and scales seamlessly to large embedding models.
Another way to make transformers efficient is by making the softmax computations faster in the attention layer. Building on our previous work on low-rank approximation of the softmax kernel, we proposed a new class of random features that provides the first “positive and bounded” random feature approximation of the softmax kernel and is computationally linear in the sequence length. We also proposed the first approach for incorporating various attention masking mechanisms, such as causal and relative position encoding, in a scalable manner (i.e., sub-quadratic with relation to the input sequence length).
Training efficiency
Efficient optimization methods are the cornerstone of modern ML applications and are particularly crucial in large scale settings. In such settings, even first order adaptive methods like Adam are often expensive, and training stability becomes challenging. In addition, these approaches are often agnostic to the architecture of the neural network, thereby ignoring the rich structure of the architecture leading to inefficient training. This motivates new techniques to more efficiently and effectively optimize modern neural network models. We are developing new architecture-aware training techniques, e.g., for training transformer networks, including new scale-invariant transformer networks and novel clipping methods that, when combined with vanilla stochastic gradient descent (SGD), results in faster training. Using this approach, for the first time, we were able to effectively train BERT using simple SGD without the need for adaptivity.
Moreover, with LocoProp we proposed a new method that achieves performance similar to that of a second-order optimizer while using the same computational and memory resources as a first-order optimizer. LocoProp takes a modular view of neural networks by decomposing them into a composition of layers. Each layer is then allowed to have its own loss function as well as output target and weight regularizer. With this setup, after a suitable forward-backward pass , LocoProp proceeds to perform parallel updates to each layer’s “local loss”. In fact, these updates can be shown to resemble those of higher-order optimizers, both theoretically and empirically. On a deep autoencoder benchmark, LocoProp achieves performance comparable to that of higher-order optimizers while being significantly faster.
One key assumption in optimizers like SGD is that each data point is sampled independently and identically from a distribution. This is unfortunately hard to satisfy in practical settings such as reinforcement learning, where the model (or agent) has to learn from data generated based on its own predictions. We proposed a new algorithmic approach named SGD with reverse experience replay , which finds optimal solutions in several settings like linear dynamical systems , non-linear dynamical systems , and in Q-learning for reinforcement learning . Furthermore, an enhanced version of this method — IER — turns out to be the state of the art and is the most stable experience replay technique on a variety of popular RL benchmarks.
Data efficiency
For many tasks, deep neural networks heavily rely on large datasets. In addition to the storage costs and potential security/privacy concerns that come along with large datasets, training modern deep neural networks on such datasets incurs high computational costs. One promising way to solve this problem is with data subset selection, where the learner aims to find the most informative subset from a large number of training samples to approximate (or even improve upon) training with the entire training set.
We analyzed a subset selection framework designed to work with arbitrary model families in a practical batch setting. In such a setting, a learner can sample examples one at a time, accessing both the context and true label, but in order to limit overhead costs, is only able to update its state (i.e., further train model weights) once a large enough batch of examples is selected. We developed an algorithm, called IWeS , that selects examples by importance sampling where the sampling probability assigned to each example is based on the entropy of models trained on previously selected batches. We provide a theoretical analysis, proving generalization and sampling rate bounds.
Another concern with training large networks is that they can be highly sensitive to distribution shifts between training data and data seen at deployment time, especially when working with limited amounts of training data that might not cover all of deployment time scenarios. A recent line of work has hypothesized “ extreme simplicity bias ” as the key issue behind this brittleness of neural networks. Our latest work makes this hypothesis actionable, leading to two new complementary approaches — DAFT and FRR — that when combined provide significantly more robust neural networks. In particular, these two approaches use adversarial fine-tuning along with inverse feature predictions to make the learned network robust.
Inference efficiency
Increasing the size of neural networks has proven surprisingly effective in improving their predictive accuracy. However, it is challenging to realize these gains in the real-world, as the inference costs of large models may be prohibitively high for deployment. This motivates strategies to improve the serving efficiency, without sacrificing accuracy. In 2022, we studied different strategies to achieve this, notably those based on knowledge distillation and adaptive computation.
Distillation
Distillation is a simple yet effective method for model compression, which greatly expands the potential applicability of large neural models. Distillation has proved widely effective in a range of practical applications, such as ads recommendation . Most use-cases of distillation involve a direct application of the basic recipe to the given domain, with limited understanding of when and why this ought to work. Our research this year has looked at tailoring distillation to specific settings and formally studying the factors that govern the success of distillation.
On the algorithmic side, by carefully modeling the noise in the teacher labels, we developed a principled approach to reweight the training examples, and a robust method to sample a subset of data to have the teacher label. In “ Teacher Guided Training ”, we presented a new distillation framework: rather than passively using the teacher to annotate a fixed dataset, we actively use the teacher to guide the selection of informative samples to annotate. This makes the distillation process shine in limited data or long-tail settings.
We also researched new recipes for distillation from a cross-encoder (e.g., BERT ) to a factorized dual-encoder , an important setting for the task of scoring the relevance of a [ query , document ] pair. We studied the reasons for the performance gap between cross- and dual-encoders, noting that this can be the result of generalization rather than capacity limitation in dual-encoders. The careful construction of the loss function for distillation can mitigate this and reduce the gap between cross- and dual-encoder performance. Subsequently, in EmbedDistill , we looked at further improving dual-encoder distillation by matching embeddings from the teacher model. This strategy can also be used to distill from a large to small dual-encoder model, wherein inheriting and freezing the teacher’s document embeddings can prove highly effective.
On the theoretical side, we provided a new perspective on distillation through the lens of supervision complexity , a measure of how well the student can predict the teacher labels. Drawing on neural tangent kernel (NTK) theory, this offers conceptual insights, such as the fact that a capacity gap may affect distillation because such teachers’ labels may appear akin to purely random labels to the student. We further demonstrated that distillation can cause the student to underfit points the teacher model finds “hard” to model. Intuitively, this may help the student focus its limited capacity on those samples that it can reasonably model.
Adaptive computation
While distillation is an effective means of reducing inference cost, it does so uniformly across all samples. Intuitively however, some “easy” samples may inherently require less compute than the “hard” samples. The goal of adaptive compute is to design mechanisms that enable such sample-dependent computation.
Confident Adaptive Language Modeling (CALM) introduced a controlled early-exit functionality to Transformer-based text generators such as T5 . In this form of adaptive computation, the model dynamically modifies the number of transformer layers that it uses per decoding step. The early-exit gates use a confidence measure with a decision threshold that is calibrated to satisfy statistical performance guarantees. In this way, the model needs to compute the full stack of decoder layers for only the most challenging predictions. Easier predictions only require computing a few decoder layers. In practice, the model uses about a third of the layers for prediction on average, yielding 2–3x speed-ups while preserving the same level of generation quality.
One popular adaptive compute mechanism is a cascade of two or more base models. A key issue in using cascades is deciding whether to simply use the current model’s predictions, or whether to defer prediction to a downstream model. Learning when to defer requires designing a suitable loss function, which can leverage appropriate signals to act as supervision for the deferral decision. We formally studied existing loss functions for this goal, demonstrating that they may underfit the training sample owing to an implicit application of label smoothing. We showed that one can mitigate this with post-hoc training of a deferral rule, which does not require modifying the model internals in any way.
For the retrieval applications, standard semantic search techniques use a fixed representation for each embedding generated by a large model. That is, irrespective of downstream task and its associated compute environment or constraints, the representation size and capability is mostly fixed. Matryoshka representation learning introduces flexibility to adapt representations according to the deployment environment. That is, it forces representations to have a natural ordering within its coordinates such that for resource constrained environments, we can use only the top few coordinates of the representation, while for richer and precision-critical settings, we can use more coordinates of the representation. When combined with standard approximate nearest neighbor search techniques like ScaNN , MRL is able to provide up to 16x lower compute with the same recall and accuracy metrics.
Concluding thoughts
Large ML models are showing transformational outcomes in several domains but efficiency in both training and inference is emerging as a critical need to make these models practical in the real-world. Google Research has been investing significantly in making large ML models efficient by developing new foundational techniques. This is an on-going effort and over the next several months we will continue to explore core challenges to make ML models even more robust and efficient.
Acknowledgements
The work in efficient deep learning is a collaboration among many researchers from Google Research, including Amr Ahmed, Ehsan Amid, Rohan Anil, Mohammad Hossein Bateni, Gantavya Bhatt, Srinadh Bhojanapalli, Zhifeng Chen, Felix Chern, Gui Citovsky, Andrew Dai, Andy Davis, Zihao Deng, Giulia DeSalvo, Nan Du, Avi Dubey, Matthew Fahrbach, Ruiqi Guo, Blake Hechtman, Yanping Huang, Prateek Jain, Wittawat Jitkrittum, Seungyeon Kim, Ravi Kumar, Aditya Kusupati, James Laudon, Quoc Le, Daliang Li, Zonglin Li, Lovish Madaan, David Majnemer, Aditya Menon, Don Metzler, Vahab Mirrokni, Vaishnavh Nagarajan, Harikrishna Narasimhan, Rina Panigrahy, Srikumar Ramalingam, Ankit Singh Rawat, Sashank Reddi, Aniket Rege, Afshin Rostamizadeh, Tal Schuster, Si Si, Apurv Suman, Phil Sun, Erik Vee, Ke Ye, Chong You, Felix Yu, Manzil Zaheer, and Yanqi Zhou.
Google Research, 2022 & beyond
This was the fourth blog post in the “Google Research, 2022 & Beyond” series. Other posts in this series are listed in the table below:
- Algorithms & Theory
- Machine Intelligence
- Year in Review
Other posts of interest

May 13, 2024
- Machine Intelligence ·
- Natural Language Processing ·
- Security, Privacy and Abuse Prevention

May 1, 2024
- Algorithms & Theory ·
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Review Article
- Open access
- Published: 05 April 2022
Recent advances and applications of deep learning methods in materials science
- Kamal Choudhary ORCID: orcid.org/0000-0001-9737-8074 1 , 2 , 3 ,
- Brian DeCost ORCID: orcid.org/0000-0002-3459-5888 4 ,
- Chi Chen ORCID: orcid.org/0000-0001-8008-7043 5 ,
- Anubhav Jain ORCID: orcid.org/0000-0001-5893-9967 6 ,
- Francesca Tavazza ORCID: orcid.org/0000-0002-5602-180X 1 ,
- Ryan Cohn ORCID: orcid.org/0000-0002-7898-0059 7 ,
- Cheol Woo Park 8 ,
- Alok Choudhary 9 ,
- Ankit Agrawal 9 ,
- Simon J. L. Billinge ORCID: orcid.org/0000-0002-9734-4998 10 ,
- Elizabeth Holm 7 ,
- Shyue Ping Ong ORCID: orcid.org/0000-0001-5726-2587 5 &
- Chris Wolverton ORCID: orcid.org/0000-0003-2248-474X 8
npj Computational Materials volume 8 , Article number: 59 ( 2022 ) Cite this article
66k Accesses
240 Citations
38 Altmetric
Metrics details
- Atomistic models
- Computational methods
Deep learning (DL) is one of the fastest-growing topics in materials data science, with rapidly emerging applications spanning atomistic, image-based, spectral, and textual data modalities. DL allows analysis of unstructured data and automated identification of features. The recent development of large materials databases has fueled the application of DL methods in atomistic prediction in particular. In contrast, advances in image and spectral data have largely leveraged synthetic data enabled by high-quality forward models as well as by generative unsupervised DL methods. In this article, we present a high-level overview of deep learning methods followed by a detailed discussion of recent developments of deep learning in atomistic simulation, materials imaging, spectral analysis, and natural language processing. For each modality we discuss applications involving both theoretical and experimental data, typical modeling approaches with their strengths and limitations, and relevant publicly available software and datasets. We conclude the review with a discussion of recent cross-cutting work related to uncertainty quantification in this field and a brief perspective on limitations, challenges, and potential growth areas for DL methods in materials science.
Similar content being viewed by others

Accurate structure prediction of biomolecular interactions with AlphaFold 3

Highly accurate protein structure prediction with AlphaFold

Augmenting large language models with chemistry tools
Introduction.
“Processing-structure-property-performance” is the key mantra in Materials Science and Engineering (MSE) 1 . The length and time scales of material structures and phenomena vary significantly among these four elements, adding further complexity 2 . For instance, structural information can range from detailed knowledge of atomic coordinates of elements to the microscale spatial distribution of phases (microstructure), to fragment connectivity (mesoscale), to images and spectra. Establishing linkages between the above components is a challenging task.
Both experimental and computational techniques are useful to identify such relationships. Due to rapid growth in automation in experimental equipment and immense expansion of computational resources, the size of public materials datasets has seen exponential growth. Several large experimental and computational datasets 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 have been developed through the Materials Genome Initiative (MGI) 11 and the increasing adoption of Findable, Accessible, Interoperable, Reusable (FAIR) 12 principles. Such an outburst of data requires automated analysis which can be facilitated by machine learning (ML) techniques 13 , 14 , 15 , 16 , 17 , 18 , 19 , 20 .
Deep learning (DL) 21 , 22 is a specialized branch of machine learning (ML). Originally inspired by biological models of computation and cognition in the human brain 23 , 24 , one of DL’s major strengths is its potential to extract higher-level features from the raw input data.
DL applications are rapidly replacing conventional systems in many aspects of our daily lives, for example, in image and speech recognition, web search, fraud detection, email/spam filtering, financial risk modeling, and so on. DL techniques have been proven to provide exciting new capabilities in numerous fields (such as playing Go 25 , self-driving cars 26 , navigation, chip design, particle physics, protein science, drug discovery, astrophysics, object recognition 27 , etc).
Recently DL methods have been outperforming other machine learning techniques in numerous scientific fields, such as chemistry, physics, biology, and materials science 20 , 28 , 29 , 30 , 31 , 32 . DL applications in MSE are still relatively new, and the field has not fully explored its potential, implications, and limitations. DL provides new approaches for investigating material phenomena and has pushed materials scientists to expand their traditional toolset.
DL methods have been shown to act as a complementary approach to physics-based methods for materials design. While large datasets are often viewed as a prerequisite for successful DL applications, techniques such as transfer learning, multi-fidelity modelling, and active learning can often make DL feasible for small datasets as well 33 , 34 , 35 , 36 .
Traditionally, materials have been designed experimentally using trial and error methods with a strong dose of chemical intuition. In addition to being a very costly and time-consuming approach, the number of material combinations is so huge that it is intractable to study experimentally, leading to the need for empirical formulation and computational methods. While computational approaches (such as density functional theory, molecular dynamics, Monte Carlo, phase-field, finite elements) are much faster and cheaper than experiments, they are still limited by length and time scale constraints, which in turn limits their respective domains of applicability. DL methods can offer substantial speedups compared to conventional scientific computing, and, for some applications, are reaching an accuracy level comparable to physics-based or computational models.
Moreover, entering a new domain of materials science and performing cutting-edge research requires years of education, training, and the development of specialized skills and intuition. Fortunately, we now live in an era of increasingly open data and computational resources. Mature, well-documented DL libraries make DL research much more easily accessible to newcomers than almost any other research field. Testing and benchmarking methodologies such as underfitting/overfitting/cross-validation 15 , 16 , 37 are common knowledge, and standards for measuring model performance are well established in the community.
Despite their many advantages, DL methods have disadvantages too, the most significant one being their black-box nature 38 which may hinder physical insights into the phenomena under examination. Evaluating and increasing the interpretability and explainability of DL models remains an active field of research. Generally a DL model has a few thousand to millions of parameters, making model interpretation and direct generation of scientific insight difficult.
Although there are several good recent reviews of ML applications in MSE 15 , 16 , 17 , 19 , 39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 , 49 , DL for materials has been advancing rapidly, warranting a dedicated review to cover the explosion of research in this field. This article discusses some of the basic principles in DL methods and highlights major trends among the recent advances in DL applications for materials science. As the tools and datasets for DL applications in materials keep evolving, we provide a github repository ( https://github.com/deepmaterials/dlmatreview ) that can be updated as new resources are made publicly available.
General machine learning concepts
It is beyond the scope of this article to give a detailed hands-on introduction to Deep Learning. There are many materials for this purpose, for example, the free online book “Neural Networks and Deep Learning” by Michael Nielsen ( http://neuralnetworksanddeeplearning.com ), Deep Learning by Goodfellow et al. 21 , and multiple online courses at Coursera, Udemy, and so on. Rather, this article aims to motivate materials scientist researchers in the types of problems that are amenable to DL, and to introduce some of the basic concepts, jargon, and materials-specific databases and software (at the time of writing) as a helpful on-ramp to help get started. With this in mind, we begin with a very basic introduction to Deep learning.
Artificial intelligence (AI) 13 is the development of machines and algorithms that mimic human intelligence, for example, by optimizing actions to achieve certain goals. Machine learning (ML) is a subset of AI, and provides the ability to learn without explicitly being programmed for a given dataset such as playing chess, social network recommendation etc. DL, in turn, is the subset of ML that takes inspiration from biological brains and uses multilayer neural networks to solve ML tasks. A schematic of AI-ML-DL context and some of the key application areas of DL in the materials science and engineering field are shown in Fig. 1 .

Deep learning is considered a part of machine learning, which is contained in an umbrella term artificial intelligence.
Some of the commonly used ML technologies are linear regression, decision trees, and random forest in which generalized models are trained to learn coefficients/weights/parameters for a given dataset (usually structured i.e., on a grid or a spreadsheet).
Applying traditional ML techniques to unstructured data (such as pixels or features from an image, sounds, text, and graphs) is challenging because users have to first extract generalized meaningful representations or features themselves (such as calculating pair-distribution for an atomic structure) and then train the ML models. Hence, the process becomes time-consuming, brittle, and not easily scalable. Here, deep learning (DL) techniques become more important.
DL methods are based on artificial neural networks and allied techniques. According to the “universal approximation theorem” 50 , 51 , neural networks can approximate any function to arbitrary accuracy. However, it is important to note that the theorem doesn’t guarantee that the functions can be learnt easily 52 .
Neural networks
A perceptron or a single artificial neuron 53 is the building block of artificial neural networks (ANNs) and performs forward propagation of information. For a set of inputs [ x 1 , x 2 , . . . , x m ] to the perceptron, we assign floating number weights (and biases to shift wights) [ w 1 , w 2 , . . . , w m ] and then we multiply them correspondingly together to get a sum of all of them. Some of the common software packages allowing NN trainings are: PyTorch 54 , Tensorflow 55 , and MXNet 56 . Please note that certain commercial equipment, instruments, or materials are identified in this paper in order to specify the experimental procedure adequately. Such identification is not intended to imply recommendation or endorsement by NIST, nor is it intended to imply that the materials or equipment identified are necessarily the best available for the purpose.
Activation function
Activation functions (such as sigmoid, hyperbolic tangent (tanh), rectified linear unit (ReLU), leaky ReLU, Swish) are the critical nonlinear components that enable neural networks to compose many small building blocks to learn complex nonlinear functions. For example, the sigmoid activation maps real numbers to the range (0, 1); this activation function is often used in the last layer of binary classifiers to model probabilities. The choice of activation function can affect training efficiency as well as final accuracy 57 .
Loss function, gradient descent, and normalization
The weight matrices of a neural network are initialized randomly or obtained from a pre-trained model. These weight matrices are multiplied with the input matrix (or output from a previous layer) and subjected to a nonlinear activation function to yield updated representations, which are often referred to as activations or feature maps. The loss function (also known as an objective function or empirical risk) is calculated by comparing the output of the neural network and the known target value data. Typically, network weights are iteratively updated via stochastic gradient descent algorithms to minimize the loss function until the desired accuracy is achieved. Most modern deep learning frameworks facilitate this by using reverse-mode automatic differentiation 58 to obtain the partial derivatives of the loss function with respect to each network parameter through recursive application of the chain rule. Colloquially, this is also known as back-propagation.
Common gradient descent algorithms include: Stochastic Gradient Descent (SGD), Adam, Adagrad etc. The learning rate is an important parameter in gradient descent. Except for SGD, all other methods use adaptive learning parameter tuning. Depending on the objective such as classification or regression, different loss functions such as Binary Cross Entropy (BCE), Negative Log likelihood (NLLL) or Mean Squared Error (MSE) are used.
The inputs of a neural network are generally scaled i.e., normalized to have zero mean and unit standard deviation. Scaling is also applied to the input of hidden layers (using batch or layer normalization) to improve the stability of ANNs.
Epoch and mini-batches
A single pass of the entire training data is called an epoch, and multiple epochs are performed until the weights converge. In DL, datasets are usually large and computing gradients for the entire dataset and network becomes challenging. Hence, the forward passes are done with small subsets of the training data called mini-batches.
Underfitting, overfitting, regularization, and early stopping
During an ML training, the dataset is split into training, validation, and test sets. The test set is never used during the training process. A model is said to be underfitting if the model performs poorly on the training set and lacks the capacity to fully learn the training data. A model is said to overfit if the model performs too well on the training data but does not perform well on the validation data. Overfitting is controlled with regularization techniques such as L2 regularization, dropout, and early stopping 37 .
Regularization discourages the model from simply memorizing the training data, resulting in a model that is more generalizable. Overfitting models are often characterized by neurons that have weights with large magnitudes. L2 regularization reduces the possibility of overfitting by adding an additional term to the loss function that penalizes the large weight values, keeping the values of the weights and biases small during training. Another popular regularization is dropout 59 in which we randomly set the activations for an NN layer to zero during training. Similar to bagging 60 , the use of dropout brings about the same effect of training a collection of randomly chosen models which prevents the co-adaptations among the neurons, consequently reducing the likelihood of the model from overfitting. In early stopping, further epochs for training are stopped before the model overfits i.e., accuracy on the validation set flattens or decreases.
Convolutional neural networks
Convolutional neural networks (CNN) 61 can be viewed as a regularized version of multilayer perceptrons with a strong inductive bias for learning translation-invariant image representations. There are four main components in CNNs: (a) learnable convolution filterbanks, (b) nonlinear activations, (c) spatial coarsening (via pooling or strided convolution), (d) a prediction module, often consisting of fully connected layers that operate on a global instance representation.
In CNNs we use convolution functions with multiple kernels or filters with trainable and shared weights or parameters, instead of general matrix multiplication. These filters/kernels are matrices with a relatively small number of rows and columns that convolve over the input to automatically extract high-level local features in the form of feature maps. The filters slide/convolve (element-wise multiply) across the input with a fixed number of strides to produce the feature map and the information thus learnt is passed to the hidden/fully connected layers. Depending on the input data, these filters can be one, two, or three-dimensional.
Similar to the fully connected NNs, nonlinearities such as ReLU are then applied that allows us to deal with nonlinear and complicated data. The pooling operation preserves spatial invariance, downsamples and reduces the dimension of each feature map obtained after convolution. These downsampling/pooling operations can be of different types such as maximum-pooling, minimum-pooling, average pooling, and sum pooling. After one or more convolutional and pooling layers, the outputs are usually reduced to a one-dimensional global representation. CNNs are especially popular for image data.
Graph neural networks
Graphs and their variants.
Classical CNNs as described above are based on a regular grid Euclidean data (such as 2D grid in images). However, real-life data structures, such as social networks, segments of images, word vectors, recommender systems, and atomic/molecular structures, are usually non-Euclidean. In such cases, graph-based non-Euclidean data structures become especially important.
Mathematically, a graph G is defined as a set of nodes/vertices V , a set of edges/links, E and node features, X : G = ( V , E , X ) 62 , 63 , 64 and can be used to represent non-Euclidean data. An edge is formed between a pair of two nodes and contains the relation information between the nodes. Each node and edge can have attributes/features associated with it. An adjacency matrix A is a square matrix indicating connections between the nodes or not in the form of 1 (connected) and 0 (unconnected). A graph can be of various types such as: undirected/directed, weighted/unweighted, homogeneous/heterogeneous, static/dynamic.
An undirected graph captures symmetric relations between nodes, while a directed one captures asymmetric relations such that A i j ≠ A j i . In a weighted graph, each edge is associated with a scalar weight rather than just 1s and 0s. In a homogeneous graph, all the nodes represent instances of the same type, and all the edges capture relations of the same type while in a heterogeneous graph, the nodes and edges can be of different types. Heterogeneous graphs provide an easy interface for managing nodes and edges of different types as well as their associated features. When input features or graph topology vary with time, they are called dynamic graphs otherwise they are considered static. If a node is connected to another node more than once it is termed a multi-graph.
Types of GNNs
At present, GNNs are probably the most popular AI method for predicting various materials properties based on structural information 33 , 65 , 66 , 67 , 68 , 69 . Graph neural networks (GNNs) are DL methods that operate on graph domain and can capture the dependence of graphs via message passing between the nodes and edges of graphs. There are two key steps in GNN training: (a) we first aggregate information from neighbors and (b) update the nodes and/or edges. Importantly, aggregation is permutation invariant. Similar to the fully connected NNs, the input node features, X (with embedding matrix) are multiplied with the adjacency matrix and the weight matrices and then multiplied with the nonlinear activation function to provide outputs for the next layer. This method is called the propagation rule.
Based on the propagation rule and aggregation methodology, there could be different variants of GNNs such as Graph convolutional network (GCN) 70 , Graph attention network (GAT) 71 , Relational-GCN 72 , graph recurrent network (GRN) 73 , Graph isomerism network (GIN) 74 , and Line graph neural network (LGNN) 75 . Graph convolutional neural networks are the most popular GNNs.
Sequence-to-sequence models
Traditionally, learning from sequential inputs such as text involves generating a fixed-length input from the data. For example, the “bag-of-words” approach simply counts the number of instances of each word in a document and produces a fixed-length vector that is the size of the overall vocabulary.
In contrast, sequence-to-sequence models can take into account sequential/contextual information about each word and produce outputs of arbitrary length. For example, in named entity recognition (NER), an input sequence of words (e.g., a chemical abstract) is mapped to an output sequence of “entities” or categories where every word in the sequence is assigned a category.
An early form of sequence-to-sequence model is the recurrent neural network, or RNN. Unlike the fully connected NN architecture, where there is no connection between hidden nodes in the same layer, but only between nodes in adjacent layers, RNN has feedback connections. Each hidden layer can be unfolded and processed similarly to traditional NNs sharing the same weight matrices. There are multiple types of RNNs, of which the most common ones are: gated recurrent unit recurrent neural network (GRURNN), long short-term memory (LSTM) network, and clockwork RNN (CW-RNN) 76 .
However, all such RNNs suffer from some drawbacks, including: (i) difficulty of parallelization and therefore difficulty in training on large datasets and (ii) difficulty in preserving long-range contextual information due to the “vanishing gradient” problem. Nevertheless, as we will later describe, LSTMs have been successfully applied to various NER problems in the materials domain.
More recently, sequence-to-sequence models based on a “transformer” architecture, such as Google’s Bidirectional Encoder Representations from Transformers (BERT) model 77 , have helped address some of the issues of traditional RNNs. Rather than passing a state vector that is iterated word-by-word, such models use an attention mechanism to allow access to all previous words simultaneously without explicit time steps. This mechanism facilitates parallelization and also better preserves long-term context.
Generative models
While the above DL frameworks are based on supervised machine learning (i.e., we know the target or ground truth data such as in classification and regression) and discriminative (i.e., learn differentiating features between various datasets), many AI tasks are based on unsupervised (such as clustering) and are generative (i.e., aim to learn underlying distributions) 78 .
Generative models are used to (a) generate data samples similar to the training set with variations i.e., augmentation and for synthetic data, (b) learn good generalized latent features, (c) guide mixed reality applications such as virtual try-on. There are various types of generative models, of which the most common are: (a) variational encoders (VAE), which explicitly define and learn likelihood of data, (b) Generative adversarial networks (GAN), which learn to directly generate samples from model’s distribution, without defining any density function.
A VAE model has two components: namely encoder and decoder. A VAE’s encoder takes input from a target distribution and compresses it into a low-dimensional latent space. Then the decoder takes that latent space representation and reproduces the original image. Once the network is trained, we can generate latent space representations of various images, and interpolate between these before forwarding them through the decoder which produces new images. A VAE is similar to a principal component analysis (PCA) but instead of linear data assumption in PCA, VAEs work in nonlinear domain. A GAN model also has two components: namely generator, and discriminator. GAN’s generator generates fake/synthetic data that could fool the discriminator. Its discriminator tries to distinguish fake data from real ones. This process is also termed as “min-max two-player game.” We note that VAE models learn the hidden state distributions during the training process, while GAN’s hidden state distributions are predefined. Rather GAN generators serve to generate images that could fool the discriminator. These techniques are widely used for images and spectra and have also been recently applied to atomic structures.
Deep reinforcement learning
Reinforcement learning (RL) deals with tasks in which a computational agent learns to make decisions by trial and error. Deep RL uses DL into the RL framework, allowing agents to make decisions from unstructured input data 79 . In traditional RL, Markov decision process (MDP) is used in which an agent at every timestep takes action to receive a scalar reward and transitions to the next state according to system dynamics to learn policy in order to maximize returns. However, in deep RL, the states are high-dimensional (such as continuous images or spectra) which act as an input to DL methods. DRL architectures can be either model-based or model-free.
Scientific machine learning
The nascent field of scientific machine learning (SciML) 80 is creating new opportunities across all paradigms of machine learning, and deep learning in particular. SciML is focused on creating ML systems that incorporate scientific knowledge and physical principles, either directly in the specific form of the model or indirectly through the optimization algorithms used for training. This offers potential improvements in sample and training complexity, robustness (particularly under extrapolation), and model interpretability. One prominent theme can be found in ref. 57 . Such implementations usually involve applying multiple physics-based constraints while training a DL model 81 , 82 , 83 . One of the key challenges of universal function approximation is that a NN can quickly learn spurious features that have nothing to do with the features that a researcher could be actually interested in, within the data. In this sense, physics-based regularization can assist. Physics-based deep learning can also aid in inverse design problems, a challenging but important task 84 , 85 . On the flip side, deep Learning using Graph Neural Nets and symbolic regression (stochastically building symbolic expressions) has even been used to “discover” symbolic equations from data that capture known (and unknown) physics behind the data 86 , i.e., to deep learn a physics model rather than to use a physics model to constrain DL.
Overview of applications
Some aspects of successful DL application that require materials-science-specific considerations are:
acquiring large, balanced, and diverse datasets (often on the order of 10,000 data points or more),
determing an appropriate DL approach and suitable vector or graph representation of the input samples, and
selecting appropriate performance metrics relevant to scientific goals.
In the following sections we discuss some of the key areas of materials science in which DL has been applied with available links to repositories and datasets that help in the reproducibility and extensibility of the work. In this review we categorize materials science applications at a high level by the type of input data considered: 11 atomistic, 12 stoichiometric, 13 spectral, 14 image, and 15 text. We summarize prevailing machine learning tasks and their impact on materials research and development within each broad materials data modality.
Applications in atomistic representations
In this section, we provide a few examples of solving materials science problems with DL methods trained on atomistic data. The atomic structure of material usually consists of atomic coordinates and atomic composition information of material. An arbitrary number of atoms and types of elements in a system poses a challenge to apply traditional ML algorithms for atomistic predictions. DL-based methods are an obvious strategy to tackle this problem. There have been several previous attempts to represent crystals and molecules using fixed-size descriptors such as Coulomb matrix 87 , 88 , 89 , classical force field inspired descriptors (CFID) 90 , 91 , 92 , pair-distribution function (PRDF), Voronoi tessellation 93 , 94 , 95 . Recently graph neural network methods have been shown to surpass previous hand-crafted feature set 28 .
DL for atomistic materials applications include: (a) force-field development, (b) direct property predictions, (c) materials screening. In addition to the above points, we also elucidate upon some of the recent generative adversarial network and complimentary methods to atomistic aproaches.
Databases and software libraries
In Table 1 we provide some of the commonly used datasets used for atomistic DL models for molecules, solids, and proteins. We note that the computational methods used for different datasets are different and many of them are continuously evolving. Generally it takes years to generate such databases using conventional methods such as density functional theory; in contrast, DL methods can be used to make predictions with much reduced computational cost and reasonable accuracy.
Table 1 we provide DL software packages used for atomistic materials design. The type of models includes general property (GP) predictors and interatomic force fields (FF). The models have been demonstrated in molecules (Mol), solid-state materials (Sol), or proteins (Prot). For some force fields, high-performance large-scale implementations (LSI) that leverage paralleling computing exist. Some of these methods mainly used interatomic distances to build graphs while others use distances as well as bond-angle information. Recently, including bond angle within GNN has been shown to drastically improve the performance with comparable computational timings.
Force-field development
The first application includes the development of DL-based force fields (FF) 96 , 97 /interatomic potentials. Some of the major advantages of such applications are that they are very fast (on the order of hundreds to thousands times 64 ) for making predictions and solving the tenuous development of FFs, but the disadvantage is they still require a large dataset using computationally expensive methods to train.
Models such as Behler-Parrinello neural network (BPNN) and its variants 98 , 99 are used for developing interatomic potentials that can be used beyond just 0 K temperature and time-dependent behavior using molecular dynamics simulations such as for nanoparticles 100 . Such FF models have been developed for molecular systems, such as water, methane, and other organic molecules 99 , 101 as well as solids such as silicon 98 , sodium 102 , graphite 103 , and titania ( T i O 2 ) 104 .
While the above works are mainly based on NNs, there has also been the development of graph neural network force-field (GNNFF) framework 105 , 106 that bypasses both computational bottlenecks. GNNFF can predict atomic forces directly using automatically extracted structural features that are not only translationally invariant, but rotationally-covariant to the coordinate space of the atomic positions, i.e., the features and hence the predicted force vectors rotate the same way as the rotation of coordinates. In addition to the development of pure NN-based FFs, there have also been recent developments of combining traditional FFs such as bond-order potentials with NNs and ReaxFF with message passing neural network (MPNN) that can help mitigate the NNs issue for extrapolation 82 , 107 .
Direct property prediction from atomistic configurations
DL methods can be used to establish a structure-property relationship between atomic structure and their properties with high accuracy 28 , 108 . Models such as SchNet, crystal graph convolutional neural network (CGCNN), improved crystal graph convolutional neural network (iCGCNN), directional message passing neural network (DimeNet), atomistic line graph neural network (ALIGNN) and materials graph neural network (MEGNet) shown in Table 1 have been used to predict up to 50 properties of crystalline and molecular materials. These property datasets are usually obtained from ab-initio calculations. A schematic of such models shown in Fig. 2 . While SchNet, CGCNN, MEGNet are primarily based on atomic distances, iCGCNN, DimeNet, and ALIGNN models capture many-body interactions using GCNN.

a CGCNN model in which crystals are converted to graphs with nodes representing atoms in the unit cell and edges representing atom connections. Nodes and edges are characterized by vectors corresponding to the atoms and bonds in the crystal, respectively [Reprinted with permission from ref. 67 Copyright 2019 American Physical Society], b ALIGNN 65 model in which the convolution layer alternates between message passing on the bond graph and its bond-angle line graph. c MEGNet in which the initial graph is represented by the set of atomic attributes, bond attributes and global state attributes [Reprinted with permission from ref. 33 Copyright 2019 American Chemical Society] model, d iCGCNN model in which multiple edges connect a node to neighboring nodes to show the number of Voronoi neighbors [Reprinted with permission from ref. 122 Copyright 2019 American Physical Society].
Some of these properties include formation energies, electronic bandgaps, solar-cell efficiency, topological spin-orbit spillage, dielectric constants, piezoelectric constants, 2D exfoliation energies, electric field gradients, elastic modulus, Seebeck coefficients, power factors, carrier effective masses, highest occupied molecular orbital, lowest unoccupied molecular orbital, energy gap, zero-point vibrational energy, dipole moment, isotropic polarizability, electronic spatial extent, internal energy.
For instance, the current state-of-the-art mean absolute error for formation energy for solids at 0 K is 0.022 eV/atom as obtained by the ALIGNN model 65 . DL is also heavily being used for predicting catalytic behavior of materials such as the Open Catalyst Project 109 which is driven by the DL methods materials design. There is an ongoing effort to continuously improve the models. Usually energy-based models such as formation and total energies are more accurate than electronic property-based models such as bandgaps and power factors.
In addition to molecules and solids, property predictions models have also been used for bio-materials such as proteins, which can be viewed as large molecules. There have been several efforts for predicting protein-based properties, such as binding affinity 66 and docking predictions 110 .
There have also been several applications for identifying reasonable chemical space using DL methods such as autoencoders 111 and reinforcement learning 112 , 113 , 114 for inverse materials design. Inverse materials design with techniques such as GAN deals with finding chemical compounds with suitable properties and act as complementary to forward prediction models. While such concepts have been widely applied to molecular systems, 115 , recently these methods have been applied to solids as well 116 , 117 , 118 , 119 , 120 .
Fast materials screening
DFT-based high-throughput methods are usually limited to a few thousands of compounds and take a long time for calculations, DL-based methods can aid this process and allow much faster predictions. DL-based property prediction models mentioned above can be used for pre-screening chemical compounds. Hence, DL-based tools can be viewed as a pre-screening tool for traditional methods such as DFT. For example, Xie et al. used CGCNN model to screen stable perovskite materials 67 as well hierarchical visualization of materials space 121 . Park et al. 122 used iCGCNN to screen T h C r 2 S i 2 -type materials. Lugier et al. used DL methods to predict thermoelectric properties 123 . Rosen et al. 124 used graph neural network models to predict the bandgaps of metal-organic frameworks. DL for molecular materials has been used to predict technologically important properties such as aqueous solubility 125 and toxicity 126 .
It should be noted that the full atomistic representations and the associated DL models are only possible if the crystal structure and atom positions are available. In practice, the precise atom positions are only available from DFT structural relaxations or experiments, and are one of the goals for materials discovery instead of the starting point. Hence, alternative methods have been proposed to bypass the necessity for atom positions in building DL models. For example, Jain and Bligaard 127 proposed the atomic position-independent descriptors and used a CNN model to learn the energies of crystals. Such descriptors include information based only on the symmetry (e.g., space group and Wyckoff position). In principle, the method can be applied universally in all crystals. Nevertheless, the model errors tend to be much higher than graph-based models. Similar coarse-grained representation using Wyckoff representation was also used by Goodall et al. 128 . Alternatively, Zuo et al. 129 started from the hypothetical structures without precise atom positions, and used a Bayesian optimization method coupled with a MEGNet energy model as an energy evaluator to perform direct structural relaxation. Applying the Bayesian optimization with symmetry relaxation (BOWSR) algorithm successfully discovered ReWB (Pca2 1 ) and MoWC 2 (P6 3 /mmc) hard materials, which were then experimentally synthesized.
Applications in chemical formula and segment representations
One of the earliest applications for DL included SMILES for molecules, elemental fractions and chemical descriptors for solids, and sequence of protein names as descriptors. Such descriptors lack explicit inclusion of atomic structure information but are still useful for various pre-screening applications for both theoretical and experimental data.
SMILES and fragment representation
The simplified molecular-input line-entry system (SMILES) is a method to represent elemental and bonding for molecular structures using short American Standard Code for Information Interchange (ASCII) strings. SMILES can express structural differences including the chirality of compounds, making it more useful than a simply chemical formula. A SMILES string is a simple grid-like (1-D grid) structure that can represent molecular sequences such as DNA, macromolecules/polymers, protein sequences also 130 , 131 . In addition to the chemical constituents as in the chemical formula, bondings (such as double and triple bondings) are represented by special symbols (such as ’=’ and ’#’). The presence of a branch point indicated using a left-hand bracket “(” while the right-hand bracket “)” indicates that all the atoms in that branch have been taken into account. SMILES strings are represented as a distributed representation termed a SMILES feature matrix (as a sparse matrix), and then we can apply DL to the matrix similar to image data. The length of the SMILES matrix is generally kept fixed (such as 400) during training and in addition to the SMILES multiple elemental attributes and bonding attributes (such as chirality, aromaticity) can be used. Key DL tasks for molecules include (a) novel molecule design, (b) molecule screening.
Novel molecules with target properties can designed using VAE, GAN and RNN based methods 132 , 133 , 134 . These DL-generated molecules might not be physically valid, but the goal is to train the model to learn the patterns in SMILES strings such that the output resembles valid molecules. Then chemical intuitions can be further used to screen the molecules. DL for SMILES can also be used for molecularscreening such as to predict molecular toxicity. Some of the common SMILES datasets are: ZINC 135 , Tox21 136 , and PubChem 137 .
Due to the limitations to enforce the generation of valid molecular structures from SMILES, fragment-based models are developed such as DeepFrag and DeepFrag-K 138 , 139 . In fragment-based models, a ligand/receptor complex is removed and then a DL model is trained to predict the most suitable fragment substituent. A set of useful tools for SMILES and fragment representations are provided in Table 2 .
Chemical formula representation
There are several ways of using the chemical formula-based representations for building ML/DL models, beginning with a simple vector of raw elemental fractions 140 , 141 or of weight percentages of alloying compositions 142 , 143 , 144 , 145 , as well as more sophisticated hand-crafted descriptors or physical attributes to add known chemistry knowledge (e.g., electronegativity, valency, etc. of constituent elements) to the feature representations 146 , 147 , 148 , 149 , 150 , 151 . Statistical and mathematical operations such as average, max, min, median, mode, and exponentiation can be carried out on elemental properties of the constituent elements to get a set of descriptors for a given compound. The number of such composition-based features can range from a few dozens to a few hundreds. One of the commonly used representations that have been shown to work for a variety of different use-cases is the materials agnostic platform for informatics and exploration (MagPie) 150 . All these composition-based representations can be used with both traditional ML methods such as Random Forest as well as DL.
It is relevant to note that ElemNet 141 , which is a 17-layer neural network composed of fully connected layers and uses only raw elemental fractions as input, was found to significantly outperform traditional ML methods such as Random Forest, even when they were allowed to use more sophisticated physical attributes based on MagPie as input. Although no periodic table information was provided to the model, it was found to self-learn some interesting chemistry, like groups (element similarity) and charge balance (element interaction). It was also able to predict phase diagrams on unseen materials systems, underscoring the power of DL for representation learning directly from raw inputs without explicit feature extraction. Further increasing the depth of the network was found to adversely affect the model accuracy due to the vanishing gradient problem. To address this issue, Jha et al. 152 developed IRNet, which uses individual residual learning to allow a smoother flow of gradients and enable deeper learning for cases where big data is available. IRNet models were tested on a variety of big and small materials datasets, such as OQMD, AFLOW, Materials Project, JARVIS, using different vector-based materials representations (element fractions, MagPie, structural) and were found to not only successfully alleviate the vanishing gradient problem and enable deeper learning, but also lead to significantly better model accuracy as compared to plain deep neural networks and traditional ML techniques for a given input materials representation in the presence of big data 153 . Further, graph-based methods such as Roost 154 have also been developed which can outperform many similar techniques.
Such methods have been used for diverse DFT datasets mentioned above in Table 1 as well as experimental datasets such as SuperCon 155 , 156 for quick pre-screening applications. In terms of applications, they have been applied for predicting properties such as formation energy 141 , bandgap, and magnetization 152 , superconducting temperatures 156 , bulk, and shear modulus 153 . They have also been used for transfer learning across datasets for enhanced predictive accuracy on small data 34 , even for different source and target properties 157 , which is especially useful to build predictive models for target properties for which big source datasets may not be readily available.
There have been libraries of such descriptors developed such as MatMiner 151 and DScribe 158 . Some examples of such models are given in Table 2 . Such representations are especially useful for experimental datasets such as those for superconducting materials where the atomic structure is not tabulated. However, these representations cannot distinguish different polymorphs of a system with different point groups and space groups. It has been recently shown that although composition-based representations can help build ML/DL models to predict some properties like formation energy with remarkable accuracy, it does not necessarily translate to accurate predictions of other properties such as stability, when compared to DFT’s own accuracy 159 .
Spectral models
When electromagnetic radiation hits materials, the interaction between the radiation and matter measured as a function of the wavelength or frequency of the radiation produces a spectroscopic signal. By studying spectroscopy, researchers can gain insights into the materials’ composition, structural, and dynamic properties. Spectroscopic techniques are foundational in materials characterization. For instance, X-ray diffraction (XRD) has been used to characterize the crystal structure of materials for more than a century. Spectroscopic analysis can involve fitting quantitative physical models (for example, Rietveld refinement) or more empirical approaches such as fitting linear combinations of reference spectra, such as with x-ray absorption near-edge spectroscopy (XANES). Both approaches require a high degree of researcher expertise through careful design of experiments; specification, revision, and iterative fitting of physical models; or the availability of template spectra of known materials. In recent years, with the advances in high-throughput experiments and computational data, spectroscopic data has multiplied, giving opportunities for researchers to learn from the data and potentially displace the conventional methods in analyzing such data. This section covers emerging DL applications in various modes of spectroscopic data analysis, aiming to offer practice examples and insights. Some of the applications are shown in Fig. 3 .

a Predicting structure information from the X-ray diffraction 374 , Reprinted according to the terms of the CC-BY license 374 . Copyright 2020. b Predicting catalysis properties from computational electronic density of states data. Reprinted according to the terms of the CC-BY license 202 . Copyright 2021.
Currently, large-scale and element-diverse spectral data mainly exist in computational databases. For example, in ref. 160 , the authors calculated the infrared spectra, piezoelectric tensor, Born effective charge tensor, and dielectric response as a part of the JARVIS-DFT DFPT database. The Materials Project has established the largest computational X-ray absorption database (XASDb), covering the K-edge X-ray near-edge fine structure (XANES) 161 , 162 and the L-edge XANES 163 of a large number of material structures. The database currently hosts more than 400,000 K-edge XANES site-wise spectra and 90,000 L-edge XANES site-wise spectra of many compounds in the Materials Project. There are considerably fewer experimental XAS spectra, being on the order of hundreds, as seen in the EELSDb and the XASLib. Collecting large experimental spectra databases that cover a wide range of elements is a challenging task. Collective efforts focused on curating data extracted from different sources, as found in the RRUFF Raman, XRD and chemistry database 164 , the open Raman database 165 , and the SOP spectra library 166 . However, data consistency is not guaranteed. It is also now possible for contributors to share experimental data in a Materials Project curated database, MPContribs 167 . This database is supported by the US Department of Energy (DOE) providing some expectation of persistence. Entries can be kept private or published and are linked to the main materials project computational databases. There is an ongoing effort to capture data from DOE-funded synchrotron light sources ( https://lightsources.materialsproject.org/ ) into MPContribs in the future.
Recent advances in sources, detectors, and experimental instrumentation have made high-throughput measurements of experimental spectra possible, giving rise to new possibilities for spectral data generation and modeling. Such examples include the HTEM database 10 that contains 50,000 optical absorption spectra and the UV-Vis database of 180,000 samples from the Joint Center for Artificial Photosynthesis. Some of the common spectra databases for spectra data are shown in Table 3 . There are beginning to appear cloud-based software as a service platforms for high-throughput data analysis, for example, pair-distribution function (PDF) in the cloud ( https://pdfitc.org ) 168 which are backed by structured databases, where data can be kept private or made public. This transition to the cloud from data analysis software installed and run locally on a user’s computer will facilitate the sharing and reuse of data by the community.
Applications
Due to the widespread deployment of XRD across many materials technologies, XRD spectra became one of the first test grounds for DL models. Phase identification from XRD can be mapped into a classification task (assuming all phases are known) or an unsupervised clustering task. Unlike the traditional analysis of XRD data, where the spectra are treated as convolved, discrete peak positions and intensities, DL methods treat the data as a continuous pattern similar to an image. Unfortunately, a significant number of experimental XRD datasets in one place are not readily available at the moment. Nevertheless, extensive, high-quality crystal structure data makes creating simulated XRD trivial.
Park et al. 169 calculated 150,000 XRD patterns from the Inorganic Crystal Structure Database (ICSD) structural database 170 and then used CNN models to predict structural information from the simulated XRD patterns. The accuracies of the CNN models reached 81.14%, 83.83%, and 94.99% for space-group, extinction-group, and crystal-system classifications, respectively.
Liu et al. 95 obtained similar accuracies by using a CNN for classifying atomic pair-distribution function (PDF) data into space groups. The PDF is obtained by Fourier transforming XRD into real space and is particularly useful for studying the local and nanoscale structure of materials. In the case of the PDF, models were trained, validated, and tested on simulated data from the ICSD. However, the trained model showed excellent performance when given experimental data, something that can be a challenge in XRD data because of the different resolutions and line-shapes of the diffraction data depending on specifics of the sample and experimental conditions. The PDF seems to be more robust against these aspects.
Similarly, Zaloga et al. 171 also used the ICSD database for XRD pattern generation and CNN models to classify crystals. The models achieved 90.02% and 79.82% accuracy for crystal systems and space groups, respectively.
It should be noted that the ICSD database contains many duplicates, and such duplicates should be filtered out to avoid information leakage. There is also a large difference in the number of structures represented in each space group (the label) in the database resulting in data normalization challenges.
Lee et al. 172 developed a CNN model for phase identification from samples consisting of a mixture of several phases in a limited chemical space relevant for battery materials. The training data are mixed patterns consisting of 1,785,405 synthetic XRD patterns from the Sr-Li-Al-O phase space. The resulting CNN can not only identify the phases but also predict the compound fraction in the mixture. A similar CNN was utilized by Wang et al. 173 for fast identification of metal-organic frameworks (MOFs), where experimental spectral noise was extracted and then synthesized into the theoretical XRD for training data augmentation.
An alternative idea was proposed by Dong et al. 174 . Instead of recognizing only phases from the CNN, a proposed “parameter quantification network” (PQ-Net) was able to extract physico-chemical information. The PQ-Net yields accurate predictions for scale factors, crystallite size, and lattice parameters for simulated and experimental XRD spectra. The work by Aguiar et al. 175 took a step further and proposed a modular neural network architecture that enables the combination of diffraction patterns and chemistry data and provided a ranked list of predictions. The ranked list predictions provide user flexibility and overcome some aspects of overconfidence in model predictions. In practical applications, AI-driven XRD identification can be beneficial for high-throughput materials discovery, as shown by Maffettone et al. 176 . In their work, an ensemble of 50 CNN models was trained on synthetic data reproducing experimental variations (missing peaks, broadening, peaking shifting, noises). The model ensemble is capable of predicting the probability of each category label. A similar data augmentation idea was adopted by Oviedo et al. 177 , where experimental XRD data for 115 thin-film metal-halides were measured, and CNN models trained on the augmented XRD data achieved accuracies of 93% and 89% for classifying dimensionality and space group, respectively.
Although not a DL method, an unsupervised machine learning approach, non-negative matrix factorization (NMF), is showing great promise for yielding chemically relevant XRD spectra from time- or spatially-dependent sets of diffraction patterns. NMF is closely related to principle component analysis in that it takes a set of patterns as a matrix and then compresses the data by reducing the dimensionality by finding the most important components. In NMF a constraint is applied that all the components and their weights must be strictly positive. This often corresponds to a real physical situation (for example, spectra tend to be positive, as are the weights of chemical constituents). As a result, it appears that the mathematical decomposition often results in interpretable, physically meaningful, components and weights, as shown by Liu et al. for PDF data 178 . An extension of this showed that in a spatially resolved study, NMF could be used to extract chemically resolved differential PDFs (similar to the information in EXAFS) from non-chemically resolved PDF measurements 179 . NMF is very quick and easy to apply and can be applied to just about any set of spectra. It is likely to become widely used and is being implemented in the PDFitc.org website to make it more accessible to potential users.
Other than XRD, the XAS, Raman, and infrared spectra, also contain rich structure-dependent spectroscopic information about the material. Unlike XRD, where relatively simple theories and equations exist to relate structures to the spectral patterns, the relationships between general spectra and structures are somewhat elusive. This difficulty has created a higher demand for machine learning models to learn structural information from other spectra.
For instance, the case of X-ray absorption spectroscopy (XAS), including the X-ray absorption near-edge spectroscopy (XANES) and extended X-ray absorption fine structure (EXAFS), is usually used to analyze the structural information on an atomic level. However, the high signal-to-noise XANES region has no equation for data fitting. DL modeling of XAS data is fascinating and offers unprecedented insights. Timoshenko et al. used neural networks to predict the coordination numbers of Pt 180 and Cu 181 in nanoclusters from the XANES. Aside from the high accuracies, the neural network also offers high prediction speed and new opportunities for quantitative XANES analysis. Timoshenko et al. 182 further carried out a novel analysis of EXAFS using DL. Although EXAFS analysis has an explicit equation to fit, the study is limited to the first few coordination shells and on relatively ordered materials. Timoshenko et al. 182 first transformed the EXAFS data into 2D maps with a wavelet transform and then supplied the 2D data to a neural network model. The model can instantly predict relatively long-range radial distribution functions, offering in situ local structure analysis of materials. The advent of high-throughput XAS databases has recently unveiled more possibilities for machine learning models to be deployed using XAS data. For example, Zheng et al. 161 used an ensemble learning method to match and fast search new spectra in the XASDb. Later, the same authors showed that random forest models outperform DL models such as MLPs or CNNs in directly predicting atomic environment labels from the XANES spectra 183 . Similar approaches were also adopted by Torrisi et al. 184 In practical applications, Andrejevic et al. 185 used the XASDb data together with the topological materials database. They constructed CNN models to classify the topology of materials from the XANES and symmetry group inputs. The model correctly predicted 81% topological and 80% trivial cases and achieved 90% accuracy in material classes containing certain elements.
Raman, infrared, and other vibrational spectroscopies provide structural fingerprints and are usually used to discriminate and estimate the concentration of components in a mixture. For example, Madden et al. 186 have used neural network models to predict the concentration of illicit materials in a mixture using the Raman spectra. Interestingly, several groups have independently found that DL models outperform chemometrics analysis in vibrational spectroscopies 187 , 188 . For learning vibrational spectra, the number of training spectra is usually less than or on the order of the number of features (intensity points), and the models can easily overfit. Hence, dimensional reduction strategies are commonly used to compress the information dimension using, for example, principal component analysis (PCA) 189 , 190 . DL approaches do not have such concerns and offer elegant and unified solutions. For example, Liu et al. 191 applied CNN models to the Raman spectra in the RRUFF spectral database and show that CNN models outperform classical machine learning models such as SVM in classification tasks. More DL applications in vibrational spectral analysis can be found in a recent review by Yang et al. 192 .
Although most current DL work focuses on the inverse problem, i.e., predicting structural information from the spectra, some innovative approaches also solve the forward problems by predicting the spectra from the structure. In this case, the spectroscopy data can be viewed simply as a high-dimensional material property of the structure. This is most common in molecular science, where predicting the infrared spectra 193 , molecular excitation spectra 194 , is of particular interest. In the early 2000s, Selzer et al. 193 and Kostka et al. 195 attempted predicting the infrared spectra directly from the molecular structural descriptors using neural networks. Non-DL models can also perform such tasks to a reasonable accuracy 196 . For DL models, Chen et al. 197 used a Euclidean neural network (E(3)NN) to predict the phonon density of state (DOS) spectra 198 from atom positions and element types. The E(3)NN model captures symmetries of the crystal structures, with no need to perform data augmentation to achieve target invariances. Hence the E(3)NN model is extremely data-efficient and can give reliable DOS spectra prediction and heat capacity using relatively sparse data of 1200 calculation results on 65 elements. A similar idea was also used to predict the XAS spectra. Carbone et al. 199 used a message passing neural network (MPNN) to predict the O and N K-edge XANES spectra from the molecular structures in the QM9 database 7 . The training XANES data were generated using the FEFF package 200 . The trained MPNN model reproduced all prominent peaks in the predicted XANES, and 90% of the predicted peaks are within 1 eV of the FEFF calculations. Similarly, Rankine et al. 201 started from the two-body radial distribution function (RDC) and used a deep neural network model to predict the Fe K-edge XANES spectra for arbitrary local environments.
In addition to learn the structure-spectra or spectra-structure relationships, a few works have also explored the possibility of relating spectra to other material properties in a non-trivial way. The DOSnet proposed by Fung et al. 202 (Fig. 3 b) uses the electronic DOS spectra calculated from DFT as inputs to a CNN model to predict the adsorption energies of H, C, N, O, S and their hydrogenated counterparts, CH, CH 2 , CH 3 , NH, OH, and SH, on bimetallic alloy surfaces. This approach extends the previous d-band theory 203 , where only the d-band center, a scalar, was used to correlate with the adsorption energy on transition metals. Similarly, Kaundinya et al. 204 used Atomistic Line Graph Neural Network (ALIGNN) to predict DOS for 56,000 materials in the JARVIS-DFT database using a direct discretized spectrum (D-ALIGNN), and a compressed low-dimensional representation using an autoencoder (AE-ALIGNN). Stein et al. 205 tried to learn the mapping between the image and the UV-vis spectrum of the material using the conditional variational encoder (cVAE) with neural network models as the backbone. Such models can generate the UV-vis spectrum directly from a simple material image, offering much faster material characterizations. Predicting gas adsorption isotherms for direct air capture (DAC) are also an important application of spectra-based DL models. There have been several important works 206 , 207 for CO 2 capture with high-performance metal-organic frameworks (MOFs) which are important for mitigating climate change issues.
Image-based models
Computer vision is often credited as precipitating the current wave of mainstream DL applications a decade ago 208 . Naturally, materials researchers have developed a broad portfolio of applications of computer vision for accelerating and improving image-based material characterization techniques. High-level microscopy vision tasks can be organized as follows: image classification (and material property regression), auto-tuning experimental imaging hyperparameters, pixelwise learning (e.g., semantic segmentation), super-resolution imaging, object/entity recognition, localization, and tracking, microstructure representation learning.
Often these tasks generalize across many different imaging modalities, spanning optical microscopy (OM), scanning electron microscopy (SEM) techniques, scanning probe microscopy (SPM, as in scanning tunneling microscopy (STM) or atomic force microscopy (AFM), and transmission electron microscopy (TEM) variants, including scanning transmission electron microscopy (STEM).
The images obtained with these techniques range from capturing local atomic to mesoscale structures (microstructure), the distribution and type of defects, and their dynamics which are critically linked to the functionality and performance of the materials. Over the past few decades, atomic-scale imaging has become widespread and near-routine due to aberration-corrected STEM 209 . The collection of large image datasets is increasingly presenting an analysis bottleneck in the materials characterization pipeline, and the immediate need for automated image analysis becomes important. Non-DL image analysis methods have driven tremendous progress in quantitative microscopy, but often image processing pipelines are brittle and require too much manual identification of image features to be broadly applicable. Thus, DL is currently the most promising solution for high-performance, high-throughput automated analysis of image datasets. For a good overview of applications in microstructure characterization specifically, see 210 .
Image datasets for materials can come from either experiments or simulations. Software libraries mentioned above can be used to generate images such as STM/STEM. Images can also be obtained from the literature. A few common examples for image datasets are shown below in Table 4 . Recently, there has been a rapid development in the field of image learning tasks for materials leading to several useful packages. We list some of them in Table 4 .
Applications in image classification and regression
DL for images can be used to automatically extract information from images or transform images into a more useful state. The benefits of automated image analysis include higher throughput, better consistency of measurements compared to manual analysis, and even the ability to measure signals in images that humans cannot detect. The benefits of altering images include image super-resolution, denoising, inferring 3D structure from 2D images, and more. Examples of the applications of each task are summarized below.
Image classification and regression
Classification and regression are the processes of predicting one or more values associated with an image. In the context of DL the only difference between the two methods is that the outputs of classification are discrete while the outputs of regression models are continuous. The same network architecture may be used for both classification and regression by choosing the appropriate activation function (i.e., linear for regression or Softmax for classification) for the output of the network. Due to its simplicity image classification is one of the most established DL techniques available in the materials science literature. Nonetheless, this technique remains an area of active research.
Modarres et al. applied DL with transfer learning to automatically classify SEM images of different material systems 211 . They demonstrated how a single approach can be used to identify a wide variety of features and material systems such as particles, fibers, Microelectromechanical systems (MEMS) devices, and more. The model achieved 90% accuracy on a test set. Misclassifications resulted from images containing objects from multiple classes, which is an inherent limitation of single-class classification. More advanced techniques such as those described in subsequent sections can be applied to avoid these limitations. Additionally, they developed a system to deploy the trained model at scale to process thousands of images in parallel. This approach is essential for large-scale, high-throughput experiments or industrial applications of classification. ImageNet-based deep transfer learning has also been successfully applied for crack detection in macroscale materials images 212 , 213 , as well as for property prediction on small, noisy, and heterogeneous industrial datasets 214 , 215 .
DL has also been applied to characterize the symmetries of simulated measurements of samples. In ref. 216 , Ziletti et al. obtained a large database of perfect crystal structures, introduced defects into the perfect lattices, and simulated diffraction patterns for each structure. DL models were trained to identify the space group of each diffraction patterns. The model achieved high classification performance, even on crystals with significant numbers of defects, surpassing the performance of conventional algorithms for detecting symmetries from diffraction patterns.
DL has also been applied to classify symmetries in simulated STM measurements of 2D material systems 217 . DFT was used to generate simulated STM images for a variety of material systems. A convolutional neural network was trained to identify which of the five 2D Bravais lattices each material belonged to using the simulated STM image as input. The model achieved an average F1 score of around 0.9 for each lattice type.
DL has also been used to improve the analysis of electron backscatter diffraction (EBSD) data, with Liu et al. 218 presenting one of the first DL-based solution for EBSD indexing capable of taking an EBSD image as input and predicting the three Euler angles representing the orientation that would have led to the given EBSD pattern. However, they considered the three Euler angles to be independent of each other, creating separate CNNs for each angle, although the three angles should be considered together. Jha et al. 219 built upon that work to train a single DL model to predict the three Euler angles in simulated EBSD patterns of polycrystalline Ni while directly minimizing the misorientation angle between the true and predicted orientations. When tested on experimental EBSD patterns, the model achieved 16% lower disorientation error than dictionary-based indexing. Similarly, Kaufman et al. trained a CNN to predict the corresponding space group for a given diffraction pattern 220 . This enables EBSD to be used for phase identification in samples where the existing phases are unknown, providing a faster or more cost-effective method of characterizing than X-ray or neutron diffraction. The results from these studies demonstrate the promise of applying DL to improve the performance and utility of EBSD experiments.
Recently, DL has also been to learn crystal plasticity using images of strain profiles as input 221 , 222 . The work in ref. 221 used domain knowledge integration in the form of two-point auto-correlation to enhance the predictive accuracy, while 222 applied residual learning to learn crystal plasticity at nanoscale. It used strain profiles of materials of varying sample widths ranging from 2 μm down to 62.5 nm obtained from discrete dislocation dynamics to build a deep residual network capable of identifying prior deformation history of the sample as low, medium, or high. Compared to the correlation function-based method (68.24% accuracy), the DL model was found to be significantly more accurate (92.48%) and also capable of predicting stress-strain curves of test samples. This work additionally used saliency maps to try to interpret the developed DL model.
Pixelwise learning
DL can also be applied to generate one or more predictions for every pixel in an image. This can provide more detailed information about the size, position, orientation, and morphology of features of interest in images. Thus, pixelwise learning has been a significant area of focus with many recent studies appearing in materials science literature.
Azimi et al. applied an ensemble of fully convolutional neural networks to segment martensite, tempered martensite, bainite, and pearlite in SEM images of carbon steels. Their model achieved 94% accuracy, demonstrating a significant improvement over previous efforts to automate the segmentation of different phases in SEM images. Decost, Francis, and Holm applied PixelNet to segment microstructural constituents in the UltraHigh Carbon Steel Database 223 , 224 . In contrast to fully convolutional neural networks, which encode and decode visual signals using a series of convolution layers, PixelNet constructs “hypercolumns”, or concatenations of feature representations corresponding to each pixel at different layers in a neural network. The hypercolumns are treated as individual feature vectors, which can then be classified using any typical classification approach, like a multilayer perceptron. This approach achieved phase segmentation precision and recall scores of 86.5% and 86.5%, respectively. Additionally, this approach was used to segment spheroidite particles in the matrix, achieving precision and recall scores of 91.1% and 91.1%, respectively.
Pixelwise DL has also been applied to automatically segment dislocations in Ni superalloys 210 . Dislocations are visually similar to \(\gamma -{\gamma }^{\prime}\) and dislocation in Ni superalloys. With limited training data, a single segmentation model could not distinguish between these features. To overcome this, a second model was trained to generate a coarse mask corresponding to the deformed region in the material. Overlaying this mask with predictions from the first model selects the dislocations, enabling them to be distinguished from \(\gamma -{\gamma }^{\prime}\) interfaces.
Stan, Thompson, and Voorhees applied Pixelwise DL to characterize dendritic growth from serial sectioning and synchrotron computed tomography data 225 . Both of these techniques generate large amounts of data, making manual analysis impractical. Conventional image processing approaches, utilizing thresholding, edge detectors, or other hand-crafted filters, cannot effectively deal with noise, contrast gradients, and other artifacts that are present in the data. Despite having a small training set of labeled images, SegNet automatically segmented these images with much higher performance.
Object/entity recognition, localization, and tracking
Object detection or localization is needed when individual instances of recognized objects in a given image need to be distinguished from each other. In cases where instances do not overlap each other by a significant amount, individual instances can be resolved through post-processing of semantic segmentation outputs. This technique has been applied extensively to detect individual atoms and defects in microstructural images.
Madsen et al. applied pixelwise DL to detect atoms in simulated atomic-resolution TEM images of graphene 226 . A neural network was trained to detect the presence of each atom as well as predict its column height. Pixelwise results are used as seeds for watershed segmentation to achieve instance-level detection. Analysis of the arrangement of the atoms led to the autonomous characterization of defects in the lattice structure of the material. Interestingly, despite being trained only on simulations, the model successfully detected atomic positions in experimental images.
Maksov et al. demonstrated atomistic defect recognition and tracking across sequences of atomic-resolution STEM images of WS 2 227 . The lattice structure and defects existing in the first frame were characterized through a physics-based approach utilizing Fourier transforms. The positions of atoms and defects in the first frame were used to train a segmentation model. Despite only using the first frame for training, the model successfully identified and tracked defects in the subsequent frames for each sequence, even when the lattice underwent significant deformation. Similarly, Yang et al. 228 used U-net architecture (as shown in Fig. 4 ) to detect vacancies and dopants in WSe 2 in STEM images with model accuracy of up to 98%. They classified the possible atomic sites based on experimental observations into five different types: tungsten, vanadium substituting for tungsten, selenium with no vacancy, mono-vacancy of selenium, and di-vacancy of selenium.

a Deep neural networks U-Net model constructed for quantification analysis of annular dark-field in the scanning transmission electron microscope (ADF-STEM) image of V-WSe 2 . b Examples of training dataset for deep learning of atom segmentation model for five different species. c Pixel-level accuracy of the atom segmentation model as a function of training epoch. d Measurement accuracy of the segmentation model compared with human-based measurements. Scale bars are 1 nm [Reprinted according to the terms of the CC-BY license ref. 228 ].
Roberts et al. developed DefectSegNet to automatically identify defects in transmission and STEM images of steel including dislocations, precipitates, and voids 229 . They provide detailed information on the model’s design, training, and evaluation. They also compare measurements generated from the model to manual measurements performed by several different human experts, demonstrating that the measurements generated by DL are quantitatively more accurate and consistent.
Kusche et al. applied DL to localize defects in panoramic SEM images of dual-phase steel 230 . Manual thresholding was applied to identify dark defects against the brighter matrix. Regions containing defects were classified via two neural networks. The first neural network distinguished between inclusions and ductile damage in the material. The second classified the type of ductile damage (i.e., notching, martensite cracking, etc.) Each defect was also segmented via a watershed algorithm to obtain detailed information on its size, position, and morphology.
Applying DL to localize defects and atomic structures is a popular area in materials science research. Thus, several other recent studies on these applications can be found in the literature 231 , 232 , 233 , 234 .
In the above examples pixelwise DL, or classification models are combined with image analysis to distinguish individual instances of detected objects. However, when several adjacent objects of the same class touch or overlap each other in the image, this approach will falsely detect them to be a single, larger object. In this case, DL models designed for the detection or instance segmentation can be used to resolve overlapping instances. In one such study, Cohn and Holm applied DL for instance-level segmentation of individual particles and satellites in dense powder images 235 . Segmenting each particle allows for computer vision to generate detailed size and morphology information which can be used to supplement experimental powder characterization for additive manufacturing. Additionally, overlaying the powder and satellite masks yielded the first method for quantifying the satellite content of powder samples, which cannot be measured experimentally.
Super-resolution imaging and auto-tuning experimental parameters
The studies listed so far focus on automating the analysis of existing data after it has been collected experimentally. However, DL can also be applied during experiments to improve the quality of the data itself. This can reduce the time for data collection or improve the amount of information captured in each image. Super-resolution and other DL techniques can also be applied in situ to autonomously adjust experimental parameters.
Recording high-resolution electron microscope images often require large dwell times, limiting the throughput of microscopy experiments. Additionally, during imaging, interactions between the electron beam and a microscopy sample can result in undesirable effects, including charging of non-conductive samples and damage to sensitive samples. Thus, there is interest in using DL to artificially increase the resolution of images without introducing these artifacts. One method of interest is applying generative adversarial networks (GANs) for this application.
De Haan et al. recorded SEM images of the same regions of interest in carbon samples containing gold nanoparticles at two resolutions 236 . Low-resolution images recorded were used as inputs to a GAN. The corresponding images with twice the resolution were used as the ground truth. After training the GAN reduced the number of undetected gaps between nanoparticles from 13.9 to 3.7%, indicating that super-resolution was successful. Thus, applying DL led to a four-fold reduction of the interaction time between the electron beam and the sample.
Ede and Beanland collected a dataset of STEM images of different samples 237 . Images were subsampled with spiral and ‘jittered’ grid masks to obtain partial images with resolutions reduced by a factor up to 100. A GAN was trained to reconstruct full images from their corresponding partial images. The results indicated that despite a significant reduction in the sampling area, this approach successfully reconstructed high-resolution images with relatively small errors.
DL has also been applied to automated tip conditioning for SPM experiments. Rashidi and Wolkow trained a model to detect artifacts in SPM measurements resulting from degradation in tip quality 238 . Using an ensemble of convolutional neural networks resulted in 99% accuracy. After detecting that a tip has degraded, the SPM was configured to automatically recondition the tip in situ until the network indicated that the atomic sharpness of the tip has been restored. Monitoring and reconditioning the tip is the most time and labor-intensive part of conducting SPM experiments. Thus, automating this process through DL can increase the throughput and decrease the cost of collecting data through SPM.
In addition to materials characterization, DL can be applied to autonomously adjust parameters during manufacturing. Scime et al. mounted a camera to multiple 3D printers 239 . Images of the build plate were recorded throughout the printing process. A dynamic segmentation convolutional neural network was trained to recognize defects such as recoater streaking, incomplete spreading, spatter, porosity, and others. The trained model achieved high performance and was transferable to multiple printers from three different methods of additive manufacturing. This work is the first step to enabling smart additive manufacturing machines that can correct defects and adjust parameters during printing.
There is also growing interest in establishing instruments and laboratories for autonomous experimentation. Eppel et al. trained multiple models to detect chemicals, materials, and transparent vessels in a chemistry lab setting 240 . This study provides a rigorous analysis of several different approaches for scene understanding. Models were trained to characterize laboratory scenes with different methods including semantic segmentation and instance segmentation, both with and without overlapping instances. The models successfully detected individual vessels and materials in a variety of settings. Finer-grained understanding of the contents of vessels, such as segmentation of individual phases in multi-phase systems, was limited, outlining the path for future work in this area. The results represent an important step towards realizing automated experimentation for laboratory-scale experiments.
Microstructure representation learning
Materials microstructure is often represented in the form of multi-phase high-dimensional 2D/3D images and thus can readily leverage image-based DL methods to learn robust, low-dimensional microstructure representations, which can subsequently be used for building predictive and generative models to learn forward and inverse structure-property linkages, which are typically studied across different length scales (multi-scale modeling). In this context, homogenization and localization refer to the transfer of information from lower length scales to higher length scales and vice-versa. DL using customized CNNs has been used both for homogenization, i.e., predicting the macroscale property of material given its microstructure information 221 , 241 , 242 , as well as for localization, i.e., predicting the strain distribution across a given microstructure for a loading condition 243 .
Transfer learning has also been widely used for analyzing materials microstructure images; methods for improving the use of transfer learning to materials science applications remain an area of active research. Goetz et al. investigated the use of unsupervised domain adaptation as an alternative to simply fine-tuning a pre-trained model 244 . In this technique a model is first trained on a labeled dataset in the source domain. Next, a discriminator model is used to train the model to generate domain-agnostic features. Compared to simple fine-tuning, unsupervised domain adaptation improved the performance of classification and segmentation neural networks on materials science datasets. However, it was determined that the highest performance was achieved when the source domain was more visually similar to the target (for example, using a different set of microstructural images instead of ImageNet.) This highlights the utility of establishing large, publicly available datasets of annotated images in materials science.
Kitaraha and Holm used the output of an intermediate layer of a pre-trained convolutional neural network as a feature representation for images of steel surface defects and Inconnel fracture surfaces 245 . Images were classified by defect type or fracture surface orientation using unsupervised DL. Even though no labeled data was used to train the neural network or the unsupervised classifier, the model found natural decision boundaries that achieved a classification performance of 98% and 88% for the defect classes and fracture surface orientations, respectively. Visualization of the representations through principal component analysis (PCA) and t-distributed stochastic neighborhood embedding (t-SNE) provided qualitative insights into the representations. Although the detailed physical interpretation of the representations is still a distant goal, this study provides tools for investigating patterns in visual signals contained in image-based datasets in materials science.
Larmuseau et al. investigated the use of triplet networks to obtain consistent representations for visually similar images of materials 246 . Triplet networks are trained with three images at a time. The first image, the reference, is classified by the network. The second image, called the positive, is another image with the same class label. The last image, called the negative, is an image from a separate class. During training the loss function includes errors in predicting the class of the reference image, the difference in representations of the reference and positive images, and the similarity in representations of the reference and negative images. This process allows the network to learn consistent representations for images in the same class while distinguishing images from different classes. The triple network outperformed an ordinary convolutional neural network trained for image classification on the same dataset.
In addition to investigating representations used to analyze existing images, DL can generate synthetic images of materials systems. Generative Adversarial Networks (GANs) are currently the predominant method for synthetic microstructure generation. GANs consist of a generator, which creates a synthetic microstructure image, and a discriminator, which attempts to predict if a given input image is real or synthetic. With careful application, GANs can be a powerful tool for microstructure representation learning and design.
Yang and Li et al. 247 , 248 developed a GAN-based model for learning a low-dimensional embedding of microstructures, which could then be easily sampled and used with the generator of the GAN model to generate realistic, statistically similar microstructure images, thus enabling microstructural materials design. The model was able to capture complex, nonlinear microstructure characteristics and learn the mapping between the latent design variables and microstructures. In order to close the loop, the method was combined with a Bayesian optimization approach to design microstructures with optimal optical absorption performance. The discovered microstructures were found to have up to 17% better property than randomly sampled microstructures. The unique architecture of their GAN model also facilitated generator scalability to generate arbitrary-sized microstructure images and discriminator transferability to build structure-property prediction models. Yang et al. 249 recently combined GANs with MDNs (mixture density networks) to enable inverse modeling in microstructural materials design, i.e., generate the microstructure for a given desired property.
Hsu et al. constructed a GAN to generate 3D synthetic solid oxide fuel cell microstructures 250 . These microstructures were compared to other synthetic microstructures generated by DREAM.3D as well as experimentally observed microstructures measured via sectioning and imaging with PFIB-SEM. Synthetic microstructures generated from the GAN were observed to qualitatively show better agreement to the experimental microstructures than the DREAM.3D microstructures, as evidenced by the more realistic phase connectivity and lower amount of agglomeration of solid phases. Additionally, a statistical analysis of various features such as volume fraction, particle size, and several other quantities demonstrated that the GAN microstructures were quantitatively more similar to the real microstructures than the DREAM.3D microstructures.
In a similar study, Chun et al. generated synthetic microstructures of high energy materials using a GAN 251 . Once again, a synthetic microstructure generated via GAN showed better qualitative visual similarity to an experimentally observed microstructure compared to a synthetic microstructure generated via a transfer learning approach, with sharper phase boundaries and fewer computational artifacts. Additionally, a statistical analysis of the void size, aspect ratio, and orientation distributions indicated that the GAN produced microstructures that were quantitatively more similar to real materials.
Applications of DL to microstructure representation learning can help researchers improve the performance of predictive models used for the applications listed above. Additionally, using generative models can generate more realistic simulated microstructures. This can help researchers develop more accurate models for predicting material properties and performance without needing to synthesize and process these materials, significantly increasing the throughput of materials selection and screening experiments.
Mesoscale modeling applications
In addition to image-based characterization, deep learning methods are increasingly used in mesoscale modeling. Dai et al. 252 trained a GNN successfully trained to predict magnetostriction in a wide range of synthetic polycrystalline systems with around 10% prediction error. The microstructure is represented by a graph where each node corresponds to a single grain, and the edges between nodes indicate an interface between neighboring grains. Five node features (3 Euler angles, volume, and the number of neighbors) were associated with each grain. The GNN outperformed other machine learning approaches for property prediction of polycrystalline materials by accounting for interactions between neighboring grains.
Similarly, Cohn and Holm present preliminary work applying GNNs to predict the occurrence of abnormal grain growth (AGG) in Monte Carlo simulations of microstructure evolution 253 . AGG appears to be stochastic, making it notoriously difficult to predict, control, and even observe experimentally in some materials. AGG has been reproduced in Monte Carlo simulations of material systems, but a model that can predict which initial microstructures will undergo AGG has not been established before. A dataset of Monte Carlo simulations was created using SPPARKS 254 , 255 . A microstructure GNN was trained to predict AGG in individual simulations, with 75% classification accuracy. In comparison, an image-based only achieved 60% accuracy. The GNN also provided physical insight to understanding AGG and indicated that only 2 neighborhood shells are needed to achieve the maximum performance achieved in the study. These early results motivate additional work on applying GNNs to predict the occurrence in both simulated and real materials during processing.
Natural language processing
Most of the existing knowledge in the materials domain is currently unavailable as structured information and only exists as unstructured text, tables, or images in various publications. There exists a great opportunity to use natural language processing (NLP) techniques to convert text to structured data or to directly learn and make inferences from the text information. However, as a relatively new field within materials science, many challenges remain unsolved in this domain, such as resolving dependencies between words and phrases across multiple sentences and paragraphs.
Datasets for NLP
Datasets relevant to natural language processing include peer-reviewed journal articles, articles published on preprint servers such as arXiv or ChemRxiv, patents, and online material such as Wikipedia. Unfortunately, accessing or parsing most such datasets remains difficult. Peer-reviewed journal articles are typically subject to copyright restrictions and thus difficult to obtain, especially in the large numbers required for machine learning. Many publishers now offer text and data mining (TDM) agreements that can be signed online, allowing at least a limited, restricted amount of work to be performed. However, gaining access to the full text of many publications still typically requires strict and dedicated agreements with each publisher. The major advantage of working with publishers is that they have often already converted the articles from a document format such as PDF into an easy-to-parse format such as HyperText Markup Language (HTML). In contrast, articles on preprint servers and patents are typically available with fewer restrictions, but are commonly available only as PDF files. It remains difficult to properly parse text from PDF files in a reliable manner, even when the text is embedded in the PDF. Therefore, new tools that can easily and automatically convert such content into well-structured HTML format with few residual errors would likely have a major impact on the field. Finally, online sources of information such as Wikipedia can serve as another type of data source. However, such online sources are often more difficult to verify in terms of accuracy and also do not contain as much domain-specific information as the research literature.
Software libraries for NLP
Applying NLP to a raw dataset involves multiple steps. These steps include retrieving the data, various forms of “pre-processing” (sentence and word tokenization, word stemming and lemmatization, featurization such as word vectors or part of speech tagging), and finally machine learning for information extraction (e.g., named entity recognition, entity-relationship modeling, question and answer, or others). Multiple software libraries exist to aid in materials NLP, as described in Table 5 . We note that although many of these steps can in theory be performed by general-purpose NLP libraries such as NLTK 256 , SpaCy 257 , or AllenNLP 258 , the specialized nature of chemistry and materials science text (including the presence of complex chemical formulas) often leads to errors. For example, researchers have developed specialized codes to perform preprocessing that better detect chemical formulas (and not split them into separate tokens or apply stemming/lemmatization to them) and scientific phrases and notation such as oxidation states or symbols for physical units.
Similarly, chemistry-specific codes for extracting entities are better at extracting the names of chemical elements (e.g., recognizing that “He” likely represents helium and not a male pronoun) and abbreviations for chemical formulas. Finally, word embeddings that convert words such as “manganese” into numerical vectors for further data mining are more informative when trained specifically on materials science text versus more generic texts, even when the latter datasets are larger 259 . Thus, domain-specific tools for NLP are required in nearly all aspects of the pipeline. The main exception is that the architecture of the specific neural network models used for information extraction (e.g., LSTM, BERT, or architectures used to generate word embeddings such as word2vec or GloVe) are typically not modified specifically for the materials domain. Thus, much of the materials and chemistry-centric work currently regards data retrieval and appropriate preprocessing. A longer discussion of this topic, with specific examples, can be found in refs. 260 , 261 .
NLP methods for materials have been applied for information extraction and search (particularly as applied to synthesis prediction) as well as materials discovery. As the domain is rapidly growing, we suggest dedicated reviews on this topic by Olivetti et al. 261 and Kononova et al. 260 for more information.
One of the major uses of NLP methods is to extract datasets from the text in published studies. Conventionally, such datasets required manual entry of datasets by researchers combing the literature, a laborious and time-consuming process. Recently, software tools such as ChemDataExtractor 262 and other methods 263 based on more conventional machine learning and rule-based approaches have enabled automated or semi-automated extraction of datasets such as Curie and Néel magnetic phase transition temperatures 264 , battery properties 265 , UV-vis spectra 266 , and surface and pore characteristics of metal-organic frameworks 267 . In the past few years, DL approaches such as LSTMs and transformer-based models have been employed to extract various categories of information 268 , and in particular materials synthesis information 269 , 270 , 271 from text sources. Such data have been used to predict synthesis maps for titania nanotubes 272 , various binary and ternary oxides 273 , and perovskites 274 .
Databases based on natural language processing have also been used to train machine learning models to identify materials with useful functional properties, such as the recent discovery of the large magnetocaloric properties of HoBe 2 275 . Similarly, Cooper et al. 276 demonstrated a “design to device approach” for designing dye-sensitized solar cells that are co-sensitized with two dyes 276 . This study used automated text mining to compile a list of candidate dyes for the application along with measured properties such as maximum absorption wavelengths and extinction coefficients. The resulting list of 9431 dyes extracted from the literature was downselected to 309 candidates using various criteria such as molecular structure and ability to absorb in the solar spectrum. These candidates were evaluated for suitable combinations for co-sensitization, yielding 33 dyes that were further downselected using density functional theory calculations and experimental constraints. The resulting 5 dyes were evaluated experimentally, both individually and in combinations, resulting in a combination of dyes that not only outperformed any of the individual dyes but demonstrated performance comparable to existing standard material. This study demonstrates the possibility of using literature-based extraction to identify materials candidates for new applications from the vast body of published work, which may have never tested those materials for the desired application.
It is even possible that natural language processing can directly make materials predictions without intermediary models. In a study reported by Tshitoyan et al. 259 (as shown in Fig. 5 ), word embeddings (i.e., numerical vectors representing distinct words) trained on materials science literature could directly predict materials applications through a simple dot product between the trained embedding for a composition word (such as PbTe) and an application words (such as thermoelectrics). The researchers demonstrated that such an approach, if applied in the past using historical data, may have subsequently predicted many recently reported thermoelectric materials; they also presented a list of potentially interesting thermoelectric compositions using the known literature at the time. Since then, several of these predictions have been tested either computationally 277 , 278 , 279 , 280 , 281 , 282 or experimentally 283 as potential thermoelectrics. Such approaches have recently been applied to search for understudied areas of metallocene catalysis 284 , although challenges still remain in such direct approaches to materials prediction.

a Network for training word embeddings for natural language processing application. A one-hot encoded vector at left represents each distinct word in the corpus; the role of a hidden layer is to predict the probability of neighboring words in the corpus. This network structure trains a relatively small hidden layer of 100–200 neurons to contain information on the context of words in the entire corpus, with the result that similar words end up with similar hidden layer weights (word embeddings). Such word embeddings can transform wordsin text form into numerical vectors that may be useful for a variety of applications. b projection of word embeddings for various materials science words, as trained on a corpus scientific abstracts, into two dimensions using principle components analysis. Without any explicit training, the word embeddings naturally preserve relationships between chemical formulas, their common oxides, and their ground state structures. [Reprinted according to the terms of the CC-BY license ref. 259 ].
Uncertainty quantification
Uncertainty quantification (UQ) is an essential step in evaluating the robustness of DL. Specifically, DL models have been criticized for lack of robustness, interpretability, and reliability and the addition of carefully quantified uncertainties would go a long way towards addressing such shortcomings. While most of the focus in the DL field currently goes into developing new algorithms or training networks to high accuracy, there is increasing attention to UQ, as exemplified by the detailed review of Abdar et al. 285 . However, determining the uncertainty associated with DL predictions is still challenging and far from a completely solved problem.
The main drawback to estimating UQ when performing DL is the fact that most of the currently available UQ implementations do not work for arbitrary, off-the-shelf models, without retraining or redesigning. Bayesian NNs are the exception; however, they require significant modifications to the training procedure, are computationally expensive compared to non-Bayesian NNs, and become increasingly inefficient the larger the datasize gets. A considerable fraction of the current research in DL UQ focuses exactly on such an issue: how to evaluate uncertainty without requiring computationally expensive retraining or DL code modifications. An example of such an effort is the work of Mi et al. 286 , where three scalable methods are explored, to evaluate the variance of output from trained NN, without requiring any amount of retraining. Another example is Teye, Azizpour, and Smith’s exploration of the use of batch normalization as a way to approximate inference in Bayesian models 287 .
Before reviewing the most common methods used to evaluate uncertainty in DL, let us briefly point out key reasons to add UQ to DL modeling. Reaching high accuracy when training DL models implicitly assume the availability of a sufficiently large and diverse training dataset. Unfortunately, this rarely occurs in material discovery applications 288 . ML/DL models are prone to perform poorly on extrapolation 289 . It is also extremely difficult for ML/DL models to recognize ambiguous samples 290 . In general, determining the amount of data necessary to train a DL to achieve the required accuracy is a challenging problem. Careful evaluation of the uncertainty associated with DL predictions would not only increase reliability in predicted results but would also provide guidance on estimating the needed training dataset size as well as suggesting what new data should be added to reach the target accuracy (uncertainty-guided decision). Zhang, Kailkhura, and Han’s work emphasizes how including a UQ-motivated reject option into the DL model substantially improves the performance of the remaining material data 288 . Such a reject option is associated with the detection of out-of-distribution samples, which is only possible through UQ analysis of the predicted results.
Two different uncertainty types are associated with each ML prediction: epistemic uncertainty and aleatory uncertainty. Epistemic uncertainty is related to insufficient training data in part of the input domain. As mentioned above, while DL is very effective at interpolation tasks, they can have more difficulty in extrapolation. Therefore, it is vital to quantify the lack of accuracy due to localized, insufficient training data. The aleatory uncertainty, instead, is related to parameters not included in the model. It relates to the possibility of training on data that our DL perceives as very similar but that are associated with different outputs because of missing features in the model. Ideally, we would like UQ methodologies to distinguish and quantify both types of uncertainties separately.
The most common approaches to evaluate uncertainty using DL are Dropout methods, Deep Ensemble methods, Quantile regression, and Gaussian Processes. Dropout methods are commonly used to avoid overfitting. In this type of approach, network nodes are disabled randomly during training, resulting in the evaluation of a different subset of the network at each training step. When a similar randomization procedure is also applied to the prediction procedure, the methodology becomes Monte-Carlo dropout 291 . Repeating such randomization multiple times produces a distribution over the outputs, from which mean and variance are determined for each prediction. Another example of using a dropout approach to approximate Bayesian inference in deep Gaussian processes is the work of Gal and Ghahramani 292 .
Deep ensemble methodologies 293 , 294 , 295 , 296 combine deep learning modelling with ensemble learning. Ensemble methods utilize multiple models and different random initializations to improve predictability. Because of the multiple predictions, statistical distributions of the outputs are generated. Combining such results into a Gaussian distribution, confidence intervals are obtained through variance evaluation. Such a multi-model strategy allows the evaluation of aleatory uncertainty when sufficient training data are provided. For areas without sufficient data, the predicted mean and variance will not be accurate, but the expectation is that a very large variance should be estimated, clearly indicating non-trustable predictions. Monte-Carlo Dropout and Deep Ensembles approaches can be combined to further improve confidence in the predicted outputs.
Quantile regression can be utilized with DL 297 . In this approach, the loss function is used in a way that allows to predict for the chosen quantile a (between 0 and 1). A choice of a = 0.5 corresponds to evaluating the Mean Absolute Error (MAE) and predicting the median of the distribution. Predicting for two more quantile values (amin and amax) determines confidence intervals of width amax − amin. For instance, predicting for amin = 0.1 and amax = 0.8 produces confidence intervals covering 70% of the population. The largest drawback of using quantile to estimate prediction intervals is the need to run the model three times, one for each quantile needed. However, a recent implementation in TensorFlow allows to simultaneously obtain multiple quantiles in one run.
Lastly, Gaussian Processes (GP) can be used within a DL approach as well and have the side benefit of providing UQ information at no extra cost. Gaussian processes are a family of infinite-dimensional multivariate Gaussian distributions completely specified by a mean function and a flexible kernel function (prior distribution). By optimizing such functions to fit the training data, the posterior distribution is determined, which is later used to predict outputs for inputs not included in the training set. Because the prior is a Gaussian process, the posterior distribution is Gaussian as well 298 , thus providing mean and variance information for each predicted data. However, in practice standard kernels under-perform 299 . In 2016, Wilson et al. 300 suggested processing inputs through a neural network prior to a Gaussian process model. This procedure could extract high-level patterns and features, but required careful design and optimization. In general, Deep Gaussian processes improve the performance of Gaussian processes by mapping the inputs through multiple Gaussian process ‘layers’. Several groups have followed this avenue and further perfected such an approach (ref. 299 and references within). A common drawback of Bayesian methods is a prohibitive computational cost if dealing with large datasets 292 .
Limitations and challenges
Although DL methods have various fascinating opportunities for materials design, they have several limitations and there is much room to improve. Reliability and quality assessment of datasets used in DL tasks are challenging because there is either a lack of ground truth data, or there are not enough metrics for global comparison, or datasets using similar or identical set-ups may not be reproducible 301 . This poses an important challenge in relying upon DL-based prediction.
Material representations based on chemical formula alone by definition do not consider structure, which on the one hand makes them more amenable to work for new compounds for which structure information may not be available, but on the other hand, makes it impossible for them to capture phenomena such as phase transitions. Properties of materials depend sensitively on structure to the extent that their properties can be quite opposite depending on the atomic arrangement, like a diamond (hard, wide-band-gap insulator) and graphite (soft, semi-metal). It is thus not a surprise that chemical formula-based methods may not be adequate in some cases 159 .
Atomistic graph-based predictions, although considered a full atomistic description, are tested on bulk materials only and not for defective systems or for multi-dimensional phases of space exploration such as using genetic algorithms. In general, this underscores that the input features must be predictive for the output labels and not be missing some key information. Although atomistic graph neural network models such as atomistic line graph neural network (ALIGNN) have achieved remarkable accuracy compared to previous atomistic based models, the model errors still need to be further brought down to reach something resembling deep learning ‘chemical-accuracies.’
In terms of images and spectra, the experimental data are too noisy most of the time and require much manipulation before applying DL. In contrast, theory-based simulated data represent an alternate path forward but may not capture realistic scenarios such as the presence of structured noise 217 .
Uncertainty quantification for deep learning for materials science is important, yet only a few works have been published in this field. To alleviate the black-box 38 nature of the DL methods, a package such as GNNExplainer 302 has been tried in the context of the material. Such attempts at greater interpretability will be important moving forward to gain the trust of the materials community.
While training-validation-test split strategies were primarily designed in DL for image classification tasks with a certain number of classes, the same for regression models in materials science may not be the best approach. This is because it is possible that during the training the model is seeing a material very similar to the test set material and in reality it is difficult to generalize the model. Best practices need to be developed for data split, normalization, and augmentation to avoid such issues 289 .
Finally, we note an important technological challenge is to make a closed-loop autonomous materials design and synthesis process 303 , 304 that can include both machine learning and experimental components in a self-driving laboratory 305 . For an overview of early proof of principle attempts see 306 . For example, in an autonomous synthesis experiment the oxidation state of copper (and therefore the oxide phase) was varied in a sample of copper oxide by automatically flowing more oxidizing or more reducing gas over the sample and monitoring the charge state of the copper using XANES. An algorithmic decision policy was then used to automatically change the gas composition for a subsequent experiment based on the prior experiments, with no human in the loop, in such a way as to autonomously move towards a target copper oxidation state 307 . This simple proof of principle experiment provides just a glimpse of what is possible moving forward.
Data availability
The data from new figures are available on reasonable request from the corresponding author. Data from other publishers are not available from the corresponding author of this work but may be available by reaching the corresponding author of the cited work.
Code availability
Software packages mentioned in the article (whichever made available by the authors) can be found at https://github.com/deepmaterials/dlmatreview . Software for other packages can be obtained by reaching the corresponding author of the cited work.
Callister, W. D. et al. Materials Science and Engineering: An Introduction (Wiley, 2021).
Saito, T. Computational Materials Design, Vol. 34 (Springer Science & Business Media, 2013).
Choudhary, K. et al. The joint automated repository for various integrated simulations (jarvis) for data-driven materials design. npj Comput. Mater. 6 , 1–13 (2020).
Article Google Scholar
Kirklin, S. et al. The open quantum materials database (oqmd): assessing the accuracy of dft formation energies. npj Comput. Mater. 1 , 1–15 (2015).
Jain, A. et al. Commentary: The materials project: A materials genome approach to accelerating materials innovation. APL Mater. 1 , 011002 (2013).
Curtarolo, S. et al. Aflow: An automatic framework for high-throughput materials discovery. Comput. Mater. Sci. 58 , 218–226 (2012).
Article CAS Google Scholar
Ramakrishnan, R., Dral, P. O., Rupp, M. & Von Lilienfeld, O. A. Quantum chemistry structures and properties of 134 kilo molecules. Sci. Data 1 , 1–7 (2014).
Draxl, C. & Scheffler, M. Nomad: The fair concept for big data-driven materials science. MRS Bull. 43 , 676–682 (2018).
Wang, R., Fang, X., Lu, Y., Yang, C.-Y. & Wang, S. The pdbbind database: methodologies and updates. J. Med. Chem. 48 , 4111–4119 (2005).
Zakutayev, A. et al. An open experimental database for exploring inorganic materials. Sci. Data 5 , 1–12 (2018).
de Pablo, J. J. et al. New frontiers for the materials genome initiative. npj Comput. Mater. 5 , 1–23 (2019).
Wilkinson, M. D. et al. The fair guiding principles for sci. data management and stewardship. Sci. Data 3 , 1–9 (2016).
Friedman, J. et al. The Elements of Statistical Learning, Vol. 1 (Springer series in statistics New York, 2001).
Agrawal, A. & Choudhary, A. Perspective: Materials informatics and big data: Realization of the “fourth paradigm” of science in materials science. APL Mater. 4 , 053208 (2016).
Vasudevan, R. K. et al. Materials science in the artificial intelligence age: high-throughput library generation, machine learning, and a pathway from correlations to the underpinning physics. MRS Commun. 9 , 821–838 (2019).
Schmidt, J., Marques, M. R., Botti, S. & Marques, M. A. Recent advances and applications of machine learning in solid-state materials science. npj Comput. Mater. 5 , 1–36 (2019).
Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O. & Walsh, A. Machine learning for molecular and materials science. Nature 559 , 547–555 (2018).
Xu, Y. et al. Deep dive into machine learning models for protein engineering. J. Chem. Inf. Model. 60 , 2773–2790 (2020).
Schleder, G. R., Padilha, A. C., Acosta, C. M., Costa, M. & Fazzio, A. From dft to machine learning: recent approaches to materials science–a review. J. Phys. Mater. 2 , 032001 (2019).
Agrawal, A. & Choudhary, A. Deep materials informatics: applications of deep learning in materials science. MRS Commun. 9 , 779–792 (2019).
Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning (MIT Press, 2016).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521 , 436–444 (2015).
McCulloch, W. S. & Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 5 , 115–133 (1943).
Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 65 , 386–408 (1958).
Gibney, E. Google ai algorithm masters ancient game of go. Nat. News 529 , 445 (2016).
Ramos, S., Gehrig, S., Pinggera, P., Franke, U. & Rother, C. Detecting unexpected obstacles for self-driving cars: Fusing deep learning and geometric modeling. in 2017 IEEE Intelligent Vehicles Symposium (IV) , 1025–1032 (IEEE, 2017).
Buduma, N. & Locascio, N. Fundamentals of deep learning: Designing next-generation machine intelligence algorithms (O’Reilly Media, Inc., O’Reilly, 2017).
Kearnes, S., McCloskey, K., Berndl, M., Pande, V. & Riley, P. Molecular graph convolutions: moving beyond fingerprints. J. Computer Aided Mol. Des. 30 , 595–608 (2016).
Albrecht, T., Slabaugh, G., Alonso, E. & Al-Arif, S. M. R. Deep learning for single-molecule science. Nanotechnology 28 , 423001 (2017).
Ge, M., Su, F., Zhao, Z. & Su, D. Deep learning analysis on microscopic imaging in materials science. Mater. Today Nano 11 , 100087 (2020).
Agrawal, A., Gopalakrishnan, K. & Choudhary, A. In Handbook on Big Data and Machine Learning in the Physical Sciences: Volume 1. Big Data Methods in Experimental Materials Discovery World Scientific Series on Emerging Technologies, 205–230 (“World Scientific, 2020).
Erdmann, M., Glombitza, J., Kasieczka, G. & Klemradt, U. Deep Learning for Physics Research (World Scientific, 2021).
Chen, C., Ye, W., Zuo, Y., Zheng, C. & Ong, S. P. Graph networks as a universal machine learning framework for molecules and crystals. Chem. Mater. 31 , 3564–3572 (2019).
Jha, D. et al. Enhancing materials property prediction by leveraging computational and experimental data using deep transfer learning. Nat. Commun . 10 , 1–12 (2019).
Cubuk, E. D., Sendek, A. D. & Reed, E. J. Screening billions of candidates for solid lithium-ion conductors: a transfer learning approach for small data. J. Chem. Phys. 150 , 214701 (2019).
Chen, C., Zuo, Y., Ye, W., Li, X. & Ong, S. P. Learning properties of ordered and disordered materials from multi-fidelity data. Nat. Comput. Sci. 1 , 46–53 (2021).
Artrith, N. et al. Best practices in machine learning for chemistry. Nat. Chem. 13 , 505–508 (2021).
Holm, E. A. In defense of the black box. Science 364 , 26–27 (2019).
Mueller, T., Kusne, A. G. & Ramprasad, R. Machine learning in materials science: Recent progress and emerging applications. Rev. Comput. Chem. 29 , 186–273 (2016).
CAS Google Scholar
Wei, J. et al. Machine learning in materials science. InfoMat 1 , 338–358 (2019).
Liu, Y. et al. Machine learning in materials genome initiative: a review. J. Mater. Sci. Technol. 57 , 113–122 (2020).
Wang, A. Y.-T. et al. Machine learning for materials scientists: an introductory guide toward best practices. Chem. Mater. 32 , 4954–4965 (2020).
Morgan, D. & Jacobs, R. Opportunities and challenges for machine learning in materials science. Annu. Rev. Mater. Res. 50 , 71–103 (2020).
Himanen, L., Geurts, A., Foster, A. S. & Rinke, P. Data-driven materials science: status, challenges, and perspectives. Adv. Sci. 6 , 1900808 (2019).
Rajan, K. Informatics for materials science and engineering: data-driven discovery for accelerated experimentation and application (Butterworth-Heinemann, 2013).
Montáns, F. J., Chinesta, F., Gómez-Bombarelli, R. & Kutz, J. N. Data-driven modeling and learning in science and engineering. Comptes Rendus Mécanique 347 , 845–855 (2019).
Aykol, M. et al. The materials research platform: defining the requirements from user stories. Matter 1 , 1433–1438 (2019).
Stanev, V., Choudhary, K., Kusne, A. G., Paglione, J. & Takeuchi, I. Artificial intelligence for search and discovery of quantum materials. Commun. Mater. 2 , 1–11 (2021).
Chen, C. et al. A critical review of machine learning of energy materials. Adv. Energy Mater. 10 , 1903242 (2020).
Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 2 , 303–314 (1989).
Kidger, P. & Lyons, T. Universal approximation with deep narrow networks . in Conference on learning theory , 2306–2327 (PMLR, 2020).
Lin, H. W., Tegmark, M. & Rolnick, D. Why does deep and cheap learning work so well? J. Stat. Phys. 168 , 1223–1247 (2017).
Minsky, M. & Papert, S. A. Perceptrons: An introduction to computational geometry (MIT press, 2017).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 32 , 8026–8037 (2019).
Google Scholar
Abadi et al., TensorFlow: A system for large-scale machine learning. arXiv:1605.08695, Preprint at https://arxiv.org/abs/1605.08695 (2006).
Chen, T. et al. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv . https://arxiv.org/abs/1512.01274 (2015).
Nwankpa, C., Ijomah, W., Gachagan, A. & Marshall, S. Activation functions: comparison of trends in practice and research for deep learning. arXiv . https://arxiv.org/abs/1811.03378 (2018).
Baydin, A. G., Pearlmutter, B. A., Radul, A. A. & Siskind, J. M. Automatic differentiation in machine learning: a survey. J. Machine Learn. Res. 18 , 1–43 (2018).
Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv. https://arxiv.org/abs/1207.0580 (2012).
Breiman, L. Bagging predictors. Machine Learn. 24 , 123–140 (1996).
LeCun, Y. et al. The Handbook of Brain Theory and Neural Networks vol. 3361 (MIT press Cambridge, MA, USA 1995).
Wilson, R. J. Introduction to Graph Theory (Pearson Education India, 1979).
West, D. B. et al. Introduction to Graph Theory Vol. 2 (Prentice hall Upper Saddle River, 2001).
Wang, M. et al. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv . https://arxiv.org/abs/1909.01315 (2019).
Choudhary, K. & DeCost, B. Atomistic line graph neural network for improved materials property predictions. npj Comput. Mater. 7 , 1–8 (2021).
Li, M. et al. Dgl-lifesci: An open-source toolkit for deep learning on graphs in life science. arXiv . https://arxiv.org/abs/2106.14232 (2021).
Xie, T. & Grossman, J. C. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties. Phys. Rev. Lett. 120 , 145301 (2018).
Klicpera, J., Groß, J. & Günnemann, S. Directional message passing for molecular graphs. arXiv . https://arxiv.org/abs/2003.03123 (2020).
Schutt, K. et al. Schnetpack: A deep learning toolbox for atomistic systems. J. Chem. Theory Comput. 15 , 448–455 (2018).
Kipf, T. N. & Welling, M. Semi-supervised classification with graph convolutional networks. arXiv . https://arxiv.org/abs/1609.02907 (2016).
Veličković, P. et al. Graph attention networks. arXiv . https://arxiv.org/abs/1710.10903 (2017).
Schlichtkrull, M. et al. Modeling relational data with graph convolutional networks. arXiv. https://arxiv.org/abs/1703.06103 (2017).
Song, L., Zhang, Y., Wang, Z. & Gildea, D. A graph-to-sequence model for AMR-to-text generation . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 1616–1626 (Association for Computational Linguistics, 2018).
Xu, K., Hu, W., Leskovec, J. & Jegelka, S. How powerful are graph neural networks? arXiv . https://arxiv.org/abs/1810.00826 (2018).
Chen, Z., Li, X. & Bruna, J. Supervised community detection with line graph neural networks. arXiv . https://arxiv.org/abs/1705.08415 (2017).
Jing, Y., Bian, Y., Hu, Z., Wang, L. & Xie, X.-Q. S. Deep learning for drug design: an artificial intelligence paradigm for drug discovery in the big data era. AAPS J. 20 , 1–10 (2018).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv. https://arxiv.org/abs/1810.04805 (2018).
De Cao, N. & Kipf, T. Molgan: An implicit generative model for small molecular graphs. arXiv . https://arxiv.org/abs/1805.11973 (2018).
Pereira, T., Abbasi, M., Ribeiro, B. & Arrais, J. P. Diversity oriented deep reinforcement learning for targeted molecule generation. J. Cheminformatics 13 , 1–17 (2021).
Baker, N. et al. Workshop report on basic research needs for scientific machine learning: core technologies for artificial intelligence. Tech. Rep . https://doi.org/10.2172/1478744 . (2019).
Chan, H. et al. Rapid 3d nanoscale coherent imaging via physics-aware deep learning. Appl. Phys. Rev. 8 , 021407 (2021).
Pun, G. P., Batra, R., Ramprasad, R. & Mishin, Y. Physically informed artificial neural networks for atomistic modeling of materials. Nat. Commun. 10 , 1–10 (2019).
Onken, D. et al. A neural network approach for high-dimensional optimal control. arXiv. https://arxiv.org/abs/2104.03270 (2021).
Zunger, A. Inverse design in search of materials with target functionalities. Nat. Rev. Chem. 2 , 1–16 (2018).
Chen, L., Zhang, W., Nie, Z., Li, S. & Pan, F. Generative models for inverse design of inorganic solid materials. J. Mater. Inform. 1 , 4 (2021).
Cranmer, M. et al. Discovering symbolic models from deep learning with inductive biases. arXiv . https://arxiv.org/abs/2006.11287 (2020).
Rupp, M., Tkatchenko, A., Müller, K.-R. & Von Lilienfeld, O. A. Fast and accurate modeling of molecular atomization energies with machine learning. Phys. Rev. Lett. 108 , 058301 (2012).
Bartók, A. P., Kondor, R. & Csányi, G. On representing chemical environments. Phys. Rev. B 87 , 184115 (2013).
Faber, F. A. et al. Prediction errors of molecular machine learning models lower than hybrid dft error. J. Chem. Theory Comput. 13 , 5255–5264 (2017).
Choudhary, K., DeCost, B. & Tavazza, F. Machine learning with force-field-inspired descriptors for materials: Fast screening and mapping energy landscape. Phys. Rev. Mater. 2 , 083801 (2018).
Choudhary, K., Garrity, K. F., Ghimire, N. J., Anand, N. & Tavazza, F. High-throughput search for magnetic topological materials using spin-orbit spillage, machine learning, and experiments. Phys. Rev. B 103 , 155131 (2021).
Choudhary, K., Garrity, K. F. & Tavazza, F. Data-driven discovery of 3d and 2d thermoelectric materials. J. Phys. Condens. Matter 32 , 475501 (2020).
Ward, L. et al. Including crystal structure attributes in machine learning models of formation energies via voronoi tessellations. Phys. Rev. B 96 , 024104 (2017).
Isayev, O. et al. Universal fragment descriptors for predicting properties of inorganic crystals. Nat. Commun. 8 , 1–12 (2017).
Liu, C.-H., Tao, Y., Hsu, D., Du, Q. & Billinge, S. J. Using a machine learning approach to determine the space group of a structure from the atomic pair distribution function. Acta Crystallogr. Sec. A 75 , 633–643 (2019).
Smith, J. S., Isayev, O. & Roitberg, A. E. Ani-1: an extensible neural network potential with dft accuracy at force field computational cost. Chem. Sci. 8 , 3192–3203 (2017).
Behler, J. Atom-centered symmetry functions for constructing high-dimensional neural network potentials. J. Chem. Phys. 134 , 074106 (2011).
Behler, J. & Parrinello, M. Generalized neural-network representation of high-dimensional potential-energy surfaces. Phys. Rev. Lett. 98 , 146401 (2007).
Ko, T. W., Finkler, J. A., Goedecker, S. & Behler, J. A fourth-generation high-dimensional neural network potential with accurate electrostatics including non-local charge transfer. Nat. Commun. 12 , 398 (2021).
Weinreich, J., Romer, A., Paleico, M. L. & Behler, J. Properties of alpha-brass nanoparticles. 1. neural network potential energy surface. J. Phys. Chem C 124 , 12682–12695 (2020).
Wang, H., Zhang, L., Han, J. & E, W. Deepmd-kit: A deep learning package for many-body potential energy representation and molecular dynamics. Computer Phys. Commun. 228 , 178–184 (2018).
Eshet, H., Khaliullin, R. Z., Kühne, T. D., Behler, J. & Parrinello, M. Ab initio quality neural-network potential for sodium. Phys. Rev. B 81 , 184107 (2010).
Khaliullin, R. Z., Eshet, H., Kühne, T. D., Behler, J. & Parrinello, M. Graphite-diamond phase coexistence study employing a neural-network mapping of the ab initio potential energy surface. Phys. Rev. B 81 , 100103 (2010).
Artrith, N. & Urban, A. An implementation of artificial neural-network potentials for atomistic materials simulations: Performance for tio2. Comput. Mater. Sci. 114 , 135–150 (2016).
Park, C. W. et al. Accurate and scalable graph neural network force field and molecular dynamics with direct force architecture. npj Comput. Mater. 7 , 1–9 (2021).
Chmiela, S., Sauceda, H. E., Müller, K.-R. & Tkatchenko, A. Towards exact molecular dynamics simulations with machine-learned force fields. Nat. Commun. 9 , 1–10 (2018).
Xue, L.-Y. et al. Reaxff-mpnn machine learning potential: a combination of reactive force field and message passing neural networks. Phys. Chem. Chem. Phys. 23 , 19457–19464 (2021).
Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O. & Dahl, G. E. Neural message passing for quantum chemistry. arXiv . https://arxiv.org/abs/1704.01212 (2017).
Zitnick, C. L. et al. An introduction to electrocatalyst design using machine learning for renewable energy storage. arXiv. https://arxiv.org/abs/2010.09435 (2020).
McNutt, A. T. et al. Gnina 1 molecular docking with deep learning. J. Cheminformatics 13 , 1–20 (2021).
Jin, W., Barzilay, R. & Jaakkola, T. Junction tree variational autoencoder for molecular graph generation. in International conference on machine learning , 2323–2332 (PMLR, 2018).
Olivecrona, M., Blaschke, T., Engkvist, O. & Chen, H. Molecular de-novo design through deep reinforcement learning. J. Cheminformatics 9 , 1–14 (2017).
You, J., Liu, B., Ying, R., Pande, V. & Leskovec, J. Graph convolutional policy network for goal-directed molecular graph generation. arXiv. https://arxiv.org/abs/1806.02473 (2018).
Putin, E. et al. Reinforced adversarial neural computer for de novo molecular design. J. Chem. Inf. Model. 58 , 1194–1204 (2018).
Sanchez-Lengeling, B., Outeiral, C., Guimaraes, G. L. & Aspuru-Guzik, A. Optimizing distributions over molecular space. an objective-reinforced generative adversarial network for inverse-design chemistry (organic). ChemRxiv https://doi.org/10.26434/chemrxiv.5309668.v3 (2017).
Nouira, A., Sokolovska, N. & Crivello, J.-C. Crystalgan: learning to discover crystallographic structures with generative adversarial networks. arXiv. https://arxiv.org/abs/1810.11203 (2018).
Long, T. et al. Constrained crystals deep convolutional generative adversarial network for the inverse design of crystal structures. npj Comput. Mater. 7 , 66 (2021).
Noh, J. et al. Inverse design of solid-state materials via a continuous representation. Matter 1 , 1370–1384 (2019).
Kim, S., Noh, J., Gu, G. H., Aspuru-Guzik, A. & Jung, Y. Generative adversarial networks for crystal structure prediction. ACS Central Sci. 6 , 1412–1420 (2020).
Long, T. et al. Inverse design of crystal structures for multicomponent systems. arXiv. https://arxiv.org/abs/2104.08040 (2021).
Xie, T. & Grossman, J. C. Hierarchical visualization of materials space with graph convolutional neural networks. J. Chem. Phys. 149 , 174111 (2018).
Park, C. W. & Wolverton, C. Developing an improved crystal graph convolutional neural network framework for accelerated materials discovery. Phys. Rev. Mater. 4 , 063801 (2020).
Laugier, L. et al. Predicting thermoelectric properties from crystal graphs and material descriptors-first application for functional materials. arXiv. https://arxiv.org/abs/1811.06219 (2018).
Rosen, A. S. et al. Machine learning the quantum-chemical properties of metal–organic frameworks for accelerated materials discovery. Matter 4 , 1578–1597 (2021).
Lusci, A., Pollastri, G. & Baldi, P. Deep architectures and deep learning in chemoinformatics: the prediction of aqueous solubility for drug-like molecules. J. Chem. Inf. Model. 53 , 1563–1575 (2013).
Xu, Y. et al. Deep learning for drug-induced liver injury. J. Chem. Inf. Model. 55 , 2085–2093 (2015).
Jain, A. & Bligaard, T. Atomic-position independent descriptor for machine learning of material properties. Phys. Rev. B 98 , 214112 (2018).
Goodall, R. E., Parackal, A. S., Faber, F. A., Armiento, R. & Lee, A. A. Rapid discovery of novel materials by coordinate-free coarse graining. arXiv . https://arxiv.org/abs/2106.11132 (2021).
Zuo, Y. et al. Accelerating Materials Discovery with Bayesian Optimization and Graph Deep Learning. arXiv . https://arxiv.org/abs/2104.10242 (2021).
Lin, T.-S. et al. Bigsmiles: a structurally-based line notation for describing macromolecules. ACS Central Sci. 5 , 1523–1531 (2019).
Tyagi, A. et al. Cancerppd: a database of anticancer peptides and proteins. Nucleic Acids Res. 43 , D837–D843 (2015).
Krenn, M., Häse, F., Nigam, A., Friederich, P. & Aspuru-Guzik, A. Self-referencing embedded strings (selfies): a 100% robust molecular string representation. Machine Learn. Sci. Technol. 1 , 045024 (2020).
Lim, J., Ryu, S., Kim, J. W. & Kim, W. Y. Molecular generative model based on conditional variational autoencoder for de novo molecular design. J. Cheminformatics 10 , 1–9 (2018).
Krasnov, L., Khokhlov, I., Fedorov, M. V. & Sosnin, S. Transformer-based artificial neural networks for the conversion between chemical notations. Sci. Rep. 11 , 1–10 (2021).
Irwin, J. J., Sterling, T., Mysinger, M. M., Bolstad, E. S. & Coleman, R. G. Zinc: a free tool to discover chemistry for biology. J. Chem. Inf. Model. 52 , 1757–1768 (2012).
Dix, D. J. et al. The toxcast program for prioritizing toxicity testing of environmental chemicals. Toxicol. Sci. 95 , 5–12 (2007).
Kim, S. et al. Pubchem 2019 update: improved access to chemical data. Nucleic Acids Res. 47 , D1102–D1109 (2019).
Hirohara, M., Saito, Y., Koda, Y., Sato, K. & Sakakibara, Y. Convolutional neural network based on smiles representation of compounds for detecting chemical motif. BMC Bioinformatics 19 , 83–94 (2018).
Gómez-Bombarelli, R. et al. Automatic chemical design using a data-driven continuous representation of molecules. ACS Central Sci. 4 , 268–276 (2018).
Liu, R. et al. Deep learning for chemical compound stability prediction . In Proceedings of ACM SIGKDD workshop on large-scale deep learning for data mining (DL-KDD) , 1–7. https://rosanneliu.com/publication/kdd/ (ACM SIGKDD, 2016).
Jha, D. et al. Elemnet: Deep learning the chem. mater. from only elemental composition. Sci. Rep. 8 , 1–13 (2018).
Agrawal, A. et al. Exploration of data science techniques to predict fatigue strength of steel from composition and processing parameters. Integr. Mater. Manuf. Innov. 3 , 90–108 (2014).
Agrawal, A. & Choudhary, A. A fatigue strength predictor for steels using ensemble data mining: steel fatigue strength predictor . In Proceedings of the 25th ACM International on Conference on information and knowledge management , 2497–2500. https://doi.org/10.1145/2983323.2983343 (2016).
Agrawal, A. & Choudhary, A. An online tool for predicting fatigue strength of steel alloys based on ensemble data mining. Int. J. Fatigue 113 , 389–400 (2018).
Agrawal, A., Saboo, A., Xiong, W., Olson, G. & Choudhary, A. Martensite start temperature predictor for steels using ensemble data mining . in 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA) , 521–530 (IEEE, 2019).
Meredig, B. et al. Combinatorial screening for new materials in unconstrained composition space with machine learning. Phys. Rev. B 89 , 094104 (2014).
Agrawal, A., Meredig, B., Wolverton, C. & Choudhary, A. A formation energy predictor for crystalline materials using ensemble data mining . in 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW) , 1276–1279 (IEEE, 2016).
Furmanchuk, A., Agrawal, A. & Choudhary, A. Predictive analytics for crystalline materials: bulk modulus. RSC Adv. 6 , 95246–95251 (2016).
Furmanchuk, A. et al. Prediction of seebeck coefficient for compounds without restriction to fixed stoichiometry: A machine learning approach. J. Comput. Chem. 39 , 191–202 (2018).
Ward, L., Agrawal, A., Choudhary, A. & Wolverton, C. A general-purpose machine learning framework for predicting properties of inorganic materials. npj Comput. Mater. 2 , 1–7 (2016).
Ward, L. et al. Matminer: An open source toolkit for materials data mining. Comput. Mater. Sci. 152 , 60–69 (2018).
Jha, D. et al. Irnet: A general purpose deep residual regression framework for materials discovery . In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , 2385–2393. https://arxiv.org/abs/1907.03222 (2019).
Jha, D. et al. Enabling deeper learning on big data for materials informatics applications. Sci. Rep. 11 , 1–12 (2021).
Goodall, R. E. & Lee, A. A. Predicting materials properties without crystal structure: Deep representation learning from stoichiometry. Nat. Commun. 11 , 1–9 (2020).
NIMS. Superconducting material database (supercon) . https://supercon.nims.go.jp/ (2021).
Stanev, V. et al. Machine learning modeling of superconducting critical temperature. npj Comput. Mater. 4 , 1–14 (2018).
Gupta, V. et al. Cross-property deep transfer learning framework for enhanced predictive analytics on small materials data. Nat. Commun . 12 , 1–10 (2021).
Himanen, L. et al. Dscribe: Library of descriptors for machine learning in materials science. Computer Phys. Commun. 247 , 106949 (2020).
Bartel, C. J. et al. A critical examination of compound stability predictions from machine-learned formation energies. npj Comput. Mater. 6 , 1–11 (2020).
Choudhary, K. et al. High-throughput density functional perturbation theory and machine learning predictions of infrared, piezoelectric, and dielectric responses. npj Comput. Mater. 6 , 1–13 (2020).
Zheng, C. et al. Automated generation and ensemble-learned matching of X-ray absorption spectra. npj Comput. Mater. 4 , 1–9 (2018).
Mathew, K. et al. High-throughput computational x-ray absorption spectroscopy. Sci. Data 5 , 1–8 (2018).
Chen, Y. et al. Database of ab initio l-edge x-ray absorption near edge structure. Sci. Data 8 , 1–8 (2021).
Lafuente, B., Downs, R. T., Yang, H. & Stone, N. In Highlights in mineralogical crystallography 1–30 (De Gruyter (O), 2015).
El Mendili, Y. et al. Raman open database: first interconnected raman–x-ray diffraction open-access resource for material identification. J. Appl. Crystallogr. 52 , 618–625 (2019).
Fremout, W. & Saverwyns, S. Identification of synthetic organic pigments: the role of a comprehensive digital raman spectral library. J. Raman Spectrosc. 43 , 1536–1544 (2012).
Huck, P. & Persson, K. A. Mpcontribs: user contributed data to the materials project database . https://docs.mpcontribs.org/ (2019).
Yang, L. et al. A cloud platform for atomic pair distribution function analysis: Pdfitc. Acta Crystallogr. A 77 , 2–6 (2021).
Park, W. B. et al. Classification of crystal structure using a convolutional neural network. IUCrJ 4 , 486–494 (2017).
Hellenbrandt, M. The Inorganic Crystal Structure Database (ICSD)—present and future. Crystallogr. Rev. 10 , 17–22 (2004).
Zaloga, A. N., Stanovov, V. V., Bezrukova, O. E., Dubinin, P. S. & Yakimov, I. S. Crystal symmetry classification from powder X-ray diffraction patterns using a convolutional neural network. Mater. Today Commun. 25 , 101662 (2020).
Lee, J.-W., Park, W. B., Lee, J. H., Singh, S. P. & Sohn, K.-S. A deep-learning technique for phase identification in multiphase inorganic compounds using synthetic XRD powder patterns. Nat. Commun. 11 , 86 (2020).
Wang, H. et al. Rapid identification of X-ray diffraction patterns based on very limited data by interpretable convolutional neural networks. J. Chem. Inf. Model. 60 , 2004–2011 (2020).
Dong, H. et al. A deep convolutional neural network for real-time full profile analysis of big powder diffraction data. npj Comput. Mater. 7 , 1–9 (2021).
Aguiar, J. A., Gong, M. L. & Tasdizen, T. Crystallographic prediction from diffraction and chemistry data for higher throughput classification using machine learning. Comput. Mater. Sci. 173 , 109409 (2020).
Maffettone, P. M. et al. Crystallography companion agent for high-throughput materials discovery. Nat. Comput. Sci. 1 , 290–297 (2021).
Oviedo, F. et al. Fast and interpretable classification of small X-ray diffraction datasets using data augmentation and deep neural networks. npj Comput. Mater. 5 , 1–9 (2019).
Liu, C.-H. et al. Validation of non-negative matrix factorization for rapid assessment of large sets of atomic pair-distribution function (pdf) data. J. Appl. Crystallogr. 54 , 768–775 (2021).
Rakita, Y. et al. Studying heterogeneities in local nanostructure with scanning nanostructure electron microscopy (snem). arXiv https://arxiv.org/abs/2110.03589 (2021).
Timoshenko, J., Lu, D., Lin, Y. & Frenkel, A. I. Supervised machine-learning-based determination of three-dimensional structure of metallic nanoparticles. J. Phys. Chem Lett. 8 , 5091–5098 (2017).
Timoshenko, J. et al. Subnanometer substructures in nanoassemblies formed from clusters under a reactive atmosphere revealed using machine learning. J. Phys. Chem C 122 , 21686–21693 (2018).
Timoshenko, J. et al. Neural network approach for characterizing structural transformations by X-ray absorption fine structure spectroscopy. Phys. Rev. Lett. 120 , 225502 (2018).
Zheng, C., Chen, C., Chen, Y. & Ong, S. P. Random forest models for accurate identification of coordination environments from X-ray absorption near-edge structure. Patterns 1 , 100013 (2020).
Torrisi, S. B. et al. Random forest machine learning models for interpretable X-ray absorption near-edge structure spectrum-property relationships. npj Comput. Mater. 6 , 1–11 (2020).
Andrejevic, N., Andrejevic, J., Rycroft, C. H. & Li, M. Machine learning spectral indicators of topology. arXiv preprint at https://arxiv.org/abs/2003.00994 (2020).
Madden, M. G. & Ryder, A. G. Machine learning methods for quantitative analysis of raman spectroscopy data . in Opto-Ireland 2002: Optics and Photonics Technologies and Applications , Vol. 4876, 1130–1139 (International Society for Optics and Photonics, 2003).
Conroy, J., Ryder, A. G., Leger, M. N., Hennessey, K. & Madden, M. G. Qualitative and quantitative analysis of chlorinated solvents using Raman spectroscopy and machine learning . in Opto-Ireland 2005: Optical Sensing and Spectroscopy, Vol. 5826, 131–142 (International Society for Optics and Photonics, 2005).
Acquarelli, J. et al. Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 954 , 22–31 (2017).
O’Connell, M.-L., Howley, T., Ryder, A. G., Leger, M. N. & Madden, M. G. Classification of a target analyte in solid mixtures using principal component analysis, support vector machines, and Raman spectroscopy . in Opto-Ireland 2005: Optical Sensing and Spectroscopy , Vol. 5826, 340–350 (International Society for Optics and Photonics, 2005).
Zhao, J., Chen, Q., Huang, X. & Fang, C. H. Qualitative identification of tea categories by near infrared spectroscopy and support vector machine. J. Pharm. Biomed. Anal. 41 , 1198–1204 (2006).
Liu, J. et al. Deep convolutional neural networks for Raman spectrum recognition: a unified solution. Analyst 142 , 4067–4074 (2017).
Yang, J. et al. Deep learning for vibrational spectral analysis: Recent progress and a practical guide. Anal. Chim. Acta 1081 , 6–17 (2019).
Selzer, P., Gasteiger, J., Thomas, H. & Salzer, R. Rapid access to infrared reference spectra of arbitrary organic compounds: scope and limitations of an approach to the simulation of infrared spectra by neural networks. Chem. Euro. J. 6 , 920–927 (2000).
Ghosh, K. et al. Deep learning spectroscopy: neural networks for molecular excitation spectra. Adv. Sci. 6 , 1801367 (2019).
Kostka, T., Selzer, P. & Gasteiger, J. A combined application of reaction prediction and infrared spectra simulation for the identification of degradation products of s-triazine herbicides. Chemistry 7 , 2254–2260 (2001).
Mahmoud, C. B., Anelli, A., Csányi, G. & Ceriotti, M. Learning the electronic density of states in condensed matter. Phys. Rev. B 102 , 235130 (2020).
Chen, Z. et al. Direct prediction of phonon density of states with Euclidean neural networks. Adv. Sci. 8 , 2004214 (2021).
Kong, S. et al. Density of states prediction for materials discovery via contrastive learning from probabilistic embeddings. arXiv . https://arxiv.org/abs/2110.11444 (2021).
Carbone, M. R., Topsakal, M., Lu, D. & Yoo, S. Machine-learning X-ray absorption spectra to quantitative accuracy. Phys. Rev. Lett. 124 , 156401 (2020).
Rehr, J. J., Kas, J. J., Vila, F. D., Prange, M. P. & Jorissen, K. Parameter-free calculations of X-ray spectra with FEFF9. Phys. Chem. Chem. Phys. 12 , 5503–5513 (2010).
Rankine, C. D., Madkhali, M. M. M. & Penfold, T. J. A deep neural network for the rapid prediction of X-ray absorption spectra. J. Phys. Chem A 124 , 4263–4270 (2020).
Fung, V., Hu, G., Ganesh, P. & Sumpter, B. G. Machine learned features from density of states for accurate adsorption energy prediction. Nat. Commun. 12 , 88 (2021).
Hammer, B. & Nørskov, J. Theoretical surface science and catalysis-calculations and concepts. Adv. Catal. Impact Surface Sci. Catal. 45 , 71–129 (2000).
Kaundinya, P. R., Choudhary, K. & Kalidindi, S. R. Prediction of the electron density of states for crystalline compounds with atomistic line graph neural networks (alignn). arXiv. https://arxiv.org/abs/2201.08348 (2022).
Stein, H. S., Soedarmadji, E., Newhouse, P. F., Guevarra, D. & Gregoire, J. M. Synthesis, optical imaging, and absorption spectroscopy data for 179072 metal oxides. Sci. Data 6 , 9 (2019).
Choudhary, A. et al. Graph neural network predictions of metal organic framework co2 adsorption properties. arXiv . https://arxiv.org/abs/2112.10231 (2021).
Anderson, R., Biong, A. & Gómez-Gualdrón, D. A. Adsorption isotherm predictions for multiple molecules in mofs using the same deep learning model. J. Chem. Theory Comput. 16 , 1271–1283 (2020).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25 , 1097–1105 (2012).
Varela, M. et al. Materials characterization in the aberration-corrected scanning transmission electron microscope. Annu. Rev. Mater. Res. 35 , 539–569 (2005).
Holm, E. A. et al. Overview: Computer vision and machine learning for microstructural characterization and analysis. Metal. Mater Trans. A 51 , 5985–5999 (2020).
Modarres, M. H. et al. Neural network for nanoscience scanning electron microscope image recognition. Sci. Rep. 7 , 1–12 (2017).
Gopalakrishnan, K., Khaitan, S. K., Choudhary, A. & Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Construct. Build. Mater. 157 , 322–330 (2017).
Gopalakrishnan, K., Gholami, H., Vidyadharan, A., Choudhary, A. & Agrawal, A. Crack damage detection in unmanned aerial vehicle images of civil infrastructure using pre-trained deep learning model. Int. J. Traffic Transp. Eng . 8 , 1–14 (2018).
Yang, Z. et al. Data-driven insights from predictive analytics on heterogeneous experimental data of industrial magnetic materials . In IEEE International Conference on Data Mining Workshops (ICDMW) , 806–813. https://doi.org/10.1109/ICDMW.2019.00119 (IEEE Computer Society, 2019).
Yang, Z. et al. Heterogeneous feature fusion based machine learning on shallow-wide and heterogeneous-sparse industrial datasets . In 25th International Conference on Pattern Recognition Workshops, ICPR 2020 , 566–577. https://doi.org/10.1007/978-3-030-68799-1_41 (Springer Science and Business Media Deutschland GmbH, 2021).
Ziletti, A., Kumar, D., Scheffler, M. & Ghiringhelli, L. M. Insightful classification of crystal structures using deep learning. Nat. Commun. 9 , 2775 (2018).
Choudhary, K. et al. Computational scanning tunneling microscope image database. Sci. Data 8 , 1–9 (2021).
Liu, R., Agrawal, A., Liao, W.-k., Choudhary, A. & De Graef, M. Materials discovery: Understanding polycrystals from large-scale electron patterns . in 2016 IEEE International Conference on Big Data (Big Data) , 2261–2269 (IEEE, 2016).
Jha, D. et al. Extracting grain orientations from EBSD patterns of polycrystalline materials using convolutional neural networks. Microsc. Microanal. 24 , 497–502 (2018).
Kaufmann, K., Zhu, C., Rosengarten, A. S. & Vecchio, K. S. Deep neural network enabled space group identification in EBSD. Microsc. Microanal. 26 , 447–457 (2020).
Yang, Z. et al. Deep learning based domain knowledge integration for small datasets: Illustrative applications in materials informatics . in 2019 International Joint Conference on Neural Networks (IJCNN) , 1–8 (IEEE, 2019).
Yang, Z. et al. Learning to predict crystal plasticity at the nanoscale: Deep residual networks and size effects in uniaxial compression discrete dislocation simulations. Sci. Rep. 10 , 1–14 (2020).
Decost, B. L. et al. Uhcsdb: Ultrahigh carbon steel micrograph database. Integr. Mater. Manuf. Innov. 6 , 197–205 (2017).
Decost, B. L., Lei, B., Francis, T. & Holm, E. A. High throughput quantitative metallography for complex microstructures using deep learning: a case study in ultrahigh carbon steel. Microsc. Microanal. 25 , 21–29 (2019).
Stan, T., Thompson, Z. T. & Voorhees, P. W. Optimizing convolutional neural networks to perform semantic segmentation on large materials imaging datasets: X-ray tomography and serial sectioning. Materials Characterization 160 , 110119 (2020).
Madsen, J. et al. A deep learning approach to identify local structures in atomic-resolution transmission electron microscopy images. Adv. Theory Simulations 1 , 1800037 (2018).
Maksov, A. et al. Deep learning analysis of defect and phase evolution during electron beam-induced transformations in ws 2. npj Comput. Mater. 5 , 1–8 (2019).
Yang, S.-H. et al. Deep learning-assisted quantification of atomic dopants and defects in 2d materials. Adv. Sci. https://doi.org/10.1002/advs.202101099 (2021).
Roberts, G. et al. Deep learning for semantic segmentation of defects in advanced stem images of steels. Sci. Rep. 9 , 1–12 (2019).
Kusche, C. et al. Large-area, high-resolution characterisation and classification of damage mechanisms in dual-phase steel using deep learning. PLoS ONE 14 , e0216493 (2019).
Vlcek, L. et al. Learning from imperfections: predicting structure and thermodynamics from atomic imaging of fluctuations. ACS Nano 13 , 718–727 (2019).
Ziatdinov, M., Maksov, A. & Kalinin, S. V. Learning surface molecular structures via machine vision. npj Comput. Mater. 3 , 1–9 (2017).
Ovchinnikov, O. S. et al. Detection of defects in atomic-resolution images of materials using cycle analysis. Adv. Struct. Chem. Imaging 6 , 3 (2020).
Li, W., Field, K. G. & Morgan, D. Automated defect analysis in electron microscopic images. npj Comput. Mater. 4 , 1–9 (2018).
Cohn, R. et al. Instance segmentation for direct measurements of satellites in metal powders and automated microstructural characterization from image data. JOM 73 , 2159–2172 (2021).
de Haan, K., Ballard, Z. S., Rivenson, Y., Wu, Y. & Ozcan, A. Resolution enhancement in scanning electron microscopy using deep learning. Sci. Rep. 9 , 1–7 (2019).
Ede, J. M. & Beanland, R. Partial scanning transmission electron microscopy with deep learning. Sci. Rep. 10 , 1–10 (2020).
Rashidi, M. & Wolkow, R. A. Autonomous scanning probe microscopy in situ tip conditioning through machine learning. ACS Nano 12 , 5185–5189 (2018).
Scime, L., Siddel, D., Baird, S. & Paquit, V. Layer-wise anomaly detection and classification for powder bed additive manufacturing processes: A machine-agnostic algorithm for real-time pixel-wise semantic segmentation. Addit. Manufact. 36 , 101453 (2020).
Eppel, S., Xu, H., Bismuth, M. & Aspuru-Guzik, A. Computer vision for recognition of materials and vessels in chemistry lab settings and the Vector-LabPics Data Set. ACS Central Sci. 6 , 1743–1752 (2020).
Yang, Z. et al. Deep learning approaches for mining structure-property linkages in high contrast composites from simulation datasets. Comput. Mater. Sci. 151 , 278–287 (2018).
Cecen, A., Dai, H., Yabansu, Y. C., Kalidindi, S. R. & Song, L. Material structure-property linkages using three-dimensional convolutional neural networks. Acta Mater. 146 , 76–84 (2018).
Yang, Z. et al. Establishing structure-property localization linkages for elastic deformation of three-dimensional high contrast composites using deep learning approaches. Acta Mater. 166 , 335–345 (2019).
Goetz, A. et al. Addressing materials’ microstructure diversity using transfer learning. arXiv . arXiv-2107. https://arxiv.org/abs/2107.13841 (2021).
Kitahara, A. R. & Holm, E. A. Microstructure cluster analysis with transfer learning and unsupervised learning. Integr. Mater. Manuf. Innov. 7 , 148–156 (2018).
Larmuseau, M. et al. Compact representations of microstructure images using triplet networks. npj Comput. Mater. 2020 6:1 6 , 1–11 (2020).
Li, X. et al. A deep adversarial learning methodology for designing microstructural material systems . in International Design Engineering Technical Conferences and Computers and Information in Engineering Conference , Vol. 51760, V02BT03A008 (American Society of Mechanical Engineers, 2018).
Yang, Z. et al. Microstructural materials design via deep adversarial learning methodology. J. Mech. Des. 140 , 111416 (2018).
Yang, Z. et al. A general framework combining generative adversarial networks and mixture density networks for inverse modeling in microstructural materials design. arXiv . https://arxiv.org/abs/2101.10553 (2021).
Hsu, T. et al. Microstructure generation via generative adversarial network for heterogeneous, topologically complex 3d materials. JOM 73 , 90–102 (2020).
Chun, S. et al. Deep learning for synthetic microstructure generation in a materials-by-design framework for heterogeneous energetic materials. Sci. Rep. 10 , 1–15 (2020).
Dai, M., Demirel, M. F., Liang, Y. & Hu, J.-M. Graph neural networks for an accurate and interpretable prediction of the properties of polycrystalline materials. npj Comput. Mater. 7 , 1–9 (2021).
Cohn, R. & Holm, E. Neural message passing for predicting abnormal grain growth in Monte Carlo simulations of microstructural evolution. arXiv. https://arxiv.org/abs/2110.09326v1 (2021).
Plimpton, S. et al. SPPARKS Kinetic Monte Carlo Simulator . https://spparks.github.io/index.html . (2021).
Plimpton, S. et al. Crossing the mesoscale no-man’s land via parallel kinetic Monte Carlo. Tech. Rep . https://doi.org/10.2172/966942 (2009).
Xue, N. Steven bird, evan klein and edward loper. natural language processing with python. oreilly media, inc.2009. isbn: 978-0-596-51649-9. Nat. Lang. Eng. 17 , 419–424 (2010).
Honnibal, M. & Montani, I. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. https://doi.org/10.5281/zenodo.3358113 (2017).
Gardner, M. et al. Allennlp: A deep semantic natural language processing platform. arXiv. https://arxiv.org/abs/1803.07640 (2018).
Tshitoyan, V. et al. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 571 , 95–98 (2019).
Kononova, O. et al. Opportunities and challenges of text mining in aterials research. iScience 24 , 102155 (2021).
Olivetti, E. A. et al. Data-driven materials research enabled by natural language processing and information extraction. Appl. Phys. Rev. 7 , 041317 (2020).
Swain, M. C. & Cole, J. M. Chemdataextractor: a toolkit for automated extraction of chemical information from the scientific literature. J. Chem. Inf. Model. 56 , 1894–1904 (2016).
Park, S. et al. Text mining metal–organic framework papers. J. Chem. Inf. Model. 58 , 244–251 (2018).
Court, C. J. & Cole, J. M. Auto-generated materials database of curie and néel temperatures via semi-supervised relationship extraction. Sci. Data 5 , 1–12 (2018).
Huang, S. & Cole, J. M. A database of battery materials auto-generated using chemdataextractor. Sci. Data 7 , 1–13 (2020).
Beard, E. J., Sivaraman, G., Vázquez-Mayagoitia, Á., Vishwanath, V. & Cole, J. M. Comparative dataset of experimental and computational attributes of uv/vis absorption spectra. Sci. Data 6 , 1–11 (2019).
Tayfuroglu, O., Kocak, A. & Zorlu, Y. In silico investigation into h2 uptake in mofs: combined text/data mining and structural calculations. Langmuir 36 , 119–129 (2019).
Weston, L. et al. Named entity recognition and normalization applied to large-scale information extraction from the materials science literature. J. Chem. Inf. Model. 59 , 3692–3702 (2019).
Vaucher, A. C. et al. Automated extraction of chemical synthesis actions from experimental procedures. Nat. Commun. 11 , 1–11 (2020).
He, T. et al. Similarity of precursors in solid-state synthesis as text-mined from scientific literature. Chem. Mater. 32 , 7861–7873 (2020).
Kononova, O. et al. Text-mined dataset of inorganic materials synthesis recipes. Sci. Data 6 , 1–11 (2019).
Kim, E. et al. Materials synthesis insights from scientific literature via text extraction and machine learning. Chem. Mater. 29 , 9436–9444 (2017).
Kim, E., Huang, K., Jegelka, S. & Olivetti, E. Virtual screening of inorganic materials synthesis parameters with deep learning. npj Comput. Mater. 3 , 1–9 (2017).
Kim, E. et al. Inorganic materials synthesis planning with literature-trained neural networks. J. Chem. Inf. Model. 60 , 1194–1201 (2020).
de Castro, P. B. et al. Machine-learning-guided discovery of the gigantic magnetocaloric effect in hob 2 near the hydrogen liquefaction temperature. NPG Asia Mater. 12 , 1–7 (2020).
Cooper, C. B. et al. Design-to-device approach affords panchromatic co-sensitized solar cells. Adv. Energy Mater. 9 , 1802820 (2019).
Yang, X., Dai, Z., Zhao, Y., Liu, J. & Meng, S. Low lattice thermal conductivity and excellent thermoelectric behavior in li3sb and li3bi. J. Phys. Condens. Matter 30 , 425401 (2018).
Wang, Y., Gao, Z. & Zhou, J. Ultralow lattice thermal conductivity and electronic properties of monolayer 1t phase semimetal site2 and snte2. Phys. E 108 , 53–59 (2019).
Jong, U.-G., Yu, C.-J., Kye, Y.-H., Hong, S.-N. & Kim, H.-G. Manifestation of the thermoelectric properties in ge-based halide perovskites. Phys. Rev. Mater. 4 , 075403 (2020).
Yamamoto, K., Narita, G., Yamasaki, J. & Iikubo, S. First-principles study of thermoelectric properties of mixed iodide perovskite cs (b, b’) i3 (b, b’= ge, sn, and pb). J. Phys. Chem. Solids 140 , 109372 (2020).
Viennois, R. et al. Anisotropic low-energy vibrational modes as an effect of cage geometry in the binary barium silicon clathrate b a 24 s i 100. Phys. Rev. B 101 , 224302 (2020).
Haque, E. Effect of electron-phonon scattering, pressure and alloying on the thermoelectric performance of tmcu _3 ch _4(tm= v, nb, ta; ch= s, se, te). arXiv . https://arxiv.org/abs/2010.08461 (2020).
Yahyaoglu, M. et al. Phase-transition-enhanced thermoelectric transport in rickardite mineral cu3–x te2. Chem. Mater. 33 , 1832–1841 (2021).
Ho, D., Shkolnik, A. S., Ferraro, N. J., Rizkin, B. A. & Hartman, R. L. Using word embeddings in abstracts to accelerate metallocene catalysis polymerization research. Computers Chem. Eng. 141 , 107026 (2020).
Abdar, M. et al. A review of uncertainty quantification in deep learning: techniques, applications and challenges. Inf. Fusion . 76 , 243–297 (2021).
Mi, Lu, et al. Training-free uncertainty estimation for dense regression: Sensitivityas a surrogate. arXiv . preprint at arXiv:1910.04858. https://arxiv.org/abs/1910.04858 (2019).
Teye, M., Azizpour, H. & Smith, K. Bayesian uncertainty estimation for batch normalized deep networks . in International Conference on Machine Learning , 4907–4916 (PMLR, 2018).
Zhang, J., Kailkhura, B. & Han, T. Y.-J. Leveraging uncertainty from deep learning for trustworthy material discovery workflows. ACS Omega 6 , 12711–12721 (2021).
Meredig, B. et al. Can machine learning identify the next high-temperature superconductor? examining extrapolation performance for materials discovery. Mol. Syst. Des. Eng. 3 , 819–825 (2018).
Zhang, J., Kailkhura, B. & Han, T. Y.-J. Mix-n-match: Ensemble and compositional methods for uncertainty calibration in deep learning . in International Conference on Machine Learning , 11117–11128 (PMLR, 2020).
Seoh, R. Qualitative analysis of monte carlo dropout. arXiv. https://arxiv.org/abs/2007.01720 (2020).
Gal, Y. & Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning . in international conference on machine learning , 1050–1059 (PMLR, 2016).
Jain, S., Liu, G., Mueller, J. & Gifford, D. Maximizing overall diversity for improved uncertainty estimates in deep ensembles . In Proceedings of the AAAI Conference on Artificial Intelligence , 34 , 4264–4271. https://doi.org/10.1609/aaai.v34i04.5849 (2020).
Ganaie, M. et al. Ensemble deep learning: a review. arXiv . https://arxiv.org/abs/2104.02395 (AAAI Technical Track: Machine Learning, 2021).
Fort, S., Hu, H. & Lakshminarayanan, B. Deep ensembles: a loss landscape perspective. arXiv. https://arxiv.org/abs/1912.02757 (2019).
Lakshminarayanan, B., Pritzel, A. & Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. arXiv. https://arxiv.org/abs/1612.01474 (2016).
Moon, S. J., Jeon, J.-J., Lee, J. S. H. & Kim, Y. Learning multiple quantiles with neural networks. J. Comput. Graph. Stat. 30 , 1–11. https://doi.org/10.1080/10618600.2021.1909601 (2021).
Rasmussen, C. E. Summer School on Machine Learning , 63–71 (Springer, 2003).
Hegde, P., Heinonen, M., Lähdesmäki, H. & Kaski, S. Deep learning with differential gaussian process flows. arXiv. https://arxiv.org/abs/1810.04066 (2018).
Wilson, A. G., Hu, Z., Salakhutdinov, R. & Xing, E. P. Deep kernel learning. in Artificial intelligence and statistics , 370–378 (PMLR, 2016).
Hegde, V. I. et al. Reproducibility in high-throughput density functional theory: a comparison of aflow, materials project, and oqmd. arXiv. https://arxiv.org/abs/2007.01988 (2020).
Ying, R., Bourgeois, D., You, J., Zitnik, M. & Leskovec, J. Gnnexplainer: Generating explanations for graph neural networks. Adv. Neural Inf. Process. Syst. 32 , 9240 (2019).
Roch, L. M. et al. Chemos: orchestrating autonomous experimentation. Sci. Robot. 3 , eaat5559 (2018).
Szymanski, N. et al. Toward autonomous design and synthesis of novel inorganic materials. Mater. Horiz. 8 , 2169–2198. https://doi.org/10.1039/D1MH00495F (2021).
MacLeod, B. P. et al. Self-driving laboratory for accelerated discovery of thin-film materials. Sci. Adv. 6 , eaaz8867 (2020).
Stach, E. A. et al. Autonomous experimentation systems for materials development: a community perspective. Matter https://www.cell.com/matter/fulltext/S2590-2385(21)00306-4 (2021).
Rakita, Y. et al. Active reaction control of cu redox state based on real-time feedback from i n situ synchrotron measurements. J. Am. Chem. Soc. 142 , 18758–18762 (2020).
Chmiela, S. et al. Machine learning of accurate energy-conserving molecular force fields. Sci. Adv. 3 , e1603015 (2017).
Thomas, R. S. et al. The us federal tox21 program: a strategic and operational plan for continued leadership. Altex 35 , 163 (2018).
Russell Johnson, N. Nist computational chemistry comparison and benchmark database . In The 4th Joint Meeting of the US Sections of the Combustion Institute . https://ci.confex.com/ci/2005/techprogram/P1309.HTM (2005).
Lopez, S. A. et al. The harvard organic photovoltaic dataset. Sci. Data 3 , 1–7 (2016).
Johnson, R. D. et al. Nist computational chemistry comparison and benchmark database . http://srdata.nist.gov/cccbdb (2006).
Mobley, D. L. & Guthrie, J. P. Freesolv: a database of experimental and calculated hydration free energies, with input files. J. Computer Aided Mol. Des. 28 , 711–720 (2014).
Andersen, C. W. et al. Optimade: an api for exchanging materials data. arXiv. https://arxiv.org/abs/2103.02068 (2021).
Chanussot, L. et al. Open catalyst 2020 (oc20) dataset and community challenges. ACS Catal. 11 , 6059–6072 (2021).
Dunn, A., Wang, Q., Ganose, A., Dopp, D. & Jain, A. Benchmarking materials property prediction methods: the matbench test set and automatminer reference algorithm. npj Comput. Mater. 6 , 1–10 (2020).
Talirz, L. et al. Materials cloud, a platform for open computational science. Sci. Data 7 , 1–12 (2020).
Chung, Y. G. et al. Advances, updates, and analytics for the computation-ready, experimental metal–organic framework database: Core mof 2019. J. Chem. Eng. Data 64 , 5985–5998 (2019).
Sussman, J. L. et al. Protein data bank (pdb): database of three-dimensional structural information of biological macromolecules. Acta Crystallogr. Sec. D Biol. Crystallogr. 54 , 1078–1084 (1998).
Benson, M. L. et al. Binding moad, a high-quality protein–ligand database. Nucleic Acids Res. 36 , D674–D678 (2007).
Fung, V., Zhang, J., Juarez, E. & Sumpter, B. G. Benchmarking graph neural networks for materials chemistry. npj Comput. Mater. 7 , 1–8 (2021).
Louis, S.-Y. et al. Graph convolutional neural networks with global attention for improved materials property prediction. Phys. Chem. Chem. Phys. 22 , 18141–18148 (2020).
Khorshidi, A. & Peterson, A. A. Amp: A modular approach to machine learning in atomistic simulations. Computer Phys. Commun. 207 , 310–324 (2016).
Yao, K., Herr, J. E., Toth, D. W., Mckintyre, R. & Parkhill, J. The tensormol-0.1 model chemistry: a neural network augmented with long-range physics. Chem. Sci. 9 , 2261–2269 (2018).
Doerr, S. et al. Torchmd: A deep learning framework for molecular simulations. J. Chem. Theory Comput. 17 , 2355–2363 (2021).
Kolb, B., Lentz, L. C. & Kolpak, A. M. Discovering charge density functionals and structure-property relationships with prophet: A general framework for coupling machine learning and first-principles methods. Sci. Rep. 7 , 1–9 (2017).
Zhang, L., Han, J., Wang, H., Car, R. & Weinan, E. Deep potential molecular dynamics: a scalable model with the accuracy of quantum mechanics. Phys. Rev. Lett. 120 , 143001 (2018).
Geiger, M. et al. e3nn/e3nn: 2021-06-21 . https://doi.org/10.5281/zenodo.5006322 (2021).
Duvenaud, D. K. et al. Convolutional networks on graphs for learning molecular fingerprints (eds. Cortes, C., Lawrence, N. D., Lee, D. D., Sugiyama, M. & Garnett, R.) in Adv. Neural Inf. Process. Syst. 28 2224–2232 (Curran Associates, Inc., 2015).
Li, X. et al. Deepchemstable: Chemical stability prediction with an attention-based graph convolution network. J. Chem. Inf. Model. 59 , 1044–1049 (2019).
Wu, Z. et al. MoleculeNet: A benchmark for molecular machine learning. Chem. Sci. 9 , 513–530 (2018).
Wang, A. Y.-T., Kauwe, S. K., Murdock, R. J. & Sparks, T. D. Compositionally restricted attention-based network for materials property predictions. npj Comput. Mater. 7 , 77 (2021).
Zhou, Q. et al. Learning atoms for materials discovery. Proc. Natl Acad. Sci. USA 115 , E6411–E6417 (2018).
O’Boyle, N. & Dalke, A. Deepsmiles: An adaptation of smiles for use in machine-learning of chemical structures. ChemRxiv https://doi.org/10.26434/chemrxiv.7097960.v1 (2018).
Green, H., Koes, D. R. & Durrant, J. D. Deepfrag: a deep convolutional neural network for fragment-based lead optimization. Chem. Sci. 12 , 8036–8047. https://doi.org/10.1039/D1SC00163A (2021).
Elhefnawy, W., Li, M., Wang, J. & Li, Y. Deepfrag-k: a fragment-based deep learning approach for protein fold recognition. BMC Bioinformatics 21 , 203 (2020).
Paul, A. et al. Chemixnet: Mixed dnn architectures for predicting chemical properties using multiple molecular representations. arXiv . https://arxiv.org/abs/1811.08283 (2018).
Paul, A. et al. Transfer learning using ensemble neural networks for organic solar cell screening . in 2019 International Joint Conference on Neural Networks (IJCNN) , 1–8 (IEEE, 2019).
Choudhary, K. et al. Computational screening of high-performance optoelectronic materials using optb88vdw and tb-mbj formalisms. Sci. Data 5 , 1–12 (2018).
Wong-Ng, W., McMurdie, H., Hubbard, C. & Mighell, A. D. Jcpds-icdd research associateship (cooperative program with nbs/nist). J. Res. Natl Inst. Standards Technol. 106 , 1013 (2001).
Belsky, A., Hellenbrandt, M., Karen, V. L. & Luksch, P. New developments in the inorganic crystal structure database (icsd): accessibility in support of materials research and design. Acta Crystallogr. Sec. B Struct. Sci. 58 , 364–369 (2002).
Gražulis, S. et al. Crystallography Open Database—an open-access collection of crystal structures. J. Appl. Crystallogr. 42 , 726–729 (2009).
Linstrom, P. J. & Mallard, W. G. The nist chemistry webbook: a chemical data resource on the internet. J. Chem. Eng. Data 46 , 1059–1063 (2001).
Saito, T. et al. Spectral database for organic compounds (sdbs). (National Institute of Advanced Industrial Science and Technology (AIST), 2006).
Steinbeck, C., Krause, S. & Kuhn, S. Nmrshiftdb constructing a free chemical information system with open-source components. J. Chem. inf. Computer Sci. 43 , 1733–1739 (2003).
Fung, V., Hu, G., Ganesh, P. & Sumpter, B. G. Machine learned features from density of states for accurate adsorption energy prediction. Nat. Commun. 12 , 1–11 (2021).
Kong, S., Guevarra, D., Gomes, C. P. & Gregoire, J. M. Materials representation and transfer learning for multi-property prediction. arXiv . https://arxiv.org/abs/2106.02225 (2021).
Bang, K., Yeo, B. C., Kim, D., Han, S. S. & Lee, H. M. Accelerated mapping of electronic density of states patterns of metallic nanoparticles via machine-learning. Sci. Rep . 11 , 1–11 (2021).
Chen, D. et al. Automating crystal-structure phase mapping by combining deep learning with constraint reasoning. Nat. Machine Intell. 3 , 812–822 (2021).
Ophus, C. A fast image simulation algorithm for scanning transmission electron microscopy. Adv. Struct. Chem. imaging 3 , 1–11 (2017).
Aversa, R., Modarres, M. H., Cozzini, S., Ciancio, R. & Chiusole, A. The first annotated set of scanning electron microscopy images for nanoscience. Sci. Data 5 , 1–10 (2018).
Ziatdinov, M. et al. Causal analysis of competing atomistic mechanisms in ferroelectric materials from high-resolution scanning transmission electron microscopy data. npj Comput. Mater. 6 , 1–9 (2020).
Souza, A. L. F. et al. Deepfreak: Learning crystallography diffraction patterns with automated machine learning. arXiv. http://arxiv.org/abs/1904.11834 (2019).
Scime, L. et al. Layer-wise imaging dataset from powder bed additive manufacturing processes for machine learning applications (peregrine v2021-03). Tech. Rep . https://www.osti.gov/biblio/1779073 (2021).
Somnath, S., Smith, C. R., Laanait, N., Vasudevan, R. K. & Jesse, S. Usid and pycroscopy–open source frameworks for storing and analyzing imaging and spectroscopy data. Microsc. Microanal. 25 , 220–221 (2019).
Savitzky, B. H. et al. py4dstem: A software package for multimodal analysis of four-dimensional scanning transmission electron microscopy datasets. arXiv. https://arxiv.org/abs/2003.09523 (2020).
Madsen, J. & Susi, T. The abtem code: transmission electron microscopy from first principles. Open Res. Euro. 1 , 24 (2021).
Koch, C. T. Determination of core structure periodicity and point defect density along dislocations . (Arizona State University, 2002).
Allen, L. J. et al. Modelling the inelastic scattering of fast electrons. Ultramicroscopy 151 , 11–22 (2015).
Maxim, Z., Jesse, S., Sumpter, B. G., Kalinin, S. V. & Dyck, O. Tracking atomic structure evolution during directed electron beam induced si-atom motion in graphene via deep machine learning. Nanotechnology 32 , 035703 (2020).
Khadangi, A., Boudier, T. & Rajagopal, V. Em-net: Deep learning for electron microscopy image segmentation . in 2020 25th International Conference on Pattern Recognition (ICPR) , 31–38 (IEEE, 2021).
Meyer, C. et al. Nion swift: Open source image processing software for instrument control, data acquisition, organization, visualization, and analysis using python. Microsc. Microanal. 25 , 122–123 (2019).
Kim, J., Tiong, L. C. O., Kim, D. & Han, S. S. Deep learning-based prediction of material properties using chemical compositions and diffraction patterns as experimentally accessible inputs. J. Phys. Chem Lett. 12 , 8376–8383 (2021).
Von Chamier, L. et al. Zerocostdl4mic: an open platform to simplify access and use of deep-learning in microscopy. BioRxiv. https://www.biorxiv.org/content/10.1101/2020.03.20.000133v4 (2020).
Jha, D. et al. Peak area detection network for directly learning phase regions from raw x-ray diffraction patterns . in 2019 International Joint Conference on Neural Networks (IJCNN) , 1–8 (IEEE, 2019).
Hawizy, L., Jessop, D. M., Adams, N. & Murray-Rust, P. Chemicaltagger: A tool for semantic text-mining in chemistry. J. Cheminformatics 3 , 1–13 (2011).
Corbett, P. & Boyle, J. Chemlistem: chemical named entity recognition using recurrent neural networks. J. Cheminformatics 10 , 1–9 (2018).
Rocktäschel, T., Weidlich, M. & Leser, U. Chemspot: a hybrid system for chemical named entity recognition. Bioinformatics 28 , 1633–1640 (2012).
Jessop, D. M., Adams, S. E., Willighagen, E. L., Hawizy, L. & Murray-Rust, P. Oscar4: a flexible architecture for chemical text-mining. J. Cheminformatics 3 , 1–12 (2011).
Leaman, R., Wei, C.-H. & Lu, Z. tmchem: a high performance approach for chemical named entity recognition and normalization. J. Cheminformatics 7 , 1–10 (2015).
Suzuki, Y. et al. Symmetry prediction and knowledge discovery from X-ray diffraction patterns using an interpretable machine learning approach. Sci. Rep. 10 , 21790 (2020).
Download references
Acknowledgements
Contributions from K.C. were supported by the financial assistance award 70NANB19H117 from the U.S. Department of Commerce, National Institute of Standards and Technology. E.A.H. and R.C. (CMU) were supported by the National Science Foundation under grant CMMI-1826218 and the Air Force D3OM2S Center of Excellence under agreement FA8650-19-2-5209. A.J., C.C., and S.P.O. were supported by the Materials Project, funded by the U.S. Department of Energy, Office of Science, Office of Basic Energy Sciences, Materials Sciences and Engineering Division under contract no. DE-AC02-05-CH11231: Materials Project program KC23MP. S.J.L.B. was supported by the U.S. National Science Foundation through grant DMREF-1922234. A.A. and A.C. were supported by NIST award 70NANB19H005 and NSF award CMMI-2053929.
Author information
Authors and affiliations.
Materials Science and Engineering Division, National Institute of Standards and Technology, Gaithersburg, MD, 20899, USA
Kamal Choudhary & Francesca Tavazza
Theiss Research, La Jolla, CA, 92037, USA
Kamal Choudhary
DeepMaterials LLC, Silver Spring, MD, 20906, USA
Material Measurement Science Division, National Institute of Standards and Technology, Gaithersburg, MD, 20899, USA
Brian DeCost
Department of NanoEngineering, University of California San Diego, San Diego, CA, 92093, USA
Chi Chen & Shyue Ping Ong
Energy Technologies Area, Lawrence Berkeley National Laboratory, Berkeley, CA, USA
- Anubhav Jain
Department of Materials Science and Engineering, Carnegie Mellon University, Pittsburgh, PA, 15213, USA
Ryan Cohn & Elizabeth Holm
Department of Materials Science and Engineering, Northwestern University, Evanston, IL, 60208, USA
Cheol Woo Park & Chris Wolverton
Department of Electrical and Computer Engineering, Northwestern University, Evanston, IL, 60208, USA
Alok Choudhary & Ankit Agrawal
Department of Applied Physics and Applied Mathematics and the Data Science Institute, Fu Foundation School of Engineering and Applied Sciences, Columbia University, New York, NY, 10027, USA
Simon J. L. Billinge
You can also search for this author in PubMed Google Scholar
Contributions
The authors contributed equally to the search as well as analysis of the literature and writing of the manuscript.
Corresponding author
Correspondence to Kamal Choudhary .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Choudhary, K., DeCost, B., Chen, C. et al. Recent advances and applications of deep learning methods in materials science. npj Comput Mater 8 , 59 (2022). https://doi.org/10.1038/s41524-022-00734-6
Download citation
Received : 25 October 2021
Accepted : 24 February 2022
Published : 05 April 2022
DOI : https://doi.org/10.1038/s41524-022-00734-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Analysis of solar energy potentials of five selected south-east cities in nigeria using deep learning algorithms.
- Samuel Ikemba
- Kim Song-hyun
- Akeeb Adepoju Fawole
Sustainable Energy Research (2024)
Correlative, ML-based and non-destructive 3D-analysis of intergranular fatigue cracking in SAC305-Bi solder balls
- Charlotte Cui
- Fereshteh Falah Chamasemani
- Roland Brunner
npj Materials Degradation (2024)
Uncertainty quantification in multivariable regression for material property prediction with Bayesian neural networks
- Jiang Chang
Scientific Reports (2024)
Application of digital twins for simulation based tailoring of laser induced graphene
- José Carlos Santos-Ceballos
- Foad Salehnia
- Xavier Vilanova
Structured information extraction from scientific text with large language models
- John Dagdelen
- Alexander Dunn
Nature Communications (2024)
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

Unsupervised Learning In Vision
3 - unsupervised reinforcement learning, 8 - overarching research theme, 9 - how to keep up.
- Lecture 13: ML Teams and Startups
- Panel Discussion: Do I need a PhD to work in ML?
- FSDL 2021 (Berkeley)
- FSDL 2020 (UW)
- FSDL 2019 (Online)
- FSDL 2019 (Bootcamp)
- FSDL 2018 (Bootcamp)
Lecture 12: Research Directions
Download slides as PDF
Download notes as PDF
Lecture by Pieter Abbeel . Notes transcribed by James Le and Vishnu Rachakonda .
Of all disciplines, deep learning is probably the one where research and practice are closest together . Often, something gets invented in research and is put into production in less than a year. Therefore, it’s good to be aware of research trends that you might want to incorporate in projects you are working on.
Because the number of ML and AI papers increases exponentially, there’s no way that you can read every paper. Thus, you need other methods to keep up with research. This lecture provides a sampling of research directions, the overall research theme running across these samples, and advice on keeping up with the relentless flood of new research.
1 - Unsupervised Learning
Deep supervised learning, the default way of doing ML, works! But it requires so much annotated data. Can we get around it by learning with fewer labels? The answer is yes! And there are two major approaches: deep semi-supervised learning and deep unsupervised learning.
Deep Semi-Supervised Learning
Semi-supervised means half supervised, half unsupervised. Assuming a classification problem where each data point belongs to one of the classes, we attempt to come up with an intuition to complete the labeling for the unlabeled data points. One way to formalize this is: If anything is close to a labeled example, then it will assume that label. Thus, we can propagate the labels out from where they are given to the neighboring data points.
How can we generalize the approach above to image classification?

Xie et al. (2020) proposes Noisy Student Training :
First, they train a teacher model with labeled data.
Then, they infer pseudo-labels on the unlabeled data. These are not real labels, but those that they get from using the trained teacher model.
Even though these labels are not perfect (because they train on a small amount of labeled data), they can still see where they are more confident about those pseudo labels and inject those into their training set as additional labeled data.
When they retrain, they use dropout, data augmentation, and stochastic depth to inject noise into the training process. This enables the student model to be more robust and generalizable.
Deep Unsupervised Learning
Deep semi-supervised learning assumes that the labels in the supervised dataset are still valid for the unsupervised dataset. There’s a limit to the applicability because we assume that the unlabeled data is roughly from the same distribution as the labeled data .

With deep unsupervised learning, we can transfer the learning with multi-headed networks .
First, we train a neural network. Then, we have two tasks and give the network two heads - one for task 1 and another for task 2.
Most parameters live in the shared trunk of the network’s body. Thus, when you train for task 1 and task 2, most of the learnings are shared. Only a little bit gets specialized to task 1 versus task 2.
The key hypothesis here is that: For task 1 (which is unsupervised), if the neural network is smart enough to do things like predicting the next word in a sentence, generating realistic images, or translating images from one scale to another; then that same neural network is ready to do deep supervised learning from a very small dataset for task 2 (what we care about).
For instance, task 1 could be predicting the next word in a sentence, while task 2 could be predicting the sentiment in a corpus. OpenAI’s GPT-2 is the landmark result for next-word prediction where deep unsupervised learning could work. The results were so realistic, and there was a lot of press coverage. OpenAI deemed it to be too dangerous to be released at the time.

Furthermore, GPT-2 can tackle complex common sense reasoning and question answering tasks for various benchmarks. The table below displays those benchmarks where GPT-2 was evaluated on. The details of the tasks do not really matter. What’s more interesting is that: This is the first time a model, trained unsupervised on a lot of text to predict the next token and fine-tuned to specific supervised tasks, beats prior methods that might have been more specialized to each of these supervised tasks .

Another fascinating insight is that as we grow the number of model parameters, the performance goes up consistently. This means with unsupervised learning, we can incorporate much more data for larger models . This research funding inspired OpenAI to fundraise $1B for future projects to essentially have more compute available to train larger models because it seems like doing that will lead to better results. So far, that has been true ( GPT-3 performs better than GPT-2).
BERT is Google’s approach that came out around the same time as GPT-2. While GPT-2 predicts the next word or token, BERT predicts a word or token that was removed. In this task, the neural network looks at the entire corpus as it fills things back in, which often helps in later tasks (as the neural network has already been unsupervised-train on the entire text).

The table below displays BERT’s performance on the GLUE benchmark . The takeaway message is not so much in the details of these supervised tasks; but the fact that these tasks have a relatively small amount of labeled data compared to the unsupervised training that happens ahead of time. As BERT outperformed all SOTA methods, it revolutionized how natural language processing should be done.

BERT is one of the biggest updates that Google has made since RankBrain in 2015 and has proven successful in comprehending the intent of the searcher behind a search query.
Can we do the same thing for vision tasks? Let’s explore a few of them.
Predict A Missing Patch: A patch is high-dimensional, so the number of possibilities in that patch is very high (much larger than the number of words in English, for instance). Therefore, it’s challenging to predict precisely and make that work as well as in languages.
Solve Jigsaw Puzzles: If the network can do this, it understands something about images of the world. The trunk of the network should hopefully be reusable.
Predict Rotation: Here, you collect random images and predict what degree has been rotated. Existing methods work immensely well for such a task.

A technique that stood out in recent times is contrastive learning , which includes two variants - SimCLR (Chen et al., 2020) and MoCo (He et al., 2019). Here’s how you train your model with contrastive learning:
Imagine that you download two images of a dog and a cat from the Internet, and you don’t have labels yet.
You duplicate the dog image and make two versions of it (a greyscale version and a cropped version).
For these two dog versions, the neural network should bring them together while pushing the cat image far away.
You then fine-tune with a simple linear classifier on top of training completely unsupervised. This means that you must get the right features extracted from the images during training. The results of contrastive learning methods confirm that the higher the number of model parameters, the better the accuracy.
2 - Reinforcement Learning
Reinforcement learning (RL) has not been practical yet but nevertheless has shown promising results. In RL, the AI is an agent, more so than just a pattern recognizer. The agent acts in an environment where it is goal-oriented. It wants to achieve something during the process, which is represented by a reward function.

Compared to unsupervised learning, RL brings about a host of additional challenges:
Credit assignment: When the RL agent sees something, it has to take action. But it is not told whether the action was good or bad right away.
Stability: Because the RL agent learns by trial and error, it can destabilize and make big mistakes. Thus, it needs to be clever in updating itself not to destroy things along the way.
Exploration: The RL agent has to try things that have not been done before.
Despite these challenges, some great RL successes have happened.
DeepMind has shown that neural networks can learn to play the Atari game back in 2013. Under the hood is the Deep Q-Network architecture, which was trained from its own trial-and-error, looking at the score in the game to internalize what actions might be good or bad.
The game of Go was cracked by DeepMind - showing that the computer can play better than the best human player ( AlphaGo , AlphaGoZero , and AlphaZero ).
RL also works for the robot locomotion task. You don’t have to design the controller yourself. You just implement the RL algorithm ( TRPO , GAE , DDPG , PPO , and more) and let the agent train itself, which is a general approach to have AI systems acquire new skills. In fact, the robot can acquire such a variety of skills, as demonstrated in this DeepMimic work.

You can also accomplish the above for non-human-like characters in dynamic animation tasks. This is going to change how you can design video games or animated movies. Instead of designing the keyframes for every step along the way in your video or your game, you can train an agent to go from point A to point B directly.
RL has been shown to work on real robots .
BRETT (Berkeley Robot for the Elimination of Tedious Tasks) could learn to put blocks into matching openings in under an hour using a neural network trained from scratch. This technique has been used for NASA SuperBall robots for space exploration ideas.
A similar idea was applied to robotic manipulation solving Rubik’s cube , done at OpenAI in 2019. The in-hand manipulation is a very difficult robotic control problem that was mastered with RL.
CovariantAI

The fact that RL worked so well actually inspired Pieter and his former students (Tianhao Zhang, Rocky Duan, and Peter Chen) to start a company called Covariant in 2017. Their goal is to bring these advances from the lab into the real world. An example is autonomous order picking .
RL achieved mastery on many simulated domains. But we must ask the question: How fast is the learning itself? Tsividis et al., 2017 shows that a human can learn in about 15 minutes to perform better than Double DQN (a SOTA approach at the time of the study) learned after 115 hours.
How can we bridge this learning gap?
Based on the 2018 DeepMind Control Suite , pixel-based learning needs 50M more training steps than state-based learning to solve the same tasks. Maybe we can develop an unsupervised learning approach to turn pixel-level representations (which are not that informative) into a new representation that is much more similar to the underlying state.

CURL brings together contrastive learning and RL.
In RL, there’s typically a replay buffer where we store the past experiences. We load observations from there and feed them into an encoder neural network. The network has two heads: an actor to estimate the best action to take next and a critic to estimate how good that action would be.
CURL adds an extra head at the bottom, which includes augmented observations, and does contrastive learning on that. Similar configurations of the robot are brought closer together, while different ones are separated.
The results confirm that CURL can match existing SOTA approaches that learn from states and from pixels. However, it struggles in hard environments, with insufficient labeled images being the root cause.
4 - Meta Reinforcement Learning
The majority of fully general RL algorithms work well for any environments that can be mathematically defined. However, environments encountered in the real world are a tiny subset of all environments that could be defined. Maybe the learning takes such a long time because the algorithms are too general. If they are a bit more specialized in things they will encounter, perhaps the learning is faster.
Can we develop a fast RL algorithm to take advantage of this?
In traditional RL research, human experts develop the RL algorithm. However, there are still no RL algorithms nearly as good as humans after many years. Can we learn a better RL algorithm? Or even learn a better entire agent?

RL^2 ( Duan et al., 2016 ) is a meta-RL framework proposed to tackle this issue:
Imagine that we have multiple meta-training environments (A, B, and so on).
We also have a meta-RL algorithm that learns the RL algorithm and outputs a “fast” RL agent (from having interacted with these environments).
In the future, our agent will be in an environment F that is related to A, B, and so on.
Formally speaking, RL^2 maximizes the expected reward on the training Markov Decision Process (MDP) but can generalize to testing MDP. The RL agent is represented as a Recurrent Neural Network (RNN), a generic computation architecture where:
Different weights in the RNN mean different RL algorithms and priors.
Different activations in the RNN mean different current policies.
The meta-trained objective can be optimized with an existing “slow” RL algorithm.
The resulting RNN is ready to be dropped in a new environment.
RL^2 was evaluated on a classic Multi-Armed Bandit setting and performed better than provably (asymptotically) optimal RL algorithms invented by humans like Gittings Index, UCB1, and Thompson Sampling. Another task that RL^2 was evaluated on is visual navigation , where the agent explores a maze and finds a specified target as quickly as possible. Although this setting is maze-specific, we can scale up RL^2 to other large-scale games and robotic environments and use it to learn in a new environment quickly.
Schmidhuber. Evolutionary principles in self-referential learning . (1987)
Wiering, Schmidhuber. Solving POMDPs with Levin search and EIRA . (1996)
Schmidhuber, Zhao, Wiering. Shifting inductive bias with success-story algorithm, adaptive Levin search, and incremental self-improvement . (MLJ 1997)
Schmidhuber, Zhao, Schraudolph. Reinforcement learning with self-modifying policies (1998)
Zhao, Schmidhuber. Solving a complex prisoner’s dilemma with self-modifying policies . (1998)
Schmidhuber. A general method for incremental self-improvement and multiagent learning . (1999)
Singh, Lewis, Barto. Where do rewards come from? (2009)
Singh, Lewis, Barto. Intrinsically Motivated Reinforcement Learning: An Evolutionary Perspective (2010)
Niekum, Spector, Barto. Evolution of reward functions for reinforcement learning (2011)
Wang et al., (2016). Learning to Reinforcement Learn
Finn et al., (2017). Model-Agnostic Meta-Learning (MAML)
Mishra, Rohinenjad et al., (2017). Simple Neural AttentIve Meta-Learner
Frans et al., (2017). Meta-Learning Shared Hierarchies
5 - Few-Shot Imitation Learning
People often complement RL with imitation learning , which is basically supervised learning where the output is an action for an agent. This gives you more signal than traditional RL since for every input, you consistently have a corresponding output. As the diagram below shows, the imitation learning algorithm learns a policy in a supervised manner from many demonstrations and outputs the correct action based on the environment.

The challenge for imitation learning is to collect enough demonstrations to train an algorithm , which is time-consuming. To make the collection of demonstrations more efficient, we can apply multi-task meta-learning. Many demonstrations for different tasks can be learned by an algorithm, whose output is fed to a one-shot imitator that picks the correct action based on a single demonstration. This process is referred to as one-shot imitation learning ( Duan et al., 2017 ), as displayed below.

Conveniently, one-shot imitators are trained using traditional network architectures. A combination of CNNs, RNNs, and MLPs perform the heavy visual processing to understand the relevant actions in training demos and recommend the right action for the current frame of an inference demo. One example of this in action is block stacking .

Abbeel et al., (2008). Learning For Control From Multiple Demonstrations
Kolter, Ng. The Stanford LittleDog: A Learning And Rapid Replanning Approach To Quadrupled Locomotion (2008)
Ziebart et al., (2008). Maximum Entropy Inverse Reinforcement Learning
Schulman et al., (2013). Motion Planning with Sequential Convex Optimization and Convex Collision Checking
Finn, Levine. Deep Visual Foresight for Planning Robot Motion (2016)
6 - Domain Randomization
Simulated data collection is a logical substitute for expensive real data collection. It is less expensive, more scalable, and less dangerous (e.g., in the case of robots) to capture at scale. Given this logic, how can we make sure simulated data best matches real-world conditions?
Use Realistic Simulated Data

One approach is to make the simulator you use for training models as realistic as possible. Two variants of doing this are to carefully match the simulation to the world ( James and John, 2016 ; Johns, Leutenegger, and Division, 2016 ; Mahler et al., 2017 ; Koenemann et al., 2015 ) and augment simulated data with real data ( Richter et al., 2016 ; Bousmalis et al., 2017 ). While this option is logically appealing, it can be hard and slow to do in practice.
Domain Confusion

Another option is domain confusion ( Tzeng et al., 2014 ; Rusu et al., 2016 ).
In this approach, suppose you train a model on real and simulated data at the same time.
After completing training, a discriminator network examines the original network at some layer to understand if the original network is learning something about the real world.
If you can fool the discriminator with the output of the layer, the original network has completely integrated its understanding of real and simulated data.
In effect, there is no difference between simulated and real data to the original network, and the layers following the examined layer can be trained fully on simulated data.
Domain Randomization

Finally, a simpler approach called domain randomization ( Tobin et al., 2017 ; Sadeghi and Levine, 2016 ) has taken off of late. In this approach, rather than making simulated data fully realistic, the priority is to generate as much variation in the simulated data as possible. For example, in the below tabletop scenes, the dramatic variety of the scenes (e.g., background colors of green and purple) can help the model generalize well to the real world, even though the real world looks nothing like these scenes. This approach has shown promise in drone flight and pose estimation . The simple logic of more data leading to better performance in real-world settings is powerfully illustrated by domain randomization and obviates the need for existing variation methods like pre-training on ImageNet.
7 - Deep Learning For Science and Engineering
In other areas of this lecture, we’ve been focusing on research areas of machine learning where humans already perform well (i.e., pose estimation or grasping). In science and engineering applications, we enter the realm of machine learning performing tasks humans cannot. The most famous result is AlphaFold , a Deepmind-created system that solved protein folding, an important biological challenge. In the CASP challenge, AlphaFold 2 far outpaced all other results in performance. AlphaFold is quite complicated, as it maps an input protein sequence to similar protein sequences and subsequently decides the folding structure based on the evolutionary history of complementary amino acids.

Other examples of DL systems solving science and engineering challenges are in circuit design , high-energy physics , and symbolic mathematics .
AlphaFold: Improved protein structure prediction using potentials from deep learning . Deepmind (Senior et al.)
BagNet: Berkeley Analog Generator with Layout Optimizer Boosted with Deep Neural Networks . K. Hakhamaneshi, N. Werblun, P. Abbeel, V. Stojanovic. IEEE/ACM International Conference on Computer-Aided Design (ICAD), Westminster, Colorado, November 2019.
Evaluating Protein Transfer Learning with TAPE . R. Rao, N. Bhattacharya, N. Thomas, Y, Duan, X. Chen, J. Canny, P. Abbeel, Y. Song.
Opening the black box: the anatomy of a deep learning atomistic potential . Justin Smith
Exploring Machine Learning Applications to Enable Next-Generation Chemistry . Jennifer Wei (Google).
GANs for HEP . Ben Nachman
Deep Learning for Symbolic Mathematics . G. Lample and F. Charton.
A Survey of Deep Learning for Scientific Discovery . Maithra Raghu, Eric Schmidt.
As compute scales to support incredible numbers of FLOPs, more science and engineering challenges will be solved with deep learning systems. There has been exponential growth in the amount of compute used to generate the most impressive research results like GPT-3.

As compute and data become more available, we open a new problem territory that we can refer to as deep learning to learn . More specifically, throughout history, the constraint on solving problems has been human ingenuity. This is a particularly challenging realm to contribute novel results to because we’re competing against the combined intellectual might available throughout history. Is our present ingenuity truly greater than that of others 20-30 years ago, let alone 200-300? Probably not. However, our ability to bring new tools like compute and data most certainly is. Therefore, spending as much time in this new problem territory, where data and compute help solve problems , is likely to generate exciting and novel results more frequently in the long run.

“ Give a man a fish and you feed him for a day, teach a man to fish and you feed him for a lifetime ” (Lao Tzu)
Here are some tips on how to keep up with ML research:
(Mostly) don’t read (most) papers. There are just too many!
When you do want to keep up, use the following:
Tutorials at conferences: these capture the essence of important concepts in a practical, distilled way
Graduate courses and seminars
Yannic Kilcher YouTube channel
Two Minutes Paper Channel
The Batch by Andrew Ng
Import AI by Jack Clark
If you DO decide to read papers,
Follow a principled process for reading papers
Use Arxiv Sanity
AI/DL Facebook Group
ML Subreddit
Start a reading group: read papers together with friends - either everyone reads then discusses, or one or two people read and give tutorials to others.

Finally, should you do a Ph.D. or not?
You don’t have to do a Ph.D. to work in AI!
However, if you REALLY want to become one of the world’s experts in a topic you care about, then a Ph.D. is a technically deep and demanding path to get there. Crudely speaking, a Ph.D. enables you to develop new tools and techniques rather than using existing tools and techniques.
We are excited to share this course with you for free .
We have more upcoming great content. Subscribe to stay up to date as we release it.
We take your privacy and attention very seriously and will never spam you. I am already a subscriber

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Springer Nature - PMC COVID-19 Collection
Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions
Iqbal h. sarker.
1 Swinburne University of Technology, Melbourne, VIC 3122 Australia
2 Chittagong University of Engineering & Technology, Chittagong, 4349 Bangladesh
Deep learning (DL), a branch of machine learning (ML) and artificial intelligence (AI) is nowadays considered as a core technology of today’s Fourth Industrial Revolution (4IR or Industry 4.0). Due to its learning capabilities from data, DL technology originated from artificial neural network (ANN), has become a hot topic in the context of computing, and is widely applied in various application areas like healthcare, visual recognition, text analytics, cybersecurity, and many more. However, building an appropriate DL model is a challenging task, due to the dynamic nature and variations in real-world problems and data. Moreover, the lack of core understanding turns DL methods into black-box machines that hamper development at the standard level. This article presents a structured and comprehensive view on DL techniques including a taxonomy considering various types of real-world tasks like supervised or unsupervised. In our taxonomy, we take into account deep networks for supervised or discriminative learning , unsupervised or generative learning as well as hybrid learning and relevant others. We also summarize real-world application areas where deep learning techniques can be used. Finally, we point out ten potential aspects for future generation DL modeling with research directions . Overall, this article aims to draw a big picture on DL modeling that can be used as a reference guide for both academia and industry professionals.
Introduction
In the late 1980s, neural networks became a prevalent topic in the area of Machine Learning (ML) as well as Artificial Intelligence (AI), due to the invention of various efficient learning methods and network structures [ 52 ]. Multilayer perceptron networks trained by “Backpropagation” type algorithms, self-organizing maps, and radial basis function networks were such innovative methods [ 26 , 36 , 37 ]. While neural networks are successfully used in many applications, the interest in researching this topic decreased later on. After that, in 2006, “Deep Learning” (DL) was introduced by Hinton et al. [ 41 ], which was based on the concept of artificial neural network (ANN). Deep learning became a prominent topic after that, resulting in a rebirth in neural network research, hence, some times referred to as “new-generation neural networks”. This is because deep networks, when properly trained, have produced significant success in a variety of classification and regression challenges [ 52 ].
Nowadays, DL technology is considered as one of the hot topics within the area of machine learning, artificial intelligence as well as data science and analytics, due to its learning capabilities from the given data. Many corporations including Google, Microsoft, Nokia, etc., study it actively as it can provide significant results in different classification and regression problems and datasets [ 52 ]. In terms of working domain, DL is considered as a subset of ML and AI, and thus DL can be seen as an AI function that mimics the human brain’s processing of data. The worldwide popularity of “Deep learning” is increasing day by day, which is shown in our earlier paper [ 96 ] based on the historical data collected from Google trends [ 33 ]. Deep learning differs from standard machine learning in terms of efficiency as the volume of data increases, discussed briefly in Section “ Why Deep Learning in Today's Research and Applications? ”. DL technology uses multiple layers to represent the abstractions of data to build computational models. While deep learning takes a long time to train a model due to a large number of parameters, it takes a short amount of time to run during testing as compared to other machine learning algorithms [ 127 ].
While today’s Fourth Industrial Revolution (4IR or Industry 4.0) is typically focusing on technology-driven “automation, smart and intelligent systems”, DL technology, which is originated from ANN, has become one of the core technologies to achieve the goal [ 103 , 114 ]. A typical neural network is mainly composed of many simple, connected processing elements or processors called neurons, each of which generates a series of real-valued activations for the target outcome. Figure Figure1 1 shows a schematic representation of the mathematical model of an artificial neuron, i.e., processing element, highlighting input ( X i ), weight ( w ), bias ( b ), summation function ( ∑ ), activation function ( f ) and corresponding output signal ( y ). Neural network-based DL technology is now widely applied in many fields and research areas such as healthcare, sentiment analysis, natural language processing, visual recognition, business intelligence, cybersecurity, and many more that have been summarized in the latter part of this paper.

Schematic representation of the mathematical model of an artificial neuron (processing element), highlighting input ( X i ), weight ( w ), bias ( b ), summation function ( ∑ ), activation function ( f ) and output signal ( y )
Although DL models are successfully applied in various application areas, mentioned above, building an appropriate model of deep learning is a challenging task, due to the dynamic nature and variations of real-world problems and data. Moreover, DL models are typically considered as “black-box” machines that hamper the standard development of deep learning research and applications. Thus for clear understanding, in this paper, we present a structured and comprehensive view on DL techniques considering the variations in real-world problems and tasks. To achieve our goal, we briefly discuss various DL techniques and present a taxonomy by taking into account three major categories: (i) deep networks for supervised or discriminative learning that is utilized to provide a discriminative function in supervised deep learning or classification applications; (ii) deep networks for unsupervised or generative learning that are used to characterize the high-order correlation properties or features for pattern analysis or synthesis, thus can be used as preprocessing for the supervised algorithm; and (ii) deep networks for hybrid learning that is an integration of both supervised and unsupervised model and relevant others. We take into account such categories based on the nature and learning capabilities of different DL techniques and how they are used to solve problems in real-world applications [ 97 ]. Moreover, identifying key research issues and prospects including effective data representation, new algorithm design, data-driven hyper-parameter learning, and model optimization, integrating domain knowledge, adapting resource-constrained devices, etc. is one of the key targets of this study, which can lead to “Future Generation DL-Modeling”. Thus the goal of this paper is set to assist those in academia and industry as a reference guide, who want to research and develop data-driven smart and intelligent systems based on DL techniques.
The overall contribution of this paper is summarized as follows:
- This article focuses on different aspects of deep learning modeling, i.e., the learning capabilities of DL techniques in different dimensions such as supervised or unsupervised tasks, to function in an automated and intelligent manner, which can play as a core technology of today’s Fourth Industrial Revolution (Industry 4.0).
- We explore a variety of prominent DL techniques and present a taxonomy by taking into account the variations in deep learning tasks and how they are used for different purposes. In our taxonomy, we divide the techniques into three major categories such as deep networks for supervised or discriminative learning, unsupervised or generative learning, as well as deep networks for hybrid learning, and relevant others.
- We have summarized several potential real-world application areas of deep learning, to assist developers as well as researchers in broadening their perspectives on DL techniques. Different categories of DL techniques highlighted in our taxonomy can be used to solve various issues accordingly.
- Finally, we point out and discuss ten potential aspects with research directions for future generation DL modeling in terms of conducting future research and system development.
This paper is organized as follows. Section “ Why Deep Learning in Today's Research and Applications? ” motivates why deep learning is important to build data-driven intelligent systems. In Section“ Deep Learning Techniques and Applications ”, we present our DL taxonomy by taking into account the variations of deep learning tasks and how they are used in solving real-world issues and briefly discuss the techniques with summarizing the potential application areas. In Section “ Research Directions and Future Aspects ”, we discuss various research issues of deep learning-based modeling and highlight the promising topics for future research within the scope of our study. Finally, Section “ Concluding Remarks ” concludes this paper.
Why Deep Learning in Today’s Research and Applications?
The main focus of today’s Fourth Industrial Revolution (Industry 4.0) is typically technology-driven automation, smart and intelligent systems, in various application areas including smart healthcare, business intelligence, smart cities, cybersecurity intelligence, and many more [ 95 ]. Deep learning approaches have grown dramatically in terms of performance in a wide range of applications considering security technologies, particularly, as an excellent solution for uncovering complex architecture in high-dimensional data. Thus, DL techniques can play a key role in building intelligent data-driven systems according to today’s needs, because of their excellent learning capabilities from historical data. Consequently, DL can change the world as well as humans’ everyday life through its automation power and learning from experience. DL technology is therefore relevant to artificial intelligence [ 103 ], machine learning [ 97 ] and data science with advanced analytics [ 95 ] that are well-known areas in computer science, particularly, today’s intelligent computing. In the following, we first discuss regarding the position of deep learning in AI, or how DL technology is related to these areas of computing.
The Position of Deep Learning in AI
Nowadays, artificial intelligence (AI), machine learning (ML), and deep learning (DL) are three popular terms that are sometimes used interchangeably to describe systems or software that behaves intelligently. In Fig. Fig.2, 2 , we illustrate the position of deep Learning, comparing with machine learning and artificial intelligence. According to Fig. Fig.2, 2 , DL is a part of ML as well as a part of the broad area AI. In general, AI incorporates human behavior and intelligence to machines or systems [ 103 ], while ML is the method to learn from data or experience [ 97 ], which automates analytical model building. DL also represents learning methods from data where the computation is done through multi-layer neural networks and processing. The term “Deep” in the deep learning methodology refers to the concept of multiple levels or stages through which data is processed for building a data-driven model.

An illustration of the position of deep learning (DL), comparing with machine learning (ML) and artificial intelligence (AI)
Thus, DL can be considered as one of the core technology of AI, a frontier for artificial intelligence, which can be used for building intelligent systems and automation. More importantly, it pushes AI to a new level, termed “Smarter AI”. As DL are capable of learning from data, there is a strong relation of deep learning with “Data Science” [ 95 ] as well. Typically, data science represents the entire process of finding meaning or insights in data in a particular problem domain, where DL methods can play a key role for advanced analytics and intelligent decision-making [ 104 , 106 ]. Overall, we can conclude that DL technology is capable to change the current world, particularly, in terms of a powerful computational engine and contribute to technology-driven automation, smart and intelligent systems accordingly, and meets the goal of Industry 4.0.
Understanding Various Forms of Data
As DL models learn from data, an in-depth understanding and representation of data are important to build a data-driven intelligent system in a particular application area. In the real world, data can be in various forms, which typically can be represented as below for deep learning modeling:
- Sequential Data Sequential data is any kind of data where the order matters, i,e., a set of sequences. It needs to explicitly account for the sequential nature of input data while building the model. Text streams, audio fragments, video clips, time-series data, are some examples of sequential data.
- Image or 2D Data A digital image is made up of a matrix, which is a rectangular array of numbers, symbols, or expressions arranged in rows and columns in a 2D array of numbers. Matrix, pixels, voxels, and bit depth are the four essential characteristics or fundamental parameters of a digital image.
- Tabular Data A tabular dataset consists primarily of rows and columns. Thus tabular datasets contain data in a columnar format as in a database table. Each column (field) must have a name and each column may only contain data of the defined type. Overall, it is a logical and systematic arrangement of data in the form of rows and columns that are based on data properties or features. Deep learning models can learn efficiently on tabular data and allow us to build data-driven intelligent systems.
The above-discussed data forms are common in the real-world application areas of deep learning. Different categories of DL techniques perform differently depending on the nature and characteristics of data, discussed briefly in Section “ Deep Learning Techniques and Applications ” with a taxonomy presentation. However, in many real-world application areas, the standard machine learning techniques, particularly, logic-rule or tree-based techniques [ 93 , 101 ] perform significantly depending on the application nature. Figure Figure3 3 also shows the performance comparison of DL and ML modeling considering the amount of data. In the following, we highlight several cases, where deep learning is useful to solve real-world problems, according to our main focus in this paper.

An illustration of the performance comparison between deep learning (DL) and other machine learning (ML) algorithms, where DL modeling from large amounts of data can increase the performance
DL Properties and Dependencies
A DL model typically follows the same processing stages as machine learning modeling. In Fig. Fig.4, 4 , we have shown a deep learning workflow to solve real-world problems, which consists of three processing steps, such as data understanding and preprocessing, DL model building, and training, and validation and interpretation. However, unlike the ML modeling [ 98 , 108 ], feature extraction in the DL model is automated rather than manual. K-nearest neighbor, support vector machines, decision tree, random forest, naive Bayes, linear regression, association rules, k-means clustering, are some examples of machine learning techniques that are commonly used in various application areas [ 97 ]. On the other hand, the DL model includes convolution neural network, recurrent neural network, autoencoder, deep belief network, and many more, discussed briefly with their potential application areas in Section 3 . In the following, we discuss the key properties and dependencies of DL techniques, that are needed to take into account before started working on DL modeling for real-world applications.

A typical DL workflow to solve real-world problems, which consists of three sequential stages (i) data understanding and preprocessing (ii) DL model building and training (iii) validation and interpretation
- Data Dependencies Deep learning is typically dependent on a large amount of data to build a data-driven model for a particular problem domain. The reason is that when the data volume is small, deep learning algorithms often perform poorly [ 64 ]. In such circumstances, however, the performance of the standard machine-learning algorithms will be improved if the specified rules are used [ 64 , 107 ].
- Hardware Dependencies The DL algorithms require large computational operations while training a model with large datasets. As the larger the computations, the more the advantage of a GPU over a CPU, the GPU is mostly used to optimize the operations efficiently. Thus, to work properly with the deep learning training, GPU hardware is necessary. Therefore, DL relies more on high-performance machines with GPUs than standard machine learning methods [ 19 , 127 ].
- Feature Engineering Process Feature engineering is the process of extracting features (characteristics, properties, and attributes) from raw data using domain knowledge. A fundamental distinction between DL and other machine-learning techniques is the attempt to extract high-level characteristics directly from data [ 22 , 97 ]. Thus, DL decreases the time and effort required to construct a feature extractor for each problem.
- Model Training and Execution time In general, training a deep learning algorithm takes a long time due to a large number of parameters in the DL algorithm; thus, the model training process takes longer. For instance, the DL models can take more than one week to complete a training session, whereas training with ML algorithms takes relatively little time, only seconds to hours [ 107 , 127 ]. During testing, deep learning algorithms take extremely little time to run [ 127 ], when compared to certain machine learning methods.
- Black-box Perception and Interpretability Interpretability is an important factor when comparing DL with ML. It’s difficult to explain how a deep learning result was obtained, i.e., “black-box”. On the other hand, the machine-learning algorithms, particularly, rule-based machine learning techniques [ 97 ] provide explicit logic rules (IF-THEN) for making decisions that are easily interpretable for humans. For instance, in our earlier works, we have presented several machines learning rule-based techniques [ 100 , 102 , 105 ], where the extracted rules are human-understandable and easier to interpret, update or delete according to the target applications.
The most significant distinction between deep learning and regular machine learning is how well it performs when data grows exponentially. An illustration of the performance comparison between DL and standard ML algorithms has been shown in Fig. Fig.3, 3 , where DL modeling can increase the performance with the amount of data. Thus, DL modeling is extremely useful when dealing with a large amount of data because of its capacity to process vast amounts of features to build an effective data-driven model. In terms of developing and training DL models, it relies on parallelized matrix and tensor operations as well as computing gradients and optimization. Several, DL libraries and resources [ 30 ] such as PyTorch [ 82 ] (with a high-level API called Lightning) and TensorFlow [ 1 ] (which also offers Keras as a high-level API) offers these core utilities including many pre-trained models, as well as many other necessary functions for implementation and DL model building.
Deep Learning Techniques and Applications
In this section, we go through the various types of deep neural network techniques, which typically consider several layers of information-processing stages in hierarchical structures to learn. A typical deep neural network contains multiple hidden layers including input and output layers. Figure Figure5 5 shows a general structure of a deep neural network ( h i d d e n l a y e r = N and N ≥ 2) comparing with a shallow network ( h i d d e n l a y e r = 1 ). We also present our taxonomy on DL techniques based on how they are used to solve various problems, in this section. However, before exploring the details of the DL techniques, it’s useful to review various types of learning tasks such as (i) Supervised: a task-driven approach that uses labeled training data, (ii) Unsupervised: a data-driven process that analyzes unlabeled datasets, (iii) Semi-supervised: a hybridization of both the supervised and unsupervised methods, and (iv) Reinforcement: an environment driven approach, discussed briefly in our earlier paper [ 97 ]. Thus, to present our taxonomy, we divide DL techniques broadly into three major categories: (i) deep networks for supervised or discriminative learning; (ii) deep networks for unsupervised or generative learning; and (ii) deep networks for hybrid learning combing both and relevant others, as shown in Fig. Fig.6. 6 . In the following, we briefly discuss each of these techniques that can be used to solve real-world problems in various application areas according to their learning capabilities.

A general architecture of a a shallow network with one hidden layer and b a deep neural network with multiple hidden layers

A taxonomy of DL techniques, broadly divided into three major categories (i) deep networks for supervised or discriminative learning, (ii) deep networks for unsupervised or generative learning, and (ii) deep networks for hybrid learning and relevant others
Deep Networks for Supervised or Discriminative Learning
This category of DL techniques is utilized to provide a discriminative function in supervised or classification applications. Discriminative deep architectures are typically designed to give discriminative power for pattern classification by describing the posterior distributions of classes conditioned on visible data [ 21 ]. Discriminative architectures mainly include Multi-Layer Perceptron (MLP), Convolutional Neural Networks (CNN or ConvNet), Recurrent Neural Networks (RNN), along with their variants. In the following, we briefly discuss these techniques.
Multi-layer Perceptron (MLP)
Multi-layer Perceptron (MLP), a supervised learning approach [ 83 ], is a type of feedforward artificial neural network (ANN). It is also known as the foundation architecture of deep neural networks (DNN) or deep learning. A typical MLP is a fully connected network that consists of an input layer that receives input data, an output layer that makes a decision or prediction about the input signal, and one or more hidden layers between these two that are considered as the network’s computational engine [ 36 , 103 ]. The output of an MLP network is determined using a variety of activation functions, also known as transfer functions, such as ReLU (Rectified Linear Unit), Tanh, Sigmoid, and Softmax [ 83 , 96 ]. To train MLP employs the most extensively used algorithm “Backpropagation” [ 36 ], a supervised learning technique, which is also known as the most basic building block of a neural network. During the training process, various optimization approaches such as Stochastic Gradient Descent (SGD), Limited Memory BFGS (L-BFGS), and Adaptive Moment Estimation (Adam) are applied. MLP requires tuning of several hyperparameters such as the number of hidden layers, neurons, and iterations, which could make solving a complicated model computationally expensive. However, through partial fit, MLP offers the advantage of learning non-linear models in real-time or online [ 83 ].
Convolutional Neural Network (CNN or ConvNet)
The Convolutional Neural Network (CNN or ConvNet) [ 65 ] is a popular discriminative deep learning architecture that learns directly from the input without the need for human feature extraction. Figure Figure7 7 shows an example of a CNN including multiple convolutions and pooling layers. As a result, the CNN enhances the design of traditional ANN like regularized MLP networks. Each layer in CNN takes into account optimum parameters for a meaningful output as well as reduces model complexity. CNN also uses a ‘dropout’ [ 30 ] that can deal with the problem of over-fitting, which may occur in a traditional network.

An example of a convolutional neural network (CNN or ConvNet) including multiple convolution and pooling layers
CNNs are specifically intended to deal with a variety of 2D shapes and are thus widely employed in visual recognition, medical image analysis, image segmentation, natural language processing, and many more [ 65 , 96 ]. The capability of automatically discovering essential features from the input without the need for human intervention makes it more powerful than a traditional network. Several variants of CNN are exist in the area that includes visual geometry group (VGG) [ 38 ], AlexNet [ 62 ], Xception [ 17 ], Inception [ 116 ], ResNet [ 39 ], etc. that can be used in various application domains according to their learning capabilities.
Recurrent Neural Network (RNN) and its Variants
A Recurrent Neural Network (RNN) is another popular neural network, which employs sequential or time-series data and feeds the output from the previous step as input to the current stage [ 27 , 74 ]. Like feedforward and CNN, recurrent networks learn from training input, however, distinguish by their “memory”, which allows them to impact current input and output through using information from previous inputs. Unlike typical DNN, which assumes that inputs and outputs are independent of one another, the output of RNN is reliant on prior elements within the sequence. However, standard recurrent networks have the issue of vanishing gradients, which makes learning long data sequences challenging. In the following, we discuss several popular variants of the recurrent network that minimizes the issues and perform well in many real-world application domains.
- Long short-term memory (LSTM) This is a popular form of RNN architecture that uses special units to deal with the vanishing gradient problem, which was introduced by Hochreiter et al. [ 42 ]. A memory cell in an LSTM unit can store data for long periods and the flow of information into and out of the cell is managed by three gates. For instance, the ‘Forget Gate’ determines what information from the previous state cell will be memorized and what information will be removed that is no longer useful, while the ‘Input Gate’ determines which information should enter the cell state and the ‘Output Gate’ determines and controls the outputs. As it solves the issues of training a recurrent network, the LSTM network is considered one of the most successful RNN.
- Bidirectional RNN/LSTM Bidirectional RNNs connect two hidden layers that run in opposite directions to a single output, allowing them to accept data from both the past and future. Bidirectional RNNs, unlike traditional recurrent networks, are trained to predict both positive and negative time directions at the same time. A Bidirectional LSTM, often known as a BiLSTM, is an extension of the standard LSTM that can increase model performance on sequence classification issues [ 113 ]. It is a sequence processing model comprising of two LSTMs: one takes the input forward and the other takes it backward. Bidirectional LSTM in particular is a popular choice in natural language processing tasks.

Basic structure of a gated recurrent unit (GRU) cell consisting of reset and update gates
Overall, the basic property of a recurrent network is that it has at least one feedback connection, which enables activations to loop. This allows the networks to do temporal processing and sequence learning, such as sequence recognition or reproduction, temporal association or prediction, etc. Following are some popular application areas of recurrent networks such as prediction problems, machine translation, natural language processing, text summarization, speech recognition, and many more.
Deep Networks for Generative or Unsupervised Learning
This category of DL techniques is typically used to characterize the high-order correlation properties or features for pattern analysis or synthesis, as well as the joint statistical distributions of the visible data and their associated classes [ 21 ]. The key idea of generative deep architectures is that during the learning process, precise supervisory information such as target class labels is not of concern. As a result, the methods under this category are essentially applied for unsupervised learning as the methods are typically used for feature learning or data generating and representation [ 20 , 21 ]. Thus generative modeling can be used as preprocessing for the supervised learning tasks as well, which ensures the discriminative model accuracy. Commonly used deep neural network techniques for unsupervised or generative learning are Generative Adversarial Network (GAN), Autoencoder (AE), Restricted Boltzmann Machine (RBM), Self-Organizing Map (SOM), and Deep Belief Network (DBN) along with their variants.
Generative Adversarial Network (GAN)
A Generative Adversarial Network (GAN), designed by Ian Goodfellow [ 32 ], is a type of neural network architecture for generative modeling to create new plausible samples on demand. It involves automatically discovering and learning regularities or patterns in input data so that the model may be used to generate or output new examples from the original dataset. As shown in Fig. Fig.9, 9 , GANs are composed of two neural networks, a generator G that creates new data having properties similar to the original data, and a discriminator D that predicts the likelihood of a subsequent sample being drawn from actual data rather than data provided by the generator. Thus in GAN modeling, both the generator and discriminator are trained to compete with each other. While the generator tries to fool and confuse the discriminator by creating more realistic data, the discriminator tries to distinguish the genuine data from the fake data generated by G .

Schematic structure of a standard generative adversarial network (GAN)
Generally, GAN network deployment is designed for unsupervised learning tasks, but it has also proven to be a better solution for semi-supervised and reinforcement learning as well depending on the task [ 3 ]. GANs are also used in state-of-the-art transfer learning research to enforce the alignment of the latent feature space [ 66 ]. Inverse models, such as Bidirectional GAN (BiGAN) [ 25 ] can also learn a mapping from data to the latent space, similar to how the standard GAN model learns a mapping from a latent space to the data distribution. The potential application areas of GAN networks are healthcare, image analysis, data augmentation, video generation, voice generation, pandemics, traffic control, cybersecurity, and many more, which are increasing rapidly. Overall, GANs have established themselves as a comprehensive domain of independent data expansion and as a solution to problems requiring a generative solution.
Auto-Encoder (AE) and Its Variants
An auto-encoder (AE) [ 31 ] is a popular unsupervised learning technique in which neural networks are used to learn representations. Typically, auto-encoders are used to work with high-dimensional data, and dimensionality reduction explains how a set of data is represented. Encoder, code, and decoder are the three parts of an autoencoder. The encoder compresses the input and generates the code, which the decoder subsequently uses to reconstruct the input. The AEs have recently been used to learn generative data models [ 69 ]. The auto-encoder is widely used in many unsupervised learning tasks, e.g., dimensionality reduction, feature extraction, efficient coding, generative modeling, denoising, anomaly or outlier detection, etc. [ 31 , 132 ]. Principal component analysis (PCA) [ 99 ], which is also used to reduce the dimensionality of huge data sets, is essentially similar to a single-layered AE with a linear activation function. Regularized autoencoders such as sparse, denoising, and contractive are useful for learning representations for later classification tasks [ 119 ], while variational autoencoders can be used as generative models [ 56 ], discussed below.

Schematic structure of a sparse autoencoder (SAE) with several active units (filled circle) in the hidden layer
- Denoising Autoencoder (DAE) A denoising autoencoder is a variant on the basic autoencoder that attempts to improve representation (to extract useful features) by altering the reconstruction criterion, and thus reduces the risk of learning the identity function [ 31 , 119 ]. In other words, it receives a corrupted data point as input and is trained to recover the original undistorted input as its output through minimizing the average reconstruction error over the training data, i.e, cleaning the corrupted input, or denoising. Thus, in the context of computing, DAEs can be considered as very powerful filters that can be utilized for automatic pre-processing. A denoising autoencoder, for example, could be used to automatically pre-process an image, thereby boosting its quality for recognition accuracy.
- Contractive Autoencoder (CAE) The idea behind a contractive autoencoder, proposed by Rifai et al. [ 90 ], is to make the autoencoders robust of small changes in the training dataset. In its objective function, a CAE includes an explicit regularizer that forces the model to learn an encoding that is robust to small changes in input values. As a result, the learned representation’s sensitivity to the training input is reduced. While DAEs encourage the robustness of reconstruction as discussed above, CAEs encourage the robustness of representation.
- Variational Autoencoder (VAE) A variational autoencoder [ 55 ] has a fundamentally unique property that distinguishes it from the classical autoencoder discussed above, which makes this so effective for generative modeling. VAEs, unlike the traditional autoencoders which map the input onto a latent vector, map the input data into the parameters of a probability distribution, such as the mean and variance of a Gaussian distribution. A VAE assumes that the source data has an underlying probability distribution and then tries to discover the distribution’s parameters. Although this approach was initially designed for unsupervised learning, its use has been demonstrated in other domains such as semi-supervised learning [ 128 ] and supervised learning [ 51 ].
Although, the earlier concept of AE was typically for dimensionality reduction or feature learning mentioned above, recently, AEs have been brought to the forefront of generative modeling, even the generative adversarial network is one of the popular methods in the area. The AEs have been effectively employed in a variety of domains, including healthcare, computer vision, speech recognition, cybersecurity, natural language processing, and many more. Overall, we can conclude that auto-encoder and its variants can play a significant role as unsupervised feature learning with neural network architecture.
Kohonen Map or Self-Organizing Map (SOM)
A Self-Organizing Map (SOM) or Kohonen Map [ 59 ] is another form of unsupervised learning technique for creating a low-dimensional (usually two-dimensional) representation of a higher-dimensional data set while maintaining the topological structure of the data. SOM is also known as a neural network-based dimensionality reduction algorithm that is commonly used for clustering [ 118 ]. A SOM adapts to the topological form of a dataset by repeatedly moving its neurons closer to the data points, allowing us to visualize enormous datasets and find probable clusters. The first layer of a SOM is the input layer, and the second layer is the output layer or feature map. Unlike other neural networks that use error-correction learning, such as backpropagation with gradient descent [ 36 ], SOMs employ competitive learning, which uses a neighborhood function to retain the input space’s topological features. SOM is widely utilized in a variety of applications, including pattern identification, health or medical diagnosis, anomaly detection, and virus or worm attack detection [ 60 , 87 ]. The primary benefit of employing a SOM is that this can make high-dimensional data easier to visualize and analyze to understand the patterns. The reduction of dimensionality and grid clustering makes it easy to observe similarities in the data. As a result, SOMs can play a vital role in developing a data-driven effective model for a particular problem domain, depending on the data characteristics.
Restricted Boltzmann Machine (RBM)
A Restricted Boltzmann Machine (RBM) [ 75 ] is also a generative stochastic neural network capable of learning a probability distribution across its inputs. Boltzmann machines typically consist of visible and hidden nodes and each node is connected to every other node, which helps us understand irregularities by learning how the system works in normal circumstances. RBMs are a subset of Boltzmann machines that have a limit on the number of connections between the visible and hidden layers [ 77 ]. This restriction permits training algorithms like the gradient-based contrastive divergence algorithm to be more efficient than those for Boltzmann machines in general [ 41 ]. RBMs have found applications in dimensionality reduction, classification, regression, collaborative filtering, feature learning, topic modeling, and many others. In the area of deep learning modeling, they can be trained either supervised or unsupervised, depending on the task. Overall, the RBMs can recognize patterns in data automatically and develop probabilistic or stochastic models, which are utilized for feature selection or extraction, as well as forming a deep belief network.
Deep Belief Network (DBN)
A Deep Belief Network (DBN) [ 40 ] is a multi-layer generative graphical model of stacking several individual unsupervised networks such as AEs or RBMs, that use each network’s hidden layer as the input for the next layer, i.e, connected sequentially. Thus, we can divide a DBN into (i) AE-DBN which is known as stacked AE, and (ii) RBM-DBN that is known as stacked RBM, where AE-DBN is composed of autoencoders and RBM-DBN is composed of restricted Boltzmann machines, discussed earlier. The ultimate goal is to develop a faster-unsupervised training technique for each sub-network that depends on contrastive divergence [ 41 ]. DBN can capture a hierarchical representation of input data based on its deep structure. The primary idea behind DBN is to train unsupervised feed-forward neural networks with unlabeled data before fine-tuning the network with labeled input. One of the most important advantages of DBN, as opposed to typical shallow learning networks, is that it permits the detection of deep patterns, which allows for reasoning abilities and the capture of the deep difference between normal and erroneous data [ 89 ]. A continuous DBN is simply an extension of a standard DBN that allows a continuous range of decimals instead of binary data. Overall, the DBN model can play a key role in a wide range of high-dimensional data applications due to its strong feature extraction and classification capabilities and become one of the significant topics in the field of neural networks.
In summary, the generative learning techniques discussed above typically allow us to generate a new representation of data through exploratory analysis. As a result, these deep generative networks can be utilized as preprocessing for supervised or discriminative learning tasks, as well as ensuring model accuracy, where unsupervised representation learning can allow for improved classifier generalization.
Deep Networks for Hybrid Learning and Other Approaches
In addition to the above-discussed deep learning categories, hybrid deep networks and several other approaches such as deep transfer learning (DTL) and deep reinforcement learning (DRL) are popular, which are discussed in the following.
Hybrid Deep Neural Networks
Generative models are adaptable, with the capacity to learn from both labeled and unlabeled data. Discriminative models, on the other hand, are unable to learn from unlabeled data yet outperform their generative counterparts in supervised tasks. A framework for training both deep generative and discriminative models simultaneously can enjoy the benefits of both models, which motivates hybrid networks.
Hybrid deep learning models are typically composed of multiple (two or more) deep basic learning models, where the basic model is a discriminative or generative deep learning model discussed earlier. Based on the integration of different basic generative or discriminative models, the below three categories of hybrid deep learning models might be useful for solving real-world problems. These are as follows:
- Hybrid M o d e l _ 1 : An integration of different generative or discriminative models to extract more meaningful and robust features. Examples could be CNN+LSTM, AE+GAN, and so on.
- Hybrid M o d e l _ 2 : An integration of generative model followed by a discriminative model. Examples could be DBN+MLP, GAN+CNN, AE+CNN, and so on.
- Hybrid M o d e l _ 3 : An integration of generative or discriminative model followed by a non-deep learning classifier. Examples could be AE+SVM, CNN+SVM, and so on.
Thus, in a broad sense, we can conclude that hybrid models can be either classification-focused or non-classification depending on the target use. However, most of the hybrid learning-related studies in the area of deep learning are classification-focused or supervised learning tasks, summarized in Table Table1. 1 . The unsupervised generative models with meaningful representations are employed to enhance the discriminative models. The generative models with useful representation can provide more informative and low-dimensional features for discrimination, and they can also enable to enhance the training data quality and quantity, providing additional information for classification.
A summary of deep learning tasks and methods in several popular real-world applications areas
Deep Transfer Learning (DTL)
Transfer Learning is a technique for effectively using previously learned model knowledge to solve a new task with minimum training or fine-tuning. In comparison to typical machine learning techniques [ 97 ], DL takes a large amount of training data. As a result, the need for a substantial volume of labeled data is a significant barrier to address some essential domain-specific tasks, particularly, in the medical sector, where creating large-scale, high-quality annotated medical or health datasets is both difficult and costly. Furthermore, the standard DL model demands a lot of computational resources, such as a GPU-enabled server, even though researchers are working hard to improve it. As a result, Deep Transfer Learning (DTL), a DL-based transfer learning method, might be helpful to address this issue. Figure Figure11 11 shows a general structure of the transfer learning process, where knowledge from the pre-trained model is transferred into a new DL model. It’s especially popular in deep learning right now since it allows to train deep neural networks with very little data [ 126 ].

A general structure of transfer learning process, where knowledge from pre-trained model is transferred into new DL model
Transfer learning is a two-stage approach for training a DL model that consists of a pre-training step and a fine-tuning step in which the model is trained on the target task. Since deep neural networks have gained popularity in a variety of fields, a large number of DTL methods have been presented, making it crucial to categorize and summarize them. Based on the techniques used in the literature, DTL can be classified into four categories [ 117 ]. These are (i) instances-based deep transfer learning that utilizes instances in source domain by appropriate weight, (ii) mapping-based deep transfer learning that maps instances from two domains into a new data space with better similarity, (iii) network-based deep transfer learning that reuses the partial of network pre-trained in the source domain, and (iv) adversarial based deep transfer learning that uses adversarial technology to find transferable features that both suitable for two domains. Due to its high effectiveness and practicality, adversarial-based deep transfer learning has exploded in popularity in recent years. Transfer learning can also be classified into inductive, transductive, and unsupervised transfer learning depending on the circumstances between the source and target domains and activities [ 81 ]. While most current research focuses on supervised learning, how deep neural networks can transfer knowledge in unsupervised or semi-supervised learning may gain further interest in the future. DTL techniques are useful in a variety of fields including natural language processing, sentiment classification, visual recognition, speech recognition, spam filtering, and relevant others.
Deep Reinforcement Learning (DRL)
Reinforcement learning takes a different approach to solving the sequential decision-making problem than other approaches we have discussed so far. The concepts of an environment and an agent are often introduced first in reinforcement learning. The agent can perform a series of actions in the environment, each of which has an impact on the environment’s state and can result in possible rewards (feedback) - “positive” for good sequences of actions that result in a “good” state, and “negative” for bad sequences of actions that result in a “bad” state. The purpose of reinforcement learning is to learn good action sequences through interaction with the environment, typically referred to as a policy.
Deep reinforcement learning (DRL or deep RL) [ 9 ] integrates neural networks with a reinforcement learning architecture to allow the agents to learn the appropriate actions in a virtual environment, as shown in Fig. Fig.12. 12 . In the area of reinforcement learning, model-based RL is based on learning a transition model that enables for modeling of the environment without interacting with it directly, whereas model-free RL methods learn directly from interactions with the environment. Q-learning is a popular model-free RL technique for determining the best action-selection policy for any (finite) Markov Decision Process (MDP) [ 86 , 97 ]. MDP is a mathematical framework for modeling decisions based on state, action, and rewards [ 86 ]. In addition, Deep Q-Networks, Double DQN, Bi-directional Learning, Monte Carlo Control, etc. are used in the area [ 50 , 97 ]. In DRL methods it incorporates DL models, e.g. Deep Neural Networks (DNN), based on MDP principle [ 71 ], as policy and/or value function approximators. CNN for example can be used as a component of RL agents to learn directly from raw, high-dimensional visual inputs. In the real world, DRL-based solutions can be used in several application areas including robotics, video games, natural language processing, computer vision, and relevant others.

Schematic structure of deep reinforcement learning (DRL) highlighting a deep neural network
Deep Learning Application Summary
During the past few years, deep learning has been successfully applied to numerous problems in many application areas. These include natural language processing, sentiment analysis, cybersecurity, business, virtual assistants, visual recognition, healthcare, robotics, and many more. In Fig. Fig.13, 13 , we have summarized several potential real-world application areas of deep learning. Various deep learning techniques according to our presented taxonomy in Fig. Fig.6 6 that includes discriminative learning, generative learning, as well as hybrid models, discussed earlier, are employed in these application areas. In Table Table1, 1 , we have also summarized various deep learning tasks and techniques that are used to solve the relevant tasks in several real-world applications areas. Overall, from Fig. Fig.13 13 and Table Table1, 1 , we can conclude that the future prospects of deep learning modeling in real-world application areas are huge and there are lots of scopes to work. In the next section, we also summarize the research issues in deep learning modeling and point out the potential aspects for future generation DL modeling.

Several potential real-world application areas of deep learning
Research Directions and Future Aspects
While existing methods have established a solid foundation for deep learning systems and research, this section outlines the below ten potential future research directions based on our study.
- Automation in Data Annotation According to the existing literature, discussed in Section 3 , most of the deep learning models are trained through publicly available datasets that are annotated. However, to build a system for a new problem domain or recent data-driven system, raw data from relevant sources are needed to collect. Thus, data annotation, e.g., categorization, tagging, or labeling of a large amount of raw data, is important for building discriminative deep learning models or supervised tasks, which is challenging. A technique with the capability of automatic and dynamic data annotation, rather than manual annotation or hiring annotators, particularly, for large datasets, could be more effective for supervised learning as well as minimizing human effort. Therefore, a more in-depth investigation of data collection and annotation methods, or designing an unsupervised learning-based solution could be one of the primary research directions in the area of deep learning modeling.
- Data Preparation for Ensuring Data Quality As discussed earlier throughout the paper, the deep learning algorithms highly impact data quality, and availability for training, and consequently on the resultant model for a particular problem domain. Thus, deep learning models may become worthless or yield decreased accuracy if the data is bad, such as data sparsity, non-representative, poor-quality, ambiguous values, noise, data imbalance, irrelevant features, data inconsistency, insufficient quantity, and so on for training. Consequently, such issues in data can lead to poor processing and inaccurate findings, which is a major problem while discovering insights from data. Thus deep learning models also need to adapt to such rising issues in data, to capture approximated information from observations. Therefore, effective data pre-processing techniques are needed to design according to the nature of the data problem and characteristics, to handling such emerging challenges, which could be another research direction in the area.
- Black-box Perception and Proper DL/ML Algorithm Selection In general, it’s difficult to explain how a deep learning result is obtained or how they get the ultimate decisions for a particular model. Although DL models achieve significant performance while learning from large datasets, as discussed in Section 2 , this “black-box” perception of DL modeling typically represents weak statistical interpretability that could be a major issue in the area. On the other hand, ML algorithms, particularly, rule-based machine learning techniques provide explicit logic rules (IF-THEN) for making decisions that are easier to interpret, update or delete according to the target applications [ 97 , 100 , 105 ]. If the wrong learning algorithm is chosen, unanticipated results may occur, resulting in a loss of effort as well as the model’s efficacy and accuracy. Thus by taking into account the performance, complexity, model accuracy, and applicability, selecting an appropriate model for the target application is challenging, and in-depth analysis is needed for better understanding and decision making.
- Deep Networks for Supervised or Discriminative Learning: According to our designed taxonomy of deep learning techniques, as shown in Fig. Fig.6, 6 , discriminative architectures mainly include MLP, CNN, and RNN, along with their variants that are applied widely in various application domains. However, designing new techniques or their variants of such discriminative techniques by taking into account model optimization, accuracy, and applicability, according to the target real-world application and the nature of the data, could be a novel contribution, which can also be considered as a major future aspect in the area of supervised or discriminative learning.
- Deep Networks for Unsupervised or Generative Learning As discussed in Section 3 , unsupervised learning or generative deep learning modeling is one of the major tasks in the area, as it allows us to characterize the high-order correlation properties or features in data, or generating a new representation of data through exploratory analysis. Moreover, unlike supervised learning [ 97 ], it does not require labeled data due to its capability to derive insights directly from the data as well as data-driven decision making. Consequently, it thus can be used as preprocessing for supervised learning or discriminative modeling as well as semi-supervised learning tasks, which ensure learning accuracy and model efficiency. According to our designed taxonomy of deep learning techniques, as shown in Fig. Fig.6, 6 , generative techniques mainly include GAN, AE, SOM, RBM, DBN, and their variants. Thus, designing new techniques or their variants for an effective data modeling or representation according to the target real-world application could be a novel contribution, which can also be considered as a major future aspect in the area of unsupervised or generative learning.
- Hybrid/Ensemble Modeling and Uncertainty Handling According to our designed taxonomy of DL techniques, as shown in Fig Fig6, 6 , this is considered as another major category in deep learning tasks. As hybrid modeling enjoys the benefits of both generative and discriminative learning, an effective hybridization can outperform others in terms of performance as well as uncertainty handling in high-risk applications. In Section 3 , we have summarized various types of hybridization, e.g., AE+CNN/SVM. Since a group of neural networks is trained with distinct parameters or with separate sub-sampling training datasets, hybridization or ensembles of such techniques, i.e., DL with DL/ML, can play a key role in the area. Thus designing effective blended discriminative and generative models accordingly rather than naive method, could be an important research opportunity to solve various real-world issues including semi-supervised learning tasks and model uncertainty.
- Dynamism in Selecting Threshold/ Hyper-parameters Values, and Network Structures with Computational Efficiency In general, the relationship among performance, model complexity, and computational requirements is a key issue in deep learning modeling and applications. A combination of algorithmic advancements with improved accuracy as well as maintaining computational efficiency, i.e., achieving the maximum throughput while consuming the least amount of resources, without significant information loss, can lead to a breakthrough in the effectiveness of deep learning modeling in future real-world applications. The concept of incremental approaches or recency-based learning [ 100 ] might be effective in several cases depending on the nature of target applications. Moreover, assuming the network structures with a static number of nodes and layers, hyper-parameters values or threshold settings, or selecting them by the trial-and-error process may not be effective in many cases, as it can be changed due to the changes in data. Thus, a data-driven approach to select them dynamically could be more effective while building a deep learning model in terms of both performance and real-world applicability. Such type of data-driven automation can lead to future generation deep learning modeling with additional intelligence, which could be a significant future aspect in the area as well as an important research direction to contribute.
- Lightweight Deep Learning Modeling for Next-Generation Smart Devices and Applications: In recent years, the Internet of Things (IoT) consisting of billions of intelligent and communicating things and mobile communications technologies have become popular to detect and gather human and environmental information (e.g. geo-information, weather data, bio-data, human behaviors, and so on) for a variety of intelligent services and applications. Every day, these ubiquitous smart things or devices generate large amounts of data, requiring rapid data processing on a variety of smart mobile devices [ 72 ]. Deep learning technologies can be incorporate to discover underlying properties and to effectively handle such large amounts of sensor data for a variety of IoT applications including health monitoring and disease analysis, smart cities, traffic flow prediction, and monitoring, smart transportation, manufacture inspection, fault assessment, smart industry or Industry 4.0, and many more. Although deep learning techniques discussed in Section 3 are considered as powerful tools for processing big data, lightweight modeling is important for resource-constrained devices, due to their high computational cost and considerable memory overhead. Thus several techniques such as optimization, simplification, compression, pruning, generalization, important feature extraction, etc. might be helpful in several cases. Therefore, constructing the lightweight deep learning techniques based on a baseline network architecture to adapt the DL model for next-generation mobile, IoT, or resource-constrained devices and applications, could be considered as a significant future aspect in the area.
- Incorporating Domain Knowledge into Deep Learning Modeling Domain knowledge, as opposed to general knowledge or domain-independent knowledge, is knowledge of a specific, specialized topic or field. For instance, in terms of natural language processing, the properties of the English language typically differ from other languages like Bengali, Arabic, French, etc. Thus integrating domain-based constraints into the deep learning model could produce better results for such particular purpose. For instance, a task-specific feature extractor considering domain knowledge in smart manufacturing for fault diagnosis can resolve the issues in traditional deep-learning-based methods [ 28 ]. Similarly, domain knowledge in medical image analysis [ 58 ], financial sentiment analysis [ 49 ], cybersecurity analytics [ 94 , 103 ] as well as conceptual data model in which semantic information, (i.e., meaningful for a system, rather than merely correlational) [ 45 , 121 , 131 ] is included, can play a vital role in the area. Transfer learning could be an effective way to get started on a new challenge with domain knowledge. Moreover, contextual information such as spatial, temporal, social, environmental contexts [ 92 , 104 , 108 ] can also play an important role to incorporate context-aware computing with domain knowledge for smart decision making as well as building adaptive and intelligent context-aware systems. Therefore understanding domain knowledge and effectively incorporating them into the deep learning model could be another research direction.
- Designing General Deep Learning Framework for Target Application Domains One promising research direction for deep learning-based solutions is to develop a general framework that can handle data diversity, dimensions, stimulation types, etc. The general framework would require two key capabilities: the attention mechanism that focuses on the most valuable parts of input signals, and the ability to capture latent feature that enables the framework to capture the distinctive and informative features. Attention models have been a popular research topic because of their intuition, versatility, and interpretability, and employed in various application areas like computer vision, natural language processing, text or image classification, sentiment analysis, recommender systems, user profiling, etc [ 13 , 80 ]. Attention mechanism can be implemented based on learning algorithms such as reinforcement learning that is capable of finding the most useful part through a policy search [ 133 , 134 ]. Similarly, CNN can be integrated with suitable attention mechanisms to form a general classification framework, where CNN can be used as a feature learning tool for capturing features in various levels and ranges. Thus, designing a general deep learning framework considering attention as well as a latent feature for target application domains could be another area to contribute.
To summarize, deep learning is a fairly open topic to which academics can contribute by developing new methods or improving existing methods to handle the above-mentioned concerns and tackle real-world problems in a variety of application areas. This can also help the researchers conduct a thorough analysis of the application’s hidden and unexpected challenges to produce more reliable and realistic outcomes. Overall, we can conclude that addressing the above-mentioned issues and contributing to proposing effective and efficient techniques could lead to “Future Generation DL” modeling as well as more intelligent and automated applications.
Concluding Remarks
In this article, we have presented a structured and comprehensive view of deep learning technology, which is considered a core part of artificial intelligence as well as data science. It starts with a history of artificial neural networks and moves to recent deep learning techniques and breakthroughs in different applications. Then, the key algorithms in this area, as well as deep neural network modeling in various dimensions are explored. For this, we have also presented a taxonomy considering the variations of deep learning tasks and how they are used for different purposes. In our comprehensive study, we have taken into account not only the deep networks for supervised or discriminative learning but also the deep networks for unsupervised or generative learning, and hybrid learning that can be used to solve a variety of real-world issues according to the nature of problems.
Deep learning, unlike traditional machine learning and data mining algorithms, can produce extremely high-level data representations from enormous amounts of raw data. As a result, it has provided an excellent solution to a variety of real-world problems. A successful deep learning technique must possess the relevant data-driven modeling depending on the characteristics of raw data. The sophisticated learning algorithms then need to be trained through the collected data and knowledge related to the target application before the system can assist with intelligent decision-making. Deep learning has shown to be useful in a wide range of applications and research areas such as healthcare, sentiment analysis, visual recognition, business intelligence, cybersecurity, and many more that are summarized in the paper.
Finally, we have summarized and discussed the challenges faced and the potential research directions, and future aspects in the area. Although deep learning is considered a black-box solution for many applications due to its poor reasoning and interpretability, addressing the challenges or future aspects that are identified could lead to future generation deep learning modeling and smarter systems. This can also help the researchers for in-depth analysis to produce more reliable and realistic outcomes. Overall, we believe that our study on neural networks and deep learning-based advanced analytics points in a promising path and can be utilized as a reference guide for future research and implementations in relevant application domains by both academic and industry professionals.
Declarations
The author declares no conflict of interest.
This article is part of the topical collection “Advances in Computational Approaches for Artificial Intelligence, Image Processing, IoT and Cloud Applications” guest edited by Bhanu Prakash K. N. and M. Shivakumar.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
- Warning : Invalid argument supplied for foreach() in /home/customer/www/opendatascience.com/public_html/wp-includes/nav-menu.php on line 95 Warning : array_merge(): Expected parameter 2 to be an array, null given in /home/customer/www/opendatascience.com/public_html/wp-includes/nav-menu.php on line 102
- ODSC EUROPE
- AI+ Training
- Speak at ODSC

- Data Analytics
- Data Engineering
- Data Visualization
- Deep Learning
- Generative AI
- Machine Learning
- NLP and LLMs
- Business & Use Cases
- Career Advice
- Write for us
- ODSC Community Slack Channel
- Upcoming Webinars

The Most Influential Deep Learning Research of 2019
Data Science Academic Research Deep Learning Modeling Research Research posted by Daniel Gutierrez, ODSC December 23, 2019 Daniel Gutierrez, ODSC
Deep learning has continued its forward movement during 2019 with advances in many exciting research areas like generative adversarial networks (GANs), auto-encoders, and reinforcement learning. In terms of deployments, deep learning is the darling of many contemporary application areas such as computer vision, image recognition, speech recognition, natural language processing, machine translation, autonomous vehicles, and many more.
[Related Article: Best Machine Learning Research of 2019]
Earlier this year, we saw Google AI Language revolutionize the NLP segment of deep learning with the new language representation model called BERT , which stands for Bidirectional Encoder Representations from Transformers . The already seminal paper was released on arXiv on May 24. This has led to a storm of follow-on research results. This is just one specific area of deep learning, with many more are pushing forward just as quickly.
Although deep learning is officially a subset of machine learning, its creative use of artificial neural networks is finely tuned to certain high-dimensional problem domains. For typical business problems, traditional machine learning algorithms ( gradient boosting is supreme) often perform better.
In this article, I’ll help kick start your effort to keep pace with this research-heavy field by curating the current large pool of research efforts published in 2019 on arXiv.org down to the manageable short-list of my favorites that follows. Enjoy!
A Comprehensive Survey on Graph Neural Networks
Deep learning has revolutionized many machine learning tasks in recent years, ranging from image classification and video processing to speech recognition and natural language understanding. The data in these tasks are typically represented in the Euclidean space. However, there is an increasing number of applications where data are generated from non-Euclidean domains and are represented as graphs with complex relationships and interdependency between objects. The complexity of graph data has imposed significant challenges on existing machine learning algorithms. Recently, many studies on extending deep learning approaches for graph data have emerged. This survey upon which this paper is based provides a comprehensive overview of graph neural networks (GNNs) in data mining and machine learning fields. The researchers propose a new taxonomy to divide the state-of-the-art graph neural networks into four categories, namely recurrent graph neural networks, convolutional graph neural networks, graph auto-encoders, and spatial-temporal graph neural networks. Included is a discussion of the applications of graph neural networks across various domains and summarize the open source codes, benchmark data sets, and model evaluation of graph neural networks. The paper concludes by proposing potential research directions in this rapidly growing field.

EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. This paper from Google Research systematically studies model scaling and identifies that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, a new scaling method is proposed that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. The paper demonstrates the effectiveness of this method on scaling up MobileNets and ResNet. To go even further, neural architecture search is used to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. Source code is available on GitHub .

Deep Learning for Anomaly Detection: A Survey
Anomaly detection is an important problem that has been well-studied within diverse research areas and application domains. The aim of this survey is two-fold, firstly to present a structured and comprehensive overview of research methods in deep learning-based anomaly detection, and additionally to review the adoption of these methods for anomaly across various application domains and assess their effectiveness. The paper groups state-of-the-art research techniques into different categories based on the underlying assumptions and approach adopted. Within each category the paper outlines the basic anomaly detection technique, along with its variants and present key assumptions, to differentiate between normal and anomalous behavior. For each category, the paper also presents the advantages and limitations and discusses the computational complexity of the techniques in real application domains. Finally, the paper outlines open issues in research and challenges faced while adopting these techniques.
Deep Learning for Symbolic Mathematics
Neural networks have a reputation for being better at solving statistical or approximate problems than at performing calculations or working with symbolic data. This paper from Facebook AI Research shows that they can be surprisingly good at more elaborated tasks in mathematics, such as symbolic integration and solving differential equations. The paper proposes a syntax for representing mathematical problems, and methods for generating large data sets that can be used to train sequence-to-sequence models. Results were achieved that outperform commercial Computer Algebra Systems such as Matlab or Mathematica.
The computations required for deep learning research have been doubling every few months, resulting in an estimated 300,000x increase from 2012 to 2018. These computations have a surprisingly large carbon footprint. Ironically, deep learning was inspired by the human brain, which is remarkably energy efficient. Moreover, the financial cost of the computations can make it difficult for academics, students, and researchers, in particular those from emerging economies, to engage in deep learning research. This position paper advocates a practical solution by making efficiency an evaluation criterion for research alongside accuracy and related measures. In addition, the paper proposes reporting the financial cost or “price tag” of developing, training, and running models to provide baselines for the investigation of increasingly efficient methods. The goal is to make AI both greener and more inclusive—enabling any inspired undergraduate with a laptop to write high-quality research papers.
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
The past decade has seen a remarkable series of advances in machine learning, and in particular deep learning approaches based on artificial neural networks, to improve our abilities to build more accurate systems across a broad range of areas, including computer vision, speech recognition, language translation, and natural language understanding tasks. This paper by Jeffrey Dean of Google Research discusses some of the advances in machine learning, and their implications on the kinds of computational devices we need to build, especially in the post-Moore’s Law-era. It also discusses some of the ways that machine learning may also be able to help with some aspects of the circuit design process. Finally, it provides a sketch of at least one interesting direction towards much larger-scale multi-task models that are sparsely activated and employ much more dynamic, example- and task-based routing than the machine learning models of today.
Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks
Batch Normalization (BN) is a highly successful and widely used batch dependent training method. Its use of mini-batch statistics to normalize the activations introduces dependence between samples, which can hurt the training if the mini-batch size is too small, or if the samples are correlated. Several alternatives, such as Batch Renormalization and Group Normalization (GN), have been proposed to address these issues. However, they either do not match the performance of BN for large batches, or still exhibit degradation in performance for smaller batches, or introduce artificial constraints on the model architecture. This paper by Google Research proposes the Filter Response Normalization (FRN) layer, a novel combination of a normalization and an activation function, that can be used as a drop-in replacement for other normalizations and activations. The new method operates on each activation map of each batch sample independently, eliminating the dependency on other batch samples or channels of the same sample. The method outperforms BN and all alternatives in a variety of settings for all batch sizes.
Neural Random Forest Imitation
This paper presents Neural Random Forest Imitation— a novel approach for transforming random forests into neural networks. Existing methods produce very inefficient architectures and do not scale. The new method is for generating data from a random forest and learning a neural network that imitates it. Without any additional training data, this transformation creates very efficient neural networks that learn the decision boundaries of a random forest. The generated model is fully differentiable and can be combined with the feature extraction in a single pipeline enabling further end-to-end processing. Experiments on several real-world benchmark datasets demonstrate outstanding performance in terms of scalability, accuracy, and learning with very few training examples. Compared to state-of-the-art mappings, this method significantly reduces the network size while achieving the same or even improved accuracy due to better generalization.
When Does Label Smoothing Help?
The generalization and learning speed of a multi-class neural network can often be significantly improved by using soft targets that are a weighted average of the hard targets and the uniform distribution over labels. Smoothing the labels in this way prevents the network from becoming over-confident and label smoothing has been used in many state-of-the-art models, including image classification, language translation and speech recognition. Despite its widespread use, label smoothing is still poorly understood. This paper from Google Brain Toronto, shows empirically that in addition to improving generalization, label smoothing improves model calibration which can significantly improve beam-search. The researcher, including Geoffrey Hinton, also observe that if a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective. To explain these observations, the paper visualizes how label smoothing changes the representations learned by the penultimate layer of the network. The paper shows that label smoothing encourages the representations of training examples from the same class to group in tight clusters. This results in loss of information in the logits about resemblances between instances of different classes, which is necessary for distillation, but does not hurt generalization or calibration of the model’s predictions.
On the Learning Dynamics of Deep Neural Networks
While a lot of progress has been made in recent years, the dynamics of learning in deep nonlinear neural networks remain to this day largely misunderstood. This paper from Microsoft Research studies the case of binary classification and proves various properties of learning in such networks under strong assumptions such as linear separability of the data. Extending existing results from the linear case, the paper confirms empirical observations by proving that the classification error also follows a sigmoidal shape in nonlinear architectures. The paper shows that given proper initialization, learning expounds parallel independent modes and that certain regions of parameter space might lead to failed training. The paper also demonstrates that input norm and features’ frequency in the data set lead to distinct convergence speeds which might shed some light on the generalization capabilities of deep neural networks. Included is a comparison between the dynamics of learning with cross-entropy and hinge losses, which could prove useful to understand recent progress in the training of generative adversarial networks. Finally, the paper identifies a phenomenon baptized “gradient starvation” where the most frequent features in a data set prevent the learning of other less frequent but equally informative features.

[ Related Article: Best Deep Reinforcement Learning Research of 2019 So Far ]
Want to learn more about these novel deep learning techniques and findings from the people who work on them? Attend ODSC East 2020 in Boston April 13-17 and learn from them directly!

Daniel Gutierrez, ODSC
Daniel D. Gutierrez is a practicing data scientist who’s been working with data long before the field came in vogue. As a technology journalist, he enjoys keeping a pulse on this fast-paced industry. Daniel is also an educator having taught data science, machine learning and R classes at the university level. He has authored four computer industry books on database and data science technology, including his most recent title, “Machine Learning and Data Science: An Introduction to Statistical Learning Methods with R.” Daniel holds a BS in Mathematics and Computer Science from UCLA.

IMF Chief Sees AI Impacting Labor like a “tsunami”
AI and Data Science News posted by ODSC Team May 14, 2024 AI is poised to dramatically impact the global labor market, akin to a “tsunami” according to...

US and China Meet to Discuss AI Risk Geneva
AI and Data Science News posted by ODSC Team May 14, 2024 The U.S. and China are set to meet in Geneva on Tuesday to discuss artificial intelligence....

ODSC East 2024 Keynote: DeepMind’s Anna Goldie on Deep Reinforcement Learning in the Real World
East 2024 Conferences posted by ODSC Team May 14, 2024 In the evolving landscape of artificial intelligence, reinforcement learning (RL) has transcended its conventional boundaries, showcasing...

Microsoft Research Blog
Mattersim: a deep-learning model for materials under real-world conditions.
Published May 13, 2024
By Han Yang , Senior Researcher Jielan Li , Researcher 2 Hongxia Hao , Senior Researcher Ziheng Lu , Principal Researcher
Share this page
- Share on Facebook
- Share on Twitter
- Share on LinkedIn
- Share on Reddit
- Subscribe to our RSS feed

In the quest for groundbreaking materials crucial to nanoelectronics, energy storage, and healthcare, a critical challenge looms: predicting a material’s properties before it is even created. This is no small feat, with any combination of 118 elements in the periodic table, and the range of temperatures and pressures under which materials are synthesized and operated. These factors drastically affect atomic interactions within materials, making accurate property prediction and behavior simulation exceedingly demanding.
Here at Microsoft Research, we developed MatterSim , a deep-learning model for accurate and efficient materials simulation and property prediction over a broad range of elements, temperatures, and pressures to enable the in silico materials design. MatterSim employs deep learning to understand atomic interactions from the very fundamental principles of quantum mechanics, across a comprehensive spectrum of elements and conditions—from 0 to 5,000 Kelvin (K), and from standard atmospheric pressure to 10,000,000 atmospheres. In our experiment, MatterSim efficiently handles simulations for a variety of materials, including metals, oxides, sulfides, halides, and their various states such as crystals, amorphous solids, and liquids. Additionally, it offers customization options for intricate prediction tasks by incorporating user-provided data.

Simulating materials under realistic conditions across the periodic table
MatterSim’s learning foundation is built on large-scale synthetic data, generated through a blend of active learning, generative models, and molecular dynamics simulations. This data generation strategy ensures extensive coverage of material space, enabling the model to predict energies, atomic forces, and stresses. It serves as a machine-learning force field with a level of accuracy compatible with first-principles predictions. Notably, MatterSim achieves a10-fold increase in accuracy for material property predictions at finite temperatures and pressures when compared to previous state-of-the-art models. Our research demonstrates its proficiency in simulating a vast array of material properties, including thermal, mechanical, and transport properties, and can even predict phase diagrams.

Adapting to complex design tasks
While trained on broad synthetic datasets, MatterSim is also adaptable for specific design requirements by incorporating additional data. The model utilizes active learning and fine-tuning to customize predictions with high data efficiency. For example, simulating water properties — a task seemingly straightforward but computationally intensive — is significantly optimized with MatterSim’s adaptive capability. The model requires only 3% of the data compared to traditional methods, to match experimental accuracy that would otherwise require 30 times more resources for a specialized model and exponentially more for first-principles methods.

Microsoft Research Podcast

AI Frontiers: AI for health and the future of research with Peter Lee
Peter Lee, head of Microsoft Research, and Ashley Llorens, AI scientist and engineer, discuss the future of AI research and the potential for GPT-4 as a medical copilot.
Bridging the gap between atomistic models and real-world measurements
Translating material properties from atomic structures is a complex task, often too intricate for current methods based on statistics, such as molecular dynamics. MatterSim addresses this by mapping these relationships directly through machine learning. It incorporates custom adaptor modules that refine the model to predict material properties from structural data, eliminating the need for intricate simulations. Benchmarking against MatBench (opens in new tab) , a renowned material property prediction benchmark set, MatterSim demonstrates significant accuracy improvement and outperforms all specialized property-specific models, showcasing its robust capability in direct material property prediction from domain-specific data.
Looking ahead
As MatterSim research advances, the emphasis is on experimental validation to reinforce its potential role in pivotal sectors, including the design of catalysts for sustainability, energy storage breakthroughs, and nanotechnology advancements. The planned integration of MatterSim with generative AI models and reinforcement learning heralds a new era in the systematic pursuit of novel materials. This synergy is expected to revolutionize the field, streamlining guided creation of materials tailored for diverse applications ranging from semiconductor technologies to biomedical engineering. Such progress promises to expedite material development and bolster sustainable industrial practices, thereby fostering technological advancements that will benefit society.
Related publications
Mattersim: a deep learning atomistic model across elements, temperatures and pressures, meet the authors.

Senior Researcher

Researcher 2

Hongxia Hao

Principal Researcher
Continue reading

Abstracts: March 21, 2024

ViSNet: A general molecular geometry modeling framework for predicting molecular properties and simulating molecular dynamics

MatterGen: Property-guided materials design

Distributional Graphormer: Toward equilibrium distribution prediction for molecular systems
Research areas.
Related labs
- Microsoft Research Lab - Asia
- Follow on Twitter
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
Share this page:
Artificial Intelligence (AI)
Work in Artificial Intelligence in the EECS department at Berkeley involves foundational research in core areas of deep learning, knowledge representation, reasoning, learning, planning, decision-making, vision, robotics, speech, and natural language processing. For more information please see the Berkeley Artificial Intelligence Research Lab (BAIR) . There are also significant efforts aimed at applying algorithmic advances to applied problems in a range of areas, including bioinformatics, networking and systems, search and information retrieval. There are active collaborations with several groups on campus, including the campus-wide vision sciences group, the information retrieval group at the I-School and the campus-wide computational biology program. There are also connections to a range of research activities in the cognitive sciences, including aspects of psychology, linguistics, and philosophy. Research in AI involves techniques and tools from statistics, neuroscience, control, optimization, and operations research.
Learning and Probabilistic Inference:
Graphical models. Kernel methods. Nonparametric Bayesian methods. Reinforcement learning. Problem solving, decisions, and games.
Knowledge Representation and Reasoning:
First order probabilistic logics. Symbolic algebra.
Search and Information Retrieval:
Collaborative filtering. Information extraction. Image and video search. Intelligent information systems.
Speech and Language:
Parsing. Machine translation. Speech Recognition. Context Modeling. Dialog Systems.
Object Recognition. Scene Understanding. Human Activity Recognition. Active Vision. Grouping and Figure-Ground. Visual Data Mining.
Deep Learning, Perception, Manipulation, Locomotion, Human Robot Interaction, Motion Planning. Applications to Logistics, Healthcare, Home and Service Robots, Agriculture.
Research Centers
- Berkeley Artificial Intelligence Research Lab
- Berkeley Center for Responsible, Decentralized Intelligence (RDI)
- Berkeley Equity and Access in Algorithms, Mechanisms, and Optimization
- Berkeley Laboratory for Information and System Sciences
- Center for Human Compatible Artificial Intelligence
- Center for the Theoretical Foundations of Learning, Inference, Information, Intelligence, Mathematics and Microeconomics at Berkeley
- CITRIS People and Robots
- FHL Vive Center for Enhanced Reality
- International Computer Science Institute
- Sky Computing Lab
- Verified Human Interfaces, Control, and Learning for Semi-Autonomous Systems
- Video and Image Processing Lab
- Pieter Abbeel
- Cameron Allen
- Gopala Krishna Anumanchipalli
- Peter Bartlett
- Christian Borgs
- John F. Canny
- Michael Cohen
- John DeNero
- Anca Dragan
- Alexei (Alyosha) Efros
- Gerald Friedland
- Ken Goldberg
- Joseph Gonzalez
- Nika Haghtalab
- Jiantao Jiao
- Michael Jordan
- Angjoo Kanazawa
- Kurt Keutzer
- Daniel Klein
- Aditi Krishnapriyan
- Sergey Levine
- Michael Lustig
- Jitendra Malik (coordinator)
- Igor Mordatch
- Narges Norouzi
- Gireeja Ranade
- Benjamin Recht
- Stuart J. Russell
- Anant Sahai
- S. Shankar Sastry
- Somayeh Sojoudi
- Jacob Steinhardt
- Martin Wainwright
- Matei Zaharia
- Venkat Anantharam
- Ruzena Bajcsy
- Alexandre Bayen
- Thomas Courtade
- Trevor Darrell
- Laurent El Ghaoui
- Richard J. Fateman
- Jerome A. Feldman
- Marti Hearst
- Nilah Ioannidis
- Preeya Khanna
- Jennifer Listgarten
- James O'Brien
- Kannan Ramchandran
- Jaijeet Roychowdhury
- Alberto L. Sangiovanni-Vincentelli
- Sanjit A. Seshia
- Yun S. Song
- Avideh Zakhor
Faculty Awards
- ACM Prize in Computing: Pieter Abbeel, 2021. Alexei (Alyosha) Efros, 2016.
- MacArthur Fellow: Dawn Song, 2010.
- National Academy of Sciences (NAS) Member: Jitendra Malik, 2015. Michael Jordan, 2010.
- National Academy of Engineering (NAE) Member: Jitendra Malik, 2011. Michael Jordan, 2010. S. Shankar Sastry, 2001. Alberto L. Sangiovanni-Vincentelli, 1998. Ruzena Bajcsy, 1997.
- American Academy of Arts and Sciences Member: Alberto L. Sangiovanni-Vincentelli, 2024. Jitendra Malik, 2013. Michael Jordan, 2010. Ruzena Bajcsy, 2007. S. Shankar Sastry, 2003.
- Berkeley Citation: Ruzena Bajcsy, 2023. S. Shankar Sastry, 2018. Jerome A. Feldman, 2009.
- UC Berkeley Distinguished Teaching Award: John DeNero, 2018. Daniel Klein, 2010. Alberto L. Sangiovanni-Vincentelli, 1981.
- Sloan Research Fellow: Nika Haghtalab, 2024. Preeya Khanna, 2024. Angjoo Kanazawa, 2023. Sergey Levine, 2019. Anca Dragan, 2018. Ren Ng, 2017. Michael Lustig, 2013. Benjamin Recht, 2011. Pieter Abbeel, 2011. Sanjit A. Seshia, 2008. Yun S. Song, 2008. Alexei (Alyosha) Efros, 2008. Dawn Song, 2007. Daniel Klein, 2007. Martin Wainwright, 2005. James O'Brien, 2003.
Related Courses
- CS C182. The Neural Basis of Thought and Language
- CS 188. Introduction to Artificial Intelligence
- CS 189. Introduction to Machine Learning
- CS C280. Computer Vision
- CS C281A. Statistical Learning Theory
- CS C281B. Advanced Topics in Learning and Decision Making
- CS 287. Advanced Robotics
- CS 289A. Introduction to Machine Learning
- EE 290P. Advanced Topics in Electrical Engineering: Advanced Topics in Bioelectronics
Future of Deep Learning according to top AI Experts of 2024
Cem is the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per Similarweb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Deep learning is currently the most effective AI technology for numerous applications. However, there is still differing opinions on how capable deep learning can become. While deep learning researchers like Geoffrey Hinton believe 1 that all problems could be solved with deep learning, there are numerous scientists who point to flaws in deep learning where remedies are not clear. 2
With increasing interest in deep learning from the general public as well as developer and research communities, there could be breakthroughs in the field. Experts such as recent Turing prize winners expect such breakthroughs come from areas such as capsule networks, deep reinforcement learning and other approaches that complement deep learning’s current limitations. For detailed answers:
What is the level of interest in deep learning?
General public.
Interest in deep learning is continuing to increase. Reasons of this interest include deep learning’s capacity to
- Improve accuracy of predictions, enabling improved data driven decisions
- Learn from unstructured and unlabelled datasets, enable analysis of unstructured data
As a result of these, deep learning solutions provide operational and financial benefits to companies. In 2012, later Turing award recipient George Hinton’s team 3 demonstrated that deep learning could provide significant accuracy benefits in common AI tasks like image recognition. 4 After this, companies started investing into deep learning and interest in the area has exploded. Since 2017, interest in deep learning appears stable.
Number of times a phrase is searched on a search engine is a proxy for its popularity. You can see the frequency with which “deep learning” was searched on Google below.

Research community
Number of deep learning publications on arXiv has increased almost 6 times in the last five years according to AI Index which provides globally sourced data to develop AI applications, ArXiv is an open-access platform for scientific articles in physics, mathematics, computer science etc. It includes both peer-reviewed and non-peer-reviewed articles.

Developer community
TensorFlow and Keras are the most popular open source libraries for deep learning. Other popular libraries are PyTorch , Sckit-learn, BVL/caffe, MXNet and Microsoft Cognitive Toolkit (CNTK). These open source platforms help developers easily build deep learning models. As can be seen below, PyTorch, released by Facebook in 2016, is also rapidly growing in popularity.

Open source libraries for deep learning are generally written in JavaScript, Python, C++ and Scala.
What are the technologies that can shape deep learning?
Deep learning is a rapidly growing domain in AI. Due to its challenges about size and diversity of data, AI experts like Geoffrey Hinton, Yoshua Bengio, Yann LeCun who received 5 the Turing prize for their work on deep learning and Gary Marcus suggest new methods to improve deep learning solutions. These methods include introducing reasoning or prior knowledge to deep learning, self-supervised learning, capsule networks, etc.
Introduction of non-learning based AI approaches to deep learning
Gary Marcus, one of the pioneers in deep learning, highlights that deep learning techniques are data hungry, shallow, brittle, and limited in their ability to generalize
- Unsupervised learning: If systems can determine their own objectives, do reasoning and problem-solving at a more abstract level, great improvements could be achieved
- Symbol-manipulation & the need for hybrid models: Integration of deep learning with symbolic systems, which excel at inference and abstraction could provide better results
- More insight from cognitive and developmental psychology: Better understanding the innate machinery in humans minds, gaining common sense knowledge and human understanding of narrative could be valuable for developing learning models
- Bolder challenges: Generalized artificial intelligence could be multi-dimensional like natural intelligence to deal with the complexity of the world
- Hybrid neuro-symbolic architectures: Gary claims that we should embrace other AI approaches such as prior knowledge, reasoning, and rich cognitive models along with deep learning for transformational change
- Construction of rich, partly-innate cognitive frameworks and large-scale knowledge databases
- Tools for abstract reasoning for effective generalization
- Mechanisms for the representation and induction of cognitive models

For more on Gary Marcus’ ideas, feel free to read his articles: Deep Learning: A Critical Appraisal from 2018 and The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence from 2020.
Capsule networks
Capsule networks (CapsNets) is a new deep neural network architecture introduced by Geoffrey Hinton and his team in 2017 . Capsules work with vectors and make calculations on the inputs. They encapsulate their results into a vector. So, when the orientation of the image is changed, the vector is moved. Geoffrey Hinton thinks that the approach of CNNs for object recognition is very different from human perception. CNNs need to be improved for dealing with some problems like rotation and scaling, and capsule networks can help to generalize better in deep learning architecture.
Deep reinforcement learning algorithms
Deep reinforcement learning is a combination of reinforcement learning and deep learning. Reinforcement learning normally works on structured data. On the other hand, deep reinforcement learning makes decisions about optimizing an objective based on unstructured data.
Deep reinforcement learning models can learn to maximize cumulative reward. It is good for target optimization actions, such as complicated control problems. Yann LeCun thinks that reinforcement learning is good for simulations but it needs lots of trials and provides weak feedback. However, reinforcement learning models do not require large data sets compared to other supervised models.
Few-shot learning (FLS)
The advantage of few-shot learning (FSL) which is a subfield of machine learning is being able to work with a small amount of training data. Few-shot learning algorithms are useful to handle with data shortage and computational costs. Especially, few-shot learning models can be beneficial in healthcare to detect rare diseases with inadequate images into the training data. Few-shot learning models have potential to strengthen deep learning models with new researches and developments.
GAN-based data augmentation
Generative adversarial networks (GANs) are popular in data augmentation applications and they can create meaningful new data by using unlabelled original data. They work in these steps:
- Deep learning models use GANs based data augmentation to generate synthetic data
- This synthetic data is used as training data
A study about insect pest classification shows that GAN-based augmentation method can help CNNs
- perform better compared to classic augmentation method
- reduce data collection needs.
Self-Supervised learning
According to Yann LeCun, self-supervised learning models would be a key component of deep learning models. Understanding how people learn quickly could allow to utilize full potential of self-supervised learning and reduce deep learning’s reliance on large, annotated training data sets. Self-supervised learning models can work without labeled data and make predictions if they have quality data and inputs of possible scenarios.
Other approaches
- Imitation learning: If there are few rewards in reinforcement learning models, imitation learning is used as an alternative method. The agent can learn performing a task by imitating supervisor’s demonstrations including observations and actions. It is also called as Learning from Demonstration or Apprenticeship Learning.
- Physics guided/informed machine learning : Physics laws are integrated into training process to induce interpretability and improve accuracy of predictions in deep learning models.
- Transfer learning which is used to help machines transfer knowledge from one domain to another
- Others: Motor learning and brain areas like cortical and subcortical neural circuits may be new fields of inspiration for machine learning models.
If you want to read more about deep learning, check our article on deep learning use cases .
If you are ready to use deep learning in your firm, we prepared a data driven list of companies offering deep learning platforms .
If you need help in choosing among deep learning vendors who can help you get started, let us know:
For more, you can watch 3 AI experts share their views during AAAI 20:
This article was drafted by former AIMultiple industry analyst Ayşegül Takımoğlu.
External Links
- 1. Hao, Karen (2020). AI pioneer Geoff Hinton: “Deep learning is going to be able to do everything”. Technology review . Revisited January 20, 2023
- 2. Polonski, V. (2018). “ Why AI can’t solve everything .” The conversation .
- 3. “ Fathers of the Deep Learning Revolution Receive ACM A.M. Turing Award. ” ACM . 2018. Revisited January 20, 2023.
- 4. Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). “ Imagenet classification with deep convolutional neural networks .” Communications of the ACM , 60 (6), 84-90.
- 5. “ Fathers of the Deep Learning Revolution Receive ACM A.M. Turing Award. ” ACM . 2018. Revisited January 20, 2023.

Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
AIMultiple.com Traffic Analytics, Ranking & Audience , Similarweb. Why Microsoft, IBM, and Google Are Ramping up Efforts on AI Ethics , Business Insider. Microsoft invests $1 billion in OpenAI to pursue artificial intelligence that’s smarter than we are , Washington Post. Data management barriers to AI success , Deloitte. Empowering AI Leadership: AI C-Suite Toolkit , World Economic Forum. Science, Research and Innovation Performance of the EU , European Commission. Public-sector digitization: The trillion-dollar challenge , McKinsey & Company. Hypatos gets $11.8M for a deep learning approach to document processing , TechCrunch. We got an exclusive look at the pitch deck AI startup Hypatos used to raise $11 million , Business Insider.
To stay up-to-date on B2B tech & accelerate your enterprise:
Next to Read
Generative adversarial networks (gan) & synthetic data [2024], data augmentation to improve deep learning models in 2024, 12 deep learning use cases / applications in healthcare [2024].
Your email address will not be published. All fields are required.
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: dehazing remote sensing and uav imagery: a review of deep learning, prior-based, and hybrid approaches.
Abstract: High-quality images are crucial in remote sensing and UAV applications, but atmospheric haze can severely degrade image quality, making image dehazing a critical research area. Since the introduction of deep convolutional neural networks, numerous approaches have been proposed, and even more have emerged with the development of vision transformers and contrastive/few-shot learning. Simultaneously, papers describing dehazing architectures applicable to various Remote Sensing (RS) domains are also being published. This review goes beyond the traditional focus on benchmarked haze datasets, as we also explore the application of dehazing techniques to remote sensing and UAV datasets, providing a comprehensive overview of both deep learning and prior-based approaches in these domains. We identify key challenges, including the lack of large-scale RS datasets and the need for more robust evaluation metrics, and outline potential solutions and future research directions to address them. This review is the first, to our knowledge, to provide comprehensive discussions on both existing and very recent dehazing approaches (as of 2024) on benchmarked and RS datasets, including UAV-based imagery.
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Supervise-Assisted Self-Supervised Deep-Learning Method for Hyperspectral Image Restoration
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
A Comprehensive Review of Bias in Deep Learning Models: Methods, Impacts, and Future Directions
- Review article
- Published: 08 May 2024
Cite this article

- Milind Shah ORCID: orcid.org/0009-0001-6077-3924 1 &
- Nitesh Sureja ORCID: orcid.org/0000-0002-4429-1597 1
52 Accesses
Explore all metrics
This comprehensive review and analysis delve into the intricate facets of bias within the realm of deep learning. As artificial intelligence and machine learning technologies become increasingly integrated into our lives, understanding and mitigating bias in these systems is of paramount importance. This paper scrutinizes the multifaceted nature of bias, encompassing data bias, algorithmic bias, and societal bias, and explores the interconnectedness among these dimensions. Through an exploration of existing literature and recent advancements in the field, this paper offers a critical assessment of various bias mitigation techniques. It examines the challenges faced in addressing bias and emphasizes the need for an intersectional and inclusive approach to effectively rectify disparities. Furthermore, this review underscores the importance of ethical considerations in the development and deployment of deep learning models. It highlights the necessity of diverse representation in data, fairness-aware algorithms, and interpretability as key elements in creating bias-free AI systems. By synthesizing existing research and providing a holistic overview of bias in deep learning, this paper aims to contribute to the ongoing discourse on mitigating bias and fostering equity in artificial intelligence systems. The insights presented herein can serve as a foundation for future research and as a guide for practitioners, policymakers, and stakeholders to navigate the complex landscape of bias in deep learning.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

The Ethics of AI Ethics: An Evaluation of Guidelines
A survey on large language model based autonomous agents.

The role of artificial intelligence in healthcare: a structured literature review
Data availability.
Not applicable.
Ferrara E (2023) The butterfly effect in artificial intelligence systems: implications for AI bias and fairness, machine learning with applications. 15(September):100525, 2024, https://doi.org/10.1016/j.mlwa.2024.100525
Yang L (2024) Characteristics of datasets for fake news detection to mitigate domain bias. Inform Eng Express 10(1):1. https://doi.org/10.52731/iee.v10.i1.786
Article Google Scholar
Giloni A et al (2024) BENN: bias estimation using a deep neural network. IEEE Trans Neural Networks Learn Syst 35(1):117–131. https://doi.org/10.1109/TNNLS.2022.3172365
.Teo CTH, Abdollahzadeh M, Cheung NM (2024) FairTL: a transfer learning approach for bias mitigation in deep generative models. IEEE Journal on Selected Topics in Signal Processing PP(XX):1–13. https://doi.org/10.1109/JSTSP.2024.3363419
Liu H, Sheng M, Sun Z, Yao Y, Hua XS, Shen HT (2024) Learning with Imbalanced noisy data by preventing bias in sample selection. IEEE Trans Multimedia PP:1–12. https://doi.org/10.1109/TMM.2024.3368910
Dominguez-Catena I, Paternain D, Galar M, Intelligence (2024) Metrics for dataset demographic bias: a case study on facial expression recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence PP:1–18 https://doi.org/10.1109/TPAMI.2024.3361979
Kulkarni A, Balachandran V, Divakaran DM, Das T (2024) MitigaTing Bias In Machine Learning Models For Phishing Webpage Detection. 2024 16th International Conference on COMmunication Systems and NETworkS, COMSNETS 2024, Ml:430–432, https://doi.org/10.1109/COMSNETS59351.2024.10427170
Zhang X, Zhang F, Xu C (2024) NExT-OOD: overcoming dual multiple-choice VQA biases. IEEE Trans Pattern Anal Mach Intell 46(4):1913–1931. https://doi.org/10.1109/TPAMI.2023.3269429
Rattanaphan S, Briassouli A (2024) Evaluating generalization, bias, and fairness in deep learning for metal surface defect detection: a comparative study. Processes 12(3):456. https://doi.org/10.3390/pr12030456
Openja M, Laberge G, Khomh F (2024) Detection and evaluation of bias-inducing features in machine learning. 29(1). https://doi.org/10.1007/s10664-023-10409-5
Dogra V, Verma S, Kavita M, Wozniak J, Shafi, Ijaz MF (2024) Shortcut learning explanations for deep natural language processing: a survey on dataset biases. IEEE Access 12(January):26183–26195, https://doi.org/10.1109/ACCESS.2024.3360306
Chen Z, Zhang JM, Sarro F, Harman M (2023) A comprehensive empirical study of bias mitigation methods for machine learning classifiers. ACM Trans Softw Eng Methodol 32(4). https://doi.org/10.1145/3583561
Hort M, Chen Z, Zhang JM, Harman M, Sarro F (2023) Bias mitigation for machine learning classifiers: a comprehensive survey. ACM J Responsible Comput. https://doi.org/10.1145/3631326
Pagano TP et al (2023) Bias and unfairness in machine learning models: a systematic review on datasets, tools, fairness metrics, and identification and mitigation methods. Big Data Cogn Comput 7(1):1–31. https://doi.org/10.3390/bdcc7010015
Siddique S, Haque MA, George R, Gupta KD, Gupta D, Faruk MJH (2023) Survey on machine learning biases and mitigation techniques. Digital 4(1):1–68. https://doi.org/10.3390/digital4010001
Miller RJH et al (2023) Mitigating bias in deep learning for diagnosis of coronary artery disease from myocardial perfusion SPECT images. Eur J Nucl Med Mol Imaging 50(2):387–397. https://doi.org/10.1007/s00259-022-05972-w
Bai M et al (2023) The uncovered biases and errors in clinical determination of bone age by using deep learning models. Eur Radiol 33(5):3544–3556. https://doi.org/10.1007/s00330-022-09330-0
Guo Y, Nie L, Cheng H, Cheng Z, Kankanhalli M, Bimbo AD (2023) On modality bias recognition and reduction. ACM Trans Multimedia Comput Commun Appl 19(3):1–22. https://doi.org/10.1145/3565266
Donald A et al (2023) Bias detection for customer interaction data: a survey on datasets, methods, and tools. IEEE Access 11(March):53703–53715, https://doi.org/10.1109/ACCESS.2023.3276757
Lin Z, Liu D, Pan W, Yang Q, Ming Z (2023) Transfer learning for collaborative recommendation with biased and unbiased data. Artif Intell 324:103992. https://doi.org/10.1016/j.artint.2023.103992
Article MathSciNet Google Scholar
Baracaldo N et al (2023) Benchmarking the effect of poisoning defenses on the security and bias of deep learning models. 2023 IEEE security and privacy Workshops (SPW) 45–56. https://doi.org/10.1109/SPW59333.2023.00010
Gilg J, Herzog F (2023) The box size confidence bias harms your object detector. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 1471–1480, https://doi.org/10.1109/WACV56688.2023.00152
Nagpal S, Singh M, Singh R (2023) In-group bias in deep learning-based face recognition models due to ethnicity and age. IEEE Trans Technol Soc 4(1):54–67. https://doi.org/10.1109/TTS.2023.3241010
Kim JW, Kim SY, Sohn KA (2023) Dataset bias prediction for few-shot image classification. Electron (Switzerland) 12(11):1–14. https://doi.org/10.3390/electronics12112470
Dreyer M, Samek W, Nov CV (2023) Revealing hidden context bias in segmentation and object detection through concept-specific explanations. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 3829–3839
Wehrli S, Hertweck C, Amirian M, Glüge S, Stadelmann T (2022) Bias, awareness, and ignorance in deep– learning– based face recognition. AI Ethics 2(3):509–522. https://doi.org/10.1007/s43681-021-00108-6
Mohammad C, Haider R, Clifton C, Metrics AF, Unfair AI (2022) It isn’t just biased data, 2022 IEEE International Conference on Data Mining (ICDM) (Icdm):957–962. https://doi.org/10.1109/ICDM54844.2022.00114
Gwyn T, Roy K (2022) Examining gender bias of convolutional neural networks via facial recognition. future internet 14(12). https://doi.org/10.3390/fi14120375
Sourlos N, Wang J, Nagaraj Y, van Ooijen P, Vliegenthart R (2022) Possible bias in supervised deep learning algorithms for CT lung nodule detection and classification. Cancers 14(16):1–15. https://doi.org/10.3390/cancers14163867
Salman H, Jain S, Ilyas A, Engstrom L, Wong E, Madry A (2022) When does bias transfer in transfer learning? arxiv. Available: http://arxiv.org/abs/2207.02842
Hall M, van der Maaten L, Gustafson L, Jones M, Adcock A (2022) A systematic study of bias amplification, computer vision and pattern recognition. 1(1). Available: http://arxiv.org/abs/2201.11706
Bashar MA, Nayak R, Kothare A, Sharma V, Kandadai K (2021) Deep learning for bias detection: from inception to deployment. Commun Comput Inform Sci 1504 CCIS:86–101. https://doi.org/10.1007/978-981-16-8531-6_7
Cha D, Pae C, Lee SA, Na G, Hur YK, Young H (2021) Differential biases and variabilities of deep learning– based artificial intelligence and human experts in clinical diagnosis: retrospective cohort and survey study corresponding author. JMIR Med Inf 9:1–12. https://doi.org/10.2196/33049
Schmid M (2021) Bias in cross-entropy-based training of deep survival networks. IEEE Trans Pattern Anal Mach Intell 43(9):3126–3137. https://doi.org/10.1109/TPAMI.2020.2979450
Shen X, Plested J (2021) Exploring biases and prejudice of facial synthesis via Semantic Latent Space. 2021 Int Joint Conf Neural Networks (IJCNN) 1–8. https://doi.org/10.1109/IJCNN52387.2021.9534287
Schaaf N, de Mitri O, Kim HB, Windberger A, Huber MF (2021) Towards measuring bias in image classification, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics. 12893 LNCS(036):433–445, https://doi.org/10.1007/978-3-030-86365-4_35
Krishnakumar A, Prabhu V, Sudhakar S, Hoffman J (2021) UDIS: Unsupervised discovery of bias in deep visual recognition models, computer vision and pattern recognition. 1–15. Available: http://arxiv.org/abs/2110.15499
He Q, Hou X, WD3 (2020) Taming the estimation bias in deep reinforcement learning. 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI) WD3:, 391–398. https://doi.org/10.1109/ICTAI50040.2020.00068
Serna I, Peña A, Morales A, Fierrez J (2020) Insidebias: measuring bias in deep networks and application to face gender biometrics. Proc - Int Conf Pattern Recognit 3720–3727. https://doi.org/10.1109/ICPR48806.2021.9412443
Wang Z et al (2020) Towards fairness in visual recognition: effective strategies for bias mitigation. Proc IEEE Comput Soc Conf Comput Vis Pattern Recognit 8916–8925. https://doi.org/10.1109/CVPR42600.2020.00894
Kortylewski A, Morel-forster A (2019) Analyzing and reducing the damage of dataset bias to face recognition with synthetic data. 2019 IEEE/CVF Conf Comput Vis Pattern Recognit Workshops 2261–2268. https://doi.org/10.1109/CVPRW.2019.00279
Guo L, Lei Y, Xing S, Yan T, Li N (2019) Deep convolutional transfer learning network: a new method for intelligent fault diagnosis of machines with unlabeled data. IEEE Trans Industr Electron 66(9):7316–7325. https://doi.org/10.1109/TIE.2018.2877090
Wang T, Zhao J, Yatskar M, Chang K.W., Ordonez V (2019) Balanced datasets are not enough: estimating and mitigating gender bias in deep image representations. Proc IEEE Int Conf Comput Vis 2019–Octob(no Iccv):5309–5318. https://doi.org/10.1109/ICCV.2019.00541
Fard S F., Hollensen P, Mcilory S, Trappenberg T (2017) Impact of biased mislabeling on learning with deep networks. 2017 Int Joint Conf Neural Networks (IJCNN) 2652–2657. https://doi.org/10.1109/IJCNN.2017.7966180
Download references
No funding was received.
Author information
Authors and affiliations.
Department of Computer Science & Engineering, Krishna School of Emerging Technology & Applied Research (KSET), Drs. Kiran & Pallavi Patel Global University (KPGU), Vadodara, Gujarat, India
Milind Shah & Nitesh Sureja
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Milind Shah .
Ethics declarations
Conflict of interest.
The authors declare that they have no conflict of interest.
Ethical Approval
We would like to emphasize that this research did not involve the use of human or animal subjects.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Shah, M., Sureja, N. A Comprehensive Review of Bias in Deep Learning Models: Methods, Impacts, and Future Directions. Arch Computat Methods Eng (2024). https://doi.org/10.1007/s11831-024-10134-2
Download citation
Received : 24 January 2024
Accepted : 22 April 2024
Published : 08 May 2024
DOI : https://doi.org/10.1007/s11831-024-10134-2
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Find a journal
- Publish with us
- Track your research
Predicting local control of brain metastases after stereotactic radiosurgery with clinical, radiomics and deep learning features
- Find this author on Google Scholar
- Find this author on PubMed
- Search for this author on this site
- For correspondence: [email protected]
- Info/History
- Preview PDF
Background and purpose: Timely identification of Local Failure (LF) after stereotactic radiosurgery offers the opportunity for appropriate treatment modifications that may result in improved treatment outcomes, patient survival, and quality of life. Previous studies showed that the addition of either radiomics or deep learning features to clinical features increased the accuracy of the models in predicting Local Control (LC) of brain metastases after stereotactic radiosurgery. To date, however, no study combined both radiomics and deep learning features together with clinical features to develop machine learning algorithms to predict LC of brain metastases. In this study, we examined whether a model trained with a combination of all these features could predict LC better than models trained with only a subset of these features. Materials and methods: Pre-treatment brain MRIs and clinical data were collected retrospectively for 129 patients at the Gamma Knife Center of Elisabeth-TweeSteden Hospital (ETZ), Tilburg, The Netherlands. The patients were split into 103 patients for training and 26 patients for testing. The segment-based radiomics features were extracted using the radiomics feature extractor of the python radiomics package. The deep learning features were extracted using a fine-tuned 3D ResNet model and then combined with the clinical and radiomics features. A Random Forest classifier was trained with the training data set and then tested with the test data set. The performance was compared across 4 different models trained with clinical features only, clinical and radiomics features, clinical and deep learning features, and clinical, radiomics and deep learning features. Results: The prediction model with only clinical variables provided an Area Under the receiver operating characteristic Curve (AUC) of 0.82 and an accuracy of 75.6%. The prediction model with the combination of clinical and radiomics features demonstrated an AUC of 0.880 and an accuracy of 83.3% whereas the prediction model with the combination of clinical and deep learning features demonstrated an AUC of 0.863 and an accuracy of 78.3%. The best prediction performance was associated with the model that combined the clinical, radiomics and deep learning features with an AUC of 0.886 and 87% accuracy. Conclusion: Machine learning models trained on radiomics features and deep learning features combined with patient characteristics show good potential to predict LC after stereotactic radiosurgery with high accuracy. The promising findings from this study demonstrate the potential for early prediction of stereotactic radiosurgery outcome for brain metastasis prior to treatment initiation and might offer the opportunity for appropriate treatment modifications that may result in improved treatment outcomes, patient survival, and quality of life.
Competing Interest Statement
The authors have declared no competing interest.
Funding Statement
This research is supported by KWF Kankerbestrijding and NWO Domain AES, as part of their joint strategic research programme: Technology for Oncology IL. The collaboration project is co-funded by the PPP Allowance made available by Health Holland, Top Sector Life Sciences & Health, to stimulate public-private partnerships.
Author Declarations
I confirm all relevant ethical guidelines have been followed, and any necessary IRB and/or ethics committee approvals have been obtained.
The details of the IRB/oversight body that provided approval or exemption for the research described are given below:
This study was approved by the ETZ science office and by the Ethics Review Board at Tilburg University.
I confirm that all necessary patient/participant consent has been obtained and the appropriate institutional forms have been archived, and that any patient/participant/sample identifiers included were not known to anyone (e.g., hospital staff, patients or participants themselves) outside the research group so cannot be used to identify individuals.
I understand that all clinical trials and any other prospective interventional studies must be registered with an ICMJE-approved registry, such as ClinicalTrials.gov. I confirm that any such study reported in the manuscript has been registered and the trial registration ID is provided (note: if posting a prospective study registered retrospectively, please provide a statement in the trial ID field explaining why the study was not registered in advance).
I have followed all appropriate research reporting guidelines, such as any relevant EQUATOR Network research reporting checklist(s) and other pertinent material, if applicable.
Data Availability
The data used for this study is available at ETZ and is accessible after approval from the ETZ Science office.
View the discussion thread.
Thank you for your interest in spreading the word about medRxiv.
NOTE: Your email address is requested solely to identify you as the sender of this article.

Citation Manager Formats
- EndNote (tagged)
- EndNote 8 (xml)
- RefWorks Tagged
- Ref Manager
- Tweet Widget
- Facebook Like
- Google Plus One
- Addiction Medicine (323)
- Allergy and Immunology (627)
- Anesthesia (163)
- Cardiovascular Medicine (2363)
- Dentistry and Oral Medicine (287)
- Dermatology (206)
- Emergency Medicine (378)
- Endocrinology (including Diabetes Mellitus and Metabolic Disease) (833)
- Epidemiology (11755)
- Forensic Medicine (10)
- Gastroenterology (701)
- Genetic and Genomic Medicine (3722)
- Geriatric Medicine (348)
- Health Economics (632)
- Health Informatics (2388)
- Health Policy (929)
- Health Systems and Quality Improvement (894)
- Hematology (340)
- HIV/AIDS (780)
- Infectious Diseases (except HIV/AIDS) (13298)
- Intensive Care and Critical Care Medicine (767)
- Medical Education (365)
- Medical Ethics (104)
- Nephrology (398)
- Neurology (3483)
- Nursing (197)
- Nutrition (522)
- Obstetrics and Gynecology (672)
- Occupational and Environmental Health (661)
- Oncology (1818)
- Ophthalmology (535)
- Orthopedics (218)
- Otolaryngology (286)
- Pain Medicine (232)
- Palliative Medicine (66)
- Pathology (445)
- Pediatrics (1030)
- Pharmacology and Therapeutics (426)
- Primary Care Research (418)
- Psychiatry and Clinical Psychology (3169)
- Public and Global Health (6128)
- Radiology and Imaging (1275)
- Rehabilitation Medicine and Physical Therapy (743)
- Respiratory Medicine (825)
- Rheumatology (379)
- Sexual and Reproductive Health (372)
- Sports Medicine (322)
- Surgery (400)
- Toxicology (50)
- Transplantation (172)
- Urology (145)
IMAGES
VIDEO
COMMENTS
In addition, exploring techniques to improve data efficiency, such as few-shot learning, active learning, or semi-supervised learning, remains an active area of research. 6.2 Ethics and fairness The challenge of ethics and fairness in deep learning underscores the critical need to address biases, discrimination, and social implications embedded ...
The discipline of AI most often mentioned these days is deep learning (DL) along with its many incarnations implemented with deep neural networks. DL also is a rapidly accelerating area of research with papers being published at a fast clip by research teams from around the globe.
The application of recent artificial intelligence (AI) and deep learning (DL) approaches integrated to radiological images finds useful to accurately detect the disease. This article introduces a new synergic deep learning (SDL)-based smart health diagnosis of COVID-19 using Chest X-Ray Images. The SDL makes use of dual deep convolutional ...
Deep learning has enabled advances in understanding biology. In this review, the authors outline advances, and limitations of deep learning in five broad areas and the future challenges for ...
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. In the last 10 years, AI and ML models have become bigger and more sophisticated — they're deeper, more complex, with more parameters, and trained on much more ...
Furthermore, we hope to outline recent key advancements in the technology, and provide insight into areas, in which deep learning can improve investigation, as well as highlight new areas of research that have yet to see the application of deep learning, but could nonetheless benefit immensely. We hope this survey provides a valuable reference ...
Deep learning (DL) is one of the fastest-growing topics in materials data science, with rapidly emerging applications spanning atomistic, image-based, spectral, and textual data modalities. DL ...
With deep unsupervised learning, we can transfer the learning with multi-headed networks. First, we train a neural network. Then, we have two tasks and give the network two heads - one for task 1 and another for task 2. Most parameters live in the shared trunk of the network's body.
The publication was founded to communicate research in a more transparent and visual way, with interactive widgets, code snippets, and animations embedded into the paper. Awesome Deep Learning Papers is a bit outdated (the last update was made two years ago) but it does list the most cited papers from 2012-2016, sorted by discipline, such as ...
Conclusions. This study investigated the landscape of deep learning research in biomedicine and confirmed its interdisciplinary nature. Although it has been successful, we believe that there is a need for diverse applications in certain areas to further boost the contributions of deep learning in addressing biomedical research problems.
Deep Networks for Unsupervised or Generative Learning As discussed in Section 3, unsupervised learning or generative deep learning modeling is one of the major tasks in the area, as it allows us to characterize the high-order correlation properties or features in data, or generating a new representation of data through exploratory analysis.
Deep learning has continued its forward movement during 2019 with advances in many exciting research areas like generative adversarial networks (GANs), auto-encoders, and reinforcement learning. In terms of deployments, deep learning is the darling of many contemporary application areas such as computer vision, image recognition, speech recognition, natural language processing,...
In this context, a semantic content analysis based on probabilistic topic modeling has been performed on 22,279 journal articles on the subject of deep learning during the last 19 years between ...
Deep learning (DL) is an important machine learn ing field that has achieved considerab le success. in many research areas. In the last decade, the -stateoftheart studies on many research areas ...
Here at Microsoft Research, we developed MatterSim, a deep-learning model for accurate and efficient materials simulation and property prediction over a broad range of elements, temperatures, and pressures to enable the in silico materials design. MatterSim employs deep learning to understand atomic interactions from the very fundamental ...
the position of deep learning in AI, or how DL technology is related to these areas of computing. The Position of Deep Learning in AI Nowadays, articial intelligence (AI), machine learning (ML), and deep learning (DL) are three popular terms that are sometimes used interchangeably to describe systems or software that behaves intelligently.
The results show that the annual publication volume of deep learning is on the rise; deep learning research has entered a rapid growth stage since 2007; the United States has published the most papers and is the center of the global deep learning research collaboration network; the countries involved in the study were often interconnected, but ...
Work in Artificial Intelligence in the EECS department at Berkeley involves foundational research in core areas of deep learning, knowledge representation, reasoning, learning, planning, decision-making, vision, robotics, speech, and natural language processing. For more information please see the Berkeley Artificial Intelligence Research Lab ...
In 2012, later Turing award recipient George Hinton's team 3 demonstrated that deep learning could provide significant accuracy benefits in common AI tasks like image recognition. 4 After this, companies started investing into deep learning and interest in the area has exploded. Since 2017, interest in deep learning appears stable.
Indeed, educational research indicates poor correspondence between student achievements, in terms of grades, and deep learning (Campbell & Cabrera, Citation 2014), but it is important to note that this connection depends on the subject area and other contextual factors (Laird, Shoup, & Kuh, Citation 2005).
High-quality images are crucial in remote sensing and UAV applications, but atmospheric haze can severely degrade image quality, making image dehazing a critical research area. Since the introduction of deep convolutional neural networks, numerous approaches have been proposed, and even more have emerged with the development of vision transformers and contrastive/few-shot learning ...
The latest progress in deep learning approaches has garnered significant attention across a variety of research fields. These techniques have revolutionized the way marine parameters are measured, enabling automated and remote data collection. This work centers on employing a deep learning model for the automated evaluation of tide and surge, aiming to deliver accurate results through the ...
Hyperspectral image (HSI) restoration is a challenging research area, covering a variety of inverse problems. Previous works have shown the great success of deep learning in HSI restoration. However, facing the problem of distribution gaps between training HSIs and target HSI, those data-driven methods falter in delivering satisfactory outcomes for the target HSIs. In addition, the degradation ...
These challenges highlight the need for ongoing research and development in this area to effectively identify and remove biases from deep learning models. 1.1 Research Questions. 1. What are the common types of biases encountered in deep learning models, and how do they manifest across different application domains? 2.
Background and purpose: Timely identification of Local Failure (LF) after stereotactic radiosurgery offers the opportunity for appropriate treatment modifications that may result in improved treatment outcomes, patient survival, and quality of life. Previous studies showed that the addition of either radiomics or deep learning features to clinical features increased the accuracy of the models ...