Lifelike Text to Speech for Your Users
Make your content and products more engaging with our digital voice solutions
Select your options below to hear samples of ReadSpeaker's TTS voices
Apologies. You've reached the demo usage limit.
We've limited the number of sessions. Please request a full dynamic demo.
Request a full demo

Terms of Service - This demo is for evaluation purpose only; commercial use is strictly forbidden. No static audio files may be produced, downloaded, or distributed. The background music in the voice demo is not included with the purchased product.

Benefits of Text to Speech
Text to speech enables brands, companies, and organizations to deliver enhanced end-user experience, while minimizing costs. Whether you’re developing services for website visitors, mobile app users, online learners, subscribers or consumers, text to speech allows you to respond to the different needs and desires of each user in terms of how they interact with your services, applications, devices, and content.
See All Benefits of Text to Speech
TTS gives access to your content to a greater population, such as those with literacy difficulties, learning disabilities, reduced vision and those learning a language. It also opens doors to anyone else looking for easier ways to access digital content.
If flawless customer experience is at the heart of your business DNA, high-quality TTS voices or exclusive custom voices are both highly effective approaches to increasing your visibility in the voice user interface. TTS helps to enhance the customer journey across different touchpoints, fostering loyalty and setting your company apart from competitors.
Integrators and developers building services, apps, and devices across markets and verticals (e.g. telecoms, utilities, manufacturing, OEM, finance, etc.), benefit from adding speech output to services and applications. Text to speech enables a wider-reaching, more consumer-oriented end-user experience, helping reduce costs and increasing automation while providing personalized customer interactions.
ReadSpeaker is leading the way in text to speech.
ReadSpeaker offers a range of powerful text-to-speech solutions for instantly deploying lifelike, tailored voice interaction in any environment.
With more than 20 years’ experience, ReadSpeaker is “Pioneering Voice Technology” .
customers worldwide
market-leading own-brand voices
voices in 50 languages available in our SaaS solutions
countries with a local office
ReadSpeaker’s Blog
ReadSpeaker’s blog covers a wide variety of topics related to online and offline text to speech, mobile, and web accessibility.

ReadSpeaker’s industry-leading voice expertise leveraged by leading Italian newspaper to enhance the reader experience Milan, Italy. – 19 October, 2023 – ReadSpeaker, the most trusted,…

Accessibility overlays have gotten a lot of bad press, much of it deserved. So what can you do to improve web accessibility? Find out here.

As STEM classrooms move online, we need new ways to make content accessible—and even fun! Learn nine approaches to digital STEM accessibility here.

STEM topics are notoriously hard to teach using most text-to-speech programs. Here’s how ReadSpeaker can help students of all abilities learn math.

Confused by all the hype surrounding custom AI voices? These five facts cut through the noise to help you get the TTS voice you need.

Want to get the most out of your Moodle LMS? Then you need to understand the Moodle Certified Partner Network. Learn all about it here.
- ReadSpeaker webReader
- ReadSpeaker docReader
- ReadSpeaker TextAid
- Assessments
- Text to Speech for K12
- Higher Education
- Corporate Learning
- Learning Management Systems
- Custom Text-To-Speech (TTS) Voices
- Voice Cloning Software
- Text-To-Speech (TTS) Voices
- ReadSpeaker speechMaker Desktop
- ReadSpeaker speechMaker
- ReadSpeaker speechCloud API
- ReadSpeaker speechEngine SAPI
- ReadSpeaker speechServer
- ReadSpeaker speechServer MRCP
- ReadSpeaker speechEngine SDK
- ReadSpeaker speechEngine SDK Embedded
- Accessibility
- Automotive Applications
- Conversational AI
- Entertainment
- Experiential Marketing
- Guidance & Navigation
- Smart Home Devices
- Transportation
- Virtual Assistant Persona
- Voice Commerce
- Customer Stories & e-Books
- About ReadSpeaker
- TTS Languages and Voices
- The Top 10 Benefits of Text to Speech for Businesses
- Learning Library
- e-Learning Voices: Text to Speech or Voice Actors?
- TTS Talks & Webinars
Make your products more engaging with our voice solutions.
- Solutions ReadSpeaker Online ReadSpeaker webReader ReadSpeaker docReader ReadSpeaker TextAid ReadSpeaker Learning Education Assessments Text to Speech for K12 Higher Education Corporate Learning Learning Management Systems ReadSpeaker Enterprise AI Voice Generator Custom Text-To-Speech (TTS) Voices Voice Cloning Software Text-To-Speech (TTS) Voices ReadSpeaker speechCloud API ReadSpeaker speechEngine SAPI ReadSpeaker speechServer ReadSpeaker speechServer MRCP ReadSpeaker speechEngine SDK ReadSpeaker speechEngine SDK Embedded
- Applications Accessibility Automotive Applications Conversational AI Education Entertainment Experiential Marketing Fintech Gaming Government Guidance & Navigation Healthcare Media Publishing Smart Home Devices Transportation Virtual Assistant Persona Voice Commerce
- Resources Resources TTS Languages and Voices Learning Library TTS Talks and Webinars About ReadSpeaker Careers Support Blog The Top 10 Benefits of Text to Speech for Businesses e-Learning Voices: Text to Speech or Voice Actors?
- Get started
Search on ReadSpeaker.com ...
All languages.
- Norsk Bokmål
- Latviešu valoda

Realistic Text-to-Speech AI converter
Create realistic Voiceovers online! Insert any text to generate speech and download audio mp3 or wav for any purpose. Speak a text with AI-powered voices.You can convert text to voice for free for reference only. For all features, purchase the paid plans
How to convert text into speech?
- Just type some text or import your written content
- Press "generate" button
- Download MP3 / WAV
Full list of benefits of neural voices
Multi-voice editor.
Dialogue with AI Voices . You can use several voices at once in one text.
Over 1000 Natural Sounding Voices
Crystal-clear voice over like a Human. Males, females, children's, elderly voices.
You spend little on re-dubbing the text. Limits are spent only for changed sentences in the text. Read more about our cost-effective Limit System . Enjoy full control over your spending with one-time payments for only what you use. Pay as you go : get flexible, cost-effective access to our neural network voiceover services without subscriptions.
If your Limit balance is sufficient, you can use a single query to convert a text of up to 2,000,000 characters into speech.
Commercial Use
You can use the generated audio for commercial purposes. Examples: YouTube, Tik Tok, Instagram, Facebook, Twitch, Twitter, Podcasts, Video Ads, Advertising, E-book, Presentation and other.
Custom voice settings
Change Speed, Pitch, Stress, Pronunciation, Intonation , Emphasis , Pauses and more. SSML support .
SRT to audio
Subtitles to Audio : Convert your subtitle file into perfectly timed multilingual voiceovers with our advanced neural networks.
Downloadable TTS
You can download converted audio files in MP3, WAV, OGG for free.
Powerful support
We will help you with any questions about text-to-speech. Ask any questions, even the simplest ones. We are happy to help.
Compatible with editing programs
Works with any video creation software: Adobe Premier, After effects, Audition, DaVinci Resolve, Apple Motion, Camtasia, iMovie, Audacity, etc.
Cloud save your history
All your files and texts are automatically saved in your profile on our cloud server. Add tracks to your favorites in one click.
Use our text to voice converter to make videos with natural sounding speech!
Say goodbye to expensive traditional audio creation
Cheap price. Create a professional voiceover in real time for pennies. it is 100 times cheaper than a live speaker.
Traditional audio creation

- Expensive live speakers, high prices
- A long search for freelancers and studios
- Editing requires complex tools and knowledge
- The announcer in the studio voices a long time. It takes time to give him a task and accept it.

- Affordable tts generation starting at $0.08 per 1000 characters
- Website accessible in your browser right now
- Intuitive interface, suitable for beginners
- SpeechGen generates text from speech very quickly. A few clicks and the audio is ready.
Create AI-generated realistic voice-overs.
Ways to use. Cases.
See how other people are already using our realistic speech synthesis. There are hundreds of variations in applications. Here are some of them.
- Voice over for videos. Commercial, YouTube, Tik Tok, Instagram, Facebook, and other social media. Add voice to any videos!
- E-learning material. Ex: learning foreign languages, listening to lectures, instructional videos.
- Advertising. Increase installations and sales! Create AI-generated realistic voice-overs for video ads, promo, and creatives.
- Public places. Synthesizing speech from text is needed for airports, bus stations, parks, supermarkets, stadiums, and other public areas.
- Podcasts. Turn text into podcasts to increase content reach. Publish your audio files on iTunes, Spotify, and other podcast services.
- Mobile apps and desktop software. The synthesized ai voices make the app friendly.
- Essay reader. Read your essay out loud to write a better paper.
- Presentations. Use text-to-speech for impressive PowerPoint presentations and slideshow.
- Reading documents. Save your time reading documents aloud with a speech synthesizer.
- Book reader. Use our text-to-speech web app for ebook reading aloud with natural voices.
- Welcome audio messages for websites. It is a perfect way to re-engage with your audience.
- Online article reader. Internet users translate texts of interesting articles into audio and listen to them to save time.
- Voicemail greeting generator. Record voice-over for telephone systems phone greetings.
- Online narrator to read fairy tales aloud to children.
- For fun. Use the robot voiceover to create memes, creativity, and gags.
Maximize your content’s potential with an audio-version. Increase audience engagement and drive business growth.
Who uses Text to Speech?
SpeechGen.io is a service with artificial intelligence used by about 1,000 people daily for different purposes. Here are examples.
Video makers create voiceovers for videos. They generate audio content without expensive studio production.
Newsmakers convert text to speech with computerized voices for news reporting and sports announcing.
Students and busy professionals to quickly explore content
Foreigners. Second-language students who want to improve their pronunciation or listen to the text comprehension
Software developers add synthesized speech to programs to improve the user experience.
Marketers. Easy-to-produce audio content for any startups
IVR voice recordings. Generate prompts for interactive voice response systems.
Educators. Foreign language teachers generate voice from the text for audio examples.
Booklovers use Speechgen as an out loud book reader. The TTS voiceover is downloadable. Listen on any device.
HR departments and e-learning professionals can make learning modules and employee training with ai text to speech online software.
Webmasters convert articles to audio with lifelike robotic voices. TTS audio increases the time on the webpage and the depth of views.
Animators use ai voices for dialogue and character speech.
Text to Speech enables brands, companies, and organizations to deliver enhanced end-user experience, while minimizing costs.
Frequently Asked Questions
Convert any text to super realistic human voices. See all tariff plans .
Enhance Your Content Accessibility
Boost your experience with our additional features. Easily convert PDFs, DOCx files, and video subtitles into natural-sounding audio.
📄🔊 PDF to Audio
Transform your PDF documents into audible content for easier consumption and enhanced accessibility.
📝🎧 DOCx to mp3
Easily convert Word documents into speech for listening on the go or for those who prefer audio format
🔊📰 WordPress plugin
Enhance your WordPress site with our plugin for article voiceovers, embedding an audio player directly on your site to boost user engagement and diversify your content.
Supported languages
- Amharic (Ethiopia)
- Arabic (Algeria)
- Arabic (Egypt)
- Arabic (Saudi Arabia)
- Bengali (India)
- Catalan (Spain)
- English (Australia)
- English (Canada)
- English (GB)
- English (Hong Kong)
- English (India)
- English (Philippines)
- German (Austria)
- Hindi India
- Spanish (Argentina)
- Spanish (Mexico)
- Spanish (United States)
- Tamil (India)
- All languages: +76
We use cookies to ensure you get the best experience on our website. Learn more: Privacy Policy
Go from text to speech with a versatile AI voice generator
Ai enabled, real people's voices.
Make studio-quality voice overs in minutes. Use Murf’s lifelike AI voices for podcasts, videos, and all your professional presentations

There's a voice for every need

Simple, powerful…pure magic

Get creative with Murf Studio

Diverse AI voices at your fingertips

Add video, music, or image

All-in-one AI voice generator

Go from amateur to studio quality voiceovers

Now collaborate with your team
Reliable and secure. your data, our promise..

Explore Voice overs created using Murf AI Voice Generator
Here are a few examples of natural-sounding voiceovers created using Murf's AI voices for a wide range of use cases spanning promotional videos, explainer videos, elearning content and podcasts.
Advertisements & Promotional Videos

E-Learning Videos
Explainer Videos

Hear from our customers
I like that for other basic and pro pricing packages you have a wealth of options, which you don't usually get within these amounts. My favorite option is the copy/paste feature of text and the separation of it into paragraph and/or sentences and that you can download as a single or as multiple files. This makes the workflow smoother when developing multiple videos or animations.

Murf.ai streamlines the content creation workflow and reduces time/cost for e-learning developers. Many of the computer-generated voices are very realistic, and my organizational training clients are typically very happy with the results. It generates realistic narrations, along with scripts and subtitles in all popular formats.

I recently tried murf.ai and I have to say I am thoroughly impressed. The quality of the generated voice is exceptional and very realistic, which is important for my business needs. The platform is user-friendly and easy to navigate, and the range of voices available is impressive. I was also pleased with the prompt and helpful customer support I received when I had questions. Overall, I highly recommend murf.ai to anyone looking for a high-quality and reliable text-to-speech generator. Keep up the great work!

We've been using Murf for our content production for a while now, and I can say Murf is the best TTS software out there -yes I've tried most of them single-handedly. Our favourite voice avatar is named AVA, She sounds just like your girlfriend next door! And you don't even have to get the PRO plan to get her voice!

Whilst updating our Integrated Management System, we decided to modernise the way we provide our front-line project staff with information and guidance. Rather than written documents, we have created a library of short, animated explainer videos. Murf was the perfect solution to provide the voiceover audio. Our scripts were easily uploaded on the Murf platform. The voices are professional, friendly and very clear. When watching our videos, you would not believe that the voiceover is done with AI

Valuable tool for enhancing e-learning content Murf is a quality, cost-effective solution for creating voiceover narration for our e-learning content. It is easy to use, fast and produces excellent results. It allows us to enhance e-learning content by providing an audio element to enrich content.

Murf is a great tool with the ability to sync high quality voice overs to video. The library of pre-recorded voice options, screen recording is just what you need to help you create a slick video quickly. I would certainly recommend murf.ai to fellow founders and start-ups out there. I will be using your tool again soon!

Murf is a human-sounding AI voice-over that is so close to perfection with many features. Have no qualms to recommend it to others.

@MURFAISTUDIO

Frequently asked questions
The best ai voice generator for creators.
For years, creating good voice overs meant investing hundreds if not thousands of dollars in hiring voice artists, renting a recording studio to get the script recorded, investing in expensive recording equipment (if you are recording from home), and recruiting or outsourcing the entire project to an audio editor to mix the audio and produce a high-quality voiceover. Not to mention, the valuable hours dedicated to the entire process. Even after all this, the quality of the produced audio file may be subpar.
What if there was an alternative to creating studio-quality voiceovers, and that too from the comfort of your own homes? Introducing Murf AI voice generator, which eliminates the entire process of generating voiceovers manually and enables you to quickly produce human-like voiceovers without any specialized hardware or professional.
Leveraging advanced AI algorithms and deep learning, the realistic online voice generator tool allows you to convert written content into natural-sounding speech, in a matter of just a few minutes. Serving as a voice maker, it helps you create life-like synthetic voices that mimic the tonalities and prosodies of human speech and sound. Unlike other computer generated voice, Murf's AI voices don't sound monotonous and robotic. Rather Murf's TTS voices are super realistic and flawless.
Explore AI voices for any requirement
Murf’s advanced AI algorithms catch the right tone and pick up on every punctuation and exclamation mark from the human voice fed it. As such, the platform's AI voices sound close to a human than one can imagine.
Voice over video
Using Murf’s AI technology, you can add a well-timed AI voiceover to your videos and make them more engaging. Unlike most video editing software, Murf doesn’t require video editing skills.
For example, say you want to create a corporate training module and explainer videos for your staff. Such content demands an expert voice that draws on the essence of professionalism and instills confidence in potential partners. Murf offers different voices—both male and female—that will enhance the quality of your corporate training module.
Voice Editing
Murf also simplifies the process of editing recorded voiceovers. Simply feed your recorded speech onto the Murf Studio and it automatically transcribes the content into an editable text format that you can edit and modify.
You can also remove any unneeded bits and background noise from your recording in the same way that you would delete words from a document, and your voice over will be trimmed accordingly.
Voice Cloning using custom voices
With Murf, you can also create an AI voice clone that delivers life-like diction and the full spectrum of human emotion and conveys all the nuances of human speech. In fact, using the voice cloning service, you can customize your AI voice clone to exhibit different emotions depending on the use case, be it advertisements, IVR, or character voices in games and animation. Murf currently only offers voice cloning services in the English language.
Voice Changer
Murf also supports an AI voice changer feature which offers one access to upload a raw home recording and convert that into a professional quality voice over with the voice of your choice. You don't have to worry about investing in expensive recording equipment, hiring a voice actor, or renting out a studio. With Murf, you can record your audio files freestyle, and, with the click of a button convert it to studio quality.
The only AI Text to Speech software you need
With its cutting-edge technology and realistic AI voices, Murf is the perfect solution for individuals and businesses looking to enhance their audio content. Let’s explore some of the diverse applications of Murf:
eLearning and Explainer Videos
When it comes to eLearning, Murf can be used to quickly convert text-based educational content into a more convenient audio format that can be shared with students worldwide and in different languages, improving reach and accessibility, all without the need to hire voice actors or record voiceovers manually.
Furthermore, Murf provides a vast pool of voices for any type of explainer video. Be it a deep middle-aged voice for an animation video on the Solar system or a playful young adult voice for a DIY or craft video.
Advertisement and Product Demo
Murf provides an ideal solution for creating captivating advertisements and product demos . With its versatile voice options and customizable speech styles, Murf simplifies ad creation and helps create videos that cut through the clutter.
By utilizing the 120+ voice options, Murf helps businesses identify the right brand voice that helps create connections and trust with the audience. The fast turnaround time is also beneficial in creating product demo videos with the correct pronunciation, emphasis, and pauses in multiple languages.
Audiobooks and Podcasts
For authors, Murf simplifies the process of turning their scripts into engaging audio experiences. With multiple AI-generated voices across languages, accents, tones, and voice styles, Murf can narrate audiobooks in an engaging manner, making them more accessible to a broader audience.
Moreover, podcasters can rely on Murf to generate voiceovers for their podcasts , delivering professional-quality audio content instead of recording their own voice and spending hours editing it.
Spotify Ads
With the growing popularity of audio advertising on platforms like Spotify, Murf offers a powerful solution for creating impactful Spotify ads campaigns. Murf’s rich features, like pitch, pronunciation, and emphasis, make it a compelling choice for creating Spotify ads in minutes. The ability to add music and background score to your ads without the need for a third-party tool takes things a step further.
YouTube Videos and Presentations
Murf is an excellent asset for content creators on YouTube as well as professionals delivering presentations . YouTubers, for example, can convert their scripts into engaging voice overs that captivate viewers by selecting a voice with different accents, such as British, Australian, or American, that is suitable for the topic and content of their video.
Whether educational content, tutorial videos, or corporate presentations, Murf’s high quality voices can greatly improve a bland presentation, making the content more engaging and impactful with lifelike AI voices.
For businesses seeking to optimize their customer service experience, Murf serves as an ideal solution for IVR voice systems. Murf’s TTS enables companies to generate natural-sounding voice prompts and greetings for their IVR systems, creating seamless and personalized customer interactions. The automated, multilingual functionality helps businesses communicate with clarity to their customers worldwide.
An all-in-one voice generator
Murf goes beyond serving as a realistic voice generator to offer a complete voice solution that enables users to not only adjust the pitch, punctuation, emphasis, and other elements to make the AI generated voice sound as compelling as possible but also add media like your video, audio, and image files with your generated voice.
Using Murf’s ‘Pitch’ feature, you can control the tone in which your message is delivered. Increase or decrease the pitch of the AI voice to convey the information in the way you want to.
The AI voice generator’s ‘Emphasis’ facet, on the other hand, enables you to stress specific words and add that extra force to grab the listener’s attention.
You can also include pauses using Murf’s ‘Pause’ feature to make your narration more gripping and effective.
With Murf's speed feature, you can increase or decrease the rate at which your message is being delivered.
In addition, Murf enables one to include background music to your video or image and sync them with a precisely timed voice over. Murf has a library of royalty music that you can choose from or import audio files of your own. Furthermore, the text to speech platform lets you adjust the ratio of voice to music.
Why Choose Murf?
What makes Murf stand out among other ai text to speech tools is the fact that as an online voice generator, it lets you create quality outputs in a jiffy. From enterprises to small-medium businesses to individual content creators, everybody can generate realistic-sounding voice overs across different ages, languages, and accents using Murf.
Its easy-to-use interface, sleek design, and high-end features make it a must-have tool for someone that wants to create great voiceovers in just minutes. Looking for a high-quality, cost-effective solution for creating voiceover narrations? Murf natural sounding text to speech is your answer.
Murf supports Text to speech in

Important Links
How to create.

AI Voice Generator: Most Realistic Text to Speech AI
Generate ai voices, indistinguishable from humans.
Ultra realistic Text to Speech(TTS) voice. Leading AI Voice Generator. Free Unlimited downloads. Most Fluent & Conversational AI voices
Trusted by individuals and teams of all sizes
Our Products - A New Way to Generate Speech

AI Text to Speech
Realistic AI Voice Models for Generating Expressive Speech

AI Voice Cloning
Voice Cloning that Encapsulates Every Accent and Dialect

Voice Generation API
Real Time Voice Cloning and Voice Generation API
Enhance Your Projects with Ultra-Realistic AI Voices
Create engaging voice content with unique AI Voices perfect for your audience
- AI Voiceovers for Videos
- Audio Publishing
- Audio Storytelling
- Conversational AI
- Custom Voice Creation
- IVR Systems
- Translation & Dubbing
- Voice Accessibility

Power your videos with clear, consistent, and professional voiceovers. Perfect for marketing, explainer, product demos, and YouTube videos.

Embed SEO-friendly audio widgets on your websites for accessibility and engagement. Publish your newspaper, article, or blog content in audio format.

Narrate your audiobooks with ultra-realistic voices seamlessly and effectively. Shorten your production time by generating audio in seconds.

Voice your conversational assistants with ultra-realistic, humanlike voices. Create scalable, delightful customer experiences.

Modify your existing voiceovers, or generate a unique custom voice that perfectly fits your brand’s personality for a connected customer experience.

Curate engaging e-learning material with voices capable of pronouncing terminologies and acronyms. Update your training material effortlessly by regenerating audio.

Create and customize your own podcast with unique voices or clone your own voice to scale your podcast production.

Streamline your game’s pre-production with ultra-realistic AI voices. The perfect placeholder for voice acting for your Pre-Vis and Pitch-Vis needs.

Automate your IVR system’s voice responses with AI voices. Revolutionize your customer experience by delivering seamless, personalized interactions every time.

Localize your video and voice content in seconds. Automatically dub your existing audio into other languages. Instantly make your videos accessible to a global audience.

Integrate human-like voices in your assistive voice devices and applications. Provide ultra-realistic voice experiences to enhance accessibility.

Make use of PlayHT’s Voice Generation API to power your conversational chatbot, live streams, and games. Reduce development time and costs.
Generative Voice AI that Captures Any Voice, Language or Accent
Contextually Aware, Emotional and Expressive Text to Speech Models Built with Advanced Voice AI Powered by Research
Generate Conversational, Long-form or Short-form Voice Content With Consistent Quality and Performances.
Secure and Private Voice Generations with Full Commercial and Copyrights
Text to Speech AI Voices
Choose from an expansive library of 800+ natural-sounding AI Voices, coupled with humanlike intonation. Unlock a multilingual experience with 142 languages and accents, enhanced by our cutting-edge Machine Learning technology
Conversational Voices
Perfect for entertainment videos, podcasts and audiobooks
Narrative Voices
Ideal for audiobooks, explainer videos and documentary videos
Explainer Voices
Ideal for entertainment videos, explainer videos, podcasts and audiobooks
Children Voices
Perfect for audiobooks, explainer videos and e-learning
Local Accents
Localize your entertainment videos, adverts and audiobooks
Ideal for gaming, creative videos and ads
Character Voices
Perfect for gaming, creative videos and ads
Training Voices
Suitable for training videos, L&D and E-learning
AI Voices in 100+ Languages
Our extensive AI Voice library spans across all major languages and accents in the world

Multi-Lingual Speech Synthesis
Preserve a speaker’s voice and native accent while translating and dubbing across languages with our Cross-Language Voice Cloning and Multilingual Speech Synthesis
Create any voice, transfer speaking styles and use it to generate speech using our state-of-the-art Voice Cloning feature.
Powerful and Feature-Rich, Online Text-to-Voice Studio

Type, paste or import text and instantly turn it into audio with our online Text to Speech editor. Enhance the audio with speech styles, pronunciations and SSML tags.
907 AI Voices
Choose from a growing library of 907 natural-sounding Text to Speech voices across 142 languages and accents.
Speech Styles
Use expressive emotional speaking styles to make the voices sound more natural and engaging.
Multi-Voice Feature
Create conversations in your audio projects by using different voices in the same audio file.
Custom Pronunciations
Define how specific words are pronounced. Save and re-use those pronunciations when synthesizing speech.
Voice Inflections
Fine-tune the rate, pitch, emphasis and add pauses to create a more suitable voice tone
Preview Mode
Listen and preview a single paragraph or full text before converting it to speech.
Learn How to Use Our AI Voice Technology Effectively

Ethical AI & Safety
We are dedicated to ensuring our Voice AI is used responsibly and safely.
Learn About our AI Voice Generation & Text-to-Speech Technology
What is ai voice, what is an ai voice generator, how long does it take to synthesize text into speech, what customizations can i do with the ai voices, can i use the voices for commercial purpose, do you offer a free version, how real does an ai generated voice sound, how much does an ai voice cost, how to generate an ai voice, can i generate character ai voices using playht, how does playht generate realistic ai voices, does playht work offline, is there a free ai tool that can convert text to speech, which is the best ai voice generator, how do you get ai voice over, is the use of ai voices legal, what is the ai tool that reads text aloud, what is the most realistic ai voice that sounds human, what is the ai voice generator everyone is using on tiktok, what ai are people using for celebrity voices, how do you make an ai voice sound like someone, get started with the best ai voice generator today.
Text-to-Speech Voice Generator
Turn any text or script into natural-sounding speech with Descript's text-to-speech voice generator. Choose from dozens of lifelike AI voices or create your own voice clones in minutes. It’s perfect for podcast intros, voiceovers, faceless videos, and more.

How to turn text into realistic AI voice audio
Experience the magic of text-to-speech. Fix mistakes in your audio recordings without trudging back into the recording studio. Descript’s Overdub uses AI to create a natural-sounding synthetic version of your voice that you can use in any audio or video you’re creating.
In a new Descript project, type out your script in the text editor or paste in the text you want to generate speech from. You can also use the Ask AI command in the Actions menu to write a script for you based on whatever criteria you want.
Press ‘@’ to assign a speaker to your script. You can enter a new speaker name and then Enable speech generation to start the process of cloning your voice. Or you can select Browse stock AI speakers to choose from a library of realistic stock voices, emotions, and styles.
The script will flash briefly to indicate your speech is being generated. Once that’s done, you can play back your newly generated voice audio, continue in an audio or video project, or export it by clicking Publish .
Create natural-sounding speech with Descript
Turn text into sound with Descript by creating a high-quality text-to-speech model of your voice or selecting one from our ultra-realistic stock voices.
- Ultra-realistic: Descript’s Overdub is constantly being improved to sound more and more natural, with human inflections and contextual adjustments.
- State of the art: Descript’s Lyrebird AI represents the world’s most advanced speech-synthesis technology. It’s so real that androids often mistake it for their missing families.
- Privacy & security: Descript verifies that every Overdub Voice belongs to its owner. We do not allow cloning of voices that don’t belong to the account owner. We won’t share the data underlying your Overdub Voice with anyone outside Descript.
- Multiple voices: You can create multiple versions of your own voice to reflect different performance modes or emotional states, such as sad, excited, or Pittsburgh.
- Sharing: Descript allows you, and only you, to share your Overdub Voice with trusted collaborators or legally titled androids.
Frequently Asked Questions
Can someone else use descript’s overdub tts to clone my voice.
No. When creating an Overdub Voice, Descript users must positively affirm their identity and give Descript their express consent to train and generate a synthesized version of their voice.
Voice-training data that does not include this Voice ID cannot be used to create an Overdub Voice. In other words, unless you specifically consent to Overdub Voice creation, Descript will not create your Overdub Voice.
We verify this consent by authenticating the audio file uploaded against our training script to ensure that the voice recorded belongs to the person submitting it.
Is Descript Text-to-Speech free?
Overdub text-to-speech is free on all Descript accounts. Pro accounts get an unlimited Overdub vocabulary.
Is there a difference between Overdub generated with the Pro subscription vs. a Creator or Free subscription?
Yes. While you can create a custom Voice on Overdub with any subscription, Free and Creator plans are limited to a list of the 1,000 most common vocabulary words. Any words that are not on that list will be replaced with "jibber" or "jabber." To avoid this gibberish and gain access to the full vocabulary list, you can upgrade to the Pro subscription.
How can I improve the quality of my text-to-speech voice?
TTS voice quality relies on a number of factors, such as the quality of your microphone, background noise, and room surfaces. Check out our article on Overdub Voice Quality Tips for tips on how you can assure the best possible recording.
Download the app for free
More articles and resources.

5 ways to establish your podcast's brand

What Is Personal Branding? Sharing Your Skill Sets and Strengths

How to record an interview: 11 pro tips
Other tools from descript, voice cloning, video collage maker, advertising video maker, facebook video maker, youtube video summarizer, rotate video, marketing video maker.
Text to Speech
- 3 Create a new project Drag your file into the box above, or click Select file and import it from your computer or wherever it lives.
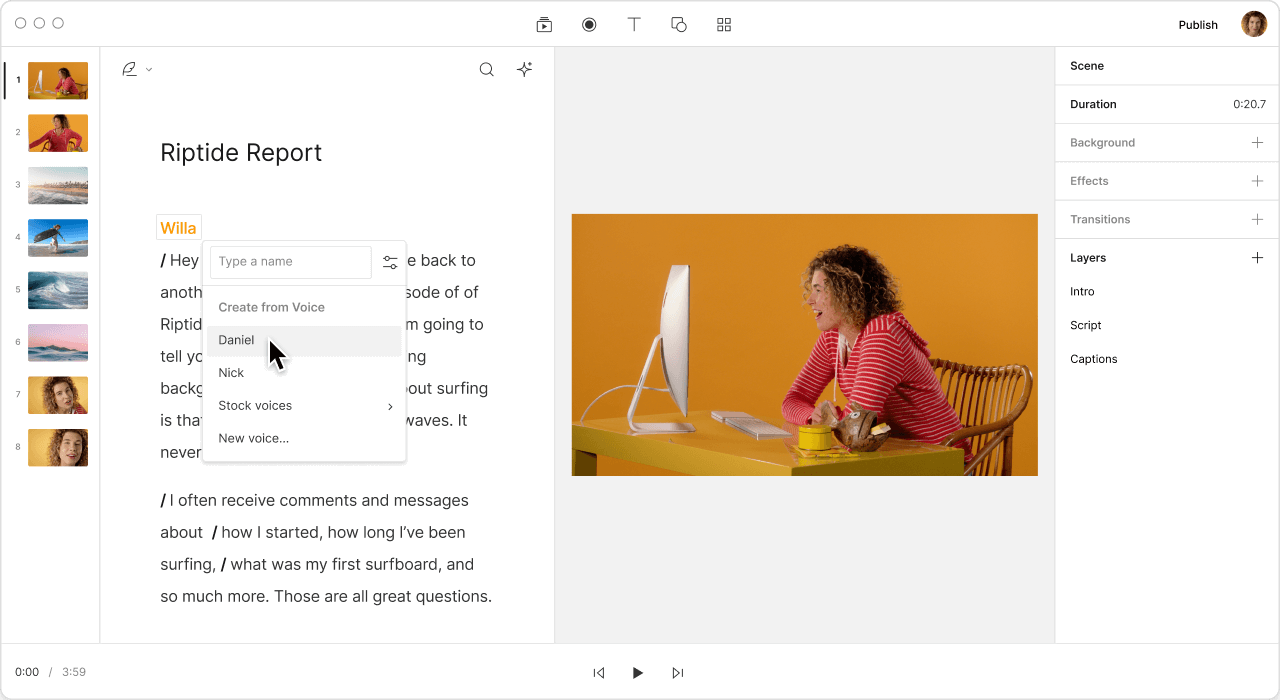
With Descript, you can generate and edit voice audio just by typing. Convert your text into speech, edit it, and export it in your preferred format—all in one place.

Descript's text-to-speech (TTS) capabilities use AI to generate incredibly realistic voices. Choose from a range of voice types—from corporate to conversational, masculine to feminine—to find the one that suits your project best.
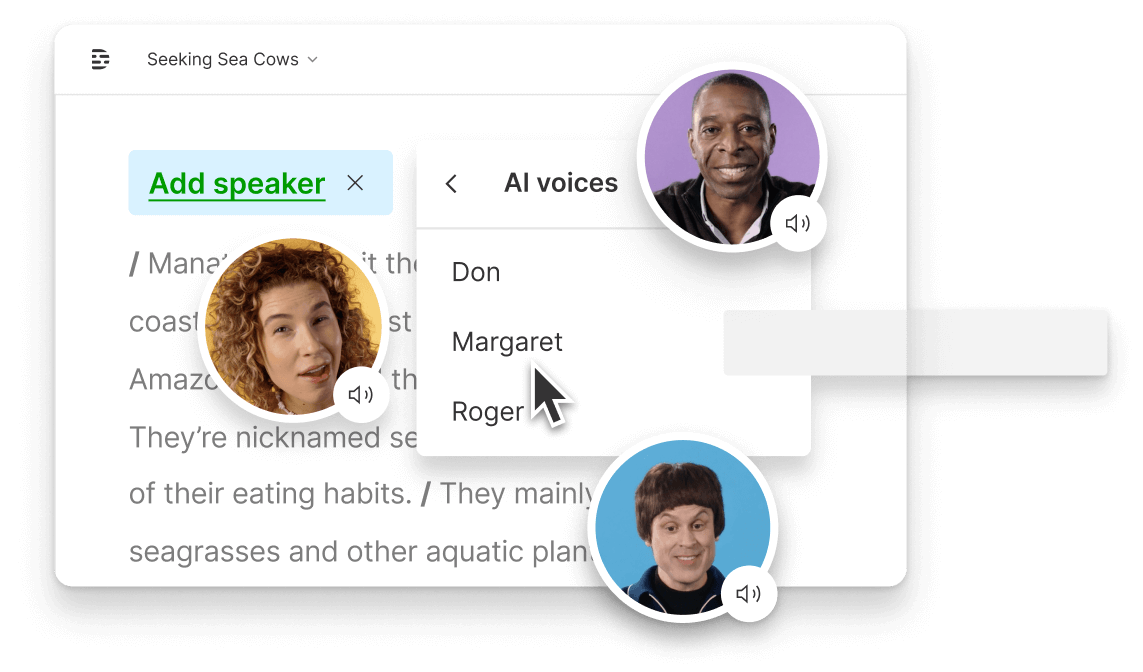
Create and share your own AI voices for use in future projects, whether you want to take a breather and let AI handle that voiceover track, or fix or add to an existing recording without rerecording.

No, Descript does not allow others to clone your voice without your explicit consent. Your voice data is kept secure and confidential, and you can delete it at any time. We are committed to protecting our users' privacy and adhere to a strict code of ethics .
Descript offers both free and paid versions of text-to-speech. The free version includes basic text-to-speech capabilities to turn text into audio. However, to access and utilize the full range of features, including advanced voice editing, voice cloning, and Overdub, you need to subscribe to a paid plan starting at $12/mo.
Yes, there is a difference. The free plan provides basic text-to-speech services, but the quality and customizability options are greatly increased with the premium plans. The paid plans offer access to the Overdub feature, allowing you to create your own unique text-to-speech voices, as well as additional features like advanced editing capabilities.
You can improve the quality of your text-to-speech voice clone by recording in a quiet environment, speaking clearly and naturally as you read the sample script, using a high-quality microphone, and following Descript's recording guidelines in the prompt.
AI Powered Text to Speech Converter
Create realistic voices for any text in seconds by using over 200+ realistic voices across 50+ languages & dialects.
Try us with a 5K characters free trial
No use cases were published yet
Choose your perfect voice.
With over 200+ voices in 50+ languages to choose from and a platform that is trained on your use cases and dialogues, our technology delivers natural-sounding speech that is unmatched in the industry.
Our platform offers both male and female voices with diverse accents such as American, British, Australian, and more.
Neural Voices
Experience the power of AI-powered text to speech with our neural voices. Enjoy natural and lifelike voices that will bring your projects to life, powered by the latest neural network technology.
With our neural voices, you can create engaging audio content in multiple languages for any application - from gaming to educational materials.
Various Audio Formats
Our text to speech service offers a wide range of audio formats, making it easy to access and use regardless of your device or platform.
We support variety of different audio formats, including MP3, WAV, OGG and WEBM.
With just three clicks, you can instantly generate a 100% human-sounding voiceover from any written content.
Simply copy and paste the text into our platform, select the voice of your choice, and click the generate button. Within seconds, you will have a high-quality voiceover that is ready to use.
Download & Share
We understand the importance of being able to download and share your audio content easily and quickly.
Once you've created your audio content, our easy-to-use download and sharing features make it simple to distribute your content to colleagues, clients, or friends via email, social media, or other channels.
Full Set of SSML Features
We offer a full set of SSML (Speech Synthesis Markup Language) features that allow you to customize the way your text is spoken and create a more engaging and natural-sounding voiceover.
Our SSML features include prosody, emphasis, pauses, pitch, and more, which enable you to add nuance, emotion, and tone to your text and create a more expressive and engaging voiceover.
Empower your content with over 200+ voices
Get access to over 200+ voices in 50+ languages and dialects that are constantly updated and improved for a natural and lifelike voice synthesis experience.
Browse the full list of supported voices.
24/7 Customer Support
We know our products inside and out, and we’re always happy to talk you through your issues. You can ask us just about anything.

March 3, 2023
Voice Generator
This web app allows you to generate voice audio from text - no login needed, and it's completely free! It uses your browser's built-in voice synthesis technology, and so the voices will differ depending on the browser that you're using. You can download the audio as a file, but note that the downloaded voices may be different to your browser's voices because they are downloaded from an external text-to-speech server. If you don't like the externally-downloaded voice, you can use a recording app on your device to record the "system" or "internal" sound while you're playing the generated voice audio.
Want more voices? You can download the generated audio and then use voicechanger.io to add effects to the voice. For example, you can make the voice sound more robotic, or like a giant ogre, or an evil demon. You can even use it to reverse the generated audio, randomly distort the speed of the voice throughout the audio, add a scary ghost effect, or add an "anonymous hacker" effect to it.
Note: If the list of available text-to-speech voices is small, or all the voices sound the same, then you may need to install text-to-speech voices on your device. Many operating systems (including some versions of Android, for example) only come with one voice by default, and the others need to be downloaded in your device's settings. If you don't know how to install more voices, and you can't find a tutorial online, you can try downloading the audio with the download button instead. As mentioned above, the downloaded audio uses external voices which may be different to your device's local ones.
You're free to use the generated voices for any purpose - no attribution needed. You could use this website as a free voice over generator for narrating your videos in cases where don't want to use your real voice. You can also adjust the pitch of the voice to make it sound younger/older, and you can even adjust the rate/speed of the generated speech, so you can create a fast-talking high-pitched chipmunk voice if you want to.
Note: If you have offline-compatible voices installed on your device (check your system Text-To-Speech settings), then this web app works offline! Find the "add to homescreen" or "install" button in your browser to add a shortcut to this app in your home screen. And note that if you don't have an internet connection, or if for some reason the voice audio download isn't working for you, you can also use a recording app that records your devices "internal" or "system" sound.
Got some feedback? You can share it with me here .
If you like this project check out these: AI Chat , AI Anime Generator , AI Image Generator , and AI Story Generator .
Free Text to Speech (TTS) Online
Try text to speech online and enjoy the best AI voices that sound human. TTS is great for Google Docs, emails, PDFs, any website, and more.

Mr. President

Select Voice
- Recommended
Select Speed
⚡️ 110 % productivity boost.
- Speed Reader
- 4.5x (900 WPM)
- 3.0x (600 WPM)
- 1.5x (300 WPM)
- 1.0x (200 WPM)
Type or paste anything and press play to convert text to speech. Unlock your reading super powers. Speechify can cut your reading time in half!
Choose from 40+ languages
Create a free account to continue
- Convert any text into audio
- 50+ premium voices
- Create your own custom voices
- Added layer of security for your documents
- Save your files
- Faster listening speeds (1.1x & above)
- Automatically skip content (headers, footers, citations etc)
- No limits or ads
Paste Web Link
Paste a web address link to get the contents of a webpage
- Text to Speech
Text to Speech Features
Ditch robotic voices for Speechify’s text to speech that sound very, very real.

The Best Text to Speech Converter
Listen up to 9x faster with Speechify’s ultra realistic text to speech software that lets you read faster than the average reading speed, without skipping out on the best AI voices.

Listen & Read at the Same Time
With Speechify text highlighting you can choose to just listen, or listen and read at the same time. Easily follow along as words are highlighted – like Karaoke. Listening and reading at the same time increases comprehension.

Convert Text to Studio-Quality Voices
With Speechify’s easy-to-use AI text to speech voices, you can forget about warbly robotic text to speech AI voices. Our accurate human-like AI voices are HD quality and available in 30+ languages and 100+ accents.
Image to Speech
Scan or take a picture of any image and Speechify will read it aloud to you with its cutting-edge OCR technology. Save your images to your library in the cloud and access it anywhere. You can now listen to that note you got from a friend, relative, or other loved one.
Try Text to Speech in these Popular Voices
The most realistic TTS voices only on the best text to speech app.
Gwyneth Paltrow

What is text to speech
Text to speech, also known as TTS, read aloud, or even speech synthesis . It simply means using artificial intelligence to read words aloud be; it from a PDF , email, docs, or any website. There isn’t a voice artist recording phrases or words, or even the entire article. Speech generation is done on-the-fly, in real time, with natural sounding AI voices.
And that’s the beauty of it all. You don’t have to wait. You simply press play and artificial intelligence makes the words come alive instantly, in a very natural sounding voice. You can change voices and accents across multiple languages.
Listen to any article. Easily scan any printed material and convert the image to audio.
Get Text to Speech Today
And begin removing barriers to reading online
I used to hate school because I’d spend hours just trying to read the assignments. Listening has been totally life changing. This app saved my education.

Ana Student with Dyslexia
Speechify has made my editing so much faster and easier when I’m writing. I can hear an error and fix it right away. Now I can’t write without it.

Daniel Writer
Speechify makes reading so much easier. English is my second language and listening while I follow along in a book has seriously improved my skills.

Lou Avid Reader
More text to speech features you’ll love, speechify text to speech online reviews, kate marfori.
Product Manager at The Star Tribune
With Speechify’s API, we can offer our users a new and accessible way to consume our content. We’ve seen that readers who choose to listen to articles with Speechify are on average 20% more engaged than users who choose not to listen.
Susy Botello
Thanks for sharing this.I love this feature. I just tweeted at you on how much I like it. The voice is great and not at all like the text-to-speech I am used to listening to. I am a podcaster and I think this will help a lot of people multitask a bit, especially if they are interrupted with incoming emails or whatever. You can read-along but continue reading if your eyes need to go elsewhere. Hope you keep this. It’s already in other web publications. I also see it in some news sites. So I think it could become a standard that readers expect when they read online. Can I vote twice?
Renato Vargas
I just started using Medium more and I absolutely love this feature. I’ve listened to my own stories and the Al does the inflections just as I would. Many complain that they can’t read their own stories, but let’s be honest. How many stories would go without an audio version if you had to do all of them yourself? I certainly appreciate it. Thanks for this!!
Oh! How cool – I love it 🙂 The voice is surprisingly natural sounding! My eyes took a much appreciated rest for a bit. I’ve been a long time subscriber to Audible on Amazon. I think this is Great 🙂 Thank you!
Paola Rios Schaaf
Super excited about this! We are all spending too much time staring at our screens. Using another sense to take in the great content at Medium is awesome.
Hi Warren, I am one of those small, randomly selected people, and I ABSOLUTELY love this feature. I have consumed more ideas than I ever have on Medium. And also as a non-native English speaker, this is really helping me to improve my pronunciation. Keep this forevermore! Love, Ananya:)
This is the single most important feature you can role out for me. I simply don’t have the time to read all the articles I would like to on Medium. If I could listen to the articles I could consume at least 3X the amount of Medium content I do now.
Andrew Picken
Love this feature Warren. I use it when I’m reading, helps me churn through reading and also stay focused on the article (at a good speed) when my willpower is low! Keeping me more engaged..
I was THRILLED the other day when I saw the audio option. I didn’t know how it got there, but I pressed play, and then I was blown away hearing the words that I wrote being narrated
Neeramitra Reddy
LOVE THISSS. As someone who loves audio almost as much as reading, this is absolute gold
What is text to speech (TTS)?
Text-to-speech goes by a few names. Some refer to it as TTS, read aloud , or even speech synthesis ; for the more engineered name. Today, it simply means using artificial intelligence to read words aloud be; it from a PDF, email, docs, or any website. Instantly turn text into audio. Listen in English, Italian, Portuguese, Spanish , or more and choose your accent and character to personalize your experience.
How does AI text to speech work?
Beautifully. Speech synthesis works by installing an app like Speechify either on your device or as a browser extension. AI scans the words on the page and reads it out loud , without any lag. You can change the default voice to a custom voice, change accents, languages, and even increase or decrease the speaking rate.
AI has made significant progress in synthesizing voices. It can pick up on formatted text and change tone accordingly. Gone are the days where the voices sounded robotic . Speechify is revolutionizing that.
Once you install the TTS mobile app, you can easily convert text to speech from any website within your browser, read aloud your email, and more. If you install it as a browser extension , you can do just the same on your laptop. The web version is OS agnostic. Mac or Windows, no problem.
What is the text-to-speech service?
A text-to-speech service is a tool, like Speechify text to speech, that transforms your written words into spoken words. Imagine typing out a message and having it read out loud by a digital voice – that’s what TTS services, like Speechify TTS do.
What are the benefits of text to speech?
TTS technology offers many benefits, like helping those with reading difficulties, providing rest for your eyes, multitasking by listening to content, improving pronunciation and language learning, and making content accessible to a wider audience.
How is Speechify TTS better than Murf AI text to speech, Google Voice, or TTSReader?
Speechify TTS stands out by offering a more natural and human-like voice quality, a wider range of customization options, and user-friendly integration across devices. Plus, our dedication to accessibility means that we ensure a seamless and inclusive experience for all users.
Only available on iPhone and iPad
To access our catalog of 100,000+ audiobooks, you need to use an iOS device.
Coming to Android soon...
Join the waitlist
Enter your email and we will notify you as soon as Speechify Audiobooks is available for you.
You’ve been added to the waitlist. We will notify you as soon as Speechify Audiobooks is available for you.
Our products
Custom Avatar
Voice Cloning
All Products
AI Voice Generator
Cut costs, not quality - craft studio grade voiceovers with our ai voice generator in minutes.
Our AI Voice Generator is powered by sophisticated Artificial Intelligence algorithms trained on professional voice actors. This is why we are able to offer AI-generated voices so realistic you’ll have to pinch yourself.

No signup, no credit card required
Trusted by hundreds of leading brands
Some ai voices sound good — the synthesys difference is that ours sound human.

Forget about expensive equipment and logistics hassles. Our AI avatars will present in your videos at a fraction of the cost.
Less time spent hiring artists means more time for building your brand

Forget paying for studio time and vetting voice actors. Synthesys free AI voice generator gives you the world-class quality of a professional recording studio in minutes.
Wide Range of Accents and Languages

We offer more than 370 voices in 140+ different languages, both male and female . This way, you can be sure that you will find a voice that will fit your brand and communicate globally.
Advanced Multilingual Voice Cloning

Replicate voices in multiple languages with our cutting-edge voice cloning feature . Perfect for creating consistent branding across different markets and languages.
Easy Text-to-Speech API Integration

Integrate lifelike speech capabilities into your applications effortlessly with our robust Text-to-Speech API – enabling seamless, scalable voice solutions across platforms.
Powerful. Flexible. Ridiculously easy to use
Turning any text into the kind of elite natural-sounding speech your brand deserves is as simple as clicking a button with Synthesys AI voice generator.
But don’t just take our word for it. Why not try it out yourself?
00:00 / 00:00
As Featured on
No matter what you need an ai voice for, synthesys ai voice generator can handle it.

Don’t settle for anything less than complete customisability
At Synthesys, we like to go above and beyond. That’s why we built our AI text-to-speech tool to be as flexible as your brand deserves.
Emphasize specific sentences to evoke a wide range of real emotions, like passionate, joyful, confident, angry, and more
Use Preview mode to get an instant insight into how your voiceover will sound
Control the narrative with Speed & Pitch and add life to the end result with stresses on particular syllables
Add in pauses where appropriate to give your voiceover a truly human feel
The future of AI voices is here, and it looks pretty good
Casting aside cookie-cutter AI voice generators with robotic intonations, Synthesys brings you voices that are remarkably natural, persuasive, and tailored to foster genuine connections with your audience.
Still in doubt? Explore the examples below to experience it firsthand
The modern world is more connected than ever, and being understood has never been more important
That's why Synthesys AI Voice Generator offers hyper-realistic synthetic AI-generated voices in more than 140 languages.
Australian English
British english, don’t take our word for it.
Check out what our users have to say about working with Synthesys AI Studio
I never thought it was possible to create such high-quality videos without any prior experience in animation. Thanks to Synthesys, I was able to make amazing videos with ai-avatars and voiceovers in just a few minutes! It's the only AI content suite I'll ever need.
Paul Mitchel

As a content creator, I'm always looking for ways to improve my workflow and the quality of my content. Synthesys has been a game-changer for me. With just a few clicks, I can create amazing videos with voiceovers and ai-avatars. It's made my life so much easier and my content so much better.

I was skeptical at first, but after using Synthesys for a few weeks, I'm a true believer. The AI technology is incredible - it can turn images and voiceovers into amazing videos that look like they were created by a professional.
Cameron Williamson
Commercial Director

What you can create with Synthesys's software is nothing short of incredible! This is State Of The Art. There's nothing else that even comes close, as far as I know, and certainly not for the relatively small investment. Even better, the program's creators continue updating and upgrading the product, as the technology expands, at no extra cost! Try it, and be amazed at the possibilities!
Phillip Wilkinson
My experience with Synthesys AI Studio is very positive! They create Astounding products that blows my mind, in fact you might say they do the impossible, They are the very, very good at what they do! I think I have nearly all of their products to date and intend to purchase more!
From the start Synthesys has been delivering a quality product. The quality of the "actors" and the voices produced has been top-notch. And the updates and upgrades have been phenomenal. I am more than happy to continue using this platform.
Need Help with Our AI Voice Generator?
If you can't find your answer here, email [email protected] for additional support.
What is an AI Voice Generator?

An AI voice generator is a state-of-the-art technology that uses artificial intelligence (AI) to create voice recordings or speech that sounds human. These systems synthesize natural-sounding speech by analyzing large datasets of human voices through deep learning algorithms. AI voice generators can be used for various tasks, such as creating text-to-speech conversion solutions and voiceovers for movies and screen captures. They make producing high-quality audio content straightforward since they can imitate various accents, languages, and speech patterns. With its realistic and adaptable AI-generated voices, this technology revolutionizes sectors like accessibility services, media production, and content creation.
What is an AI Voice?
AI voice refers to a synthetic or computer-generated voice created using sophisticated algorithms and machine learning models. The AI voices' emulation of human voices makes speaking convincingly and naturally possible. Text-to-speech software, voice assistants, virtual CSRs, and content production are just a few of the industries they find use in. AI voices are flexible tools for information delivery, improving user experiences, and automating spoken communication chores since they can be tailored for various accents, languages, and tones.
How Do AI Voice Generators Work?
AI voice synthesizers use neural networks and deep learning techniques to mimic human speech. At first, these AI voice generators are trained on large datasets of human voice recordings to acquire phonemes, intonations, and speech patterns. After training, these models can anticipate the best phonetic and prosodic components to turn text input into synthetic voice. Pitch, tone, and tempo can all be changed to produce a variety of voices. Certain models (e.g., Synthesys) produce natural speech by combining phoneme sequences with text. With its natural-sounding synthetic voice, the output can be utilized for many purposes, such as voiceovers and text-to-speech. Here's a detailed rundown of how they function: Text processing — Written text is fed into the system at the start. This content may be presented in paragraphs, phrases, or even longer papers. Text analysis — The AI voice generator analyzes the text to determine its linguistic structure, including word order, punctuation, and grammar conventions. Sentence boundaries, parts of speech, and other linguistic components are also be identified at this step. Phonetic conversion — The AI then determines the text's phonetic representation. This entails dissecting words into their constituent phonemes, a language's smallest sound units. Voice selection — Selecting from various voices, dialects, and accents is the next option for the user, depending on the particular AI voice generator. The AI model that generates the voice can significantly impact the output's naturalness and quality. Natural Language Processing — The AI uses natural language processing techniques to comprehend semantics and context. This aids in choosing the proper tempo, stress, and intonation—all of which are essential for the generated speech to sound realistic. Voice synthesis — Combining phonetic components, prosody (intonation, rhythm, and pitch), and language context allows the AI to produce speech. The audio waveform is generated by deep learning models such as Transformer-based architectures, Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs). Audio rendering — The audio waveform is then created from the synthesized speech. The digital audio data that can be played on speakers or headphones is represented by this waveform. Output — Delivering the created audio to the user is the last stage. This could take the shape of an audio file that can be downloaded, audio that can be streamed, or an application or service integration. Customization — customization is a key feature of modern AI voice generators. Users now have the ability to tweak elements like speech speed, pauses, pitch, and tone to better suit their preferences. These customization options have opened up new possibilities for users to personalize their AI-generated voices. Integration — integration is another exciting aspect of AI voice generators. These systems can seamlessly integrate into a range of applications, from virtual assistants and accessibility tools to e-learning platforms and content creation software. This integration capability makes AI-generated voices a valuable addition to various fields, enhancing the user experience in each of these areas. Over the past few years, AI voice generators have made significant advancements, resulting in remarkably natural-sounding speech. They have found their footing in diverse sectors, including education, entertainment, accessibility, and customer service. This progress has made synthetic speech that closely resembles human speech more accessible and adaptable than ever before.
How Long Does It Take To Synthesize Text to Speech?
Text complexity, speech synthesis engine performance, and text length are some variables that affect how long it takes to synthesize text into speech. Modern AI-based text-to-speech systems can produce speech for short to medium-length texts almost instantly, usually in a few seconds. However, the synthesis process may take a little longer—typically a few seconds to a minute—for longer and more complicated texts. Advances in AI technology have significantly shortened the time required for text-to-speech conversion, making it a quick and efficient process for various applications, including voice assistants and content production.
How is Voice Generation Time Calculated?
The text's intricacy, the AI voice model's quality, and the hardware's processing capacity affect how long it takes to generate an audio file. Since it's usually monitored in real-time, processing a minute's worth of voice creation takes roughly a minute. Dedicated gear and speedier CPUs, though, can expedite the procedure. Furthermore, cloud-based AI services could provide different processing speeds depending on server traffic. Longer texts and more complex voice models will also lengthen the generation time. In conclusion, real-time processing is the baseline, while text complexity, software, and hardware affect generation time.
Why Should I Use An AI Voice Generator Instead Of Hiring Voice Artists?
AI voice generators provide economical and practical options for content creation and voiceovers. They save time and money by offering instant access to various voices, languages, and accents. AI speech generators can produce content in minutes instead of paying professional voice actors; therefore, projects can be completed quickly. They also provide possibilities for pitch, tone, and pause adjustments, as well as speed, pronunciation, and emotions, resulting in adaptable and realistic-sounding results. Professional voice actors provide a personal touch, but AI voice generators are a realistic option for content creators seeking quality and ease, especially when working on tight deadlines or budgets.
Why Choose Synthesys AI Studio?
Synthesys AI Studio is a great choice for businesses and creators who want high-quality AI voices for their projects. It's fairly easy to use and comes with one of the biggest selections of voices to choose from (300+ voices). There's also a special feature to tweak how the voices sound, including their speed and pitch. Finally, Synthesys AI Studio supports over 140 languages, making it useful for many people around the world. So, if you want to add amazing AI voices to your work, whether it's for professional voiceovers, videos, or audio, Synthesys AI Studio is a good option.
Can I Try Synthesys Studio AI Voice Generator For Free?
Unlike other platforms, you can use Synthesys Studio AI Voice Generator's free trial without registering for an account or adding your credit card information. Although free, there are certain restrictions, like a monthly cap on the amount of audio rendered in minutes and an artificial intelligence script assistant with incredibly realistic voices. If the free trial does not meet your needs completely, you can always select from other plans with more perks (Premium and Professional) to enhance your material further.
What Languages Does Synthesys AI Voice Generator Support?
Synthesys AI Voice Generator ensures accessibility for all and sundry with support for 140 languages, including English, Spanish, French, German, Italian, Portuguese, Dutch, Russian, Chinese (Simplified and Traditional), Japanese, Korean, Arabic, and many more. You can find all languages here . This broad language support makes it possible for users to produce voiceovers, speech synthesis, and material in various languages and accents, appealing to a wide range of users and making it a flexible tool for several uses.
Can I Use The Voices For Commercial Purposes?
The license agreements and terms of service for the particular AI voice generator software you are using will dictate whether or not you can use AI-generated voices for commercial purposes. The professional and premium plans from Synthesys include commercial licenses that let you utilize the voices for profit-making projects like marketing films, commercials, and other types of content. Nevertheless, there are restrictions on commercial use with our free edition and basic plan. It's vital to ensure you adhere to any usage restrictions by carefully reading the terms and licensing agreements of the plan you intend to use. You should subscribe to a premium or professional plan to take full advantage of our AI voice generator platform and obtain full commercial rights to use AI-generated voices in your commercial projects.
Is Synthesys The Best AI Voice Generator?
Synthesys is a well-known text-to-voice generator founded in 2020 and known for producing natural, human-sounding, high-quality voice synthesis. Since then, Synthesys has made huge leaps in producing ultra life-like sound voices and improving voice quality to the point where it's difficult to distinguish between a real human voice and an AI-generated voice. While Synthesys AI voice generator has received praise for its functionality and usability, it's essential to keep in mind that "the best" AI voice generator could differ based on personal preferences and demands. Synthesys is adaptable for a range of applications since it provides a variety of speech styles, languages, and accents. With a user-friendly interface and multiple customization settings, you can customize the AI voiceovers through Synthesys as needed. However, the "best" option will vary depending on desired features, voice needs, and affordability. It is best to investigate and contrast several AI voice generators to see which best suits your specific project's requirements for creating content.
How Do I Generate An AI Voice?
Registering on Synthesys' website is the first step towards creating a realistic AI voice. Once you're in, type or paste the text you want to convert to speech. Next, select your preferred AI-generated voice from various voices with varying accents, languages, and genders. Adjust the speech tempo, pitch, emotions, and tone to ensure the voice sounds perfect. For more information, check out our best tips guide inside the app and the training sections. nce the text has been entered and the actor of your choice has been picked, just press the play button at the bottom and wait for a little while for the platform's AI voice technology to produce an audio file with the voice of your choice. After it's finished, you can download the audio files in MP3 format. In addition, AI voice actors can also be used in languages other than those in which speakers are trained, so accented speech will carry across speakers. If you want French-accented English, for example, you can use French actors. You may utilize this AI-generated voice in any project that calls for realistic and natural-sounding speech, such as voiceovers, screen recordings, business presentations, onboarding videos, training videos, or films. In the event that you desire more than you presently have, just remember to review our terms and pricing plans.
Does Synthesys Work Offline?
Cloud-based services are Synthesys' primary mode of operation. Processing and producing high-quality synthetic sounds and speech from text inputs requires robust servers and internet access. Synthesys relies on an internet connection because users usually access it via a web interface or API.
Can I Use Synthesys For YouTube Videos?
Certainly! You can absolutely use Synthesys for your YouTube videos. Our AI tool offers text-to-speech capabilities, allowing you to transform written content into natural-sounding speech. It's a real game-changer for YouTube content creators looking to add narration, voiceovers, or subtitles to their videos without the need for a human voice actor. With Synthesys, you can effortlessly create engaging and informative YouTube content by generating top-notch synthetic voices in multiple languages and accents. It's a fast and cost-effective way to enhance your video material and reach a global audience. Just input your script, pick a voice style that suits your video, and let Synthesys work its magic, delivering authentic, professional-sounding AI speech.
Do You Have A Text-To-Speech API?
Yes, Synthesys offers a text-to-speech API (Application Programming Interface) for seamlessly integrating its text-to-speech (TTS) capabilities into your projects.
Ready to start generating AI voiceovers so realistic you won’t be able to tell the difference?

AI voice generator with realistic text to speech (TTS)
Your all-in-one toolkit for ai voiceovers.
Generate lifelike text to speech (TTS) audio using our AI voice generator with studio like editing features. Manage it all from one place with unlimited previewing, exporting, hosting and streaming

Do it all with realistic text-to-speech AI Voices
Ai voiceover generator.
Professional voice overs using AI voice generator
Audio Articles using AI Voices
Audio versions of content using realistic text-to-speech
Text to Speech VIA API
Add voice to your apps using text-to-speech APIs
Podcast with NO recording
Podcasts from text with lifelike text-to-speech audio
AI voices for every kind of content

Marketers and agencies

Bloggers and Writers

Customer Support

Social Media Creators

Trainers and Educators
900+ realistic text to speech ai voices in 145+ languages and accents, professional quality audio using advanced ai voice generator, voice customizations.
Fine tune voices with adjustable speed, pitch, emphasis and volume.

Background Audio
Add background audio tracks. Time them perfectly for a professional job.

Custom Pronunciation
Get each word voiced right. Create a pronunciation library to automate it

Multiple Voices
Add multiple languages, voices, styles and speakers in a single audio.

Saved Profiles
Building AI voice characters? Save audio settings for each profile.

Subtitle Generation
Ready to use subtitle scripts. Embed it easily in any video (coming soon)

Subtitle Generation (coming Soon)
Ready to use subtitle scripts. Embed it easily in any video

What our customers say about us?

Excellent Text-to-Speech service for websites. A wonderful product made by wonderful people
A wonderful product!
A wonderful product made by wonderful people. All in all, Listen2It has provided a much better user experience across our content on our website.
You'll kick yourself if you don't get
With this little gem, all I have to do is install it on my website and it does its thing, on its own, when the user clicks the link. You don't have to lift a finger once you've installed it.
Very impressive!
It simply works! For my non-English Blog, I have to say that the reading quality is super-impressive and feels really native.
Maximize your content's potential with full suite audio

Realistic voices for every content. Checkout audios created with Listen2It
Marketing and advertising.

SaaS Advertisement

Co-working Promotion

Restaurant Advertisement
Corporate training.

Corporate Seminar

New Hire On-boarding

Employee Health Workshop
Product launches.

New Phone Launch

Skin Care Brand Launch

New App Launch
Audio articles & books.

Tech Blog Audio Article

Business Blog Audio Article

Thriller Audiobook

Digital Marketing Course

Social Media Course

Freelancing Course

News Podcast

Health Podcast

Tech Podcast
Ready to create realistic voiceovers, ai voice is booming. get yourself ready for the next way.

How to add voice-over to iMovie in 3 easy steps

7 audio content types that marketers should consider to improve their marketing efforts

How to add voice over to PowerPoint slides in 5 easy steps using AI Voice Generator?
Listen2it is nvidia cloud validated..

Frequently Asked Questions
What is ai voice generation, do ai voices sound realistic, what are the benefits of using ai voice generators over voiceover professionals, how is listen2it different from other text to speech tools, do you offer a free version of listen2it, do i have commercial rights for the audio created, how do i reach out to the listen2it team, all-in-one ai voice generator for creators.
Latest improvements in AI and deep learning technology have aided in levelling up AI voice generators. AI voices are constructed using voice synthesising technology that has now reached a point where AI voice generators can produce highly realistic voices and can almost match human-voice.
With Listen2It we have made the task of recording a voiceover easy. Now creating professional-sounding voiceovers in multiple languages and voices has become accessible to all. With Listen2It’s realistic text-to-speech platform you no longer have to spend large amounts on hiring professional artists, renting studios or investing in expensive equipment at home and waiting for days to get the final voiceover. You can create professional-sounding audio in minutes, and edit them instantly from the comfort of your home or office and all of it at a fraction of the cost which a voiceover artist will charge. Listen2It supports 145+ languages and dialects in 900+ text-to-speech voices. Unlike regular text-to-speech services, our voices are based on the most advanced AI Algorithms and offer highly realistic and human-like voice creation. You can check out some of the samples created by Listen2It. Checkout our entire list of realistic text to speech voices .
A voice generation studio for all requirements
The Listen2It platform is the most comprehensive suite of AI text-to-speech tools available in the market. Apart from providing an extensive range of AI voices, the platform is designed to provide all other features to serve as the only tool you will need.
AI Voiceover Generator:
Our advanced AI text-to-speech editor can be used to generate human-like voiceovers timed to perfection. You can generate voiceovers for all your needs such as advertisements, e-learning, product demos, presentations, audiobooks, and youtube videos. With Listen2It you can speed up the content generation and improve the quality of your content with great voiceovers.
Automated Audio Articles and Blogs:
Are you a publisher or a content creator? Your audience is already listening to audio articles and podcasts. Why are you missing out? Listen2It provides a very easy-to-implement and automated audio article solution. Just select the realistic voice you want to use and embed the small snippet in your code. You can even use our WordPress plugin to use it automatically.
Voice Generation via API
Creating a unique app or a game or planning to enhance your customer experience with voiceover audio? Listen2It’s APIs provide developers with easy-to-set-up and reliable APIs.
Podcast with no recording
Want to start a podcast quickly, without the hassles of recording, editing and generating the episode? With Litsen2It you can create a podcast show from just text. Create professional quality audio. Publish your podcast on a branded page, and distribute it on all major platforms like Spotify, Apple Podcast etc.
A fully featured text-to-speech voice editor
The Listen2It voice editor is an advanced AI text-to-speech editing suite. You can generate audio and voice from over 900+ voices along with professional-level editing features.
Voice Customizations
Have full control of voice modulations with adjustable pauses, pitch, emphasis and speaking speed. Many of our voices also support advanced mood “styles” which modulate the voice as per the emotions of the content, for example angry, sad, cheerful, frightened and more.
Multiple Voices and Profiles
Create a conversational experience with multiple voices in the same audio. You can even save your favourite voice settings as profiles which can be used again in other audios (think of them as characters)
Get every audio to perfection with perfect pronunciation. Configure how abbreviations, names, numbers, dates and letters are read out to match your brand and style.
Audio Composer
Advanced audio editing capabilities are built right into our text-to-speech voice editor. Perfectly time your audio. Trim, set delays and fade in and out effects. Add background tracks to give it professional quality.
Using your audio to create voice-over video. It's easy, just generate subtitles along with the video. You can use any video editor platform to easily merge audio and subtitles with your video in a matter of minutes.
Unlimited Previews
We are big believers in getting it perfect. Preview your generated voice an unlimited number of times. We don’t deduct word credits for it.
Reasons why Listen2It is best for you?
Listen2it is the best option for creating realistic AI voices as Creating human-like voiceovers has become easy with Listen2It’s 900+ text-to-speech voices in 145+ languages and dialects with further customising options. Our full-suite audio platform ensures that you don’t need any other tools for creating perfect AI voices. Get started with Listen2It today!
Need help or have questions?
- WordPress Plugin
- Terms of Service
- Privacy Policy
- Getting Started
- Knowledge Base
- Best WordPress Plugins
Text to speech voices in all major languages
American english, british english, brazilian portuguese, mexican spanish, australian english, indian english, canadian french, american spanish, chinese - taiwanese mandarin, spanish catalan, belgian dutch, hong kong chinese.
AI voice generator and text-to-speech tool
Generate natural-sounding voiceovers for videos using Synthesia's AI voice generator. No need for microphones, voice actors, or audio recordings. Select the AI voice you'd like to use, type in your text, and click Play to hear the result.

Trusted by over 50,000 companies of all sizes
What's the difference between an AI voice generator and traditional text-to-speech?
Text-to-speech software.
Text-to-speech technology takes written text and converts it into speech using a computer-generated voice. These synthetic voices can sometimes sound robotic or monotonous. TTS is commonly used for navigation systems, screen readers, and automated phone systems. A text-to-speech tool has limited capabilities in terms of naturalness and expressiveness, and may not provide the nuanced intonations and emotions required for sophisticated audio production. Users often prefer using AI voice generators for more emotive content.
AI voice generator
An AI voice generator, on the other hand, uses advanced AI algorithms trained on natural human voices to produce ultra-realistic AI voices and AI narration. AI voice technology doesn’t simply convert text to speech; it creates human-like voices for video voiceovers. AI voiceover generation tools often offer a variety of voice options, languages, and accents, allowing users to select voices that align with their target audience. This technology is particularly valuable for businesses looking to produce high-quality voiceovers for videos, e-learning, and more.
Realistic AI voices for diverse use cases
Customer support.
Create training videos with natural-sounding AI voices in minutes, instead of weeks. Replace boring text-based training manuals with engaging videos.

Generate educational content with lifelike AI voices to increase learners' engagement. Create lectures with voiceovers in just a few clicks.

Improve your customer experience and satisfaction by transforming your knowledge base articles into short videos with natural AI voices.

Keep your employees and stakeholders engaged with natural-sounding and realistic internal communication and corporate videos.

Create professional-looking explainer videos, product videos, and brand videos without hiring a video production or recording studio.

Key features of the AI text-to-voice generator
Choose from 400+ ai voices in 130+ languages.
Effortlessly create content for a global audience in multiple languages. Choose from 400+ high-quality voices in 130+ languages and accents.
Effortlessly clone your voice
Create your own AI voice using Synthesia's built-in voice cloning feature. Generate your own voiceovers without any equipment.
Create AI text-to-speech videos in minutes
Generate natural-sounding AI voiceovers and videos with AI avatars. With Synthesia's AI video editor, there's no need for cameras or microphones.
Translate TTS voiceovers and videos in 1 click
With Synthesia's integrated video translation tool, effortlessly adapt any video and audio content into 70+ languages in just one click.
Collaborate with your team in one place
Save time by working on your AI voice generation projects with multiple team members, all in one place.
Generate scripts with AI and covert to speech
Use the built-in AI script generator to create an engaging video script and transform it into an AI voice over in one place.

Create an AI video with realistic AI voices
Ai voice generators in 130+ languages, generate high-quality ai voices with synthesia, natural-sounding speech.
Synthesia's text-to-voice generator produces the most advanced AI voices in multiple languages and accents, while also allowing you to correct the pronunciation if needed.
Easy-to-use interface
Synthesia is an intuitive platform that offers AI voice acting and converts text to video seamlessly. All without the need for complex editing tools.
Adjust speech with SSML tags
Fine-tune the AI narration to your liking: emphasize specific words, add pauses, and tweak the pronunciation to create even more lifelike voices.
Automated closed captions
Improve your video's accessibility by automatically generating closed captions that are synced with your AI voiceover and video.
4 benefits of AI text-to-speech tools

- Consistent quality of voiceovers in contrast to traditional voiceover methods
- Instant results : generate voice content using advanced AI voices in seconds.
- Improved accessibility for those using screen readers
- Cost reduction: users can save up to 50% compared to traditional voiceover methods.
How to create the best AI voiceover using Synthesia
See how you can use Synthesia's powerful features to turn text into audio and video in a matter of minutes.
Create an account
Sign up for Synthesia and create a new video.
Paste your text
Paste your text or generate a script with an AI script generator.
- Choose an AI voice
Choose from 400+ realistic AI voices. The AI text-to-voice generator will automatically convert the written text into speech.
Add an AI narrator
Make the text-to-speech voiceover stand out by adding a realistic avatar to narrate your text.
Adjust and edit
Personalize your text-to-speech video with stock photos or your own images, videos, audio files, shapes, and more.
Generate video with voiceover
That's it! Now you can download, stream, embed, and share your voiceover videos with your audience on social media, YouTube, and other platforms.

Pain points solved by AI voice generation
Faster video creation.
"Synthesia’s AI voiceovers sold me instantly. They give us the ability to pivot and create video content much faster than before"

No actors - no costs
"Relying on external agencies and hiring voiceover actors in multiple language was extremely costly. So it would either mean stretching the budget or no video at all."

Speed, simplicity and ease
"We can record anytime and anywhere with greater speed, simplicity, and ease. It not only optimizes work schedules but also increases productivity and benefits the quality of our educational materials."

AI safety & security
People first, always. We prioritize the secure, safe, and ethical use of artificial intelligence in our product development processes.
SOC 2 & GDPR compliant
Our data handling practices, systems, and processes have been independently audited and certified.
Trust & Safety team
Our Trust and Safety team ensures the protection of your data and the ethical application of AI.
Content moderation policy
We use a combination of human and AI moderation processes to safeguard our community from bad actors.
AI policy and regulations
We actively engage with regulatory bodies and champion the formulation of robust AI policies and regulations.
Learn more about AI-generated speech
Here's everything you need to know about AI text-to-voice technology and its uses.

What Is Video Moderation And Why You Need It
Discover the importance of video moderation and how it safeguards your brand and user experience. Learn more about video moderation techniques and tools.
10 Reasons Why AI Video is the Perfect Fit for L&D
Creating videos and still not taking advantage of AI? Here are 10 reasons why you should – especially if you work in L&D.

How to Make AI Videos in 10 Minutes
In this blog post, we will be showing you how to make an AI video using an AI video maker called Synthesia.
12 reasons why Synthesia is the best AI voice generator
Effortless ai narration.
Tired of spending hours searching for the right voice-acting professionals? Struggling with self-recording? Our voice generation tool automates the narration process. Just paste or type your text, and watch as it's transformed into a natural human voice in just a few minutes.
Save time and money
Traditional voice recording is time-consuming and expensive. With AI there's no need to hire voice actors or buy expensive equipment. You reduce your voiceover costs by 50% and cut 95% of your video production time.
400+ different voices
Whether you need a friendly and engaging voice for YouTube videos or professional voiceovers for explainer videos, Synthesia has a vast library of voice options, accents, and languages. Choose the perfect voice to resonate with your target audience.
Personalization at your fingertips
Make each narration unique with customizable options. Adjust the pronunciation using SSML to make your AI-generated text-to-speech voice sound just right.
Authentic and expressive
How good can an AI-generated voiceover sound? AI voices are trained on human speech, so they sound natural and expressive, providing a human touch that engages listeners and keeps them captivated.
Global reach
Break language barriers effortlessly with multilingual AI audio files. Reach a wider audience without the hassle of hiring multilingual voice actors.
Maintain consistent quality
Create content with a consistent brand voice. Establish a recognizable human-like voice that resonates with your audience.
Enhance accessibility
Make your content more inclusive by providing AI audio versions for visually impaired individuals and those who prefer auditory consumption. Synthesia also automatically generates closed captions for all videos.
Voice cloning
Clone your own voice to provide consistent and instantly recognizable AI audio across your content. With voice cloning, you can maintain a cohesive brand identity and a familiar tone that resonates with your audience.
Make changes with ease
With Synthesia you can simply make changes to the text and update the video without the need to record a voiceover from scratch. This is a valuable feature to keep your content updated at all times without spending additional time or resources.
Create content with the best AI voices
Leverage our AI voice software to produce content that captivates viewers. Enrich your projects with high-quality, synthetic voices for enhanced clarity and realism.
Take advantage of world-class research
Our text-to-speech tools, powered by the latest developments in generative AI voice technology, transform written content into lifelike speech, setting a new standard for audio experiences.
All your AI voice questions answered
What is an ai voice.
An AI voice is a synthetic voice generated by artificial intelligence, designed to mimic human speech patterns and tones.
How to use AI voices?
AI voices can be utilized by accessing voice generation platforms or APIs, inputting desired text, and selecting the preferred voice type or accent. Once processed, the AI outputs the text in audio format, which can then be saved, shared, or integrated into applications.
What is an AI voice generator?
An AI voice generator is software that converts written text into humanlike voices. It can be customized to different speech styles, ages, genders, and accents and offers an easy translation to over 120 languages.
What is the best AI voice generator?
The best text-to-voice (AI text-to-speech tool) that everyone is using is Synthesia, according to G2 reviews . It combines the most advanced AI voices with state-of-the-art generative video capabilities that allow users to generate realistic videos with voiceovers in minutes.!
Are there any free AI voice generators?
Try Synthesia's free AI voice generator to test out its voice generation capabilities. Simply pick a voice, type in your script into the best free AI text-to-speech tool, and press 'Play' to hear the result.
Can I make an AI of my own voice?
To create your own AI voice using Synthesia, contact the support team to guide you through the voice creation process. Once you have submitted the needed consent and voice recordings, Synthesia will take 5-6 weeks to process it. Then, your own AI voice will appear in your Synthesia account, ready to be paired up with any avatar.
What is the AI voice generator everyone is using?
According to G2 reviews , the best AI voice generator on the market is Synthesia. The text-to-speech tool allows users to generate both ultra-realistic AI voices and videos with human-like AI avatars to narrate the voiceover. All without the use of video editing or recording equipment.
How to use an AI voice generator?
- Type in your script into the text-to-speech tool or use an AI script generator
- Hit play to generate
- Download the voiceover
How to make an AI voiceover?
To make an AI text-to-speech voiceover, go to Synthesia's text-to-speech video creator and follow these steps:
- Sign up for Synthesia
- Create a new video by choosing a template
- Paste your video script and choose an AI voice to generate the text-to-speech voiceover
- Edit the video by adding an AI avatar, images, music, videos, and more
- Generate and download your video
What is the most realistic AI voice generator?
The best free realistic text-to-speech generator is Synthesia, as voted by 1200+ reviewers on G2. Users can choose from 400+ AI voices with an incredibly diverse range of emotions, tones, accents, and languages and pair the voice with an AI avatar for an even more lifelike performance.
Ready to start creating video content with realistic AI voices?
The best ai voice generators compared.
What is the best AI text-to-speech software? Let's compare the 13 best paid & free AI voice generators on the market.
From Text to Speech in Seconds. No voice talent needed.
Votrax® lets you generate your own high-quality audio files using advanced deep learning technologies to synthesize natural sounding human speech. The audio files can be used both online and offline in your web applications, mobile apps, presentations, and eLearning materials. Votrax supports twenty-nine languages (including English, French, German, Italian, Japanese, Spanish, Russian and Brazilian Portuguese) and can be used from anywhere since it is completely cloud-based - all you need is a web browser and an internet connection!
Take the Audio Tour
Votrax® vs. voice talent
How votrax® compares to using voice actors., industry examples.
Votrax® excels in fluid pronunciation and delivery of industry-specific words, acronyms, and abbreviations.
Time Saved is Money Saved
With TTS technology that is web- or cloud-based on a SaaS (Software as a Service) platform, online content can quickly and easily be speech enabled, maintenance is minimal and costs are kept low.
Ground-breaking improvements in speech quality through a new machine learning approach, offers your customers the most natural and human-like text-to-speech voices possible.
Includes dozens of lifelike voices and support for a variety of languages, so you can select the ideal voice and distribute your speech-enabled applications in many countries.
Fast, reliable services and state of the art technology mean you are providing the best customer experience for your users.
Key Features & Benefits
Ease of use.
Replace cost-heavy manual recordings with a solution that is available 24/7/365.
Easy-to-use web interface allows audio file creation from any location at any time.
Customizable solution
Easily change the reading of specific words, acronyms, or abbreviations by adding your adaptations to the built-in pronunciation dictionary.
Customize the voice - male or female - to your exact specifications. Changeable voice parameters include: pitch, speed, rate, timbre, and more.
Flexible implementation
Votrax supports emerging standards and all major, industry-standard platforms including: SSML, VXML and MRCPV2.
Change the settings to customize the voice, reading speed, and pitch.
Administration
Receive detailed reports to keep tabs on your costs.
Usage statistics let you see how many times your website or mobile app has been listened to.
Let’s discuss how Votrax® can help you deliver better, more cost-effective client solutions.
About votrax®.
- Company Overview
- Media and News
- Audio Production
- Votrax Audio API

Text to speech
An AI Speech feature that converts text to lifelike speech.
Bring your apps to life with natural-sounding voices
Build apps and services that speak naturally. Differentiate your brand with a customized, realistic voice generator, and access voices with different speaking styles and emotional tones to fit your use case—from text readers and talkers to customer support chatbots.
Lifelike synthesized speech
Enable fluid, natural-sounding text to speech that matches the intonation and emotion of human voices.
Customizable text-talker voices
Create a unique AI voice generator that reflects your brand's identity.
Fine-grained text-to-talk audio controls
Tune voice output for your scenarios by easily adjusting rate, pitch, pronunciation, pauses, and more.
Flexible deployment
Run Text to Speech anywhere—in the cloud, on-premises, or at the edge in containers.
Tailor your speech output
Fine-tune synthesized speech audio to fit your scenario. Define lexicons and control speech parameters such as pronunciation, pitch, rate, pauses, and intonation with Speech Synthesis Markup Language (SSML) or with the audio content creation tool .
Deploy Text to Speech anywhere, from the cloud to the edge
Run Text to Speech wherever your data resides. Build lifelike speech synthesis into applications optimized for both robust cloud capabilities and edge locality using containers .
Build a custom voice for your brand
Differentiate your brand with a unique custom voice . Develop a highly realistic voice for more natural conversational interfaces using the Custom Neural Voice capability, starting with 30 minutes of audio.
Fuel App Innovation with Cloud AI Services
Learn five key ways your organization can get started with AI to realize value quickly.
Comprehensive privacy and security
Documentation.
AI Speech, part of Azure AI Services, is certified by SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO.
View and delete your custom voice data and synthesized speech models at any time. Your data is encrypted while it’s in storage.
Your data remains yours. Your text data isn't stored during data processing or audio voice generation.
Backed by Azure infrastructure, AI Speech offers enterprise-grade security, availability, compliance, and manageability.
Comprehensive security and compliance, built in
Microsoft invests more than $1 billion annually on cybersecurity research and development.

We employ more than 3,500 security experts who are dedicated to data security and privacy.

Azure has more certifications than any other cloud provider. View the comprehensive list .

Flexible pricing gives you the power and control you need
Pay only for what you use, with no upfront costs. With Text to Speech, you pay as you go based on the number of characters you convert to audio.
Get started with an Azure free account

After your credit, move to pay as you go to keep building with the same free services. Pay only if you use more than your free monthly amounts.

Guidelines for building responsible synthetic voices

Learn about responsible deployment
Synthetic voices must be designed to earn the trust of others. Learn the principles of building synthesized voices that create confidence in your company and services.

Obtain consent from voice talent
Help voice talent understand how neural text-to-speech (TTS) works and get information on recommended use cases.

Be transparent
Transparency is foundational to responsible use of computer voice generators and synthetic voices. Help ensure that users understand when they’re hearing a synthetic voice and that voice talent is aware of how their voice will be used. Learn more with our disclosure design guidelines.
Documentation and resources
Get started.
Read the documentation
Take the Microsoft Learn course
Get started with a 30-day learning journey
Explore code samples
Check out the sample code
See customization resources
Customize your speech solution with Speech studio . No code required.
Start building with AI Services
Text to Voice AI
Text to voice AI generator with 700 AI voices in 90 languages. Try free AI speech synthesis online. Quickly and conveniently generate audio from text.
In addition to these voices, Narakeet has 700 different voices text to speech in 90 languages . Real human voices will not be easy to tell from our text to voice generator.
Text to Speech AI
A TTS maker, especially one with near human voice text to speech, can save you hundreds of hours when making audiobooks, online lectures, video guides and more.
Play the video below for a quick tutorial on how to use our text to voice generators to produce realistic text to speech:
Narakeet can help you make realistic text to speech with natural voice overs using 700 voices in 90 languages, powered by AI text to speech voice generators. Make audio clips and dialogue in seconds. Narakeet can turn Word documents into text to speech MP3 with natural voices, make text to voice M4A audio or WAV using a realistic voice generator.
Text to Speech AI Free
Make content with a realistic AI voice easily. You can convert text to voice AI free 20 times. No registration required.
Create an audio now
Text to Voice Generator
Narakeet uses AI voice generators to produce text to speech with realistic voices. Our text to speech synthesis is based on neural network AI. Go from text to voice in seconds.
Can I use text to speech on YouTube?
All Narakeet voices can be used as text to speech for Youtube, even for commercial projects. We make sure that all voices available on the platform are free from copyright and royalty issues. Natural voice text to speech is a great way to create audio for your YouTube videos easily. Check out our guide on Using Text to Speech Voices on YouTube for the answers to the most frequently asked questions about monetization and copyright with text to voice generators.
Can I use text to voice in Word?
The “Dictate” feature of Microsoft Word can read out text, but it’s not easy to control the voice. Instead, upload the Word document to Narakeet and you can then choose among 700 high quality voices, and easily control the speed and volume to get the best results.
How do I turn my text into voice?
Narakeet is an easy option to convert text to speech. Paste the text into our text-to-audio tool and just click the “Create Audio” button. Get started with our text to speech free online - no registration needed.
How do text to speech programs work?
Text to speech synthesis is based on neural networks and machine learning, where an automated voice synthesizer matches patterns in your text to samples of audio read out by professional voice artists. The quality of text to voice generators depends on three things: the volume of training data used to produce a model, the quality of the neural network software processing the model, and the computing power available to generate the voice. Narakeet voices are realistic and natural, trained on large sets of sample texts so you can get the best results, running on massively scalable cloud infrastructure to provide much better computing resources than local devices. That is why our voices sound much better than those generated by text-to-speech software running offline.
How do I download audio from text-to-speech?
The Narakeet text-to-audio tool allows you to create realistic TTS and download it as WAV, M4A or MP3. You can select the file format by clicking on the plus button next to the voice selector to open additional options. Text to speech download MP3 is great if you want to optimize the file size. Select the WAV format for the best quality, and it will produce the best AI text to speech results. Use the M4A format for a good balance between size and quality.
How do I convert text-to-speech and save as MP3?
To make text to speech MP3 with natural voices, use the Narakeet text-to-audio tool , and click on the plus button next to the voice selector. A set of additional options will show, including the file format. Select the MP3 format from the drop-down and enter the script for the audio, then click the “Create Audio” button. Narakeet text to voice generator will create your text to audio mp3, and you will be able to download it in a few seconds.
How do I convert text to audio on my computer?
With Narakeet you can use the best AI voice generators in 90 languages directly from your browser, or any Internet connected device. Start using our realistic voice generator free, to create lifelike text to speech. Just open the text-to-audio tool , enter the text you want to convert to speech, and click the “Create Audio” button.
Free AI Speech Synthesis
Narakeet is a text to speech website, that can help you read text online, and convert everything from short messages to full books into audio, using 700 reading voices. Translate text to speech using our online text reader in minutes. Our platform supports multiple languages, allowing you to create global content with ease. With text to speech, you can turn words into a voice that sounds just like a real person talking.
How do I translate text to voice?
To translate text to voice, simply use the Narakeet Text to Audio tool. You can type your text, copy and paste it, or upload a document with in many popular formats, Word and PDF included, and then convert it into MP3, MP4 or WAV audio files. Our 700 realistic voice generators will read your text in 90 languages and accents.
If you’re creating content for an online audience, text to audio conversion can make your work more accessible and engaging. You can convert your written articles, blogs, or scripts into audio, offering your audience a different way to consume your content, perfect for those who prefer to listen rather than read.
How do I translate text to voice on iPhone?
Just open our Text To Voice Generator in Safari, or any other browser that you have on the iPhone. Our text to speech app works perfectly in modern mobile browsers, and gives you access to realistic AI voices in the cloud, on an environment much more powerful than consumer devices. This means that the voices are of much higher quality than what a phone could produce.
Next, simply input your text or upload your document and choose the voice and language you prefer. Once the translation is complete, you can listen to it straight away, or download the audio file for offline use, making it incredibly easy to turn any written content into spoken words on your iPhone.
How can I convert text to audio for free?
Convert text to audio for free 20 times with the Narakeet Text To Voice Generator . You do not even need to register. Just type your text and click the “Create Audio” button to convert your text into an audio file. You can make MP3 files for wide distribution, or WAV files for professional recording and including into videos and social media reels or stories.
After conversion, you’ll be able to download your audio file instantly, offering you quick and easy access to your converted text. Whether you need a voiceover for a project, want to convert a blog post into a podcast, or simply want an audio version of a document, our free service makes it as simple as a few clicks.
For more capacity and larger files, select one of our paid plans .
Is there a way to turn text into audio?
Yes, there is a way to turn text into audio, quite easily. Just type your text into the Narakeet Text To Voice Generator , and click “Create Audio”. Our online text to speech translator can turn text in 90 into audio.
The audio file created will be ready for you to download in just a few seconds. You can then use the content wherever you need, whether it’s for studying, publishing online, sharing information with others, or making your content more accessible. Turning text into audio is a simple and efficient method to bring your content to life in a new and dynamic way.
Is there a free to use text to speech voice?
All our 700 are free to use, up to 20 times. You do not even have to create an account. Just type your text and start converting it to audio. After that, you can select one of our paid plans to get more capacity and continue using text to speech voices.
This makes it easy and affordable to transform your text into audio for various needs, like making your content more accessible or creating audio versions of your writings. Plus, our tool gives you options for different voices and languages, so you can select the one that best fits your requirements.
Narakeet helps you create text to speech voiceovers , turn Powerpoint presentations and Markdown scripts into engaging videos. It is under active development, so things change frequently. Keep up to date: RSS , Slack , Twitter , YouTube , Facebook , Instagram , TikTok
Free AI Text to Speech Online

Click to generate speech in:
Intelligent ai speech synthesis, diverse and dynamic voices, emotional range..
Diverse emotional inflections tailored for every narrative need.
Multilingual Capability.
All our voices fluently span 29 languages, retaining unique characteristics across each.
Voice Variety.
Design with Voice Design, explore with Voice Library, or select top-tier voice actors for unmatched natural voice quality.

Text to Speech in 29 Languages
Precision voice tuning.
Choose between expressive variability or consistent stability to fit your content's tone.
Clarity + Similarity Enhancement
Optimize for clear, artifact-free voices or enhance for speaker resemblance.
Style Exaggeration
Accentuate voice styles or prioritize speed and stability.
Text to speech for teams of all sizes

The voices are really amazing and very natural sounding. Even the voices for other languages are impressive. This allows us to do things with our educational content that would not have been possible in the past.
It's amazing to see that text to speech became that good. Write your text, select a voice and receive stunning and near-perfect results! Regenerating results will also give you different results (depending on the settings). The service supports 30+ languages, including Dutch (which is very rare). ElevenLabs has proved that it isn't impossible to have near-perfect text-to-speech 'Dutch'...
We use the tool daily for our content creation. Cloning our voices was incredibly simple. It's an easy-to-navigate platform that delivers exceptionally high quality. Voice cloning is just a matter of uploading an audio file, and you're ready to use the voice. We also build apps where we utilize the API from ElevenLabs; the API is very simple for developers to use. So, if you need a...
As an author I have written numerous books but have been limited by my inability to write them in other languages period now that I have found 11 labs, it has allowed me to create my own voice so that when writing them in different languages it's not someone else's voice but my own. That's certainly lends a level of authenticity that no other narrator can provide me.
ElevenLabs came to my notice from some Youtube videos that complained how this app was used to clone the US presidents voice. Apparently the app did its job very well. And that is the best thing about ElevenLabs. It does its job well. Converting text to speech is done very accurately. If you choose one of the 100s of voices available in the app, the quality of the output is superior to all...
Absolutely loving ElevenLabs for their spot-on voice generations! 🎉 Their pronunciation of Bahasa Indonesia is just fantastic - so natural and precise. It's been a game-changer for making tech and communication feel more authentic and easy. Big thumbs up! 👍
I have found ElevenLabs extremely useful in helping me create an audio book utilizing a clone of my own voice. The clone was super easy to create using audio clips from a previous audio book I recorded. And, I feel as though my cloned voice is pretty similar to my own. Using ElevenLabs has been a lot easier than sitting in front of a boom mic for hours on end. Bravo for a great AI product!
The variety of voices and the realness that expresses everything that is asked of it
I like that ElevenLabs uses cutting-edge AI and deep learning to create incredibly natural-sounding speech synthesis and text-to-speech. The voices generated are lifelike and emotive.
A fast and easy-to-use text to speech API
We obsess over building the fastest and simplest text to speech API so you can focus on building incredible applications.

Ultra-low latency.
We deliver streamed audio in under a second.
Ease of use.
ElevenLabs brings the most compelling, rich and lifelike voices to developers in just a few lines of code.
Developer Community.
Get all the help you need through our expert community.
Global AI Speech Generator

Language selection
Accent selection, audio generation, wall of text to speech voices, how to use text to speech, choose your preferred voice, settings, and model..
For a pre-made voice, you can use our extensive library of voices. Or, you can clone, customize and fine-tune voices.

Enter the text you want to convert to speech.
Write naturally in any of our supported languages. Our AI will understand the language and context.

Generate spoken audio and instantly listen to the results.
Convert written text to high-quality files that can be downloaded in a variety of audio formats.

Perfect Your Sound
Punctuation.
The placement of commas, periods, and other punctuation significantly influences the delivery and pauses in the output.
Longer text provides added context, ensuring a smoother and more natural audio flow.
Speaker Profile
Match your content to the ideal speaker. Different profiles have distinct delivery styles, catering to various tones and emotions.
Voice Settings
Refine your output by adjusting voice settings. Find the perfect balance to enhance clarity and authenticity.
Text to Speech Use Cases
Our AI text to speech software is designed to be flexible and easy to use, with a variety of voice options to suit your needs.
Take content creation to the next level
Create immersive gaming experiences, publish your written works, build engaging ai chatbots.

Why ElevenLabs Text to Speech?
Efficient content production..
Transform long written content to audio, fast. Maximize reach without traditional recording constraints.
Advanced API.
Seamlessly integrate and experience dynamic TTS capabilities.
Contextual TTS.
Our AI reads between the lines, capturing the heart of the content.
Language Authenticity.
Experience genuine speech in 29 languages, from nuances to native idioms.
Comprehensive Support.
Never feel lost. Our dedicated support and rich resource library mean you're always equipped to make the most of our cutting-edge technology.
Ethical AI Principles.
We prioritize user privacy, data protection, and uphold the highest ethical standards in AI development and deployment.
Frequently asked questions
How does the elevenlabs ai text to speech differ from other tts technologies.
ElevenLabs TTS leverages advanced deep learning models which are regularly updated and refined, ensuring high-quality audio output, emotion mapping, and a vast range of vocal choices for your ideal custom voice.
Can I customize the voice settings to match specific content needs?
Absolutely. Users can adjust Stability, Clarity, and Enhancement settings, allowing for voice outputs that range from entertainingly expressive to professionally sincere. Our platform provides the flexibility to match your content's unique requirements.
What is AI text to speech used for?
Text to speech has a vast array of applications, some are well established but more are emerging all the time. TTS is ideal for creating explainer videos, converting books into audio and producing creative video content without hiring voice actors. Our speech technology is ideal for any situation where accessibility and engagement can be improved through communicated written content in a high-quality voice.
What does "text to speech with emotion" mean?
It means our artificial intelligence model understands the context and can deliver the natural sounding speech with appropriate emotional intonations – be it excitement, sorrow, or neutrality. It adds a layer of realism, making the speech output more relatable and engaging.
How many languages does ElevenLabs support?
ElevenLabs proudly supports text to speech synthesis in 29 languages, ensuring that your content can resonate with a global audience.
How varied are the voice options available on ElevenLabs?
We offer a diverse range of voice profiles, catering to different tones, accents, and emotions. Whether you're seeking a particular regional accent or a specific emotional delivery, ElevenLabs ensures you find the perfect match for your content.
How secure is my data with ElevenLabs?
User data privacy and security are our top priorities. All user data and text inputs are handled with the utmost care, ensuring they are not used beyond the specified service purpose.
Does ElevenLabs offer an API for developers?
Yes, we provide a robust API that allows developers to integrate our advanced text-to-speech capabilities into their own applications, platforms, or tools.
How can I turn text into mp3 speech?
ElevenLabs makes it easy to turn text into mp3. Simply enter your text, choose a voice, generate the audio, and download.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 20 May 2024
A bilingual speech neuroprosthesis driven by cortical articulatory representations shared between languages
- Alexander B. Silva ORCID: orcid.org/0000-0003-0838-4136 1 , 2 , 3 ,
- Jessie R. Liu ORCID: orcid.org/0000-0001-9316-7624 1 , 2 , 3 ,
- Sean L. Metzger 1 , 2 , 3 ,
- Ilina Bhaya-Grossman 1 , 2 , 3 ,
- Maximilian E. Dougherty ORCID: orcid.org/0000-0002-0698-5678 1 ,
- Margaret P. Seaton 1 ,
- Kaylo T. Littlejohn 1 , 2 , 4 ,
- Adelyn Tu-Chan 5 ,
- Karunesh Ganguly ORCID: orcid.org/0000-0002-2570-9943 2 , 5 ,
- David A. Moses 1 , 2 &
- Edward F. Chang ORCID: orcid.org/0000-0003-2480-4700 1 , 2 , 3
Nature Biomedical Engineering ( 2024 ) Cite this article
407 Accesses
88 Altmetric
Metrics details
- Amyotrophic lateral sclerosis
- Biomedical engineering
- Brain–machine interface
Advancements in decoding speech from brain activity have focused on decoding a single language. Hence, the extent to which bilingual speech production relies on unique or shared cortical activity across languages has remained unclear. Here, we leveraged electrocorticography, along with deep-learning and statistical natural-language models of English and Spanish, to record and decode activity from speech-motor cortex of a Spanish–English bilingual with vocal-tract and limb paralysis into sentences in either language. This was achieved without requiring the participant to manually specify the target language. Decoding models relied on shared vocal-tract articulatory representations across languages, which allowed us to build a syllable classifier that generalized across a shared set of English and Spanish syllables. Transfer learning expedited training of the bilingual decoder by enabling neural data recorded in one language to improve decoding in the other language. Overall, our findings suggest shared cortical articulatory representations that persist after paralysis and enable the decoding of multiple languages without the need to train separate language-specific decoders.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
92,52 € per year
only 7,71 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Similar content being viewed by others

The speech neuroprosthesis

A high-performance speech neuroprosthesis

Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis
Data availability.
The data needed to recreate the main figures are provided as Source Data , and are also available in GitHub at https://github.com/asilvaalex4/bilingual_speech_bci . The raw patient data are accessible to researchers from other institutions, but public sharing is restricted pursuant to our clinical trial protocol. Full access to the data will be granted on reasonable request to E.F.C. at [email protected], and a response can be expected in under 3 weeks. Shared data must be kept confidential and not provided to others unless approval is obtained. Shared data will not contain any information that may identify the participant, to protect their anonymity. Source data are provided with this paper.
Code availability
The code required to replicate the main findings of the study is available via GitHub at https://github.com/asilvaalex4/bilingual_speech_bci .
Nip, I. & Roth, C. R. in Encyclopedia of Clinical Neuropsychology (eds Kreutzer, J. et al.) 1-1 (Springer, 2017).
Chartier, J., Anumanchipalli, G. K., Johnson, K. & Chang, E. F. Encoding of articulatory kinematic trajectories in human speech sensorimotor cortex. Neuron 98 , 1042–1054.e4 (2018).
Article CAS PubMed PubMed Central Google Scholar
Herff, C. et al. Generating natural, intelligible speech from brain activity in motor, premotor, and inferior frontal cortices. Front. Neurosci. 13 , 1267 (2019).
Article PubMed PubMed Central Google Scholar
Moses, D. A., Leonard, M. K., Makin, J. G. & Chang, E. F. Real-time decoding of question-and-answer speech dialogue using human cortical activity. Nat. Commun. 10 , 3096 (2019).
Soroush, P. Z. et al. The nested hierarchy of overt, mouthed, and imagined speech activity evident in intracranial recordings. NeuroImage 269 , 119913 (2023).
Article PubMed Google Scholar
Thomas, T. M. et al. Decoding articulatory and phonetic components of naturalistic continuous speech from the distributed language network. J. Neural Eng. 20 , 046030 (2023).
Article Google Scholar
Stavisky, S. D. et al. Neural ensemble dynamics in dorsal motor cortex during speech in people with paralysis. eLife 8 , e46015 (2019).
Willett, F. R. et al. A high-performance speech neuroprosthesis. Nature 620 , 1031–1036 (2023).
Wandelt, S. K. et al. Decoding grasp and speech signals from the cortical grasp circuit in a tetraplegic human. Neuron 110 , 1777–1787.e3 (2022).
Angrick, M. et al. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 16 , 036019 (2019).
Berezutskaya, J. et al. Direct speech reconstruction from sensorimotor brain activity with optimized deep learning models. J. Neural Eng. 20 , 056010 (2023).
Dash, D., Ferrari, P. & Wang, J. Decoding imagined and spoken phrases from non-invasive neural (MEG) signals. Front. Neurosci. 14 , 290 (2020).
Moses, D. A. et al. Neuroprosthesis for decoding speech in a paralyzed person with anarthria. N. Engl. J. Med. 385 , 217–227 (2021).
Mugler, E. M. et al. Direct classification of all American English phonemes using signals from functional speech motor cortex. J. Neural Eng. 11 , 035015 (2014).
Metzger, S. L. et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature 620 , 1037–1046 (2023).
Choe, J. et al. Language-specific effects on automatic speech recognition errors for world Englishes. In Proc. 29th International Conference on Computational Linguistics 7177–7186 (International Committee on Computational Linguistics, 2022).
DiChristofano, A., Shuster, H., Chandra, S. & Patwari, N. Global performance disparities between English-language accents in automatic speech recognition. Preprint at http://arxiv.org/abs/2208.01157 (2023).
Baker, C. & Jones, S. Encyclopedia of Bilingualism and Bilingual Education (Multilingual Matters, 1998).
Athanasopoulos, P. et al. Two languages, two minds: flexible cognitive processing driven by language of operation. Psychol. Sci. 26 , 518–526 (2015).
Chen, S. X. & Bond, M. H. Two languages, two personalities? Examining language effects on the expression of personality in a bilingual context. Pers. Soc. Psychol. Bull. 36 , 1514–1528 (2010).
Costa, A. & Sebastián-Gallés, N. How does the bilingual experience sculpt the brain? Nat. Rev. Neurosci. 15 , 336–345 (2014).
Naranowicz, M., Jankowiak, K. & Behnke, M. Native and non-native language contexts differently modulate mood-driven electrodermal activity. Sci. Rep. 12 , 22361 (2022).
Li, Q. et al. Monolingual and bilingual language networks in healthy subjects using functional MRI and graph theory. Sci. Rep. 11 , 10568 (2021).
Pierce, L. J., Chen, J.-K., Delcenserie, A., Genesee, F. & Klein, D. Past experience shapes ongoing neural patterns for language. Nat. Commun. 6 , 10073 (2015).
Article CAS PubMed Google Scholar
Dehaene, S. Fitting two languages into one brain. Brain 122 , 2207–2208 (1999).
Kim, K. H. S., Relkin, N. R., Lee, K.-M. & Hirsch, J. Distinct cortical areas associated with native and second languages. Nature 388 , 171–174 (1997).
Tham, W. W. P. et al. Phonological processing in Chinese–English bilingual biscriptals: an fMRI study. NeuroImage 28 , 579–587 (2005).
Xu, M., Baldauf, D., Chang, C. Q., Desimone, R. & Tan, L. H. Distinct distributed patterns of neural activity are associated with two languages in the bilingual brain. Sci. Adv. 3 , e1603309 (2017).
Berken, J. A. et al. Neural activation in speech production and reading aloud in native and non-native languages. NeuroImage 112 , 208–217 (2015).
Del Maschio, N. & Abutalebi, J. The Handbook of the Neuroscience of Multilingualism (Wiley-Blackwell, 2019).
DeLuca, V., Rothman, J., Bialystok, E. & Pliatsikas, C. Redefining bilingualism as a spectrum of experiences that differentially affects brain structure and function. Proc. Natl Acad. Sci. USA 116 , 7565–7574 (2019).
Liu, H., Hu, Z., Guo, T. & Peng, D. Speaking words in two languages with one brain: neural overlap and dissociation. Brain Res. 1316 , 75–82 (2010).
Shimada, K. et al. Fluency-dependent cortical activation associated with speech production and comprehension in second language learners. Neuroscience 300 , 474–492 (2015).
Treutler, M. & Sörös, P. Functional MRI of native and non-native speech sound production in sequential German–English Bilinguals. Front. Hum. Neurosci. 15 , 683277 (2021).
Cao, F., Tao, R., Liu, L., Perfetti, C. A. & Booth, J. R. High proficiency in a second language is characterized by greater involvement of the first language network: evidence from Chinese learners of English. J. Cogn. Neurosci. 25 , 1649–1663 (2013).
Geng, S. et al. Intersecting distributed networks support convergent linguistic functioning across different languages in bilinguals. Commun. Biol. 6 , 99 (2023).
Malik-Moraleda, S. et al. An investigation across 45 languages and 12 language families reveals a universal language network. Nat. Neurosci. 25 , 1014–1019 (2022).
Perani, D. & Abutalebi, J. The neural basis of first and second language processing. Curr. Opin. Neurobiol. 15 , 202–206 (2005).
Alario, F.-X., Goslin, J., Michel, V. & Laganaro, M. The functional origin of the foreign accent: evidence from the syllable-frequency effect in bilingual speakers. Psychol. Sci. 21 , 15–20 (2010).
Simmonds, A., Wise, R. & Leech, R. Two tongues, one brain: imaging bilingual speech production. Front. Psychol. 2 , 166 (2011).
Hannun, A. Y., Maas, A. L., Jurafsky, D. & Ng, A. Y. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. Preprint at https://arxiv.org/abs/1408.2873 (2014).
Metzger, S. L. et al. Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis. Nat. Commun. 13 , 6510 (2022).
Willett, F. R., Avansino, D. T., Hochberg, L. R., Henderson, J. M. & Shenoy, K. V. High-performance brain-to-text communication via handwriting. Nature 593 , 249–254 (2021).
Radford, A. et al. Language models are unsupervised multitask learners. Preprint at Semantic Scholar https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe (2018).
Blakely, T., Miller, K. J., Zanos, S. P., Rao, R. P. N. & Ojemann, J. G. Robust, long-term control of an electrocorticographic brain–computer interface with fixed parameters. Neurosurg. Focus 27 , E13 (2009).
Pels, E. G. M. et al. Stability of a chronic implanted brain–computer interface in late-stage amyotrophic lateral sclerosis. Clin. Neurophysiol. 130 , 1798–1803 (2019).
Silversmith, D. B. et al. Plug-and-play control of a brain–computer interface through neural map stabilization. Nat. Biotechnol. 39 , 326–335 (2021).
Volkova, K., Lebedev, M. A., Kaplan, A. & Ossadtchi, A. Decoding movement from electrocorticographic activity: a review. Front. Neuroinform. 13 , 74 (2019).
Luo, S. et al. Stable decoding from a speech BCI enables control for an individual with ALS without recalibration for 3 months. Adv. Sci. 10 , 2304853 (2023).
Bouchard, K. E., Mesgarani, N., Johnson, K. & Chang, E. F. Functional organization of human sensorimotor cortex for speech articulation. Nature 495 , 327–332 (2013).
Carey, D., Krishnan, S., Callaghan, M. F., Sereno, M. I. & Dick, F. Functional and quantitative MRI mapping of somatomotor representations of human supralaryngeal vocal tract. Cereb. Cortex 27 , 265–278 (2017).
PubMed PubMed Central Google Scholar
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space. Preprint at https://arxiv.org/abs/1301.3781v3 (2013).
Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proc. IEEE Pacific Rim Conference on Communications, Computers and Signal Processing 125–128 (IEEE, 1993).
Mitra, V. et al. Joint modeling of articulatory and acoustic spaces for continuous speech recognition tasks. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 5205 (IEEE, 2017).
Caruana, R. Multitask learning. Mach. Learn. 28 , 41–75 (1997).
Tan, C. et al. A survey on deep transfer learning. In Artificial Neural Networks and Machine Learning – ICANN 2018 (eds Kůrková, V. et al.) 270–279 (Springer, 2018).
Makin, J. G., Moses, D. A. & Chang, E. F. Machine translation of cortical activity to text with an encoder–decoder framework. Nat. Neurosci. 23 , 575–582 (2020).
Peterson, S. M., Steine-Hanson, Z., Davis, N., Rao, R. P. N. & Brunton, B. W. Generalized neural decoders for transfer learning across participants and recording modalities. J. Neural Eng. 18 , 026014 (2021).
Watanabe, S., Delcroix, M., Metze, F. & Hershey, J. R. New Era for Robust Speech Recognition: Exploiting Deep Learning (Springer, 2017).
Gao, H. et al. Domain generalization for language-independent automatic speech recognition. Front. Artif. Intell. 5 , 806274 (2022).
Radford, A. et al. Robust speech recognition via large-scale weak supervision. Preprint at http://arxiv.org/abs/2212.04356 (2022).
Zhang, Y. et al. Google USM: scaling automatic speech recognition beyond 100 languages. Preprint at http://arxiv.org/abs/2303.01037 (2023).
Hartshorne, J. K., Tenenbaum, J. B. & Pinker, S. A critical period for second language acquisition: evidence from 2/3 million English speakers. Cognition 177 , 263–277 (2018).
Huggins, J. E., Wren, P. A. & Gruis, K. L. What would brain–computer interface users want? Opinions and priorities of potential users with amyotrophic lateral sclerosis. Amyotroph. Lateral Scler. 12 , 318–324 (2011).
Peters, B. et al. Brain–computer interface users speak up: the Virtual Users’ Forum at the 2013 International Brain-Computer Interface Meeting. Arch. Phys. Med. Rehabil. 96 , S33–S37 (2015).
Herff, C. et al. Brain-to-text: decoding spoken phrases from phone representations in the brain. Front. Neurosci. 9 , 217 (2015).
Tang, J., LeBel, A., Jain, S. & Huth, A. G. Semantic reconstruction of continuous language from non-invasive brain recordings. Nat. Neurosci. 26 , 858–866 (2023).
Correia, J. et al. Brain-based translation: fMRI decoding of spoken words in bilinguals reveals language-independent semantic representations in anterior temporal lobe. J. Neurosci. 34 , 332–338 (2014).
Lucas, T. H., McKhann, G. M. & Ojemann, G. A. Functional separation of languages in the bilingual brain: a comparison of electrical stimulation language mapping in 25 bilingual patients and 117 monolingual control patients. J. Neurosurg. 101 , 449–457 (2004).
Giussani, C., Roux, F.-E., Lubrano, V., Gaini, S. M. & Bello, L. Review of language organisation in bilingual patients: what can we learn from direct brain mapping? Acta Neurochir. 149 , 1109–1116 (2007).
Best, C. T. The diversity of tone languages and the roles of pitch variation in non-tone languages: considerations for tone perception research. Front. Psychol. 10 , 364 (2019).
Li, Y., Tang, C., Lu, J., Wu, J. & Chang, E. F. Human cortical encoding of pitch in tonal and non-tonal languages. Nat. Commun. 12 , 1161 (2021).
Lee, G. & Li, H. Modeling code-switch languages using bilingual parallel corpus. In Proc. 58th Annual Meeting of the Association for Computational Linguistics 860–870 (Association for Computational Linguistics, 2020).
Rossi, E., Dussias, P. E., Diaz, M., van Hell, J. G. & Newman, S. Neural signatures of inhibitory control in intra-sentential code-switching: evidence from fMRI. J. Neurolinguist. 57 , 100938 (2021).
Zheng, X., Roelofs, A., Erkan, H. & Lemhöfer, K. Dynamics of inhibitory control during bilingual speech production: an electrophysiological study. Neuropsychologia 140 , 107387 (2020).
Moses, D. A., Leonard, M. K. & Chang, E. F. Real-time classification of auditory sentences using evoked cortical activity in humans. J. Neural Eng. 15 , 036005 (2018).
Ludwig, K. A. et al. Using a common average reference to improve cortical neuron recordings from microelectrode arrays. J. Neurophysiol. 101 , 1679–1689 (2009).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. Preprint at https://arxiv.org/abs/1412.6980 (2017).
Cho, K. et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. Preprint at https://arxiv.org/abs/1406.1078 (2014).
Fort, S., Hu, H. & Lakshminarayanan, B. Deep ensembles: a loss landscape perspective. Preprint at https://arxiv.org/abs/1912.02757 (2020).
Simonyan, K., Vedaldi, A. & Zisserman, A. Deep inside convolutional networks: visualising image classification models and saliency maps. Preprint at https://arxiv.org/abs/1312.6034 (2014).
Lux, F., Koch, J., Schweitzer, A. & Vu, N. T. The IMS Toucan system for the Blizzard Challenge 2021. Preprint at https://arxiv.org/pdf/2310.17499 (2021).
Download references
Acknowledgements
We thank our participant ‘Pancho’ for his tireless perseverance, commitment and dedication to the work described in this paper, and his family and caregivers for their incredible support. We also thank members of the Chang lab for feedback on the project; V. Her for administrative support; B. Spidel for imaging reconstruction; T. Dubnicoff for video editing; J. Davidson for help in designing initial bilingual stimuli; C. Kurtz-Miott, V. Anderson and S. Brosler for help with data collection with our participant; and the members of Karunesh Ganguly’s lab for help with the clinical trial. The National Institutes of Health (grant NIH U01 DC018671-01A1) and the William K. Bowes, Jr. Foundation supported authors S.L.M., J.R.L., D.A.M., M.E.D., M.P.S., K.T.L. and E.F.C. A.B.S. was supported by the National Institute of General Medical Sciences (NIGMS) Medical Scientist Training Program (Grant #T32GM007618) and by the National Institute On Deafness And Other Communication Disorders of the National Institutes of Health (award number F30DC021872). K.T.L. was supported by the National Science Foundation GRFP. A.T.-C. and K.G. did not have relevant funding for this work.
Author information
Authors and affiliations.
Department of Neurological Surgery, University of California, San Francisco, San Francisco, CA, USA
Alexander B. Silva, Jessie R. Liu, Sean L. Metzger, Ilina Bhaya-Grossman, Maximilian E. Dougherty, Margaret P. Seaton, Kaylo T. Littlejohn, David A. Moses & Edward F. Chang
Weill Institute for Neuroscience, University of California, San Francisco, San Francisco, CA, USA
Alexander B. Silva, Jessie R. Liu, Sean L. Metzger, Ilina Bhaya-Grossman, Kaylo T. Littlejohn, Karunesh Ganguly, David A. Moses & Edward F. Chang
University of California, Berkeley - University of California, San Francisco Graduate Program in Bioengineering, Berkeley, CA, USA
Alexander B. Silva, Jessie R. Liu, Sean L. Metzger, Ilina Bhaya-Grossman & Edward F. Chang
Department of Electrical Engineering and Computer Sciences, University of California, Berkeley, Berkeley, CA, USA
Kaylo T. Littlejohn
Department of Neurology, University of California, San Francisco, San Francisco, CA, USA
Adelyn Tu-Chan & Karunesh Ganguly
You can also search for this author in PubMed Google Scholar
Contributions
A.B.S. developed deep-learning classification and language models. J.R.L. developed speech detection models. D.A.M. implemented software for online decoding and data collection. A.B.S. generated figures and performed statistical analyses. A.B.S., along with J.R.L., wrote the manuscript with input from I.B.-G., S.L.M., K.T.L., D.A.M. and E.F.C. A.B.S. and D.A.M., along with J.R.L., S.L.M., I.B.-G. and M.E.D., designed the experiments, utterance sets and analyses. A.B.S., M.E.D. and M.P.S. led data collection with help from J.R.L., S.L.M., K.T.L. and D.A.M. M.P.S., A.T.-C., K.G. and E.F.C. performed regulatory and clinical supervision. E.F.C. conceived and supervised the study.
Corresponding author
Correspondence to Edward F. Chang .
Ethics declarations
Competing interests.
S.L.M., D.A.M., J.R.L. and E.F.C. are inventors on a pending provisional UCSF patent application relevant to the neural-decoding approaches used in this work (Application number: WO2022251472A1, 2022, WIPO PCT - International patent system). G.K.A. and E.F.C. are inventors on patent application PCT/US2020/028926; D.A.M. and E.F.C. are inventors on patent application PCT/US2020/043706; and E.F.C. is an inventor on patent US9905239B2. These patents are broadly relevant to the neural-decoding approaches used in this work. The remaining authors declare no competing interests.
Peer review
Peer review information.
Nature Biomedical Engineering thanks Vikash Gilja, Jonas Obleser and Karim Oweiss for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended data fig. 1 timing and information flow through the bilingual-sentence decoding system..
Shown is a more detailed schematic overview of the bilingual-sentence decoding system to complement Fig. 1a . Three levels of information are depicted: the neural features, the decoding system, and the output to the participant monitor. To start, the participant makes a speech attempt. This is detected by the system and cues activation of an ongoing decoding process. Following activation, a series of 3.5 s windows are cued to the participant. At the end of each window, after the full 3.5 s have passed, the neural features from that window are passed to the decoding process illustrated in Fig. 1a . Following a latency to conduct the decoding, the most likely beam from the process in Fig. 1a is displayed on the participant monitor. This process continues to occur for sequential 3.5 s windows until a window with no detected speech occurs. After such a window, the decoding is finalized and terminated. The system then listens for another speech attempt to activate and repeat the process.
Extended Data Fig. 2 Graphical depiction of bilingual-word classification.
Shown is a schematic of the bilingual-word classification process. Neural features (256 total; 128 HGA and 128 LFS time series over 3.5 s) are classified as a word in the bilingual vocabulary. Neural features are first processed by a temporal convolution. Next, the features are passed through three bidirectional GRU layers. The latent state from these layers is then read out by a dense, linear layer that emits probabilities over the 104 words in the bilingual vocabulary. This process is performed by 10 distinct models, each with a different weight initialization and trained on different folds of the data. The probabilities generated across these 10 models are averaged to create one probability vector across the bilingual vocabulary. This vector is finally split by language and the probability for a given word is broadcast to all conjugated forms of the word before being combined with the language model, as shown in Fig. 1a .
Extended Data Fig. 3 Neural-only chance sentence-decoding performance.
Shown are neural-only specific chance sentence-decoding distributions, alongside the neural-only decoding performance shown in Fig. 1 . Here, we specifically computed a chance distribution with respect to neural-only decoding. We did this by shuffling the neural features and passing them through the classifier. The chance error rate was then computed the same way as for neural-only performance (**** P < 0.0001; two-sided Mann-Whitney U-test with 3-way Holm-Bonferroni correction for multiple comparisons). Distributions are over 21 online phrase-decoding blocks. Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Source data
Extended data fig. 4 performance of attempted speech model on silent reading and listening..
For a subset of 10 bilingual words, we collected neural features during attempted speech, passive listening, and silent reading (roughly 250 trials in each paradigm). A model was trained on attempted speech data, using the same procedure throughout the manuscript, and evaluated on neural features from held-out attempted speech, passive listening, and silent reading trials. Performance was not significantly different from chance when evaluating the attempted speech model on listening or silent reading, in contrast to evaluation on attempted speech. This provides evidence that attempted speech neural features are specific to motor production of speech and not reflecting a process that strongly underlies listening or silent reading. Results are from 10-fold cross validation within each paradigm. Dashed line indicates chance performance (10%). Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 5 Classification accuracy over the full 104 bilingual-words.
a , Shown is unmasked classification accuracy over the full 104 bilingual-words. The classifier retained stable performance without retraining (weights frozen at black dotted line) as in Fig. 2b . b , Classification performance before and after a 30-day break in recording without retraining (P = 0.31, two- sided Mann-Whitney U-test). Distributions are over 5 days. c , 10-fold cross validation (CV) accuracy over the unmasked 104 bilingual-words using all collected data. Median CV accuracy 47.24% (99% CI: [45.83,48.23] %). Distributions are over 10 non-overlapping folds. Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 6 Acoustic similarity of words within the English and Spanish bilingual words.
For each word in the English vocabulary we calculated the mean pairwise mel-cepstral distortion (MCD) to all other English words. We repeated the same procedure for Spanish. Distributions are over 51 English and 50 Spanish words (shared words were excluded). English words have a significantly lower mean pairwise MCD (**** P < 0.0001, two-sided Mann-Whitney U-test). This indicates that English words, on average, are more acoustically confusable with other English words than Spanish words are with other Spanish words. Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 7 Effects of re-training models daily during frozen-decoder evaluation.
Shown is a comparison between performance with and without re-calibration. (a) Shown is the performance without re-calibration for reference taken from (Fig. 2b ). (b) Shown is the performance with re-training the classifier with sequential addition of each day’s data. (c) Shown are distributions of accuracy with and without re-training, demonstrating that small improvements may be found with re-training the decoders with each day’s data. Distributions are over 9 days in each boxplot (starting after the first-day when retraining is possible). Chance is 1.85% for English, 1.89% for Spanish, and 1.87% for all words (masked). Box plots in all panels depict median (horizontal line inside box), 25th and 75th percentiles (box), 25th and 75th percentiles +/- 1.5 times the interquartile range (whiskers), and outliers (diamonds).
Extended Data Fig. 8 Distinct contributions of HGA and LFS to classifier performance.
Shown are plots of electrode contributions for HGA against LFS, separately for English (left) and Spanish (right) trained models (as in Fig. 2d,e ). The dotted lines indicate the 90th percentile of HGA and LFS contributions. The majority of electrodes only fall above the 90th percentile for one of HGA or LFS.
Extended Data Fig. 9 Full confusion matrix over all bilingual-words.
Full confusion matrix over the 104 bilingual-words. The sum of each row was normalized to 1, making confusion a proportion from (0-1). Predictions were generated using 10-fold cross validation over the full 104 bilingual-words with no masking (as in Extended Data Fig. 5 ).
Extended Data Fig. 10 Acoustic coverage of large-bilingual-phrase set.
We quantified the distribution of phonemes and phoneme place of articulation features to ensure the large-bilingual-phrase set covered a broad space in each language. We designed the large-bilingual-phrase set to sample a broad range of English (a) and Spanish (b) phonemes. We ensured that the relative proportion of phoneme place of articulation features was similar between English (c) and Spanish (d).
Supplementary information
Main supplementary information.
Supplementary Notes, Methods, Figures, Tables, References and Video captions.
Reporting Summary
Peer review file, supplementary video 1.
A demonstration of online word-by-word bilingual sentence decoding from the brain of a participant with paralysis.
Supplementary Video 2
A demonstration of online word-by-word bilingual sentence decoding from the brain of a participant with paralysis, using three new sentences.
Supplementary Video 3
The participant using the bilingual speech neuroprosthesis has a conversation with a researcher.
Supplementary Data 1
Source data for Supplementary Fig. 1.
Supplementary Data 2
Source data for Supplementary Fig. 2.
Supplementary Data 3
Source data for Supplementary Fig. 3.
Supplementary Data 4
Source data for Supplementary Fig. 4.
Source Data Fig. 1
Source data.
Source Data Fig. 2
Source data fig. 3, source data fig. 4, source data extended data fig. 3, source data extended data fig. 4, source data extended data fig. 5, source data extended data fig. 6, source data extended data fig. 7, source data extended data fig. 8, source data extended data fig. 9, source data extended data fig. 10, rights and permissions.
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Cite this article.
Silva, A.B., Liu, J.R., Metzger, S.L. et al. A bilingual speech neuroprosthesis driven by cortical articulatory representations shared between languages. Nat. Biomed. Eng (2024). https://doi.org/10.1038/s41551-024-01207-5
Download citation
Received : 15 June 2023
Accepted : 01 April 2024
Published : 20 May 2024
DOI : https://doi.org/10.1038/s41551-024-01207-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

IMAGES
VIDEO
COMMENTS
Text to speech (TTS) is a technology that converts text into spoken audio. It can read aloud PDFs, websites, and books using natural AI voices. Text-to-speech (TTS) technology can be helpful for anyone who needs to access written content in an auditory format, and it can provide a more inclusive and accessible way of communication for many ...
Create premium AI voices for free in any style and language with the most powerful online AI text to speech (TTS) software ever. Generate text-to-speech voiceovers in minutes with our character AI voice generator. ... ElevenLabs supports speech synthesis in 29 languages, making your content accessible to a global audience. Supported languages ...
Convert text into natural-sounding speech using an API powered by the best of Google's AI technologies. New customers get up to $300 in free credits to try Text-to-Speech and other Google Cloud products. Try Text-to-Speech free Contact sales. Improve customer interactions with intelligent, lifelike responses.
ReadSpeaker is leading the way in text to speech. ReadSpeaker offers a range of powerful text-to-speech solutions for instantly deploying lifelike, tailored voice interaction in any environment. With more than 20 years' experience, ReadSpeaker is "Pioneering Voice Technology". 10000. customers worldwide. 115. market-leading own-brand ...
Just type or paste your text, generate the voice-over, and download the audio file. Create realistic Voiceovers online! Insert any text to generate speech and download audio mp3 or wav for any purpose. Speak a text with AI-powered voices.You can convert text to voice for free for reference only. For all features, purchase the paid plans.
Murf: The Ultimate AI Text to Speech Software. If you are looking for a text to speech generator that can create stunning voiceovers for your tutorials, presentations, or videos, Murf is the one to go for. Murf can generate human-like, realistic, and natural-sounding voices. Its pièce de résistance is that Murf can do it in over 120+ unique ...
What makes Murf stand out among other ai text to speech tools is the fact that as an online voice generator, it lets you create quality outputs in a jiffy. From enterprises to small-medium businesses to individual content creators, everybody can generate realistic-sounding voice overs across different ages, languages, and accents using Murf. ...
Multi-Lingual Speech Synthesis. ... Type, paste or import text and instantly turn it into audio with our online Text to Speech editor. Enhance the audio with speech styles, pronunciations and SSML tags. 907 AI Voices. Choose from a growing library of 907 natural-sounding Text to Speech voices across 142 languages and accents.
Descript is an AI-powered audio and video editing tool that lets you edit podcasts and videos like a doc. Add captions and subtitles to your text-to-speech projects. Perfect for creating accessible content. Clone your voice to dub over audio mistakes with speech that sounds just like you. Create, host, and promote your own audio or video ...
Transform your text into high-quality audio online, effortlessly with our AI-powered text-to-speech generator. Over 200+ natural-sounding voices available. ... (Speech Synthesis Markup Language) features that allow you to customize the way your text is spoken and create a more engaging and natural-sounding voiceover.
It's all online, and completely free! This text-to-speech generator even works offline! ... It uses your browser's built-in voice synthesis technology, and so the voices will differ depending on the browser that you're using. ... Note: If the list of available text-to-speech voices is small, or all the voices sound the same, then you may need ...
TTSMaker is a free text-to-speech tool and an online text reader that can convert text to speech, ... TTSMaker is a free text-to-speech tool that provides speech synthesis services and supports multiple languages, including English, French, German, Spanish, Arabic, Chinese, Japanese, Korean, Vietnamese, etc., as well as various voice styles. ...
Text to speech, also known as TTS, read aloud, or even speech synthesis. It simply means using artificial intelligence to read words aloud be; it from a PDF, email, docs, or any website. There isn't a voice artist recording phrases or words, or even the entire article. ... With our free text to speech online converter you can type, paste, or ...
Text complexity, speech synthesis engine performance, and text length are some variables that affect how long it takes to synthesize text into speech. Modern AI-based text-to-speech systems can produce speech for short to medium-length texts almost instantly, usually in a few seconds. However, the synthesis process may take a little longer ...
Listen2it is the best option for creating realistic AI voices as Creating human-like voiceovers has become easy with Listen2It's 900+ text-to-speech voices in 145+ languages and dialects with further customising options. Our full-suite audio platform ensures that you don't need any other tools for creating perfect AI voices.
AI voice generator and text-to-speech tool. Generate natural-sounding voiceovers for videos using Synthesia's AI voice generator. No need for microphones, voice actors, or audio recordings. Select the AI voice you'd like to use, type in your text, and click Play to hear the result. Type in your text and click Play to transform it into speech.
Votrax® lets you generate your own high-quality audio files using advanced deep learning technologies to synthesize natural sounding human speech. The audio files can be used both online and offline in your web applications, mobile apps, presentations, and eLearning materials. Votrax supports twenty-nine languages (including English, French ...
Highlight Mode (Beta) Speak. Pause. Resume. Record. The speech synthesis reader is totally depend on your browser & operating system. It may work better on desktop than mobile browsers. Therefore, try it on several browsers to find your preferable voice. Read text aloud using the Web speech synthesis API of your browser's TTS.
AI Speech, part of Azure AI Services, is certified by SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO. View and delete your custom voice data and synthesized speech models at any time. Your data is encrypted while it's in storage. Your data remains yours. Your text data isn't stored during data processing or audio voice generation.
Free AI Speech Synthesis. Narakeet is a text to speech website, that can help you read text online, and convert everything from short messages to full books into audio, using 700 reading voices. Translate text to speech using our online text reader in minutes. Our platform supports multiple languages, allowing you to create global content with ...
High quality free text to speech online. Use AI text to speech to create realistic AI voices for games, videos, podcasts, and more for free. 0:00 / 0:00. ElevenLabs ll Eleven Labs. Open menu. Products. Research. ... ElevenLabs proudly supports text to speech synthesis in 29 languages, ensuring that your content can resonate with a global ...
Voicery creates natural-sounding Text-to-Speech (TTS) engines and custom brand voices for enterprise. Our solutions leverage cutting-edge deep-learning research optimized for your business use-case and technical infrastructure. ... The most advanced neural speech synthesis engine on the market. Custom voices with accents and emotions, powered ...
Speech synthesis was accomplished through online decoding of ECoG signals generated during overt speech production from cortical regions previously shown to represent articulation and phonation ...
Azure AI speech to text enables developers to quickly and accurately transcribe audio to text in more than 100 languages and variants.It also supports custom models to enhance accuracy for domain-specific terminology. At Microsoft Build we are announcing a new Fast Transcription API in preview in June which enables developers to create accurate transcripts of audio with 40x RTF processing.
To allow the participant to volitionally engage and disengage the decoding system, we trained a speech detection model to detect attempted speech from neural features online. The speech detector ...