
80+ Rewards and Recognition Speech Examples for Inspiration
Discover impactful rewards and recognition speech example. Inspire your team with words of appreciation. Elevate your recognition game today!
Jan 25th 2024 • 26 min read
In today's competitive corporate landscape, where employee motivation and engagement are crucial for success, rewards and recognition speech examples have emerged as powerful tools to inspire and appreciate the efforts of employees. Whether it's to celebrate milestones, acknowledge outstanding performance, or simply boost morale, a well-crafted rewards and recognition speech can leave a lasting impact on the recipients.
If you're searching for the perfect blend of words to uplift and motivate your team, look no further. In this blog, we will delve into the art of rewards and recognition speeches, exploring examples that encapsulate the essence of appreciation and inspire employees to reach new heights of success.
Whether you're a team leader, manager, or someone looking to express your appreciation to a colleague, our blog will provide you with a treasure trove of rewards and recognition speech examples that are sure to captivate and inspire. So, grab a cup of coffee, sit back, and let us guide you through the world of appreciation and recognition in the workplace.
What Is A Rewards and Recognition Speech?
A rewards and recognition speech is a formal address given to acknowledge and appreciate individuals or groups for their exceptional achievements or contributions. It serves as a platform to publicly recognize the efforts and accomplishments of deserving individuals , boosting morale, and fostering a positive work culture. This type of speech is commonly delivered during award ceremonies, employee appreciation events, or annual gatherings where appreciation and recognition are key objectives.
A well-crafted rewards and recognition speech celebrates the recipients' accomplishments, highlights their impact on the organization, and inspires others to strive for similar success. In essence, it is an opportunity to acknowledge, motivate, and express gratitude towards individuals who have made a significant difference in their field or organization.
Related Reading
• Employee Recognition Ideas • Recognizing Employees • Power Of Recognition • Recognition Of Achievement • Culture Of Appreciation • Employee Rewards And Recognition
How Rewards and Recognition Impact Employee Motivation and Engagement
Employee motivation and engagement are crucial factors in determining the success of a company. One effective way to enhance motivation and engagement is through rewards and recognition. By acknowledging and appreciating employees' efforts and accomplishments, organizations can create a positive work environment that encourages productivity and fosters loyalty. We will explore how rewards and recognition can impact employee motivation and engagement.
1. Increased Job Satisfaction
Rewarding and recognizing employees for their hard work not only boosts their confidence but also increases their overall job satisfaction. When employees feel valued and appreciated, they are more likely to enjoy their work and feel a sense of fulfillment in their roles . This satisfaction translates into higher motivation and engagement, as employees are more committed to their tasks and strive to exceed expectations.
2. Improved Performance
Rewards and recognition serve as powerful motivators that drive employees to perform at their best. When employees know that their efforts will be acknowledged and rewarded, they are more likely to go the extra mile and demonstrate exceptional performance. As a result, organizations witness improved productivity, increased efficiency, and higher quality outputs. By recognizing and rewarding outstanding performance, companies can create a culture of excellence and continuous improvement.
3. Enhanced Employee Morale
Recognition plays a significant role in boosting employee morale. When employees receive acknowledgment for their achievements, it reinforces their belief in their capabilities and contributions. This positive reinforcement not only motivates employees to continue performing well but also creates a supportive and encouraging work environment. High employee morale leads to increased job satisfaction, lower turnover rates, and a stronger sense of belonging within the organization.
4. Strengthened Employee Engagement
Rewards and recognition contribute to higher levels of employee engagement. Engaged employees are those who are fully committed to their work and actively contribute to the success of the organization. When employees feel recognized and valued, they develop a stronger emotional connection to their work and the company's goals. This emotional investment drives their engagement, leading to increased productivity, creativity, and innovation.
5. Retention and Attraction of Talent
An effective rewards and recognition program can significantly impact employee retention and attraction. Recognized and rewarded employees are more likely to remain loyal to their organization and less likely to seek employment elsewhere. In addition, a positive work culture that emphasizes rewards and recognition becomes an attractive selling point for potential candidates. By showcasing a commitment to employee motivation and engagement, organizations can attract top talent, reduce turnover costs, and maintain a highly skilled workforce.
Rewards and recognition have a profound impact on employee motivation and engagement. By implementing a comprehensive program that appreciates and acknowledges employees' efforts, organizations can create a work environment that fosters satisfaction, productivity, and loyalty. Investing in rewards and recognition not only benefits individual employees but also contributes to the long-term success of the organization as a whole.
• Words Of Appreciation For Good Work Done By Team • How To Recognize Employees • Recognition Examples • How Do You Like To Be Recognized • Recognizing A Coworker • Reward And Recognition Ideas • Fun Employee Recognition Ideas • Formal Recognition • Team Member Recognition • Performance Recognition • Reasons To Recognize Employees • Reward And Recognition Strategies • Recognition For Leadership • How To Recognize Employees For A Job Well Done • Reasons For Rewarding Employees • Employee Wall Of Fame Ideas
1. Celebrating Team Milestones
Recognizing and rewarding the achievements of individual team members or the entire team when they reach significant milestones, such as completing a project, meeting a target, or reaching a certain number of sales.
2. Employee of the Month
Recognizing outstanding employees by selecting one as the Employee of the Month, based on their exceptional performance, dedication, and positive impact on the organization.
3. Sales Contest Winners
Acknowledging the top performers in sales contests and rewarding them with incentives, such as cash bonuses, gift cards, or extra vacation days.
4. Most Improved Employee
Recognizing employees who have shown significant improvement in their performance, skills, or productivity, and highlighting their dedication to personal growth and development.
5. Customer Service Heroes
Acknowledging employees who have gone above and beyond to provide exceptional customer service, resolving challenging situations, and ensuring customer satisfaction.
6. Leadership Excellence
Recognizing managers or team leaders who have demonstrated exceptional leadership skills, inspiring and motivating their team members to achieve outstanding results.
7. Innovation Champions
Celebrating employees who have introduced innovative ideas, processes, or solutions that have had a positive impact on the organization, encouraging a culture of creativity and continuous improvement.
8. Outstanding Team Player
Recognizing individuals who consistently contribute to the success of their team, displaying a collaborative mindset, and supporting their colleagues in achieving common goals.
9. Safety Initiatives
Acknowledging employees who have taken proactive measures to ensure a safe working environment, promoting safety protocols, and reducing accidents or injuries.
10. Excellence in Problem-Solving
Recognizing employees who have demonstrated exceptional problem-solving skills, showcasing their ability to analyze complex situations and find effective solutions.
11. Mentorship and Coaching
Celebrating individuals who have dedicated their time and expertise to mentor and coach their colleagues, supporting their professional growth and development.
12. Going the Extra Mile
Recognizing employees who consistently go above and beyond their regular duties, displaying exceptional commitment and dedication to their work.
13. Team Building Champions
Acknowledging individuals who have organized and led successful team-building activities, fostering a positive team spirit and enhancing collaboration within the organization.
14. Employee Wellness Advocates
Recognizing employees who have actively promoted and contributed to the well-being of their colleagues, encouraging a healthy work-life balance and creating a positive work environment.
15. Community Service
Celebrating employees who have actively participated in community service initiatives, volunteering their time and skills to make a positive impact on society.
16. Outstanding Project Management
Recognizing individuals who have demonstrated exceptional project management skills, successfully leading and delivering complex projects on time and within budget.
17. Customer Appreciation
Acknowledging employees who have received positive feedback or testimonials from customers, highlighting their exceptional service and dedication to customer satisfaction.
18. Quality Excellence
Recognizing employees who consistently deliver high-quality work, ensuring that the organization maintains its standards of excellence and customer satisfaction.
19. Team Spirit
Celebrating the unity and camaraderie within a team, acknowledging their strong bond and collaborative efforts in achieving shared goals.
20. Creativity and Innovation
Recognizing employees who have shown creativity and innovative thinking in their work, introducing new ideas, and driving positive change within the organization.
21. Initiative and Proactivity
Acknowledging employees who take the initiative and demonstrate a proactive approach to their work, identifying opportunities for improvement and taking action to implement them.
22. Cross-Functional Collaboration
Celebrating individuals who have successfully collaborated with colleagues from different departments or teams, fostering a culture of teamwork and achieving synergy in their projects.
23. Learning and Development Champions
Recognizing employees who have shown a commitment to their own learning and development, actively seeking opportunities to acquire new skills and knowledge.
24. Outstanding Customer Retention
Acknowledging employees who have played a crucial role in ensuring customer loyalty and retention, consistently delivering exceptional service and building strong relationships with customers.
25. Adaptability and Flexibility
Celebrating employees who have demonstrated adaptability and flexibility in their work, successfully navigating through change and embracing new challenges.
26. Continuous Improvement
Recognizing individuals who consistently seek ways to improve processes, systems, or workflows, contributing to the organization's overall efficiency and effectiveness.
27. Employee Engagement Advocates
Acknowledging employees who have actively promoted employee engagement initiatives, creating a positive and motivating work environment.
28. Exceptional Time Management
Recognizing employees who have demonstrated exceptional time management skills, effectively prioritizing tasks and meeting deadlines.
29. Resilience and Perseverance
Celebrating individuals who have shown resilience and perseverance in the face of challenges or setbacks, inspiring others to overcome obstacles and achieve success.
30. Teamwork in Crisis
Acknowledging the teamwork and collaboration displayed by employees during a crisis or challenging situation, highlighting their ability to work together under pressure.
31. Leadership in Diversity and Inclusion
Recognizing leaders who have actively promoted diversity and inclusion within the organization, fostering an inclusive and equitable work environment.
32. Outstanding Problem-Solving
Celebrating employees who consistently demonstrate exceptional problem-solving skills, showcasing their ability to analyze complex situations and find innovative solutions.
33. Excellence in Customer Retention
Recognizing employees who have played a crucial role in ensuring customer loyalty and satisfaction, consistently delivering exceptional service and building strong relationships.
34. Inspirational Leadership
Acknowledging leaders who have inspired and motivated their team members to achieve outstanding results, displaying exceptional leadership qualities.
35. Customer Service Excellence
Celebrating employees who consistently provide exceptional customer service, going above and beyond to meet customer needs and exceed expectations.
36. Collaboration and Teamwork
Recognizing individuals or teams who have demonstrated outstanding collaboration and teamwork, achieving common goals through effective communication and cooperation.
37. Employee Empowerment
Acknowledging employees who have actively empowered their colleagues, fostering a culture of autonomy, trust, and accountability within the organization.
38. Sales Achievement Awards
Celebrating top performers in sales, acknowledging their exceptional sales skills, and their contribution to the organization's growth and success.
39. Learning and Development Pioneers
Recognizing employees who have taken the initiative in their own learning and development, actively seeking opportunities to acquire new skills and knowledge.
40. Innovation and Creativity
Celebrating individuals who have introduced innovative ideas, processes, or solutions that have had a positive impact on the organization, encouraging a culture of creativity and continuous improvement.
41. Leadership in Crisis
Acknowledging leaders who have displayed exceptional leadership skills during a crisis or challenging situation, guiding their team members and making effective decisions under pressure.
42. Outstanding Customer Service
Recognizing employees who consistently provide exceptional customer service, demonstrating a commitment to customer satisfaction and building strong customer relationships.
43. Collaboration Across Departments
Celebrating individuals or teams who have successfully collaborated with colleagues from different departments, fostering cross-functional synergy and achieving shared goals.
44. Employee Growth and Development
Acknowledging employees who have shown dedication to their own growth and development, actively seeking opportunities to enhance their skills and knowledge.
45. Quality Excellence
46. resilience and adaptability.
Celebrating individuals who have demonstrated resilience and adaptability in the face of challenges or change, inspiring others to overcome obstacles and embrace new opportunities.
47. Leadership in Employee Engagement
Acknowledging leaders who have actively promoted employee engagement initiatives, creating a positive and motivating work environment.
48. Outstanding Problem-Solving
Recognizing employees who consistently demonstrate exceptional problem-solving skills, showcasing their ability to analyze complex situations and find innovative solutions.
49. Customer Appreciation
Celebrating employees who have received positive feedback or testimonials from customers, highlighting their exceptional service and commitment to customer satisfaction.
50. Teamwork in Crisis
51. leadership in diversity and inclusion, 52. inspirational leadership.
Celebrating leaders who have inspired and motivated their team members to achieve outstanding results, displaying exceptional leadership qualities.
53. Exceptional Time Management
Acknowledging employees who have demonstrated exceptional time management skills, effectively prioritizing tasks and meeting deadlines.
54. Continuous Improvement
55. employee empowerment.
Celebrating employees who have actively empowered their colleagues, fostering a culture of autonomy, trust, and accountability within the organization.
56. Sales Achievement Awards
Recognizing top performers in sales, acknowledging their exceptional sales skills, and their contribution to the organization's growth and success.
57. Learning and Development Pioneers
Celebrating employees who have taken the initiative in their own learning and development, actively seeking opportunities to acquire new skills and knowledge.
58. Innovation and Creativity
Acknowledging individuals who have introduced innovative ideas, processes, or solutions that have had a positive impact on the organization, encouraging a culture of creativity and continuous improvement.
59. Leadership in Crisis
Recognizing leaders who have displayed exceptional leadership skills during a crisis or challenging situation, guiding their team members and making effective decisions under pressure.
60. Outstanding Customer Service
Celebrating employees who consistently provide exceptional customer service, demonstrating a commitment to customer satisfaction and building strong customer relationships.
61. Collaboration Across Departments
Recognizing individuals or teams who have successfully collaborated with colleagues from different departments, fostering cross-functional synergy and achieving shared goals.
62. Employee Growth and Development
Celebrating employees who have shown dedication to their own growth and development, actively seeking opportunities to enhance their skills and knowledge.
63. Quality Excellence
Acknowledging employees who consistently deliver high-quality work, ensuring that the organization maintains its standards of excellence and customer satisfaction.
64. Resilience and Adaptability
Recognizing individuals who have demonstrated resilience and adaptability in the face of challenges or change, inspiring others to overcome obstacles and embrace new opportunities.
65. Leadership in Employee Engagement
Celebrating leaders who have actively promoted employee engagement initiatives, creating a positive and motivating work environment.
66. Outstanding Problem-Solving
Acknowledging employees who consistently demonstrate exceptional problem-solving skills, showcasing their ability to analyze complex situations and find innovative solutions.
67. Customer Appreciation
Recognizing employees who have received positive feedback or testimonials from customers, highlighting their exceptional service and commitment to customer satisfaction.
68. Teamwork in Crisis
Celebrating the teamwork and collaboration displayed by employees during a crisis or challenging situation, highlighting their ability to work together under pressure.
69. Leadership in Diversity and Inclusion
Acknowledging leaders who have actively promoted diversity and inclusion within the organization, fostering an inclusive and equitable work environment.
70. Inspirational Leadership
Recognizing leaders who have inspired and motivated their team members to achieve outstanding results, displaying exceptional leadership qualities.
71. Exceptional Time Management
Celebrating employees who have demonstrated exceptional time management skills, effectively prioritizing tasks and meeting deadlines.
72. Continuous Improvement
Acknowledging individuals who consistently seek ways to improve processes, systems, or workflows, contributing to the organization's overall efficiency and effectiveness.
73. Employee Empowerment
Recognizing employees who have actively empowered their colleagues, fostering a culture of autonomy, trust, and accountability within the organization.
74. Sales Achievement Awards
75. learning and development pioneers.
Acknowledging employees who have taken the initiative in their own learning and development, actively seeking opportunities to acquire new skills and knowledge.
76. Innovation and Creativity
Recognizing individuals who have introduced innovative ideas, processes, or solutions that have had a positive impact on the organization, encouraging a culture of creativity and continuous improvement.
77. Leadership in Crisis
Celebrating leaders who have displayed exceptional leadership skills during a crisis or challenging situation, guiding their team members and making effective decisions under pressure.
78. Outstanding Customer Service
Acknowledging employees who consistently provide exceptional customer service, demonstrating a commitment to customer satisfaction and building strong customer relationships.
79. Collaboration Across Departments
80. employee growth and development, the importance of a rewards and recognition speech.
In the business world, rewards and recognition play a crucial role in motivating employees and fostering a positive company culture. While giving a gift with a note may be a thoughtful gesture, delivering a rewards and recognition speech adds a personal touch and amplifies the impact of the recognition. This is especially significant for major employee rewards, such as a 10-year anniversary or other significant recognition events.
1. Personal Connection and Appreciation
A rewards and recognition speech allows the business owner to personally connect with the employee and express gratitude for their dedication and achievements. By taking the time to deliver a speech, the business owner demonstrates that they genuinely value and appreciate the employee's contributions. This personal touch fosters a deeper sense of connection and appreciation within the company culture.
2. Public Acknowledgment and Inspiration
When a rewards and recognition speech is delivered in a public setting, such as a company-wide event or meeting, it not only acknowledges the efforts of the individual employee but also inspires and motivates others. Seeing their colleagues being recognized and appreciated encourages other employees to strive for excellence and contribute to the success of the company. It creates a positive competitive environment where employees are motivated to perform their best.
3. Reinforcement of Company Values
A rewards and recognition speech provides an opportunity for the business owner to reinforce the company's values and goals. By highlighting the employee's achievements and how they align with the company's mission, vision, and values, the speech emphasizes the importance of these core principles. This reinforcement helps to solidify a positive company culture that is built on shared values and a sense of purpose.
4. Celebration and Team Building
Delivering a rewards and recognition speech creates a celebratory atmosphere that brings employees together as a team. It showcases the collective achievements of the company and encourages a sense of camaraderie and unity. Celebrating accomplishments through a speech allows employees to feel proud of their individual and team successes, which further strengthens the bonds within the organization.
5. Emotional Connection and Employee Engagement
A rewards and recognition speech taps into the emotional aspect of recognition. It goes beyond a simple gift and note, as it allows the business owner to communicate genuine appreciation and admiration for the employee's contributions. This emotional connection enhances employee engagement and makes them feel valued and invested in the company's success. Engaged employees are more likely to be loyal, productive, and committed to the organization.
Delivering a rewards and recognition speech is a powerful way for business owners to show appreciation and reinforce a positive company culture. It establishes a personal connection, inspires others, reinforces company values, builds team spirit, and fosters employee engagement. By recognizing and celebrating employees through a speech, business owners can create a work environment that thrives on recognition, motivation, and a shared sense of purpose.
How To Implement A Successful Rewards and Recognition Program
Creating and implementing a rewards and recognition program in a company can have numerous benefits, such as increasing employee motivation, improving performance, and enhancing employee satisfaction. It is essential to approach the implementation strategically to ensure its effectiveness. Here are some effective strategies for implementing a successful rewards and recognition program:
1. Define Clear Objectives and Goals
Before designing your rewards and recognition program, it is crucial to define clear objectives and goals. What do you want to achieve with the program? Are you aiming to boost employee morale, increase productivity, or enhance teamwork? Clearly defining your objectives will help you tailor the program to meet specific needs and ensure that it aligns with the company's overall goals.
2. Involve Employees in the Process
To make your rewards and recognition program truly effective, involve employees in the process. Conduct surveys or focus groups to gather their input and preferences. By involving employees, you can ensure that the program resonates with them, making it more meaningful and valuable. Involving employees in the decision-making process can foster a sense of ownership and engagement.
3. Develop a Variety of Recognition Initiatives
To cater to the diverse needs and preferences of your employees, it is essential to develop a variety of recognition initiatives. Consider implementing both formal and informal recognition programs. Formal recognition may include annual awards ceremonies or performance-based bonuses, while informal recognition can involve small gestures like personalized thank-you notes or shout-outs during team meetings. By offering a range of initiatives, you can ensure that different types of accomplishments are acknowledged and valued.
4. Make the Program Transparent and Equitable
Transparency and equity are crucial in a rewards and recognition program. Clearly communicate the criteria for receiving recognition and the rewards associated with it. Ensure that the criteria are fair, consistent, and unbiased . This transparency will promote a sense of fairness and prevent any perception of favoritism or inequality within the organization.
5. Create a Culture of Appreciation
Implementing a rewards and recognition program is not enough; it must be supported by a culture of appreciation. Encourage managers and leaders to regularly acknowledge and appreciate their team members' efforts. Foster a work environment where recognition is not limited to the formal program but becomes a natural part of everyday interactions. This culture of appreciation will amplify the impact of the formal program and create a positive and motivating work atmosphere.
6. Evaluate and Refine
Continuous evaluation and refinement are essential for the long-term success of a rewards and recognition program. Regularly collect feedback from employees and managers to identify areas of improvement. Analyze the effectiveness of different initiatives and adjust them as necessary. By regularly evaluating and refining the program, you can ensure that it remains relevant, impactful, and aligned with the evolving needs of the organization.
Implementing a rewards and recognition program requires thoughtful planning and execution. By following these strategies, you can create a program that not only rewards and recognizes employees' contributions but also inspires and motivates them to achieve their best.
10 Reasons for Rewards and Recognition & How To Determine Who To Reward
1. boost employee morale.
Rewarding and recognizing employees for their hard work can significantly boost morale. It shows employees that their efforts are valued and appreciated, which in turn motivates them to continue performing at their best.
2. Improve Employee Engagement
When employees feel recognized and rewarded, they are more likely to be engaged in their work. Engaged employees are more productive, creative, and willing to go above and beyond to achieve company goals.
3. Increase Employee Retention
Recognizing and rewarding employees for their contributions can help increase employee retention. Employees who feel valued are more likely to stay with the company, reducing turnover rates and the associated costs of hiring and training new employees.
4. Foster a Positive Work Culture
Implementing a rewards and recognition program can help foster a positive work culture. When employees see their peers being acknowledged for their achievements, it creates a supportive and collaborative environment where everyone strives for success.
5. Reinforce Desired Behaviors
Rewards and recognition can be used to reinforce desired behaviors and values within the organization. By publicly acknowledging and rewarding employees who exemplify these behaviors, it encourages others to follow suit.
6. Encourage Continuous Improvement
Recognizing employees for their good work encourages a culture of continuous improvement. It motivates employees to seek out opportunities to enhance their skills and knowledge, leading to personal and professional growth .
7. Enhance Team Collaboration
Rewarding and recognizing the efforts of individuals within a team can strengthen team collaboration. It fosters a sense of camaraderie and encourages teamwork, as employees understand the importance of supporting one another to achieve common goals.
8. Increase Customer Satisfaction
When employees feel recognized and appreciated, they are more likely to provide excellent customer service. Happy and engaged employees create positive interactions with customers, leading to increased customer satisfaction and loyalty.
9. Drive Innovation
Rewards and recognition can also drive innovation within an organization. When employees are acknowledged for their innovative ideas or problem-solving skills, it encourages a culture of creativity and encourages others to think outside the box.
10. Attract Top Talent
A well-established rewards and recognition program can help attract top talent to the company. By showcasing the company's commitment to valuing and rewarding its employees, it becomes an attractive proposition for potential candidates.
How To Determine Who To Reward as a Business Owner
1. performance metrics.
Use performance metrics such as sales targets, customer satisfaction ratings, or project completion rates to identify employees who have consistently exceeded expectations.
2. Peer Feedback
Seek feedback from colleagues and team members to identify individuals who have made significant contributions to the team or have gone above and beyond their assigned duties.
3. Customer Feedback
Consider customer feedback when determining who to reward. Look for employees who have received positive feedback or have gone the extra mile to ensure customer satisfaction.
4. Quality of Work
Consider the quality of work produced by employees. Reward those who consistently deliver high-quality work and attention to detail.
5. Leadership and Initiative
Identify employees who display leadership qualities and take initiative in solving problems or improving processes. These individuals often have a positive impact on the team and deserve recognition.
6. Innovation and Creativity
Recognize employees who have demonstrated innovation and creativity in their work. These individuals contribute fresh ideas and solutions that drive the company forward.
7. Collaboration and Teamwork
Acknowledge employees who excel at collaboration and teamwork. These individuals build strong relationships with their colleagues and contribute to a positive and productive work environment.
8. Longevity and Seniority
Consider rewarding employees based on their longevity and seniority within the company. This recognizes their loyalty and commitment to the organization over the years.
9. Going Above and Beyond
Identify employees who consistently go above and beyond their job responsibilities. Reward those who have taken on additional tasks, volunteered for extra projects, or contributed to the company's success in exceptional ways.
10. Personal Development and Growth
Recognize employees who actively seek opportunities for personal development and growth. Reward those who have acquired new skills or certifications that benefit both themselves and the company.
By considering these factors, business owners can fairly determine who to reward and ensure that recognition is given to those who truly deserve it.
Potential Challenges To Avoid When Implementing A Rewards and Recognition Program
1. lack of clarity and consistency in criteria.
The success of a rewards and recognition program depends on clearly defined and consistent criteria for determining who is eligible for recognition and what types of rewards are available. Failing to establish and communicate these criteria can lead to confusion and dissatisfaction among employees . It is essential to ensure that the criteria are fair, transparent, and aligned with organizational goals.
2. Inadequate communication and feedback
Effective communication is crucial when implementing a rewards and recognition program. Employees need to understand the purpose of the program, how it works, and what is expected of them to be eligible for recognition. Regular feedback is also vital to ensure that employees understand why they are being recognized and to reinforce positive behaviors. Without proper communication and feedback, employees may feel undervalued or uncertain about the program's objectives.
3. Limited variety and personalization of rewards
Offering a limited range of rewards or failing to personalize them to individual preferences can diminish the impact of a rewards and recognition program. Different employees may value different types of rewards, whether it's financial incentives, professional development opportunities, or public recognition. It is important to consider individual preferences and offer a variety of rewards that align with employees' needs and aspirations.
4. Lack of alignment with organizational values
A rewards and recognition program should align with the core values and goals of an organization. If the program does not reflect the organization's values or reinforce behaviors that contribute to its success, it may be perceived as inauthentic or disconnected from the broader objectives. It is essential to design a program that supports the desired culture and drives employee engagement and performance in a way that aligns with the organization's mission and values.
5. Failure to recognize team efforts
While recognizing individual achievements is important, it is equally crucial to acknowledge and reward team accomplishments. Neglecting to recognize the contributions of teams can create a sense of competition and undermine collaboration, which are essential for overall organizational success. Incorporate team-based rewards and recognition initiatives to foster a sense of camaraderie and motivate collective efforts.
6. Inconsistent and infrequent recognition
Recognition should be timely and consistent to be effective. Delayed or infrequent recognition can diminish its impact and may lead to a decrease in employee motivation. Establish a regular cadence for recognition and ensure that it is provided promptly when deserved. Consistency in recognizing achievements will help reinforce positive behaviors and maintain employee engagement.
7. Lack of management support and involvement
The success of a rewards and recognition program relies heavily on the support and involvement of management. If leaders do not actively participate or demonstrate enthusiasm for the program, employees may perceive it as insignificant or insincere. It is crucial to engage managers at all levels and empower them to recognize and reward employees' achievements. Managers should serve as role models and champions of the program to foster a culture of appreciation and recognition.
Implementing a rewards and recognition program can be a powerful tool for motivating employees, increasing engagement, and driving organizational success. By addressing and avoiding these potential challenges and pitfalls, organizations can create a program that effectively recognizes and rewards employees for their contributions and accomplishments.
Best Practices for Implementing A Rewards and Recognition Program
Implementing a rewards and recognition program is a crucial step in fostering employee engagement, motivation, and loyalty within an organization. It requires careful planning and execution to ensure its effectiveness. We will explore the best practices for implementing a successful rewards and recognition program.
1. Clearly Define Program Objectives
Before implementing a rewards and recognition program, it is essential to define clear objectives. This involves identifying the behaviors, achievements, or contributions that will be rewarded, as well as the desired outcomes of the program. By clearly defining program objectives, organizations can align the program with their overall business goals and ensure its relevance and effectiveness.
2. Align Rewards with Employee Preferences
To ensure the success of a rewards and recognition program, it is important to align the rewards with the preferences and aspirations of employees. Conducting surveys or focus groups can help gather employee feedback and identify the types of rewards that would motivate and resonate with them the most. This could include monetary incentives, non-monetary rewards, or a combination of both.
3. Make the Recognition Timely and Specific
Recognition should be timely and specific to have a lasting impact on employee motivation and morale. It is important to recognize and reward employees promptly after they have achieved the desired behaviors or accomplishments. Recognition should be specific, highlighting the specific actions or contributions that led to the recognition. This helps reinforce desired behaviors and demonstrates the value placed on those actions.
4. Foster a Culture of Peer-to-Peer Recognition
In addition to formal recognition from managers or supervisors, organizations should encourage peer-to-peer recognition. This creates a positive and inclusive work environment where employees feel valued and appreciated by their colleagues. Implementing a platform or system for employees to easily recognize and appreciate each other's efforts can enhance teamwork, collaboration, and overall employee satisfaction.
5. Communicate and Promote the Program
Effective communication and promotion of the rewards and recognition program are essential for its success. Organizations should clearly communicate the program's objectives, eligibility criteria, and rewards to all employees. This can be done through email announcements, intranet postings, or even in-person meetings. Regular reminders and updates about the program can help maintain awareness and encourage participation.
6. Ensure Fairness and Transparency
A successful rewards and recognition program should be perceived as fair and transparent by employees. The criteria for eligibility and selection of recipients should be clearly communicated and consistently applied. To build trust and credibility, it is important to ensure that the program is free from favoritism or bias. Regular evaluations of the program's effectiveness and fairness can help identify any areas for improvement.
7. Measure and Track Results
To evaluate the effectiveness of a rewards and recognition program, it is important to measure and track its results. This can be done through employee surveys, performance metrics, or feedback sessions. By analyzing the data, organizations can identify any gaps or areas for improvement and make necessary adjustments to enhance the program's impact.
By following these best practices, organizations can implement a rewards and recognition program that effectively motivates and engages employees. This, in turn, leads to increased productivity, employee satisfaction, and overall organizational success. Implementing a well-designed program that aligns with the organization's goals and employee preferences is crucial for achieving these desired outcomes.
Find Meaningful Corporate Gifts for Employees With Ease with Giftpack
In today's world, where connections are made across borders and cultures, the act of gift-giving has evolved into a meaningful gesture that transcends mere material objects. Giftpack , a pioneering platform in the realm of corporate gifting, understands the importance of personalized and impactful gifts that can forge and strengthen relationships.
Simplifying the Corporate Gifting Process
The traditional approach to corporate gifting often involves hours of deliberation, browsing through countless options, and struggling to find the perfect gift that truly resonates with the recipient. Giftpack recognizes this challenge and aims to simplify the corporate gifting process for individuals and businesses alike. By leveraging the power of technology and their custom AI algorithm, Giftpack offers a streamlined and efficient solution that takes the guesswork out of gift selection.
Customization at its Best
One of the key features that sets Giftpack apart is their ability to create highly customized scenario swag box options for each recipient. They achieve this by carefully considering the individual's basic demographics, preferences, social media activity, and digital footprint. This comprehensive approach ensures that every gift is tailored to the recipient's unique personality and tastes, enhancing the overall impact and meaning behind the gesture.
A Vast Catalog of Global Gifts
Giftpack boasts an extensive catalog of over 3.5 million products from around the world, with new additions constantly being made. This vast selection allows Giftpack to cater to a wide range of preferences and interests, ensuring that there is something for everyone. Whether the recipient is an employee, a customer, a VIP client, a friend, or a family member, Giftpack has the ability to curate the most fitting gifts that will leave a lasting impression.
User-Friendly Platform and Global Delivery
Giftpack understands the importance of convenience and accessibility, which is why they have developed a user-friendly platform that is intuitive and easy to navigate. This ensures a seamless experience for both individuals and businesses, saving them time and effort in the gift selection process. Giftpack offers global delivery, allowing gifts to be sent to recipients anywhere in the world. This global reach further reinforces their commitment to connecting people through personalized gifting.
Meaningful Connections Across the Globe
At its core, Giftpack's mission is to foster meaningful connections through the power of personalized gifting. By taking into account the recipient's individuality and preferences, Giftpack ensures that each gift is a reflection of thoughtfulness and care. Whether it's strengthening relationships with employees, delighting customers, or expressing gratitude to valued clients, Giftpack enables individuals and businesses to make a lasting impact on those who matter most.
In a world where personalization and meaningful connections are highly valued, Giftpack stands out as a trailblazer in revolutionizing the corporate gifting landscape. With their innovative approach, vast catalog of global gifts, user-friendly platform, and commitment to personalized experiences, Giftpack is transforming the way we think about rewards and recognition.
• Modern Employee Recognition Programs • Employee Award Programs • Recognizing Employee Contributions • Employee Recognition Program Best Practices • Rewards And Recognition System • How To Create An Employee Recognition Program
Make your gifting efficient and improve employee attrition rates with Giftpack AI
Visit our product page to unlock the power of personalized employee appreciation gifts.
About Giftpack
Giftpack's AI-powered solution simplifies the corporate gifting process and amplifies the impact of personalized gifts. We're crafting memorable touchpoints by sending personalized gifts selected out of a curated pool of 3 million options with just one click. Our AI technology efficiently analyzes each recipient's social media, cultural background, and digital footprint to customize gift options at scale. We take care of generating, ordering, and shipping gifts worldwide. We're transforming the way people build authentic business relationships by sending smarter gifts faster with gifting CRM.
Sign up for our newsletter
Enter your email to receive the latest news and updates from giftpack..
By clicking the subscribe button, I accept that I'll receive emails from the Giftpack Blog, and my data will be processed in accordance with Giftpack's Privacy Policy.
- Presentation Hacks
How To Give a Speech of Recognition
- By: Amy Boone
Your boss sends you an email to say she’ll be dropping by your office later that afternoon to talk about the employee of the year award. You start to get excited, thinking about how hard you’ve worked and how nice it would be to get recognized. However, when your boss arrives, she says, “I know you are a great speaker, so I’d like you to be the one to present the employee of the year award at our company banquet in December. I’ll already be speaking during the ceremony a lot, so I’d like to feature other employees, and I think you’d be great at it.” Your excitement falters. So you aren’t up for the award after all. You are just delivering a speech of recognition. But, hey, at least your presentation skills got your boss’s attention.
Sometimes you aren’t the main event or keynote. Like in the scenario above, sometimes you’ll be asked to give another type of speech. But presenting someone else with an award or honor is still an important task. Here are 3 tips for delivering a great speech of recognition.
1. Get the Audience’s Attention
Many times a speech of recognition follows something else. It could be dinner, or another award presentation, or a longer message. At any rate, part of your job is to transition from whatever has been happening to the award presentation. That means you’ll need to get the audience’s attention. This can be done many ways, but here are two of our favorites.
- Take the stage and wait a few moments. Dr. Alex Lickerman says when we use silence strategically, it makes us appear more powerful and charismatic . Both of these can get the attention of our audience. So when you pause, people will try to figure out why. And so your silence effectively captures the attention of the crowd.
- Start with a story. Whenever a speaker begins a story, the audience tends to perk up. It’s human nature to not want to miss a story that is being told. And don’t announce that you are going to tell a story. Just jump right in. This is called a jump start , and it’s a great way to capture attention fast.
2. Know the Recipient
If the whole purpose of the speech of recognition is to shine the spotlight on someone else’s achievements, it helps to know that someone else. You can only give a great speech honoring them if you know how they would like to be honored. For example, you wouldn’t want to lightly roast someone who may be offended or who dislikes being the center of attention. So do a little research. Ask the recipient’s family and friends what makes him/her feel special. Get to know the personality of the recipient a little bit. Is this person more reserved or someone who is boisterous and loves to joke? Match the tone and content of your speech of recognition to the recipient’s personality. And aim to meet all 5 of what Marc Junele calls the characteristics of effective praise . Make it personal, appropriate, specific, timely, and authentic.
3. Show, Don’t Tell
No one wants to sit and listen to a long list of qualifications. So instead of telling why the recipient deserves the award or honor, show it. Use a story to illustrate or paint a mental picture during your speech of recognition. One of the best examples of this I’ve seen happened during the National Funeral Service honoring former president Ronald Reagan. During his eulogy, former President George W. Bush Sr. says he learned a lot about decency from Reagan. He then tells the story of the time he went to visit Reagan after he had been shot. When he entered the hospital room, he found him in his hospital gown, on the floor wiping water up that he had spilled because he was worried his nurse would get blamed for it and get in trouble. It’s one thing to say someone is humble and decent. It’s quite another to show it with a story.
While you are preparing your speech to recognize someone else, remember this. Every chance you get to stand up and present is a chance to hone your speaking skills whether you are the keynote, or not.
Got a presentation problem that we can help you solve? Get in touch with us now.

Join our newsletter today!
© 2006-2024 Ethos3 – An Award Winning Presentation Design and Training Company ALL RIGHTS RESERVED
- Terms & Conditions
- Privacy Policy
- Diversity and Inclusion
Use These Employee Appreciation Speech Examples In 2024 To Show Your Team You Care

The simple act of saying “thank you” does wonders.
Yet sometimes, those two words alone don’t seem to suffice. Sometimes your team made such a difference, and your gratitude is so profound, that a pat on the back just isn’t enough.
Because appreciation is more than saying thank you . It’s about demonstrating that your team is truly seen and heard by thanking them for specific actions. It’s about showing that you understand and empathize with the struggles your team faces every day. And it’s about purpose too. True appreciation connects your team’s efforts back to a grand vision and mission.
According to Investopedia ,
“Appreciation is an increase in the value of an asset over time.”
So it’s time to diversify your portfolio of reliable tips and go-to words of wisdom for expressing your undying appreciation. After all, you diversify your portfolio of investments, and really, workplace appreciation is an investment.
Let’s set aside the standard definition of appreciation for a second and take a look at the financial definition.
In the workplace, appreciation increases the value of your most important assets—your employees—over time.
Here are some ways appreciation enhances employee relations:
- Appreciation makes employees stick around. In fact, statistics suggest that a lack of appreciation is the main driver of employee turnover , which costs companies an average of about $15,000 per worker .
- Appreciation reinforces employees’ understanding of their roles and expectations, which drives engagement and performance.
- Appreciation builds a strong company culture that is magnetic to both current and prospective employees.
- Appreciation might generate positive long-term mental effects for both the giver and the receiver.
- Appreciation motivates employees. One experiment showed that a few simple words of appreciation compelled employees to make more fundraising calls.
We searched through books, movies, songs, and even TED Talks to bring you 141 amazing motivational quotes for employees you’ll be proud to put in a Powerpoint, an intra-office meme or a foam board printing cutout! Find plenty of fantastic workplace quotes to motivate any team.
Some of the most successful entrepreneurs in American business built companies, and lasting legacies, by developing employees through the simple act of appreciation.
Charles Schwab, founder of the Charles Schwab Corporation, once said:
“I consider my ability to arouse enthusiasm among my people the greatest asset I possess, and the way to develop the best that is in a person is by appreciation and encouragement. There is nothing else that so kills the ambitions of a person as criticism from superiors. I never criticize anyone. I believe in giving a person incentive to work. So I am anxious to praise but loath to find fault. If I like anything, I am hearty in my appreciation and lavish in my praise.”
Boost your ability to arouse enthusiasm by learning how to deliver employee appreciation speeches that make an impact. Once you master the habits and rules below, sincere appreciation will flow from you like sweet poetry. Your employees are going to love it!
Page Contents (Click To Jump)
The Employee Appreciation Speech Checklist
Planning employee appreciation speeches can be fast and easy when you follow a go-to “recipe” that works every time. From a simple thank you to a heart felt work anniversary speech, it all has a template.
Maritz®studies human behavior and highlights relevant findings that could impact the workplace. They developed the Maritz Recognition Model to help everyone deliver the best appreciation possible. The model asserts that effective reward and recognition speech examples touch on three critical elements: the behavior, the effect, and the thank you.
Here’s a summary of the model, distilled into a checklist for your employee appreciation speeches:
- Talk about the behavior(s). While most employee appreciation speeches revolve around the vague acknowledgment of “hard word and dedication,” it’s best to call out specific actions and accomplishments so employees will know what they did well, feel proud, and get inspired to repeat the action. Relay an anecdote about one specific behavior to hook your audience and then expand the speech to cover everyone. You can even include appreciation stories from other managers or employees in your speech.
- Talk about the effect(s) of the behavior(s). What positive effect did the employee behaviors have on your company’s mission? If you don’t have any statistics to share, simply discuss how you expect the behaviors to advance your mission.
- Deliver the “thank you” with heartfelt emotion. Infusing speeches with emotion will help employees feel your appreciation in addition to hearing it. To pinpoint the emotional core of your speech, set the “speech” part aside and casually consider why you’re grateful for your employees. Write down everything that comes to mind. Which aspects made you tear up? Which gave you goosebumps? Follow those points to find the particular emotional way you want to deliver your “thank you” to the team .

Tips and tricks:
- Keep a gratitude journal (online or offline) . Record moments of workplace gratitude and employee acts you appreciate. This practice will make you feel good, and it also provides plenty of fodder for appreciation speeches or employee appreciation day .
- Make mini-speeches a habit. Try to deliver words of recognition to employees every single day. As you perfect small-scale appreciation speeches, the longer ones will also feel more natural.
- When speaking, pause frequently to let your words sink in.
- Making eye contact
- Controlling jittery gestures
- Acting out verbs
- Matching facial expression to words
- Moving around the stage
- Varied pace. Don’t drone on at the same pace. Speak quickly and then switch to speaking slowly.
- Varied volume. Raise your voice on key points and closings.
Employee Appreciation Speech Scripts
Build on these customizable scripts to deliver employee appreciation speeches and casual meeting shout-outs every chance you get. Each script follows the 3-step approach we discussed above. Once you get the hang of appreciation speech basics, you’ll be able to pull inspirational monologues from your hat at a moment’s notice.
Swipe the examples below, but remember to infuse each speech with your own unique perspectives, personality, and heartfelt emotions.

All-Purpose Appreciation Speech
Greet your audience..
I feel so lucky to work with you all. In fact, [insert playful aside: e.g. My wife doesn’t understand how I don’t hate Mondays. It drives her nuts!]
Thanks to you, I feel lucky to come to work every day.
Talk about behaviors you appreciate.
Everyone here is [insert applicable team soft skills: e.g. positive, inspiring, creative, and intelligent ]. I’m constantly amazed by the incredible work you do.
Let’s just look at the past few months, for example. [Insert bullet points of specific accomplishments from every department].
- Finance launched an amazing new online payroll system.
- Business Development doubled their sales last quarter.
- Human Resources trained us all in emotional intelligence.
Talk about the effects of the behaviors.
These accomplishment aren’t just nice bullet points for my next presentation. Each department’s efforts has deep and lasting impacts on our business. [Explain the effects of each highlighted accomplishment].
- The new payroll system is going to save us at least $20,000 on staff hours and paper.
- Revenue from those doubled sales will go into our core investments, including a new training program .
- And I can already see the effects of that emotional intelligence training each time I’m in a meeting and a potential argument is resolved before it starts.
Say thank you.
I can’t thank you enough for everything you do for this company and for me. Knowing I have your support and dedication makes me a better, happier person both at work and at home.

Formal Appreciation Speech
Greet your audience by explaining why you were excited to come to work today..
I was not thrilled when my alarm went off this morning, but I must admit, I’m luckier than most people. As I got out of bed and thought about doing [insert daily workplace activities that inspire you], I felt excitement instead of dread. It’s an incredible feeling, looking forward to work every day, and for that, I have each and every one of you to thank.
Just last week, [insert specific anecdote: e.g. I remembered, ironically, that I forgot to create a real-time engagement plan for TECHLO’s giant conference next month. As you all know, they’re one of our biggest clients, so needless to say, I was panicking. Then I sit down for my one-on-one with MEGAN, worried that I didn’t even have time for our meeting, and what does she say? She wants to remind me that we committed to submit a promotional plan by the end of the week. She had some ideas for the TECHLO conference, so she went ahead and created a draft.]
[Insert the outcome of the anecdote: e.g. Her initiative dazzled me, and it saved my life! We met our deadline and also blew TECHLO away. In fact, they asked us to plan a similar initiative for their upcoming mid-year conference.]
[Insert a short thank-you paragraph tying everything together: e.g. And you know what, it was hard for me to pick just one example to discuss tonight. You all do so many things that blow me away every day. Thank you for everything. Thank you for making each day of work something we can all be proud of.]
Tip! Encourage your entire team to join in on the appreciation with CareCards ! This digital appreciation board allows you to recognize your colleague with a dedicated space full of personalized well wishes, thank-yous, and anything else you want to shout them out with! To explore Caroo’s CareCard program, take this 60-second tour !
Visionary Appreciation Speech
Greet your audience by explaining why you do what you do..
Here at [company name] we [insert core competency: e.g. build nonprofit websites], but we really [insert the big-picture outcome of your work: e.g. change the world by helping amazing nonprofits live up to their inspiring visions.]
I want to emphasize the “we” here. This company would be nothing without your work.
Talk about behaviors and explain how each works toward your mission.
Have you guys ever thought about that? How what you do [recap the big-picture outcome at your work: e.g. changes the world by helping amazing nonprofits live up to their inspiring visions]?
[Insert specific examples of recent work and highlight the associated outcomes: e.g. Let’s explore in terms of the websites we launched recently. I know every single person here played a role in developing each of these websites, and you should all be proud.]
- The launch of foodangel.org means that at least 500 homeless people in the greater metro area will eat dinner tonight.
- The launch of happyup.org means thousands of depressed teenagers will get mental health counseling.
Now if that’s not [recap the big-picture outcome], then I don’t know what is.
Thank you for joining me on the mission to [big-picture outcome]. With any other team, all we’re trying to do might just not be possible, but you all make me realize we can do anything together.

Casual Appreciation Speech
Greet your audience by discussing what upcoming work-related items you are most excited about..
I’ve been thinking nonstop about [insert upcoming initiative: e.g. our upcoming gallery opening]. This [initiative] is the direct result of your amazing work. To me, this [initiative] represents [insert what the initiative means to you: e.g. our true debut into the budding arts culture of our city.]
You’ve all been pulling out all the stops, [insert specific example: e.g. staying late, making 1,000 phone calls a day, and ironing out all the details.]
Because of your hard work, I’m absolutely confident the [initiative] will [insert key performance indicator: e.g. sell out on opening night.]
Thank you, not just for making this [initiative] happen, but also for making the journey such a positive and rewarding experience.
Funny Appreciation Speech
Greet your audience by telling an inside joke..
I want to thank you all for the good times, especially [insert inside joke: e.g. that time we put a glitter bomb in Jeff’s office.]
Talk about behaviors you appreciate and highlight comical outcomes.
But seriously, you guys keep me sane. For example [insert comical examples: e.g.]:
- The Operations team handled the merger so beautifully, I only had to pull out half my hair.
- The Marketing team landed a new client, and now we can pay you all for another year.
- And thanks to the Web team’s redesign of our website, I actually know what we do here.
Talk about the real effects of the behaviors.
But for real for real, all your work this year has put us on a new level. [Insert outcomes: e.g. We have an amazing roster of clients, a growing staff, and an incredible strategic plan that makes me feel unqualified to work here.] You guys made all this happen.
So thank you. This is when I would usually tell a joke to deflect my emotions, but for once in my life, I actually don’t want to hide. I want you all to know how much I appreciate all you do.
That was hard; I’m going to sit down now.
Appreciation Speech for Employee of the Month
Greet your audience by giving a shout-out to the employee of the month..
Shout out to [insert employee’s name] for being such a reliable member of our team. Your work ethics and outstanding performance are an inspiration to all of us! Keep up the amazing work!
Talk about behaviors you appreciate in them and highlight their best traits.
It’s not only essential to work diligently, but it is likewise crucial to be kind while you’re at it–and you’ve done both wonderfully!
Talk about the effects of their behaviors on the success of the company.
You bring optimism, happiness, and an all-around positive attitude to this team.
Thank you bring you!
Appreciation Speech for Good Work
Greet your audience with a round of applause to thank them for their hard work..
You always put in 100% and we see it. Proud of you, team!
Talk about behaviors you appreciate in your team members.
You work diligently, you foster a positive team environment, and you achieve or exceed your goals.
Talk about the effects of your team’s behaviors on the company.
Your dedication to the team is commendable, as is your readiness to do whatever needs to be done for the company – even if it’s not technically part of your job description. Thank you.
No matter the situation, you always rise to the occasion! Thank you for your unwavering dedication; it doesn’t go unnoticed.
People Also Ask These Questions:
Q: how can i show that i appreciate my employees .
- A: An appreciation speech is a great first step to showing your employees that you care. The SnackNation team also recommends pairing your words of appreciation with a thoughtful act or activity for employees to enjoy. We’ve researched, interviewed, and tested all the best peer-to-peer recognition platforms, office-wide games, celebration events, and personalized rewards to bring you the top 39 recognition and appreciation ideas to start building a culture of acknowledgment in your office.
Q: What should I do after giving an appreciation speech?
- A: In order to drive home the point of your employee appreciation speech, it can be effective to reward your employees for their excellent work. Rewards are a powerful tool used for employee engagement and appreciation. Recognizing your employees effectively is crucial for retaining top talent and keeping employees happy. To make your search easier, we sought out the top 121 creative ways that companies can reward their employees that you can easily implement at your office.
Q: Why should I give an employee appreciation speech?
- A: Appreciation and employee motivation are intimately linked together. A simple gesture of an employee appreciation gift can have a positive effect on your company culture. When an employee is motivated to work they are more productive. For more ideas to motivate your team, we’ve interviewed leading employee recognition and engagement experts to curate a list of the 22 best tips here !
We hope adapting these tips and scripts will help you articulate the appreciation we know you already feel!
Free Download: Download this entire list as a PDF . Easily save it on your computer for quick reference or print it for future team gatherings.
Employee Recognition & Appreciation Resources:
39 impactful employee appreciation & recognition ideas [updated], 12 effective tools & strategies to improve teamwork in the workplace, your employee referral program guide: the benefits, how-tos, incentives & tools, 21 unforgettable work anniversary ideas [updated], 15 ideas to revolutionize your employee of the month program, 16 awesome employee perks your team will love, 71 employee recognition quotes every manager should know, how to retain employees: 18 practical takeaways from 7 case studies, boost your employee recognition skills and words (templates included).
Interested in a content partnership? Let’s chat!
Get Started

About SnackNation

SnackNation is a healthy office snack delivery service that makes healthy snacking fun, life more productive, and workplaces awesome. We provide a monthly, curated selection of healthy snacks from the hottest, most innovative natural food brands in the industry, giving our members a hassle-free experience and delivering joy to their offices.

Popular Posts
Want to become a better professional in just 5 minutes?
You May Also Like

✅ 13 Best Employee Training Plan Templates In 2024

🚀 12 Best Employee Improvement Plan Templates for 2024

10 Comments

great piece of work love it, great help, thanks.

great tips !!!!

Helpful piece. LAVISH MAYOR

Enjoy reading this. Nice work

Thank you. Very helpful tips.

This is the most helpful and practical article I have found for writing a Colleague Appreciation speech. The Funny Appreciation Speech section was written for me 🙂 Ashley Bell, you’re a rock star!

Very nice speech Well explanation of words And very helpful for work

Hi, Your notes are awesome. Thank you for the share.

Your article is very helpful. Thankyou :).

Your stuff is really awesome. Thankyou for sharing such nice information
Leave a Reply Cancel Reply
Save my name, email, and website in this browser for the next time I comment.
SnackNation About Careers Blog Tech Blog Contact Us Privacy Policy Online Accessibility Statement
Pricing How It Works Member Reviews Take the Quiz Guides and Resources FAQ Terms and Conditions Website Accessibility Policy
Exciting Employee Engagement Ideas Employee Wellness Program Ideas Thoughtful Employee Appreciation Ideas Best ATS Software Fun Office Games & Activities for Employees Best Employee Engagement Software Platforms For High Performing Teams [HR Approved] Insanely Fun Team Building Activities for Work
Fun Virtual Team Building Activities The Best Employee Recognition Software Platforms Seriously Awesome Gifts For Coworkers Company Swag Ideas Employees Really Want Unique Gifts For Employees Corporate Gift Ideas Your Clients and Customers Will Love
© 2024 SnackNation. Handcrafted in Los Angeles
- Recipient Choice Gifts
- Free Work Personality Assessment
- Happy Hour & Lunches
- Group eCards
- Office Snacks
- Employee Recognition Software
- Join Our Newsletter
- Partner With Us
- SnackNation Blog
- Employee Template Directory
- Gifts For Remote Employees
- ATS Software Guide
- Best Swag Vendors
- Top HR Tools
- Ways To Reward Employees
- Employee Appreciation Gift Guide
- More Networks
- Privacy Overview
- Strictly Necessary Cookies
- 3rd Party Cookies
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
This website uses Google Analytics to collect anonymous information such as the number of visitors to the site, and the most popular pages.
Keeping this cookie enabled helps us to improve our website.
Please enable Strictly Necessary Cookies first so that we can save your preferences!

Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format.
While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal format to a text one whereas voice recognition just seeks to identify an individual user’s voice.
IBM has had a prominent role within speech recognition since its inception, releasing of “Shoebox” in 1962. This machine had the ability to recognize 16 different words, advancing the initial work from Bell Labs from the 1950s. However, IBM didn’t stop there, but continued to innovate over the years, launching VoiceType Simply Speaking application in 1996. This speech recognition software had a 42,000-word vocabulary, supported English and Spanish, and included a spelling dictionary of 100,000 words.
While speech technology had a limited vocabulary in the early days, it is utilized in a wide number of industries today, such as automotive, technology, and healthcare. Its adoption has only continued to accelerate in recent years due to advancements in deep learning and big data. Research (link resides outside ibm.com) shows that this market is expected to be worth USD 24.9 billion by 2025.
Explore the free O'Reilly ebook to learn how to get started with Presto, the open source SQL engine for data analytics.
Register for the guide on foundation models
Many speech recognition applications and devices are available, but the more advanced solutions use AI and machine learning . They integrate grammar, syntax, structure, and composition of audio and voice signals to understand and process human speech. Ideally, they learn as they go — evolving responses with each interaction.
The best kind of systems also allow organizations to customize and adapt the technology to their specific requirements — everything from language and nuances of speech to brand recognition. For example:
- Language weighting: Improve precision by weighting specific words that are spoken frequently (such as product names or industry jargon), beyond terms already in the base vocabulary.
- Speaker labeling: Output a transcription that cites or tags each speaker’s contributions to a multi-participant conversation.
- Acoustics training: Attend to the acoustical side of the business. Train the system to adapt to an acoustic environment (like the ambient noise in a call center) and speaker styles (like voice pitch, volume and pace).
- Profanity filtering: Use filters to identify certain words or phrases and sanitize speech output.
Meanwhile, speech recognition continues to advance. Companies, like IBM, are making inroads in several areas, the better to improve human and machine interaction.
The vagaries of human speech have made development challenging. It’s considered to be one of the most complex areas of computer science – involving linguistics, mathematics and statistics. Speech recognizers are made up of a few components, such as the speech input, feature extraction, feature vectors, a decoder, and a word output. The decoder leverages acoustic models, a pronunciation dictionary, and language models to determine the appropriate output.
Speech recognition technology is evaluated on its accuracy rate, i.e. word error rate (WER), and speed. A number of factors can impact word error rate, such as pronunciation, accent, pitch, volume, and background noise. Reaching human parity – meaning an error rate on par with that of two humans speaking – has long been the goal of speech recognition systems. Research from Lippmann (link resides outside ibm.com) estimates the word error rate to be around 4 percent, but it’s been difficult to replicate the results from this paper.
Various algorithms and computation techniques are used to recognize speech into text and improve the accuracy of transcription. Below are brief explanations of some of the most commonly used methods:
- Natural language processing (NLP): While NLP isn’t necessarily a specific algorithm used in speech recognition, it is the area of artificial intelligence which focuses on the interaction between humans and machines through language through speech and text. Many mobile devices incorporate speech recognition into their systems to conduct voice search—e.g. Siri—or provide more accessibility around texting.
- Hidden markov models (HMM): Hidden Markov Models build on the Markov chain model, which stipulates that the probability of a given state hinges on the current state, not its prior states. While a Markov chain model is useful for observable events, such as text inputs, hidden markov models allow us to incorporate hidden events, such as part-of-speech tags, into a probabilistic model. They are utilized as sequence models within speech recognition, assigning labels to each unit—i.e. words, syllables, sentences, etc.—in the sequence. These labels create a mapping with the provided input, allowing it to determine the most appropriate label sequence.
- N-grams: This is the simplest type of language model (LM), which assigns probabilities to sentences or phrases. An N-gram is sequence of N-words. For example, “order the pizza” is a trigram or 3-gram and “please order the pizza” is a 4-gram. Grammar and the probability of certain word sequences are used to improve recognition and accuracy.
- Neural networks: Primarily leveraged for deep learning algorithms, neural networks process training data by mimicking the interconnectivity of the human brain through layers of nodes. Each node is made up of inputs, weights, a bias (or threshold) and an output. If that output value exceeds a given threshold, it “fires” or activates the node, passing data to the next layer in the network. Neural networks learn this mapping function through supervised learning, adjusting based on the loss function through the process of gradient descent. While neural networks tend to be more accurate and can accept more data, this comes at a performance efficiency cost as they tend to be slower to train compared to traditional language models.
- Speaker Diarization (SD): Speaker diarization algorithms identify and segment speech by speaker identity. This helps programs better distinguish individuals in a conversation and is frequently applied at call centers distinguishing customers and sales agents.
A wide number of industries are utilizing different applications of speech technology today, helping businesses and consumers save time and even lives. Some examples include:
Automotive: Speech recognizers improves driver safety by enabling voice-activated navigation systems and search capabilities in car radios.
Technology: Virtual agents are increasingly becoming integrated within our daily lives, particularly on our mobile devices. We use voice commands to access them through our smartphones, such as through Google Assistant or Apple’s Siri, for tasks, such as voice search, or through our speakers, via Amazon’s Alexa or Microsoft’s Cortana, to play music. They’ll only continue to integrate into the everyday products that we use, fueling the “Internet of Things” movement.
Healthcare: Doctors and nurses leverage dictation applications to capture and log patient diagnoses and treatment notes.
Sales: Speech recognition technology has a couple of applications in sales. It can help a call center transcribe thousands of phone calls between customers and agents to identify common call patterns and issues. AI chatbots can also talk to people via a webpage, answering common queries and solving basic requests without needing to wait for a contact center agent to be available. It both instances speech recognition systems help reduce time to resolution for consumer issues.
Security: As technology integrates into our daily lives, security protocols are an increasing priority. Voice-based authentication adds a viable level of security.
Convert speech into text using AI-powered speech recognition and transcription.
Convert text into natural-sounding speech in a variety of languages and voices.
AI-powered hybrid cloud software.
Enable speech transcription in multiple languages for a variety of use cases, including but not limited to customer self-service, agent assistance and speech analytics.
Learn how to keep up, rethink how to use technologies like the cloud, AI and automation to accelerate innovation, and meet the evolving customer expectations.
IBM watsonx Assistant helps organizations provide better customer experiences with an AI chatbot that understands the language of the business, connects to existing customer care systems, and deploys anywhere with enterprise security and scalability. watsonx Assistant automates repetitive tasks and uses machine learning to resolve customer support issues quickly and efficiently.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Front Syst Neurosci
Speech perception as an active cognitive process
Shannon l. m. heald.
Department of Psychology, The University of Chicago, Chicago, IL, USA
Howard C. Nusbaum
One view of speech perception is that acoustic signals are transformed into representations for pattern matching to determine linguistic structure. This process can be taken as a statistical pattern-matching problem, assuming realtively stable linguistic categories are characterized by neural representations related to auditory properties of speech that can be compared to speech input. This kind of pattern matching can be termed a passive process which implies rigidity of processing with few demands on cognitive processing. An alternative view is that speech recognition, even in early stages, is an active process in which speech analysis is attentionally guided. Note that this does not mean consciously guided but that information-contingent changes in early auditory encoding can occur as a function of context and experience. Active processing assumes that attention, plasticity, and listening goals are important in considering how listeners cope with adverse circumstances that impair hearing by masking noise in the environment or hearing loss. Although theories of speech perception have begun to incorporate some active processing, they seldom treat early speech encoding as plastic and attentionally guided. Recent research has suggested that speech perception is the product of both feedforward and feedback interactions between a number of brain regions that include descending projections perhaps as far downstream as the cochlea. It is important to understand how the ambiguity of the speech signal and constraints of context dynamically determine cognitive resources recruited during perception including focused attention, learning, and working memory. Theories of speech perception need to go beyond the current corticocentric approach in order to account for the intrinsic dynamics of the auditory encoding of speech. In doing so, this may provide new insights into ways in which hearing disorders and loss may be treated either through augementation or therapy.
In order to achieve flexibility and generativity, spoken language understanding depends on active cognitive processing (Nusbaum and Schwab, 1986 ; Nusbaum and Magnuson, 1997 ). Active cognitive processing is contrasted with passive processing in terms of the control processes that organize the nature and sequence of cognitive operations (Nusbaum and Schwab, 1986 ). A passive process is one in which inputs map directly to outputs with no hypothesis testing or information-contingent operations. Automatized cognitive systems (Shiffrin and Schneider, 1977 ) behave as though passive, in that stimuli are mandatorily mapped onto responses without demand on cognitive resources. However it is important to note that cognitive automatization does not have strong implications for the nature of the mediating control system such that various different mechanisms have been proposed to account for automatic processing (e.g., Logan, 1988 ). By comparison, active cognitive systems however have a control structure that permits “information contingent processing” or the ability to change the sequence or nature of processing in the context of new information or uncertainty. In principle, active systems can generate hypotheses to be tested as new information arrives or is derived (Nusbaum and Schwab, 1986 ) and thus provide substantial cognitive flexibility to respond to novel situations and demands.
Active and passive processes
The distinction between active and passive processes comes from control theory and reflects the degree to which a sequence of operations, in this case neural population responses, is contingent on processing outcomes (see Nusbaum and Schwab, 1986 ). A passive process is an open loop sequence of transformations that are fixed, such that there is an invariant mapping from input to output (MacKay, 1951 , 1956 ). Figure Figure1A 1A illustrates a passive process in which a pattern of inputs (e.g., basilar membrane responses) is transmitted directly over the eighth nerve to the next population of neurons (e.g., in the auditory brainstem) and upward to cortex. This is the fundamental assumption of a number of theories of auditory processing in which a fixed cascade of neural population responses are transmitted from one part of the brain to the other (e.g., Barlow, 1961 ). This type of system operates the way reflexes are assumed to operate in which neural responses are transmitted and presumably transformed but in a fixed and immutable way (outside the context of longer term reshaping of responses). Considered in this way, such passive processing networks should process in a time frame that is simply the sum of the neural response times, and should not be influenced by processing outside this network, functioning something like a module (Fodor, 1983 ). In this respect then, such passive networks should operate “automatically” and not place any demands on cognitive resources. Some purely auditory theories seem to have this kind of organization (e.g., Fant, 1962 ; Diehl et al., 2004 ) and some more classical neural models (e.g., Broca, 1865 ; Wernicke, 1874/1977 ; Lichtheim, 1885 ; Geschwind, 1970 ) appear to be organized this way. In these cases, auditory processes project to perceptual interpretations with no clearly specified role for feedback to modify or guide processing.

Schematic representation of passive and active processes . The top panel (A) represents a passive process. A stimulus presented to sensory receptors is transformed through a series of processes (Ti) into a sequence of pattern representations until a final perceptual representation is the result. This could be thought of as a pattern of hair cell stimulation being transformed up to a phonological representation in cortex. The middle panel (B) represents a top-down active process. Sensory stimulation is compared as a pattern to hypothesized patterns derived from some knowledge source either derived from context or expectations. Error signals from the comparison interact with the hypothesized patterns until constrained to a single interpretation. The generation of hypothesized patterns may be in parallel or accomplished sequentially. The bottom panel (C) represents a bottom-up active process in which sensory stimulation is transformed into an initial pattern, which can be transformed into some representation. If this representation is sensitive to the unfolding of context or immediate perceptual experience, it could generate a pattern from the immediate input and context that is different than the initial pattern. Feedback from the context-based pattern in comparison with the initial pattern can generate an error signal to the representation changing how context is integrated to produce a new pattern for comparison purposes.
By contrast, active processes are variable in nature, as network processing is adjusted by an error-correcting mechanism or feedback loop. As such, outcomes may differ in different contexts. These feedback loops provide information to correct or modify processing in real time, rather than retrospectively. Nusbaum and Schwab ( 1986 ) describe two different ways an active, feedback-based system may be achieved. In one form, as illustrated in Figure Figure1B, 1B , expectations (derived from context) provide a hypothesis about a stimulus pattern that is being processed. In this case, sensory patterns (e.g., basilar membrane responses) are transmitted in much the same way as in a passive process (e.g., to the auditory brainstem). However, descending projections may modify the nature of neural population responses in various ways as a consequence of neural responses in cortical systems. For example, top-down effects of knowledge or expectations have been shown to alter low level processing in the auditory brainstem (e.g., Galbraith and Arroyo, 1993 ) or in the cochlea (e.g., Giard et al., 1994 ). Active systems may occur in another form, as illustrated in Figure Figure1C. 1C . In this case, there may be a strong bottom-up processing path as in a passive system, but feedback signals from higher cortical levels can change processing in real time at lower levels (e.g., brainstem). An example of this would be the kind of observation made by Spinelli and Pribram ( 1966 ) in showing that electrical stimulation of the inferotemporal cortex changed the receptive field structure for lateral geniculate neurons or Moran and Desimone’s ( 1985 ) demonstration that spatial attentional cueing changes effective receptive fields in striate and extrastriate cortex. In either case, active processing places demands on the system’s limited cognitive resources in order to achieve cognitive and perceptual flexibility. In this sense, active and passive processes differ in the cognitive and perceptual demands they place on the system.
Although the distinction between active and passive processes seems sufficiently simple, examination of computational models of spoken word recognition makes the distinctions less clear. For a very simple example of this potential issue consider the original Cohort theory (Marslen-Wilson and Welsh, 1978 ). Activation of a set of lexical candidates was presumed to occur automatically from the initial sounds in a word. This can be designated as a passive process since there is a direct invariant mapping from initial sounds to activation of a lexical candidate set, i.e., a cohort of words. Each subsequent sound in the input then deactivates members of this candidate set giving the appearance of a recurrent hypothesis testing mechanism in which the sequence of input sounds deactivates cohort members. One might consider this an active system overall with a passive first stage since the initial cohort set constitutes a set of lexical hypotheses that are tested by the use of context. However, it is important to note that the original Cohort theory did not include any active processing at the phonemic level, as hypothesis testing is carried out in the context of word recognition. Similarly, the architecture of the Distributed Cohort Model (Gaskell and Marslen-Wilson, 1997 ) asserts that activation of phonetic features is accomplished by a passive system whereas context interacts (through a hidden layer) with the mapping of phonetic features onto higher order linguistic units (phonemes and words) representing an interaction of context with passively derived phonetic features. In neither case is the activation of the features or sound input to linguistic categorization treated as hypothesis testing in the context of other sounds or linguistic information. Thus, while the Cohort models can be thought of as an active system for the recognition of words (and sometimes phonemes), they treat phonetic features as passively derived and not influenced from context or expectations.
This is often the case in a number of word recognition models. The Shortlist models (Shortlist: Norris, 1994 ; Shortlist B: Norris and McQueen, 2008 ) assume that phoneme perception is a largely passive process (at least it can be inferred as such by lack of any specification in the alternative). While Shortlist B uses phoneme confusion data (probability functions as input) and could in principle adjust the confusion data based on experience (through hypothesis testing and feedback), the nature of the derivation of the phoneme confusions is not specified; in essence assuming the problem of phoneme perception is solved. This appears to be common to models (e.g., NAM, Luce and Pisoni, 1998 ) in which the primary goal is to account for word perception rather than phoneme perception. Similarly, the second Trace model (McClelland and Elman, 1986 ) assumed phoneme perception was passively achieved albeit with competition (not feedback to the input level). It is interesting that the first Trace model (Elman and McClelland, 1986 ) did allow for feedback from phonemes to adjust activation patterns from acoustic-phonetic input, thus providing an active mechanism. However, this was not carried over into the revised version. This model was developed to account for some aspects of phoneme perception unaccounted for in the second model. It is interesting to note that the Hebb-Trace model (Mirman et al., 2006a ), while seeking to account for aspects of lexical influence on phoneme perception and speaker generalization did not incorporate active processing of the input patterns. As such, just the classification of those inputs was actively governed.
This can be understood in the context schema diagrammed in Figure Figure1. 1 . Any process that maps inputs onto representations in an invariant manner or that would be classified as a finite-state deterministic system can be considered passive. A process that changes the classification of inputs contingent on context or goals or hypotheses can be considered an active system. Although word recognition models may treat the recognition of words or even phonemes as an active process, this active processing is not typically extended down to lower levels of auditory processing. These systems tend to operate as though there is a fixed set of input features (e.g., phonetic features) and the classification of such features takes place in a passive, automatized fashion.
By contrast, Elman and McClelland ( 1986 ) did describe a version of Trace in which patterns of phoneme activation actively changes processing at the feature input level. Similarly, McClelland et al. ( 2006 ) described a version of their model in which lexical information can modify input patterns at the subphonemic level. Both of these models represent active systems for speech processing at the sublexical level. However, it is important to point out that such theoretical propositions remain controversial. McQueen et al. ( 2006 ) have argued that there are no data to argue for lexical influences over sublexical processing, although Mirman et al. ( 2006b ) have countered this with empirical arguments. However, the question of whether there are top-down effects on speech perception is not the same as asking if there are active processes governing speech perception. Top-down effects assume higher level knowledge constrains interpretations, but as indicated in Figure Figure1C, 1C , there can be bottom-up active processing where by antecedent auditory context constrains subsequent perception. This could be carried out in a number of ways. As an example, Ladefoged and Broadbent ( 1957 ) demonstrated that hearing a context sentence produced by one vocal tract could shift the perception of subsequent isolated vowels such that they would be consistent with the vowel space of the putative speaker. Some have accounted for this result by asserting there is an automatic auditory tuning process that shifts perception of the subsequent vowels (Huang and Holt, 2012 ; Laing et al., 2012 ). While the behavioral data could possibly be accounted for by such a simple passive mechanism, it might also be the case the auditory pattern input produces constraints on the possible vowel space or auditory mappings that might be expected. In this sense, the question of whether early auditory processing of speech is an active or passive process is still a point of open investigation and discussion.
It is important to make three additional points in order to clarify the distinction between active and passive processes. First, a Bayesian mechanism is not on its own merits necessarily active or passive. Bayes rule describes the way different statistics can be used to estimate the probability of a diagnosis or classification of an event or input. But this is essentially a computation theoretic description much in the same way Fourier’s theorem is independent of any implementation of the theorem to actually decompose a signal into its spectrum (cf. Marr, 1982 ). The calculation and derivation of relevant statistics for a Bayesian inference can be carried out passively or actively. Second, the presence of learning within a system does not on its own merits confer active processing status on a system. Learning can occur by a number of algorithms (e.g., Hebbian learning) that can be implemented passively. However to the extent that a system’s inputs are plastic during processing, would suggest whether an active system is at work. Finally, it is important to point out that active processing describes the architecture of a system (the ability to modify processing on the fly based on the processing itself) but not the behavior at any particular point in time. Given a fixed context and inputs, any active system can and likely would mimic passive behavior. The detection of an active process therefore depends on testing behavior under contextual variability or resource limitations to observe changes in processing as a consequence of variation in the hypothesized alternatives for interpretation (e.g., slower responses, higher error rate or confusions, increase in working memory load).
Computational need for active control systems in speech perception
Understanding how and why active cognitive processes are involved in speech perception is fundamental to the development of a theory of speech perception. Moreover, the nature of the theoretical problems that challenge most explanations of speech perception are structurally similar to some of the theoretical issues in language comprehension when considered more broadly. In addition to addressing the basis for language comprehension broadly, to the extent that such mechanisms play a critical role in spoken language processing, understanding their operation may be important to understanding both the effect of hearing loss on speech perception as well as suggesting ways of remediating hearing loss. If one takes an overly simplified view of hearing (and thus damage to hearing resulting in loss) as an acoustic-to-neural signal transduction mechanism comparable to a microphone-amplifier system, the simplifying assumptions may be very misleading. The notion of the peripheral auditory system as a passive acoustic transducer leads to theories that postulate passive conversion of acoustic energy to neural signals and this may underestimate both the complexity and potential of the human auditory system for processing speech. At the very least, early auditory encoding in the brain (reflected by the auditory brainstem response) is conditioned by experience (Skoe and Kraus, 2012 ) and so the distribution of auditory experiences shapes the basic neural patterns extracted from acoustic signals. However, it is appears that this auditory encoding is shaped from the top-down under active and adaptive processing of higher-level knowledge and attention (e.g., Nusbaum and Schwab, 1986 ; Strait et al., 2010 ).
This conceptualization of speech perception as an active process has large repercussions for understanding the nature of hearing loss in older adults. Rabbitt ( 1991 ) has argued, as have others, that older adults, compared with younger adults, must employ additional perceptual and cognitive processing to offset sensory deficits in frequency and temporal resolution as well as in frequency range (Murphy et al., 2000 ; Pichora-Fuller and Souza, 2003 ; McCoy et al., 2005 ; Wingfield et al., 2005 ; Surprenant, 2007 ). Wingfield et al. ( 2005 ) have further argued that the use of this extra processing at the sensory level is costly and may affect the availability of cognitive resources that could be needed for other kinds of processing. While these researchers consider the cognitive consequences that may be encountered more generally given the demands on cognitive resources, such as the deficits found in the encoding of speech content in memory, there is less consideration of the way these demands may impact speech processing itself. If speech perception itself is mediated by active processes, which require cognitive resources, then the increasing demands on additional cognitive and perceptual processing for older adults becomes more problematic. The competition for cognitive resources may shortchange aspects of speech perception. Additionally, the difference between a passive system that simply involves the transduction, filtering, and simple pattern recognition (computing a distance between stored representations and input patterns and selecting the closest fit) and an active system that uses context dependent pattern recognition and signal-contingent adaptive processing has implications for the nature of augmentative hearing aids and programs of therapy for remediating aspects of hearing loss. It is well known that simple amplification systems are not sufficient remediation for hearing loss because they amplify noise as well as signal. Understanding how active processing operates and interacts with signal properties and cognitive processing might lead to changes in the way hearing aids operate, perhaps through cueing changes in attention, or by modifying the signal structure to affect the population coding of frequency information or attentional segregation of relevant signals. Training to use such hearing aids might be more effective by simple feedback or by systematically changing the level and nature of environmental sound challenges presented to listeners.
Furthermore, understanding speech perception as an active process has implications for explaining some of the findings of the interaction of hearing loss with cognitive processes (e.g., Wingfield et al., 2005 ). One explanation of the demands on cognitive mechanisms through hearing loss is a compensatory model as noted above (e.g., Rabbitt, 1991 ). This suggests that when sensory information is reduced, cognitive processes operate inferentially to supplement or replace the missing information. In many respects this is a kind of postperceptual explanation that might be like a response bias. It suggests that mechanisms outside of normal speech perception can be called on when sensory information is degraded. However an alternative view of the same situation is that it reflects the normal operation of speech recognition processing rather than an extra postperceptual inference system. Hearing loss may specifically exacerbate the fundamental problem of lack of invariance in acoustic-phonetic relationships.
The fundamental problem faced by all theories of speech perception derives from the lack of invariance in the relationship between the acoustic patterns of speech and the linguistic interpretation of those patterns. Although the many-to-many mapping between acoustic patterns of speech and perceptual interpretations is a longstanding well-known problem (e.g., Liberman et al., 1967 ), the core computational problem only truly emerges when a particular pattern has many different interpretations or can be classified in many different ways. It is widely established that individuals are adept in understanding the constituents of a given category, for traditional categories (Rosch et al., 1976 ) or ad hoc categories developed in response to the demands of a situation (Barsalou, 1983 ). In this sense, a many-to-one mapping does not pose a substantial computational challenge. As Nusbaum and Magnuson ( 1997 ) argue, a many-to-one mapping can be understood with a simple class of deterministic computational mechanisms. In essence, a deterministic system establishes one-to-one mappings between inputs and outputs and thus can be computed by passive mechanisms such as feature detectors. It is important to note that a many-to-one mapping (e.g., rising formant transitions signaling a labial stop and diffuse consonant release spectrum signaling a labial stop) can be instantiated as a collection of one-to-one mappings.
However, when a particular sensory pattern must be classified as a particular linguistic category and there are multiple possible interpretations, this constitutes a computational problem for recognition. In this case (e.g., a formant pattern that could signal either the vowel in BIT or BET) there is ambiguity about the interpretation of the input without additional information. One solution is that additional context or information could eliminate some alternative interpretations as in talker normalization (Nusbaum and Magnuson, 1997 ). But this leaves the problem of determining the nature of the constraining information and processing it, which is contingent on the ambiguity itself. This suggests that there is no automatic or passive means of identifying and using the constraining information. Thus an active mechanism, which tests hypotheses about interpretations and tentatively identifies sources of constraining information (Nusbaum and Schwab, 1986 ), may be needed.
Given that there are multiple alternative interpretations for a particular segment of speech signal, the nature of the information needed to constrain the selection depends on the source of variability that produced the one-to-many non-determinism. Variations in speaking rate, or talker, or linguistic context or other signal modifications are all potential sources of variability that are regularly encountered by listeners. Whether the system uses articulatory or linguistic information as a constraint, the perceptual system needs to flexibly use context as a guide in determining the relevant properties needed for recognition (Nusbaum and Schwab, 1986 ). The process of eliminating or weighing potential interpretations could well involve demands on working memory. Additionally, there may be changes in attention, towards more diagnostic patterns of information. Further, the system may be required to adapt to new sources of lawful variability in order to understand the context (cf. Elman and McClelland, 1986 ).
Generally speaking, these same kinds of mechanisms could be implicated in higher levels of linguistic processing in spoken language comprehension, although the neural implementation of such mechanisms might well differ. A many-to-many mapping problem extends to all levels of linguistic analysis in language comprehension and can be observed between patterns at the syllabic, lexical, prosodic and sentential level in speech and the interpretations of those patterns as linguistic messages. This is due to the fact that across linguistic contexts, speaker differences (idiolect, dialect, etc.) and other contextual variations, there are no patterns (acoustic, phonetic, syllabic, prosodic, lexical etc.) in speech that have an invariant relationship to the interpretation of those patterns. For this reason, it could be beneficial to consider how these phenomena of acoustic perception, phonetic perception, syllabic perception, prosodic perception, lexical perception, etc., are related computationally to one another and understand the computational similarities among the mechanisms that may subserve them (Marr, 1982 ). Given that such a mechanism needs to flexibly respond to changes in context (and different kinds of context—word or sentence or talker or speaking rate) and constrain linguistic interpretations in context, suggests that the mechanism for speech understanding needs to be plastic. In other words, speech recognition should inherently demonstrate learning.
Learning mechanisms in speech
While on its face this seems uncontroversial, theories of speech perception have not traditionally incorporated learning although some have evolved over time to do so (e.g., Shortlist-B, Hebb-Trace). Indeed, there remains some disagreement about the plasticity of speech processing in adults. One issue is how the long-term memory structures that guide speech processing are modified to allow for this plasticity while at the same time maintaining and protecting previously learned information from being expunged. This is especially important as often newly acquired information may represent irrelevant information to the system in a long-term sense (Carpenter and Grossberg, 1988 ; Born and Wilhelm, 2012 ).
To overcome this problem, researchers have proposed various mechanistic accounts, and while there is no consensus amongst them, a hallmark characteristic of these accounts is that learning occurs in two stages. In the first stage, the memory system is able to use fast learning temporary storage to achieve adaptability, and in a subsequent stage, during an offline period such as sleep, this information is consolidated into long-term memory structures if the information is found to be germane (Marr, 1971 ; McClelland et al., 1995 ; Ashby et al., 2007 ). While this is a general cognitive approach to the formation of categories for recognition, this kind of mechanism does not figure into general thinking about speech recognition theories. The focus of these theories is less on the formation of category representations and the need for plasticity during recognition, than it is on the stability and structure of the categories (e.g., phonemes) to be recognized. Theories of speech perception often avoid the plasticity-stability trade off problem by proposing that the basic categories of speech are established early in life, tuned by exposure, and subsequently only operate as a passive detection system (e.g., Abbs and Sussman, 1971 ; Fodor, 1983 ; McClelland and Elman, 1986 ; although see Mirman et al., 2006b ). According to these kinds of theories, early exposure to a system of speech input has important effects on speech processing.
Given the importance of early exposure for establishing the phonological system, there is no controversy regarding the significance of linguistic experience in shaping an individual’s ability to discriminate and identify speech sounds (Lisker and Abramson, 1964 ; Strange and Jenkins, 1978 ; Werker and Tees, 1984 ; Werker and Polka, 1993 ). An often-used example of this is found in how infants’ perceptual abilities change via exposure to their native language. At birth, infants are able to discriminate a wide range of speech sounds whether present or not in their native language (Werker and Tees, 1984 ). However, as a result of early linguistic exposure and experience, infants gain sensitivity to phonetic contrasts to which they are exposed and eventually lose sensitivity for phonetic contrasts that are not experienced (Werker and Tees, 1983 ). Additionally, older children continue to show developmental changes in perceptual sensitivity to acoustic-phonetic patterns (e.g., Nittrouer and Miller, 1997 ; Nittrouer and Lowenstein, 2007 ) suggesting that learning a phonology is not simply a matter of acquiring a simple set of mappings between the acoustic patterns of speech and the sound categories of language. Further, this perceptual learning does not end with childhood as it is quite clear that even adult listeners are capable of learning new phonetic distinctions not present in their native language (Werker and Logan, 1985 ; Pisoni et al., 1994 ; Francis and Nusbaum, 2002 ; Lim and Holt, 2011 ).
A large body of research has now established that adult listeners can learn a variety of new phonetic contrasts from outside their native language. Adults are able to learn to split a single native phonological category into two functional categories, such as Thai pre-voicing when learned by native English speakers (Pisoni et al., 1982 ) as well as to learn completely novel categories such as Zulu clicks for English speakers (Best et al., 1988 ). Moreover, adults possess the ability to completely change the way they attend to cues, for example Japanese speakers are able to learn the English /r/-/l/ distinction, a contrast not present in their native language (e.g., Logan et al., 1991 ; Yamada and Tohkura, 1992 ; Lively et al., 1993 ). While learning is limited, Francis and Nusbaum ( 2002 ) demonstrated that given appropriate feedback, listeners can learn to direct perceptual attention to acoustic cues that were not previously used to form phonetic distinctions in their native language. In their study, learning new categories was manifest as a change in the structure of the acoustic-phonetic space wherein individuals shifted from the use of one perceptual dimension (e.g., voicing) to a complex of two perceptual dimensions, enabling native English speakers to correctly perceive Korean stops after training. How can we describe this change? What is the mechanism by which this change in perceptual processing occurs?
From one perspective this change in perceptual processing can be described as a shift in attention (Nusbaum and Schwab, 1986 ). Auditory receptive fields may be tuned (e.g., Cruikshank and Weinberger, 1996 ; Weinberger, 1998 ; Wehr and Zador, 2003 ; Znamenskiy and Zador, 2013 ) or reshaped as a function of appropriate feedback (cf. Moran and Desimone, 1985 ) or context (Asari and Zador, 2009 ). This is consistent with theories of category learning (e.g., Schyns et al., 1998 ) in which category structures are related to corresponding sensory patterns (Francis et al., 2007 , 2008 ). From another perspective this adaptation process could be described as the same kind of cue weighting observed in the development of phonetic categories (e.g., Nittrouer and Miller, 1997 ; Nittrouer and Lowenstein, 2007 ). Yamada and Tohkura ( 1992 ) describe native Japanese listeners as typically directing attention to acoustic properties of /r/-/l/ stimuli that are not the dimensions used by English speakers, and as such are not able to discriminate between these categories. This misdirection of attention occurs because these patterns are not differentiated functionally in Japanese as they are in English. For this reason, Japanese and English listeners distribute attention in the acoustic pattern space for /r/ and /l/ differently as determined by the phonological function of this space in their respective languages. Perceptual learning of these categories by Japanese listeners suggests a shift of attention to the English phonetically relevant cues.
This idea of shifting attention among possible cues to categories is part and parcel of a number of theories of categorization that are not at all specific to speech perception (e.g., Gibson, 1969 ; Nosofsky, 1986 ; Goldstone, 1998 ; Goldstone and Kersten, 2003 ) but have been incorporated into some theories of speech perception (e.g., Jusczyk, 1993 ). Recently, McMurray and Jongman ( 2011 ) proposed the C-Cure model of phoneme classification in which the relative importance of cues varies with context, although the model does not specify a mechanism by which such plasticity is implemented neurally.
One issue to consider in examining the paradigm of training non-native phonetic contrasts is that adult listeners bring an intact and complete native phonological system to bear on any new phonetic category-learning problem. This pre-existing phonological knowledge about the sound structure of a native language operates as a critical mass of an acoustic-phonetic system with which a new category likely does not mesh (Nusbaum and Lee, 1992 ). New contrasts can re-parse the acoustic cue space into categories that are at odds with the native system, can be based on cues that are entirely outside the system (e.g., clicks), or can completely remap native acoustic properties into new categories (see Best et al., 2001 ). In all these cases however listeners need to not only learn the pattern information that corresponds to these categories, but additionally learn the categories themselves. In most studies participants do not actually learn a completely new phonological system that exhibits an internal structure capable of supporting the acquisition of new categories, but instead learn isolated contrasts that are not part of their native system. Thus, learning non-native phonological contrasts requires individuals to learn both new category structures, as well as how to direct attention to the acoustic cues that define those categories without colliding with extant categories.
How do listeners accommodate the signal changes encountered on a daily basis in listening to speech? Echo and reverberation can distort speech. Talkers speak while eating. Accents can change the acoustic to percept mappings based on the articulatory phonetics of a native language. While some of the distortions in signals can probably be handled by some simple filtering in the auditory system, more complex signal changes that are systematic cannot be handled in this way. The use of filtering as a solution for speech signal distortion assumes a model of speech perception whereby a set of acoustic-phonetic representations (whether talker-specific or not) are obscured by some distortion and that some simple acoustic transform (like amplification or time-dilation) is used to restore the signal.
An alternative to this view was proposed by Elman and McClelland ( 1986 ). They suggested that the listener can use systematicity in distortions of acoustic patterns as information about the sources of variability that affected the signal in the conditions under which the speech was produced. This idea, that systematic variability in acoustic patterns of phonetic categories provides information about the intended phonetic message, suggests that even without learning new phonetic categories or contrasts, learning the sources and structure of acoustic-phonetic variability may be a fundamental aspect of speech perception. Nygaard et al. ( 1994 ) and Nygaard and Pisoni ( 1998 ) demonstrated that listeners learning the speech of talkers using the same phonetic categories as the listeners show significant improvements in speech recognition. Additionally, Dorman et al. ( 1977 ) elegantly demonstrated that different talkers speaking the same language can use different acoustic cues to make the same phonetic contrasts. In these situations, in order to recognize speech, listeners must learn to direct attention to the specific cues for a particular talker in order to ameliorate speech perception. In essence, this suggests that learning may be an intrinsic part of speech perception rather than something added on. Phonetic categories must remain plastic even in adults in order to flexibly respond to the changing demands of the lack of invariance problem across talkers and contexts of speaking.
One way of investigating those aspects of learning that are specific to directing attention to appropriate and meaningful acoustic cues without additionally having individuals learn new phonetic categories or a new phonological system, is to examine how listeners adapt to synthetic speech that uses their own native phonological categories. Synthetic speech generated by rule is “defective” in relation to natural speech in that it oversimplifies the acoustic pattern structure (e.g., fewer cues, less cue covariation) and some cues may actually be misleading (Nusbaum and Pisoni, 1985 ). Learning synthetic speech requires listeners to learn how acoustic information, produced by a particular talker, is used to define the speech categories the listener already possesses. In order to do this, listeners need to make use of degraded, sparse and often misleading acoustic information, which contributes to the poor intelligibility of synthesized speech. Given that such cues are not available to awareness, and that most of such learning is presumed to occur early in life, it seems difficult to understand that adult listeners could even do this. In fact, it is this ability to rapidly learn synthetic speech that lead Nusbaum and Schwab ( 1986 ) to conclude that speech must be guided by active control processes.
Generalization learning
In a study reported by Schwab et al. ( 1985 ), listeners were trained on synthetic speech for 8 days with feedback and tested before and after training. Before training, recognition was about 20% correct, but improved after training to about 70% correct. More impressively this learning occurred even though listeners were never trained or tested on the same words twice, meaning that individuals had not just explicitly learned what they were trained on, but instead gained generalized knowledge about the synthetic speech. Additionally, Schwab et al. ( 1985 ) demonstrated that listeners are able to substantially retain this generalized knowledge without any additionally exposure to the synthesizer, as listeners showed similar performance 6 months later. This suggests that even without hearing the same words over and over again, listeners were able to change the way they used acoustic cues at a sublexical level. In turn, listeners used this sublexical information to drive recognition of these cues in completely novel lexical contexts. This is far different from simply memorizing the specific and complete acoustic patterns of particular words, but instead could reflect a kind of procedural knowledge of how to direct attention to the speech of the synthetic talker.
This initial study demonstrated clear generalization beyond the specific patterns heard during training. However on its own it gives little insight into the way such generalization emerges. In a subsequent study, Greenspan et al. ( 1988 ) expanded on this and examined the ability of adult listeners to generalize from various training regimes asking the question of how acoustic-phonetic variability affects generalization of speech learning. Listeners were either given training on repeated words or novel words, and when listeners memorize specific acoustic patterns of spoken words, there is very good recognition performance for those words. However this does not afford the same level of perceptual generalization that is produced by highly variable training experiences. This is akin to the benefits of training variability seen in motor learning in which generalization of a motor behavior is desired (e.g., Lametti and Ostry, 2010 ; Mattar and Ostry, 2010 ; Coelho et al., 2012 ). Given that training set variability modulates the type of learning, adult perceptual learning of spoken words cannot be seen as simply a rote process. Moreover, even from a small amount of repeated and focused rote training there is some reliable generalization indicating that listeners can use even restricted variability in learning to go beyond the training examples (Greenspan et al., 1988 ). Listeners may infer this generalized information from the training stimuli, or they might develop a more abstract representation of sound patterns based on variability in experience and apply this knowledge to novel speech patterns in novel contexts.
Synthetic speech, produced by rule, as learned in those studies, represents a complete model of speech production from orthographic-to-phonetic-to-acoustic generation. The speech that is produced is recognizable but it is artificial. Thus learning of this kind of speech is tantamount to learning a strange idiolect of speech that contains acoustic-phonetic errors, missing acoustic cues and does not possess correct cue covariation. However if listeners learn this speech by gleaning the new acoustic-phonetic properties for this kind of talker, it makes sense that listeners should be able to learn other kinds of speech as well. This is particularly true if learning is accomplished by changing the way listeners attend to the acoustic properties of speech by focusing on the acoustic properties that are most phonetically diagnostic. And indeed, beyond being able to learn synthesized speech in this fashion, adults have been shown to quickly adapt to a variety of other forms of distorted speech where the distortions initially cause a reduction in intelligibility, such as simulated cochlear implant speech (Shannon et al., 1995 ), spectrally shifted speech (Rosen et al., 1999 ) as well as foreign-accented speech (Weil, 2001 ; Clarke and Garrett, 2004 ; Bradlow and Bent, 2008 ; Sidaras et al., 2009 ). In these studies, listeners learn speech that has been produced naturally with coarticulation and the full range of acoustic-phonetic structure, however, the speech signal deviates from listener expectations due to a transform of some kind, either through signal processing or through phonological changes in speaking. Different signal transforms may distort or mask certain cues and phonological changes may change cue complex structure. These distortions are unlike synthetic speech however, as these transforms tend to be uniform across the phonological inventory. This would provide listeners with a kind of lawful variability (as described by Elman and McClelland, 1986 ) that can be exploited as an aid to recognition. Given that in all these speech distortions listeners showed a robust ability to apply what they learned during training to novel words and contexts, learning does not appear to be simply understanding what specific acoustic cues mean, but rather understanding what acoustic cues are most relevant for a given source and how to attend to them (Nusbaum and Lee, 1992 ; Nygaard et al., 1994 ; Francis and Nusbaum, 2002 ).
How do individuals come to learn what acoustic cues are most diagnostic for a given source? One possibility is that acoustic cues are mapped to their perceptual counterparts in an unguided fashion, that is, without regard for the systematicity of native acoustic-phonetic experience. Conversely, individuals may rely on their native phonological system to guide the learning process. In order to examine if perceptual learning is influenced by an individual’s native phonological experience, Davis et al. ( 2005 ) examined if perceptual learning was more robust when individuals were trained on words versus non-words. Their rationale was that if training on words led to better perceptual learning than non-words, then one could conclude that the acoustic to phonetic remapping process is guided or structured by information at the lexical level. Indeed, Davis et al. ( 2005 ) showed that training was more effective when the stimuli consisted of words than non-words, indicating that information at the lexical level allows individuals to use their knowledge about how sounds are related in their native phonological system to guide the perceptual learning process. The idea that perceptual learning in speech is driven to some extent by lexical knowledge is consistent with both autonomous (e.g., Shortlist: Norris, 1994 ; Merge: Norris et al., 2000 ; Shortlist B: Norris and McQueen, 2008 ) and interactive (e.g., TRACE: McClelland and Elman, 1986 ; Hebb-Trace: Mirman et al., 2006a ) models of speech perception (although whether learning can successfully operate in these models is a different question altogether). A subsequent study by Dahan and Mead ( 2010 ) examined the structure of the learning process further by asking how more localized or recent experience, such as the specific contrasts present during training, may organize and determine subsequent learning. To do this, Dahan and Mead ( 2010 ) systematically controlled the relationship between training and test stimuli as individuals learned to understand noise vocoded speech. Their logic was that if localized or recent experience organizes learning, then the phonemic contrasts present during training may provide such a structure, such that phonemes will be better recognized at test if they had been heard in a similar syllable position or vocalic context during training than if they had been heard in a different context. Their results showed that individuals’ learning was directly related to the local phonetic context of training, as consonants were recognized better if they had been heard in a similar syllable position or vocalic context during training than if they had been heard in a dissimilar context.
This is unsurprising as the acoustic realization of a given consonant can be dramatically different depending on the position of a consonant within a syllable (Sproat and Fujimura, 1993 ; Browman and Goldstein, 1995 ). Further, there are coarticulation effects such that the acoustic characteristics of a consonant are heavily modified by the phonetic context in which it occurs (Liberman et al., 1954 ; Warren and Marslen-Wilson, 1987 ; Whalen, 1991 ). In this sense, the acoustic properties of speech are not dissociable beads on a string and as such, the linguistic context of a phoneme is very much apart of the acoustic definition of a phoneme. While experience during training does appear to be the major factor underlying learning, individuals also show transfer of learning to phonemes that were not presented during training provided that were perceptually similar to the phonemes that were present. This is consistent with a substantial body of speech research using perceptual contrast procedures that showed that there are representations for speech sounds both at the level of the allophonic or acoustic-phonetic specification as well as at a more abstract phonological level (e.g., Sawusch and Jusczyk, 1981 ; Sawusch and Nusbaum, 1983 ; Hasson et al., 2007 ). Taken together both the Dahan and Mead ( 2010 ) and the Davis et al. ( 2005 ) studies provide clear evidence that previous experience, such as the knowledge of one’s native phonological system, as well as more localized experience relating to the occurrence of specific contrasts in a training set help to guide the perceptual learning process.
What is the nature of the mechanism underlying the perceptual learning process that leads to better recognition after training? To examine if training shifts attention to phonetically meaningful cues and away from misleading cues, Francis et al. ( 2000 ), trained listeners on CV syllables containing /b/, /d/, and or /g/ cued by a chimeric acoustic structure containing either consistent or conflicting properties. The CV syllables were constructed such that the place of articulation was specified by the spectrum of the burst (Blumstein and Stevens, 1980 ) as well as by the formant transitions from the consonant to the vowel (e.g., Liberman et al., 1967 ). However, for some chimeric CVs, the spectrum of the burst indicated a different place of articulation than the transition cue. Previously Walley and Carrell ( 1983 ) had demonstrated that listeners tend to identify place of articulation based on transition information rather than the spectrum of the burst when these cues conflict. And of course listeners never consciously hear either of these as separate signals—they simply hear a consonant at a particular place of articulation. Given that listeners cannot identify the acoustic cues that define the place of articulation consciously and only experience the categorical identity of the consonant itself, it seems hard to understand how attention can be directed towards these cues.
Francis et al. ( 2000 ) trained listeners to recognize the chimeric speech in their experiment by providing feedback about the consonant identity that was either consistent with the burst cues or the transition cues depending on the training group. For the burst-trained group, when listeners heard a CV and identified it as a B, D, or G, they would receive feedback following identification. For a chimeric consonant cued with a labial burst and an alveolar transition pattern (combined), whether listeners identified the consonant as B (correct for the burst-trained group) or another place, after identification they would hear the CV again and see feedback printed identifying the consonant as B. In other words, burst-trained listeners would get feedback during training consistent with the spectrum of the burst whereas transition-trained listeners would get feedback consistent with the pattern of the transitions. The results showed that cue-based feedback shifted identification performance over training trials such that listeners were able to learn to use the specific cue (either transition based or spectral burst based) that was consistent with the feedback and generalized to novel stimuli. This kind of learning research (also Francis and Nusbaum, 2002 ; Francis et al., 2007 ) suggests shifting attention may serve to restructure perceptual space as a result of appropriate feedback.
Although the standard view of speech perception is one that does not explicitly incorporate learning mechanisms, this is in part because of a very static view of speech recognition whereby stimulus patterns are simply mapped onto phonological categories during recognition, and learning may occur, if it does, afterwards. These theories never directly solve the lack of invariance problem, given a fundamentally deterministic computational process in which input states (whether acoustic or articulatory) must correspond uniquely to perceptual states (phonological categories). An alternative is to consider speech perception is an active process in which alternative phonetic interpretations are activated, each corresponding to a particular input pattern from speech (Nusbaum and Schwab, 1986 ). These alternatives must then be reduced to the recognized form, possibly by testing these alternatives as hypotheses shifting attention among different aspects of context, knowledge, or cues to find the best constraints. This view suggests that there should be an increase in cognitive load on the listener until a shift of attention to more diagnostic information occurs when there is a one-to-many mapping, either due to speech rate variability (Francis and Nusbaum, 1996 ) or talker variability (Nusbaum and Morin, 1992 ). Variation in talker or speaking rate or distortion can change the way attention is directed at a particular source of speech, shifting attention towards the most diagnostic cues and away from the misleading cues. This suggests a direct link between attention and learning, with the load on working memory reflecting the uncertainty of recognition given a one-to-many mapping of acoustic cues to phonemes.
If a one-to-many mapping increases the load on working memory because of active alternative phonetic hypotheses, and learning shifts attention to more phonetically diagnostic cues, learning to perceive synthetic speech should reduce the load on working memory. In this sense, focusing attention on the diagnostic cues should reduce the number of phonetic hypotheses. Moreover, this should not simply be a result of improved intelligibility, as increasing speech intelligibility without training should not have the same effect. To investigate this, Francis and Nusbaum ( 2009 ) used a speeded spoken target monitoring procedure and manipulated memory load to see if the effect of such a manipulation would change as a function of learning synthetic speech. The logic of the study was that varying a working memory load explicitly should affect recognition speed if working memory plays a role in recognition. Before training, working memory should have a higher load than after training, suggesting that there should be an interaction between working memory load and the training in recognition time (cf. Navon, 1984 ). When the extrinsic working memory load (to the speech task) is high, there should be less working memory available for recognition but when the extrinsic load is low there should be more working memory available. This suggests that training should interact with working memory load by showing a larger improvement of recognition time in the low load case than in the high load case. Of course if speech is directly mapped from acoustic cues to phonetic categories, there is no reason to predict a working memory load effect and certainly no interaction with training. The results demonstrated however a clear interaction of working memory load and training as predicted by the use of working memory and attention (Francis and Nusbaum, 2009 ). These results support the view that training reorganizes perception, shifting attention to more informative cues allowing working memory to be used more efficiently and effectively. This has implications for older adults who suffer from hearing loss. If individuals recruit additional cognitive and perceptual resources to ameliorate sensory deficits, then they will lack the necessary resources to cope with situations where there is an increase in talker or speaking rate variability. In fact, Peelle and Wingfield ( 2005 ) report that while older adults can adapt to time-compressed speech, they are unable to transfer learning on one speech rate to a second speech rate.
Mechanisms of Memory
Changes in the allocation of attention and the demands on working memory are likely related to substantial modifications of category structures in long term memory (Nosofsky, 1986 ; Ashby and Maddox, 2005 ). Effects of training on synthetic speech have been shown to be retained for 6 months suggesting that categorization structures in long-term memory that guide perception have been altered (Schwab et al., 1985 ). How are these category structures that guide perception (Schyns et al., 1998 ) modified? McClelland and Rumelhart ( 1985 ) and McClelland et al. ( 1995 ) have proposed a neural cognitive model that explains how individuals are able to adapt to new information in their environment. According to their model, specific memory traces are initially encoded during learning via a fast-learning hippocampal based memory system. Then, via a process of repeated reactivation or rehearsal, memory traces are strengthened and ultimately represented solely in the neocortical memory system. One of the main benefits of McClelland’s model is that it explains how previously learned information is protected against newly acquired information that may potentially be irrelevant for long-term use. In their model, the hippocampal memory system acts as temporary storage where fast-learning occurs, while the neocortical memory system, which houses the long-term memory category that guide perception, are modified later, presumably offline when there are no encoding demands on the system. This allows the representational system to remain adaptive without the loss of representational stability as only memory traces that are significant to the system will be strengthened and rehearsed. This kind of two-stage model of memory is consistent with a large body of memory data, although the role of the hippocampus outlined in this model is somewhat different than other theories of memory (e.g., Eichenbaum et al., 1992 ; Wood et al., 1999 , 2000 ).
Ashby et al. ( 2007 ) have also posited a two-stage model for category learning, but implementing the basis for the two stages, as well as their function in category formation, very differently. They suggest that the basal ganglia and the thalamus, rather than the hippocampus, together mediate the development of more permanent neorcortical memory structures. In their model, the striatum, globus pallidus, and thalamus comprise the fast learning temporary memory system. This subcortical circuit is has greater adaptability due to the dopamine-mediated learning that can occur in the basal ganglia, while representations in the neocortical circuit are much more slow to change as they rely solely on Hebbian learning to be amended.
McClelland’s neural model relies on the hippocampal memory system as a substrate to support the development of the long-term memory structures in neocortex. Thus hippocampal memories are comprised of recent specific experiences or rote memory traces that are encoded during training. In this sense, the hippocampal memory circuit supports the longer-term reorganization or consolidation of declarative memories. In contrast, in the basal ganglia based model of learning put forth by Ashby a striatum to thalamus circuit provides the foundation for the development of consolidation in cortical circuits. This is seen as a progression from a slow based hypothesis-testing system to a faster processing, implicit memory system. Therefore the striatum to thalamus circuit mediates the reorganization or consolidation of procedural memories. To show evidence for this, Ashby et al. ( 2007 ) use information-integration categorization tasks, where the rules that govern the categories that are to be learned are not easily verbalized. In these tasks, the learner is required to integrate information from two or more dimensions at some pre-decisional stage. The logic is that information-integration tasks use the dopamine-mediated reward signals afforded by the basal ganglia. In contrast, in rule-based categorization tasks the categories to be learned are explicitly verbally defined, and thus rely on conscious hypothesis generation and testing. As such, this explicit category learning is thought (Ashby et al., 2007 ) to be mediated by the anterior cingulate and the prefrontal cortex. For this reason, demands on working memory and executive attention are hypothesized to affect only the learning of explicit based categories and not implicit procedural categories, as working memory and executive attention are processes that are largely governed by the prefrontal cortex (Kane and Engle, 2000 ).
The differences between McClelland and Ashby’s models appear to be related in part to the distinction between declarative versus procedural learning. While it is certainly reasonable to divide memory in this way, it is unarguable that both types of memories involve encoding and consolidation. While it may be the case that the declarative and procedural memories operate through different systems, this seems unlikely given that there are data suggesting the role of the hippocampus in procedural learning (Chun and Phelps, 1999 ) even when this is not a verbalizable and an explicit rule-based learning process. Elements of the theoretic assumptions of both models seem open to criticism in one way or another. But both models make explicit a process by which rapidly learned, short-term memories can be consolidated into more stable forms. Therefore it is important to consider such models in trying to understand the process by which stable memories are formed as the foundation of phonological knowledge in speech perception.
As noted previously, speech appears to have separate representations for the specific acoustic patterns of speech as well as more abstract phonological categories (e.g., Sawusch and Jusczyk, 1981 ; Sawusch and Nusbaum, 1983 ; Hasson et al., 2007 ). Learning appears to occur at both levels as well (Greenspan et al., 1988 ) suggesting the importance of memory theory differentiating both short-term and long-term representations as well as stimulus specific traces and more abstract representations. It is widely accepted that any experience may be represented across various levels of abstraction. For example, while only specific memory traces are encoded for many connectionist models (e.g., McClelland and Rumelhart’s 1985 model), various levels of abstraction can be achieved in the retrieval process depending on the goals of the task. This is in fact the foundation of Goldinger’s ( 1998 ) echoic trace model based on Hintzman’s ( 1984 ) MINERVA2 model. Specific auditory representations of the acoustic pattern of a spoken word are encoded into memory and abstractions are derived during the retrieval process using working memory.
In contrast to these trace-abstraction models is another possibility wherein stimulus-specific and abstracted information are both stored in memory. For example an acoustic pattern description of speech as well as a phonological category description are represented separately in memory in the TRACE model (McClelland and Elman, 1986 ; Mirman et al., 2006a ). In this respect then, the acoustic patterns of speech—as particular representations of a specific perceptual experience—are very much like the echoic traces of Goldinger’s model. However where Goldinger argued against forming and storing abstract representations, others have suggested that such abstractions may in fact be formed and stored in the lexicon (see Luce et al., 2003 ; Ju and Luce, 2006 ). Indeed, Hasson et al. ( 2007 ) demonstrated repetition suppression effects specific to the abstract phonological representation of speech sounds given that the effect held between an illusory syllable /ta/ and a physical syllable /ta/ based on a network spanning sensory and motor cortex. Such abstractions are unlikely to simply be an assemblage of prior sensory traces given that the brain areas involved are not the same as those typically activated in recognizing those traces. In this way, memory can be theoretically distinguished into rote representational structures that consist of specific experienced items or more generalized structures that consist of abstracted information. Rote memories are advantageous for precise recall of already experienced stimuli where as generalized memory would favor performance for a larger span of stimuli in a novel context.
This distinction between rote and generalized representations cuts across the distinction between procedural and declarative memory. Both declarative and procedural memories may be encoded as either rote or generalized memory representational structures. For example, an individual may be trained to press a specific sequence of keys on a keyboard. This would lead to the development of a rote representational memory structure, allowing the individual to improve his or her performance on that specific sequence. Alternatively, the individual may be trained to press several sequences of keys on a keyboard. This difference in training would lead to the development of a more generalized memory structure, resulting in better performance both experienced and novel key sequences. Similarly declarative memories may be encoded as either rote or generalized structures as a given declarative memory structures may consist of either the specific experienced instances of a particular stimulus, as in a typical episodic memory experiment, or the “gist” of the experienced instances as in the formation of semantic memories or possibly illusory memories based on associations (see Gallo, 2006 ).
The argument about the distinction between rote and generalized or abstracted memory representations becomes important when considering the way in which memories become stabilized through consolidation. In particular, for perceptual learning of speech, two aspects are critical. First, given the generativity of language and the context-sensitive nature of acoustic-phonetics, listeners are not going to hear the same utterances again and again and further, the acoustic pattern variation in repeated utterances, even if they occurred, would be immense due to changes in linguistic context, speaking rate, and talkers. As such, this makes the use of rote-memorization of acoustic patterns untenable as a speech recognition system. Listeners either have to be able to generalize in real time from prior auditory experiences (as suggested by Goldinger, 1998 ) or there must be more abstract representations that go beyond the specific sensory patterns of any particular utterance (as suggested by Hasson et al., 2007 ). This is unlikely due to the second consideration, which is that any generalizations in speech perception must be made quickly and remain stable to be useful. As demonstrated by Greenspan et al. ( 1988 ) even learning a small number of spoken words from a particular speech synthesizer will produce some generalization to novel utterances, although increasing the variability in experiences will increase the amount of generalization.
The separation between rote and generalization learning is further demonstrated by the effects of sleep consolidation on the stability of memories. In the original synthetic speech learning study by Schwab et al. ( 1985 ), listeners demonstrated significant learning in spite of never hearing the same words twice. Moreover this generalization learning lasted for roughly 6 months without subsequent training. This demonstrates that high variability in training examples with appropriate feedback can produce large improvements in generalized performance that can remain robust and stable for a long time. Fenn et al. ( 2003 ) demonstrated that this stability is a consequence of sleep consolidation of learning. In addition, when some forgetting takes place over the course of a day following learning, sleep restores the forgotten memories. It appears that this may well be due to sleep separately consolidating both the initial learning as well as any interference that occurs following learning (Brawn et al., 2013 ). Furthermore, Fenn and Hambrick ( 2012 ) have demonstrated that the effectiveness of sleep consolidation is related to individual differences in working memory such that higher levels of working memory performance are related to better consolidation. This links the effectiveness of sleep consolidation to a mechanism closely tied to active processing in speech perception. Most recently though, Fenn et al. ( 2013 ) found that sleep operates differently for rote and generalized learning.
These findings have several implications for therapy with listeners with hearing loss. First, training and testing should be separated by a period of sleep in order to measure the amount of learning that is stable. Second, although variability in training experiences seems to produce slower rates of learning, it produces greater generalization learning. Third, measurements of working memory can give a rough guide to the relative effectiveness of sleep consolidation thereby indicating how at risk learning may be to interference and suggesting that training may need to be more prolonged for people with lower working memory capacity.
Theories of speech perception have often conceptualized the earliest stages of auditory processing of speech to be independent of higher level linguistic and cognitive processing. In many respects this kind of approach (e.g., in Shortlist B) treats the phonetic processing of auditory inputs as a passive system in which acoustic patterns are directly mapped onto phonetic features or categories, albeit with some distribution of performance. Such theories treat the distributions of input phonetic properties as relatively immutable. However, our argument is that even early auditory processes are subject to descending attentional control and active processing. Just as echolocation in the bat is explained by a cortofugal system in which cortical and subcortical structures are viewed as processing cotemporaneously and interactively (Suga, 2008 ), the idea that descending projects from cortex to thalamus and to the cochlea provide a neural substrate for cortical tuning of auditory inputs. Descending projections from the lateral olivary complex to the inner hair cells and from the medial olivary complex to the outer hair cells provide a potential basis for changing auditory encoding in real time as a result of shifts of attention. This kind of mechanism could support the kinds of effects seen in increased auditory brainstem response fidelity to acoustic input following training (Strait et al., 2010 ).
Understanding speech perception as an active process suggests that learning or plasticity is not simply a higher-level process grafted on top of word recognition. Rather the kinds of mechanisms involved in shifting attention to relevant acoustic cues for phoneme perception (e.g., Francis et al., 2000 , 2007 ) are needed for tuning speech perception to the specific vocal characteristics of a new speaker or to cope with distortion of speech or noise in the environment. Given that such plasticity is linked to attention and working memory, we argue that speech perception is inherently a cognitive process, even in terms of the involvement of sensory encoding. This has implications for remediation of hearing loss either with augmentative aids or therapy. First, understanding the cognitive abilities (e.g., working memory capacity, attention control etc.) may provide guidance on how to design a training program by providing different kinds of sensory cues that are correlated or reducing the cognitive demands of training. Second, increasing sensory variability within the limits of individual tolerance should be part of a therapeutic program. Third, understanding the sleep practice of participants using sleep logs, record of drug and alcohol consumption, and exercise are important to the consolidation of learning. If speech perception is continuously plastic but there are limitations based on prior experiences and cognitive capacities, this shapes the basic nature of remediation of hearing loss in a number of different ways.
Finally, we would note that there is a dissociation among the three classes of models that are relevant to understanding speech perception as an active process. Although cognitive models of spoken word processing (e.g., Cohort, TRACE, and Shortlist) have been developed to include some plasticity and to account for different patterns of the influence of lexical knowledge, even the most recent versions (e.g., Distributed Cohort, Hebb-TRACE, and Shortlist B) do not specifically account for active processing of auditory input. It is true that some models have attempted to account for active processing below the level of phonemes (e.g., TRACE I: Elman and McClelland, 1986 ; McClelland et al., 2006 ), these models not been related or compared systematically to the kinds of models emerging from neuroscience research. For example, Friederici ( 2012 ) and Rauschecker and Scott ( 2009 ) and Hickok and Poeppel ( 2007 ) have all proposed neurally plausible models largely around the idea of dorsal and ventral processing streams. Although these models differ in details, in principle the model proposed by Friederici ( 2012 ) and Rauschecker and Scott ( 2009 ) have more extensive feedback mechanisms to support active processing of sensory input. These models are constructed in a neuroanatomical vernacular rather than the cognitive vernacular (even the Hebb-TRACE is still largely a cognitive model) of the others. But both sets of models are notable for two important omissions.
First, while the cognitive models mention learning and even model it, and the neural models refer to some aspects of learning, these models do not relate to the two-process learning models (e.g., complementary learning systems (CLS; McClelland et al., 1995 ; Ashby and Maddox, 2005 ; Ashby et al., 2007 )). Although CLS focuses on episodic memory and Ashby et al. ( 2007 ) focus on category learning, two process models involving either hippocampus, basal ganglia, or cerebellum as a fast associator and cortico-cortical connections as a slower more robust learning system, have garnered substantial interest and research support. Yet learning in the models of speech recognition has yet to seriously address the neural bases of learning and memory except descriptively.
This points to a second important omission. All of the speech recognition models are cortical models. There is no serious consideration to the role of the thalamus, amygdala, hippocampus, cerebellum or other structures in these models. In taking a corticocentric view (see Parvizi, 2009 ), these models exhibit an unrealistic myopia about neural explanations of speech perception. Research by Kraus et al. (Wong et al., 2007 ; Song et al., 2008 ) demonstrates that there are measurable effects of training and experience on speech processing in the auditory brainstem. This is consistent with an active model of speech perception in which attention and experience shape the earliest levels of sensory encoding of speech. Although current data do not exist to support online changes in this kind of processing, this is exactly the kind of prediction an active model of speech perception would make but is entirely unexpected from any of the current models of speech perception.
Author contributions
Shannon L. M. Heald prepared the first draft and Howard C. Nusbaum revised and both refined the manuscript to final form.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Preparation of this manuscript was supported in part by an ONR grant DoD/ONR N00014-12-1-0850, and in part by the Division of Social Sciences at the University of Chicago.
- Abbs J. H., Sussman H. M. (1971). Neurophysiological feature detectors and speech perception: a discussion of theoretical implications . J. Speech Hear. Res. 14 , 23–36 [ PubMed ] [ Google Scholar ]
- Asari H., Zador A. M. (2009). Long-lasting context dependence constrains neural encoding models in rodent auditory cortex . J. Neurophysiol. 102 , 2638–2656 10.1152/jn.00577.2009 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Ashby F. G., Ennis J. M., Spiering B. J. (2007). A neurobiological theory of automaticity in perceptual categorization . Psychol. Rev. 114 , 632–656 10.1037/0033-295x.114.3.632 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Ashby F. G., Maddox W. T. (2005). Human category learning . Annu. Rev. Psychol. 56 , 149–178 10.1146/annurev.psych.56.091103.070217 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Barlow H. B. (1961). “ Possible principles underlying the transformations of sensory messages ,” in Sensory Communication , ed Rosenblith W. (Cambridge, MA: MIT Press; ), 217–234 [ Google Scholar ]
- Barsalou L. W. (1983). Ad hoc categories . Mem. Cognit. 11 , 211–227 10.3758/bf03196968 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Best C. T., McRoberts G. W., Goodell E. (2001). Discrimination of non-native consonant contrasts varying in perceptual assimilation to the listener’s native phonological system . J. Acoust. Soc. Am. 109 , 775–794 10.1121/1.1332378 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Best C. T., McRoberts G. W., Sithole N. M. (1988). Examination of perceptual reorganization for nonnative speech contrasts: Zulu click discrimination by English-speaking adults and infants . J. Exp. Psychol. Hum. Percept. Perform. 14 , 345–360 10.1037//0096-1523.14.3.345 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Blumstein S. E., Stevens K. N. (1980). Perceptual invariance and onset spectra for stop consonants in different vowel environments . J. Acoust. Soc. Am. 67 , 648–662 10.1121/1.383890 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Born J., Wilhelm I. (2012). System consolidation of memory during sleep . Psychol. Res. 76 , 192–203 10.1007/s00426-011-0335-6 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Bradlow A. R., Bent T. (2008). Perceptual adaptation to non-native speech . Cognition 106 , 707–729 10.1016/j.cognition.2007.04.005 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Brawn T., Nusbaum H. C., Margoliash D. (2013). Sleep consolidation of interfering auditory memories in starlings . Psychol. Sci. 24 , 439–447 10.1177/0956797612457391 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Broca P. (1865). Sur le sieège de la faculté du langage articulé . Bull. Soc. Anthropol. 6 , 377–393 10.3406/bmsap.1865.9495 [ CrossRef ] [ Google Scholar ]
- Browman C. P., Goldstein L. (1995). “ Gestural syllable position effects in American English ,” in Producing Speech: Contemporary Issues. For Katherine Safford Harris , eds Bell-Berti F., Raphael L. J. (Woodbury, NY: American Institute of Physics; ), 19–34 [ Google Scholar ]
- Carpenter G. A., Grossberg S. (1988). The ART of adaptive pattern recognition by a self-organizing neural network . Computer 21 , 77–88 10.1109/2.33 [ CrossRef ] [ Google Scholar ]
- Chun M. M., Phelps E. A. (1999). Memory deficits for implicit contextual information in amnesic subjects with hippocampal damage . Nat. Neurosci. 2 , 844–847 10.1038/12222 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Clarke C. M., Garrett M. F. (2004). Rapid adaptation to foreign-accented English . J. Acoust. Soc. Am. 116 , 3647–3658 10.1121/1.1815131 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Coelho C., Rosenbaum D., Nusbaum H. C., Fenn K. M. (2012). Imagined actions aren’t just weak actions: task variability promotes skill learning in physical but not in mental practice . J. Exp. Psychol. Learn. Mem. Cogn. 38 , 1759–1764 10.1037/a0028065 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Cruikshank S. J., Weinberger N. M. (1996). Receptive-field plasticity in the adult auditory cortex induced by Hebbian covariance . J. Neurosci. 16 , 861–875 [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Dahan D., Mead R. L. (2010). Context-conditioned generalization in adaptation to distorted speech . J. Exp. Psychol. Hum. Percept. Perform. 36 , 704–728 10.1037/a0017449 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Davis M. H., Johnsrude I. S., Hervais-Adelman A., Taylor K., McGettigan C. (2005). Lexical information drives perceptual learning of distorted speech: evidence from the comprehension of noise-vocoded sentences . J. Exp. Psychol. Gen. 134 , 222–241 10.1037/0096-3445.134.2.222 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Diehl R. L., Lotto A. J., Holt L. L. (2004). Speech perception . Annu. Rev. Psychol. 55 , 149–179 10.1146/annurev.psych.55.090902.142028 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Dorman M. F., Studdert-Kennedy M., Raphael L. J. (1977). Stop-consonant recognition: release bursts and formant transitions as functionally equivalent, context-dependent cues . Percept. Psychophys. 22 , 109–122 10.3758/bf03198744 [ CrossRef ] [ Google Scholar ]
- Eichenbaum H., Otto T., Cohen N. J. (1992). The hippocampus: what does it do? Behav. Neural Biol. 57 , 2–36 10.1016/0163-1047(92)90724-I [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Elman J. L., McClelland J. L. (1986). “ Exploiting the lawful variability in the speech wave ,” in In Variance and Variability in Speech Processes , eds Perkell J. S., Klatt D. H. (Hillsdale, NJ: Erlbaum; ), 360–385 [ Google Scholar ]
- Fant C. G. (1962). Descriptive analysis of the acoustic aspects of speech . Logos 5 , 3–17 [ PubMed ] [ Google Scholar ]
- Fenn K. M., Hambrick D. Z. (2012). Individual differences in working memory capacity predict sleep-dependent memory consolidation . J. Exp. Psychol. Gen. 141 , 404–410 10.1037/a0025268 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Fenn K. M., Margoliash D., Nusbaum H. C. (2013). Sleep restores loss of generalized but not rote learning of synthetic speech . Cognition 128 , 280–286 10.1016/j.cognition.2013.04.007 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Fenn K. M., Nusbaum H. C., Margoliash D. (2003). Consolidation during sleep of perceptual learning of spoken language . Nature 425 , 614–616 10.1038/nature01951 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Fodor J. A. (1983). Modularity of Mind: An Essay on Faculty Psychology. Cambridge, MA: MIT Press [ Google Scholar ]
- Francis A. L., Baldwin K., Nusbaum H. C. (2000). Effects of training on attention to acoustic cues . Percept. Psychophys. 62 , 1668–1680 10.3758/bf03212164 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Francis A. L., Nusbaum H. C. (2009). Effects of intelligibility on working memory demand for speech perception . Atten. Percept. Psychophys. 71 , 1360–1374 10.3758/APP.71.6.1360 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Francis A. L., Nusbaum H. C. (2002). Selective attention and the acquisition of new phonetic categories . J. Exp. Psychol. Hum. Percept. Perform. 28 , 349–366 10.1037/0096-1523.28.2.349 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Francis A. L., Kaganovich N., Driscoll-Huber C. J. (2008). Cue-specific effects of categorization training on the relative weighting of acoustic cues to consonant voicing in English . J. Acoust. Soc. Am. 124 , 1234–1251 10.1121/1.2945161 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Francis A. L., Nusbaum H. C., Fenn K. (2007). Effects of training on the acoustic phonetic representation of synthetic speech . J. Speech Lang. Hear. Res. 50 , 1445–1465 10.1044/1092-4388(2007/100) [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Francis A. L., Nusbaum H. C. (1996). Paying attention to speaking rate . ICSLP 96 Proceedings of the Fourth International Conference on Spoken Language 3 , 1537–1540 [ Google Scholar ]
- Friederici A. D. (2012). The cortical language circuit: from auditory perception to sentence comprehension . Trends Cogn. Sci. 16 , 262–268 10.1016/j.tics.2012.04.001 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Galbraith G. C., Arroyo C. (1993). Selective attention and brainstem frequency-following responses . Biol. Psychol. 37 , 3–22 10.1016/0301-0511(93)90024-3 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Gallo D. A. (2006). Associative Illusions of Memory. New York: Psychology Press [ Google Scholar ]
- Gaskell M. G., Marslen-Wilson W. D. (1997). Integrating form and meaning: a distributed model of speech perception . Lang. Cogn. Process. 12 , 613–656 10.1080/016909697386646 [ CrossRef ] [ Google Scholar ]
- Geschwind N. (1970). The organization of language and the brain . Science 170 , 940–944 [ PubMed ] [ Google Scholar ]
- Giard M. H., Collet L., Bouchet P., Pernier J. (1994). Auditory selective attention in the human cochlea . Brain Res. 633 , 353–356 10.1016/0006-8993(94)91561-x [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Gibson E. J. (1969). Principles of Perceptual Learning and Development. New York: Appleton-Century-Crofts [ Google Scholar ]
- Goldinger S. D. (1998). Echoes of echoes? An episodic theory of lexical access . Psychol. Rev. 105 , 251–279 10.1037/0033-295x.105.2.251 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Goldstone R. L. (1998). Perceptual learning . Annu. Rev. Psychol. 49 , 585–612 10.1146/annurev.psych.49.1.585 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Goldstone R. L., Kersten A. (2003). “ Concepts and categories ,” in Comprehensive Handbook of Psychology, Experimental Psychology (Vol. 4), eds Healy A. F., Proctor R. W. (New York: Wiley; ), 591–621 [ Google Scholar ]
- Greenspan S. L., Nusbaum H. C., Pisoni D. B. (1988). Perceptual learning of synthetic speech produced by rule . J. Exp. Psychol. Learn. Mem. Cogn. 14 , 421–433 10.1037/0278-7393.14.3.421 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hasson U., Skipper J. I., Nusbaum H. C., Small S. L. (2007). Abstract coding of audiovisual speech: beyond sensory representation . Neuron 56 , 1116–1126 10.1016/j.neuron.2007.09.037 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hickok G., Poeppel D. (2007). The cortical organization of speech processing . Nat. Rev. Neurosci. 8 , 393–402 10.1038/nrn2113 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hintzman D. L. (1984). MINERVA 2: a simulation model of human memory . Behav. Res. Methods Instrum. Comput. 16 , 96–101 10.3758/bf03202365 [ CrossRef ] [ Google Scholar ]
- Huang J., Holt L. L. (2012). Listening for the norm: adaptive coding in speech categorization . Front. Psychol. 3 :10 10.3389/fpsyg.2012.00010 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Ju M., Luce P. A. (2006). Representational specificity of within-category phonetic variation in the long-term mental lexicon . J. Exp. Psychol. Hum. Percept. Perform. 32 , 120–138 10.1037/0096-1523.32.1.120 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Jusczyk P. W. (1993). From general to language-specific capacities: the WRAPSA model of how speech perception develops . J. Phon. – A Special Issue on Phon. Development 21 , 3–28 [ Google Scholar ]
- Kane M. J., Engle R. W. (2000). Working memory capacity, proactive interference and divided attention: limits on long-term memory retrieval . J. Exp. Psychol. Learn. Mem. Cogn. 26 , 336–358 10.1037/0278-7393.26.2.336 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Ladefoged P., Broadbent D. E. (1957). Information conveyed by vowels . J. Acoust. Soc. Am. 29 , 98–104 10.1121/1.1908694 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Laing E. J. C., Liu R., Lotto A. J., Holt L. L. (2012). Tuned with a tune: talker normalization via general auditory processes . Front. Psychol. 3 :203 10.3389/fpsyg.2012.00203 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Lametti D. R., Ostry D. J. (2010). Postural constraint on movement variability . J. Neurophysiol. 104 , 1061–1067 10.1152/jn.00306.2010 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Liberman A. M., Cooper F. S., Shankweiler D. P., StuddertKennedy M. (1967). Perception of the speech code . Psychol. Rev. 74 , 431–461 10.1037/h0020279 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Liberman A. M., Delattre P. C., Cooper F. S., Gerstman L. J. (1954). The role of consonant-vowel transitions in the perception of the stop and nasal consonants . Psychol. Monogr. Gen. Appl. 68 , 1–13 10.1037/h0093673 [ CrossRef ] [ Google Scholar ]
- Lichtheim L. (1885). On aphasia . Brain 7 , 433–484 [ Google Scholar ]
- Lim S. J., Holt L. L. (2011). Learning foreign sounds in an alien world: videogame training improves non-native speech categorization . Cogn. Sci. 35 , 1390–1405 10.1111/j.1551-6709.2011.01192.x [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Lisker L., Abramson A. S. (1964). A cross-language study of voicing in initial stops: acoustical measurements . Word 20 , 384–422 [ Google Scholar ]
- Lively S. E., Logan J. S., Pisoni D. B. (1993). Training Japanese listeners to identify English/r/and/l/. II: the role of phonetic environment and talker variability in learning new perceptual categories . J. Acoust. Soc. Am. 94 , 1242–1255 10.1121/1.408177 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Logan G. D. (1988). Toward an instance theory of automatization . Psychol. Rev. 95 , 492–527 10.1037/0033-295x.95.4.492 [ CrossRef ] [ Google Scholar ]
- Logan J. S., Lively S. E., Pisoni D. B. (1991). Training Japanese listeners to identify English/r/and/l: a first report . J. Acoust. Soc. Am. 89 , 874–886 10.1121/1.1894649 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Luce P. A., Pisoni D. B. (1998). Recognizing spoken words: the neighborhood activation model . Ear Hear. 19 , 1–36 10.1097/00003446-199802000-00001 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Luce P. A., McLennan C., Charles-Luce J. (2003). “ Abstractness and specificity in spoken word recognition: indexical and allophonic variability in long-term repetition priming ,” in Rethinking Implicit Memory , eds Bowers J., Marsolek C. (Oxford: Oxford University Press; ), 197–214 [ Google Scholar ]
- MacKay D. M. (1951). Mindlike Behavior in artefacts . Br. J. Philos. Sci. 2 , 105–121 10.10.1093/bjps/ii.6.105 [ CrossRef ] [ Google Scholar ]
- MacKay D. M. (1956). “ The epistemological problem for automata ,” in Automata Studies , eds Shannon C. E., McCarthy J. (Princeton: Princeton University Press; ). [ Google Scholar ]
- Marr D. (1982). Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. San Francisco: Freeman [ Google Scholar ]
- Marr D. (1971). Simple memory: a theory for archicortex . Philos. Trans. R. Soc. Lond. B Biol. Sci. 262 , 23–81 [ PubMed ] [ Google Scholar ]
- Marslen-Wilson W., Welsh A. (1978). Processing interactions and lexical access during word recognition in continuous speech . Cogn. Psychol. 10 , 29–63 10.1016/0010-0285(78)90018-x [ CrossRef ] [ Google Scholar ]
- Mattar A. A. G., Ostry D. J. (2010). Generalization of dynamics learning across changes in movement amplitude . J. Neurophysiol. 104 , 426–438 10.1152/jn.00886.2009 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- McClelland J. L., Elman J. L. (1986). The TRACE model of speech perception . Cogn. Psychol. 18 , 1–86 [ PubMed ] [ Google Scholar ]
- McClelland J. L., Rumelhart D. E. (1985). Distributed memory and the representation of general and specific information . J. Exp. Psychol. Gen. 114 , 159–197 [ PubMed ] [ Google Scholar ]
- McClelland J. L., McNaughton B. L., O’Reilly R. C. (1995). Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory . Psychol. Rev. 102 , 419–457 10.1037//0033-295x.102.3.419 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- McClelland J. L., Mirman D., Holt L. L. (2006). Are there interactive processes in speech perception? Trends Cogn. Sci. 10 , 363–369 10.1016/j.tics.2006.06.007 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- McCoy S. L., Tun P. A., Cox L. C., Colangelo M., Stewart R. A., Wingfield A. (2005). Hearing loss and perceptual effort: downstream effects on older adults’ memory for speech . Q. J. Exp. Psychol. A 58 , 22–33 10.1080/02724980443000151 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- McMurray B., Jongman A. (2011). What information is necessary for speech categorization? Harnessing variability in the speech signal by integrating cues computed relative to expectations . Psychol. Rev. 118 , 219–246 10.1037/a0022325 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- McQueen J. M., Norris D., Cutler A. (2006). Are there really interactive speech processes in speech perception? Trends Cogn. Sci. 10 :533 [ PubMed ] [ Google Scholar ]
- Mirman D., McClelland J. L., Holt L. L. (2006a). An interactive Hebbian account of lexically guided tuning of speech perception . Psychon. Bull. Rev. 13 , 958–965 10.3758/bf03213909 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Mirman D., McClelland J. L., Holt L. L. (2006b). Theoretical and empirical arguments support interactive processing . Trends Cogn. Sci. 10 , 534 10.1016/j.tics.2006.10.003 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Moran J., Desimone R. (1985). Selective attention gates visual processing in the extrastriate cortex . Science 229 , 782–784 10.1126/science.4023713 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Murphy D. R., Craik F. I., Li K. Z., Schneider B. A. (2000). Comparing the effects of aging and background noise of short-term memory performance . Psychol. Aging 15 , 323–334 10.1037/0882-7974.15.2.323 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Navon D. (1984). Resources—a theoretical soup stone? Psychol. Rev. 91 , 216–234 10.1037/0033-295x.91.2.216 [ CrossRef ] [ Google Scholar ]
- Nittrouer S., Miller M. E. (1997). Predicting developmental shifts in perceptual weighting schemes . J. Acoust. Soc. Am. 101 , 2253–2266 10.1121/1.418207 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Nittrouer S., Lowenstein J. H. (2007). Children’s weighting strategies for word-final stop voicing are not explained by auditory capacities . J. Speech Lang. Hear. Res. 50 , 58–73 10.1044/1092-4388(2007/005) [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Norris D. (1994). Shortlist: a connectionist model of continuous speech recognition . Cognition 52 , 189–234 10.1016/0010-0277(94)90043-4 [ CrossRef ] [ Google Scholar ]
- Norris D., McQueen J. M. (2008). Shortlist B: a Bayesian model of continuous speech recognition . Psychol. Rev. 115 , 357–395 10.1037/0033-295x.115.2.357 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Norris D., McQueen J. M., Cutler A. (2000). Merging information in speech recognition: feedback is never necessary . Behav. Brain Sci. 23 , 299–325 10.1017/s0140525x00003241 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Nosofsky R. M. (1986). Attention, similarity and the identification - categorization relationship . J. Exp. Psychol. Gen. 115 , 39–57 10.1037/0096-3445.115.1.39 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Nusbaum H. C., Lee L. (1992). “ Learning to hear phonetic information ,” in Speech Perception, Production, and Linguistic Structure , eds Tohkura Y., Vatikiotis-Bateson E., Sagisaka Y. (Tokyo: OHM Publishing Company; ), 265–273 [ Google Scholar ]
- Nusbaum H. C., Magnuson J. (1997). “ Talker normalization: phonetic constancy as a cognitive process ,” in Talker Variability in Speech Processing , eds Johnson K., Mullennix J. W. (San Diego: Academic Press; ), 109–129 [ Google Scholar ]
- Nusbaum H. C., Morin T. M. (1992). “ Paying attention to differences among talkers ,” in Speech Perception, Production, and Linguistic Structure , eds Tohkura Y., Vatikiotis-Bateson E., Sagisaka Y. (Tokyo: OHM Publishing Company; ), 113–134 [ Google Scholar ]
- Nusbaum H. C., Pisoni D. B. (1985). Constraints on the perception of synthetic speech generated by rule . Behav. Res. Methods Instrum. Comput. 17 , 235–242 10.3758/bf03214389 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Nusbaum H. C., Schwab E. C. (1986). “ The role of attention and active processing in speech perception ,” in Pattern Recognition by Humans and Machines: Speech Perception (Vol. 1), eds Schwab E. C., Nusbaum H. C. (San Diego: Academic Press; ), 113–157 [ Google Scholar ]
- Nygaard L. C., Pisoni D. B. (1998). Talker-specific perceptual learning in spoken word recognition . Percept. Psychophys. 60 , 355–376 10.1121/1.397688 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Nygaard L. C., Sommers M., Pisoni D. B. (1994). Speech perception as a talker-contingent process . Psychol. Sci. 5 , 42–46 10.1111/j.1467-9280.1994.tb00612.x [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Parvizi J. (2009). Corticocentric myopia: old bias in new cognitive sciences . Trends Cogn. Sci. 13 , 354–359 10.1016/j.tics.2009.04.008 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Peelle J. E., Wingfield A. (2005). Dissociable components of perceptual learning revealed by adult age differences in adaptation to time-compressed speech . J. Exp. Psychol. Hum. Percept. Perform. 31 , 1315–1330 10.1037/0096-1523.31.6.1315 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Peterson G. E., Barney H. L. (1952). Control methods used in a study of the vowels . J. Acoust. Soc. Am. 24 , 175–184 10.1121/1.1906875 [ CrossRef ] [ Google Scholar ]
- Pichora-Fuller M. K., Souza P. E. (2003). Effects of aging on auditory processing of speech . Int. J. Audiol. 42 , 11–16 10.3109/14992020309074638 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Pisoni D. B., Aslin R. N., Perey A. J., Hennessy B. L. (1982). Some effects of laboratory training on identification and discrimination of voicing contrasts in stop consonants . J. Exp. Psychol. Hum. Percept. Perform. 8 , 297–314 10.1037//0096-1523.8.2.297 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Pisoni D. B., Lively S. E., Logan J. S. (1994). “ Perceptual learning of non-native speech contrasts: implications for theories of speech perception ,” in Development of Speech Perception: The Transition from Speech Sounds to Spoken Words , eds Goodman J., Nusbaum H. C. (Cambridge, MA: MIT Press; ), 121–166 [ Google Scholar ]
- Rabbitt P. (1991). Mild hearing loss can cause apparent memory failures which increase with age and reduce with IQ . Acta Otolaryngol. Suppl. 111 , 167–176 10.3109/00016489109127274 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Rauschecker J. P., Scott S. K. (2009). Maps and streams in the auditory cortex: nonhuman primates illuminate human speech processing . Nat. Neurosci. 12 , 718–724 10.1038/nn.2331 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Rosch E., Mervis C. B., Gray W., Johnson D., Boyes-Braem P. (1976). Basic objects in natural categories . Cogn. Psychol. 8 , 382–439 10.1016/0010-0285(76)90013-x [ CrossRef ] [ Google Scholar ]
- Rosen S., Faulkner A., Wilkinson L. (1999). Perceptual adaptation by normal listeners to upward shifts of spectral information in speech and its relevance for users of cochlear implants . J. Acoust. Soc. Am. 106 , 3629–3636 10.1121/1.428215 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Sawusch J. R., Nusbaum H. C. (1983). Auditory and phonetic processes in place perception for stops . Percept. Psychophys. 34 , 560–568 10.3758/bf03205911 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Sawusch J. R., Jusczyk P. W. (1981). Adaptation and contrast in the perception of voicing . J. Exp. Psychol. Hum. Percept. Perform. 7 , 408–421 10.1037/0096-1523.7.2.408 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Schwab E. C., Nusbaum H. C., Pisoni D. B. (1985). Some effects of training on the perception of synthetic speech . Hum. Factors 27 , 395–408 [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Schyns P. G., Goldstone R. L., Thibaut J. P. (1998). The development of features in object concepts . Behav. Brain Sci. 21 , 1–17 10.1017/s0140525x98000107 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Shannon R. V., Zeng F.-G., Kamath V., Wygonski J., Ekelid M. (1995). Speech recognition with primarily temporal cues . Science 270 , 303–304 10.1126/science.270.5234.303 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Shiffrin R. M., Schneider W. (1977). Controlled and automatic human information processing: II. Perceptual learning, automatic attending and a general theory . Psychol. Rev. 84 , 127–190 10.1037//0033-295x.84.2.127 [ CrossRef ] [ Google Scholar ]
- Sidaras S. K., Alexander J. E., Nygaard L. C. (2009). Perceptual learning of systematic variation in Spanish-accented speech . J. Acoust. Soc. Am. 125 , 3306–3316 10.1121/1.3101452 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Skoe E., Kraus N. (2012). A little goes a long way: how the adult brain is shaped by musical training in childhood . J. Neurosci. 32 , 11507–11510 10.1523/JNEUROSCI.1949-12.2012 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Song J. H., Skoe E., Wong P. C. M., Kraus N. (2008). Plasticity in the adult human auditory brainstem following short-term linguistic training . J. Cogn. Neurosci. 20 , 1892–1902 10.1162/jocn.2008.20131 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Spinelli D. N., Pribram K. H. (1966). Changes in visual recovery functions produced by temporal lobe stimulation in monkeys . Electroencephalogr. Clin. Neurophysiol. 20 , 44–49 10.1016/0013-4694(66)90139-8 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Sproat R., Fujimura O. (1993). Allophonic variation in English /l/ and its implications for phonetic implementation . J. Phon. 21 , 291–311 [ Google Scholar ]
- Strait D. L., Kraus N., Parbery-Clark A., Ashley R. (2010). Musical experience shapes top-down auditory mechanisms: evidence from masking and auditory attention performance . Hear. Res. 261 , 22–29 10.1016/j.heares.2009.12.021 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Strange W., Jenkins J. J. (1978). “ Role of linguistic experience in the perception of speech ,” in Perception and Experience , eds Walk R. D., Pick H. L. (New York: Plenum Press; ), 125–169 [ Google Scholar ]
- Suga N. (2008). Role of corticofugal feedback in hearing . J. Comp. Physiol. A Neuroethol. Sens. Neural Behav. Physiol. 194 , 169–183 10.1007/s00359-007-0274-2 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Surprenant A. M. (2007). Effects of noise on identification and serial recall of nonsense syllables in older and younger adults . Neuropsychol. Dev. Cogn. B Aging Neuropsychol. Cogn. 14 , 126–143 10.1080/13825580701217710 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Walley A. C., Carrell T. D. (1983). Onset spectra and formant transitions in the adult’s and child’s perception of place of articulation in stop consonants . J. Acoust. Soc. Am. 73 , 1011–1022 10.1121/1.389149 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Warren P., Marslen-Wilson W. (1987). Continuous uptake of acoustic cues in spoken word recognition . Percept. Psychophys. 41 , 262–275 10.3758/bf03208224 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Wehr M., Zador A. M. (2003). Balanced inhibition underlies tuning and sharpens spike timing in auditory cortex . Nature 426 , 442–446 10.1038/nature02116 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Weil S. A. (2001). Foreign Accented Speech: Adaptation and Generalization. The Ohio State University: Doctoral Dissertation [ Google Scholar ]
- Weinberger N. M. (1998). Tuning the brain by learning and by stimulation of the nucleus basalis . Trends Cogn. Sci. 2 , 271–273 10.1016/s1364-6613(98)01200-5 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Werker J. F., Logan J. S. (1985). Cross-language evidence for three factors in speech perception . Percept. Psychophys. 37 , 35–44 10.3758/bf03207136 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Werker J. F., Polka L. (1993). Developmental changes in speech perception: new challenges and new directions . J. Phon. 83 , 101 [ Google Scholar ]
- Werker J. F., Tees R. C. (1983). Developmental changes across childhood in the perception of non-native speech sounds . Can. J. Psychol. 37 , 278–286 10.1037/h0080725 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Werker J. F., Tees R. C. (1984). Cross-language speech perception: evidence for perceptual reorganization during the first year of life . Infant. Behav. Dev. 7 , 49–63 10.1016/s0163-6383(84)80022-3 [ CrossRef ] [ Google Scholar ]
- Wernicke C. (1874/1977). “ Der aphasische symptomencomplex: eine psychologische studie auf anatomischer basis ,” in Wernicke’s Works on Aphasia: A Sourcebook and Review , ed Eggert G. H. (The Hague: Mouton; ), 91–145 [ Google Scholar ]
- Whalen D. H. (1991). Subcategorical phonetic mismatches and lexical access . Percept. Psychophys. 50 , 351–360 10.3758/bf03212227 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Wingfield A., Tun P. A., McCoy S. L. (2005). Hearing loss in older adulthood. What it is and how it interacts with cognitive performance . Curr. Dir. Psychol. Sci. 14 , 144–148 10.1111/j.0963-7214.2005.00356.x [ CrossRef ] [ Google Scholar ]
- Wong P. C. M., Skoe E., Russo N. M., Dees T., Kraus N. (2007). Musical experience shapes human brainstem encoding of linguistic pitch patterns . Nat. Neurosci. 10 , 420–422 10.1038/nn1872 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Wood E. R., Dudchenko P. A., Eichenbaum H. (1999). The global record of memory in hippocampal neuronal activity . Nature 397 , 613–616 10.1038/17605 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Wood E. R., Dudchenko P. A., Robitsek R. J., Eichenbaum H. (2000). Hippocampal neurons encode information about different types of memory episodes occurring in the same location . Neuron 27 , 623–633 10.1016/s0896-6273(00)00071-4 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Yamada R. A., Tohkura Y. (1992). The effects of experimental variables on the perception of American English /r/ and /l/ by Japanese listeners . Percept. Psychophys. 52 , 376–392 10.3758/bf03206698 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Znamenskiy P., Zador A. M. (2013). Corticostriatal neurons in auditory cortex drive decisions during auditory discrimination . Nature 497 , 482–486 10.1038/nature12077 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Audiometers
- Tympanometers
- Hearing Aid Fitting
- Research Systems
- Research Unit
- ACT Research
- Our History
- Distributors
- Sustainability
- Environmental Sustainability
Training in Speech Audiometry
- Why Perform Functional Hearing Tests?
Speech Audiometry: An Introduction
Description, table of contents, what is speech audiometry, why perform speech audiometry.
- Contraindications and considerations
Audiometers that can perform speech audiometry
How to perform speech audiometry, results interpretation, calibration for speech audiometry.
Speech audiometry is an umbrella term used to describe a collection of audiometric tests using speech as the stimulus. You can perform speech audiometry by presenting speech to the subject in both quiet and in the presence of noise (e.g. speech babble or speech noise). The latter is speech-in-noise testing and is beyond the scope of this article.
Speech audiometry is a core test in the audiologist’s test battery because pure tone audiometry (the primary test of hearing sensitivity) is a limited predictor of a person’s ability to recognize speech. Improving an individual’s access to speech sounds is often the main motivation for fitting them with a hearing aid. Therefore, it is important to understand how a person with hearing loss recognizes or discriminates speech before fitting them with amplification, and speech audiometry provides a method of doing this.
A decrease in hearing sensitivity, as measured by pure tone audiometry, results in greater difficulty understanding speech. However, the literature also shows that two individuals of the same age with similar audiograms can have quite different speech recognition scores. Therefore, by performing speech audiometry, an audiologist can determine how well a person can access speech information.
Acquiring this information is key in the diagnostic process. For instance, it can assist in differentiating between different types of hearing loss. You can also use information from speech audiometry in the (re)habilitation process. For example, the results can guide you toward the appropriate amplification technology, such as directional microphones or remote microphone devices. Speech audiometry can also provide the audiologist with a prediction of how well a subject will hear with their new hearing aids. You can use this information to set realistic expectations and help with other aspects of the counseling process.
Below are some more examples of how you can use the results obtained from speech testing.
Identify need for further testing
Based on the results from speech recognition testing, it may be appropriate to perform further testing to get more information on the nature of the hearing loss. An example could be to perform a TEN test to detect a dead region or to perform the Audible Contrast Threshold (ACT™) test .
Inform amplification decisions
You can use the results from speech audiometry to determine whether binaural amplification is the most appropriate fitting approach or if you should consider alternatives such as CROS aids.
You can use the results obtained through speech audiometry to discuss and manage the amplification expectations of patients and their communication partners.
Unexpected asymmetric speech discrimination, significant roll-over , or particularly poor speech discrimination may warrant further investigation by a medical professional.
Non-organic hearing loss
You can use speech testing to cross-check the results from pure tone audiometry for suspected non‑organic hearing loss.
Contraindications and considerations when performing speech audiometry
Before speech audiometry, it is important that you perform pure tone audiometry and otoscopy. Results from these procedures can reveal contraindications to performing speech audiometry.
Otoscopic findings
Speech testing using headphones or inserts is generally contraindicated when the ear canal is occluded with:
- Foreign body
- Or infective otitis externa
In these situations, you can perform bone conduction speech testing or sound field testing.
Audiometric findings
Speech audiometry can be challenging to perform in subjects with severe-to-profound hearing losses as well as asymmetrical hearing losses where the level of stimulation and/or masking noise required is beyond the limits of the audiometer or the patient's uncomfortable loudness levels (ULLs).
Subject variables
Depending on the age or language ability of the subject, complex words may not be suitable. This is particularly true for young children and adults with learning disabilities or other complex presentations such as dementia and reduced cognitive function.
You should also perform speech audiometry in a language which is native to your patient. Speech recognition testing may not be suitable for patients with expressive speech difficulties. However, in these situations, speech detection testing should be possible.
Before we discuss speech audiometry in more detail, let’s briefly consider the instrumentation to deliver the speech stimuli. As speech audiometry plays a significant role in diagnostic audiometry, many audiometers include – or have the option to include – speech testing capabilities.
Table 1 outlines which audiometers from Interacoustics can perform speech audiometry.
Table 1: Audiometers from Interacoustics that can perform speech audiometry.
Because speech audiometry uses speech as the stimulus and languages are different across the globe, the way in which speech audiometry is implemented varies depending on the country where the test is being performed. For the purposes of this article, we will start with addressing how to measure speech in quiet using the international organization of standards ISO 8252-3:2022 as the reference to describe the terminology and processes encompassing speech audiometry. We will describe two tests: speech detection testing and speech recognition testing.
Speech detection testing
In speech detection testing, you ask the subject to identify when they hear speech (not necessarily understand). It is the most basic form of speech testing because understanding is not required. However, it is not commonly performed. In this test, words are normally presented to the ear(s) through headphones (monaural or binaural testing) or through a loudspeaker (binaural testing).
Speech detection threshold (SDT)
Here, the tester will present speech at varying intensity levels and the patient identifies when they can detect speech. The goal is to identify the level at which the patient detects speech in 50% of the trials. This is the speech detection threshold. It is important not to confuse this with the speech discrimination threshold. The speech discrimination threshold looks at a person’s ability to recognize speech and we will explain it later in this article.
The speech detection threshold has been found to correlate well with the pure tone average, which is calculated from pure tone audiometry. Because of this, the main application of speech detection testing in the clinical setting is confirmation of the audiogram.
Speech recognition testing
In speech recognition testing, also known as speech discrimination testing, the subject must not only detect the speech, but also correctly recognize the word or words presented. This is the most popular form of speech testing and provides insights into how a person with hearing loss can discriminate speech in ideal conditions.
Across the globe, the methods of obtaining this information are different and this often leads to confusion about speech recognition testing. Despite there being differences in the way speech recognition testing is performed, there are some core calculations and test parameters which are used globally.
Speech recognition testing: Calculations
There are two main calculations in speech recognition testing.
1. Speech recognition threshold (SRT)
This is the level in dB HL at which the patient recognizes 50% of the test material correctly. This level will differ depending on the test material used. Some references describe the SRT as the speech discrimination threshold or SDT. This can be confusing because the acronym SDT belongs to the speech detection threshold. For this reason, we will not use the term discrimination but instead continue with the term speech recognition threshold.
2. Word recognition score (WRS)
In word recognition testing, you present a list of phonetically balanced words to the subject at a single intensity and ask them to repeat the words they hear. You score if the patient repeats these words correctly or incorrectly. This score, expressed as a percentage of correct words, is calculated by dividing the number of words correctly identified by the total number of words presented.
In some countries, multiple word recognition scores are recorded at various intensities and plotted on a graph. In other countries, a single word recognition score is performed using a level based on the SRT (usually presented 20 to 40 dB louder than the SRT).
Speech recognition testing: Parameters
Before completing a speech recognition test, there are several parameters to consider.
1. Test transducer
You can perform speech recognition testing using air conduction, bone conduction, and speakers in a sound-field setup.
2. Types of words
Speech recognition testing can be performed using a variety of different words or sentences. Some countries use monosyllabic words such as ‘boat’ or ‘cat’ whereas other countries prefer to use spondee words such as ‘baseball’ or ‘cowboy’. These words are then combined with other words to create a phonetically balanced list of words called a word list.
3. Number of words
The number of words in a word list can impact the score. If there are too few words in the list, then there is a risk that not enough data points are acquired to accurately calculate the word recognition score. However, too many words may lead to increased test times and patient fatigue. Word lists often consist of 10 to 25 words.
You can either score words as whole words or by the number of phonemes they contain.
An example of scoring can be illustrated by the word ‘boat’. When scoring using whole words, anything other than the word ‘boat’ would result in an incorrect score.
However, in phoneme scoring, the word ‘boat’ is broken down into its individual phonemes: /b/, /oa/, and /t/. Each phoneme is then scored as a point, meaning that the word boat has a maximum score of 3. An example could be that a patient mishears the word ‘boat’ and reports the word to be ‘float’. With phoneme scoring, 2 points would be awarded for this answer whereas in word scoring, the word float would be marked as incorrect.
5. Delivery of material
Modern audiometers have the functionality of storing word lists digitally onto the hardware of the device so that you can deliver a calibrated speech signal the same way each time you test a patient. This is different from the older methods of testing using live voice or a CD recording of the speech material. Using digitally stored and calibrated speech material in .wav files provides the most reliable and repeatable results as the delivery of the speech is not influenced by the tester.
6. Aided or unaided
You can perform speech recognition testing either aided or unaided. When performing aided measurements, the stimulus is usually played through a loudspeaker and the test is recorded binaurally.
Global examples of how speech recognition testing is performed and reported
Below are examples of how speech recognition testing is performed in the US and the UK. This will show how speech testing varies across the globe.
Speech recognition testing in the US: Speech tables
In the US, the SRT and WRS are usually performed as two separate tests using different word lists for each test. The results are displayed in tables called speech tables.
The SRT is the first speech test which is performed and typically uses spondee words (a word with two equally stressed syllables, such as ‘hotdog’) as the stimulus. During this test, you present spondee words to the patient at different intensities and a bracketing technique establishes the threshold at where the patient correctly identifies 50% of the words.
In the below video, we can see how an SRT is performed using spondee words.
Below, you can see a table showing the results from an SRT test (Figure 1). Here, we can see that the SRT has been measured in each ear. The table shows the intensity at which the SRT was found as well as the transducer, word list, and the level at which masking noise was presented (if applicable). Here we see an unaided SRT of 30 dB HL in both the left and right ears.

Once you have established the intensity of the SRT in dB HL, you can use it to calculate the intensity to present the next list of words to measure the WRS. In WRS testing, it is common to start at an intensity of between 20 dB and 40 dB louder than the speech recognition threshold and to use a different word list from the SRT. The word lists most commonly used in the US for WRS are the NU-6 and CID-W22 word lists.
In word recognition score testing, you present an entire word list to the test subject at a single intensity and score each word based on whether the subject can correctly repeat it or not. The results are reported as a percentage.
The video below demonstrates how to perform the word recognition score.
Below is an image of a speech table showing the word recognition score in the left ear using the NU‑6 word list at an intensity of 55 dB HL (Figure 2). Here we can see that the patient in this example scored 90%, indicating good speech recognition at moderate intensities.
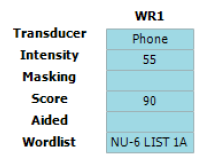
Speech recognition testing in the UK: Speech audiogram
In the UK, speech recognition testing is performed with the goal of obtaining a speech audiogram. A speech audiogram is a graphical representation of how well an individual can discriminate speech across a variety of intensities (Figure 3).
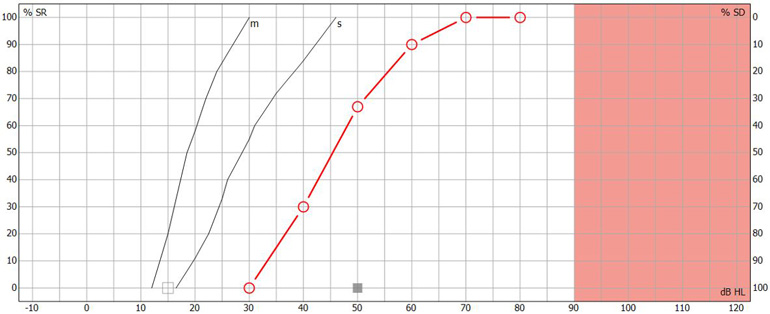
In the UK, the most common method of recording a speech audiogram is to present several different word lists to the subject at varying intensities and calculate multiple word recognition scores. The AB (Arthur Boothroyd) word lists are the most used lists. The initial list is presented around 20 to 30 dB sensation level with subsequent lists performed at quieter intensities before finally increasing the sensation level to determine how well the patient can recognize words at louder intensities.
The speech audiogram is made up of plotting the WRS at each intensity on a graph displaying word recognition score in % as a function of intensity in dB HL. The following video explains how it is performed.
Below is an image of a completed speech audiogram (Figure 4). There are several components.
Point A on the graph shows the intensity in dB HL where the person identified 50% of the speech material correctly. This is the speech recognition threshold or SRT.
Point B on the graph shows the maximum speech recognition score which informs the clinician of the maximum score the subject obtained.
Point C on the graph shows the reference speech recognition curve; this is specific to the test material used (e.g., AB words) and method of presentation (e.g., headphones), and shows a curve which describes the median speech recognition scores at multiple intensities for a group of normal hearing individuals.

Having this displayed on a single graph can provide a quick and easy way to determine and analyze the ability of the person to hear speech and compare their results to a normative group. Lastly, you can use the speech audiogram to identify roll-over. Roll-over occurs when the speech recognition deteriorates at loud intensities and can be a sign of retro-cochlear hearing loss. We will discuss this further in the interpretation section.
Masking in speech recognition testing
Just like in audiometry, cross hearing can also occur in speech audiometry. Therefore, it is important to mask the non-test ear when testing monaurally. Masking is important because word recognition testing is usually performed at supra-threshold levels. Speech encompasses a wide spectrum of frequencies, so the use of narrowband noise as a masking stimulus is not appropriate, and you need to modify the masking noise for speech audiometry. In speech audiometry, speech noise is typically used to mask the non-test ear.
There are several approaches to calculating required masking noise level. An equation by Coles and Priede (1975) suggests one approach which applies to all types of hearing loss (sensorineural, conductive, and mixed):
- Masking level = D S plus max ABG NT minus 40 plus E M
It considers the following factors.
1. Dial setting
D S is the level of dial setting in dB HL for presentation of speech to the test ear.
2. Air-bone gap
Max ABG NT is the maximum air-bone gap between 250 to 4000 Hz in the non‑test ear.
3. Interaural attenuation
Interaural attenuation: The value of 40 comes from the minimum interaural attenuation for masking in audiometry using headphones (for insert earphones, this would be 55 dB).
4. Effective masking
E M is effective masking. Modern audiometers are calibrated in E M , so you don’t need to include this in the calculation. However, if you are using an old audiometer calibrated to an older calibration standard, then you should calculate the E M .
You can calculate it by measuring the difference in the speech dial setting presented to normal listeners at a level that yields a score of 95% in quiet and the noise dial setting presented to the same ear that yields a score less than 10%.
You can use the results from speech audiometry for many purposes. The below section describes these applications.
1. Cross-check against pure tone audiometry results
The cross-check principle in audiology states that no auditory test result should be accepted and used in the diagnosis of hearing loss until you confirm or cross-check it by one or more independent measures (Hall J. W., 3rd, 2016). Speech-in-quiet testing serves this purpose for the pure tone audiogram.
The following scores and their descriptions identify how well the speech detection threshold and the pure tone average correlate (Table 2).
Table 2: Correlation between speech detection threshold and pure tone average.
If there is a poor correlation between the speech detection threshold and the pure tone average, it warrants further investigation to determine the underlying cause or to identify if there was a technical error in the recordings of one of the tests.
2. Detect asymmetries between ears
Another core use of speech audiometry in quiet is to determine the symmetry between the two ears and whether it is appropriate to fit binaural amplification. Significant differences between ears can occur when there are two different etiologies causing hearing loss.
An example of this could be a patient with sensorineural hearing loss who then also contracts unilateral Meniere’s disease . In this example, it would be important to understand if there are significant differences in the word recognition scores between the two ears. If there are significant differences, then it may not be appropriate for you to fit binaural amplification, where other forms of amplification such as contralateral routing of sound (CROS) devices may be more appropriate.
3. Identify if further testing is required
The results from speech audiometry in quiet can identify whether further testing is required. This could be highlighted in several ways.
One example could be a severe difference in the SRT and the pure tone average. Another example could be significant asymmetries between the two ears. Lastly, very poor speech recognition scores in quiet might also be a red flag for further testing.
In these examples, the clinician might decide to perform a test to detect the presence of cochlear dead regions such as the TEN test or an ACT test to get more information.
4. Detect retro-cochlear hearing loss
In subjects with retro-cochlear causes of hearing loss, speech recognition can begin to deteriorate as sounds are made louder. This is called ‘roll-over’ and is calculated by the following equation:
- Roll-over index = (maximum score minus minimum score) divided by maximum score
If roll-over is detected at a certain value (the value is dependent on the word list chosen for testing but is commonly larger than 0.4), then it is considered to be a sign of retro-cochlear pathology. This could then have an influence on the fitting strategy for patients exhibiting these results.
It is important to note however that as the cross-check principle states, you should interpret any roll-over with caution and you should perform additional tests such as acoustic reflexes , the reflex decay test, or auditory brainstem response measurements to confirm the presence of a retro-cochlear lesion.
5. Predict success with amplification
The maximum speech recognition score is a useful measure which you can use to predict whether a person will benefit from hearing aids. More recent, and advanced tests such as the ACT test combined with the Acceptable Noise Level (ANL) test offer good alternatives to predicting hearing success with amplification.
Just like in pure tone audiometry, the stimuli which are presented during speech audiometry require annual calibration by a specialized technician ster. Checking of the transducers of the audiometer to determine if the speech stimulus contains any distortions or level abnormalities should also be performed daily. This process replicates the daily checks a clinicians would do for pure tone audiometry. If speech is being presented using a sound field setup, then you can use a sound level meter to check if the material is being presented at the correct level.
The next level of calibration depends on how the speech material is delivered to the audiometer. Speech material can be presented in many ways including live voice, CD, or installed WAV files on the audiometer. Speech being presented as live voice cannot be calibrated but instead requires the clinician to use the VU meter on the audiometer (which indicates the level of the signal being presented) to determine if they are speaking at the correct intensity. Speech material on a CD requires daily checks and is also performed using the VU meter on the audiometer. Here, a speech calibration tone track on the CD is used, and the VU meter is adjusted accordingly to the desired level as determined by the manufacturer of the speech material.
The most reliable way to deliver a speech stimulus is through a WAV file. By presenting through a WAV file, you can skip the daily tone-based calibration as this method allows you to calibrate the speech material as part of the annual calibration process. This saves the clinician time and ensures the stimulus is calibrated to the same standard as the pure tones in their audiometer. To calibrate the WAV file stimulus, the speech material is calibrated against a speech calibration tone. This is stored on the audiometer. Typically, a 1000 Hz speech tone is used for the calibration and the calibration process is the same as for a 1000 Hz pure tone calibration.
Lastly, if the speech is being presented through the sound field, a calibration professional should perform an annual sound field speaker calibration using an external free field microphone aimed directly at the speaker from the position of the patient’s head.
Coles, R. R., & Priede, V. M. (1975). Masking of the non-test ear in speech audiometry . The Journal of laryngology and otology , 89 (3), 217–226.
Graham, J. Baguley, D. (2009). Ballantyne's Deafness, 7th Edition. Whiley Blackwell.
Hall J. W., 3rd (2016). Crosscheck Principle in Pediatric Audiology Today: A 40-Year Perspective . Journal of audiology & otology , 20 (2), 59–67.
Katz, J. (2009). Handbook of Clinical Audiology. Wolters Kluwer.
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners . The Journal of the Acoustical Society of America , 116 (4), 2395–2405.
Stach, B.A (1998). Clinical Audiology: An Introduction, Cengage Learning.

Popular Academy Advancements
Getting started: assr, what is nhl-to-ehl correction, what is the ce-chirp® family of stimuli, nhl-to-ehl correction for abr stimuli.
- Find a distributor
- Customer stories
- Made Magazine
- ABR equipment
- OAE devices
- Hearing aid fitting systems
- Balance testing equipment
Certificates
- Privacy policy
- Cookie Policy
Introduction to Automatic Speech Recognition (ASR)
Speech Processing
16 minute read

Maël Fabien
co-founder & ceo @ biped.ai
- Switzerland
- Custom Social Profile Link
This article provides a summary of the course “Automatic speech recognition” by Gwénolé Lecorvé from the Research in Computer Science (SIF) master , to which I added notes of the Statistical Sequence Processing course of EPFL, and from some tutorials/personal notes. All references are presented at the end.
Introduction to ASR
What is asr.
Automatic Speech Recognition (ASR), or Speech-to-text (STT) is a field of study that aims to transform raw audio into a sequence of corresponding words.
Some of the speech-related tasks involve:
- speaker diarization: which speaker spoke when?
- speaker recognition: who spoke?
- spoken language understanding: what’s the meaning?
- sentiment analysis: how does the speaker feel?
The classical pipeline in an ASR-powered application involves the Speech-to-text, Natural Language Processing and Text-to-speech.

ASR is not easy since there are lots of variabilities:
- variability between speakers (inter-speaker)
- variability for the same speaker (intra-speaker)
- noise, reverberation in the room, environment…
- articulation
- elisions (grouping some words, not pronouncing them)
- words with similar pronounciation
- size of vocabulary
- word variations
From a Machine Learning perspective, ASR is also really hard:
- very high dimensional output space, and a complex sequence to sequence problem
- few annotated training data
- data is noisy
How is speech produced?
Let us first focus on how speech is produced. An excitation \(e\) is produced through lungs. It takes the form of an initial waveform, describes as an airflow over time.
Then, vibrations are produced by vocal cords, filters \(f\) are applied through pharynx, tongue…

The output signal produced can be written as \(s = f * e\), a convolution between the excitation and the filters. Hence, assuming \(f\) is linear and time-independent:
From the initial waveform, we generate the glotal spectrum, right out of the vocal cords. A bit higher the vocal tract, at the level of the pharynx, pitches are formed and produce the formants of the vocal tract. Finally, the output spectrum gives us the intensity over the range of frequencies produced.

Breaking down words
In automatic speech recognition, you do not train an Artificial Neural Network to make predictions on a set of 50’000 classes, each of them representing a word.
In fact, you take an input sequence, and produce an output sequence. And each word is represented as a phoneme , a set of elementary sounds in a language based on the International Phonetic Alphabet (IPA). To learn more about linguistics and phonetic, feel free to check this course from Harvard. There are around 40 to 50 different phonemes in English.
Phones are speech sounds defined by the acoustics, potentially unlimited in number,
For example, the word “French” is written under IPA as : / f ɹ ɛ n t ʃ /. The phoneme describes the voiceness / unvoiceness as well as the position of articulators.
Phonemes are language-dependent, since the sounds produced in languages are not the same. We define a minimal pair as two words that differ by only one phoneme. For example, “kill” and “kiss”.
For the sake of completeness, here are the consonant and vowel phonemes in standard french:

There are several ways to see a word:
- as a sequence of phonemes
- as a sequence of graphemes (mostly a written symbol representing phonemes)
- as a sequence of morphemes (meaningful morphological unit of a language that cannot be further divided) (e.g “re” + “cogni” + “tion”)
- as a part-of-speech (POS) in morpho-syntax: grammatical class, e.g noun, verb, … and flexional information, e.g singular, plural, gender…
- as a syntax describing the function of the word (subject, object…)
- as a meaning
Therefore, labeling speech can be done at several levels:
And the labels may be time-algined if we know when they occur in speech.
The vocabulary is defined as the set of words in a specific task, a language or several languages based on the ASR system we want to build. If we have a large vocabulary, we talk about Large vocabulary continuous speech recognition (LVCSR) . If some words we encounter in production have never been seen in training, we talk about Out Of Vocabulary words (OOV).
We distinguish 2 types of speech recognition tasks:
- isolated word recognition
- continuous speech recognition, which we will focus on
Evaluation metrics
We usually evaluate the performance of an ASR system using Word Error Rate (WER). We take as a reference a manual transcript. We then compute the number of mistakes made by the ASR system. Mistakes might include:
- Substitutions, \(N_{SUB}\), a word gets replaced
- Insertions, \(N_{INS}\), a word which was not pronounced in added
- Deletions, \(N_{DEL}\), a word is omitted from the transcript
The WER is computed as:
The perfect WER should be as close to 0 as possible. The number of substitutions, insertions and deletions is computed using the Wagner-Fischer dynamic programming algorithm for word alignment.
Statistical historical approach to ASR
Let us denote the optimal word sequence \(W^{\star}\) from the vocabulary. Let the input sequence of acoustic features be \(X\). Stastically, our aim is to identify the optimal sequence such that:
This is known as the “Fundamental Equation of Statistical Speech Processing”. Using Bayes Rule, we can rewrite is as :
Finally, we suppose independence and remove the term \(P(X)\). Hence, we can re-formulate our problem as:
- \(argmax_W\) is the search space, a function of the vocabulary
- \(P(X \mid W)\) is called the acoustic model
- \(P(W)\) is called the language model
The steps are presented in the following diagram:

Feature extraction \(X\)
From the speech analysis, we should extract features \(X\) which are:
- robust across speakers
- robust against noise and channel effects
- low dimension, at equal accuracy
- non-redondant among features
Features we typically extract include:
- Mel-Frequency Cepstral Coefficients (MFCC), as desbribed here
- Perceptual Linear Prediction (PLP)
We should then normalize the features extracted to avoid mismatches across samples with mean and variance normalization.
Acoustic model
1. hmm-gmm acoustic model.
The acoustic model is a complex model, usually based on Hidden Markov Models and Artificial Neural Networks, modeling the relationship between the audio signal and the phonetic units in the language.
In isolated word/pattern recognition, the acoustic features (here \(Y\)) are used as an input to a classifier whose rose is to output the correct word. However, we take input sequence and should output sequences too when it comes to continuous speech recognition .

The acoustic model goes further than a simple classifier. It outputs a sequence of phonemes.

Hidden Markov Models are natural candidates for Acoustic Models since they are great at modeling sequences. If you want to read more on HMMs and HMM-GMM training, you can read this article . The HMM has underlying states \(s_i\), and at each state, observations \(o_i\) are generated.

In HMMs, 1 phoneme is typically represented by a 3 or 5 state linear HMM (generally the beginning, middle and end of the phoneme).

The topology of HMMs is flexible by nature, and we can choose to have each phoneme being represented by a single state, or 3 states for example:

The HMM supposes observation independence, in the sense that:
The HMM can also output context-dependent phonemes, called triphones. Triphones are simply a group of 3 phonemes, the left one being the left context, and the right one, the right context.
The HMM is trained using Baum-Welsch algorithm. The HMMs learns to give the probability of each end of phoneme at time t. We usually suppose the observations are generated by a mixture of Gaussians (Gaussian Mixture Models, GMMs) at each state, i.e:
The training of the HMM-GMM is solved by Expectation Maximization (EM). In the EM training, the outputs of the GMM \(P(X \mid W)\) are used as inputs for the GMM training iteratively, and the Viterbi or Baum Welsch algorithm trains the HMM (i.e. identifies the transition matrices) to produce the best state sequence.
The full pipeline is presented below:

2. HMM-DNN acoustic model
Latest models focus on hybrid HMM-DNN architectures and approach the acoustic model in another way. In such approach, we do not care about the acoustic model \(P(X \mid W)\), but we directly tackle \(P(W \mid X)\) as the probability of observing state sequences given \(X\).
Hence, back to the first acoustic modeling equation, we target:
The aim of the DNN is to model the posterior probabilities over HMM states.

Some considerations on the HMM-DNN framework:
- we usually take a large number of hidden layers
- the inputs features typically are extracted from large windows (up to 1-2 seconds) to have a large context
- early stopping can be used
You might have noticed that the training of the DNN produces posterior, whereas the Viterbi Backward-Forward algorithm requires \(P(X \mid W)\) to identify the optimal sequence when training the HMM. Therefore, we use Bayes Rule:
The probability of the acoustic feature \(P(X)\) is not known, but it just scales all the likelihoods by the same factor, and therefore does not modify the alignment.
The training of HMM-DNN architectures is based:
- E-step keeps DNN and HMM parameters constant and estimates the DNN outputs to produce scaled likelihoods
- M-step re-trains the DNN parameters on the new targets from E-step
- either using REMAP, with a similar architecture, except that the states priors are also given as inputs to the DNN
3. HMM-DNN vs. HMM-GMM
Here is a brief summary of the pros and cons of HMM/DNN and HMM/GMM:
4. End-to-end models
In End-to-end models, the steps of feature extraction and phoneme prediction are combined:

This concludes the part on acoustic modeling.
Pronunciation
In small vocabulary sizes, it is quite easy to collect a lot of utterances for each word, and the HMM-GMM or HMM-DNN training is efficient. However, “statistical modeling requires a sufficient number of examples to get a good estimate of the relationship between speech input and the parts of words”. In large-vocabulary tasks, we might collect 1 or even 0 training examples. t. Thus, it is not feasible to train a model for each word, and we need to share information across words, based on the pronunciation.
We consider words are being sequences of states \(Q\).
Where \(P(Q \mid W)\) is the pronunciation model .
The pronunciation dictionary is written by human experts, and defined in the IPA. The pronunciation of words is typically stored in a lexical tree, a data structure that allows us to share histories between words in the lexicon.

When decoding a sequence in prediction, we must identify the most likely path in the tree based on the HMM-DNN output.
In ASR, most recent approaches are:
- either end to end
- or at the character level
In both approaches, we do not care about the full pronunciation of the words. Grapheme-to-phoneme (G2P) models try to learn automatically the pronunciation of new words.
Language Modeling
Let’s get back to our ASR base equation:
The language model is defined as \(P(W)\). It assigns a probability estimate to word sequences, and defines:
- what the speaker may say
- the vocabulary
- the probability over possible sequences, by training on some texts
The contraint on \(P(W)\) is that \(\sum_W P(W) = 1\).
In statistical language modeling, we aim to disambiguate sequences such as:
“recognize speech”, “wreck a nice beach”
The maximum likelihood estimation of a sequence is given by:
Where \(C(w_1, ..., w_i)\) is the observed count in the training data. For example:

We call this ratio the relative frequency . The probability of a whole sequence is given by the chain rule of probabilities:
This approach seems logic, but the longer the sequence, the most likely it will be that we encounter 0’s, hence bringing the probability of the whole sequence at 0.
What solutions can we apply?
- smoothing: redistribute the probability mass from observed to unobserved events (e.g Laplace smoothing, Add-k smoothing)
- backoff: explained below
1. N-gram language model
But one of the most popular solution is the n-gram model . The idea behind the n-gram model is to truncate the word history to the last 2, 3, 4 or 5 words, and therefore approximate the history of the word:
We take \(n\) as being 1 (unigram), 2 (bigram), 3 (trigram)…
Let us now discuss some practical implementation tricks:
- we compute the log of the probabilities, rather than the probabilities themselves (to avoid floating point approximation to 0)
- for the first word of a sequence, we need to define pseudo-words as being the first 2 missing words for the trigram: \(P(I \mid <s><s>)\)
With N-grams, it is possible that we encounter unseen N-grams in prediction. There is a technique called backoff that states that if we miss the trigram evidence, we use the bigram instead, and if we miss the bigram evidence, we use the unigram instead…
Another approach is linear interpolate , where we combine different order n-grams by linearly interpolating all the models:
2. Language models evaluation metrics
There are 2 types of evaluation metrics for language models:
- extrinsic evaluation , for which we embed the language model in an application and see by which factor the performance is improved
- intrinsic evaluation that measures the quality of a model independent of any application
Extrinsic evaluations are often heavy to implement. Hence, when focusing on intrinsic evaluations, we:
- split the dataset/corpus into train and test (and development set if needed)
- learn transition probabilities from the trainig set
- use the perplexity metric to evaluate the language model on the test set
We could also use the raw probabilities to evaluate the language model, but the perpeplixity is defined as the inverse probability of the test set, normalized by the number of words. For example, for a bi-gram model, the perpeplexity (noted PP) is defined as:
The lower the perplexity, the better
3. Limits of language models
Language models are trained on a closed vocabulary. Hence, when a new unknown word is met, it is said to be Out of Vocabulary (OOV).
4. Deep learning language models
More recently in Natural Language Processing, neural network-based language models have become more and more popular. Word embeddings project words into a continuous space \(R^d\), and respect topological properties (semantics and morpho-syntaxic).
Recurrent neural networks and LSTMs are natural candidates when learning such language models.
The training is now done. The final step to cover is the decoding, i.e. the predictions to make when we collect audio features and want to produce transcript.
We need to find:
However, exploring the whole spact, especially since the Language Model \(P(W)\) has a really large scale factor, can be incredibly long.
One of the solutions is to explore the Beam Search . The Beam Search algorithm greatly reduces the scale factor within a language model (whether N-gram based or Neural-network-based). In Beam Search, we:
- identify the probability of each word in the vocabulary for the first position, and keep the top K ones (K is called the Beam width)
- for each of the K words, we compute the conditional probability of observing each of the second words of the vocabulary
- among all produced probabilities, we keep only the top K ones
- and we move on to the third word…
Let us illustrate this process the following way. We want to evaluate the sequence that is the most likely. We first compute the probability of the different words of the vocabulary to be the starting word of the sentence:

Here, we fix the beam width to 2, meaning that we only select the 2 most likely words to start with. Then, we move on to the next word, and compute the probability of observing it using conditional probability in the language model: \(P(w_2, w_1 \mid W) = P(w_1 \mid W) P(w_2 \mid w_1, W)\). We might see that a potential candidate, e.g. “The”, when selecting the top 2 candidates second words among all possible words, is not a possible path anymore. In that case, we narrow the search, since we know that the first must must be “a”.

And so on… Another approach to decoding is the Weighted Finite State Transducers (I’ll make an article on that).
Summary of the ASR pipeline
In their paper “Word Embeddings for Speech Recognition” , Samy Bengio and Georg Heigold present a good summary of a modern ASR architecture:
- Words are represented through lexicons as phonemes
- Typically, for context, we cluster triphones
- We then assume that these triphones states were in fact HMM states
- And the the observations each HMM state generates are produced by DNNs or GMMs

End-to-end approach
Alright, this article is already long, but we’re almost done. So far, we mostly covered historical statistical approaches. These approaches work very well. However, most recent papers and implementations focus on end-to-end approaches, where:
- we encode \(X\) as a sequence of contexts \(C\)
- we decode \(C\) into a sequence of words \(W\)
These approaches, also called encoder-decoder, are part of sequence-to-sequence models. Sequence to sequence models learn to map a sequence of inputs to a sequence of outputs, even though their length might differ. This is widely used in Machine Translation for example.
As illustrated below, the Encoder reduces the input sequence to a encoder vector through a stack of RNNs, and the decoder vector uses this vector as an input.

I will write more about End-to-end models in another article.
This is all for this quite long introduction to automatic speech recognition. After a brief introduction to speech production, we covered historical approaches to speech recognition with HMM-GMM and HMM-DNN approaches. We also mentioned the more recent end-to-end approaches. If you want to improve this article or have a question, feel free to leave a comment below :)
References:
- “Automatic speech recognition” by Gwénolé Lecorvé from the Research in Computer Science (SIF) master
- EPFL Statistical Sequence Processing course
- Stanford CS224S
- Rasmus Robert HMM-DNN
- A Tutorial on Pronunciation Modeling for Large Vocabulary Speech Recognition
- N-gram Language Models, Stanford
- Andrew Ng’s Beam Search explanation
- Encoder Decoder model
- Automatic Speech Recognition Introduction, University of Edimburgh
Copyright © 2024 AudiologyOnline - All Rights Reserved
- Back to Basics: Speech Audiometry
Janet R. Schoepflin, PhD
- Hearing Evaluation - Adults
Editor's Note: This is a transcript of an AudiologyOnline live seminar. Please download supplemental course materials . Speech is the auditory stimulus through which we communicate. The recognition of speech is therefore of great interest to all of us in the fields of speech and hearing. Speech audiometry developed originally out of the work conducted at Bell Labs in the 1920s and 1930s where they were looking into the efficiency of communication systems, and really gained momentum post World War II as returning veterans presented with hearing loss. The methods and materials for testing speech intelligibility were of interest then, and are still of interest today. It is due to this ongoing interest as seen in the questions that students ask during classes, by questions new audiologists raise as they begin their practice, and by the comments and questions we see on various audiology listservs about the most efficient and effective ways to test speech in the clinical setting, that AudiologyOnline proposed this webinar as part of their Back to Basics series. I am delighted to participate. I am presenting a review of the array of speech tests that we use in clinical evaluation with a summary of some of the old and new research that has come about to support the recommended practices. The topics that I will address today are an overview of speech threshold testing, suprathreshold speech recognition testing, the most comfortable listening level testing, uncomfortable listening level, and a brief mention of some new directions that speech testing is taking. In the context of testing speech, I will assume that the environment in which you are testing meets the ANSI permissible noise criteria and that the audiometer transducers that are being used to perform speech testing are all calibrated to the ANSI standards for speech. I will not be talking about those standards, but it's of course important to keep those in mind.
Speech Threshold testing involves several considerations. They include the purposes of the test or the reasons for performing the test, the materials that should be used in testing, and the method or procedure for testing. Purposes of Speech Threshold Testing A number of purposes have been given for speech threshold testing. In the past, speech thresholds were used as a means to cross-check the validity of pure tone thresholds. This purpose lacks some validity because we have other physiologic and electrophysiologic procedures like OAEs and imittance test results to help us in that cross-check. However, the speech threshold measure is a test of hearing. It is not entirely invalid to be performed as a cross-check for pure tone hearing. I think sometimes we are anxious to get rid of things because we feel we have a better handle from other tests, but in this case, it may not be the wisest thing to toss out. Also in past years, speech thresholds were used to determine the level for suprathreshold speech recognition testing. That also lacks validity, because the level at which suprathreshold testing is conducted depends on the reason you are doing the test itself. It is necessary to test speech thresholds if you are going to bill 92557. Aside from that, the current purpose for speech threshold testing is in the evaluation of pediatric and difficult to test patients. Clinical practice surveys tell us that the majority of clinicians do test speech thresholds for all their patients whether it is for billing purposes or not. It is always important that testing is done in the recommended, standardized manner. The accepted measures for speech thresholds are the Speech Recognition Threshold (SRT) and the Speech Detection Threshold (SDT). Those terms are used because they specify the material or stimulus, i.e. speech, as well as the task that the listener is required to do, which is recognition or identification in the case of the SRT, and detection or noticing of presence versus absence of the stimulus in the case of SDT. The terms also specify the criterion for performance which is threshold or generally 50%. The SDT is most commonly performed on those individuals who have been unable to complete an SRT, such as very young children. Because recognition is not required in the speech detection task, it is expected that the SDT will be about 5 to 10 dB better than the SRT, which requires recognition of the material. Materials for Speech Threshold Testing The materials that are used in speech threshold testing are spondees, which are familiar two-syllable words that have a fairly steep psychometric function. Cold running speech or connected discourse is an alternative for speech detection testing since recognition is not required in that task. Whatever material is used, it should be noted on the audiogram. It is important to make notations on the audiogram about the protocols and the materials we are using, although in common practice many of us are lax in doing so. Methods for Speech Threshold Testing The methods consideration in speech threshold testing is how we are going to do the test. This would include whether we use monitored live voice or recorded materials, and whether we familiarize the patient with the materials and the technique that we use to elicit threshold. Monitored live voice and recorded speech can both be used in SRT testing. However, recorded presentation is recommended because recorded materials standardize the test procedure. With live voice presentation, the monitoring of each syllable of each spondee, so that it peaks at 0 on the VU meter can be fairly difficult. The consistency of the presentation is lost then. Using recorded materials is recommended, but it is less important in speech threshold testing than it is in suprathreshold speech testing. As I mentioned with the materials that are used, it is important to note on the audiogram what method of presentation has been used. As far as familiarization goes, we have known for about 50 years, since Tillman and Jerger (1959) identified familiarity as a factor in speech thresholds, that familiarization of the patient with the test words should be included as part of every test. Several clinical practice surveys suggest that familiarization is not often done with the patients. This is not a good practice because familiarization does influence thresholds and should be part of the procedure. The last consideration under methods is regarding the technique that is going to be used. Several different techniques have been proposed for the determination of SRT. Clinical practice surveys suggest the most commonly used method is a bracketing procedure. The typical down 10 dB, up 5 dB is often used with two to four words presented at each level, and the threshold then is defined as the lowest level at which 50% or at least 50% of the words are correctly repeated. This is not the procedure that is recommended by ASHA (1988). The ASHA-recommended procedure is a descending technique where two spondees are presented at each decrement from the starting level. There are other modifications that have been proposed, but they are not widely used.
Suprathreshold speech testing involves considerations as well. They are similar to those that we mentioned for threshold tests, but they are more complicated than the threshold considerations. They include the purposes of the testing, the materials that should be used in testing, whether the test material should be delivered via monitored live voice or recorded materials, the level or levels at which the testing should be conducted, whether a full list, half list, or an abbreviated word list should be used, and whether or not the test should be given in quiet or noise. Purposes of Suprathreshold Testing There are several reasons to conduct suprathreshold tests. They include estimating the communicative ability of the individual at a normal conversational level; determining whether or not a more thorough diagnostic assessment is going to be conducted; hearing aid considerations, and analysis of the error patterns in speech recognition. When the purpose of testing is to estimate communicative ability at a normal conversational level, then the test should be given at a level around 50 to 60 dBHL since that is representative of a normal conversational level at a communicating distance of about 1 meter. While monosyllabic words in quiet do not give a complete picture of communicative ability in daily situations, it is a procedure that people like to use to give some broad sense of overall communicative ability. If the purpose of the testing is for diagnostic assessment, then a psychometric or performance-intensity function should be obtained. If the reason for the testing is for hearing aid considerations, then the test is often given using words or sentences and either in quiet or in a background of noise. Another purpose is the analysis of error patterns in speech recognition and in that situation, a test other than some open set monosyllabic word test would be appropriate. Materials for Suprathreshold Testing The choice of materials for testing depends on the purpose of the test and on the age and abilities of the patients. The issues in materials include the set and the test items themselves.
Closed set vs. Open set. The first consideration is whether a closed set or an open set is appropriate. Closed set tests limit the number of response alternatives to a fairly small set, usually between 4 and 10 depending on the procedure. The number of alternatives influences the guess rate. This is a consideration as well. The Word Intelligibility by Picture Identification or the WIPI test is a commonly used closed set test for children as it requires only the picture pointing response and it has a receptive language vocabulary that is as low as about 5 years. It is very useful in pediatric evaluations as is another closed set test, the Northwestern University Children's Perception of Speech test (NU-CHIPS).
In contrast, the open set protocol provides an unlimited number of stimulus alternatives. Therefore, open set tests are more difficult. The clinical practice surveys available suggest for routine audiometric testing that monosyllabic word lists are the most widely used materials in suprathreshold speech recognition testing for routine evaluations, but sentences in noise are gaining popularity for hearing aid purposes.
CID W-22 vs. NU-6. The most common materials for speech recognition testing are the monosyllabic words, the Central Institute of the Deaf W-22 and the Northwestern University-6 word list. These are the most common open set materials and there has been some discussion among audiologists concerning the differences between those. From a historical perspective, the CID W-22 list came from the original Harvard PAL-PB50 words and the W-22s are a group of the more familiar of those. They were developed into four 50-word lists. They are still commonly used by audiologists today. The NU-6 lists were developed later and instead of looking for phonetic balance, they considered a more phonemic balance. The articulation function for both of those using recorded materials is about the same, 4% per dB. The NU-6 tests are considered somewhat more difficult than the W-22s. Clinical surveys show that both materials are used by practicing audiologists, with usage of the NU-6 lists beginning to surpass usage of W-22s.
Nonsense materials. There are other materials that are available for suprathreshold speech testing. There are other monosyllabic word lists like the Gardner high frequency word list (Gardner, 1971) that could be useful for special applications or special populations. There are also nonsense syllabic tasks which were used in early research in communication. An advantage of the nonsense syllables is that the effects of word familiarity and lexical constraints are reduced as compared to using actual words as test materials. A few that are available are the City University of New York Nonsense Syllable test, the Nonsense Syllable test, and others.
Sentence materials. Sentence materials are gaining popularity, particularly in hearing aid applications. This is because speech that contains contextual cues and is presented in a noise background is expected to have better predictive validity than words in quiet. The two sentence procedures that are popular are the Hearing In Noise Test (HINT) (Nilsson, Soli,& Sullivan, 1994) and the QuickSIN (Killion, Niquette, Gudmundsen, Revit & Banerjee, 2004). Other sentence tests that are available that have particular applications are the Synthetic Sentence Identification test (SSI), the Speech Perception and Noise test (SPIN), and the Connected Speech test.
Monitored Live Voice vs. Recorded. As with speech threshold testing, the use of recorded materials for suprathreshold speech testing standardizes the test administration. The recorded version of the test is actually the test in my opinion. This goes back to a study in 1969 where the findings said the test is not just the written word list, but rather it is a recorded version of those words.
Inter-speaker and intra-speaker variability makes using recorded materials the method of choice in almost all cases for suprathreshold testing. Monitored live voice (MLV) is not recommended. In years gone by, recorded materials were difficult to manipulate, but the ease and flexibility that is afforded us by CDs and digital recordings makes recorded materials the only way to go for testing suprathreshold speech recognition. Another issue to consider is the use of the carrier phrase. Since the carrier phrase is included on recordings and recorded materials are the recommended procedure, that issue is settled. However, I do know that monitored live voice is necessary in certain situations and if monitored live voice is used in testing, then the carrier phrase should precede the test word. In monitored live voice, the carrier phrase is intended to allow the test word to have its own natural inflection and its own natural power. The VU meter should peak at 0 for the carrier phrase and the test word then is delivered at its own natural or normal level for that word in the phrase.
Levels. The level at which testing is done is another consideration. The psychometric or performance-intensity function plots speech performance in percent correct on the Y-axis, as a function of the level of the speech signal on the X-axis. This is important because testing at only one level, which is fairly common, gives us insufficient information about the patient's optimal performance or what we commonly call the PB-max. It also does not allow us to know anything about any possible deterioration in performance if the level is increased. As a reminder, normal hearers show a function that reaches its maximum around 25 to 40 dB SL (re: SRT) and that is the reason why suprathreshold testing is often conducted at that level. For normals, the performance remains at that level, 100% or so, as the level increases. People with conductive hearing loss also show a similar function. Individuals with sensorineural hearing loss, however, show a performance function that reaches its maximum at generally less than 100%. They can either show performance that stays at that level as intensity increases, or they can show a curve that reaches its maximum and then decreases in performance as intensity increases. This is known as roll-over. A single level is not the best way to go as we cannot anticipate which patients may have rollover during testing, unless we test at a level higher than where the maximum score was obtained. I recognize that there are often time constraints in everyday practice, but two levels are recommended so that the performance-intensity function can be observed for an individual patient at least in an abbreviated way.
Recently, Guthrie and Mackersie (2009) published a paper that compared several different presentation levels to ascertain which level would result in maximum word recognition in individuals who had different hearing loss configurations. They looked at a number of presentation levels ranging from 10 dB above the SRT to a level at the UCL (uncomfortable listening level) -5 dB. Their results indicated that individuals with mild to moderate losses and those with more steeply sloping losses reached their best scores at a UCL -5 dB. That was also true for those patients who had moderately-severe to severe losses. The best phoneme recognition scores for their populations were achieved at a level of UCL -5 dB. As a reminder about speech recognition testing, masking is frequently needed because the test is being presented at a level above threshold, in many cases well above the threshold. Masking will always be needed for suprathreshold testing when the presentation level in the test ear is 40 dB or greater above the best bone conduction threshold in the non-test ear if supra-aural phones are used.
Full lists vs. half-lists. Another consideration is whether a full list or a half-list should be administered. Original lists were composed of 50 words and those 50 words were created for phonetic balance and for simplicity in scoring. It made it easy for the test to be scored if 50 words were administered and each word was worth 2%. Because 50-word lists take a long time, people often use half-lists or even shorter lists for the purpose of suprathreshold speech recognition testing. Let's look into this practice a little further.
An early study was done by Thornton and Raffin (1978) using the Binomial Distribution Model. They investigated the critical differences between one score and a retest score that would be necessary for those scores to be considered statistically significant. Their findings showed that with an increasing set size, variability decreased. It would seem that more items are better. More recently Hurley and Sells (2003) conducted a study that looked at developing a test methodology that would identify those patients requiring a full 50 item suprathreshold test and allow abbreviated testing of patients who do not need a full 50 item list. They used Auditec recordings and developed 10-word and 25-word screening tests. They found that the four lists of NU-6 10-word and the 25-word screening tests were able to differentiate listeners who had impaired word recognition who needed a full 50-word list from those with unimpaired word recognition ability who only needed the 10-word or 25-word list. If abbreviated testing is important, then it would seem that this would be the protocol to follow. These screening lists are available in a recorded version and their findings were based on a recorded version. Once again, it is important to use recorded materials whether you are going to use a full list or use an abbreviated list.
Quiet vs. Noise. Another consideration in suprathreshold speech recognition testing is whether to test in quiet or in noise. The effects of sensorineural hearing loss beyond the threshold loss, such as impaired frequency resolution or impaired temporal resolution, makes speech recognition performance in quiet a poor predictor for how those individuals will perform in noise. Speech recognition in noise is being promoted by a number of experts because adding noise improves the sensitivity of the test and the validity of the test. Giving the test at several levels will provide for a better separation between people who have hearing loss and those who have normal hearing. We know that individuals with hearing loss have a lot more difficulty with speech recognition in noise than those with normal hearing, and that those with sensorineural hearing loss often require a much greater signal-to-noise ratio (SNR), 10 to 15 better, than normal hearers.
Monosyllabic words in noise have not been widely used in clinical evaluation. However there are several word lists that are available. One of them is the Words in Noise test or WIN test which presents NU-6 words in a multi-talker babble. The words are presented at several different SNRs with the babble remaining at a constant level. One of the advantages of using these kinds of tests is that they are adaptive. They can be administered in a shorter period of time and they do not run into the same problems that we see with ceiling effects and floor effects. As I mentioned earlier, sentence tests in noise have become increasingly popular in hearing aid applications. Testing speech in noise is one way to look at amplification pre and post fitting. The Hearing in Noise Test and QuickSin, have gained popularity in those applications. The HINT was developed by Nilsson and colleagues in 1994 and later modified. It is scored as the dB to noise ratio that is necessary to get a 50% correct performance on the sentences. The sentences are the BKB (Bamford-Kowal-Bench) sentences. They are presented in sets of 10 and the listener listens and repeats the entire sentence correctly in order to get credit. In the HINT, the speech spectrum noise stays constant and the signal level is varied to obtain that 50% point. The QuickSin is a test that was developed by Killion and colleagues (2004) and uses the IEEE sentences. It has six sentences per list with five key words that are the scoring words in each sentence. All of them are presented in a multi-talker babble. The sentences get presented one at a time in 5 dB decrements from a high positive SNR down to 0 dB SNR. Again the test is scored as the 50% point in terms of dB signal-to-noise ratio. The guide proposed by Killion on the SNR is if an individual has somewhere around a 0 to 3 dB SNR it would be considered normal, 3 to 7 would be a mild SNR loss, 7 to15 dB would be a moderate SNR loss, and greater than 15 dB would be a severe SNR loss.
Scoring. Scoring is another issue in suprathreshold speech recognition testing. It is generally done on a whole word basis. However phoneme scoring is another option. If phoneme scoring is used, it is a way of increasing the set size and you have more items to score without adding to the time of the test. If whole word scoring is used, the words have to be exactly correct. In this situation, being close does not count. The word must be absolutely correct in order to be judged as being correct. Over time, different scoring categorizations have been proposed, although the percentages that are attributed to those categories vary among the different proposals.
The traditional categorizations include excellent, good, fair, poor, and very poor. These categories are defined as:
- Excellent or within normal limits = 90 - 100% on whole word scoring
- Good or slight difficulty = 78 - 88%
- Fair to moderate difficulty = 66 - 76%
- Poor or great difficulty = 54 - 64 %
- Very poor is < 52%
A very useful test routinely administered to those who are being considered for hearing aids is the level at which a listener finds listening most comfortable. The materials that are used for this are usually cold running speech or connected discourse. The listener is asked to rate the level at which listening is found to be most comfortable. Several trials are usually completed because most comfortable listening is typically a range, not a specific level or a single value. People sometimes want sounds a little louder or a little softer, so the range is a more appropriate term for this than most comfortable level. However whatever is obtained, whether it is a most comfortable level or a most comfortable range, should be recorded on the audiogram. Again, the material used should also be noted on the audiogram. As I mentioned earlier the most comfortable level (MCL) is often not the level at which a listener achieves maximum intelligibility. Using MCL in order to determine where the suprathreshold speech recognition measure will be done is not a good reason to use this test. MCL is useful, but not for determining where maximum intelligibility will be. The study I mentioned earlier showed that maximum intelligibility was reached for most people with hearing loss at a UCL -5. MCL is useful however in determining ANL or acceptable noise level.
The uncomfortable listening level (UCL) is also conducted with cold running speech. The instructions for this test can certainly influence the outcome since uncomfortable or uncomfortably loud for some individuals may not really be their UCL, but rather a preference for listening at a softer level. It is important to define for the patient what you mean by uncomfortably loud. The utility of the UCL is in providing an estimate for the dynamic range for speech which is the difference between the UCL and the SRT. In normals, this range is usually 100 dB or more, but it is reduced in ears with sensorineural hearing loss often dramatically. By doing the UCL, you can get an estimate of the individual's dynamic range for speech.
Acceptable Noise Level (ANL) is the amount of background noise that a listener is willing to accept while listening to speech (Nabelek, Tucker, & Letowski, 1991). It is a test of noise tolerance and it has been shown to be related to the successful use of hearing aids and to potential benefit with hearing aids (Nabelek, Freyaldenhoven, Tampas, & Muenchen, 2006). It uses the MCL and a measure known as BNL or background noise level. To conduct the test, a recorded speech passage is presented to the listener in the sound field for the MCL. Again note the use of recorded materials. The noise is then introduced to the listener to a level that will be the highest level that that person is able to accept or "put up with" while they are listening to and following the story in the speech passage. The ANL then becomes the difference between the MCL and the BNL. Individuals that have very low scores on the ANL are considered successful hearing aid users or good candidates for hearing aids. Those that have very high scores are considered unsuccessful users or poor hearing aid candidates. Obviously there are number of other applications for speech in audiologic practice, not the least of which is in the assessment of auditory processing. Many seminars could be conducted on this topic alone. Another application or future direction for speech audiometry is to more realistically assess hearing aid performance in "real world" environments. This is an area where research is currently underway.
Question: Are there any more specific instructions for the UCL measurement? Answer: Instructions are very important. We need to make it clear to a patient exactly what we expect them to do. I personally do not like things loud. If I am asked to indicate what is uncomfortably loud, I am much below what is really my UCL. I think you have to be very direct in instructing your patients in that you are not looking for a little uncomfortable, but where they just do not want to hear it or cannot take it. Question: Can you sum up what the best methods are to test hearing aid performance? I assume this means with speech signals. Answer: I think the use of the HINT or the QuickSin would be the most useful on a behavioral test. We have other ways of looking at performance that are not behavioral. Question: What about dialects? In my area, some of the local dialects have clipped words during speech testing. I am not sure if I should count those as correct or incorrect. Answer: It all depends on your situation. If a patient's production is really reflective of the dialect of that region and they are saying the word as everyone else in that area would say it, then I would say they do have the word correct. If necessary, if you are really unclear, you can always ask the patient to spell the word or write it down. This extra time can be inconvenient, but that is the best way to be sure that they have correctly identified the word. Question: Is there a reference for the bracketing method? Answer: The bracketing method is based on the old modified Hughson-Westlake that many people use for pure tone threshold testing. It is very similar to that traditional down 10 dB, up 5 dB. I am sure there are more references, but the Hughson-Westlake is what bracketing is based on. Question: Once you get an SRT result, if you want to compare it to the thresholds to validate your pure tones, how do you compare it to the audiogram? Answer: If it is a flat hearing loss, then you can compare to the 3-frequency pure tone average (PTA). If there is a high frequency loss, where audibility at perhaps 2000 Hz is greatly reduced, then it is better to use just the average of 500Hz and 1000Hz as your comparison. If it is a steeply sloping loss, then you look for agreement with the best threshold, which would probably be the 500 Hz threshold. The reverse is also true for patients who have rising configurations. Compare the SRT to the best two frequencies of the PTA, if the loss has either a steep slope or a steep rise, or the best frequency in the PTA if it is a really precipitous change in configuration. Question: Where can I find speech lists in Russian or other languages? Answer: Auditec has some material available in languages other than English - it would be best to contact them directly. You can also view their catalog at www.auditec.com Carolyn Smaka: This raises a question I have. If an audiologist is not fluent in a particular language, such as Spanish, is it ok to obtain a word list or recording in that language and conduct speech testing? Janet Schoepflin: I do not think that is a good practice. If you are not fluent in a language, you do not know all the subtleties of that language and the allophonic variations. People want to get an estimation of suprathreshold speech recognition and this would be an attempt to do that. This goes along with dialect. Whether you are using a recording, or doing your best to say these words exactly as there are supposed to be said, and your patient is fluent in a language and they say the word back to you, since you are not familiar with all the variations in the language it is possible that you will score the word incorrectly. You may think it is correct when it is actually incorrect, or you may think it is incorrect when it is correct based on the dialect or variation of that language. Question: In school we were instructed to use the full 50-word list for any word discrimination testing at suprathreshold, but if we are pressed for time, a half word list would be okay. However, my professor warned us that we absolutely must go in order on the word list. Can you clarify this? Answer: I'm not sure why that might have been said. I was trained in the model to use the 50-word list. This was because the phonetic balance that was proposed for those words was based on the 50 words. If you only used 25 words, you were not getting the phonetic balance. I think the more current findings from Hurley and Sells show us that it is possible to use a shorter list developed specifically for this purpose. It should be the recorded version of those words. These lists are available through Auditec. Question: On the NU-6 list, the words 'tough' and 'puff' are next to each other. 'Tough' is often mistaken for 'puff' so then when we reads 'puff', the person looks confused. Is it okay to mix up the order on the word list? Answer: I think in that case it is perfectly fine to move that one word down. Question: When do you recommend conducting speech testing, before or after pure tone testing? Answer: I have always been a person who likes to interact with my patients. My own procedure is to do an SRT first. Frequently for an SRT I do use live voice. I do not use monitored live voice for suprathreshold testing. It gives me a time to interact with the patient. People feel comfortable with speech. It is a communicative act. Then I do pure tone testing. Personally I would not do suprathreshold until I finished pure tone testing. My sequence is often SRT, pure tone, and suprathreshold. If this is not a good protocol for you based on time, then I would conduct pure tone testing, SRT, and then suprathreshold. Question: Some of the spondee words are outdated such as inkwell and whitewash. Is it okay to substitute other words that we know are spondee words, but may not be on the list? Or if we familiarize people, does it matter? Answer: The words that are on the list were put there for their so-called familiarity, but also because they were somewhat homogeneous and equal in intelligibility. I think inkwell, drawbridge and whitewash are outdated. If you follow a protocol where you are using a representative sample of the words and you are familiarizing, I think it is perfectly fine to eliminate those words you do not want to use. You just do not want to end up only using five or six words as it will limit the test set. Question: At what age is it appropriate to expect a child to perform suprathreshold speech recognition testing? Answer: If the child has a receptive language age of around 4 or 5 years, even 3 years maybe, it is possible to use the NU-CHIPS as a measure. It really does depend on language more than anything else, and the fact that the child can sit still for a period of time to do the test. Question: Regarding masking, when you are going 40 dB above the bone conduction threshold in the non-test ear, what frequency are you looking at? Are you comparing speech presented at 40 above a pure tone average of the bone conduction threshold? Answer: The best bone conduction threshold in the non-test ear is what really should be used. Question: When seeing a patient in follow-up after an ENT prescribes a steroid therapy for hydrops, do you recommend using the same word list to compare their suprathreshold speech recognition? Answer: I think it is better to use a different list, personally. Word familiarity as we said can influence even threshold and it certainly can affect suprathreshold performance. I think it is best to use a different word list. Carolyn Smaka: Thanks to everyone for their questions. Dr. Schoepflin has provided her email address with the handout. If your question was not answered or if you have further thoughts after the presentation, please feel free to follow up directly with her via email. Janet Schoepflin: Thank you so much. It was my pleasure and I hope everyone found the presentation worthwhile.
American Speech, Language and Hearing Association. (1988). Determining Threshold Level for Speech [Guidelines]. Available from www.asha.org/policy Gardner, H.(1971). Application of a high-frequency consonant discrimination word list in hearing-aid evaluation. Journal of Speech and Hearing Disorders, 36 , 354-355. Guthrie, L. & Mackersie, C. (2009). A comparison of presentation levels to maximize word recognition scores. Journal of the American Academy of Audiology, 20 (6), 381-90. Hurley, R. & Sells, J. (2003). An abbreviated word recognition protocol based on item difficulty. Ear & Hearing, 24 (2), 111-118. Killion, M., Niquette, P., Gudmundsen, G., Revit, L., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America, 116 (4 Pt 1), 2395-405. Nabelek, A., Freyaldenhoven, M., Tampas, J., Burchfield, S., & Muenchen, R. (2006). Acceptable noise level as a predictor of hearing aid use. Journal of the American Academy of Audiology, 17 , 626-639. Nabelek, A., Tucker, F., & Letowski, T. (1991). Toleration of background noises: Relationship with patterns of hearing aid use by elderly persons. Journal of Speech and Hearing Research, 34 , 679-685. Nilsson, M., Soli. S,, & Sullivan, J. (1994). Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise. Journal of the Acoustical Society of America, 95 (2), 1085-99. Thornton, A.. & Raffin, M, (1978). Speech-discrimination scores modeled as a binomial variable. Journal of Speech and Hearing Research, 21 , 507-518. Tillman, T., & Jerger, J. (1959). Some factors affecting the spondee threshold in normal-hearing subjects. Journal of Speech and Hearing Research, 2 , 141-146.

Chair, Communication Sciences and Disorders, Adelphi University
Janet Schoepflin is an Associate Professor and Chair of the Department of Communication Sciences and Disorders at Adelphi University and a member of the faculty of the Long Island AuD Consortium. Her areas of research interest include speech perception in children and adults, particularly those with hearing loss, and the effects of noise on audition and speech recognition performance.
Related Courses
Using gsi for cochlear implant evaluations, course: #39682 level: introductory 1 hour, empowerment and behavioral insights in client decision making, presented in partnership with nal, course: #37124 level: intermediate 1 hour, cognition and audition: supporting evidence, screening options, and clinical research, course: #37381 level: introductory 1 hour, innovative audiologic care delivery, course: #38661 level: intermediate 4 hours, aurical hit applications part 1 - applications for hearing instrument fittings and beyond, course: #28678 level: intermediate 1 hour.
Our site uses cookies to improve your experience. By using our site, you agree to our Privacy Policy .
- IEEE Xplore Digital Library
- IEEE Standards
- IEEE Spectrum
- Subscribe to Newsletter
- Resource Center
- Create Account
What is Signal Processing?
- Board of Governors
- Executive Committee
- Awards Board
- Conferences Board
- Membership Board
- Publications Board
- Technical Directions Board
- Standing Committees
- Liaisons & Representatives
- Education Board
- Our Members
- Society History
- State of the Society
- SPS Branding Materials
- Publications & Resources
- IEEE Signal Processing Magazine
- IEEE Journal of Selected Topics in Signal Processing
- IEEE Signal Processing Letters
- IEEE/ACM Transactions on Audio Speech and Language Processing
- IEEE Transactions on Computational Imaging
- IEEE Transactions on Image Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Transactions on Signal and Information Processing over Networks
- IEEE Transactions on Signal Processing
- Data & Challenges
- Submit Manuscript
- Information for Authors
- Special Issue Deadlines
- Overview Articles
- Top Accessed Articles
- SPS Newsletter
- SPS Resource Center
- Publications Feedback
- Publications FAQ
- Dataset Papers
- Conferences & Events
- Conferences
- Attend an Event
- Conference Call for Papers
- Calls for Proposals
- Conference Sponsorship Info
- Conference Resources
- SPS Travel Grants
- Conferences FAQ
- Getting Involved
- Young Professionals
- Our Technical Committees
- Contact Technical Committee
- Technical Committees FAQ
- Data Science Initiative
- Join Technical Committee
- Young Professionals Resources
- Member-driven Initiatives
- Chapter Locator
- Award Recipients
- IEEE Fellows Program
- Call for Nominations
- Professional Development
- Distinguished Lecturers
- Past Lecturers
- Nominations
- DIS Nominations
- Seasonal Schools
- Industry Resources
- Job Submission Form
- IEEE Training Materials
- For Volunteers
- Board Agenda/Minutes
- Chapter Resources
- Governance Documents
- Membership Development Reports
- TC Best Practices
- SPS Directory
- Society FAQ
- Information for Authors-OJSP
spotlight.jpg

Industry Leader in Signal Processing and Machine Learning: Mehrnaz Shokrollahi
Short_course_general.jpg.

SPS Gujarat Chapter Event: How to Write a Technical Paper for Publication with IEEE
Sp_ml_general.jpg.

Action: Promote Half-Price Dues to Recruit New Members
- Celebrating 75 Years of IEEE SPS
- Diversity, Equity, and Inclusion
- General SP Multimedia Content

- Submit a Manuscript
- Editorial Board Nominations
- Challenges & Data Collections
- Publication Guidelines
- Unified EDICS
- Signal Processing Magazine The premier publication of the society.
- SPS Newsletter Monthly updates in Signal Processing
- SPS Resource Center Online library of tutorials, lectures, and presentations.
- SigPort Online repository for reports, papers, and more.
- SPS Feed The latest news, events, and more from the world of Signal Processing.
- IEEE SP Magazine
- IEEE SPS Content Gazette
- IEEE SP Letters
- IEEE/ACM TASLP
- All SPS Publications
- SPS Entrepreneurship Forum
- Call for Papers
- Call for Proposals
- Request Sponsorship
- Conference Organizer Resources
- Past Conferences & Events
- Event Calendar
- Conferences Meet colleagues and advance your career.
- Webinars Register for upcoming webinars.
- Distinguished Lectures Learn from experts in signal processing.
- Seasonal Schools For graduate students and early stage researchers.
- All Events Browse all upcoming events.
- Join SPS The IEEE Signal Processing Magazine, Conference, Discounts, Awards, Collaborations, and more!
- Chapter Locator Find your local chapter and connect with fellow industry professionals, academics and students
- Women in Signal Processing Networking and engagement opportunities for women across signal processing disciplines
- Students Scholarships, conference discounts, travel grants, SP Cup, VIP Cup, 5-MICC
- Young Professionals Career development opportunities, networking
- Chapters & Communities
- Member Advocate
- Awards & Submit an Award Nomination
- Volunteer Opportunities
- Organize Local Initiatives
- Autonomous Systems Initiative
- Applied Signal Processing Systems
- Audio and Acoustic Signal Processing
- Bio Imaging and Signal Processing
- Computational Imaging
- Image Video and Multidimensional Signal Processing
- Information Forensics and Security
- Machine Learning for Signal Processing
- Multimedia Signal Processing
- Sensor Array and Multichannel
- Signal Processing for Communication and Networking
- Signal Processing Theory and Methods
- Speech and Language Processing
- Synthetic Aperture Technical Working Group
- Industry Technical Working Group
- Integrated Sensing and Communication Technical Working Group
- TC Affiliate Membership
- Co-Sponsorship of Non-Conference TC Events
- Mentoring Experiences for Underrepresented Young Researchers (ME-UYR)
- Micro Mentoring Experience Program (MiME)
- Distinguished Lecturer Program
- Distinguished Lecturer Nominations
- Distinguished Industry Speaker Program
- Distinguished Industry Speakers
- Distinguished Industry Speaker Nominations
- Jobs in Signal Processing: IEEE Job Site
- SPS Education Program Educational content in signal processing and related fields.
- Distinguished Lecturer Program Chapters have access to educators and authors in the fields of Signal Processing
- PROGRESS Initiative Promoting diversity in the field of signal processing.
- Job Opportunities Signal Processing and Technical Committee specific job opportunities
- Job Submission Form Employers may submit opportunities in the area of Signal Processing.
- Technical Committee Best Practices
- Conflict of Interest
- Policy and Procedures Manual
- Constitution
- Board Agenda/Minutes* Agendas, minutes and supporting documentation for Board and Committee Members
- SPS Directory* Directory of volunteers, society and division directory for Board and Committee Members.
- Membership Development Reports* Insight into the Society’s month-over-month and year-over-year growths and declines for Board and Committee Members
Popular Pages
- SPS Scholarship Program
- Call for Proposals: IEEE MLSP 2026
- (ISBI 2025) 2025 IEEE International Symposium on Biomedical Imaging
- Call for Proposals: IEEE ASRU 2025
- Inside Signal Processing Newsletter
- (MLSP 2024) 2024 IEEE International Workshop on Machine Learning for Signal Processing
- Information for Authors-SPL
- Signal Processing 101
Last viewed:
- (DCC 2025) 2025 Data Compression Conference
- (ICASSP 2023) 2023 IEEE International Conference on Acoustics, Speech and Signal Processing
- 5th Deep Noise Suppression Challenge: IEEE ICASSP 2023
- Information for Authors OJSP
- About TASLP
- IEEE Open Journal of Signal Processing
- Video Super-Resolution With Convolutional Neural Networks
- Access Restricted
- (ISBI 2024) 2024 IEEE International Symposium on Biomedical Imaging
- (EUSIPCO 2025) 2025 European Signal Processing Conference
What Are the Benefits of Speech Recognition Technology?
Search form, you are here.
- Publications
- Challenges & Data Collections Members
- Data Challenges
- Dataset Resources
- Challenge Papers
For Authors
- IEEE Author Center
- IEEE Copyright Form
Submit a Manuscript
Editorial Board Nominations

Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine 2. Signal Processing Digital Library* 3. Inside Signal Processing Newsletter 4. SPS Resource Center 5. Career advancement & recognition 6. Discounts on conferences and publications 7. Professional networking 8. Communities for students, young professionals, and women 9. Volunteer opportunities 10. Coming soon! PDH/CEU credits Click here to learn more .
spoken_lang_1.jpg

Speech recognition technology allows computers to take spoken audio, interpret it and generate text from it. But how do computers understand human speech? The short answer is…the wonder of signal processing. Speech is simply a series of sound waves created by our vocal chords when they cause air to vibrate around them. These soundwaves are recorded by a microphone, and then converted into an electrical signal. The signal is then processed using advanced signal processing technologies, isolating syllables and words. Over time, the computer can learn to understand speech from experience, thanks to incredible recent advances in artificial intelligence and machine learning. But signal processing is what makes it all possible.
So, what are the benefits of speech recognition technology? Why, exactly, do we need computers to understand our speech when typing is usually faster (and quieter)? Speech is a natural interface for many programs that don’t run on computers, which are becoming more common. Here are some important ways in which speech recognition technology plays a vital role in people’s lives.
Talking to Robots : You might not think that speaking with robots is a common activity. But robots are increasingly being employed in roles once performed by humans, including in conversation and interface. For example, firms are already exploring using robots and software to perform initial job interviews. As interviews must be conversational, it’s essential that the robot can interpret what the interviewee is saying. That requires speech recognition technology.

Aiding the Visually- and Hearing-Impaired : There are many people with visual impairments who rely on screen readers and text-to-speech dictation systems. And converting audio into text can be a critical communication tool for the hearing-impaired.
Enabling Hands Free Technology: When your eyes and hands are busy, such as when you’re driving, speech is incredibly useful. Being able to communicate with Apple’s Siri or Google Maps to take you where you need to go reduces your chances of getting lost and removes the need to pull over and navigate a phone or read a map.
Why Speech Recognition Technology is a Growth Skillset: Speech recognition technology is already a part of our everyday lives, but for now is still limited to relatively simple commands. As the technology advances, researchers will be able to create more intelligent systems that understand conversational speech (remember the robot job interviewers?). One day, you will be able to talk to your computer the way you would talk to any human, and it will be able to transmit reasoned responses back to you. All this will be made possible by signal processing technologies. The number of specialists needed in this field are growing, and many companies are looking for talented people who want to be a part of it. Processing, interpreting and understanding a speech signal is the key to many powerful new technologies and methods of communication. Given current trends, speech recognition technology will be a fast-growing (and world-changing) subset of signal processing for years to come.
- THIS WEEK: Join NASA’s Dr. Jacqueline Le Moigne as she shares her journey through academia, the private sector, and pivotal roles at NASA, emphasizing her work in signal processing, computer vision, and related technologies. Register now! https://x.com/IEEEsps/status/1785057479606288505
- Join NASA’s Dr. Jacqueline Le Moigne for this interactive webinar as she shares her journey through the realms of signal processing, computer vision, and related technologies, including her pivotal roles at NASA. https://x.com/IEEEsps/status/1782468413551423536
- Great crowd at the Student Job Fair at #ICASSP2024! Thank you to our sponsors for furnishing an exciting, engaging event! https://x.com/IEEEsps/status/1780817453569687559
- Thank you to our Women in Signal Processing Luncheon panelists for their wisdom and insights during today’s event at #ICASSP2024! https://x.com/IEEEsps/status/1780458637338530252
- Free Machine Learning (ML) Lecture Series from IEEE SPS From basics to recent advances, unlock the secrets of ML with Prof. Sergios Theodoridis! https://x.com/IEEEsps/status/1779931297093222415
IEEE SPS Educational Resources

Home | Sitemap | Contact | Accessibility | Nondiscrimination Policy | IEEE Ethics Reporting | IEEE Privacy Policy | Terms | Feedback
© Copyright 2024 IEEE – All rights reserved. Use of this website signifies your agreement to the IEEE Terms and Conditions . A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity.
Speech Recognition: Everything You Need to Know in 2024
Speech recognition, also known as automatic speech recognition (ASR) , enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications , including customer service, healthcare, finance and sales.
In this comprehensive guide, we will explain speech recognition, exploring how it works, the algorithms involved, and the use cases of various industries.
If you require training data for your speech recognition system, here is a guide to finding the right speech data collection services.
What is speech recognition?
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text.
Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents, dialects, and speech patterns.
What are the features of speech recognition systems?
Speech recognition systems have several components that work together to understand and process human speech. Key features of effective speech recognition are:
- Audio preprocessing: After you have obtained the raw audio signal from an input device, you need to preprocess it to improve the quality of the speech input The main goal of audio preprocessing is to capture relevant speech data by removing any unwanted artifacts and reducing noise.
- Feature extraction: This stage converts the preprocessed audio signal into a more informative representation. This makes raw audio data more manageable for machine learning models in speech recognition systems.
- Language model weighting: Language weighting gives more weight to certain words and phrases, such as product references, in audio and voice signals. This makes those keywords more likely to be recognized in a subsequent speech by speech recognition systems.
- Acoustic modeling : It enables speech recognizers to capture and distinguish phonetic units within a speech signal. Acoustic models are trained on large datasets containing speech samples from a diverse set of speakers with different accents, speaking styles, and backgrounds.
- Speaker labeling: It enables speech recognition applications to determine the identities of multiple speakers in an audio recording. It assigns unique labels to each speaker in an audio recording, allowing the identification of which speaker was speaking at any given time.
- Profanity filtering: The process of removing offensive, inappropriate, or explicit words or phrases from audio data.
What are the different speech recognition algorithms?
Speech recognition uses various algorithms and computation techniques to convert spoken language into written language. The following are some of the most commonly used speech recognition methods:
- Hidden Markov Models (HMMs): Hidden Markov model is a statistical Markov model commonly used in traditional speech recognition systems. HMMs capture the relationship between the acoustic features and model the temporal dynamics of speech signals.
- Estimate the probability of word sequences in the recognized text
- Convert colloquial expressions and abbreviations in a spoken language into a standard written form
- Map phonetic units obtained from acoustic models to their corresponding words in the target language.
- Speaker Diarization (SD): Speaker diarization, or speaker labeling, is the process of identifying and attributing speech segments to their respective speakers (Figure 1). It allows for speaker-specific voice recognition and the identification of individuals in a conversation.
Figure 1: A flowchart illustrating the speaker diarization process

- Dynamic Time Warping (DTW): Speech recognition algorithms use Dynamic Time Warping (DTW) algorithm to find an optimal alignment between two sequences (Figure 2).
Figure 2: A speech recognizer using dynamic time warping to determine the optimal distance between elements

5. Deep neural networks: Neural networks process and transform input data by simulating the non-linear frequency perception of the human auditory system.
6. Connectionist Temporal Classification (CTC): It is a training objective introduced by Alex Graves in 2006. CTC is especially useful for sequence labeling tasks and end-to-end speech recognition systems. It allows the neural network to discover the relationship between input frames and align input frames with output labels.
Speech recognition vs voice recognition
Speech recognition is commonly confused with voice recognition, yet, they refer to distinct concepts. Speech recognition converts spoken words into written text, focusing on identifying the words and sentences spoken by a user, regardless of the speaker’s identity.
On the other hand, voice recognition is concerned with recognizing or verifying a speaker’s voice, aiming to determine the identity of an unknown speaker rather than focusing on understanding the content of the speech.
What are the challenges of speech recognition with solutions?
While speech recognition technology offers many benefits, it still faces a number of challenges that need to be addressed. Some of the main limitations of speech recognition include:
Acoustic Challenges:
- Assume a speech recognition model has been primarily trained on American English accents. If a speaker with a strong Scottish accent uses the system, they may encounter difficulties due to pronunciation differences. For example, the word “water” is pronounced differently in both accents. If the system is not familiar with this pronunciation, it may struggle to recognize the word “water.”
Solution: Addressing these challenges is crucial to enhancing speech recognition applications’ accuracy. To overcome pronunciation variations, it is essential to expand the training data to include samples from speakers with diverse accents. This approach helps the system recognize and understand a broader range of speech patterns.
- For instance, you can use data augmentation techniques to reduce the impact of noise on audio data. Data augmentation helps train speech recognition models with noisy data to improve model accuracy in real-world environments.
Figure 3: Examples of a target sentence (“The clown had a funny face”) in the background noise of babble, car and rain.

Linguistic Challenges:
- Out-of-vocabulary words: Since the speech recognizers model has not been trained on OOV words, they may incorrectly recognize them as different or fail to transcribe them when encountering them.
Figure 4: An example of detecting OOV word
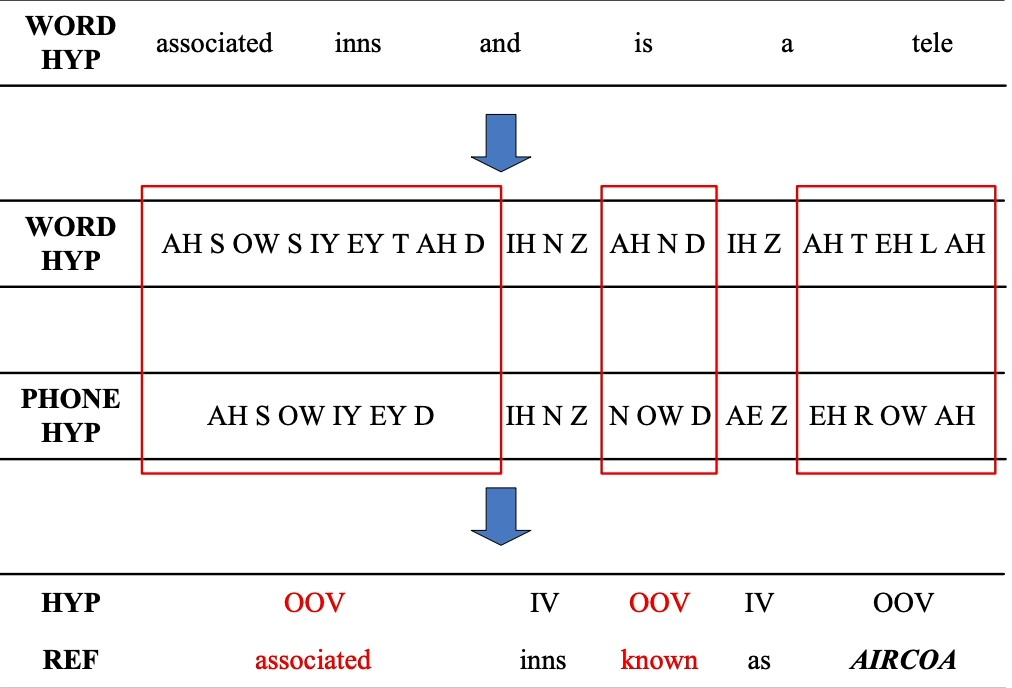
Solution: Word Error Rate (WER) is a common metric that is used to measure the accuracy of a speech recognition or machine translation system. The word error rate can be computed as:
Figure 5: Demonstrating how to calculate word error rate (WER)

- Homophones: Homophones are words that are pronounced identically but have different meanings, such as “to,” “too,” and “two”. Solution: Semantic analysis allows speech recognition programs to select the appropriate homophone based on its intended meaning in a given context. Addressing homophones improves the ability of the speech recognition process to understand and transcribe spoken words accurately.
Technical/System Challenges:
- Data privacy and security: Speech recognition systems involve processing and storing sensitive and personal information, such as financial information. An unauthorized party could use the captured information, leading to privacy breaches.
Solution: You can encrypt sensitive and personal audio information transmitted between the user’s device and the speech recognition software. Another technique for addressing data privacy and security in speech recognition systems is data masking. Data masking algorithms mask and replace sensitive speech data with structurally identical but acoustically different data.
Figure 6: An example of how data masking works

- Limited training data: Limited training data directly impacts the performance of speech recognition software. With insufficient training data, the speech recognition model may struggle to generalize different accents or recognize less common words.
Solution: To improve the quality and quantity of training data, you can expand the existing dataset using data augmentation and synthetic data generation technologies.
13 speech recognition use cases and applications
In this section, we will explain how speech recognition revolutionizes the communication landscape across industries and changes the way businesses interact with machines.
Customer Service and Support
- Interactive Voice Response (IVR) systems: Interactive voice response (IVR) is a technology that automates the process of routing callers to the appropriate department. It understands customer queries and routes calls to the relevant departments. This reduces the call volume for contact centers and minimizes wait times. IVR systems address simple customer questions without human intervention by employing pre-recorded messages or text-to-speech technology . Automatic Speech Recognition (ASR) allows IVR systems to comprehend and respond to customer inquiries and complaints in real time.
- Customer support automation and chatbots: According to a survey, 78% of consumers interacted with a chatbot in 2022, but 80% of respondents said using chatbots increased their frustration level.
- Sentiment analysis and call monitoring: Speech recognition technology converts spoken content from a call into text. After speech-to-text processing, natural language processing (NLP) techniques analyze the text and assign a sentiment score to the conversation, such as positive, negative, or neutral. By integrating speech recognition with sentiment analysis, organizations can address issues early on and gain valuable insights into customer preferences.
- Multilingual support: Speech recognition software can be trained in various languages to recognize and transcribe the language spoken by a user accurately. By integrating speech recognition technology into chatbots and Interactive Voice Response (IVR) systems, organizations can overcome language barriers and reach a global audience (Figure 7). Multilingual chatbots and IVR automatically detect the language spoken by a user and switch to the appropriate language model.
Figure 7: Showing how a multilingual chatbot recognizes words in another language
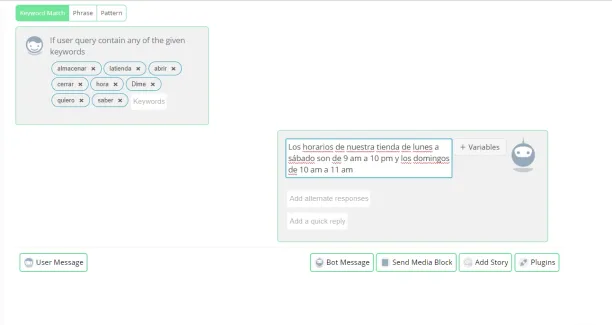
- Customer authentication with voice biometrics: Voice biometrics use speech recognition technologies to analyze a speaker’s voice and extract features such as accent and speed to verify their identity.
Sales and Marketing:
- Virtual sales assistants: Virtual sales assistants are AI-powered chatbots that assist customers with purchasing and communicate with them through voice interactions. Speech recognition allows virtual sales assistants to understand the intent behind spoken language and tailor their responses based on customer preferences.
- Transcription services : Speech recognition software records audio from sales calls and meetings and then converts the spoken words into written text using speech-to-text algorithms.
Automotive:
- Voice-activated controls: Voice-activated controls allow users to interact with devices and applications using voice commands. Drivers can operate features like climate control, phone calls, or navigation systems.
- Voice-assisted navigation: Voice-assisted navigation provides real-time voice-guided directions by utilizing the driver’s voice input for the destination. Drivers can request real-time traffic updates or search for nearby points of interest using voice commands without physical controls.
Healthcare:
- Recording the physician’s dictation
- Transcribing the audio recording into written text using speech recognition technology
- Editing the transcribed text for better accuracy and correcting errors as needed
- Formatting the document in accordance with legal and medical requirements.
- Virtual medical assistants: Virtual medical assistants (VMAs) use speech recognition, natural language processing, and machine learning algorithms to communicate with patients through voice or text. Speech recognition software allows VMAs to respond to voice commands, retrieve information from electronic health records (EHRs) and automate the medical transcription process.
- Electronic Health Records (EHR) integration: Healthcare professionals can use voice commands to navigate the EHR system , access patient data, and enter data into specific fields.
Technology:
- Virtual agents: Virtual agents utilize natural language processing (NLP) and speech recognition technologies to understand spoken language and convert it into text. Speech recognition enables virtual agents to process spoken language in real-time and respond promptly and accurately to user voice commands.
Further reading
- Top 5 Speech Recognition Data Collection Methods in 2023
- Top 11 Speech Recognition Applications in 2023
External Links
- 1. Databricks
- 2. PubMed Central
- 3. Qin, L. (2013). Learning Out-of-vocabulary Words in Automatic Speech Recognition . Carnegie Mellon University.
- 4. Wikipedia
Next to Read
10+ speech data collection services in 2024, top 5 speech recognition data collection methods in 2024, top 4 speech recognition challenges & solutions in 2024.
Your email address will not be published. All fields are required.
Related research

Top 11 Voice Recognition Applications in 2024
SpeechRecognition 3.10.4
pip install SpeechRecognition Copy PIP instructions
Released: May 5, 2024
Library for performing speech recognition, with support for several engines and APIs, online and offline.
Verified details
Maintainers.

Unverified details
Project links, github statistics.
- Open issues:
View statistics for this project via Libraries.io , or by using our public dataset on Google BigQuery
License: BSD License (BSD)
Author: Anthony Zhang (Uberi)
Tags speech, recognition, voice, sphinx, google, wit, bing, api, houndify, ibm, snowboy
Requires: Python >=3.8
Classifiers
- 5 - Production/Stable
- OSI Approved :: BSD License
- MacOS :: MacOS X
- Microsoft :: Windows
- POSIX :: Linux
- Python :: 3
- Python :: 3.8
- Python :: 3.9
- Python :: 3.10
- Python :: 3.11
- Multimedia :: Sound/Audio :: Speech
- Software Development :: Libraries :: Python Modules
Project description

UPDATE 2022-02-09 : Hey everyone! This project started as a tech demo, but these days it needs more time than I have to keep up with all the PRs and issues. Therefore, I’d like to put out an open invite for collaborators - just reach out at me @ anthonyz . ca if you’re interested!
Speech recognition engine/API support:
Quickstart: pip install SpeechRecognition . See the “Installing” section for more details.
To quickly try it out, run python -m speech_recognition after installing.
Project links:
Library Reference
The library reference documents every publicly accessible object in the library. This document is also included under reference/library-reference.rst .
See Notes on using PocketSphinx for information about installing languages, compiling PocketSphinx, and building language packs from online resources. This document is also included under reference/pocketsphinx.rst .
You have to install Vosk models for using Vosk. Here are models avaiable. You have to place them in models folder of your project, like “your-project-folder/models/your-vosk-model”
See the examples/ directory in the repository root for usage examples:
First, make sure you have all the requirements listed in the “Requirements” section.
The easiest way to install this is using pip install SpeechRecognition .
Otherwise, download the source distribution from PyPI , and extract the archive.
In the folder, run python setup.py install .
Requirements
To use all of the functionality of the library, you should have:
The following requirements are optional, but can improve or extend functionality in some situations:
The following sections go over the details of each requirement.
The first software requirement is Python 3.8+ . This is required to use the library.
PyAudio (for microphone users)
PyAudio is required if and only if you want to use microphone input ( Microphone ). PyAudio version 0.2.11+ is required, as earlier versions have known memory management bugs when recording from microphones in certain situations.
If not installed, everything in the library will still work, except attempting to instantiate a Microphone object will raise an AttributeError .
The installation instructions on the PyAudio website are quite good - for convenience, they are summarized below:
PyAudio wheel packages for common 64-bit Python versions on Windows and Linux are included for convenience, under the third-party/ directory in the repository root. To install, simply run pip install wheel followed by pip install ./third-party/WHEEL_FILENAME (replace pip with pip3 if using Python 3) in the repository root directory .
PocketSphinx-Python (for Sphinx users)
PocketSphinx-Python is required if and only if you want to use the Sphinx recognizer ( recognizer_instance.recognize_sphinx ).
PocketSphinx-Python wheel packages for 64-bit Python 3.4, and 3.5 on Windows are included for convenience, under the third-party/ directory . To install, simply run pip install wheel followed by pip install ./third-party/WHEEL_FILENAME (replace pip with pip3 if using Python 3) in the SpeechRecognition folder.
On Linux and other POSIX systems (such as OS X), follow the instructions under “Building PocketSphinx-Python from source” in Notes on using PocketSphinx for installation instructions.
Note that the versions available in most package repositories are outdated and will not work with the bundled language data. Using the bundled wheel packages or building from source is recommended.
Vosk (for Vosk users)
Vosk API is required if and only if you want to use Vosk recognizer ( recognizer_instance.recognize_vosk ).
You can install it with python3 -m pip install vosk .
You also have to install Vosk Models:
Here are models avaiable for download. You have to place them in models folder of your project, like “your-project-folder/models/your-vosk-model”
Google Cloud Speech Library for Python (for Google Cloud Speech API users)
Google Cloud Speech library for Python is required if and only if you want to use the Google Cloud Speech API ( recognizer_instance.recognize_google_cloud ).
If not installed, everything in the library will still work, except calling recognizer_instance.recognize_google_cloud will raise an RequestError .
According to the official installation instructions , the recommended way to install this is using Pip : execute pip install google-cloud-speech (replace pip with pip3 if using Python 3).
FLAC (for some systems)
A FLAC encoder is required to encode the audio data to send to the API. If using Windows (x86 or x86-64), OS X (Intel Macs only, OS X 10.6 or higher), or Linux (x86 or x86-64), this is already bundled with this library - you do not need to install anything .
Otherwise, ensure that you have the flac command line tool, which is often available through the system package manager. For example, this would usually be sudo apt-get install flac on Debian-derivatives, or brew install flac on OS X with Homebrew.
Whisper (for Whisper users)
Whisper is required if and only if you want to use whisper ( recognizer_instance.recognize_whisper ).
You can install it with python3 -m pip install SpeechRecognition[whisper-local] .
Whisper API (for Whisper API users)
The library openai is required if and only if you want to use Whisper API ( recognizer_instance.recognize_whisper_api ).
If not installed, everything in the library will still work, except calling recognizer_instance.recognize_whisper_api will raise an RequestError .
You can install it with python3 -m pip install SpeechRecognition[whisper-api] .
Troubleshooting
The recognizer tries to recognize speech even when i’m not speaking, or after i’m done speaking..
Try increasing the recognizer_instance.energy_threshold property. This is basically how sensitive the recognizer is to when recognition should start. Higher values mean that it will be less sensitive, which is useful if you are in a loud room.
This value depends entirely on your microphone or audio data. There is no one-size-fits-all value, but good values typically range from 50 to 4000.
Also, check on your microphone volume settings. If it is too sensitive, the microphone may be picking up a lot of ambient noise. If it is too insensitive, the microphone may be rejecting speech as just noise.
The recognizer can’t recognize speech right after it starts listening for the first time.
The recognizer_instance.energy_threshold property is probably set to a value that is too high to start off with, and then being adjusted lower automatically by dynamic energy threshold adjustment. Before it is at a good level, the energy threshold is so high that speech is just considered ambient noise.
The solution is to decrease this threshold, or call recognizer_instance.adjust_for_ambient_noise beforehand, which will set the threshold to a good value automatically.
The recognizer doesn’t understand my particular language/dialect.
Try setting the recognition language to your language/dialect. To do this, see the documentation for recognizer_instance.recognize_sphinx , recognizer_instance.recognize_google , recognizer_instance.recognize_wit , recognizer_instance.recognize_bing , recognizer_instance.recognize_api , recognizer_instance.recognize_houndify , and recognizer_instance.recognize_ibm .
For example, if your language/dialect is British English, it is better to use "en-GB" as the language rather than "en-US" .
The recognizer hangs on recognizer_instance.listen ; specifically, when it’s calling Microphone.MicrophoneStream.read .
This usually happens when you’re using a Raspberry Pi board, which doesn’t have audio input capabilities by itself. This causes the default microphone used by PyAudio to simply block when we try to read it. If you happen to be using a Raspberry Pi, you’ll need a USB sound card (or USB microphone).
Once you do this, change all instances of Microphone() to Microphone(device_index=MICROPHONE_INDEX) , where MICROPHONE_INDEX is the hardware-specific index of the microphone.
To figure out what the value of MICROPHONE_INDEX should be, run the following code:
This will print out something like the following:
Now, to use the Snowball microphone, you would change Microphone() to Microphone(device_index=3) .
Calling Microphone() gives the error IOError: No Default Input Device Available .
As the error says, the program doesn’t know which microphone to use.
To proceed, either use Microphone(device_index=MICROPHONE_INDEX, ...) instead of Microphone(...) , or set a default microphone in your OS. You can obtain possible values of MICROPHONE_INDEX using the code in the troubleshooting entry right above this one.
The program doesn’t run when compiled with PyInstaller .
As of PyInstaller version 3.0, SpeechRecognition is supported out of the box. If you’re getting weird issues when compiling your program using PyInstaller, simply update PyInstaller.
You can easily do this by running pip install --upgrade pyinstaller .
On Ubuntu/Debian, I get annoying output in the terminal saying things like “bt_audio_service_open: […] Connection refused” and various others.
The “bt_audio_service_open” error means that you have a Bluetooth audio device, but as a physical device is not currently connected, we can’t actually use it - if you’re not using a Bluetooth microphone, then this can be safely ignored. If you are, and audio isn’t working, then double check to make sure your microphone is actually connected. There does not seem to be a simple way to disable these messages.
For errors of the form “ALSA lib […] Unknown PCM”, see this StackOverflow answer . Basically, to get rid of an error of the form “Unknown PCM cards.pcm.rear”, simply comment out pcm.rear cards.pcm.rear in /usr/share/alsa/alsa.conf , ~/.asoundrc , and /etc/asound.conf .
For “jack server is not running or cannot be started” or “connect(2) call to /dev/shm/jack-1000/default/jack_0 failed (err=No such file or directory)” or “attempt to connect to server failed”, these are caused by ALSA trying to connect to JACK, and can be safely ignored. I’m not aware of any simple way to turn those messages off at this time, besides entirely disabling printing while starting the microphone .
On OS X, I get a ChildProcessError saying that it couldn’t find the system FLAC converter, even though it’s installed.
Installing FLAC for OS X directly from the source code will not work, since it doesn’t correctly add the executables to the search path.
Installing FLAC using Homebrew ensures that the search path is correctly updated. First, ensure you have Homebrew, then run brew install flac to install the necessary files.
To hack on this library, first make sure you have all the requirements listed in the “Requirements” section.
To install/reinstall the library locally, run python -m pip install -e .[dev] in the project root directory .
Before a release, the version number is bumped in README.rst and speech_recognition/__init__.py . Version tags are then created using git config gpg.program gpg2 && git config user.signingkey DB45F6C431DE7C2DCD99FF7904882258A4063489 && git tag -s VERSION_GOES_HERE -m "Version VERSION_GOES_HERE" .
Releases are done by running make-release.sh VERSION_GOES_HERE to build the Python source packages, sign them, and upload them to PyPI.
To run all the tests:
To run static analysis:
To ensure RST is well-formed:
Testing is also done automatically by GitHub Actions, upon every push.
FLAC Executables
The included flac-win32 executable is the official FLAC 1.3.2 32-bit Windows binary .
The included flac-linux-x86 and flac-linux-x86_64 executables are built from the FLAC 1.3.2 source code with Manylinux to ensure that it’s compatible with a wide variety of distributions.
The built FLAC executables should be bit-for-bit reproducible. To rebuild them, run the following inside the project directory on a Debian-like system:
The included flac-mac executable is extracted from xACT 2.39 , which is a frontend for FLAC 1.3.2 that conveniently includes binaries for all of its encoders. Specifically, it is a copy of xACT 2.39/xACT.app/Contents/Resources/flac in xACT2.39.zip .
Please report bugs and suggestions at the issue tracker !
How to cite this library (APA style):
Zhang, A. (2017). Speech Recognition (Version 3.8) [Software]. Available from https://github.com/Uberi/speech_recognition#readme .
How to cite this library (Chicago style):
Zhang, Anthony. 2017. Speech Recognition (version 3.8).
Also check out the Python Baidu Yuyin API , which is based on an older version of this project, and adds support for Baidu Yuyin . Note that Baidu Yuyin is only available inside China.
Copyright 2014-2017 Anthony Zhang (Uberi) . The source code for this library is available online at GitHub .
SpeechRecognition is made available under the 3-clause BSD license. See LICENSE.txt in the project’s root directory for more information.
For convenience, all the official distributions of SpeechRecognition already include a copy of the necessary copyright notices and licenses. In your project, you can simply say that licensing information for SpeechRecognition can be found within the SpeechRecognition README, and make sure SpeechRecognition is visible to users if they wish to see it .
SpeechRecognition distributes source code, binaries, and language files from CMU Sphinx . These files are BSD-licensed and redistributable as long as copyright notices are correctly retained. See speech_recognition/pocketsphinx-data/*/LICENSE*.txt and third-party/LICENSE-Sphinx.txt for license details for individual parts.
SpeechRecognition distributes source code and binaries from PyAudio . These files are MIT-licensed and redistributable as long as copyright notices are correctly retained. See third-party/LICENSE-PyAudio.txt for license details.
SpeechRecognition distributes binaries from FLAC - speech_recognition/flac-win32.exe , speech_recognition/flac-linux-x86 , and speech_recognition/flac-mac . These files are GPLv2-licensed and redistributable, as long as the terms of the GPL are satisfied. The FLAC binaries are an aggregate of separate programs , so these GPL restrictions do not apply to the library or your programs that use the library, only to FLAC itself. See LICENSE-FLAC.txt for license details.
Project details
Release history release notifications | rss feed.
May 5, 2024
Mar 30, 2024
Mar 28, 2024
Dec 6, 2023
Mar 13, 2023
Dec 4, 2022
Dec 5, 2017
Jun 27, 2017
Apr 13, 2017
Mar 11, 2017
Jan 7, 2017
Nov 21, 2016
May 22, 2016
May 11, 2016
May 10, 2016
Apr 9, 2016
Apr 4, 2016
Apr 3, 2016
Mar 5, 2016
Mar 4, 2016
Feb 26, 2016
Feb 20, 2016
Feb 19, 2016
Feb 4, 2016
Nov 5, 2015
Nov 2, 2015
Sep 2, 2015
Sep 1, 2015
Aug 30, 2015
Aug 24, 2015
Jul 26, 2015
Jul 12, 2015
Jul 3, 2015
May 20, 2015
Apr 24, 2015
Apr 14, 2015
Apr 7, 2015
Apr 5, 2015
Apr 4, 2015
Mar 31, 2015
Dec 10, 2014
Nov 17, 2014
Sep 11, 2014
Sep 6, 2014
Aug 25, 2014
Jul 6, 2014
Jun 10, 2014
Jun 9, 2014
May 29, 2014
Apr 23, 2014
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages .
Source Distribution
Uploaded May 5, 2024 Source
Built Distribution
Uploaded May 5, 2024 Python 2 Python 3
Hashes for speechrecognition-3.10.4.tar.gz
Hashes for speechrecognition-3.10.4-py2.py3-none-any.whl.
- português (Brasil)
Supported by


Use voice recognition in Windows
On Windows 11 22H2 and later, Windows Speech Recognition (WSR) will be replaced by voice access starting in September 2024. Older versions of Windows will continue to have WSR available. To learn more about voice access, go to Use voice access to control your PC & author text with your voice .
Set up a microphone
Before you set up speech recognition, make sure you have a microphone set up.
Select (Start) > Settings > Time & language > Speech .

The Speech wizard window opens, and the setup starts automatically. If the wizard detects issues with your microphone, they will be listed in the wizard dialog box. You can select options in the dialog box to specify an issue and help the wizard solve it.
Help your PC recognize your voice
You can teach Windows 11 to recognize your voice. Here's how to set it up:
Press Windows logo key+Ctrl+S. The Set up Speech Recognition wizard window opens with an introduction on the Welcome to Speech Recognition page.
Tip: If you've already set up speech recognition, pressing Windows logo key+Ctrl+S opens speech recognition and you're ready to use it. If you want to retrain your computer to recognize your voice, press the Windows logo key, type Control Panel , and select Control Panel in the list of results. In Control Panel , select Ease of Access > Speech Recognition > Train your computer to better understand you .
Select Next . Follow the instructions on your screen to set up speech recognition. The wizard will guide you through the setup steps.
After the setup is complete, you can choose to take a tutorial to learn more about speech recognition. To take the tutorial, select Start Tutorial in the wizard window. To skip the tutorial, select Skip Tutorial . You can now start using speech recognition.
Windows Speech Recognition commands
Before you set up voice recognition, make sure you have a microphone set up.
Select the Start button, then select Settings > Time & Language > Speech .

You can teach Windows 10 to recognize your voice. Here's how to set it up:
In the search box on the taskbar, type Windows Speech Recognition , and then select Windows Speech Recognition in the list of results.
If you don't see a dialog box that says "Welcome to Speech Recognition Voice Training," then in the search box on the taskbar, type Control Panel , and select Control Panel in the list of results. Then select Ease of Access > Speech Recognition > Train your computer to understand you better .
Follow the instructions to set up speech recognition.

Need more help?
Want more options.
Explore subscription benefits, browse training courses, learn how to secure your device, and more.

Microsoft 365 subscription benefits

Microsoft 365 training

Microsoft security

Accessibility center
Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.

Ask the Microsoft Community

Microsoft Tech Community

Windows Insiders
Microsoft 365 Insiders
Find solutions to common problems or get help from a support agent.

Online support
Was this information helpful?
Thank you for your feedback.
How to set up and use Windows 10 Speech Recognition
Windows 10 has a hands-free using Speech Recognition feature, and in this guide, we show you how to set up the experience and perform common tasks.

On Windows 10 , Speech Recognition is an easy-to-use experience that allows you to control your computer entirely with voice commands.
Anyone can set up and use this feature to navigate, launch applications, dictate text, and perform a slew of other tasks. However, Speech Recognition was primarily designed to help people with disabilities who can't use a mouse or keyboard.
In this Windows 10 guide, we walk you through the steps to configure and start using Speech Recognition to control your computer only with voice.
How to configure Speech Recognition on Windows 10
How to train speech recognition to improve accuracy, how to change speech recognition settings, how to use speech recognition on windows 10.
To set up Speech Recognition on your device, use these steps:
- Open Control Panel .
- Click on Ease of Access .
- Click on Speech Recognition .

- Click the Start Speech Recognition link.

- In the "Set up Speech Recognition" page, click Next .
- Select the type of microphone you'll be using. Note: Desktop microphones are not ideal, and Microsoft recommends headset microphones or microphone arrays.

- Click Next .
- Click Next again.

- Read the text aloud to ensure the feature can hear you.

- Speech Recognition can access your documents and emails to improve its accuracy based on the words you use. Select the Enable document review option, or select Disable document review if you have privacy concerns.

- Use manual activation mode — Speech Recognition turns off the "Stop Listening" command. To turn it back on, you'll need to click the microphone button or use the Ctrl + Windows key shortcut.
- Use voice activation mode — Speech Recognition goes into sleep mode when not in use, and you'll need to invoke the "Start Listening" voice command to turn it back on.

- If you're not familiar with the commands, click the View Reference Sheet button to learn more about the voice commands you can use.

- Select whether you want this feature to start automatically at startup.

- Click the Start tutorial button to access the Microsoft video tutorial about this feature, or click the Skip tutorial button to complete the setup.

Once you complete these steps, you can start using the feature with voice commands, and the controls will appear at the top of the screen.
Quick Tip: You can drag and dock the Speech Recognition interface anywhere on the screen.
After the initial setup, we recommend training Speech Recognition to improve its accuracy and to prevent the "What was that?" message as much as possible.
Get the Windows Central Newsletter
All the latest news, reviews, and guides for Windows and Xbox diehards.
- Click the Train your computer to better understand you link.

- Click Next to continue with the training as directed by the application.

After completing the training, Speech Recognition should have a better understanding of your voice to provide an improved experience.
If you need to change the Speech Recognition settings, use these steps:
- Click the Advanced speech options link in the left pane.

Inside "Speech Properties," in the Speech Recognition tab, you can customize various aspects of the experience, including:
- Recognition profiles.
- User settings.
- Microphone.

In the Text to Speech tab, you can control voice settings, including:
- Voice selection.
- Voice speed.

Additionally, you can always right-click the experience interface to open a context menu to access all the different features and settings you can use with Speech Recognition.

While there is a small learning curve, Speech Recognition uses clear and easy-to-remember commands. For example, using the "Start" command opens the Start menu, while saying "Show Desktop" will minimize everything on the screen.
If Speech Recognition is having difficulties understanding your voice, you can always use the Show numbers command as everything on the screen has a number. Then say the number and speak OK to execute the command.

Here are some common tasks that will get you started with Speech Recognition:
Starting Speech Recognition
To launch the experience, just open the Start menu , search for Windows Speech Recognition , and select the top result.
Turning on and off
To start using the feature, click the microphone button or say Start listening depending on your configuration.

In the same way, you can turn it off by saying Stop listening or clicking the microphone button.
Using commands
Some of the most frequent commands you'll use include:
- Open — Launches an app when saying "Open" followed by the name of the app. For example, "Open Mail," or "Open Firefox."
- Switch to — Jumps to another running app when saying "Switch to" followed by the name of the app. For example, "Switch to Microsoft Edge."
- Control window in focus — You can use the commands "Minimize," "Maximize," and "Restore" to control an active window.
- Scroll — Allows you to scroll in a page. Simply use the command "Scroll down" or "Scroll up," "Scroll left" or "Scroll right." It's also possible to specify long scrolls. For example, you can try: "Scroll down two pages."
- Close app — Terminates an application by saying "Close" followed by the name of the running application. For example, "Close Word."
- Clicks — Inside an application, you can use the "Click" command followed by the name of the element to perform a click. For example, in Word, you can say "Click Layout," and Speech Recognition will open the Layout tab. In the same way, you can use "Double-click" or "Right-click" commands to perform those actions.
- Press — This command lets you execute shortcuts. For example, you can say "Press Windows A" to open Action Center.
Using dictation
Speech Recognition also includes the ability to convert voice into text using the dictation functionality, and it works automatically.
If you need to dictate text, open the application (making sure the feature is in listening mode) and start dictating. However, remember that you'll have to say each punctuation mark and special character.
For example, if you want to insert the "Good morning, where do you like to go today?" sentence, you'll need to speak, "Open quote good morning comma where do you like to go today question mark close quote."
In the case that you need to correct some text that wasn't recognized accurately, use the "Correct" command followed by the text you want to change. For example, if you meant to write "suite" and the feature recognized it as "suit," you can say "Correct suit," select the suggestion using the correction panel or say "Spell it" to speak the correct text, and then say "OK".

Wrapping things up
Although Speech Recognition doesn't offer a conversational experience like a personal assistant, it's still a powerful tool for anyone who needs to control their device entirely using only voice.
Cortana also provides the ability to control a device with voice, but it's limited to a specific set of input commands, and it's not possible to control everything that appears on the screen.
However, that doesn't mean that you can't get the best of both worlds. Speech Recognition runs independently of Cortana, which means that you can use the Microsoft's digital assistant for certain tasks and Speech Recognition to navigate and execute other commands.
It's worth noting that this speech recognition isn't available in every language. Supported languages include English (U.S. and UK), French, German, Japanese, Mandarin (Chinese Simplified and Chinese Traditional), and Spanish.
While this guide is focused on Windows 10, Speech Recognition has been around for a long time, so you can refer to it even if you're using Windows 8.1 or Windows 7.
More Windows 10 resources
For more helpful articles, coverage, and answers to common questions about Windows 10, visit the following resources:
- Windows 10 on Windows Central – All you need to know
- Windows 10 help, tips, and tricks
- Windows 10 forums on Windows Central
Mauro Huculak is technical writer for WindowsCentral.com. His primary focus is to write comprehensive how-tos to help users get the most out of Windows 10 and its many related technologies. He has an IT background with professional certifications from Microsoft, Cisco, and CompTIA, and he's a recognized member of the Microsoft MVP community.
- 2 Microsoft might have blocked a sneaky bypass that let you setup Windows 11 without a Microsoft Account
- 3 The enormity of Microsoft's Windows Phone shut-down mistake is becoming increasingly clear in the AI era
- 4 NVIDIA is bringing Copilot Plus to RTX-enabled devices
- 5 ROG Ally X vs ROG Ally (2023): What's the difference?
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
Open-source, accurate and easy-to-use video speech recognition & clipping tool, LLM based AI clipping intergrated.
modelscope/FunClip
Folders and files, repository files navigation.
「 简体中文 | English」
⚡ Open-source, accurate and easy-to-use video clipping tool
🧠 Explore LLM based video clipping with FunClip

What's New | On Going | Install | Usage | Community
FunClip is a fully open-source, locally deployed automated video clipping tool. It leverages Alibaba TONGYI speech lab's open-source FunASR Paraformer series models to perform speech recognition on videos. Then, users can freely choose text segments or speakers from the recognition results and click the clip button to obtain the video clip corresponding to the selected segments (Quick Experience Modelscope⭐ HuggingFace🤗 ).
Highlights🎨
- 🔥Try AI clipping using LLM in FunClip now.
- FunClip integrates Alibaba's open-source industrial-grade model Paraformer-Large , which is one of the best-performing open-source Chinese ASR models available, with over 13 million downloads on Modelscope. It can also accurately predict timestamps in an integrated manner.
- FunClip incorporates the hotword customization feature of SeACo-Paraformer , allowing users to specify certain entity words, names, etc., as hotwords during the ASR process to enhance recognition results.
- FunClip integrates the CAM++ speaker recognition model, enabling users to use the auto-recognized speaker ID as the target for trimming, to clip segments from a specific speaker.
- The functionalities are realized through Gradio interaction, offering simple installation and ease of use. It can also be deployed on a server and accessed via a browser.
- FunClip supports multi-segment free clipping and automatically returns full video SRT subtitles and target segment SRT subtitles, offering a simple and convenient user experience.
What's New🚀
- After the recognition, select the name of the large model and configure your own apikey;
- Click on the 'LLM Smart Paragraph Selection' button, and FunClip will automatically combine two prompts with the video's srt subtitles;
- Click on the 'LLM Smart Clipping' button, and based on the output results of the large language model from the previous step, FunClip will extract the timestamps for clipping;
- You can try changing the prompt to leverage the capabilities of the large language models to get the results you want;
- Support configuration of output file directory, saving ASR intermediate results and video clipping intermediate files;
- UI upgrade (see guide picture below), video and audio cropping function are on the same page now, button position adjustment;
- Fixed a bug introduced due to FunASR interface upgrade, which has caused some serious clipping errors;
- Support configuring different start and end time offsets for each paragraph;
- Code update, etc;
- 2024/03/06 Fix bugs in using FunClip with command line.
- 2024/02/28 FunASR is updated to 1.0 version, use FunASR1.0 and SeACo-Paraformer to conduct ASR with hotword customization.
- 2023/10/17 Fix bugs in multiple periods chosen, used to return video with wrong length.
- 2023/10/10 FunClipper now supports recognizing with speaker diarization ability, choose 'yes' button in 'Recognize Speakers' and you will get recognition results with speaker id for each sentence. And then you can clip out the periods of one or some speakers (e.g. 'spk0' or 'spk0#spk3') using FunClipper.
- FunClip will support Whisper model for English users, coming soon.
- FunClip will further explore the abilities of large langage model based AI clipping, welcome to discuss about prompt setting and clipping, etc.
- Reverse periods choosing while clipping.
- Removing silence periods.
Python env install
FunClip basic functions rely on a python environment only.
imagemagick install (Optional)
If you want to clip video file with embedded subtitles
- ffmpeg and imagemagick is required
Download and install imagemagick https://imagemagick.org/script/download.php#windows
Find your python install path and change the IMAGEMAGICK_BINARY to your imagemagick install path in file site-packages\moviepy\config_defaults.py
- Download font file to funclip/font
Use FunClip
A. use funclip as local gradio service.
You can establish your own FunClip service which is same as Modelscope Space as follow:
then visit localhost:7860 you will get a Gradio service like below and you can use FunClip following the steps:
- Step1: Upload your video file (or try the example videos below)
- Step2: Copy the text segments you need to 'Text to Clip'
- Step3: Adjust subtitle settings (if needed)
- Step4: Click 'Clip' or 'Clip and Generate Subtitles'

Follow the guide below to explore LLM based clipping:

B. Experience FunClip in Modelscope
FunClip@Modelscope Space⭐
FunClip@HuggingFace Space🤗
C. Use FunClip in command line
FunClip supports you to recognize and clip with commands:
Community Communication🍟
FunClip is firstly open-sourced bu FunASR team, any useful PR is welcomed.
You can also scan the following DingTalk group or WeChat group QR code to join the community group for communication.
Support Us🌟
Find Speech Models in FunASR
FunASR hopes to build a bridge between academic research and industrial applications on speech recognition. By supporting the training & finetuning of the industrial-grade speech recognition model released on ModelScope, researchers and developers can conduct research and production of speech recognition models more conveniently, and promote the development of speech recognition ecology. ASR for Fun!
Contributors 8
- Python 98.7%
Katy Perry Chops Controversial Harrison Butker Speech Into Feminist, Pro-LGBTQ Message

Senior Reporter

Katy Perry just made a few choice tweaks to Kansas City Chiefs kicker Harrison Butker’s contentious Benedictine College commencement speech that made waves last month.
On Saturday, the “Roar” singer shared a heavily edited version of the football player’s comments, which the star remixed in honor of June’s LGBTQ+ Pride month.
“Fixed this for my girls, my graduates, and my gays,” she wrote in the caption. “You can do anything, congratulations and happy pride.”
While Butker railed against “degenerate cultural values” like reproductive choice and working women in his speech at the Catholic college, Perry’s edit made it look like he was celebrating female graduates and the queer community.
Starting with stretches of the kicker’s original words, the video began with him saying, “For the ladies present today, congratulations on an amazing accomplishment. You should be proud of all that you have achieved to this point in your young lives.”
“How many of you are sitting here now, about to cross this stage, and are thinking about all the promotions and titles you’re going to get in your career?” he continued.
View this post on Instagram A post shared by KATY PERRY (@katyperry)
Veering from Butker’s lines about the “diabolical lie” of women working, Perry reordered his speech to say, “I would venture to guess the women here today are going to lead successful careers in the world.”
Dicing up his words even more, Butker’s edited address went on, “I say all of this to you because I have seen it firsthand, how much happier someone can be supporting women and not saying that the majority of you are most excited about your marriage and the children you will bring into this world.”
“The road ahead is bright, things are changing, society is shifting and people young and old are embracing diversity, equity and inclusion,” the remix continued.
Chopping the speech up word-by-word for its final message, Perry’s edit finished by saying, “With that said, I want to say happy Pride Month to all of you. And congratulations class of 2024.”
Though Butker’s speech was widely criticized for its retrograde views, the football player was unapologetic while addressing his comments ― and the backlash ― for the first time late last month.
“If it wasn’t clear that the timeless Catholic values are hated by many, it is now,” he told attendees of the “Courage Under Fire Gala” in Nashville, Tennessee.
Check out Perry’s post above for the full edit.
Popular in the Community
From our partner, more in entertainment.

Travis Kelce on Harrison Butker’s speech: ‘I don’t think that I should judge him by his views’

Kansas City Chiefs tight end Travis Kelce said he doesn’t agree with “the majority” of Harrison Butker’s recent commencement speech but said he won’t judge the place kicker by his views.
“He’s treated friends and family that I’ve introduced to him with nothing but respect and kindness,” Kelce said of Butker on Friday’s episode of his “New Heights” podcast . “And that’s how he treats everyone. When it comes down to his views and what he said (in his) commencement speech, those are his.
Advertisement
“I can’t say I agree with the majority of it or just about any of it outside of just him loving his family and his kids. And I don’t think that I should judge him by his views, especially his religious views, of how to go about life, that’s just not who I am.”
Kelce also commended Chiefs quarterback Patrick Mahomes’ take on Butker’s controversial commencement speech, where Mahomes said he judges Butker by his character.
“I’ve known (Butker) for seven years,” Mahomes told reporters Wednesday . “I judge him by the character he shows every day and that’s a good person. … We’re not always going to agree. He said certain things I don’t agree with.”
During his commencement speech at Benedictine College, Butker referred to Pride Month as an example of the “deadly sins.” He also addressed gender ideologies and said a woman’s most important title is “homemaker.”
“It is you, the women, who have had the most diabolic lies told to you,” Butker said during his speech to graduates earlier this month. “Some of you may go on to lead successful careers in the world but I would venture to guess that the majority of you are most excited about your marriage and the children you will bring into this world.”
Kelce pointed out that both his mother and father, Donna and Ed Kelce, were “homemakers and providers” during his childhood.
“They were unbelievable at being present every single day of my life,” Kelce said. “That was a beautiful upbringing for me. … I’m not the same person without both of them being who they were in my life.”

Free, daily NFL updates direct to your inbox. Sign up
Although Butker referenced a Taylor Swift lyric in his speech, Kelce, Swift’s boyfriend, did not address it.
“As my teammate’s girlfriend says, ‘Familiarity breeds contempt,'” Butker said, referencing Swift’s song, “Bejeweled,” during the speech.
Butker also used the speech to criticize President Joe Biden on several issues, including abortion and the COVID-19 pandemic, and questioned Biden’s devotion to Catholicism.
Despite Butker’s comments on Biden, Chiefs coach Andy Reid said Wednesday that he believes Butker will go with the team to the White House on May 31 to celebrate its 2024 Super Bowl victory.
“I didn’t think I need to (address it). We’re a microcosm of life,” Reid said when asked about Butker’s comments. “We all respect each other’s opinions. We all have a voice.”
A few days after Butker delivered his speech, the NFL released a statement distancing itself from his comments and said Butker’s views are not the same as the league as an organization.
When asked about Butker’s speech at the league meetings in Nashville on Wednesday, NFL commissioner Roger Goodell said the league has a “diversity of opinions and thoughts.”
Kelce echoed a similar sentiment when discussing how teammates don’t always share the same views but can work together: “You put your differences aside for one goal in common, and that’s the beauty of team sports. That’s the beauty of the NFL.”
Required reading
- Chiefs kicker Harrison Butker says Pride Month is example of ‘deadly sin’ during commencement speech
- NFL distances itself from Chiefs’ Harrison Butker’s Benedictine College speech
- Benedictine Sisters denounce Harrison Butker’s speech as his jersey sales rise
- Patrick Mahomes: I didn’t agree with all of Harrison Butker’s speech comments, but he’s ‘a good person’
(Photo of Harrison Butker (left) and Travis Kelce (right): Arne Dedert / picture alliance via Getty Images)
Get all-access to exclusive stories.
Subscribe to The Athletic for in-depth coverage of your favorite players, teams, leagues and clubs. Try a week on us.
Jenna West is a staff editor on The Athletic's news team. Before joining The Athletic, she served as a writer and producer for Sports Illustrated's national news desk. Jenna is a graduate of Northwestern University.
IMAGES
VIDEO
COMMENTS
When a rewards and recognition speech is delivered in a public setting, such as a company-wide event or meeting, it not only acknowledges the efforts of the individual employee but also inspires and motivates others. ... Recognition should be specific, highlighting the specific actions or contributions that led to the recognition. This helps ...
Your recognition speech should be happy and upbeat, smiling will add to the positivity of your message. Step 3: Customize the Environment to Your Employee's Preferences Informal recognition speech: When giving informal recognition, try to adapt the environment to make the recipient comfortable. If you are recognizing an employee whose culture ...
But presenting someone else with an award or honor is still an important task. Here are 3 tips for delivering a great speech of recognition. 1. Get the Audience's Attention. Many times a speech of recognition follows something else. It could be dinner, or another award presentation, or a longer message. At any rate, part of your job is to ...
The model asserts that effective reward and recognition speech examples touch on three critical elements: the behavior, the effect, and the thank you. ... 71 Employee Recognition Quotes Every Manager Should Know How to Retain Employees: 18 Practical Takeaways from 7 Case Studies Boost Your Employee Recognition Skills and Words (Templates ...
acceptance speech. a speech that gives thanks for a gift, an award, or some other form of public recognition. commemorative speech. a speech that pays tribute to a person, a group of people, an institution, or an idea. speeches of introduction. -be brief. -make sure your remarks are completely accurate. -adapt your remarks to the occasion.
This article provides an in-depth and scholarly look at the evolution of speech recognition technology. The Past, Present and Future of Speech Recognition Technology by Clark Boyd at The Startup. This blog post presents an overview of speech recognition technology, with some thoughts about the future. Some good books about speech recognition:
The individual should repeat or in some other way indicate recognition of the speech material 50% of the time. The term speech recognition threshold is synonymous with speech reception threshold. Speech recognition threshold is the preferred term because it more accurately describes the listener's task. Spondaic words are the usual and ...
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format. While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal ...
In other words, speech recognition should inherently demonstrate learning. Learning mechanisms in speech. While on its face this seems uncontroversial, theories of speech perception have not traditionally incorporated learning although some have evolved over time to do so (e.g., Shortlist-B, Hebb-Trace). ...
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT).It incorporates knowledge and research in the computer ...
Before completing a speech recognition test, there are several parameters to consider. 1. Test transducer. You can perform speech recognition testing using air conduction, bone conduction, and speakers in a sound-field setup. 2. Types of words. Speech recognition testing can be performed using a variety of different words or sentences.
In isolated word/pattern recognition, the acoustic features (here \(Y\)) are used as an input to a classifier whose rose is to output the correct word. However, we take input sequence and should output sequences too when it comes to continuous speech recognition. The acoustic model goes further than a simple classifier.
The recognition of speech is therefore of great interest to all of us in the fields of speech and hearing. Speech audiometry developed originally out of the work conducted at Bell Labs in the 1920s and 1930s where they were looking into the efficiency of communication systems, and really gained momentum post World War II as returning veterans ...
spoken_lang_1.jpg. Speech recognition technology allows computers to take spoken audio, interpret it and generate text from it. But how do computers understand human speech? The short answer is…the wonder of signal processing. Speech is simply a series of sound waves created by our vocal chords when they cause air to vibrate around them.
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text. Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents ...
Library for performing speech recognition, with support for several engines and APIs, online and offline. UPDATE 2022-02-09: Hey everyone!This project started as a tech demo, but these days it needs more time than I have to keep up with all the PRs and issues.
voice portal (vortal): A voice portal (sometimes called a vortal ) is a Web portal that can be accessed entirely by voice. Ideally, any type of information, service, or transaction found on the Internet could be accessed through a voice portal.
The speech recognition threshold can be met by using synonyms in addition to spelling words. Listeners are not required to recognize the material as speech, but they should be aware of its presence. The following sections include an alphabetical list of 36 spondaic words appropriate for adults, as well as a list of 15 homogeneous words from ...
Speech recognition and speech-to-text programs have a number of applications for users with and without disabilities. Speech-to-text has been used to help struggling writers boost their writing production ii and to provide alternate access to a computer for individuals with physical impairments iii.Other applications include speech recognition for foreign language learning, iv voice activated ...
Tip: If you've already set up speech recognition, pressing Windows logo key+Ctrl+S opens speech recognition and you're ready to use it.If you want to retrain your computer to recognize your voice, press the Windows logo key, type Control Panel, and select Control Panel in the list of results. In Control Panel, select Ease of Access > Speech Recognition > Train your computer to better ...
About Speech Testing. An audiologist may do a number of tests to check your hearing. Speech testing will look at how well you listen to and repeat words. One test is the speech reception threshold, or SRT. The SRT is for older children and adults who can talk. The results are compared to pure-tone test results to help identify hearing loss.
To use all of the functionality of the library, you should have: Python 3.8+ (required); PyAudio 0.2.11+ (required only if you need to use microphone input, Microphone); PocketSphinx (required only if you need to use the Sphinx recognizer, recognizer_instance.recognize_sphinx); Google API Client Library for Python (required only if you need to use the Google Cloud Speech API, recognizer ...
Students at New York University's commencement in 1998. Like a wedding toast, a commencement address is not supposed to surpass its occasion. The speaker is generally someone who has said or ...
Open Control Panel. Click on Ease of Access. Click on Speech Recognition. Click the Start Speech Recognition link. In the "Set up Speech Recognition" page, click Next. Select the type of ...
Facts First : Trump's claim that "I didn't say 'lock her up'" is false. He called for Clinton's imprisonment on multiple occasions, including by using the phrase "lock her up ...
Note: chunk_size is the configuration for streaming latency. [0,10,5] indicates that the real-time display granularity is 10*60=600ms, and the lookahead information is 5*60=300ms.Each inference input is 600ms (sample points are 16000*0.6=960), and the output is the corresponding text.For the last speech segment input, is_final=True needs to be set to force the output of the last word.
FunASR hopes to build a bridge between academic research and industrial applications on speech recognition. By supporting the training & finetuning of the industrial-grade speech recognition model released on ModelScope, researchers and developers can conduct research and production of speech recognition models more conveniently, and promote the development of speech recognition ecology.
Katy Perry just made a few choice tweaks to Kansas City Chiefs kicker Harrison Butker's contentious Benedictine College commencement speech that made waves last month. On Saturday, the "Roar" singer shared a heavily edited version of the football player's comments, which the star remixed in honor of June's LGBTQ+ Pride month.
Doug Mills/The New York Times. By Michael M. Grynbaum. May 31, 2024. Several major networks cut away from former President Donald J. Trump on Friday during an appearance that had been promoted as ...
Butker also used the speech to criticize President Joe Biden on several issues, including abortion and the COVID-19 pandemic, and questioned Biden's devotion to Catholicism. Advertisement