Loading metrics
Open Access

Ten simple rules for tackling your first mathematical models: A guide for graduate students by graduate students
Roles Conceptualization, Investigation, Writing – original draft, Writing – review & editing
* E-mail: [email protected]
Affiliations Department of Biological Sciences, University of Toronto Scarborough, Toronto, Ontario, Canada, Department of Ecology and Evolution, University of Toronto, Toronto, Ontario, Canada
Affiliation Department of Ecology and Evolution, University of Toronto, Toronto, Ontario, Canada
Affiliation Department of Physical and Environmental Sciences, University of Toronto Scarborough, Toronto, Ontario, Canada
Affiliation Department of Biology, Memorial University of Newfoundland, St John’s, Newfoundland, Canada
- Korryn Bodner,
- Chris Brimacombe,
- Emily S. Chenery,
- Ariel Greiner,
- Anne M. McLeod,
- Stephanie R. Penk,
- Juan S. Vargas Soto
Published: January 14, 2021
- https://doi.org/10.1371/journal.pcbi.1008539
- Reader Comments
Citation: Bodner K, Brimacombe C, Chenery ES, Greiner A, McLeod AM, Penk SR, et al. (2021) Ten simple rules for tackling your first mathematical models: A guide for graduate students by graduate students. PLoS Comput Biol 17(1): e1008539. https://doi.org/10.1371/journal.pcbi.1008539
Editor: Scott Markel, Dassault Systemes BIOVIA, UNITED STATES
Copyright: © 2021 Bodner et al. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Funding: The authors received no specific funding for this work.
Competing interests: The authors have declared that no competing interests exist.
Introduction
Biologists spend their time studying the natural world, seeking to understand its various patterns and the processes that give rise to them. One way of furthering our understanding of natural phenomena is through laboratory or field experiments, examining the effects of changing one, or several, variables on a measured response. Alternatively, one may conduct an observational study, collecting field data and comparing a measured response along natural gradients. A third and complementary way of understanding natural phenomena is through mathematical models. In the life sciences, more scientists are incorporating these quantitative methods into their research. Given the vast utility of mathematical models, ranging from providing qualitative predictions to helping disentangle multiple causation (see Hurford [ 1 ] for a more complete list), their increased adoption is unsurprising. However, getting started with mathematical models may be quite daunting for those with traditional biological training, as in addition to understanding new terminology (e.g., “Jacobian matrix,” “Markov chain”), one may also have to adopt a different way of thinking and master a new set of skills.
Here, we present 10 simple rules for tackling your first mathematical models. While many of these rules are applicable to basic scientific research, our discussion relates explicitly to the process of model-building within ecological and epidemiological contexts using dynamical models. However, many of the suggestions outlined below generalize beyond these disciplines and are applicable to nondynamic models such as statistical models and machine-learning algorithms. As graduate students ourselves, we have created rules we wish we had internalized before beginning our model-building journey—a guide by graduate students, for graduate students—and we hope they prove insightful for anyone seeking to begin their own adventures in mathematical modelling.
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
Boxes represent susceptible, infected, and recovered compartments, and directed arrows represent the flow of individuals between these compartments with the rate of flow being controlled by the contact rate, c , the probability of infection, γ , and the recovery rate, θ .
https://doi.org/10.1371/journal.pcbi.1008539.g001
Rule 1: Know your question
“All models are wrong, some are useful” is a common aphorism, generally attributed to statistician George Box, but determining which models are useful is dependent upon the question being asked. The practice of clearly defining a research question is often drilled into aspiring researchers in the context of selecting an appropriate research design, interpreting statistical results, or when outlining a research paper. Similarly, the practice of defining a clear research question is important for mathematical models as their results are only as interesting as the questions that motivate them [ 5 ]. The question defines the model’s main purpose and, in all cases, should extend past the goal of merely building a model for a system (the question can even answer whether a model is even necessary). Ultimately, the model should provide an answer to the research question that has been proposed.
When the research question is used to inform the purpose of the model, it also informs the model’s structure. Given that models can be modified in countless ways, providing a purpose to the model can highlight why certain aspects of reality were included in the structure while others were ignored [ 6 ]. For example, when deciding whether we should adopt a more realistic model (i.e., add more complexity), we can ask whether we are trying to inform general theory or whether we are trying to model a response in a specific system. For example, perhaps we are trying to predict how fast an epidemic will grow based on different age-dependent mixing patterns. In this case, we may wish to adapt our basic SIR model to have age-structured compartments if we suspect this factor is important for the disease dynamics. However, if we are exploring a different question, such as how stochasticity influences general SIR dynamics, the age-structured approach would likely be unnecessary. We suggest that one of the first steps in any modelling journey is to choose the processes most relevant to your question (i.e., your hypothesis) and the direct and indirect causal relationships among them: Are the relationships linear, nonlinear, additive, or multiplicative? This challenge can be aided with a good literature review. Depending on your model purpose, you may also need to spend extra time getting to know your system and/or the data before progressing forward. Indeed, the more background knowledge acquired when forming your research question, the more informed your decision-making when selecting the structure, parameters, and data for your model.
Rule 2: Define multiple appropriate models
Natural phenomena are complicated to study and often impossible to model in their entirety. We are often unsure about the variables or processes required to fully answer our research question(s). For example, we may not know how the possibility of reinfection influences the dynamics of a disease system. In cases such as these, our advice is to produce and sketch out a set of candidate models that consider alternative terms/variables which may be relevant for the phenomena under investigation. As in Fig 2 , we construct 2 models, one that includes the ability for recovered individuals to become infected again, and one that does not. When creating multiple models, our general objective may be to explore how different processes, inputs, or drivers affect an outcome of interest or it may be to find a model or models that best explain a given set of data for an outcome of interest. In our example, if the objective is to determine whether reinfection plays an important role in explaining the patterns of a disease, we can test our SIR candidate models using incidence data to determine which model receives the most empirical support. Here we consider our candidate models to be alternative hypotheses, where the candidate model with the least support is discarded. While our perspective of models as hypotheses is a view shared by researchers such as Hilborn and Mangel [ 7 ], and Penk and colleagues [ 8 ], please note that others such as Oreskes and colleagues [ 9 ] believe that models are not subject to proof and hence disagree with this notion. We encourage modellers who are interested in this debate to read the provided citations.
(A) A susceptible/infected/recovered model where individuals remain immune (gold) and (B) a susceptible/infected/recovered model where individuals can become susceptible again (blue). Arrows indicate the direction of movement between compartments, c is the contact rate, γ is the infection rate given contact, and θ is the recovery rate. The text below each conceptual model are the hypotheses ( H1 and H2 ) that represent the differences between these 2 SIR models.
https://doi.org/10.1371/journal.pcbi.1008539.g002
Finally, we recognize that time and resource constraints may limit the ability to build multiple models simultaneously; however, even writing down alternative models on paper can be helpful as you can always revisit them if your primary model does not perform as expected. Of course, some candidate models may not be feasible or relevant for your system, but by engaging in the activity of creating multiple models, you will likely have a broader perspective of the potential factors and processes that fundamentally shape your system.
Rule 3: Determine the skills you will need (and how to get them)
Equipping yourself with the necessary analytical tools that form the basis of all quantitative techniques is essential. As Darwin said, those that have knowledge of mathematics seem to be endowed with an extra sense [ 10 ], and having a background in calculus, linear algebra, and statistics can go a long way. Thus, make it a habit to set time for yourself to learn these mathematical skills, and do not treat all your methods like a black box. For instance, if you plan to use ODEs, consider brushing up on your calculus, e.g., using Stewart [ 11 ]. If you are working with a system of ODEs, also read up on linear algebra, e.g., using Poole [ 12 ]. Some universities also offer specialized math biology courses that combine topics from different math courses to teach the essentials of mathematical modelling. Taking these courses can help save time, and if they are not available, their syllabi can help focus your studying. Also note that while narrowing down a useful skillset in the early stages of model-building will likely spare you from some future headaches, as you progress in your project, it is inevitable that new skills will be required. Therefore, we advise you to check in at different stages of your modelling journey to assess the skills that would be most relevant for your next steps and how best to acquire them. Hopefully, these decisions can also be made with the help of your supervisor and/or a modelling mentor. Building these extra skills can at first seem daunting but think of it as an investment that will pay dividends in improving your future modelling work.
When first attempting to tackle a specific problem, find relevant research that accomplishes the same tasks and determine if you understand the processes and techniques that are used in that study. If you do, then you can implement similar techniques and methods, and perhaps introduce new methods. If not, then determine which tools you need to add to your toolbox. For instance, if the problem involves a system of ODEs (e.g., SIR models, see above), can you use existing symbolic software (e.g., Maple, Matlab, Mathematica) to determine the systems dynamics via a general solution, or is the complexity too great that you will need to create simulations to infer the dynamics? Figuring out questions like these is key to understanding what skills you will need to work with the model you develop. While there is a time and a place for involving collaborators to help facilitate methods that are beyond your current reach, we strongly advocate that you approach any potential collaborator only after you have gained some knowledge of the methods first. Understanding the methodology, or at least its foundation, is not only crucial for making a fruitful collaboration, but also important for your development as a scientist.
Rule 4: Do not reinvent the wheel
While we encourage a thorough understanding of the methods researchers employ, we simultaneously discourage unnecessary effort redoing work that has already been done. Preventing duplication can be ensured by a thorough review of the literature (but note that reproducing original model results can advance your knowledge of how a model functions and lead to new insights in the system). Often, we are working from established theory that provides an existing framework that can be applied to different systems. Adapting these frameworks can help advance your own research while also saving precious time. When digging through articles, bear in mind that most modelling frameworks are not system-specific. Do not be discouraged if you cannot immediately find a model in your field, as the perfect model for your question may have been applied in a different system or be published only as a conceptual model. These models are still useful! Also, do not be shy about reaching out to authors of models that you think may be applicable to your system. Finally, remember that you can be critical of what you find, as some models can be deceptively simple or involve assumptions that you are not comfortable making. You should not reinvent the wheel, but you can always strive to build a better one.
Rule 5: Study and apply good coding practices
The modelling process will inevitably require some degree of programming, and this can quickly become a challenge for some biologists. However, learning to program in languages commonly adopted by the scientific community (e.g., R, Python) can increase the transparency, accessibility, and reproducibility of your models. Even if you only wish to adopt preprogrammed models, you will likely still need to create code of your own that reads in data, applies functions from a collection of packages to analyze the data, and creates some visual output. Programming can be highly rewarding—you are creating something after all—but it can also be one of the most frustrating parts of your research. What follows are 3 suggestions to avoid some of the frustration.
Organization is key, both in your workflow and your written code. Take advantage of existing software and tools that facilitate keeping things organized. For example, computational notebooks like Jupyter notebooks or R-Markdown documents allow you to combine text, commands, and outputs in an easily readable and shareable format. Version control software like Git makes it simple to both keep track of changes as well as to safely explore different model variants via branches without worrying that the original model has been altered. Additionally, integrating with hosting services such as Github allows you to keep your changes safely stored in the cloud. For more details on learning to program, creating reproducible research, programming with Jupyter notebooks, and using Git and Github, see the 10 simple rules by Carey and Papin [ 13 ], Sandve and colleagues [ 14 ], Rule and colleagues [ 15 ], and Perez-Riverol and colleagues [ 16 ], respectively.
Comment your code and comment it well (see Fig 3 ). These comments can be the pseudocode you have written on paper prior to coding. Assume that when you revisit your code weeks, months, or years later, you will have forgotten most of what you did and why you did it. Good commenting can also help others read and use your code, making it a critical part of increasing scientific transparency. It is always good practice to write your comments before you write the code, explaining what the code should do. When coding a function, include a description of its inputs and outputs. We also encourage you to publish your commented model code in repositories such that they are easily accessible to others—not only to get useful feedback for yourself but to provide the modelling foundation for others to build on.
Two functionally identical codes in R [ 17 ] can look very different without comments (left) and with descriptive comments (right). Writing detailed comments will help you and others understand, adapt, and use your code.
https://doi.org/10.1371/journal.pcbi.1008539.g003
When writing long code, test portions of it separately. If you are writing code that will require a lot of processing power or memory to run, use a simple example first, both to estimate how long the project will take, and to avoid waiting 12 hours to see if it works. Additionally, when writing code, try to avoid too many packages and “tricks” as it can make your code more difficult to understand. Do not be afraid of writing 2 separate functions if it will make your code more intuitive. As with writing, your skill as a writer is not dependent on your ability to use big words, but instead about making sure your reader understands what you are trying to communicate.
Rule 6: Sweat the “right” small stuff
By “sweat the ‘right’ small stuff,” we mean considering the details and assumptions that can potentially make or break a mathematical model. A good start would be to ensure your model follows the rules of mass and energy conservation. In a closed system, mass and energy cannot be created nor destroyed, and thus, the left side of the mathematical equation must equal the right under all circumstances. For example, in Eq 2 , if the number of susceptible individuals decreases due to infection, we must include a negative term in this equation (− cγIS ) to indicate that loss and its conjugate (+ cγIS ) to the infected individuals equation, Eq 3 , to represent that gain. Similarly, units of all terms must also be balanced on both sides of the equation. For example, if we wish to add or subtract 2 values, we must ensure their units are equivalent (e.g., cannot add day −1 and year −1 ). Simple oversights in units can lead to major setbacks and create bizarre dynamics, so it is worth taking the time to ensure the units match up.
Modellers should also consider the fundamental boundary conditions of each parameter to determine if there are some values that are illogical. Logical constraints and boundaries can be developed for each parameter using prior knowledge and assumptions (e.g., Huntley [ 18 ]). For example, when considering an SIR model, there are 2 parameters that comprise the transmission rate—the contact rate, c , and the probability of infection given contact, γ . Using our intuition, we can establish some basic rules: (1) the contact rate cannot be negative; (2) the number of susceptible, infected, and recovered individuals cannot be below 0; and (3) the probability of infection given contact must fall between 0 and 1. Keeping these in mind as you test your model’s dynamics can alert you to problems in your model’s structure. Finally, simulating your model is an excellent method to obtain more reasonable bounds for inputs and parameters and ensure behavior is as expected. See Otto and Day [ 5 ] for more information on the “basic ingredients” of model-building.
Rule 7: Simulate, simulate, simulate
Even though there is a lot to be learned from analyzing simple models and their general solutions, modelling a complex world sometimes requires complex equations. Unfortunately, the cost of this complexity is often the loss of general solutions [ 19 ]. Instead, many biologists must calculate a numerical solution, an approximate solution, and simulate the dynamics of these models [ 20 ]. Simulations allow us to explore model behavior, given different structures, initial conditions, and parameters ( Fig 4 ). Importantly, they allow us to understand the dynamics of complex systems that may otherwise not be ethical, feasible, or economically viable to explore in natural systems [ 21 ].
Gold lines represent the SIR structure ( Fig 2A ) where lifelong immunity of individuals is inferred after infection, and blue lines represent an SIRS structure ( Fig 2B ) where immunity is lost over time. The solid lines represent model dynamics assuming a recovery rate ( θ ) of 0.05, while dotted lines represent dynamics assuming a recovery rate of 0.1. All model runs assume a transmission rate, cγ , of 0.2 and an immunity loss rate, ψ , of 0.01. By using simulations, we can explore how different processes and rates change the system’s dynamics and furthermore determine at what point in time these differences are detectable. SIR, Susceptible-Infected-Recovered; SIRS, Susceptible-Infected-Recovered-Susceptible.
https://doi.org/10.1371/journal.pcbi.1008539.g004
One common method of exploring the dynamics of complex systems is through sensitivity analysis (SA). We can use this simulation-based technique to ascertain how changes in parameters and initial conditions will influence the behavior of a system. For example, if simulated model outputs remain relatively similar despite large changes in a parameter value, we can expect the natural system represented by that model to be robust to similar perturbations. If instead, simulations are very sensitive to parameter values, we can expect the natural system to be sensitive to its variation. Here in Fig 4 , we can see that both SIR models are very sensitive to the recovery rate parameter ( θ ) suggesting that the natural system would also be sensitive to individuals’ recovery rates. We can therefore use SA to help inform which parameters are most important and to determine which are distinguishable (i.e., identifiable). Additionally, if observed system data are available, we can use SA to help us establish what are the reasonable boundaries for our initial conditions and parameters. When adopting SA, we can either vary parameters or initial conditions one at a time (local sensitivity) or preferably, vary multiple of them in tandem (global sensitivity). We recognize this topic may be overwhelming to those new to modelling so we recommend reading Marino and colleagues [ 22 ] and Saltelli and colleagues [ 23 ] for details on implementing different SA methods.
Simulations are also a useful tool for testing how accurately different model fitting approaches (e.g., Maximum Likelihood Estimation versus Bayesian Estimation) can recover parameters. Given that we know the parameter values for simulated model outputs (i.e., simulated data), we can properly evaluate the fitting procedures of methods when used on that simulated data. If your fitting approach cannot even recover simulated data with known parameters, it is highly unlikely your procedure will be successful given real, noisy data. If a procedure performs well under these conditions, try refitting your model to simulated data that more closely resembles your own dataset (i.e., imperfect data). If you know that there was limited sampling and/or imprecise tools used to collect your data, consider adding noise, reducing sample sizes, and adding temporal and spatial gaps to see if the fitting procedure continues to return reasonably correct estimates. Remember, even if your fitting procedures continue to perform well given these additional complexities, issues may still arise when fitting to empirical data. Models are approximations and consequently their simulations are imperfect representations of your measured outcome of interest. However, by evaluating procedures on perfectly known imperfect data, we are one step closer to having a fitting procedure that works for us even when it seems like our data are against us.
Rule 8: Expect model fitting to be a lengthy, arduous but creative task
Model fitting requires an understanding of both the assumptions and limitations of your model, as well as the specifics of the data to be used in the fitting. The latter can be challenging, particularly if you did not collect the data yourself, as there may be additional uncertainties regarding the sampling procedure, or the variables being measured. For example, the incidence data commonly adopted to fit SIR models often contain biases related to underreporting, selective reporting, and reporting delays [ 24 ]. Taking the time to understand the nuances of the data is critical to prevent mismatches between the model and the data. In a bad case, a mismatch may lead to a poor-fitting model. In the worst case, a model may appear well-fit, but will lead to incorrect inferences and predictions.
Model fitting, like all aspects of modelling, is easier with the appropriate set of skills (see Rule 2). In particular, being proficient at constructing and analyzing mathematical models does not mean you are prepared to fit them. Fitting models typically requires additional in-depth statistical knowledge related to the characteristics of probability distributions, deriving statistical moments, and selecting appropriate optimization procedures. Luckily, a substantial portion of this knowledge can be gleaned from textbooks and methods-based research articles. These resources can range from covering basic model fitting, such as determining an appropriate distribution for your data and constructing a likelihood for that distribution (e.g., Hilborn and Mangel [ 7 ]), to more advanced topics, such as accounting for uncertainties in parameters, inputs, and structures during model fitting (e.g., Dietze [ 25 ]). We find these sources among others (e.g., Hobbs and Hooten [ 26 ] for Bayesian methods; e.g., Adams and colleagues [ 27 ] for fitting noisy and sparse datasets; e.g., Sirén and colleagues [ 28 ] for fitting individual-based models; and Williams and Kendall [ 29 ] for multiobject optimization—to name a few) are not only useful when starting to fit your first models, but are also useful when switching from one technique or model to another.
After you have learned about your data and brushed up on your statistical knowledge, you may still run into issues when model fitting. If you are like us, you will have incomplete data, small sample sizes, and strange data idiosyncrasies that do not seem to be replicated anywhere else. At this point, we suggest you be explorative in the resources you use and accept that you may have to combine multiple techniques and/or data sources before it is feasible to achieve an adequate model fit (see Rosenbaum and colleagues [ 30 ] for parameter estimation with multiple datasets). Evaluating the strength of different techniques can be aided by using simulated data to test these techniques, while SA can be used to identify insensitive parameters which can often be ignored in the fitting process (see Rule 7).
Model accuracy is an important metric but “good” models are also precise (i.e., reliable). During model fitting, to make models more reliable, the uncertainties in their inputs, drivers, parameters, and structures, arising due to natural variability (i.e., aleatory uncertainty) or imperfect knowledge (i.e., epistemic uncertainty), should be identified, accounted for, and reduced where feasible [ 31 ]. Accounting for uncertainty may entail measurements of uncertainties being propagated through a model (a simple example being a confidence interval), while reducing uncertainty may require building new models or acquiring additional data that minimize the prioritized uncertainties (see Dietze [ 25 ] and Tsigkinopoulou and colleagues [ 32 ] for a more thorough review on the topic). Just remember that although the steps outlined in this rule may take a while to complete, when you do achieve a well-fitted reliable model, it is truly something to be celebrated.
Rule 9: Give yourself time (and then add more)
Experienced modellers know that it often takes considerable time to build a model and that even more time may be required when fitting to real data. However, the pervasive caricature of modelling as being “a few lines of code here and there” or “a couple of equations” can lead graduate students to hold unrealistic expectations of how long finishing a model may take (or when to consider a model “finished”). Given the multiple considerations that go into selecting and implementing models (see previous rules), it should be unsurprising that the modelling process may take weeks, months, or even years. Remembering that a published model is the final product of long and hard work may help reduce some of your time-based anxieties. In reality, the finished product is just the tip of the iceberg and often unseen is the set of failed or alternative models providing its foundation. Note that taking time early on to establish what is “good enough” given your objective, and to instill good modelling practices, such as developing multiple models, simulating your models, and creating well-documented code, can save you considerable time and stress.
Rule 10: Care about the process, not just the endpoint
As a graduate student, hours of labor coupled with relative inexperience may lead to an unwillingness to change to a new model later down the line. But being married to one model can restrict its efficacy, or worse, lead to incorrect conclusions. Early planning may mitigate some modelling problems, but many issues will only become apparent as time goes on. For example, perhaps model parameters cannot be estimated as you previously thought, or assumptions made during model formulation have since proven false. Modelling is a dynamic process, and some steps will need to be revisited many times as you correct, refine, and improve your model. It is also important to bear in mind that the process of model-building is worth the effort. The process of translating biological dynamics into mathematical equations typically forces us to question our assumptions, while a misspecified model often leads to novel insights. While we may wish we had the option to skip to a final finished product, in the words of Drake, “sometimes it’s the journey that teaches you a lot about your destination”.
There is no such thing as a failed model. With every new error message or wonky output, we learn something useful about modelling (mostly begrudgingly) and, if we are lucky, perhaps also about the study system. It is easy to cave in to the ever-present pressure to perform, but as graduate students, we are still learning. Luckily, you are likely surrounded by other graduate students, often facing similar challenges who can be an invaluable resource for learning and support. Finally, remember that it does not matter if this was your first or your 100th mathematical model, challenges will always present themselves. However, with practice and determination, you will become more skilled at overcoming them, allowing you to grow and take on even greater challenges.
Acknowledgments
We thank Marie-Josée Fortin, Martin Krkošek, Péter K. Molnár, Shawn Leroux, Carina Rauen Firkowski, Cole Brookson, Gracie F.Z. Wild, Cedric B. Hunter, and Philip E. Bourne for their helpful input on the manuscript.
- 1. Hurford A. Overview of mathematical modelling in biology II. 2012 [cite 2020 October 25]. Available: https://theartofmodelling.wordpress.com/2012/01/04/overview-of-mathematical-modelling-in-biology-ii/
- View Article
- PubMed/NCBI
- Google Scholar
- 3. Maki Y, Hirose H, ADSIR M. Infectious Disease Spread Analysis Using Stochastic Differential Equations for SIR Model. International Conference on Intelligent Systems, Modelling and Simulation. IEEE. 2013.
- 5. Otto SP, Day T. A biologist’s guide to mathematical modeling in ecology and evolution. Princeton, NJ: Princeton University Press; 2007.
- 7. Hilborn R, Mangel M. The ecological detective: Confronting models with data. Princeton, NJ: Princeton University Press; 1997.
- 10. Darwin C. The autobiography of Charles Darwin. Darwin F, editor. 2008. Available: https://www.gutenberg.org/files/2010/2010-h/2010-h.htm
- 11. Stewart J. Calculus: Early transcendentals. Eighth. Boston, MA: Cengage Learning; 2015.
- 12. Poole D. Linear algebra: A modern introduction. Fourth. Stamford, CT: Cengage Learning; 2014.
- 17. R Core Team. R: A language and environment for statistical computing (version 3.6.0, R foundation for statistical computing). 2020.
- 18. Huntley HE. Dimensional analysis. First. New York, NY: Dover Publications; 1967.
- 19. Corless RM, Fillion N. A graduate introduction to numerical methods. New York, NY: Springer; 2016.
- 23. Saltelli A, Ratto M, Andres T, Campolongo F, Cariboni J, Gatelli D, et al. Global sensitivity analysis: The primer. Chichester: Wiley; 2008.
- 25. Dietze MC. Ecological forecasting. Princeton, NJ: Princeton University Press; 2017.
- 26. Hobbs NT, Hooten MB. Bayesian models: A statistical primer for ecologists. Princeton, NJ: Princeton University Press
The use of mathematical modeling studies for evidence synthesis and guideline development: A glossary
Affiliations.
- 1 Population Health and Optimal Health Practices Research Unit, Department of Social and Preventative Medicine, Faculty of Medicine, Université Laval, Quebec, Canada.
- 2 Department of Information, Evidence and Research, World Health Organization, Geneva, Switzerland.
- 3 Institute of Social and Preventive Medicine, University of Bern, Bern, Switzerland.
- 4 Centre for Infectious Disease Epidemiology and Research, University of Cape Town, Cape Town, South Africa.
- 5 Centre for Epidemiology and Biostatistics, Melbourne School of Population and Global Health, University of Melbourne, Melbourne, Australia.
- PMID: 30508309
- PMCID: PMC6491984
- DOI: 10.1002/jrsm.1333
Mathematical modeling studies are increasingly recognised as an important tool for evidence synthesis and to inform clinical and public health decision-making, particularly when data from systematic reviews of primary studies do not adequately answer a research question. However, systematic reviewers and guideline developers may struggle with using the results of modeling studies, because, at least in part, of the lack of a common understanding of concepts and terminology between evidence synthesis experts and mathematical modellers. The use of a common terminology for modeling studies across different clinical and epidemiological research fields that span infectious and non-communicable diseases will help systematic reviewers and guideline developers with the understanding, characterisation, comparison, and use of mathematical modeling studies. This glossary explains key terms used in mathematical modeling studies that are particularly salient to evidence synthesis and knowledge translation in clinical medicine and public health.
Keywords: evidence synthesis; glossary; guidelines; knowledge translation; mathematical modeling studies.
© 2018 The Authors. Research Synthesis Methods Published by John Wiley & Sons Ltd.
- Calibration
- Computer Simulation
- Decision Making
- Evidence-Based Medicine*
- Extensively Drug-Resistant Tuberculosis / prevention & control
- Extensively Drug-Resistant Tuberculosis / therapy
- Guidelines as Topic*
- Markov Chains
- Models, Statistical
- Models, Theoretical*
- Monte Carlo Method
- Public Health
- Research Design / standards*
- Stochastic Processes
- Translational Research, Biomedical
- World Health Organization
Grants and funding
- 001/WHO_/World Health Organization/International
- JA Simpson's research is supported by two NHMRC Centres of Research Excellence (Victoria Centre for Biostatistics, ViCBiostat; and Policy relevant infectious disease simulation and mathematical modelling, PRISM).
- Special Programme for Research and Training in Tropical Diseases (TDR)
- 1104975/JA Simpson is funded by a NHMRC Senior Research Fellowship
Advertisement
Mathematical modeling for theory-oriented research in educational technology
- Development Article
- Published: 29 November 2021
- Volume 70 , pages 149–167, ( 2022 )
Cite this article

- Elena Novak ORCID: orcid.org/0000-0003-0873-2081 1
897 Accesses
2 Altmetric
Explore all metrics
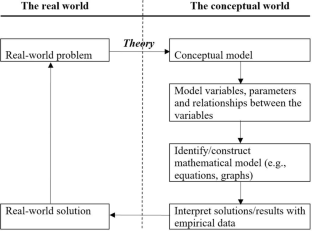
Mathematical modeling describes how events, concepts, and systems of interest behave in the world using mathematical concepts. This research approach can be applied to theory construction and testing by using empirical data to evaluate whether the specific theory can explain the empirical data or whether the theory fits the data available. Although extensively used in the physical sciences and engineering, as well as some social and behavioral sciences to examine theoretical claims and form predictions of future events and behaviors, theory-oriented mathematical modeling is less common in educational technology research. This article explores the potential of using theory-oriented mathematical modeling for theory construction and testing in the field of educational technology. It presents examples of how this approach was used in social, behavioral, and educational disciplines, and provides rationale for why educational technology research can benefit from a theory-oriented model-testing approach.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Adapted from Bessière et al. ( 2006 )
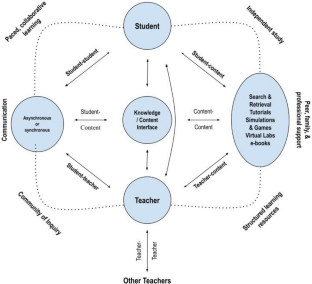
Adapted from Anderson ( 2011 )
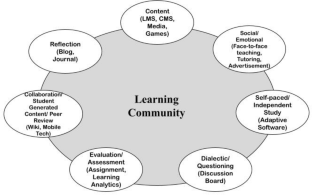
Adapted from Picciano ( 2017 )
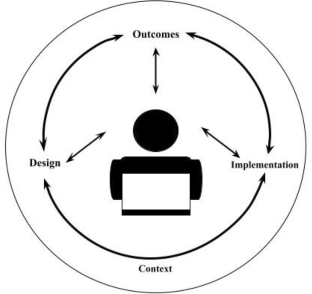
Adapted from Means et al. ( 2014 )
Similar content being viewed by others

The Philosophy of Science and Educational Technology Research

Educational design research: grappling with methodological fit
Educational design research, explore related subjects.
- Digital Education and Educational Technology
Anderson, T. (2008). The theory and practice of online learning (2nd ed.). AU Press.
Google Scholar
Anderson, T. (2011). The theory and practice of online learning . AU Press.
Atkinson, R. C., & Schiffrin, R. M. (1971). The control of short-term memory. Scientific American, 225 , 82–90.
Atkinson, R. C., & Shiffrin, R. M. (1968a). Human memory: A proposed system and its control processes. In K. W. Spence & J. T. Spence (Eds.), The psychology of learning and motivation (Volume 2) (pp. 89–195). Academic Press.
Atkinson, R. C., & Shiffrin, R. M. (1968b). Human memory: A proposed system and its control processes. In K. W. Spence & J. T. Spence (Eds.), The psychology of learning and motivation: Advances in research and theory (Vol 2) (pp. 89–195). Academic Press.
Bessière, K., Newhagen, J. E., Robinson, J. P., & Shneiderman, B. (2006). A model for computer frustration: The role of instrumental and dispositional factors on incident, session, and post-session frustration and mood. Computers in Human Behavior, 22 (6), 941–961. https://doi.org/10.1016/j.chb.2004.03.015
Article Google Scholar
Blömeke, S., & Kaiser, G. (2011). Homogeneity or heterogeneity? Profiles of opportunities to learn in primary teacher education and their relationship to cultural context and outcomes. ZDM Mathematics Education, 44 (3), 249–264. https://doi.org/10.1007/s11858-011-0378-6
Boland, L. A. (2014). Model building in economics: Its purposes and limitations . Cambridge University Press.
Bulfin, S., Henderson, M., Johnson, N. F., & Selwyn, N. (2014). Methodological capacity within the field of “educational technology” research: An initial investigation. British Journal of Educational Technology, 45 (3), 403–414.
Cilesiz, S., & Spector, J. M. (2014). The philosophy of science and educational technology research. In J. M. Spector, M. D. Merrill, J. Elen, & M. J. Bishop (Eds.), Handbook of research on educational communications and technology (pp. 875–884). New York: Springer.
Cronbach, L. J. (1975). Beyond the two disciplines of scientific psychology. American Psychologist, 20 , 116–117.
Dabbaghian, V., & Mago, V. K. (2014). Theories and simulations of complex social systems . Springer.
Dym, C. (2004). Principles of mathematical modeling . Academic Press.
Ertmer, P. A. (1999). Addressing first- and second-order barriers to change: Strategies for technology integration. Educational Technology Research and Development, 47 (4), 47–61.
Garrison, D. R., Anderson, T., & Archer, W. (2000). Critical inquiry in a text-based environment: Computer conferencing in higher education model. The Internet and Higher Education, 2 (2–3), 87–105.
Goe, L. (2007). The link between teacher quality and student outcomes: A research synthesis . Washington, DC: National Comprehensive Center for Teacher Quality. Retrieved from http://ncctq.learningpt.org/publications/LinkBetweenTQandStudentOutcomes.pdf
Gollwitzer, P. M. (1999). Implementation intentions. Strong effects of simple plans. American Psychologist, 54 (7), 493–503.
Harasim, L. (2012). Learning theory and online technologies . Routledge/Taylor & Francis.
Hew, K. F., & Brush, T. (2007). Integrating technology into K-12 teaching and learning: Current knowledge gaps and recommendations for future research. Education Technology Research and Development, 55 , 223–252. https://doi.org/10.1007/s11423-006-9022-5
Hew, K. F., Lan, M., Tang, Y., Jia, C., & Lo, C. K. (2019). Where is the “theory” within the field of educational technology research? British Journal of Educational Technology . https://doi.org/10.1111/bjet.12770
Hoffman, B. (2010). “I think I can, but I’m afraid to try”: The role of self-efficacy beliefs and mathematics anxiety in mathematics problem-solving efficiency. Learning and Individual Differences, 20 (3), 276–283.
Hoffman, R. (2003). Why buy that theory? In O. Sacks (Ed.), The best American science writing: 2003 (pp. 222–227). Harper-Collins.
Hollander, E. P. (1967). Principles and methods of social psychology . Oxford University Press.
Holmberg (1985). The feasibility of t heory of teaching for distance education and a proposed theory (ZIFF Paiere 60). Hagen, West Germany: Fern Universitat, Zentrales Institute fur Fernstudienforscgung Arbeitsbereich. (ERIC Document Reproduction Service No. ED290013).
Huang, W.-H., Huang, W.-Y., & Tschopp, J. (2010). Sustaining iterative game playing processes in DGBL: The relationship between motivational processing and outcome processing. Computers & Education, 55 (2), 789–797.
Jaccard, J., & Jacoby, J. (2009). Theory construction and model building skills: A practical guide for social scientists . Guilford Press.
Johns, G. (2006). The essential impact of context on organizational behavior. Academy of Management Review, 31 (2), 386–408.
Jones, C., & Czerniewicz, L. (2011). Theory in learning technology. Research in Learning Technology, 19 (3), 173–177.
Keller, J. M. (1999). Using the ARCS motivational process in computer-based instruction and distance education. New Directions for Teaching and Learning, 78 , 39–48.
Keller, J. M. (2008). An integrative theory of motivation, volition, and performance. Technology, Instruction, Cognition and Learning, 16 , 79–104.
Knowles, M. S., Holton, E. F., & Swanson, R. A. (1998). The adult learner (5th ed.). Butterworth-Heinemann Publishers.
Kuhl, J. (1987). Action control: The maintenance of motivational states. In F. Halisch & J. Kuhl (Eds.), Motivation, intention and volition (pp. 279–291). Springer.
Kuhn, T. S. (1996). The structure of scientific revolutions . University of Chicago Press.
Malone, T. W. (1985). Designing organizational interfaces. In L. Borman & R. Smith (Eds.), Proceedings of the CHI’85 Conference on Human Factors in Computing Systems (pp. 66–71). New York, NY: ACM Press.
Markauskaite, L., & Reimann, P. (2014). Editorial: e-Research for education: Applied, methodological and critical perspectives. British Journal of Educational Technology, 45 (3), 385–391.
Mayer, R. E. (2001). Multimedia learning . Cambridge University Press.
McDonnell, L. M. (1995). Opportunity to learn as a research concept and a policy instrument. Educational Evaluation and Policy Analysis, 17 (3), 305–322.
McKenney, S., & Reeves, T. C. (2014). Educational design research. In J. M. Spector, M. D. Merrill, J. Elen, & M. J. Bishop (Eds.), Handbook of research on educational communications and technology (pp. 131–140). Springer.
Means, B., Bakia, M., & Murphy, R. (2014). Learning online: What research tells us about whether, when and how . Routledge.
Means, B., Toyama, Y., Murphy, R., & Baki, M. (2013). The effectiveness of online and blended learning: A meta-analysis of the empirical literature. Teachers College Record, 115 , 1–47.
Mintzberg, H. (2005). Developing theory about the development of theory. In M. Hitt & K. Smith (Eds.), Minds in management: The process of theory development (pp. 355–372). Oxford University Press.
Moore, M. G. (1997). Theory of transactional distance. In D. Keegan (Ed.), Theoretical principles of distance education (pp. 22–38). Routledge.
Moore, M. G., & Diehl, W. C. (2018). Handbook of distance education . Routledge.
Morgan, C., & Wildemuth, B. M. (2009). Questions related to theory. Applications of social research methods to questions in information and library science (pp. 40–50). Libraries Unlimited.
Nelson, R., & Winter, S. (1974). Neoclassical vs. evolutionary theories of economic growth: Critique and prospectus. Economic Journal, 84 (336), 886–905.
Novak, E. (2014). Toward a mathematical model of motivation, volition, and performance. Computers & Education, 74 , 73–80. https://doi.org/10.1016/j.compedu.2014.01.009
Novak, E., Daday, J., & McDaniel, K. (2018). Using a mathematical model of motivation, volition, and performance to examine students’ e-text learning experiences. Educational Technology Research & Development, 66 (5), 1189–1209. https://doi.org/10.1007/s11423-018-9599-5
Novak, E., McDaniel, K., Daday, J., & Soyturk, I. (2021). Understanding student frustration with e-learning materials: Development and validation of an E-Text Frustration scale . Featured Research Paper presented at the Association for Educational Communications and Technology (AECT), Chicago, IL. November 2021.
Opp, K.-D. (1970). Theories of the middle range as a strategy for the construction of a general sociological theory. Quality and Quantity, 4 (2), 243–253. https://doi.org/10.1007/BF00199565
Pearl, J. (2000). Causality: Models, reasoning, and inference . Cambridge University Press.
Picciano, A. G. (2017). Theories and frameworks for online education: Seeking an integrated model. Online Learning, 21 (3), 166–190. https://doi.org/10.24059/olj.v21i3.1225
Puntambekar, S., et al. (2018). Design-based research. In F. Fisher (Ed.), International handbook of the learning sciences (pp. 383–392). Routledge.
Qian, H., & Youngs, P. (2016). The effect of teacher education programs on future elementary mathematics teachers’ knowledge: A five-country analysis using TEDS-M data. Journal of Mathematics Teacher Education, 19 (4), 371–396. https://doi.org/10.1007/s10857-014-9297-0
Reeves, T. C. (2006). Design research from the technology perspective. In J. V. Akker, K. Gravemeijer, S. McKenney, & N. Nieveen (Eds.), Educational design research (pp. 86–109). Routledge.
Rodgers, J. L. (2003). EMOSA sexuality models, memes, and the tipping point: Policy and program implications. In D. Romer (Ed.), Reducing adolescent risk: Toward an integrated approach (pp. 185–192). Sage.
Rodgers, J. L. (2010). The epistemology of mathematical and statistical modeling: A quiet methodological revolution. American Psychologist, 65 (1), 1–12.
Rodgers, J. L., & Doughty, D. (2001). Does having boys or girls run in the family? Chance, 14 , 8–13.
Rodgers, J. L., & Rowe, D. C. (1993). Social contagion and adolescent sexual behavior: A developmental EMOSA model. Psychological Review, 100 , 479–510. https://doi.org/10.1037/0033-295X.100.3.479
Rowe, D. C., & Rodgers, J. L. (1991). Adolescent smoking and drinking: Are they epidemics? Journal of Studies on Alcohol, 52 , 110–117.
Scheerens, J., & Blömeke, S. (2016). Integrating teacher education effectiveness research into educational effectiveness models. Educational Research Review, 18 , 70–87. https://doi.org/10.1016/j.edurev.2016.03.002
Seel, N. M. (2009). Bonjour tristesse: Why don’t we research as we have been taught? Methodological considerations on instructional technology research. Technology, Instrustion, Cognition and Learning, 6 , 151–176.
Shadish, W., Cook, T. D., & Campbell, D. T. (2002). Experimental and quasi-experimental designs for generalized causal inference . Houghton Mifflin.
Shepard, R. N. (1982). Geometrical approximations to the structure of musical pitch. Psychological Review, 89 , 305–333.
Siemens, G. (2004). Connectivism: A learning theory for the digital age. International Journal of Instructional Technology and Distance Learning, 2 , 1–8.
Simon, H. A., & Newell, A. (1956). Models: Their uses and limitations. In D. White (Ed.), The state of the social sciences (pp. 61–83). University of Chicago Press.
Straub, D. W. (2009). Editor’s comments: Why top journals accept your paper. MIS Quarterly, 33 (3), iii–x.
Suppes, P. (1978). Impact of research on education: Some case studies . National Academy of Education.
Tatto, M. T., Schwille, J., Senk, S., Ingvarson, L., Peck, R., & Rowley, G. (2008). Teacher education and development study in mathematics (TEDS-M): Policy, practice, and readiness to teach primary and secondary mathematics. Conceptual framework . Teacher Education and Development International, Study Center, College of Education, Michigan State University.
Tipton, E., & Olsen, R. B. (2018). A review of statistical methods for generalizing from evaluations of educational interventions. Educational Researcher, 47 (8), 516–524. https://doi.org/10.3102/0013189x18781522
Venkatesh, V., Morris, M. G., Davis, G. B., & Davis, F. D. (2003). User acceptance of information technology: Toward a unified view. MIS Quarterly, 27 (3), 425–478.
Venkatesh, V., Thong, J. Y. L., & Xu, X. (2016). Unified theory of acceptance and use of technology: A synthesis and the road ahead. Journal of the Association for Information Systems, 17 (5), 328–376.
Wedemeyer, C. A. (1981). Learning at the back door: Reflections on non-traditional learning in the lifespan . The University of Wisconsin Press.
Wenger, E. (1998). Communities of practice: Learning, meaning, and identity . Cambridge University Press.
Wenger, E., & Lave, J. (1991). Learning in doing: Social, cognitive and computational perspectives. Situated learning: Legitimate peripheral participation . Cambridge University Press.
Willingham, D. (2008). What is developmentally appropriate? American Educator, 32 (2), 34–39.
Zawacki-Richter, O., Bäcker, E., & Vogt, S. (2009). Review of distance education research (2000 to 2008): Analysis of research areas, methods, and authorship patterns. International Review of Research in Open and Distributed Learning, 10 (6), 21–50. https://doi.org/10.19173/irrodl.v10i6.741
Zimmerman, B. J. (2001). Theories of self-regulated learning and academic achievement: An overview and analysis. In B. J. Zimmerman & D. H. Schunk (Eds.), Self-regulated learning and academic achievement. Theoretical perspectives (pp. 1–38). Mahwah.
Download references
Author information
Authors and affiliations.
School of Teaching, Learning and Curriculum Studies, Kent State University, 150 Terrace Drive, P.O. Box 5190, Kent, OH, 44242-0001, USA
Elena Novak
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Elena Novak .
Ethics declarations
Conflict of interest.
The author declares that she has no conflict of interest.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Novak, E. Mathematical modeling for theory-oriented research in educational technology. Education Tech Research Dev 70 , 149–167 (2022). https://doi.org/10.1007/s11423-021-10069-6
Download citation
Accepted : 21 November 2021
Published : 29 November 2021
Issue Date : February 2022
DOI : https://doi.org/10.1007/s11423-021-10069-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Model-testing
- Mathematical modeling
- Educational technology
- Find a journal
- Publish with us
- Track your research
IMAGES
VIDEO