How-To Geek
What is json and how do you use it.
JSON (JavaScript Object Notation) is a standardized format for representing structured data.

Quick Links
Json basics, a basic json example, json data types, semantics and validation, designating json content, working with json, json limitations, json alternatives.
JSON (JavaScript Object Notation) is a standardized format for representing structured data. Although JSON grew out of the JavaScript programming language, it's now an ubiquitous method of data exchange between systems. Most modern-day APIs accept JSON requests and issue JSON responses so it's useful to have a good working knowledge of the format and its features.
In this article, we'll explain what JSON is, how it expresses different data types, and the ways you can produce and consume it in popular programming languages. We'll also cover some of JSON's limitations and the alternatives that have emerged.
JSON was originally devised by Douglas Crockford as a stateless format for communicating data between browsers and servers. Back in the early 2000s, websites were beginning to asynchronously fetch extra data from their server, after the initial page load. As a text-based format derived from JavaScript, JSON made it simpler to fetch and consume data within these applications. The specification was eventually standardized as ECMA-404 in 2013 .
JSON is always transmitted as a string. These strings can be decoded into a range of basic data types, including numbers, booleans, arrays, and objects. This means object hierarchies and relationships can be preserved during transmission, then reassembled on the receiving end in a way that's appropriate for the programming environment.
This is a JSON representation of a blog post:
"id": 1001,
"title": "What is JSON?",
"author": {
"name": "James Walker"
"tags": ["api", "json", "programming"],
"published": false,
"publishedTimestamp": null
This example demonstrates all the JSON data types. It also illustrates the concision of JSON-formatted data, one of the characteristics that's made it so appealing for use in APIs. In addition, JSON is relatively easy to read as-is, unlike more verbose formats such as XML .
Six types of data can be natively represented in JSON:
- Strings - Strings are written between double quotation marks; characters may be escaped using backslashes.
- Numbers - Numbers are written as digits without quotation marks. You can include a fractional component to denote a float. Most JSON parsing implementations assume an integer when there's no decimal point present.
- Booleans - The literal values true and false are supported.
- Null - The null literal value can be used to signify an empty or omitted value.
- Arrays - An array is a simple list denoted by square brackets. Each element in the list is separated by a comma. Arrays can contain any number of items and they can use all the supported data types.
- Objects - Objects are created by curly brackets. They're a collection of key-value pairs where the keys are strings, wrapped in double quotation marks. Each key has a value that can take any of the available data types. You can nest objects to create cascading hierarchies. A comma must follow each value, signifying the end of that key-value pair.
JSON parsers automatically convert these data types into structures appropriate to their language. You don't need to manually cast
to an integer, for example. Parsing the entire JSON string is sufficient to map values back to their original data format.
JSON has certain rules that need to be respected when you encode your data. Strings that don't adhere to the syntax won't be parseable by consumers.
It's particularly important to pay attention to quotation marks around strings and object keys. You must also ensure a comma's used after each entry in an object or array. JSON doesn't allow a trailing comma after the last entry though - unintentionally including one is a common cause of validation errors. Most text editors will highlight syntax problems for you, helping to uncover mistakes.
Despite these common trip points, JSON is one of the easiest data formats to write by hand. Most people find the syntax quick and convenient once they gain familiarity with it. Overall JSON tends to be less error-prone than XML, where mismatched opening and closing tags, invalid schema declarations, and character encoding problems often cause issues.
extension is normally used when JSON is saved to a file. JSON content has the standardized MIME type
is sometimes used for compatibility reasons. Nowadays you should rely on
HTTP headers.
Most APIs that use JSON will encapsulate everything in a top-level object:
"error": 1000
This isn't required though - a literal type is valid as the top-level node in a file, so the following examples are all valid JSON too:
They'll decode to their respective scalars in your programming language.
Most programming languages have built-in JSON support. Here's how to interact with JSON data in a few popular environments.
In JavaScript the
methods are used to encode and decode JSON strings:
const post = {
title: "What Is JSON?",
name: "James Walker"
const encodedJson = JSON.stringify(post);
// {"id": 1001, "title": "What Is JSON?", ...}
console.log(encodedJson);
const decodedJson = JSON.parse(encodedJson);
// James Walker
console.log(decodedJson.author.name);
The equivalent functions in PHP are
"id" => 1001,
"title" => "What Is JSON?",
"author" => [
"id" => 1,
"name" => "James Walker"
$encodedJson = json_encode($post);
echo $encodedJson;
$decodedJson = json_decode($encodedJson, true);
echo $decodedJson["author"]["name"];
Python provides
to serialize and deserialize respectively:
import json
"title": "What Is JSON?",
encodedJson = json.dumps(post)
# {"id": 1001, "title": "What Is JSON?", ...}
print(encodedJson)
decodedJson = json.loads(encodedJson)
# James Walker
print(decodedJson["author"]["name"])
Ruby offers
require "json"
"author" => {
encodedJson = JSON.generate(post)
puts encodedJson
decodedJson = JSON.parse(encodedJson)
puts decodedJson["author"]["name"]
JSON is a lightweight format that's focused on conveying the values within your data structure. This makes it quick to parse and easy to work with but means there are drawbacks that can cause frustration. Here are some of the biggest problems.
No Comments
JSON data can't include comments. The lack of annotations reduces clarity and forces you to put documentation elsewhere. This can make JSON unsuitable for situations such as config files, where modifications are infrequent and the purposes of fields could be unclear.
JSON doesn't let you define a schema for your data. There's no way to enforce that
is a required integer field, for example. This can lead to unintentionally malformed data structures.
No References
Fields can't reference other values in the data structure. This often causes repetition that increases filesize. Returning to the blog post example from earlier, you could have a list of blog posts as follows:
"id": 1002,
"title": "What is SaaS?",
Both posts have the same author but the information associated with that object has had to be duplicated. In an ideal world, JSON parser implementations would be able to produce the structure shown above from input similar to the following:
"author": "{{ .authors.james }}"
"authors": {
This is not currently possible with standard JSON.
No Advanced Data Types
The six supported data types omit many common kinds of value. JSON can't natively store dates, times, or geolocation points, so you need to decide on your own format for this information.
This causes inconvenient discrepancies and edge cases. If your application handles timestamps as strings, like
, but an external API presents time as seconds past the Unix epoch -
- you'll need to remember when to use each of the formats.
YAML is the leading JSON alternative. It's a superset of the format that has a more human-readable presentation, custom data types, and support for references. It's intended to address most of the usability challenges associated with JSON.
YAML has seen wide adoption for config files and within DevOps , IaC , and observability tools. It's less frequently used as a data exchange format for APIs. YAML's relative complexity means it's less approachable to newcomers. Small syntax errors can cause confusing parsing failures.
Protocol buffers (protobufs) are another emerging JSON contender designed to serialize structured data. Protobufs have data type declarations, required fields, and support for most major programming languages. The system is gaining popularity as a more efficient way of transmitting data over networks.
JSON is a text-based data representation format that can encode six different data types. JSON has become a staple of the software development ecosystem; it's supported by all major programming languages and has become the default choice for most REST APIs developed over the past couple of decade.
While JSON's simplicity is part of its popularity, it also imposes limitations on what you can achieve with the format. The lack of support for schemas, comments, object references, and custom data types means some applications will find they outgrow what's possible with JSON. Younger alternatives such as YAML and Protobuf have helped to address these challenges, while XML remains a contender for applications that want to define a data schema and don't mind the verbosity.
JSON for Beginners – JavaScript Object Notation Explained in Plain English

Many software applications need to exchange data between a client and server.
For a long time, XML was the preferred data format when it came to information exchange between the two points. Then in early 2000, JSON was introduced as an alternate data format for information exchange.
In this article, you will learn all about JSON. You'll understand what it is, how to use it, and we'll clarify a few misconceptions. So, without any further delay, let's get to know JSON.
What is JSON?
JSON ( J ava S cript O bject N otation) is a text-based data exchange format. It is a collection of key-value pairs where the key must be a string type, and the value can be of any of the following types:
A couple of important rules to note:
- In the JSON data format, the keys must be enclosed in double quotes.
- The key and value must be separated by a colon (:) symbol.
- There can be multiple key-value pairs. Two key-value pairs must be separated by a comma (,) symbol.
- No comments (// or /* */) are allowed in JSON data. (But you can get around that , if you're curious.)
Here is how some simple JSON data looks:
Valid JSON data can be in two different formats:
- A collection of key-value pairs enclosed by a pair of curly braces {...} . You saw this as an example above.
- A collection of an ordered list of key-value pairs separated by comma (,) and enclosed by a pair of square brackets [...] . See the example below:
Suppose you are coming from a JavaScript developer background. In that case, you may feel like the JSON format and JavaScript objects (and array of objects) are very similar. But they are not. We will see the differences in detail soon.
The structure of the JSON format was derived from the JavaScript object syntax. That's the only relationship between the JSON data format and JavaScript objects.
JSON is a programming language-independent format. We can use the JSON data format in Python, Java, PHP, and many other programming languages.
JSON Data Format Examples
You can save JSON data in a file with the extension of .json . Let's create an employee.json file with attributes (represented by keys and values) of an employee.
The above JSON data shows the attributes of an employee. The attributes are:
- name : the name of the employee. The value is of String type. So, it is enclosed with double quotes.
- id : a unique identifier of an employee. It is a String type again.
- role : the roles an employee plays in the organization. There could be multiple roles played by an employee. So Array is the preferred data type.
- age : the current age of the employee. It is a Number .
- doj : the date the employee joined the company. As it is a date, it must be enclosed within double-quotes and treated like a String .
- married : is the employee married? If so, true or false. So the value is of Boolean type.
- address : the address of the employee. An address can have multiple parts like street, city, country, zip, and many more. So, we can treat the address value as an Object representation (with key-value pairs).
- referred-by : the id of an employee who referred this employee in the organization. If this employee joined using a referral, this attribute would have value. Otherwise, it will have null as a value.
Now let's create a collection of employees as JSON data. To do that, we need to keep multiple employee records inside the square brackets [...].
Did you notice the referred-by attribute value for the second employee, Bob Washington? It is null . It means he was not referred by any of the employees.
How to Use JSON Data as a String Value
We have seen how to format JSON data inside a JSON file. Alternatively, we can use JSON data as a string value and assign it to a variable. As JSON is a text-based format, it is possible to handle as a string in most programming languages.
Let's take an example to understand how we can do it in JavaScript. You can enclose the entire JSON data as a string within a single quote '...' .
If you want to keep the JSON formatting intact, you can create the JSON data with the help of template literals.
It is also useful when you want to build JSON data using dynamic values.
JavaScript Objects and JSON are NOT the Same
The JSON data format is derived from the JavaScript object structure. But the similarity ends there.
Objects in JavaScript:
- Can have methods, and JSON can't.
- The keys can be without quotes.
- Comments are allowed.
- Are JavaScript's own entity.
Here's a Twitter thread that explains the differences with a few examples.
JavaScript Object and JSON(JavaScript Object Notation) are NOT the same. We often think they are similar. That's NOT TRUE 👀 Let's Understand 🔥 A Thread 🧵 👇 — Tapas Adhikary (@tapasadhikary) November 24, 2021
How to Convert JSON to a JavaScript Object, and vice-versa
JavaScript has two built-in methods to convert JSON data into a JavaScript object and vice-versa.
How to Convert JSON Data to a JavaScript Object
To convert JSON data into a JavaScript object, use the JSON.parse() method. It parses a valid JSON string into a JavaScript object.

How to Convert a JavaScript Object to JSON Data
To convert a JavaScript object into JSON data, use the JSON.stringify() method.

Did you notice the JSON term we used to invoke the parse() and stringify() methods above? That's a built-in JavaScript object named JSON (could have been named JSONUtil as well) but it's not related to the JSON data format we've discussed so far. So, please don't get confused.
How to Handle JSON Errors like "Unexpected token u in JSON at position 1"?
While handling JSON, it is very normal to get an error like this while parsing the JSON data into a JavaScript object:

Whenever you encounter this error, please question the validity of your JSON data format. You probably made a trivial error and that is causing it. You can validate the format of your JSON data using a JSON Linter .
Before We End...
I hope you found the article insightful and informative. My DMs are open on Twitter if you want to discuss further.
Recently I have published a few helpful tips for beginners to web development. You may want to have a look:

Let's connect. I share my learnings on JavaScript, Web Development, and Blogging on these platforms as well:
- Follow me on Twitter
- Subscribe to my YouTube Channel
- Side projects on GitHub
Writer . YouTuber . Creator . Mentor
If you read this far, thank the author to show them you care. Say Thanks
Learn to code for free. freeCodeCamp's open source curriculum has helped more than 40,000 people get jobs as developers. Get started
- React Native
- CSS Frameworks
- JS Frameworks
- Web Development
- What is HTML ?
- What is CSS ?
- What is JavaScript ?
- What is TypeScript ?
What is JSON
- What is NPM & How to use it ?
- What is React?
- What is React Router?
- What is Material UI ?
- What is Node?
- What is Express?
- What is SQL?
- What is PHP and Why we use it ?
- What is WordPress?
JSON, short for JavaScript Object Notation , is a lightweight data-interchange format used for transmitting and storing data. It has become a standard format for web-based APIs due to its simplicity and ease of use.
What is JSON?
JSON is a text-based data format that is easy for humans to read and write, as well as parse and generate programmatically. It is based on a subset of JavaScript’s object literal syntax but is language-independent, making it widely adopted in various programming languages beyond JavaScript.
JSON Structure
Data Representation : JSON represents data in key-value pairs. Each key is a string enclosed in double quotes, followed by a colon, and then its corresponding value. Values can be strings, numbers, arrays, objects, booleans, or null.
Why do we use JSON?
- Lightweight and Human-Readable : JSON’s syntax is simple and human-readable, making it easy to understand and work with both by developers and machines.
- Data Interchange Format : JSON is commonly used for transmitting data between a server and a client in web applications. It’s often used in APIs to send and receive structured data.
- Language Independence : JSON is language-independent, meaning it can be used with any programming language that has JSON parsing capabilities.
- Supported Data Types : JSON supports various data types such as strings, numbers, booleans, arrays, objects, and null values, making it versatile for representing complex data structures.
- Compatibility : Most modern programming languages provide built-in support for JSON parsing and serialization, making it easy to work with JSON data in different environments.
- Web APIs : JSON is widely used in web APIs to format data responses sent from a server to a client or vice versa. APIs often return JSON-formatted data for easy consumption by front-end applications.
- Configuration Files : JSON is used in configuration files for web applications, software settings, and data storage due to its readability and ease of editing.
- Data Storage : JSON is also used for storing and exchanging data in NoSQL databases like MongoDB, as it aligns well with document-based data structures.
JSON Data Types
Converting a json text to a javascript object.
In JavaScript, you can parse a JSON text into a JavaScript object using the JSON.parse() method:
JavaScript Object:
JSON vs XML
JSON is a versatile and widely adopted data format that plays a crucial role in modern web development, especially in building APIs and handling data interchange between different systems. Its simplicity, readability, and compatibility with various programming languages make it a preferred choice for developers working with data-driven applications.
Please Login to comment...
Similar reads.
- Web Technologies
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript Programming Language Standard ECMA-262 3rd Edition - December 1999. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.
JSON is built on two structures:
- A collection of name/value pairs. In various languages, this is realized as an object , record, struct, dictionary, hash table, keyed list, or associative array.
- An ordered list of values. In most languages, this is realized as an array , vector, list, or sequence.
These are universal data structures. Virtually all modern programming languages support them in one form or another. It makes sense that a data format that is interchangeable with programming languages also be based on these structures.
In JSON, they take on these forms:
An object is an unordered set of name/value pairs. An object begins with { left brace and ends with } right brace . Each name is followed by : colon and the name/value pairs are separated by , comma .

An array is an ordered collection of values. An array begins with [ left bracket and ends with ] right bracket . Values are separated by , comma .

A value can be a string in double quotes, or a number , or true or false or null , or an object or an array . These structures can be nested.

A string is a sequence of zero or more Unicode characters, wrapped in double quotes, using backslash escapes. A character is represented as a single character string. A string is very much like a C or Java string.

A number is very much like a C or Java number, except that the octal and hexadecimal formats are not used.

Whitespace can be inserted between any pair of tokens. Excepting a few encoding details, that completely describes the language.

json element
value object array string number "true" "false" "null"
object '{' ws '}' '{' members '}'
members member member ',' members
member ws string ws ':' element
array '[' ws ']' '[' elements ']'
elements element element ',' elements
element ws value ws
string '"' characters '"'
characters "" character characters
character '0020' . '10FFFF' - '"' - '\' '\' escape
escape '"' '\' '/' 'b' 'f' 'n' 'r' 't' 'u' hex hex hex hex
hex digit 'A' . 'F' 'a' . 'f'
number integer fraction exponent
integer digit onenine digits '-' digit '-' onenine digits
digits digit digit digits
digit '0' onenine
onenine '1' . '9'
fraction "" '.' digits
exponent "" 'E' sign digits 'e' sign digits
sign "" '+' '-'
ws "" '0020' ws '000A' ws '000D' ws '0009' ws
- ActionScript3
- GNATCOLL.JSON
- JSON for ASP
- JSON ASP utility class
- JSON_checker
- json-parser
- M's JSON parser
- ThorsSerializer
- JSON for Modern C++
- ArduinoJson
- JSON library for IoT
- JSON Support in Qt
- JsonWax for Qt
- Qentem-Engine
- JSON for .NET
- Manatee Json
- FastJsonParser
- Liersch.Json
- Liersch.JsonSerialization
- JSON Essentials
- Redvers COBOL JSON Interface
- SerializeJSON
- vibe.data.json
- json library
- Delphi Web Utils
- JSON Delphi Library
- JSON in TermL
- json-fortran
- package json
- RJson package
- json package
- json-taglib
- json-simple
- google-gson
- FOSS Nova JSON
- Corn CONVERTER
- Apache johnzon
- Common Lisp JSON
- JSON Modules
- netdata-json
- Module json
- NSJSONSerialization
- json-framework
- JSON Photoshop Scripting
- picolisp-json
- Public.Parser.JSON
- Public.Parser.JSON2
- The Python Standard Library
- metamagic.json
- json-parsing
- JSON Utilities
- json-stream
- JSON-struct
- .NET-JSON-Transformer
- Videos about JSON
- Videos about the JSON Logo
- Heresy & Heretical Open Source: A Heretic's Perspective
- Nota Message Format
- United States
- United Kingdom
What is JSON? The universal data format
Json is the leading data interchange format for web applications and more. here’s what you need to know about javascript object notation..
Contributor, InfoWorld |
A little bit of history
Why developers use json, how json works, json vs. xml, json vs. yaml and csv, complex json: nesting, objects, and arrays, parsing and generating json, json schema and json formatter, using json with typescript.
JSON, or JavaScript Object Notation, is a format used to represent data. It was introduced in the early 2000s as part of JavaScript and gradually expanded to become the most common medium for describing and exchanging text-based data. Today, JSON is the universal standard of data exchange. It is found in every area of programming, including front-end and server-side development, systems, middleware, and databases.
This article introduces you to JSON. You'll get an overview of the technology, find out how it compares to similar standards like XML, YAML, and CSV, and see examples of JSON in a variety of programs and use cases.
JSON was initially developed as a format for communicating between JavaScript clients and back-end servers. It quickly gained popularity as a human-readable format that front-end programmers could use to communicate with the back end using a terse, standardized format. Developers also discovered that JSON was very flexible: you could add, remove, and update fields ad hoc. (That flexibility came at the cost of safety, which was later addressed with the JSON schema.)
In a curious turn, JSON was popularized by the AJAX revolution . Strange, given the emphasis on XML, but it was JSON that made AJAX really shine. Using REST as the convention for APIs and JSON as the medium for exchange proved a potent combination for balancing simplicity, flexibility, and consistency.
Next, JSON spread from front-end JavaScript to client-server communication, and from there to system config files, back-end languages, and all the way to databases. JSON even helped spur the NoSQL movement that revolutionized data storage. It turned out that database administrators also enjoyed JSON's flexibility and ease of programming.
Today, document-oriented data stores like MongoDB provide an API that works with JSON-like data structures. In an interview in early 2022, MongoDB CTO Mark Porter noted that, from his perspective, JSON is still pushing the frontier of data . Not bad for a data format that started with a humble curly brace and a colon.
No matter what type of program or use case they're working on, software developers need a way to describe and exchange data. This need is found in databases, business logic, user interfaces, and in all systems communication. There are many approaches to structuring data for exchange. The two broad camps are binary and text-based data. JSON is a text-based format, so it is readable by both people and machines.
JSON is a wildly successful way of formatting data for several reasons. First, it's native to JavaScript, and it's used inside of JavaScript programs as JSON literals. You can also use JSON with other programming languages, so it's useful for data exchange between heterogeneous systems. Finally, it is human readable. For a language data structure, JSON is an incredibly versatile tool. It is also fairly painless to use, especially when compared to other formats.
When you enter your username and password into a form on a web page, you are interacting with an object with two fields: username and password. As an example, consider the login page in Figure 1.
Figure 1. A simple login page.
Listing 1 shows this page described using JSON.
Listing 1. JSON for a login page
Everything inside of the braces or squiggly brackets ( {...} ) belongs to the same object. An object , in this case, refers in the most general sense to a “single thing." Inside the braces are the properties that belong to the thing. Each property has two parts: a name and a value, separated by a colon. These are known as the keys and values. In Listing 1, "username" is a key and "Bilbo Baggins" is a value.
The key takeaway here is that JSON does everything necessary to handle the need—in this case, holding the information in the form—without a lot of extra information. You can glance at this JSON file and understand it. That is why we say that JSON is concise . Conciseness also makes JSON an excellent format for sending over the wire.
JSON was created as an alternative to XML, which was once the dominant format for data exchange. The login form in Listing 2 is described using XML.
Listing 2. Login form in XML
Yikes! Just looking at this form is tiring. Imagine having to create and parse it in code. In contrast, using JSON in JavaScript is dead simple. Try it out. Hit F12 in your browser to open a JavaScript console, then paste in the JSON shown in Listing 3.
Listing 3. Using JSON in JavaScript
XML is hard to read and leaves much to be desired in terms of coding agility. JSON was created to resolve these issues. It's no wonder it has more or less supplanted XML.
Two data formats sometimes compared to JSON are YAML and CSV. The two formats are on opposite ends of the temporal spectrum. CSV is an ancient, pre-digital format that eventually found its way to being used in computers. YAML was inspired by JSON and is something of its conceptual descendant.
CSV is a simple list of values, with each entry denoted by a comma or other separator character, with an optional first row of header fields. It is rather limited as a medium of exchange and programming structure, but it is still useful for outputting large amounts of data to disk. And, of course, CSV's organization of tabular data is perfect for things like spreadsheets.
YAML is actually a superset of JSON, meaning it will support anything JSON supports. But YAML also supports a more stripped-down syntax, intended to be even more concise than JSON. For example, YAML uses indentation for hierarchy, forgoing the braces. Although YML is sometimes used as a data exchange format, its biggest use case is in configuration files.
So far, you've only seen examples of JSON used with shallow (or simple) objects. That just means every field on the object holds the value of a primitive. JSON is also capable of modeling arbitrary complex data structures such as object graphs and cyclic graphs—that is, structures with circular references. In this section, you'll see examples of complex modeling via nesting, object references, and arrays.
JSON with nested objects
Listing 4 shows how to define nested JSON objects.
Listing 4. Nested JSON
The bestfriend property in Listing 4 refers to another object, which is defined inline as a JSON literal.
JSON with object references
Now consider Listing 5, where instead of holding a name in the bestfriend property, we hold a reference to the actual object.
Listing 5. An object reference
In Listing 5, we put the handle to the merry object on the bestfriend property. Then, we are able to obtain the actual merry object off the pippin object via the bestfriend property. We obtained the name off the merry object with the name property. This is called traversing the object graph , which is done using the dot operator.
JSON with arrays
Another type of structure that JSON properties can have is arrays. These look just like JavaScript arrays and are denoted with a square bracket, as shown in Listing 6.
Listing 6. An array property
Of course, arrays may hold references to other objects, as well. With these two structures, JSON can model any range of complex object relations.
Parsing and generating JSON means reading it and creating it, respectively. You’ve seen JSON.stringify() in action already. That is the built-in mechanism for JavaScript programs to take an in-memory object representation and turn it into a JSON string. To go in the other direction—that is, take a JSON string and turn it into an in-memory object—you use JSON.parse() .
In most other languages, it’s necessary to use a third-party library for parsing and generating. For example, in Java there are numerous libraries , but the most popular are Jackson and GSON . These libraries are more complex than stringify and parse in JavaScript, but they also offer advanced capabilities such as mapping to and from custom types and dealing with other data formats.
In JavaScript, it is common to send and receive JSON to servers. For example with the built in fetch() API. When doing so, you can automatically parse the response, as shown in Listing 7.
Listing 7. Parsing a JSON response with fetch()
Once you turn JSON into an in-memory data structure, be it JavaScript or another language, you can employ the APIs for manipulating the structure. For example, in JavaScript, the JSON parsed in Listing 7 would be accessed like any other JavaScript object—perhaps by looping through data.keys or accessing known properties on the data object.
JavaScript and JSON are incredibly flexible, but sometimes you need more structure than they provide. In a language like Java, strong typing and abstract types (like interfaces) help structure large-scale programs. In SQL stores, a schema provides a similar structure. If you need more structure in your JSON documents, you can use JSON schema to explicitly define the characteristics of your JSON objects. Once defined, you can use the schema to validate object instances and ensure that they conform to the schema.
Another issue is dealing with machine-processed JSON that is minified and illegible. Fortunately, this problem is easy to solve. Just jump over to the JSON Formatter & Validator (I like this tool but there are others), paste in your JSON, and hit the Process button. You'll see a human-readable version that you can use. Most IDEs also have a built-in JavaScript formatter to format your JSON.
TypeScript allows for defining types and interfaces, so there are times when using JSON with TypeScript is useful. A class, like a schema, outlines the acceptable properties of an instance of a given type. In plain JavaScript there’s no way to restrict properties and their types. JavaScript classes are like suggestions; the programmer can set them now and modify the JSON later. A TypeScript class, however, enforces what properties the JSON can have and what types they can be.
JSON is one of the most essential technologies used in the modern software landscape. It is crucial to JavaScript but also used as a common mode of interaction between a wide range of technologies. Fortunately, the very thing that makes JSON so useful makes it relatively easy to understand. It is a concise and readable format for representing textual data.
Next read this:
- Why companies are leaving the cloud
- 5 easy ways to run an LLM locally
- Coding with AI: Tips and best practices from developers
- Meet Zig: The modern alternative to C
- What is generative AI? Artificial intelligence that creates
- The best open source software of 2023
- Web Development
- Software Development
Matthew Tyson is a founder of Dark Horse Group, Inc. He believes in people-first technology. When not playing guitar, Matt explores the backcountry and the philosophical hinterlands. He has written for JavaWorld and InfoWorld since 2007.
Copyright © 2022 IDG Communications, Inc.
A beginner's guide to JSON, the data format for the internet
When APIs send data, chances are they send it as JSON objects. Here's a primer on why JSON is how networked applications send data.

As the web grows in popularity and power, so does the amount of data stored and transferred between systems, many of which know nothing about each other. From early on, the format that this data was transferred in mattered, and like the web, the best formats were open standards that anyone could use and contribute to. XML gained early popularity, as it looked like HTML, the foundation of the web. But it was clunky and confusing.
That’s where JSON (JavaScript Object Notation) comes in. If you’ve consumed an API in the last five to ten years, you’ve probably seen JSON data. While the format was first developed in the early 2000s, the first standards were published in 2006. Understanding what JSON is and how it works is a foundational skill for any web developer.
In this article, we’ll cover the basics of what JSON looks like and how to use it in your web applications, as well as talk about serialized JSON—JST and JWT—and the competing data formats.
What JSON looks like
JSON is a human-readable format for storing and transmitting data. As the name implies, it was originally developed for JavaScript, but can be used in any language and is very popular in web applications. The basic structure is built from one or more keys and values:
You’ll often see a collection of key:value pairs enclosed in brackets described as a JSON object. While the key is any string, the value can be a string, number, array, additional object, or the literals, false, true and null. For example, the following is valid JSON:
JSON doesn't have to have only key:value pairs; the specification allows to any value to be passed without a key. However, almost all of the JSON objects that you see will contain key:value pairs.
Using JSON in API calls
One of the most common uses for JSON is when using an API, both in requests and responses. It is much more compact than other standards and allows for easy consumption in web browsers as JavaScript can easily parse JSON strings, only requiring JSON.parse() to start using it.
JSON.parse(string) takes a string of valid JSON and returns a JavaScript object. For example, it can be called on the body of an API response to give you a usable object. The inverse of this function is JSON.stringify(object) which takes a JavaScript object and returns a string of JSON, which can then be transmitted in an API request or response.
JSON isn’t required by REST or GraphQL, both very popular API formats. However, they are often used together, particularly with GraphQL, where it is best practice to use JSON due to it being small and mostly text. If necessary, it compresses very well with GZIP.
GraphQL's requests aren’t made in JSON, instead using a system that resembles JSON, like this
Which will return the relevant data, and if using JSON, it will match very closely:
Using JSON files in JavaScript
In some cases, you may want to load JSON from a file, such as for configuration files or mock data. Using pure JavaScript, it currently isn’t possible to import a JSON file, however a proposal has been created to allow this . In addition, it is a very common feature in bundlers and compilers, like webpack and Babel . Currently, you can get equivalent functionality by exporting a JavaScript Object the same as your desired JSON from a JavaScript file.
export const data = {"foo": "bar"}
Now this object will be stored in the constant, data, and will be accessible throughout your application using import or require statements. Note that this will import a copy of the data, so modifying the object won’t write the data back to the file or allow the modified data to be used in other files.
Accessing and modifying JavaScript objects
Once you have a variable containing your data, in this example data, to access a key’s value inside it, you could use either data.key or data["key"]. Square brackets must be used for array indexing; for example if that value was an array, you could do data.key[0], but data.key.0 wouldn’t work.
Object modification works in the same way. You can just set data.key = "foo" and that key will now have the value “foo”. Although only the final element in the chain of objects can be replaced; for example if you tried to set data.key.foo.bar to something, it would fail as you would first have to set data.key.foo to an object.
Comparison to YAML and XML
JSON isn’t the only web-friendly data standard out there. The major competitor for JSON in APIs is XML. Instead of the following JSON:
in XML, you’d instead have:
JSON was standardized much later than XML, with the specification for XML coming in 1998, whereas Ecma International standardized JSON in 2013. XML was extremely popular and seen in standards such as AJAX (Asynchronous JavaScript and XML) and the XMLHttpRequest function in JavaScript.
XML used by a major API standard: Simple Object Access Protocol (SOAP). This standard can be significantly more verbose than REST and GraphQL, in part due to the usage of XML and because the standard includes more information, such as describing the XML namespace as part of the envelope system. This might be a reason why SOAP usage has declined for years.

Another alternative is YAML, which is much more similar in length to JSON compared to XML, with the same example being:
However, unlike XML, YAML doesn’t really compete with JSON as an API data format. Instead, it’s primarily used for configuration files— Kubernetes primarily uses YAML to configure infrastructure. YAML offers features that JSON doesn’t have, such as comments. Unlike JSON and XML, browsers cannot parse YAML, so a parser would need to be added as a library if you want to use YAML for data interchange.
Signed JSON
While many of JSONs use cases transmit it as clear text, the format can be used for secure data transfers as well. JSON web signatures (JWS) are JSON objects securely signed using either a secret or a public/private key pair. These are composed of a header , payload , and signature .
The header specifies the type of token and the signing algorithm being used. The only required field is alg to specify the encryption algorithm used, but many other keys can be included, such as typ for the type of signature it is.
The payload of a JWS is the information being transmitted and doesn’t need to be formatted in JSON though commonly is.
The signature is constructed by applying the encryption algorithm specified in the header to the base64 versions of the header and payload joined by a dot. The final JWS is then the base64 header, base64 payload, and signature joined by dots. For example:
eyJ0eXAiOiJKV1QiLA0KICJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJqb2UiLA0KICJleHAiOjEzMDA4MTkzODAsDQogImh0dHA6Ly9leGFtcGxlLmNvbS9pc19yb290Ijp0cnVlfQ.dBjftJeZ4CVP-mB92K27uhbUJU1p1r_wW1gFWFOEjXk
JSON Web Tokens (JWT) are a special form of a JWS. These are particularly useful for authorization : when a user logs into a website, they will be provided with a JWT. For each subsequent request, they will include this token as a bearer token in the authorization header.
To create a JWT from a JWS, you’ll need to configure each section specifically. In the header , ensure that the typ key is JWT. For the alg key, the options of HS256 (HMAC SHA-256) and none (unencrypted) must be supported by the authorization server in order to be a conforming JWT implementation, so can always be used. Additional algorithms are recommended but not enforced.
In the payload are a series of keys called claims, which are pieces of information about a subject, as JWTs are most commonly used for authentication, this is commonly a user, but could be anything when used for exchanging information.
The signature is then constructed in the same way as all other JWSs.
Compared to Security Assertion Markup Language Tokens (SAML), a similar standard that uses XML, JSON allows for JWTs to be smaller than SAML tokens and is easier to parse due to the use of both tokens in the browser, where JavaScript is the primary language, and can easily parse JSON.
JSON has come to be one of the most popular standards for data interchange, being easy for humans to read while being lightweight to ensure small transmission size. Its success has also been caused by it being equivalent to JavaScript objects, making it simple to process in web frontends. However, JSON isn’t the solution for everything, and alternate standards like YAML are more popular for things like configuration files, so it’s important to consider your purpose before choosing.
- Skip to main content
- Skip to search
- Skip to select language
- Sign up for free
- Português (do Brasil)
The JSON namespace object contains static methods for parsing values from and converting values to JavaScript Object Notation ( JSON ).
Description
Unlike most global objects, JSON is not a constructor. You cannot use it with the new operator or invoke the JSON object as a function. All properties and methods of JSON are static (just like the Math object).
JavaScript and JSON differences
JSON is a syntax for serializing objects, arrays, numbers, strings, booleans, and null . It is based upon JavaScript syntax, but is distinct from JavaScript: most of JavaScript is not JSON. For example:
Property names must be double-quoted strings; trailing commas are forbidden.
Leading zeros are prohibited. A decimal point must be followed by at least one digit. NaN and Infinity are unsupported.
Any JSON text is a valid JavaScript expression, but only after the JSON superset revision. Before the revision, U+2028 LINE SEPARATOR and U+2029 PARAGRAPH SEPARATOR are allowed in string literals and property keys in JSON; but the same use in JavaScript string literals is a SyntaxError .
Other differences include allowing only double-quoted strings and no support for undefined or comments. For those who wish to use a more human-friendly configuration format based on JSON, there is JSON5 , used by the Babel compiler, and the more commonly used YAML .
The same text may represent different values in JavaScript object literals vs. JSON as well. For more information, see Object literal syntax vs. JSON .
Full JSON grammar
Valid JSON syntax is formally defined by the following grammar, expressed in ABNF , and copied from IETF JSON standard (RFC) :
Insignificant whitespace may be present anywhere except within a JSONNumber (numbers must contain no whitespace) or JSONString (where it is interpreted as the corresponding character in the string, or would cause an error). The tab character ( U+0009 ), carriage return ( U+000D ), line feed ( U+000A ), and space ( U+0020 ) characters are the only valid whitespace characters.
Static properties
The initial value of the @@toStringTag property is the string "JSON" . This property is used in Object.prototype.toString() .
Static methods
Tests whether a value is an object returned by JSON.rawJSON() .
Parse a piece of string text as JSON, optionally transforming the produced value and its properties, and return the value.
Creates a "raw JSON" object containing a piece of JSON text. When serialized to JSON, the raw JSON object is treated as if it is already a piece of JSON. This text is required to be valid JSON.
Return a JSON string corresponding to the specified value, optionally including only certain properties or replacing property values in a user-defined manner.
Example JSON
You can use the JSON.parse() method to convert the above JSON string into a JavaScript object:
Lossless number serialization
JSON can contain number literals of arbitrary precision. However, it is not possible to represent all JSON numbers exactly in JavaScript, because JavaScript uses floating point representation which has a fixed precision. For example, 12345678901234567890 === 12345678901234567000 in JavaScript because they have the same floating point representation. This means there is no JavaScript number that corresponds precisely to the 12345678901234567890 JSON number.
Let's assume you have a exact representation of some number (either via BigInt or a custom library):
You want to serialize it and then parse to the same exact number. There are several difficulties:
- On the serialization side, in order to obtain a number in JSON, you have to pass a number to JSON.stringify , either via the replacer function or via the toJSON method. But, in either case, you have already lost precision during number conversion. If you pass a string to JSON.stringify , it will be serialized as a string, not a number.
- On the parsing side, not all numbers can be represented exactly. For example, JSON.parse("12345678901234567890") returns 12345678901234568000 because the number is rounded to the nearest representable number. Even if you use a reviver function, the number will already be rounded before the reviver function is called.
There are, in general, two ways to ensure that numbers are losslessly converted to JSON and parsed back: one involves a JSON number, another involves a JSON string. JSON is a communication format , so if you use JSON, you are likely communicating with another system (HTTP request, storing in database, etc.). The best solution to choose depends on the recipient system.
Using JSON strings
If the recipient system does not have same JSON-handling capabilities as JavaScript, and does not support high precision numbers, you may want to serialize the number as a string, and then handle it as a string on the recipient side. This is also the only option in older JavaScript.
To specify how custom data types (including BigInt ) should be serialized to JSON, either add a toJSON method to your data type, or use the replacer function of JSON.stringify() .
In either case, the JSON text will look like {"gross_gdp":"12345678901234567890"} , where the value is a string, not a number. Then, on the recipient side, you can parse the JSON and handle the string.
Using JSON numbers
If the recipient of this message natively supports high precision numbers (such as Python integers), passing numbers as JSON numbers is obviously better, because they can directly parse to the high precision type instead of parsing a string from JSON, and then parsing a number from the string. In JavaScript, you can serialize arbitrary data types to JSON numbers without producing a number value first (resulting in loss of precision) by using JSON.rawJSON() to precisely specify what the JSON source text should be.
The text passed to JSON.rawJSON is treated as if it is already a piece of JSON, so it won't be serialized again as a string. Therefore, the JSON text will look like {"gross_gdp":12345678901234567890} , where the value is a number. This JSON can then be parsed by the recipient without any extra processing, provided that the recipient system does not have the same precision limitations as JavaScript.
When parsing JSON containing high-precision numbers in JavaScript, take extra care because when JSON.parse() invokes the reviver function, the value you receive is already parsed (and has lost precision). You can use the context.source parameter of the JSON.parse() reviver function to re-parse the number yourself.
Specifications
Browser compatibility.
BCD tables only load in the browser with JavaScript enabled. Enable JavaScript to view data.
- Date.prototype.toJSON()
- JSON Beautifier/editor
- JSON Parser
- JSON Validator
A Beginner's Guide to JSON with Examples
Syntax and data types, json strings, json numbers, json booleans, json objects, json arrays, nesting objects & arrays, transforming json data in javascript, json vs xml, json resources, further reading.
JSON — short for JavaScript Object Notation — is a popular format for storing and exchanging data. As the name suggests, JSON is derived from JavaScript but later embraced by other programming languages.
JSON file ends with a .json extension but not compulsory to store the JSON data in a file. You can define a JSON object or an array in JavaScript or HTML files.
In a nutshell, JSON is lightweight, human-readable, and needs less formatting, which makes it a good alternative to XML.
JSON data is stored as key-value pairs similar to JavaScript object properties, separated by commas, curly braces, and square brackets. A key-value pair consists of a key , called name (in double quotes), followed by a colon ( : ), followed by value (in double-quotes):
Multiple key-value pairs are separated by a comma:
JSON keys are strings , always on the left of the colon, and must be wrapped in double quotes . Within each object, keys need to be unique and can contain whitespaces , as in "author name": "John Doe" .
It is not recommended to use whitespaces in keys. It will make it difficult to access the key during programming. Instead, use an underscore in keys as in "author_name": "John Doe" .
JSON values must be one of the following data types:
- Boolean ( true or false )
Note: Unlike JavaScript, JSON values cannot be a function, a date or undefined .
String values in JSON are a set of characters wrapped in double-quotes:
A number value in JSON must be an integer or a floating-point:
Boolean values are simple true or false in JSON:
Null values in JSON are empty words:
JSON objects are wrapped in curly braces. Inside the object, we can list any number of key-value pairs, separated by commas:
JSON arrays are wrapped in square brackets. Inside an array, we can declare any number of objects, separated by commas:
In the above JSON array, there are three objects. Each object is a record of a person (with name, gender, and age).
JSON can store nested objects and arrays as values assigned to keys. It is very helpful for storing different sets of data in one file:
The JSON format is syntactically similar to the way we create JavaScript objects. Therefore, it is easier to convert JSON data into JavaScript native objects.
JavaScript built-in JSON object provides two important methods for encoding and decoding JSON data: parse() and stringify() .
JSON.parse() takes a JSON string as input and converts it into JavaScript object:
JSON.stringify() does the opposite. It takes a JavaScript object as input and transforms it into a string that represents it in JSON:
A few years back, XML (Extensible Markup Language) was a popular choice for storing and sharing data over the network. But that is not the case anymore.
JSON has emerged as a popular alternative to XML for the following reasons:
- Less verbose — XML uses many more words than required, which makes it time-consuming to read and write.
- Lightweight & faster — XML must be parsed by an XML parser, but JSON can be parsed using JavaScript built-in functions. Parsing large XML files is slow and requires a lot of memory.
- More data types — You cannot store arrays in XML which are extensively used in JSON format.
Let us see an example of an XML document and then the corresponding document written in JSON:
databases.xml
databases.json
As you can see above, the XML structure is not intuitive , making it hard to represent in code. On the other hand, the JSON structure is much more compact and intuitive , making it easy to read and map directly to domain objects in any programming language.
There are many useful resources available online for free to learn and work with JSON:
- Introducing JSON — Learn the JSON language supported features.
- JSONLint — A JSON validator that you can use to verify if the JSON string is valid.
- JSON.dev — A little tool for viewing, parsing, validating, minifying, and formatting JSON.
- JSON Schema — Annotate and validate JSON documents according to your own specific format.
A few more articles related to JSON that you might be interested in:
- How to read and write JSON files in Node.js
- Reading and Writing JSON Files in Java
- How to read and write JSON using Jackson in Java
- How to read and write JSON using JSON.simple in Java
- Understanding JSON.parse() and JSON.stringify()
- Processing JSON Data in Spring Boot
- Export PostgreSQL Table Data as JSON
✌️ Like this article? Follow me on Twitter and LinkedIn . You can also subscribe to RSS Feed .
You might also like...
- How to convert XML to JSON in Node.js
- How to send JSON request using XMLHttpRequest (XHR)
- How to read JSON from a file using Gson in Java
- How to write JSON to a file using Gson in Java
- Read and write JSON as a stream using Gson
- How to pretty print JSON using Gson in Java
The simplest cloud platform for developers & teams. Start with a $200 free credit.
Buy me a coffee ☕
If you enjoy reading my articles and want to help me out paying bills, please consider buying me a coffee ($5) or two ($10). I will be highly grateful to you ✌️
Enter the number of coffees below:
✨ Learn to build modern web applications using JavaScript and Spring Boot
I started this blog as a place to share everything I have learned in the last decade. I write about modern JavaScript, Node.js, Spring Boot, core Java, RESTful APIs, and all things web development.
The newsletter is sent every week and includes early access to clear, concise, and easy-to-follow tutorials, and other stuff I think you'd enjoy! No spam ever, unsubscribe at any time.
- JavaScript, Node.js & Spring Boot
- In-depth tutorials
- Super-handy protips
- Cool stuff around the web
- 1-click unsubscribe
- No spam, free-forever!
Build more. Break less. Empower others.
Json schema enables the confident and reliable use of the json data format..
Please visit the official list of adopters and discover more companies using JSON Schema.
Why JSON Schema?
While JSON is probably the most popular format for exchanging data, JSON Schema is the vocabulary that enables JSON data consistency, validity, and interoperability at scale.
Streamline testing and validation
Simplify your validation logic to reduce your code’s complexity and save time on development. Define constraints for your data structures to catch and prevent errors, inconsistencies, and invalid data.
Exchange data seamlessly
Establish a common language for data exchange, no matter the scale or complexity of your project. Define precise validation rules for your data structures to create shared understanding and increase interoperability across different systems and platforms.
Document your data
Create a clear, standardized representation of your data to improve understanding and collaboration among developers, stakeholders, and collaborators.
Vibrant tooling ecosystem
Adopt JSON Schema with an expansive range of community-driven tools, libraries, and frameworks across many programming languages.
Start learning JSON Schema
Explore the json schema ecosystem.
Discover JSON Schema tooling to help your organization leverage the benefits of JSON Schema. Because JSON Schema is much more than a Specification, it is a vibrant ecosystem of Validators, Generators, Linters, and other JSON Schema Utilities made by this amazing Community.
Welcome to the JSON Schema Community
With over 60 million weekly downloads, JSON Schema has a large and active developer community across the world. Join the Community to learn, share ideas, ask questions, develop JSON Schema tooling and build new connections.
Join the JSON Schema Slack Workspace!

Join our Slack to ask questions, get feedback on your projects, and connect with +5000 practitioners and experts.
The JSON Schema Blog

Understanding JSON Schema Lexical and Dynamic Scopes
Juan Cruz Viotti
JSON Schema Community Meetings & Events
We hold monthly Office Hours and weekly Open Community Working Meetings. Office Hours are every first Tuesday of the month at 15:00 BST, and by appointment. Open Community Working Meetings are every Monday at 14:00 PT.
Upcoming events
JSON Schema Open Community Working Meeting
June 3rd 2024, 9:00 pm ( UTC )
JSON Schema Office Hours
June 4th 2024, 2:00 pm ( UTC )
June 10th 2024, 9:00 pm ( UTC )
June 17th 2024, 9:00 pm ( UTC )
June 24th 2024, 9:00 pm ( UTC )
July 1st 2024, 9:00 pm ( UTC )
Start contributing to JSON Schema
If you ❤️ JSON Schema consider becoming a sponsor or a backer .
Support us!
Gold Sponsors
Silver sponsors, bronze sponsors.
Supported by
The following companies support us by letting us use their products. Email us for more info!
- Python »
- 3.12.3 Documentation »
- The Python Standard Library »
- Internet Data Handling »
- json — JSON encoder and decoder
- Theme Auto Light Dark |
json — JSON encoder and decoder ¶
Source code: Lib/json/__init__.py
JSON (JavaScript Object Notation) , specified by RFC 7159 (which obsoletes RFC 4627 ) and by ECMA-404 , is a lightweight data interchange format inspired by JavaScript object literal syntax (although it is not a strict subset of JavaScript [ 1 ] ).
Be cautious when parsing JSON data from untrusted sources. A malicious JSON string may cause the decoder to consume considerable CPU and memory resources. Limiting the size of data to be parsed is recommended.
json exposes an API familiar to users of the standard library marshal and pickle modules.
Encoding basic Python object hierarchies:
Compact encoding:
Pretty printing:
Decoding JSON:
Specializing JSON object decoding:
Extending JSONEncoder :
Using json.tool from the shell to validate and pretty-print:
See Command Line Interface for detailed documentation.
JSON is a subset of YAML 1.2. The JSON produced by this module’s default settings (in particular, the default separators value) is also a subset of YAML 1.0 and 1.1. This module can thus also be used as a YAML serializer.
This module’s encoders and decoders preserve input and output order by default. Order is only lost if the underlying containers are unordered.
Basic Usage ¶
Serialize obj as a JSON formatted stream to fp (a .write() -supporting file-like object ) using this conversion table .
If skipkeys is true (default: False ), then dict keys that are not of a basic type ( str , int , float , bool , None ) will be skipped instead of raising a TypeError .
The json module always produces str objects, not bytes objects. Therefore, fp.write() must support str input.
If ensure_ascii is true (the default), the output is guaranteed to have all incoming non-ASCII characters escaped. If ensure_ascii is false, these characters will be output as-is.
If check_circular is false (default: True ), then the circular reference check for container types will be skipped and a circular reference will result in a RecursionError (or worse).
If allow_nan is false (default: True ), then it will be a ValueError to serialize out of range float values ( nan , inf , -inf ) in strict compliance of the JSON specification. If allow_nan is true, their JavaScript equivalents ( NaN , Infinity , -Infinity ) will be used.
If indent is a non-negative integer or string, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0, negative, or "" will only insert newlines. None (the default) selects the most compact representation. Using a positive integer indent indents that many spaces per level. If indent is a string (such as "\t" ), that string is used to indent each level.
Changed in version 3.2: Allow strings for indent in addition to integers.
If specified, separators should be an (item_separator, key_separator) tuple. The default is (', ', ': ') if indent is None and (',', ': ') otherwise. To get the most compact JSON representation, you should specify (',', ':') to eliminate whitespace.
Changed in version 3.4: Use (',', ': ') as default if indent is not None .
If specified, default should be a function that gets called for objects that can’t otherwise be serialized. It should return a JSON encodable version of the object or raise a TypeError . If not specified, TypeError is raised.
If sort_keys is true (default: False ), then the output of dictionaries will be sorted by key.
To use a custom JSONEncoder subclass (e.g. one that overrides the default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
Changed in version 3.6: All optional parameters are now keyword-only .
Unlike pickle and marshal , JSON is not a framed protocol, so trying to serialize multiple objects with repeated calls to dump() using the same fp will result in an invalid JSON file.
Serialize obj to a JSON formatted str using this conversion table . The arguments have the same meaning as in dump() .
Keys in key/value pairs of JSON are always of the type str . When a dictionary is converted into JSON, all the keys of the dictionary are coerced to strings. As a result of this, if a dictionary is converted into JSON and then back into a dictionary, the dictionary may not equal the original one. That is, loads(dumps(x)) != x if x has non-string keys.
Deserialize fp (a .read() -supporting text file or binary file containing a JSON document) to a Python object using this conversion table .
object_hook is an optional function that will be called with the result of any object literal decoded (a dict ). The return value of object_hook will be used instead of the dict . This feature can be used to implement custom decoders (e.g. JSON-RPC class hinting).
object_pairs_hook is an optional function that will be called with the result of any object literal decoded with an ordered list of pairs. The return value of object_pairs_hook will be used instead of the dict . This feature can be used to implement custom decoders. If object_hook is also defined, the object_pairs_hook takes priority.
Changed in version 3.1: Added support for object_pairs_hook .
parse_float , if specified, will be called with the string of every JSON float to be decoded. By default, this is equivalent to float(num_str) . This can be used to use another datatype or parser for JSON floats (e.g. decimal.Decimal ).
parse_int , if specified, will be called with the string of every JSON int to be decoded. By default, this is equivalent to int(num_str) . This can be used to use another datatype or parser for JSON integers (e.g. float ).
Changed in version 3.11: The default parse_int of int() now limits the maximum length of the integer string via the interpreter’s integer string conversion length limitation to help avoid denial of service attacks.
parse_constant , if specified, will be called with one of the following strings: '-Infinity' , 'Infinity' , 'NaN' . This can be used to raise an exception if invalid JSON numbers are encountered.
Changed in version 3.1: parse_constant doesn’t get called on ‘null’, ‘true’, ‘false’ anymore.
To use a custom JSONDecoder subclass, specify it with the cls kwarg; otherwise JSONDecoder is used. Additional keyword arguments will be passed to the constructor of the class.
If the data being deserialized is not a valid JSON document, a JSONDecodeError will be raised.
Changed in version 3.6: fp can now be a binary file . The input encoding should be UTF-8, UTF-16 or UTF-32.
Deserialize s (a str , bytes or bytearray instance containing a JSON document) to a Python object using this conversion table .
The other arguments have the same meaning as in load() .
Changed in version 3.6: s can now be of type bytes or bytearray . The input encoding should be UTF-8, UTF-16 or UTF-32.
Changed in version 3.9: The keyword argument encoding has been removed.
Encoders and Decoders ¶
Simple JSON decoder.
Performs the following translations in decoding by default:
It also understands NaN , Infinity , and -Infinity as their corresponding float values, which is outside the JSON spec.
object_hook , if specified, will be called with the result of every JSON object decoded and its return value will be used in place of the given dict . This can be used to provide custom deserializations (e.g. to support JSON-RPC class hinting).
object_pairs_hook , if specified will be called with the result of every JSON object decoded with an ordered list of pairs. The return value of object_pairs_hook will be used instead of the dict . This feature can be used to implement custom decoders. If object_hook is also defined, the object_pairs_hook takes priority.
If strict is false ( True is the default), then control characters will be allowed inside strings. Control characters in this context are those with character codes in the 0–31 range, including '\t' (tab), '\n' , '\r' and '\0' .
Changed in version 3.6: All parameters are now keyword-only .
Return the Python representation of s (a str instance containing a JSON document).
JSONDecodeError will be raised if the given JSON document is not valid.
Decode a JSON document from s (a str beginning with a JSON document) and return a 2-tuple of the Python representation and the index in s where the document ended.
This can be used to decode a JSON document from a string that may have extraneous data at the end.
Extensible JSON encoder for Python data structures.
Supports the following objects and types by default:
Changed in version 3.4: Added support for int- and float-derived Enum classes.
To extend this to recognize other objects, subclass and implement a default() method with another method that returns a serializable object for o if possible, otherwise it should call the superclass implementation (to raise TypeError ).
If skipkeys is false (the default), a TypeError will be raised when trying to encode keys that are not str , int , float or None . If skipkeys is true, such items are simply skipped.
If check_circular is true (the default), then lists, dicts, and custom encoded objects will be checked for circular references during encoding to prevent an infinite recursion (which would cause a RecursionError ). Otherwise, no such check takes place.
If allow_nan is true (the default), then NaN , Infinity , and -Infinity will be encoded as such. This behavior is not JSON specification compliant, but is consistent with most JavaScript based encoders and decoders. Otherwise, it will be a ValueError to encode such floats.
If sort_keys is true (default: False ), then the output of dictionaries will be sorted by key; this is useful for regression tests to ensure that JSON serializations can be compared on a day-to-day basis.
Implement this method in a subclass such that it returns a serializable object for o , or calls the base implementation (to raise a TypeError ).
For example, to support arbitrary iterators, you could implement default() like this:
Return a JSON string representation of a Python data structure, o . For example:
Encode the given object, o , and yield each string representation as available. For example:
Exceptions ¶
Subclass of ValueError with the following additional attributes:
The unformatted error message.
The JSON document being parsed.
The start index of doc where parsing failed.
The line corresponding to pos .
The column corresponding to pos .
Added in version 3.5.
Standard Compliance and Interoperability ¶
The JSON format is specified by RFC 7159 and by ECMA-404 . This section details this module’s level of compliance with the RFC. For simplicity, JSONEncoder and JSONDecoder subclasses, and parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some extensions that are valid JavaScript but not valid JSON. In particular:
Infinite and NaN number values are accepted and output;
Repeated names within an object are accepted, and only the value of the last name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not RFC-compliant, this module’s deserializer is technically RFC-compliant under default settings.
Character Encodings ¶
The RFC requires that JSON be represented using either UTF-8, UTF-16, or UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets ensure_ascii=True by default, thus escaping the output so that the resulting strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in terms of conversion between Python objects and Unicode strings , and thus does not otherwise directly address the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text, and this module’s serializer does not add a BOM to its output. The RFC permits, but does not require, JSON deserializers to ignore an initial BOM in their input. This module’s deserializer raises a ValueError when an initial BOM is present.
The RFC does not explicitly forbid JSON strings which contain byte sequences that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16 surrogates), but it does note that they may cause interoperability problems. By default, this module accepts and outputs (when present in the original str ) code points for such sequences.
Infinite and NaN Number Values ¶
The RFC does not permit the representation of infinite or NaN number values. Despite that, by default, this module accepts and outputs Infinity , -Infinity , and NaN as if they were valid JSON number literal values:
In the serializer, the allow_nan parameter can be used to alter this behavior. In the deserializer, the parse_constant parameter can be used to alter this behavior.
Repeated Names Within an Object ¶
The RFC specifies that the names within a JSON object should be unique, but does not mandate how repeated names in JSON objects should be handled. By default, this module does not raise an exception; instead, it ignores all but the last name-value pair for a given name:
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values ¶
The old version of JSON specified by the obsolete RFC 4627 required that the top-level value of a JSON text must be either a JSON object or array (Python dict or list ), and could not be a JSON null, boolean, number, or string value. RFC 7159 removed that restriction, and this module does not and has never implemented that restriction in either its serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere to the restriction yourself.
Implementation Limitations ¶
Some JSON deserializer implementations may set limits on:
the size of accepted JSON texts
the maximum level of nesting of JSON objects and arrays
the range and precision of JSON numbers
the content and maximum length of JSON strings
This module does not impose any such limits beyond those of the relevant Python datatypes themselves or the Python interpreter itself.
When serializing to JSON, beware any such limitations in applications that may consume your JSON. In particular, it is common for JSON numbers to be deserialized into IEEE 754 double precision numbers and thus subject to that representation’s range and precision limitations. This is especially relevant when serializing Python int values of extremely large magnitude, or when serializing instances of “exotic” numerical types such as decimal.Decimal .
Command Line Interface ¶
Source code: Lib/json/tool.py
The json.tool module provides a simple command line interface to validate and pretty-print JSON objects.
If the optional infile and outfile arguments are not specified, sys.stdin and sys.stdout will be used respectively:
Changed in version 3.5: The output is now in the same order as the input. Use the --sort-keys option to sort the output of dictionaries alphabetically by key.
Command line options ¶
The JSON file to be validated or pretty-printed:
If infile is not specified, read from sys.stdin .
Write the output of the infile to the given outfile . Otherwise, write it to sys.stdout .
Sort the output of dictionaries alphabetically by key.
Disable escaping of non-ascii characters, see json.dumps() for more information.
Added in version 3.9.
Parse every input line as separate JSON object.
Added in version 3.8.
Mutually exclusive options for whitespace control.
Show the help message.
Table of Contents
- Basic Usage
- Encoders and Decoders
- Character Encodings
- Infinite and NaN Number Values
- Repeated Names Within an Object
- Top-level Non-Object, Non-Array Values
- Implementation Limitations
- Command line options
Previous topic
email.iterators : Iterators
mailbox — Manipulate mailboxes in various formats
- Report a Bug
- Show Source
JSON document representation
JSON documents consist of fields, which are name-value pair objects. The fields can be in any order, and be nested or arranged in arrays. Db2® can work with JSON documents in either their original JSON format or in the binary-encoded format called BSON (Binary JSON).
For more information about JSON documents, see JSON documents .
JSON data must be provided in Unicode and use UTF-8 encoding. Data in the BSON format must use the little-endian format internally.
For your convenience, the SYSIBM.JSON_TO_BSON and SYSIBM.BSON_TO_JSON conversion functions are provided. You can run these functions to convert a file from one format to the other, as needed.
When JSON data is presented to Db2 as input to a JSON SQL function, that data is first interpreted and stored within an appropriate Db2 data type based on the normal Db2 data type expectations. Then, the value is converted to the format that is needed for the equivalent original JSON data type based on the source Db2 data type. This JSON data value is then processed by the JSON SQL function.
- Numerical, Boolean, and NULL values are not affected.
- Character string values are enclosed with double quotation marks and any special character within the string is escaped.
- Date, time, and time stamp values are enclosed with double quotation marks.
- Binary values are interpreted as UTF-8 data.
Specifying the FORMAT JSON clause indicates that the data is already in JSON format and does not need to be changed by Db2 into a valid JSON value. This clause determines only what format processing is or is not done by Db2 . The clause does not detect invalid JSON.
The following table provides some examples of how values are processed from their Db2 data type representation to the equivalent JSON data representation. Among these examples, processing is done with and without the specification of the optional FORMAT JSON clause.
Data in BSON format does not get converted and is passed directly to the JSON SQL function for processing as BSON.
Data that is presented to a JSON SQL function by using a Db2 binary data type is assumed to be in BSON format unless the optional FORMAT JSON clause is specified.
Duplicate keys
Similar to JSON itself, Db2 does not enforce uniqueness for key names in a JSON document. By not enforcing uniqueness, it is possible for the same key name to exist one or more times within the same JSON document and even within the same JSON object. Keys with the same name in the same JSON object are considered to be duplicate keys. If duplicate keys exist in a JSON object, Db2 processing returns only the first key that is encountered. The first key might or might not be the first occurrence of that key in the document.
For example, the key "a" occurs multiple times in this JSON document (which is formatted to make the example more obvious):
In this case, the key "a" is considered a duplicate key name as it appears twice within the same JSON object. Only one key with the name "a"is returned by Db2 from this JSON object.
In this example, the key "a" is not considered a duplicate key name and both values of "a" are returned by Db2 if the appropriate JSON object is queried. Similarly, while the key name "b" occurs multiple times in the example, it also appears once only in each unique JSON object. As a result, none of its occurrences are considered to be duplicate keys.
BSON format
Db2 supports data that is presented in BSON format as input to the JSON SQL functions. The BSON data can be supplied by the customer or produced from the complimentary [ SYSIBM.JSON_TO_BSON ] conversion function.
All the standard BSON data type limits and restrictions apply to values provided as input to the JSON SQL functions. For example, the maximum long number supported by the BSON format is 9,223,372,036,854,775,807 (2 64 - 1).
- BSON binary
- BSON object ID
- BSON regular expression
- BSON DB pointer
- BSON JavaScript code
- BSON JavaScript code with scope
- BSON symbol
- BSON time stamp
- BSON min key
- BSON max key

How to Convert XML to JSON: A Step-by-Step Guide

XML (eXtensible Markup Language) and JSON (JavaScript Object Notation) are two of the most popular data interchange formats available.
5 Key Takeaways from this post:
Parse XML data by breaking down structures into manageable components.
Use tools like ‘ xmltodict ’ and ‘ json ’ for seamless conversion.
Handle nested XML structures by translating them into JSON arrays and objects.
Optimize JSON by removing unnecessary data and following best practices.
Validate JSON output by comparing it with the original XML source.
Table of Contents
Understanding xml and json, benefits of converting xml to json, preparing for xml to json conversion, step-by-step guide: how to convert xml to json, challenges, considerations, and best practices for xml to json conversion.
XML was developed in the late 1990s as a markup language that defines a set of rules for encoding documents. It does so in a data format that is both human-readable and machine-readable. With its structured nature of tags defining elements, it is ideal for the representation of complex hierarchical data.
In contrast, JSON is a lightweight alternative with a focus on simplicity and ease of use for web applications. Its text-based format uses key-value pairs and arrays to represent data, making it particularly suitable for data exchange between a server and web applications.
Modern web development and data processing tasks often require converting XML to JSON. Due to its simplicity and efficiency, JSON is usually the preferred choice for APIs and web services. By converting XML data to JSON, developers can leverage easier data parsing, improved performance, and other advantages. This conversion is critical to ensure data interoperability, enhance system compatibility, and optimize data handling and storage.
The Unified Stack for Modern Data Teams
Get a personalized platform demo & 30-minute q&a session with a solution engineer.
In this post, we guide you through the step-by-step process of converting XML to JSON. We'll cover essential concepts, offer expert tips, and provide clear instructions to ensure effective conversion.
Explanation of XML structure and syntax
XML is designed to store and transfer data. Given that it’s both human-readable and machine-readable, it's a versatile tool for interchanging data. The structure of XML is hierarchical and made up of nested elements. An XML document typically starts with a declaration, followed by a root element encompassing all other elements. Every element is enclosed in tags, with the opening tag defining the element’s name and attributes and the closing tag representing the element’s end.
For example, an XML document representing a book may look like this:
<book>
<title>XML Developer's Guide</title>
<author>Author Name</author>
<price>44.95</price>
</book>
Attributes can provide additional information about elements and are included within the opening tag. Elements can contain text, other elements, or a combination of both, allowing XML to represent complex data structures. However, XML's verbosity can lead to larger file sizes, which may impact performance in data-heavy applications.
Introduction to JSON and its key features
JSON , or JavaScript Object Notation, is a lightweight data-interchange format that is easy to read and write for humans and easy to parse and generate for machines. It is derived from JavaScript but it’s language-independent, making it a popular choice across various programming environments.
JSON structures data using key-value pairs and arrays. Each key-value pair is separated by a colon, and each pair is separated by a comma. Curly braces ‘ { } ’ define objects, while square brackets ‘ [ ] ’ define arrays. Here is an example of a JSON object representing the same book data:
"book": {
"title": "JSON Developer's Guide",
"author": "Author Name",
"price": 44.95
Key features of JSON include its simplicity, ease of use, and efficiency. JSON is less verbose than XML, resulting in smaller file sizes and faster parsing. It is particularly well-suited for web applications, where quick data interchange is crucial.
Comparison between XML and JSON formats
Both XML and JSON serve as data interchange formats, but they have distinct differences that make them suitable for different use cases:
Structure and Syntax: XML is more rigid with a strict hierarchical structure, while JSON uses a more flexible, less verbose syntax with key-value pairs and arrays.
Readability: XML's use of tags makes it more verbose and sometimes harder to read, whereas JSON's straightforward key-value pairs enhance readability and simplicity.
Data Types: JSON supports more data types, such as strings, numbers, arrays, booleans, and null, whereas XML is primarily text-based, requiring additional processing to handle non-text data.
Performance: JSON's compactness results in smaller file sizes and faster parsing, making it more efficient for web applications where performance is critical.
Usability: XML's ability to define custom tags and attributes provides more flexibility for complex data structures, whereas JSON's simplicity makes it easier to use and integrate with modern programming languages and APIs.
Improved Data Interoperability and Compatibility
One of the key benefits on offer when converting XML to JSON is improving data interoperability and compatibility. Given how widely supported JSON is across a variety of programming languages and platforms, it’s easier to integrate with modern web applications, APIs , and mobile apps.
XML can be quite rigid and complex, while JSON’s straightforward key-value pair structure facilitates seamless data exchange between varying systems. This improved interoperability, smoother communication, and data sharing is essential to keep up with the pace of modern digital ecosystems.
Simplified Data Parsing and Manipulation
Thanks to the concise and readable format JSON is presented in, developers are able to work with data far more efficiently. Most programming languages available today, such as JavaScript, Python, and Java, have libraries for parsing and generating JSON data built-in. With these libraries, it’s possible to convert JSON into native data structures with ease. These data structures, including objects and arrays, can be manipulated directly within the code, offering a streamlined process that reduces development time and minimizes the risk of errors.
Enhanced Performance and Scalability
Converting XML to JSON also results in enhanced performance and scalability. Due to JSON’s lightweight nature of minimal tags and attributes, JSON file sizes are generally smaller when compared to an XML file. With smaller files, less bandwidth is consumed, resulting in faster data transmission and an improvement in load times for web applications. With faster parsing and processing possible, the computational overhead on servers and clients is also fairly reduced. This increased efficiency is desirable for applications handling large volumes of data or those requiring real-time processing.
Moreover, JSON's scalability supports the growing needs of modern applications. As volumes of data continue to increase, so does the importance of being able to efficiently parse and process this data. JSON’s performance benefits allow applications to remain responsible and capable of handling their expanding datasets without compromising speed or reliability.
Assessing XML Data Structure and Complexity
Before converting XML to JSON, it’s crucial to assess the XML data structure and its complexity. Examine the XML document's hierarchy, including nested elements and attributes. Identify the depth of nesting and any complex data types. This assessment helps plan the conversion process and anticipate potential challenges, such as handling deeply nested structures or large datasets.
Identifying Conversion Tools and Libraries
The next step involves identifying appropriate tools and libraries for the conversion. Popular choices include Python's ‘ xmltodict ’ and ‘ json ’ libraries, JavaScript's ‘ xml2js ’ library, and any online JSON converter like Code Beautify. Select a tool based on your programming environment, the complexity of the XML data, and specific project needs. Ensure the chosen tool supports efficient handling of nested structures and large files.
Ensuring Data Integrity and Quality
Maintaining data integrity and quality throughout the conversion process is paramount. Validate the XML document to ensure it is well-formed and adheres to the required schema. During conversion, monitor for errors or discrepancies. After conversion, review the JSON output to verify its accuracy and completeness. Implement automated testing and validation checks to identify and correct any issues, ensuring the final JSON data maintains the integrity and quality of the original XML.
By assessing the XML data, selecting the right tools, and ensuring data integrity, you can streamline the XML to JSON conversion process and achieve reliable results.
Converting XML to JSON involves several steps to ensure the data is accurately transformed and remains useful. Here’s a detailed tutorial to help you through the process.
Step 1: Parse the XML Data
Breaking Down XML Structure into Manageable Components
Start by parsing the XML data. Parsing involves reading the XML document and breaking it down into a format that can be easily processed. This step is crucial for understanding the structure of the data and identifying its key components.
Identifying Data Elements and Attributes
Once the XML is parsed, identify the data elements and attributes. Elements are the building blocks of XML, and attributes provide additional information about elements. Ensure you correctly map these elements and attributes as they will form the keys and values in the JSON format.
Step 2: Convert XML to JSON
Utilizing Conversion Tools or Libraries
Use appropriate tools or libraries to convert the parsed XML data into JSON. Many programming languages offer built-in libraries for this task. Select the tool or library that best suits your needs based on your programming environment.
Handling Nested Structures and Arrays
When converting, ensure that nested structures and arrays are properly handled. Nested elements in XML should translate into nested dictionaries or arrays in JSON. If the XML structure contains repeated elements at the same level, they should be converted into JSON arrays.
Step 3: Check Output for Accuracy
Verifying JSON Output for Accuracy and Completeness
After conversion, verify the JSON output for accuracy and completeness. Ensure that all elements and attributes from the XML are correctly represented in the JSON format. Cross-check a few sample entries manually to ensure that the data has been transformed as expected.
Resolving Any Conversion Errors or Discrepancies
If there are discrepancies or errors, resolve them by adjusting the parsing and conversion logic. This might involve handling special cases in the XML, such as empty tags or attributes with special characters.
Step 4: Optimize Structure
Streamlining JSON Structure for Efficiency
Optimize the JSON structure for efficiency. This involves removing any unnecessary data, renaming keys for better readability, and ensuring a consistent structure. Streamlining helps in reducing the size of the JSON data and improves its usability.
Implementing Best Practices for Performance
Implement best practices such as minimizing the use of deeply nested structures and avoiding redundant data. These practices improve performance by making the data easier to parse and process in applications.
Step 5: Test and Validate Resulting Data
Conducting Thorough Testing of JSON Data
Conduct thorough testing to ensure that the JSON data works as intended in your application. This includes unit tests, integration tests, and functional tests to check for any issues that might arise when the data is used in different scenarios.
Validating JSON Output Against XML Source
Finally, validate the JSON output against the XML source to ensure data integrity. This involves comparing the original XML data with the JSON data to ensure that all information has been accurately and completely transferred. Automated validation tools or scripts can be used to streamline this process.
By following these steps, you can effectively convert XML to JSON, ensuring the data remains accurate, efficient, and ready for use in modern applications.
Addressing Common Challenges and Pitfalls
Converting XML to JSON can present several challenges. One common issue is handling complex and deeply nested XML structures, which can lead to overly complicated JSON outputs. Additionally, differences in data types and encoding can cause discrepancies during conversion. For example, XML attributes might not have a direct counterpart in JSON, leading to potential data loss or misinterpretation. Handling special characters and preserving the hierarchical structure without redundancy are other common pitfalls.
Implementing Error Handling and Fallback Mechanisms
To ensure a smooth conversion process, it’s essential to implement robust import error handling and fallback mechanisms. This includes validating the XML document before conversion to ensure it is well-formed and free of errors. During the conversion process, monitor for exceptions and implement try-catch blocks to handle unexpected issues gracefully.
Logging errors and providing meaningful error messages can help diagnose and address problems quickly. Additionally, consider creating fallback mechanisms that can revert to a previous stable state if a critical error occurs, ensuring that data integrity is maintained throughout the process.
Related Reading:
Navigating XML Import Errors: A Guide for Data Professionals
Troubleshooting Common JSON Import Errors
Adopting Industry Standards and Guidelines
Adhering to industry standards and best practices can significantly enhance the reliability and efficiency of the conversion process. Use standardized libraries and tools that are widely accepted and maintained within the developer community. This not only ensures compatibility but also benefits from community support and regular updates.
When structuring your JSON output, follow conventions such as using camelCase for key names and avoiding unnecessary nesting to keep the data structure clean and manageable. Additionally, consider documenting your conversion process and maintaining clear and consistent coding standards to facilitate future maintenance and collaboration.
Effectively Converting XML to JSON
Converting XML to JSON involves several critical steps: parsing the XML data, converting it to JSON using appropriate tools, verifying the accuracy of the output, optimizing the JSON structure, and thoroughly testing and validating the resulting data. Key takeaways include the importance of understanding the XML structure, selecting the right conversion tools, ensuring data integrity, and adhering to best practices for efficiency and performance.
By mastering this process, you can enhance data interoperability, simplify data parsing and manipulation, and improve overall performance and scalability. We encourage you to apply the knowledge gained from this guide to your data conversion tasks, ensuring that your applications run smoothly and efficiently.
Simplify Conversions with Integrate.io
Integrate.io offers robust tools and resources to simplify your XML to JSON conversions. Our platform provides seamless integration, efficient data handling, and user-friendly interfaces to streamline your data transformation processes. Explore additional resources and tools on our website to further enhance your data management capabilities.
Try Integrate.io today with a free, 14-day trial to experience our comprehensive data integration solutions. If you need personalized assistance, schedule an intro call with our experts who can guide you through optimizing your data conversion processes.
Take advantage of our expertise and tools to ensure your data transformations are effective and reliable.
How do I convert XML to JSON using Python?
To convert XML to JSON using Python, you can use libraries like ‘ xmltodict ’ and ‘ json ’ . First, parse the XML using ‘ xmltodict.parse() ’, then convert the resulting dictionary to JSON using ‘ json.dumps() ’. This method ensures a smooth transition from XML to JSON format while maintaining data integrity.
What are the advantages of using JSON over XML?
JSON offers several advantages over XML, including a more compact and readable format, faster parsing and generation, and better performance in web applications. JSON's structure, which uses key-value pairs and arrays, makes it easier to work with in modern programming environments and facilitates efficient data interchange.
Can I convert complex XML structures to JSON seamlessly?
Converting complex XML structures to JSON can be challenging due to nested elements and attributes. However, with the right tools and careful handling, it is possible to achieve a seamless conversion. Tools like ‘ xmltodict ’ in Python can help manage these complexities by correctly mapping XML elements to JSON objects and arrays.
Tags: conversions, json, XML
Subscribe To The Stack Newsletter
[email protected] +1-888-884-6405
©2024 Integrate.io
- Solutions Home
- Release Notes
- Support & Resources
- Documentation
- Documentation API
- Service Status
- Privacy Policy
- Terms of Service
- Consent Preferences
- White Papers
Get the Integrate.io Newsletter
Choose your free trial, etl & reverse etl, formerly xplenty.
Low-code ETL with 220+ data transformations to prepare your data for insights and reporting.
Formerly FlyData
Replicate data to your warehouses giving you real-time access to all of your critical data.
API Generation
Formerly dreamfactory.
Generate a REST API on any data source in seconds to power data products.
The JSON Validator: A Custom Processor to Ensure Your JSON Payload is Syntactically Accurate

Before we get to building your custom JSON validator, let’s talk about the author and their thoughts on why JSON has become so essential in data engineering.
The author, Joel Klo , is a consultant at Bigspark *, UK’s engineering powerhouse, delivering next level data platforms and solutions to their clients. Their clients use modern cloud platforms and open source technologies, prioritize security, risk, and resilience, and leverage distributed and containerized workloads *
Introduction
The JavaScript Object Notation, popularly referred to by its acronym JSON, has become the most used format for the transfer of data on the web, especially with the advent and dominance of the Representational State Transfer (REST) software architectural style for designing and building web services.
Its popularity (and flexibility) have also made it one of the most common formats for file storage. It has inspired and become the choice for structuring or representing data in NoSQL Document stores like MongoDB.
From capturing user input to transferring data to and from web services and source systems or data stores, the JSON format has become essential. Its increased dependence, therefore, makes its validation all the more important.
This blog post explores the features of a custom StreamSets Data Collector Engine (SDC) processor built to validate JSON data with the help of an associated schema and how it can be used in a StreamSets pipeline.
The JSON Schema
A JSON Schema is a JSON document structured in a way to describe (or annotate) and validate other JSON documents. It is more or less the blueprint of a JSON document. The JSON Schema is a specification currently available on the Internet Engineering Task Force (IETF) main site as an Internet-Draft . The spec is also presented as the definition for the media type “application/schema+json”.
The validation vocabulary of the JSON Schema is captured in the JSON Schema Validation specification Internet-Draft .
Below is an example JSON document with an associated example schema.
Example JSON Document
Example JSON Schema
The JSON Schema Validator Library
The JSON Schema Validator library is a Java library that uses the JSON schema specification to validate JSON data. It relies on the org.json or JSON-Java API , enabling the creation, manipulation, and parsing of JSON data. This is the main library used in the building of the custom StreamSets Data Collector Engine processor.
For a tutorial on how to build a custom StreamSets processor, click here.
Note: Be sure to specify your StreamSets Data Collector Engine version in the archetypeVersion maven argument when using the provided maven archetype to generate the custom stage project.
The Custom StreamSets Data Collector JSON Validator Processor
Installation
The JSON Validator Processor binary is available as a .zip file here . The zip file must be extracted in the StreamSets Data Collector Engine user-libs directory, after which it can be seen in the SDC stage library on restart.
Configuration of Properties in Your JSON Validator Processor
To use the JSON Validator Processor in a pipeline, there are two of three configuration properties that must be specified:
- The Record as JSON String config
- If checked, this config option converts the full SDC record into the JSON string which will be validated. This allows all data formats which can be sourced by a data collector origin stage to be validated by the JSON schema (even though they are not JSON documents).
- If unchecked, the processor will perform the validation on the field specified by the JSON String Field config option.
- The JSON String Field config: this represents the field from the incoming SDC record that contains the ‘stringified’ JSON data which needs to be validated.
- If the specified field contains an invalid JSON object string, an exception will be thrown on pipeline validation.
- The JSON Schema config: this allows the user to define the draft-04 , draft-06 or draft-07 JSON schema that will be used to validate the JSON data captured by the JSON String Field or SDC record.
- An exception will be thrown on pipeline validation if the schema is an invalid JSON object or does not conform to the specified schema version.

Example Pipeline Using the JSON Validator
To demonstrate the capability of the JSON Validator Processor, a basic 3-stage pipeline consisting of a single origin, processor, and destination will be used:
- origin stage (Directory): containing a .csv file of NYC taxi data ,
- processor stage (the JSON Validator) and
- destination stage (Trash)

The JSON Validator in this example pipeline is configured as follows:

On validation of the pipeline:
- be a valid JSON object
- to conform to the specified $schema (i.e. our schema is validated with the draft-07 schema specification in this case)
In our JSON schema, we specify a rule which expects the fare_amount field of our NYC taxi data to be a number not less than one. We, however, expect our JSON Validator processor to produce an error for each record when we preview or run the pipeline, as all the fields in our NYC taxi data coming from our Directory origin are strings.
Let’s preview our pipeline…

As expected, we receive a Schema validation error stating that the expected type for the fare_amount field is a Number but the actual type is a String .
Running the pipeline…

On monitoring the JSON Validator processor, we can view the error metrics and record details from the Errors tab. From this, we observe that all 5386 records of our NYC taxi data have validation errors according to our specified JSON schema (as expected).
Closing Thoughts
In a world where a number presented as text, a digit stripped of a number, a boolean flag displayed as an integer (1 or 0), a duplicated item in a list, a special character missing from a string of text, or any one of the million things that could go wrong with data and its representation could cost individuals and businesses lots of money, a tool like the JSON Validator Processor and the role it plays in a strategic platform like StreamSets comes in handy.
Please enter your information to subscribe to the Microsoft Fabric Blog.
Microsoft fabric updates blog.
Visualize and Explore Data with Real-Time Dashboards
- Uncategorized
In today’s data-driven world, the ability to quickly explore, analyze, and derive insights from fresh, high granularity data is paramount. With the ever-increasing volume and complexity of data, organizations need powerful tools that not only streamline data exploration but also provide real-time insights. That’s why we’re thrilled to announce the public preview of Real-Time Dashboards , that empower users to interact with their data dynamically and in real time.
Unveiling Real-Time Dashboards
At its core, each Real-Time Dashboard is a collection of tiles, organized in pages, where each tile corresponds to an underlying query and a visual representation. With extensive slice and dice features, and advanced exploration capabilities, Real-Time Dashboards not only provide dynamic, real-time access to fresh data, but also empower you to make informed decisions and gain insights on-the-fly.
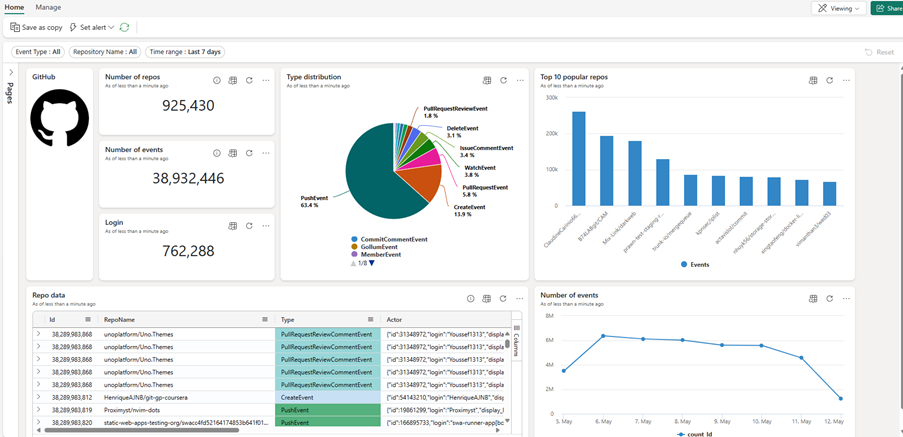
Advanced Visualization Options
One of the highlights of Real-Time Dashboards is the rich portfolio of visualization types available. From traditional bar and line charts to sophisticated anomaly detection and map visuals, Real-Time Dashboards provide a comprehensive toolkit for creating lightweight, scalable and compelling data representations. What’s more, you can customize these visuals with conditional formatting rules, making it easier to identify significant data points at a glance.
Real-Time Interaction and no-code exploration
Real-Time Dashboards aren’t just about static data representations; they enable dynamic interaction and collaboration. With features like parameters, cross filters, and drill through capabilities, users can slice and dice data, filter visuals, and gain different viewpoints effortlessly.
With a friendly UI, users gain the critical ability to seamlessly drill down from any visualization to examine the specific data points behind it, ensuring transparency and eliminating “cliffs” in analysis. This intuitive, no-code UI empowers users of all levels to delve deep into their data, down to the level of individual events, without the need for specialized KQL expertise.
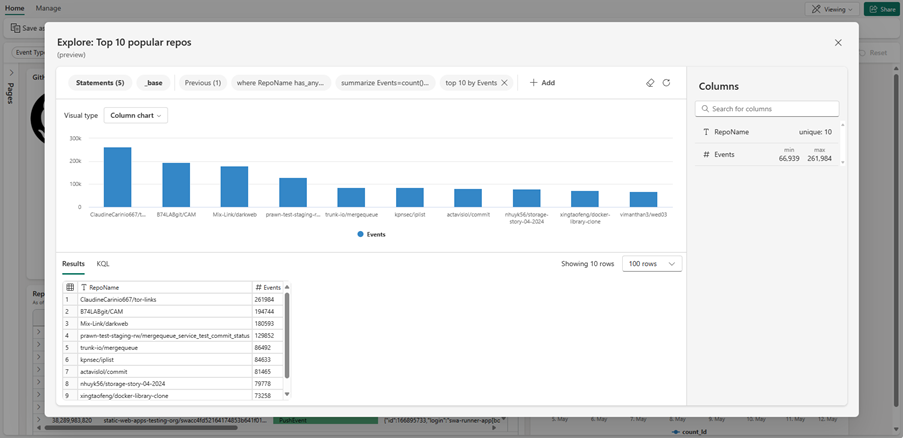
Streamlined Visualization Creation
Real-Time Dashboards revolutionize the way visualizations are created. With the ability to effortlessly export Kusto Query Language (KQL) queries from any KQL Queryset, to dashboards as visuals, authors can quickly assemble compelling representations of their data. What’s more, the user-friendly tile authoring experience empowers users to modify visuals with ease, ensuring that every dashboard is tailored to meet their specific needs.
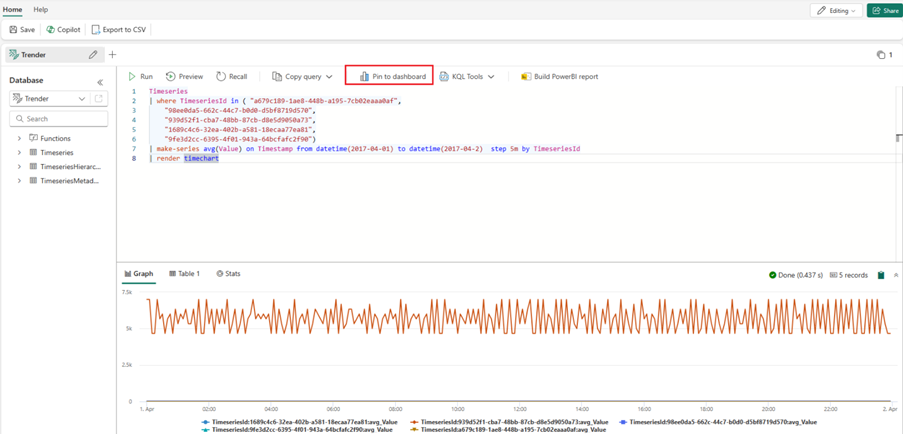
When to use Real-Time Dashboards?
Real-Time Dashboards natively visualize data stored in Eventhouses, making them the preferred choice for timestamped, fast-flowing, high-volume data with JSON or detailed text elements, leveraging Eventhouse’s capabilities for low-latency data availability and flexible querying.
They stand out with their streamlined approach, focusing on functionality based on KQL queries, offering a leaner overhead and real-time query capabilities. They are ideal for scenarios where immediate data access and exploration are needed, particularly in environments where KQL expertise is prevalent. On the other hand, Power BI (PBI) provides a comprehensive feature set and rich visualization options, making it suitable for scenarios requiring complex parameterization, and broad sharing capabilities. Choose Real-Time Dashboards for real-time insights and agile exploration with KQL proficiency, while opting for PBI when diverse data sources, and extensive customization are priorities.
To read more about setting Real-Time Dashboards, check out the documentation.
To find out more about Real-Time Intelligence, read Yitzhak Kesselman’s announcement . As we launch our preview, we’d love to hear what you think and how you’re using the product. The best way to get in touch with us is through our community forum or submit an idea . For detailed how-tos, tutorials and other resources, check out the documentation .
This is part of a series of blog posts that dive into all the capabilities of Real-Time Intelligence. Stay tuned for more!
Related blog posts
Query activity: a one-stop view to monitor your running and completed t-sql queries.
We’re excited to announce Query activity, a one-stop view of all running and historical T-SQL queries for workspace admins! We know monitoring T-SQL queries is essential for maintaining the performance and efficiency of the warehouse to ensure that queries aren’t taking longer than expected to execute and are completed successfully. This feature enhances your ability … Continue reading “Query activity: A one-stop view to monitor your running and completed T-SQL queries”
Announcing General Availability of Fabric Private Links, Trusted Workspace Access, and Managed Private Endpoints
As more and more enterprises store and analyze data on the cloud, the need for securing sensitive data has become paramount. Microsoft Fabric offers security at different levels – for instance, access control using workspace roles/permissions and granular security at the data layer. In addition to these, Network security provides a critical level of isolation, … Continue reading “Announcing General Availability of Fabric Private Links, Trusted Workspace Access, and Managed Private Endpoints”
KQIR: a query engine for Apache Kvrocks that supports both SQL and RediSearch queries

Pretty cool, right? Let's dive in!
(The full example is provided in the final section .)
Apache Kvrocks
Apache Kvrocks is a Redis -compatible database built on RocksDB .
It supports the RESP protocol (version 2 and 3) and a wide range of Redis commands , encompassing core data structures like Strings, Sets, Hashes, Sorted Sets, Stream, GEO, as well as Lua Scripts, Transactions, Functions and even BloomFilter , JSON from the Redis Stack.
Unlike Redis which stores data in memory, Kvrocks persists data on disk for improved storage capabilities without being constrained by machine memory limit.
The capability to query
In recent years, NoSQL databases have become more popular than traditional databases because they perform better, scale easily, and are more flexible for different industries.
However, many users are unwilling to abandon the essential features of SQL databases just for performance reasons. These include ACID transactions, expressive query capabilities inherent in SQL, as well as optimization and abstraction possibilities offered by structured data and relational algebra. Consequently, a new category of databases known as NewSQL has emerged gradually.
Kvrocks is a NoSQL database. While not classified as NewSQL, Kvrocks aims to strike a balance between NoSQL and NewSQL paradigms: It aims to maintain the high performance of NoSQL while also implementing transaction guarantees and supporting more complex queries.
RediSearch?
RediSearch is a Redis module that enhances Redis with query, secondary indexing, and full-text search functionalities. While its Redis commands begin with FT. (i.e. full text), it goes beyond just full-text search.
In fact, it is Redis moving closer to SQL databases: RediSearch enables users to create structured schemas on existing Redis JSON or HASH data for index building. Its schema supports various field types such as numeric, tag, geo, text, and vector - the latter two are utilized for full-text and vector searches. Instead of SQL support, RediSearch provides a unique query syntax known as the RediSearch query language.
RediSearch finds applications in various fields. One recent application involves utilizing its vector search feature to develop retrieval-augmented generation (RAG). For instance, LangChain utilizes Redis as one of its vector database. If Kvrocks can be compatible with RediSearch, it could benefit from these ecosystem from RediSearch.
RediSearch uses a unique syntax for queries, but there are some issues to consider:
Firstly, RediSearch's schema (a.k.a. index, created with FT.CREATE ) can be regarded as a table in an SQL database. Its query syntax also aligns semantically with SQL queries. Given this similarity, supporting SQL should not increase significant challenges; why not include SQL support as well?
Secondly, SQL enjoys broader usage and is familiar to more individuals. It is simpler to learn at the syntax level. While developers may need time to understand RediSearch query syntax, adapting to a new SQL database often requires less effort. Furthermore, SQL offers robust support for various query features, enhanced expressive capabilities (like JOINs, subqueries, aggregations).
Finally, RediSearch query syntax suffers from some historical designs. For example, the operator precedence of AND and OR (represented by space and | operator in RediSearch queries) varies across different dialect versions (dialect 1 vs. dialect 2). This tribal knowledge might lead users to prefer established query languages.
To sum up, we believe that supporting SQL as a querying language would be a good decision.
How we support both?

To introduce SQL capability to Kvrocks, we need to design a robust architecture with scalability, maintainability, and strong query planning and optimization features.
We plan to accomplish this through KQIR . In the context of Kvrocks, KQIR stands for both:
- The complete query engine, covering frontend language parsing, query optimization and execution, etc.
- An intermediate language (IR) that traverses the entire query engine.
KQIR: a multiple-level IR
To support both SQL and RediSearch queries, an intermediate language (IR) is necessary to handle them consistently in subsequent processes without concern for the user's input language.
We have developed parsers for a subset of MySQL syntax and RediSearch queries, converting the resulting syntax tree into KQIR.
And KQIR is a multi-level IR that can represent query structures at various levels during optimization. The initial transformation from the syntax tree results in Syntactical IR, a high-level representation of certain syntactic expressions. As it undergoes processing by an IR optimizer, KQIR evolves into Planning IR, a low-level representation used to express query execution plans within the query engine.
Additionally, we will conduct semantic checks on the IR before optimization to ensure that the query is semantically correct. This includes verifying that it does not include any undefined schemas or fields and uses the appropriate field types.
IR Optimizer
The KQIR optimizer consists of multiple passes, a concept borrowed from LLVM . Each pass takes IR as input, conducts analysis and modifications, and generates a new IR.
Currently, the optimizer's passes are categorized into three main groups:
- expression passes for optimizing logical expressions like AND , OR , NOT operators;
- numeric passes for optimizing numerical comparisons with an interval analysis (i.e. analyze the mathematical properties of numerical comparisons in terms of intervals) to enhance query optimization by eliminating unnecessary comparisons or improving comparison expressions;
- planning passes for converting syntactical IR to planning IR and enhancing query plans through a cost model that selects optimal indexes and removes unnecessary sortings.
Pass execution order is controlled by the pass manager. A pass may run multiple times at different stages to simplify individual passes by combining them.
Plan Executor
The KQIR plan executor is built on the Volcano model.
Once the IR optimizer finishes all optimizations, the resulting IR becomes a planning IR. This will then be passed to the plan executor to create execution logic based on certain context corresponding to the plan operator.
Subsequently, Kvrocks retrieves query results through iterative execution.
On-disk indexing
Unlike Redis, which stores index data in memory, Kvrocks requires the construction of indexes on the disk. This means that for any field type (e.g. tag, numeric), we need an encoding to reduce such index to RocksDB's key-values.
Furthermore, we incrementally create indexes before and after JSON or HASH commands getting executed to guarantee that query results are in real-time.
Current status
The KQIR functionality is currently available on the unstable branch, supporting commands like FT.CREATE , FT.SEARCH , and FT.SEARCHSQL (an extension for running SQL queries) to encourage user to test.
However, as KQIR is still in early development, compatibility cannot be guaranteed and many features remain incomplete. Thus the upcoming release (version 2.9.0) will not include any KQIR component.
Supported field types
Currently, we only support two field types: tag and numeric.
Tag fields label each data record with multiple tags for filtering in queries. And numeric fields hold numerical data within double-precision floating-point ranges. They allow sorting and filtering by specific numerical ranges.
In the future, we plan to expand support to include vector search and full-text search capabilities alongside other field types.
Transaction guarantees
Currently, the transaction guarantee of KQIR is weak, which may lead to unexpected issues during use.
Another project in the Kvrocks community aims to enhance Kvrocks' transaction support by establishing a structured framework. We will leverage these efforts to uphold the ACID properties of KQIR and release an official version incorporating KQIR after that.
Limitation on IR optimizer
Currently, KQIR does not use the cost model when optimizing record sorting. Instead, it relies on specialized logic. This could be an area for improvement soon.
Furthermore, KQIR does not currently utilize optimizations based on runtime statistics. Our future focus will be on integrating runtime statistics into the cost model for more precise index selection.
Relationship with other features
KQIR integrates well with the namespace feature. Any index created is restricted to the current namespace and cannot be accessed in other namespaces, aligning with how other data is accessed within the namespace.
Currently, KQIR cannot be enabled in the cluster mode . Cluster mode support may not be implemented in the short term, but we encourage anyone to submit discussions, design proposals, or suggestions.
Compliance
While KQIR is designed to be compatible with RediSearch at the interface level, it does not include any code from RediSearch. As previously mentioned, KQIR features a completely new framework, and its query architecture (including parsing, optimization, execution) is independent of RediSearch.
This distinction is important due to the proprietary license under which RediSearch is released.
High experimental!
The current implementation of KQIR is in its early experimental stage. We advise users to consider carefully when using KQIR functionalities in a production environment, as we do not guarantee compatibility, and there may be unexpected errors.
Future outlook
KQIR is currently in development, and all mentioned aspects will continue to evolve. If you're interested, please stay updated on the progress.
Developers keen on KQIR are encouraged to get involved in the development process and join the Apache Kvrocks community.
Note that our community consists entirely of volunteers. As an ASF community, we strive to offer an open, inclusive, and vendor-neutral environment.
Vector search
The design and implementation of vector search support are currently underway, which is very exciting.
In the Kvrocks community, some members have raised discussions and proposed an encoding design for implementing vector search on KQIR.
As per the plan, we will initially implement an on-disk HNSW index and introduce the vector field type.
Full-text search
There is currently no design proposal for full-text search.
However, community members are exploring the potential of incorporating full-text indexing in KQIR via CLucene or PISA .
We encourage anyone interested to share their ideas or suggestions and get involved in the development and implementation.
More SQL features
In the future, we aim to progressively broaden our support for SQL features, potentially encompassing subqueries (including common table expressions), JOIN operations, aggregation functions, and other functionalities.
Our primary focus will remain on transaction processing rather than analytical tasks.
First, we can easily set up a Kvrocks instance via Docker images. You also have the choice to manually build executable from the source code in the unstable branch.
Then, we can connect to kvrocks locally using redis-cli , and create an index named testidx consisting a tag field a and numeric field b with the following command:
Next, we can add some new data using Redis JSON commands: (Note that it is also possible to add data before running FT.CREATE .)
Finally, we can execute some SQL queries to get the desired results:
Or an equivalent RediSearch query:
If you experience any issues with KQIR, please feel free to report them .
- Apache Kvrocks
- The capability to query
- RediSearch?
- KQIR: a multiple-level IR
- IR Optimizer
- Plan Executor
- On-disk indexing
- Supported field types
- Transaction guarantees
- Limitation on IR optimizer
- Relationship with other features
- High experimental!
- Vector search
- Full-text search
- More SQL features

Data Science Journal

- Download PDF (English) XML (English) Supplement 1 (English)
- Alt. Display
The FAIR Assessment Conundrum: Reflections on Tools and Metrics
- Leonardo Candela
- Dario Mangione
- Gina Pavone
Several tools for assessing FAIRness have been developed. Although their purpose is common, they use different assessment techniques, they are designed to work with diverse research products, and they are applied in specific scientific disciplines. It is thus inevitable that they perform the assessment using different metrics. This paper provides an overview of the actual FAIR assessment tools and metrics landscape to highlight the challenges characterising this task. In particular, 20 relevant FAIR assessment tools and 1180 relevant metrics were identified and analysed concerning (i) the tool’s distinguishing aspects and their trends, (ii) the gaps between the metric intents and the FAIR principles, (iii) the discrepancies between the declared intent of the metrics and the actual aspects assessed, including the most recurring issues, (iv) the technologies used or mentioned the most in the assessment metrics. The findings highlight (a) the distinguishing characteristics of the tools and the emergence of trends over time concerning those characteristics, (b) the identification of gaps at both metric and tool levels, (c) discrepancies observed in 345 metrics between their declared intent and the actual aspects assessed, pointing at several recurring issues, and (d) the variety in the technology used for the assessments, the majority of which can be ascribed to linked data solutions. This work also highlights some open issues that FAIR assessment still needs to address.
- FAIR assessment tools
- FAIR assessment metrics
1 Introduction
Wilkinson et al. formulated the FAIR guiding principles to support data producers and publishers in dealing with four fundamental challenges in scientific data management and formal scholarly digital publishing, namely Findability, Accessibility, Interoperability, and Reusability ( Wilkinson et al. 2016 ). The principles were minimally defined to keep, as low as possible, the barrier-to-entry for data producers, publishers, and stewards who wish to make their data holdings FAIR. Moreover, the intent was to formulate principles that apply not only to ‘data’ in the conventional sense but also to the algorithms, tools, and workflows that led to that data. All scholarly digital research objects were expected to benefit from applying these principles since all components of the research process must be available to ensure transparency, reusability and, whenever possible, reproducibility. Later, homologous principles were formulated to deal with specific typologies of research products ( Goble et al. 2020 ; Katz, Gruenpeter & Honeyman 2021 ; Lamprecht et al. 2020 ).
Such principles were well received by several communities and are nowadays in the research agenda of almost any community dealing with research data despite the absence of concrete implementation details ( Jacobsen et al. 2020 ; Mons et al. 2017 ). This situation is producing a proliferation of approaches and initiatives related to their interpretation and concrete implementation ( Mangione, Candela & Castelli 2022 ; Thompson et al. 2020 ). It also requires evaluating the level of FAIRness achieved, which results in a multitude of maturity indicators, metrics, and assessment frameworks, e.g. ( Bahim, Dekkers & Wyns 2019 ; De Miranda Azevedo & Dumontier 2020 ; Krans et al. 2022 ).
Having a clear and up-to-date understanding of FAIR assessment practices and approaches helps in perceiving the differences that characterise them, properly interpreting their results, and eventually envisaging new solutions to overcome the limitations affecting the current landscape. This paper analyses a comprehensive set of FAIR assessment tools and the metrics used by these tools for the assessment to highlight the challenges characterising this valuable task. In particular, the research questions this study focuses on are: (i) to highlight the characteristics and trends of the currently existing tools, and (ii) to identify the relationships that exist among the FAIR principles and the approaches exploited to assess them in practice thus to discuss whether the resulting assessment is practical or there are gaps to deal with. A comprehensive ensemble of tools and metrics is needed to respond to these questions. This ensemble was developed by carefully analysing the literature, the information on the web and the actual implementation of tools and metrics. The resulting data set is openly available (see Data Accessibility Statements).
The rest of the paper is organised as follows. Section 2 discusses the related works, namely the surveys and analysis of FAIR assessment tools performed before this study. Section 3 presents the research questions this study focuses on, and the methodology used to respond to them. Section 4 describes the results of the study. Section 5 critically discusses the results by analysing them and providing insights. Finally, Section 6 concludes the paper by summarising the study’s findings. An appendix mainly containing the tabular representation of the data underlying the findings complements the paper.
2 Related Work
Several comparative studies and surveys on the existing FAIR assessment tools can be found in the literature.
Bahim et al. ( Bahim, Dekkers & Wyns 2019 ) conducted a landscape analysis to define FAIR indicators by assessing the approaches and the metrics developed until 2019. They produced a list of twelve tools (The twelve tools analysed were: the ANDS-NECTAR-RDS-FAIR data assessment tool, the DANS-Fairdat, the DANS-Fair enough?, the CSIRO 5-star Data Rating tool, the FAIR Metrics Questionnaire, the Stewardship Maturity Mix, the FAIR Evaluator, the Data Stewardship Wizard, the Checklist for Evaluation of Dataset Fitness for Use, the RDA-SHARC Evaluation, the WMO-Wide Stewardship Maturity Matrix for Climate Data, and the Data Use and Services Maturity Matrix.). They also produced a comparison of the different 148 metrics characterising the selected tools, ultimately presenting a classification of the metrics by FAIR principle and specifically by five dimensions: ‘Findable’, ‘Accessible’, ‘Interoperable’, ‘Reusable’, and ‘Beyond FAIR’.
Peters-von Gehlen et al. ( 2022 ) widened the FAIR assessment tool list originating from Bahim, Dekkers and Wyns ( 2019 ). By adopting a research data repository’s perspective, they shifted their attention to the different evaluation results obtained by employing five FAIR evaluation tools for assessing the same set of discipline-specific data resources. Their study showed that the evaluation results produced by the selected tools reliably reflected the curation status of the data resources assessed and that the scores, although consistent on the overall FAIRness level, were more likely to be similar among the tools that shared the same manual or automated methodology. They also concluded that even if manual approaches proved to be better suited for capturing contextual information, when focusing on assessing discipline-specific FAIRness there is no FAIR evaluation tool that meets the need, and promising solutions would be envisaging hybrid approaches.
Krans et al. ( 2022 ) classified and described ten assessment tools (selected through online searches in June 2020) to highlight the gaps between the FAIR data practices and the ones currently characterising the field of human risk assessment of microplastics and nanomaterials. The ten tools discussed were: FAIRdat, FAIRenough? (no longer available), ARDC FAIR self-assessment, FAIRshake, SATIFYD, FAIR maturity indicators for nanosafety, FAIR evaluator software, RDA-SHARC Simple Grids, GARDIAN (no longer available), and Data Stewardship Wizard. These tools were classified by type, namely ‘online survey’, ‘(semi-)automated’, ‘offline survey’, and ‘other’, and evaluated using two sets of criteria: developer-centred and user-centred. The first characterised the tools binarily based on their extensibility and degree of maturity; the latter distinguished nine user friendliness dimensions (‘expertise’, ‘guidance’, ‘ease of use’, ‘type of input’, ‘applicability’, ‘time investment’, ‘type of output’, ‘detail’, and ‘improvement’) grouped in three sets (‘prerequisites’, ‘use’, and ‘output’). Their study showed that the instruments based on human judgement could not guarantee the consistency of the results even if used by domain experts. In contrast, the (semi-)automated ones were more objective. Overall, they registered a lack of consensus in the score systems and on how FAIRness should be measured.
Sun et al. ( 2022 ) focused on comparing three automated FAIR evaluation tools (F-UJI, FAIR Evaluator, and FAIR checker) based on three dimensions: ‘usability’, ‘evaluation metrics’, and ‘metric test results’. They highlighted three significant differences among the tools, which heavily influenced the results: the different understanding of data and metadata identifiers, the different extent of information extraction, and the differences in the metrics implementation.
In this paper, we have extended the previous analyses by including more tools and, above all, by including a concrete study of the metrics that these tools use. The original contribution of the paper consists of a precise analysis of the metrics used for the assessment and what issues arise in FAIRness assessment processes. The aim is to examine the various implementation choices and the challenges that emerge in the FAIR assessment process related to them. These implementation choices are in fact necessary for transitioning from the principle level to the factual check level. Such checks are rule-based and depend on the selection of parameters and methods for verification. Our analysis shows the issues associated with the implementation choices that define the current FAIR assessment process.
3 Methodology
We defined the following research questions to drive the study:
- RQ1. What are the aspects characterising existing tools? What are the trends characterising these aspects?
- RQ2. Are there any gaps between the FAIR principles coverage and the metrics’ overall coverage emerging from the declared intents?
- RQ3. Are there discrepancies between the declared intent of the metrics and the actual aspects assessed? What are the most recurring issues?
- RQ4. Which approaches and technologies are the most cited and used by the metrics implementations for each principle?
To reply to these questions, we identified a suitable ensemble of existing tools and metrics. The starting point was the list provided by FAIRassist ( https://fairassist.org/ ). To achieve an up-to-date ensemble of tools, we enriched the tool list by referring to Mangione et al. ( 2022 ), by snowballing, and, lastly, by web searching. From the overall resulting list of tools, we removed the no longer running ones and the ones not intended for the assessment of FAIR principles in the strict sense. In particular: the GARDIAN FAIR Metrics, the 5 Star Data Rating Tool, and the FAIR enough? were removed because they are no longer running; the FAIR-Aware, the Data Stewardship Wizard, the Do I-PASS for FAIR, the TRIPLE Training Toolkit, and the CLARIN Metadata Curation Dashboard were removed because they were considered out of scope. Table 1 reports the resulting list of the 20 tools identified and surveyed.
List of FAIR assessment tools analysed.
We used several sources to collect the list of existing metrics. In particular, we carefully analysed the specific websites, papers, and any additional documentation characterising the selected tools, including the source code and information deriving from the use of the tools themselves. For the tools that enable users to define their specific metrics, we considered all documented metrics, except those created by users for testing purposes or written in a language other than English. In the case of metrics structured as questions with multiple answers (not just binary), each answer was considered a different metric as the different checks cannot be put into a single formulation. This approach was necessary for capturing the different degrees of FAIRness that the tool creators conceived. The selection process resulted in a data set of 1180 metrics.
Some tools associate each metric with specific principles. To observe the distribution of the metrics and the gaps concerning the FAIR principles, we considered the FAIR principle (or the letter of the FAIR acronym) which were designed to assess, as declared in the papers describing the tools, but also in the source code, and the results of the assessments performed by the tools themselves.
To analyse the metrics for the identification of discrepancies between the declared intent of the metrics and the actual aspects assessed, we adopted a classification approach based on a close reading of the FAIR principles, assigning one or more principles to each metric. This approach was preferred to one envisaging the development of our list of checks, as any such list would merely constitute an additional FAIR interpretation. This process was applied to both the tools that already had principles associated with the metrics and those that did not. We classified each metric under the FAIR principle we deemed the closest, depending on the metric formulation or implementation. We relied on the metrics implementation source code, when available, to better understand the checks performed. The classification is provided in the accompanying data set and it is summarised in Figure 3 .
The analysis of the approaches and technologies used by the metrics is based on the metric formulation, their source code, and the results of the assessments performed by the tools. With regard to the approaches, we classified the approach of each metric linked to a specific FAIR principle, as declared by the metric authors, following a bottom to top process. We grouped the metrics by specific FAIR principle and then we created a taxonomy of approaches based on the ones observed in each group (App. A.5). For the technologies, we annotated each metric with the technologies mentioned in the metric formulation, in the results of the assessments performed by the tools, and as observed through a source code review.
This section reports the study findings concerning the tool-related and metric-related research questions. Findings are discussed and analysed in Section 5.
4.1 Assessment tools
Table 1 enumerates the 20 FAIR Assessment tools analysed by reporting their name, URL, and the year the tool was initially proposed.
The tools were analysed through the following characteristics: (i) the target , i.e. the digital object the tool focuses on (e.g., dataset, software); (ii) the methodology , i.e. whether the assessment process is manual or automatic; (iii) the adaptability , i.e. whether the assessment process is fixed or can be adapted (specific methods and metrics can be added); (iv) the discipline-specificity , i.e. whether the assessment method is tailored for a specific discipline (or conceived to be) or discipline-agnostic; (v) the community-specificity , i.e. whether the assessment method is tailored for a specific community (or conceived to be) or community-agnostic; (vi) the provisioning , i.e. whether the tool is made available as-a-service or on-premises.
Table 2 shows the differentiation of the analysed tools based on the identified distinguishing characteristics.
Differentiation of analysed tools based on identified distinguishing characteristics. The term ‘enabled’ signifies that the configuration allows the addition of new metrics, allowing individuals to include metrics relevant to their discipline or community. The ‘any dig. obj.*’ value means that there is a large number of typologies supported yet this is specialised rather than actually supporting ‘any’.
By observing the emergence of the identified characteristics over time, from 2017 to 2023, it is possible to highlight trends in the development of tools created for FAIR assessment purposes. Figure 1 depicts these trends.

FAIR assessment tools trends.
Target. We observed an increasing variety of digital objects ( Figure 1 Target), reflecting the growing awareness of the specificities of different research products stemming from the debates that followed the publication of the FAIR guiding principles. However, 45% of the tools deal with datasets. We assigned the label any dig. obj . (any digital object) to the tools that allow the creation of user-defined metrics, but also when the checks performed are generic enough to be applied notwithstanding the digital object type, e.g., evaluations based on the existence of a persistent identifier such as a DOI and the use of a generic metadata schema, such as the Dublin Core, for describing a digital object. The asterisk that follows the label ‘ any dig. obj.’ in Table 2 indicates that, although many types of objects are supported, the tools specifically assess some of them. In particular: (a) AUT deals with datasets, tools, and a combination of them in workflows, and (b) FRO is intended for assessing a specific format of digital objects, namely RO-Crate ( Soiland-Reyes et al. 2022 ), which can package any type of digital object.
Methodology. The tools implement three modes of operation: (i) manual , i.e. if the assessment is performed manually by the user; (ii) automatic , i.e. if it does not require user judgement; (iii) hybrid , i.e. a combination of manual and automated approaches. Manual and hybrid approaches were the first implemented, but over time, automatic approaches were preferred due to the high subjectivity characterising the first two methodologies ( Figure 1 . Assessment methodology). Fifty-five per cent of the tools implement automatic assessments. Notable exceptions are MAT (2020 – hybrid) and FES (2023 – manual), assessing the FAIRness of a repository and requiring metrics that include organisational aspects, which are not easily measured and whose automation still poses difficulties.
Adaptability. We distinguished tools between (i) non-adaptable (whose metrics are predefined and cannot be extended) and (ii) adaptable (when it is possible to add user-defined metrics). Only three tools of the ensemble are adaptable, namely FSH, EVL, and ENO. EVA was considered a ‘fixed’ tool, although it supports the implementation of plug-ins that specialise the actual checks performed by a given metric. Despite their limitations, the preference for non-adaptable tools is observed to persist over time ( Figure 1 . Assessment method).
Discipline-specific. A further feature is whether a tool is conceived to assess the FAIRness of discipline-specific research outputs or is discipline agnostic. We grouped three tools as discipline-specific: AUT, CHE, and MAT. While the adaptable tools (FSH, EVL, and ENO) may not include discipline-specific metrics at the moment, they enable such possibility, as well as EVA, since it allows defining custom configurations for the existing assessments. The trend observed is a preference for discipline-agnostic tools ( Figure 1 . Discipline-specific nature).
Community-specific. Among the tools, some include checks related to community-specific standards (e.g. the OpenAIRE Guidelines) or that allow the possibility of defining community-relevant evaluations. As for the case of discipline-specific tools, the adaptable tools (FSH, EVL, and ENO) also enable community-specific evaluations, as well as EVA. Figure 1 . Community-specific nature shows that, in general, community-agnostic solutions were preferred.
Provisioning. The tools are offered following the as-a-service model or as an on-premises application (we included in the latter category the self-assessment questionnaires in a PDF format). While on-premises solutions are still being developed (e.g. python notebooks and libraries), the observed trend is a preference for the as-a-service model ( Figure 1 . Provisioning).
4.2 Assessment metrics
Existing assessment metrics are analysed to (i) identify gaps between the FAIR principles’ coverage and the metrics’ overall coverage emerging from the declared intents (cf. Section 4.2.1), (ii) highlight discrepancies among metrics intent and observed behaviour concerning FAIR principles and distil the issues leading to the mismatch (cf. Section 4.2.2), and (iii) determine frequent approaches and technologies considered in metrics implementations (cf. Section 4.2.3).
4.2.1 Assessment metrics: gaps with respect to FAIR principles
To identify possible gaps in the FAIR assessment process we observed the distributions of the selected metrics grouped according to the FAIR principle they were designed to assess. Such information was taken from different sources, including the papers describing the tools, other available documentation, the source code, and the use of the tools themselves.
Figure 2 reports the distribution of metrics with respect to the declared target principle, if any, for each tool. Appendix A.1 reports a table with the detailed data. In the left diagram, a metric falls in the F, A, I, and R when it refers only to Findable, Accessible, Interoperable, and Reusable and not to a numbered/specific principle. The ‘n/a’ series is used for counting the metrics that do not declare a reference to a specific principle or even to a letter of the FAIR acronym. In the right diagram, the metrics are aggregated by class of principles, e.g. the F-related metrics include all the ones that in the left diagram are either F, F1, F2, F3 or F4.

FAIR assessment tools’ declared metric intent distribution. In the left diagram, F, A, I, and R series refer to metrics with declared intent Findable, Accessible, Interoperable, and Reusable rather than a numbered/specific principle. The ‘n/a’ series is for metrics that do not declare an intent referring to a specific principle or even to a letter of the FAIR acronym. In the right diagram, the metrics are aggregated by class of principles, e.g. the F-related metrics include all the ones that in the left diagram are either F, F1, F2, F3 or F4.

FAIR assessment tools’ observed metric goal distribution. In the left diagram, metrics are associated either with a specific principle, ‘many’ principles or ‘none’ principle. In the right diagram, the metrics associated with a specific principle are aggregated by class of principles, e.g. the R-related metrics include all the ones that in the left diagram are either F1, F2, F3 or F4.
Only 12 tools (CHE, ENO, EVA, EVL, FOO, FRO, FSH, FUJ, MAT, OFA, OPE, RDA) out of 20 identify a specific principle linked to the metrics. The rest either refer only to Findable, Accessible, Interoperable, or Reusable to annotate their metrics (namely, AUT, DAT, FDB, FES, SAG, SAT, SET) or do not refer to specific principles nor letters of the acronym for annotating their metrics (namely, HFI). Even among those tools that make explicit connections, some metrics remain detached from any particular FAIR principle or acronym letter, as indicated with ‘n/a’ in Figure 2 and Table A.1.
The figures also document that assessment metrics exist for each FAIR principle, but not every principle is equally covered, and not all the tools implement metrics for all the principles.
When focusing on the 12 tools explicitly referring to principles in metrics declared intents and considering the total amount of metrics exploited by a given tool to perform the assessment, it is easy to observe that some tools use a larger set of metrics than others. For instance, FSH uses 339 distinct metrics, while MAT uses only 13 distinct metrics. The tools having a lower number of metrics tend to overlook some principles.
The distribution of metrics with respect to their target highlights that, for each principle, some kind of check has been conceived, even though with different numbers. They, in fact, range from the A1.2 minimum (covered by 16 metrics) to the F1 maximum (covered by 76 metrics). It is also to be noted that for each group of principles linked to a letter of the FAIR acronym, the largest number of metrics is concentrated on the first of them. In particular, this is evident for the A group, with 71 metrics focusing on A1 and around 20 for the others.
Four principles are somehow considered by all the tools, namely F1, F2, I1, and R1.1. While for F1, F2, and I1, the tools use many metrics for their assessment, for R1.1, few metrics were exploited.
Four principles experience relatively lower emphasis, namely A1.2, F3, A1.1, and A2, with fewer metrics dedicated to their assessment. While at the tool level, A1.2, A2, R1.2, and R1.3 are principles that remain unexplored by several of them. A1.2 is not assessed at all by four tools out of 12; A2 is not assessed at all by three tools out of 12; R1.2 is not assessed at all by three tools out of 12; R1.3 is not assessed at all by two tools out of 12.
4.2.2 Assessment metrics: observed behaviours and FAIR principles discrepancies
In addition to the metrics not linked to a specific FAIR principle, we noticed that the implementation of some metrics was misaligned with the principle it declared to target. The implementation term is used with a comprehensive meaning thus including metrics from manual tools and metrics from automatic tools. By analysing the implementation of the metrics, we assigned to each the FAIR principle or set of principles sounding closer.
We identified three discrepancy cases: (i) from a FAIR principle to another, (ii) from a letter of the FAIR acronym to a FAIR principle of a different letter of the acronym (e.g. from A to R1.1), and (iii) from any declared or undeclared FAIR principle to a formulation that we consider beyond FAIRness (‘none’ in Figure 3 ).
An example of a metric with a discrepancy from one FAIR principle to another is ‘Data access information is machine readable’ declared for the assessment of A1, but rather attributable to I1. Likewise, the metric ‘Metadata is given in a way major search engines can ingest it for their catalogues (JSON-LD, Dublin Core, RDFa)’, declared for F4, can be rather linked to I1, as it leverages a serialisation point of view.
The metric ‘Which of the usage licenses provided by EASY did you choose in order to comply with the access rights attached to the data? Open access (CC0)’ with only the letter ‘A’ declared is instead a case in which the assessment concerns a different principle (i.e. R1.1).
Regarding the discrepancies from any declared or undeclared FAIR principle to a formulation that we consider beyond FAIRness, examples are the metrics ‘Tutorials for the tool are available on the tools homepage’ and ‘The tool’s compatibility information is provided’.
In addition to the three identified types of discrepancies, we also encountered metrics that were not initially assigned a FAIR principle or corresponding letter. However, we mapped these metrics to one of the FAIR principles. An example is the metric ‘Available in a standard machine-readable format’, attributable to I1. The latter case is indicative of how wide the implementation spectrum of the FAIRness assessment can be, to the point of distancing particularly far from the formulation of the principles themselves. These metrics that we have called ‘beyond FAIRness’ do not necessarily betray the objective of the principles, but for sure they ask for technologies or solutions which cannot be strictly considered related to FAIR principles.
Figure 3 shows the distribution of all the metrics in our sample resulting from the analysis and assignment to FAIR principles activity. Appendix A.2 reports the table with the detailed data.
This figure confirms that (a) all the principles are somehow assessed, (b) few tools assess all the principles (namely, EVA, FSH, OFA, and RDA), (c) there is a significant amount of metrics (136 out of 1180) that refer to more than one principle at the same time (the ‘many’), and (d) there is a significant amount of metrics (170 out of 1180) that sounds far from the FAIR principles at all (the ‘none’).
Figure 4 depicts the distribution of declared ( Figure 2 , detailed data in Appendix A.1) and observed ( Figure 3 , detailed data in Appendix A.2) metrics intent with respect to FAIR principles. Apart from the absence of metrics referring to one of the overall areas of FAIR, the distribution of the metrics’ observed intents highlights the great number of metrics that either refer to many FAIR principles or any. Concerning the principles, the graph shows a significant growth in the number of metrics assessing F1 (from 76 to 114), F4 (from 39 to 62), A1.1 (from 26 to 56), I1 (from 56 to 113), R1 (from 56 to 79), R1.1 (from 44 to 73), and R1.2 (from 52 to 74). All in all, for 835 metrics out of the 1180 analysed, the declared metric intent and the observed metric intent correspond (i.e. if (i) the referred principle corresponds, or (ii) the declared intent is either F, A, I, or R while the observed intent is a specific principle of the same class). The cases of misalignment are carefully discussed in the remainder of the section.

Comparison of the metrics distributions with regard to their declared and observed intent.
While the declared metrics intent is always linked to one principle only – or even to only one letter of the FAIR acronym – we noted that 136 metrics can be related to more than one FAIR principle at once. These correspond to the ‘many’ series in Figure 4 counting the number of times we associated more than one FAIR principle to a metric of a tool (see also Table A.2, column ‘many’).
Figure 5 shows the distribution of these co-occurrences among the FAIR principles we observed (see also Table A.3 in Section A.3).

Co-occurrences among metrics observed FAIR principles in numbers and percentages.
Such co-occurrences involve all FAIR principles. In some cases, assessment metrics on a specific principle are also considered to be about many diverse principles, notably: (i) metrics dealing with I1 also deal with either F1, F2, A1, I2, I3, or a Reproducibility-related principle, (ii) metrics dealing with R1.3 also deal with either F2, A1, A1.1, an Interoperability principle or R1.2. The number of different principles we found co-occurring with I1 hints at the importance given to the machine-readability of metadata, which is a recurrent parameter in the assessments, particularly for automated ones, so that it can be considered an implementation prerequisite notwithstanding the FAIR guidelines. The fact that R1.3 is the second principle for the number of co-occurrences with other principles is an indicator of the role of the communities in shaping actual practices and workflows.
In some cases, there is a significant number of co-occurrences between two principles, e.g. we observed that many metrics deal with both F2 and R1 (36) or I1 and R1.3 (35). The co-occurrences between F2 and R1 are strictly connected to the formulation of the principles and symptomatic of a missing clear demarcation between the two. The case of metrics with both I1 and R1.3 is ascribable to the overlapping of the ubiquitous machine-readable requirement and the actual implementation of machine-readable solutions by communities of practice.
We also observed metrics that we could not link to any FAIR principle ( Figure 3 ‘none’ series) because of the parameters used in the assessment. Examples of metrics we considered not matching any FAIR principle include (a) those focusing on the openness of the object since ‘FAIR is not equal to open’ ( Mons et al. 2017 ), (b) those focusing on the downloadability of the object, (c) those focusing on the long-term availability of the object since A2 only requires that the metadata of the object must be preserved, (d) those relying on the concept of data or metadata validity, e.g. a metric verifying that the contact information given is valid, (e) those focusing on trustworthiness (for repositories), and (f) those focusing on multilingualism of the digital object.
To identify the discrepancies between declared intents and observed behaviour, we considered misaligned the metrics with a different FAIR principle declared than the one we observed. In addition, all the metrics counted as none in Figure 3 are discrepancies since they include concepts beyond FAIRness assessment. For the metrics that are referred only to a letter of the FAIR acronym, we based the misalignments on the discordance with the FAIR principle letter. Concerning the metrics linked to more than one FAIR principle, we considered as discrepancies only the cases where the principle or letter declared does not match any of the observed possibilities. Figure 6 documents these discrepancies (detailed data are in Appendix A.4).

Discrepancies among metrics declared and observed FAIR principles in numbers and percentages.
When looking at the observed intent, including the metrics in the ‘many’ column, all FAIR principles are in the codomain of the mismatches, except for A1.2 and A2 (in fact, there is no column for that in Figure 6 ). Moreover, misaligned metrics for Findability and Accessibility are always relocated to other letters of the acronym, implying a higher tendency to confusion in the assessment of F and A principles .
While it is possible to observe misalignments in metrics implementations that we linked to more than one principle, no such cases involve accessibility-oriented declared metrics. For metrics pertaining to the other FAIR areas, there are a few cases, mainly involving findability and metrics with no declared intent. No metrics that we could not link to a FAIR principle were found for F4, A1.2, and I2 principles, indicating that the checks on indexing (F4), authentication and authorisation (A1.2), and use of vocabularies (I2) tend to be more unambiguous .
Concerning metrics with findability-oriented declared intents, we did not observe misalignments with any findability principle. Still, we found misalignments with accessibility, interoperability, and reusability principles, including metrics that can be linked with more than one principle and metrics that we could not associate with any principle. Accessibility-related misalignments concern A1 (9), with references to the use of standard protocols to access metadata and to the resolvability of an identifier, and A1.1 (12), because of references to free accessibility to a digital object. Interoperability-related misalignment concern I1 (23) and are linked to references to machine-readability (e.g. the presence of machine-readable metadata, such as the JSON-LD format, or structured metadata in general) and semantic resources (e.g. the use of controlled vocabularies or knowledge representation languages like RDF). Reusability-related misalignments concern R1 (4), because of references to metadata that cannot be easily linked to a findability aim (e.g. the size of a digital object), R1.2 (7), as we observed references to versioning and provenance information, and R1.3 (3), for references to community standards (e.g. community accepted terminologies). Concerning the findability-oriented metrics we classify as ‘many’ (18), we observed they intertwine concepts pertaining to A1, A1.1, I1, I2, or R1.3. About the metrics we could not link to a principle (19), they include references to parameters such as free downloadability and the existence of a landing page.
Concerning metrics with accessibility-oriented declared intents, we did not observe misalignments with an accessibility principle. There is one misalignment with F2, regarding the existence of a title associated with a digital object, and few with I1 (5) because of references to the machine-readability (e.g. machine-readable access information) and semantic artefacts (e.g. controlled vocabularies for access terms). The majority of misalignments are observed with reusability, as we observed metrics involving R1 (9), with references to metadata elements related to access conditions (e.g. dc:rights) and to the current status of a digital object (e.g. owl:deprecated), R1.1 (2), because of mentions to the presence of a licence (e.g. creative commons licence), and R1.2 (2), since there are references to versioning information (e.g. if metadata on versioning information is provided). There are also metrics (43) that we cannot link to any principle, which refer to parameters such as the availability of tutorials, long-term preservation of digital objects, and free downloadability.
Concerning metrics with interoperability-oriented declared intents mismatches concern F1 (11) with references to the use of identifiers (e.g. URI), A1 (2) because of references to the resolvability of a metadata element identifier, I1 (5) for checks limited to the scope of I1 even if declared for assessing I2 or I3 (e.g. metadata represented in an RDF serialisation), and I3 (4) because of checks only aimed at verifying that other semantic resources are used even if declared to assess I2. We also observed metrics declared to assess I2 (2) linked to multiple principles; they intertwine aspects pertaining to F2, I1, and R1.3. Except for I2, there are 20 interoperability-oriented metrics that we could not link to any principle (e.g. citing the availability of source code in the case of software).
Concerning metrics with reusability-oriented declared intents, mismatches regard F4 (1) because of a reference to software hosted in a repository, I1 (6) with references to machine-readability, specific semantic artefacts (e.g. Schema.org ), or to lists of formats, and I3 (1) as there is a reference to ontology elements defined through a property restriction or an equivalent class, but they mainly involve reusability principles. Looking at reusability to reusability mismatches: (i) for R1 declared metrics, we observed mismatches with R1.1 (2) concerning licences, R1.2 (2) because of references to provenance information, and R1.3 (3) since there are references to community-specific or domain-specific semantic artefacts (e.g. Human Phenotype Ontology); (ii) for R1.1 declared metrics, there are mismatches concerning R1 (3) since there are references to access rights metadata elements (e.g. cc:morePermissions); (iii) for R1.2 declared metrics, we observed mismatches concerning R1 (1) and R1.1 (1) because of references to contact and licence information respectively; (iv) for R1.3 declared metrics mismatches concern R1.1 (2) since there are references to licences. Only in the case of one R1.2 declared metric we observed a link with more than one FAIR principle, F2 and R1, because of references to citation information. The reusability declared metrics we could not link to any principle (40) concern references such as the availability of helpdesk support or the existence of a rationale among the documentation provided for a digital object.
Concerning the metrics whose intent was not declared (80), we observed that 40% (32) are linked to at least one principle, while the remaining 60% (48) are beyond FAIRness. In this set of metrics we found metrics concerning F4 (10), e.g. verifying if a software source code is in a registry; I1 (1) a metric verifying the availability of a standard machine-readable format; R1 (2), e.g. for a reference to terms of service; R1.1 (4), because of references to licences; R1.2 (2), e.g. a metric verifies if all the steps to reproduce the data are provided. Some metrics can be linked to more than one principle (13); these metrics intertwin aspects pertaining to F2, F3, I1, I2, I3, R1, and R1.2. An example is a reference to citation information, which can be linked to F2 and R1.
4.2.3 Assessment metrics: approaches and technologies
Having observed that assessment metrics have been proposed for each FAIR principle, it is important to understand how these metrics have been formulated in practice in terms of approaches and technologies with respect to the specific principles they target.
Analysing the metrics explicitly having one of the FAIR principles as a target of their declared intent (cf. Section 4.2.1), it emerged that some (101 out of 677) are simply implemented by repeating the principle formulation or part of it. These metrics do not give any help or indication to the specific assessment task that remains as generic and open to diverse interpretations as the principle formulation is. The rest of the implementations are summarised in Appendix A.5 together with concrete examples to offer an overview of the wealth of approaches proposed for implementing FAIR assessment rules. These approaches include identifier-centred ones (e.g. checking whether the identifier is compliant with a given format, belongs to a list of controlled values or can be successfully resolved), metadata-element centred ones (e.g. verifying the presence of a specific metadata element), metadata-value centred ones (e.g. verify if a specific value or string is used for compiling a given metadata element), service-based ones (e.g. checking whether an object can be found by a search engine or a registry). All approaches involve more than one FAIR area, except for: (a) policy-centred approaches (i.e. looking for the existence of a policy regarding the identifier persistency) for F1, (b) documentation-centred approaches (i.e. an URL to a document describing the required assessment feature), only used for A1.1, A1.2, and A2 verifications, (c) service-centred approaches (i.e. the presence of a given feature in a registry or in a repository), only used for F4, and (d) metadata schema-centred approaches (i.e. verify that a schema rather than an element of it is used), used for R1.3.
Approaches based on the label of the metadata element employed to describe an object, and those based on an identifier, assigned to the object or identifying a metadata element, are the most prevalent. The former is utilised for assessing 14 out of 15 principles (with the exception of A2), while the latter is applied in the assessment of 13 out of 15 principles (excluding F4 and A2).
By analysing the metrics and, when possible, their implementation, we identified 535 metrics mentioning or using technologies for the specific assessment purpose, with four of them referring only to the generic use of linked data. Of the 535 metrics, 174 declare to assess findability, 92 accessibility, 120 interoperability, 147 reusability, and two are not explicitly linked with any FAIR principle or area. Overall, these metrics refer to 215 distinct technologies (the term ‘technology’ is used in its widest acceptation thus including very diverse typologies ranging from (meta)data formats to standards, semantic technologies, protocols, and services). These do not include a generic reference to the IANA media types mentioned by one metric, which alone are 2007. Selected technologies can be categorised as (i) application programming interfaces (referred by 19 metrics), (ii) formats (referred by 91 metrics), (iii) identifiers (referred by 184 metrics), (iv) software libraries (referred by 22 metrics), (v) licences (referred by two metrics), (vi) semantic artefacts (referred by 291 metrics), (vii) protocols (referred by 29 metrics), (viii) query languages (referred by 5 metrics), (ix) registries (referred by 28 metrics), (x) repositories (referred by 14 metrics), and (xi) search engines (referred by 5 metrics). When referring to the number of metrics per technology class, it should be noted that each metric can mention or use one or more technologies.
Figure 7 depicts how these technologies are exploited across the principles using the metric’s declared intent for classifying the technology.

Technology types per declared metric intent.
The most cited or used technologies in the metrics or their implementations are semantic artefacts and identifiers . In particular, Dublin Core and Schema.org are the most mentioned, followed by standards related to knowledge representation languages (Web Ontology Language and Resource Description Framework) and ontologies (Ontology Metadata Vocabulary and Metadata for Ontology Description). The most cited identifier is the uniform resource locator (URL), followed by mentions of uniform resource identifiers (even if technically all URLs are URIs) and, among persistent identifiers, digital object identifiers (DOI).
Semantic artefacts are among the most cited for findability assessments (e.g., Dublin Core, Schema.org , Web Ontology Language, Metadata for Ontology Description, Ontology Metadata Vocabulary, Friend of a Friend, and Vann), followed by identifiers (URL, DOI, URI).
Identifiers are the most cited technologies for accessibility assessments (URL, URI, Handle, DOI, InChi key), followed by protocols (HTTP, OAI-PMH), semantic artefacts (Web Ontology Language, Dublin Core), and formats (XML).
The most mentioned technologies for interoperability assessments are semantic artefacts (Ontology Metadata Vocabulary, Dublin Core, Friend of a Friend, Web Ontology Language) and formats (JSON-LD, XML, RDF/XML, turtle), followed by identifiers (URI, DOI, Handle).
For reusability assessments, besides Dublin Core, Schema.org , Metadata for Ontology Description (MOD), Datacite metadata schema, and Open Graph, also figure semantic artefacts that are specific for provenance (Provenance Ontology and Provenance, Authoring and Versioning) and licensing (Creative Commons Rights Expression Language). Identifiers (URLs) and formats (XML) are also among the most used technologies for reusability purposes.
Ultimately, HTTP-based and linked data technologies are the most used technologies in the metrics, either if considering all metrics at once or just focusing on a single dimension of the FAIR principles.
5 Discussion
The current state of FAIR assessment practices is characterised by different issues, linked to the way the assessment is performed both at a tool and metric level. In the remainder of this section, we critically discuss what emerged in Section 4 concerning assessment tools and assessment metrics.
5.1 Assessment tools
The variety of the tools and their characteristics discussed in Section 4.1 demonstrates the various flavours of solutions that can be envisaged for FAIR assessment. This variety is due to several factors, namely (a) the willingness to assess diverse objects (from any digital object to software), (b) the need to rely on either automatic, manual or hybrid approaches, (c) the necessity to respond to specific settings by adaptability or by being natively designed to be discipline-specific or community-specific. This denotes a certain discretionality in the interpretation and application of the principles themselves, in addition to producing different results and scores for the same product ( Krans et al. 2022 ). In other words, the aspirational formulation of the FAIR principles is hardly reconcilable with punctual measurement .
The characteristics of the tools and their assessment approaches impact assessment tasks and results. Manual assessment tools rely on the assessor’s knowledge, so they do not typically need to be as specific as the automated ones, e.g. when citing a specific technology expected to be exploited to implement a principle, they do not have to clarify how that technology is expected to be used thus catering for diverse interpretations from different assessors. Manual assessment practices tend to be subjective, making it challenging to achieve a unanimous consensus on results. Automatic assessment tools require that (meta)data are machine-readable and only apparently solve the subjectivity issue. While it is true that automatic assessments have to rely on a defined and granular process, which does not leave space for interpretations, every automated tool actually proposes its own FAIRness implementation by defining the granular process itself, especially those tools that do not allow the creation and integration of user-defined metrics. Consequently, the assessment process is objective, but the results are still subjective and biassed by the specific FAIR principles interpretation implemented by the tool developer.
Although the trends observed for tools characteristics in Section 4.1 seems to suggest some tendencies (namely, in the last years more automatic tools than manual ones were developed, more non-adaptable tools than adaptable ones were released, and discipline-agnostic and community-agnostic were emerging over the others) it is almost impossible to figure out whether tools with these characteristics are actually better serving the needs of communities than others. The specific nature of FAIRness assessment is likely to promote the development of tools where community-specific FAIR implementation choices can be easily and immediately vehiculated into assessment pipelines, no matter the tool design decisions regarding methodology, adaptability, etc.
5.2 Assessment metrics
The following three subsections retrace the analysis of assessment metrics as discussed in Section 4.2 subsections to give some reasoning about them. In particular, they elaborate on the findings stemming from the analysis of the gaps between declared metrics intents and the FAIR principles, the discrepancies between declared intents and observed behaviours, and the set of technologies cited for assessing FAIRness, respectively.
5.2.1 Assessment approaches: gaps with respect to FAIR principles
The results reported in Section 4.2.1 highlighted the apparently comprehensive coverage of proposed metrics with respect to principles, the fuzziness of some metrics as well as the variety of metrics implementations for assessing the same principle.
Regarding the coverage , the fact that there exist metrics to assess any principle while the number of metrics per principle and per tool is diverse depends on the principle and tool characteristics. It does not guarantee that all principles are equally assessed. Some principles are multifaceted by formulation, which might lead to many metrics to assess them. This is the case of F1 requiring uniqueness and persistence of identifiers; the number of metrics dedicated to assessing it was the highest we found (Table A.3). However, F1 also has the ‘ (Meta)data ’ multifaceted formulation that is occurring in many other principles without leading to a proliferation of assessment metrics. R1.1 is similar to F1 since it has the (meta)data aspect as well as the accessibility and intelligibility of the licence, yet this is not causing the proliferation of metrics. In contrast with these two principles that are explicitly assessed by all the tools declaring an association among metrics and principles (together with F2 and I1), there are multifaceted principles, like A1.2 and R1.2, that were not explicitly assessed by some tools, actually by automatic tools that are probably facing issues in assessing them programmatically. This diversity of approaches for assessing the same principle further demonstrates the gaps among the principles and their many implementations, thus making any attempt to assess FAIRness in absolute terms almost impossible and meaningless .
Regarding the fuzziness , we observed metrics that either replicate or rephrase the principle itself, thus remaining as generic as the principles are. The effectiveness of these metrics is also limited in the case of manual assessment tools. In practice, using these metrics, the actual assessment check remains hidden either in the assessor’s understanding or in the tool implementation.
Regarding the variety of implementations , every implementation of a metric inevitably comes with implementation choices impacting the scope of cases passing the assessment check. In fact, it is not feasible to implement metrics capturing all the different real-world cases that can be considered suitable for a positive assessment of a given principle. Consequently, even if ‘FAIR is not equal to RDF, Linked Data, or the Semantic Web’ ( Mons et al. 2017 ), linked data technologies are understandably among the main adopted solutions for creating assessment metric implementations. However, the reuse of common implementations across tools is not promoted or facilitated; FAIR Implementation Profiles (FIP) ( Schultes et al. 2020 ) and metadata templates ( Musen et al. 2022 ) could facilitate this by identifying sets of community standards and requirements to be then exploited by various tools. The availability of ‘implementation profiles’ could help to deal with the principles requiring ‘rich metadata’ (namely F2 and R1), whose dedicated metrics seem quite poor for both discoverability and reusability aspects.
5.2.2 Assessment metrics: observed behaviours and FAIR principles discrepancies
The results reported in Section 4.2.2 revealed 345 misaligned metrics ( Figure 6 , Table A.4). Overall, we found metrics that seemed to be very discretionary and not immediately adhering to the FAIR principles, also injecting in assessment pipelines checks going beyond FAIRness . Although these misalignments result from our reading of the FAIR principles, they reveal the following recurring issues characterising metrics implementations realising surprising/unexpected interpretations of FAIR principles aspects.
Access rights. Checks verifying the existence of access rights or access condition metadata are used for assessing accessibility, in particular, the A1 principle. This is problematic because (a) the accessibility principles focus on something different, e.g. the protocols used and the long-term availability of (meta)data, and (b) they overlook the equal treatment A1 envisages for both data and metadata.
Long-term preservation. It is used to assess digital objects rather than just metadata (as requested by A2). In particular, long-term preservation-oriented metrics were proposed for assessing accessibility and reusability (R1.3), thus introducing an extensive interpretation of principles requiring (domain-oriented and community-oriented) standardised way for accessing the metadata.
Openness and free downloadability. These recur among the metrics and are also used contextually for assessing adherence to community standards (R1.3). When used alone, we observed that openness-related metrics are employed for assessing reusability, while free-download-related metrics are used for assessing findability and accessibility (in particular for A1.1). Strictly speaking, it was already clarified that none of the FAIR principles necessitate data being ‘open’ or ‘free’ ( Mons et al. 2017 ). Nonetheless, there is a tendency to give a positive, or more positive, assessment when the object is open. While this is in line with the general intentions of the principles (increasing reusability and re-use of data or other research products), this may be at odds with the need to protect certain types of data (e.g. sensitive data, commercial data, etc.).
Machine-readability. This metadata characteristic is found in metrics assessing findability (F2, F4), accessibility (A1), and reusability (R1.3). As the FAIR principles were conceived for lowering the barriers of data discovery and reuse for both humans and machines, machine-readability is at the very core of the requirements for the FAIRification of a research object. While it is understandably emphasised across the assessment metrics, the concept is frequently used as an additional assessment parameter in metrics assessing other principles rather than the ones defined for interoperability.
Resolvability of identifiers. This aspect characterises metrics assessing findability (specifically for F1, F2, and F3) and interoperability (I2). While resolvability is widely associated with persistent and unique identifiers and is indeed a desirable characteristic, we argue that it is not inherently connected to an identifier itself. URNs are a typical example of this. In the context of the FAIR principles, resolvability should be considered an aspect of accessibility, specifically related to A1, which concerns retrievability through an identifier and the use of a standardised communication protocol.
Validity. Metadata or information validity is used for assessing findability, accessibility, interoperability (specifically I3), and reusability (in particular R1), i.e. FAIR aspects that call for ‘rich’ metadata or metadata suitable for a certain scope. However, although metadata is indeed expected to be ‘valid’ to play their envisaged role, in reality, FAIR advocates and requires a plurality of metadata to facilitate the exploitation of the objects in a wider variety of contexts, without tackling data quality issues.
Versions. The availability of version information or different versions of a digital object is used for assessing findability and accessibility (specifically the A2 principle).
5.2.3 Assessment metrics: approaches and technologies
The fact that the vast majority of approaches encompass more than one FAIR area (Section 4.2.3) is indicative of an assessment that is inherently metadata-oriented. It is indeed the metadata, rather than the object itself, that are used in the verifications. This also explains why there are metrics developed for data assessment tools that are applicable for evaluating any digital object.
Challenges arise when evaluating accessibility principles (namely, A1.1, A1.2, and A2), which are the only ones for which an approach based on the availability of documentation pertaining to an assessment criterion (e.g. a metadata retention policy) is found. This approach further highlights the persistent obstacles in developing automated solutions that address all the FAIR principles comprehensively.
The results reported in Section 4.2.3 about the technologies referred in metrics implementations suggest there is an evident gap between the willingness to provide communities with FAIR assessment tools and metrics and the specific decisions and needs characterising the processes of FAIRification and FAIRness assessment in community settings. There is no single technology that is globally considered suitable for implementing any of the FAIR principles , and each community is entitled to pick any technology they deem suitable for implementing a FAIR principle by the formulation of the principle. The fact that some tools cater for injecting community-specific assessment metrics into their assessment pipelines aims at compensating this gap by bringing the risk of ‘implicit knowledge’, i.e. when a given technology is a de-facto standard in a context or for a community, it is likely that this technology is taken for granted and disappear from the assessment practices produced by the community itself.
5.3 FAIR assessment prospects
The findings and discussions reported so far allow us to envisage some potential enhancements that might make future FAIR assessments more effective. It is desirable for forthcoming FAIR assessment tools to perform their assessment by (a) making the assessment process as automatic as possible, (b) making openly available the assessment process specification, including details on the metrics exploited, (c) allowing assessors to inject context-specific assessment specifications and metrics, (d) providing assessors with concrete suggestions (eventually AI-based) aiming at augmenting the FAIRness of the assessed objects. All in all, assessment tools should contribute to refrain from the diffusion of the feeling that FAIRness is a ‘yes’ or ‘no’ feature; every FAIR assessment exercise or FAIRness indicator associated with the object should always be accompanied with context-related documentation clarifying the settings leading to it.
It is also desirable to gradually reduce the need for FAIR assessment tools by developing data production and publication pipelines that are FAIR ‘ by design ’. Although any of such pipelines will indeed implement a specific interpretation of the FAIR principles, the one deemed suitable for the specific context, it will certainly result in a new generation of datasets, more generally resources, that are born with a flavour of FAIRness. These datasets should be accompanied by metadata clarifying the specification implemented by the pipeline to make them FAIR (this was already envisaged in R1.2). The richer and wider in scope the specification driving the FAIR by design pipelines is, the larger will be the set of contexts benefitting from the FAIRification. Data Management Plans might play a crucial role ( David et al. 2023 ; Salazar et al. 2023 ; Specht et al. 2023 ) in promoting the development of documented FAIR by design management pipelines. The FIP2DMP pipeline can be used to automatically inform Data Management Plans about the decisions taken by a community regarding the use of FAIR Enabling Resources ( Hettne et al. 2023 ). This can facilitate easier adoption of community standards by the members of that community and promote FAIR by design data management practices.
In the development of FAIR by design pipelines, community involvement is pivotal. Indeed, it is within each community that the requirements for a FAIR implementation profile to be followed can be established. Since it is ultimately the end-user who verifies the FAIRness of a digital object, particularly in terms of reusability, it is essential for each community to foster initiatives that define actual FAIR implementations through a bottom to top process, aiming to achieve an informed consensus on machine-actionable specifics. An example in this direction is NASA, which, as a community, has committed to establishing interpretative boundaries and actions to achieve and measure the FAIRness of their research products in the context of their data infrastructures ( SMD Data Repository Standards and Guidelines Working Group 2024 ).
Community-tailored FAIR by design pipelines would, on one hand, overcome the constraints of a top-down defined FAIRness, which may not suit the broad spectrum of existing scenarios. One of these constraints is exemplified by the number of technologies that a rule-based assessment tool ought to incorporate. While a community may establish reference technologies, it is far more challenging for a checklist to suffice for the needs of diverse communities. On the other hand, community-tailored FAIR by design pipelines can aid in establishing a concept of minimum requirements for absolute FAIRness, derived from the intersection of different specifications, or, on the contrary, in proving its unfeasibility.
Instead of attempting to devise a tool for a generic FAIR assessment within a rule-based control context, which cannot cover the different scenarios in which research outputs are produced, it may be more advantageous to focus on community-specific assessment tools. Even in this scenario, the modularity of the tools and the granularity of the assessments performed would be essential for creating an adaptable instrument that changes with the ever-evolving technologies and standards.
For examining the FAIRness of an object from a broad standpoint, large language models (LLMs) could serve as an initial benchmark for a preliminary FAIR evaluation. Such an approach would have the advantage of not being bound to a rule-based verification, since the model would be based on a comprehensive training set, allowing it to identify a wide range of possibilities, while managing to provide a consistent and close interpretation of the FAIR principles through different scenarios.
6 Conclusion
This study analysed 20 FAIR assessment tools and their related 1180 metrics to answer four research questions to develop a comprehensive and up-to-date view of the FAIR assessment.
The tools were analysed along seven axes (assessment unit, assessment methodology, adaptability, discipline specificity, community specificity, and provisioning mode), highlighting the emergence of trends over time: the increasing variety in the assessment units and the preference for automatic assessment methodologies, non-adaptable assessment methods, discipline and community generality, and the as-a-Service provisioning model. The inherent subjectivity in interpreting and applying the FAIR principles leads to a spectrum of assessment solutions, underscoring the challenge of reconciling the aspirational nature of the FAIR principles with precise measurement. Manual assessment practices fail to yield consistent results for the same reason that they constitute a valuable resource, that is, they facilitate the adaptability to the variety of assessment contexts by avoiding extensional formulations. Automated tools, although objective in their processes, are not immune to subjectivity as they reflect the biases and interpretations of their developers. This is particularly evident in tools that do not support user-defined metrics, which could otherwise allow for a more nuanced FAIR assessment.
The metrics were analysed with respect to the FAIR principles’ coverage, the discrepancies between the declared intent of the metrics and the actual aspects assessed, and the approaches and technologies employed for the assessment. This revealed gaps, discrepancies, and high heterogeneity among the existing metrics and the principles. This was quite expected and depended on the difference of intents among a set of aspirational principles by design that was oriented to allow many different approaches to rendering the target items FAIR and metrics called to assess in practice concrete implementations of FAIR principles. Principles do not represent a standard to adhere to ( Mons et al. 2017 ) and some of them are multifaceted, while metrics have to be implemented by making decisions on principles implementations to make the assessment useful or remain at the same level of genericity of the principle, thus leaving room for interpretation from the assessor and making the assessment exposed to personal biases. Multifaceted principles are not uniformly assessed, with tools, especially automated ones, struggling to evaluate them programmatically. Accessibility principles, in particular, are not consistently addressed. The controls envisaged for assessing FAIRness also encompass aspects that extend beyond the original intentions of the principles’ authors. Concepts such as open, free, and valid are in fact employed within the context of FAIR assessment, reflecting a shifting awareness of the interconnected yet distinct issues associated with data management practices. Just as closed digital objects can be FAIR, data and metadata that are not valid may comply with the principles as well, depending on the context they were produced. The diversity of assessment approaches for the same principle and the absence of a universally accepted technology for implementing FAIR principles, reflecting the diverse needs and preferences of scientific communities, further highlights the variability in interpretation, ultimately rendering absolute assessments of FAIRness impractical and, arguably, nonsensical.
Forthcoming FAIR assessment tools should include among their features the possibility of implementing new checks and allow user-defined assessment profiles. The ‘publication’ of metrics will allow the development of a repository or a registry for FAIR assessment implementations, fostering their peer review process and the reuse or repurposing of them by different assessment tools, ultimately being an effective solution for enabling and promoting the awareness of the available solutions without depending on a specific tool. The recently proposed FAIR Cookbook (Life Science) ( Rocca-Serra et al. 2023 ) goes in this direction. In addition, the need for assessment tools will likely be limited if FAIR-by-design data production and publication pipelines are developed, thus leading to FAIR-born items. Of course, the FAIR-born items are not universally FAIR, they are simply compliant with the specific implementation choices decided by the data publishing community in their FAIR-by-design pipeline. Rather than trying to define a FAIRness that can fit all purposes, shifting the focus from generic FAIR assessment solutions to community-specific FAIR assessment solutions would bring better results in the long run. A bottom-up approach would yield greater benefits, both short-term and long-term, as it would enable the immediate production of results that are informed by the specific needs of each community, thus ensuring immediate reusability. Furthermore, it would facilitate the identification of commonalities, thereby allowing for a shared definition of a broader FAIRness. LLMs could bring advantages to FAIR assessment processes by untying them from rule-based constraints and by ensuring a consistent interpretation of the FAIR principles amidst the variety characterising scientific settings and outputs.
All in all, we argue that FAIRness is a valuable concept yet FAIR is by design far from being a standard or a concrete specification whose compliance can be univocally assessed and measured. FAIR principles were proposed to guide data producers and publishers; thus FAIRness assessment tools are expected to help these key players to identify possible limitations in their data management practices with respect to good data management and stewardship.
Data Accessibility Statements
The data that support the findings of this study are openly available on Zenodo at https://doi.org/10.5281/zenodo.10082195 .
Additional File
The additional file for this article can be found as follows:
Appendixes A.1 to A.5. DOI: https://doi.org/10.5334/dsj-2024-033.s1
Funding Statement
Funded by: European Union’s Horizon 2020 and Horizon Europe research and innovation programmes.
Acknowledgements
We really thank D. Castelli (CNR-ISTI) for her valuable support and the many helpful comments she gave during the preparation of the manuscript. We sincerely thank the anonymous reviewers for their valuable feedback.
Funding information
This work has received funding from the European Union’s Horizon 2020 and Horizon Europe research and innovation programmes under the Blue Cloud project (grant agreement No. 862409), the Blue-Cloud 2026 project (grant agreement No. 101094227), the Skills4EOSC project (grant agreement No. 101058527), and the SoBigData-PlusPlus project (grant agreement No. 871042).
Competing Interests
The authors have no competing interests to declare.
Author Contributions
- LC: Conceptualization, Funding acquisition, Methodology, Supervision, Validation, Visualization, Writing.
- DM: Data curation, Formal Analysis, Investigation, Writing.
- GP: Data curation, Formal Analysis, Investigation, Writing.
Aguilar Gómez, F 2022 FAIR EVA (Evaluator, Validator & Advisor). Spanish National Research Council. DOI: https://doi.org/10.20350/DIGITALCSIC/14559
Amdouni, E, Bouazzouni, S and Jonquet, C 2022 O’FAIRe: Ontology FAIRness Evaluator in the AgroPortal Semantic Resource Repository. In: Groth, P, et al. (eds.), The Semantic Web: ESWC 2022 Satellite Events . Cham: Springer International Publishing (Lecture Notes in Computer Science). pp. 89–94. DOI: https://doi.org/10.1007/978-3-031-11609-4_17
Ammar, A, et al. 2020 A semi-automated workflow for fair maturity indicators in the life sciences. Nanomaterials , 10(10): 2068. DOI: https://doi.org/10.3390/nano10102068
Bahim, C, et al. 2020 The FAIR Data Maturity Model: An approach to harmonise FAIR Assessments. Data Science Journal , 19: 41. DOI: https://doi.org/10.5334/dsj-2020-041
Bahim, C, Dekkers, M and Wyns, B 2019 Results of an Analysis of Existing FAIR Assessment Tools . RDA Report. DOI: https://doi.org/10.15497/rda00035
Bonello, J, Cachia, E and Alfino, N 2022 AutoFAIR-A portal for automating FAIR assessments for bioinformatics resources. Biochimica et Biophysica Acta (BBA) – Gene Regulatory Mechanisms , 1865(1): 194767. DOI: https://doi.org/10.1016/j.bbagrm.2021.194767
Clarke, D J B, et al. 2019 FAIRshake: Toolkit to Evaluate the FAIRness of Research Digital Resources. Cell Systems , 9(5): 417–421. DOI: https://doi.org/10.1016/j.cels.2019.09.011
Czerniak, A, et al. 2021 Lightweight FAIR assessment in the OpenAIRE Validator. In: Open Science Fair 2021 . Available at: https://pub.uni-bielefeld.de/record/2958070 .
David, R, et al. 2023 Umbrella Data Management Plans to integrate FAIR Data: Lessons from the ISIDORe and BY-COVID Consortia for Pandemic Preparedness. Data Science Journal , 22: 35. DOI: https://doi.org/10.5334/dsj-2023-035
d’Aquin, M, et al. 2023 FAIREST: A framework for assessing research repositories. Data Intelligence , 5(1): 202–241. DOI: https://doi.org/10.1162/dint_a_00159
De Miranda Azevedo, R and Dumontier, M 2020 considerations for the conduction and interpretation of FAIRness evaluations. Data Intelligence , 2(1–2): 285–292. DOI: https://doi.org/10.1162/dint_a_00051
Devaraju, A and Huber, R 2020 F-UJI – An automated FAIR Data Assessment tool. Zenodo . DOI: https://doi.org/10.5281/ZENODO.4063720
Gaignard, A, et al. 2023 FAIR-Checker: Supporting digital resource findability and reuse with Knowledge Graphs and Semantic Web standards. Journal of Biomedical Semantics , 14(1): 7. DOI: https://doi.org/10.1186/s13326-023-00289-5
Garijo, D, Corcho, O and Poveda-Villalòn, M 2021 FOOPS!: An ontology pitfall scanner for the FAIR Principles. [Posters, Demos, and Industry Tracks]. In: International Semantic Web Conference (ISWC) 2021.
Gehlen, K P, et al. 2022 Recommendations for discipline-specific FAIRness Evaluation derived from applying an ensemble of evaluation tools. Data Science Journal , 21: 7. DOI: https://doi.org/10.5334/dsj-2022-007
Goble, C, et al. 2020 FAIR Computational Workflows. Data Intelligence , 2(1–2): 108–121. DOI: https://doi.org/10.1162/dint_a_00033
González, E, Benítez, A and Garijo, D 2022 FAIROs: Towards FAIR Assessment in research objects. Lecture Notes in Computer Science, vol 13541 In: Silvello, G, et al. (eds.), Linking Theory and Practice of Digital Libraries . Cham: Springer International Publishing. pp. 68–80. DOI: https://doi.org/10.1007/978-3-031-16802-4_6
Hettne, K M, et al. 2023 FIP2DMP: Linking data management plans with FAIR implementation profiles. FAIR Connect , 1(1): 23–27. DOI: https://doi.org/10.3233/FC-221515
Jacobsen, A, et al. 2020 FAIR Principles: Interpretations and implementation considerations. Data Intelligence , 2(1–2): 10–29. DOI: https://doi.org/10.1162/dint_r_00024
Katz, D S, Gruenpeter, M and Honeyman, T 2021 Taking a fresh look at FAIR for research software. Patterns , 2(3): 100222. DOI: https://doi.org/10.1016/j.patter.2021.100222
Krans, N A, et al. 2022 FAIR assessment tools: evaluating use and performance. NanoImpact , 27: 100402. DOI: https://doi.org/10.1016/j.impact.2022.100402
Lamprecht, A L, et al. 2020 Towards FAIR principles for research software. Data Science , 3(1): 37–59. DOI: https://doi.org/10.3233/DS-190026
Mangione, D, Candela, L and Castelli, D 2022 A taxonomy of tools and approaches for FAIRification, In: 18th Italian Research Conference on Digital Libraries. IRCDL, Padua, Italy, 2022.
Matentzoglu, N, et al. 2018 MIRO: guidelines for minimum information for the reporting of an ontology. Journal of Biomedical Semantics , 9(1):. 6. DOI: https://doi.org/10.1186/s13326-017-0172-7
Mons, B, et al. 2017 Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. Information Services & Use , 37(1): 49–56. DOI: https://doi.org/10.3233/ISU-170824
Musen, M A, O’Connor, M J, Schultes, E, et al. 2022 Modeling community standards for metadata as templates makes data FAIR. Sci Data , 9: 696. DOI: https://doi.org/10.1038/s41597-022-01815-3
Rocca-Serra, P, et al. 2023 The FAIR Cookbook – The essential resource for and by FAIR doers. Scientific Data , 10(1): 292. DOI: https://doi.org/10.1038/s41597-023-02166-3
Salazar, A, et al. 2023 How research data management plans can help in harmonizing open science and approaches in the digital economy. Chemistry – A European Journal , 29(9): e202202720. DOI: https://doi.org/10.1002/chem.202202720
Schultes, E, Magagna, B, Hettne, K M, Pergl, R, Suchánek, M and Kuhn, T. 2020 Reusable FAIR implementation profiles as accelerators of FAIR convergence. In: Grossmann, G and Ram, S (eds.), Advances in Conceptual Modeling . ER 2020, Lecture Notes in Computer Science, Vol. 12584. Cham: Springer. DOI: https://doi.org/10.1007/978-3-030-65847-2_13
SMD Data Repository Standards and Guidelines Working Group 2024 How to make NASA Science Data more FAIR . Available at: https://docs.google.com/document/d/1ELb2c7ajYywt8_pzHsNq2a352YjgzixmDh5KP4WfY9s/edit?usp=sharing .
Soiland-Reyes, S, et al. 2022 Packaging research artefacts with RO-Crate. Data Science , 5(2): 97–138. DOI: https://doi.org/10.3233/DS-210053
Specht, A, et al. 2023 The Value of a data and digital object management plan (D(DO)MP) in fostering sharing practices in a multidisciplinary multinational project. Data Science Journal , 22: 38. DOI: https://doi.org/10.5334/dsj-2023-038
Sun, C, Emonet, V and Dumontier, M 2022 A comprehensive comparison of automated FAIRness Evaluation Tools, In: Semantic Web Applications and Tools for Health Care and Life Sciences. 13th International Conference on Semantic Web Applications and Tools for Health Care and Life Sciences. Leiden, Netherlands (Virtual Event) on 10th–14th January 2022, pp. 44–53.
Thompson, M, et al. 2020 Making FAIR easy with FAIR Tools: From creolization to convergence. Data Intelligence , 2(1–2): 87–95. DOI: https://doi.org/10.1162/dint_a_00031
Wilkinson, M D, et al. 2016 The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data , 3(1): 160018. DOI: https://doi.org/10.1038/sdata.2016.18
Wilkinson, M D, et al. 2019 Evaluating FAIR maturity through a scalable, automated, community-governed framework. Scientific Data , 6(1): 174. DOI: https://doi.org/10.1038/s41597-019-0184-5
- Skip to content
- Accessibility Policy
- Oracle blogs
- Lorem ipsum dolor
- Java Technology ,
The Arrival of Java 22
The arrival of Java 22!
Follow Java and OpenJDK on X
JDK 22 is now available!
Oracle is proud to announce the general availability of JDK 22 for developers, enterprises, and end-users.
New with Java 22
JDK 22 delivers 12 enhancements that are significant enough to warrant their own JDK Enhancement Proposals (JEPs) , including seven preview features and one incubator feature. They cover improvements to the Java Language, its APIs, its performance, and the tools included in the JDK.
1) Language Improvements:
Unnamed Variables & Patterns - JEP 456
Improves readability when variable declarations or nested patterns are required but not used. Both are denoted by the underscore character
- Captures developer intent that a given binding or lambda parameter is unused, and enforces that property to clarify programs and reduce opportunities for error.
- Improves the maintainability of all code by identifying variables that must be declared (e.g., in catch clauses) but are not used.
- Allows multiple patterns to appear in a single case label, if none of them declare any pattern variables.
- Improves the readability of record patterns by eliding unnecessary nested type patterns.
1.1) Language Previews
Statements before super (…) [Preview] - JEP 447:
In constructors, allow for statements that do not reference the instance being created to appear before an explicit constructor invocation.
- Gives developers greater freedom to express the behavior of constructors, enabling the more natural placement of logic that currently must be factored into auxiliary static methods, auxiliary intermediate constructors, or constructor arguments.
- Preserves the existing guarantee that constructors run in top-down order during class instantiation, ensuring that code in a subclass constructor cannot interfere with superclass instantiation.
- Does not require any changes to the Java Virtual Machine. This Java language feature relies only on the current ability of the JVM to verify and execute code that appears before explicit constructor invocations within constructors.
String Templates (Second Preview) - JEP 459:
String templates complement Java's existing string literals and text blocks by coupling literal text with embedded expressions and template processors to produce specialized results.
- Simplifies the writing of Java programs by making it easy to express strings that include values computed at run time.
- Enhances the readability of expressions that mix text and expressions, whether the text fits on a single source line (as with string literals) or spans several source lines (as with text blocks).
- Improves the security of Java programs that compose strings from user-provided values and pass them to other systems (e.g., building queries for databases) by supporting validation and transformation of both the template and the values of its embedded expressions.
- Retains flexibility by allowing Java libraries to define the formatting syntax used in string templates.
- Simplifies the use of APIs that accept strings written in non-Java languages (e.g., SQL, XML, and JSON).
- Enables the creation of non-string values computed from literal text and embedded expressions without having to transit through an intermediate string representation.
Implicitly Declared Classes and Instance Main Methods (Second Preview) - JEP 463:
Students can write their first Java programs without needing to understand language features designed for large programs. Instead of using a separate dialect of the language, students can write streamlined declarations for single-class programs and then seamlessly expand their programs to use more advanced features as their skills grow.
To accelerate learning of Java -
- Offers a smooth on-ramp to Java programming so that instructors can introduce concepts in a gradual manner.
- Helps students to write basic programs in a concise manner and grow their code gracefully as their skills grow.
- Reduces the ceremony of writing simple programs such as scripts and command-line utilities.
- Does not introduce a separate beginners' dialect of the Java language.
- Does not introduce a separate beginners' toolchain; student programs should be compiled and run with the same tools that compile and run any Java program.
2) Libraries
Foreign Function & Memory API - JEP 454:
Allows Java programs to interoperate with code and data outside of the Java runtime. By efficiently invoking foreign functions (i.e., code outside the JVM), and by safely accessing foreign memory (i.e., memory not managed by the JVM), the API enables Java programs to call native libraries and process native data without the brittleness and danger of JNI.
- Productivity — Replace the brittle machinery of native methods and the Java Native Interface (JNI) with a concise, readable, and pure-Java API.
- Performance — Provide access to foreign functions and memory with overhead comparable to, if not better than, JNI and sun.misc.Unsafe .
- Broad platform support — Enable the discovery and invocation of native libraries on every platform where the JVM runs.
- Uniformity — Provide ways to operate on structured and unstructured data, of unlimited size, in multiple kinds of memory (e.g., native memory, persistent memory, and managed heap memory).
- Soundness — Guarantee no use-after-free bugs, even when memory is allocated and deallocated across multiple threads.
- Integrity — Allow programs to perform unsafe operations with native code and data but warn users about such operations by default.
2.1) Library Previews and Incubator
Class-File API (Preview) - JEP 457:
Provides a standard API for parsing, generating, and transforming Java class files.
- The API allows frameworks and programs that rely on it to support the latest class files from the latest JDK automatically, so that the new language and VM features with representation in class files could be adopted quickly and easily.
Stream Gatherers (Preview) - JEP 461:
Enhances the Stream API to support custom intermediate operations. This will allow stream pipelines to transform data in ways that are not easily achievable with the existing built-in intermediate operations.
- Improves developer productivity and code readability by making common custom operations in streams more flexible and expressive. As much as possible, allows intermediate operations to manipulate streams of infinite size.
Structured Concurrency (2 nd Preview) - JEP 462:
Simplifies concurrent programming. Structured concurrency treats groups of related tasks running in different threads as a single unit of work, thereby streamlining error handling and cancellation, improving reliability, and enhancing observability.
- Simplifies development of concurrent code by promoting a style of programming that can eliminate common risks arising from cancellation and shutdown, such as thread leaks and cancellation delays, and improves the observability of concurrent code.
Scoped Values (2 nd Preview) - JEP 464:
Enables efficient sharing of immutable data within and across threads.
- Ease of use — Provides a programming model to share data both within a thread and with child threads, to simplify reasoning about data flow.
- Comprehensibility — Makes the lifetime of shared data visible from the syntactic structure of code.
- Robustness — Ensures that data shared by a caller can be retrieved only by legitimate callees.
- Performance — Treats shared data as immutable to allow sharing by a large number of threads, and to enable runtime optimizations.
Vector API (7 th Incubator) - JEP 460:
An API to express vector computations that reliably compile at runtime to optimal vector instructions on supported CPU architectures, thus achieving performance superior to equivalent scalar computations.
This JEP proposes to re-incubate the API in JDK 22, with minor enhancements in the API relative to JDK 21. The implementation includes bug fixes and performance enhancements. We include the following notable changes:
- Support vector access with heap MemorySegments that are backed by an array of any primitive element type. Previously access was limited to heap MemorySegments backed by an array of byte.
- Offers a clear and concise API that is capable of clearly and concisely expressing a wide range of vector computations consisting of sequences of vector operations composed within loops, and possibly with control flow.
- The API is designed to be CPU architecture agnostic, enabling implementations on multiple architectures supporting vector instructions.
- Offers a reliable runtime compilation and performance on x64 and AArch64 architectures.
- Aligns with Project Valhalla.
3) Performance
Regional Pinning for G1 - JEP 423:
Reduces latency by implementing regional pinning in G1, so that garbage collection need not be disabled during Java Native Interface (JNI) critical regions.
Improves developer productivity by eliminating the need for Java threads to wait before G1 GC operation to complete while using JNI.
Launch Multi-File Source-Code Programs - JEP 458:
Allows users to run a program supplied as multiple files of Java source code without first having to compile it.
- Improves developer productivity by making the transition from small programs to larger ones more gradual, enabling developers to choose whether and when to go to the trouble of configuring a build tool.
Note that preview features are fully specified and fully implemented Language or VM Features of the Java SE Platform, but are impermanent. They are made available in JDK Feature Releases to allow for developer feedback based on real-world uses, before them becoming permanent in a future release. This also affords tool vendors the opportunity to work towards supporting features before they are finalized into the Java SE Standard.
APIs in Incubator modules put non-final APIs and non-final tools in the hands of developers and users to gather feedback that will ultimately improve the quality of the Java platform.
Besides the changes described in the JEPs, there are many smaller updates listed in the release notes which will be of interest to many application developers and system administrators. These include deprecation of obsolete APIs and removal of previously deprecated ones.
Some of the key updates from the Java 22 release notes:
- Addition of additional algorithms to keytool and jarsigner.
- Garbage collector throughput improvements especially as it relates to “young” garbage.
- Better version reporting for system module descriptors.
- Improved “wait” handling options for native code.
- Unicode Common Locale Data Repository has been updated to version 44.
- Type annotations support for types loaded from bytecode.
- ForkJoinPool and ForJoinTasks can now better handle uninterruptable tasks.
- Additional flexibility for configuring client versus server TLS connection properties.
- Improved native memory tracking including ability to report peak usage.
Finally, like all Feature releases, JDK 22 includes hundreds of performance, stability, and security updates including adapting to underlying OS and firmware updates and standards. Users and application developers usually benefit from these changes without noticing them.
And the constant feature included in all JDK releases: Predictability
JDK 22 is the 13 th Feature Release delivered on time through the six-month release cadence. This level of predictability allows developers to easily manage their adoption of innovation thanks to a steady stream of expected improvements.
Java’s ability to boost performance, stability, and security continues to make it the world’s most popular programming language.
Oracle will not offer long-term support for JDK 22; we will provide updates until September 2024 when it will be superseded by Oracle JDK 23.
Java 22, Together
As with previous releases , Java 22 celebrates the contributions of many individuals and organizations in the OpenJDK Community — we all build Java, together!
JDK 22 Fix Ratio
The rate of change over time in the JDK releases has remained largely constant for years, but under the six-month cadence the pace at which production-ready features and improvements are delivered has sharply increased.
Instead of making tens of thousands of fixes and delivering close to one hundred JEPs (JDK Enhancement Proposals) every few years, as we did with past Major Releases, enhancements are delivered in leaner Feature Releases on a more manageable and predictable six-month schedule. The changes range from significant new features to small enhancements to routine maintenance, bug fixes, and documentation improvements. Each change is represented in a single commit for a single issue in the JDK Bug System.
Of the 26,447 JIRA issues marked as fixed in Java 11 through Java 22 at the time of their GA, 18,842 were completed by Oracle employees while 7,605 were contributed by individual developers and developers working for other organizations. Going through the issues and collating the organization data from assignees results in the following chart of organizations sponsoring the development of contributions in Java:
In Java 22, of the 2,251 JIRA issues marked as fixed, 1,554 were completed by Oracle, while 697 were contributed by other members of the Java community.
Oracle would like to thank the developers working for organizations including Amazon, ARM, Google, Huawei, IBM, Intel, ISCAS, Microsoft, Red Hat, Rivos, SAP, and Tencent for their notable contributions. We are also thankful to see contributions from smaller organizations such as Bellsoft Data Dog and Loongson, as well as independent developers who collectively contributed 7% of the fixes in Java 22.
Additionally, through the OpenJDK Quality Outreach program we would like to thank the following FOSS projects that provided excellent feedback on testing Java 22 early access builds to help improve the quality of the release:
- Apache Syncope (Francesco Chicchiriccò)
- Apache Tomcat (Mark Thomas)
- ApprovalTests.Java (Lars Eckart)
- AssertJ (Stefano Cordio)
- Avaje (Josiah Noel)
- Jetty (Simone Bordet)
- MyBatis (Iwao Ave)
- Parallel Collectors (Grzegorz Piwowarek)
- RxJava (David Karnok)
Java continues to be the #1 programming language for today’s technology trends. As the on-time delivery of improvements with Java 22 demonstrates, through continued thoughtful planning and ecosystem involvement, the Java platform is well-positioned for modern development and growth in the cloud.
Continue staying current with news and updates by:
- Visiting Dev.java (Oracle’s dedicated portal to advance your Java knowledge and community participation).
- Visiting Inside.java (news and views by the Java Team at Oracle).
- Listening to the Inside.java podcasts (an audio show for Java Developers brought to you directly from the people that make Java at Oracle. Conversations will discuss the language, the JVM, OpenJDK, platform security, innovation projects like Loom and Panama, and everything in between).
- Watching Inside.java Newscasts (a video show extending the Inside.java podcast into a video format).
- Watching Java on YouTube (Oracle’s collection of relevant Java videos to help grow your Java expertise).
- Watching JEP Café (Oracle’s technical exploration into popular JDK Enhancement Proposals).
- Watching Sip of Java (Oracle’s 1-minute short form videos offering introductions into lesser known Java enhancements that offer performance, stability, and security improvements).
- Joining the OpenJDK mailing lists (the place to learn about the progress of your favorite OpenJDK projects).
- Following OpenJDK and Java on X (social streams offering updates and news on the continual evolution of Java).
- Subscribing to the Inside Java Newsletter (a monthly publication summarizing many of the key Java technology and community updates from Oracle).
Sharat Chander
Director, java se product management.
Sharat Chander has worked in the IT industry for 20 years, for firms such as Bell Atlantic, Verizon, Sun Microsystems, and Oracle. His background and technical specialty is in Java development tools, graphics design, and product/community management. Chander has been actively involved in the Java Community for 15 years, helping drive greater Java awareness, acceptance, adoption, and advocacy. At Oracle, as the director of Java developer relations, Chander serves as the JavaOne conference content chairperson, a role he's filled for 7 years, where he drives the technical content strategy and Java community involvement in the conference. He is a frequent keynote speaker and participant in developer programs worldwide. Chander holds a BS in corporate finance from the University of Maryland and an MBA in international business from Loyola College, Maryland. You can find Chander at multiple global developer events and Java community engagements. When not growing visibility for Java, he follows his other passion for baseball and fanatically following his hometown Baltimore Orioles.
Twitter handle: @Sharat_Chander
Sharat Chander has worked in the IT industry for 20 years, for firms such as Bell Atlantic, Verizon, Sun Microsystems, and Oracle. His background and technical specialty is in Java development tools, graphics design, and product/community management. Chander has been actively involved in the Java Community for 15 years, helping drive greater Java awareness, acceptance, adoption, and advocacy. At Oracle, as the director of Java developer relations, Chander serves as the JavaOne conference content chairperson, a role he's filled for 7 years, where he drives the technical content strategy and Java community involvement in the conference. He is a frequent keynote speaker and participant in developer programs worldwide. Chander holds a BS in corporate finance from the University of Maryland and an MBA in international business from Loyola College, Maryland. You can find Chander at multiple global developer events and Java community engagements. When not growing visibility for Java, he follows his other passion for baseball and fanatically following his hometown Baltimore Orioles.
­The arrival of Java 22!
JDK 22 delivers 12 enhancements that are significant enough to warrant their own JDK Enhancement Proposals (JEPs) , including seven preview features and one incubator feature. They cover improvements to the Java Language, its APIs, its performance, and the tools included in the JDK.
Unnamed Variables & Patterns - JEP 456
Statements before super (…) [Preview] - JEP 447:
String templates complement Java's existing string literals and text blocks by coupling literal text with embedded expressions and template processors to produce specialized results.
- Does not introduce a separate beginners' dialect of the Java language.
- Does not introduce a separate beginners' toolchain; student programs should be compiled and run with the same tools that compile and run any Java program.
Foreign Function & Memory API - JEP 454:
- Productivity — Replace the brittle machinery of native methods and the Java Native Interface (JNI) with a concise, readable, and pure-Java API.
- Performance — Provide access to foreign functions and memory with overhead comparable to, if not better than, JNI and sun.misc.Unsafe .
- Broad platform support — Enable the discovery and invocation of native libraries on every platform where the JVM runs.
- Uniformity — Provide ways to operate on structured and unstructured data, of unlimited size, in multiple kinds of memory (e.g., native memory, persistent memory, and managed heap memory).
- Soundness — Guarantee no use-after-free bugs, even when memory is allocated and deallocated across multiple threads.
- Integrity — Allow programs to perform unsafe operations with native code and data but warn users about such operations by default.
- Ease of use — Provides a programming model to share data both within a thread and with child threads, to simplify reasoning about data flow.
- Comprehensibility — Makes the lifetime of shared data visible from the syntactic structure of code.
- Robustness — Ensures that data shared by a caller can be retrieved only by legitimate callees.
- Performance — Treats shared data as immutable to allow sharing by a large number of threads, and to enable runtime optimizations.
This JEP proposes to re-incubate the API in JDK 22, with minor enhancements in the API relative to JDK 21. The implementation includes bug fixes and performance enhancements. We include the following notable changes:
- Garbage collector throughput improvements especially as it relates to “young” garbage.
- Improved “wait” handling options for native code.
Finally, like all Feature releases, JDK 22 includes hundreds of performance, stability, and security updates including adapting to underlying OS and firmware updates and standards. Users and application developers usually benefit from these changes without noticing them.
Java’s ability to boost performance, stability, and security continues to make it the world’s most popular programming language.
As with previous releases , Java 22 celebrates the contributions of many individuals and organizations in the OpenJDK Community — we all build Java, together!
- Apache Syncope (Francesco Chicchiriccò)
Java continues to be the #1 programming language for today’s technology trends. As the on-time delivery of improvements with Java 22 demonstrates, through continued thoughtful planning and ecosystem involvement, the Java platform is well-positioned for modern development and growth in the cloud.
- Visiting Dev.java (Oracle’s dedicated portal to advance your Java knowledge and community participation).
- Watching Java on YouTube (Oracle’s collection of relevant Java videos to help grow your Java expertise).
- Watching JEP Café (Oracle’s technical exploration into popular JDK Enhancement Proposals).
- Watching Sip of Java (Oracle’s 1-minute short form videos offering introductions into lesser known Java enhancements that offer performance, stability, and security improvements).
Previous Post
Java users on macOS 14 running on Apple silicon systems should skip macOS 14.4 and update directly to macOS 14.4.1
Announcing oracle graalvm for jdk 22, resources for.
- Analyst Reports
- Cloud Economics
- Corporate Responsibility
- Diversity and Inclusion
- Security Practices
- What is Customer Service?
- What is ERP?
- What is Marketing Automation?
- What is Procurement?
- What is Talent Management?
- What is VM?
- Try Oracle Cloud Free Tier
- Oracle Sustainability
- Oracle COVID-19 Response
- Oracle and SailGP
- Oracle and Premier League
- Oracle and Red Bull Racing Honda
- US Sales 1.800.633.0738
- How can we help?
- Subscribe to Oracle Content
- © 2022 Oracle
- Privacy / Do Not Sell My Info
JS Tutorial
Js versions, js functions, js html dom, js browser bom, js web apis, js vs jquery, js graphics, js examples, js references, json data types, valid data types.
In JSON, values must be one of the following data types:
- an object (JSON object)
JSON values cannot be one of the following data types:
JSON Strings
Strings in JSON must be written in double quotes.
JSON Numbers
Numbers in JSON must be an integer or a floating point.
JSON Objects
Values in JSON can be objects.
Objects as values in JSON must follow the JSON syntax.
Advertisement
JSON Arrays
Values in JSON can be arrays.
JSON Booleans
Values in JSON can be true/false.
Values in JSON can be null.

COLOR PICKER

Contact Sales
If you want to use W3Schools services as an educational institution, team or enterprise, send us an e-mail: [email protected]
Report Error
If you want to report an error, or if you want to make a suggestion, send us an e-mail: [email protected]
Top Tutorials
Top references, top examples, get certified.
IMAGES
VIDEO
COMMENTS
Data can be encoded in XML in several ways. The most expansive form using tag pairs results in a much larger (in character count) representation than JSON, but if data is stored in attributes and 'short tag' form where the closing tag is replaced with />, the representation is often about the same size as JSON or just a little larger. However ...
Next. JavaScript Object Notation (JSON) is a standard text-based format for representing structured data based on JavaScript object syntax. It is commonly used for transmitting data in web applications (e.g., sending some data from the server to the client, so it can be displayed on a web page, or vice versa). You'll come across it quite often ...
JSON is a text-based data representation format that can encode six different data types. JSON has become a staple of the software development ecosystem; it's supported by all major programming languages and has become the default choice for most REST APIs developed over the past couple of decade.
JSON ( J ava S cript O bject N otation) is a text-based data exchange format. It is a collection of key-value pairs where the key must be a string type, and the value can be of any of the following types: A couple of important rules to note: In the JSON data format, the keys must be enclosed in double quotes.
JSON Structure. Data Representation: JSON represents data in key-value pairs.Each key is a string enclosed in double quotes, followed by a colon, and then its corresponding value. Values can be strings, numbers, arrays, objects, booleans, or null.
JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language. JSON is built on two structures: A collection of name/value pairs.
JSON is a lightweight data-interchange format. JSON is plain text written in JavaScript object notation. JSON is used to send data between computers. JSON is language independent *. *. The JSON syntax is derived from JavaScript object notation, but the JSON format is text only. Code for reading and generating JSON exists in many programming ...
JSON is a lightweight format for storing and transporting data. JSON is often used when data is sent from a server to a web page. JSON is "self-describing" and easy to understand. JSON Example. This example defines an employees object: an array of 3 employee records (objects):
Conclusion. JSON, or JavaScript Object Notation, is a format used to represent data. It was introduced in the early 2000s as part of JavaScript and gradually expanded to become the most common ...
That's where JSON (JavaScript Object Notation) comes in. If you've consumed an API in the last five to ten years, you've probably seen JSON data. While the format was first developed in the early 2000s, the first standards were published in 2006. Understanding what JSON is and how it works is a foundational skill for any web developer.
JSON is a syntax for serializing objects, arrays, numbers, strings, booleans, and null. It is based upon JavaScript syntax, but is distinct from JavaScript: most of JavaScript is not JSON. For example: Objects and Arrays. Property names must be double-quoted strings; trailing commas are forbidden. Numbers.
A Beginner's Guide to JSON with Examples. JSON — short for JavaScript Object Notation — is a popular format for storing and exchanging data. As the name suggests, JSON is derived from JavaScript but later embraced by other programming languages. JSON file ends with a .json extension but not compulsory to store the JSON data in a file.
Instead of going straight from the custom data type to JSON, you can throw in an intermediary step. All you need to do is represent your data in terms of the built-in types json already understands. Essentially, you translate the more complex object into a simpler representation, which the json module then translates into JSON. It's like the ...
While JSON is probably the most popular format for exchanging data, JSON Schema is the vocabulary that enables JSON data consistency, validity, and interoperability at scale. ... Create a clear, standardized representation of your data to improve understanding and collaboration among developers, stakeholders, and collaborators.
JSON (JavaScript Object Notation) is a lightweight format that is used for data interchanging. It is based on a subset of JavaScript language (the way objects are built in JavaScript). As stated in the MDN, some JavaScript is not JSON, and some JSON is not JavaScript. An example of where this is used is web services responses.
Decode a JSON document from s (a str beginning with a JSON document) and return a 2-tuple of the Python representation and the index in s where the document ended. This can be used to decode a JSON document from a string that may have extraneous data at the end.
JSON documents consist of fields, which are name-value pair objects. The fields can be in any order, and be nested or arranged in arrays. Db2® can work with JSON documents in either their original JSON format or in the binary-encoded format called BSON (Binary JSON). For more information about JSON documents, see JSON documents.. JSON data must be provided in Unicode and use UTF-8 encoding.
JSONLint is a validator and reformatter for JSON, a lightweight data-interchange format. Copy and paste, directly type, or input a URL in the editor above and let JSONLint tidy and validate your messy JSON code. ... effectively making it into a universal data representation understood by all systems. Other reasons include: Readability - JSON ...
In JSON, values must be one of the following data types: a string; a number; an object; an array; a boolean; null; In JavaScript values can be all of the above, plus any other valid JavaScript expression, including: a function; a date; undefined; In JSON, string values must be written with double quotes:
Data Types: JSON supports more data types, such as strings, numbers, arrays, booleans, and null, whereas XML is primarily text-based, requiring additional processing to handle non-text data. Performance: JSON's compactness results in smaller file sizes and faster parsing, making it more efficient for web applications where performance is critical.
The JSON Schema config: this allows the user to define the draft-04, draft-06 or draft-07 JSON schema that will be used to validate the JSON data captured by the JSON String Field or SDC record. An exception will be thrown on pipeline validation if the schema is an invalid JSON object or does not conform to the specified schema version.
In today's data-driven world, the ability to quickly explore, analyze, and derive insights from fresh, high granularity data is paramount. ... Dashboard is a collection of tiles, organized in pages, where each tile corresponds to an underlying query and a visual representation. With extensive slice and dice features, and advanced ...
In fact, it is Redis moving closer to SQL databases: RediSearch enables users to create structured schemas on existing Redis JSON or HASH data for index building. Its schema supports various field types such as numeric, tag, geo, text, and vector - the latter two are utilized for full-text and vector searches.
To truly prevent 'more than one value with same compound key', you'll want to maintain the same order of the keys, e.g. sort the key alphabetically. Whereas re: Also (optional), point me to a JSON to Java serializer/deserializer that will support your representation. One notable example might be Gson - Google's JSON serializer library for Java ...
The CODATA Data Science Journal is a peer-reviewed, open access, electronic journal, publishing papers on the management, dissemination, use and reuse of research data and databases across all research domains, including science, technology, the humanities and the arts. The scope of the journal includes descriptions of data systems, their implementations and their publication, applications ...
Simplifies the use of APIs that accept strings written in non-Java languages (e.g., SQL, XML, and JSON). Enables the creation of non-string values computed from literal text and embedded expressions without having to transit through an intermediate string representation. Implicitly Declared Classes and Instance Main Methods (Second Preview ...
This can be used to bypass access controls, obtain sensitive data, or achieve code execution in cases where images and other "safe" file types can be uploaded and included. 2024-05-22: 9.8: CVE-2024-5147 [email protected] ... JSON Based Animation Lottie & Bodymovin for Elementor plugin for WordPress is vulnerable to Stored Cross-Site ...
Inside the JSON string there is a JSON array literal: Arrays in JSON are almost the same as arrays in JavaScript. In JSON, array values must be of type string, number, object, array, boolean or null. In JavaScript, array values can be all of the above, plus any other valid JavaScript expression, including functions, dates, and undefined.
In JSON, values must be one of the following data types: a string. a number. an object (JSON object) an array. a boolean. null. JSON values cannot be one of the following data types: a function.