Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.

10 Experimental research
Experimental research—often considered to be the ‘gold standard’ in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research—rather than for descriptive or exploratory research—where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalisability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments are conducted in field settings such as in a real organisation, and are high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favourably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receiving a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the ‘cause’ in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and ensures that each unit in the population has a positive chance of being selected into the sample. Random assignment, however, is a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group prior to treatment administration. Random selection is related to sampling, and is therefore more closely related to the external validity (generalisability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam.
Not conducting a pretest can help avoid this threat.
Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
Regression threat —also called a regression to the mean—refers to the statistical tendency of a group’s overall performance to regress toward the mean during a posttest rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest were possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-group experimental designs

Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest-posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement—especially if the pretest introduces unusual topics or content.
Posttest -only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

The treatment effect is measured simply as the difference in the posttest scores between the two groups:
![\[E = (O_{1} - O_{2})\,.\]](https://usq.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-90f2ce47275e7b35def5c5b52b7d7d45_l3.png "Rendered by QuickLaTeX.com")
The appropriate statistical analysis of this design is also a two-group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.

Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:
Due to the presence of covariates, the right statistical analysis of this design is a two-group analysis of covariance (ANCOVA). This design has all the advantages of posttest-only design, but with internal validity due to the controlling of covariates. Covariance designs can also be extended to pretest-posttest control group design.
Factorial designs
Two-group designs are inadequate if your research requires manipulation of two or more independent variables (treatments). In such cases, you would need four or higher-group designs. Such designs, quite popular in experimental research, are commonly called factorial designs. Each independent variable in this design is called a factor , and each subdivision of a factor is called a level . Factorial designs enable the researcher to examine not only the individual effect of each treatment on the dependent variables (called main effects), but also their joint effect (called interaction effects).

In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for three hours/week of instructional time than for one and a half hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid experimental designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomised bocks design, Solomon four-group design, and switched replications design.
Randomised block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full-time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between the treatment group (receiving the same treatment) and the control group (see Figure 10.5). The purpose of this design is to reduce the ‘noise’ or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.

Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs, but not in posttest-only designs. The design notation is shown in Figure 10.6.

Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organisational contexts where organisational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.

Quasi-experimental designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organisation is used as the treatment group, while another section of the same class or a different organisation in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impacted by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.

In addition, there are quite a few unique non-equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to the treatment or control group based on a cut-off score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardised test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program.

Because of the use of a cut-off score, it is possible that the observed results may be a function of the cut-off score rather than the treatment, which introduces a new threat to internal validity. However, using the cut-off score also ensures that limited or costly resources are distributed to people who need them the most, rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design do not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.

Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, say you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data is not available from the same subjects.

An interesting variation of the NEDV design is a pattern-matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique—based on the degree of correspondence between theoretical and observed patterns—is a powerful way of alleviating internal validity concerns in the original NEDV design.

Perils of experimental research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, often experimental research uses inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies, and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artefact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if in doubt, use tasks that are simple and familiar for the respondent sample rather than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- A Quick Guide to Experimental Design | 5 Steps & Examples
A Quick Guide to Experimental Design | 5 Steps & Examples
Published on 11 April 2022 by Rebecca Bevans . Revised on 5 December 2022.
Experiments are used to study causal relationships . You manipulate one or more independent variables and measure their effect on one or more dependent variables.
Experimental design means creating a set of procedures to systematically test a hypothesis . A good experimental design requires a strong understanding of the system you are studying.
There are five key steps in designing an experiment:
- Consider your variables and how they are related
- Write a specific, testable hypothesis
- Design experimental treatments to manipulate your independent variable
- Assign subjects to groups, either between-subjects or within-subjects
- Plan how you will measure your dependent variable
For valid conclusions, you also need to select a representative sample and control any extraneous variables that might influence your results. If if random assignment of participants to control and treatment groups is impossible, unethical, or highly difficult, consider an observational study instead.
Table of contents
Step 1: define your variables, step 2: write your hypothesis, step 3: design your experimental treatments, step 4: assign your subjects to treatment groups, step 5: measure your dependent variable, frequently asked questions about experimental design.
You should begin with a specific research question . We will work with two research question examples, one from health sciences and one from ecology:
To translate your research question into an experimental hypothesis, you need to define the main variables and make predictions about how they are related.
Start by simply listing the independent and dependent variables .
Then you need to think about possible extraneous and confounding variables and consider how you might control them in your experiment.
Finally, you can put these variables together into a diagram. Use arrows to show the possible relationships between variables and include signs to show the expected direction of the relationships.

Here we predict that increasing temperature will increase soil respiration and decrease soil moisture, while decreasing soil moisture will lead to decreased soil respiration.
Prevent plagiarism, run a free check.
Now that you have a strong conceptual understanding of the system you are studying, you should be able to write a specific, testable hypothesis that addresses your research question.
The next steps will describe how to design a controlled experiment . In a controlled experiment, you must be able to:
- Systematically and precisely manipulate the independent variable(s).
- Precisely measure the dependent variable(s).
- Control any potential confounding variables.
If your study system doesn’t match these criteria, there are other types of research you can use to answer your research question.
How you manipulate the independent variable can affect the experiment’s external validity – that is, the extent to which the results can be generalised and applied to the broader world.
First, you may need to decide how widely to vary your independent variable.
- just slightly above the natural range for your study region.
- over a wider range of temperatures to mimic future warming.
- over an extreme range that is beyond any possible natural variation.
Second, you may need to choose how finely to vary your independent variable. Sometimes this choice is made for you by your experimental system, but often you will need to decide, and this will affect how much you can infer from your results.
- a categorical variable : either as binary (yes/no) or as levels of a factor (no phone use, low phone use, high phone use).
- a continuous variable (minutes of phone use measured every night).
How you apply your experimental treatments to your test subjects is crucial for obtaining valid and reliable results.
First, you need to consider the study size : how many individuals will be included in the experiment? In general, the more subjects you include, the greater your experiment’s statistical power , which determines how much confidence you can have in your results.
Then you need to randomly assign your subjects to treatment groups . Each group receives a different level of the treatment (e.g. no phone use, low phone use, high phone use).
You should also include a control group , which receives no treatment. The control group tells us what would have happened to your test subjects without any experimental intervention.
When assigning your subjects to groups, there are two main choices you need to make:
- A completely randomised design vs a randomised block design .
- A between-subjects design vs a within-subjects design .
Randomisation
An experiment can be completely randomised or randomised within blocks (aka strata):
- In a completely randomised design , every subject is assigned to a treatment group at random.
- In a randomised block design (aka stratified random design), subjects are first grouped according to a characteristic they share, and then randomly assigned to treatments within those groups.
Sometimes randomisation isn’t practical or ethical , so researchers create partially-random or even non-random designs. An experimental design where treatments aren’t randomly assigned is called a quasi-experimental design .
Between-subjects vs within-subjects
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment.
In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same variety of test subjects in the same proportions.
In a within-subjects design (also known as a repeated measures design), every individual receives each of the experimental treatments consecutively, and their responses to each treatment are measured.
Within-subjects or repeated measures can also refer to an experimental design where an effect emerges over time, and individual responses are measured over time in order to measure this effect as it emerges.
Counterbalancing (randomising or reversing the order of treatments among subjects) is often used in within-subjects designs to ensure that the order of treatment application doesn’t influence the results of the experiment.
Finally, you need to decide how you’ll collect data on your dependent variable outcomes. You should aim for reliable and valid measurements that minimise bias or error.
Some variables, like temperature, can be objectively measured with scientific instruments. Others may need to be operationalised to turn them into measurable observations.
- Ask participants to record what time they go to sleep and get up each day.
- Ask participants to wear a sleep tracker.
How precisely you measure your dependent variable also affects the kinds of statistical analysis you can use on your data.
Experiments are always context-dependent, and a good experimental design will take into account all of the unique considerations of your study system to produce information that is both valid and relevant to your research question.
Experimental designs are a set of procedures that you plan in order to examine the relationship between variables that interest you.
To design a successful experiment, first identify:
- A testable hypothesis
- One or more independent variables that you will manipulate
- One or more dependent variables that you will measure
When designing the experiment, first decide:
- How your variable(s) will be manipulated
- How you will control for any potential confounding or lurking variables
- How many subjects you will include
- How you will assign treatments to your subjects
The key difference between observational studies and experiments is that, done correctly, an observational study will never influence the responses or behaviours of participants. Experimental designs will have a treatment condition applied to at least a portion of participants.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word ‘between’ means that you’re comparing different conditions between groups, while the word ‘within’ means you’re comparing different conditions within the same group.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bevans, R. (2022, December 05). A Quick Guide to Experimental Design | 5 Steps & Examples. Scribbr. Retrieved 22 April 2024, from https://www.scribbr.co.uk/research-methods/guide-to-experimental-design/
Is this article helpful?

Rebecca Bevans

Research Methodology and Scientific Writing pp 93–133 Cite as
Experimental Research
- C. George Thomas 2
- First Online: 25 February 2021
4280 Accesses
Experiments are part of the scientific method that helps to decide the fate of two or more competing hypotheses or explanations on a phenomenon. The term ‘experiment’ arises from Latin, Experiri, which means, ‘to try’. The knowledge accrues from experiments differs from other types of knowledge in that it is always shaped upon observation or experience. In other words, experiments generate empirical knowledge. In fact, the emphasis on experimentation in the sixteenth and seventeenth centuries for establishing causal relationships for various phenomena happening in nature heralded the resurgence of modern science from its roots in ancient philosophy spearheaded by great Greek philosophers such as Aristotle.
The strongest arguments prove nothing so long as the conclusions are not verified by experience. Experimental science is the queen of sciences and the goal of all speculation . Roger Bacon (1214–1294)
This is a preview of subscription content, log in via an institution .
Buying options
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Bibliography
Best, J.W. and Kahn, J.V. 1993. Research in Education (7th Ed., Indian Reprint, 2004). Prentice–Hall of India, New Delhi, 435p.
Google Scholar
Campbell, D. and Stanley, J. 1963. Experimental and quasi-experimental designs for research. In: Gage, N.L., Handbook of Research on Teaching. Rand McNally, Chicago, pp. 171–247.
Chandel, S.R.S. 1991. A Handbook of Agricultural Statistics. Achal Prakashan Mandir, Kanpur, 560p.
Cox, D.R. 1958. Planning of Experiments. John Wiley & Sons, New York, 308p.
Fathalla, M.F. and Fathalla, M.M.F. 2004. A Practical Guide for Health Researchers. WHO Regional Publications Eastern Mediterranean Series 30. World Health Organization Regional Office for the Eastern Mediterranean, Cairo, 232p.
Fowkes, F.G.R., and Fulton, P.M. 1991. Critical appraisal of published research: Introductory guidelines. Br. Med. J. 302: 1136–1140.
Gall, M.D., Borg, W.R., and Gall, J.P. 1996. Education Research: An Introduction (6th Ed.). Longman, New York, 788p.
Gomez, K.A. 1972. Techniques for Field Experiments with Rice. International Rice Research Institute, Manila, Philippines, 46p.
Gomez, K.A. and Gomez, A.A. 1984. Statistical Procedures for Agricultural Research (2nd Ed.). John Wiley & Sons, New York, 680p.
Hill, A.B. 1971. Principles of Medical Statistics (9th Ed.). Oxford University Press, New York, 390p.
Holmes, D., Moody, P., and Dine, D. 2010. Research Methods for the Bioscience (2nd Ed.). Oxford University Press, Oxford, 457p.
Kerlinger, F.N. 1986. Foundations of Behavioural Research (3rd Ed.). Holt, Rinehart and Winston, USA. 667p.
Kirk, R.E. 2012. Experimental Design: Procedures for the Behavioural Sciences (4th Ed.). Sage Publications, 1072p.
Kothari, C.R. 2004. Research Methodology: Methods and Techniques (2nd Ed.). New Age International, New Delhi, 401p.
Kumar, R. 2011. Research Methodology: A Step-by step Guide for Beginners (3rd Ed.). Sage Publications India, New Delhi, 415p.
Leedy, P.D. and Ormrod, J.L. 2010. Practical Research: Planning and Design (9th Ed.), Pearson Education, New Jersey, 360p.
Marder, M.P. 2011. Research Methods for Science. Cambridge University Press, 227p.
Panse, V.G. and Sukhatme, P.V. 1985. Statistical Methods for Agricultural Workers (4th Ed., revised: Sukhatme, P.V. and Amble, V. N.). ICAR, New Delhi, 359p.
Ross, S.M. and Morrison, G.R. 2004. Experimental research methods. In: Jonassen, D.H. (ed.), Handbook of Research for Educational Communications and Technology (2nd Ed.). Lawrence Erlbaum Associates, New Jersey, pp. 10211043.
Snedecor, G.W. and Cochran, W.G. 1980. Statistical Methods (7th Ed.). Iowa State University Press, Ames, Iowa, 507p.
Download references
Author information
Authors and affiliations.
Kerala Agricultural University, Thrissur, Kerala, India
C. George Thomas
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to C. George Thomas .
Rights and permissions
Reprints and permissions
Copyright information
© 2021 The Author(s)
About this chapter
Cite this chapter.
Thomas, C.G. (2021). Experimental Research. In: Research Methodology and Scientific Writing . Springer, Cham. https://doi.org/10.1007/978-3-030-64865-7_5
Download citation
DOI : https://doi.org/10.1007/978-3-030-64865-7_5
Published : 25 February 2021
Publisher Name : Springer, Cham
Print ISBN : 978-3-030-64864-0
Online ISBN : 978-3-030-64865-7
eBook Packages : Education Education (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
- Foundations
- Write Paper
Search form
- Experiments
- Anthropology
- Self-Esteem
- Social Anxiety
Experimental Research

Experimental research is commonly used in sciences such as sociology and psychology, physics, chemistry, biology and medicine etc.
This article is a part of the guide:
- Pretest-Posttest
- Third Variable
- Research Bias
- Independent Variable
- Between Subjects
Browse Full Outline
- 1 Experimental Research
- 2.1 Independent Variable
- 2.2 Dependent Variable
- 2.3 Controlled Variables
- 2.4 Third Variable
- 3.1 Control Group
- 3.2 Research Bias
- 3.3.1 Placebo Effect
- 3.3.2 Double Blind Method
- 4.1 Randomized Controlled Trials
- 4.2 Pretest-Posttest
- 4.3 Solomon Four Group
- 4.4 Between Subjects
- 4.5 Within Subject
- 4.6 Repeated Measures
- 4.7 Counterbalanced Measures
- 4.8 Matched Subjects
It is a collection of research designs which use manipulation and controlled testing to understand causal processes. Generally, one or more variables are manipulated to determine their effect on a dependent variable.
The experimental method is a systematic and scientific approach to research in which the researcher manipulates one or more variables, and controls and measures any change in other variables.
Experimental Research is often used where:
- There is time priority in a causal relationship ( cause precedes effect )
- There is consistency in a causal relationship (a cause will always lead to the same effect)
- The magnitude of the correlation is great.
(Reference: en.wikipedia.org)
The word experimental research has a range of definitions. In the strict sense, experimental research is what we call a true experiment .
This is an experiment where the researcher manipulates one variable, and control/randomizes the rest of the variables. It has a control group , the subjects have been randomly assigned between the groups, and the researcher only tests one effect at a time. It is also important to know what variable(s) you want to test and measure.
A very wide definition of experimental research, or a quasi experiment , is research where the scientist actively influences something to observe the consequences. Most experiments tend to fall in between the strict and the wide definition.
A rule of thumb is that physical sciences, such as physics, chemistry and geology tend to define experiments more narrowly than social sciences, such as sociology and psychology, which conduct experiments closer to the wider definition.

Aims of Experimental Research
Experiments are conducted to be able to predict phenomenons. Typically, an experiment is constructed to be able to explain some kind of causation . Experimental research is important to society - it helps us to improve our everyday lives.

Identifying the Research Problem
After deciding the topic of interest, the researcher tries to define the research problem . This helps the researcher to focus on a more narrow research area to be able to study it appropriately. Defining the research problem helps you to formulate a research hypothesis , which is tested against the null hypothesis .
The research problem is often operationalizationed , to define how to measure the research problem. The results will depend on the exact measurements that the researcher chooses and may be operationalized differently in another study to test the main conclusions of the study.
An ad hoc analysis is a hypothesis invented after testing is done, to try to explain why the contrary evidence. A poor ad hoc analysis may be seen as the researcher's inability to accept that his/her hypothesis is wrong, while a great ad hoc analysis may lead to more testing and possibly a significant discovery.
Constructing the Experiment
There are various aspects to remember when constructing an experiment. Planning ahead ensures that the experiment is carried out properly and that the results reflect the real world, in the best possible way.
Sampling Groups to Study
Sampling groups correctly is especially important when we have more than one condition in the experiment. One sample group often serves as a control group , whilst others are tested under the experimental conditions.
Deciding the sample groups can be done in using many different sampling techniques. Population sampling may chosen by a number of methods, such as randomization , "quasi-randomization" and pairing.
Reducing sampling errors is vital for getting valid results from experiments. Researchers often adjust the sample size to minimize chances of random errors .
Here are some common sampling techniques :
- probability sampling
- non-probability sampling
- simple random sampling
- convenience sampling
- stratified sampling
- systematic sampling
- cluster sampling
- sequential sampling
- disproportional sampling
- judgmental sampling
- snowball sampling
- quota sampling
Creating the Design
The research design is chosen based on a range of factors. Important factors when choosing the design are feasibility, time, cost, ethics, measurement problems and what you would like to test. The design of the experiment is critical for the validity of the results.
Typical Designs and Features in Experimental Design
- Pretest-Posttest Design Check whether the groups are different before the manipulation starts and the effect of the manipulation. Pretests sometimes influence the effect.
- Control Group Control groups are designed to measure research bias and measurement effects, such as the Hawthorne Effect or the Placebo Effect . A control group is a group not receiving the same manipulation as the experimental group. Experiments frequently have 2 conditions, but rarely more than 3 conditions at the same time.
- Randomized Controlled Trials Randomized Sampling, comparison between an Experimental Group and a Control Group and strict control/randomization of all other variables
- Solomon Four-Group Design With two control groups and two experimental groups. Half the groups have a pretest and half do not have a pretest. This to test both the effect itself and the effect of the pretest.
- Between Subjects Design Grouping Participants to Different Conditions
- Within Subject Design Participants Take Part in the Different Conditions - See also: Repeated Measures Design
- Counterbalanced Measures Design Testing the effect of the order of treatments when no control group is available/ethical
- Matched Subjects Design Matching Participants to Create Similar Experimental- and Control-Groups
- Double-Blind Experiment Neither the researcher, nor the participants, know which is the control group. The results can be affected if the researcher or participants know this.
- Bayesian Probability Using bayesian probability to "interact" with participants is a more "advanced" experimental design. It can be used for settings were there are many variables which are hard to isolate. The researcher starts with a set of initial beliefs, and tries to adjust them to how participants have responded
Pilot Study
It may be wise to first conduct a pilot-study or two before you do the real experiment. This ensures that the experiment measures what it should, and that everything is set up right.
Minor errors, which could potentially destroy the experiment, are often found during this process. With a pilot study, you can get information about errors and problems, and improve the design, before putting a lot of effort into the real experiment.
If the experiments involve humans, a common strategy is to first have a pilot study with someone involved in the research, but not too closely, and then arrange a pilot with a person who resembles the subject(s) . Those two different pilots are likely to give the researcher good information about any problems in the experiment.
Conducting the Experiment
An experiment is typically carried out by manipulating a variable, called the independent variable , affecting the experimental group. The effect that the researcher is interested in, the dependent variable(s) , is measured.
Identifying and controlling non-experimental factors which the researcher does not want to influence the effects, is crucial to drawing a valid conclusion. This is often done by controlling variables , if possible, or randomizing variables to minimize effects that can be traced back to third variables . Researchers only want to measure the effect of the independent variable(s) when conducting an experiment , allowing them to conclude that this was the reason for the effect.
Analysis and Conclusions
In quantitative research , the amount of data measured can be enormous. Data not prepared to be analyzed is called "raw data". The raw data is often summarized as something called "output data", which typically consists of one line per subject (or item). A cell of the output data is, for example, an average of an effect in many trials for a subject. The output data is used for statistical analysis, e.g. significance tests, to see if there really is an effect.
The aim of an analysis is to draw a conclusion , together with other observations. The researcher might generalize the results to a wider phenomenon, if there is no indication of confounding variables "polluting" the results.
If the researcher suspects that the effect stems from a different variable than the independent variable, further investigation is needed to gauge the validity of the results. An experiment is often conducted because the scientist wants to know if the independent variable is having any effect upon the dependent variable. Variables correlating are not proof that there is causation .
Experiments are more often of quantitative nature than qualitative nature, although it happens.
Examples of Experiments
This website contains many examples of experiments. Some are not true experiments , but involve some kind of manipulation to investigate a phenomenon. Others fulfill most or all criteria of true experiments.
Here are some examples of scientific experiments:
Social Psychology
- Stanley Milgram Experiment - Will people obey orders, even if clearly dangerous?
- Asch Experiment - Will people conform to group behavior?
- Stanford Prison Experiment - How do people react to roles? Will you behave differently?
- Good Samaritan Experiment - Would You Help a Stranger? - Explaining Helping Behavior
- Law Of Segregation - The Mendel Pea Plant Experiment
- Transforming Principle - Griffith's Experiment about Genetics
- Ben Franklin Kite Experiment - Struck by Lightning
- J J Thomson Cathode Ray Experiment
- Psychology 101
- Flags and Countries
- Capitals and Countries
Oskar Blakstad (Jul 10, 2008). Experimental Research. Retrieved Apr 23, 2024 from Explorable.com: https://explorable.com/experimental-research
You Are Allowed To Copy The Text
The text in this article is licensed under the Creative Commons-License Attribution 4.0 International (CC BY 4.0) .
This means you're free to copy, share and adapt any parts (or all) of the text in the article, as long as you give appropriate credit and provide a link/reference to this page.
That is it. You don't need our permission to copy the article; just include a link/reference back to this page. You can use it freely (with some kind of link), and we're also okay with people reprinting in publications like books, blogs, newsletters, course-material, papers, wikipedia and presentations (with clear attribution).
Want to stay up to date? Follow us!
Get all these articles in 1 guide.
Want the full version to study at home, take to school or just scribble on?
Whether you are an academic novice, or you simply want to brush up your skills, this book will take your academic writing skills to the next level.

Download electronic versions: - Epub for mobiles and tablets - For Kindle here - For iBooks here - PDF version here
Save this course for later
Don't have time for it all now? No problem, save it as a course and come back to it later.
Footer bottom
- Privacy Policy

- Subscribe to our RSS Feed
- Like us on Facebook
- Follow us on Twitter

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
1.10: Correlational and Experimental Research
- Last updated
- Save as PDF
- Page ID 60387
- Lumen Learning
Learning Outcomes
- Explain correlational research
- Describe the value of experimental research
Correlational Research
When scientists passively observe and measure phenomena it is called correlational research . Here, researchers do not intervene and change behavior, as they do in experiments. In correlational research, the goal is to identify patterns of relationships, but not cause and effect. Importantly, with correlational research, you can examine only two variables at a time, no more and no less.
So, what if you wanted to test whether spending money on others is related to happiness, but you don’t have $20 to give to each participant in order to have them spend it for your experiment? You could use a correlational design—which is exactly what Professor Elizabeth Dunn (2008) at the University of British Columbia did when she conducted research on spending and happiness. She asked people how much of their income they spent on others or donated to charity, and later she asked them how happy they were. Do you think these two variables were related? Yes, they were! The more money people reported spending on others, the happier they were.
Understanding Correlation
To find out how well two variables correlate, you can plot the relationship between the two scores on what is known as a scatterplot . In the scatterplot, each dot represents a data point. (In this case it’s individuals, but it could be some other unit.) Importantly, each dot provides us with two pieces of information—in this case, information about how good the person rated the past month (x-axis) and how happy the person felt in the past month (y-axis). Which variable is plotted on which axis does not matter.

The association between two variables can be summarized statistically using the correlation coefficient (abbreviated as r). A correlation coefficient provides information about the direction and strength of the association between two variables. For the example above, the direction of the association is positive. This means that people who perceived the past month as being good reported feeling more happy, whereas people who perceived the month as being bad reported feeling less happy.
With a positive correlation , the two variables go up or down together. In a scatterplot, the dots form a pattern that extends from the bottom left to the upper right (just as they do in Figure 1). The r value for a positive correlation is indicated by a positive number (although, the positive sign is usually omitted). Here, the r value is .81.
A negative correlation is one in which the two variables move in opposite directions. That is, as one variable goes up, the other goes down. Figure 2 shows the association between the average height of males in a country (y-axis) and the pathogen prevalence (or commonness of disease; x-axis) of that country. In this scatterplot, each dot represents a country. Notice how the dots extend from the top left to the bottom right. What does this mean in real-world terms? It means that people are shorter in parts of the world where there is more disease. The r value for a negative correlation is indicated by a negative number—that is, it has a minus (–) sign in front of it. Here, it is –.83.

The strength of a correlation has to do with how well the two variables align. Recall that in Professor Dunn’s correlational study, spending on others positively correlated with happiness; the more money people reported spending on others, the happier they reported to be. At this point you may be thinking to yourself, I know a very generous person who gave away lots of money to other people but is miserable! Or maybe you know of a very stingy person who is happy as can be. Yes, there might be exceptions. If an association has many exceptions, it is considered a weak correlation. If an association has few or no exceptions, it is considered a strong correlation. A strong correlation is one in which the two variables always, or almost always, go together. In the example of happiness and how good the month has been, the association is strong. The stronger a correlation is, the tighter the dots in the scatterplot will be arranged along a sloped line.
The r value of a strong correlation will have a high absolute value (a perfect correlation has an absolute value of the whole number one, or 1.00). In other words, you disregard whether there is a negative sign in front of the r value, and just consider the size of the numerical value itself. If the absolute value is large, it is a strong correlation. A weak correlation is one in which the two variables correspond some of the time, but not most of the time. Figure 3 shows the relation between valuing happiness and grade point average (GPA). People who valued happiness more tended to earn slightly lower grades, but there were lots of exceptions to this. The r value for a weak correlation will have a low absolute value. If two variables are so weakly related as to be unrelated, we say they are uncorrelated, and the r value will be zero or very close to zero. In the previous example, is the correlation between height and pathogen prevalence strong? Compared to Figure 3, the dots in Figure 2 are tighter and less dispersed. The absolute value of –.83 is large (closer to one than to zero). Therefore, it is a strong negative correlation.

Problems with correlation
If generosity and happiness are positively correlated, should we conclude that being generous causes happiness? Similarly, if height and pathogen prevalence are negatively correlated, should we conclude that disease causes shortness? From a correlation alone, we can’t be certain. For example, in the first case, it may be that happiness causes generosity, or that generosity causes happiness. Or, a third variable might cause both happiness and generosity, creating the illusion of a direct link between the two. For example, wealth could be the third variable that causes both greater happiness and greater generosity. This is why correlation does not mean causation—an often repeated phrase among psychologists.
In this video, University of Pennsylvania psychologist and bestselling author, Angela Duckworth describes the correlational research that informed her understanding of grit.

A TED element has been excluded from this version of the text. You can view it online here: http://pb.libretexts.org/lsdm/?p=66
You can view the transcript for “Grit: The power of passion and perseverance | Angela Lee Duckworth” here (opens in new window) .
link to learning
Click through this interactive presentation to examine actual research studies.
https://assessments.lumenlearning.co...essments/16503
Experimental Research
Experiments are designed to test hypotheses (or specific statements about the relationship between variables ) in a controlled setting in efforts to explain how certain factors or events produce outcomes. A variable is anything that changes in value. Concepts are operationalized or transformed into variables in research which means that the researcher must specify exactly what is going to be measured in the study. For example, if we are interested in studying marital satisfaction, we have to specify what marital satisfaction really means or what we are going to use as an indicator of marital satisfaction. What is something measurable that would indicate some level of marital satisfaction? Would it be the amount of time couples spend together each day? Or eye contact during a discussion about money? Or maybe a subject’s score on a marital satisfaction scale? Each of these is measurable but these may not be equally valid or accurate indicators of marital satisfaction. What do you think? These are the kinds of considerations researchers must make when working through the design.
The experimental method is the only research method that can measure cause and effect relationships between variables. Three conditions must be met in order to establish cause and effect. Experimental designs are useful in meeting these conditions:
- The independent and dependent variables must be related. In other words, when one is altered, the other changes in response. The independent variable is something altered or introduced by the researcher; sometimes thought of as the treatment or intervention. The dependent variable is the outcome or the factor affected by the introduction of the independent variable; the dependent variable depends on the independent variable. For example, if we are looking at the impact of exercise on stress levels, the independent variable would be exercise; the dependent variable would be stress.
- The cause must come before the effect. Experiments measure subjects on the dependent variable before exposing them to the independent variable (establishing a baseline). So we would measure the subjects’ level of stress before introducing exercise and then again after the exercise to see if there has been a change in stress levels. (Observational and survey research does not always allow us to look at the timing of these events which makes understanding causality problematic with these methods.)
- The cause must be isolated. The researcher must ensure that no outside, perhaps unknown variables, are actually causing the effect we see. The experimental design helps make this possible. In an experiment, we would make sure that our subjects’ diets were held constant throughout the exercise program. Otherwise, the diet might really be creating a change in stress level rather than exercise.
A basic experimental design involves beginning with a sample (or subset of a population) and randomly assigning subjects to one of two groups: the experimental group or the control group . Ideally, to prevent bias, the participants would be blind to their condition (not aware of which group they are in) and the researchers would also be blind to each participant’s condition (referred to as “ double blind “). The experimental group is the group that is going to be exposed to an independent variable or condition the researcher is introducing as a potential cause of an event. The control group is going to be used for comparison and is going to have the same experience as the experimental group but will not be exposed to the independent variable. This helps address the placebo effect, which is that a group may expect changes to happen just by participating. After exposing the experimental group to the independent variable, the two groups are measured again to see if a change has occurred. If so, we are in a better position to suggest that the independent variable caused the change in the dependent variable . The basic experimental model looks like this:
The major advantage of the experimental design is that of helping to establish cause and effect relationships. A disadvantage of this design is the difficulty of translating much of what concerns us about human behavior into a laboratory setting.
Link to Learning
Have you ever wondered why people make decisions that seem to be in opposition to their longterm best interest? In Eldar Shafir’s TED Talk Living Under Scarcity , Shafir describes a series of experiments that shed light on how scarcity (real or perceived) affects our decisions.
https://assessments.lumenlearning.co...essments/16504
https://assessments.lumenlearning.co...essments/16505
https://assessments.lumenlearning.co...essments/16506
https://assessments.lumenlearning.co...essments/16507 https://assessments.lumenlearning.co...essments/16508
[glossary-page] [glossary-term]control group:[/glossary-term] [glossary-definition]a comparison group that is equivalent to the experimental group, but is not given the independent variable[/glossary-definition]
[glossary-term]correlation:[/glossary-term] [glossary-definition]the relationship between two or more variables; when two variables are correlated, one variable changes as the other does[/glossary-definition]
[glossary-term]correlation coefficient:[/glossary-term] [glossary-definition]number from -1 to +1, indicating the strength and direction of the relationship between variables, and usually represented by r[/glossary-definition]
[glossary-term]correlational research:[/glossary-term] [glossary-definition]research design with the goal of identifying patterns of relationships, but not cause and effect[/glossary-definition]
[glossary-term]dependent variable:[/glossary-term] [glossary-definition]the outcome or variable that is supposedly affected by the independent variable[/glossary-definition]
[glossary-term]double-blind:[/glossary-term] [glossary-definition]a research design in which neither the participants nor the researchers know whether an individual is assigned to the experimental group or the control group[/glossary-definition]
[glossary-term]experimental group:[/glossary-term] [glossary-definition]the group of participants in an experiment who receive the independent variable[/glossary-definition]
[glossary-term]experiments:[/glossary-term] [glossary-definition]designed to test hypotheses in a controlled setting in efforts to explain how certain factors or events produce outcomes; the only research method that measures cause and effect relationships between variables[/glossary-definition]
[glossary-term]hypotheses:[/glossary-term] [glossary-definition]specific statements or predictions about the relationship between variables[/glossary-definition]
[glossary-term]independent variable:[/glossary-term] [glossary-definition]something that is manipulated or introduced by the researcher to the experimental group; treatment or intervention[/glossary-definition]
[glossary-term]negative correlation:[/glossary-term] [glossary-definition]two variables change in different directions, with one becoming larger as the other becomes smaller; a negative correlation is not the same thing as no correlation[/glossary-definition]
[glossary-term]operationalized:[/glossary-term] [glossary-definition]concepts transformed into variables that can be measured in research[/glossary-definition]
[glossary-term]positive correlation:[/glossary-term] [glossary-definition]two variables change in the same direction, both becoming either larger or smaller[/glossary-definition]
[glossary-term]scatterplot:[/glossary-term] [glossary-definition]a plot or mathematical diagram consisting of data points that represent two variables[/glossary-definition]
[glossary-term]variables:[/glossary-term] [glossary-definition]factors that change in value[/glossary-definition] [/glossary-page]
Contributors and Attributions
- Modification, adaptation, and original content. Provided by : Lumen Learning. License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Psyc 200 Lifespan Psychology. Authored by : Laura Overstreet. Located at : http://opencourselibrary.org/econ-201/ . License : CC BY: Attribution
- Research Designs. Authored by : Christie Napa Scollon. Provided by : Singapore Management University. Project : The Noba Project. License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Vocabulary and review about correlational research. Provided by : Lumen Learning. Located at : https://courses.lumenlearning.com/waymaker-psychology/wp-admin/post.php?post=1848&action=edit . License : CC BY: Attribution
- Grit: The power of passion and perseverance. Authored by : Angela Lee Duckworth. Provided by : TED. Located at : https://www.ted.com/talks/angela_lee_duckworth_grit_the_power_of_passion_and_perseverance . License : CC BY-NC-ND: Attribution-NonCommercial-NoDerivatives
Experimental Design: Types, Examples & Methods
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Experimental design refers to how participants are allocated to different groups in an experiment. Types of design include repeated measures, independent groups, and matched pairs designs.
Probably the most common way to design an experiment in psychology is to divide the participants into two groups, the experimental group and the control group, and then introduce a change to the experimental group, not the control group.
The researcher must decide how he/she will allocate their sample to the different experimental groups. For example, if there are 10 participants, will all 10 participants participate in both groups (e.g., repeated measures), or will the participants be split in half and take part in only one group each?
Three types of experimental designs are commonly used:
1. Independent Measures
Independent measures design, also known as between-groups , is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
This should be done by random allocation, ensuring that each participant has an equal chance of being assigned to one group.
Independent measures involve using two separate groups of participants, one in each condition. For example:

- Con : More people are needed than with the repeated measures design (i.e., more time-consuming).
- Pro : Avoids order effects (such as practice or fatigue) as people participate in one condition only. If a person is involved in several conditions, they may become bored, tired, and fed up by the time they come to the second condition or become wise to the requirements of the experiment!
- Con : Differences between participants in the groups may affect results, for example, variations in age, gender, or social background. These differences are known as participant variables (i.e., a type of extraneous variable ).
- Control : After the participants have been recruited, they should be randomly assigned to their groups. This should ensure the groups are similar, on average (reducing participant variables).
2. Repeated Measures Design
Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants.
Repeated Measures design is also known as within-groups or within-subjects design .
- Pro : As the same participants are used in each condition, participant variables (i.e., individual differences) are reduced.
- Con : There may be order effects. Order effects refer to the order of the conditions affecting the participants’ behavior. Performance in the second condition may be better because the participants know what to do (i.e., practice effect). Or their performance might be worse in the second condition because they are tired (i.e., fatigue effect). This limitation can be controlled using counterbalancing.
- Pro : Fewer people are needed as they participate in all conditions (i.e., saves time).
- Control : To combat order effects, the researcher counter-balances the order of the conditions for the participants. Alternating the order in which participants perform in different conditions of an experiment.
Counterbalancing
Suppose we used a repeated measures design in which all of the participants first learned words in “loud noise” and then learned them in “no noise.”
We expect the participants to learn better in “no noise” because of order effects, such as practice. However, a researcher can control for order effects using counterbalancing.
The sample would be split into two groups: experimental (A) and control (B). For example, group 1 does ‘A’ then ‘B,’ and group 2 does ‘B’ then ‘A.’ This is to eliminate order effects.
Although order effects occur for each participant, they balance each other out in the results because they occur equally in both groups.

3. Matched Pairs Design
A matched pairs design is an experimental design where pairs of participants are matched in terms of key variables, such as age or socioeconomic status. One member of each pair is then placed into the experimental group and the other member into the control group .
One member of each matched pair must be randomly assigned to the experimental group and the other to the control group.

- Con : If one participant drops out, you lose 2 PPs’ data.
- Pro : Reduces participant variables because the researcher has tried to pair up the participants so that each condition has people with similar abilities and characteristics.
- Con : Very time-consuming trying to find closely matched pairs.
- Pro : It avoids order effects, so counterbalancing is not necessary.
- Con : Impossible to match people exactly unless they are identical twins!
- Control : Members of each pair should be randomly assigned to conditions. However, this does not solve all these problems.
Experimental design refers to how participants are allocated to an experiment’s different conditions (or IV levels). There are three types:
1. Independent measures / between-groups : Different participants are used in each condition of the independent variable.
2. Repeated measures /within groups : The same participants take part in each condition of the independent variable.
3. Matched pairs : Each condition uses different participants, but they are matched in terms of important characteristics, e.g., gender, age, intelligence, etc.
Learning Check
Read about each of the experiments below. For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design.
1 . To compare the effectiveness of two different types of therapy for depression, depressed patients were assigned to receive either cognitive therapy or behavior therapy for a 12-week period.
The researchers attempted to ensure that the patients in the two groups had similar severity of depressed symptoms by administering a standardized test of depression to each participant, then pairing them according to the severity of their symptoms.
2 . To assess the difference in reading comprehension between 7 and 9-year-olds, a researcher recruited each group from a local primary school. They were given the same passage of text to read and then asked a series of questions to assess their understanding.
3 . To assess the effectiveness of two different ways of teaching reading, a group of 5-year-olds was recruited from a primary school. Their level of reading ability was assessed, and then they were taught using scheme one for 20 weeks.
At the end of this period, their reading was reassessed, and a reading improvement score was calculated. They were then taught using scheme two for a further 20 weeks, and another reading improvement score for this period was calculated. The reading improvement scores for each child were then compared.
4 . To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions.
Condition one attempted to recall a list of words that were organized into meaningful categories; condition two attempted to recall the same words, randomly grouped on the page.
Experiment Terminology
Ecological validity.
The degree to which an investigation represents real-life experiences.
Experimenter effects
These are the ways that the experimenter can accidentally influence the participant through their appearance or behavior.
Demand characteristics
The clues in an experiment lead the participants to think they know what the researcher is looking for (e.g., the experimenter’s body language).
Independent variable (IV)
The variable the experimenter manipulates (i.e., changes) is assumed to have a direct effect on the dependent variable.
Dependent variable (DV)
Variable the experimenter measures. This is the outcome (i.e., the result) of a study.
Extraneous variables (EV)
All variables which are not independent variables but could affect the results (DV) of the experiment. Extraneous variables should be controlled where possible.
Confounding variables
Variable(s) that have affected the results (DV), apart from the IV. A confounding variable could be an extraneous variable that has not been controlled.
Random Allocation
Randomly allocating participants to independent variable conditions means that all participants should have an equal chance of taking part in each condition.
The principle of random allocation is to avoid bias in how the experiment is carried out and limit the effects of participant variables.
Order effects
Changes in participants’ performance due to their repeating the same or similar test more than once. Examples of order effects include:
(i) practice effect: an improvement in performance on a task due to repetition, for example, because of familiarity with the task;
(ii) fatigue effect: a decrease in performance of a task due to repetition, for example, because of boredom or tiredness.

Variables in Research | Types, Definiton & Examples

Introduction
What is a variable, what are the 5 types of variables in research, other variables in research.
Variables are fundamental components of research that allow for the measurement and analysis of data. They can be defined as characteristics or properties that can take on different values. In research design , understanding the types of variables and their roles is crucial for developing hypotheses , designing methods , and interpreting results .
This article outlines the the types of variables in research, including their definitions and examples, to provide a clear understanding of their use and significance in research studies. By categorizing variables into distinct groups based on their roles in research, their types of data, and their relationships with other variables, researchers can more effectively structure their studies and achieve more accurate conclusions.

A variable represents any characteristic, number, or quantity that can be measured or quantified. The term encompasses anything that can vary or change, ranging from simple concepts like age and height to more complex ones like satisfaction levels or economic status. Variables are essential in research as they are the foundational elements that researchers manipulate, measure, or control to gain insights into relationships, causes, and effects within their studies. They enable the framing of research questions, the formulation of hypotheses, and the interpretation of results.
Variables can be categorized based on their role in the study (such as independent and dependent variables ), the type of data they represent (quantitative or categorical), and their relationship to other variables (like confounding or control variables). Understanding what constitutes a variable and the various variable types available is a critical step in designing robust and meaningful research.
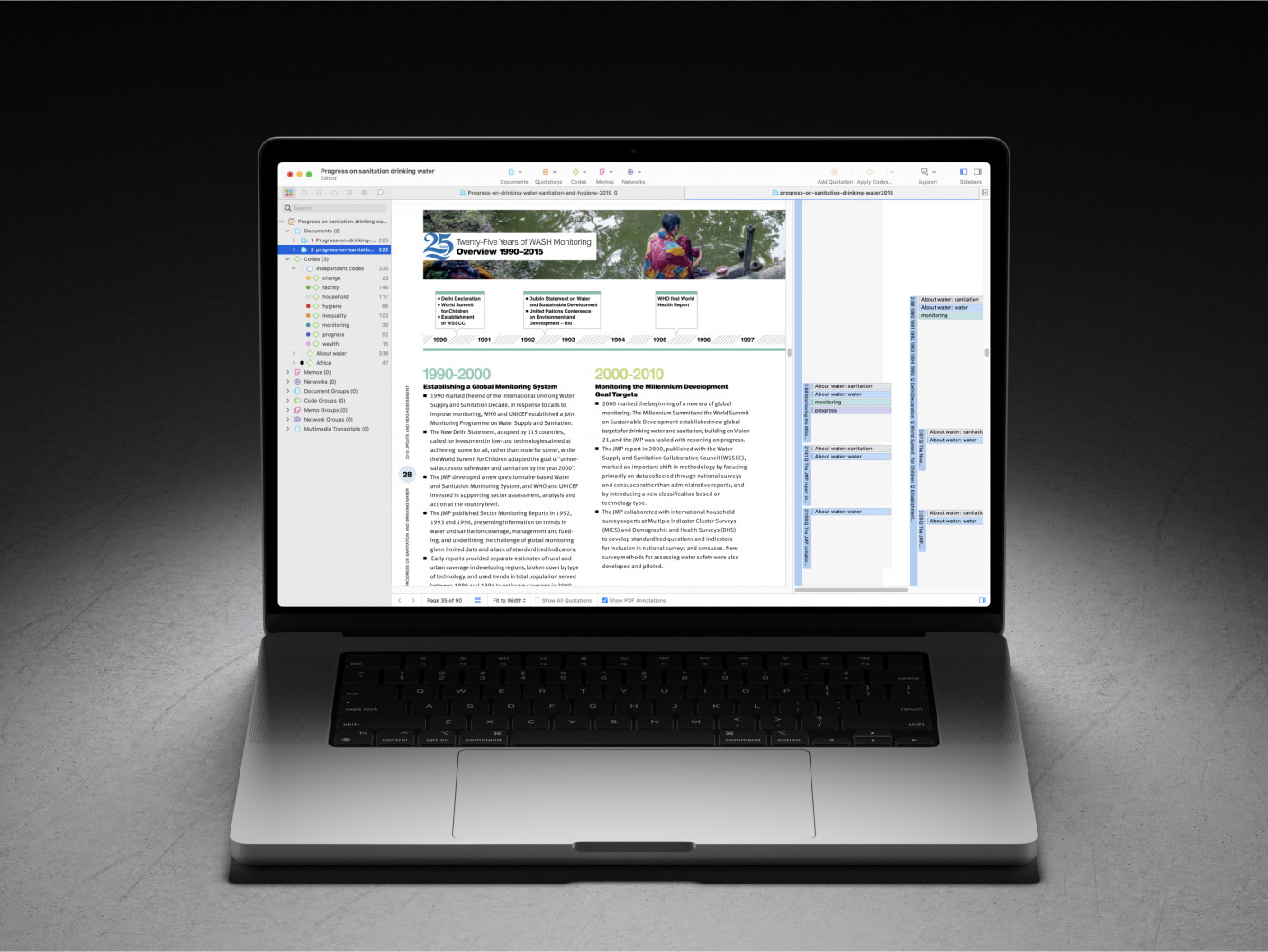
ATLAS.ti makes complex data easy to understand
Turn to our powerful data analysis tools to make the most of your research. Get started with a free trial.
Variables are crucial components in research, serving as the foundation for data collection , analysis , and interpretation . They are attributes or characteristics that can vary among subjects or over time, and understanding their types is essential for any study. Variables can be broadly classified into five main types, each with its distinct characteristics and roles within research.
This classification helps researchers in designing their studies, choosing appropriate measurement techniques, and analyzing their results accurately. The five types of variables include independent variables, dependent variables, categorical variables, continuous variables, and confounding variables. These categories not only facilitate a clearer understanding of the data but also guide the formulation of hypotheses and research methodologies.
Independent variables
Independent variables are foundational to the structure of research, serving as the factors or conditions that researchers manipulate or vary to observe their effects on dependent variables. These variables are considered "independent" because their variation does not depend on other variables within the study. Instead, they are the cause or stimulus that directly influences the outcomes being measured. For example, in an experiment to assess the effectiveness of a new teaching method on student performance, the teaching method applied (traditional vs. innovative) would be the independent variable.
The selection of an independent variable is a critical step in research design, as it directly correlates with the study's objective to determine causality or association. Researchers must clearly define and control these variables to ensure that observed changes in the dependent variable can be attributed to variations in the independent variable, thereby affirming the reliability of the results. In experimental research, the independent variable is what differentiates the control group from the experimental group, thereby setting the stage for meaningful comparison and analysis.
Dependent variables
Dependent variables are the outcomes or effects that researchers aim to explore and understand in their studies. These variables are called "dependent" because their values depend on the changes or variations of the independent variables.
Essentially, they are the responses or results that are measured to assess the impact of the independent variable's manipulation. For instance, in a study investigating the effect of exercise on weight loss, the amount of weight lost would be considered the dependent variable, as it depends on the exercise regimen (the independent variable).
The identification and measurement of the dependent variable are crucial for testing the hypothesis and drawing conclusions from the research. It allows researchers to quantify the effect of the independent variable , providing evidence for causal relationships or associations. In experimental settings, the dependent variable is what is being tested and measured across different groups or conditions, enabling researchers to assess the efficacy or impact of the independent variable's variation.
To ensure accuracy and reliability, the dependent variable must be defined clearly and measured consistently across all participants or observations. This consistency helps in reducing measurement errors and increases the validity of the research findings. By carefully analyzing the dependent variables, researchers can derive meaningful insights from their studies, contributing to the broader knowledge in their field.
Categorical variables
Categorical variables, also known as qualitative variables, represent types or categories that are used to group observations. These variables divide data into distinct groups or categories that lack a numerical value but hold significant meaning in research. Examples of categorical variables include gender (male, female, other), type of vehicle (car, truck, motorcycle), or marital status (single, married, divorced). These categories help researchers organize data into groups for comparison and analysis.
Categorical variables can be further classified into two subtypes: nominal and ordinal. Nominal variables are categories without any inherent order or ranking among them, such as blood type or ethnicity. Ordinal variables, on the other hand, imply a sort of ranking or order among the categories, like levels of satisfaction (high, medium, low) or education level (high school, bachelor's, master's, doctorate).
Understanding and identifying categorical variables is crucial in research as it influences the choice of statistical analysis methods. Since these variables represent categories without numerical significance, researchers employ specific statistical tests designed for a nominal or ordinal variable to draw meaningful conclusions. Properly classifying and analyzing categorical variables allow for the exploration of relationships between different groups within the study, shedding light on patterns and trends that might not be evident with numerical data alone.
Continuous variables
Continuous variables are quantitative variables that can take an infinite number of values within a given range. These variables are measured along a continuum and can represent very precise measurements. Examples of continuous variables include height, weight, temperature, and time. Because they can assume any value within a range, continuous variables allow for detailed analysis and a high degree of accuracy in research findings.
The ability to measure continuous variables at very fine scales makes them invaluable for many types of research, particularly in the natural and social sciences. For instance, in a study examining the effect of temperature on plant growth, temperature would be considered a continuous variable since it can vary across a wide spectrum and be measured to several decimal places.
When dealing with continuous variables, researchers often use methods incorporating a particular statistical test to accommodate a wide range of data points and the potential for infinite divisibility. This includes various forms of regression analysis, correlation, and other techniques suited for modeling and analyzing nuanced relationships between variables. The precision of continuous variables enhances the researcher's ability to detect patterns, trends, and causal relationships within the data, contributing to more robust and detailed conclusions.
Confounding variables
Confounding variables are those that can cause a false association between the independent and dependent variables, potentially leading to incorrect conclusions about the relationship being studied. These are extraneous variables that were not considered in the study design but can influence both the supposed cause and effect, creating a misleading correlation.
Identifying and controlling for a confounding variable is crucial in research to ensure the validity of the findings. This can be achieved through various methods, including randomization, stratification, and statistical control. Randomization helps to evenly distribute confounding variables across study groups, reducing their potential impact. Stratification involves analyzing the data within strata or layers that share common characteristics of the confounder. Statistical control allows researchers to adjust for the effects of confounders in the analysis phase.
Properly addressing confounding variables strengthens the credibility of research outcomes by clarifying the direct relationship between the dependent and independent variables, thus providing more accurate and reliable results.

Beyond the primary categories of variables commonly discussed in research methodology , there exists a diverse range of other variables that play significant roles in the design and analysis of studies. Below is an overview of some of these variables, highlighting their definitions and roles within research studies:
- Discrete variables : A discrete variable is a quantitative variable that represents quantitative data , such as the number of children in a family or the number of cars in a parking lot. Discrete variables can only take on specific values.
- Categorical variables : A categorical variable categorizes subjects or items into groups that do not have a natural numerical order. Categorical data includes nominal variables, like country of origin, and ordinal variables, such as education level.
- Predictor variables : Often used in statistical models, a predictor variable is used to forecast or predict the outcomes of other variables, not necessarily with a causal implication.
- Outcome variables : These variables represent the results or outcomes that researchers aim to explain or predict through their studies. An outcome variable is central to understanding the effects of predictor variables.
- Latent variables : Not directly observable, latent variables are inferred from other, directly measured variables. Examples include psychological constructs like intelligence or socioeconomic status.
- Composite variables : Created by combining multiple variables, composite variables can measure a concept more reliably or simplify the analysis. An example would be a composite happiness index derived from several survey questions .
- Preceding variables : These variables come before other variables in time or sequence, potentially influencing subsequent outcomes. A preceding variable is crucial in longitudinal studies to determine causality or sequences of events.

Master qualitative research with ATLAS.ti
Turn data into critical insights with our data analysis platform. Try out a free trial today.

Types of Variable
All experiments examine some kind of variable(s). A variable is not only something that we measure, but also something that we can manipulate and something we can control for. To understand the characteristics of variables and how we use them in research, this guide is divided into three main sections. First, we illustrate the role of dependent and independent variables. Second, we discuss the difference between experimental and non-experimental research. Finally, we explain how variables can be characterised as either categorical or continuous.
Dependent and Independent Variables
An independent variable, sometimes called an experimental or predictor variable, is a variable that is being manipulated in an experiment in order to observe the effect on a dependent variable, sometimes called an outcome variable.
Imagine that a tutor asks 100 students to complete a maths test. The tutor wants to know why some students perform better than others. Whilst the tutor does not know the answer to this, she thinks that it might be because of two reasons: (1) some students spend more time revising for their test; and (2) some students are naturally more intelligent than others. As such, the tutor decides to investigate the effect of revision time and intelligence on the test performance of the 100 students. The dependent and independent variables for the study are:
Dependent Variable: Test Mark (measured from 0 to 100)
Independent Variables: Revision time (measured in hours) Intelligence (measured using IQ score)
The dependent variable is simply that, a variable that is dependent on an independent variable(s). For example, in our case the test mark that a student achieves is dependent on revision time and intelligence. Whilst revision time and intelligence (the independent variables) may (or may not) cause a change in the test mark (the dependent variable), the reverse is implausible; in other words, whilst the number of hours a student spends revising and the higher a student's IQ score may (or may not) change the test mark that a student achieves, a change in a student's test mark has no bearing on whether a student revises more or is more intelligent (this simply doesn't make sense).
Therefore, the aim of the tutor's investigation is to examine whether these independent variables - revision time and IQ - result in a change in the dependent variable, the students' test scores. However, it is also worth noting that whilst this is the main aim of the experiment, the tutor may also be interested to know if the independent variables - revision time and IQ - are also connected in some way.
In the section on experimental and non-experimental research that follows, we find out a little more about the nature of independent and dependent variables.
Experimental and Non-Experimental Research
- Experimental research : In experimental research, the aim is to manipulate an independent variable(s) and then examine the effect that this change has on a dependent variable(s). Since it is possible to manipulate the independent variable(s), experimental research has the advantage of enabling a researcher to identify a cause and effect between variables. For example, take our example of 100 students completing a maths exam where the dependent variable was the exam mark (measured from 0 to 100), and the independent variables were revision time (measured in hours) and intelligence (measured using IQ score). Here, it would be possible to use an experimental design and manipulate the revision time of the students. The tutor could divide the students into two groups, each made up of 50 students. In "group one", the tutor could ask the students not to do any revision. Alternately, "group two" could be asked to do 20 hours of revision in the two weeks prior to the test. The tutor could then compare the marks that the students achieved.
- Non-experimental research : In non-experimental research, the researcher does not manipulate the independent variable(s). This is not to say that it is impossible to do so, but it will either be impractical or unethical to do so. For example, a researcher may be interested in the effect of illegal, recreational drug use (the independent variable(s)) on certain types of behaviour (the dependent variable(s)). However, whilst possible, it would be unethical to ask individuals to take illegal drugs in order to study what effect this had on certain behaviours. As such, a researcher could ask both drug and non-drug users to complete a questionnaire that had been constructed to indicate the extent to which they exhibited certain behaviours. Whilst it is not possible to identify the cause and effect between the variables, we can still examine the association or relationship between them. In addition to understanding the difference between dependent and independent variables, and experimental and non-experimental research, it is also important to understand the different characteristics amongst variables. This is discussed next.
Categorical and Continuous Variables
Categorical variables are also known as discrete or qualitative variables. Categorical variables can be further categorized as either nominal , ordinal or dichotomous .
- Nominal variables are variables that have two or more categories, but which do not have an intrinsic order. For example, a real estate agent could classify their types of property into distinct categories such as houses, condos, co-ops or bungalows. So "type of property" is a nominal variable with 4 categories called houses, condos, co-ops and bungalows. Of note, the different categories of a nominal variable can also be referred to as groups or levels of the nominal variable. Another example of a nominal variable would be classifying where people live in the USA by state. In this case there will be many more levels of the nominal variable (50 in fact).
- Dichotomous variables are nominal variables which have only two categories or levels. For example, if we were looking at gender, we would most probably categorize somebody as either "male" or "female". This is an example of a dichotomous variable (and also a nominal variable). Another example might be if we asked a person if they owned a mobile phone. Here, we may categorise mobile phone ownership as either "Yes" or "No". In the real estate agent example, if type of property had been classified as either residential or commercial then "type of property" would be a dichotomous variable.
- Ordinal variables are variables that have two or more categories just like nominal variables only the categories can also be ordered or ranked. So if you asked someone if they liked the policies of the Democratic Party and they could answer either "Not very much", "They are OK" or "Yes, a lot" then you have an ordinal variable. Why? Because you have 3 categories, namely "Not very much", "They are OK" and "Yes, a lot" and you can rank them from the most positive (Yes, a lot), to the middle response (They are OK), to the least positive (Not very much). However, whilst we can rank the levels, we cannot place a "value" to them; we cannot say that "They are OK" is twice as positive as "Not very much" for example.

Continuous variables are also known as quantitative variables. Continuous variables can be further categorized as either interval or ratio variables.
- Interval variables are variables for which their central characteristic is that they can be measured along a continuum and they have a numerical value (for example, temperature measured in degrees Celsius or Fahrenheit). So the difference between 20°C and 30°C is the same as 30°C to 40°C. However, temperature measured in degrees Celsius or Fahrenheit is NOT a ratio variable.
- Ratio variables are interval variables, but with the added condition that 0 (zero) of the measurement indicates that there is none of that variable. So, temperature measured in degrees Celsius or Fahrenheit is not a ratio variable because 0°C does not mean there is no temperature. However, temperature measured in Kelvin is a ratio variable as 0 Kelvin (often called absolute zero) indicates that there is no temperature whatsoever. Other examples of ratio variables include height, mass, distance and many more. The name "ratio" reflects the fact that you can use the ratio of measurements. So, for example, a distance of ten metres is twice the distance of 5 metres.
Ambiguities in classifying a type of variable
In some cases, the measurement scale for data is ordinal, but the variable is treated as continuous. For example, a Likert scale that contains five values - strongly agree, agree, neither agree nor disagree, disagree, and strongly disagree - is ordinal. However, where a Likert scale contains seven or more value - strongly agree, moderately agree, agree, neither agree nor disagree, disagree, moderately disagree, and strongly disagree - the underlying scale is sometimes treated as continuous (although where you should do this is a cause of great dispute).
It is worth noting that how we categorise variables is somewhat of a choice. Whilst we categorised gender as a dichotomous variable (you are either male or female), social scientists may disagree with this, arguing that gender is a more complex variable involving more than two distinctions, but also including measurement levels like genderqueer, intersex and transgender. At the same time, some researchers would argue that a Likert scale, even with seven values, should never be treated as a continuous variable.

Experimental Research Design — 6 mistakes you should never make!
Since school days’ students perform scientific experiments that provide results that define and prove the laws and theorems in science. These experiments are laid on a strong foundation of experimental research designs.
An experimental research design helps researchers execute their research objectives with more clarity and transparency.
In this article, we will not only discuss the key aspects of experimental research designs but also the issues to avoid and problems to resolve while designing your research study.
Table of Contents
What Is Experimental Research Design?
Experimental research design is a framework of protocols and procedures created to conduct experimental research with a scientific approach using two sets of variables. Herein, the first set of variables acts as a constant, used to measure the differences of the second set. The best example of experimental research methods is quantitative research .
Experimental research helps a researcher gather the necessary data for making better research decisions and determining the facts of a research study.
When Can a Researcher Conduct Experimental Research?
A researcher can conduct experimental research in the following situations —
- When time is an important factor in establishing a relationship between the cause and effect.
- When there is an invariable or never-changing behavior between the cause and effect.
- Finally, when the researcher wishes to understand the importance of the cause and effect.
Importance of Experimental Research Design
To publish significant results, choosing a quality research design forms the foundation to build the research study. Moreover, effective research design helps establish quality decision-making procedures, structures the research to lead to easier data analysis, and addresses the main research question. Therefore, it is essential to cater undivided attention and time to create an experimental research design before beginning the practical experiment.
By creating a research design, a researcher is also giving oneself time to organize the research, set up relevant boundaries for the study, and increase the reliability of the results. Through all these efforts, one could also avoid inconclusive results. If any part of the research design is flawed, it will reflect on the quality of the results derived.
Types of Experimental Research Designs
Based on the methods used to collect data in experimental studies, the experimental research designs are of three primary types:
1. Pre-experimental Research Design
A research study could conduct pre-experimental research design when a group or many groups are under observation after implementing factors of cause and effect of the research. The pre-experimental design will help researchers understand whether further investigation is necessary for the groups under observation.
Pre-experimental research is of three types —
- One-shot Case Study Research Design
- One-group Pretest-posttest Research Design
- Static-group Comparison
2. True Experimental Research Design
A true experimental research design relies on statistical analysis to prove or disprove a researcher’s hypothesis. It is one of the most accurate forms of research because it provides specific scientific evidence. Furthermore, out of all the types of experimental designs, only a true experimental design can establish a cause-effect relationship within a group. However, in a true experiment, a researcher must satisfy these three factors —
- There is a control group that is not subjected to changes and an experimental group that will experience the changed variables
- A variable that can be manipulated by the researcher
- Random distribution of the variables
This type of experimental research is commonly observed in the physical sciences.
3. Quasi-experimental Research Design
The word “Quasi” means similarity. A quasi-experimental design is similar to a true experimental design. However, the difference between the two is the assignment of the control group. In this research design, an independent variable is manipulated, but the participants of a group are not randomly assigned. This type of research design is used in field settings where random assignment is either irrelevant or not required.
The classification of the research subjects, conditions, or groups determines the type of research design to be used.

Advantages of Experimental Research
Experimental research allows you to test your idea in a controlled environment before taking the research to clinical trials. Moreover, it provides the best method to test your theory because of the following advantages:
- Researchers have firm control over variables to obtain results.
- The subject does not impact the effectiveness of experimental research. Anyone can implement it for research purposes.
- The results are specific.
- Post results analysis, research findings from the same dataset can be repurposed for similar research ideas.
- Researchers can identify the cause and effect of the hypothesis and further analyze this relationship to determine in-depth ideas.
- Experimental research makes an ideal starting point. The collected data could be used as a foundation to build new research ideas for further studies.
6 Mistakes to Avoid While Designing Your Research
There is no order to this list, and any one of these issues can seriously compromise the quality of your research. You could refer to the list as a checklist of what to avoid while designing your research.
1. Invalid Theoretical Framework
Usually, researchers miss out on checking if their hypothesis is logical to be tested. If your research design does not have basic assumptions or postulates, then it is fundamentally flawed and you need to rework on your research framework.
2. Inadequate Literature Study
Without a comprehensive research literature review , it is difficult to identify and fill the knowledge and information gaps. Furthermore, you need to clearly state how your research will contribute to the research field, either by adding value to the pertinent literature or challenging previous findings and assumptions.
3. Insufficient or Incorrect Statistical Analysis
Statistical results are one of the most trusted scientific evidence. The ultimate goal of a research experiment is to gain valid and sustainable evidence. Therefore, incorrect statistical analysis could affect the quality of any quantitative research.
4. Undefined Research Problem
This is one of the most basic aspects of research design. The research problem statement must be clear and to do that, you must set the framework for the development of research questions that address the core problems.
5. Research Limitations
Every study has some type of limitations . You should anticipate and incorporate those limitations into your conclusion, as well as the basic research design. Include a statement in your manuscript about any perceived limitations, and how you considered them while designing your experiment and drawing the conclusion.
6. Ethical Implications
The most important yet less talked about topic is the ethical issue. Your research design must include ways to minimize any risk for your participants and also address the research problem or question at hand. If you cannot manage the ethical norms along with your research study, your research objectives and validity could be questioned.
Experimental Research Design Example
In an experimental design, a researcher gathers plant samples and then randomly assigns half the samples to photosynthesize in sunlight and the other half to be kept in a dark box without sunlight, while controlling all the other variables (nutrients, water, soil, etc.)
By comparing their outcomes in biochemical tests, the researcher can confirm that the changes in the plants were due to the sunlight and not the other variables.
Experimental research is often the final form of a study conducted in the research process which is considered to provide conclusive and specific results. But it is not meant for every research. It involves a lot of resources, time, and money and is not easy to conduct, unless a foundation of research is built. Yet it is widely used in research institutes and commercial industries, for its most conclusive results in the scientific approach.
Have you worked on research designs? How was your experience creating an experimental design? What difficulties did you face? Do write to us or comment below and share your insights on experimental research designs!
Frequently Asked Questions
Randomization is important in an experimental research because it ensures unbiased results of the experiment. It also measures the cause-effect relationship on a particular group of interest.
Experimental research design lay the foundation of a research and structures the research to establish quality decision making process.
There are 3 types of experimental research designs. These are pre-experimental research design, true experimental research design, and quasi experimental research design.
The difference between an experimental and a quasi-experimental design are: 1. The assignment of the control group in quasi experimental research is non-random, unlike true experimental design, which is randomly assigned. 2. Experimental research group always has a control group; on the other hand, it may not be always present in quasi experimental research.
Experimental research establishes a cause-effect relationship by testing a theory or hypothesis using experimental groups or control variables. In contrast, descriptive research describes a study or a topic by defining the variables under it and answering the questions related to the same.

good and valuable
Very very good
Good presentation.
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Publishing Research
- Reporting Research
How to Optimize Your Research Process: A step-by-step guide
For researchers across disciplines, the path to uncovering novel findings and insights is often filled…

- Industry News
- Trending Now
Breaking Barriers: Sony and Nature unveil “Women in Technology Award”
Sony Group Corporation and the prestigious scientific journal Nature have collaborated to launch the inaugural…

Achieving Research Excellence: Checklist for good research practices
Academia is built on the foundation of trustworthy and high-quality research, supported by the pillars…

- Promoting Research
Plain Language Summary — Communicating your research to bridge the academic-lay gap
Science can be complex, but does that mean it should not be accessible to the…

Science under Surveillance: Journals adopt advanced AI to uncover image manipulation
Journals are increasingly turning to cutting-edge AI tools to uncover deceitful images published in manuscripts.…
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for…
Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right…
Research Recommendations – Guiding policy-makers for evidence-based decision making

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What should universities' stance be on AI tools in research and academic writing?
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2023 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
Types of Variables in Psychology Research
Examples of Independent and Dependent Variables
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "in experimental research all variables are measured")
James Lacy, MLS, is a fact-checker and researcher.
:max_bytes(150000):strip_icc():format(webp)/James-Lacy-1000-73de2239670146618c03f8b77f02f84e.jpg "in experimental research all variables are measured")
Dependent and Independent Variables
- Intervening Variables
- Extraneous Variables
- Controlled Variables
- Confounding Variables
- Operationalizing Variables
Frequently Asked Questions
Variables in psychology are things that can be changed or altered, such as a characteristic or value. Variables are generally used in psychology experiments to determine if changes to one thing result in changes to another.
Variables in psychology play a critical role in the research process. By systematically changing some variables in an experiment and measuring what happens as a result, researchers are able to learn more about cause-and-effect relationships.
The two main types of variables in psychology are the independent variable and the dependent variable. Both variables are important in the process of collecting data about psychological phenomena.
This article discusses different types of variables that are used in psychology research. It also covers how to operationalize these variables when conducting experiments.
Students often report problems with identifying the independent and dependent variables in an experiment. While this task can become more difficult as the complexity of an experiment increases, in a psychology experiment:
- The independent variable is the variable that is manipulated by the experimenter. An example of an independent variable in psychology: In an experiment on the impact of sleep deprivation on test performance, sleep deprivation would be the independent variable. The experimenters would have some of the study participants be sleep-deprived while others would be fully rested.
- The dependent variable is the variable that is measured by the experimenter. In the previous example, the scores on the test performance measure would be the dependent variable.
So how do you differentiate between the independent and dependent variables? Start by asking yourself what the experimenter is manipulating. The things that change, either naturally or through direct manipulation from the experimenter, are generally the independent variables. What is being measured? The dependent variable is the one that the experimenter is measuring.
Intervening Variables in Psychology
Intervening variables, also sometimes called intermediate or mediator variables, are factors that play a role in the relationship between two other variables. In the previous example, sleep problems in university students are often influenced by factors such as stress. As a result, stress might be an intervening variable that plays a role in how much sleep people get, which may then influence how well they perform on exams.
Extraneous Variables in Psychology
Independent and dependent variables are not the only variables present in many experiments. In some cases, extraneous variables may also play a role. This type of variable is one that may have an impact on the relationship between the independent and dependent variables.
For example, in our previous example of an experiment on the effects of sleep deprivation on test performance, other factors such as age, gender, and academic background may have an impact on the results. In such cases, the experimenter will note the values of these extraneous variables so any impact can be controlled for.
There are two basic types of extraneous variables:
- Participant variables : These extraneous variables are related to the individual characteristics of each study participant that may impact how they respond. These factors can include background differences, mood, anxiety, intelligence, awareness, and other characteristics that are unique to each person.
- Situational variables : These extraneous variables are related to things in the environment that may impact how each participant responds. For example, if a participant is taking a test in a chilly room, the temperature would be considered an extraneous variable. Some participants may not be affected by the cold, but others might be distracted or annoyed by the temperature of the room.
Other extraneous variables include the following:
- Demand characteristics : Clues in the environment that suggest how a participant should behave
- Experimenter effects : When a researcher unintentionally suggests clues for how a participant should behave
Controlled Variables in Psychology
In many cases, extraneous variables are controlled for by the experimenter. A controlled variable is one that is held constant throughout an experiment.
In the case of participant variables, the experiment might select participants that are the same in background and temperament to ensure that these factors don't interfere with the results. Holding these variables constant is important for an experiment because it allows researchers to be sure that all other variables remain the same across all conditions.
Using controlled variables means that when changes occur, the researchers can be sure that these changes are due to the manipulation of the independent variable and not caused by changes in other variables.
It is important to also note that a controlled variable is not the same thing as a control group . The control group in a study is the group of participants who do not receive the treatment or change in the independent variable.
All other variables between the control group and experimental group are held constant (i.e., they are controlled). The dependent variable being measured is then compared between the control group and experimental group to see what changes occurred because of the treatment.
Confounding Variables in Psychology
If a variable cannot be controlled for, it becomes what is known as a confounding variable. This type of variable can have an impact on the dependent variable, which can make it difficult to determine if the results are due to the influence of the independent variable, the confounding variable, or an interaction of the two.
Operationalizing Variables in Psychology
An operational definition describes how the variables are measured and defined in the study. Before conducting a psychology experiment , it is essential to create firm operational definitions for both the independent variable and dependent variables.
For example, in our imaginary experiment on the effects of sleep deprivation on test performance, we would need to create very specific operational definitions for our two variables. If our hypothesis is "Students who are sleep deprived will score significantly lower on a test," then we would have a few different concepts to define:
- Students : First, what do we mean by "students?" In our example, let’s define students as participants enrolled in an introductory university-level psychology course.
- Sleep deprivation : Next, we need to operationally define the "sleep deprivation" variable. In our example, let’s say that sleep deprivation refers to those participants who have had less than five hours of sleep the night before the test.
- Test variable : Finally, we need to create an operational definition for the test variable. For this example, the test variable will be defined as a student’s score on a chapter exam in the introductory psychology course.
Once all the variables are operationalized, we're ready to conduct the experiment.
Variables play an important part in psychology research. Manipulating an independent variable and measuring the dependent variable allows researchers to determine if there is a cause-and-effect relationship between them.
A Word From Verywell
Understanding the different types of variables used in psychology research is important if you want to conduct your own psychology experiments. It is also helpful for people who want to better understand what the results of psychology research really mean and become more informed consumers of psychology information .
Independent and dependent variables are used in experimental research. Unlike some other types of research (such as correlational studies ), experiments allow researchers to evaluate cause-and-effect relationships between two variables.
Researchers can use statistical analyses to determine the strength of a relationship between two variables in an experiment. Two of the most common ways to do this are to calculate a p-value or a correlation. The p-value indicates if the results are statistically significant while the correlation can indicate the strength of the relationship.
In an experiment on how sugar affects short-term memory, sugar intake would be the independent variable and scores on a short-term memory task would be the independent variable.
In an experiment looking at how caffeine intake affects test anxiety, the amount of caffeine consumed before a test would be the independent variable and scores on a test anxiety assessment would be the dependent variable.
Just as with other types of research, the independent variable in a cognitive psychology study would be the variable that the researchers manipulate. The specific independent variable would vary depending on the specific study, but it might be focused on some aspect of thinking, memory, attention, language, or decision-making.
American Psychological Association. Operational definition . APA Dictionary of Psychology.
American Psychological Association. Mediator . APA Dictionary of Psychology.
Altun I, Cınar N, Dede C. The contributing factors to poor sleep experiences in according to the university students: A cross-sectional study . J Res Med Sci . 2012;17(6):557-561. PMID:23626634
Skelly AC, Dettori JR, Brodt ED. Assessing bias: The importance of considering confounding . Evid Based Spine Care J . 2012;3(1):9-12. doi:10.1055/s-0031-1298595
- Evans, AN & Rooney, BJ. Methods in Psychological Research. Thousand Oaks, CA: SAGE Publications; 2014.
- Kantowitz, BH, Roediger, HL, & Elmes, DG. Experimental Psychology. Stamfort, CT: Cengage Learning; 2015.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Experimental Research
25 Experimentation and Validity
Learning objectives.
- Explain what internal validity is and why experiments are considered to be high in internal validity.
- Explain what external validity is and evaluate studies in terms of their external validity.
- Explain the concepts of construct and statistical validity.
Four Big Validities
When we read about psychology experiments with a critical view, one question to ask is “is this study valid (accurate)?” However, that question is not as straightforward as it seems because, in psychology, there are many different kinds of validities. Researchers have focused on four validities to help assess whether an experiment is sound (Judd & Kenny, 1981; Morling, 2014) [1] [2] : internal validity, external validity, construct validity, and statistical validity. We will explore each validity in depth.
Internal Validity
Two variables being statistically related does not necessarily mean that one causes the other. In your psychology education, you have probably heard the term, “Correlation does not imply causation.” For example, if it were the case that people who exercise regularly are happier than people who do not exercise regularly, this implication would not necessarily mean that exercising increases people’s happiness. It could mean instead that greater happiness causes people to exercise or that something like better physical health causes people to exercise and be happier.
The purpose of an experiment, however, is to show that two variables are statistically related and to do so in a way that supports the conclusion that the independent variable caused any observed differences in the dependent variable. The logic is based on this assumption: If the researcher creates two or more highly similar conditions and then manipulates the independent variable to produce just one difference between them, then any later difference between the conditions must have been caused by the independent variable. For example, because the only difference between Darley and Latané’s conditions was the number of students that participants believed to be involved in the discussion, this difference in belief must have been responsible for differences in helping between the conditions.
An empirical study is said to be high in internal validity if the way it was conducted supports the conclusion that the independent variable caused any observed differences in the dependent variable. Thus experiments are high in internal validity because the way they are conducted—with the manipulation of the independent variable and the control of extraneous variables (such as through the use of random assignment to minimize confounds)—provides strong support for causal conclusions. In contrast, non-experimental research designs (e.g., correlational designs), in which variables are measured but are not manipulated by an experimenter, are low in internal validity.
External Validity
At the same time, the way that experiments are conducted sometimes leads to a different kind of criticism. Specifically, the need to manipulate the independent variable and control extraneous variables means that experiments are often conducted under conditions that seem artificial (Bauman, McGraw, Bartels, & Warren, 2014) [3] . In many psychology experiments, the participants are all undergraduate students and come to a classroom or laboratory to fill out a series of paper-and-pencil questionnaires or to perform a carefully designed computerized task. Consider, for example, an experiment in which researcher Barbara Fredrickson and her colleagues had undergraduate students come to a laboratory on campus and complete a math test while wearing a swimsuit (Fredrickson, Roberts, Noll, Quinn, & Twenge, 1998) [4] . At first, this manipulation might seem silly. When will undergraduate students ever have to complete math tests in their swimsuits outside of this experiment?
The issue we are confronting is that of external validity . An empirical study is high in external validity if the way it was conducted supports generalizing the results to people and situations beyond those actually studied. As a general rule, studies are higher in external validity when the participants and the situation studied are similar to those that the researchers want to generalize to and participants encounter every day, often described as mundane realism . Imagine, for example, that a group of researchers is interested in how shoppers in large grocery stores are affected by whether breakfast cereal is packaged in yellow or purple boxes. Their study would be high in external validity and have high mundane realism if they studied the decisions of ordinary people doing their weekly shopping in a real grocery store. If the shoppers bought much more cereal in purple boxes, the researchers would be fairly confident that this increase would be true for other shoppers in other stores. Their study would be relatively low in external validity, however, if they studied a sample of undergraduate students in a laboratory at a selective university who merely judged the appeal of various colors presented on a computer screen; however, this study would have high psychological realism where the same mental process is used in both the laboratory and in the real world. If the students judged purple to be more appealing than yellow, the researchers would not be very confident that this preference is relevant to grocery shoppers’ cereal-buying decisions because of low external validity but they could be confident that the visual processing of colors has high psychological realism.
We should be careful, however, not to draw the blanket conclusion that experiments are low in external validity. One reason is that experiments need not seem artificial. Consider that Darley and Latané’s experiment provided a reasonably good simulation of a real emergency situation. Or consider field experiments that are conducted entirely outside the laboratory. In one such experiment, Robert Cialdini and his colleagues studied whether hotel guests choose to reuse their towels for a second day as opposed to having them washed as a way of conserving water and energy (Cialdini, 2005) [5] . These researchers manipulated the message on a card left in a large sample of hotel rooms. One version of the message emphasized showing respect for the environment, another emphasized that the hotel would donate a portion of their savings to an environmental cause, and a third emphasized that most hotel guests choose to reuse their towels. The result was that guests who received the message that most hotel guests choose to reuse their towels, reused their own towels substantially more often than guests receiving either of the other two messages. Given the way they conducted their study, it seems very likely that their result would hold true for other guests in other hotels.
A second reason not to draw the blanket conclusion that experiments are low in external validity is that they are often conducted to learn about psychological processes that are likely to operate in a variety of people and situations. Let us return to the experiment by Fredrickson and colleagues. They found that the women in their study, but not the men, performed worse on the math test when they were wearing swimsuits. They argued that this gender difference was due to women’s greater tendency to objectify themselves—to think about themselves from the perspective of an outside observer—which diverts their attention away from other tasks. They argued, furthermore, that this process of self-objectification and its effect on attention is likely to operate in a variety of women and situations—even if none of them ever finds herself taking a math test in her swimsuit.
Construct Validity
In addition to the generalizability of the results of an experiment, another element to scrutinize in a study is the quality of the experiment’s manipulations or the construct validity . The research question that Darley and Latané started with is “does helping behavior become diffused?” They hypothesized that participants in a lab would be less likely to help when they believed there were more potential helpers besides themselves. This conversion from research question to experiment design is called operationalization (see Chapter 4 for more information about the operational definition). Darley and Latané operationalized the independent variable of diffusion of responsibility by increasing the number of potential helpers. In evaluating this design, we would say that the construct validity was very high because the experiment’s manipulations very clearly speak to the research question; there was a crisis, a way for the participant to help, and increasing the number of other students involved in the discussion, they provided a way to test diffusion.
What if the number of conditions in Darley and Latané’s study changed? Consider if there were only two conditions: one student involved in the discussion or two. Even though we may see a decrease in helping by adding another person, it may not be a clear demonstration of diffusion of responsibility, just merely the presence of others. We might think it was a form of Bandura’s concept of social inhibition. The construct validity would be lower. However, had there been five conditions, perhaps we would see the decrease continue with more people in the discussion or perhaps it would plateau after a certain number of people. In that situation, we may develop a more nuanced understanding of the phenomenon. But by adding still more conditions, the construct validity may not get higher. When designing your own experiment, consider how well the research question is operationalized your study.
Statistical Validity
Statistical validity concerns the proper statistical treatment of data and the soundness of the researchers’ statistical conclusions. There are many different types of inferential statistics tests (e.g., t- tests, ANOVA, regression, correlation) and statistical validity concerns the use of the proper type of test to analyze the data. When considering the proper type of test, researchers must consider the scale of measure their dependent variable was measured on and the design of their study. Further, many inferential statistics tests carry certain assumptions (e.g., the data are normally distributed) and statistical validity is threatened when these assumptions are not met but the statistics are used nonetheless.
One common critique of experiments is that a study did not have enough participants. The main reason for this criticism is that it is difficult to generalize about a population from a small sample. At the outset, it seems as though this critique is about external validity but there are studies where small sample sizes are not a problem (subsequent chapters will discuss how small samples, even of only one person, are still very illuminating for psychological research). Therefore, small sample sizes are actually a critique of statistical validity . The statistical validity speaks to whether the statistics conducted in the study are sound and support the conclusions that are made.
The proper statistical analysis should be conducted on the data to determine whether the difference or relationship that was predicted was indeed found. Interestingly, the likelihood of detecting an effect of the independent variable on the dependent variable depends on not just whether a relationship really exists between these variables, but also the number of conditions and the size of the sample. This is why it is important to conduct a power analysis when designing a study, which is a calculation that informs you of the number of participants you need to recruit to detect an effect of a specific size.
Prioritizing Validities
These four big validities–internal, external, construct, and statistical–are useful to keep in mind when both reading about other experiments and designing your own. However, researchers must prioritize and often it is not possible to have high validity in all four areas. In Cialdini’s study on towel usage in hotels, the external validity was high but the statistical validity was more modest. This discrepancy does not invalidate the study but it shows where there may be room for improvement for future follow-up studies (Goldstein, Cialdini, & Griskevicius, 2008) [6] . Morling (2014) points out that many psychology studies have high internal and construct validity but sometimes sacrifice external validity.
- Judd, C.M. & Kenny, D.A. (1981). Estimating the effects of social interventions . Cambridge, MA: Cambridge University Press. ↵
- Morling, B. (2014, April). Teach your students to be better consumers. APS Observer . Retrieved from http://www.psychologicalscience.org/index.php/publications/observer/2014/april-14/teach-your-students-to-be-better-consumers.html ↵
- Bauman, C.W., McGraw, A.P., Bartels, D.M., & Warren, C. (2014). Revisiting external validity: Concerns about trolley problems and other sacrificial dilemmas in moral psychology. Social and Personality Psychology Compass, 8/9 , 536-554. ↵
- Fredrickson, B. L., Roberts, T.-A., Noll, S. M., Quinn, D. M., & Twenge, J. M. (1998). The swimsuit becomes you: Sex differences in self-objectification, restrained eating, and math performance. Journal of Personality and Social Psychology, 75 , 269–284. ↵
- Cialdini, R. (2005, April). Don’t throw in the towel: Use social influence research. APS Observer . Retrieved from http://www.psychologicalscience.org/index.php/publications/observer/2005/april-05/dont-throw-in-the-towel-use-social-influence-research.html ↵
- Goldstein, N. J., Cialdini, R. B., & Griskevicius, V. (2008). A room with a viewpoint: Using social norms to motivate environmental conservation in hotels. Journal of Consumer Research, 35 , 472–482. ↵
Refers to the degree to which we can confidently infer a causal relationship between variables.
Refers to the degree to which we can generalize the findings to other circumstances or settings, like the real-world environment.
When the participants and the situation studied are similar to those that the researchers want to generalize to and participants encounter every day.
Where the same mental process is used in both the laboratory and in the real world.
One of the "big four" validities, whereby the research question is clearly operationalized by the study's methods.
The specification of exactly how the research question will be studied in the experiment design.
Concerns the proper statistical treatment of data and the soundness of the researchers’ statistical conclusions.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Chapter 10 Experimental Research
Experimental research, often considered to be the “gold standard” in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research (rather than for descriptive or exploratory research), where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalizability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments , conducted in field settings such as in a real organization, and high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic Concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favorably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receives a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the “cause” in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and assures that each unit in the population has a positive chance of being selected into the sample. Random assignment is however a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group, prior to treatment administration. Random selection is related to sampling, and is therefore, more closely related to the external validity (generalizability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
- History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
- Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
- Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam. Not conducting a pretest can help avoid this threat.
- Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
- Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
- Regression threat , also called a regression to the mean, refers to the statistical tendency of a group’s overall performance on a measure during a posttest to regress toward the mean of that measure rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest was possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-Group Experimental Designs
The simplest true experimental designs are two group designs involving one treatment group and one control group, and are ideally suited for testing the effects of a single independent variable that can be manipulated as a treatment. The two basic two-group designs are the pretest-posttest control group design and the posttest-only control group design, while variations may include covariance designs. These designs are often depicted using a standardized design notation, where R represents random assignment of subjects to groups, X represents the treatment administered to the treatment group, and O represents pretest or posttest observations of the dependent variable (with different subscripts to distinguish between pretest and posttest observations of treatment and control groups).
Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Figure 10.1. Pretest-posttest control group design
The effect E of the experimental treatment in the pretest posttest design is measured as the difference in the posttest and pretest scores between the treatment and control groups:
E = (O 2 – O 1 ) – (O 4 – O 3 )
Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement (especially if the pretest introduces unusual topics or content).
Posttest-only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

Figure 10.2. Posttest only control group design.
The treatment effect is measured simply as the difference in the posttest scores between the two groups:
E = (O 1 – O 2 )
The appropriate statistical analysis of this design is also a two- group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.
Covariance designs . Sometimes, measures of dependent variables may be influenced by extraneous variables called covariates . Covariates are those variables that are not of central interest to an experimental study, but should nevertheless be controlled in an experimental design in order to eliminate their potential effect on the dependent variable and therefore allow for a more accurate detection of the effects of the independent variables of interest. The experimental designs discussed earlier did not control for such covariates. A covariance design (also called a concomitant variable design) is a special type of pretest posttest control group design where the pretest measure is essentially a measurement of the covariates of interest rather than that of the dependent variables. The design notation is shown in Figure 10.3, where C represents the covariates:

Figure 10.3. Covariance design
Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:

Figure 10.4. 2 x 2 factorial design
Factorial designs can also be depicted using a design notation, such as that shown on the right panel of Figure 10.4. R represents random assignment of subjects to treatment groups, X represents the treatment groups themselves (the subscripts of X represents the level of each factor), and O represent observations of the dependent variable. Notice that the 2 x 2 factorial design will have four treatment groups, corresponding to the four combinations of the two levels of each factor. Correspondingly, the 2 x 3 design will have six treatment groups, and the 2 x 2 x 2 design will have eight treatment groups. As a rule of thumb, each cell in a factorial design should have a minimum sample size of 20 (this estimate is derived from Cohen’s power calculations based on medium effect sizes). So a 2 x 2 x 2 factorial design requires a minimum total sample size of 160 subjects, with at least 20 subjects in each cell. As you can see, the cost of data collection can increase substantially with more levels or factors in your factorial design. Sometimes, due to resource constraints, some cells in such factorial designs may not receive any treatment at all, which are called incomplete factorial designs . Such incomplete designs hurt our ability to draw inferences about the incomplete factors.
In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for 3 hours/week of instructional time than for 1.5 hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid Experimental Designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomized bocks design, Solomon four-group design, and switched replications design.
Randomized block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full -time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between treatment group (receiving the same treatment) or control group (see Figure 10.5). The purpose of this design is to reduce the “noise” or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.
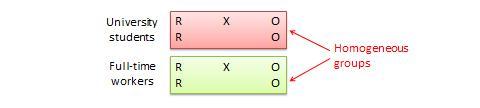
Figure 10.5. Randomized blocks design.
Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs but not in posttest only designs. The design notation is shown in Figure 10.6.

Figure 10.6. Solomon four-group design
Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organizational contexts where organizational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.
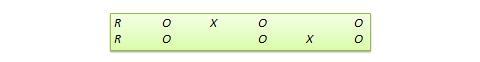
Figure 10.7. Switched replication design.
Quasi-Experimental Designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organization is used as the treatment group, while another section of the same class or a different organization in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of a certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impact by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.
Many true experimental designs can be converted to quasi-experimental designs by omitting random assignment. For instance, the quasi-equivalent version of pretest-posttest control group design is called nonequivalent groups design (NEGD), as shown in Figure 10.8, with random assignment R replaced by non-equivalent (non-random) assignment N . Likewise, the quasi -experimental version of switched replication design is called non-equivalent switched replication design (see Figure 10.9).

Figure 10.8. NEGD design.
Figure 10.9. Non-equivalent switched replication design.
In addition, there are quite a few unique non -equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression-discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to treatment or control group based on a cutoff score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardized test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program. The design notation can be represented as follows, where C represents the cutoff score:
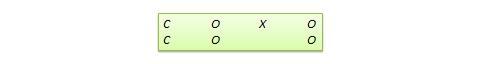
Figure 10.10. RD design.
Because of the use of a cutoff score, it is possible that the observed results may be a function of the cutoff score rather than the treatment, which introduces a new threat to internal validity. However, using the cutoff score also ensures that limited or costly resources are distributed to people who need them the most rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design does not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.
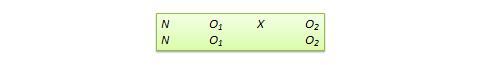
Figure 10.11. Proxy pretest design.
Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data are not available from the same subjects.

Figure 10.12. Separate pretest-posttest samples design.
Nonequivalent dependent variable (NEDV) design . This is a single-group pre-post quasi-experimental design with two outcome measures, where one measure is theoretically expected to be influenced by the treatment and the other measure is not. For instance, if you are designing a new calculus curriculum for high school students, this curriculum is likely to influence students’ posttest calculus scores but not algebra scores. However, the posttest algebra scores may still vary due to extraneous factors such as history or maturation. Hence, the pre-post algebra scores can be used as a control measure, while that of pre-post calculus can be treated as the treatment measure. The design notation, shown in Figure 10.13, indicates the single group by a single N , followed by pretest O 1 and posttest O 2 for calculus and algebra for the same group of students. This design is weak in internal validity, but its advantage lies in not having to use a separate control group.
An interesting variation of the NEDV design is a pattern matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique, based on the degree of correspondence between theoretical and observed patterns is a powerful way of alleviating internal validity concerns in the original NEDV design.
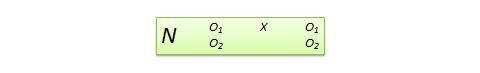
Figure 10.13. NEDV design.
Perils of Experimental Research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, many experimental research use inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artifact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if doubt, using tasks that are simpler and familiar for the respondent sample than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
- Social Science Research: Principles, Methods, and Practices. Authored by : Anol Bhattacherjee. Provided by : University of South Florida. Located at : http://scholarcommons.usf.edu/oa_textbooks/3/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Privacy Policy
Buy Me a Coffee
Home » Experimental Design – Types, Methods, Guide
Experimental Design – Types, Methods, Guide
Table of Contents

Experimental Design
Experimental design is a process of planning and conducting scientific experiments to investigate a hypothesis or research question. It involves carefully designing an experiment that can test the hypothesis, and controlling for other variables that may influence the results.
Experimental design typically includes identifying the variables that will be manipulated or measured, defining the sample or population to be studied, selecting an appropriate method of sampling, choosing a method for data collection and analysis, and determining the appropriate statistical tests to use.
Types of Experimental Design
Here are the different types of experimental design:
Completely Randomized Design
In this design, participants are randomly assigned to one of two or more groups, and each group is exposed to a different treatment or condition.
Randomized Block Design
This design involves dividing participants into blocks based on a specific characteristic, such as age or gender, and then randomly assigning participants within each block to one of two or more treatment groups.
Factorial Design
In a factorial design, participants are randomly assigned to one of several groups, each of which receives a different combination of two or more independent variables.
Repeated Measures Design
In this design, each participant is exposed to all of the different treatments or conditions, either in a random order or in a predetermined order.
Crossover Design
This design involves randomly assigning participants to one of two or more treatment groups, with each group receiving one treatment during the first phase of the study and then switching to a different treatment during the second phase.
Split-plot Design
In this design, the researcher manipulates one or more variables at different levels and uses a randomized block design to control for other variables.
Nested Design
This design involves grouping participants within larger units, such as schools or households, and then randomly assigning these units to different treatment groups.
Laboratory Experiment
Laboratory experiments are conducted under controlled conditions, which allows for greater precision and accuracy. However, because laboratory conditions are not always representative of real-world conditions, the results of these experiments may not be generalizable to the population at large.
Field Experiment
Field experiments are conducted in naturalistic settings and allow for more realistic observations. However, because field experiments are not as controlled as laboratory experiments, they may be subject to more sources of error.
Experimental Design Methods
Experimental design methods refer to the techniques and procedures used to design and conduct experiments in scientific research. Here are some common experimental design methods:
Randomization
This involves randomly assigning participants to different groups or treatments to ensure that any observed differences between groups are due to the treatment and not to other factors.
Control Group
The use of a control group is an important experimental design method that involves having a group of participants that do not receive the treatment or intervention being studied. The control group is used as a baseline to compare the effects of the treatment group.
Blinding involves keeping participants, researchers, or both unaware of which treatment group participants are in, in order to reduce the risk of bias in the results.
Counterbalancing
This involves systematically varying the order in which participants receive treatments or interventions in order to control for order effects.
Replication
Replication involves conducting the same experiment with different samples or under different conditions to increase the reliability and validity of the results.
This experimental design method involves manipulating multiple independent variables simultaneously to investigate their combined effects on the dependent variable.
This involves dividing participants into subgroups or blocks based on specific characteristics, such as age or gender, in order to reduce the risk of confounding variables.
Data Collection Method
Experimental design data collection methods are techniques and procedures used to collect data in experimental research. Here are some common experimental design data collection methods:
Direct Observation
This method involves observing and recording the behavior or phenomenon of interest in real time. It may involve the use of structured or unstructured observation, and may be conducted in a laboratory or naturalistic setting.
Self-report Measures
Self-report measures involve asking participants to report their thoughts, feelings, or behaviors using questionnaires, surveys, or interviews. These measures may be administered in person or online.
Behavioral Measures
Behavioral measures involve measuring participants’ behavior directly, such as through reaction time tasks or performance tests. These measures may be administered using specialized equipment or software.
Physiological Measures
Physiological measures involve measuring participants’ physiological responses, such as heart rate, blood pressure, or brain activity, using specialized equipment. These measures may be invasive or non-invasive, and may be administered in a laboratory or clinical setting.
Archival Data
Archival data involves using existing records or data, such as medical records, administrative records, or historical documents, as a source of information. These data may be collected from public or private sources.
Computerized Measures
Computerized measures involve using software or computer programs to collect data on participants’ behavior or responses. These measures may include reaction time tasks, cognitive tests, or other types of computer-based assessments.
Video Recording
Video recording involves recording participants’ behavior or interactions using cameras or other recording equipment. This method can be used to capture detailed information about participants’ behavior or to analyze social interactions.
Data Analysis Method
Experimental design data analysis methods refer to the statistical techniques and procedures used to analyze data collected in experimental research. Here are some common experimental design data analysis methods:
Descriptive Statistics
Descriptive statistics are used to summarize and describe the data collected in the study. This includes measures such as mean, median, mode, range, and standard deviation.
Inferential Statistics
Inferential statistics are used to make inferences or generalizations about a larger population based on the data collected in the study. This includes hypothesis testing and estimation.
Analysis of Variance (ANOVA)
ANOVA is a statistical technique used to compare means across two or more groups in order to determine whether there are significant differences between the groups. There are several types of ANOVA, including one-way ANOVA, two-way ANOVA, and repeated measures ANOVA.
Regression Analysis
Regression analysis is used to model the relationship between two or more variables in order to determine the strength and direction of the relationship. There are several types of regression analysis, including linear regression, logistic regression, and multiple regression.
Factor Analysis
Factor analysis is used to identify underlying factors or dimensions in a set of variables. This can be used to reduce the complexity of the data and identify patterns in the data.
Structural Equation Modeling (SEM)
SEM is a statistical technique used to model complex relationships between variables. It can be used to test complex theories and models of causality.
Cluster Analysis
Cluster analysis is used to group similar cases or observations together based on similarities or differences in their characteristics.
Time Series Analysis
Time series analysis is used to analyze data collected over time in order to identify trends, patterns, or changes in the data.
Multilevel Modeling
Multilevel modeling is used to analyze data that is nested within multiple levels, such as students nested within schools or employees nested within companies.
Applications of Experimental Design
Experimental design is a versatile research methodology that can be applied in many fields. Here are some applications of experimental design:
- Medical Research: Experimental design is commonly used to test new treatments or medications for various medical conditions. This includes clinical trials to evaluate the safety and effectiveness of new drugs or medical devices.
- Agriculture : Experimental design is used to test new crop varieties, fertilizers, and other agricultural practices. This includes randomized field trials to evaluate the effects of different treatments on crop yield, quality, and pest resistance.
- Environmental science: Experimental design is used to study the effects of environmental factors, such as pollution or climate change, on ecosystems and wildlife. This includes controlled experiments to study the effects of pollutants on plant growth or animal behavior.
- Psychology : Experimental design is used to study human behavior and cognitive processes. This includes experiments to test the effects of different interventions, such as therapy or medication, on mental health outcomes.
- Engineering : Experimental design is used to test new materials, designs, and manufacturing processes in engineering applications. This includes laboratory experiments to test the strength and durability of new materials, or field experiments to test the performance of new technologies.
- Education : Experimental design is used to evaluate the effectiveness of teaching methods, educational interventions, and programs. This includes randomized controlled trials to compare different teaching methods or evaluate the impact of educational programs on student outcomes.
- Marketing : Experimental design is used to test the effectiveness of marketing campaigns, pricing strategies, and product designs. This includes experiments to test the impact of different marketing messages or pricing schemes on consumer behavior.
Examples of Experimental Design
Here are some examples of experimental design in different fields:
- Example in Medical research : A study that investigates the effectiveness of a new drug treatment for a particular condition. Patients are randomly assigned to either a treatment group or a control group, with the treatment group receiving the new drug and the control group receiving a placebo. The outcomes, such as improvement in symptoms or side effects, are measured and compared between the two groups.
- Example in Education research: A study that examines the impact of a new teaching method on student learning outcomes. Students are randomly assigned to either a group that receives the new teaching method or a group that receives the traditional teaching method. Student achievement is measured before and after the intervention, and the results are compared between the two groups.
- Example in Environmental science: A study that tests the effectiveness of a new method for reducing pollution in a river. Two sections of the river are selected, with one section treated with the new method and the other section left untreated. The water quality is measured before and after the intervention, and the results are compared between the two sections.
- Example in Marketing research: A study that investigates the impact of a new advertising campaign on consumer behavior. Participants are randomly assigned to either a group that is exposed to the new campaign or a group that is not. Their behavior, such as purchasing or product awareness, is measured and compared between the two groups.
- Example in Social psychology: A study that examines the effect of a new social intervention on reducing prejudice towards a marginalized group. Participants are randomly assigned to either a group that receives the intervention or a control group that does not. Their attitudes and behavior towards the marginalized group are measured before and after the intervention, and the results are compared between the two groups.
When to use Experimental Research Design
Experimental research design should be used when a researcher wants to establish a cause-and-effect relationship between variables. It is particularly useful when studying the impact of an intervention or treatment on a particular outcome.
Here are some situations where experimental research design may be appropriate:
- When studying the effects of a new drug or medical treatment: Experimental research design is commonly used in medical research to test the effectiveness and safety of new drugs or medical treatments. By randomly assigning patients to treatment and control groups, researchers can determine whether the treatment is effective in improving health outcomes.
- When evaluating the effectiveness of an educational intervention: An experimental research design can be used to evaluate the impact of a new teaching method or educational program on student learning outcomes. By randomly assigning students to treatment and control groups, researchers can determine whether the intervention is effective in improving academic performance.
- When testing the effectiveness of a marketing campaign: An experimental research design can be used to test the effectiveness of different marketing messages or strategies. By randomly assigning participants to treatment and control groups, researchers can determine whether the marketing campaign is effective in changing consumer behavior.
- When studying the effects of an environmental intervention: Experimental research design can be used to study the impact of environmental interventions, such as pollution reduction programs or conservation efforts. By randomly assigning locations or areas to treatment and control groups, researchers can determine whether the intervention is effective in improving environmental outcomes.
- When testing the effects of a new technology: An experimental research design can be used to test the effectiveness and safety of new technologies or engineering designs. By randomly assigning participants or locations to treatment and control groups, researchers can determine whether the new technology is effective in achieving its intended purpose.
How to Conduct Experimental Research
Here are the steps to conduct Experimental Research:
- Identify a Research Question : Start by identifying a research question that you want to answer through the experiment. The question should be clear, specific, and testable.
- Develop a Hypothesis: Based on your research question, develop a hypothesis that predicts the relationship between the independent and dependent variables. The hypothesis should be clear and testable.
- Design the Experiment : Determine the type of experimental design you will use, such as a between-subjects design or a within-subjects design. Also, decide on the experimental conditions, such as the number of independent variables, the levels of the independent variable, and the dependent variable to be measured.
- Select Participants: Select the participants who will take part in the experiment. They should be representative of the population you are interested in studying.
- Randomly Assign Participants to Groups: If you are using a between-subjects design, randomly assign participants to groups to control for individual differences.
- Conduct the Experiment : Conduct the experiment by manipulating the independent variable(s) and measuring the dependent variable(s) across the different conditions.
- Analyze the Data: Analyze the data using appropriate statistical methods to determine if there is a significant effect of the independent variable(s) on the dependent variable(s).
- Draw Conclusions: Based on the data analysis, draw conclusions about the relationship between the independent and dependent variables. If the results support the hypothesis, then it is accepted. If the results do not support the hypothesis, then it is rejected.
- Communicate the Results: Finally, communicate the results of the experiment through a research report or presentation. Include the purpose of the study, the methods used, the results obtained, and the conclusions drawn.
Purpose of Experimental Design
The purpose of experimental design is to control and manipulate one or more independent variables to determine their effect on a dependent variable. Experimental design allows researchers to systematically investigate causal relationships between variables, and to establish cause-and-effect relationships between the independent and dependent variables. Through experimental design, researchers can test hypotheses and make inferences about the population from which the sample was drawn.
Experimental design provides a structured approach to designing and conducting experiments, ensuring that the results are reliable and valid. By carefully controlling for extraneous variables that may affect the outcome of the study, experimental design allows researchers to isolate the effect of the independent variable(s) on the dependent variable(s), and to minimize the influence of other factors that may confound the results.
Experimental design also allows researchers to generalize their findings to the larger population from which the sample was drawn. By randomly selecting participants and using statistical techniques to analyze the data, researchers can make inferences about the larger population with a high degree of confidence.
Overall, the purpose of experimental design is to provide a rigorous, systematic, and scientific method for testing hypotheses and establishing cause-and-effect relationships between variables. Experimental design is a powerful tool for advancing scientific knowledge and informing evidence-based practice in various fields, including psychology, biology, medicine, engineering, and social sciences.
Advantages of Experimental Design
Experimental design offers several advantages in research. Here are some of the main advantages:
- Control over extraneous variables: Experimental design allows researchers to control for extraneous variables that may affect the outcome of the study. By manipulating the independent variable and holding all other variables constant, researchers can isolate the effect of the independent variable on the dependent variable.
- Establishing causality: Experimental design allows researchers to establish causality by manipulating the independent variable and observing its effect on the dependent variable. This allows researchers to determine whether changes in the independent variable cause changes in the dependent variable.
- Replication : Experimental design allows researchers to replicate their experiments to ensure that the findings are consistent and reliable. Replication is important for establishing the validity and generalizability of the findings.
- Random assignment: Experimental design often involves randomly assigning participants to conditions. This helps to ensure that individual differences between participants are evenly distributed across conditions, which increases the internal validity of the study.
- Precision : Experimental design allows researchers to measure variables with precision, which can increase the accuracy and reliability of the data.
- Generalizability : If the study is well-designed, experimental design can increase the generalizability of the findings. By controlling for extraneous variables and using random assignment, researchers can increase the likelihood that the findings will apply to other populations and contexts.
Limitations of Experimental Design
Experimental design has some limitations that researchers should be aware of. Here are some of the main limitations:
- Artificiality : Experimental design often involves creating artificial situations that may not reflect real-world situations. This can limit the external validity of the findings, or the extent to which the findings can be generalized to real-world settings.
- Ethical concerns: Some experimental designs may raise ethical concerns, particularly if they involve manipulating variables that could cause harm to participants or if they involve deception.
- Participant bias : Participants in experimental studies may modify their behavior in response to the experiment, which can lead to participant bias.
- Limited generalizability: The conditions of the experiment may not reflect the complexities of real-world situations. As a result, the findings may not be applicable to all populations and contexts.
- Cost and time : Experimental design can be expensive and time-consuming, particularly if the experiment requires specialized equipment or if the sample size is large.
- Researcher bias : Researchers may unintentionally bias the results of the experiment if they have expectations or preferences for certain outcomes.
- Lack of feasibility : Experimental design may not be feasible in some cases, particularly if the research question involves variables that cannot be manipulated or controlled.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Questionnaire – Definition, Types, and Examples

Case Study – Methods, Examples and Guide

Observational Research – Methods and Guide

Quantitative Research – Methods, Types and...

Qualitative Research Methods

Explanatory Research – Types, Methods, Guide

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
Construct Validation of Experimental Manipulations in Social Psychology: Current Practices and Recommendations for the Future
Associated data.
Experimental manipulations in social psychology must exhibit construct validity by influencing their intended psychological constructs. Yet how do experimenters in social psychology attempt to establish the construct validity of their manipulations? Following a preregistered plan, we coded 348 experimental manipulations from the 2017 issues of the Journal of Personality and Social Psychology . Representing a reliance upon ‘on the fly’ experimentation, the vast majority of these manipulations were created ad hoc for a given study and not previously validated prior to implementation. A minority of manipulations had their construct validity evaluated by pilot testing prior to implementation or via a manipulation check. Of the manipulation checks administered, most were face-valid, single item self-reports and only a few met criteria for ‘true’ validation. In aggregate, roughly two-fifths of manipulations relied solely on face validity. To the extent that they are representative of the field, these results suggest that best practices for validating manipulations are not commonplace — a potential contributor to replicability issues. These issues can be remedied by validating manipulations prior to implementation, using validated manipulation checks, standardizing manipulation protocols, estimating the size and duration of manipulations’ effects, and estimating each manipulation’s effects on multiple constructs within the target nomological network.
Introduction
Social psychology emphasizes the power of the situation ( Lewin, 1939 ). To examine the causal effects of situational variables, social psychological studies often employ experimental manipulations of such factors and examine their impact on human thoughts, feelings, and behaviors ( Campbell, 1957 ; Cook & Campbell, 1979 ). However, experimental manipulations are only as useful as the extent to which they exhibit construct validity (i.e., that they meaningfully affect the psychological processes that they are intended to affect; Brewer, 2000 ; Garner, Hake, & Eriksen, 1956 ; Wilson, Aronson, & Carlsmith, 2010 ). Yet few recent studies have systematically documented the approaches that social psychological experiments use to estimate and establish the construct validity of their manipulations. Towards addressing this limitation in our understanding, we meta-analyzed the frequency with which various manipulation validation practices were adopted (or not adopted) by a representative sample of studies from what is widely perceived as the flagship publication for experimental social psychology: the Journal of Personality and Social Psychology ( JPSP ).
Validity in Experimental Manipulations of Psychological Processes
Experimental social psychologists often focus on ‘internal validity’ and ‘external validity’ ( Haslam & McGarty, 2004 ). Internal validity is present when experimenters (I) eliminate extraneous variables that might incidentally influence the outcome-of-interest and (II) maximize features of the experimental manipulation that ensure a precise, causal conduit from manipulation to outcome ( Brewer, 2000 ). Experimenters establish internal validity via practices such as removing sources of experimenter bias and demand characteristics and by cultivating ‘experimental realism’, which maximize the chances that the manipulation is the source of experimental effects and not some unwanted artifact of design ( Cook & Campbell, 1979 ; Wilson et al., 2010 ). Other efforts are directed toward maximizing ‘external validity’, ensuring that the experiment captures effects that exist in the ‘real world and that findings of the experiment are able to generalize to other settings, populations, time periods, and cultures ( Highhouse, 2009 ; c.f. Berkowitz & Donnerstein, 1982 ; Mook, 1983 ). Integral to both internal and external validity is a concept most often invoked in the context of clinical assessments and personality questionnaires — construct validity .
Psychological Constructs and the Nomological Network
Psychological scientists often seek to measure and manipulate psychological constructs — so called because they are psychological entities constructed by people, they are not objective realities ( Cronbach & Meehl, 1955 ). Such constructs are considered latent as they are readily imperceptible, as compared to their associated manifestations that are designed to capture (e.g., psychological questionnaires) or influence (e.g., experimental manipulations) them. Latent constructs exist in a nomological (i.e., lawful) network, which is a prescribed array of relationships (or lack thereof) with other constructs ( Cronbach & Meehl, 1955 ). In a nomological network, constructs exist in varying degrees of proximity to one another, with closer proximities reflecting stronger patterns of association. Each construct has its own idiographic network, including construct-specific arrays of associated constructs and construct-specific patterns of associations with those constructs. The constellations of constructs within each nomological network are articulated by psychological theory ( Gray, 2017 ). Nomological networks, when distilled accurately from strong theory, are the basis of construct validity ( Messick, 1995 ).
Construct Validity of Psychological Measures
Construct validity is a methodological and philosophical property that largely reflects how accurately a given manifestation of a study has mapped onto a construct’s latent nomological network ( Borsboom, Mellenbergh, & van Heerden, 2004 ; Embretson, 1983 ; Strauss & Smith, 2009 ). Conventionally, construct validity has been largely invoked in the context of psychological measurement, assessment, and tests. In this context, construct validity is present when a manifest psychological measure (I) accurately quantifies its intended latent psychological construct, (II) shares theoretically-appropriate associations with other latent variables in that construct’s nomological network, and (III) does not capture confounding extraneous latent constructs ( Cronbach & Meehl, 1955 ; Messick, 1995 ; Figure 1 ). According to modern standards in psychology, construct validity is not a property of a given measure or the scores derived from it, but instead such validity pertains to the uses and interpretations of the scores that are derived from the measure ( AERA, APA, & NCME, 2014 ).

Schematic depiction of a hypothetical nomological network surrounding the construct of ‘rejection’. Plus signs depict positive associations and minus signs depict negative associations. Greater numbers of plus signs and thicker arrows depict stronger associations and effects.
As depicted in the above schematic, a measure of a given construct (e.g., a scale that measures feelings of rejection), should exhibit a pattern of associations with theoretically-linked variables (e.g., positive correlations with pain and shame, negative correlation with happiness) and null associations with variables outside of the nomological network (e.g., awe).
Estimating the Construct Validity of Psychological Measures
The process of testing the construct validity of measures is well defined (for an overview see Flake, Pek, & Hehman, 2017 ). First, investigators should conduct a comprehensive literature review to define the properties of the construct, prominent theories of the construct, and its associated nomological network ( Simms, 2008 ). This substantive portion of construct validation and research design more broadly is perhaps the most crucial (and oft neglected) aspect. Rigorous theoretical work prior to measure construction is needed to ensure that the manifestation of the measure accurately captures the full range of the construct, distinguishes it from related constructs, and includes measures of other constructs to test the construct’s nomological network ( Benson, 1998 ; Loevinger, 1957 ; Zumbo & Chan, 2014 ).
Second, researchers apply their theoretical understanding to design the content of the measure to capture the breadth and depth of the construct (i.e., content validity; Haynes, Richard, & Kubany, 1995), often in consultation with experts outside the study team. Third, this preliminary measure is administered and empirical analyses (e.g., item response theory, exploratory and confirmatory factor analyses) are used on the resulting data to (A) ensure that the measure’s data structure exhibits the expected form, to (B) select content with good empirical qualities, and to (C) ensure the measure is invariant across groups it should be invariant across ( Clark & Watson, 2019 ). Fourth, a refined version of the measure is administered alongside other measures to ensure that it (A) positively corresponds to measures of the same or similar constructs (i.e., convergent validity), it (B) negatively or weakly corresponds to measures of different or dissimilar constructs (i.e., discriminant validity), it (C) is linked to theoretically-appropriate real-world outcomes (i.e., criterion validity), and that it (D) differs across groups that it should differ across ( Smith, 2005 ). Measures that meet these stringent psychometric criteria can be said to exhibit construct validity (i.e., they measure the construct they are intended to measure and do not capture problematically large amounts of unintended constructs). Yet how do these concepts and practices translate to experimental manipulations of psychological processes?
Construct Validity of Psychological Manipulations
Construct validity is not confined to psychometrics and is a crucial element in experimental psychology ( Cook & Campbell, 1979 ). Translated to an experimental setting, construct validity is present when a manifest psychological manipulation (I) accurately and causally affects its intended latent psychological construct in the intended direction, (II) exerts theoretically-appropriate effects upon other latent variables in that construct’s nomological network, and (III) does not affect or weakly affects confounding extraneous latent constructs ( Campbell, 1957 ; Shadish, Cook, & Campbell, 2002 ). This desired pattern of effects is illustrated in a phenomenon we deem the nomological shockwave .
The nomological shockwave.
In a nomological shockwave, a psychological manipulation (e.g., a social rejection manipulation; Chester, DeWall, & Pond, 2016 ) exerts its initial and strongest causal effects on the target latent construct in the intended direction (e.g., greatly increased feelings of rejection; Figure 2 ). This change in the target construct then ripples out through that construct’s latent nomological network — causally affecting related constructs in ways that reflect the degree and strength of their latent associations with the target construct. More specifically, the shockwave exerts stronger effects upon constructs that are closer to the manipulation’s point of impact (e.g., moderately increased pain). Conversely, the shockwave’s effects get progressively weaker as the theoretical distance from the target construct increases (e.g., modestly increased shame, modestly reduced happiness). The shockwave will not reach constructs that lie beyond the target construct’s nomological network (e.g., no effect on awe). Back in the manifest domain, these latent shockwave effects are then captured with manipulation check and the various discriminant validity checks that are causally affected by the latent nomological shockwave.

Schematic depiction of a hypothetical nomological shockwave elicited by a construct valid social rejection manipulation. Plus signs depict positive effects and minus signs depict negative effects. Greater numbers of plus signs and thicker arrows depict stronger associations and effects.
Internal versus construct validity.
Construct validity differs from another type of validity that is critical for experimental manipulations — internal validity. Internal validity reflects the extent to which the intended aspects of the manifest experimental manipulation — and not some artifact(s) of the research methodology — exerted a causal effect on an outcome ( Campbell, 1957 ; Shadish et al., 2002 ; Wilson et al., 2010 ). Threats to internal validity include unintended differences between the participants in the experimental conditions, participant attrition and fatigue over the course of the experiment, environmental and experimenter effects that undermine the manipulation, measures that are not valid or reliable, and participant awareness (of the experiment’s hypotheses, of deceptive elements of the study, or that they are being studied; Shadish et al., 2002 ; Wilson et al., 2010 ). Each of these issues can elicit spurious effects that are not due to the intended aspects of the experimental manipulation.
Although construct validity requires that the causal chain of events from manipulation to outcome effect was intact (i.e., that the manipulation possessed internal validity), its focus is on the ability of the manipulation to impact the intended constructs in the intended manner ( Shadish et al., 2002 ). In other words, internal validity ensures that the manipulation’s effect was causal and construct validity ensures that the manipulation’s effect was accurate. Threats to a manipulation’s construct validity are ‘instrumental incidentals’ --- or confounding aspects of the manipulation that elicited the intended cause in the targeted constructs but were not the aspects of the manipulation that were intended to elicit that effect ( Campbell, 1969 ). For instance, imagine that an experimental condition (e.g., writing an essay that recalls an experience of rejection) was compared to an inappropriate control condition (e.g., writing an essay that tells a story of a brave and adorable otter). This manipulation design would cause an intended increase in rejection, but this effect would be due to both the intended aspect of the manipulation (i.e., the rejection-related content of the essay) and unintended, confounding aspects as well (e.g., positive attitudes towards brave and adorable otters, ease of writing about a fictional character). Another threat to construct validity is a lack specificity, in which a manipulation exerts a similarly-sized impact on a broad array of constructs instead of isolating the target construct (e.g., a rejection manipulation that also increases sadness and anger to the same extent as it does feelings of rejection). A construct valid experimental manipulation will exert its intended, targeted effects on the intended, specific constructs only through theoretically-appropriate aspects of the manipulation ( Reichardt, 2006 ).
Whereas internal validity can be established prior to testing the construct validity of a manipulation, construct validity first requires that a manipulation exhibit internal validity. Indeed, if an experimental artifact caused by some other aspect of the experiment (e.g., participant selection bias caused by a lack of random assignment) was the actual and unintended source of an observed experimental effect, then it is impossible to claim that the manipulation is what affected the target construct ( Cook & Campbell, 1979 ). This is akin to how psychological questionnaires can have internal consistency among their items without exhibiting construct validity, yet the construct validity of this measure requires the presence of internal consistency. The process through which measures are validated can be instructive for determining how to establish the construct validity of experimental manipulations.
Current Construct Validity Practices for Psychological Manipulations
A survey of the literature on experimental manipulation in social psychology revealed three primary approaches to establishing that a given manipulation has construct validity. These approaches do not map neatly onto the process through which psychological measures are validated, an issue we return to in the Discussion.
Employ previously validated manipulations.
The simplest means to establish the validity of a manipulation is to replicate one that has been already validated in previous research. Many experimental paradigms are frequently re-used in other investigations and modified for other purposes. For instance, the seminal article that introduced the Cyberball social rejection paradigm has been cited over 1,900 times ( Williams, Cheung, & Choi, 2000 ). However, the value of employing previously-used manipulations is predicated on the extent to which they were adequately validated in such pre-existing work. Previously-used manipulations, whether they have been validated or not, are often modified prior to implementation (e.g., the identities of the Cyberball partners are varied; Gonsalkorale & Williams, 2007) or are conceptually-replicated by implementing the manipulation through an entirely different paradigm (e.g., being left out of an online chatroom instead of a ball-tossing game; Donate et al., 2017 ). These conceptual replications are important means to establish the ability of the manipulated construct’s ability to exert its effects irrespective of the manifest characteristics of the manipulation. However, conceptual replication cannot alone establish construct validity.
Pilot validity studies.
Whether a manipulation is newly created or acquired from a prior publication, authors often ‘pilot test’ them prior to implementation in hypothesis testing. This practice entails conducting at least one separate, ‘pilot study’ of the manipulation outside of the context of the full study procedure ( Ellsworth & Gonzalez, 2003 ). Such pilot studies are used to examine various aspects of the manipulation, from its feasibility to participant comprehension of the instructions to various forms of validity. Of particular interest to the present research, pilot validity studies (a subset of the broader ‘pilot study’ category) estimate the manipulation’s effect on the target construct (i.e., they pilot test the manipulation’s construct validity). In this way, pilot validity studies are a hybrid of experimental pilot studies and the ‘validation studies’ used by clinical and personality psychologists who examine the psychometric properties of new measures using the steps we previously outlined.
Pilot validity testing of a new manipulation is an essential step to ensure that the manipulation has the intended effect on a target manipulation check and to rule out confounding processes ( Wilson et al., 2010 ). Pilot validity testing can also estimate the magnitude and duration of the intended effect. If the effect is so small or transient that it is nearly impossible to detect or if the effect is so strong or long-lasting that it produces ceiling effects or excessive distress among your participants, then the manipulation can be altered to address these issues and re-piloted. If deception is used, suspicion probes can be included in a pilot study to estimate whether the deception was perceived by your participants ( Blackhart, Brown, Clark, Pierce, & Shell, 2012 ). Even if the manipulation has been acquired from previous work, pilot validity testing is a crucial way to ensure that you have accurately recreated the protocol and replicated the validity of the manipulation ( Ellsworth & Gonzalez, 2003 ). As all of these factors have an immense impact on whether a given manipulation will affect its target construct, pilot validity studies are an important means of ensuring the construct validity of a manipulation.
Manipulation checks.
A diverse array of measurements fall under the umbrella term of ‘manipulation check’. The over-arching theme of such measures is to ensure that a given manipulation had its intended effect ( Hauser, Ellsworth, & Gonzalez, 2018 ). We adopt a more narrow definition to conform to the topic of construct validity — manipulation checks are measures of the construct that the manipulation is intended to affect. This definition excludes attention checks, comprehension checks, and other forms of instructional manipulation checks ( Oppenheimer, Meyvis, & Davidenko, 2009 ), as they do not explicitly quantify the target construct. These instructional manipulation checks are useful tools, especially because they can identify construct irrelevant variance that is caused by the manipulation. However, our present focus on construct validity entails that we apply the label of ‘manipulation check’ to measures of a manipulation’s target construct. Measures of different constructs that are used to ensure that a given manipulation did not exert similarly robust effects onto other, non-target constructs we refer to as ‘discriminant validity checks’. Such discriminant validity checks are specific to each investigation and should include theoretically-related constructs to the target construct so that the manipulation’s specificity and nomological shockwave can be estimated.
Many articles have debated the utility and validity of manipulation checks, with some scholars arguing for their exclusion ( Fayant, Sigall, Lemonnier, Retsin, & Alexopoulos, 2017 ; Sigall & Mills, 1998 ). Indeed, manipulation checks can have unintended consequences (e.g., drawing participants’ attention to deceptive elements of the experiment, interrupting naturally unfolding psychological processes). Minimally intrusive validation assessments are thus preferable to overt self-report scales ( Hauser et al., 2018 ). Although many such challenges remain with the use of manipulation checks, they are a necessary source of construct validity data that an empirical science cannot forego. Without manipulation checks, the validity of experimental manipulations would be asserted by weaker forms of validity (e.g., face validity), which provide deeply flawed footing when used as the sole basis for construct validity ( Grand, Ryan, Schmitt, & Hmurovic, 2010 ). In an ideal world, such manipulation checks would be validated according to best psychometric practices (see Flake et al., 2017 ). Without validated manipulation checks, it is uncertain what construct the given check is capturing. As such, an apparently ‘successful’ manipulation check could be an artifact of another construct entirely.
The Present Research
The present research was purposed with a central, descriptive research aim related to construct validation practices for experimental manipulations in social psychology: document the frequency with which manipulations were (I) acquired from previous research or newly created, (II) paired with a pilot validity study, and/or (III) paired with a manipulation check. It was impractical to estimate whether each manipulation that was acquired from previous research was adequately validated by that prior work, so we gave authors the benefit of the doubt and assumed that the research that they cited alongside their manipulations presented sufficient evidence of the manipulation’s construct validity. Based on findings from the present research, it is likely that many of these cited papers did not report sufficient evidence for the manipulation’s construct validity. Therefore, this is a relatively liberal criterion that probably overestimates the extent to which manipulations have been truly validated.
We focused on social psychology given its heavy reliance upon experimental manipulations, our membership in this field, and this field’s ongoing reckoning with replication issues that may result, in part, from experimental practices. We hope that other experimentally-focused fields such as cognitive and developmental psychology, economics, management, marketing, and neuroscience may glean insights into their own manipulation validation practices and standards from this investigation. Further, clinical and counseling psychologists might learn approaches to improving the construct validity of clinical trials, which are similar to experiments in many ways.
In addition to these descriptive analyses, we also empirically examined several important qualities of pilot validity studies and manipulation checks. There is only a sparse literature on these topics and we aimed to fill this gap in our understanding. Given the widespread evidence for publication bias in the field of psychology ( Head, Holman, Lanfear, Kahn, & Jennions, 2015 ), our primary goal in these analyses was to estimate the extent to which pilot and manipulation check effects are impacted by such biases. First, we tested the evidentiary value of these effects via p -curve analyses in order to estimate the extent to which pilot validity studies and manipulation checks capture ‘true’ underlying effects and are not merely the result of publication bias and questionable research practices ( Simonsohn, Nelson, & Simmons, 2014 ). Second, p -curve analyses estimated the statistical power of these reported pilot validity and check effects to examine whether long-standing claims that pilot validity studies in social psychology are underpowered ( Albers & Lakens, 2018 ; Kraemer, Mintz, Noda, Tinklenberg, & Yesavage, 2006). Third, we employed conventional meta-analyses to estimate the average size and heterogeneity of pilot validity study and manipulation check effects, useful information for future power analyses. Fourth, these meta-analyses also estimated the presence of publication bias to establish the extent to which pilot validity studies and manipulation checks are selectively reported based on the favorability of their results.
Finally, we returned to our descriptive approach to examine the presence of suspicion probes in the literature. Given the crucial role of suspicion probes in much of social psychological experiments ( Blackhart et al., 2012 ; Nichols & Edlund, 2015 ), we examined whether manipulations were associated with a suspicion probe and whether suspicious participants were retained or excluded from analyses.
Open Science Statement
This project was intended to capture an exploratory snapshot of the literature and therefore no hypotheses were advanced a priori . The preregistration plan for the present research is publicly available online (original plan: https://osf.io/rtbwj ; amendment: https://osf.io/zvg3a ), as is the disclosure table of all included studies and their associated codes ( https://osf.io/je9xu/files/ ).
Literature Search Strategy
We conducted our literature search within a journal that is often reputed to be the flagship journal of experimental social psychology, JPSP . We limited our literature search to a single year of publication (as in Flake et al., 2017 ), selecting the year 2017 because it was recent enough to reflect current practices in the field. Our preregistration plan stated that we would examine volume 113 of JPSP , limiting our coding procedures to the two experimentally focused sections: Attitudes and Social Cognition ( ASC ) and Interpersonal Relations and Group Processes ( IRGP ). We excluded the Personality Processes and Individual Differences ( PPID ) section of JPSP due to its focus on measurement and not manipulation. However, we deviated from our preregistration plan by also including volume 112 in our analysis in order to increase our sample size and therefore our confidence in our findings.
Inclusion Criteria
We sought to first identify every experimental manipulation within the articles that fell within our literature search. In our initial preregistration plan, we defined experimental manipulations as “any systematic alteration of a study’s procedure meant to change a specific psychological construct.” However, this definition did not always provide clear guidance in many instances in which a systematically-altered aspect of a given study might or might not constitute an experimental manipulation. The ambiguity around many of these early decisions caused us to rapidly deem it impossible to implement this definition in any rigorous or objective manner. Instead, we revised our preregistration plan to follow two, simple heuristics. First, we decided that a study aspect would be deemed an experimental manipulation if it was described by the authors as a ‘manipulation’. This approach lifted the burden of determining whether a given aspect of a study was a ‘true’ manipulation from the coders and instead allowed a given article’s authors, their peer reviewers, and editor to determine whether something could be accurately described as an experimental manipulation. Second, if participants were ‘randomly assigned’ to different treatments or conditions, this aspect of the study procedure would be considered an experimental manipulation, as random assignment is the core aspect of experimental manipulation ( Wilson et al., 2010 ). We deviated from our preregistration plans by deciding to exclude studies from our analyses that were not presented as part of the main sequence of hypothesis-testing studies in each paper (e.g., pilot studies). This deviation was motivated by the realization that pilot validity studies were often provided as the very sources of purported validity evidence we sought to identify for each paper’s main experiments, and therefore should be examined separately.
Coding Strategy
We coded every experimental manipulation for several criteria that either provided descriptive detail or spoke to the evidence put forward for the construct validity of the manipulation.
Coding process.
All manipulations were coded independently by the first and last author, who each possess considerable expertise and training in experimental social psychology, research methodology, and construct validation. The first and last authors met frequently throughout the coding process to identify coding discrepancies. Such discrepancies were reviewed by both authors until both authors agreed upon one coding outcome (as in Flake et al., 2017 ). Prior to such discrepancy reviews and meetings, the authors each created 459 codes of the nine key coded variables of our meta-analysis (e.g., whether a given study included a manipulation, how many manipulations were included in each study, whether a manipulation was paired with a manipulation check) from the first 11 articles in our literature review. In an exploratory fashion, we examined the inter-rater agreement in these initial codes (459 codes per rater × 2 raters = 918 codes; 102 codes per coded variable), which were uncontaminated because the authors had yet to meet and conduct a discrepancy review. These initial codes exhibited substantial inter-rater agreement across all coded variables, κ = .89. Inter-rater agreement estimates for each of the uncontaminated coded variables are presented below.
Condition number and type.
Each manipulation was coded for the number of conditions it contained, κ = .94, and whether it was administered in a between- or within-participants fashion, κ = .92. Deviation from our preregistration plan, we also coded whether each of the between-participants manipulations were described as randomly-assigning participants to each condition of the manipulation, κ = .63.
Use in prior research.
We coded each manipulation for whether the manipulation was paired with a citation that indicated the manipulation was acquired from previously published research, κ = .84. If this was not the case, we assumed that the manipulation was uniquely created for the given study. Manipulations that were acquired from prior publications were then coded for whether or not the authors stated that the manipulations were modified from the referenced version of the manipulation, κ = .75. Crucially, we did not code for or select manipulations based on whether that manipulation had been previously validated by the cited work. We refrained from doing so for two reasons. First, because each cited manipulation could have required a laborious search through a trail of citations in order to find evidence of validation. Second, because simply citing a paper in which the manipulation was previously used is likely an implicit argument that the manipulation has been validated by that work.
As a deviation from our preregistration plans, we also coded each manipulation for whether the manipulation’s construct validity was pilot tested. More specifically, we coded whether each manipulation was paired with any pilot validity studies that empirically tested the effect of the manipulation on the intended construct (i.e., tested the manipulation’s construct validity), κ = .91.
Each manipulation was coded for whether a manipulation check was employed, κ = .88. If such a check was employed, we coded the form of the manipulation check (e.g., self-report measure) and whether it was validated in previously published research or was created uniquely for the given study and not validated. We did not rely on authors to make this determination (i.e., we did not deem a measure a manipulation check simply because the authors of an article referred to it as such, and we did not exclude a measure from consideration as a manipulation check simply because the authors did not refer to it as a manipulation check). Instead, we defined a manipulation check as any measure of the construct that the given manipulation was intended to influence ( Hauser et al., 2018 ; Lench, Taylor, & Bench, 2014 ) and included any measure that met this criterion. This process therefore excluded instructional manipulation checks and other measures that authors deemed ‘manipulation checks’, but did not actually assess the construct that the manipulation was designed to alter (as in Lench et al., 2014 ). For each manipulation check we identified, we then coded the form that it took (e.g., self-report questionnaire) and the number of measurements that comprised it (e.g., the number of items in the questionnaire).
Suspicion probes.
We also coded for whether investigators assessed for participant suspicion of their manipulation, κ = .92. If such a suspicion probe was used, we coded the form that it took and whether participants who were deemed ‘suspicious’ were excluded from analyses, κ = .92.
Volumes 112 and 113 of the ASC and IRGP sections of JPSP contained 58 articles. Four of these articles were excluded as they were meta-analyses or non-empirical, leaving 54 articles that summarized 355 independent studies. Of these studies, 244 (68.73%) presented at least one experimental manipulation for a total of 348 experimental manipulations acquired from 49 articles.
Manipulations Per Study
The majority of studies that contained experimental manipulations reported one (66.80%) or two (25.00%) manipulations, though there was considerable variability in the number of manipulations per study: M = 1.43, SD = 0.68, mode = 1, range = 1 – 4.
Conditions Per Manipulation
The majority of studies reported two (82.18%) or three (12.64%) conditions for each manipulation, though we observed wide variation in the number of conditions per manipulation: M = 2.30, SD = 0.98, mode = 2, range = 2 – 13).
Between- Versus Within-Participants Designs
The overwhelming majority of manipulations were conducted in a between-participants manner (94.54%), as opposed to a within-participants (5.46%) approach. Variability in the number of conditions was observed in both within- and between-participants manipulations. These frequencies are depicted in Figure 3 , an alluvial plot created with SankeyMATIC: https://github.com/nowthis/sankeymatic . Alluvial plots visually mimic the flow of rivers into an alluvial fan of smaller tributaries. These flowing figures depict how frequency distributions fall from left to right into a hierarchy of categories. In each plot, a full distribution originates on the left-hand side that then ‘flows’ to the right into different categories whose width is based on the proportion assigned to that initial category. These streams then flow into even more specific sub-categories based on their proportions in an additional category.

Alluvial plot of condition frequencies by condition type.
Manipulation Validation Practices
Of the manipulations, only a modest majority of 202 (58.04%) were accompanied by at least one of the following sources of purported validity evidence: a citation indicating that the manipulation was used in prior research, a pilot validity study, and/or a manipulation check (see Table 1 and Figure 4 for a breakdown of these statistics). Pilot validity study analyses were not preregistered and therefore, exploratory.

Alluvial plot depicting distributions of the types of purported validity evidence reported for each manipulation.
Frequencies and percentages (in parentheses) of the number of manipulations that were presented alongside each type of purported validity evidence (i.e., a citation indicating published research that the manipulation had been acquired from, a pilot validity study, and/or a manipulation check measure).
Citations from previous publications.
Of all manipulations, 67 (19.25%) were paired with a citation that indicated the manipulation was used in previously published research. Of these cited manipulations, 16 (23.88%) were described as being modified in some way from their original version. The majority of the remaining 51 cited manipulations were not described in a way in which it was clear whether they had been modified from the original citation or not. Therefore, the number of modified manipulations provided here may be an underestimate of their presence in the larger literature.
Across all manipulations, 127 (36.49%) were accompanied by a manipulation check measure. These 127 manipulation checks took the form of self-report questionnaires ( n = 105; 82.68%), coded behavior ( n = 3; 2.36%), behavioral task performance ( n = 9; 7.09%), or an unspecified format ( n = 10; 7.87%; Figure 5 ). Of the 105 self-report manipulation check questionnaires, 68 (64.76%) were comprised of a single item and the rest included a range of items: M = 1.68, SD = 1.27, range = 1 – 10 ( Figure 5 ).

Alluvial plot depicting distributions of the types of manipulation check measures reported for each manipulation and numbers of self-report items.
Suspicion Probes
Of all manipulations, only 31 (8.90%) were accompanied by a suspicion probe. Probing procedures were invariably described in vague terms (e.g., ‘a funnel interview’) and no experimenter scripts or sample materials were provided that gave any further detail. Of these probed manipulations, only five (16.10%) from two articles reported that they excluded ‘suspicious’ participants from analyses. The exact criteria for what determined whether a participant was ‘suspicious’ or not was not provided in any of these cases nor was the impact of excluding these participants estimated.
Exploratory Analyses
Random assignment..
We found that 205 (62.31%) of between-participants manipulations declared that participants were randomly assigned to conditions. No articles described the method they used to randomly assign participants.
Pilot validity study meta-analyses.
Pilot validity studies were reported as purported validity evidence for 77 (22.13%) of all manipulations. However, the majority of these studies either did not report inferential statistics, described the results too vaguely to identify the target effect, or were drawn from overlapping samples of participants. Often, the results of pilot validity studies were summarized in a qualitative fashion without accompanying inferential statistics or methodological details (e.g., “Pilot testing suggested that the effect … tended to be large”; Gill & Cerce, 2017 , p. 364). Based on the 15 pilot validity study effects that we could extract, p -curve analyses revealed that pilot validity studies exhibited remarkable evidentiary value and were statistically powered at 99% ( Figure 6 ).

Results of the p -curve analysis on pilot validity study effects.
Exploratory random-effects meta-analyses on 14 of the Fisher’s Z -transformed pilot validity effects (one effect could not be translated into an effect size estimate) revealed an overall medium-to-large effect size, r = .46 [ 95% CI = .34, .59], SE = 0.06, Z = 7.28, p < .001, with significant underlying inter-study heterogeneity, Q (13) = 136.70, p < .001. The average sample size of these studies was N = 186.47, which explains the high statistical power we observed for such relatively strong effects. Given that the Little evidence was found for publication bias in pilot validity studies (see Supplemental Document 1 ).
Manipulation check meta-analyses.
Of the 127 manipulations with manipulation checks, six did not report the results of the manipulation check and 14 others reported incomplete inferential statistics (e.g., a range of p-values, no test statistics) such that it was difficult to verify the veracity of their claims. From these manipulation checks, 82 independent manipulation check effects were extracted and submitted to exploratory p -curve analyses, which revealed that manipulation checks exhibited remarkable evidentiary value and were statistically powered at 99% ( Figure 7 ).

Results of the p-curve analysis of manipulation check effects.
Exploratory random-effects meta-analyses on these Fisher’s Z -transformed manipulation check effects revealed an overall medium-to-large effect size, r = .55 [ 95% CI = .48, .62], SE = 0.03, Z = 16.31, p < .001, with significant underlying inter-study heterogeneity, Q (81) = 2,167.90, p < .001. The average sample size of these studies was N = 304.79, which explains the high statistical power we observed for such relatively strong effects. No evidence was found for publication bias (see Supplemental Document 1 ).
Internal consistency of manipulation checks.
Among the 37 manipulation checks that took the form of multiple item self-report scales, exact Cronbach’s alphas were provided for 18 (48.65%) of them and these estimates by-and-large exhibited sufficient internal consistency: M = .83, SD = .12, range = .49 – .98.
Validity of manipulation checks.
Crucially, only eight of all of the manipulation checks (6.30%) were accompanied by a citation indicating that the check was acquired from previous research. After reading the cited validity evidence for each case, only six (4.27%) manipulation checks actually met the criteria for established validation, taking the forms of the Need Threat Scale (NTS; Williams, 2009 ) and the Positive Affect Negative Affect Schedule (PANAS; Watson, Clark, & Tellegen, 1988 ).
Construct valid measures in psychology are able to accurately capture the target construct and not extraneous variables ( Borsboom et al., 2004 ; Cronbach & Meehl, 1955 ; Embretson, 1983 ; Strauss & Smith, 2009 ). Such construct validity is not limited to psychometrics but applies equally to experimental manipulations of psychological processes. Indeed, construct valid manipulations must affect their intended construct in the intended way, and not exert their effect via confounding variables ( Cook & Campbell, 1979 ). To better understand the current practices through which experimental social psychologists provide evidence that their manipulations possess construct validity, we examined published articles from the field’s flagship journal: JPSP .
Chief among our findings was that approximately 42% of experimental manipulations were paired with no evidence beyond face validity of their underlying construct validity — no citations, no pilot validity testing, and no manipulation checks. Indeed, the most common approach in our review was that of presenting no construct validity evidence whatsoever. To the extent that this estimate generalizes across the field, this suggests that social psychology’s experimental foundations rest upon considerably unknown ground instead of empirical adamant. In what follows, we highlight other key findings from each domain of our meta-analysis, while providing recommendations for future practice in the hope of improving the state of experimental psychological science.
Prevalence and Complexity of Experimental Manipulations
At a first glance, we find that experimental manipulation is alive and well in social psychology. A little more than two-thirds of the studies we reviewed had at least one experimental manipulation. Suggesting a preference for simplicity, over 90% of studies with manipulations employed only one or two manipulations, and a similar number of manipulations contained only two or three conditions. This prevalence of relatively simple experimental designs is promising as exceedingly complex designs (e.g., a 2 × 3 × 2 factorial design) undermine statistical power and inflate type I and II error rates ( Smith, Levine, Lachlan, & Fediuk, 2002 ).
Over 90% of manipulations were conducted in a between-participant manner, demonstrating a neglect of within-participants experimental designs. Within-participants designs are able to maximize statistical power, as compared to between-participants designs ( Aberson, 2019 ). As such, the over-reliance we observed on between-participants designs may undermine the overall power of the findings from experimental social psychology. However, many manipulations may simply be impossible to present in a repeated-measures fashion without undermining the internal validity thereof.
Random Assignment and the Lack of Detail in Descriptions of Manipulations
Of the between-participants manipulations, a considerable number (approximately two-fifths) failed to mention whether participants were randomly assigned to their experimental conditions. Given that random assignment is a necessary condition for a true experimental manipulation ( Cook & Campbell, 1979 ; Wilson et al., 2010 ), explicit statements of what assignment procedure was used to place participants in their given condition should be included in every report of experimental results. Furthermore, none of the manipulations that did mention random assignment to condition described precisely what procedure was used to randomize the assignment process. Without this information, it is impossible to know if condition assignment was truly randomized or perhaps the randomization procedure could have introduced a systematic bias of some kind. Relatedly, we did not learn about whether or how within-participants manipulations randomized the order of the conditions across participants. Future research would benefit from examining the prevalence of these practices and their impact on the construct validity of within-participants manipulations.
This lack of information about random assignment reflected a much more general lack of basic information that authors provided about their manipulations. It was often the case where manuscripts did not even mention the validity information we sought. Pilot validity studies and manipulation checks were frequently described in a cursory fashion, absent necessary methodological detail and inferential statistics. More transparency is needed in order to evaluate each manipulation’s validity and for researchers to replicate the procedure in their own labs. Towards this end, we have created a checklist of information that we hope peer reviewers will apply to new research in order to ensure that each manipulation, manipulation check, and pilot validity study is described in sufficient detail ( Appendix A ). We further encourage experimenters to use this checklist to adequately detail these important aspects of their experimental methodology.
Previously Used vs. ‘On The Fly’ Manipulations
Approximately 80% of manipulations were not acquired from previous research and were instead created ad hoc for a given study. This suggests that researchers heavily rely upon ‘on the fly’ manipulation (term adapted from Flake et al., 2017 ), in which ad hoc manipulations are routinely created from scratch to fit the parameters of a given study. The prevalence of this ‘on the fly’ manipulation is almost twice that of ‘on the fly’ measurement in social and personality psychology (~46%; Flake et al., 2017 ). This prevalence rate may be inflated by a tendency for authors to simply fail to provide such citations for manipulations that have, in fact, been implemented in prior publications. We encourage experimenters to cite publications that empirically examine the validity of their manipulations, whenever they exist. These ad hoc procedures appear to acutely afflict experimental designs and future work is needed to determine the reasons underlying this disproportionate practice.
The field’s reliance on creating manipulations de novo is concerning. This practice entails that much time and resources are spent on creating new manipulations instead of implementing and improving upon existing, validated manipulations. This tendency towards ‘on the fly’ manipulation may reflect psychological science’s bias towards novelty and away from replicating past research ( Neuliep & Crandall, 1993 ), which has known adverse consequences ( Open Science Collaboration, 2015 ). We therefore recommend that experimenters avoid ‘on the fly’ manipulation and instead employ existing, previously validated manipulations whenever possible (Recommendation 1), though we note few of such manipulations are likely available.
Of the relatively small number of manipulations that were acquired from previous research, roughly one-fourth of them were modified from their original form. This is likely an underestimate of modification rates, as none of the articles we coded explicitly stated that their manipulation was not modified in any way. As such, modification rates may be considerably higher. This practice can have consequences as modifying a manipulation undermines the established validity of that manipulation, just as modifying a questionnaire often requires it to be re-validated ( Flake et al., 2017 ). This practice of unvalidated modification compounds these issues when the original manipulation that has been modified was never validated itself. We therefore recommend that experimenters avoid modifying previously validated manipulations whenever possible (Recommendation 2A). When modification is unavoidable, we recommend that investigators re-validate the modified manipulation prior to implementation (Recommendation 2B).
We realize that Recommendations 1 and 2 are likely to be difficult to adhere to given the pessimistic nature of our findings. Indeed, it is difficult to avoid ‘on the fly’ manipulation development and modification when there are no validated versions of a given manipulation already in existence. However, we are optimistic that if experimenters begin to improve their validation practices, this will not be an issue for long. These recommendations are given with that bright future in mind.
Pilot Validity Testing
Approximately one in five manipulations were associated with a pilot validity study prior to implementation in hypothesis testing. This low adoption rate of pilot validity studies suggests that the practice of pilot validity testing is somewhat rare, which is problematic as such testing is a critical means of establishing the construct validity of a manipulation ( Ellsworth & Gonzalez, 2003 ; Wilson et al., 2010 ). Pilot validity testing has several advantages over simply including manipulation checks during hypothesis testing. First, pilot validity testing prevents unwanted effects of a manipulation check from intruding upon other aspects of the study ( Hauser et al., 2018 ). Second, pilot validity studies allow for changes to be made to the manipulation to optimize its effects before it is implemented. Pilot validity testing would further ensure that time and resources are not wasted on testing hypotheses with manipulations of unknown construct validity. We therefore recommend that experimenters conduct well-powered pilot validity studies for each manipulation prior to implementation in hypothesis testing (Recommendation 3A).
These relatively rare reports of pilot validity studies may have been artificially suppressed by the practice of not publishing pilot validity evidence ( Westlund & Stuart, 2017 ). However, all pilot validity evidence should be published alongside the later studies it was used to develop in order to transparently communicate the evidence for and against the validity of the given manipulation ( Asendorpf et al., 2013 ). Keeping pilot validity studies behind a veil may also reflect a broader culture that under-values this crucial phase of the manipulation validation process. Pilot validity studies should not be viewed as mere ‘dress rehearsals’ for the main event (i.e., hypothesis testing), but should be granted the same importance, resources, and time as the studies in which they are subsequently employed. Robust training, investment, and transparency in pilot validity testing will produce more valid manipulations and therefore, more valid experimental findings. We therefore recommend that the results of pilot validity studies should be published as validation articles (Recommendation 3B) and these validation articles should be accompanied by detailed protocols and stimuli needed to replicate the manipulation (Recommendation 3C).
On an optimistic note, meta-analyses revealed that pilot validity studies exhibited substantial evidentiary value and a robust meta-analytic effect size. These findings imply that researchers are conducting pilot validity tests that capture real and impactful effects and are not just capitalizing on sources of flexibility or variability. Little evidence of p -hacking ( Simonsohn et al., 2014 ) or publication bias were observed, suggesting that researchers are not simply selectively reporting their pilot validity data to artificially evince an underlying effect, nor are they merely submitting unsuccessful pilot validity studies to the ‘file drawer’ and cherry picking those that obtain effects. These meta-analyses also revealed that these studies were statistically powered to a maximal degree, arguing against characterizations of pilot validity studies as underpowered ( Albers & Lakens, 2018 ; Kraemer et al., 2006).
Manipulation Checks
Approximately one-third of manipulations were paired with a manipulation check measure. This estimate is much lower than those from other meta-analyses. Hauser and colleagues (2018) reported that 63% of articles in the Attitudes & Social Cognition section of 2016 JPSP included at least one manipulation check. Sigall and Mills (1998) reported that 68% of JPSP articles in 1998 reported an experimental manipulation. The differences in our estimates are likely due to our focus at the manipulation-level, rather than the article-level, which we employed because articles present multiple studies with multiple manipulations and article-level analyses obscure these statistics. We also applied a strict definition of a manipulation check, whereas the authors of these other investigations may have counted any measure that the authors referred to as a ‘manipulation check’. It is also possible that manipulation check prevalence rates have actually decreased in recent years, due to published critiques of manipulation checks (e.g., Fayant et al., 2017 ; Sigall & Mills, 1998 ).
A central issue with manipulation checks is that they intrude upon the experiment, calling participants’ attention and suspicion to the manipulation and subsequently to the construct under study ( Hauser et al. 2018 ). For instance, asking participants how rejected they felt may raise suspicions about the ball-tossing task they were just excluded from. Such effects can be manifold and insidious, causing participants to guess at the experimenters’ hypotheses, heighten their suspicion, change their thoughts or feelings by reflecting upon them, or change the nature of the manipulation itself ( Hauser et al., 2018 ). However, the concerns raised by these critiques are obviated if the manipulation check is administered during the pilot validation of the manipulation and excluded during implementation of the manipulation in hypothesis testing. We therefore recommend that experimenters administer manipulation checks during the pilot validity testing of each manipulation (Recommendation 4A) and post-pilot manipulation checks should only be administered if they do not negatively impact other aspects of the study (Recommendation 4B).
Pilot validity studies may differ substantially from the primary experiments that employ the manipulations that they seek to validate. Indeed, the presence of other manipulations, measures, and environmental factors might lead a manipulation that exhibited evidence of possessing construct validity to no longer exert its ‘established’ effect on the target construct. When such differences occur between pilot validity studies and focal experiments, including a manipulation check in the focal experiment could establish whether these changes have affected the manipulation’s construct validity. If there are legitimate concerns that including a manipulation check could negatively impact the validity of the manipulation, then experimenters could randomly-assign participants to either receive the check or not in order to estimate the effect that the check has on the manipulation’s hypothesized effects (assuming sufficient power to detect such effects).
As with the manipulations themselves, the overwhelming majority of manipulation checks were created ad hoc for the given manipulation. The purported validity evidence provided for the manipulation checks was often simple face validity and in some cases, a Cronbach’s α . Many were single-item self-report measures. These forms of purported validity evidence are insufficient to establish the construct validity of a measure ( Flake et al., 2017 ). Not knowing whether the check captured the latent construct of interest, or instead tapped into some other construct(s), renders any inferences drawn upon such measures theoretically compromised. We therefore recommend that experimenters validate the instruments they use as manipulation checks prior to use in pilot validity testing (Recommendation 4C). Requiring that manipulation checks be validated would entail a large-scale shift in the practices of experimental social psychologists, who would now often find themselves having to preempt new experiments with the task of creating and validating a new state measure. This would require a new emphasis on training in psychometrics, resources devoted to the manipulation check validation process, and rewards given to those who do so.
Meta-analyses revealed that manipulation checks exhibited evidentiary value and a robust meta-analytic effect size. Though these findings are promising indicators that the manipulations employed in these studies exerted true effects that these checks were able to capture, they cannot speak to the underlying construct validity of these manipulation effects. Indeed, just because manipulations are exerting some effect on their manipulation checks, these findings do not tell us whether the intended aspect of the manipulation exerted the observed effect or whether the manipulation checks measured the target construct. Manipulation check effects were also maximally statistically powered, which implies that manipulations are at least well powered enough to influence their intended constructs. As with pilot validity studies, there was no evidence for publication bias.
Only approximately one-tenth of manipulations assessed the extent to which participants were suspicious of the deceptive elements of the study. Though studies vary in the extent to which they are deceptive, almost all experimental manipulations entail some degree of deception in that participants are being influenced without their explicit awareness of the full nature and intent of the manipulation. As such, the majority of studies were unable to estimate the extent to which participants detected their manipulation procedures. Even fewer adequately described how suspicion was assessed, often referring vaguely to an experimenter interview or an open-ended survey question. No specific criteria were given for what delineated ‘suspicious’ from ‘non-suspicious’ participants, and only five studies excluded participants from the former group. Given that no well-validated, standardized suspicion assessment procedures exist and there is little in the way of data on what effect that removing ‘suspicious’ participants from analyses might have on subsequent results ( Blackhart et al., 2012 ), we do not make any recommendations in this domain. Much work is needed to establish the best practices of suspicion assessment and analysis.
Size and Duration of Manipulation Effects
Although many articles established the size of a manipulation’s effect on the manipulation check, no manipulation checks repeatedly assessed any manipulation’s effect in order to estimate the timecourse of these effects. The effect of a given experimental manipulation wanes over time (e.g., Zadro, Boland, & Richardson, 2006 ) and its timecourse is a critical element to determine for several reasons. First, experimenters need to know if the manipulation’s effect is still psychologically active at the time point in which they administer their outcome measures, and its strength at that given timepoint. This would allow experimenters to identify an experimental ‘sweet spot’ when the manipulation’s effect is strongest. Second, for ethical reasons it is crucial to ensure that the manipulation’s effect has adequately decayed by the time the study has ended and participants are returned to the real world. This is especially important when the manipulated process is distressing or interferes with daily functioning ( Miketta & Friese, 2019 ). We therefore recommend that whenever possible, that experimenters estimate the timecourse of their manipulation’s effect by repeatedly administering manipulation checks during pilot validity testing (Recommendation 5).
Estimating the Nomological Shockwave via Discriminant Validity Checks
Across the manipulations we surveyed, construct validity was most often assessed (when it was assessed) by estimating the manipulation’s effect on the construct that the manipulation was primarily intended to affect. However, a requisite of construct validity is discriminant validity, such that the given manipulation influences the target construct and not a different, confounding construct ( Cronbach & Meehl, 1955 ). Absent this practice, ‘successful’ manipulation checks may obscure the possibility that although the manipulation influences the desired construct, it also impacts a related, non-targeted variable to a confounding degree. In this context, discriminant validity can be established by examining the manipulation’s nomological shockwave (i.e., the manipulation’s effect on other constructs that exist in within the target construct’s nomological network). This can be done by administering discriminant validity checks, which are measures of constructs within the target construct’s nomological network. In its simplest form, the nomological shockwave can empirically established by demonstrating that the manipulation’s largest effect is upon the target construct and then exerts progressively weaker and non-overlapping effects on theoretically-related constructs as a function of their proximity to the target construct in the nomological network. We therefore recommend that experimenters administer measures of theoretically related constructs in pilot testing (i.e., discriminant validity checks; Recommendation 6A) and that these are used to estimate the nomological shockwave of the manipulation (Recommendation 6B).
Estimating the nomological shockwave by simply comparing effect sizes and their confidence intervals is admittedly a crude empirical approach. Inherently, the shockwave rests on the assumption that the manipulation exerts a causal effect on the target construct, this target construct then exerts a causal effect on the discriminant validity constructs by virtue of their latent associations. Ideally, causal models could test this sequence of effects, though such quantitative approaches are often limited in their abilities to do so ( Fiedler, Schott, & Meiser, 2011 ). Future research is needed to understand the accuracy and utility of employing causal modeling to estimate nomological shockwaves.
Limitations and Future Directions
This project only examined articles from JPSP and did not include a wider array of publication outlets in social psychology. It may be that our assessment of validation practices would change if we had cast a wider meta-analytic net. Future work should test whether our findings replicate in other journals and in other subfields of psychology. Other experimentally focused fields such as cognitive, developmental, and biological psychology may also vary in their approaches to the validation of their experimental manipulations. Future research is needed in these areas to see if this is the case. We also used subjective codes and definitions of the manipulation features that we coded, allowing for our own biases to have influenced our findings. We have made all of our codes publicly available so that interested parties might review them for such biases and modify the codes according to their own sensibilities and examine their effect on our results. Indeed, we do not see our findings as conclusive but that the coded dataset we have created will be a resource for other investigators to examine in the future.
Experimental manipulations are the methodological foundation of much of social psychology. Our meta-analytic review suggests that the construct validity of such manipulations rests on practices that could be improved. We have made recommendations for how to make such changes, which largely revolve around translating the validation approach taken towards personality questionnaires to experimental manipulations. This new model would entail that validated manipulations are used whenever available and when new manipulations are created, they are validated (i.e., pilot validated) prior to implementation in hypothesis testing. Validity would then be established by demonstrating that the manipulation has its strongest effect on the target construct and theoretically appropriate effects on the nomological network surrounding it. Adopting this model would mean a dramatic change in practices for most laboratories in experimental social psychology. The costs inherent in doing so should be counteracted by a rise in replicability and veridicality of the field’s findings. We hope that our assessment of the field’s practices is an important initial step in that direction.
Supplementary Material
Acknowledgments.
Research reported in this publication was supported by the National Institute on Alcohol Abuse and Alcoholism (NIAAA) of the National Institutes of Health under award number K01AA026647 (PI: Chester).
Appendix A. Peer Reviewer Manipulation Information Checklist
Below are pieces of information that should be included for research using experimental manipulations in psychology. If you don’t see them mentioned, consider requesting that the authors ensure that this information is explicitly stated in the manuscript.
- The number of manipulations in each study.
- The number of conditions in each manipulation.
- The definition of the construct that each manipulation was intended to affect.
- Whether each manipulation was administered between- or within-participants.
- Whether random assignment (for between-participants designs) or counterbalancing (for within-participants designs) were used in each manipulation.
- How random assignment or counterbalancing was conducted in each manipulation.
- Whether each manipulation was acquired from previous research or newly-created for the study.
- The pre-existing validity evidence for each manipulation that was acquired from previous research.
- Whether each manipulation that was acquired from previous research was modified from the version of the manipulation detailed in the previous research.
- The validity evidence for each manipulation that was modified from previous research.
- Whether each manipulation was pilot tested prior to implementation.
- The validity evidence for each measure employed in each pilot study.
- The pilot validity evidence for each manipulation that was pilot tested.
- The detailed Methods and Results of each pilot study.
- Whether each manipulation was paired with a manipulation check that quantified the manipulation’s target construct.
- The validity evidence for each manipulation check.
- Whether each manipulation was paired with a discriminant validity check that quantified potentially confounding constructs.
- The validity evidence for each discriminant validity check.
- Whether deception-by-omission was used for each manipulation (i.e., facts about the manipulation were withheld from participants).
- Whether deception-by-commission was used for each manipulation (i.e., untrue information about the manipulation was provided to participants).
- Whether each deceptive manipulation was paired with a suspicion probe.
- The methodological details of each suspicion probe.
- The validity evidence for each suspicion probe.
- How each suspicion probe was scored.
- How participants were deemed to be suspicious or not for each suspicion probe.
- How suspicious participants were handled (e.g., excluded from analysis, suspicion used as a covariate) in each manipulation study.
- Aberson CL (2019). Applied power analysis for the behavioral sciences . Routledge. [ Google Scholar ]
- AERA (American Educational Research Association), APA (American Psychological Association), & NCME (National Council on Measurement in Education). (2014). Standards for educational and psychological testing . American Educational Research Association. [ Google Scholar ]
- Albers C, & Lakens D (2018). When power analyses based on pilot data are biased: Inaccurate effect size estimators and follow-up bias . Journal of Experimental Social Psychology , 74 , 187–195. [ Google Scholar ]
- Asendorpf JB, Conner M, De Fruyt F, De Houwer J, Denissen JJ, Fiedler K, … & Perugini M (2013). Recommendations for increasing replicability in psychology . European Journal of Personality , 27 ( 2 ), 108–119. [ Google Scholar ]
- Begg CB, & Mazumdar M (1994). Operating characteristics of a rank correlation test for publication bias . Biometrics , 1088–1101. [ PubMed ] [ Google Scholar ]
- Benson J (1998). Developing a strong program of construct validation: A test anxiety example. Educational Measurement : Issues and Practice , 17 ( 1 ), 10–17. [ Google Scholar ]
- Berkowitz L, & Donnerstein E (1982). External validity is more than skin deep: Some answers to criticisms of laboratory experiments . American Psychologist , 37 ( 3 ), 245–257. [ Google Scholar ]
- Blackhart GC, Brown KE, Clark T, Pierce DL, & Shell K (2012). Assessing the adequacy of postexperimental inquiries in deception research and the factors that promote participant honesty . Behavior Research Methods , 44 ( 1 ), 24–40. [ PubMed ] [ Google Scholar ]
- Borsboom D, Mellenbergh GJ, & van Heerden J (2004). The concept of validity . Psychological Review , 111 ( 4 ), 1061–1071. [ PubMed ] [ Google Scholar ]
- Brewer MB (2000). Research design and issues of validity. In Reis HT & Judd CM (Eds). Handbook of research: Methods in social and personality psychology (pp. 3–39). Cambridge University Press. [ Google Scholar ]
- Campbell DT (1957). Factors relevant to the validity of experiments in social settings . Psychological Bulletin , 54 ( 4 ), 297–312. [ PubMed ] [ Google Scholar ]
- Campbell DT (1969). Prospective: Artifact and control. In Rosenthal R & Rosnow RL (Eds.), Artifact in behavioral research (pp. 351–382). Academic Press. [ Google Scholar ]
- Chester DS, DeWall CN, & Pond RS (2016). The push of social pain: Does rejection’s sting motivate subsequent social reconnection? Cognitive, Affective, & Behavioral Neuroscience , 16 ( 3 ), 541–550. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Clark LA, & Watson D (2019). Constructing validity: New developments in creating objective measuring instruments . Psychological Assessment , 31 ( 12 ), 1412. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Cook TD, & Campbell DT (1979). Quasi-experimentation: Design & analysis issues for field settings . Rand McNally. [ Google Scholar ]
- Cronbach L, & Meehl P (1955). Construct validity in psychological tests . Psychological Bulletin , 52 ( 4 ), 281–302. [ PubMed ] [ Google Scholar ]
- Donate APG, Marques LM, Lapenta OM, Asthana MK, Amodio D, & Boggio PS (2017). Ostracism via virtual chat room: Effects on basic needs, anger and pain . PLoS One , 12 ( 9 ), e0184215. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Duval S, & Tweedie R (2000). Trim and fill: A simple funnel-plot–based method of testing and adjusting for publication bias in meta-analysis . Biometrics , 56 ( 2 ), 455–463. [ PubMed ] [ Google Scholar ]
- Egger M, Smith GD, Schneider M, & Minder C (1997). Bias in meta-analysis detected by a simple, graphical test . British Medical Journal , 315 ( 7109 ), 629. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Ellsworth PC, & Gonzalez R (2003). Questions and comparisons: Methods of research in social psychology. In Hogg M & Cooper J (Eds.), The sage handbook of social psychology (pp. 24–42). Sage. [ Google Scholar ]
- Embretson S (1983). Construct validity: Construct representation versus nomothetic span . Psychological Bulletin , 93 ( 1 ), 179–197. [ Google Scholar ]
- Fayant MP, Sigall H, Lemonnier A, Retsin E, & Alexopoulos T (2017). On the limitations of manipulation checks: An obstacle toward cumulative science . Psychology , 30 ( 1 ), 125–130. [ Google Scholar ]
- Fiedler K, Schott M, & Meiser T (2011). What mediation analysis can (not) do . Journal of Experimental Social Psychology , 47 ( 6 ), 1231–1236. [ Google Scholar ]
- Flake JK, & Fried EI (2019). Measurement schmeasurement: Questionable measurement practices and how to avoid them . Unpublished preprint available at https://psyarxiv.com/hs7wm/
- Flake JK, Pek J, & Hehman E (2017). Construct validation in social and personality research: Current practice and recommendations . Social Psychological and Personality Science , 8 ( 4 ), 370–378. [ Google Scholar ]
- Garner W, Hake H, & Eriksen C (1956). Operationism and the concept of perception . Psychological Review , 63 ( 3 ), 149–159. [ PubMed ] [ Google Scholar ]
- Gill M, & Cerce S (2017). He never willed to have the will he has: Historicist narratives, “civilized” blame, and the need to distinguish two notions of free will . Journal of Personality and Social Psychology , 112 ( 3 ), 361–382. [ PubMed ] [ Google Scholar ]
- Grand JA, Ryan AM, Schmitt N, & Hmurovic J (2010). How far does stereotype threat reach? The potential detriment of face validity in cognitive ability testing . Human Performance , 24 ( 1 ), 1–28. [ Google Scholar ]
- Gray K (2017). How to map theory: Reliable methods are fruitless without rigorous theory . Perspectives on Psychological Science , 12 ( 5 ), 731–741. [ PubMed ] [ Google Scholar ]
- Haslam SA, & McGarty C (2004). Experimental design and causality in social psychological research. In Sanson C, Morf CC, & Panter AT (Eds.), Handbook of methods in social psychology (pp. 235–264). Sage. [ Google Scholar ]
- Hauser DJ, Ellsworth PC, & Gonzalez R (2018). Are manipulation checks necessary? Frontiers in Psychology , 9 . [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Head ML, Holman L, Lanfear R, Kahn AT, & Jennions MD (2015). The extent and consequences of p -hacking in science . PLoS Biology , 13 ( 3 ). [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Highhouse S (2009). Designing experiments that generalize . Organizational Research Methods , 12 ( 3 ), 554–566. [ Google Scholar ]
- Lench HC, Taylor AB, & Bench SW (2014). An alternative approach to analysis of mental states in experimental social cognition research . Behavior Research Methods , 46 ( 1 ), 215–228. [ PubMed ] [ Google Scholar ]
- Lewin K (1939). Field theory and experiment in social psychology: Concepts and methods . American Journal of Sociology , 44 ( 6 ), 868–896. [ Google Scholar ]
- Loevinger J (1957). Objective tests as instruments of psychological theory . Psychological Reports , 3 , 635–694. [ Google Scholar ]
- Messick S (1995). Validity of psychological assessment: Validation of inferences from persons’ responses and performances as scientific inquiry into score meaning . American Psychologist , 50 ( 9 ), 741–749. [ Google Scholar ]
- Miketta S, & Friese M (2019). Debriefed but still troubled? About the (in) effectiveness of postexperimental debriefings after ego threat . Journal of Personality and Social Psychology , 117 ( 2 ), 282–309. [ PubMed ] [ Google Scholar ]
- Mook D (1983). In defense of external invalidity . American Psychologist , 38 ( 4 ), 379–387. [ Google Scholar ]
- Neuliep JW, & Crandall R (1993). Reviewer bias against replication research . Journal of Social Behavior and Personality , 8 ( 6 ), 21–29. [ Google Scholar ]
- Nichols AL, & Edlund JE (2015). Practicing what we preach (and sometimes study): Methodological issues in experimental laboratory research . Review of General Psychology , 19 ( 2 ), 191–202. [ Google Scholar ]
- Open Science Collaboration. (2015). Estimating the reproducibility of psychological science . Science , 349 ( 6251 ), 253–267. [ PubMed ] [ Google Scholar ]
- Oppenheimer DM, Meyvis T, & Davidenko N (2009). Instructional manipulation checks: Detecting satisficing to increase statistical power . Journal of Experimental Social Psychology , 45 ( 4 ), 867–872. [ Google Scholar ]
- Orwin RG (1983). A fail-safe N for effect size in meta-analysis . Journal of Educational Statistics , 8 ( 2 ), 157–159. [ Google Scholar ]
- Reichardt CS (2006). The principle of parallelism in the design of studies to estimate treatment effects . Psychological Methods , 11 ( 1 ), 1–18. [ PubMed ] [ Google Scholar ]
- Shadish WR, Cook TD, & Campbell DT (2002). Experimental and quasi-experimental designs for generalized causal inference . Houghton Mifflin. [ Google Scholar ]
- Sigall H, & Mills J (1998). Measures of independent variables and mediators are useful in social psychology experiments: But are they necessary? Personality and Social Psychology Review , 2 ( 3 ), 218–226. [ PubMed ] [ Google Scholar ]
- Simms LJ (2008). Classical and modern methods of psychological scale construction . Social and Personality Psychology Compass , 2 ( 1 ), 414–433. [ Google Scholar ]
- Simonsohn U, Nelson LD, & Simmons JP (2014). P-curve: A key to the file-drawer . Journal of Experimental Psychology. General , 143 ( 2 ), 534–547. [ PubMed ] [ Google Scholar ]
- Smith GT (2005). On construct validity: Issues of method and measurement . Psychological Assessment , 17 ( 4 ), 396–408 [ PubMed ] [ Google Scholar ]
- Smith RA, Levine TR, Lachlan KA, & Fediuk TA (2002). The high cost of complexity in experimental design and data analysis: Type I and type II error rates in multiway ANOVA . Human Communication Research , 28 ( 4 ), 515–530. [ Google Scholar ]
- Strauss ME, & Smith GT (2009). Construct validity: Advances in theory and methodology . Annual Review of Clinical Psychology , 5 , 1–25. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Watson D, Clark LA, & Tellegen A (1988). Development and validation of brief measures of positive and negative affect: The PANAS scales . Journal of Personality and Social Psychology , 54 ( 6 ), 1063–1070. [ PubMed ] [ Google Scholar ]
- Westlund E, & Stuart EA (2017). The nonuse, misuse, and proper use of pilot studies in experimental evaluation research . American Journal of Evaluation , 38 ( 2 ), 246–261. [ Google Scholar ]
- Williams KD (2009). Ostracism: Effects of being ignored and excluded. In Zanna M (Ed.), Advances in experimental social psychology (Vol. 41 , pp. 279–314). Academic Press. [ Google Scholar ]
- Williams K, Cheung C, & Choi W (2000). Cyberostracism: Effects of being ignored over the internet . Journal of Personality and Social Psychology , 79 ( 5 ), 748–762. [ PubMed ] [ Google Scholar ]
- Wilson TD, Aronson E, & Carlsmith K (2010). The art of laboratory experimentation. In Fiske ST, Gilbert DT, & Lindzey G (Eds.), Handbook of social psychology (Vol. 1 , pp. 51–81). Wiley. [ Google Scholar ]
- Zadro L, Boland C, & Richardson R (2006). How long does it last? The persistence of the effects of ostracism in the socially anxious . Journal of Experimental Social Psychology , 42 ( 5 ), 692–697. [ Google Scholar ]
- Zumbo BD, & Chan EKH (2014). Setting the stage for validity and validation in social, behavioral, and health sciences: Trends in validation practices. In Zumbo BD & Chan EKH (Eds.), Validity and validation in social, behavioral, and health sciences (pp. 3–8). Springer. [ Google Scholar ]
Facility for Rare Isotope Beams
At michigan state university, frib researchers lead team to merge nuclear physics experiments and astronomical observations to advance equation-of-state research, world-class particle-accelerator facilities and recent advances in neutron-star observation give physicists a new toolkit for describing nuclear interactions at a wide range of densities..
For most stars, neutron stars and black holes are their final resting places. When a supergiant star runs out of fuel, it expands and then rapidly collapses on itself. This act creates a neutron star—an object denser than our sun crammed into a space 13 to 18 miles wide. In such a heavily condensed stellar environment, most electrons combine with protons to make neutrons, resulting in a dense ball of matter consisting mainly of neutrons. Researchers try to understand the forces that control this process by creating dense matter in the laboratory through colliding neutron-rich nuclei and taking detailed measurements.
A research team—led by William Lynch and Betty Tsang at FRIB—is focused on learning about neutrons in dense environments. Lynch, Tsang, and their collaborators used 20 years of experimental data from accelerator facilities and neutron-star observations to understand how particles interact in nuclear matter under a wide range of densities and pressures. The team wanted to determine how the ratio of neutrons to protons influences nuclear forces in a system. The team recently published its findings in Nature Astronomy .
“In nuclear physics, we are often confined to studying small systems, but we know exactly what particles are in our nuclear systems. Stars provide us an unbelievable opportunity, because they are large systems where nuclear physics plays a vital role, but we do not know for sure what particles are in their interiors,” said Lynch, professor of nuclear physics at FRIB and in the Michigan State University (MSU) Department of Physics and Astronomy. “They are interesting because the density varies greatly within such large systems. Nuclear forces play a dominant role within them, yet we know comparatively little about that role.”
When a star with a mass that is 20-30 times that of the sun exhausts its fuel, it cools, collapses, and explodes in a supernova. After this explosion, only the matter in the deepest part of the star’s interior coalesces to form a neutron star. This neutron star has no fuel to burn and over time, it radiates its remaining heat into the surrounding space. Scientists expect that matter in the outer core of a cold neutron star is roughly similar to the matter in atomic nuclei but with three differences: neutron stars are much larger, they are denser in their interiors, and a larger fraction of their nucleons are neutrons. Deep within the inner core of a neutron star, the composition of neutron star matter remains a mystery.
“If experiments could provide more guidance about the forces that act in their interiors, we could make better predictions of their interior composition and of phase transitions within them. Neutron stars present a great research opportunity to combine these disciplines,” said Lynch.
Accelerator facilities like FRIB help physicists study how subatomic particles interact under exotic conditions that are more common in neutron stars. When researchers compare these experiments to neutron-star observations, they can calculate the equation of state (EOS) of particles interacting in low-temperature, dense environments. The EOS describes matter in specific conditions, and how its properties change with density. Solving EOS for a wide range of settings helps researchers understand the strong nuclear force’s effects within dense objects, like neutron stars, in the cosmos. It also helps us learn more about neutron stars as they cool.
“This is the first time that we pulled together such a wealth of experimental data to explain the equation of state under these conditions, and this is important,” said Tsang, professor of nuclear science at FRIB. “Previous efforts have used theory to explain the low-density and low-energy end of nuclear matter. We wanted to use all the data we had available to us from our previous experiences with accelerators to obtain a comprehensive equation of state.”
Researchers seeking the EOS often calculate it at higher temperatures or lower densities. They then draw conclusions for the system across a wider range of conditions. However, physicists have come to understand in recent years that an EOS obtained from an experiment is only relevant for a specific range of densities. As a result, the team needed to pull together data from a variety of accelerator experiments that used different measurements of colliding nuclei to replace those assumptions with data. “In this work, we asked two questions,” said Lynch. “For a given measurement, what density does that measurement probe? After that, we asked what that measurement tells us about the equation of state at that density.”
In its recent paper, the team combined its own experiments from accelerator facilities in the United States and Japan. It pulled together data from 12 different experimental constraints and three neutron-star observations. The researchers focused on determining the EOS for nuclear matter ranging from half to three times a nuclei’s saturation density—the density found at the core of all stable nuclei. By producing this comprehensive EOS, the team provided new benchmarks for the larger nuclear physics and astrophysics communities to more accurately model interactions of nuclear matter.
The team improved its measurements at intermediate densities that neutron star observations do not provide through experiments at the GSI Helmholtz Centre for Heavy Ion Research in Germany, the RIKEN Nishina Center for Accelerator-Based Science in Japan, and the National Superconducting Cyclotron Laboratory (FRIB’s predecessor). To enable key measurements discussed in this article, their experiments helped fund technical advances in data acquisition for active targets and time projection chambers that are being employed in many other experiments world-wide.
In running these experiments at FRIB, Tsang and Lynch can continue to interact with MSU students who help advance the research with their own input and innovation. MSU operates FRIB as a scientific user facility for the U.S. Department of Energy Office of Science (DOE-SC), supporting the mission of the DOE-SC Office of Nuclear Physics. FRIB is the only accelerator-based user facility on a university campus as one of 28 DOE-SC user facilities . Chun Yen Tsang, the first author on the Nature Astronomy paper, was a graduate student under Betty Tsang during this research and is now a researcher working jointly at Brookhaven National Laboratory and Kent State University.
“Projects like this one are essential for attracting the brightest students, which ultimately makes these discoveries possible, and provides a steady pipeline to the U.S. workforce in nuclear science,” Tsang said.
The proposed FRIB energy upgrade ( FRIB400 ), supported by the scientific user community in the 2023 Nuclear Science Advisory Committee Long Range Plan , will allow the team to probe at even higher densities in the years to come. FRIB400 will double the reach of FRIB along the neutron dripline into a region relevant for neutron-star crusts and to allow study of extreme, neutron-rich nuclei such as calcium-68.
Eric Gedenk is a freelance science writer.
Michigan State University operates the Facility for Rare Isotope Beams (FRIB) as a user facility for the U.S. Department of Energy Office of Science (DOE-SC), supporting the mission of the DOE-SC Office of Nuclear Physics. Hosting what is designed to be the most powerful heavy-ion accelerator, FRIB enables scientists to make discoveries about the properties of rare isotopes in order to better understand the physics of nuclei, nuclear astrophysics, fundamental interactions, and applications for society, including in medicine, homeland security, and industry.
The U.S. Department of Energy Office of Science is the single largest supporter of basic research in the physical sciences in the United States and is working to address some of today’s most pressing challenges. For more information, visit energy.gov/science.
IMAGES
VIDEO
COMMENTS
The Role of Variables in Research. In scientific research, variables serve several key functions: Define Relationships: Variables allow researchers to investigate the relationships between different factors and characteristics, providing insights into the underlying mechanisms that drive phenomena and outcomes. Establish Comparisons: By manipulating and comparing variables, scientists can ...
10 Experimental research. 10. Experimental research. Experimental research—often considered to be the 'gold standard' in research designs—is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different ...
Systematically and precisely manipulate the independent variable(s). Precisely measure the dependent variable(s). Control any potential confounding variables. If your study system doesn't match these criteria, there are other types of research you can use to answer your research question. Step 3: Design your experimental treatments
In research, a variable is any characteristic, number, or quantity that can be measured or counted in experimental investigations. One is called the dependent variable, and the other is the independent variable. In research, the independent variable is manipulated to observe its effect, while the dependent variable is the measured outcome.
Types of Variables in Research & Statistics | Examples. Published on September 19, 2022 by Rebecca Bevans. Revised on June 21, 2023. In statistical research, a variable is defined as an attribute of an object of study. Choosing which variables to measure is central to good experimental design.
Systematically and precisely manipulate the independent variable(s). Precisely measure the dependent variable(s). Control any potential confounding variables. If your study system doesn't match these criteria, there are other types of research you can use to answer your research question. Step 3: Design your experimental treatments
Experimental research serves as a fundamental scientific method aimed at unraveling. cause-and-effect relationships between variables across various disciplines. This. paper delineates the key ...
1. Lab Experiment. A laboratory experiment in psychology is a research method in which the experimenter manipulates one or more independent variables and measures the effects on the dependent variable under controlled conditions. A laboratory experiment is conducted under highly controlled conditions (not necessarily a laboratory) where ...
Experimental science is the queen of sciences and the goal of all speculation. Roger Bacon (1214-1294) Download chapter PDF. Experiments are part of the scientific method that helps to decide the fate of two or more competing hypotheses or explanations on a phenomenon. The term 'experiment' arises from Latin, Experiri, which means, 'to ...
Experimental research is commonly used in sciences such as sociology and psychology, physics, chemistry, biology and medicine etc. It is a collection of research designs which use manipulation and controlled testing to understand causal processes. Generally, one or more variables are manipulated to determine their effect on a dependent variable.
Independent vs. Dependent Variables | Definition & Examples. Published on February 3, 2022 by Pritha Bhandari.Revised on June 22, 2023. In research, variables are any characteristics that can take on different values, such as height, age, temperature, or test scores. Researchers often manipulate or measure independent and dependent variables in studies to test cause-and-effect relationships.
The experimental method is the only research method that can measure cause and effect relationships between variables. Three conditions must be met in order to establish cause and effect. Experimental designs are useful in meeting these conditions: The independent and dependent variables must be related.
Three types of experimental designs are commonly used: 1. Independent Measures. Independent measures design, also known as between-groups, is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
Research variables Learn about independent, dependent, and more. All types explained. With examples. Read more! ... In experimental research, the independent variable is what differentiates the control group from the experimental group, ... These variables are measured along a continuum and can represent very precise measurements. Examples of ...
Experimental and Non-Experimental Research. Experimental research: In experimental research, the aim is to manipulate an independent variable(s) and then examine the effect that this change has on a dependent variable(s).Since it is possible to manipulate the independent variable(s), experimental research has the advantage of enabling a researcher to identify a cause and effect between variables.
Experimental research design is a framework of protocols and procedures created to conduct experimental research with a scientific approach using two sets of variables. Herein, the first set of variables acts as a constant, used to measure the differences of the second set. The best example of experimental research methods is quantitative research.
By systematically changing some variables in an experiment and measuring what happens as a result, researchers are able to learn more about cause-and-effect relationships. The two main types of variables in psychology are the independent variable and the dependent variable. Both variables are important in the process of collecting data about ...
In contrast, non-experimental research designs (e.g., correlational designs), in which variables are measured but are not manipulated by an experimenter, are low in internal validity. External Validity. At the same time, the way that experiments are conducted sometimes leads to a different kind of criticism.
Chapter 10 Experimental Research. Experimental research, often considered to be the "gold standard" in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels ...
Experimental Design. Experimental design is a process of planning and conducting scientific experiments to investigate a hypothesis or research question. It involves carefully designing an experiment that can test the hypothesis, and controlling for other variables that may influence the results. Experimental design typically includes ...
Variables are factors that influence an experiment or that are of interest as a result. These include variables you change to test a hypothesis, variables you measure to determine results and variables you hold constant to produce a valid experiment. The following are the basic types of variable that are relevant to experiments.
Research Methods Chapter 12. One of the major learning objectives of this chapter is to define the goal or purpose of the correlational research strategy and distinguish between a correlational study and experimental and differential research. The purpose of a correlational study is to establish that a relationship exists between variables and ...
Validity in Experimental Manipulations of Psychological Processes. Experimental social psychologists often focus on 'internal validity' and 'external validity' (Haslam & McGarty, 2004).Internal validity is present when experimenters (I) eliminate extraneous variables that might incidentally influence the outcome-of-interest and (II) maximize features of the experimental manipulation ...
After that, we asked what that measurement tells us about the equation of state at that density." In its recent paper, the team combined its own experiments from accelerator facilities in the United States and Japan. It pulled together data from 12 different experimental constraints and three neutron-star observations.