Hypothesis Testing - Chi Squared Test
Lisa Sullivan, PhD
Professor of Biostatistics
Boston University School of Public Health


Introduction
This module will continue the discussion of hypothesis testing, where a specific statement or hypothesis is generated about a population parameter, and sample statistics are used to assess the likelihood that the hypothesis is true. The hypothesis is based on available information and the investigator's belief about the population parameters. The specific tests considered here are called chi-square tests and are appropriate when the outcome is discrete (dichotomous, ordinal or categorical). For example, in some clinical trials the outcome is a classification such as hypertensive, pre-hypertensive or normotensive. We could use the same classification in an observational study such as the Framingham Heart Study to compare men and women in terms of their blood pressure status - again using the classification of hypertensive, pre-hypertensive or normotensive status.
The technique to analyze a discrete outcome uses what is called a chi-square test. Specifically, the test statistic follows a chi-square probability distribution. We will consider chi-square tests here with one, two and more than two independent comparison groups.
Learning Objectives
After completing this module, the student will be able to:
- Perform chi-square tests by hand
- Appropriately interpret results of chi-square tests
- Identify the appropriate hypothesis testing procedure based on type of outcome variable and number of samples
Tests with One Sample, Discrete Outcome
Here we consider hypothesis testing with a discrete outcome variable in a single population. Discrete variables are variables that take on more than two distinct responses or categories and the responses can be ordered or unordered (i.e., the outcome can be ordinal or categorical). The procedure we describe here can be used for dichotomous (exactly 2 response options), ordinal or categorical discrete outcomes and the objective is to compare the distribution of responses, or the proportions of participants in each response category, to a known distribution. The known distribution is derived from another study or report and it is again important in setting up the hypotheses that the comparator distribution specified in the null hypothesis is a fair comparison. The comparator is sometimes called an external or a historical control.
In one sample tests for a discrete outcome, we set up our hypotheses against an appropriate comparator. We select a sample and compute descriptive statistics on the sample data. Specifically, we compute the sample size (n) and the proportions of participants in each response
Test Statistic for Testing H 0 : p 1 = p 10 , p 2 = p 20 , ..., p k = p k0
We find the critical value in a table of probabilities for the chi-square distribution with degrees of freedom (df) = k-1. In the test statistic, O = observed frequency and E=expected frequency in each of the response categories. The observed frequencies are those observed in the sample and the expected frequencies are computed as described below. χ 2 (chi-square) is another probability distribution and ranges from 0 to ∞. The test above statistic formula above is appropriate for large samples, defined as expected frequencies of at least 5 in each of the response categories.
When we conduct a χ 2 test, we compare the observed frequencies in each response category to the frequencies we would expect if the null hypothesis were true. These expected frequencies are determined by allocating the sample to the response categories according to the distribution specified in H 0 . This is done by multiplying the observed sample size (n) by the proportions specified in the null hypothesis (p 10 , p 20 , ..., p k0 ). To ensure that the sample size is appropriate for the use of the test statistic above, we need to ensure that the following: min(np 10 , n p 20 , ..., n p k0 ) > 5.
The test of hypothesis with a discrete outcome measured in a single sample, where the goal is to assess whether the distribution of responses follows a known distribution, is called the χ 2 goodness-of-fit test. As the name indicates, the idea is to assess whether the pattern or distribution of responses in the sample "fits" a specified population (external or historical) distribution. In the next example we illustrate the test. As we work through the example, we provide additional details related to the use of this new test statistic.
A University conducted a survey of its recent graduates to collect demographic and health information for future planning purposes as well as to assess students' satisfaction with their undergraduate experiences. The survey revealed that a substantial proportion of students were not engaging in regular exercise, many felt their nutrition was poor and a substantial number were smoking. In response to a question on regular exercise, 60% of all graduates reported getting no regular exercise, 25% reported exercising sporadically and 15% reported exercising regularly as undergraduates. The next year the University launched a health promotion campaign on campus in an attempt to increase health behaviors among undergraduates. The program included modules on exercise, nutrition and smoking cessation. To evaluate the impact of the program, the University again surveyed graduates and asked the same questions. The survey was completed by 470 graduates and the following data were collected on the exercise question:
Based on the data, is there evidence of a shift in the distribution of responses to the exercise question following the implementation of the health promotion campaign on campus? Run the test at a 5% level of significance.
In this example, we have one sample and a discrete (ordinal) outcome variable (with three response options). We specifically want to compare the distribution of responses in the sample to the distribution reported the previous year (i.e., 60%, 25%, 15% reporting no, sporadic and regular exercise, respectively). We now run the test using the five-step approach.
- Step 1. Set up hypotheses and determine level of significance.
The null hypothesis again represents the "no change" or "no difference" situation. If the health promotion campaign has no impact then we expect the distribution of responses to the exercise question to be the same as that measured prior to the implementation of the program.
H 0 : p 1 =0.60, p 2 =0.25, p 3 =0.15, or equivalently H 0 : Distribution of responses is 0.60, 0.25, 0.15
H 1 : H 0 is false. α =0.05
Notice that the research hypothesis is written in words rather than in symbols. The research hypothesis as stated captures any difference in the distribution of responses from that specified in the null hypothesis. We do not specify a specific alternative distribution, instead we are testing whether the sample data "fit" the distribution in H 0 or not. With the χ 2 goodness-of-fit test there is no upper or lower tailed version of the test.
- Step 2. Select the appropriate test statistic.
The test statistic is:
We must first assess whether the sample size is adequate. Specifically, we need to check min(np 0 , np 1, ..., n p k ) > 5. The sample size here is n=470 and the proportions specified in the null hypothesis are 0.60, 0.25 and 0.15. Thus, min( 470(0.65), 470(0.25), 470(0.15))=min(282, 117.5, 70.5)=70.5. The sample size is more than adequate so the formula can be used.
- Step 3. Set up decision rule.
The decision rule for the χ 2 test depends on the level of significance and the degrees of freedom, defined as degrees of freedom (df) = k-1 (where k is the number of response categories). If the null hypothesis is true, the observed and expected frequencies will be close in value and the χ 2 statistic will be close to zero. If the null hypothesis is false, then the χ 2 statistic will be large. Critical values can be found in a table of probabilities for the χ 2 distribution. Here we have df=k-1=3-1=2 and a 5% level of significance. The appropriate critical value is 5.99, and the decision rule is as follows: Reject H 0 if χ 2 > 5.99.
- Step 4. Compute the test statistic.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) and the expected frequencies into the formula for the test statistic identified in Step 2. The computations can be organized as follows.
Notice that the expected frequencies are taken to one decimal place and that the sum of the observed frequencies is equal to the sum of the expected frequencies. The test statistic is computed as follows:
- Step 5. Conclusion.
We reject H 0 because 8.46 > 5.99. We have statistically significant evidence at α=0.05 to show that H 0 is false, or that the distribution of responses is not 0.60, 0.25, 0.15. The p-value is p < 0.005.
In the χ 2 goodness-of-fit test, we conclude that either the distribution specified in H 0 is false (when we reject H 0 ) or that we do not have sufficient evidence to show that the distribution specified in H 0 is false (when we fail to reject H 0 ). Here, we reject H 0 and concluded that the distribution of responses to the exercise question following the implementation of the health promotion campaign was not the same as the distribution prior. The test itself does not provide details of how the distribution has shifted. A comparison of the observed and expected frequencies will provide some insight into the shift (when the null hypothesis is rejected). Does it appear that the health promotion campaign was effective?
Consider the following:
If the null hypothesis were true (i.e., no change from the prior year) we would have expected more students to fall in the "No Regular Exercise" category and fewer in the "Regular Exercise" categories. In the sample, 255/470 = 54% reported no regular exercise and 90/470=19% reported regular exercise. Thus, there is a shift toward more regular exercise following the implementation of the health promotion campaign. There is evidence of a statistical difference, is this a meaningful difference? Is there room for improvement?
The National Center for Health Statistics (NCHS) provided data on the distribution of weight (in categories) among Americans in 2002. The distribution was based on specific values of body mass index (BMI) computed as weight in kilograms over height in meters squared. Underweight was defined as BMI< 18.5, Normal weight as BMI between 18.5 and 24.9, overweight as BMI between 25 and 29.9 and obese as BMI of 30 or greater. Americans in 2002 were distributed as follows: 2% Underweight, 39% Normal Weight, 36% Overweight, and 23% Obese. Suppose we want to assess whether the distribution of BMI is different in the Framingham Offspring sample. Using data from the n=3,326 participants who attended the seventh examination of the Offspring in the Framingham Heart Study we created the BMI categories as defined and observed the following:
- Step 1. Set up hypotheses and determine level of significance.
H 0 : p 1 =0.02, p 2 =0.39, p 3 =0.36, p 4 =0.23 or equivalently
H 0 : Distribution of responses is 0.02, 0.39, 0.36, 0.23
H 1 : H 0 is false. α=0.05
The formula for the test statistic is:
We must assess whether the sample size is adequate. Specifically, we need to check min(np 0 , np 1, ..., n p k ) > 5. The sample size here is n=3,326 and the proportions specified in the null hypothesis are 0.02, 0.39, 0.36 and 0.23. Thus, min( 3326(0.02), 3326(0.39), 3326(0.36), 3326(0.23))=min(66.5, 1297.1, 1197.4, 765.0)=66.5. The sample size is more than adequate, so the formula can be used.
Here we have df=k-1=4-1=3 and a 5% level of significance. The appropriate critical value is 7.81 and the decision rule is as follows: Reject H 0 if χ 2 > 7.81.
We now compute the expected frequencies using the sample size and the proportions specified in the null hypothesis. We then substitute the sample data (observed frequencies) into the formula for the test statistic identified in Step 2. We organize the computations in the following table.
The test statistic is computed as follows:
We reject H 0 because 233.53 > 7.81. We have statistically significant evidence at α=0.05 to show that H 0 is false or that the distribution of BMI in Framingham is different from the national data reported in 2002, p < 0.005.
Again, the χ 2 goodness-of-fit test allows us to assess whether the distribution of responses "fits" a specified distribution. Here we show that the distribution of BMI in the Framingham Offspring Study is different from the national distribution. To understand the nature of the difference we can compare observed and expected frequencies or observed and expected proportions (or percentages). The frequencies are large because of the large sample size, the observed percentages of patients in the Framingham sample are as follows: 0.6% underweight, 28% normal weight, 41% overweight and 30% obese. In the Framingham Offspring sample there are higher percentages of overweight and obese persons (41% and 30% in Framingham as compared to 36% and 23% in the national data), and lower proportions of underweight and normal weight persons (0.6% and 28% in Framingham as compared to 2% and 39% in the national data). Are these meaningful differences?
In the module on hypothesis testing for means and proportions, we discussed hypothesis testing applications with a dichotomous outcome variable in a single population. We presented a test using a test statistic Z to test whether an observed (sample) proportion differed significantly from a historical or external comparator. The chi-square goodness-of-fit test can also be used with a dichotomous outcome and the results are mathematically equivalent.
In the prior module, we considered the following example. Here we show the equivalence to the chi-square goodness-of-fit test.
The NCHS report indicated that in 2002, 75% of children aged 2 to 17 saw a dentist in the past year. An investigator wants to assess whether use of dental services is similar in children living in the city of Boston. A sample of 125 children aged 2 to 17 living in Boston are surveyed and 64 reported seeing a dentist over the past 12 months. Is there a significant difference in use of dental services between children living in Boston and the national data?
We presented the following approach to the test using a Z statistic.
- Step 1. Set up hypotheses and determine level of significance
H 0 : p = 0.75
H 1 : p ≠ 0.75 α=0.05
We must first check that the sample size is adequate. Specifically, we need to check min(np 0 , n(1-p 0 )) = min( 125(0.75), 125(1-0.75))=min(94, 31)=31. The sample size is more than adequate so the following formula can be used
This is a two-tailed test, using a Z statistic and a 5% level of significance. Reject H 0 if Z < -1.960 or if Z > 1.960.
We now substitute the sample data into the formula for the test statistic identified in Step 2. The sample proportion is:
We reject H 0 because -6.15 < -1.960. We have statistically significant evidence at a =0.05 to show that there is a statistically significant difference in the use of dental service by children living in Boston as compared to the national data. (p < 0.0001).
We now conduct the same test using the chi-square goodness-of-fit test. First, we summarize our sample data as follows:
H 0 : p 1 =0.75, p 2 =0.25 or equivalently H 0 : Distribution of responses is 0.75, 0.25
We must assess whether the sample size is adequate. Specifically, we need to check min(np 0 , np 1, ...,np k >) > 5. The sample size here is n=125 and the proportions specified in the null hypothesis are 0.75, 0.25. Thus, min( 125(0.75), 125(0.25))=min(93.75, 31.25)=31.25. The sample size is more than adequate so the formula can be used.
Here we have df=k-1=2-1=1 and a 5% level of significance. The appropriate critical value is 3.84, and the decision rule is as follows: Reject H 0 if χ 2 > 3.84. (Note that 1.96 2 = 3.84, where 1.96 was the critical value used in the Z test for proportions shown above.)
(Note that (-6.15) 2 = 37.8, where -6.15 was the value of the Z statistic in the test for proportions shown above.)
We reject H 0 because 37.8 > 3.84. We have statistically significant evidence at α=0.05 to show that there is a statistically significant difference in the use of dental service by children living in Boston as compared to the national data. (p < 0.0001). This is the same conclusion we reached when we conducted the test using the Z test above. With a dichotomous outcome, Z 2 = χ 2 ! In statistics, there are often several approaches that can be used to test hypotheses.
Tests for Two or More Independent Samples, Discrete Outcome
Here we extend that application of the chi-square test to the case with two or more independent comparison groups. Specifically, the outcome of interest is discrete with two or more responses and the responses can be ordered or unordered (i.e., the outcome can be dichotomous, ordinal or categorical). We now consider the situation where there are two or more independent comparison groups and the goal of the analysis is to compare the distribution of responses to the discrete outcome variable among several independent comparison groups.
The test is called the χ 2 test of independence and the null hypothesis is that there is no difference in the distribution of responses to the outcome across comparison groups. This is often stated as follows: The outcome variable and the grouping variable (e.g., the comparison treatments or comparison groups) are independent (hence the name of the test). Independence here implies homogeneity in the distribution of the outcome among comparison groups.
The null hypothesis in the χ 2 test of independence is often stated in words as: H 0 : The distribution of the outcome is independent of the groups. The alternative or research hypothesis is that there is a difference in the distribution of responses to the outcome variable among the comparison groups (i.e., that the distribution of responses "depends" on the group). In order to test the hypothesis, we measure the discrete outcome variable in each participant in each comparison group. The data of interest are the observed frequencies (or number of participants in each response category in each group). The formula for the test statistic for the χ 2 test of independence is given below.
Test Statistic for Testing H 0 : Distribution of outcome is independent of groups
and we find the critical value in a table of probabilities for the chi-square distribution with df=(r-1)*(c-1).
Here O = observed frequency, E=expected frequency in each of the response categories in each group, r = the number of rows in the two-way table and c = the number of columns in the two-way table. r and c correspond to the number of comparison groups and the number of response options in the outcome (see below for more details). The observed frequencies are the sample data and the expected frequencies are computed as described below. The test statistic is appropriate for large samples, defined as expected frequencies of at least 5 in each of the response categories in each group.
The data for the χ 2 test of independence are organized in a two-way table. The outcome and grouping variable are shown in the rows and columns of the table. The sample table below illustrates the data layout. The table entries (blank below) are the numbers of participants in each group responding to each response category of the outcome variable.
Table - Possible outcomes are are listed in the columns; The groups being compared are listed in rows.
In the table above, the grouping variable is shown in the rows of the table; r denotes the number of independent groups. The outcome variable is shown in the columns of the table; c denotes the number of response options in the outcome variable. Each combination of a row (group) and column (response) is called a cell of the table. The table has r*c cells and is sometimes called an r x c ("r by c") table. For example, if there are 4 groups and 5 categories in the outcome variable, the data are organized in a 4 X 5 table. The row and column totals are shown along the right-hand margin and the bottom of the table, respectively. The total sample size, N, can be computed by summing the row totals or the column totals. Similar to ANOVA, N does not refer to a population size here but rather to the total sample size in the analysis. The sample data can be organized into a table like the above. The numbers of participants within each group who select each response option are shown in the cells of the table and these are the observed frequencies used in the test statistic.
The test statistic for the χ 2 test of independence involves comparing observed (sample data) and expected frequencies in each cell of the table. The expected frequencies are computed assuming that the null hypothesis is true. The null hypothesis states that the two variables (the grouping variable and the outcome) are independent. The definition of independence is as follows:
Two events, A and B, are independent if P(A|B) = P(A), or equivalently, if P(A and B) = P(A) P(B).
The second statement indicates that if two events, A and B, are independent then the probability of their intersection can be computed by multiplying the probability of each individual event. To conduct the χ 2 test of independence, we need to compute expected frequencies in each cell of the table. Expected frequencies are computed by assuming that the grouping variable and outcome are independent (i.e., under the null hypothesis). Thus, if the null hypothesis is true, using the definition of independence:
P(Group 1 and Response Option 1) = P(Group 1) P(Response Option 1).
The above states that the probability that an individual is in Group 1 and their outcome is Response Option 1 is computed by multiplying the probability that person is in Group 1 by the probability that a person is in Response Option 1. To conduct the χ 2 test of independence, we need expected frequencies and not expected probabilities . To convert the above probability to a frequency, we multiply by N. Consider the following small example.
The data shown above are measured in a sample of size N=150. The frequencies in the cells of the table are the observed frequencies. If Group and Response are independent, then we can compute the probability that a person in the sample is in Group 1 and Response category 1 using:
P(Group 1 and Response 1) = P(Group 1) P(Response 1),
P(Group 1 and Response 1) = (25/150) (62/150) = 0.069.
Thus if Group and Response are independent we would expect 6.9% of the sample to be in the top left cell of the table (Group 1 and Response 1). The expected frequency is 150(0.069) = 10.4. We could do the same for Group 2 and Response 1:
P(Group 2 and Response 1) = P(Group 2) P(Response 1),
P(Group 2 and Response 1) = (50/150) (62/150) = 0.138.
The expected frequency in Group 2 and Response 1 is 150(0.138) = 20.7.
Thus, the formula for determining the expected cell frequencies in the χ 2 test of independence is as follows:
Expected Cell Frequency = (Row Total * Column Total)/N.
The above computes the expected frequency in one step rather than computing the expected probability first and then converting to a frequency.
In a prior example we evaluated data from a survey of university graduates which assessed, among other things, how frequently they exercised. The survey was completed by 470 graduates. In the prior example we used the χ 2 goodness-of-fit test to assess whether there was a shift in the distribution of responses to the exercise question following the implementation of a health promotion campaign on campus. We specifically considered one sample (all students) and compared the observed distribution to the distribution of responses the prior year (a historical control). Suppose we now wish to assess whether there is a relationship between exercise on campus and students' living arrangements. As part of the same survey, graduates were asked where they lived their senior year. The response options were dormitory, on-campus apartment, off-campus apartment, and at home (i.e., commuted to and from the university). The data are shown below.
Based on the data, is there a relationship between exercise and student's living arrangement? Do you think where a person lives affect their exercise status? Here we have four independent comparison groups (living arrangement) and a discrete (ordinal) outcome variable with three response options. We specifically want to test whether living arrangement and exercise are independent. We will run the test using the five-step approach.
H 0 : Living arrangement and exercise are independent
H 1 : H 0 is false. α=0.05
The null and research hypotheses are written in words rather than in symbols. The research hypothesis is that the grouping variable (living arrangement) and the outcome variable (exercise) are dependent or related.
- Step 2. Select the appropriate test statistic.
The condition for appropriate use of the above test statistic is that each expected frequency is at least 5. In Step 4 we will compute the expected frequencies and we will ensure that the condition is met.
The decision rule depends on the level of significance and the degrees of freedom, defined as df = (r-1)(c-1), where r and c are the numbers of rows and columns in the two-way data table. The row variable is the living arrangement and there are 4 arrangements considered, thus r=4. The column variable is exercise and 3 responses are considered, thus c=3. For this test, df=(4-1)(3-1)=3(2)=6. Again, with χ 2 tests there are no upper, lower or two-tailed tests. If the null hypothesis is true, the observed and expected frequencies will be close in value and the χ 2 statistic will be close to zero. If the null hypothesis is false, then the χ 2 statistic will be large. The rejection region for the χ 2 test of independence is always in the upper (right-hand) tail of the distribution. For df=6 and a 5% level of significance, the appropriate critical value is 12.59 and the decision rule is as follows: Reject H 0 if c 2 > 12.59.
We now compute the expected frequencies using the formula,
Expected Frequency = (Row Total * Column Total)/N.
The computations can be organized in a two-way table. The top number in each cell of the table is the observed frequency and the bottom number is the expected frequency. The expected frequencies are shown in parentheses.
Notice that the expected frequencies are taken to one decimal place and that the sums of the observed frequencies are equal to the sums of the expected frequencies in each row and column of the table.
Recall in Step 2 a condition for the appropriate use of the test statistic was that each expected frequency is at least 5. This is true for this sample (the smallest expected frequency is 9.6) and therefore it is appropriate to use the test statistic.
We reject H 0 because 60.5 > 12.59. We have statistically significant evidence at a =0.05 to show that H 0 is false or that living arrangement and exercise are not independent (i.e., they are dependent or related), p < 0.005.
Again, the χ 2 test of independence is used to test whether the distribution of the outcome variable is similar across the comparison groups. Here we rejected H 0 and concluded that the distribution of exercise is not independent of living arrangement, or that there is a relationship between living arrangement and exercise. The test provides an overall assessment of statistical significance. When the null hypothesis is rejected, it is important to review the sample data to understand the nature of the relationship. Consider again the sample data.
Because there are different numbers of students in each living situation, it makes the comparisons of exercise patterns difficult on the basis of the frequencies alone. The following table displays the percentages of students in each exercise category by living arrangement. The percentages sum to 100% in each row of the table. For comparison purposes, percentages are also shown for the total sample along the bottom row of the table.
From the above, it is clear that higher percentages of students living in dormitories and in on-campus apartments reported regular exercise (31% and 23%) as compared to students living in off-campus apartments and at home (10% each).
Test Yourself
Pancreaticoduodenectomy (PD) is a procedure that is associated with considerable morbidity. A study was recently conducted on 553 patients who had a successful PD between January 2000 and December 2010 to determine whether their Surgical Apgar Score (SAS) is related to 30-day perioperative morbidity and mortality. The table below gives the number of patients experiencing no, minor, or major morbidity by SAS category.
Question: What would be an appropriate statistical test to examine whether there is an association between Surgical Apgar Score and patient outcome? Using 14.13 as the value of the test statistic for these data, carry out the appropriate test at a 5% level of significance. Show all parts of your test.
In the module on hypothesis testing for means and proportions, we discussed hypothesis testing applications with a dichotomous outcome variable and two independent comparison groups. We presented a test using a test statistic Z to test for equality of independent proportions. The chi-square test of independence can also be used with a dichotomous outcome and the results are mathematically equivalent.
In the prior module, we considered the following example. Here we show the equivalence to the chi-square test of independence.
A randomized trial is designed to evaluate the effectiveness of a newly developed pain reliever designed to reduce pain in patients following joint replacement surgery. The trial compares the new pain reliever to the pain reliever currently in use (called the standard of care). A total of 100 patients undergoing joint replacement surgery agreed to participate in the trial. Patients were randomly assigned to receive either the new pain reliever or the standard pain reliever following surgery and were blind to the treatment assignment. Before receiving the assigned treatment, patients were asked to rate their pain on a scale of 0-10 with higher scores indicative of more pain. Each patient was then given the assigned treatment and after 30 minutes was again asked to rate their pain on the same scale. The primary outcome was a reduction in pain of 3 or more scale points (defined by clinicians as a clinically meaningful reduction). The following data were observed in the trial.
We tested whether there was a significant difference in the proportions of patients reporting a meaningful reduction (i.e., a reduction of 3 or more scale points) using a Z statistic, as follows.
H 0 : p 1 = p 2
H 1 : p 1 ≠ p 2 α=0.05
Here the new or experimental pain reliever is group 1 and the standard pain reliever is group 2.
We must first check that the sample size is adequate. Specifically, we need to ensure that we have at least 5 successes and 5 failures in each comparison group or that:
In this example, we have
Therefore, the sample size is adequate, so the following formula can be used:
Reject H 0 if Z < -1.960 or if Z > 1.960.
We now substitute the sample data into the formula for the test statistic identified in Step 2. We first compute the overall proportion of successes:
We now substitute to compute the test statistic.
- Step 5. Conclusion.
We now conduct the same test using the chi-square test of independence.
H 0 : Treatment and outcome (meaningful reduction in pain) are independent
H 1 : H 0 is false. α=0.05
The formula for the test statistic is:
For this test, df=(2-1)(2-1)=1. At a 5% level of significance, the appropriate critical value is 3.84 and the decision rule is as follows: Reject H0 if χ 2 > 3.84. (Note that 1.96 2 = 3.84, where 1.96 was the critical value used in the Z test for proportions shown above.)
We now compute the expected frequencies using:
The computations can be organized in a two-way table. The top number in each cell of the table is the observed frequency and the bottom number is the expected frequency. The expected frequencies are shown in parentheses.
A condition for the appropriate use of the test statistic was that each expected frequency is at least 5. This is true for this sample (the smallest expected frequency is 22.0) and therefore it is appropriate to use the test statistic.
(Note that (2.53) 2 = 6.4, where 2.53 was the value of the Z statistic in the test for proportions shown above.)
Chi-Squared Tests in R
The video below by Mike Marin demonstrates how to perform chi-squared tests in the R programming language.
Answer to Problem on Pancreaticoduodenectomy and Surgical Apgar Scores
We have 3 independent comparison groups (Surgical Apgar Score) and a categorical outcome variable (morbidity/mortality). We can run a Chi-Squared test of independence.
H 0 : Apgar scores and patient outcome are independent of one another.
H A : Apgar scores and patient outcome are not independent.
Chi-squared = 14.3
Since 14.3 is greater than 9.49, we reject H 0.
There is an association between Apgar scores and patient outcome. The lowest Apgar score group (0 to 4) experienced the highest percentage of major morbidity or mortality (16 out of 57=28%) compared to the other Apgar score groups.
- Flashes Safe Seven
- FlashLine Login
- Faculty & Staff Phone Directory
- Emeriti or Retiree
- All Departments
- Maps & Directions

- Building Guide
- Departments
- Directions & Parking
- Faculty & Staff
- Give to University Libraries
- Library Instructional Spaces
- Mission & Vision
- Newsletters
- Circulation
- Course Reserves / Core Textbooks
- Equipment for Checkout
- Interlibrary Loan
- Library Instruction
- Library Tutorials
- My Library Account
- Open Access Kent State
- Research Support Services
- Statistical Consulting
- Student Multimedia Studio
- Citation Tools
- Databases A-to-Z
- Databases By Subject
- Digital Collections
- Discovery@Kent State
- Government Information
- Journal Finder
- Library Guides
- Connect from Off-Campus
- Library Workshops
- Subject Librarians Directory
- Suggestions/Feedback
- Writing Commons
- Academic Integrity
- Jobs for Students
- International Students
- Meet with a Librarian
- Study Spaces
- University Libraries Student Scholarship
- Affordable Course Materials
- Copyright Services
- Selection Manager
- Suggest a Purchase
Library Locations at the Kent Campus
- Architecture Library
- Fashion Library
- Map Library
- Performing Arts Library
- Special Collections and Archives
Regional Campus Libraries
- East Liverpool
- College of Podiatric Medicine
- Kent State University
- SPSS Tutorials
Chi-Square Test of Independence
Spss tutorials: chi-square test of independence.
- The SPSS Environment
- The Data View Window
- Using SPSS Syntax
- Data Creation in SPSS
- Importing Data into SPSS
- Variable Types
- Date-Time Variables in SPSS
- Defining Variables
- Creating a Codebook
- Computing Variables
- Computing Variables: Mean Centering
- Computing Variables: Recoding Categorical Variables
- Computing Variables: Recoding String Variables into Coded Categories (Automatic Recode)
- rank transform converts a set of data values by ordering them from smallest to largest, and then assigning a rank to each value. In SPSS, the Rank Cases procedure can be used to compute the rank transform of a variable." href="https://libguides.library.kent.edu/SPSS/RankCases" style="" >Computing Variables: Rank Transforms (Rank Cases)
- Weighting Cases
- Sorting Data
- Grouping Data
- Descriptive Stats for One Numeric Variable (Explore)
- Descriptive Stats for One Numeric Variable (Frequencies)
- Descriptive Stats for Many Numeric Variables (Descriptives)
- Descriptive Stats by Group (Compare Means)
- Frequency Tables
- Working with "Check All That Apply" Survey Data (Multiple Response Sets)
- Pearson Correlation
- One Sample t Test
- Paired Samples t Test
- Independent Samples t Test
- One-Way ANOVA
- How to Cite the Tutorials
Sample Data Files
Our tutorials reference a dataset called "sample" in many examples. If you'd like to download the sample dataset to work through the examples, choose one of the files below:
- Data definitions (*.pdf)
- Data - Comma delimited (*.csv)
- Data - Tab delimited (*.txt)
- Data - Excel format (*.xlsx)
- Data - SAS format (*.sas7bdat)
- Data - SPSS format (*.sav)
- SPSS Syntax (*.sps) Syntax to add variable labels, value labels, set variable types, and compute several recoded variables used in later tutorials.
- SAS Syntax (*.sas) Syntax to read the CSV-format sample data and set variable labels and formats/value labels.
The Chi-Square Test of Independence determines whether there is an association between categorical variables (i.e., whether the variables are independent or related). It is a nonparametric test.
This test is also known as:
- Chi-Square Test of Association.
This test utilizes a contingency table to analyze the data. A contingency table (also known as a cross-tabulation , crosstab , or two-way table ) is an arrangement in which data is classified according to two categorical variables. The categories for one variable appear in the rows, and the categories for the other variable appear in columns. Each variable must have two or more categories. Each cell reflects the total count of cases for a specific pair of categories.
There are several tests that go by the name "chi-square test" in addition to the Chi-Square Test of Independence. Look for context clues in the data and research question to make sure what form of the chi-square test is being used.
Common Uses
The Chi-Square Test of Independence is commonly used to test the following:
- Statistical independence or association between two categorical variables.
The Chi-Square Test of Independence can only compare categorical variables. It cannot make comparisons between continuous variables or between categorical and continuous variables. Additionally, the Chi-Square Test of Independence only assesses associations between categorical variables, and can not provide any inferences about causation.
If your categorical variables represent "pre-test" and "post-test" observations, then the chi-square test of independence is not appropriate . This is because the assumption of the independence of observations is violated. In this situation, McNemar's Test is appropriate.
Data Requirements
Your data must meet the following requirements:
- Two categorical variables.
- Two or more categories (groups) for each variable.
- There is no relationship between the subjects in each group.
- The categorical variables are not "paired" in any way (e.g. pre-test/post-test observations).
- Expected frequencies for each cell are at least 1.
- Expected frequencies should be at least 5 for the majority (80%) of the cells.
The null hypothesis ( H 0 ) and alternative hypothesis ( H 1 ) of the Chi-Square Test of Independence can be expressed in two different but equivalent ways:
H 0 : "[ Variable 1 ] is independent of [ Variable 2 ]" H 1 : "[ Variable 1 ] is not independent of [ Variable 2 ]"
H 0 : "[ Variable 1 ] is not associated with [ Variable 2 ]" H 1 : "[ Variable 1 ] is associated with [ Variable 2 ]"
Test Statistic
The test statistic for the Chi-Square Test of Independence is denoted Χ 2 , and is computed as:
$$ \chi^{2} = \sum_{i=1}^{R}{\sum_{j=1}^{C}{\frac{(o_{ij} - e_{ij})^{2}}{e_{ij}}}} $$
\(o_{ij}\) is the observed cell count in the i th row and j th column of the table
\(e_{ij}\) is the expected cell count in the i th row and j th column of the table, computed as
$$ e_{ij} = \frac{\mathrm{ \textrm{row } \mathit{i}} \textrm{ total} * \mathrm{\textrm{col } \mathit{j}} \textrm{ total}}{\textrm{grand total}} $$
The quantity ( o ij - e ij ) is sometimes referred to as the residual of cell ( i , j ), denoted \(r_{ij}\).
The calculated Χ 2 value is then compared to the critical value from the Χ 2 distribution table with degrees of freedom df = ( R - 1)( C - 1) and chosen confidence level. If the calculated Χ 2 value > critical Χ 2 value, then we reject the null hypothesis.
Data Set-Up
There are two different ways in which your data may be set up initially. The format of the data will determine how to proceed with running the Chi-Square Test of Independence. At minimum, your data should include two categorical variables (represented in columns) that will be used in the analysis. The categorical variables must include at least two groups. Your data may be formatted in either of the following ways:
If you have the raw data (each row is a subject):

- Cases represent subjects, and each subject appears once in the dataset. That is, each row represents an observation from a unique subject.
- The dataset contains at least two nominal categorical variables (string or numeric). The categorical variables used in the test must have two or more categories.
If you have frequencies (each row is a combination of factors):
An example of using the chi-square test for this type of data can be found in the Weighting Cases tutorial .

- Each row in the dataset represents a distinct combination of the categories.
- The value in the "frequency" column for a given row is the number of unique subjects with that combination of categories.
- You should have three variables: one representing each category, and a third representing the number of occurrences of that particular combination of factors.
- Before running the test, you must activate Weight Cases, and set the frequency variable as the weight.
Run a Chi-Square Test of Independence
In SPSS, the Chi-Square Test of Independence is an option within the Crosstabs procedure. Recall that the Crosstabs procedure creates a contingency table or two-way table , which summarizes the distribution of two categorical variables.
To create a crosstab and perform a chi-square test of independence, click Analyze > Descriptive Statistics > Crosstabs .

A Row(s): One or more variables to use in the rows of the crosstab(s). You must enter at least one Row variable.
B Column(s): One or more variables to use in the columns of the crosstab(s). You must enter at least one Column variable.
Also note that if you specify one row variable and two or more column variables, SPSS will print crosstabs for each pairing of the row variable with the column variables. The same is true if you have one column variable and two or more row variables, or if you have multiple row and column variables. A chi-square test will be produced for each table. Additionally, if you include a layer variable, chi-square tests will be run for each pair of row and column variables within each level of the layer variable.
C Layer: An optional "stratification" variable. If you have turned on the chi-square test results and have specified a layer variable, SPSS will subset the data with respect to the categories of the layer variable, then run chi-square tests between the row and column variables. (This is not equivalent to testing for a three-way association, or testing for an association between the row and column variable after controlling for the layer variable.)
D Statistics: Opens the Crosstabs: Statistics window, which contains fifteen different inferential statistics for comparing categorical variables.

To run the Chi-Square Test of Independence, make sure that the Chi-square box is checked.
E Cells: Opens the Crosstabs: Cell Display window, which controls which output is displayed in each cell of the crosstab. (Note: in a crosstab, the cells are the inner sections of the table. They show the number of observations for a given combination of the row and column categories.) There are three options in this window that are useful (but optional) when performing a Chi-Square Test of Independence:

1 Observed : The actual number of observations for a given cell. This option is enabled by default.
2 Expected : The expected number of observations for that cell (see the test statistic formula).
3 Unstandardized Residuals : The "residual" value, computed as observed minus expected.
F Format: Opens the Crosstabs: Table Format window, which specifies how the rows of the table are sorted.

Example: Chi-square Test for 3x2 Table
Problem statement.
In the sample dataset, respondents were asked their gender and whether or not they were a cigarette smoker. There were three answer choices: Nonsmoker, Past smoker, and Current smoker. Suppose we want to test for an association between smoking behavior (nonsmoker, current smoker, or past smoker) and gender (male or female) using a Chi-Square Test of Independence (we'll use α = 0.05).
Before the Test
Before we test for "association", it is helpful to understand what an "association" and a "lack of association" between two categorical variables looks like. One way to visualize this is using clustered bar charts. Let's look at the clustered bar chart produced by the Crosstabs procedure.
This is the chart that is produced if you use Smoking as the row variable and Gender as the column variable (running the syntax later in this example):
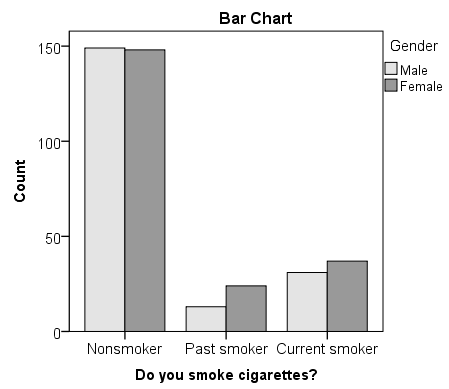
The "clusters" in a clustered bar chart are determined by the row variable (in this case, the smoking categories). The color of the bars is determined by the column variable (in this case, gender). The height of each bar represents the total number of observations in that particular combination of categories.
This type of chart emphasizes the differences within the categories of the row variable. Notice how within each smoking category, the heights of the bars (i.e., the number of males and females) are very similar. That is, there are an approximately equal number of male and female nonsmokers; approximately equal number of male and female past smokers; approximately equal number of male and female current smokers. If there were an association between gender and smoking, we would expect these counts to differ between groups in some way.
Running the Test
- Open the Crosstabs dialog ( Analyze > Descriptive Statistics > Crosstabs ).
- Select Smoking as the row variable, and Gender as the column variable.
- Click Statistics . Check Chi-square , then click Continue .
- (Optional) Check the box for Display clustered bar charts .
The first table is the Case Processing summary, which tells us the number of valid cases used for analysis. Only cases with nonmissing values for both smoking behavior and gender can be used in the test.

The next tables are the crosstabulation and chi-square test results.

The key result in the Chi-Square Tests table is the Pearson Chi-Square.
- The value of the test statistic is 3.171.
- The footnote for this statistic pertains to the expected cell count assumption (i.e., expected cell counts are all greater than 5): no cells had an expected count less than 5, so this assumption was met.
- Because the test statistic is based on a 3x2 crosstabulation table, the degrees of freedom (df) for the test statistic is $$ df = (R - 1)*(C - 1) = (3 - 1)*(2 - 1) = 2*1 = 2 $$.
- The corresponding p-value of the test statistic is p = 0.205.
Decision and Conclusions
Since the p-value is greater than our chosen significance level ( α = 0.05), we do not reject the null hypothesis. Rather, we conclude that there is not enough evidence to suggest an association between gender and smoking.
Based on the results, we can state the following:
- No association was found between gender and smoking behavior ( Χ 2 (2)> = 3.171, p = 0.205).
Example: Chi-square Test for 2x2 Table
Let's continue the row and column percentage example from the Crosstabs tutorial, which described the relationship between the variables RankUpperUnder (upperclassman/underclassman) and LivesOnCampus (lives on campus/lives off-campus). Recall that the column percentages of the crosstab appeared to indicate that upperclassmen were less likely than underclassmen to live on campus:
- The proportion of underclassmen who live off campus is 34.8%, or 79/227.
- The proportion of underclassmen who live on campus is 65.2%, or 148/227.
- The proportion of upperclassmen who live off campus is 94.4%, or 152/161.
- The proportion of upperclassmen who live on campus is 5.6%, or 9/161.
Suppose that we want to test the association between class rank and living on campus using a Chi-Square Test of Independence (using α = 0.05).
The clustered bar chart from the Crosstabs procedure can act as a complement to the column percentages above. Let's look at the chart produced by the Crosstabs procedure for this example:
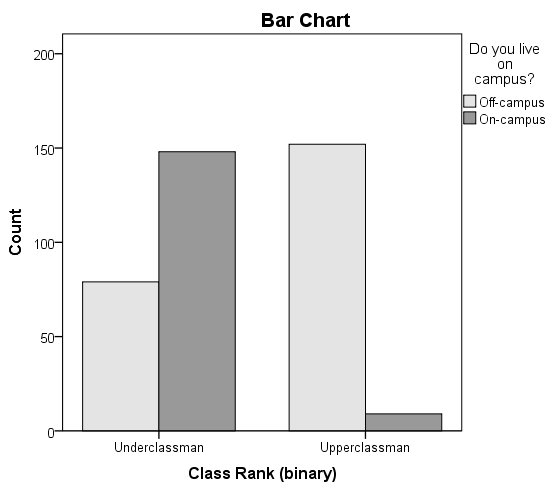
The height of each bar represents the total number of observations in that particular combination of categories. The "clusters" are formed by the row variable (in this case, class rank). This type of chart emphasizes the differences within the underclassmen and upperclassmen groups. Here, the differences in number of students living on campus versus living off-campus is much starker within the class rank groups.
- Select RankUpperUnder as the row variable, and LiveOnCampus as the column variable.
- (Optional) Click Cells . Under Counts, check the boxes for Observed and Expected , and under Residuals, click Unstandardized . Then click Continue .
The first table is the Case Processing summary, which tells us the number of valid cases used for analysis. Only cases with nonmissing values for both class rank and living on campus can be used in the test.

The next table is the crosstabulation. If you elected to check off the boxes for Observed Count, Expected Count, and Unstandardized Residuals, you should see the following table:

With the Expected Count values shown, we can confirm that all cells have an expected value greater than 5.
These numbers can be plugged into the chi-square test statistic formula:
$$ \chi^{2} = \sum_{i=1}^{R}{\sum_{j=1}^{C}{\frac{(o_{ij} - e_{ij})^{2}}{e_{ij}}}} = \frac{(-56.147)^{2}}{135.147} + \frac{(56.147)^{2}}{91.853} + \frac{(56.147)^{2}}{95.853} + \frac{(-56.147)^{2}}{65.147} = 138.926 $$
We can confirm this computation with the results in the Chi-Square Tests table:

The row of interest here is Pearson Chi-Square and its footnote.
- The value of the test statistic is 138.926.
- Because the crosstabulation is a 2x2 table, the degrees of freedom (df) for the test statistic is $$ df = (R - 1)*(C - 1) = (2 - 1)*(2 - 1) = 1 $$.
- The corresponding p-value of the test statistic is so small that it is cut off from display. Instead of writing "p = 0.000", we instead write the mathematically correct statement p < 0.001.
Since the p-value is less than our chosen significance level α = 0.05, we can reject the null hypothesis, and conclude that there is an association between class rank and whether or not students live on-campus.
- There was a significant association between class rank and living on campus ( Χ 2 (1) = 138.9, p < .001).
- << Previous: Analyzing Data
- Next: Pearson Correlation >>
- Last Updated: May 10, 2024 1:32 PM
- URL: https://libguides.library.kent.edu/SPSS
Street Address
Mailing address, quick links.
- How Are We Doing?
- Student Jobs
Information
- Accessibility
- Emergency Information
- For Our Alumni
- For the Media
- Jobs & Employment
- Life at KSU
- Privacy Statement
- Technology Support
- Website Feedback
11.3 - Chi-Square Test of Independence
The chi-square (\(\chi^2\)) test of independence is used to test for a relationship between two categorical variables. Recall that if two categorical variables are independent, then \(P(A) = P(A \mid B)\). The chi-square test of independence uses this fact to compute expected values for the cells in a two-way contingency table under the assumption that the two variables are independent (i.e., the null hypothesis is true).
Even if two variables are independent in the population, samples will vary due to random sampling variation. The chi-square test is used to determine if there is evidence that the two variables are not independent in the population using the same hypothesis testing logic that we used with one mean, one proportion, etc.
Again, we will be using the five step hypothesis testing procedure:
The assumptions are that the sample is randomly drawn from the population and that all expected values are at least 5 (we will see what expected values are later).
Our hypotheses are:
\(H_0:\) There is not a relationship between the two variables in the population (they are independent)
\(H_a:\) There is a relationship between the two variables in the population (they are dependent)
Note: When you're writing the hypotheses for a given scenario, use the names of the variables, not the generic "two variables."
The p-value can be found using Minitab. Look up the area to the right of your chi-square test statistic on a chi-square distribution with the correct degrees of freedom. Chi-square tests are always right-tailed tests.
If \(p \leq \alpha\) reject the null hypothesis.
If \(p>\alpha\) fail to reject the null hypothesis.
Write a conclusion in terms of the original research question.
11.3.1 - Example: Gender and Online Learning
Gender and online learning.
A sample of 314 Penn State students was asked if they have ever taken an online course. Their genders were also recorded. The contingency table below was constructed. Use a chi-square test of independence to determine if there is a relationship between gender and whether or not someone has taken an online course.
\(H_0:\) There is not a relationship between gender and whether or not someone has taken an online course (they are independent)
\(H_a:\) There is a relationship between gender and whether or not someone has taken an online course (they are dependent)
Looking ahead to our calculations of the expected values, we can see that all expected values are at least 5. This means that the sampling distribution can be approximated using the \(\chi^2\) distribution.
In order to compute the chi-square test statistic we must know the observed and expected values for each cell. We are given the observed values in the table above. We must compute the expected values. The table below includes the row and column totals.
Note that all expected values are at least 5, thus this assumption of the \(\chi^2\) test of independence has been met.
Observed and expected counts are often presented together in a contingency table. In the table below, expected values are presented in parentheses.
\(\chi^2=\sum \dfrac{(O-E)^2}{E} \)
\(\chi^2=\dfrac{(43-46.586)^2}{46.586}+\dfrac{(63-59.414)^2}{59.414}+\dfrac{(95-91.414)^2}{91.414}+\dfrac{(113-116.586)^2}{116.586}=0.276+0.216+0.141+0.110=0.743\)
The chi-square test statistic is 0.743
\(df=(number\;of\;rows-1)(number\;of\;columns-1)=(2-1)(2-1)=1\)
We can determine the p-value by constructing a chi-square distribution plot with 1 degree of freedom and finding the area to the right of 0.743.

\(p = 0.388702\)
\(p>\alpha\), therefore we fail to reject the null hypothesis.
There is not enough evidence to conclude that gender and whether or not an individual has completed an online course are related.
Note that we cannot say for sure that these two categorical variables are independent, we can only say that we do not have enough evidence that they are dependent.
11.3.2 - Minitab: Test of Independence
Raw vs summarized data.
If you have a data file with the responses for individual cases then you have "raw data" and can follow the directions below. If you have a table filled with data, then you have "summarized data." There is an example of conducting a chi-square test of independence using summarized data on a later page. After data entry the procedure is the same for both data entry methods.
Minitab ® – Chi-square Test Using Raw Data
Research question : Is there a relationship between where a student sits in class and whether they have ever cheated?
- Null hypothesis : Seat location and cheating are not related in the population.
- Alternative hypothesis : Seat location and cheating are related in the population.
To perform a chi-square test of independence in Minitab using raw data:
- Open Minitab file: class_survey.mpx
- Select Stat > Tables > Chi-Square Test for Association
- Select Raw data (categorical variables) from the dropdown.
- Choose the variable Seating to insert it into the Rows box
- Choose the variable Ever_Cheat to insert it into the Columns box
- Click the Statistics button and check the boxes Chi-square test for association and Expected cell counts
- Click OK and OK
This should result in the following output:
Rows: Seating Columns: Ever_Cheat
Chi-square test.
All expected values are at least 5 so we can use the Pearson chi-square test statistic. Our results are \(\chi^2 (2) = 1.539\). \(p = 0.463\). Because our \(p\) value is greater than the standard alpha level of 0.05, we fail to reject the null hypothesis. There is not enough evidence of a relationship in the population between seat location and whether a student has cheated.
11.3.2.1 - Example: Raw Data
Example: dog & cat ownership.
Is there a relationship between dog and cat ownership in the population of all World Campus STAT 200 students? Let's conduct an hypothesis test using the dataset: fall2016stdata.mpx
\(H_0:\) There is not a relationship between dog ownership and cat ownership in the population of all World Campus STAT 200 students \(H_a:\) There is a relationship between dog ownership and cat ownership in the population of all World Campus STAT 200 students
Assumption: All expected counts are at least 5. The expected counts here are 176.02, 75.98, 189.98, and 82.02, so this assumption has been met.
Let's use Minitab to calculate the test statistic and p-value.
- After entering the data, select Stat > Tables > Cross Tabulation and Chi-Square
- Enter Dog in the Rows box
- Enter Cat in the Columns box
- Select the Chi-Square button and in the new window check the box for the Chi-square test and Expected cell counts
Rows: Dog Columns: Cat
Since the assumption was met in step 1, we can use the Pearson chi-square test statistic.
\(Pearson\;\chi^2 = 1.771\)
\(p = 0.183\)
Our p value is greater than the standard 0.05 alpha level, so we fail to reject the null hypothesis.
There is not enough evidence of a relationship between dog ownership and cat ownership in the population of all World Campus STAT 200 students.
11.3.2.2 - Example: Summarized Data
Example: coffee and tea preference.
Is there a relationship between liking tea and liking coffee?
The following table shows data collected from a random sample of 100 adults. Each were asked if they liked coffee (yes or no) and if they liked tea (yes or no).
Let's use the 5 step hypothesis testing procedure to address this research question.
\(H_0:\) Liking coffee an liking tea are not related (i.e., independent) in the population \(H_a:\) Liking coffee and liking tea are related (i.e., dependent) in the population
Assumption: All expected counts are at least 5.
- Select Stat > Tables > Cross Tabulation and Chi-Square
- Select Summarized data in a two-way table from the dropdown
- Enter the columns Likes Coffee-Yes and Likes Coffee-No in the Columns containing the table box
- For the row labels enter Likes Tea (leave the column labels blank)
- Select the Chi-Square button and check the boxes for Chi-square test and Expected cell counts .
Rows: Likes Tea Columns: Worksheet columns
\(Pearson\;\chi^2 = 10.774\)
\(p = 0.001\)
Our p value is less than the standard 0.05 alpha level, so we reject the null hypothesis.
There is evidence of a relationship between between liking coffee and liking tea in the population.
11.3.3 - Relative Risk
A chi-square test of independence will give you information concerning whether or not a relationship between two categorical variables in the population is likely. As was the case with the single sample and two sample hypothesis tests that you learned earlier this semester, with a large sample size statistical power is high and the probability of rejecting the null hypothesis is high, even if the relationship is relatively weak. In addition to examining statistical significance by looking at the p value, we can also examine practical significance by computing the relative risk .
In Lesson 2 you learned that risk is often used to describe the probability of an event occurring. Risk can also be used to compare the probabilities in two different groups. First, we'll review risk, then you'll be introduced to the concept of relative risk.
The risk of an outcome can be expressed as a fraction or as the percent of a group that experiences the outcome.
Examples of Risk
60 out of 1000 teens have asthma. The risk is \(\frac{60}{1000}=.06\). This means that 6% of all teens experience asthma.
45 out of 100 children get the flu each year. The risk is \(\frac{45}{100}=.45\) or 45%
Thus, relative risk gives the risk for group 1 as a multiple of the risk for group 2.
Example of Relative Risk
Suppose that the risk of a child getting the flu this year is .45 and the risk of an adult getting the flu this year is .10. What is the relative risk of children compared to adults?
- \(Relative\;risk=\dfrac{.45}{.10}=4.5\)
Children are 4.5 times more likely than adults to get the flu this year.
Watch out for relative risk statistics where no baseline information is given about the actual risk. For instance, it doesn't mean much to say that beer drinkers have twice the risk of stomach cancer as non-drinkers unless we know the actual risks. The risk of stomach cancer might actually be very low, even for beer drinkers. For example, 2 in a million is twice the size of 1 in a million but is would still be a very low risk. This is known as the baseline with which other risks are compared.
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
AP®︎/College Statistics
Course: ap®︎/college statistics > unit 12, chi-square statistic for hypothesis testing.
- Chi-square goodness-of-fit example
- Expected counts in a goodness-of-fit test
- Conditions for a goodness-of-fit test
- Test statistic and P-value in a goodness-of-fit test
- Conclusions in a goodness-of-fit test
Want to join the conversation?
- Upvote Button navigates to signup page
- Downvote Button navigates to signup page
- Flag Button navigates to signup page

Video transcript
Chi square test
A chi-square test is a type of statistical hypothesis test that is used for populations that exhibit a chi-square distribution.
There are a number of different types of chi-square tests, the most commonly used of which is the Pearson's chi-square test. The Pearson's chi-square test is typically used for data that is categorical (types of data that may be divided into groups, e.g. age, race, sex, age), and may be used to test three types of comparison: independence, goodness of fit, and homogeneity. Most commonly, it is used to test for independence and goodness of fit. These are the two types of chi-square test discussed on this page. The procedure for conducting both tests follows the same general procedure, but certain aspects differ, such as the calculation of the test statistic and degrees of freedom, the conditions under which each test is used, the form of their null and alternative hypotheses, and the conditions for rejection of the null hypothesis. The general procedure for a chi-square test is as follows:
- State the null and alternative hypotheses.
- Select the significance level, α.
- Calculate the test statistic (the chi-square statistic, χ 2 , for the observed value).
- Determine the critical region for the selected level of significance and the appropriate degrees of freedom.
- Compare the test statistic to the critical value, and reject or fail to reject the null hypothesis based on the result.
Chi-square goodness of fit test
The chi-square goodness of fit test is used to test how well a sample of data fits some theoretical distribution. In other words, it can be used to help determine how well a model actually reflects the data based on how close observed values are to what we would expect of values for a normally distributed model.
To conduct a chi-square goodness of fit test, it is necessary to first state the null and alternative hypotheses, which take the following form for this type of test:
Like other hypothesis tests, the significance level of the test is selected by the researcher. The chi-square statistic is then calculated using a sample taken from the relevant population. The sample is grouped into categories such that each category contains a certain number of observed values, referred to as the frequency for the category. As a rule of thumb, the expected frequency for a category should be at least 5 for the chi-square approximation to valid; it is not valid for small samples. The formula for the chi-square statistic, χ 2 , is shown below
where O i is the observed frequency for category i, E i is the observed frequency for category i, and n is the number of categories.
Once the test statistic has been calculated, the critical value for the selected level of significance can be determined using a chi-square table given that the degrees of freedom is n - 1. The value of the test statistic is then compared to the critical value, and if it is greater than the critical value, the null hypothesis is rejected in favor of the alternative hypothesis; if the value of the test statistic is less than the critical value, we fail to reject the null hypothesis.
Jennifer wants to know if a six-sided die she just purchased is fair (each side has an equal probability of occurring). She rolls the die 60 times and records the following outcomes:
Use a chi-square goodness of fit test with a significance level of α = 0.05 to test the fairness of the die.
The null and alternative hypotheses can be stated as follows:
Since there is a 1/6 probability of any one of the numbers occurring on any given roll, and Jennifer rolled the die 60 times, she can expect to roll each face 10 times. Given the expected frequency, χ 2 can then be calculated as follows:
Thus, χ 2 = 10. The degrees of freedom can be found as n - 1, or 6 - 1 = 5. Thus df = 5. Referencing an upper-tail chi-square table for a significance level of 0.05 and df = 5, the critical value, is 11.07. Since the test statistic is less than the critical value, we fail to reject the null hypothesis. Thus, there is insufficient evidence to suggest that the die is unfair at a significance level of 0.05. This is depicted in the figure below.

Chi-square test of independence
The chi-square test of independence is used to help determine whether the differences between the observed and expected values of certain variables of interest indicate a statistically significant association between the variables, or if the differences can be simply attributed to chance; in other words, it is used to determine whether the value of one categorical variable depends on that of the other variable(s). In this type of hypothesis test, the null and alternative hypotheses take the following form:
Though the chi-square statistic is defined similarly for both the test of independence and goodness of fit, the expected value for the test of independence is calculated differently, since it involves two variables rather than one. Let X and Y be the two variables being tested such that X has i categories and Y has j categories. The number of combinations of the categories for X and Y forms a contingency table that has i rows and j columns. Since we are assuming that the null hypothesis is true, and X and Y are independent variables, the expected value can be computed as
where n i is the total of the observed frequencies in the i th row, n j is the total of the observed frequencies in the j th column, and n is the sample size. χ 2 is then defined as
where O ij is the observed value in row i and column j , E ij is the expected value in row i and column j , p is the number of rows, and q is the number of columns in the contingency table. Also, note that p represents the number of categories for one of the variables while q represents the number of categories for the other variable.
For a chi-square test of independence, the degrees of freedom can be determined as:
df = (p - 1)(q - 1)
Once df is known, the critical value and critical region can be determined for the selected significance level, and we can either reject or fail to reject the null hypothesis based on the results. Specifically:
- For an upper-tailed one-sided test, use a table of upper-tail critical values. If the test statistic is greater than the value in the column of the table corresponding to (1 - α), reject the null hypothesis.
- For a lower-tailed one-sided test, use a table of lower-tail critical values. If the test statistic is less than the value in the column of the table corresponding to α, reject the null hypothesis.
- Upper tail: if the test statistic is greater than the value in the column corresponding to (1 - α/2), reject the null hypothesis.
- Lower tail: if the test statistic is less than the value in the column corresponding to α/2, reject the null hypothesis.
The figure below depicts the above criteria for rejection of the null hypothesis.
A survey of 500 people is conducted to determine whether there is a relationship between a person's sex and their favorite color. A choice of three colors (blue, red, green) was provided, and the results of the survey are shown in the contingency table below:
Conduct a chi-square test of independence to test whether there is a relationship between sex and color preference at a significance level of α = 0.05.
E ij is computed for each row and column as follows:
The chi-square statistic is then computed as:
The degrees of freedom is computed as:
df = (2 - 1)(3 - 1) = 2
Thus, using a chi-square table, the critical value for α = 0.05 and df = 2 is 5.99. Since the test statistic, χ 2 = 13.5, is greater than the critical value, it lies in the critical region, so we reject the null hypothesis in favor of the alternative hypothesis at a significance level of 0.05.
JMP | Statistical Discovery.™ From SAS.
Statistics Knowledge Portal
A free online introduction to statistics
The Chi-Square Test
What is a chi-square test.
A Chi-square test is a hypothesis testing method. Two common Chi-square tests involve checking if observed frequencies in one or more categories match expected frequencies.
Is a Chi-square test the same as a χ² test?
Yes, χ is the Greek symbol Chi.
What are my choices?
If you have a single measurement variable, you use a Chi-square goodness of fit test . If you have two measurement variables, you use a Chi-square test of independence . There are other Chi-square tests, but these two are the most common.
Types of Chi-square tests
You use a Chi-square test for hypothesis tests about whether your data is as expected. The basic idea behind the test is to compare the observed values in your data to the expected values that you would see if the null hypothesis is true.
There are two commonly used Chi-square tests: the Chi-square goodness of fit test and the Chi-square test of independence . Both tests involve variables that divide your data into categories. As a result, people can be confused about which test to use. The table below compares the two tests.
Visit the individual pages for each type of Chi-square test to see examples along with details on assumptions and calculations.
Table 1: Choosing a Chi-square test
How to perform a chi-square test.
For both the Chi-square goodness of fit test and the Chi-square test of independence , you perform the same analysis steps, listed below. Visit the pages for each type of test to see these steps in action.
- Define your null and alternative hypotheses before collecting your data.
- Decide on the alpha value. This involves deciding the risk you are willing to take of drawing the wrong conclusion. For example, suppose you set α=0.05 when testing for independence. Here, you have decided on a 5% risk of concluding the two variables are independent when in reality they are not.
- Check the data for errors.
- Check the assumptions for the test. (Visit the pages for each test type for more detail on assumptions.)
- Perform the test and draw your conclusion.
Both Chi-square tests in the table above involve calculating a test statistic. The basic idea behind the tests is that you compare the actual data values with what would be expected if the null hypothesis is true. The test statistic involves finding the squared difference between actual and expected data values, and dividing that difference by the expected data values. You do this for each data point and add up the values.
Then, you compare the test statistic to a theoretical value from the Chi-square distribution . The theoretical value depends on both the alpha value and the degrees of freedom for your data. Visit the pages for each test type for detailed examples.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
11.7: Test of a Single Variance
- Last updated
- Save as PDF
- Page ID 1363

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
A test of a single variance assumes that the underlying distribution is normal . The null and alternative hypotheses are stated in terms of the population variance (or population standard deviation). The test statistic is:
\[\chi^{2} = \frac{(n-1)s^{2}}{\sigma^{2}} \label{test}\]
- \(n\) is the the total number of data
- \(s^{2}\) is the sample variance
- \(\sigma^{2}\) is the population variance
You may think of \(s\) as the random variable in this test. The number of degrees of freedom is \(df = n - 1\). A test of a single variance may be right-tailed, left-tailed, or two-tailed. The next example will show you how to set up the null and alternative hypotheses. The null and alternative hypotheses contain statements about the population variance.
Example \(\PageIndex{1}\)
Math instructors are not only interested in how their students do on exams, on average, but how the exam scores vary. To many instructors, the variance (or standard deviation) may be more important than the average.
Suppose a math instructor believes that the standard deviation for his final exam is five points. One of his best students thinks otherwise. The student claims that the standard deviation is more than five points. If the student were to conduct a hypothesis test, what would the null and alternative hypotheses be?
Even though we are given the population standard deviation, we can set up the test using the population variance as follows.
- \(H_{0}: \sigma^{2} = 5^{2}\)
- \(H_{a}: \sigma^{2} > 5^{2}\)
Exercise \(\PageIndex{1}\)
A SCUBA instructor wants to record the collective depths each of his students dives during their checkout. He is interested in how the depths vary, even though everyone should have been at the same depth. He believes the standard deviation is three feet. His assistant thinks the standard deviation is less than three feet. If the instructor were to conduct a test, what would the null and alternative hypotheses be?
- \(H_{0}: \sigma^{2} = 3^{2}\)
- \(H_{a}: \sigma^{2} > 3^{2}\)
Example \(\PageIndex{2}\)
With individual lines at its various windows, a post office finds that the standard deviation for normally distributed waiting times for customers on Friday afternoon is 7.2 minutes. The post office experiments with a single, main waiting line and finds that for a random sample of 25 customers, the waiting times for customers have a standard deviation of 3.5 minutes.
With a significance level of 5%, test the claim that a single line causes lower variation among waiting times (shorter waiting times) for customers .
Since the claim is that a single line causes less variation, this is a test of a single variance. The parameter is the population variance, \(\sigma^{2}\), or the population standard deviation, \(\sigma\).
Random Variable: The sample standard deviation, \(s\), is the random variable. Let \(s = \text{standard deviation for the waiting times}\).
- \(H_{0}: \sigma^{2} = 7.2^{2}\)
- \(H_{a}: \sigma^{2} < 7.2^{2}\)
The word "less" tells you this is a left-tailed test.
Distribution for the test: \(\chi^{2}_{24}\), where:
- \(n = \text{the number of customers sampled}\)
- \(df = n - 1 = 25 - 1 = 24\)
Calculate the test statistic (Equation \ref{test}):
\[\chi^{2} = \frac{(n-1)s^{2}}{\sigma^{2}} = \frac{(25-1)(3.5)^{2}}{7.2^{2}} = 5.67 \nonumber\]
where \(n = 25\), \(s = 3.5\), and \(\sigma = 7.2\).

Probability statement: \(p\text{-value} = P(\chi^{2} < 5.67) = 0.000042\)
Compare \(\alpha\) and the \(p\text{-value}\) :
\[\alpha = 0.05 (p\text{-value} = 0.000042 \alpha > p\text{-value} \nonumber\]
Make a decision: Since \(\alpha > p\text{-value}\), reject \(H_{0}\). This means that you reject \(\sigma^{2} = 7.2^{2}\). In other words, you do not think the variation in waiting times is 7.2 minutes; you think the variation in waiting times is less.
Conclusion: At a 5% level of significance, from the data, there is sufficient evidence to conclude that a single line causes a lower variation among the waiting times or with a single line, the customer waiting times vary less than 7.2 minutes.
In 2nd DISTR , use 7:χ2cdf . The syntax is (lower, upper, df) for the parameter list. For Example , χ2cdf(-1E99,5.67,24) . The \(p\text{-value} = 0.000042\).
Exercise \(\PageIndex{2}\)
The FCC conducts broadband speed tests to measure how much data per second passes between a consumer’s computer and the internet. As of August of 2012, the standard deviation of Internet speeds across Internet Service Providers (ISPs) was 12.2 percent. Suppose a sample of 15 ISPs is taken, and the standard deviation is 13.2. An analyst claims that the standard deviation of speeds is more than what was reported. State the null and alternative hypotheses, compute the degrees of freedom, the test statistic, sketch the graph of the p -value, and draw a conclusion. Test at the 1% significance level.
- \(H_{0}: \sigma^{2} = 12.2^{2}\)
- \(H_{a}: \sigma^{2} > 12.2^{2}\)
In 2nd DISTR , use7: χ2cdf . The syntax is (lower, upper, df) for the parameter list. χ2cdf(16.39,10^99,14) . The \(p\text{-value} = 0.2902\).
\(df = 14\)
\[\text{chi}^{2} \text{test statistic} = 16.39 \nonumber\]

The \(p\text{-value}\) is \(0.2902\), so we decline to reject the null hypothesis. There is not enough evidence to suggest that the variance is greater than \(12.2^{2}\).
- “AppleInsider Price Guides.” Apple Insider, 2013. Available online at http://appleinsider.com/mac_price_guide (accessed May 14, 2013).
- Data from the World Bank, June 5, 2012.
To test variability, use the chi-square test of a single variance. The test may be left-, right-, or two-tailed, and its hypotheses are always expressed in terms of the variance (or standard deviation).
Formula Review
\(\chi^{2} = \frac{(n-1) \cdot s^{2}}{\sigma^{2}}\) Test of a single variance statistic where:
\(n: \text{sample size}\)
\(s: \text{sample standard deviation}\)
\(\sigma: \text{population standard deviation}\)
\(df = n – 1 \text{Degrees of freedom}\)
Test of a Single Variance
- Use the test to determine variation.
- The degrees of freedom is the \(\text{number of samples} - 1\).
- The test statistic is \(\frac{(n-1) \cdot s^{2}}{\sigma^{2}}\), where \(n = \text{the total number of data}\), \(s^{2} = \text{sample variance}\), and \(\sigma^{2} = \text{population variance}\).
- The test may be left-, right-, or two-tailed.
Use the following information to answer the next three exercises: An archer’s standard deviation for his hits is six (data is measured in distance from the center of the target). An observer claims the standard deviation is less.
Exercise \(\PageIndex{3}\)
What type of test should be used?
a test of a single variance
Exercise \(\PageIndex{4}\)
State the null and alternative hypotheses.
Exercise \(\PageIndex{5}\)
Is this a right-tailed, left-tailed, or two-tailed test?
a left-tailed test
Use the following information to answer the next three exercises: The standard deviation of heights for students in a school is 0.81. A random sample of 50 students is taken, and the standard deviation of heights of the sample is 0.96. A researcher in charge of the study believes the standard deviation of heights for the school is greater than 0.81.
Exercise \(\PageIndex{6}\)
\(H_{0}: \sigma^{2} = 0.81^{2}\);
\(H_{a}: \sigma^{2} > 0.81^{2}\)
\(df =\) ________
Use the following information to answer the next four exercises: The average waiting time in a doctor’s office varies. The standard deviation of waiting times in a doctor’s office is 3.4 minutes. A random sample of 30 patients in the doctor’s office has a standard deviation of waiting times of 4.1 minutes. One doctor believes the variance of waiting times is greater than originally thought.
Exercise \(\PageIndex{7}\)
Exercise \(\pageindex{8}\).
What is the test statistic?
Exercise \(\PageIndex{9}\)
What is the \(p\text{-value}\)?
Exercise \(\PageIndex{10}\)
What can you conclude at the 5% significance level?
AP® Biology
The chi square test: ap® biology crash course.
- The Albert Team
- Last Updated On: March 7, 2024

The statistics section of the AP® Biology exam is without a doubt one of the most notoriously difficult sections. Biology students are comfortable with memorizing and understanding content, which is why this topic seems like the most difficult to master. In this article, The Chi Square Test: AP® Biology Crash Course , we will teach you a system for how to perform the Chi Square test every time. We will begin by reviewing some topics that you must know about statistics before you can complete the Chi Square test. Next, we will simplify the equation by defining each of the Chi Square variables. We will then use a simple example as practice to make sure that we have learned every part of the equation. Finally, we will finish with reviewing a more difficult question that you could see on your AP® Biology exam .
Null and Alternative Hypotheses
As background information, first you need to understand that a scientist must create the null and alternative hypotheses prior to performing their experiment. If the dependent variable is not influenced by the independent variable , the null hypothesis will be accepted. If the dependent variable is influenced by the independent variable, the data should lead the scientist to reject the null hypothesis . The null and alternative hypotheses can be a difficult topic to describe. Let’s look at an example.
Consider an experiment about flipping a coin. The null hypothesis would be that you would observe the coin landing on heads fifty percent of the time and the coin landing on tails fifty percent of the time. The null hypothesis predicts that you will not see a change in your data due to the independent variable.
The alternative hypothesis for this experiment would be that you would not observe the coins landing on heads and tails an even number of times. You could choose to hypothesize you would see more heads, that you would see more tails, or that you would just see a different ratio than 1:1. Any of these hypotheses would be acceptable as alternative hypotheses.
Defining the Variables
Now we will go over the Chi-Square equation. One of the most difficult parts of learning statistics is the long and confusing equations. In order to master the Chi Square test, we will begin by defining the variables.
This is the Chi Square test equation. You must know how to use this equation for the AP® Bio exam. However, you will not need to memorize the equation; it will be provided to you on the AP® Biology Equations and Formulas sheet that you will receive at the beginning of your examination.

Now that you have seen the equation, let’s define each of the variables so that you can begin to understand it!
• X 2 :The first variable, which looks like an x, is called chi squared. You can think of chi like x in algebra because it will be the variable that you will solve for during your statistical test. • ∑ : This symbol is called sigma. Sigma is the symbol that is used to mean “sum” in statistics. In this case, this means that we will be adding everything that comes after the sigma together. • O : This variable will be the observed data that you record during your experiment. This could be any quantitative data that is collected, such as: height, weight, number of times something occurs, etc. An example of this would be the recorded number of times that you get heads or tails in a coin-flipping experiment. • E : This variable will be the expected data that you will determine before running your experiment. This will always be the data that you would expect to see if your independent variable does not impact your dependent variable. For example, in the case of coin flips, this would be 50 heads and 50 tails.
The equation should begin to make more sense now that the variables are defined.
Working out the Coin Flip
We have talked about the coin flip example and, now that we know the equation, we will solve the problem. Let’s pretend that we performed the coin flip experiment and got the following data:
Now we put these numbers into the equation:
Heads (55-50) 2 /50= .5
Tails (45-50) 2 /50= .5
Lastly, we add them together.
c 2 = .5+.5=1
Now that we have c 2 we must figure out what that means for our experiment! To do that, we must review one more concept.
Degrees of Freedom and Critical Values
Degrees of freedom is a term that statisticians use to determine what values a scientist must get for the data to be significantly different from the expected values. That may sound confusing, so let’s try and simplify it. In order for a scientist to say that the observed data is different from the expected data, there is a numerical threshold the scientist must reach, which is based on the number of outcomes and a chosen critical value.
Let’s return to our coin flipping example. When we are flipping the coin, there are two outcomes: heads and tails. To get degrees of freedom, we take the number of outcomes and subtract one; therefore, in this experiment, the degree of freedom is one. We then take that information and look at a table to determine our chi-square value:
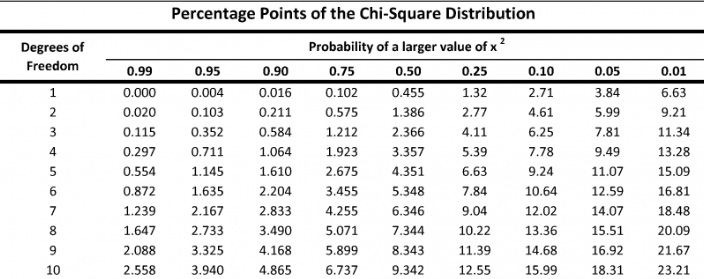
We will look at the column for one degree of freedom. Typically, scientists use a .05 critical value. A .05 critical value represents that there is a 95% chance that the difference between the data you expected to get and the data you observed is due to something other than chance. In this example, our value will be 3.84.
Coin Flip Results
In our coin flip experiment, Chi Square was 1. When we look at the table, we see that Chi Square must have been greater than 3.84 for us to say that the expected data was significantly different from the observed data. We did not reach that threshold. So, for this example, we will say that we failed to reject the null hypothesis.
The best way to get better at these statistical questions is to practice. Next, we will go through a question using the Chi Square Test that you could see on your AP® Bio exam.
AP® Biology Exam Question
This question was adapted from the 2013 AP® Biology exam.
In an investigation of fruit-fly behavior, a covered choice chamber is used to test whether the spatial distribution of flies is affected by the presence of a substance placed at one end of the chamber. To test the flies’ preference for glucose, 60 flies are introduced into the middle of the choice chamber at the insertion point. A ripe banana is placed at one end of the chamber, and an unripe banana is placed at the other end. The positions of flies are observed and recorded after 1 minute and after 10 minutes. Perform a Chi Square test on the data for the ten minute time point. Specify the null hypothesis and accept or reject it.
Okay, we will begin by identifying the null hypothesis . The null hypothesis would be that the flies would be evenly distributed across the three chambers (ripe, middle, and unripe).
Next, we will perform the Chi-Square test just like we did in the heads or tails experiment. Because there are three conditions, it may be helpful to use this set up to organize yourself:
Ok, so we have a Chi Square of 48.9. Our degrees of freedom are 3(ripe, middle, unripe)-1=2. Let’s look at that table above for a confidence variable of .05. You should get a value of 5.99. Our Chi Square value of 48.9 is much larger than 5.99 so in this case we are able to reject the null hypothesis. This means that the flies are not randomly assorting themselves, and the banana is influencing their behavior.
The Chi Square test is something that takes practice. Once you learn the system of solving these problems, you will be able to solve any Chi Square problem using the exact same method every time! In this article, we have reviewed the Chi Square test using two examples. If you are still interested in reviewing the bio-statistics that will be on your AP® Biology Exam, please check out our article The Dihybrid Cross Problem: AP® Biology Crash Course . Let us know how studying is going and if you have any questions!
Need help preparing for your AP® Biology exam?

Albert has hundreds of AP® Biology practice questions, free response, and full-length practice tests to try out.
Interested in a school license?
Popular posts.

AP® Score Calculators
Simulate how different MCQ and FRQ scores translate into AP® scores

AP® Review Guides
The ultimate review guides for AP® subjects to help you plan and structure your prep.

Core Subject Review Guides
Review the most important topics in Physics and Algebra 1 .
SAT® Score Calculator
See how scores on each section impacts your overall SAT® score
ACT® Score Calculator
See how scores on each section impacts your overall ACT® score
Grammar Review Hub
Comprehensive review of grammar skills

AP® Posters
Download updated posters summarizing the main topics and structure for each AP® exam.
LEARN STATISTICS EASILY
Learn Data Analysis Now!
Understanding the Null Hypothesis in Chi-Square
The null hypothesis in chi square testing suggests no significant difference between a study’s observed and expected frequencies. It assumes any observed difference is due to chance and not because of a meaningful statistical relationship.
Introduction
The chi-square test is a valuable tool in statistical analysis. It’s a non-parametric test applied when the data are qualitative or categorical. This test helps to establish whether there is a significant association between 2 categorical variables in a sample population.
Central to any chi-square test is the concept of the null hypothesis. In the context of chi-square, the null hypothesis assumes no significant difference exists between the categories’ observed and expected frequencies. Any difference seen is likely due to chance or random error rather than a meaningful statistical difference.
- The chi-square null hypothesis assumes no significant difference between observed and expected frequencies.
- Failing to reject the null hypothesis doesn’t prove it true, only that data lacks strong evidence against it.
- A p-value < the significance level indicates a significant association between variables.
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Understanding the Concept of Null Hypothesis in Chi Square
The null hypothesis in chi-square tests is essentially a statement of no effect or no relationship. When it comes to categorical data, it indicates that the distribution of categories for one variable is not affected by the distribution of categories of the other variable.
For example, if we compare the preference for different types of fruit among men and women, the null hypothesis would state that the preference is independent of gender. The alternative hypothesis, on the other hand, would suggest a dependency between the two.
Steps to Formulate the Null Hypothesis in Chi-Square Tests
Formulating the null hypothesis is a critical step in any chi-square test. First, identify the variables being tested. Then, once the variables are determined, the null hypothesis can be formulated to state no association between them.
Next, collect your data. This data must be frequencies or counts of categories, not percentages or averages. Once the data is collected, you can calculate the expected frequency for each category under the null hypothesis.
Finally, use the chi-square formula to calculate the chi-square statistic. This will help determine whether to reject or fail to reject the null hypothesis.
Practical Example and Case Study
Consider a study evaluating whether smoking status is independent of a lung cancer diagnosis. The null hypothesis would state that smoking status (smoker or non-smoker) is independent of cancer diagnosis (yes or no).
If we find a p-value less than our significance level (typically 0.05) after conducting the chi-square test, we would reject the null hypothesis and conclude that smoking status is not independent of lung cancer diagnosis, suggesting a significant association between the two.
Observed Table
Expected table, common misunderstandings and pitfalls.
One common misunderstanding is the interpretation of failing to reject the null hypothesis. It’s important to remember that failing to reject the null does not prove it true. Instead, it merely suggests that our data do not provide strong enough evidence against it.
Another pitfall is applying the chi-square test to inappropriate data. The chi-square test requires categorical or nominal data. Applying it to ordinal or continuous data without proper binning or categorization can lead to incorrect results.
The null hypothesis in chi-square testing is a powerful tool in statistical analysis. It provides a means to differentiate between observed variations due to random chance versus those that may signify a significant effect or relationship. As we continue to generate more data in various fields, the importance of understanding and correctly applying chi-square tests and the concept of the null hypothesis grows.
Recommended Articles
Interested in diving deeper into statistics? Explore our range of statistical analysis and data science articles to broaden your understanding. Visit our blog now!
- Simple Null Hypothesis – an overview (External Link)
- Chi-Square Calculator: Enhance Your Data Analysis Skills
- Effect Size for Chi-Square Tests: Unveiling its Significance
- What is the Difference Between the T-Test vs. Chi-Square Test?
Understanding the Assumptions for Chi-Square Test of Independence
- How to Report Chi-Square Test Results in APA Style: A Step-By-Step Guide
Frequently Asked Questions (FAQs)
It’s a statistical test used to determine if there’s a significant association between two categorical variables.
The null hypothesis suggests no significant difference between observed and expected frequencies exists. The alternative hypothesis suggests a significant difference.
No, we never “accept” the null hypothesis. We only fail to reject it if the data doesn’t provide strong evidence against it.
Rejecting the null hypothesis implies a significant difference between observed and expected frequencies, suggesting an association between variables.
Chi-Square tests are appropriate for categorical or nominal data.
The significance level, often 0.05, is the probability threshold below which the null hypothesis can be rejected.
A p-value < the significance level indicates a significant association between variables, leading to rejecting the null hypothesis.
Using the Chi-Square test for improper data, like ordinal or continuous data, without proper categorization can lead to incorrect results.
Identify the variables, state their independence, collect data, calculate expected frequencies, and apply the Chi-Square formula.
Understanding the null hypothesis is essential for correctly interpreting and applying Chi-Square tests, helping to make informed decisions based on data.
Similar Posts

If You Torture the Data Long Enough, It Will Confess to Anything
Explore the risks of unethical data analysis — ‘If you torture the data long enough, it will confess to anything’ — Learn best practices.

Create Great Graphs Easily (+Bonus)
Master the art of graph creation using iNZight, a free software offering various chart types and inferential analysis for compelling data presentations.

Understanding Convenience Sampling: Pros, Cons, and Best Practices
Dive into the world of convenience sampling! Understand its pros, cons, and best practices in our comprehensive guide.

Parametric vs. Nonparametric Tests: Choosing the Right Tool for Your Data
Explore the essence of Parametric vs. Nonparametric Tests to select the ideal statistical tool for your data analysis, enhancing accuracy.

Explore the assumptions and applications of the Chi-Square Test of Independence, a crucial tool for analyzing categorical data in various fields.

Coefficient of Determination vs. Coefficient of Correlation in Data Analysis
Uncover the differences between the coefficient of determination vs coefficient of correlation and their crucial roles in data analysis.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
9.1 Null and Alternative Hypotheses
The actual test begins by considering two hypotheses . They are called the null hypothesis and the alternative hypothesis . These hypotheses contain opposing viewpoints.
H 0 , the — null hypothesis: a statement of no difference between sample means or proportions or no difference between a sample mean or proportion and a population mean or proportion. In other words, the difference equals 0.
H a —, the alternative hypothesis: a claim about the population that is contradictory to H 0 and what we conclude when we reject H 0 .
Since the null and alternative hypotheses are contradictory, you must examine evidence to decide if you have enough evidence to reject the null hypothesis or not. The evidence is in the form of sample data.
After you have determined which hypothesis the sample supports, you make a decision. There are two options for a decision. They are reject H 0 if the sample information favors the alternative hypothesis or do not reject H 0 or decline to reject H 0 if the sample information is insufficient to reject the null hypothesis.
Mathematical Symbols Used in H 0 and H a :
H 0 always has a symbol with an equal in it. H a never has a symbol with an equal in it. The choice of symbol depends on the wording of the hypothesis test. However, be aware that many researchers use = in the null hypothesis, even with > or < as the symbol in the alternative hypothesis. This practice is acceptable because we only make the decision to reject or not reject the null hypothesis.
Example 9.1
H 0 : No more than 30 percent of the registered voters in Santa Clara County voted in the primary election. p ≤ 30 H a : More than 30 percent of the registered voters in Santa Clara County voted in the primary election. p > 30
A medical trial is conducted to test whether or not a new medicine reduces cholesterol by 25 percent. State the null and alternative hypotheses.
Example 9.2
We want to test whether the mean GPA of students in American colleges is different from 2.0 (out of 4.0). The null and alternative hypotheses are the following: H 0 : μ = 2.0 H a : μ ≠ 2.0
We want to test whether the mean height of eighth graders is 66 inches. State the null and alternative hypotheses. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : μ __ 66
- H a : μ __ 66
Example 9.3
We want to test if college students take fewer than five years to graduate from college, on the average. The null and alternative hypotheses are the following: H 0 : μ ≥ 5 H a : μ < 5
We want to test if it takes fewer than 45 minutes to teach a lesson plan. State the null and alternative hypotheses. Fill in the correct symbol ( =, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : μ __ 45
- H a : μ __ 45
Example 9.4
An article on school standards stated that about half of all students in France, Germany, and Israel take advanced placement exams and a third of the students pass. The same article stated that 6.6 percent of U.S. students take advanced placement exams and 4.4 percent pass. Test if the percentage of U.S. students who take advanced placement exams is more than 6.6 percent. State the null and alternative hypotheses. H 0 : p ≤ 0.066 H a : p > 0.066
On a state driver’s test, about 40 percent pass the test on the first try. We want to test if more than 40 percent pass on the first try. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : p __ 0.40
- H a : p __ 0.40
Collaborative Exercise
Bring to class a newspaper, some news magazines, and some internet articles. In groups, find articles from which your group can write null and alternative hypotheses. Discuss your hypotheses with the rest of the class.
As an Amazon Associate we earn from qualifying purchases.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute Texas Education Agency (TEA). The original material is available at: https://www.texasgateway.org/book/tea-statistics . Changes were made to the original material, including updates to art, structure, and other content updates.
Access for free at https://openstax.org/books/statistics/pages/1-introduction
- Authors: Barbara Illowsky, Susan Dean
- Publisher/website: OpenStax
- Book title: Statistics
- Publication date: Mar 27, 2020
- Location: Houston, Texas
- Book URL: https://openstax.org/books/statistics/pages/1-introduction
- Section URL: https://openstax.org/books/statistics/pages/9-1-null-and-alternative-hypotheses
© Jan 23, 2024 Texas Education Agency (TEA). The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
Teach yourself statistics
Chi-Square Test of Homogeneity
This lesson explains how to conduct a chi-square test of homogeneity . The test is applied to a single categorical variable from two or more different populations. It is used to determine whether frequency counts are distributed identically across different populations.
For example, in a survey of TV viewing preferences, we might ask respondents to identify their favorite program. We might ask the same question of two different populations, such as males and females. We could use a chi-square test for homogeneity to determine whether male viewing preferences differed significantly from female viewing preferences. The sample problem at the end of the lesson considers this example.
When to Use Chi-Square Test for Homogeneity
The test procedure described in this lesson is appropriate when the following conditions are met:
- For each population, the sampling method is simple random sampling .
- The variable under study is categorical .
- If sample data are displayed in a contingency table (Populations x Category levels), the expected frequency count for each cell of the table is at least 5.
This approach consists of four steps: (1) state the hypotheses, (2) formulate an analysis plan, (3) analyze sample data, and (4) interpret results.
State the Hypotheses
Every hypothesis test requires the analyst to state a null hypothesis and an alternative hypothesis . The hypotheses are stated in such a way that they are mutually exclusive. That is, if one is true, the other must be false; and vice versa.
Suppose that data were sampled from r populations, and assume that the categorical variable had c levels. At any specified level of the categorical variable, the null hypothesis states that each population has the same proportion of observations. Thus,
The alternative hypothesis (H a ) is that at least one of the null hypothesis statements is false.
Formulate an Analysis Plan
The analysis plan describes how to use sample data to accept or reject the null hypothesis. The plan should specify the following elements.
- Significance level. Often, researchers choose significance levels equal to 0.01, 0.05, or 0.10; but any value between 0 and 1 can be used.
- Test method. Use the chi-square test for homogeneity to determine whether observed sample frequencies differ significantly from expected frequencies specified in the null hypothesis. The chi-square test for homogeneity is described in the next section.
Analyze Sample Data
Using sample data from the contingency tables, find the degrees of freedom, expected frequency counts, test statistic, and the P-value associated with the test statistic. The analysis described in this section is illustrated in the sample problem at the end of this lesson.
DF = (r - 1) * (c - 1)
E r,c = (n r * n c ) / n
Χ 2 = Σ [ (O r,c - E r,c ) 2 / E r,c ]
- P-value. The P-value is the probability of observing a sample statistic as extreme as the test statistic. Since the test statistic is a chi-square, use the Chi-Square Distribution Calculator to assess the probability associated with the test statistic. Use the degrees of freedom computed above.
Interpret Results
If the sample findings are unlikely, given the null hypothesis, the researcher rejects the null hypothesis. Typically, this involves comparing the P-value to the significance level , and rejecting the null hypothesis when the P-value is less than the significance level.
Test Your Understanding
In a study of the television viewing habits of children, a developmental psychologist selects a random sample of 300 first graders - 100 boys and 200 girls. Each child is asked which of the following TV programs they like best: The Lone Ranger, Sesame Street, or The Simpsons. Results are shown in the contingency table below.
Do the boys' preferences for these TV programs differ significantly from the girls' preferences? Use a 0.05 level of significance.
The solution to this problem takes four steps: (1) state the hypotheses, (2) formulate an analysis plan, (3) analyze sample data, and (4) interpret results. We work through those steps below:
State the hypotheses. The first step is to state the null hypothesis and an alternative hypothesis.
- Alternative hypothesis: At least one of the null hypothesis statements is false.
- Formulate an analysis plan . For this analysis, the significance level is 0.05. Using sample data, we will conduct a chi-square test for homogeneity .
DF = (r - 1) * (c - 1) DF = (r - 1) * (c - 1) = (2 - 1) * (3 - 1) = 2
E r,c = (n r * n c ) / n E 1,1 = (100 * 100) / 300 = 10000/300 = 33.3 E 1,2 = (100 * 110) / 300 = 11000/300 = 36.7 E 1,3 = (100 * 90) / 300 = 9000/300 = 30.0 E 2,1 = (200 * 100) / 300 = 20000/300 = 66.7 E 2,2 = (200 * 110) / 300 = 22000/300 = 73.3 E 2,3 = (200 * 90) / 300 = 18000/300 = 60.0
Χ 2 = Σ[ (O r,c - E r,c ) 2 / E r,c ] Χ 2 = (50 - 33.3) 2 /33.3 + (30 - 36.7) 2 /36.7 + (20 - 30) 2 /30 + (50 - 66.7) 2 /66.7 + (80 - 73.3) 2 /73.3 + (70 - 60) 2 /60 Χ 2 = (16.7) 2 /33.3 + (-6.7) 2 /36.7 + (-10.0) 2 /30 + (-16.7) 2 /66.7 + (3.3) 2 /73.3 + (10) 2 /60 Χ 2 = 8.38 + 1.22 + 3.33 + 4.18 + 0.61 + 1.67 = 19.39
where DF is the degrees of freedom, r is the number of populations, c is the number of levels of the categorical variable, n r is the number of observations from population r , n c is the number of observations from level c of the categorical variable, n is the number of observations in the sample, E r,c is the expected frequency count in population r for level c , and O r,c is the observed frequency count in population r for level c .
The P-value is the probability that a chi-square statistic having 2 degrees of freedom is more extreme than 19.39. We use the Chi-Square Distribution Calculator to find P(Χ 2 > 19.39) = 0.00006.
- Interpret results . Since the P-value (0.00006) is less than the significance level (0.05), we reject the null hypothesis.
Note: If you use this approach on an exam, you may also want to mention why this approach is appropriate. Specifically, the approach is appropriate because the sampling method was simple random sampling, the variable under study was categorical, and the expected frequency count was at least 5 in each population at each level of the categorical variable.

Statistics Made Easy
Chi-Square Goodness of Fit Test: Definition, Formula, and Example
A Chi-Square goodness of fit test is used to determine whether or not a categorical variable follows a hypothesized distribution.
This tutorial explains the following:
- The motivation for performing a Chi-Square goodness of fit test.
- The formula to perform a Chi-Square goodness of fit test.
- An example of how to perform a Chi-Square goodness of fit test.
Chi-Square Goodness of Fit Test: Motivation
A Chi-Square goodness of fit test can be used in a wide variety of settings. Here are a few examples:
- We want to know if a die is fair, so we roll it 50 times and record the number of times it lands on each number.
- We want to know if an equal number of people come into a shop each day of the week, so we count the number of people who come in each day during a random week.
- We want to know if the percentage of M&M’s that come in a bag are as follows: 20% yellow, 30% blue, 30% red, 20% other. To test this, we open a random bag of M&M’s and count how many of each color appear.
In each of these scenarios, we want to know if some variable follows a hypothesized distribution. In each scenario, we can use a Chi-Square goodness of fit test to determine if there is a statistically significant difference in the number of expected counts for each level of a variable compared to the observed counts.
Chi-Square Goodness of Fit Test: Formula
A Chi-Square goodness of fit test uses the following null and alternative hypotheses:
- H 0 : (null hypothesis) A variable follows a hypothesized distribution.
- H 1 : (alternative hypothesis) A variable does not follow a hypothesized distribution.
We use the following formula to calculate the Chi-Square test statistic X 2 :
X 2 = Σ(O-E) 2 / E
- Σ: is a fancy symbol that means “sum”
- O: observed value
- E: expected value
If the p-value that corresponds to the test statistic X 2 with n-1 degrees of freedom (where n is the number of categories) is less than your chosen significance level (common choices are 0.10, 0.05, and 0.01) then you can reject the null hypothesis.
Chi-Square Goodness of Fit Test: Example
A shop owner claims that an equal number of customers come into his shop each weekday. To test this hypothesis, an independent researcher records the number of customers that come into the shop on a given week and finds the following:
- Monday: 50 customers
- Tuesday: 60 customers
- Wednesday: 40 customers
- Thursday: 47 customers
- Friday: 53 customers
We will use the following steps to perform a Chi-Square goodness of fit test to determine if the data is consistent with the shop owner’s claim.
Step 1: Define the hypotheses.
We will perform the Chi-Square goodness of fit test using the following hypotheses:
- H 0 : An equal number of customers come into the shop each day.
- H 1 : An equal number of customers do not come into the shop each day.
Step 2: Calculate (O-E) 2 / E for each day.
There were a total of 250 customers that came into the shop during the week. Thus, if we expected an equal amount to come in each day then the expected value “E” for each day would be 50.
- Monday: (50-50) 2 / 50 = 0
- Tuesday: (60-50) 2 / 50 = 2
- Wednesday: (40-50) 2 / 50 = 2
- Thursday: (47-50) 2 / 50 = 0.18
- Friday: (53-50) 2 / 50 = 0.18
Step 3: Calculate the test statistic X 2 .
X 2 = Σ(O-E) 2 / E = 0 + 2 + 2 + 0.18 + 0.18 = 4.36
Step 4: Calculate the p-value of the test statistic X 2 .
According to the Chi-Square Score to P Value Calculator , the p-value associated with X 2 = 4.36 and n-1 = 5-1 = 4 degrees of freedom is 0.359472 .
Step 5: Draw a conclusion.
Since this p-value is not less than 0.05, we fail to reject the null hypothesis. This means we do not have sufficient evidence to say that the true distribution of customers is different from the distribution that the shop owner claimed.
Note: You can also perform this entire test by simply using the Chi-Square Goodness of Fit Test Calculator .
Additional Resources
The following tutorials explain how to perform a Chi-Square goodness of fit test using different statistical programs:
How to Perform a Chi-Square Goodness of Fit Test in Excel How to Perform a Chi-Square Goodness of Fit Test in Stata How to Perform a Chi-Square Goodness of Fit Test in SPSS How to Perform a Chi-Square Goodness of Fit Test in Python How to Perform a Chi-Square Goodness of Fit Test in R Chi-Square Goodness of Fit Test on a TI-84 Calculator Chi-Square Goodness of Fit Test Calculator
Featured Posts

Hey there. My name is Zach Bobbitt. I have a Masters of Science degree in Applied Statistics and I’ve worked on machine learning algorithms for professional businesses in both healthcare and retail. I’m passionate about statistics, machine learning, and data visualization and I created Statology to be a resource for both students and teachers alike. My goal with this site is to help you learn statistics through using simple terms, plenty of real-world examples, and helpful illustrations.
2 Replies to “Chi-Square Goodness of Fit Test: Definition, Formula, and Example”
You are welome, gav!
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Join the Statology Community
Sign up to receive Statology's exclusive study resource: 100 practice problems with step-by-step solutions. Plus, get our latest insights, tutorials, and data analysis tips straight to your inbox!
By subscribing you accept Statology's Privacy Policy.
Chi Square Test
Ai generator.

The chi-square test, a cornerstone of statistical analysis, is utilized to examine the independence of two categorical variables, offering a method to assess observed versus expected frequencies in categorical data. This test extends beyond basic algebra and rational numbers , involving computations with square and square roots , which are integral in determining the chi-square statistic. Unlike dealing with integers or continuous rational and irrational numbers directly, this test quantifies how much observed counts deviate from expected counts in categorical data, rooted in the realm of probability and discrete mathematics . Additionally, while it diverges from the least squares method used for continuous data regression, both share a common goal of minimizing deviation to optimize fit between observed and expected models. In statistics , understanding and applying the chi-square test provides crucial insights into data relationships, crucial for robust analytical conclusions in research and real-world applications.
What is Chi Square Test?
Chi-square distribution.
The chi-square distribution is a fundamental probability distribution in statistics, widely used in hypothesis testing and confidence interval estimation for variance. It arises primarily when summing the squares of independent, standard normal variables, and is characterized by its degrees of freedom, which influence its shape. As the degrees of freedom increase, the distribution becomes more symmetric and approaches a normal distribution. This distribution is crucial in constructing the chi-square test for independence and goodness-of-fit tests, helping to determine whether observed frequencies significantly deviate from expected frequencies under a given hypothesis. It is also integral to the analysis of variance (ANOVA) and other statistical procedures that assess the variability among group means.
Finding P-Value
Step 1: understand the p-value.
The p-value represents the probability of observing a test statistic as extreme as, or more extreme than, the value calculated from the sample data, under the null hypothesis. A low p-value (typically less than 0.05) suggests that the observed data is inconsistent with the null hypothesis, leading to its rejection.
Step 2: Calculate the Test Statistic
Depending on the statistical test being used (like t-test, chi-square test, ANOVA, etc.), first calculate the appropriate test statistic based on your data. This involves different formulas depending on the test and the data structure.
Step 3: Determine the Distribution
Identify the distribution that the test statistic follows under the null hypothesis. For example, the test statistic in a chi-square test follows a chi-square distribution, while a t-test statistic follows a t-distribution.
Step 4: Find the P-Value
Use the distribution identified in Step 3 to find the probability of obtaining a test statistic as extreme as the one you calculated. This can be done using statistical software, tables, or online calculators. You will compare your test statistic to the critical values from the distribution, calculating the area under the curve that lies beyond the test statistic.
Step 5: Interpret the P-Value
- If the p-value is less than the chosen significance level (usually 0.05) , reject the null hypothesis, suggesting that the effect observed in the data is statistically significant.
- If the p-value is greater than the significance level , you do not have enough evidence to reject the null hypothesis, and it is assumed that any observed differences could be due to chance.
Practical Example
For a simpler illustration, suppose you’re conducting a two-tailed t-test with a t-statistic of 2.3, and you’re using a significance level of 0.05. You would:
- Identify that the t-statistic follows a t-distribution with degrees of freedom dependent on your sample size.
- Using a t-distribution table or software, find the probability that a t-value is at least as extreme as ±2.3.
- Sum the probabilities of obtaining a t-value of 2.3 or higher and -2.3 or lower. This sum is your p-value.
Properties of Chi-Square
1. non-negativity.
- The chi-square statistic is always non-negative. This property arises because it is computed as the sum of the squares of standardized differences between observed and expected frequencies.
2. Degrees of Freedom
- The shape and scale of the chi-square distribution are primarily determined by its degrees of freedom, which in turn depend on the number of categories or variables involved in the analysis. The degrees of freedom for a chi-square test are generally calculated as (𝑟−1)(𝑐−1) for an 𝑟×𝑐 contingency table.
3. Distribution Shape
- The chi-square distribution is skewed to the right, especially with fewer degrees of freedom. As the degrees of freedom increase, the distribution becomes more symmetric and starts to resemble a normal distribution.
4. Additivity
- The chi-square distributions are additive. This means that if two independent chi-square variables are added together, their sum also follows a chi-square distribution, with degrees of freedom equal to the sum of their individual degrees of freedom.
5. Dependency on Sample Size
- The chi-square statistic is sensitive to sample size. Larger sample sizes tend to give more reliable estimates of the chi-square statistic, reducing the influence of sampling variability. This property emphasizes the need for adequate sample sizes in experiments intending to use chi-square tests for valid inference.
Chi-Square Formula

Components of the Formula:
- χ ² is the chi-square statistic.
- 𝑂ᵢ represents the observed frequency for each category.
- 𝐸ᵢ represents the expected frequency for each category, based on the hypothesis being tested.
- The summation (∑) is taken over all categories involved in the test.
Chi-Square Test of Independence
The Chi-Square Test of Independence assesses whether two categorical variables are independent, meaning whether the distribution of one variable differs depending on the value of the other variable.
Assumptions
Before conducting the test, certain assumptions must be met:
- Sample Size : All expected frequencies should be at least 1, and no more than 20% of expected frequencies are less than 5.
- Independence : Observations must be independent of each other, typically achieved by random sampling.
- Data Level : Both variables should be categorical (nominal or ordinal).
Example of Categorical Data
Breakdown of the table.
- Rows : Represent different categories of pet ownership (Owns a Pet, Does Not Own a Pet).
- Columns : Represent preferences for types of pet food (Organic, Non-Organic).
- Cells : Show the frequency of respondents in each combination of categories (e.g., 120 people own a pet and prefer organic pet food).
Below is the representation of a chi-square distribution table with three probability levels (commonly used significance levels: 0.05, 0.01, and 0.001) for degrees of freedom up to 50. The degrees of freedom (DF) for a chi-square test in a contingency table are calculated as (r-1)(c-1), where r is the number of rows and c is the number of columns. This table is vital for determining critical values when testing hypotheses involving categorical data.
This table provides critical values for various degrees of freedom and significance levels, which can be used to determine the likelihood of observing a chi-square statistic at least as extreme as the test statistic calculated from your data, under the assumption that the null hypothesis is true.
Example of Chi-Square Test for Independence
The Chi-square test for independence is a statistical test commonly used to determine if there is a significant relationship between two categorical variables in a population. Let’s go through a detailed example to understand how to apply this test.
Imagine a researcher wants to investigate whether gender (male or female) affects the choice of a major (science or humanities) among university students.
Data Collection
The researcher surveys a sample of 300 students and compiles the data into the following contingency table:
- Null Hypothesis (H₀): There is no relationship between gender and choice of major.
- Alternative Hypothesis (H₁): There is a relationship between gender and choice of major.
1. Calculate Expected Counts:
- Under the null hypothesis, if there’s no relationship between gender and major, the expected count for each cell of the table is calculated by the formula:
Eᵢⱼ = (Row Total×Column Total)/Total Observations
For the ‘Male & Science’ cell:
𝐸ₘₐₗₑ, ₛ꜀ᵢₑₙ꜀ₑ = (150×130)/300 = 65
Repeat this for each cell.
Compute Chi-Square Statistic
The chi-square statistic is calculated using:
χ ² = ∑( O − E )²/E
Where 𝑂 is the observed frequency, and 𝐸 is the expected frequency. For each cell:
χ ² = 65(70−65)²+85(80−85)²+65(60−65)²+85(90−85) = 1.615
Determine Significance
With 1 degree of freedom (df = (rows – 1)/ times (columns – 1)), check the critical value from the chi-square distribution table at the desired significance level (e.g., 0.05). If 𝜒² calculated is greater than the critical value from the table, reject the null hypothesis.
What does the Chi-Square value indicate?
The Chi-Square value indicates how much the observed frequencies deviate from the expected frequencies under the null hypothesis of independence. A higher Chi-Square value suggests a greater deviation, which may lead to the rejection of the null hypothesis if the value exceeds the critical value from the Chi-Square distribution table for the given degrees of freedom and significance level.
How do you interpret the results of a Chi-Square Test?
To interpret the results of a Chi-Square Test, compare the calculated Chi-Square statistic to the critical value from the Chi-Square distribution table at your chosen significance level (commonly 0.05 or 0.01). If the calculated value is greater than the critical value, reject the null hypothesis, suggesting a significant association between the variables. If it is less, fail to reject the null hypothesis, indicating no significant association.
What are the limitations of the Chi-Square Test?
The Chi-Square Test assumes that the data are from a random sample, observations are independent, and expected frequencies are sufficiently large, typically at least 5 in each cell of the table. When these conditions are not met, the test results may not be valid. Additionally, the test does not provide information about the direction or strength of the association, only its existence.
Text prompt
- Instructive
- Professional
10 Examples of Public speaking
20 Examples of Gas lighting
- Mastering Hypothesis Testing in Excel: A Practical Guide for Students
Excel for Hypothesis Testing: A Practical Approach for Students

Hypothesis testing lies at the heart of statistical inference, serving as a cornerstone for drawing meaningful conclusions from data. It's a methodical process used to evaluate assumptions about a population parameter, typically based on sample data. The fundamental idea behind hypothesis testing is to assess whether observed differences or relationships in the sample are statistically significant enough to warrant generalizations to the larger population. This process involves formulating null and alternative hypotheses, selecting an appropriate statistical test, collecting sample data, and interpreting the results to make informed decisions. In the realm of statistical software, SAS stands out as a robust and widely used tool for data analysis in various fields such as academia, industry, and research. Its extensive capabilities make it particularly favored for complex analyses, large datasets, and advanced modeling techniques. However, despite its versatility and power, SAS can have a steep learning curve, especially for students who are just beginning their journey into statistics. The intricacies of programming syntax, data manipulation, and interpreting output may pose challenges for novice users, potentially hindering their understanding of statistical concepts like hypothesis testing. If you need assistance with your Excel homework , understanding hypothesis testing is essential for performing statistical analyses and drawing meaningful conclusions from data using Excel's built-in functions and tools.

Enter Excel, a ubiquitous spreadsheet software that most students are already familiar with to some extent. While Excel may not offer the same level of sophistication as SAS in terms of advanced statistical procedures, it remains a valuable tool, particularly for introductory and intermediate-level analyses. Its intuitive interface, user-friendly features, and widespread accessibility make it an attractive option for students seeking a practical approach to learning statistics. By leveraging Excel's built-in functions, data visualization tools, and straightforward formulas, students can gain hands-on experience with hypothesis testing in a familiar environment. In this blog post, we aim to bridge the gap between theoretical concepts and practical application by demonstrating how Excel can serve as a valuable companion for students tackling hypothesis testing problems, including those typically encountered in SAS assignments. We will focus on demystifying the process of hypothesis testing, breaking it down into manageable steps, and showcasing Excel's capabilities for conducting various tests commonly encountered in introductory statistics courses.
Understanding the Basics
Hypothesis testing is a fundamental concept in statistics that allows researchers to draw conclusions about a population based on sample data. At its core, hypothesis testing involves making a decision about whether a statement regarding a population parameter is likely to be true. This decision is based on the analysis of sample data and is guided by two competing hypotheses: the null hypothesis (H0) and the alternative hypothesis (Ha). The null hypothesis represents the status quo or the absence of an effect. It suggests that any observed differences or relationships in the sample data are due to random variation or chance. On the other hand, the alternative hypothesis contradicts the null hypothesis and suggests the presence of an effect or difference in the population. It reflects the researcher's belief or the hypothesis they aim to support with their analysis.
Formulating Hypotheses
In Excel, students can easily formulate hypotheses using simple formulas and logical operators. For instance, suppose a researcher wants to test whether the mean of a sample is equal to a specified value. They can use the AVERAGE function in Excel to calculate the sample mean and then compare it to the specified value using logical operators like "=" for equality. If the calculated mean is equal to the specified value, it supports the null hypothesis; otherwise, it supports the alternative hypothesis.
Excel's flexibility allows students to customize their hypotheses based on the specific parameters they are testing. Whether it's comparing means, proportions, variances, or other population parameters, Excel provides a user-friendly interface for formulating hypotheses and conducting statistical analysis.
Selecting the Appropriate Test
Excel offers a plethora of functions and tools for conducting various types of hypothesis tests, including t-tests, z-tests, chi-square tests, and ANOVA (analysis of variance). However, selecting the appropriate test requires careful consideration of the assumptions and conditions associated with each test. Students should familiarize themselves with the assumptions underlying each hypothesis test and assess whether their data meets those assumptions. For example, t-tests assume that the data follow a normal distribution, while chi-square tests require categorical data and independence between observations.
Furthermore, students should consider the nature of their research question and the type of data they are analyzing. Are they comparing means of two independent groups or assessing the association between categorical variables? By understanding the characteristics of their data and the requirements of each test, students can confidently choose the appropriate hypothesis test in Excel.
T-tests are statistical tests commonly used to compare the means of two independent samples or to compare the mean of a single sample to a known value. These tests are valuable in various fields, including psychology, biology, economics, and more. In Excel, students can employ the T.TEST function to conduct t-tests, providing them with a practical and accessible way to analyze their data and draw conclusions about population parameters based on sample statistics.
Independent Samples T-Test
The independent samples t-test, also known as the unpaired t-test, is utilized when comparing the means of two independent groups. This test is often employed in experimental and observational studies to assess whether there is a significant difference between the means of the two groups. In Excel, students can easily organize their data into separate columns representing the two groups, calculate the sample means and standard deviations for each group, and then use the T.TEST function to obtain the p-value. The p-value obtained from the T.TEST function represents the probability of observing the sample data if the null hypothesis, which typically states that there is no difference between the means of the two groups, is true.
A small p-value (typically less than the chosen significance level, commonly 0.05) indicates that there is sufficient evidence to reject the null hypothesis in favor of the alternative hypothesis, suggesting a significant difference between the group means. By conducting an independent samples t-test in Excel, students can not only assess the significance of differences between two groups but also gain valuable experience in data analysis and hypothesis testing, which are essential skills in various academic and professional settings.
Paired Samples T-Test
The paired samples t-test, also known as the dependent t-test or matched pairs t-test, is employed when comparing the means of two related groups. This test is often used in studies where participants are measured before and after an intervention or when each observation in one group is matched or paired with a specific observation in the other group. Examples include comparing pre-test and post-test scores, analyzing the performance of individuals under different conditions, and assessing the effectiveness of a treatment or intervention. In Excel, students can perform a paired samples t-test by first calculating the differences between paired observations (e.g., subtracting the before-measurement from the after-measurement). Next, they can use the one-sample t-test function, specifying the calculated differences as the sample data. This approach allows students to determine whether the mean difference between paired observations is statistically significant, indicating whether there is a meaningful change or effect between the two related groups.
Interpreting the results of a paired samples t-test involves assessing the obtained p-value in relation to the chosen significance level. A small p-value suggests that there is sufficient evidence to reject the null hypothesis, indicating a significant difference between the paired observations. This information can help students draw meaningful conclusions from their data and make informed decisions based on statistical evidence. By conducting paired samples t-tests in Excel, students can not only analyze the relationship between related groups but also develop critical thinking skills and gain practical experience in hypothesis testing, which are valuable assets in both academic and professional contexts. Additionally, mastering the application of statistical tests in Excel can enhance students' data analysis skills and prepare them for future research endeavors and real-world challenges.
Chi-Square Test
The chi-square test is a versatile statistical tool used to assess the association between two categorical variables. In essence, it helps determine whether the observed frequencies in a dataset significantly deviate from what would be expected under certain assumptions. Excel provides a straightforward means to perform chi-square tests using the CHISQ.TEST function, which calculates the probability associated with the chi-square statistic.
Goodness-of-Fit Test
One application of the chi-square test is the goodness-of-fit test, which evaluates how well the observed frequencies in a single categorical variable align with the expected frequencies dictated by a theoretical distribution. This test is particularly useful when researchers wish to ascertain whether their data conforms to a specific probability distribution. In Excel, students can organize their data into a frequency table, listing the categories of the variable of interest along with their corresponding observed frequencies. They can then specify the expected frequencies based on the theoretical distribution they are testing against. For example, if analyzing the outcomes of a six-sided die roll, where each face is expected to occur with equal probability, the expected frequency for each category would be the total number of observations divided by six.
Once the observed and expected frequencies are determined, students can employ the CHISQ.TEST function in Excel to calculate the chi-square statistic and its associated p-value. The p-value represents the probability of obtaining a chi-square statistic as extreme or more extreme than the observed value under the assumption that the null hypothesis is true (i.e., the observed frequencies match the expected frequencies). Interpreting the results of the goodness-of-fit test involves comparing the calculated p-value to a predetermined significance level (commonly denoted as α). If the p-value is less than α (e.g., α = 0.05), there is sufficient evidence to reject the null hypothesis, indicating that the observed frequencies significantly differ from the expected frequencies specified by the theoretical distribution. Conversely, if the p-value is greater than α, there is insufficient evidence to reject the null hypothesis, suggesting that the observed frequencies align well with the expected frequencies.
Test of Independence
Another important application of the chi-square test in Excel is the test of independence, which evaluates whether there is a significant association between two categorical variables in a contingency table. This test is employed when researchers seek to determine whether the occurrence of one variable is related to the occurrence of another. To conduct a test of independence in Excel, students first create a contingency table that cross-tabulates the two categorical variables of interest. Each cell in the table represents the frequency of occurrences for a specific combination of categories from the two variables.
Similar to the goodness-of-fit test, students then calculate the expected frequencies for each cell under the assumption of independence between the variables. Using the CHISQ.TEST function in Excel, students can calculate the chi-square statistic and its associated p-value based on the observed and expected frequencies in the contingency table. The interpretation of the test results follows a similar procedure to that of the goodness-of-fit test, with the p-value indicating whether there is sufficient evidence to reject the null hypothesis of independence between the two variables.
Excel, despite being commonly associated with spreadsheet tasks, offers a plethora of features that make it a versatile and powerful tool for statistical analysis, especially for students diving into the intricacies of hypothesis testing. Its widespread availability and user-friendly interface make it accessible to students at various levels of statistical proficiency. However, the true value of Excel lies not just in its accessibility but also in its ability to facilitate a hands-on learning experience that reinforces theoretical concepts.
At the core of utilizing Excel for hypothesis testing is a solid understanding of the fundamental principles of statistical inference. Students need to grasp concepts such as the null and alternative hypotheses, significance levels, p-values, and test statistics. Excel provides a practical platform for students to apply these concepts in a real-world context. Through hands-on experimentation with sample datasets, students can observe how changes in data inputs and statistical parameters affect the outcome of hypothesis tests, thus deepening their understanding of statistical theory.
Post a comment...
Mastering hypothesis testing in excel: a practical guide for students submit your homework, attached files.
COMMENTS
Example: Chi-square test of independence. Null hypothesis (H 0): The proportion of people who are left-handed is the same for Americans and Canadians. Alternative hypothesis (H A): The proportion of people who are left-handed differs between nationalities. Other types of chi-square tests
A Chi-Square test of independence uses the following null and alternative hypotheses: H0: (null hypothesis) The two variables are independent. H1: (alternative hypothesis) The two variables are not independent. (i.e. they are associated) We use the following formula to calculate the Chi-Square test statistic X2: X2 = Σ (O-E)2 / E.
Like any statistical hypothesis test, the Chi-square test has both a null hypothesis and an alternative hypothesis. Null hypothesis: There are no relationships between the categorical variables. If you know the value of one variable, it does not help you predict the value of another variable. Alternative hypothesis: There are relationships ...
We then determine the appropriate test statistic for the hypothesis test. The formula for the test statistic is given below. Test Statistic for Testing H0: p1 = p 10 , p2 = p 20 , ..., pk = p k0. We find the critical value in a table of probabilities for the chi-square distribution with degrees of freedom (df) = k-1.
To conduct this test we compute a Chi-Square test statistic where we compare each cell's observed count to its respective expected count. In a summary table, we have r × c = r c cells. Let O 1, O 2, …, O r c denote the observed counts for each cell and E 1, E 2, …, E r c denote the respective expected counts for each cell.
The two categorical variables are dependent. Chi-Square Test Statistic. χ 2 = ∑ ( O − E) 2 / E. where O represents the observed frequency. E is the expected frequency under the null hypothesis and computed by: E = row total × column total sample size. We will compare the value of the test statistic to the critical value of χ α 2 with ...
Computational Exercises. In each of the following exercises, specify the number of degrees of freedom of the chi-square statistic, give the value of the statistic and compute the P -value of the test. A coin is tossed 100 times, resulting in 55 heads. Test the null hypothesis that the coin is fair.
The null hypothesis (H 0) and alternative hypothesis (H 1) of the Chi-Square Test of Independence can be expressed in two different but equivalent ways: H 0: "[Variable 1] is independent of [Variable 2]" H 1: "[Variable 1] is not independent of [Variable 2]" OR.
The chi-square (\(\chi^2\)) test of independence is used to test for a relationship between two categorical variables. ... Null hypothesis: Seat location and cheating are not related in the population. Alternative hypothesis: Seat location and cheating are related in the population. To perform a chi-square test of independence in Minitab using ...
And we got a chi-squared value. Our chi-squared statistic was six. So this right over here tells us the probability of getting a 6.25 or greater for our chi-squared value is 10%. If we go back to this chart, we just learned that this probability from 6.25 and up, when we have three degrees of freedom, that this right over here is 10%.
Thus, using a chi-square table, the critical value for α = 0.05 and df = 2 is 5.99. Since the test statistic, χ 2 = 13.5, is greater than the critical value, it lies in the critical region, so we reject the null hypothesis in favor of the alternative hypothesis at a significance level of 0.05.
Hypotheses. Null hypothesis: Assumes that there is no association between the two variables. Alternative hypothesis: Assumes that there is an association between the two variables. Hypothesis testing: Hypothesis testing for the chi-square test of independence as it is for other tests like ANOVA, where a test statistic is computed and compared to a critical value.
You use a Chi-square test for hypothesis tests about whether your data is as expected. The basic idea behind the test is to compare the observed values in your data to the expected values that you would see if the null hypothesis is true. There are two commonly used Chi-square tests: the Chi-square goodness of fit test and the Chi-square test ...
11.7: Test of a Single Variance. A test of a single variance assumes that the underlying distribution is normal. The null and alternative hypotheses are stated in terms of the population variance (or population standard deviation). The test statistic is: χ2 = (n − 1)s2 σ2 (11.7.1) (11.7.1) χ 2 = ( n − 1) s 2 σ 2.
of the chi-square test statistic is large enough to reject the null hypothesis. Statistical software makes this determination much easier. For the purpose of this analysis, only the Pearson Chi-Square statistic is needed. The p-value for the chi-square statistic is .000, which is smaller than the alpha level of .05.
You should get a value of 5.99. Our Chi Square value of 48.9 is much larger than 5.99 so in this case we are able to reject the null hypothesis. This means that the flies are not randomly assorting themselves, and the banana is influencing their behavior. Summary. The Chi Square test is something that takes practice.
The null hypothesis in chi-square testing is a powerful tool in statistical analysis. It provides a means to differentiate between observed variations due to random chance versus those that may signify a significant effect or relationship. As we continue to generate more data in various fields, the importance of understanding and correctly ...
The actual test begins by considering two hypotheses.They are called the null hypothesis and the alternative hypothesis.These hypotheses contain opposing viewpoints. H 0, the —null hypothesis: a statement of no difference between sample means or proportions or no difference between a sample mean or proportion and a population mean or proportion. In other words, the difference equals 0.
This lesson explains how to conduct a chi-square test of homogeneity. The test is applied to a single categorical variable from two or more different populations. It is used to determine whether frequency counts are distributed identically across different populations. ... The first step is to state the null hypothesis and an alternative ...
A Chi-Square goodness of fit test uses the following null and alternative hypotheses: H 0: (null hypothesis) A variable follows a hypothesized distribution. H 1: (alternative hypothesis) A variable does not follow a hypothesized distribution. We use the following formula to calculate the Chi-Square test statistic X 2: X 2 = Σ(O-E) 2 / E. where:
The Chi-Square value indicates how much the observed frequencies deviate from the expected frequencies under the null hypothesis of independence. A higher Chi-Square value suggests a greater deviation, which may lead to the rejection of the null hypothesis if the value exceeds the critical value from the Chi-Square distribution table for the ...
The null hypothesis (H 0) answers "No, there's no effect in the population." The alternative hypothesis (H a) answers "Yes, there is an effect in the population." The null and alternative are always claims about the population. That's because the goal of hypothesis testing is to make inferences about a population based on a sample.
Master Chi-Square Analysis in Business Intelligence. ... Before you dive into calculations, you must clearly define your null hypothesis and alternative hypothesis. The null hypothesis (H0 ...
On the other hand, the alternative hypothesis contradicts the null hypothesis and suggests the presence of an effect or difference in the population. It reflects the researcher's belief or the hypothesis they aim to support with their analysis. ... The chi-square test is a versatile statistical tool used to assess the association between two ...
a. Answer: A) The p-value is the probability of observing the given data under the null hypothesis. If the p-value is less than the significance level (α), the null hypothesis is rejected, indicating that the observed results are unlikely to occur by chance alone. 5.