Home Blog Design Understanding Data Presentations (Guide + Examples)

Understanding Data Presentations (Guide + Examples)

In this age of overwhelming information, the skill to effectively convey data has become extremely valuable. Initiating a discussion on data presentation types involves thoughtful consideration of the nature of your data and the message you aim to convey. Different types of visualizations serve distinct purposes. Whether you’re dealing with how to develop a report or simply trying to communicate complex information, how you present data influences how well your audience understands and engages with it. This extensive guide leads you through the different ways of data presentation.
Table of Contents
What is a Data Presentation?
What should a data presentation include, line graphs, treemap chart, scatter plot, how to choose a data presentation type, recommended data presentation templates, common mistakes done in data presentation.
A data presentation is a slide deck that aims to disclose quantitative information to an audience through the use of visual formats and narrative techniques derived from data analysis, making complex data understandable and actionable. This process requires a series of tools, such as charts, graphs, tables, infographics, dashboards, and so on, supported by concise textual explanations to improve understanding and boost retention rate.
Data presentations require us to cull data in a format that allows the presenter to highlight trends, patterns, and insights so that the audience can act upon the shared information. In a few words, the goal of data presentations is to enable viewers to grasp complicated concepts or trends quickly, facilitating informed decision-making or deeper analysis.
Data presentations go beyond the mere usage of graphical elements. Seasoned presenters encompass visuals with the art of data storytelling , so the speech skillfully connects the points through a narrative that resonates with the audience. Depending on the purpose – inspire, persuade, inform, support decision-making processes, etc. – is the data presentation format that is better suited to help us in this journey.
To nail your upcoming data presentation, ensure to count with the following elements:
- Clear Objectives: Understand the intent of your presentation before selecting the graphical layout and metaphors to make content easier to grasp.
- Engaging introduction: Use a powerful hook from the get-go. For instance, you can ask a big question or present a problem that your data will answer. Take a look at our guide on how to start a presentation for tips & insights.
- Structured Narrative: Your data presentation must tell a coherent story. This means a beginning where you present the context, a middle section in which you present the data, and an ending that uses a call-to-action. Check our guide on presentation structure for further information.
- Visual Elements: These are the charts, graphs, and other elements of visual communication we ought to use to present data. This article will cover one by one the different types of data representation methods we can use, and provide further guidance on choosing between them.
- Insights and Analysis: This is not just showcasing a graph and letting people get an idea about it. A proper data presentation includes the interpretation of that data, the reason why it’s included, and why it matters to your research.
- Conclusion & CTA: Ending your presentation with a call to action is necessary. Whether you intend to wow your audience into acquiring your services, inspire them to change the world, or whatever the purpose of your presentation, there must be a stage in which you convey all that you shared and show the path to staying in touch. Plan ahead whether you want to use a thank-you slide, a video presentation, or which method is apt and tailored to the kind of presentation you deliver.
- Q&A Session: After your speech is concluded, allocate 3-5 minutes for the audience to raise any questions about the information you disclosed. This is an extra chance to establish your authority on the topic. Check our guide on questions and answer sessions in presentations here.
Bar charts are a graphical representation of data using rectangular bars to show quantities or frequencies in an established category. They make it easy for readers to spot patterns or trends. Bar charts can be horizontal or vertical, although the vertical format is commonly known as a column chart. They display categorical, discrete, or continuous variables grouped in class intervals [1] . They include an axis and a set of labeled bars horizontally or vertically. These bars represent the frequencies of variable values or the values themselves. Numbers on the y-axis of a vertical bar chart or the x-axis of a horizontal bar chart are called the scale.

Real-Life Application of Bar Charts
Let’s say a sales manager is presenting sales to their audience. Using a bar chart, he follows these steps.
Step 1: Selecting Data
The first step is to identify the specific data you will present to your audience.
The sales manager has highlighted these products for the presentation.
- Product A: Men’s Shoes
- Product B: Women’s Apparel
- Product C: Electronics
- Product D: Home Decor
Step 2: Choosing Orientation
Opt for a vertical layout for simplicity. Vertical bar charts help compare different categories in case there are not too many categories [1] . They can also help show different trends. A vertical bar chart is used where each bar represents one of the four chosen products. After plotting the data, it is seen that the height of each bar directly represents the sales performance of the respective product.
It is visible that the tallest bar (Electronics – Product C) is showing the highest sales. However, the shorter bars (Women’s Apparel – Product B and Home Decor – Product D) need attention. It indicates areas that require further analysis or strategies for improvement.
Step 3: Colorful Insights
Different colors are used to differentiate each product. It is essential to show a color-coded chart where the audience can distinguish between products.
- Men’s Shoes (Product A): Yellow
- Women’s Apparel (Product B): Orange
- Electronics (Product C): Violet
- Home Decor (Product D): Blue

Bar charts are straightforward and easily understandable for presenting data. They are versatile when comparing products or any categorical data [2] . Bar charts adapt seamlessly to retail scenarios. Despite that, bar charts have a few shortcomings. They cannot illustrate data trends over time. Besides, overloading the chart with numerous products can lead to visual clutter, diminishing its effectiveness.
For more information, check our collection of bar chart templates for PowerPoint .
Line graphs help illustrate data trends, progressions, or fluctuations by connecting a series of data points called ‘markers’ with straight line segments. This provides a straightforward representation of how values change [5] . Their versatility makes them invaluable for scenarios requiring a visual understanding of continuous data. In addition, line graphs are also useful for comparing multiple datasets over the same timeline. Using multiple line graphs allows us to compare more than one data set. They simplify complex information so the audience can quickly grasp the ups and downs of values. From tracking stock prices to analyzing experimental results, you can use line graphs to show how data changes over a continuous timeline. They show trends with simplicity and clarity.
Real-life Application of Line Graphs
To understand line graphs thoroughly, we will use a real case. Imagine you’re a financial analyst presenting a tech company’s monthly sales for a licensed product over the past year. Investors want insights into sales behavior by month, how market trends may have influenced sales performance and reception to the new pricing strategy. To present data via a line graph, you will complete these steps.
First, you need to gather the data. In this case, your data will be the sales numbers. For example:
- January: $45,000
- February: $55,000
- March: $45,000
- April: $60,000
- May: $ 70,000
- June: $65,000
- July: $62,000
- August: $68,000
- September: $81,000
- October: $76,000
- November: $87,000
- December: $91,000
After choosing the data, the next step is to select the orientation. Like bar charts, you can use vertical or horizontal line graphs. However, we want to keep this simple, so we will keep the timeline (x-axis) horizontal while the sales numbers (y-axis) vertical.
Step 3: Connecting Trends
After adding the data to your preferred software, you will plot a line graph. In the graph, each month’s sales are represented by data points connected by a line.

Step 4: Adding Clarity with Color
If there are multiple lines, you can also add colors to highlight each one, making it easier to follow.
Line graphs excel at visually presenting trends over time. These presentation aids identify patterns, like upward or downward trends. However, too many data points can clutter the graph, making it harder to interpret. Line graphs work best with continuous data but are not suitable for categories.
For more information, check our collection of line chart templates for PowerPoint and our article about how to make a presentation graph .
A data dashboard is a visual tool for analyzing information. Different graphs, charts, and tables are consolidated in a layout to showcase the information required to achieve one or more objectives. Dashboards help quickly see Key Performance Indicators (KPIs). You don’t make new visuals in the dashboard; instead, you use it to display visuals you’ve already made in worksheets [3] .
Keeping the number of visuals on a dashboard to three or four is recommended. Adding too many can make it hard to see the main points [4]. Dashboards can be used for business analytics to analyze sales, revenue, and marketing metrics at a time. They are also used in the manufacturing industry, as they allow users to grasp the entire production scenario at the moment while tracking the core KPIs for each line.
Real-Life Application of a Dashboard
Consider a project manager presenting a software development project’s progress to a tech company’s leadership team. He follows the following steps.
Step 1: Defining Key Metrics
To effectively communicate the project’s status, identify key metrics such as completion status, budget, and bug resolution rates. Then, choose measurable metrics aligned with project objectives.
Step 2: Choosing Visualization Widgets
After finalizing the data, presentation aids that align with each metric are selected. For this project, the project manager chooses a progress bar for the completion status and uses bar charts for budget allocation. Likewise, he implements line charts for bug resolution rates.

Step 3: Dashboard Layout
Key metrics are prominently placed in the dashboard for easy visibility, and the manager ensures that it appears clean and organized.
Dashboards provide a comprehensive view of key project metrics. Users can interact with data, customize views, and drill down for detailed analysis. However, creating an effective dashboard requires careful planning to avoid clutter. Besides, dashboards rely on the availability and accuracy of underlying data sources.
For more information, check our article on how to design a dashboard presentation , and discover our collection of dashboard PowerPoint templates .
Treemap charts represent hierarchical data structured in a series of nested rectangles [6] . As each branch of the ‘tree’ is given a rectangle, smaller tiles can be seen representing sub-branches, meaning elements on a lower hierarchical level than the parent rectangle. Each one of those rectangular nodes is built by representing an area proportional to the specified data dimension.
Treemaps are useful for visualizing large datasets in compact space. It is easy to identify patterns, such as which categories are dominant. Common applications of the treemap chart are seen in the IT industry, such as resource allocation, disk space management, website analytics, etc. Also, they can be used in multiple industries like healthcare data analysis, market share across different product categories, or even in finance to visualize portfolios.
Real-Life Application of a Treemap Chart
Let’s consider a financial scenario where a financial team wants to represent the budget allocation of a company. There is a hierarchy in the process, so it is helpful to use a treemap chart. In the chart, the top-level rectangle could represent the total budget, and it would be subdivided into smaller rectangles, each denoting a specific department. Further subdivisions within these smaller rectangles might represent individual projects or cost categories.
Step 1: Define Your Data Hierarchy
While presenting data on the budget allocation, start by outlining the hierarchical structure. The sequence will be like the overall budget at the top, followed by departments, projects within each department, and finally, individual cost categories for each project.
- Top-level rectangle: Total Budget
- Second-level rectangles: Departments (Engineering, Marketing, Sales)
- Third-level rectangles: Projects within each department
- Fourth-level rectangles: Cost categories for each project (Personnel, Marketing Expenses, Equipment)
Step 2: Choose a Suitable Tool
It’s time to select a data visualization tool supporting Treemaps. Popular choices include Tableau, Microsoft Power BI, PowerPoint, or even coding with libraries like D3.js. It is vital to ensure that the chosen tool provides customization options for colors, labels, and hierarchical structures.
Here, the team uses PowerPoint for this guide because of its user-friendly interface and robust Treemap capabilities.
Step 3: Make a Treemap Chart with PowerPoint
After opening the PowerPoint presentation, they chose “SmartArt” to form the chart. The SmartArt Graphic window has a “Hierarchy” category on the left. Here, you will see multiple options. You can choose any layout that resembles a Treemap. The “Table Hierarchy” or “Organization Chart” options can be adapted. The team selects the Table Hierarchy as it looks close to a Treemap.
Step 5: Input Your Data
After that, a new window will open with a basic structure. They add the data one by one by clicking on the text boxes. They start with the top-level rectangle, representing the total budget.

Step 6: Customize the Treemap
By clicking on each shape, they customize its color, size, and label. At the same time, they can adjust the font size, style, and color of labels by using the options in the “Format” tab in PowerPoint. Using different colors for each level enhances the visual difference.
Treemaps excel at illustrating hierarchical structures. These charts make it easy to understand relationships and dependencies. They efficiently use space, compactly displaying a large amount of data, reducing the need for excessive scrolling or navigation. Additionally, using colors enhances the understanding of data by representing different variables or categories.
In some cases, treemaps might become complex, especially with deep hierarchies. It becomes challenging for some users to interpret the chart. At the same time, displaying detailed information within each rectangle might be constrained by space. It potentially limits the amount of data that can be shown clearly. Without proper labeling and color coding, there’s a risk of misinterpretation.
A heatmap is a data visualization tool that uses color coding to represent values across a two-dimensional surface. In these, colors replace numbers to indicate the magnitude of each cell. This color-shaded matrix display is valuable for summarizing and understanding data sets with a glance [7] . The intensity of the color corresponds to the value it represents, making it easy to identify patterns, trends, and variations in the data.
As a tool, heatmaps help businesses analyze website interactions, revealing user behavior patterns and preferences to enhance overall user experience. In addition, companies use heatmaps to assess content engagement, identifying popular sections and areas of improvement for more effective communication. They excel at highlighting patterns and trends in large datasets, making it easy to identify areas of interest.
We can implement heatmaps to express multiple data types, such as numerical values, percentages, or even categorical data. Heatmaps help us easily spot areas with lots of activity, making them helpful in figuring out clusters [8] . When making these maps, it is important to pick colors carefully. The colors need to show the differences between groups or levels of something. And it is good to use colors that people with colorblindness can easily see.
Check our detailed guide on how to create a heatmap here. Also discover our collection of heatmap PowerPoint templates .
Pie charts are circular statistical graphics divided into slices to illustrate numerical proportions. Each slice represents a proportionate part of the whole, making it easy to visualize the contribution of each component to the total.
The size of the pie charts is influenced by the value of data points within each pie. The total of all data points in a pie determines its size. The pie with the highest data points appears as the largest, whereas the others are proportionally smaller. However, you can present all pies of the same size if proportional representation is not required [9] . Sometimes, pie charts are difficult to read, or additional information is required. A variation of this tool can be used instead, known as the donut chart , which has the same structure but a blank center, creating a ring shape. Presenters can add extra information, and the ring shape helps to declutter the graph.
Pie charts are used in business to show percentage distribution, compare relative sizes of categories, or present straightforward data sets where visualizing ratios is essential.
Real-Life Application of Pie Charts
Consider a scenario where you want to represent the distribution of the data. Each slice of the pie chart would represent a different category, and the size of each slice would indicate the percentage of the total portion allocated to that category.
Step 1: Define Your Data Structure
Imagine you are presenting the distribution of a project budget among different expense categories.
- Column A: Expense Categories (Personnel, Equipment, Marketing, Miscellaneous)
- Column B: Budget Amounts ($40,000, $30,000, $20,000, $10,000) Column B represents the values of your categories in Column A.
Step 2: Insert a Pie Chart
Using any of the accessible tools, you can create a pie chart. The most convenient tools for forming a pie chart in a presentation are presentation tools such as PowerPoint or Google Slides. You will notice that the pie chart assigns each expense category a percentage of the total budget by dividing it by the total budget.
For instance:
- Personnel: $40,000 / ($40,000 + $30,000 + $20,000 + $10,000) = 40%
- Equipment: $30,000 / ($40,000 + $30,000 + $20,000 + $10,000) = 30%
- Marketing: $20,000 / ($40,000 + $30,000 + $20,000 + $10,000) = 20%
- Miscellaneous: $10,000 / ($40,000 + $30,000 + $20,000 + $10,000) = 10%
You can make a chart out of this or just pull out the pie chart from the data.

3D pie charts and 3D donut charts are quite popular among the audience. They stand out as visual elements in any presentation slide, so let’s take a look at how our pie chart example would look in 3D pie chart format.

Step 03: Results Interpretation
The pie chart visually illustrates the distribution of the project budget among different expense categories. Personnel constitutes the largest portion at 40%, followed by equipment at 30%, marketing at 20%, and miscellaneous at 10%. This breakdown provides a clear overview of where the project funds are allocated, which helps in informed decision-making and resource management. It is evident that personnel are a significant investment, emphasizing their importance in the overall project budget.
Pie charts provide a straightforward way to represent proportions and percentages. They are easy to understand, even for individuals with limited data analysis experience. These charts work well for small datasets with a limited number of categories.
However, a pie chart can become cluttered and less effective in situations with many categories. Accurate interpretation may be challenging, especially when dealing with slight differences in slice sizes. In addition, these charts are static and do not effectively convey trends over time.
For more information, check our collection of pie chart templates for PowerPoint .
Histograms present the distribution of numerical variables. Unlike a bar chart that records each unique response separately, histograms organize numeric responses into bins and show the frequency of reactions within each bin [10] . The x-axis of a histogram shows the range of values for a numeric variable. At the same time, the y-axis indicates the relative frequencies (percentage of the total counts) for that range of values.
Whenever you want to understand the distribution of your data, check which values are more common, or identify outliers, histograms are your go-to. Think of them as a spotlight on the story your data is telling. A histogram can provide a quick and insightful overview if you’re curious about exam scores, sales figures, or any numerical data distribution.
Real-Life Application of a Histogram
In the histogram data analysis presentation example, imagine an instructor analyzing a class’s grades to identify the most common score range. A histogram could effectively display the distribution. It will show whether most students scored in the average range or if there are significant outliers.
Step 1: Gather Data
He begins by gathering the data. The scores of each student in class are gathered to analyze exam scores.
After arranging the scores in ascending order, bin ranges are set.
Step 2: Define Bins
Bins are like categories that group similar values. Think of them as buckets that organize your data. The presenter decides how wide each bin should be based on the range of the values. For instance, the instructor sets the bin ranges based on score intervals: 60-69, 70-79, 80-89, and 90-100.
Step 3: Count Frequency
Now, he counts how many data points fall into each bin. This step is crucial because it tells you how often specific ranges of values occur. The result is the frequency distribution, showing the occurrences of each group.
Here, the instructor counts the number of students in each category.
- 60-69: 1 student (Kate)
- 70-79: 4 students (David, Emma, Grace, Jack)
- 80-89: 7 students (Alice, Bob, Frank, Isabel, Liam, Mia, Noah)
- 90-100: 3 students (Clara, Henry, Olivia)
Step 4: Create the Histogram
It’s time to turn the data into a visual representation. Draw a bar for each bin on a graph. The width of the bar should correspond to the range of the bin, and the height should correspond to the frequency. To make your histogram understandable, label the X and Y axes.
In this case, the X-axis should represent the bins (e.g., test score ranges), and the Y-axis represents the frequency.

The histogram of the class grades reveals insightful patterns in the distribution. Most students, with seven students, fall within the 80-89 score range. The histogram provides a clear visualization of the class’s performance. It showcases a concentration of grades in the upper-middle range with few outliers at both ends. This analysis helps in understanding the overall academic standing of the class. It also identifies the areas for potential improvement or recognition.
Thus, histograms provide a clear visual representation of data distribution. They are easy to interpret, even for those without a statistical background. They apply to various types of data, including continuous and discrete variables. One weak point is that histograms do not capture detailed patterns in students’ data, with seven compared to other visualization methods.
A scatter plot is a graphical representation of the relationship between two variables. It consists of individual data points on a two-dimensional plane. This plane plots one variable on the x-axis and the other on the y-axis. Each point represents a unique observation. It visualizes patterns, trends, or correlations between the two variables.
Scatter plots are also effective in revealing the strength and direction of relationships. They identify outliers and assess the overall distribution of data points. The points’ dispersion and clustering reflect the relationship’s nature, whether it is positive, negative, or lacks a discernible pattern. In business, scatter plots assess relationships between variables such as marketing cost and sales revenue. They help present data correlations and decision-making.
Real-Life Application of Scatter Plot
A group of scientists is conducting a study on the relationship between daily hours of screen time and sleep quality. After reviewing the data, they managed to create this table to help them build a scatter plot graph:
In the provided example, the x-axis represents Daily Hours of Screen Time, and the y-axis represents the Sleep Quality Rating.

The scientists observe a negative correlation between the amount of screen time and the quality of sleep. This is consistent with their hypothesis that blue light, especially before bedtime, has a significant impact on sleep quality and metabolic processes.
There are a few things to remember when using a scatter plot. Even when a scatter diagram indicates a relationship, it doesn’t mean one variable affects the other. A third factor can influence both variables. The more the plot resembles a straight line, the stronger the relationship is perceived [11] . If it suggests no ties, the observed pattern might be due to random fluctuations in data. When the scatter diagram depicts no correlation, whether the data might be stratified is worth considering.
Choosing the appropriate data presentation type is crucial when making a presentation . Understanding the nature of your data and the message you intend to convey will guide this selection process. For instance, when showcasing quantitative relationships, scatter plots become instrumental in revealing correlations between variables. If the focus is on emphasizing parts of a whole, pie charts offer a concise display of proportions. Histograms, on the other hand, prove valuable for illustrating distributions and frequency patterns.
Bar charts provide a clear visual comparison of different categories. Likewise, line charts excel in showcasing trends over time, while tables are ideal for detailed data examination. Starting a presentation on data presentation types involves evaluating the specific information you want to communicate and selecting the format that aligns with your message. This ensures clarity and resonance with your audience from the beginning of your presentation.
1. Fact Sheet Dashboard for Data Presentation

Convey all the data you need to present in this one-pager format, an ideal solution tailored for users looking for presentation aids. Global maps, donut chats, column graphs, and text neatly arranged in a clean layout presented in light and dark themes.
Use This Template
2. 3D Column Chart Infographic PPT Template
Represent column charts in a highly visual 3D format with this PPT template. A creative way to present data, this template is entirely editable, and we can craft either a one-page infographic or a series of slides explaining what we intend to disclose point by point.
3. Data Circles Infographic PowerPoint Template
An alternative to the pie chart and donut chart diagrams, this template features a series of curved shapes with bubble callouts as ways of presenting data. Expand the information for each arch in the text placeholder areas.
4. Colorful Metrics Dashboard for Data Presentation
This versatile dashboard template helps us in the presentation of the data by offering several graphs and methods to convert numbers into graphics. Implement it for e-commerce projects, financial projections, project development, and more.
5. Animated Data Presentation Tools for PowerPoint & Google Slides

A slide deck filled with most of the tools mentioned in this article, from bar charts, column charts, treemap graphs, pie charts, histogram, etc. Animated effects make each slide look dynamic when sharing data with stakeholders.
6. Statistics Waffle Charts PPT Template for Data Presentations
This PPT template helps us how to present data beyond the typical pie chart representation. It is widely used for demographics, so it’s a great fit for marketing teams, data science professionals, HR personnel, and more.
7. Data Presentation Dashboard Template for Google Slides
A compendium of tools in dashboard format featuring line graphs, bar charts, column charts, and neatly arranged placeholder text areas.
8. Weather Dashboard for Data Presentation
Share weather data for agricultural presentation topics, environmental studies, or any kind of presentation that requires a highly visual layout for weather forecasting on a single day. Two color themes are available.
9. Social Media Marketing Dashboard Data Presentation Template
Intended for marketing professionals, this dashboard template for data presentation is a tool for presenting data analytics from social media channels. Two slide layouts featuring line graphs and column charts.
10. Project Management Summary Dashboard Template
A tool crafted for project managers to deliver highly visual reports on a project’s completion, the profits it delivered for the company, and expenses/time required to execute it. 4 different color layouts are available.
11. Profit & Loss Dashboard for PowerPoint and Google Slides
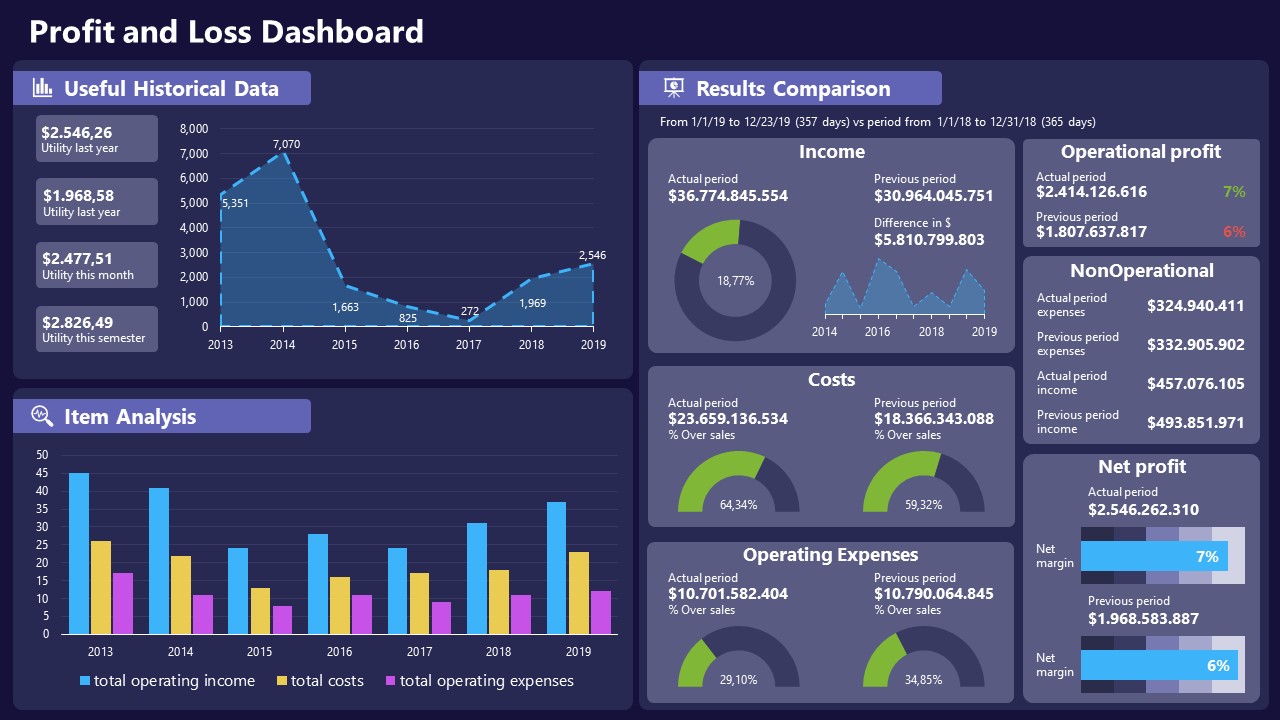
A must-have for finance professionals. This typical profit & loss dashboard includes progress bars, donut charts, column charts, line graphs, and everything that’s required to deliver a comprehensive report about a company’s financial situation.
Overwhelming visuals
One of the mistakes related to using data-presenting methods is including too much data or using overly complex visualizations. They can confuse the audience and dilute the key message.
Inappropriate chart types
Choosing the wrong type of chart for the data at hand can lead to misinterpretation. For example, using a pie chart for data that doesn’t represent parts of a whole is not right.
Lack of context
Failing to provide context or sufficient labeling can make it challenging for the audience to understand the significance of the presented data.
Inconsistency in design
Using inconsistent design elements and color schemes across different visualizations can create confusion and visual disarray.
Failure to provide details
Simply presenting raw data without offering clear insights or takeaways can leave the audience without a meaningful conclusion.
Lack of focus
Not having a clear focus on the key message or main takeaway can result in a presentation that lacks a central theme.
Visual accessibility issues
Overlooking the visual accessibility of charts and graphs can exclude certain audience members who may have difficulty interpreting visual information.
In order to avoid these mistakes in data presentation, presenters can benefit from using presentation templates . These templates provide a structured framework. They ensure consistency, clarity, and an aesthetically pleasing design, enhancing data communication’s overall impact.
Understanding and choosing data presentation types are pivotal in effective communication. Each method serves a unique purpose, so selecting the appropriate one depends on the nature of the data and the message to be conveyed. The diverse array of presentation types offers versatility in visually representing information, from bar charts showing values to pie charts illustrating proportions.
Using the proper method enhances clarity, engages the audience, and ensures that data sets are not just presented but comprehensively understood. By appreciating the strengths and limitations of different presentation types, communicators can tailor their approach to convey information accurately, developing a deeper connection between data and audience understanding.
[1] Government of Canada, S.C. (2021) 5 Data Visualization 5.2 Bar Chart , 5.2 Bar chart . https://www150.statcan.gc.ca/n1/edu/power-pouvoir/ch9/bargraph-diagrammeabarres/5214818-eng.htm
[2] Kosslyn, S.M., 1989. Understanding charts and graphs. Applied cognitive psychology, 3(3), pp.185-225. https://apps.dtic.mil/sti/pdfs/ADA183409.pdf
[3] Creating a Dashboard . https://it.tufts.edu/book/export/html/1870
[4] https://www.goldenwestcollege.edu/research/data-and-more/data-dashboards/index.html
[5] https://www.mit.edu/course/21/21.guide/grf-line.htm
[6] Jadeja, M. and Shah, K., 2015, January. Tree-Map: A Visualization Tool for Large Data. In GSB@ SIGIR (pp. 9-13). https://ceur-ws.org/Vol-1393/gsb15proceedings.pdf#page=15
[7] Heat Maps and Quilt Plots. https://www.publichealth.columbia.edu/research/population-health-methods/heat-maps-and-quilt-plots
[8] EIU QGIS WORKSHOP. https://www.eiu.edu/qgisworkshop/heatmaps.php
[9] About Pie Charts. https://www.mit.edu/~mbarker/formula1/f1help/11-ch-c8.htm
[10] Histograms. https://sites.utexas.edu/sos/guided/descriptive/numericaldd/descriptiven2/histogram/ [11] https://asq.org/quality-resources/scatter-diagram

Like this article? Please share
Data Analysis, Data Science, Data Visualization Filed under Design
Related Articles

Filed under Design • March 27th, 2024
How to Make a Presentation Graph
Detailed step-by-step instructions to master the art of how to make a presentation graph in PowerPoint and Google Slides. Check it out!

Filed under Presentation Ideas • January 6th, 2024
All About Using Harvey Balls
Among the many tools in the arsenal of the modern presenter, Harvey Balls have a special place. In this article we will tell you all about using Harvey Balls.

Filed under Business • December 8th, 2023
How to Design a Dashboard Presentation: A Step-by-Step Guide
Take a step further in your professional presentation skills by learning what a dashboard presentation is and how to properly design one in PowerPoint. A detailed step-by-step guide is here!
Leave a Reply
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Present Your Data Like a Pro
- Joel Schwartzberg

Demystify the numbers. Your audience will thank you.
While a good presentation has data, data alone doesn’t guarantee a good presentation. It’s all about how that data is presented. The quickest way to confuse your audience is by sharing too many details at once. The only data points you should share are those that significantly support your point — and ideally, one point per chart. To avoid the debacle of sheepishly translating hard-to-see numbers and labels, rehearse your presentation with colleagues sitting as far away as the actual audience would. While you’ve been working with the same chart for weeks or months, your audience will be exposed to it for mere seconds. Give them the best chance of comprehending your data by using simple, clear, and complete language to identify X and Y axes, pie pieces, bars, and other diagrammatic elements. Try to avoid abbreviations that aren’t obvious, and don’t assume labeled components on one slide will be remembered on subsequent slides. Every valuable chart or pie graph has an “Aha!” zone — a number or range of data that reveals something crucial to your point. Make sure you visually highlight the “Aha!” zone, reinforcing the moment by explaining it to your audience.
With so many ways to spin and distort information these days, a presentation needs to do more than simply share great ideas — it needs to support those ideas with credible data. That’s true whether you’re an executive pitching new business clients, a vendor selling her services, or a CEO making a case for change.
- JS Joel Schwartzberg oversees executive communications for a major national nonprofit, is a professional presentation coach, and is the author of Get to the Point! Sharpen Your Message and Make Your Words Matter and The Language of Leadership: How to Engage and Inspire Your Team . You can find him on LinkedIn and X. TheJoelTruth
Partner Center
Advancing Big Data Best Practices
- Why the Enterprise Big Data Framework Alliance?
- What We Offer
- Enterprise Big Data Framework
Learn about indivual memberships.

Learn about enterprise memberships.

Learn about Educator Memberships

- Memberships
Certifications
Role-based progressive Big Data certifications.

Certificates
Individual specialized programs in critical data concepts.

Certification Overview
Enterprise Big Data Professional
Enterprise Big Data Analyst
Enterprise Big Data Scientist
Enterprise Big Data Engineer
Enterprise Big Data Architect
Ambassador Program
Learn about the EBDFA Ambassador Program
Academic Partners
Learn about the terms and benefits of the EBDFA Academic Partner Program
Training Partners
Learn how to become an Accredited Training Organization
Corporate Partners
Join the Corporate Partner Program and connect with the EBDFA community.
Partnerships
Become an Ambassador
- Become an Academic Partner New
- Become a Corporate Partner
Become a Training Partner
- Find a Training Partner
- Blog & Big Data News
- Big Data Events & Webinars
Big Data Days 2024
Big Data Knowledge Base
Big Data Talks Podcast
- Free Downloads & Store
What is Data Analysis? An Introductory Guide

Data analysis is the process of inspecting, cleaning, transforming, and modeling data to derive meaningful insights and make informed decisions. It involves examining raw data to identify patterns, trends, and relationships that can be used to understand various aspects of a business, organization, or phenomenon. This process often employs statistical methods, machine learning algorithms, and data visualization techniques to extract valuable information from data sets.
At its core, data analysis aims to answer questions, solve problems, and support decision-making processes. It helps uncover hidden patterns or correlations within data that may not be immediately apparent, leading to actionable insights that can drive business strategies and improve performance. Whether it’s analyzing sales figures to identify market trends, evaluating customer feedback to enhance products or services, or studying medical data to improve patient outcomes, data analysis plays a crucial role in numerous domains.
Effective data analysis requires not only technical skills but also domain knowledge and critical thinking. Analysts must understand the context in which the data is generated, choose appropriate analytical tools and methods, and interpret results accurately to draw meaningful conclusions. Moreover, data analysis is an iterative process that may involve refining hypotheses, collecting additional data, and revisiting analytical techniques to ensure the validity and reliability of findings.
Why spend time to learn data analysis?
Learning about data analysis is beneficial for your career because it equips you with the skills to make data-driven decisions, which are highly valued in today’s data-centric business environment. Employers increasingly seek professionals who can gather, analyze, and interpret data to drive innovation, optimize processes, and achieve strategic objectives.
The Data Analysis Process
The data analysis process is a systematic approach to extracting valuable insights and making informed decisions from raw data. It begins with defining the problem or question at hand, followed by collecting and cleaning the relevant data. Exploratory data analysis (EDA) helps in understanding the data’s characteristics and uncovering patterns, while data modeling and analysis apply statistical or machine learning techniques to derive meaningful conclusions. In most organizations, data analysis is structured in a number of steps:
- Define the Problem or Question: The first step is to clearly define the problem or question you want to address through data analysis. This could involve understanding business objectives, identifying research questions, or defining hypotheses to be tested.
- Data Collection: Once the problem is defined, gather relevant data from various sources. This could include structured data from databases, spreadsheets, or surveys, as well as unstructured data like text documents or social media posts.
- Data Cleaning and Preprocessing: Clean and preprocess the data to ensure its quality and reliability. This step involves handling missing values, removing duplicates, standardizing formats, and transforming data if needed (e.g., scaling numerical data, encoding categorical variables).
- Exploratory Data Analysis (EDA): Explore the data through descriptive statistics, visualizations (e.g., histograms, scatter plots, heatmaps), and data profiling techniques. EDA helps in understanding the distribution of variables, detecting outliers, and identifying patterns or trends.
- Data Modeling and Analysis: Apply appropriate statistical or machine learning models to analyze the data and answer the research questions or address the problem. This step may involve hypothesis testing, regression analysis, clustering, classification, or other analytical techniques depending on the nature of the data and objectives.
- Interpretation of Results: Interpret the findings from the data analysis in the context of the problem or question. Determine the significance of results, draw conclusions, and communicate insights effectively.
- Decision Making and Action: Use the insights gained from data analysis to make informed decisions, develop strategies, or take actions that drive positive outcomes. Monitor the impact of these decisions and iterate the analysis process as needed.
- Communication and Reporting: Present the findings and insights derived from data analysis in a clear and understandable manner to stakeholders, using visualizations, dashboards, reports, or presentations. Effective communication ensures that the analysis results are actionable and contribute to informed decision-making.
These steps form a cyclical process, where feedback from decision-making may lead to revisiting earlier stages, refining the analysis, and continuously improving outcomes.
Key Data Analysis Skills
Key data analysis skills encompass a blend of technical expertise, critical thinking, and domain knowledge. Some of the essential skills for effective data analysis include:
Statistical Knowledge: Understanding statistical concepts and methods such as hypothesis testing, regression analysis, probability distributions, and statistical inference is fundamental for data analysis.
Data Manipulation and Cleaning: Proficiency in tools like Python, R, SQL, or Excel for data manipulation, cleaning, and transformation tasks, including handling missing values, removing duplicates, and standardizing data formats.
Data Visualization: Creating clear and insightful visualizations using tools like Matplotlib, Seaborn, Tableau, or Power BI to communicate trends, patterns, and relationships within data to non-technical stakeholders.
Machine Learning: Familiarity with machine learning algorithms such as decision trees, random forests, logistic regression, clustering, and neural networks for predictive modeling, classification, clustering, and anomaly detection tasks.
Programming Skills: Competence in programming languages such as Python, R, or SQL for data analysis, scripting, automation, and building data pipelines, along with version control using Git.
Critical Thinking: Ability to think critically, ask relevant questions, formulate hypotheses, and design robust analytical approaches to solve complex problems and extract actionable insights from data.
Domain Knowledge: Understanding the context and domain-specific nuances of the data being analyzed, whether it’s finance, healthcare, marketing, or any other industry, is crucial for meaningful interpretation and decision-making.
Data Ethics and Privacy: Awareness of data ethics principles , privacy regulations (e.g., GDPR, CCPA), and best practices for handling sensitive data responsibly and ensuring data security and confidentiality.
Communication and Storytelling: Effectively communicating analysis results through clear reports, presentations, and data-driven storytelling to convey insights, recommendations, and implications to diverse audiences, including non-technical stakeholders.
These skills are crucial in data analysis because they empower analysts to effectively extract, interpret, and communicate insights from complex datasets across various domains. Statistical knowledge forms the foundation for making data-driven decisions and drawing reliable conclusions. Proficiency in data manipulation and cleaning ensures data accuracy and consistency, essential for meaningful analysis. Here

Start your journey into Data Analysis with the official Enterpise Big Data Analyst Certification
The Enterprise Big Data Analyst certification is aimed at Data Analyst and provides in-depth theory and practical guidance to deduce value out of Big Data sets. The curriculum segments between different kinds of Big Data problems and its corresponding solutions. This course will teach participants how to autonomously find valuable insights in large data sets in order to realize business benefits.
Data Analysis Examples in the Enterprise
Data analysis plays an important role in driving informed decision-making and strategic planning within enterprises across various industries. By harnessing the power of data, organizations can gain valuable insights into market trends, customer behaviors, operational efficiency, and performance metrics. Data analysis enables businesses to identify opportunities for growth, optimize processes, mitigate risks, and enhance overall competitiveness in the market. Examples of data analysis in the enterprise span a wide range of applications, including sales and marketing optimization, customer segmentation, financial forecasting, supply chain management, fraud detection, and healthcare analytics.
- Sales and Marketing Optimization: Enterprises use data analysis to analyze sales trends, customer preferences, and marketing campaign effectiveness. By leveraging techniques like customer segmentation and predictive modeling, businesses can tailor marketing strategies, optimize pricing strategies, and identify cross-selling or upselling opportunities.
- Customer Segmentation: Data analysis helps enterprises segment customers based on demographics, purchasing behavior, and preferences. This segmentation allows for targeted marketing efforts, personalized customer experiences, and improved customer retention and loyalty.
- Financial Forecasting: Data analysis is used in financial forecasting to analyze historical data, identify trends, and predict future financial performance. This helps businesses make informed decisions regarding budgeting, investment strategies, and risk management.
- Supply Chain Management: Enterprises use data analysis to optimize supply chain operations, improve inventory management, reduce lead times, and enhance overall efficiency. Analyzing supply chain data helps identify bottlenecks, forecast demand, and streamline logistics processes.
- Fraud Detection: Data analysis is employed to detect and prevent fraud in financial transactions, insurance claims, and online activities. By analyzing patterns and anomalies in data, enterprises can identify suspicious activities, mitigate risks, and protect against fraudulent behavior.
- Healthcare Analytics: In the healthcare sector, data analysis is used for patient care optimization, disease prediction, treatment effectiveness evaluation, and resource allocation. Analyzing healthcare data helps improve patient outcomes, reduce healthcare costs, and support evidence-based decision-making.
These examples illustrate how data analysis is a vital tool for enterprises to gain actionable insights, improve decision-making processes, and achieve strategic objectives across diverse areas of business operations.
Frequently Asked Questions (FAQs)
Below are some of the most frequently asked questions about data analysis and their answers:
What role does domain knowledge play in data analysis?
Domain knowledge is crucial as it provides context, understanding of data nuances, insights into relevant variables and metrics, and helps in interpreting results accurately within specific industries or domains.
How do you ensure the quality and accuracy of data for analysis?
Ensuring data quality and accuracy involves data validation, cleaning techniques like handling missing values and outliers, standardizing data formats, performing data integrity checks, and validating results through cross-validation or data audits.
What tools and techniques are commonly used in data analysis?
Commonly used tools and techniques in data analysis include programming languages like Python and R, statistical methods such as regression analysis and hypothesis testing, machine learning algorithms for predictive modeling, data visualization tools like Tableau and Matplotlib, and database querying languages like SQL.
What are the steps involved in the data analysis process?
The data analysis process typically includes defining the problem, collecting data, cleaning and preprocessing the data, conducting exploratory data analysis, applying statistical or machine learning models for analysis, interpreting results, making decisions based on insights, and communicating findings to stakeholders.
What is data analysis, and why is it important?
Data analysis involves examining, cleaning, transforming, and modeling data to derive meaningful insights and make informed decisions. It is crucial because it helps organizations uncover trends, patterns, and relationships within data, leading to improved decision-making, enhanced business strategies, and competitive advantage.

Big Data Framework
Official account of the Enterprise Big Data Framework Alliance.
Stay in the loop
Subscribe to our free newsletter.
Related articles.

Understanding the Importance of Data Literacy Across All Job Roles

Data Lakes and Warehousing: Building Bridges Between Raw Data and Actionable Insights

Navigating the Layers of Hadoop: Understanding the Framework’s Architecture
The framework.
Framework Overview
Download the Guides
About the Big Data Framework
PARTNERSHIPS
Academic Partner Program
Corporate Partnerships
CERTIFICATIONS
Big data events.
Events and Webinars
CERTIFICATES
Data Literacy Fundamentals
Data Governance Fundamentals
Data Management Fundamentals
Data Privacy Fundamentals
BIG DATA RESOURCES
Big Data News & Updates
Downloads and Resources
CONNECT WITH US
Endenicher Allee 12 53115, DE Bonn Germany
SOCIAL MEDIA
© Copyright 2021 | Enterprise Big Data Framework© | All Rights Reserved | Privacy Policy | Terms of Use | Contact
Data presentation: A comprehensive guide
Learn how to create data presentation effectively and communicate your insights in a way that is clear, concise, and engaging.
Raja Bothra
Building presentations

Hey there, fellow data enthusiast!
Welcome to our comprehensive guide on data presentation.
Whether you're an experienced presenter or just starting, this guide will help you present your data like a pro.
We'll dive deep into what data presentation is, why it's crucial, and how to master it. So, let's embark on this data-driven journey together.
What is data presentation?
Data presentation is the art of transforming raw data into a visual format that's easy to understand and interpret. It's like turning numbers and statistics into a captivating story that your audience can quickly grasp. When done right, data presentation can be a game-changer, enabling you to convey complex information effectively.
Why are data presentations important?
Imagine drowning in a sea of numbers and figures. That's how your audience might feel without proper data presentation. Here's why it's essential:
- Clarity : Data presentations make complex information clear and concise.
- Engagement : Visuals, such as charts and graphs, grab your audience's attention.
- Comprehension : Visual data is easier to understand than long, numerical reports.
- Decision-making : Well-presented data aids informed decision-making.
- Impact : It leaves a lasting impression on your audience.
Types of data presentation
Now, let's delve into the diverse array of data presentation methods, each with its own unique strengths and applications. We have three primary types of data presentation, and within these categories, numerous specific visualization techniques can be employed to effectively convey your data.
1. Textual presentation
Textual presentation harnesses the power of words and sentences to elucidate and contextualize your data. This method is commonly used to provide a narrative framework for the data, offering explanations, insights, and the broader implications of your findings. It serves as a foundation for a deeper understanding of the data's significance.
2. Tabular presentation
Tabular presentation employs tables to arrange and structure your data systematically. These tables are invaluable for comparing various data groups or illustrating how data evolves over time. They present information in a neat and organized format, facilitating straightforward comparisons and reference points.
3. Graphical presentation
Graphical presentation harnesses the visual impact of charts and graphs to breathe life into your data. Charts and graphs are powerful tools for spotlighting trends, patterns, and relationships hidden within the data. Let's explore some common graphical presentation methods:
- Bar charts: They are ideal for comparing different categories of data. In this method, each category is represented by a distinct bar, and the height of the bar corresponds to the value it represents. Bar charts provide a clear and intuitive way to discern differences between categories.
- Pie charts: It excel at illustrating the relative proportions of different data categories. Each category is depicted as a slice of the pie, with the size of each slice corresponding to the percentage of the total value it represents. Pie charts are particularly effective for showcasing the distribution of data.
- Line graphs: They are the go-to choice when showcasing how data evolves over time. Each point on the line represents a specific value at a particular time period. This method enables viewers to track trends and fluctuations effortlessly, making it perfect for visualizing data with temporal dimensions.
- Scatter plots: They are the tool of choice when exploring the relationship between two variables. In this method, each point on the plot represents a pair of values for the two variables in question. Scatter plots help identify correlations, outliers, and patterns within data pairs.
The selection of the most suitable data presentation method hinges on the specific dataset and the presentation's objectives. For instance, when comparing sales figures of different products, a bar chart shines in its simplicity and clarity. On the other hand, if your aim is to display how a product's sales have changed over time, a line graph provides the ideal visual narrative.
Additionally, it's crucial to factor in your audience's level of familiarity with data presentations. For a technical audience, more intricate visualization methods may be appropriate. However, when presenting to a general audience, opting for straightforward and easily understandable visuals is often the wisest choice.
In the world of data presentation, choosing the right method is akin to selecting the perfect brush for a masterpiece. Each tool has its place, and understanding when and how to use them is key to crafting compelling and insightful presentations. So, consider your data carefully, align your purpose, and paint a vivid picture that resonates with your audience.
What to include in data presentation
When creating your data presentation, remember these key components:
- Data points : Clearly state the data points you're presenting.
- Comparison : Highlight comparisons and trends in your data.
- Graphical methods : Choose the right chart or graph for your data.
- Infographics : Use visuals like infographics to make information more digestible.
- Numerical values : Include numerical values to support your visuals.
- Qualitative information : Explain the significance of the data.
- Source citation : Always cite your data sources.
How to structure an effective data presentation
Creating a well-structured data presentation is not just important; it's the backbone of a successful presentation. Here's a step-by-step guide to help you craft a compelling and organized presentation that captivates your audience:
1. Know your audience
Understanding your audience is paramount. Consider their needs, interests, and existing knowledge about your topic. Tailor your presentation to their level of understanding, ensuring that it resonates with them on a personal level. Relevance is the key.
2. Have a clear message
Every effective data presentation should convey a clear and concise message. Determine what you want your audience to learn or take away from your presentation, and make sure your message is the guiding light throughout your presentation. Ensure that all your data points align with and support this central message.
3. Tell a compelling story
Human beings are naturally wired to remember stories. Incorporate storytelling techniques into your presentation to make your data more relatable and memorable. Your data can be the backbone of a captivating narrative, whether it's about a trend, a problem, or a solution. Take your audience on a journey through your data.
4. Leverage visuals
Visuals are a powerful tool in data presentation. They make complex information accessible and engaging. Utilize charts, graphs, and images to illustrate your points and enhance the visual appeal of your presentation. Visuals should not just be an accessory; they should be an integral part of your storytelling.
5. Be clear and concise
Avoid jargon or technical language that your audience may not comprehend. Use plain language and explain your data points clearly. Remember, clarity is king. Each piece of information should be easy for your audience to digest.
6. Practice your delivery
Practice makes perfect. Rehearse your presentation multiple times before the actual delivery. This will help you deliver it smoothly and confidently, reducing the chances of stumbling over your words or losing track of your message.
A basic structure for an effective data presentation
Armed with a comprehensive comprehension of how to construct a compelling data presentation, you can now utilize this fundamental template for guidance:
In the introduction, initiate your presentation by introducing both yourself and the topic at hand. Clearly articulate your main message or the fundamental concept you intend to communicate.
Moving on to the body of your presentation, organize your data in a coherent and easily understandable sequence. Employ visuals generously to elucidate your points and weave a narrative that enhances the overall story. Ensure that the arrangement of your data aligns with and reinforces your central message.
As you approach the conclusion, succinctly recapitulate your key points and emphasize your core message once more. Conclude by leaving your audience with a distinct and memorable takeaway, ensuring that your presentation has a lasting impact.
Additional tips for enhancing your data presentation
To take your data presentation to the next level, consider these additional tips:
- Consistent design : Maintain a uniform design throughout your presentation. This not only enhances visual appeal but also aids in seamless comprehension.
- High-quality visuals : Ensure that your visuals are of high quality, easy to read, and directly relevant to your topic.
- Concise text : Avoid overwhelming your slides with excessive text. Focus on the most critical points, using visuals to support and elaborate.
- Anticipate questions : Think ahead about the questions your audience might pose. Be prepared with well-thought-out answers to foster productive discussions.
By following these guidelines, you can structure an effective data presentation that not only informs but also engages and inspires your audience. Remember, a well-structured presentation is the bridge that connects your data to your audience's understanding and appreciation.
Do’s and don'ts on a data presentation
- Use visuals : Incorporate charts and graphs to enhance understanding.
- Keep it simple : Avoid clutter and complexity.
- Highlight key points : Emphasize crucial data.
- Engage the audience : Encourage questions and discussions.
- Practice : Rehearse your presentation.
Don'ts:
- Overload with data : Less is often more; don't overwhelm your audience.
- Fit Unrelated data : Stay on topic; don't include irrelevant information.
- Neglect the audience : Ensure your presentation suits your audience's level of expertise.
- Read word-for-word : Avoid reading directly from slides.
- Lose focus : Stick to your presentation's purpose.
Summarizing key takeaways
- Definition : Data presentation is the art of visualizing complex data for better understanding.
- Importance : Data presentations enhance clarity, engage the audience, aid decision-making, and leave a lasting impact.
- Types : Textual, Tabular, and Graphical presentations offer various ways to present data.
- Choosing methods : Select the right method based on data, audience, and purpose.
- Components : Include data points, comparisons, visuals, infographics, numerical values, and source citations.
- Structure : Know your audience, have a clear message, tell a compelling story, use visuals, be concise, and practice.
- Do's and don'ts : Do use visuals, keep it simple, highlight key points, engage the audience, and practice. Don't overload with data, include unrelated information, neglect the audience's expertise, read word-for-word, or lose focus.
1. What is data presentation, and why is it important in 2023?
Data presentation is the process of visually representing data sets to convey information effectively to an audience. In an era where the amount of data generated is vast, visually presenting data using methods such as diagrams, graphs, and charts has become crucial. By simplifying complex data sets, presentation of the data may helps your audience quickly grasp much information without drowning in a sea of chart's, analytics, facts and figures.
2. What are some common methods of data presentation?
There are various methods of data presentation, including graphs and charts, histograms, and cumulative frequency polygons. Each method has its strengths and is often used depending on the type of data you're using and the message you want to convey. For instance, if you want to show data over time, try using a line graph. If you're presenting geographical data, consider to use a heat map.
3. How can I ensure that my data presentation is clear and readable?
To ensure that your data presentation is clear and readable, pay attention to the design and labeling of your charts. Don't forget to label the axes appropriately, as they are critical for understanding the values they represent. Don't fit all the information in one slide or in a single paragraph. Presentation software like Prezent and PowerPoint can help you simplify your vertical axis, charts and tables, making them much easier to understand.
4. What are some common mistakes presenters make when presenting data?
One common mistake is trying to fit too much data into a single chart, which can distort the information and confuse the audience. Another mistake is not considering the needs of the audience. Remember that your audience won't have the same level of familiarity with the data as you do, so it's essential to present the data effectively and respond to questions during a Q&A session.
5. How can I use data visualization to present important data effectively on platforms like LinkedIn?
When presenting data on platforms like LinkedIn, consider using eye-catching visuals like bar graphs or charts. Use concise captions and e.g., examples to highlight the single most important information in your data report. Visuals, such as graphs and tables, can help you stand out in the sea of textual content, making your data presentation more engaging and shareable among your LinkedIn connections.
Create your data presentation with prezent
Prezent can be a valuable tool for creating data presentations. Here's how Prezent can help you in this regard:
- Time savings : Prezent saves up to 70% of presentation creation time, allowing you to focus on data analysis and insights.
- On-brand consistency : Ensure 100% brand alignment with Prezent's brand-approved designs for professional-looking data presentations.
- Effortless collaboration : Real-time sharing and collaboration features make it easy for teams to work together on data presentations.
- Data storytelling : Choose from 50+ storylines to effectively communicate data insights and engage your audience.
- Personalization : Create tailored data presentations that resonate with your audience's preferences, enhancing the impact of your data.
In summary, Prezent streamlines the process of creating data presentations by offering time-saving features, ensuring brand consistency, promoting collaboration, and providing tools for effective data storytelling. Whether you need to present data to clients, stakeholders, or within your organization, Prezent can significantly enhance your presentation-making process.
So, go ahead, present your data with confidence, and watch your audience be wowed by your expertise.
Thank you for joining us on this data-driven journey. Stay tuned for more insights, and remember, data presentation is your ticket to making numbers come alive!
Sign up for our free trial or book a demo !
More zenpedia articles

5 Essential leadership presentation ideas to master

Engage your audience: The secret weapon of active listening in presentations

Empathy in communication: The role of empathetic communication for successful business
Get the latest from Prezent community
Join thousands of subscribers who receive our best practices on communication, storytelling, presentation design, and more. New tips weekly. (No spam, we promise!)
Skills for Learning : Research Skills
Data analysis is an ongoing process that should occur throughout your research project. Suitable data-analysis methods must be selected when you write your research proposal. The nature of your data (i.e. quantitative or qualitative) will be influenced by your research design and purpose. The data will also influence the analysis methods selected.
We run interactive workshops to help you develop skills related to doing research, such as data analysis, writing literature reviews and preparing for dissertations. Find out more on the Skills for Learning Workshops page.
We have online academic skills modules within MyBeckett for all levels of university study. These modules will help your academic development and support your success at LBU. You can work through the modules at your own pace, revisiting them as required. Find out more from our FAQ What academic skills modules are available?
Quantitative data analysis
Broadly speaking, 'statistics' refers to methods, tools and techniques used to collect, organise and interpret data. The goal of statistics is to gain understanding from data. Therefore, you need to know how to:
- Produce data – for example, by handing out a questionnaire or doing an experiment.
- Organise, summarise, present and analyse data.
- Draw valid conclusions from findings.
There are a number of statistical methods you can use to analyse data. Choosing an appropriate statistical method should follow naturally, however, from your research design. Therefore, you should think about data analysis at the early stages of your study design. You may need to consult a statistician for help with this.
Tips for working with statistical data
- Plan so that the data you get has a good chance of successfully tackling the research problem. This will involve reading literature on your subject, as well as on what makes a good study.
- To reach useful conclusions, you need to reduce uncertainties or 'noise'. Thus, you will need a sufficiently large data sample. A large sample will improve precision. However, this must be balanced against the 'costs' (time and money) of collection.
- Consider the logistics. Will there be problems in obtaining sufficient high-quality data? Think about accuracy, trustworthiness and completeness.
- Statistics are based on random samples. Consider whether your sample will be suited to this sort of analysis. Might there be biases to think about?
- How will you deal with missing values (any data that is not recorded for some reason)? These can result from gaps in a record or whole records being missed out.
- When analysing data, start by looking at each variable separately. Conduct initial/exploratory data analysis using graphical displays. Do this before looking at variables in conjunction or anything more complicated. This process can help locate errors in the data and also gives you a 'feel' for the data.
- Look out for patterns of 'missingness'. They are likely to alert you if there’s a problem. If the 'missingness' is not random, then it will have an impact on the results.
- Be vigilant and think through what you are doing at all times. Think critically. Statistics are not just mathematical tricks that a computer sorts out. Rather, analysing statistical data is a process that the human mind must interpret!
Top tips! Try inventing or generating the sort of data you might get and see if you can analyse it. Make sure that your process works before gathering actual data. Think what the output of an analytic procedure will look like before doing it for real.
(Note: it is actually difficult to generate realistic data. There are fraud-detection methods in place to identify data that has been fabricated. So, remember to get rid of your practice data before analysing the real stuff!)
Statistical software packages
Software packages can be used to analyse and present data. The most widely used ones are SPSS and NVivo.
SPSS is a statistical-analysis and data-management package for quantitative data analysis. Click on ‘ How do I install SPSS? ’ to learn how to download SPSS to your personal device. SPSS can perform a wide variety of statistical procedures. Some examples are:
- Data management (i.e. creating subsets of data or transforming data).
- Summarising, describing or presenting data (i.e. mean, median and frequency).
- Looking at the distribution of data (i.e. standard deviation).
- Comparing groups for significant differences using parametric (i.e. t-test) and non-parametric (i.e. Chi-square) tests.
- Identifying significant relationships between variables (i.e. correlation).
NVivo can be used for qualitative data analysis. It is suitable for use with a wide range of methodologies. Click on ‘ How do I access NVivo ’ to learn how to download NVivo to your personal device. NVivo supports grounded theory, survey data, case studies, focus groups, phenomenology, field research and action research.
- Process data such as interview transcripts, literature or media extracts, and historical documents.
- Code data on screen and explore all coding and documents interactively.
- Rearrange, restructure, extend and edit text, coding and coding relationships.
- Search imported text for words, phrases or patterns, and automatically code the results.
Qualitative data analysis
Miles and Huberman (1994) point out that there are diverse approaches to qualitative research and analysis. They suggest, however, that it is possible to identify 'a fairly classic set of analytic moves arranged in sequence'. This involves:
- Affixing codes to a set of field notes drawn from observation or interviews.
- Noting reflections or other remarks in the margins.
- Sorting/sifting through these materials to identify: a) similar phrases, relationships between variables, patterns and themes and b) distinct differences between subgroups and common sequences.
- Isolating these patterns/processes and commonalties/differences. Then, taking them out to the field in the next wave of data collection.
- Highlighting generalisations and relating them to your original research themes.
- Taking the generalisations and analysing them in relation to theoretical perspectives.
(Miles and Huberman, 1994.)
Patterns and generalisations are usually arrived at through a process of analytic induction (see above points 5 and 6). Qualitative analysis rarely involves statistical analysis of relationships between variables. Qualitative analysis aims to gain in-depth understanding of concepts, opinions or experiences.
Presenting information
There are a number of different ways of presenting and communicating information. The particular format you use is dependent upon the type of data generated from the methods you have employed.
Here are some appropriate ways of presenting information for different types of data:
Bar charts: These may be useful for comparing relative sizes. However, they tend to use a large amount of ink to display a relatively small amount of information. Consider a simple line chart as an alternative.
Pie charts: These have the benefit of indicating that the data must add up to 100%. However, they make it difficult for viewers to distinguish relative sizes, especially if two slices have a difference of less than 10%.
Other examples of presenting data in graphical form include line charts and scatter plots .
Qualitative data is more likely to be presented in text form. For example, using quotations from interviews or field diaries.
- Plan ahead, thinking carefully about how you will analyse and present your data.
- Think through possible restrictions to resources you may encounter and plan accordingly.
- Find out about the different IT packages available for analysing your data and select the most appropriate.
- If necessary, allow time to attend an introductory course on a particular computer package. You can book SPSS and NVivo workshops via MyHub .
- Code your data appropriately, assigning conceptual or numerical codes as suitable.
- Organise your data so it can be analysed and presented easily.
- Choose the most suitable way of presenting your information, according to the type of data collected. This will allow your information to be understood and interpreted better.
Primary, secondary and tertiary sources
Information sources are sometimes categorised as primary, secondary or tertiary sources depending on whether or not they are ‘original’ materials or data. For some research projects, you may need to use primary sources as well as secondary or tertiary sources. However the distinction between primary and secondary sources is not always clear and depends on the context. For example, a newspaper article might usually be categorised as a secondary source. But it could also be regarded as a primary source if it were an article giving a first-hand account of a historical event written close to the time it occurred.
- Primary sources
- Secondary sources
- Tertiary sources
- Grey literature
Primary sources are original sources of information that provide first-hand accounts of what is being experienced or researched. They enable you to get as close to the actual event or research as possible. They are useful for getting the most contemporary information about a topic.
Examples include diary entries, newspaper articles, census data, journal articles with original reports of research, letters, email or other correspondence, original manuscripts and archives, interviews, research data and reports, statistics, autobiographies, exhibitions, films, and artists' writings.
Some information will be available on an Open Access basis, freely accessible online. However, many academic sources are paywalled, and you may need to login as a Leeds Beckett student to access them. Where Leeds Beckett does not have access to a source, you can use our Request It! Service .
Secondary sources interpret, evaluate or analyse primary sources. They're useful for providing background information on a topic, or for looking back at an event from a current perspective. The majority of your literature searching will probably be done to find secondary sources on your topic.
Examples include journal articles which review or interpret original findings, popular magazine articles commenting on more serious research, textbooks and biographies.
The term tertiary sources isn't used a great deal. There's overlap between what might be considered a secondary source and a tertiary source. One definition is that a tertiary source brings together secondary sources.
Examples include almanacs, fact books, bibliographies, dictionaries and encyclopaedias, directories, indexes and abstracts. They can be useful for introductory information or an overview of a topic in the early stages of research.
Depending on your subject of study, grey literature may be another source you need to use. Grey literature includes technical or research reports, theses and dissertations, conference papers, government documents, white papers, and so on.
Artificial intelligence tools
Before using any generative artificial intelligence or paraphrasing tools in your assessments, you should check if this is permitted on your course.
If their use is permitted on your course, you must acknowledge any use of generative artificial intelligence tools such as ChatGPT or paraphrasing tools (e.g., Grammarly, Quillbot, etc.), even if you have only used them to generate ideas for your assessments or for proofreading.
- Academic Integrity Module in MyBeckett
- Assignment Calculator
- Building on Feedback
- Disability Advice
- Essay X-ray tool
- International Students' Academic Introduction
- Manchester Academic Phrasebank
- Quote, Unquote
- Skills and Subject Suppor t
- Turnitin Grammar Checker
{{You can add more boxes below for links specific to this page [this note will not appear on user pages] }}
- Research Methods Checklist
- Sampling Checklist
Skills for Learning FAQs

0113 812 1000
- University Disclaimer
- Accessibility
A Step-by-Step Guide to the Data Analysis Process
Like any scientific discipline, data analysis follows a rigorous step-by-step process. Each stage requires different skills and know-how. To get meaningful insights, though, it’s important to understand the process as a whole. An underlying framework is invaluable for producing results that stand up to scrutiny.
In this post, we’ll explore the main steps in the data analysis process. This will cover how to define your goal, collect data, and carry out an analysis. Where applicable, we’ll also use examples and highlight a few tools to make the journey easier. When you’re done, you’ll have a much better understanding of the basics. This will help you tweak the process to fit your own needs.
Here are the steps we’ll take you through:
- Defining the question
- Collecting the data
- Cleaning the data
- Analyzing the data
- Sharing your results
- Embracing failure
On popular request, we’ve also developed a video based on this article. Scroll further along this article to watch that.
Ready? Let’s get started with step one.
1. Step one: Defining the question
The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the ‘problem statement’.
Defining your objective means coming up with a hypothesis and figuring how to test it. Start by asking: What business problem am I trying to solve? While this might sound straightforward, it can be trickier than it seems. For instance, your organization’s senior management might pose an issue, such as: “Why are we losing customers?” It’s possible, though, that this doesn’t get to the core of the problem. A data analyst’s job is to understand the business and its goals in enough depth that they can frame the problem the right way.
Let’s say you work for a fictional company called TopNotch Learning. TopNotch creates custom training software for its clients. While it is excellent at securing new clients, it has much lower repeat business. As such, your question might not be, “Why are we losing customers?” but, “Which factors are negatively impacting the customer experience?” or better yet: “How can we boost customer retention while minimizing costs?”
Now you’ve defined a problem, you need to determine which sources of data will best help you solve it. This is where your business acumen comes in again. For instance, perhaps you’ve noticed that the sales process for new clients is very slick, but that the production team is inefficient. Knowing this, you could hypothesize that the sales process wins lots of new clients, but the subsequent customer experience is lacking. Could this be why customers don’t come back? Which sources of data will help you answer this question?
Tools to help define your objective
Defining your objective is mostly about soft skills, business knowledge, and lateral thinking. But you’ll also need to keep track of business metrics and key performance indicators (KPIs). Monthly reports can allow you to track problem points in the business. Some KPI dashboards come with a fee, like Databox and DashThis . However, you’ll also find open-source software like Grafana , Freeboard , and Dashbuilder . These are great for producing simple dashboards, both at the beginning and the end of the data analysis process.
2. Step two: Collecting the data
Once you’ve established your objective, you’ll need to create a strategy for collecting and aggregating the appropriate data. A key part of this is determining which data you need. This might be quantitative (numeric) data, e.g. sales figures, or qualitative (descriptive) data, such as customer reviews. All data fit into one of three categories: first-party, second-party, and third-party data. Let’s explore each one.
What is first-party data?
First-party data are data that you, or your company, have directly collected from customers. It might come in the form of transactional tracking data or information from your company’s customer relationship management (CRM) system. Whatever its source, first-party data is usually structured and organized in a clear, defined way. Other sources of first-party data might include customer satisfaction surveys, focus groups, interviews, or direct observation.
What is second-party data?
To enrich your analysis, you might want to secure a secondary data source. Second-party data is the first-party data of other organizations. This might be available directly from the company or through a private marketplace. The main benefit of second-party data is that they are usually structured, and although they will be less relevant than first-party data, they also tend to be quite reliable. Examples of second-party data include website, app or social media activity, like online purchase histories, or shipping data.
What is third-party data?
Third-party data is data that has been collected and aggregated from numerous sources by a third-party organization. Often (though not always) third-party data contains a vast amount of unstructured data points (big data). Many organizations collect big data to create industry reports or to conduct market research. The research and advisory firm Gartner is a good real-world example of an organization that collects big data and sells it on to other companies. Open data repositories and government portals are also sources of third-party data .
Tools to help you collect data
Once you’ve devised a data strategy (i.e. you’ve identified which data you need, and how best to go about collecting them) there are many tools you can use to help you. One thing you’ll need, regardless of industry or area of expertise, is a data management platform (DMP). A DMP is a piece of software that allows you to identify and aggregate data from numerous sources, before manipulating them, segmenting them, and so on. There are many DMPs available. Some well-known enterprise DMPs include Salesforce DMP , SAS , and the data integration platform, Xplenty . If you want to play around, you can also try some open-source platforms like Pimcore or D:Swarm .
Want to learn more about what data analytics is and the process a data analyst follows? We cover this topic (and more) in our free introductory short course for beginners. Check out tutorial one: An introduction to data analytics .
3. Step three: Cleaning the data
Once you’ve collected your data, the next step is to get it ready for analysis. This means cleaning, or ‘scrubbing’ it, and is crucial in making sure that you’re working with high-quality data . Key data cleaning tasks include:
- Removing major errors, duplicates, and outliers —all of which are inevitable problems when aggregating data from numerous sources.
- Removing unwanted data points —extracting irrelevant observations that have no bearing on your intended analysis.
- Bringing structure to your data —general ‘housekeeping’, i.e. fixing typos or layout issues, which will help you map and manipulate your data more easily.
- Filling in major gaps —as you’re tidying up, you might notice that important data are missing. Once you’ve identified gaps, you can go about filling them.
A good data analyst will spend around 70-90% of their time cleaning their data. This might sound excessive. But focusing on the wrong data points (or analyzing erroneous data) will severely impact your results. It might even send you back to square one…so don’t rush it! You’ll find a step-by-step guide to data cleaning here . You may be interested in this introductory tutorial to data cleaning, hosted by Dr. Humera Noor Minhas.
Carrying out an exploratory analysis
Another thing many data analysts do (alongside cleaning data) is to carry out an exploratory analysis. This helps identify initial trends and characteristics, and can even refine your hypothesis. Let’s use our fictional learning company as an example again. Carrying out an exploratory analysis, perhaps you notice a correlation between how much TopNotch Learning’s clients pay and how quickly they move on to new suppliers. This might suggest that a low-quality customer experience (the assumption in your initial hypothesis) is actually less of an issue than cost. You might, therefore, take this into account.
Tools to help you clean your data
Cleaning datasets manually—especially large ones—can be daunting. Luckily, there are many tools available to streamline the process. Open-source tools, such as OpenRefine , are excellent for basic data cleaning, as well as high-level exploration. However, free tools offer limited functionality for very large datasets. Python libraries (e.g. Pandas) and some R packages are better suited for heavy data scrubbing. You will, of course, need to be familiar with the languages. Alternatively, enterprise tools are also available. For example, Data Ladder , which is one of the highest-rated data-matching tools in the industry. There are many more. Why not see which free data cleaning tools you can find to play around with?
4. Step four: Analyzing the data
Finally, you’ve cleaned your data. Now comes the fun bit—analyzing it! The type of data analysis you carry out largely depends on what your goal is. But there are many techniques available. Univariate or bivariate analysis, time-series analysis, and regression analysis are just a few you might have heard of. More important than the different types, though, is how you apply them. This depends on what insights you’re hoping to gain. Broadly speaking, all types of data analysis fit into one of the following four categories.
Descriptive analysis
Descriptive analysis identifies what has already happened . It is a common first step that companies carry out before proceeding with deeper explorations. As an example, let’s refer back to our fictional learning provider once more. TopNotch Learning might use descriptive analytics to analyze course completion rates for their customers. Or they might identify how many users access their products during a particular period. Perhaps they’ll use it to measure sales figures over the last five years. While the company might not draw firm conclusions from any of these insights, summarizing and describing the data will help them to determine how to proceed.
Learn more: What is descriptive analytics?
Diagnostic analysis
Diagnostic analytics focuses on understanding why something has happened . It is literally the diagnosis of a problem, just as a doctor uses a patient’s symptoms to diagnose a disease. Remember TopNotch Learning’s business problem? ‘Which factors are negatively impacting the customer experience?’ A diagnostic analysis would help answer this. For instance, it could help the company draw correlations between the issue (struggling to gain repeat business) and factors that might be causing it (e.g. project costs, speed of delivery, customer sector, etc.) Let’s imagine that, using diagnostic analytics, TopNotch realizes its clients in the retail sector are departing at a faster rate than other clients. This might suggest that they’re losing customers because they lack expertise in this sector. And that’s a useful insight!
Predictive analysis
Predictive analysis allows you to identify future trends based on historical data . In business, predictive analysis is commonly used to forecast future growth, for example. But it doesn’t stop there. Predictive analysis has grown increasingly sophisticated in recent years. The speedy evolution of machine learning allows organizations to make surprisingly accurate forecasts. Take the insurance industry. Insurance providers commonly use past data to predict which customer groups are more likely to get into accidents. As a result, they’ll hike up customer insurance premiums for those groups. Likewise, the retail industry often uses transaction data to predict where future trends lie, or to determine seasonal buying habits to inform their strategies. These are just a few simple examples, but the untapped potential of predictive analysis is pretty compelling.
Prescriptive analysis
Prescriptive analysis allows you to make recommendations for the future. This is the final step in the analytics part of the process. It’s also the most complex. This is because it incorporates aspects of all the other analyses we’ve described. A great example of prescriptive analytics is the algorithms that guide Google’s self-driving cars. Every second, these algorithms make countless decisions based on past and present data, ensuring a smooth, safe ride. Prescriptive analytics also helps companies decide on new products or areas of business to invest in.
Learn more: What are the different types of data analysis?
5. Step five: Sharing your results
You’ve finished carrying out your analyses. You have your insights. The final step of the data analytics process is to share these insights with the wider world (or at least with your organization’s stakeholders!) This is more complex than simply sharing the raw results of your work—it involves interpreting the outcomes, and presenting them in a manner that’s digestible for all types of audiences. Since you’ll often present information to decision-makers, it’s very important that the insights you present are 100% clear and unambiguous. For this reason, data analysts commonly use reports, dashboards, and interactive visualizations to support their findings.
How you interpret and present results will often influence the direction of a business. Depending on what you share, your organization might decide to restructure, to launch a high-risk product, or even to close an entire division. That’s why it’s very important to provide all the evidence that you’ve gathered, and not to cherry-pick data. Ensuring that you cover everything in a clear, concise way will prove that your conclusions are scientifically sound and based on the facts. On the flip side, it’s important to highlight any gaps in the data or to flag any insights that might be open to interpretation. Honest communication is the most important part of the process. It will help the business, while also helping you to excel at your job!
Tools for interpreting and sharing your findings
There are tons of data visualization tools available, suited to different experience levels. Popular tools requiring little or no coding skills include Google Charts , Tableau , Datawrapper , and Infogram . If you’re familiar with Python and R, there are also many data visualization libraries and packages available. For instance, check out the Python libraries Plotly , Seaborn , and Matplotlib . Whichever data visualization tools you use, make sure you polish up your presentation skills, too. Remember: Visualization is great, but communication is key!
You can learn more about storytelling with data in this free, hands-on tutorial . We show you how to craft a compelling narrative for a real dataset, resulting in a presentation to share with key stakeholders. This is an excellent insight into what it’s really like to work as a data analyst!
6. Step six: Embrace your failures
The last ‘step’ in the data analytics process is to embrace your failures. The path we’ve described above is more of an iterative process than a one-way street. Data analytics is inherently messy, and the process you follow will be different for every project. For instance, while cleaning data, you might spot patterns that spark a whole new set of questions. This could send you back to step one (to redefine your objective). Equally, an exploratory analysis might highlight a set of data points you’d never considered using before. Or maybe you find that the results of your core analyses are misleading or erroneous. This might be caused by mistakes in the data, or human error earlier in the process.
While these pitfalls can feel like failures, don’t be disheartened if they happen. Data analysis is inherently chaotic, and mistakes occur. What’s important is to hone your ability to spot and rectify errors. If data analytics was straightforward, it might be easier, but it certainly wouldn’t be as interesting. Use the steps we’ve outlined as a framework, stay open-minded, and be creative. If you lose your way, you can refer back to the process to keep yourself on track.
In this post, we’ve covered the main steps of the data analytics process. These core steps can be amended, re-ordered and re-used as you deem fit, but they underpin every data analyst’s work:
- Define the question —What business problem are you trying to solve? Frame it as a question to help you focus on finding a clear answer.
- Collect data —Create a strategy for collecting data. Which data sources are most likely to help you solve your business problem?
- Clean the data —Explore, scrub, tidy, de-dupe, and structure your data as needed. Do whatever you have to! But don’t rush…take your time!
- Analyze the data —Carry out various analyses to obtain insights. Focus on the four types of data analysis: descriptive, diagnostic, predictive, and prescriptive.
- Share your results —How best can you share your insights and recommendations? A combination of visualization tools and communication is key.
- Embrace your mistakes —Mistakes happen. Learn from them. This is what transforms a good data analyst into a great one.
What next? From here, we strongly encourage you to explore the topic on your own. Get creative with the steps in the data analysis process, and see what tools you can find. As long as you stick to the core principles we’ve described, you can create a tailored technique that works for you.
To learn more, check out our free, 5-day data analytics short course . You might also be interested in the following:
- These are the top 9 data analytics tools
- 10 great places to find free datasets for your next project
- How to build a data analytics portfolio
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Qualitative Data Analysis
23 Presenting the Results of Qualitative Analysis
Mikaila Mariel Lemonik Arthur
Qualitative research is not finished just because you have determined the main findings or conclusions of your study. Indeed, disseminating the results is an essential part of the research process. By sharing your results with others, whether in written form as scholarly paper or an applied report or in some alternative format like an oral presentation, an infographic, or a video, you ensure that your findings become part of the ongoing conversation of scholarship in your field, forming part of the foundation for future researchers. This chapter provides an introduction to writing about qualitative research findings. It will outline how writing continues to contribute to the analysis process, what concerns researchers should keep in mind as they draft their presentations of findings, and how best to organize qualitative research writing
As you move through the research process, it is essential to keep yourself organized. Organizing your data, memos, and notes aids both the analytical and the writing processes. Whether you use electronic or physical, real-world filing and organizational systems, these systems help make sense of the mountains of data you have and assure you focus your attention on the themes and ideas you have determined are important (Warren and Karner 2015). Be sure that you have kept detailed notes on all of the decisions you have made and procedures you have followed in carrying out research design, data collection, and analysis, as these will guide your ultimate write-up.
First and foremost, researchers should keep in mind that writing is in fact a form of thinking. Writing is an excellent way to discover ideas and arguments and to further develop an analysis. As you write, more ideas will occur to you, things that were previously confusing will start to make sense, and arguments will take a clear shape rather than being amorphous and poorly-organized. However, writing-as-thinking cannot be the final version that you share with others. Good-quality writing does not display the workings of your thought process. It is reorganized and revised (more on that later) to present the data and arguments important in a particular piece. And revision is totally normal! No one expects the first draft of a piece of writing to be ready for prime time. So write rough drafts and memos and notes to yourself and use them to think, and then revise them until the piece is the way you want it to be for sharing.
Bergin (2018) lays out a set of key concerns for appropriate writing about research. First, present your results accurately, without exaggerating or misrepresenting. It is very easy to overstate your findings by accident if you are enthusiastic about what you have found, so it is important to take care and use appropriate cautions about the limitations of the research. You also need to work to ensure that you communicate your findings in a way people can understand, using clear and appropriate language that is adjusted to the level of those you are communicating with. And you must be clear and transparent about the methodological strategies employed in the research. Remember, the goal is, as much as possible, to describe your research in a way that would permit others to replicate the study. There are a variety of other concerns and decision points that qualitative researchers must keep in mind, including the extent to which to include quantification in their presentation of results, ethics, considerations of audience and voice, and how to bring the richness of qualitative data to life.
Quantification, as you have learned, refers to the process of turning data into numbers. It can indeed be very useful to count and tabulate quantitative data drawn from qualitative research. For instance, if you were doing a study of dual-earner households and wanted to know how many had an equal division of household labor and how many did not, you might want to count those numbers up and include them as part of the final write-up. However, researchers need to take care when they are writing about quantified qualitative data. Qualitative data is not as generalizable as quantitative data, so quantification can be very misleading. Thus, qualitative researchers should strive to use raw numbers instead of the percentages that are more appropriate for quantitative research. Writing, for instance, “15 of the 20 people I interviewed prefer pancakes to waffles” is a simple description of the data; writing “75% of people prefer pancakes” suggests a generalizable claim that is not likely supported by the data. Note that mixing numbers with qualitative data is really a type of mixed-methods approach. Mixed-methods approaches are good, but sometimes they seduce researchers into focusing on the persuasive power of numbers and tables rather than capitalizing on the inherent richness of their qualitative data.
A variety of issues of scholarly ethics and research integrity are raised by the writing process. Some of these are unique to qualitative research, while others are more universal concerns for all academic and professional writing. For example, it is essential to avoid plagiarism and misuse of sources. All quotations that appear in a text must be properly cited, whether with in-text and bibliographic citations to the source or with an attribution to the research participant (or the participant’s pseudonym or description in order to protect confidentiality) who said those words. Where writers will paraphrase a text or a participant’s words, they need to make sure that the paraphrase they develop accurately reflects the meaning of the original words. Thus, some scholars suggest that participants should have the opportunity to read (or to have read to them, if they cannot read the text themselves) all sections of the text in which they, their words, or their ideas are presented to ensure accuracy and enable participants to maintain control over their lives.
Audience and Voice
When writing, researchers must consider their audience(s) and the effects they want their writing to have on these audiences. The designated audience will dictate the voice used in the writing, or the individual style and personality of a piece of text. Keep in mind that the potential audience for qualitative research is often much more diverse than that for quantitative research because of the accessibility of the data and the extent to which the writing can be accessible and interesting. Yet individual pieces of writing are typically pitched to a more specific subset of the audience.
Let us consider one potential research study, an ethnography involving participant-observation of the same children both when they are at daycare facility and when they are at home with their families to try to understand how daycare might impact behavior and social development. The findings of this study might be of interest to a wide variety of potential audiences: academic peers, whether at your own academic institution, in your broader discipline, or multidisciplinary; people responsible for creating laws and policies; practitioners who run or teach at day care centers; and the general public, including both people who are interested in child development more generally and those who are themselves parents making decisions about child care for their own children. And the way you write for each of these audiences will be somewhat different. Take a moment and think through what some of these differences might look like.
If you are writing to academic audiences, using specialized academic language and working within the typical constraints of scholarly genres, as will be discussed below, can be an important part of convincing others that your work is legitimate and should be taken seriously. Your writing will be formal. Even if you are writing for students and faculty you already know—your classmates, for instance—you are often asked to imitate the style of academic writing that is used in publications, as this is part of learning to become part of the scholarly conversation. When speaking to academic audiences outside your discipline, you may need to be more careful about jargon and specialized language, as disciplines do not always share the same key terms. For instance, in sociology, scholars use the term diffusion to refer to the way new ideas or practices spread from organization to organization. In the field of international relations, scholars often used the term cascade to refer to the way ideas or practices spread from nation to nation. These terms are describing what is fundamentally the same concept, but they are different terms—and a scholar from one field might have no idea what a scholar from a different field is talking about! Therefore, while the formality and academic structure of the text would stay the same, a writer with a multidisciplinary audience might need to pay more attention to defining their terms in the body of the text.
It is not only other academic scholars who expect to see formal writing. Policymakers tend to expect formality when ideas are presented to them, as well. However, the content and style of the writing will be different. Much less academic jargon should be used, and the most important findings and policy implications should be emphasized right from the start rather than initially focusing on prior literature and theoretical models as you might for an academic audience. Long discussions of research methods should also be minimized. Similarly, when you write for practitioners, the findings and implications for practice should be highlighted. The reading level of the text will vary depending on the typical background of the practitioners to whom you are writing—you can make very different assumptions about the general knowledge and reading abilities of a group of hospital medical directors with MDs than you can about a group of case workers who have a post-high-school certificate. Consider the primary language of your audience as well. The fact that someone can get by in spoken English does not mean they have the vocabulary or English reading skills to digest a complex report. But the fact that someone’s vocabulary is limited says little about their intellectual abilities, so try your best to convey the important complexity of the ideas and findings from your research without dumbing them down—even if you must limit your vocabulary usage.
When writing for the general public, you will want to move even further towards emphasizing key findings and policy implications, but you also want to draw on the most interesting aspects of your data. General readers will read sociological texts that are rich with ethnographic or other kinds of detail—it is almost like reality television on a page! And this is a contrast to busy policymakers and practitioners, who probably want to learn the main findings as quickly as possible so they can go about their busy lives. But also keep in mind that there is a wide variation in reading levels. Journalists at publications pegged to the general public are often advised to write at about a tenth-grade reading level, which would leave most of the specialized terminology we develop in our research fields out of reach. If you want to be accessible to even more people, your vocabulary must be even more limited. The excellent exercise of trying to write using the 1,000 most common English words, available at the Up-Goer Five website ( https://www.splasho.com/upgoer5/ ) does a good job of illustrating this challenge (Sanderson n.d.).
Another element of voice is whether to write in the first person. While many students are instructed to avoid the use of the first person in academic writing, this advice needs to be taken with a grain of salt. There are indeed many contexts in which the first person is best avoided, at least as long as writers can find ways to build strong, comprehensible sentences without its use, including most quantitative research writing. However, if the alternative to using the first person is crafting a sentence like “it is proposed that the researcher will conduct interviews,” it is preferable to write “I propose to conduct interviews.” In qualitative research, in fact, the use of the first person is far more common. This is because the researcher is central to the research project. Qualitative researchers can themselves be understood as research instruments, and thus eliminating the use of the first person in writing is in a sense eliminating information about the conduct of the researchers themselves.
But the question really extends beyond the issue of first-person or third-person. Qualitative researchers have choices about how and whether to foreground themselves in their writing, not just in terms of using the first person, but also in terms of whether to emphasize their own subjectivity and reflexivity, their impressions and ideas, and their role in the setting. In contrast, conventional quantitative research in the positivist tradition really tries to eliminate the author from the study—which indeed is exactly why typical quantitative research avoids the use of the first person. Keep in mind that emphasizing researchers’ roles and reflexivity and using the first person does not mean crafting articles that provide overwhelming detail about the author’s thoughts and practices. Readers do not need to hear, and should not be told, which database you used to search for journal articles, how many hours you spent transcribing, or whether the research process was stressful—save these things for the memos you write to yourself. Rather, readers need to hear how you interacted with research participants, how your standpoint may have shaped the findings, and what analytical procedures you carried out.
Making Data Come Alive
One of the most important parts of writing about qualitative research is presenting the data in a way that makes its richness and value accessible to readers. As the discussion of analysis in the prior chapter suggests, there are a variety of ways to do this. Researchers may select key quotes or images to illustrate points, write up specific case studies that exemplify their argument, or develop vignettes (little stories) that illustrate ideas and themes, all drawing directly on the research data. Researchers can also write more lengthy summaries, narratives, and thick descriptions.
Nearly all qualitative work includes quotes from research participants or documents to some extent, though ethnographic work may focus more on thick description than on relaying participants’ own words. When quotes are presented, they must be explained and interpreted—they cannot stand on their own. This is one of the ways in which qualitative research can be distinguished from journalism. Journalism presents what happened, but social science needs to present the “why,” and the why is best explained by the researcher.
So how do authors go about integrating quotes into their written work? Julie Posselt (2017), a sociologist who studies graduate education, provides a set of instructions. First of all, authors need to remain focused on the core questions of their research, and avoid getting distracted by quotes that are interesting or attention-grabbing but not so relevant to the research question. Selecting the right quotes, those that illustrate the ideas and arguments of the paper, is an important part of the writing process. Second, not all quotes should be the same length (just like not all sentences or paragraphs in a paper should be the same length). Include some quotes that are just phrases, others that are a sentence or so, and others that are longer. We call longer quotes, generally those more than about three lines long, block quotes , and they are typically indented on both sides to set them off from the surrounding text. For all quotes, be sure to summarize what the quote should be telling or showing the reader, connect this quote to other quotes that are similar or different, and provide transitions in the discussion to move from quote to quote and from topic to topic. Especially for longer quotes, it is helpful to do some of this writing before the quote to preview what is coming and other writing after the quote to make clear what readers should have come to understand. Remember, it is always the author’s job to interpret the data. Presenting excerpts of the data, like quotes, in a form the reader can access does not minimize the importance of this job. Be sure that you are explaining the meaning of the data you present.
A few more notes about writing with quotes: avoid patchwriting, whether in your literature review or the section of your paper in which quotes from respondents are presented. Patchwriting is a writing practice wherein the author lightly paraphrases original texts but stays so close to those texts that there is little the author has added. Sometimes, this even takes the form of presenting a series of quotes, properly documented, with nothing much in the way of text generated by the author. A patchwriting approach does not build the scholarly conversation forward, as it does not represent any kind of new contribution on the part of the author. It is of course fine to paraphrase quotes, as long as the meaning is not changed. But if you use direct quotes, do not edit the text of the quotes unless how you edit them does not change the meaning and you have made clear through the use of ellipses (…) and brackets ([])what kinds of edits have been made. For example, consider this exchange from Matthew Desmond’s (2012:1317) research on evictions:
The thing was, I wasn’t never gonna let Crystal come and stay with me from the get go. I just told her that to throw her off. And she wasn’t fittin’ to come stay with me with no money…No. Nope. You might as well stay in that shelter.
A paraphrase of this exchange might read “She said that she was going to let Crystal stay with her if Crystal did not have any money.” Paraphrases like that are fine. What is not fine is rewording the statement but treating it like a quote, for instance writing:
The thing was, I was not going to let Crystal come and stay with me from beginning. I just told her that to throw her off. And it was not proper for her to come stay with me without any money…No. Nope. You might as well stay in that shelter.
But as you can see, the change in language and style removes some of the distinct meaning of the original quote. Instead, writers should leave as much of the original language as possible. If some text in the middle of the quote needs to be removed, as in this example, ellipses are used to show that this has occurred. And if a word needs to be added to clarify, it is placed in square brackets to show that it was not part of the original quote.
Data can also be presented through the use of data displays like tables, charts, graphs, diagrams, and infographics created for publication or presentation, as well as through the use of visual material collected during the research process. Note that if visuals are used, the author must have the legal right to use them. Photographs or diagrams created by the author themselves—or by research participants who have signed consent forms for their work to be used, are fine. But photographs, and sometimes even excerpts from archival documents, may be owned by others from whom researchers must get permission in order to use them.
A large percentage of qualitative research does not include any data displays or visualizations. Therefore, researchers should carefully consider whether the use of data displays will help the reader understand the data. One of the most common types of data displays used by qualitative researchers are simple tables. These might include tables summarizing key data about cases included in the study; tables laying out the characteristics of different taxonomic elements or types developed as part of the analysis; tables counting the incidence of various elements; and 2×2 tables (two columns and two rows) illuminating a theory. Basic network or process diagrams are also commonly included. If data displays are used, it is essential that researchers include context and analysis alongside data displays rather than letting them stand by themselves, and it is preferable to continue to present excerpts and examples from the data rather than just relying on summaries in the tables.
If you will be using graphs, infographics, or other data visualizations, it is important that you attend to making them useful and accurate (Bergin 2018). Think about the viewer or user as your audience and ensure the data visualizations will be comprehensible. You may need to include more detail or labels than you might think. Ensure that data visualizations are laid out and labeled clearly and that you make visual choices that enhance viewers’ ability to understand the points you intend to communicate using the visual in question. Finally, given the ease with which it is possible to design visuals that are deceptive or misleading, it is essential to make ethical and responsible choices in the construction of visualization so that viewers will interpret them in accurate ways.
The Genre of Research Writing
As discussed above, the style and format in which results are presented depends on the audience they are intended for. These differences in styles and format are part of the genre of writing. Genre is a term referring to the rules of a specific form of creative or productive work. Thus, the academic journal article—and student papers based on this form—is one genre. A report or policy paper is another. The discussion below will focus on the academic journal article, but note that reports and policy papers follow somewhat different formats. They might begin with an executive summary of one or a few pages, include minimal background, focus on key findings, and conclude with policy implications, shifting methods and details about the data to an appendix. But both academic journal articles and policy papers share some things in common, for instance the necessity for clear writing, a well-organized structure, and the use of headings.
So what factors make up the genre of the academic journal article in sociology? While there is some flexibility, particularly for ethnographic work, academic journal articles tend to follow a fairly standard format. They begin with a “title page” that includes the article title (often witty and involving scholarly inside jokes, but more importantly clearly describing the content of the article); the authors’ names and institutional affiliations, an abstract , and sometimes keywords designed to help others find the article in databases. An abstract is a short summary of the article that appears both at the very beginning of the article and in search databases. Abstracts are designed to aid readers by giving them the opportunity to learn enough about an article that they can determine whether it is worth their time to read the complete text. They are written about the article, and thus not in the first person, and clearly summarize the research question, methodological approach, main findings, and often the implications of the research.
After the abstract comes an “introduction” of a page or two that details the research question, why it matters, and what approach the paper will take. This is followed by a literature review of about a quarter to a third the length of the entire paper. The literature review is often divided, with headings, into topical subsections, and is designed to provide a clear, thorough overview of the prior research literature on which a paper has built—including prior literature the new paper contradicts. At the end of the literature review it should be made clear what researchers know about the research topic and question, what they do not know, and what this new paper aims to do to address what is not known.
The next major section of the paper is the section that describes research design, data collection, and data analysis, often referred to as “research methods” or “methodology.” This section is an essential part of any written or oral presentation of your research. Here, you tell your readers or listeners “how you collected and interpreted your data” (Taylor, Bogdan, and DeVault 2016:215). Taylor, Bogdan, and DeVault suggest that the discussion of your research methods include the following:
- The particular approach to data collection used in the study;
- Any theoretical perspective(s) that shaped your data collection and analytical approach;
- When the study occurred, over how long, and where (concealing identifiable details as needed);
- A description of the setting and participants, including sampling and selection criteria (if an interview-based study, the number of participants should be clearly stated);
- The researcher’s perspective in carrying out the study, including relevant elements of their identity and standpoint, as well as their role (if any) in research settings; and
- The approach to analyzing the data.
After the methods section comes a section, variously titled but often called “data,” that takes readers through the analysis. This section is where the thick description narrative; the quotes, broken up by theme or topic, with their interpretation; the discussions of case studies; most data displays (other than perhaps those outlining a theoretical model or summarizing descriptive data about cases); and other similar material appears. The idea of the data section is to give readers the ability to see the data for themselves and to understand how this data supports the ultimate conclusions. Note that all tables and figures included in formal publications should be titled and numbered.
At the end of the paper come one or two summary sections, often called “discussion” and/or “conclusion.” If there is a separate discussion section, it will focus on exploring the overall themes and findings of the paper. The conclusion clearly and succinctly summarizes the findings and conclusions of the paper, the limitations of the research and analysis, any suggestions for future research building on the paper or addressing these limitations, and implications, be they for scholarship and theory or policy and practice.
After the end of the textual material in the paper comes the bibliography, typically called “works cited” or “references.” The references should appear in a consistent citation style—in sociology, we often use the American Sociological Association format (American Sociological Association 2019), but other formats may be used depending on where the piece will eventually be published. Care should be taken to ensure that in-text citations also reflect the chosen citation style. In some papers, there may be an appendix containing supplemental information such as a list of interview questions or an additional data visualization.
Note that when researchers give presentations to scholarly audiences, the presentations typically follow a format similar to that of scholarly papers, though given time limitations they are compressed. Abstracts and works cited are often not part of the presentation, though in-text citations are still used. The literature review presented will be shortened to only focus on the most important aspects of the prior literature, and only key examples from the discussion of data will be included. For long or complex papers, sometimes only one of several findings is the focus of the presentation. Of course, presentations for other audiences may be constructed differently, with greater attention to interesting elements of the data and findings as well as implications and less to the literature review and methods.
Concluding Your Work
After you have written a complete draft of the paper, be sure you take the time to revise and edit your work. There are several important strategies for revision. First, put your work away for a little while. Even waiting a day to revise is better than nothing, but it is best, if possible, to take much more time away from the text. This helps you forget what your writing looks like and makes it easier to find errors, mistakes, and omissions. Second, show your work to others. Ask them to read your work and critique it, pointing out places where the argument is weak, where you may have overlooked alternative explanations, where the writing could be improved, and what else you need to work on. Finally, read your work out loud to yourself (or, if you really need an audience, try reading to some stuffed animals). Reading out loud helps you catch wrong words, tricky sentences, and many other issues. But as important as revision is, try to avoid perfectionism in writing (Warren and Karner 2015). Writing can always be improved, no matter how much time you spend on it. Those improvements, however, have diminishing returns, and at some point the writing process needs to conclude so the writing can be shared with the world.
Of course, the main goal of writing up the results of a research project is to share with others. Thus, researchers should be considering how they intend to disseminate their results. What conferences might be appropriate? Where can the paper be submitted? Note that if you are an undergraduate student, there are a wide variety of journals that accept and publish research conducted by undergraduates. Some publish across disciplines, while others are specific to disciplines. Other work, such as reports, may be best disseminated by publication online on relevant organizational websites.
After a project is completed, be sure to take some time to organize your research materials and archive them for longer-term storage. Some Institutional Review Board (IRB) protocols require that original data, such as interview recordings, transcripts, and field notes, be preserved for a specific number of years in a protected (locked for paper or password-protected for digital) form and then destroyed, so be sure that your plans adhere to the IRB requirements. Be sure you keep any materials that might be relevant for future related research or for answering questions people may ask later about your project.
And then what? Well, then it is time to move on to your next research project. Research is a long-term endeavor, not a one-time-only activity. We build our skills and our expertise as we continue to pursue research. So keep at it.
- Find a short article that uses qualitative methods. The sociological magazine Contexts is a good place to find such pieces. Write an abstract of the article.
- Choose a sociological journal article on a topic you are interested in that uses some form of qualitative methods and is at least 20 pages long. Rewrite the article as a five-page research summary accessible to non-scholarly audiences.
- Choose a concept or idea you have learned in this course and write an explanation of it using the Up-Goer Five Text Editor ( https://www.splasho.com/upgoer5/ ), a website that restricts your writing to the 1,000 most common English words. What was this experience like? What did it teach you about communicating with people who have a more limited English-language vocabulary—and what did it teach you about the utility of having access to complex academic language?
- Select five or more sociological journal articles that all use the same basic type of qualitative methods (interviewing, ethnography, documents, or visual sociology). Using what you have learned about coding, code the methods sections of each article, and use your coding to figure out what is common in how such articles discuss their research design, data collection, and analysis methods.
- Return to an exercise you completed earlier in this course and revise your work. What did you change? How did revising impact the final product?
- Find a quote from the transcript of an interview, a social media post, or elsewhere that has not yet been interpreted or explained. Write a paragraph that includes the quote along with an explanation of its sociological meaning or significance.
The style or personality of a piece of writing, including such elements as tone, word choice, syntax, and rhythm.
A quotation, usually one of some length, which is set off from the main text by being indented on both sides rather than being placed in quotation marks.
A classification of written or artistic work based on form, content, and style.
A short summary of a text written from the perspective of a reader rather than from the perspective of an author.
Social Data Analysis Copyright © 2021 by Mikaila Mariel Lemonik Arthur is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Data Collection, Presentation and Analysis
- First Online: 25 May 2023
Cite this chapter

- Uche M. Mbanaso 4 ,
- Lucienne Abrahams 5 &
- Kennedy Chinedu Okafor 6
569 Accesses
This chapter covers the topics of data collection, data presentation and data analysis. It gives attention to data collection for studies based on experiments, on data derived from existing published or unpublished data sets, on observation, on simulation and digital twins, on surveys, on interviews and on focus group discussions. One of the interesting features of this chapter is the section dealing with using measurement scales in quantitative research, including nominal scales, ordinal scales, interval scales and ratio scales. It explains key facets of qualitative research including ethical clearance requirements. The chapter discusses the importance of data visualization as key to effective presentation of data, including tabular forms, graphical forms and visual charts such as those generated by Atlas.ti analytical software.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as EPUB and PDF
- Read on any device
- Instant download
- Own it forever
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Bibliography
Abdullah, M. F., & Ahmad, K. (2013). The mapping process of unstructured data to structured data. Proceedings of the 2013 International Conference on Research and Innovation in Information Systems (ICRIIS) , Malaysia , 151–155. https://doi.org/10.1109/ICRIIS.2013.6716700
Adnan, K., & Akbar, R. (2019). An analytical study of information extraction from unstructured and multidimensional big data. Journal of Big Data, 6 , 91. https://doi.org/10.1186/s40537-019-0254-8
Article Google Scholar
Alsheref, F. K., & Fattoh, I. E. (2020). Medical text annotation tool based on IBM Watson Platform. Proceedings of the 2020 6th international conference on advanced computing and communication systems (ICACCS) , India , 1312–1316. https://doi.org/10.1109/ICACCS48705.2020.9074309
Cinque, M., Cotroneo, D., Della Corte, R., & Pecchia, A. (2014). What logs should you look at when an application fails? Insights from an industrial case study. Proceedings of the 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks , USA , 690–695. https://doi.org/10.1109/DSN.2014.69
Gideon, L. (Ed.). (2012). Handbook of survey methodology for the social sciences . Springer.
Google Scholar
Leedy, P., & Ormrod, J. (2015). Practical research planning and design (12th ed.). Pearson Education.
Madaan, A., Wang, X., Hall, W., & Tiropanis, T. (2018). Observing data in IoT worlds: What and how to observe? In Living in the Internet of Things: Cybersecurity of the IoT – 2018 (pp. 1–7). https://doi.org/10.1049/cp.2018.0032
Chapter Google Scholar
Mahajan, P., & Naik, C. (2019). Development of integrated IoT and machine learning based data collection and analysis system for the effective prediction of agricultural residue/biomass availability to regenerate clean energy. Proceedings of the 2019 9th International Conference on Emerging Trends in Engineering and Technology – Signal and Information Processing (ICETET-SIP-19) , India , 1–5. https://doi.org/10.1109/ICETET-SIP-1946815.2019.9092156 .
Mahmud, M. S., Huang, J. Z., Salloum, S., Emara, T. Z., & Sadatdiynov, K. (2020). A survey of data partitioning and sampling methods to support big data analysis. Big Data Mining and Analytics, 3 (2), 85–101. https://doi.org/10.26599/BDMA.2019.9020015
Miswar, S., & Kurniawan, N. B. (2018). A systematic literature review on survey data collection system. Proceedings of the 2018 International Conference on Information Technology Systems and Innovation (ICITSI) , Indonesia , 177–181. https://doi.org/10.1109/ICITSI.2018.8696036
Mosina, C. (2020). Understanding the diffusion of the internet: Redesigning the global diffusion of the internet framework (Research report, Master of Arts in ICT Policy and Regulation). LINK Centre, University of the Witwatersrand. https://hdl.handle.net/10539/30723
Nkamisa, S. (2021). Investigating the integration of drone management systems to create an enabling remote piloted aircraft regulatory environment in South Africa (Research report, Master of Arts in ICT Policy and Regulation). LINK Centre, University of the Witwatersrand. https://hdl.handle.net/10539/33883
QuestionPro. (2020). Survey research: Definition, examples and methods . https://www.questionpro.com/article/survey-research.html
Rajanikanth, J. & Kanth, T. V. R. (2017). An explorative data analysis on Bangalore City Weather with hybrid data mining techniques using R. Proceedings of the 2017 International Conference on Current Trends in Computer, Electrical, Electronics and Communication (CTCEEC) , India , 1121-1125. https://doi/10.1109/CTCEEC.2017.8455008
Rao, R. (2003). From unstructured data to actionable intelligence. IT Professional, 5 , 29–35. https://www.researchgate.net/publication/3426648_From_Unstructured_Data_to_Actionable_Intelligence
Schulze, P. (2009). Design of the research instrument. In P. Schulze (Ed.), Balancing exploitation and exploration: Organizational antecedents and performance effects of innovation strategies (pp. 116–141). Gabler. https://doi.org/10.1007/978-3-8349-8397-8_6
Usanov, A. (2015). Assessing cybersecurity: A meta-analysis of threats, trends and responses to cyber attacks . The Hague Centre for Strategic Studies. https://www.researchgate.net/publication/319677972_Assessing_Cyber_Security_A_Meta-analysis_of_Threats_Trends_and_Responses_to_Cyber_Attacks
Van de Kaa, G., De Vries, H. J., van Heck, E., & van den Ende, J. (2007). The emergence of standards: A meta-analysis. Proceedings of the 2007 40th Annual Hawaii International Conference on Systems Science (HICSS’07) , USA , 173a–173a. https://doi.org/10.1109/HICSS.2007.529
Download references
Author information
Authors and affiliations.
Centre for Cybersecurity Studies, Nasarawa State University, Keffi, Nigeria
Uche M. Mbanaso
LINK Centre, University of the Witwatersrand, Johannesburg, South Africa
Lucienne Abrahams
Department of Mechatronics Engineering, Federal University of Technology, Owerri, Nigeria
Kennedy Chinedu Okafor
You can also search for this author in PubMed Google Scholar
Rights and permissions
Reprints and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Mbanaso, U.M., Abrahams, L., Okafor, K.C. (2023). Data Collection, Presentation and Analysis. In: Research Techniques for Computer Science, Information Systems and Cybersecurity. Springer, Cham. https://doi.org/10.1007/978-3-031-30031-8_7
Download citation
DOI : https://doi.org/10.1007/978-3-031-30031-8_7
Published : 25 May 2023
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-30030-1
Online ISBN : 978-3-031-30031-8
eBook Packages : Engineering Engineering (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
A Guide To The Methods, Benefits & Problems of The Interpretation of Data

Table of Contents
1) What Is Data Interpretation?
2) How To Interpret Data?
3) Why Data Interpretation Is Important?
4) Data Interpretation Skills
5) Data Analysis & Interpretation Problems
6) Data Interpretation Techniques & Methods
7) The Use of Dashboards For Data Interpretation
8) Business Data Interpretation Examples
Data analysis and interpretation have now taken center stage with the advent of the digital age… and the sheer amount of data can be frightening. In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 trillion gigabytes! Based on that amount of data alone, it is clear the calling card of any successful enterprise in today’s global world will be the ability to analyze complex data, produce actionable insights, and adapt to new market needs… all at the speed of thought.
Business dashboards are the digital age tools for big data. Capable of displaying key performance indicators (KPIs) for both quantitative and qualitative data analyses, they are ideal for making the fast-paced and data-driven market decisions that push today’s industry leaders to sustainable success. Through the art of streamlined visual communication, data dashboards permit businesses to engage in real-time and informed decision-making and are key instruments in data interpretation. First of all, let’s find a definition to understand what lies behind this practice.
What Is Data Interpretation?
Data interpretation refers to the process of using diverse analytical methods to review data and arrive at relevant conclusions. The interpretation of data helps researchers to categorize, manipulate, and summarize the information in order to answer critical questions.
The importance of data interpretation is evident, and this is why it needs to be done properly. Data is very likely to arrive from multiple sources and has a tendency to enter the analysis process with haphazard ordering. Data analysis tends to be extremely subjective. That is to say, the nature and goal of interpretation will vary from business to business, likely correlating to the type of data being analyzed. While there are several types of processes that are implemented based on the nature of individual data, the two broadest and most common categories are “quantitative and qualitative analysis.”
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding measurement scales. Before any serious data analysis can begin, the measurement scale must be decided for the data as this will have a long-term impact on data interpretation ROI. The varying scales include:
- Nominal Scale: non-numeric categories that cannot be ranked or compared quantitatively. Variables are exclusive and exhaustive.
- Ordinal Scale: exclusive categories that are exclusive and exhaustive but with a logical order. Quality ratings and agreement ratings are examples of ordinal scales (i.e., good, very good, fair, etc., OR agree, strongly agree, disagree, etc.).
- Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories. There is always an arbitrary zero point.
- Ratio: contains features of all three.
For a more in-depth review of scales of measurement, read our article on data analysis questions . Once measurement scales have been selected, it is time to select which of the two broad interpretation processes will best suit your data needs. Let’s take a closer look at those specific methods and possible data interpretation problems.
How To Interpret Data? Top Methods & Techniques

When interpreting data, an analyst must try to discern the differences between correlation, causation, and coincidences, as well as many other biases – but he also has to consider all the factors involved that may have led to a result. There are various data interpretation types and methods one can use to achieve this.
The interpretation of data is designed to help people make sense of numerical data that has been collected, analyzed, and presented. Having a baseline method for interpreting data will provide your analyst teams with a structure and consistent foundation. Indeed, if several departments have different approaches to interpreting the same data while sharing the same goals, some mismatched objectives can result. Disparate methods will lead to duplicated efforts, inconsistent solutions, wasted energy, and inevitably – time and money. In this part, we will look at the two main methods of interpretation of data: qualitative and quantitative analysis.
Qualitative Data Interpretation
Qualitative data analysis can be summed up in one word – categorical. With this type of analysis, data is not described through numerical values or patterns but through the use of descriptive context (i.e., text). Typically, narrative data is gathered by employing a wide variety of person-to-person techniques. These techniques include:
- Observations: detailing behavioral patterns that occur within an observation group. These patterns could be the amount of time spent in an activity, the type of activity, and the method of communication employed.
- Focus groups: Group people and ask them relevant questions to generate a collaborative discussion about a research topic.
- Secondary Research: much like how patterns of behavior can be observed, various types of documentation resources can be coded and divided based on the type of material they contain.
- Interviews: one of the best collection methods for narrative data. Inquiry responses can be grouped by theme, topic, or category. The interview approach allows for highly focused data segmentation.
A key difference between qualitative and quantitative analysis is clearly noticeable in the interpretation stage. The first one is widely open to interpretation and must be “coded” so as to facilitate the grouping and labeling of data into identifiable themes. As person-to-person data collection techniques can often result in disputes pertaining to proper analysis, qualitative data analysis is often summarized through three basic principles: notice things, collect things, and think about things.
After qualitative data has been collected through transcripts, questionnaires, audio and video recordings, or the researcher’s notes, it is time to interpret it. For that purpose, there are some common methods used by researchers and analysts.
- Content analysis : As its name suggests, this is a research method used to identify frequencies and recurring words, subjects, and concepts in image, video, or audio content. It transforms qualitative information into quantitative data to help discover trends and conclusions that will later support important research or business decisions. This method is often used by marketers to understand brand sentiment from the mouths of customers themselves. Through that, they can extract valuable information to improve their products and services. It is recommended to use content analytics tools for this method as manually performing it is very time-consuming and can lead to human error or subjectivity issues. Having a clear goal in mind before diving into it is another great practice for avoiding getting lost in the fog.
- Thematic analysis: This method focuses on analyzing qualitative data, such as interview transcripts, survey questions, and others, to identify common patterns and separate the data into different groups according to found similarities or themes. For example, imagine you want to analyze what customers think about your restaurant. For this purpose, you do a thematic analysis on 1000 reviews and find common themes such as “fresh food”, “cold food”, “small portions”, “friendly staff”, etc. With those recurring themes in hand, you can extract conclusions about what could be improved or enhanced based on your customer’s experiences. Since this technique is more exploratory, be open to changing your research questions or goals as you go.
- Narrative analysis: A bit more specific and complicated than the two previous methods, it is used to analyze stories and discover their meaning. These stories can be extracted from testimonials, case studies, and interviews, as these formats give people more space to tell their experiences. Given that collecting this kind of data is harder and more time-consuming, sample sizes for narrative analysis are usually smaller, which makes it harder to reproduce its findings. However, it is still a valuable technique for understanding customers' preferences and mindsets.
- Discourse analysis : This method is used to draw the meaning of any type of visual, written, or symbolic language in relation to a social, political, cultural, or historical context. It is used to understand how context can affect how language is carried out and understood. For example, if you are doing research on power dynamics, using discourse analysis to analyze a conversation between a janitor and a CEO and draw conclusions about their responses based on the context and your research questions is a great use case for this technique. That said, like all methods in this section, discourse analytics is time-consuming as the data needs to be analyzed until no new insights emerge.
- Grounded theory analysis : The grounded theory approach aims to create or discover a new theory by carefully testing and evaluating the data available. Unlike all other qualitative approaches on this list, grounded theory helps extract conclusions and hypotheses from the data instead of going into the analysis with a defined hypothesis. This method is very popular amongst researchers, analysts, and marketers as the results are completely data-backed, providing a factual explanation of any scenario. It is often used when researching a completely new topic or with little knowledge as this space to start from the ground up.
Quantitative Data Interpretation
If quantitative data interpretation could be summed up in one word (and it really can’t), that word would be “numerical.” There are few certainties when it comes to data analysis, but you can be sure that if the research you are engaging in has no numbers involved, it is not quantitative research, as this analysis refers to a set of processes by which numerical data is analyzed. More often than not, it involves the use of statistical modeling such as standard deviation, mean, and median. Let’s quickly review the most common statistical terms:
- Mean: A mean represents a numerical average for a set of responses. When dealing with a data set (or multiple data sets), a mean will represent the central value of a specific set of numbers. It is the sum of the values divided by the number of values within the data set. Other terms that can be used to describe the concept are arithmetic mean, average, and mathematical expectation.
- Standard deviation: This is another statistical term commonly used in quantitative analysis. Standard deviation reveals the distribution of the responses around the mean. It describes the degree of consistency within the responses; together with the mean, it provides insight into data sets.
- Frequency distribution: This is a measurement gauging the rate of a response appearance within a data set. When using a survey, for example, frequency distribution, it can determine the number of times a specific ordinal scale response appears (i.e., agree, strongly agree, disagree, etc.). Frequency distribution is extremely keen in determining the degree of consensus among data points.
Typically, quantitative data is measured by visually presenting correlation tests between two or more variables of significance. Different processes can be used together or separately, and comparisons can be made to ultimately arrive at a conclusion. Other signature interpretation processes of quantitative data include:
- Regression analysis: Essentially, it uses historical data to understand the relationship between a dependent variable and one or more independent variables. Knowing which variables are related and how they developed in the past allows you to anticipate possible outcomes and make better decisions going forward. For example, if you want to predict your sales for next month, you can use regression to understand what factors will affect them, such as products on sale and the launch of a new campaign, among many others.
- Cohort analysis: This method identifies groups of users who share common characteristics during a particular time period. In a business scenario, cohort analysis is commonly used to understand customer behaviors. For example, a cohort could be all users who have signed up for a free trial on a given day. An analysis would be carried out to see how these users behave, what actions they carry out, and how their behavior differs from other user groups.
- Predictive analysis: As its name suggests, the predictive method aims to predict future developments by analyzing historical and current data. Powered by technologies such as artificial intelligence and machine learning, predictive analytics practices enable businesses to identify patterns or potential issues and plan informed strategies in advance.
- Prescriptive analysis: Also powered by predictions, the prescriptive method uses techniques such as graph analysis, complex event processing, and neural networks, among others, to try to unravel the effect that future decisions will have in order to adjust them before they are actually made. This helps businesses to develop responsive, practical business strategies.
- Conjoint analysis: Typically applied to survey analysis, the conjoint approach is used to analyze how individuals value different attributes of a product or service. This helps researchers and businesses to define pricing, product features, packaging, and many other attributes. A common use is menu-based conjoint analysis, in which individuals are given a “menu” of options from which they can build their ideal concept or product. Through this, analysts can understand which attributes they would pick above others and drive conclusions.
- Cluster analysis: Last but not least, the cluster is a method used to group objects into categories. Since there is no target variable when using cluster analysis, it is a useful method to find hidden trends and patterns in the data. In a business context, clustering is used for audience segmentation to create targeted experiences. In market research, it is often used to identify age groups, geographical information, and earnings, among others.
Now that we have seen how to interpret data, let's move on and ask ourselves some questions: What are some of the benefits of data interpretation? Why do all industries engage in data research and analysis? These are basic questions, but they often don’t receive adequate attention.
Your Chance: Want to test a powerful data analysis software? Use our 14-days free trial & start extracting insights from your data!
Why Data Interpretation Is Important

The purpose of collection and interpretation is to acquire useful and usable information and to make the most informed decisions possible. From businesses to newlyweds researching their first home, data collection and interpretation provide limitless benefits for a wide range of institutions and individuals.
Data analysis and interpretation, regardless of the method and qualitative/quantitative status, may include the following characteristics:
- Data identification and explanation
- Comparing and contrasting data
- Identification of data outliers
- Future predictions
Data analysis and interpretation, in the end, help improve processes and identify problems. It is difficult to grow and make dependable improvements without, at the very least, minimal data collection and interpretation. What is the keyword? Dependable. Vague ideas regarding performance enhancement exist within all institutions and industries. Yet, without proper research and analysis, an idea is likely to remain in a stagnant state forever (i.e., minimal growth). So… what are a few of the business benefits of digital age data analysis and interpretation? Let’s take a look!
1) Informed decision-making: A decision is only as good as the knowledge that formed it. Informed data decision-making can potentially set industry leaders apart from the rest of the market pack. Studies have shown that companies in the top third of their industries are, on average, 5% more productive and 6% more profitable when implementing informed data decision-making processes. Most decisive actions will arise only after a problem has been identified or a goal defined. Data analysis should include identification, thesis development, and data collection, followed by data communication.
If institutions only follow that simple order, one that we should all be familiar with from grade school science fairs, then they will be able to solve issues as they emerge in real-time. Informed decision-making has a tendency to be cyclical. This means there is really no end, and eventually, new questions and conditions arise within the process that need to be studied further. The monitoring of data results will inevitably return the process to the start with new data and sights.
2) Anticipating needs with trends identification: data insights provide knowledge, and knowledge is power. The insights obtained from market and consumer data analyses have the ability to set trends for peers within similar market segments. A perfect example of how data analytics can impact trend prediction is evidenced in the music identification application Shazam . The application allows users to upload an audio clip of a song they like but can’t seem to identify. Users make 15 million song identifications a day. With this data, Shazam has been instrumental in predicting future popular artists.
When industry trends are identified, they can then serve a greater industry purpose. For example, the insights from Shazam’s monitoring benefits not only Shazam in understanding how to meet consumer needs but also grant music executives and record label companies an insight into the pop-culture scene of the day. Data gathering and interpretation processes can allow for industry-wide climate prediction and result in greater revenue streams across the market. For this reason, all institutions should follow the basic data cycle of collection, interpretation, decision-making, and monitoring.
3) Cost efficiency: Proper implementation of analytics processes can provide businesses with profound cost advantages within their industries. A recent data study performed by Deloitte vividly demonstrates this in finding that data analysis ROI is driven by efficient cost reductions. Often, this benefit is overlooked because making money is typically viewed as “sexier” than saving money. Yet, sound data analyses have the ability to alert management to cost-reduction opportunities without any significant exertion of effort on the part of human capital.
A great example of the potential for cost efficiency through data analysis is Intel. Prior to 2012, Intel would conduct over 19,000 manufacturing function tests on their chips before they could be deemed acceptable for release. To cut costs and reduce test time, Intel implemented predictive data analyses. By using historical and current data, Intel now avoids testing each chip 19,000 times by focusing on specific and individual chip tests. After its implementation in 2012, Intel saved over $3 million in manufacturing costs. Cost reduction may not be as “sexy” as data profit, but as Intel proves, it is a benefit of data analysis that should not be neglected.
4) Clear foresight: companies that collect and analyze their data gain better knowledge about themselves, their processes, and their performance. They can identify performance challenges when they arise and take action to overcome them. Data interpretation through visual representations lets them process their findings faster and make better-informed decisions on the company's future.
Key Data Interpretation Skills You Should Have
Just like any other process, data interpretation and analysis require researchers or analysts to have some key skills to be able to perform successfully. It is not enough just to apply some methods and tools to the data; the person who is managing it needs to be objective and have a data-driven mind, among other skills.
It is a common misconception to think that the required skills are mostly number-related. While data interpretation is heavily analytically driven, it also requires communication and narrative skills, as the results of the analysis need to be presented in a way that is easy to understand for all types of audiences.
Luckily, with the rise of self-service tools and AI-driven technologies, data interpretation is no longer segregated for analysts only. However, the topic still remains a big challenge for businesses that make big investments in data and tools to support it, as the interpretation skills required are still lacking. It is worthless to put massive amounts of money into extracting information if you are not going to be able to interpret what that information is telling you. For that reason, below we list the top 5 data interpretation skills your employees or researchers should have to extract the maximum potential from the data.
- Data Literacy: The first and most important skill to have is data literacy. This means having the ability to understand, work, and communicate with data. It involves knowing the types of data sources, methods, and ethical implications of using them. In research, this skill is often a given. However, in a business context, there might be many employees who are not comfortable with data. The issue is the interpretation of data can not be solely responsible for the data team, as it is not sustainable in the long run. Experts advise business leaders to carefully assess the literacy level across their workforce and implement training instances to ensure everyone can interpret their data.
- Data Tools: The data interpretation and analysis process involves using various tools to collect, clean, store, and analyze the data. The complexity of the tools varies depending on the type of data and the analysis goals. Going from simple ones like Excel to more complex ones like databases, such as SQL, or programming languages, such as R or Python. It also involves visual analytics tools to bring the data to life through the use of graphs and charts. Managing these tools is a fundamental skill as they make the process faster and more efficient. As mentioned before, most modern solutions are now self-service, enabling less technical users to use them without problem.
- Critical Thinking: Another very important skill is to have critical thinking. Data hides a range of conclusions, trends, and patterns that must be discovered. It is not just about comparing numbers; it is about putting a story together based on multiple factors that will lead to a conclusion. Therefore, having the ability to look further from what is right in front of you is an invaluable skill for data interpretation.
- Data Ethics: In the information age, being aware of the legal and ethical responsibilities that come with the use of data is of utmost importance. In short, data ethics involves respecting the privacy and confidentiality of data subjects, as well as ensuring accuracy and transparency for data usage. It requires the analyzer or researcher to be completely objective with its interpretation to avoid any biases or discrimination. Many countries have already implemented regulations regarding the use of data, including the GDPR or the ACM Code Of Ethics. Awareness of these regulations and responsibilities is a fundamental skill that anyone working in data interpretation should have.
- Domain Knowledge: Another skill that is considered important when interpreting data is to have domain knowledge. As mentioned before, data hides valuable insights that need to be uncovered. To do so, the analyst needs to know about the industry or domain from which the information is coming and use that knowledge to explore it and put it into a broader context. This is especially valuable in a business context, where most departments are now analyzing data independently with the help of a live dashboard instead of relying on the IT department, which can often overlook some aspects due to a lack of expertise in the topic.
Common Data Analysis And Interpretation Problems

The oft-repeated mantra of those who fear data advancements in the digital age is “big data equals big trouble.” While that statement is not accurate, it is safe to say that certain data interpretation problems or “pitfalls” exist and can occur when analyzing data, especially at the speed of thought. Let’s identify some of the most common data misinterpretation risks and shed some light on how they can be avoided:
1) Correlation mistaken for causation: our first misinterpretation of data refers to the tendency of data analysts to mix the cause of a phenomenon with correlation. It is the assumption that because two actions occurred together, one caused the other. This is inaccurate, as actions can occur together, absent a cause-and-effect relationship.
- Digital age example: assuming that increased revenue results from increased social media followers… there might be a definitive correlation between the two, especially with today’s multi-channel purchasing experiences. But that does not mean an increase in followers is the direct cause of increased revenue. There could be both a common cause and an indirect causality.
- Remedy: attempt to eliminate the variable you believe to be causing the phenomenon.
2) Confirmation bias: our second problem is data interpretation bias. It occurs when you have a theory or hypothesis in mind but are intent on only discovering data patterns that support it while rejecting those that do not.
- Digital age example: your boss asks you to analyze the success of a recent multi-platform social media marketing campaign. While analyzing the potential data variables from the campaign (one that you ran and believe performed well), you see that the share rate for Facebook posts was great, while the share rate for Twitter Tweets was not. Using only Facebook posts to prove your hypothesis that the campaign was successful would be a perfect manifestation of confirmation bias.
- Remedy: as this pitfall is often based on subjective desires, one remedy would be to analyze data with a team of objective individuals. If this is not possible, another solution is to resist the urge to make a conclusion before data exploration has been completed. Remember to always try to disprove a hypothesis, not prove it.
3) Irrelevant data: the third data misinterpretation pitfall is especially important in the digital age. As large data is no longer centrally stored and as it continues to be analyzed at the speed of thought, it is inevitable that analysts will focus on data that is irrelevant to the problem they are trying to correct.
- Digital age example: in attempting to gauge the success of an email lead generation campaign, you notice that the number of homepage views directly resulting from the campaign increased, but the number of monthly newsletter subscribers did not. Based on the number of homepage views, you decide the campaign was a success when really it generated zero leads.
- Remedy: proactively and clearly frame any data analysis variables and KPIs prior to engaging in a data review. If the metric you use to measure the success of a lead generation campaign is newsletter subscribers, there is no need to review the number of homepage visits. Be sure to focus on the data variable that answers your question or solves your problem and not on irrelevant data.
4) Truncating an Axes: When creating a graph to start interpreting the results of your analysis, it is important to keep the axes truthful and avoid generating misleading visualizations. Starting the axes in a value that doesn’t portray the actual truth about the data can lead to false conclusions.
- Digital age example: In the image below, we can see a graph from Fox News in which the Y-axes start at 34%, making it seem that the difference between 35% and 39.6% is way higher than it actually is. This could lead to a misinterpretation of the tax rate changes.

* Source : www.venngage.com *
- Remedy: Be careful with how your data is visualized. Be respectful and realistic with axes to avoid misinterpretation of your data. See below how the Fox News chart looks when using the correct axis values. This chart was created with datapine's modern online data visualization tool.

5) (Small) sample size: Another common problem is using a small sample size. Logically, the bigger the sample size, the more accurate and reliable the results. However, this also depends on the size of the effect of the study. For example, the sample size in a survey about the quality of education will not be the same as for one about people doing outdoor sports in a specific area.
- Digital age example: Imagine you ask 30 people a question, and 29 answer “yes,” resulting in 95% of the total. Now imagine you ask the same question to 1000, and 950 of them answer “yes,” which is again 95%. While these percentages might look the same, they certainly do not mean the same thing, as a 30-person sample size is not a significant number to establish a truthful conclusion.
- Remedy: Researchers say that in order to determine the correct sample size to get truthful and meaningful results, it is necessary to define a margin of error that will represent the maximum amount they want the results to deviate from the statistical mean. Paired with this, they need to define a confidence level that should be between 90 and 99%. With these two values in hand, researchers can calculate an accurate sample size for their studies.
6) Reliability, subjectivity, and generalizability : When performing qualitative analysis, researchers must consider practical and theoretical limitations when interpreting the data. In some cases, this type of research can be considered unreliable because of uncontrolled factors that might or might not affect the results. This is paired with the fact that the researcher has a primary role in the interpretation process, meaning he or she decides what is relevant and what is not, and as we know, interpretations can be very subjective.
Generalizability is also an issue that researchers face when dealing with qualitative analysis. As mentioned in the point about having a small sample size, it is difficult to draw conclusions that are 100% representative because the results might be biased or unrepresentative of a wider population.
While these factors are mostly present in qualitative research, they can also affect the quantitative analysis. For example, when choosing which KPIs to portray and how to portray them, analysts can also be biased and represent them in a way that benefits their analysis.
- Digital age example: Biased questions in a survey are a great example of reliability and subjectivity issues. Imagine you are sending a survey to your clients to see how satisfied they are with your customer service with this question: “How amazing was your experience with our customer service team?”. Here, we can see that this question clearly influences the response of the individual by putting the word “amazing” on it.
- Remedy: A solution to avoid these issues is to keep your research honest and neutral. Keep the wording of the questions as objective as possible. For example: “On a scale of 1-10, how satisfied were you with our customer service team?”. This does not lead the respondent to any specific answer, meaning the results of your survey will be reliable.
Data Interpretation Best Practices & Tips

Data analysis and interpretation are critical to developing sound conclusions and making better-informed decisions. As we have seen with this article, there is an art and science to the interpretation of data. To help you with this purpose, we will list a few relevant techniques, methods, and tricks you can implement for a successful data management process.
As mentioned at the beginning of this post, the first step to interpreting data in a successful way is to identify the type of analysis you will perform and apply the methods respectively. Clearly differentiate between qualitative (observe, document, and interview notice, collect and think about things) and quantitative analysis (you lead research with a lot of numerical data to be analyzed through various statistical methods).
1) Ask the right data interpretation questions
The first data interpretation technique is to define a clear baseline for your work. This can be done by answering some critical questions that will serve as a useful guideline to start. Some of them include: what are the goals and objectives of my analysis? What type of data interpretation method will I use? Who will use this data in the future? And most importantly, what general question am I trying to answer?
Once all this information has been defined, you will be ready for the next step: collecting your data.
2) Collect and assimilate your data
Now that a clear baseline has been established, it is time to collect the information you will use. Always remember that your methods for data collection will vary depending on what type of analysis method you use, which can be qualitative or quantitative. Based on that, relying on professional online data analysis tools to facilitate the process is a great practice in this regard, as manually collecting and assessing raw data is not only very time-consuming and expensive but is also at risk of errors and subjectivity.
Once your data is collected, you need to carefully assess it to understand if the quality is appropriate to be used during a study. This means, is the sample size big enough? Were the procedures used to collect the data implemented correctly? Is the date range from the data correct? If coming from an external source, is it a trusted and objective one?
With all the needed information in hand, you are ready to start the interpretation process, but first, you need to visualize your data.
3) Use the right data visualization type
Data visualizations such as business graphs , charts, and tables are fundamental to successfully interpreting data. This is because data visualization via interactive charts and graphs makes the information more understandable and accessible. As you might be aware, there are different types of visualizations you can use, but not all of them are suitable for any analysis purpose. Using the wrong graph can lead to misinterpretation of your data, so it’s very important to carefully pick the right visual for it. Let’s look at some use cases of common data visualizations.
- Bar chart: One of the most used chart types, the bar chart uses rectangular bars to show the relationship between 2 or more variables. There are different types of bar charts for different interpretations, including the horizontal bar chart, column bar chart, and stacked bar chart.
- Line chart: Most commonly used to show trends, acceleration or decelerations, and volatility, the line chart aims to show how data changes over a period of time, for example, sales over a year. A few tips to keep this chart ready for interpretation are not using many variables that can overcrowd the graph and keeping your axis scale close to the highest data point to avoid making the information hard to read.
- Pie chart: Although it doesn’t do a lot in terms of analysis due to its uncomplex nature, pie charts are widely used to show the proportional composition of a variable. Visually speaking, showing a percentage in a bar chart is way more complicated than showing it in a pie chart. However, this also depends on the number of variables you are comparing. If your pie chart needs to be divided into 10 portions, then it is better to use a bar chart instead.
- Tables: While they are not a specific type of chart, tables are widely used when interpreting data. Tables are especially useful when you want to portray data in its raw format. They give you the freedom to easily look up or compare individual values while also displaying grand totals.
With the use of data visualizations becoming more and more critical for businesses’ analytical success, many tools have emerged to help users visualize their data in a cohesive and interactive way. One of the most popular ones is the use of BI dashboards . These visual tools provide a centralized view of various graphs and charts that paint a bigger picture of a topic. We will discuss the power of dashboards for an efficient data interpretation practice in the next portion of this post. If you want to learn more about different types of graphs and charts , take a look at our complete guide on the topic.
4) Start interpreting
After the tedious preparation part, you can start extracting conclusions from your data. As mentioned many times throughout the post, the way you decide to interpret the data will solely depend on the methods you initially decided to use. If you had initial research questions or hypotheses, then you should look for ways to prove their validity. If you are going into the data with no defined hypothesis, then start looking for relationships and patterns that will allow you to extract valuable conclusions from the information.
During the process of interpretation, stay curious and creative, dig into the data, and determine if there are any other critical questions that should be asked. If any new questions arise, you need to assess if you have the necessary information to answer them. Being able to identify if you need to dedicate more time and resources to the research is a very important step. No matter if you are studying customer behaviors or a new cancer treatment, the findings from your analysis may dictate important decisions in the future. Therefore, taking the time to really assess the information is key. For that purpose, data interpretation software proves to be very useful.
5) Keep your interpretation objective
As mentioned above, objectivity is one of the most important data interpretation skills but also one of the hardest. Being the person closest to the investigation, it is easy to become subjective when looking for answers in the data. A good way to stay objective is to show the information related to the study to other people, for example, research partners or even the people who will use your findings once they are done. This can help avoid confirmation bias and any reliability issues with your interpretation.
Remember, using a visualization tool such as a modern dashboard will make the interpretation process way easier and more efficient as the data can be navigated and manipulated in an easy and organized way. And not just that, using a dashboard tool to present your findings to a specific audience will make the information easier to understand and the presentation way more engaging thanks to the visual nature of these tools.
6) Mark your findings and draw conclusions
Findings are the observations you extracted from your data. They are the facts that will help you drive deeper conclusions about your research. For example, findings can be trends and patterns you found during your interpretation process. To put your findings into perspective, you can compare them with other resources that use similar methods and use them as benchmarks.
Reflect on your own thinking and reasoning and be aware of the many pitfalls data analysis and interpretation carry—correlation versus causation, subjective bias, false information, inaccurate data, etc. Once you are comfortable with interpreting the data, you will be ready to develop conclusions, see if your initial questions were answered, and suggest recommendations based on them.
Interpretation of Data: The Use of Dashboards Bridging The Gap
As we have seen, quantitative and qualitative methods are distinct types of data interpretation and analysis. Both offer a varying degree of return on investment (ROI) regarding data investigation, testing, and decision-making. But how do you mix the two and prevent a data disconnect? The answer is professional data dashboards.
For a few years now, dashboards have become invaluable tools to visualize and interpret data. These tools offer a centralized and interactive view of data and provide the perfect environment for exploration and extracting valuable conclusions. They bridge the quantitative and qualitative information gap by unifying all the data in one place with the help of stunning visuals.
Not only that, but these powerful tools offer a large list of benefits, and we will discuss some of them below.
1) Connecting and blending data. With today’s pace of innovation, it is no longer feasible (nor desirable) to have bulk data centrally located. As businesses continue to globalize and borders continue to dissolve, it will become increasingly important for businesses to possess the capability to run diverse data analyses absent the limitations of location. Data dashboards decentralize data without compromising on the necessary speed of thought while blending both quantitative and qualitative data. Whether you want to measure customer trends or organizational performance, you now have the capability to do both without the need for a singular selection.
2) Mobile Data. Related to the notion of “connected and blended data” is that of mobile data. In today’s digital world, employees are spending less time at their desks and simultaneously increasing production. This is made possible because mobile solutions for analytical tools are no longer standalone. Today, mobile analysis applications seamlessly integrate with everyday business tools. In turn, both quantitative and qualitative data are now available on-demand where they’re needed, when they’re needed, and how they’re needed via interactive online dashboards .
3) Visualization. Data dashboards merge the data gap between qualitative and quantitative data interpretation methods through the science of visualization. Dashboard solutions come “out of the box” and are well-equipped to create easy-to-understand data demonstrations. Modern online data visualization tools provide a variety of color and filter patterns, encourage user interaction, and are engineered to help enhance future trend predictability. All of these visual characteristics make for an easy transition among data methods – you only need to find the right types of data visualization to tell your data story the best way possible.
4) Collaboration. Whether in a business environment or a research project, collaboration is key in data interpretation and analysis. Dashboards are online tools that can be easily shared through a password-protected URL or automated email. Through them, users can collaborate and communicate through the data in an efficient way. Eliminating the need for infinite files with lost updates. Tools such as datapine offer real-time updates, meaning your dashboards will update on their own as soon as new information is available.
Examples Of Data Interpretation In Business
To give you an idea of how a dashboard can fulfill the need to bridge quantitative and qualitative analysis and help in understanding how to interpret data in research thanks to visualization, below, we will discuss three valuable examples to put their value into perspective.
1. Customer Satisfaction Dashboard
This market research dashboard brings together both qualitative and quantitative data that are knowledgeably analyzed and visualized in a meaningful way that everyone can understand, thus empowering any viewer to interpret it. Let’s explore it below.

**click to enlarge**
The value of this template lies in its highly visual nature. As mentioned earlier, visuals make the interpretation process way easier and more efficient. Having critical pieces of data represented with colorful and interactive icons and graphs makes it possible to uncover insights at a glance. For example, the colors green, yellow, and red on the charts for the NPS and the customer effort score allow us to conclude that most respondents are satisfied with this brand with a short glance. A further dive into the line chart below can help us dive deeper into this conclusion, as we can see both metrics developed positively in the past 6 months.
The bottom part of the template provides visually stunning representations of different satisfaction scores for quality, pricing, design, and service. By looking at these, we can conclude that, overall, customers are satisfied with this company in most areas.
2. Brand Analysis Dashboard
Next, in our list of data interpretation examples, we have a template that shows the answers to a survey on awareness for Brand D. The sample size is listed on top to get a perspective of the data, which is represented using interactive charts and graphs.

When interpreting information, context is key to understanding it correctly. For that reason, the dashboard starts by offering insights into the demographics of the surveyed audience. In general, we can see ages and gender are diverse. Therefore, we can conclude these brands are not targeting customers from a specified demographic, an important aspect to put the surveyed answers into perspective.
Looking at the awareness portion, we can see that brand B is the most popular one, with brand D coming second on both questions. This means brand D is not doing wrong, but there is still room for improvement compared to brand B. To see where brand D could improve, the researcher could go into the bottom part of the dashboard and consult the answers for branding themes and celebrity analysis. These are important as they give clear insight into what people and messages the audience associates with brand D. This is an opportunity to exploit these topics in different ways and achieve growth and success.
3. Product Innovation Dashboard
Our third and last dashboard example shows the answers to a survey on product innovation for a technology company. Just like the previous templates, the interactive and visual nature of the dashboard makes it the perfect tool to interpret data efficiently and effectively.

Starting from right to left, we first get a list of the top 5 products by purchase intention. This information lets us understand if the product being evaluated resembles what the audience already intends to purchase. It is a great starting point to see how customers would respond to the new product. This information can be complemented with other key metrics displayed in the dashboard. For example, the usage and purchase intention track how the market would receive the product and if they would purchase it, respectively. Interpreting these values as positive or negative will depend on the company and its expectations regarding the survey.
Complementing these metrics, we have the willingness to pay. Arguably, one of the most important metrics to define pricing strategies. Here, we can see that most respondents think the suggested price is a good value for money. Therefore, we can interpret that the product would sell for that price.
To see more data analysis and interpretation examples for different industries and functions, visit our library of business dashboards .
To Conclude…
As we reach the end of this insightful post about data interpretation and analysis, we hope you have a clear understanding of the topic. We've covered the definition and given some examples and methods to perform a successful interpretation process.
The importance of data interpretation is undeniable. Dashboards not only bridge the information gap between traditional data interpretation methods and technology, but they can help remedy and prevent the major pitfalls of the process. As a digital age solution, they combine the best of the past and the present to allow for informed decision-making with maximum data interpretation ROI.
To start visualizing your insights in a meaningful and actionable way, test our online reporting software for free with our 14-day trial !
We use essential cookies to make Venngage work. By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts.
Manage Cookies
Cookies and similar technologies collect certain information about how you’re using our website. Some of them are essential, and without them you wouldn’t be able to use Venngage. But others are optional, and you get to choose whether we use them or not.
Strictly Necessary Cookies
These cookies are always on, as they’re essential for making Venngage work, and making it safe. Without these cookies, services you’ve asked for can’t be provided.
Show cookie providers
- Google Login
Functionality Cookies
These cookies help us provide enhanced functionality and personalisation, and remember your settings. They may be set by us or by third party providers.
Performance Cookies
These cookies help us analyze how many people are using Venngage, where they come from and how they're using it. If you opt out of these cookies, we can’t get feedback to make Venngage better for you and all our users.
- Google Analytics
Targeting Cookies
These cookies are set by our advertising partners to track your activity and show you relevant Venngage ads on other sites as you browse the internet.
- Google Tag Manager
- Infographics
- Daily Infographics
- Popular Templates
- Accessibility
- Graphic Design
- Graphs and Charts
- Data Visualization
- Human Resources
- Beginner Guides
Blog Data Visualization 10 Data Presentation Examples For Strategic Communication
10 Data Presentation Examples For Strategic Communication
Written by: Krystle Wong Sep 28, 2023

Knowing how to present data is like having a superpower.
Data presentation today is no longer just about numbers on a screen; it’s storytelling with a purpose. It’s about captivating your audience, making complex stuff look simple and inspiring action.
To help turn your data into stories that stick, influence decisions and make an impact, check out Venngage’s free chart maker or follow me on a tour into the world of data storytelling along with data presentation templates that work across different fields, from business boardrooms to the classroom and beyond. Keep scrolling to learn more!
Click to jump ahead:
10 Essential data presentation examples + methods you should know
What should be included in a data presentation, what are some common mistakes to avoid when presenting data, faqs on data presentation examples, transform your message with impactful data storytelling.
Data presentation is a vital skill in today’s information-driven world. Whether you’re in business, academia, or simply want to convey information effectively, knowing the different ways of presenting data is crucial. For impactful data storytelling, consider these essential data presentation methods:
1. Bar graph
Ideal for comparing data across categories or showing trends over time.
Bar graphs, also known as bar charts are workhorses of data presentation. They’re like the Swiss Army knives of visualization methods because they can be used to compare data in different categories or display data changes over time.
In a bar chart, categories are displayed on the x-axis and the corresponding values are represented by the height of the bars on the y-axis.

It’s a straightforward and effective way to showcase raw data, making it a staple in business reports, academic presentations and beyond.
Make sure your bar charts are concise with easy-to-read labels. Whether your bars go up or sideways, keep it simple by not overloading with too many categories.

2. Line graph
Great for displaying trends and variations in data points over time or continuous variables.
Line charts or line graphs are your go-to when you want to visualize trends and variations in data sets over time.
One of the best quantitative data presentation examples, they work exceptionally well for showing continuous data, such as sales projections over the last couple of years or supply and demand fluctuations.

The x-axis represents time or a continuous variable and the y-axis represents the data values. By connecting the data points with lines, you can easily spot trends and fluctuations.
A tip when presenting data with line charts is to minimize the lines and not make it too crowded. Highlight the big changes, put on some labels and give it a catchy title.

3. Pie chart
Useful for illustrating parts of a whole, such as percentages or proportions.
Pie charts are perfect for showing how a whole is divided into parts. They’re commonly used to represent percentages or proportions and are great for presenting survey results that involve demographic data.
Each “slice” of the pie represents a portion of the whole and the size of each slice corresponds to its share of the total.

While pie charts are handy for illustrating simple distributions, they can become confusing when dealing with too many categories or when the differences in proportions are subtle.
Don’t get too carried away with slices — label those slices with percentages or values so people know what’s what and consider using a legend for more categories.

4. Scatter plot
Effective for showing the relationship between two variables and identifying correlations.
Scatter plots are all about exploring relationships between two variables. They’re great for uncovering correlations, trends or patterns in data.
In a scatter plot, every data point appears as a dot on the chart, with one variable marked on the horizontal x-axis and the other on the vertical y-axis.

By examining the scatter of points, you can discern the nature of the relationship between the variables, whether it’s positive, negative or no correlation at all.
If you’re using scatter plots to reveal relationships between two variables, be sure to add trendlines or regression analysis when appropriate to clarify patterns. Label data points selectively or provide tooltips for detailed information.

5. Histogram
Best for visualizing the distribution and frequency of a single variable.
Histograms are your choice when you want to understand the distribution and frequency of a single variable.
They divide the data into “bins” or intervals and the height of each bar represents the frequency or count of data points falling into that interval.

Histograms are excellent for helping to identify trends in data distributions, such as peaks, gaps or skewness.
Here’s something to take note of — ensure that your histogram bins are appropriately sized to capture meaningful data patterns. Using clear axis labels and titles can also help explain the distribution of the data effectively.

6. Stacked bar chart
Useful for showing how different components contribute to a whole over multiple categories.
Stacked bar charts are a handy choice when you want to illustrate how different components contribute to a whole across multiple categories.
Each bar represents a category and the bars are divided into segments to show the contribution of various components within each category.

This method is ideal for highlighting both the individual and collective significance of each component, making it a valuable tool for comparative analysis.
Stacked bar charts are like data sandwiches—label each layer so people know what’s what. Keep the order logical and don’t forget the paintbrush for snazzy colors. Here’s a data analysis presentation example on writers’ productivity using stacked bar charts:

7. Area chart
Similar to line charts but with the area below the lines filled, making them suitable for showing cumulative data.
Area charts are close cousins of line charts but come with a twist.
Imagine plotting the sales of a product over several months. In an area chart, the space between the line and the x-axis is filled, providing a visual representation of the cumulative total.

This makes it easy to see how values stack up over time, making area charts a valuable tool for tracking trends in data.
For area charts, use them to visualize cumulative data and trends, but avoid overcrowding the chart. Add labels, especially at significant points and make sure the area under the lines is filled with a visually appealing color gradient.

8. Tabular presentation
Presenting data in rows and columns, often used for precise data values and comparisons.
Tabular data presentation is all about clarity and precision. Think of it as presenting numerical data in a structured grid, with rows and columns clearly displaying individual data points.
A table is invaluable for showcasing detailed data, facilitating comparisons and presenting numerical information that needs to be exact. They’re commonly used in reports, spreadsheets and academic papers.

When presenting tabular data, organize it neatly with clear headers and appropriate column widths. Highlight important data points or patterns using shading or font formatting for better readability.
9. Textual data
Utilizing written or descriptive content to explain or complement data, such as annotations or explanatory text.
Textual data presentation may not involve charts or graphs, but it’s one of the most used qualitative data presentation examples.
It involves using written content to provide context, explanations or annotations alongside data visuals. Think of it as the narrative that guides your audience through the data.
Well-crafted textual data can make complex information more accessible and help your audience understand the significance of the numbers and visuals.
Textual data is your chance to tell a story. Break down complex information into bullet points or short paragraphs and use headings to guide the reader’s attention.
10. Pictogram
Using simple icons or images to represent data is especially useful for conveying information in a visually intuitive manner.
Pictograms are all about harnessing the power of images to convey data in an easy-to-understand way.
Instead of using numbers or complex graphs, you use simple icons or images to represent data points.
For instance, you could use a thumbs up emoji to illustrate customer satisfaction levels, where each face represents a different level of satisfaction.

Pictograms are great for conveying data visually, so choose symbols that are easy to interpret and relevant to the data. Use consistent scaling and a legend to explain the symbols’ meanings, ensuring clarity in your presentation.

Looking for more data presentation ideas? Use the Venngage graph maker or browse through our gallery of chart templates to pick a template and get started!
A comprehensive data presentation should include several key elements to effectively convey information and insights to your audience. Here’s a list of what should be included in a data presentation:
1. Title and objective
- Begin with a clear and informative title that sets the context for your presentation.
- State the primary objective or purpose of the presentation to provide a clear focus.

2. Key data points
- Present the most essential data points or findings that align with your objective.
- Use charts, graphical presentations or visuals to illustrate these key points for better comprehension.

3. Context and significance
- Provide a brief overview of the context in which the data was collected and why it’s significant.
- Explain how the data relates to the larger picture or the problem you’re addressing.
4. Key takeaways
- Summarize the main insights or conclusions that can be drawn from the data.
- Highlight the key takeaways that the audience should remember.
5. Visuals and charts
- Use clear and appropriate visual aids to complement the data.
- Ensure that visuals are easy to understand and support your narrative.

6. Implications or actions
- Discuss the practical implications of the data or any recommended actions.
- If applicable, outline next steps or decisions that should be taken based on the data.

7. Q&A and discussion
- Allocate time for questions and open discussion to engage the audience.
- Address queries and provide additional insights or context as needed.
Presenting data is a crucial skill in various professional fields, from business to academia and beyond. To ensure your data presentations hit the mark, here are some common mistakes that you should steer clear of:
Overloading with data
Presenting too much data at once can overwhelm your audience. Focus on the key points and relevant information to keep the presentation concise and focused. Here are some free data visualization tools you can use to convey data in an engaging and impactful way.
Assuming everyone’s on the same page
It’s easy to assume that your audience understands as much about the topic as you do. But this can lead to either dumbing things down too much or diving into a bunch of jargon that leaves folks scratching their heads. Take a beat to figure out where your audience is coming from and tailor your presentation accordingly.
Misleading visuals
Using misleading visuals, such as distorted scales or inappropriate chart types can distort the data’s meaning. Pick the right data infographics and understandable charts to ensure that your visual representations accurately reflect the data.
Not providing context
Data without context is like a puzzle piece with no picture on it. Without proper context, data may be meaningless or misinterpreted. Explain the background, methodology and significance of the data.
Not citing sources properly
Neglecting to cite sources and provide citations for your data can erode its credibility. Always attribute data to its source and utilize reliable sources for your presentation.
Not telling a story
Avoid simply presenting numbers. If your presentation lacks a clear, engaging story that takes your audience on a journey from the beginning (setting the scene) through the middle (data analysis) to the end (the big insights and recommendations), you’re likely to lose their interest.
Infographics are great for storytelling because they mix cool visuals with short and sweet text to explain complicated stuff in a fun and easy way. Create one with Venngage’s free infographic maker to create a memorable story that your audience will remember.
Ignoring data quality
Presenting data without first checking its quality and accuracy can lead to misinformation. Validate and clean your data before presenting it.
Simplify your visuals
Fancy charts might look cool, but if they confuse people, what’s the point? Go for the simplest visual that gets your message across. Having a dilemma between presenting data with infographics v.s data design? This article on the difference between data design and infographics might help you out.
Missing the emotional connection
Data isn’t just about numbers; it’s about people and real-life situations. Don’t forget to sprinkle in some human touch, whether it’s through relatable stories, examples or showing how the data impacts real lives.
Skipping the actionable insights
At the end of the day, your audience wants to know what they should do with all the data. If you don’t wrap up with clear, actionable insights or recommendations, you’re leaving them hanging. Always finish up with practical takeaways and the next steps.
Can you provide some data presentation examples for business reports?
Business reports often benefit from data presentation through bar charts showing sales trends over time, pie charts displaying market share,or tables presenting financial performance metrics like revenue and profit margins.
What are some creative data presentation examples for academic presentations?
Creative data presentation ideas for academic presentations include using statistical infographics to illustrate research findings and statistical data, incorporating storytelling techniques to engage the audience or utilizing heat maps to visualize data patterns.
What are the key considerations when choosing the right data presentation format?
When choosing a chart format , consider factors like data complexity, audience expertise and the message you want to convey. Options include charts (e.g., bar, line, pie), tables, heat maps, data visualization infographics and interactive dashboards.
Knowing the type of data visualization that best serves your data is just half the battle. Here are some best practices for data visualization to make sure that the final output is optimized.
How can I choose the right data presentation method for my data?
To select the right data presentation method, start by defining your presentation’s purpose and audience. Then, match your data type (e.g., quantitative, qualitative) with suitable visualization techniques (e.g., histograms, word clouds) and choose an appropriate presentation format (e.g., slide deck, report, live demo).
For more presentation ideas , check out this guide on how to make a good presentation or use a presentation software to simplify the process.
How can I make my data presentations more engaging and informative?
To enhance data presentations, use compelling narratives, relatable examples and fun data infographics that simplify complex data. Encourage audience interaction, offer actionable insights and incorporate storytelling elements to engage and inform effectively.
The opening of your presentation holds immense power in setting the stage for your audience. To design a presentation and convey your data in an engaging and informative, try out Venngage’s free presentation maker to pick the right presentation design for your audience and topic.
What is the difference between data visualization and data presentation?
Data presentation typically involves conveying data reports and insights to an audience, often using visuals like charts and graphs. Data visualization , on the other hand, focuses on creating those visual representations of data to facilitate understanding and analysis.
Now that you’ve learned a thing or two about how to use these methods of data presentation to tell a compelling data story , it’s time to take these strategies and make them your own.
But here’s the deal: these aren’t just one-size-fits-all solutions. Remember that each example we’ve uncovered here is not a rigid template but a source of inspiration. It’s all about making your audience go, “Wow, I get it now!”
Think of your data presentations as your canvas – it’s where you paint your story, convey meaningful insights and make real change happen.
So, go forth, present your data with confidence and purpose and watch as your strategic influence grows, one compelling presentation at a time.
Discover popular designs

Infographic maker

Brochure maker

White paper online

Newsletter creator

Flyer maker
Timeline maker

Letterhead maker
Mind map maker

Ebook maker

Published: 5 April 2024 Contributors: Tim Mucci, Cole Stryker
Big data analytics refers to the systematic processing and analysis of large amounts of data and complex data sets, known as big data, to extract valuable insights. Big data analytics allows for the uncovering of trends, patterns and correlations in large amounts of raw data to help analysts make data-informed decisions. This process allows organizations to leverage the exponentially growing data generated from diverse sources, including internet-of-things (IoT) sensors, social media, financial transactions and smart devices to derive actionable intelligence through advanced analytic techniques.
In the early 2000s, advances in software and hardware capabilities made it possible for organizations to collect and handle large amounts of unstructured data. With this explosion of useful data, open-source communities developed big data frameworks to store and process this data. These frameworks are used for distributed storage and processing of large data sets across a network of computers. Along with additional tools and libraries, big data frameworks can be used for:
- Predictive modeling by incorporating artificial intelligence (AI) and statistical algorithms
- Statistical analysis for in-depth data exploration and to uncover hidden patterns
- What-if analysis to simulate different scenarios and explore potential outcomes
- Processing diverse data sets, including structured, semi-structured and unstructured data from various sources.
Four main data analysis methods – descriptive, diagnostic, predictive and prescriptive – are used to uncover insights and patterns within an organization's data. These methods facilitate a deeper understanding of market trends, customer preferences and other important business metrics.
IBM named a Leader in the 2024 Gartner® Magic Quadrant™ for Augmented Data Quality Solutions.
Structured vs unstructured data
What is data management?
The main difference between big data analytics and traditional data analytics is the type of data handled and the tools used to analyze it. Traditional analytics deals with structured data, typically stored in relational databases . This type of database helps ensure that data is well-organized and easy for a computer to understand. Traditional data analytics relies on statistical methods and tools like structured query language (SQL) for querying databases.
Big data analytics involves massive amounts of data in various formats, including structured, semi-structured and unstructured data. The complexity of this data requires more sophisticated analysis techniques. Big data analytics employs advanced techniques like machine learning and data mining to extract information from complex data sets. It often requires distributed processing systems like Hadoop to manage the sheer volume of data.
These are the four methods of data analysis at work within big data:
The "what happened" stage of data analysis. Here, the focus is on summarizing and describing past data to understand its basic characteristics.
The “why it happened” stage. By delving deep into the data, diagnostic analysis identifies the root patterns and trends observed in descriptive analytics.
The “what will happen” stage. It uses historical data, statistical modeling and machine learning to forecast trends.
Describes the “what to do” stage, which goes beyond prediction to provide recommendations for optimizing future actions based on insights derived from all previous.
The following dimensions highlight the core challenges and opportunities inherent in big data analytics.
The sheer volume of data generated today, from social media feeds, IoT devices, transaction records and more, presents a significant challenge. Traditional data storage and processing solutions are often inadequate to handle this scale efficiently. Big data technologies and cloud-based storage solutions enable organizations to store and manage these vast data sets cost-effectively, protecting valuable data from being discarded due to storage limitations.
Data is being produced at unprecedented speeds, from real-time social media updates to high-frequency stock trading records. The velocity at which data flows into organizations requires robust processing capabilities to capture, process and deliver accurate analysis in near real-time. Stream processing frameworks and in-memory data processing are designed to handle these rapid data streams and balance supply with demand.
Today's data comes in many formats, from structured to numeric data in traditional databases to unstructured text, video and images from diverse sources like social media and video surveillance. This variety demans flexible data management systems to handle and integrate disparate data types for comprehensive analysis. NoSQL databases , data lakes and schema -on-read technologies provide the necessary flexibility to accommodate the diverse nature of big data.
Data reliability and accuracy are critical, as decisions based on inaccurate or incomplete data can lead to negative outcomes. Veracity refers to the data's trustworthiness, encompassing data quality, noise and anomaly detection issues. Techniques and tools for data cleaning, validation and verification are integral to ensuring the integrity of big data, enabling organizations to make better decisions based on reliable information.
Big data analytics aims to extract actionable insights that offer tangible value. This involves turning vast data sets into meaningful information that can inform strategic decisions, uncover new opportunities and drive innovation. Advanced analytics, machine learning and AI are key to unlocking the value contained within big data, transforming raw data into strategic assets.
Data professionals, analysts, scientists and statisticians prepare and process data in a data lakehouse, which combines the performance of a data lakehouse with the flexibility of a data lake to clean data and ensure its quality. The process of turning raw data into valuable insights encompasses several key stages:
- Collect data: The first step involves gathering data, which can be a mix of structured and unstructured forms from myriad sources like cloud, mobile applications and IoT sensors. This step is where organizations adapt their data collection strategies and integrate data from varied sources into central repositories like a data lake, which can automatically assign metadata for better manageability and accessibility.
- Process data: After being collected, data must be systematically organized, extracted, transformed and then loaded into a storage system to ensure accurate analytical outcomes. Processing involves converting raw data into a format that is usable for analysis, which might involve aggregating data from different sources, converting data types or organizing data into structure formats. Given the exponential growth of available data, this stage can be challenging. Processing strategies may vary between batch processing, which handles large data volumes over extended periods and stream processing, which deals with smaller real-time data batches.
- Clean data: Regardless of size, data must be cleaned to ensure quality and relevance. Cleaning data involves formatting it correctly, removing duplicates and eliminating irrelevant entries. Clean data prevents the corruption of output and safeguard’s reliability and accuracy.
- Analyze data: Advanced analytics, such as data mining, predictive analytics, machine learning and deep learning, are employed to sift through the processed and cleaned data. These methods allow users to discover patterns, relationships and trends within the data, providing a solid foundation for informed decision-making.
Under the Analyze umbrella, there are potentially many technologies at work, including data mining, which is used to identify patterns and relationships within large data sets; predictive analytics, which forecasts future trends and opportunities; and deep learning , which mimics human learning patterns to uncover more abstract ideas.
Deep learning uses an artificial neural network with multiple layers to model complex patterns in data. Unlike traditional machine learning algorithms, deep learning learns from images, sound and text without manual help. For big data analytics, this powerful capability means the volume and complexity of data is not an issue.
Natural language processing (NLP) models allow machines to understand, interpret and generate human language. Within big data analytics, NLP extracts insights from massive unstructured text data generated across an organization and beyond.
Structured Data
Structured data refers to highly organized information that is easily searchable and typically stored in relational databases or spreadsheets. It adheres to a rigid schema, meaning each data element is clearly defined and accessible in a fixed field within a record or file. Examples of structured data include:
- Customer names and addresses in a customer relationship management (CRM) system
- Transactional data in financial records, such as sales figures and account balances
- Employee data in human resources databases, including job titles and salaries
Structured data's main advantage is its simplicity for entry, search and analysis, often using straightforward database queries like SQL. However, the rapidly expanding universe of big data means that structured data represents a relatively small portion of the total data available to organizations.
Unstructured Data
Unstructured data lacks a pre-defined data model, making it more difficult to collect, process and analyze. It comprises the majority of data generated today, and includes formats such as:
- Textual content from documents, emails and social media posts
- Multimedia content, including images, audio files and videos
- Data from IoT devices, which can include a mix of sensor data, log files and time-series data
The primary challenge with unstructured data is its complexity and lack of uniformity, requiring more sophisticated methods for indexing, searching and analyzing. NLP, machine learning and advanced analytics platforms are often employed to extract meaningful insights from unstructured data.
Semi-structured data
Semi-structured data occupies the middle ground between structured and unstructured data. While it does not reside in a relational database, it contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data. Examples include:
- JSON (JavaScript Object Notation) and XML (eXtensible Markup Language) files, which are commonly used for web data interchange
- Email, where the data has a standardized format (e.g., headers, subject, body) but the content within each section is unstructured
- NoSQL databases, can store and manage semi-structured data more efficiently than traditional relational databases
Semi-structured data is more flexible than structured data but easier to analyze than unstructured data, providing a balance that is particularly useful in web applications and data integration tasks.
Ensuring data quality and integrity, integrating disparate data sources, protecting data privacy and security and finding the right talent to analyze and interpret data can present challenges to organizations looking to leverage their extensive data volumes. What follows are the benefits organizations can realize once they see success with big data analytics:
Real-time intelligence
One of the standout advantages of big data analytics is the capacity to provide real-time intelligence. Organizations can analyze vast amounts of data as it is generated from myriad sources and in various formats. Real-time insight allows businesses to make quick decisions, respond to market changes instantaneously and identify and act on opportunities as they arise.
Better-informed decisions
With big data analytics, organizations can uncover previously hidden trends, patterns and correlations. A deeper understanding equips leaders and decision-makers with the information needed to strategize effectively, enhancing business decision-making in supply chain management, e-commerce, operations and overall strategic direction.
Cost savings
Big data analytics drives cost savings by identifying business process efficiencies and optimizations. Organizations can pinpoint wasteful expenditures by analyzing large datasets, streamlining operations and enhancing productivity. Moreover, predictive analytics can forecast future trends, allowing companies to allocate resources more efficiently and avoid costly missteps.
Better customer engagement
Understanding customer needs, behaviors and sentiments is crucial for successful engagement and big data analytics provides the tools to achieve this understanding. Companies gain insights into consumer preferences and tailor their marketing strategies by analyzing customer data.
Optimized risk management strategies
Big data analytics enhances an organization's ability to manage risk by providing the tools to identify, assess and address threats in real time. Predictive analytics can foresee potential dangers before they materialize, allowing companies to devise preemptive strategies.
As organizations across industries seek to leverage data to drive decision-making, improve operational efficiencies and enhance customer experiences, the demand for skilled professionals in big data analytics has surged. Here are some prominent career paths that utilize big data analytics:
Data scientist
Data scientists analyze complex digital data to assist businesses in making decisions. Using their data science training and advanced analytics technologies, including machine learning and predictive modeling, they uncover hidden insights in data.
Data analyst
Data analysts turn data into information and information into insights. They use statistical techniques to analyze and extract meaningful trends from data sets, often to inform business strategy and decisions.
Data engineer
Data engineers prepare, process and manage big data infrastructure and tools. They also develop, maintain, test and evaluate data solutions within organizations, often working with massive datasets to assist in analytics projects.
Machine learning engineer
Machine learning engineers focus on designing and implementing machine learning applications. They develop sophisticated algorithms that learn from and make predictions on data.
Business intelligence analyst
Business intelligence (BI) analysts help businesses make data-driven decisions by analyzing data to produce actionable insights. They often use BI tools to convert data into easy-to-understand reports and visualizations for business stakeholders.
Data visualization specialist
These specialists focus on the visual representation of data. They create data visualizations that help end users understand the significance of data by placing it in a visual context.
Data architect
Data architects design, create, deploy and manage an organization's data architecture. They define how data is stored, consumed, integrated and managed by different data entities and IT systems.
IBM and Cloudera have partnered to create an industry-leading, enterprise-grade big data framework distribution plus a variety of cloud services and products — all designed to achieve faster analytics at scale.
IBM Db2 Database on IBM Cloud Pak for Data combines a proven, AI-infused, enterprise-ready data management system with an integrated data and AI platform built on the security-rich, scalable Red Hat OpenShift foundation.
IBM Big Replicate is an enterprise-class data replication software platform that keeps data consistent in a distributed environment, on-premises and in the hybrid cloud, including SQL and NoSQL databases.
A data warehouse is a system that aggregates data from different sources into a single, central, consistent data store to support data analysis, data mining, artificial intelligence and machine learning.
Business intelligence gives organizations the ability to get answers they can understand. Instead of using best guesses, they can base decisions on what their business data is telling them — whether it relates to production, supply chain, customers or market trends.
Cloud computing is the on-demand access of physical or virtual servers, data storage, networking capabilities, application development tools, software, AI analytic tools and more—over the internet with pay-per-use pricing. The cloud computing model offers customers flexibility and scalability compared to traditional infrastructure.
Purpose-built data-driven architecture helps support business intelligence across the organization. IBM analytics solutions allow organizations to simplify raw data access, provide end-to-end data management and empower business users with AI-driven self-service analytics to predict outcomes.
Do not include words like a, and, for, the, etc.
Advanced Query Syntax
NASA's Roman to Use Rare Events to Calculate Expansion Rate of Universe

Lensed supernovae offer precise, independent measurement
With a panoramic view 200 times larger than the Hubble Space Telescope’s infrared view, the sheer amount of data captured by the upcoming Nancy Grace Roman Space Telescope will change the landscape of astronomy.
Astronomers interested in studying a variety of topics, including the mystery of dark energy and the acceleration rate of the universe, are readying themselves to best harness this torrent of data the moment it arrives on Earth soon after Roman’s launch.
One team in particular is focused on training Roman to find gravitationally lensed supernovae, objects that can be used in a unique method to measure the expansion rate of the universe. They say Roman’s study of these elusive lensed supernovae can have enormous potential for the future of cosmology.
Full Article
Supernova Refsdal (Hubble image)
Astronomers investigating one of the most pressing mysteries of the cosmos – the rate at which the universe is expanding – are readying themselves to study this puzzle in a new way using NASA’s Nancy Grace Roman Space Telescope. Once it launches by May 2027, astronomers will mine Roman’s wide swaths of images for gravitationally lensed supernovae, which can be used to measure the expansion rate of the universe.
There are multiple independent ways astronomers can measure the present expansion rate of the universe, known as the Hubble constant . Different techniques have yielded different values, referred to as the Hubble tension . Much of Roman’s cosmological investigations will be into elusive dark energy, which affects how the universe is expanding over time. One primary tool for these investigations is a fairly traditional method, which compares the intrinsic brightness of objects like type Ia supernovae to their perceived brightness to determine distances. Alternatively, astronomers could use Roman to examine gravitationally lensed supernovae. This method of exploring the Hubble constant is unique from traditional methods because it’s based on geometric methods, and not brightness.
“Roman is the ideal tool to let the study of gravitationally lensed supernovae take off,” said Lou Strolger of the Space Telescope Science Institute (STScI) in Baltimore, co-lead of the team preparing for Roman’s study of these objects. “They are rare, and very hard to find. We have had to get lucky in detecting a few of them early enough. Roman’s extensive field of view and repeated imaging in high resolution will help those chances.”
Using various observatories like NASA’s Hubble Space Telescope and James Webb Space Telescope, astronomers have discovered just eight gravitationally lensed supernovae in the universe. However, only two of those eight have been viable candidates to measure the Hubble constant due to the type of supernovae they are and the duration of their time-delayed imaging.
Gravitational lensing occurs when the light from an object like a stellar explosion, on its way to Earth, passes through a galaxy or galaxy cluster and gets deflected by the immense gravitational field. The light splits along different paths and forms multiple images of the supernova on the sky as we see it. Depending on the differences between the paths, the supernova images appear delayed by hours to months, or even years. Precisely measuring this difference in arrival times between the multiple images leads to a combination of distances that constrain the Hubble constant.
“Probing these distances in a fundamentally different way than more common methods, with the same observatory in this case, can help shed light on why various measurement techniques have yielded different results,” added Justin Pierel of STScI, Strolger’s co-lead on the program.
Finding the Needle in the Haystack
Roman's extensive surveys will be able to map the universe much faster than Hubble can, with the telescope “seeing” more than 100 times the area of Hubble in a single image.
“Rather than gathering several pictures of trees, this new telescope will allow us to see the entire forest in a single snapshot,” Pierel explained.
In particular, the High Latitude Time Domain Survey will observe the same area of sky repeatedly, which will allow astronomers to study targets that change over time. This means there will be an extraordinary amount of data – over 5 billion pixels each time – to sift through in order to find these very rare events.
A team led by Strolger and Pierel at STScI is laying the groundwork for finding gravitationally lensed supernovae in Roman data through a project funded by NASA’s Research Opportunities in Space and Earth Science (ROSES) Nancy Grace Roman Space Telescope Research and Support Participation Opportunities program.
“Because these are rare, leveraging the full potential of gravitationally lensed supernovae depends on a high level of preparation,” said Pierel. “We want to make all the tools for finding these supernovae ready upfront so we don’t waste any time sifting through terabytes of data when it arrives.”
The project will be carried out by a team of researchers from various NASA centers and universities around the country.
The preparation will occur in several stages. The team will create data reduction pipelines designed to automatically detect gravitationally lensed supernovae in Roman imaging. To train those pipelines, the researchers will also create simulated imaging: 50,000 simulated lenses are needed, and there are only 10,000 actual lenses currently known.
The data reduction pipelines created by Strolger and Pierel’s team will complement pipelines being created to study dark energy with Type Ia supernovae.
“Roman is truly the first opportunity to create a gold-standard sample of gravitationally lensed supernovae,” concluded Strolger. “All our preparations now will produce all the components needed to ensure we can effectively leverage the enormous potential for cosmology.”
The Nancy Grace Roman Space Telescope is managed at NASA’s Goddard Space Flight Center in Greenbelt, Maryland, with participation by NASA's Jet Propulsion Laboratory and Caltech/IPAC in Southern California, the Space Telescope Science Institute in Baltimore, and a science team comprising scientists from various research institutions. The primary industrial partners are Ball Aerospace and Technologies Corporation in Boulder, Colorado; L3Harris Technologies in Melbourne, Florida; and Teledyne Scientific & Imaging in Thousand Oaks, California.
About This Release
Media contact.
Hannah Braun Space Telescope Science Institute, Baltimore, Maryland
Christine Pulliam Space Telescope Science Institute, Baltimore, Maryland
Permissions
Content Use Policy
- Gravitational Lensing
Related Links and Documents
- Resource: Abstract of ROSES-2023 accepted proposal by L. Strolger et al., PDF (152.68 KB)
- Roman’s Key Science Themes
Distant Supernova Multiply Imaged by Foreground Cluster
Inbox Astronomy
Sign up to receive the latest news, images, and discoveries about the universe:
Contact our News Team
Ask the News Team
Contact our Outreach Office
Ask the Outreach Office
ChatGPT will put your data into interactive tables and charts with GPT-4o

OpenAI just announced new changes to ChatGPT's data analysis feature. Users can now create customizable, interactive tables and charts with the AI chatbot's help that they can later download for presentations and documents. They can also upload files to ChatGPT from Google Drive and Microsoft OneDrive.
However, not all ChatGPT users will gain access to the new data analysis features. The upgrade will roll out for ChatGPT Plus, Team, and Enterprise users over the coming weeks. The new data analysis capabilities will be available in GPT-4o , OpenAI's new flagship model recently released as part of the company's Spring Update.
Also: ChatGPT vs. ChatGPT Plus: Is a paid subscription still worth it?
With the data analysis improvements, users can upload datasets, including tables and documents, and have ChatGPT create an interactive table. They will see the information in an expandable view, edit and customize it, and click on certain areas to ask follow-up questions.
"ChatGPT walks me through data analysis and helps me better understand insights," said Lauren Nowak, marketing manager at Afterpay. "It makes my job more fulfilling, helps me learn, and frees up my time to focus on more strategic parts of my job."
ChatGPT users will also be able to customize and interact with bar, line, pie, and scatter plot charts and download them for presentations.
Also: How to use ChatGPT (and how to access GPT-4o)
A user can upload a spreadsheet and ask the AI chatbot to create a chart on a specific statistic. Once the chart is created, they can hover over chart elements to ask ChatGPT additional questions or select colors.
OpenAI described GPT-4o as a much faster model than GPT-4, with improved text, vision, and audio capabilities. The model will be available for free and paid users in 50 languages, although the interactive tables will only be available to paying users.
OpenAI is unveiling new ChatGPT features today - search engine not included
Your reddit posts will now help train chatgpt - what we know so far, bigid announces new ai data security features for microsoft copilot.
A .gov website belongs to an official government organization in the United States.
A lock ( ) or https:// means you've safely connected to the .gov website. Share sensitive information only on official, secure websites.
- About Adverse Childhood Experiences
- Risk and Protective Factors
- Program: Essentials for Childhood: Preventing Adverse Childhood Experiences through Data to Action
- Adverse childhood experiences can have long-term impacts on health, opportunity and well-being.
- Adverse childhood experiences are common and some groups experience them more than others.

What are adverse childhood experiences?
Adverse childhood experiences, or ACEs, are potentially traumatic events that occur in childhood (0-17 years). Examples include: 1
- Experiencing violence, abuse, or neglect.
- Witnessing violence in the home or community.
- Having a family member attempt or die by suicide.
Also included are aspects of the child’s environment that can undermine their sense of safety, stability, and bonding. Examples can include growing up in a household with: 1
- Substance use problems.
- Mental health problems.
- Instability due to parental separation.
- Instability due to household members being in jail or prison.
The examples above are not a complete list of adverse experiences. Many other traumatic experiences could impact health and well-being. This can include not having enough food to eat, experiencing homelessness or unstable housing, or experiencing discrimination. 2 3 4 5 6
Quick facts and stats
ACEs are common. About 64% of adults in the United States reported they had experienced at least one type of ACE before age 18. Nearly one in six (17.3%) adults reported they had experienced four or more types of ACEs. 7
Preventing ACEs could potentially reduce many health conditions. Estimates show up to 1.9 million heart disease cases and 21 million depression cases potentially could have been avoided by preventing ACEs. 1
Some people are at greater risk of experiencing one or more ACEs than others. While all children are at risk of ACEs, numerous studies show inequities in such experiences. These inequalities are linked to the historical, social, and economic environments in which some families live. 5 6 ACEs were highest among females, non-Hispanic American Indian or Alaska Native adults, and adults who are unemployed or unable to work. 7
ACEs are costly. ACEs-related health consequences cost an estimated economic burden of $748 billion annually in Bermuda, Canada, and the United States. 8
ACEs can have lasting effects on health and well-being in childhood and life opportunities well into adulthood. 9 Life opportunities include things like education and job potential. These experiences can increase the risks of injury, sexually transmitted infections, and involvement in sex trafficking. They can also increase risks for maternal and child health problems including teen pregnancy, pregnancy complications, and fetal death. Also included are a range of chronic diseases and leading causes of death, such as cancer, diabetes, heart disease, and suicide. 1 10 11 12 13 14 15 16 17
ACEs and associated social determinants of health, such as living in under-resourced or racially segregated neighborhoods, can cause toxic stress. Toxic stress, or extended or prolonged stress, from ACEs can negatively affect children’s brain development, immune systems, and stress-response systems. These changes can affect children’s attention, decision-making, and learning. 18
Children growing up with toxic stress may have difficulty forming healthy and stable relationships. They may also have unstable work histories as adults and struggle with finances, jobs, and depression throughout life. 18 These effects can also be passed on to their own children. 19 20 21 Some children may face further exposure to toxic stress from historical and ongoing traumas. These historical and ongoing traumas refer to experiences of racial discrimination or the impacts of poverty resulting from limited educational and economic opportunities. 1 6
Adverse childhood experiences can be prevented. Certain factors may increase or decrease the risk of experiencing adverse childhood experiences.
Preventing adverse childhood experiences requires understanding and addressing the factors that put people at risk for or protect them from violence.
Creating safe, stable, nurturing relationships and environments for all children can prevent ACEs and help all children reach their full potential. We all have a role to play.
- Merrick MT, Ford DC, Ports KA, et al. Vital Signs: Estimated Proportion of Adult Health Problems Attributable to Adverse Childhood Experiences and Implications for Prevention — 25 States, 2015–2017. MMWR Morb Mortal Wkly Rep 2019;68:999-1005. DOI: http://dx.doi.org/10.15585/mmwr.mm6844e1 .
- Cain KS, Meyer SC, Cummer E, Patel KK, Casacchia NJ, Montez K, Palakshappa D, Brown CL. Association of Food Insecurity with Mental Health Outcomes in Parents and Children. Science Direct. 2022; 22:7; 1105-1114. DOI: https://doi.org/10.1016/j.acap.2022.04.010 .
- Smith-Grant J, Kilmer G, Brener N, Robin L, Underwood M. Risk Behaviors and Experiences Among Youth Experiencing Homelessness—Youth Risk Behavior Survey, 23 U.S. States and 11 Local School Districts. Journal of Community Health. 2022; 47: 324-333.
- Experiencing discrimination: Early Childhood Adversity, Toxic Stress, and the Impacts of Racism on the Foundations of Health | Annual Review of Public Health ( annualreviews.org).
- Sedlak A, Mettenburg J, Basena M, et al. Fourth national incidence study of child abuse and neglect (NIS-4): Report to Congress. Executive Summary. Washington, DC: U.S. Department of Health an Human Services, Administration for Children and Families.; 2010.
- Font S, Maguire-Jack K. Pathways from childhood abuse and other adversities to adult health risks: The role of adult socioeconomic conditions. Child Abuse Negl. 2016;51:390-399.
- Swedo EA, Aslam MV, Dahlberg LL, et al. Prevalence of Adverse Childhood Experiences Among U.S. Adults — Behavioral Risk Factor Surveillance System, 2011–2020. MMWR Morb Mortal Wkly Rep 2023;72:707–715. DOI: http://dx.doi.org/10.15585/mmwr.mm7226a2 .
- Bellis, MA, et al. Life Course Health Consequences and Associated Annual Costs of Adverse Childhood Experiences Across Europe and North America: A Systematic Review and Meta-Analysis. Lancet Public Health 2019.
- Adverse Childhood Experiences During the COVID-19 Pandemic and Associations with Poor Mental Health and Suicidal Behaviors Among High School Students — Adolescent Behaviors and Experiences Survey, United States, January–June 2021 | MMWR
- Hillis SD, Anda RF, Dube SR, Felitti VJ, Marchbanks PA, Marks JS. The association between adverse childhood experiences and adolescent pregnancy, long-term psychosocial consequences, and fetal death. Pediatrics. 2004 Feb;113(2):320-7.
- Miller ES, Fleming O, Ekpe EE, Grobman WA, Heard-Garris N. Association Between Adverse Childhood Experiences and Adverse Pregnancy Outcomes. Obstetrics & Gynecology . 2021;138(5):770-776. https://doi.org/10.1097/AOG.0000000000004570 .
- Sulaiman S, Premji SS, Tavangar F, et al. Total Adverse Childhood Experiences and Preterm Birth: A Systematic Review. Matern Child Health J . 2021;25(10):1581-1594. https://doi.org/10.1007/s10995-021-03176-6 .
- Ciciolla L, Shreffler KM, Tiemeyer S. Maternal Childhood Adversity as a Risk for Perinatal Complications and NICU Hospitalization. Journal of Pediatric Psychology . 2021;46(7):801-813. https://doi.org/10.1093/jpepsy/jsab027 .
- Mersky JP, Lee CP. Adverse childhood experiences and poor birth outcomes in a diverse, low-income sample. BMC pregnancy and childbirth. 2019;19(1). https://doi.org/10.1186/s12884-019-2560-8.
- Reid JA, Baglivio MT, Piquero AR, Greenwald MA, Epps N. No youth left behind to human trafficking: Exploring profiles of risk. American journal of orthopsychiatry. 2019;89(6):704.
- Diamond-Welch B, Kosloski AE. Adverse childhood experiences and propensity to participate in the commercialized sex market. Child Abuse & Neglect. 2020 Jun 1;104:104468.
- Shonkoff, J. P., Garner, A. S., Committee on Psychosocial Aspects of Child and Family Health, Committee on Early Childhood, Adoption, and Dependent Care, & Section on Developmental and Behavioral Pediatrics (2012). The lifelong effects of early childhood adversity and toxic stress. Pediatrics, 129(1), e232–e246. https://doi.org/10.1542/peds.2011-2663
- Narayan AJ, Kalstabakken AW, Labella MH, Nerenberg LS, Monn AR, Masten AS. Intergenerational continuity of adverse childhood experiences in homeless families: unpacking exposure to maltreatment versus family dysfunction. Am J Orthopsych. 2017;87(1):3. https://doi.org/10.1037/ort0000133.
- Schofield TJ, Donnellan MB, Merrick MT, Ports KA, Klevens J, Leeb R. Intergenerational continuity in adverse childhood experiences and rural community environments. Am J Public Health. 2018;108(9):1148-1152. https://doi.org/10.2105/AJPH.2018.304598.
- Schofield TJ, Lee RD, Merrick MT. Safe, stable, nurturing relationships as a moderator of intergenerational continuity of child maltreatment: a meta-analysis. J Adolesc Health. 2013;53(4 Suppl):S32-38. https://doi.org/10.1016/j.jadohealth.2013.05.004 .
Adverse Childhood Experiences (ACEs)
ACEs can have a tremendous impact on lifelong health and opportunity. CDC works to understand ACEs and prevent them.
Official website of the State of California
Resources for California
- Key services
- Health insurance or Medi-Cal
- Business licenses
- Food & social assistance
- Find a CA state job
- Vehicle registration
- Digital vaccine record
- Traffic tickets
- Birth certificates
- Lottery numbers
- Unemployment
- View all CA.gov services
- Popular topics
- Building California
- Climate Action
- Mental health care for all
May 10, 2024
Governor Newsom Unveils Revised State Budget, Prioritizing Balanced Solutions for a Leaner, More Efficient Government
Para leer este comunicado en español, haga clic aquí .
The Budget Proposal — Covering Two Years — Cuts Spending, Makes Government Leaner, and Preserves Core Services Without New Taxes on Hardworking Californians
Watch Governor Newsom’s May Revise presentation here
WHAT YOU NEED TO KNOW: The Governor’s revised budget proposal closes both this year’s remaining $27.6 billion budget shortfall and next year’s projected $28.4 billion deficit while preserving many key services that Californians rely on — including education, housing, health care, and food assistance.
SACRAMENTO – Governor Gavin Newsom today released a May Revision proposal for the 2024-25 fiscal year that ensures the budget is balanced over the next two fiscal years by tightening the state’s belt and stabilizing spending following the tumultuous COVID-19 pandemic, all while preserving key ongoing investments.
Under the Governor’s proposal, the state is projected to achieve a positive operating reserve balance not only in this budget year but also in the next. This “budget year, plus one” proposal is designed to bring longer-term stability to state finances without delay and create an operating surplus in the 2025-26 budget year.
In the years leading up to this May Revision, the Newsom Administration recognized the threats of an uncertain stock market and federal tax deadline delays – setting aside $38 billion in reserves that could be utilized for shortfalls. That has put California in a strong position to maintain fiscal stability.
Even when revenues were booming, we were preparing for possible downturns by investing in reserves and paying down debts – that’s put us in a position to close budget gaps while protecting core services that Californians depend on. Without raising taxes on Californians, we’re delivering a balanced budget over two years that continues the progress we’ve fought so hard to achieve, from getting folks off the streets to addressing the climate crisis to keeping our communities safe.
Governor Gavin Newsom
Below are the key takeaways from Governor Newsom’s proposed budget:
A BALANCED BUDGET OVER TWO YEARS. The Governor is solving two years of budget problems in a single budget, tightening the state’s belt to get the budget back to normal after the tumultuous years of the COVID-19 pandemic. By addressing the shortfall for this budget year — and next year — the Governor is eliminating the 2024-25 deficit and eliminating a projected deficit for the 2025-26 budget year that is $27.6 billion (after taking an early budget action) and $28.4 billion respectively.
CUTTING SPENDING, MAKING GOVERNMENT LEANER. Governor Newsom’s revised balanced state budget cuts one-time spending by $19.1 billion and ongoing spending by $13.7 billion through 2025-26. This includes a nearly 8% cut to state operations and a targeted elimination of 10,000 unfilled state positions, improving government efficiency and reducing non-essential spending — without raising taxes on individuals or proposing state worker furloughs. The budget makes California government more efficient, leaner, and modern — saving costs by streamlining procurement, cutting bureaucratic red tape, and reducing redundancies.
PRESERVING CORE SERVICES & SAFETY NETS. The budget maintains service levels for key housing, food, health care, and other assistance programs that Californians rely on while addressing the deficit by pausing the expansion of certain programs and decreasing numerous recent one-time and ongoing investments.
NO NEW TAXES & MORE RAINY DAY SAVINGS. Governor Newsom is balancing the budget by getting state spending under control — cutting costs, not proposing new taxes on hardworking Californians and small businesses — and reducing the reliance on the state’s “Rainy Day” reserves this year.
HOW WE GOT HERE: California’s budget shortfall is rooted in two separate but related developments over the past two years.
- First, the state’s revenue, heavily reliant on personal income taxes including capital gains, surged in 2021 due to a robust stock market but plummeted in 2022 following a market downturn. While the market bounced back by late 2023, the state continued to collect less tax revenue than projected in part due to something called “capital loss carryover,” which allows losses from previous years to reduce how much an individual is taxed.
- Second, the IRS extended the tax filing deadline for most California taxpayers in 2023 following severe winter storms, delaying the revelation of reduced tax receipts. When these receipts were able to eventually be processed, they were 22% below expectations. Without the filing delay, the revenue drop would have been incorporated into last year’s budget and the shortfall this year would be significantly smaller.
CALIFORNIA’S ECONOMY REMAINS STRONG: The Governor’s revised balanced budget sets the state up for continued economic success. California’s economy remains the 5th largest economy in the world and for the first time in years, the state’s population is increasing and tourism spending recently experienced a record high. California is #1 in the nation for new business starts , #1 for access to venture capital funding , and the #1 state for manufacturing , high-tech , and agriculture .
Additional details on the May Revise proposal can be found in this fact sheet and at www.ebudget.ca.gov .
Press Releases
IMAGES
VIDEO
COMMENTS
In a few words, the goal of data presentations is to enable viewers to grasp complicated concepts or trends quickly, facilitating informed decision-making or deeper analysis. What Should a Data Presentation Include? Data presentations go beyond the mere usage of graphical elements.
Data analysis is a comprehensive method of inspecting, cleansing, transforming, and modeling data to discover useful information, draw conclusions, and support decision-making. It is a multifaceted process involving various techniques and methodologies to interpret data from various sources in different formats, both structured and unstructured.
TheJoelTruth. While a good presentation has data, data alone doesn't guarantee a good presentation. It's all about how that data is presented. The quickest way to confuse your audience is by ...
An Introductory Guide. Data analysis is the process of inspecting, cleaning, transforming, and modeling data to derive meaningful insights and make informed decisions. It involves examining raw data to identify patterns, trends, and relationships that can be used to understand various aspects of a business, organization, or phenomenon.
Key Objectives of Data Presentation. Here are some key objectives to think about when presenting financial analysis: Visual communication. Audience and context. Charts, graphs, and images. Focus on important points. Design principles. Storytelling. Persuasiveness.
A method of data analysis that is the umbrella term for engineering metrics and insights for additional value, direction, and context. By using exploratory statistical evaluation, data mining aims to identify dependencies, relations, patterns, and trends to generate advanced knowledge.
Definition: Data presentation is the art of visualizing complex data for better understanding. Importance: Data presentations enhance clarity, engage the audience, aid decision-making, and leave a lasting impact. Types: Textual, Tabular, and Graphical presentations offer various ways to present data.
Data analytics is a multidisciplinary field that employs a wide range of analysis techniques, including math, statistics, and computer science, to draw insights from data sets. Data analytics is a broad term that includes everything from simply analyzing data to theorizing ways of collecting data and creating the frameworks needed to store it.
What Is Data Analysis? (With Examples) Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorise before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock Holmes proclaims ...
Overview. Data analysis is an ongoing process that should occur throughout your research project. Suitable data-analysis methods must be selected when you write your research proposal. The nature of your data (i.e. quantitative or qualitative) will be influenced by your research design and purpose. The data will also influence the analysis ...
data analysis, the process of systematically collecting, cleaning, transforming, describing, modeling, and interpreting data, generally employing statistical techniques. Data analysis is an important part of both scientific research and business, where demand has grown in recent years for data-driven decision making.Data analysis techniques are used to gain useful insights from datasets, which ...
Data analysis is the process of cleaning, transforming, and interpreting data to uncover insights, patterns, and trends. It plays a crucial role in decision making, problem solving, and driving innovation across various domains. In addition to further exploring the role data analysis plays this blog post will discuss common data analysis ...
1. Step one: Defining the question. The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the 'problem statement'. Defining your objective means coming up with a hypothesis and figuring how to test it.
There are a variety of other concerns and decision points that qualitative researchers must keep in mind, including the extent to which to include quantification in their presentation of results, ethics, considerations of audience and voice, and how to bring the richness of qualitative data to life. Quantification, as you have learned, refers ...
Abstract. This chapter covers the topics of data collection, data presentation and data analysis. It gives attention to data collection for studies based on experiments, on data derived from existing published or unpublished data sets, on observation, on simulation and digital twins, on surveys, on interviews and on focus group discussions.
Data analysis is the process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, informing conclusions, and supporting decision-making. Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, and is used in different business, science, and social science domains.
2. Brand Analysis Dashboard. Next, in our list of data interpretation examples, we have a template that shows the answers to a survey on awareness for Brand D. The sample size is listed on top to get a perspective of the data, which is represented using interactive charts and graphs. **click to enlarge**.
What Is Data Presentation? Data presentation is a process of comparing two or more data sets with visual aids, such as graphs. Using a graph, you can represent how the information relates to other data. This process follows data analysis and helps organise information by visualising and putting it into a more readable format.
In this article, we take up this open question as a point of departure and offer thematic analysis, an analytic method commonly used to identify patterns across language-based data (Braun & Clarke, 2006), as a useful starting point for learning about the qualitative analysis process.In doing so, we do not advocate for only learning the nuances of thematic analysis, but rather see it as a ...
What data analysis entails. Data analysis is an analytical process which involves recording and tabulating (recording and entering, entering and tabulating) the quantities of a product, such as numbers of units produced, costs of materials and expenses. While data analyst can take different forms, for example in databases, in other structures ...
What Is Data Analysis? (With Examples) Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock Holme's proclaims ...
8. Tabular presentation. Presenting data in rows and columns, often used for precise data values and comparisons. Tabular data presentation is all about clarity and precision. Think of it as presenting numerical data in a structured grid, with rows and columns clearly displaying individual data points.
4.1 INTRODUCTION. This chapter presents themes and categories that emerged from the data, including the defining attributes, antecedents and consequences of the concept, and the different cases that illuminate the concept critical thinking. The data are presented from the most general (themes) to the most specific (data units/chunks).
What is big data analytics? Big data analytics refers to the systematic processing and analysis of large amounts of data and complex data sets, known as big data, to extract valuable insights. Big data analytics allows for the uncovering of trends, patterns and correlations in large amounts of raw data to help analysts make data-informed decisions.
The data reduction pipelines created by Strolger and Pierel's team will complement pipelines being created to study dark energy with Type Ia supernovae. "Roman is truly the first opportunity to create a gold-standard sample of gravitationally lensed supernovae," concluded Strolger.
The new data analysis capabilities will be available in GPT-4o, OpenAI's new flagship model recently released as part of the company's Spring Update. Also: ChatGPT vs. ChatGPT Plus: Is a paid ...
Examples can include growing up in a household with: 1. Substance use problems. Mental health problems. Instability due to parental separation. Instability due to household members being in jail or prison. The examples above are not a complete list of adverse experiences. Many other traumatic experiences could impact health and well-being.
How data analysis works in ChatGPT. These improvements build on ChatGPT's ability to understand datasets and complete tasks in natural language. To start, upload one or more data files, and ChatGPT will analyze your data by writing and running Python code on your behalf. It can handle a range of data tasks, like merging and cleaning large ...
Under the Governor's proposal, the state is projected to achieve a positive operating reserve balance not only in this budget year but also in the next. This "budget year, plus one" proposal is designed to bring longer-term stability to state finances without delay and create an operating surplus in the 2025-26 budget year.
Today, we're adding a new self-serve plan: ChatGPT Team. ChatGPT Team offers access to our advanced models like GPT-4 and DALL·E 3, and tools like Advanced Data Analysis. It additionally includes a dedicated collaborative workspace for your team and admin tools for team management. As with ChatGPT Enterprise, you own and control your ...