Subscribe to the PwC Newsletter
Join the community, edit dataset, edit dataset tasks.
Some tasks are inferred based on the benchmarks list.

Add a Data Loader
Remove a data loader.
- huggingface/datasets -
- tensorflow/datasets -
- pytorch/text -
Edit Dataset Modalities
Edit dataset languages, edit dataset variants.
The benchmarks section lists all benchmarks using a given dataset or any of its variants. We use variants to distinguish between results evaluated on slightly different versions of the same dataset. For example, ImageNet 32⨉32 and ImageNet 64⨉64 are variants of the ImageNet dataset.
Add a new evaluation result row
Imdb movie reviews.

The IMDb Movie Reviews dataset is a binary sentiment analysis dataset consisting of 50,000 reviews from the Internet Movie Database (IMDb) labeled as positive or negative. The dataset contains an even number of positive and negative reviews. Only highly polarizing reviews are considered. A negative review has a score ≤ 4 out of 10, and a positive review has a score ≥ 7 out of 10. No more than 30 reviews are included per movie. The dataset contains additional unlabeled data.
Benchmarks Edit Add a new result Link an existing benchmark
Dataset loaders edit add remove.

Similar Datasets
License edit, modalities edit, languages edit.
- Español – América Latina
- Português – Brasil
- Tiếng Việt
TFDS now supports the Croissant 🥐 format ! Read the documentation to know more.
imdb_reviews
- Description :
Large Movie Review Dataset. This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well.
Additional Documentation : Explore on Papers With Code north_east
Homepage : http://ai.stanford.edu/~amaas/data/sentiment/
Source code : tfds.datasets.imdb_reviews.Builder
- 1.0.0 (default): New split API ( https://tensorflow.org/datasets/splits )
Download size : 80.23 MiB
Auto-cached ( documentation ): Yes
Supervised keys (See as_supervised doc ): ('text', 'label')
Figure ( tfds.show_examples ): Not supported.
imdb_reviews/plain_text (default config)
Config description : Plain text
Dataset size : 129.83 MiB
Feature structure :
- Feature documentation :
- Examples ( tfds.as_dataframe ):
imdb_reviews/bytes
Config description : Uses byte-level text encoding with tfds.deprecated.text.ByteTextEncoder
Dataset size : 129.88 MiB
imdb_reviews/subwords8k
Config description : Uses tfds.deprecated.text.SubwordTextEncoder with 8k vocab size
Dataset size : 54.72 MiB
imdb_reviews/subwords32k
Config description : Uses tfds.deprecated.text.SubwordTextEncoder with 32k vocab size
Dataset size : 50.33 MiB
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2022-12-10 UTC.
IMDb Non-Commercial Datasets
Subsets of IMDb data are available for access to customers for personal and non-commercial use. You can hold local copies of this data, and it is subject to our terms and conditions. Please refer to the Non-Commercial Licensing and copyright/license and verify compliance.
As of March 18, 2024 the datasets on this page are backed by a new data source. There has been no change in location or schema, but if you encounter issues with the datasets following the March 18th update, please contact [email protected].
Data Location
The dataset files can be accessed and downloaded from https://datasets.imdbws.com/ . The data is refreshed daily.
IMDb Dataset Details
Each dataset is contained in a gzipped, tab-separated-values (TSV) formatted file in the UTF-8 character set. The first line in each file contains headers that describe what is in each column. A ‘\N’ is used to denote that a particular field is missing or null for that title/name. The available datasets are as follows:
title.akas.tsv.gz
- titleId (string) - a tconst, an alphanumeric unique identifier of the title
- ordering (integer) – a number to uniquely identify rows for a given titleId
- title (string) – the localized title
- region (string) - the region for this version of the title
- language (string) - the language of the title
- types (array) - Enumerated set of attributes for this alternative title. One or more of the following: "alternative", "dvd", "festival", "tv", "video", "working", "original", "imdbDisplay". New values may be added in the future without warning
- attributes (array) - Additional terms to describe this alternative title, not enumerated
- isOriginalTitle (boolean) – 0: not original title; 1: original title
title.basics.tsv.gz
- tconst (string) - alphanumeric unique identifier of the title
- titleType (string) – the type/format of the title (e.g. movie, short, tvseries, tvepisode, video, etc)
- primaryTitle (string) – the more popular title / the title used by the filmmakers on promotional materials at the point of release
- originalTitle (string) - original title, in the original language
- isAdult (boolean) - 0: non-adult title; 1: adult title
- startYear (YYYY) – represents the release year of a title. In the case of TV Series, it is the series start year
- endYear (YYYY) – TV Series end year. ‘\N’ for all other title types
- runtimeMinutes – primary runtime of the title, in minutes
- genres (string array) – includes up to three genres associated with the title
title.crew.tsv.gz
- directors (array of nconsts) - director(s) of the given title
- writers (array of nconsts) – writer(s) of the given title
title.episode.tsv.gz
- tconst (string) - alphanumeric identifier of episode
- parentTconst (string) - alphanumeric identifier of the parent TV Series
- seasonNumber (integer) – season number the episode belongs to
- episodeNumber (integer) – episode number of the tconst in the TV series
title.principals.tsv.gz
- nconst (string) - alphanumeric unique identifier of the name/person
- category (string) - the category of job that person was in
- job (string) - the specific job title if applicable, else '\N'
- characters (string) - the name of the character played if applicable, else '\N'
title.ratings.tsv.gz
- averageRating – weighted average of all the individual user ratings
- numVotes - number of votes the title has received
name.basics.tsv.gz
- primaryName (string)– name by which the person is most often credited
- birthYear – in YYYY format
- deathYear – in YYYY format if applicable, else '\N'
- primaryProfession (array of strings)– the top-3 professions of the person
- knownForTitles (array of tconsts) – titles the person is known for
Get started
Contact us to see how IMDb data can solve your customers needs.
IMDB movie review sentiment classification dataset
Load_data function.
Loads the IMDB dataset .
This is a dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a list of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data. This allows for quick filtering operations such as: "only consider the top 10,000 most common words, but eliminate the top 20 most common words".
As a convention, "0" does not stand for a specific word, but instead is used to encode the pad token.
- path : where to cache the data (relative to ~/.keras/dataset ).
- num_words : integer or None. Words are ranked by how often they occur (in the training set) and only the num_words most frequent words are kept. Any less frequent word will appear as oov_char value in the sequence data. If None, all words are kept. Defaults to None .
- skip_top : skip the top N most frequently occurring words (which may not be informative). These words will appear as oov_char value in the dataset. When 0, no words are skipped. Defaults to 0 .
- maxlen : int or None. Maximum sequence length. Any longer sequence will be truncated. None, means no truncation. Defaults to None .
- seed : int. Seed for reproducible data shuffling.
- start_char : int. The start of a sequence will be marked with this character. 0 is usually the padding character. Defaults to 1 .
- oov_char : int. The out-of-vocabulary character. Words that were cut out because of the num_words or skip_top limits will be replaced with this character.
- index_from : int. Index actual words with this index and higher.
- Tuple of Numpy arrays : (x_train, y_train), (x_test, y_test) .
x_train , x_test : lists of sequences, which are lists of indexes (integers). If the num_words argument was specific, the maximum possible index value is num_words - 1 . If the maxlen argument was specified, the largest possible sequence length is maxlen .
y_train , y_test : lists of integer labels (1 or 0).
Note : The 'out of vocabulary' character is only used for words that were present in the training set but are not included because they're not making the num_words cut here. Words that were not seen in the training set but are in the test set have simply been skipped.
get_word_index function
Retrieves a dict mapping words to their index in the IMDB dataset.
The word index dictionary. Keys are word strings, values are their index.
Exploring the IMDB Dataset with TensorFlow: A Python Guide
💡 Problem Formulation: When working with machine learning and natural language processing, having access to a rich dataset is crucial. The IMDB dataset, which contains movie reviews for sentiment analysis, is a common starting point. The goal is to download the IMDB dataset conveniently, then process and explore it in Python using TensorFlow, transforming the raw data into a usable format for ML models. We need methods that are efficient, straightforward, and suitable for downstream tasks like sentiment analysis.
Method 1: TensorFlow Datasets API
The TensorFlow Datasets API is a collection of datasets ready to use with TensorFlow. It encapsulates fetching, parsing, and preparing the data into a format that’s easy to use with TensorFlow models. For the IMDB dataset, the API provides utilities to download and preprocess the data, including tokenizing and encoding the reviews.
Here’s an example:
This code snippet utilizes the tfds.load function to download the IMDB dataset and prepares it for training and testing. By specifying the split argument, you can control which subset of the data to load. The example iterates over the first item returning a dictionary with text and label pairs.
Method 2: Keras IMDB Dataset Utility
Keras, which is now part of TensorFlow’s core API, has a module for loading the IMDB dataset that is more tailored to neural network training. It allows you to specify the number of words to use, and it automatically tokenizes and encodes the text data.
This code snippet calls the imdb.load_data() method to fetch the IMDB dataset. By setting the num_words parameter, the data will be limited to the top 10,000 most frequent words. The output is a sequence of word indices representing the words of the first movie review.
Method 3: Manual Download and Parsing
If you want maximum control over the dataset downloading and preprocessing steps, you can manually download the IMDB dataset and write custom parsing code. This is more complex but allows for fine-grained control over the data processing logic.
In this example, we use the requests library to download the dataset as a compressed file and then extract it using tarfile . The files are read directly from the disk, offering an opportunity to implement custom preprocessing procedures.
Method 4: TensorFlow’s TextLineDataset
For those looking to work directly with the raw text data line by line, TensorFlow’s TextLineDataset can be used to stream text from a file and is particularly useful for large text files that do not fit into memory.
This snippet demonstrates how to use TensorFlow’s TextLineDataset to read lines of text from a file. This line-by-line approach is memory-efficient and handy for large datasets, ensuring that the whole dataset does not need to be loaded into memory.
Bonus One-Liner Method 5: pandas and TensorFlow
For quick exploration and prototyping, you can combine the strengths of pandas and TensorFlow. This method takes advantage of pandas for initial dataset loading and manipulation, and TensorFlow for later processing and model training.
In this example, we create a pandas DataFrame from a CSV version of the IMDb dataset and then convert it into a TensorFlow Dataset, which can be used for model training and evaluation.
Summary/Discussion
- Method 1: TensorFlow Datasets API. Strengths: Simplifies the process, handling most of the heavy lifting. Weaknesses: Less flexibility in data preprocessing.
- Method 2: Keras IMDB Dataset Utility. Strengths: Integrated with Keras, making it straightforward for neural networks training. Weaknesses: The fixed preprocessing may not be suitable for all projects.
- Method 3: Manual Download and Parsing. Strengths: Full control over the preprocessing steps. Weaknesses: More complex and time-consuming.
- Method 4: TensorFlow’s TextLineDataset. Strengths: Efficient memory use, reads files line by line. Weaknesses: Less straightforward for advanced preprocessing techniques.
- Bonus One-Liner Method 5: pandas and TensorFlow. Strengths: Combines the ease of use of pandas with the TensorFlow modeling capabilities. Weaknesses: May not scale well for very large datasets.
Emily Rosemary Collins is a tech enthusiast with a strong background in computer science, always staying up-to-date with the latest trends and innovations. Apart from her love for technology, Emily enjoys exploring the great outdoors, participating in local community events, and dedicating her free time to painting and photography. Her interests and passion for personal growth make her an engaging conversationalist and a reliable source of knowledge in the ever-evolving world of technology.
Datasets: scikit-learn / imdb like 0

Git LFS Details
- SHA256: dfc447764f82be365fa9c2beef4e8df89d3919e3da95f5088004797d79695aa2
- Pointer size: 133 Bytes
- Size of remote file: 66.2 MB
Git Large File Storage (LFS) replaces large files with text pointers inside Git, while storing the file contents on a remote server. More info .
IMDB Large Movie Review Dataset
The core dataset contains 50,000 reviews split evenly into 25k train and 25k test sets. The overall distribution of labels is balanced (25k pos and 25k neg).
http://ai.stanford.edu/~amaas/data/sentiment/
Character, path to directory where data will be stored. If NULL , user_cache_dir will be used to determine path.
Character. Return training ("train") data or testing ("test") data. Defaults to "train".
Logical, set TRUE to delete dataset.
Logical, set TRUE to return the path of the dataset.
Logical, set TRUE to remove intermediate files. This can greatly reduce the size. Defaults to FALSE.
Logical, set TRUE if you have manually downloaded the file and placed it in the folder designated by running this function with return_path = TRUE .
A tibble with 25,000 rows and 2 variables:
Character, denoting the sentiment
Character, text of the review
In the entire collection, no more than 30 reviews are allowed for any given movie because reviews for the same movie tend to have correlated ratings. Further, the train and test sets contain a disjoint set of movies, so no significant performance is obtained by memorizing movie-unique terms and their associated with observed labels. In the labeled train/test sets, a negative review has a score <= 4 out of 10, and a positive review has a score >= 7 out of 10. Thus reviews with more neutral ratings are not included in the train/test sets. In the unsupervised set, reviews of any rating are included and there are an even number of reviews > 5 and <= 5.
When using this dataset, please cite the ACL 2011 paper
InProceedings{maas-EtAl:2011:ACL-HLT2011, author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher}, title = {Learning Word Vectors for Sentiment Analysis}, booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies}, month = {June}, year = {2011}, address = {Portland, Oregon, USA}, publisher = {Association for Computational Linguistics}, pages = {142--150}, url = {http://www.aclweb.org/anthology/P11-1015} }
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
imdb-dataset
Here are 347 public repositories matching this topic..., cmasch / cnn-text-classification.
Text classification with Convolution Neural Networks on Yelp, IMDB & sentence polarity dataset v1.0
- Updated Sep 10, 2021
- Jupyter Notebook
uzaymacar / comparatively-finetuning-bert
Comparatively fine-tuning pretrained BERT models on downstream, text classification tasks with different architectural configurations in PyTorch.
- Updated Jul 2, 2020
RyanMarcus / imdb_pg_dataset
A Vagrant box that automatically loads the IMDB dataset into Postgres
- Updated Mar 22, 2024
zyh040521 / distilbert-base-uncased-finetuning
This repository contains a DistilBERT model fine-tuned using the Hugging Face Transformers library on the IMDb movie review dataset. The model is trained for sentiment analysis, enabling the determination of sentiment polarity (positive or negative) within text reviews.
- Updated Dec 17, 2023
kunalnagarco / imdb-scraper
🎬 An attempt at the most complete IMDb API
- Updated Jan 12, 2024
mansik95 / IMDB-Analysis
This repository contains analysis of IMDB data from multiple sources and analysis of movies/cast/box office revenues, movie brands and franchises.
- Updated Jun 1, 2020
madnight / imdb-series-chart
Visualize the IMDB rating of every episode for any TV series.
- Updated Nov 10, 2023
leohsuofnthu / Pytorch-TextCNN
Pytorch implementation of the paper Convolutional Neural Networks for Sentence Classification
- Updated Jan 21, 2020
RafaelMenesesRibeiro / FaceRecognition
Detect actor / actress faces in an image and list their work (movies / series)
- Updated Oct 8, 2017
M-Taghizadeh / flan-t5-base-imdb-text-classification
In this implementation, using the Flan T5 large language model, we performed the Text Classification task on the IMDB dataset and obtained a very good accuracy of 93%.
- Updated May 12, 2023
erictleung / pixarfilms
🎥 R data package to explore Pixar films, the people, and reception data
- Updated May 28, 2023
surfertas / deep_learning
Topics related to Deep Learning
- Updated Jul 6, 2023
gaurav104 / TextClassification
Repository of state of the art text/documentation classification algorithms in Pytorch.
- Updated Feb 15, 2019
Prajwal10031999 / Movie-Recommendation-System-Using-Cosine-Similarity
A machine learning model to recommend movies & tv series
- Updated Oct 26, 2020
pushshift / imdb_to_json
Fetch movie data from IMDB and output in JSON format.
- Updated Sep 6, 2020
sleepingdog / IMdb-sql-queries
Builds a Microsoft SQL Server 2016+ relational database from IMDb official data files, to support personal querying.
- Updated Mar 22, 2021
aryanraj2713 / Imdb-movie-review-analysis-using-NLP
- Updated Sep 28, 2022
mohdahmad242 / Transfer-Learning-Model-hosted-on-Heroku-using-React-Flask
Transfer Learning model using RoBERTa on IMDb dataset deployed on React and Flask ( Regional Winner in Facebook Developer Community Challenge 2020 )
- Updated Dec 1, 2020
advaitsave / Text-preprocessing-and-classification
IMDB Movie Reviews - Text preprocessing and classification. Includes BOW model, TF_IDF, VADER entiment analysis, Topic Modelling using Latent Dirichlet Allocation and Word Embeddings. (Python)
- Updated Mar 26, 2019
tareqmahmud / IMDBScraping
Scrape Data From IMDB Movie DataBase
- Updated Jan 11, 2019
Improve this page
Add a description, image, and links to the imdb-dataset topic page so that developers can more easily learn about it.
Curate this topic
Add this topic to your repo
To associate your repository with the imdb-dataset topic, visit your repo's landing page and select "manage topics."
Sentiment analysis of movie reviews based on NB approaches using TF–IDF and count vectorizer
- Original Article
- Published: 16 April 2024
- Volume 14 , article number 87 , ( 2024 )
Cite this article

- Mian Muhammad Danyal 1 , 2 na1 ,
- Sarwar Shah Khan 3 , 4 ,
- Muzammil Khan 3 na1 ,
- Subhan Ullah 2 na1 ,
- Muhammad Bilal Ghaffar 2 na1 &
- Wahab Khan 2 na1
71 Accesses
Explore all metrics
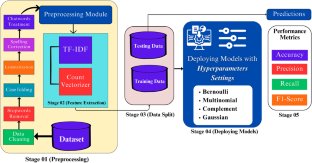
Movies have been important in our lives for many years. Movies provide entertainment, inspire, educate, and offer an escape from reality. Movie reviews help us choose better movies, but reading them all can be time-consuming and overwhelming. To make it easier, sentiment analysis can classify movie reviews into positive and negative categories. Opinion mining (OP), called sentiment analysis (SA), uses natural language processing to identify and extract opinions expressed through text. Naive Bayes, a supervised learning algorithm, offers simplicity, efficiency, and strong performance in classification tasks due to its feature independence assumption. This study evaluates the performance of four Naïve Bayes variations using two vectorization techniques, Count Vectorizer and Term Frequency–Inverse Document Frequency (TF–IDF), on two movie review datasets: IMDb Movie Reviews Dataset and Rotten Tomatoes Movie Reviews. Bernoulli Naive Bayes achieved the highest accuracy using Count Vectorizer on the IMDB and Rotten Tomatoes datasets. Multinomial Naive Bayes, on the other hand, achieved better accuracy on the IMDB dataset with TF–IDF. During preprocessing, we implemented different techniques to enhance the quality of our datasets. These included data cleaning, spelling correction, fixing chat words, lemmatization, and removing stop words. Additionally, we fine-tuned our models through hyperparameter tuning to achieve optimal results. Using TF–IDF, we observed a slight performance improvement compared to using the count vectorizer. The experiment highlights the significant role of sentiment analysis in understanding the attitudes and emotions expressed in movie reviews. By predicting the sentiments of each review and calculating the average sentiment of all reviews, it becomes possible to make an accurate prediction about a movie’s overall performance.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

Sentiment Analysis of IMDb Movie Reviews: A Comparative Analysis of Feature Selection and Feature Extraction Techniques

Sentiment Analysis through Word Vectors: A Study on Movie Reviews from IMDb

Complement Naive Bayes Classifier for Sentiment Analysis of Internet Movie Database
Data availibility statement.
The data that support the findings of this study are openly available through the Open Science Framework at https://github.com/Ankit152/IMDB-sentiment-analysis.git and https://www.kaggle.com/datasets/talha002/rottentomatoes-400k-review
Abbreviations
Aspect-based sentiment analysis
Artificial intelligence
Bag-of-words
Bernoulli Naive Bayes
Complement Naive Bayes
Cross-validation
Deep learning
Gaussian Naive Bayes
Grid search
Internet movie database
K-Nearest Neighbours
Support vector machines
Machine learning
Multinomial Naive Bayes
- Naive Bayes
Natural language processing
Natural language tool kit
Opinion mining
Rotten Tomatoes
True Positive
True Negative
False Positive
False Negative
- Sentiment analysis
Term Frequency–Inverse Document Frequency
Word to vector
Abimanyu AJ, Dwifebri M, Astuti W (2023) Sentiment analysis on movie review from rotten tomatoes using logistic regression and information gain feature selection. Build Inf Technol Sci (BITS) 5(1):162–170
Google Scholar
Adam NL, Rosli NH, Soh SC (2021) Sentiment analysis on movie review using Naïve Bayes. In: 2021 2nd International conference on artificial intelligence and data sciences (AiDAS), pp 1–6. https://doi.org/10.1109/AiDAS53897.2021.9574419
Agrawal T (2021) Introduction to hyperparameters. In: Hyperparameter optimization in machine learning: make your machine learning and deep learning models more efficient, pp 1–8. APRESS: New York
Arsyah UI, Pratiwi M, Muhammad A (2024) Twitter sentiment analysis of public space opinions using SVM and TF–IDF methods. Indon J Comput Sci 13(1)
Artur M (2021) Review the performance of the bernoulli Naïve Bayes classifier in intrusion detection systems using recursive feature elimination with cross-validated selection of the best number of features. Proc Comput Sci 190:564–570
Article Google Scholar
Asghar MZ, Khan A, Ahmad S, Kundi FM (2014) A review of feature extraction in sentiment analysis. J Basic Appl Sci Res 4(3):181–186
Baid P, Gupta A, Chaplot N (2017) Sentiment analysis of movie reviews using machine learning techniques. Int J Comput Appl 179(7):45–49
Banik N, Rahman MHH (2018) Evaluation of Naïve Bayes and support vector machines on Bangla textual movie reviews. In: 2018 International conference on Bangla speech and language processing (ICBSLP), pp 1–6. IEEE
Başarslan MS, Kayaalp F (2023) MBI-GRUMCONV: a novel multi BI-GRU and multi CNN-based deep learning model for social media sentiment analysis. J Cloud Comput. https://doi.org/10.1186/s13677-022-00386-3
Bilal Khan S, Muhammad Arshad SK (2023) Comparative analysis of machine learning models for pdf malware detection: Evaluating different training and testing criteria. J Cyber Secur 5(1), 1–11 https://doi.org/10.32604/jcs.2023.042501
Bodapati JD, Veeranjaneyulu N, Shareef SN (2019) Sentiment analysis from movie reviews using LSTMS. Ingénierie des Systèmes d Inf 24(1):125–129
Cahyanti FE, AlFaraby S (2020) On the feature extraction for sentiment analysis of movie reviews based on SVM. In: 2020 8th International conference on information and communication technology (ICoICT), pp 1–5, IEEE
Danyal MM, Khan SS, Khan M, Ullah S, Mehmood F, Ali I (2024) Proposing sentiment analysis model based on BERT and XLNET for movie reviews. Multimed Tools Appl 1–25
Deepa D, Raaji Tamilarasi A (2019) Sentiment analysis using feature extraction and dictionary-based approaches. In: 2019 Third international conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, pp 786–790. https://doi.org/10.1109/I-SMAC47947.2019.9032456
Dewi C, Chen R-C, Christanto HJ, Cauteruccio F (2023) Multinomial Naïve Bayes classifier for sentiment analysis of internet movie database. Vietnam J Comput Sci 10(04):485–498
Dey L, Chakraborty S, Biswas A, Bose B, Tiwari S (2016) Sentiment analysis of review datasets using Naive Bayes and k-NN classifier. arXiv preprint arXiv:1610.09982
Danyal M M, Haseeb M, Khan S S, Khan B, Ullah S (2024) Opinion Mining on Movie Reviews Based on Deep Learning Models. J Artif Intell (6):(2579–0021).
Danyal M M, Khan S S, Khan M, Ghaffar M B, Khan B, Arshad, M (2023) Sentiment Analysis Based on Performance of Linear Support Vector Machine and Multinomial Naïve Bayes Using Movie Reviews with Baseline Techniques. J Big Data (5).
Horsa OG, Tune KK, et al (2023) Aspect-based sentiment analysis for AFAAN OROMOO movie reviews using machine learning techniques. Appl Comput Intell Soft Comput 2023
Jahromi AH, Taheri M (2017) A non-parametric mixture of gaussian Naive Bayes classifiers based on local independent features. In: 2017 Artificial intelligence and signal processing conference (AISP), pp 209–212. IEEE
Khan M, Khan M S, Alharbi Y (2020) Text mining challenges and applications—a comprehensive review. IJCSNS 20(12):138
Khan SS, Khan M, Ran Q, Naseem R (2018) Challenges in opinion mining, comprehensive. Sci Technol J (Ciencia e Tecnica Vitivinicola) 33(11):123–135
Maas AL, Daly R, Pham PT, Huang D, Ng AY, Potts C (2011) Learning word vectors for sentiment analysis. In: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, Portland, Oregon, USA, pp 142–150
Mall P, Kumar M, Kumar A, Gupta A, Srivastava S, Narayan V, Chauhan AS, Srivastava AP (2024) Self-attentive CNN + BERT: An approach for analysis of sentiment on movie reviews using word embedding. Int J Intell Syst Appl Eng 12(12s):612–623
Maulana R, Rahayuningsih PA, Irmayani W, Saputra D, Jayanti WE (2020) Improved accuracy of sentiment analysis movie review using support vector machine based information gain. J Phys Conf Ser 1641:012060
Pimpalkar A, Raj RJR (2022) Mbilstmglove: embedding glove knowledge into the corpus using multi-layer Bilstm deep learning model for social media sentiment analysis. Exp Syst Appl 203:117581. https://doi.org/10.1016/j.eswa.2022.117581
Rahat AM, Kahir A, Masum AKM (2019) Comparison of Naive Bayes and SVM algorithm based on sentiment analysis using review dataset. In: 2019 8th International conference system modeling and advancement in research trends (SMART), pp 266–270. IEEE
Rahman R, Masud MA, Mimi RJ, Dina MNS (2021) Sentiment analysis on Bengali movie reviews using multinomial Naïve Bayes. In: 2021 24th International conference on computer and information technology (ICCIT), pp 1–6. https://doi.org/10.1109/ICCIT54785.2021.9689787
Rizal C, Kifta DA, Nasution RH, Rengganis A, Watrianthos R (2023) Opinion classification for IMDB review based using Naive Bayes method. In: AIP conference proceedings, vol 2913. AIP Publishing: New York
Rotten Tomatoes Movie Reviews dataset https://www.rottentomatoes.com . Accessed on 02 Mar 2023 (2020)
Samsir S, Kusmanto K, Dalimunthe AH, Aditiya R, Watrianthos R (2022) Implementation Naïve Bayes classification for sentiment analysis on internet movie database. Build Inf Technol Sci (BITS) 4(1):1–6
Shackley D, Folajimi Y (2023) Sentiment analysis of fake health news using Naive Bayes classification models. Int J Cognit Lang Sci 17(3):217–224
Sudha N, Govindarajan M (2016) Mining movie reviews using machine learning techniques. Int J Comput Appl 144 (5)
Teja JS, Sai GK, Kumar MD, Manikandan R (2018) Sentiment analysis of movie reviews using machine learning algorithms—a survey. Int J Pure Appl Math 118(20):3277–3284
Ullah K, Rashad, A, Khan M, Ghadi Y, Aljuaid H, Nawaz Z et al (2022) A deep neural network-based approach for sentiment analysis of movie reviews. Complexity 2022
Veziroğlu M, Eziroğlu E, Bucak İ.Ö (2024) Performance comparison between Naive Bayes and machine learning algorithms for news classification. In: Bayesian inference-recent trends. IntechOpen
Vielma C, Verma A, Bein D (2023) Sentiment analysis with novel GRU based deep learning networks. In: 2023 IEEE World AI IoT congress (AIIoT), pp 0440–0446. https://doi.org/10.1109/AIIoT58121.2023.10174396
Yang L, Shami A (2020) On hyperparameter optimization of machine learning algorithms: theory and practice. Neurocomputing 415(1):295–316
Yusran M, Siswanto S, Islamiyati A (2024) Comparison of multinomial Naïve Bayes and Bernoulli Naïve Bayes on sentiment analysis of Kurikulum Merdeka with query expansion ranking. SISTEMASI 13(1):96–106
Download references
Acknowledgements
We sincerely thank everyone who helped us finish this research paper. We are grateful to the participants for their helpful feedback and ideas, which improved our research methods and the quality of our results. We appreciate everyone who gave their time to join our study, as this research wouldn’t have been possible without them. Thank you to everyone who took the time to contribute to this research paper.
This paper is for free publication.
Author information
Mian Muhammad Danyal, Muzammil Khan, Subhan Ullah, Muhammad Bilal Ghaffar, Wahab Khan have contributed equally to this work.
Authors and Affiliations
Center for Excellence in Information Technology, Institute of Management Sciences, Peshawar, 24720, Pakistan
Mian Muhammad Danyal
Department of Computer Science, City University of Science and Information Technology, Peshawar, 25000, Pakistan
Mian Muhammad Danyal, Subhan Ullah, Muhammad Bilal Ghaffar & Wahab Khan
Department of Computer and Software Technology, University of Swat, Swat, 19130, Pakistan
Sarwar Shah Khan & Muzammil Khan
Department of Computer Science, Iqra University Swat Campus, Swat, 19130, Pakistan
Sarwar Shah Khan
You can also search for this author in PubMed Google Scholar
Contributions
The author contributions are as follow: “Conceptualization, MMD and SSK; methodology, MBG and MK; software, MMD, SU; validation, SSK and WK; formal analysis, MK, WK, and MBG; investigation, SU; data curation, SU and SSK; writing-original draft preparation, MMD, and MBG; writing-review and editing, SSK; visualization, MBG, and MK.
Corresponding author
Correspondence to Muzammil Khan .
Ethics declarations
Conflict of interest.
The authors of this paper declare that they do not have any conflicts of interest.
Financial interests
The authors of this paper have no Conflict of interest relevant to this article’s content to declare.
Ethical approval
Not applicable.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Danyal, M.M., Khan, S.S., Khan, M. et al. Sentiment analysis of movie reviews based on NB approaches using TF–IDF and count vectorizer. Soc. Netw. Anal. Min. 14 , 87 (2024). https://doi.org/10.1007/s13278-024-01250-9
Download citation
Received : 02 April 2023
Revised : 16 March 2024
Accepted : 20 March 2024
Published : 16 April 2024
DOI : https://doi.org/10.1007/s13278-024-01250-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- IMDB dataset
- Rotten tomatoes dataset
- Count vectorizer
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO
COMMENTS
Large Movie Review Dataset. code. New Notebook. table_chart. New Dataset. tenancy. New Model. emoji_events. New Competition. corporate_fare. New Organization. No Active Events. Create notebooks and keep track of their status here. add New Notebook. auto_awesome_motion. 0 Active Events. expand_more.
The IMDb Movie Reviews dataset is a binary sentiment analysis dataset consisting of 50,000 reviews from the Internet Movie Database (IMDb) labeled as positive or negative. The dataset contains an even number of positive and negative reviews. Only highly polarizing reviews are considered. A negative review has a score ≤ 4 out of 10, and a positive review has a score ≥ 7 out of 10.
imdb_reviews. Large Movie Review Dataset. This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well.
IMDb Dataset Details. Each dataset is contained in a gzipped, tab-separated-values (TSV) formatted file in the UTF-8 character set. The first line in each file contains headers that describe what is in each column. A '\N' is used to denote that a particular field is missing or null for that title/name. The available datasets are as follows:
Notebook to train an XLNet model to perform sentiment analysis. The dataset used is a balanced collection of (50,000 - 1:1 train-test ratio) IMDB movie reviews with binary labels: postive or negative from the paper by Maas et al. (2011).The current state-of-the-art model on this dataset is XLNet by Yang et al. (2019) which has an accuracy of 96.2%.We get an accuracy of 92.2% due to the ...
load_data function. Loads the IMDB dataset. This is a dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a list of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3 ...
The IMDB dataset, which contains movie reviews for sentiment analysis, is a common starting point. The goal is to download the IMDB dataset conveniently, then process and explore it in Python using TensorFlow, transforming the raw data into a usable format for ML models. ... we create a pandas DataFrame from a CSV version of the IMDb dataset ...
Sentiment of a movie review is predicted using three different neural network models - MLP, CNN and LSTM. GloVe embedding is used for vector representation of words. - SK7here/Movie-Review-Sentim...
This dataset contains nearly 1 Million unique movie reviews from 1150 different IMDb movies spread across 17 IMDb genres - Action, Adventure, Animation, Biography, Comedy, Crime, Drama, Fantasy, History, Horror, Music, Mystery, Romance, Sci-Fi, Sport, Thriller and War. The dataset also contains movie metadata such as date of release of the movie, run length, IMDb rating, movie rating (PG-13, R ...
The IMDB movie review data consists of 50,000 reviews -- 25,000 for training and 25,000 for testing. The training and test files are evenly divided into 12,500 positive reviews and 12,500 negative reviews. ... The Large Movie Review Dataset is the primary storage site for the raw IMDB movie reviews data, but you can also find it at other ...
IMDB Movie Reviews Large Dataset - 50k Reviews. Contribute to laxmimerit/IMDB-Movie-Reviews-Large-Dataset-50k development by creating an account on GitHub.
Upload IMDB Dataset.csv. f27efa2 almost 2 years ago. download history blame contribute delete. No virus. 66.2 MB. This file is stored with Git LFS . It is too big to display, but you can still download it.
IMDb movie reviews dataset is preprocessed, cleaned, and tokenized, followed by feature extraction using Bag-of-Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF) methods.
The core dataset contains 50,000 reviews split evenly into 25k train and 25k test sets. The overall distribution of labels is balanced (25k pos and 25k neg). ... How to add a data set. Changelog; IMDB Large Movie Review Dataset Source: R/dataset_imdb.R. dataset_imdb.Rd. The core dataset contains 50,000 reviews split evenly into 25k train and ...
Sentiment Analysis. Large Movie Review Dataset. This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well.
Cannot retrieve latest commit at this time. About Dataset IMDB dataset having 50K movie reviews for natural language processing or Text analytics. This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training and ...
The Large Movie Review Dataset (often referred to as the IMDB dataset) contains 25,000 highly-polar movie reviews (good or bad) for training and the same amount again for testing. The problem is to determine whether a given movie review has a positive or negative sentiment. The data was collected by Stanford researchers and was used in a 2011 ...
Explore and run machine learning code with Kaggle Notebooks | Using data from IMDB Dataset of 50K Movie Reviews. code. New Notebook. table_chart. New Dataset. tenancy. New Model. emoji_events. New Competition. corporate_fare. New Organization. No Active Events. Create notebooks and keep track of their status here. add New Notebook. auto_awesome ...
Load the IMDb Database. IMDb has made essential susbsets of its database available for non-commercial use of the public and its customers on the IMDb website, where you can also find all relevant details described in the corresponding IMDb data dictionary.In this analysis I focus on mainly 2 datasets (title.basics and title.ratings) which offers 9 and 3 features respectively that include the ...
Transfer Learning model using RoBERTa on IMDb dataset deployed on React and Flask ( Regional Winner in Facebook Developer Community Challenge 2020 ) ... IMDB Movie Reviews - Text preprocessing and classification. Includes BOW model, TF_IDF, VADER entiment analysis, Topic Modelling using Latent Dirichlet Allocation and Word Embeddings. ...
This experiment uses two different movie review datasets: the IMDB movie review dataset and the Rotten Tomatoes movie review dataset. Both Datasets offer labeled sentiment data for machine-learning experiments. 4.1.1 IMDB dataset of movie reviews. The IMDb dataset is a large collection of movie reviews obtained from the IMDB website.
Explore 10000+ movies worldwide with the IMDB Movies dataset. code. New Notebook. table_chart. New Dataset. tenancy. New Model. emoji_events. New Competition. corporate_fare. New Organization. No Active Events. Create notebooks and keep track of their status here. add New Notebook. auto_awesome_motion. 0 Active Events. expand_more. menu. Skip ...
Top 1000 Movies by IMDB Rating. Top 1000 Movies by IMDB Rating. code. New Notebook. table_chart. New Dataset. tenancy. New Model. emoji_events. New Competition. corporate_fare. New Organization. No Active Events. Create notebooks and keep track of their status here.
Sentiment data from the Large Movie Review dataset. Sentiment data from the Large Movie Review dataset. code. New Notebook. table_chart. New Dataset ... table_chart. New Dataset. tenancy. New Model. emoji_events. New Competition. corporate_fare. New Organization. No Active Events. Create notebooks and keep track of their status here. add New ...